

SQL Server 索引结构
索引是数据库的基础,只有先搞明白索引的结构,才能搞明白索引运行的逻辑
本文通过 索引表、数据页、执行计划、IO统计、B+Tree 来尽可能的介绍 SQL 语句中 WHERE 部分,和 SELECT 部分 的运行逻辑
名词介绍
B+Tree:一种数据结构
数据页:数据库保存数据的最小单位。(SQL Server一个数据页的大小是 8K,一个表中所有的数据都被保存到一个个的数据页中)
索引组织表:大白话一张表有聚集索引就是索引组织表(把表中的数据页以 B+Tree 的方式组织起来)
索引表:一个索引对应一张索引表,索引表中每条数据都对应一张数据页。
通过 DBCC IND(数据库, 表名, 索引Id) 命令可以获取到表中指定索引的索引表信息
通过 DBCC PAGE(数据库, 1, 数据页Id, 3) 命令可以获取到某个数据页中的数据
B+Tree结构
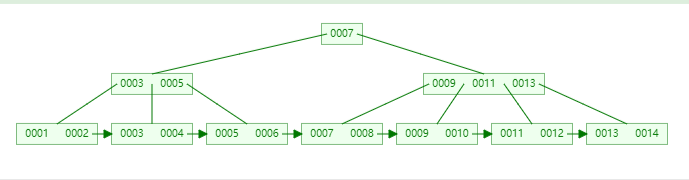
准备数据
DROP TABLE Org_User -- 创建测试表 CREATE TABLE Org_User(Id INT,UserName NVARCHAR(50),Age INT) -- 创建聚集索引和非聚集索引 CREATE CLUSTERED INDEX Org_User_Id ON Org_User(Id) CREATE NONCLUSTERED INDEX Org_User_Name ON Org_User(UserName) CREATE TABLE #Temp(Id INT) INSERT INTO #Temp VALUES(1) INSERT INTO #Temp VALUES(2) INSERT INTO #Temp VALUES(3) INSERT INTO #Temp VALUES(4) INSERT INTO #Temp VALUES(5) INSERT INTO #Temp VALUES(6) INSERT INTO #Temp VALUES(7) INSERT INTO #Temp VALUES(8) INSERT INTO #Temp VALUES(9) INSERT INTO #Temp VALUES(10) -- 批量插入10W条数据 INSERT INTO dbo.Org_User SELECT T1.Id, 'UserName_' + CONVERT(NVARCHAR(20), T1.Id) AS 'UserName', T1.Id + 10 AS 'Age' FROM ( SELECT TOP 100000 Id = ROW_NUMBER() OVER (ORDER BY T1.Id) FROM #Temp AS T1 CROSS JOIN #Temp AS T2 CROSS JOIN #Temp AS T3 CROSS JOIN #Temp AS T4 CROSS JOIN #Temp AS T5 ORDER BY T1.Id ) AS T1

