Elasticsearch学习笔记
Elasticsearch学习笔记

1.Elasticsearch术语
<6.0
| Elasticsearch | MySQL |
|---|---|
| 索引 | DB |
| 类型 | TABLE |
| 文档 | ROW |
| 字段 | CLOUMN |
6.0>
| Elasticsearch | MySQL |
|---|---|
| 索引 | TABLE |
| 类型(废弃) | _doc |
| 文档 | ROW |
| 字段 | CLOUMN |
2.ES安装
下载完成后
1.修改elasticsearch.yml
# ======================== Elasticsearch Configuration =========================
#
# NOTE: Elasticsearch comes with reasonable defaults for most settings.
# Before you set out to tweak and tune the configuration, make sure you
# understand what are you trying to accomplish and the consequences.
#
# The primary way of configuring a node is via this file. This template lists
# the most important settings you may want to configure for a production cluster.
#
# Please consult the documentation for further information on configuration options:
# https://www.elastic.co/guide/en/elasticsearch/reference/index.html
#
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
cluster.name: nowcoder #集群名
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
#node.name: node-1
#
# Add custom attributes to the node:
#
#node.attr.rack: r1
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
path.data: D:\Dev\Environment\DATA\elasticsearch-6.4.3\data #数据存放地址
#
# Path to log files:
#
path.logs: D:\Dev\Environment\DATA\elasticsearch-6.4.3\logs #日志存放地址
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#
#bootstrap.memory_lock: true
#
# Make sure that the heap size is set to about half the memory available
# on the system and that the owner of the process is allowed to use this
# limit.
#
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
#network.host: 192.168.0.1
#
# Set a custom port for HTTP:
#
#http.port: 9200
#
# For more information, consult the network module documentation.
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when new node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
