
根据业务需求,需要对pyspark内存资源进行限制
本文使用的环境为pyspark 3.1.2,standalone模式
不足之处还请指出
pyspark进程说明
首先我们需要知道对pyspark进行内存限制,是限制哪部分的内存。
先看一下执行pyspark任务需要启动哪些进程
pyspark与原版基于scala的spark启动的进程大体相似但略有不同。
当启动一个pyspark任务时,可以看到产生了2个系列的进程,分别是负责driver和executor
driver:

| 编号 | 说明 | 内存 |
|---|---|---|
| d1 | spark的driver端,spark-submit进程,运行在jvm,启动sparkContext,构建dag等 | spark算子在driver端用到的内存,包括collect等 |
| d2 | spark的driver端启动的pyspark的driver端,执行python部分代码,通过py4j与d1通信 | python代码中所用到的内存,包括创建一些变量等 |
executor:
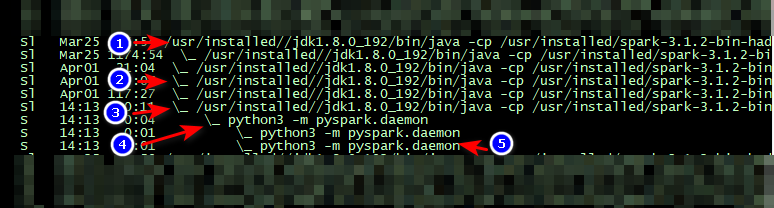
| 编号 | 说明 | 内存 |
|---|---|---|
| e1 | spark的worker节点 | 不关注 |
| e2 | 设备上其他spark任务的executor backend,与本文无关 | 不关注 |
| e3 | 本任务对应的spark的executor backend,运行jvm中 | spark在executor端使用的内存,包括collect等算子、shuffle等 |
| e4 | 本任务对应的pyspark的executor backend,管理具体执行task的worker | 占用少量内存 |
| e5 | 具体执行pyspark中的python task的任务的worker,由e4 fork得到,执行算子中的自定义Python函数等 | pyspark在executor端使用的内存,通过python执行,包括map中的func等 |
可以看到,pyspark任务中,主要需要对4处进行内存限制
- spark的driver
- spark的executor
- pyspark的driver
- pyspark的executor
后两个是pyspark比spark多出来的。
官方配置
关于spark中的内存,可以关注官方配置文档
其中,重点关注3条配置信息
| Property Name | Default | Meaning | Since Version |
|---|---|---|---|
| spark.driver.memory | 1g | Amount of memory to use for the driver process, i.e. where SparkContext is initialized, in the same format as JVM memory strings with a size unit suffix ("k", "m", "g" or "t") (e.g. 512m, 2g). Note: In client mode, this config must not be set through the SparkConf directly in your application, because the driver JVM has already started at that point. Instead, please set this through the --driver-memory command line option or in your default properties file. |
1.1.1 |
| spark.executor.memory | 1g | Amount of memory to use per executor process, in the same format as JVM memory strings with a size unit suffix ("k", "m", "g" or "t") (e.g. 512m, 2g). |
0.7.0 |
| spark.executor.pyspark.memory | Not set | The amount of memory to be allocated to PySpark in each executor, in MiB unless otherwise specified. If set, PySpark memory for an executor will be limited to this amount. If not set, Spark will not limit Python's memory use and it is up to the application to avoid exceeding the overhead memory space shared with other non-JVM processes. When PySpark is run in YARN or Kubernetes, this memory is added to executor resource requests. Note: This feature is dependent on Python's resource module; therefore, the behaviors and limitations are inherited. For instance, Windows does not support resource limiting and actual resource is not limited on MacOS. |
2.4.0 |
spark.driver.memory和spark.executor.memory这两个参数限制就是spark端driver和executor的内存,
对需要在jvm中执行的任务进行了很好的限制,
但如上文所述,还需要对pyspark端的内存进行限制。
pyspark的executor内存限制
spark.executor.pyspark.memory这个参数是对pyspark的executor内存进行了限制
根据pyspark中worker.py
# set up memory limits
memory_limit_mb = int(os.environ.get('PYSPARK_EXECUTOR_MEMORY_MB', "-1"))
if memory_limit_mb > 0 and has_resource_module:
total_memory = resource.RLIMIT_AS
try:
(soft_limit, hard_limit) = resource.getrlimit(total_memory)
msg = "Current mem limits: {0} of max {1}\n".format(soft_limit, hard_limit)
print(msg, file=sys.stderr)
# convert to bytes
new_limit = memory_limit_mb * 1024 * 1024
if soft_limit == resource.RLIM_INFINITY or new_limit < soft_limit:
msg = "Setting mem limits to {0} of max {1}\n".format(new_limit, new_limit)
print(msg, file=sys.stderr)
resource.setrlimit(total_memory, (new_limit, new_limit))
except (resource.error, OSError, ValueError) as e:
# not all systems support resource limits, so warn instead of failing
print("WARN: Failed to set memory limit: {0}\n".format(e), file=sys.stderr)
看到,其实这个参数主要是使用了Python的resource模块进行了内存限制
然而,这里面设置的resource.RLIMIT_AS是对虚拟内存进行限制
我们通常想限制的是驻留内存。
例如一个小测试
import resource
resource.setrlimit(resource.RLIMIT_AS, (1*1024**3, -1))
def fun():
tmp = []
for i in range(1024**3):
try:
tmp.append('a'*1024)
except MemoryError:
break
return tmp
x = fun(), fun(), fun(), fun()
通过resource.setrlimit限制了1g内存。resource.RLIMIT_AS为虚拟内存的flag,RLIMIT_RSS为驻留内存,但只在老linux内核中生效,现在无法对内核态操作
运行后资源如下

