关于SQL优化的辟谣
列举一些关于 SQL 语句的谣言,避免一些生瓜蛋子面试的时候被另外一群生瓜蛋子的 SQL 优化宝典给坑了。
以下所有内容都是 SQL Server 中的,其他数据库只能参考和借鉴
一、全表扫描
全表扫描: 这种说法是有问题的,因为不够精确,或者就是错的
扫描在 SQL Server 分为三种情况
Heap:Table scan (全表扫描)
Clustered index :Clustered index scan (聚集索引扫描)
Nonclustered index :Index scan (索引扫描)
准备测试数据
DROP TABLE Org_User DROP TABLE Org_User1 -- 创建测试表 CREATE TABLE Org_User(Id INT,UserName NVARCHAR(50),Age INT) CREATE TABLE Org_User1(Id INT,UserName NVARCHAR(50),Age INT) -- 创建聚集索引和非聚集索引 CREATE CLUSTERED INDEX Index_Org_User_Id ON Org_User(Id) CREATE NONCLUSTERED INDEX NoNIndex_Org_User_Name ON Org_User(UserName) CREATE TABLE #Temp(Id INT) INSERT INTO #Temp VALUES(1) INSERT INTO #Temp VALUES(2) INSERT INTO #Temp VALUES(3) INSERT INTO #Temp VALUES(4) INSERT INTO #Temp VALUES(5) INSERT INTO #Temp VALUES(6) INSERT INTO #Temp VALUES(7) INSERT INTO #Temp VALUES(8) INSERT INTO #Temp VALUES(9) INSERT INTO #Temp VALUES(10) -- 批量插入10W条测试数据 SELECT T1.Id, 'UserName_' + CONVERT(NVARCHAR(20), T1.Id) AS 'UserName', T1.Id + 10 AS 'Age' INTO #Temp1 FROM ( SELECT TOP 100000 Id = ROW_NUMBER() OVER (ORDER BY T1.Id) FROM #Temp AS T1 CROSS JOIN #Temp AS T2 CROSS JOIN #Temp AS T3 CROSS JOIN #Temp AS T4 CROSS JOIN #Temp AS T5 ORDER BY T1.Id ) AS T1 INSERT INTO dbo.Org_User SELECT * FROM #Temp1 INSERT INTO dbo.Org_User1 SELECT * FROM #Temp1 SELECT * FROM dbo.Org_User1 SELECT * FROM dbo.Org_User SELECT UserName FROM dbo.Org_User WHERE UserName LIKE '%Name%'
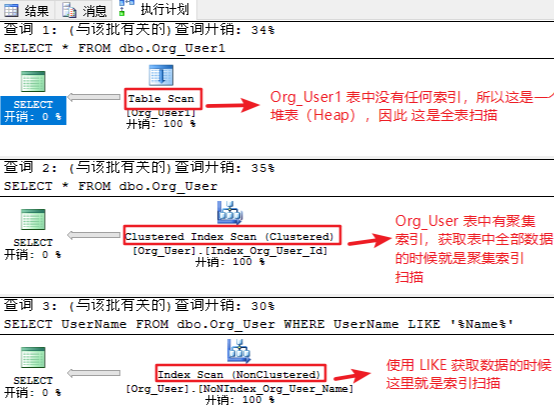
因此可以理解成,只要表中有聚集索引就不可能有全表扫描,只能是聚集索引扫描
-- 在 Age 列上创建一个非聚集索引 CREATE NONCLUSTERED INDEX NoNIndex_Org_User_Age ON Org_User(Age)