#discovery.zen.ping.unicast.hosts: ["host1", "host2"]
#
# Prevent the "split brain" by configuring the majority of nodes (total number of master-eligible nodes / 2 + 1):
#
#discovery.zen.minimum_master_nodes:
#
# For more information, consult the zen discovery module documentation.
#
# ---------------------------------- Gateway -----------------------------------
#
# Block initial recovery after a full cluster restart until N nodes are started:
#
#gateway.recover_after_nodes: 3
#
# For more information, consult the gateway module documentation.
#
# ---------------------------------- Various -----------------------------------
#
# Require explicit names when deleting indices:
#
#action.destructive_requires_name: true
2.配置IK中文分词器
https://github.com/medcl/elasticsearch-analysis-ik
将ik分词器解压缩到
elasticsearch-6.4.3\plugins\ik\...
3.使用ES
windows系统下运行elasticsearch.bat
1.启动
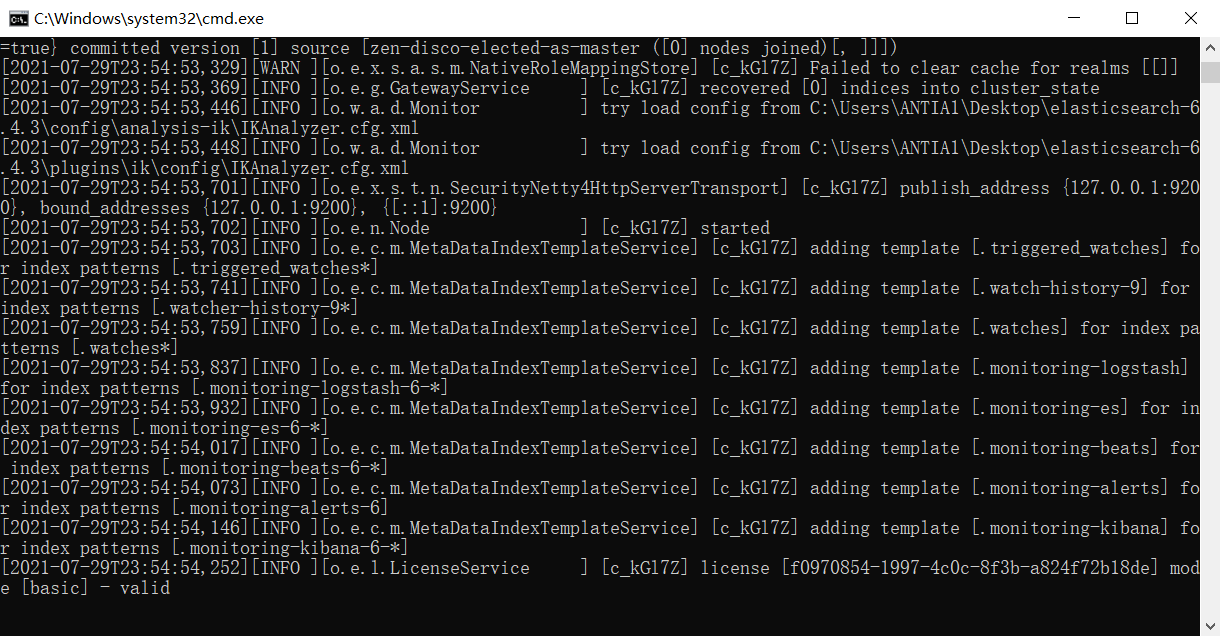
启动成功
运行命令检查ES状态
curl -X GET "localhost:9200/_cat/health?v"

查看节点
curl -X GET "localhost:9200/_cat/nodes?v"

查看索引
curl -X GET "localhost:9200/_cat/indices?v"
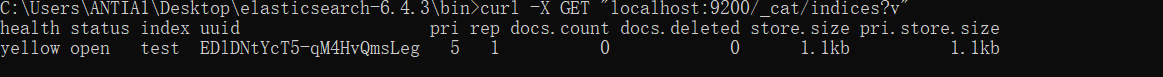
创建索引
curl -X PUT "localhost:9200/索引名"

删除索引
curl -X DELETE "localhost:9200/索引名"

插入数据
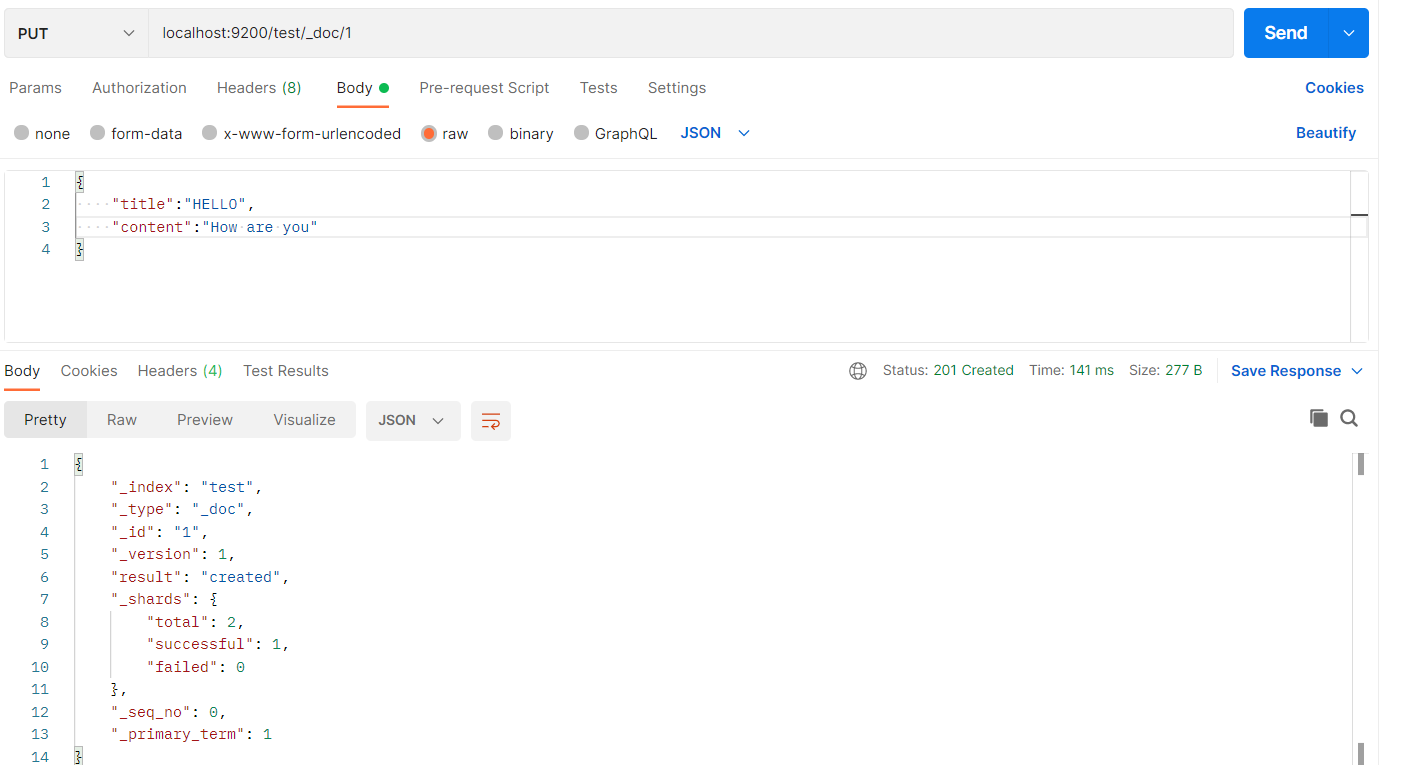
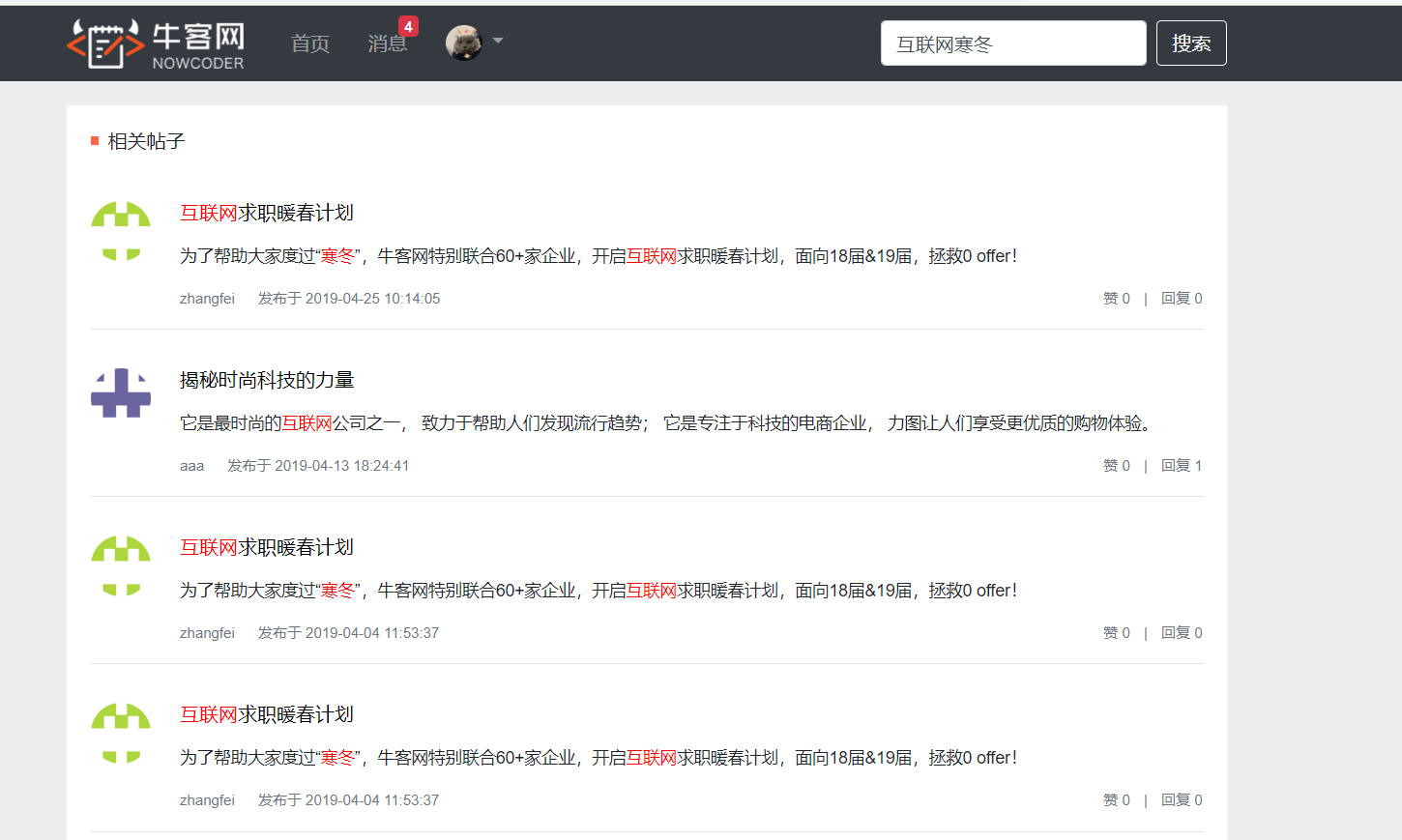
查询数据
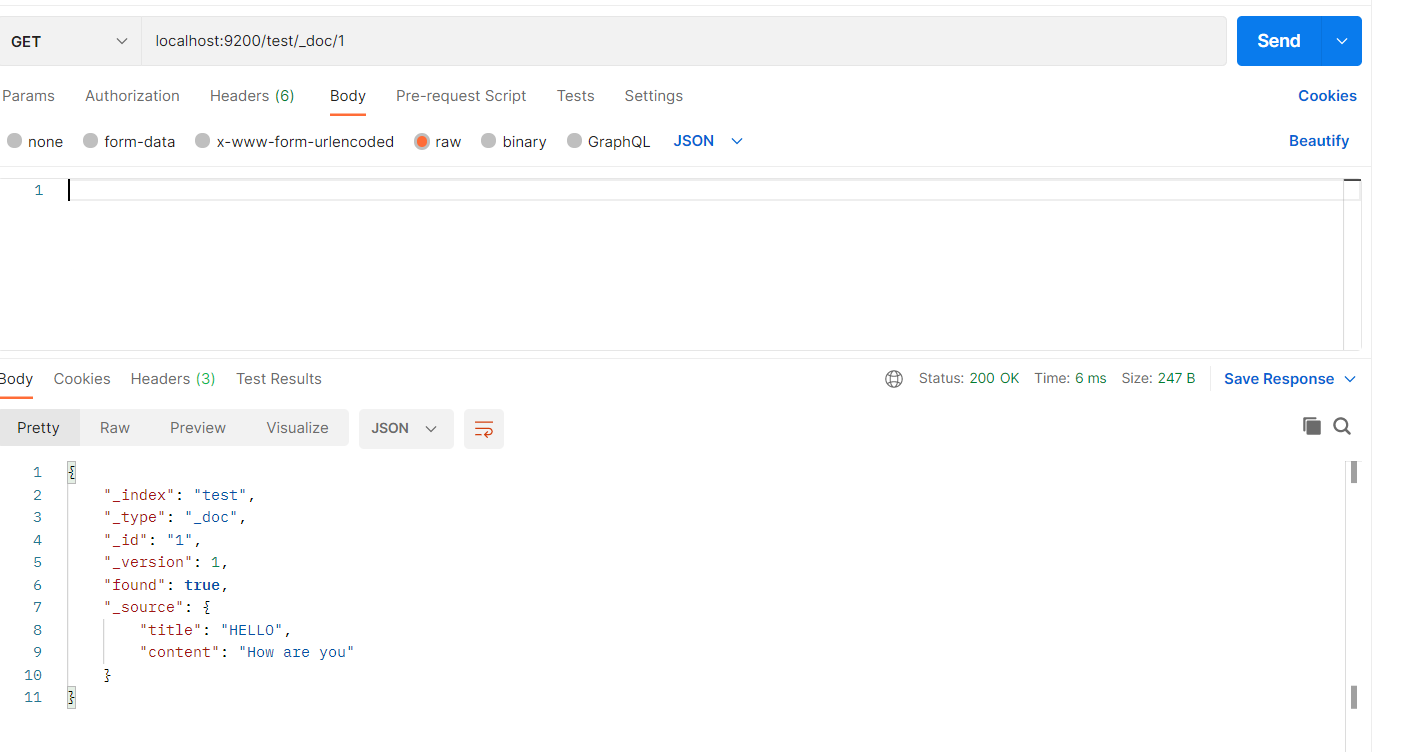
删除数据
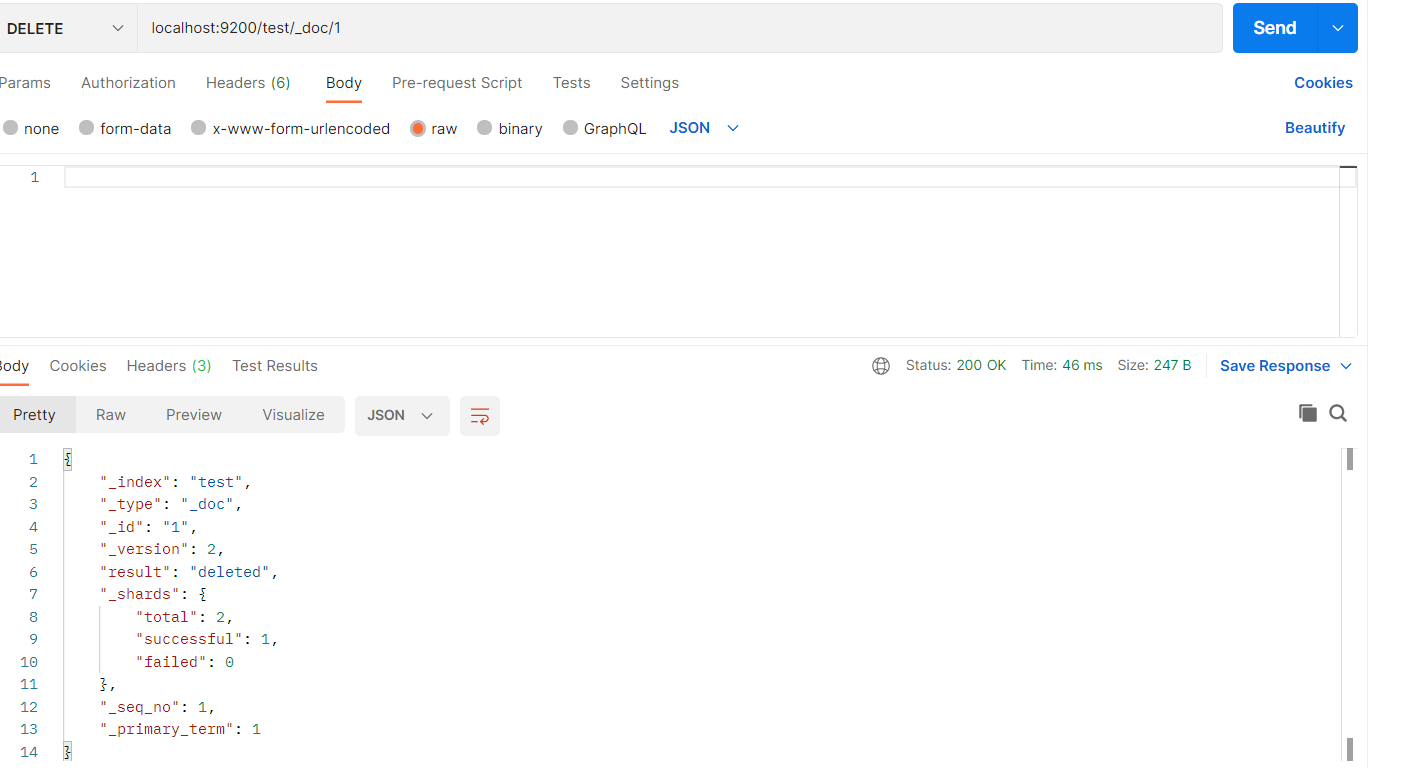
搜索全部
{
"took": 75,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 1.0,
"hits": [
{
"_index": "test",
"_type": "_doc",
"_id": "2",
"_score": 1.0,
"_source": {
"title": "互联网招聘",
"content": "招聘一名资深程序员"
}
},
{
"_index": "test",
"_type": "_doc",
"_id": "1",
"_score": 1.0,
"_source": {
"title": "互联网求职",
"content": "寻求一份开发的岗位"
}
},
{
"_index": "test",
"_type": "_doc",
"_id": "3",
"_score": 1.0,
"_source": {
"title": "实习生推荐",
"content": "本人在一家互联网公司任职,可推荐实习开发岗位"
}
}
]
}
}
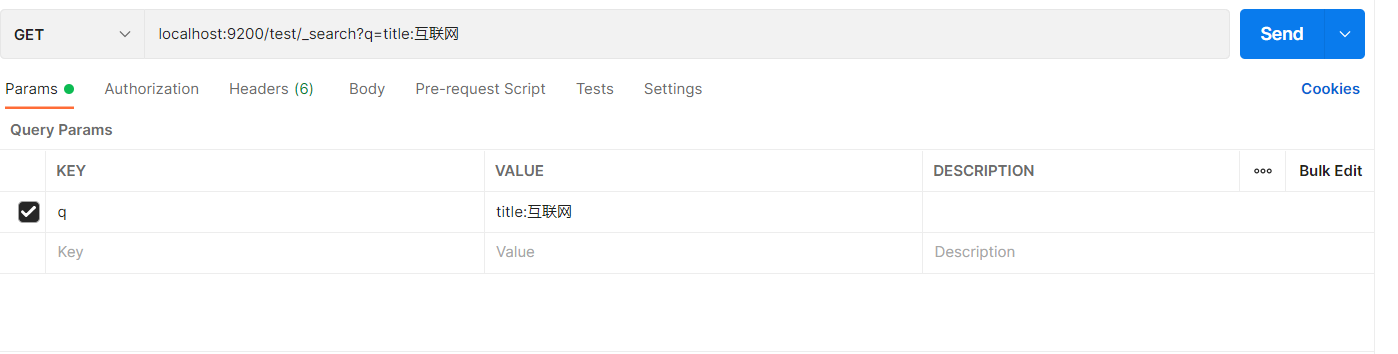
条件搜索
