
Attention Is All You Need
模型结构
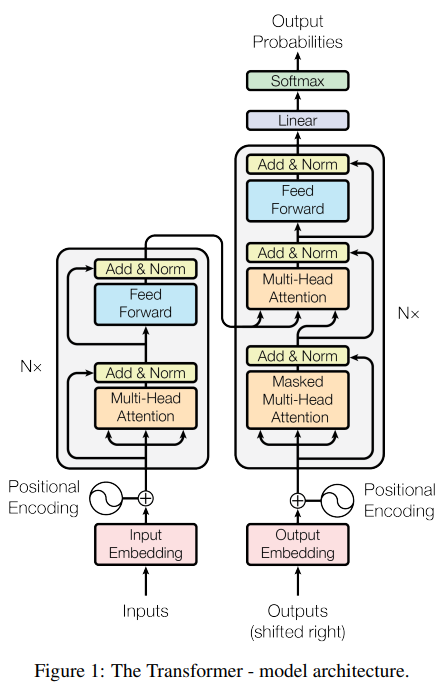
Encoder
Encoder是有N=6层的一个整体。是这6层按顺序走下来的一个整体。
每层有两个子层。分别是多头自注意力和全连接前馈网络。
对于每个子层,先采用残差连接,后采用layer normalization
为保证能够进行残差连接,所有隐变量(包含embedding)都保持\(d_{model}=512\)
Decoder
同样共N=6层,
与Encoder不同,额外增加了一个子层,在encoder堆栈输出上进行多头注意力。
同样对于每个子层,先残差后layer normalization、
修改了自注意力子层,避免每个位置融入了后续位置的信息。这种mask,保证了每个输出的embedding对应了一个位置,在对位置i进行预测时,只依赖i之前的位置,这种位置的结果是已知的。
注意力
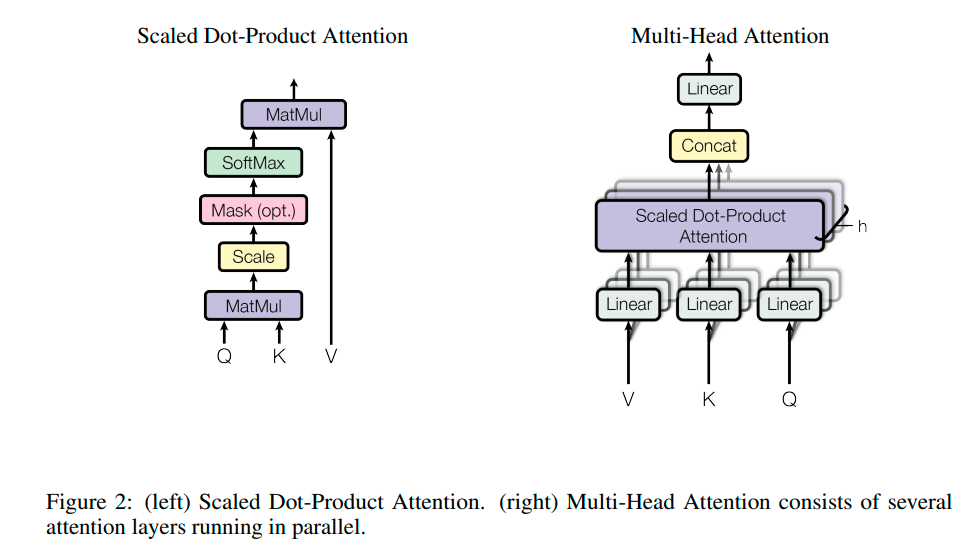
注意力函数可以描述为将一个q和一组k,v映射到一个输出,其中q、k、v和输出都是向量。 输出为每个位置对应的v的加权总和,其中分配给每个v的权重由q与相应k计算 。
- Scaled Dot-Product Attention
additive attention和dot-product (multiplicative) attention是两种常见attention,相比dot-product attention,transformer增加了放缩因子。
additive attention采用单隐层前馈网络,两种方法在理论上复杂度相似,但dot-product attention在实际中更快更节约空间,因为其矩阵乘法运算能被优化。
计算时,若\(d_{k}\)比较大,点积会很大,导致softmax梯度很小,所以增加放缩因子\(\frac{1}{\sqrt{d_{k}}}\)
- additive attention
采用单隐层前馈网络计算attention score
其中\(v_{a}\)和\(W_{a}\)为注意力参数,可以学习。
暂时这么理解,h是q,s是v。
参考
- Multi-Head Attention
多组qkv构成多头注意力计算。从不同表示子空间连接信息\[MultiHead(Q,K,V) = Concat(head_{1},...,head_{h})W^{O} \]\[where \space head_{i}=Attention(QW_{i}^{Q},KW_{i}^{K},VW_{i}^{V}) \]注意,根据上式,上一层结果h,分别作为QKV,输入多头注意力,每个head下,先通过一个权重矩阵相乘得到对应head下的qkv。 - Applications of Attention in our Model
- 在encoder-decoder attention层,q来自前一个decoder层,k、v来自encoder堆栈的输出,这样允许decoder的每个位置获取input序列所有位置的信息。这样做模仿了seq2seq
- encoder包含了self-attention层。在一个sa层里,所有qkv均为上一层的输出,每个位置都包含了上一层所有位置的信息
- 同样,decoder的sa层中,每个位置都包含了这个位置之前的所有位置的信息。为了自回归,防止右边的信息流入左边,在scaled dot-product attention时,计算softmax之前进行mask
Position-wise Feed-Forward Networks
这是另一个子层,每个encoder和decoder都包含这个子层
Embeddings and Softmax
两个Embedding采用相同的权重,同时采用相同的pre-softmax线性转换。
在Embedding层,权重乘以一个系数\(\sqrt{d_{model}}\)
Positional Encoding
因为transformer没有递推,没有卷积,需要采用位置编码的方式提供序列顺序。
pe与embedding采用相加的方式
在transformer中,采用正余弦方法表示位置编码
pos是位置,i是维度。
固定i的话,可以看到根据pos变化,得到一个正弦波形。
对于固定k,\(PE_{pos+k}\)何以表示成\(PE_{pos}\)的线性变换。
为什么使用自注意力
- 每层计算复杂度
- 并行度,最少的顺序操作
- 长范围依赖,输入和输出序列建路径越短,越容易学习长范围依赖

 浙公网安备 33010602011771号
浙公网安备 33010602011771号