-- 执行这个 SQL SET STATISTICS TIME ON SET STATISTICS IO ON WITH Temp AS ( SELECT Id,Age FROM Org_User WHERE Age > 100 AND Age < 1000 ) SELECT * FROM Org_User AS T1 INNER JOIN Temp AS T2 ON T1.Id = T2.Id /* (899 行受影响) 表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 表 'Org_User'。扫描计数 2,逻辑读取 14 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 (1 行受影响) SQL Server 执行时间: CPU 时间 = 0 毫秒,占用时间 = 136 毫秒。 */
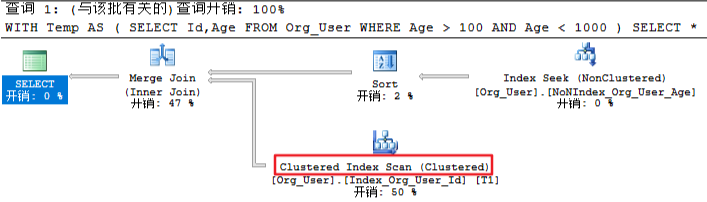
上面这个例子,执行计划中显示的是 Clustered index scan(聚集索引扫描),但是通过IO统计可以看到他其实是范围扫描(逻辑读取 14 次)
最后:并不是索引扫描的效率就一定低,合理的运用索引扫描(范围扫描)反而会提高查询速度(下面的临时表会给出一个例子)
在其他数据库中有自己特有的扫描比如说分区扫描等
二、IN 和 EXISTS
先说结论:无所谓谁好谁坏,想用哪个就用那个
准备测试数据
DROP TABLE IdTable DROP TABLE Temp CREATE TABLE Temp(Id INT) CREATE CLUSTERED INDEX Index_Temp_Id ON Temp(Id) CREATE TABLE IdTable(Id INT, Id_Index INT, Id_NonIndex INT) CREATE CLUSTERED INDEX Index_Id_Index ON IdTable(Id_Index) CREATE NONCLUSTERED INDEX NonIndex_Id_Index ON IdTable(Id_NonIndex) INSERT INTO Temp VALUES(1) INSERT INTO Temp VALUES(22) INSERT INTO Temp VALUES(33) INSERT INTO Temp VALUES(44) INSERT INTO Temp VALUES(55) INSERT INTO Temp VALUES(66) INSERT INTO Temp VALUES(77) INSERT INTO Temp VALUES(88) INSERT INTO Temp VALUES(99) INSERT INTO Temp VALUES(110) INSERT INTO dbo.IdTable SELECT T1.Id, T1.Id AS 'Id_Index', T1.Id AS 'Id_NonIndex' FROM ( SELECT TOP 100000 Id = ROW_NUMBER() OVER (ORDER BY T1.Id) FROM Temp AS T1 CROSS JOIN Temp AS T2 CROSS JOIN Temp AS T3 CROSS JOIN Temp AS T4 CROSS JOIN Temp AS T5 ORDER BY T1.Id ) AS T1 SET STATISTICS IO ON SET STATISTICS TIME ON