搜索 title 中包含 “互联网” 的数据
{
"took": 46,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 0.8630463,
"hits": [
{
"_index": "test",
"_type": "_doc",
"_id": "2",
"_score": 0.8630463,
"_source": {
"title": "互联网招聘",
"content": "招聘一名资深程序员"
}
},
{
"_index": "test",
"_type": "_doc",
"_id": "1",
"_score": 0.8630463,
"_source": {
"title": "互联网求职",
"content": "寻求一份开发的岗位"
}
}
]
}
}
多条件搜索
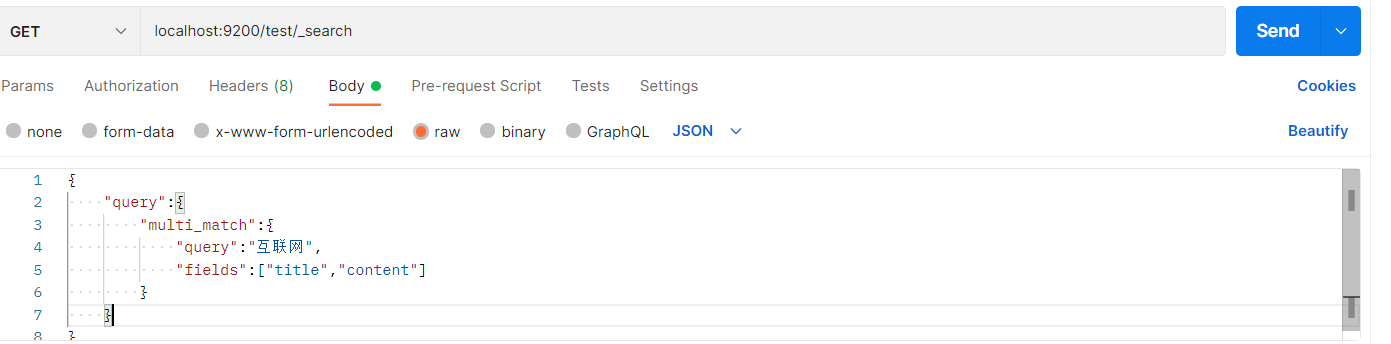
{
"took": 13,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 0.8630463,
"hits": [
{
"_index": "test",
"_type": "_doc",
"_id": "2",
"_score": 0.8630463,
"_source": {
"title": "互联网招聘",
"content": "招聘一名资深程序员"
}
},
{
"_index": "test",
"_type": "_doc",
"_id": "1",
"_score": 0.8630463,
"_source": {
"title": "互联网求职",
"content": "寻求一份开发的岗位"
}
},
{
"_index": "test",
"_type": "_doc",
"_id": "3",
"_score": 0.8630463,
"_source": {
"title": "实习生推荐",
"content": "本人在一家互联网公司任职,可推荐实习开发岗位"
}
}
]
}
}
4.SpringBoot整合ES
1.导入依赖
<!-- https://mvnrepository.com/artifact/org.springframework.data/spring-data-elasticsearch -->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-elasticsearch</artifactId>
</dependency>
2.配置application.properties
spring.elasticsearch.rest.uris=http://127.0.0.1:9200
3.创建接口继承ElasticsearchRepository
继承ElasticsearchRepository的接口会默认实现一些方法,可以用来对ES进行操作
package com.zhuantai.community.dao.elasticsearch;
import com.zhuantai.community.entity.DiscussPost;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;
/**
* @author ANTIA1
* @date 2021/7/30 1:14
*/
@Repository
public interface DiscussPostRepository extends ElasticsearchRepository<DiscussPost,Integer> {
}
4.测试
package com.zhuantai.community;
import com.zhuantai.community.dao.DiscussPostMapper;
import com.zhuantai.community.dao.elasticsearch.DiscussPostRepository;
import com.zhuantai.community.entity.DiscussPost;
import org.elasticsearch.index.query.MultiMatchQueryBuilder;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.sort.SortBuilder;