virt达到了限制的1g,但res只有900m。在其他情况下,通常virt远远大于res,这样virt达到了我们限制好的数值,但是res很小,内存远远没得到充分利用,造成资源浪费。
另注:
在standalone模式下,每个worker(e5)限制的virt内存是在application启动时计算好的。通过spark.executor.pyspark.memory 除以 --executor-cores 得到。
\(workerMemoryMb =memoryMb / execCores\)
减少每个stage的task个数并不能增加每个worker的virt内存限制大小
pyspark的driver内存限制
pyspark的driver负责执行python流程代码,内存包含Python中创建的各种变量等
spark官方似乎没有参数对这部分内存进行限制
可以自行使用resource模块,对virt内存进行限制
报错信息参考
spark的driver和executor出现oom后,会产生java.lang.OutOfMemoryError: Java heap space报错信息
pyspark的driver和executor出现oom后,产生MemoryError,附有对应python代码
cgroup管理内存
Control groups,是一种Linux内核特性,对进程进行分级分组管理,不同组用不同资源限制并监控。
可以对pyspark的驻留内存进行管理
安装
以centos为例
yum install -y libcgroup libcgroup-tools
分组配置
这里先设置了一个组,用作pyspark的总体控制
再在这个组中设置两个组,分别对driver端的进程和executor的进程进行了限制
/sys/fs/cgroup/memory这个路径是cgroup对memory进行控制的配置,在这里建立对应文件夹来建立具体分组
首先是整体分组
mkdir /sys/fs/cgroup/memory/pyspark
再driver和executor分别建组控制
mkdir /sys/fs/cgroup/memory/pyspark/driver
mkdir /sys/fs/cgroup/memory/pyspark/executor
建组后,cgroup会自动生成一些配置文件,如下图
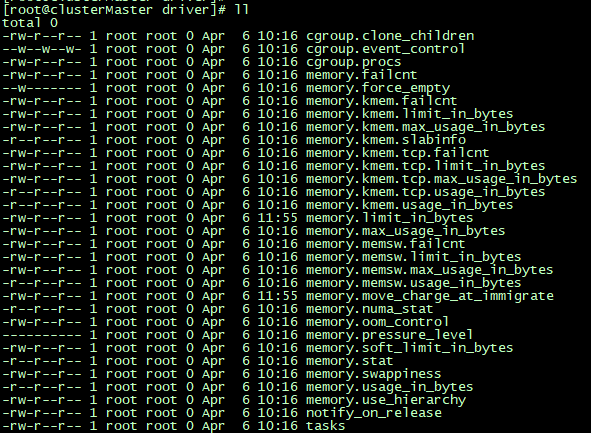
关于每一项的说明可以参考大佬的文档
在这里主要关注memory.limit_in_bytes和cgroup.procs
memory.limit_in_bytes为当前限制的内存额度。超过额度的话会对相应进程进行kill
可以使用echo重定向对这个进行限制
echo 10g > /sys/fs/cgroup/memory/ai_pyspark/driver/memory.limit_in_bytes
echo 50g > /sys/fs/cgroup/memory/ai_pyspark/executor/memory.limit_in_bytes
则将这个分组的内存限制为10g和50g
cgroup.procs中包含这个分组中的pid
可将spark-submit和worker的pid追加进这个文件,cgroup便将这个进行拉进这个分组进行管理

echo 160224 >> /sys/fs/cgroup/memory/ai_pyspark/driver/cgroup.procs
echo 167910 >> /sys/fs/cgroup/memory/ai_pyspark/executor/cgroup.procs
cgroup会将进程中新产生的子进程自动加入cgroup.procs
例如当产生新的pyspark.daemon时,cgroup会将对应的pid添加到executor分组中
linux系统中每一个进程都有自己的分组,我们没配置分组的进程会在/sys/fs/cgroup/memory分组中,如果想将某个分组中的某个pid移除这个分组,只需将他移动到另一个分组,例如
echo 167910 >> /sys/fs/cgroup/memory/cgroup.procs
另注:
如果executor发生oom,当前spark executor backend进程挂掉,spark会启动一个新的executor backend,不要忘记将新的executor pid再加入cgroup.procs
参考
cgroups(7) — Linux manual page

 浙公网安备 33010602011771号
浙公网安备 33010602011771号