进行四组对比
对比的时候,所有的SQL执行前都执行一次 DBCC DROPCLEANBUFFERS 避免内存对查询造成影响
第一组
/* 没有索引 */ --清除所有缓存 DBCC DROPCLEANBUFFERS SELECT * FROM dbo.IdTable WHERE Id IN (SELECT Id FROM Temp) --清除所有缓存 DBCC DROPCLEANBUFFERS SELECT * FROM dbo.IdTable AS T1 WHERE EXISTS (SELECT Id FROM Temp AS T2 WHERE T1.Id = T2.Id)
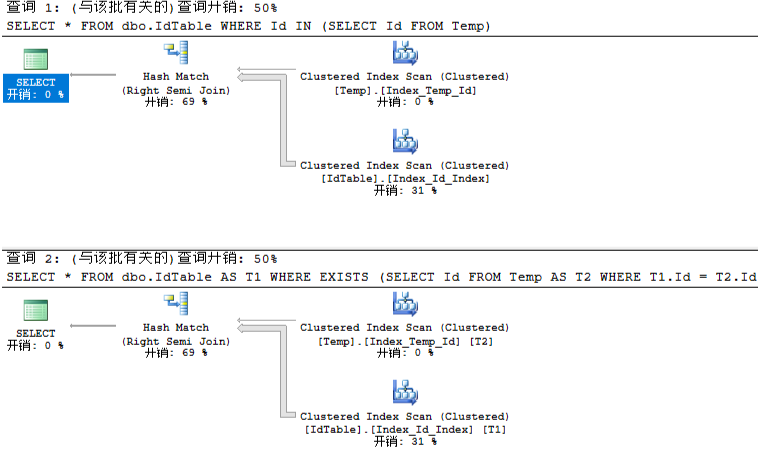

各种扫描,这一组没有什么意义,实际工作中就不应该出现这种情况
第二组
/* 使用聚集索引 */ --清除所有缓存 DBCC DROPCLEANBUFFERS SELECT * FROM dbo.IdTable WHERE Id_Index IN (SELECT Id FROM Temp) --清除所有缓存 DBCC DROPCLEANBUFFERS SELECT * FROM dbo.IdTable AS T1 WHERE EXISTS (SELECT Id FROM Temp AS T2 WHERE T1.Id_Index = T2.Id)


执行计划一模一样
IO 统计也一模一样
TIME IN 远远的好于 EXISTS (CPU资源和更多的时间)
第三组
/* 使用非聚集索引 */ --清除所有缓存 DBCC DROPCLEANBUFFERS SELECT * FROM dbo.IdTable WHERE Id_NonIndex IN (SELECT Id FROM Temp) --清除所有缓存 DBCC DROPCLEANBUFFERS SELECT * FROM dbo.IdTable AS T1 WHERE EXISTS (SELECT Id FROM Temp AS T2 WHERE T1.Id_NonIndex = T2.Id)
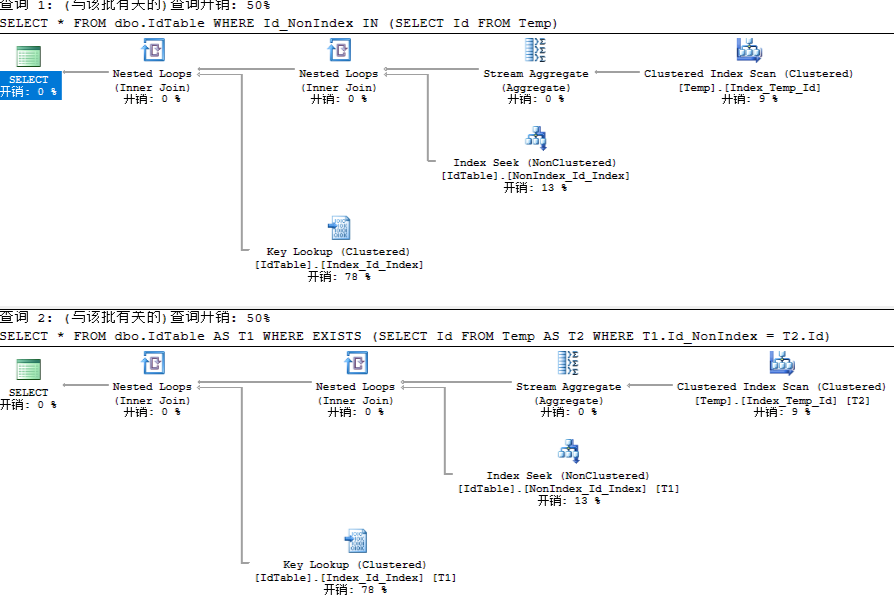

执行计划一模一样
IO 统计也一模一样
TIME 基本一样,多次执行几次观察输出内容得出 IN 要比 EXISTS 慢个 1 - 6 毫秒左右
第四组
CREATE TABLE IdTable1(Id INT, Id_Index INT, Id_NonIndex INT) CREATE CLUSTERED INDEX Index_Id_Index ON IdTable1(Id_Index) CREATE NONCLUSTERED INDEX NonIndex_Id_Index ON IdTable1(Id_NonIndex) INSERT INTO dbo.IdTable1 SELECT T1.Id, T1.Id AS 'Id_Index', T1.Id AS 'Id_NonIndex' FROM ( SELECT TOP 100000 Id = ROW_NUMBER() OVER (ORDER BY T1.Id) FROM Temp AS T1 CROSS JOIN Temp AS T2 CROSS JOIN Temp AS T3 CROSS JOIN Temp AS T4 CROSS JOIN Temp AS T5 ORDER BY T1.Id ) AS T1 --清除所有缓存 DBCC DROPCLEANBUFFERS SELECT * FROM dbo.IdTable