import org.elasticsearch.search.sort.SortBuilders;
import org.elasticsearch.search.sort.SortOrder;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.data.elasticsearch.core.IndexOperations;
import org.springframework.data.elasticsearch.core.SearchHit;
import org.springframework.data.elasticsearch.core.SearchHits;
import org.springframework.data.elasticsearch.core.document.Document;
import org.springframework.data.elasticsearch.core.query.NativeSearchQuery;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
/**
* @author ANTIA1
* @date 2021/7/30 1:15
*/
@SpringBootTest
public class ElasicSearchTest {
@Autowired
DiscussPostMapper discussPostMapper;
@Autowired
private DiscussPostRepository repository;
@Autowired
private ElasticsearchRestTemplate restTemplate;
/**
* 插入数据
*/
@Test
public void testInsert(){
repository.save(discussPostMapper.selectDiscussPostById(241));
repository.save(discussPostMapper.selectDiscussPostById(242));
repository.save(discussPostMapper.selectDiscussPostById(243));
}
/**
* 插入多条数据
*/
@Test
public void testInsertList(){
repository.saveAll(discussPostMapper.selectDiscussPosts(101,0,100));
repository.saveAll(discussPostMapper.selectDiscussPosts(102,0,100));
repository.saveAll(discussPostMapper.selectDiscussPosts(103,0,100));
repository.saveAll(discussPostMapper.selectDiscussPosts(111,0,100));
repository.saveAll(discussPostMapper.selectDiscussPosts(112,0,100));
repository.saveAll(discussPostMapper.selectDiscussPosts(131,0,100));
repository.saveAll(discussPostMapper.selectDiscussPosts(132,0,100));
repository.saveAll(discussPostMapper.selectDiscussPosts(133,0,100));
repository.saveAll(discussPostMapper.selectDiscussPosts(134,0,100));
}
/**
* 修改数据
*/
@Test
public void testUpdate(){
DiscussPost post = discussPostMapper.selectDiscussPostById(231);
post.setContent("我爱肥肥肥肥肥肥");
repository.save(post);
}
/**
* 删除数据