SELECT name, index_id,type_desc FROM SYS.INDEXES WHERE object_id = OBJECT_ID('Org_User'); SELECT index_id , index_type_desc , index_depth , page_count FROM sys.dm_db_index_physical_stats(DB_ID('Core2022'), OBJECT_ID('Org_User'), NULL, NULL, NULL)
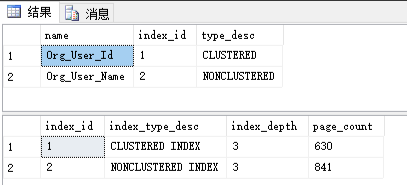
在 sys.dm_db_index_physical_stats 这张系统表中
index_depth 表示索引的深度 (对应上图B+Tree就是树的高度)
page_cout 表示索引数据页的数量 (对应上图B+Tree就是叶子节点的数量)
这里获取索引信息主要是为了 index_id
索引表
DBCC IND(Core2022, Org_User, 1)
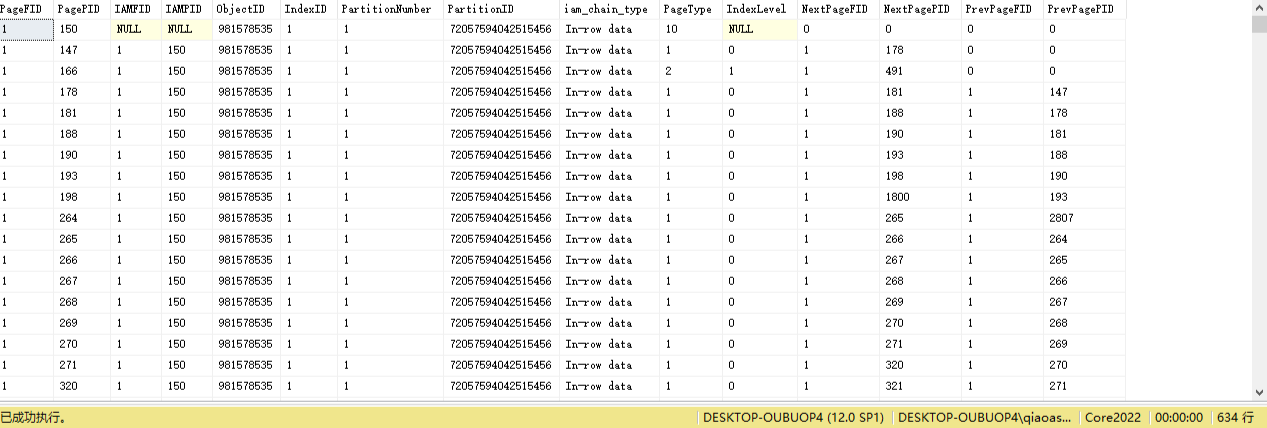
DROP TABLE dbcc_ind -- 创建一张表用来保存索引表信息 CREATE TABLE dbcc_ind ( PageFID NUMERIC(20), PagePID NUMERIC(20), IAMFID NUMERIC(20), IAMPID NUMERIC(20), ObjectID NUMERIC(20), IndexID NUMERIC(20), PartitionNumber NUMERIC(20), PartitionID NUMERIC(20), iam_chain_type VARCHAR(100), PageType NUMERIC(20), IndexLevel NUMERIC(20), NextPageFID NUMERIC(20), NextPagePID NUMERIC(20), PrevPageFID NUMERIC(20), PrevPagePID NUMERIC(20) ) --DROP PROC proc_dbcc_ind -- 创建存储过程 CREATE PROC proc_dbcc_ind AS DBCC IND(Core2022,Org_User,1) -- 把索引表中的数据批量插入到 dbcc_ind 中 INSERT INTO dbcc_ind EXEC proc_dbcc_ind