WHERE Id_Index IN (SELECT Id FROM IdTable1 WHERE (Id_Index > 1000 AND Id_Index < 2000) OR (Id_Index > 10000 AND Id_Index < 12000) OR (Id_Index > 20000 AND Id_Index < 22000)) --清除所有缓存 DBCC DROPCLEANBUFFERS SELECT * FROM dbo.IdTable AS T1 WHERE EXISTS (SELECT Id FROM IdTable1 AS T2 WHERE (Id_Index > 1000 AND Id_Index < 2000 AND T1.Id_Index = T2.Id_Index) OR (Id_Index > 10000 AND Id_Index < 12000 AND T1.Id_Index = T2.Id_Index) OR (Id_Index > 20000 AND Id_Index < 22000 AND T1.Id_Index = T2.Id_Index))
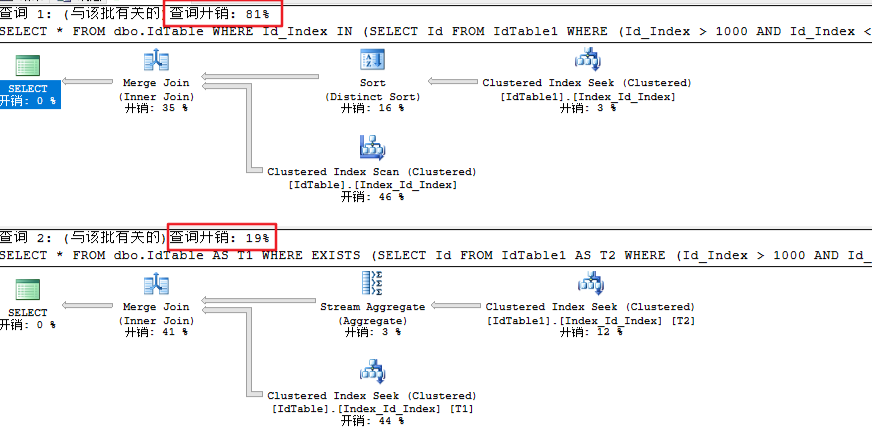

这是一组很极端的SQL语句
两个 OR 链接了三个查询条件,每个条件都是查询一个范围内的数据
EXISTS 对 CPU 的消耗更大
IN 对聚集索引的一部分进行了扫描 (逻辑读只有 60 次,从第一组测试结果中可以得出对整个聚集索引进行扫描应该是 262 次)
总结:
首先这是一次并不是很严谨的测试,只对 INT 这种类型的字段进行了四组测试,没有包含其他类型的字段,测试的数据也都很简单,实际情况会更加的复杂。
这四种测试中
第一和第四种,都是有问题的
第一种进行了各种扫描,一定要避免这种情况
第四种我基本上没有写过这种SQL,类似的需求我会用 UNION ALL 代替。
使用 UNION ALL 主要是因为用 UNION ALL 写的 SQL 清晰,一眼看下去就知道这段SQL干了什么,便于维护
而性能上 UNION ALL 也很快,并且把一个复杂的SQL拆分成多个简单的SQL也是SQL优化的一个点
第二种和第三种代表了大多数的 IN 和 EXISTS
不管业务怎么变,不管数据怎么不一样,他们的底层索引执行的逻辑都是一致的
执行计划和逻辑读大致的逻辑(第三组测试结果)
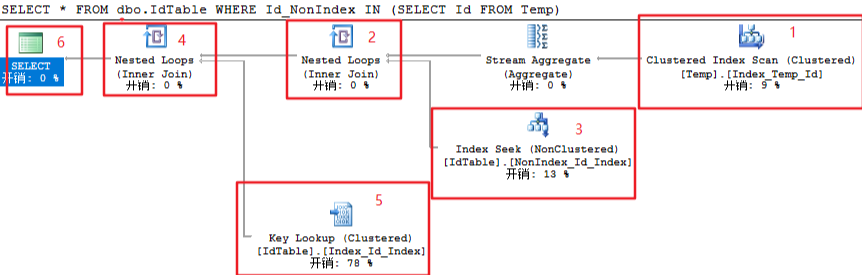
表 'IdTable'。扫描计数 10,逻辑读取 40 次,物理读取 1 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 表 'Temp'。扫描计数 1,逻辑读取 2 次,物理读取 1 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
物理读就是把硬盘上的数据读取到内存中
扫描计数可以简单粗暴的理解成调用索引的次数
1、对 Temp 表进行聚集索引扫描
2、对 1 的结果进行遍历
3、通过 Temp.Id 字段的值到 NonIndex_Id_Index 这个非聚集索引中查询数据,把结果返回给 2
4、第 2、3执行完成之后,临时的结果集中只有 Id_Index 和 Id_NonIndex 这两个字段,缺少 Id 字段,所以对该结果集进行遍历
5、通过 NonIndex_Id_Index.Id_Index 字段的值 Index_Id_Index 这个聚集索引中查询数据,把结果返回给 4
6、返回最终结果
最后
虽然 IN 和 EXISTS 有些差别