*/
@Test
public void testDelete(){
repository.deleteById(231);
}
/**
* 查询
*/
@Test
public void testSearch(){
// 构建查询条件
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.multiMatchQuery("互联网寒冬", "title", "content"))
.withSort(SortBuilders.fieldSort("type").order(SortOrder.DESC))// 按照帖子分类排序
.withSort(SortBuilders.fieldSort("score").order(SortOrder.DESC))// 按照帖子分数排序
.withSort(SortBuilders.fieldSort("createTime").order(SortOrder.DESC))// 按照帖子发布日期排序
.withPageable(PageRequest.of(0, 10))// 每页十条数据
.withHighlightFields(
// 标题和内容中的匹配字段高亮展示
new HighlightBuilder.Field("title").preTags("<em>").postTags("</em>"),
new HighlightBuilder.Field("content").preTags("<em>").postTags("</em>")
).build();
// 得到查询结果返回容纳指定内容对象的集合SearchHits
SearchHits<DiscussPost> searchHits = restTemplate.search(searchQuery, DiscussPost.class);
// 设置一个需要返回的实体类集合
List<DiscussPost> discussPosts = new ArrayList<>();
// 遍历返回的内容进行处理
for (SearchHit<DiscussPost> searchHit : searchHits) {
// 高亮的内容
Map<String, List<String>> highlightFields = searchHit.getHighlightFields();
// 将高亮的内容填充到content中
searchHit.getContent().setTitle(highlightFields.get("title") == null ?
searchHit.getContent().getTitle() : highlightFields.get("title").get(0));
searchHit.getContent().setTitle(highlightFields.get("content") == null ?
searchHit.getContent().getContent() : highlightFields.get("content").get(0));
// 放到实体类中
discussPosts.add(searchHit.getContent());
}
// 输出结果
System.out.println(discussPosts.size());
for (DiscussPost discussPost : discussPosts) {
System.out.println(discussPost);
}
}
}
5.开发搜索功能

1.创建ESSERVICE
ElasticsearchService.java
package com.zhuantai.community.service;
import com.zhuantai.community.dao.elasticsearch.DiscussPostRepository;
import com.zhuantai.community.entity.DiscussPost;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.sort.SortBuilders;
