
在使用Spark,尤其是Spark SQL时,经常会出现一些奇奇怪怪的效率低下问题。比如说,如果lineage比较长的时候,或者lineage比较复杂需要shuffle的时候,可能存在一定的rdd复用问题。
通常在需要复用一个rdd的时候,建议进行persist。但是在实际情况下,又会经常出现不确定是否存在复用的问题。(主要对Spark理解不够深)
下面举一个例子进行学习
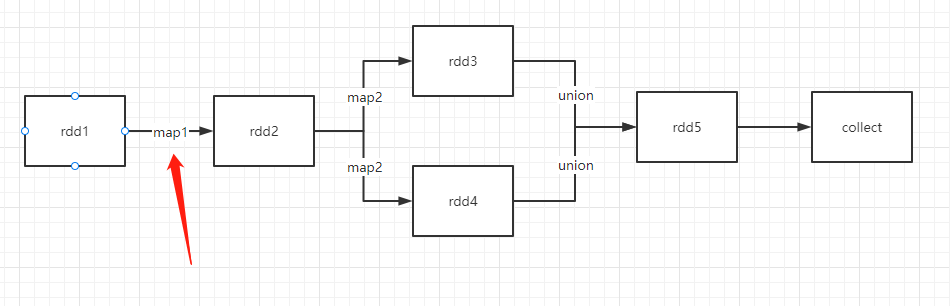
将箭头指向的map称作map1,右边两个map称作map2.
可以看到,rdd5是由rdd3和rdd4进行union得到,而rdd3和rdd4都最终来自于rdd1,rdd1到rdd2的map1实际承担了两条线路,所以按道理来说应该会执行两次。
rdd1 = sc.parallelize([[i, i+100] for i in range(10)], numSlices=50)
accumulator = sc.accumulator(0)
def map1(x):
accumulator.add(1)
return x
def map2(x):
return x
rdd2 = rdd1.map(map1)
# rdd2.persist()
rdd3 = rdd2.map(map2)
rdd4 = rdd2.map(map2)
rdd5 = rdd3.union(rdd4)
rdd5.collect()
print(accumulator.value)
输出为20。因为rdd1中有10个元素,对应两遍map让累加器变为20.
如果对rdd2进行persist,这样就切断rdd2之前的dag,所以map1只需计算一遍。累加器的计算结果果然为10。
再看Spark SQL
用DataFrame实现上述步骤
df1 = spark.createDataFrame([[i, i+100] for i in range(10)]).toDF("a", 'v').repartition(50)
accumulator = sc.accumulator(0)
@udf
def map1(x):
accumulator.add(1)
return x
@udf
def map2(x):
return x
df2 = df1.withColumn("b", map1("a"))
df3 = df2.withColumn("c", map2("b"))
df4 = df2.withColumn("c", map2("b"))
df5 = df3.union(df4)
df5.collect()
print(accumulator.value)
输出结果竟然是40?
先把df2.persist()一下看看,输出结果为10,这就合理多了。
但是为什么会出现40这个结果。原来是withColumn这个函数使用不当。。。。
学艺不精,惭愧。
df5.columns为['a', 'v', 'b', 'c']
因为是union而来,'b'列执行了两次map1,'c'由'b'经map2得到,'c'因为'b'也需要两次map1,所以一共4次,输出40。
如果不需要'b',仅select出['a', 'v', 'c'], 这样只需要两次,输出结果也与预期一样是20.
归根结底,最后还是要看DataFrame用到了哪些数据,这些列是怎么来的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号