(转)PyTorch DDP模式单机多卡训练
一、启动训练的命令
python -m torch.distributed.launch --nproc_per_node=NUM_GPUS_YOU_HAVE train.py
其中torch.distributed.launch表示以分布式的方式启动训练,--nproc_per_node指定一共就多少个节点,可以设置成显卡的个数
二、启动之后每个进程可以自动获取到参数
import argparse
import torch
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", type=int,default=-1)
opt = parser.parse_args()
local_rank = opt.local_rank
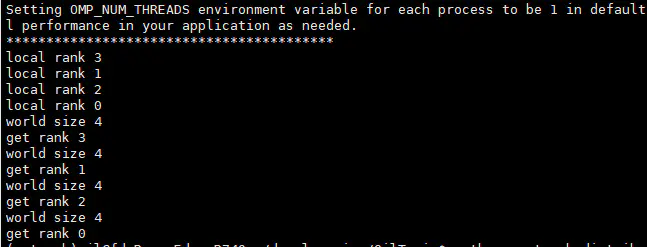
print("local rank {}".format(local_rank))
assert torch.cuda.device_count() > opt.local_rank
torch.cuda.set_device(opt.local_rank)
device = torch.device('cuda', opt.local_rank)
dist.init_process_group(backend='nccl', init_method='env://') # distributed backend
opt.world_size = dist.get_world_size()
print("world size {}".format(opt.world_size))
print("get rank {}".format(dist.get_rank()))
每个进程都能获取到local rank,local rank 表示的是进程的优先级,该优先级是自动分配的。world size 表示的一共运行的进程数和nproc_per_node设置的数值相对应。
三、正式开始DDP介绍训练模式设置
1.导入包
import torch
import torchvision
print("current torch version is {}".format(torch.__version__))
print("current torchvision version is {}".format(torchvision.__version__))
import sys
from models.resnet import *
from torchvision import datasets, transforms
import os
import torch.optim as optim
from torch.optim import lr_scheduler
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
import time
import copy
from torch.nn import DataParallel
import argparse
- 参数解读
parser = argparse.ArgumentParser()
parser.add_argument("--image_folder",type=str,default='/home/jl/datasets/oilrecognition',help='train and val folder path')
parser.add_argument("--local_rank", type=int,default=-1,help='DDP parameter, do not modify')#不需要赋值,启动命令 torch.distributed.launch会自动赋值
parser.add_argument("--distribute",action='store_true',help='whether using multi gpu train')
parser.add_argument("--distribute_mode",type=str,default='DDP',help="using which mode to ")
parser.add_argument('--epochs', type=int, default=20)
parser.add_argument('--batch_size', type=int, default=64, help='total batch size for all GPUs')
parser.add_argument("--save_path",type=str,default= "./save",help="the path used to save state_dict")
opt = parser.parse_args()
- 初始化部分
if opt.distribute and opt.local_rank != -1:
global device
torch.cuda.set_device(opt.local_rank)
torch.distributed.init_process_group(backend='nccl', init_method='env://')
device = torch.device('cuda', opt.local_rank)
- 数据部分
data_dir = opt.image_folder
image_datasets={}
image_datasets['train'] = datasets.ImageFolder(os.path.join(data_dir, 'train'),data_transforms['train'])
image_datasets['val'] = datasets.ImageFolder(os.path.join(data_dir, 'val'),data_transforms['val'])
word_size = dist.get_world_size()
if opt.distribute and opt.local_rank != -1:
train_sampler = torch.utils.data.distributed.DistributedSampler(image_datasets['train'],num_replicas = word_size,rank = opt.local_rank)
else:
train_sampler = None
print("batch size is : {}".format(opt.batch_size))
dataloaders = {}
dataloaders['train'] = torch.utils.data.DataLoader(image_datasets['train'], batch_size=opt.batch_size,shuffle=(train_sampler is None), num_workers=4, pin_memory=True, sampler=train_sampler)
dataloaders['val'] = torch.utils.data.DataLoader(image_datasets['val'], batch_size=opt.batch_size,shuffle = False,num_workers=4)
- 模型部分
if opt.distribute and opt.local_rank != -1:
model.to(device)
model = DDP(model, device_ids=[opt.local_rank])
6.模型保存部分
if dist.get_rank()== -1 or 0:
save_path = './oil_net.pt'
torch.save(model.state_dict(), save_path)
作者:RunningJiang
链接:https://www.jianshu.com/p/7818b128b9cd
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号