import org.elasticsearch.search.sort.SortOrder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.data.elasticsearch.core.SearchHit;
import org.springframework.data.elasticsearch.core.SearchHits;
import org.springframework.data.elasticsearch.core.query.NativeSearchQuery;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.stereotype.Service;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* @author ANTIA1
* @date 2021/7/30 12:36
*/
@Service
public class ElasticsearchService {
@Autowired
private DiscussPostRepository repository;
@Autowired
private ElasticsearchRestTemplate restTemplate;
/**
* 向ES中添加新产生的帖子
*/
public void saveDiscussPost(DiscussPost post){
repository.save(post);
}
/**
* 根据id从ES中删除一条帖子数据
* @param id
*/
public void deleteDiscussPost(int id){
repository.deleteById(id);
}
/**
* 搜索帖子
*
* @param keyword 关键字
* @param current 当前页
* @param limit 每页展示数据的数量
* @return
*/
public Map<String,Object> searchDiscussPost(String keyword,int current,int limit){
Map<String,Object> map = new HashMap<>();
// 构建查询条件对象
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.multiMatchQuery(keyword, "title", "content"))
.withSort(SortBuilders.fieldSort("type").order(SortOrder.DESC))// 按照帖子分类排序
.withSort(SortBuilders.fieldSort("score").order(SortOrder.DESC))// 按照帖子分数排序
.withSort(SortBuilders.fieldSort("createTime").order(SortOrder.DESC))// 按照帖子发布日期排序
.withPageable(PageRequest.of(current, limit))// 分页
.withHighlightFields(// 要高亮显示的字段
new HighlightBuilder.Field("title").preTags("<em>").postTags("</em>"),
new HighlightBuilder.Field("content").preTags("<em>").postTags("</em>")
).build();
// SearchHit:将搜索到的数据与索的条件对象一起封装
// SearchHits:容纳多个 SearchHit 的集合
// 根据查询条件查询,并返回 SearchHits 对象
SearchHits<DiscussPost> searchHits = restTemplate.search(searchQuery, DiscussPost.class);
// 设置一个需要返回的实体类集合
List<DiscussPost> discussPosts = new ArrayList<>();
// 遍历返回的内容进行处理
for (SearchHit<DiscussPost> searchHit : searchHits) {
// 高亮内容的map集合