但是 不应该纠结使用 IN 还是 EXISTS
因为:
一、他们索引执行的逻辑基本上是差不多的,两条等价的SQL多次执行有可能会得到不同的结果(第三组SQL)。
二、把 IN 换成 EXISTS 或者把 EXISTS 换成 IN 的收益能有多大心里面要有谱。
三、很难说到底谁好谁坏,IN有些情况下效率更高,EXISTS 会额外的消耗CPU资源。交给优化器就好了
三、OR 会导致XX扫描
OR 会导致 XX扫描这是一个极其离谱的谣言
上面第四组的两条这么极端的SQL 一个对聚集索引进行了范围扫描,一个是索引搜索
四、关于用不用临时表的问题
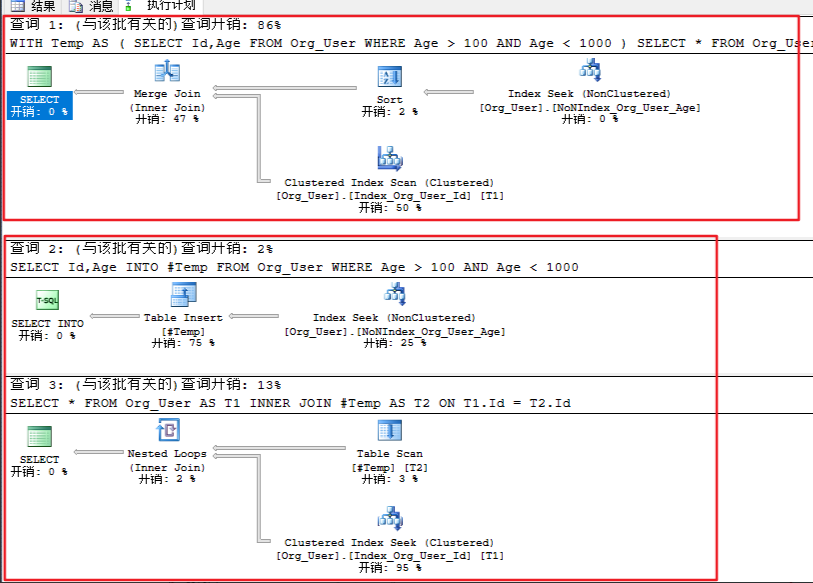
SET STATISTICS TIME ON SET STATISTICS IO ON DROP TABLE #Temp; --清除所有缓存 DBCC DROPCLEANBUFFERS; WITH Temp AS ( SELECT Id,Age FROM Org_User WHERE Age > 100 AND Age < 1000 ) SELECT * FROM Org_User AS T1 INNER JOIN Temp AS T2 ON T1.Id = T2.Id --清除所有缓存 DBCC DROPCLEANBUFFERS SELECT Id,Age INTO #Temp FROM Org_User WHERE Age > 100 AND Age < 1000 SELECT * FROM Org_User AS T1 INNER JOIN #Temp AS T2 ON T1.Id = T2.Id
上面两个SQL返回的结果是等价的
SQL Server 分析和编译时间: CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 (899 行受影响) 表 'Worktable'。扫描计数 0,逻辑读取 0 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 表 'Org_User'。扫描计数 2,逻辑读取 14 次,物理读取 2 次,预读 629 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 (1 行受影响) SQL Server 执行时间: CPU 时间 = 0 毫秒,占用时间 = 84 毫秒。 SQL Server 分析和编译时间: CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。 表 'Org_User'。扫描计数 1,逻辑读取 4 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 (899 行受影响) (1 行受影响) SQL Server 执行时间: CPU 时间 = 0 毫秒,占用时间 = 1 毫秒。 SQL Server 分析和编译时间: CPU 时间 = 3 毫秒,占用时间 = 3 毫秒。 (899 行受影响) 表 'Org_User'。扫描计数 899,逻辑读取 3431 次,物理读取 3 次,预读 16 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 表 '#Temp_______________________________________________________________________________________________________________00000000000E'。扫描计数 1,逻辑读取 2 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 (1 行受影响) SQL Server 执行时间: CPU 时间 = 0 毫秒,占用时间 = 173 毫秒。