Map<String, List<String>> highlightFields = searchHit.getHighlightFields();
if (highlightFields.get("title") != null) {
searchHit.getContent().setTitle(highlightFields.get("title").get(0));
}
if (highlightFields.get("content") != null) {
searchHit.getContent().setContent(highlightFields.get("content").get(0));
}
// 放到实体类中
discussPosts.add(searchHit.getContent());
}
Long totalHits = searchHits.getTotalHits();
map.put("discussPosts",discussPosts);
map.put("totalHits",totalHits!=0?totalHits.intValue():0);
return map;
}
}
2.触发发帖事件
在发帖时,通过kafka触发发帖事件,将新的帖子存入ES
/**
* @author ANTIA1
* @date 2021/7/25 0:25
*/
@Controller
@RequestMapping("/discuss")
public class DiscussPostController implements CommunityConstant {
@Autowired
DiscussPostService discussPostService;
@Autowired
HostHolder hostHolder;
@Autowired
UserService userService;
@Autowired
CommentService commentService;
@Autowired
LikeService likeService;
@Autowired
EventProducer producer;
@RequestMapping(value = "/add",method = RequestMethod.POST)
@ResponseBody
public String addDiscussPost(String title,String content){
User user = hostHolder.getUser();
if (user == null){
return CommunityUtil.getJSONString(403,"你还没有登录");
}
DiscussPost post = new DiscussPost();
post.setUserId(user.getId());
post.setTitle(title);
post.setContent(content);
post.setType(0);
post.setStatus(0);
post.setCommentCount(0);
post.setScore(0.0);
post.setCreateTime(new Date());
discussPostService.addDiscussPost(post);
//触发发帖事件
Event event = new Event()
.setTopic(TOPIC_PUBLISH)
.setUserId(user.getId())
.setEntityType(ENTITY_TYPE_POST)
.setEntityId(post.getId());
producer.fireEvent(event);
//报错的情况,将来统一处理
return CommunityUtil.getJSONString(0,"发布成功!");
}
}
3.在消费者中消费发帖事件
//消费发帖事件
@KafkaListener(topics = {TOPIC_PUBLISH})
public void handlePublishMessage(ConsumerRecord record){
if (record == null || record.value() == null ){
LOGGER.error("消息内容为空!");
return;
}
Event event = JSONObject.parseObject(record.value().toString(),Event.class);
if (event == null ){
LOGGER.error("消息格式错误!");
return;
}
DiscussPost post = discussPostService.findDiscussPostById(event.getEntityId());
elasticsearchService.saveDiscussPost(post);
}
4.构建SearchController
SearchController.java
package com.zhuantai.community.controller;
import com.zhuantai.community.entity.DiscussPost;
import com.zhuantai.community.entity.Page;
import com.zhuantai.community.service.ElasticsearchService;
import com.zhuantai.community.service.LikeService;
import com.zhuantai.community.service.UserService;
import com.zhuantai.community.uitls.CommunityConstant;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* @author ANTIA1
* @date 2021/7/30 12:54
*/
@Controller
public class SearchController implements CommunityConstant {
@Autowired
private ElasticsearchService elasticsearchService;
@Autowired
private UserService userService;
@Autowired
private LikeService likeService;
// search?keyword=xxx
@RequestMapping(path = "/search",method = RequestMethod.GET)
public String search(String keyword, Page page, Model model){
//搜索帖子
Map<String, Object> discussPostVo = elasticsearchService.searchDiscussPost(keyword, page.getCurrent() - 1, page.getSize());
List<DiscussPost> discussPosts = (List<DiscussPost>) discussPostVo.get("discussPosts");
//聚合数据
List<Map<String,Object>> discussPostList = new ArrayList<>();
for (DiscussPost post : discussPosts) {
Map<String,Object> map = new HashMap<>();
//帖子
map.put("post",post);
//作者
map.put("user",userService.findUserById(post.getUserId()));
//点赞数量
map.put("likeCount",likeService.findEntityLikeCount(ENTITY_TYPE_POST,post.getId()));
discussPostList.add(map);
}
model.addAttribute("discussPosts",discussPostList);
model.addAttribute("keyword",keyword);
//分页信息
page.setPath("/search?keyword="+keyword);
page.setTotal((Integer) discussPostVo.get("totalHits"));
return "/site/search";
}
}