通过执行计划,和系统资源的统计
类似的SQL我一定是用 WITH 而不是临时表
临时表是保存在 TempDB 中的,使用临时表就会给TempDB造成压力(新增、删除)
使用临时表的时候他是两条SQL,需要进行两次分析和编译,最后一个SQL不会进行缓存
大量的逻辑读(相较于 WITH而言)
使用 WITH
从IO统计开看预读 629 次,但是后面在执行的时候就都是 0 了
使用 WITH 把一个结果集存到内存中不会对 TempDB 造成压力(相较于临时表不会占用多余的资源)
从执行计划来看,索引范围扫描的造成的逻辑读取远远低于 索引搜索(Clustered Index Seek)
最后我在写SQL的时候想起来用 WITH 就用 WITH,想不起来就用临时表。在SQL Server中他们还是有差别的。
在其他的数据库中 使用临时表后 DELETE 临时表的时候需要注意回滚段的问题
最后的最后:
上面给出的例子,我都写了相关的逻辑,搞明白索引执行的逻辑后,再去看别人写的SQL优化宝典、干货等就知道自己面试的时候,死在了哪一个环节
还有就是上面的索引都只有一列,生产环境中大多数都是复合索引
--再写一些我认为是谣言的干货,这些谣言我不写DEMO去验证了,思路上面的DEMO都有 /* 谣言 一、尽量避免使用in 会导致引擎走全表扫描。 二、尽量避免进行null值的判断,会导致数据库引擎放弃索引进行全表扫描。 三、多表关联查询时,小表在前,大表在后。 四、where条件有些字段要放前面,有些字段要放后面 一、我上面写的SQL已经对他进行辟谣了 二、搞明白索引的结构,在一个可为null 的字段上建一个索引,自个试试就知道了 三和四、数据库中有一个东西叫做优化器,这些东西优化器会做,自个写个DEMO试试就知道了 */ /* 看情况 一、尽量避免在where条件中等号的左侧进行表达式、函数操作,会导致数据库引擎放弃索引进行全表扫描。 二、查询条件不能用 <> 或者 != 、NOT IN 、NOT EXISTS 这两个呢不全对,因为 WHERE 条件中如果只有上面的条件一定会有问题的 但是,下面这个例子中 SELECT Id,Age FROM Org_User WHERE Age > 100 AND Age < 1000 AND Age != 200 我用了 != 这种写法,并没有进行索引扫描 原因就是在执行 Age > 100 AND Age < 1000 AND 的时候 先找到 Age = 100 的这条数据,再根据数据页进行扫描,一直扫描到 Age = 1000 这条数据, 在扫描的过程中会排除掉 Age = 200 的数据 */
在不考虑硬件等外部环境的情况下
SQL优化的思路是:
会用数据库中各种统计工具,会用执行计划、知道索引执行的逻辑
一、减少数据访问
更少的扫描计数
更少的逻辑读
没有物理读(物理读就是把硬盘上的数据读取到内存中,硬盘IO和内存IO谁高谁低就不用多说了)
二、减少CPU和内存的开销
减少 排序、合并这些操作
知道那些语句会造成CPU和内存的额外开销。UNION、DISTINCT等
SQL语句怎么写
连接的表越多,性能越差
优先执行可显著减少数据量的连接,既降低了复杂度,也能够容易按照预期执行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号