SELECT PagePID, -- 改行数据对应的数据页 IndexLevel, -- 表示改行数据的级别 0叶子节点,1分支节点,=2根节点,仅限该Demo NextPagePID, -- 当前节点的后继节点 (后面的那个数据页) PrevPagePID -- 当前节点的前驱节点 (前面的那个数据页) FROM dbcc_ind
SELECT PagePID, IndexLevel, NextPagePID, PrevPagePID FROM dbcc_ind WHERE IndexLevel = 0 ORDER BY NextPagePID
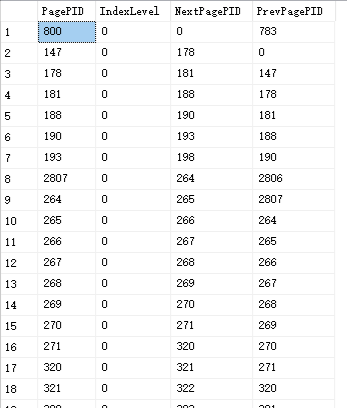
对 DBCC IND 中的数据进行一个总结
通过观察叶子节点的数据可以得到,每个节点都有一个前驱指针和后继指针,构成了一个双向链表
通过 IndexLevel 这个字段区分 根节点、分支节点、叶子节点
通过 NextPagePID 和 PrevPagePID 两个字段把相同深度的节点构成了一个双向链表
数据页
DBCC TRACEON(3604) — 打开跟踪标记,不打开的话 DBCC PAGE 只能查看分支节点中的数据,不能查看叶子节点中的数据
根节点

分支节点
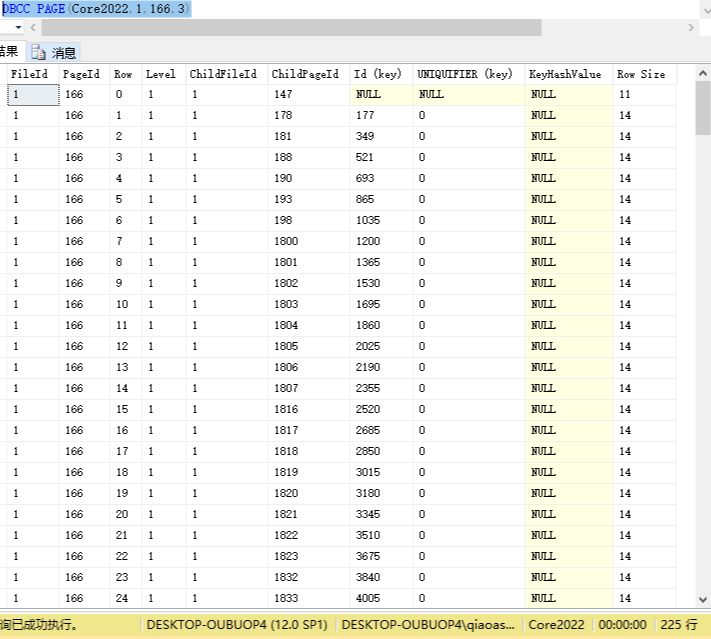
叶子节点
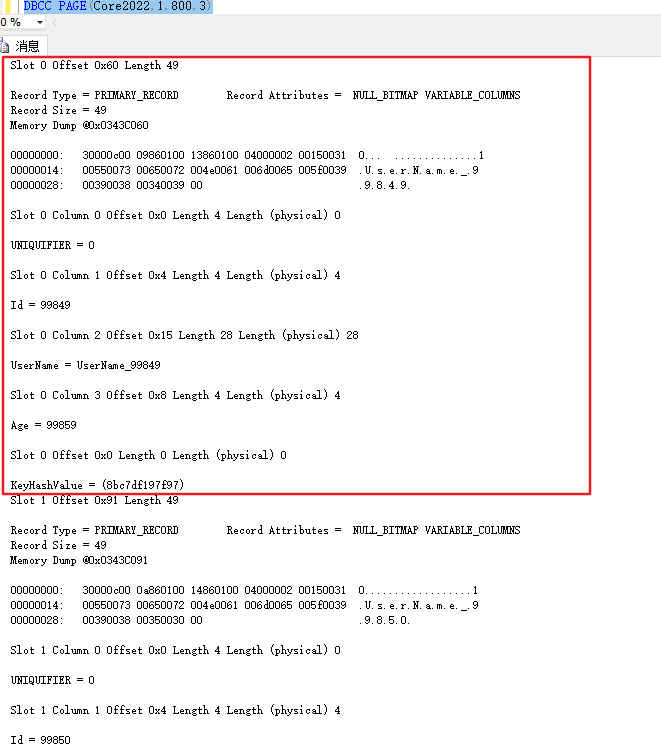
非聚集索引的叶子节点
对索引表和根节点对应的数据页,分支节点对应的数据页,叶子节点对应的数据页进行总结
聚集索引
叶子节点中保存的是 Org_User 表中的数据
根节点和分支节点中保存的是指向下一级节点的条件
索引表中同级的节点都有一个前驱和后继指针,这两个指针把同级的节点构建成了一个双向链表
非聚集索引
根节点和分支节点与聚集索引一直,都是指向下一级节点的条件
叶子节点有区别包含 创建非聚集索引是指定的Key、指向该行数据实际地址的Key、保证索引唯一的Key
UserName 就是创建索引时指定的,如果创建时指定多个,这里也会有多个
Id 这个是指向这行数据真实地址的指针表结构不同这个Key也不一样
索引组织表:这个Key就是创建聚集索引时指定的 Key
堆表:就值这个行数据所在堆表的地址
UNIQUIFIER 如果创建索引时指定该索引时唯一索引,那么这里就不会有这个字段,否则就会有这个字段用来区分重复的数据
通过索引表,找到 Id = 66666 的这行数据所在的数据页
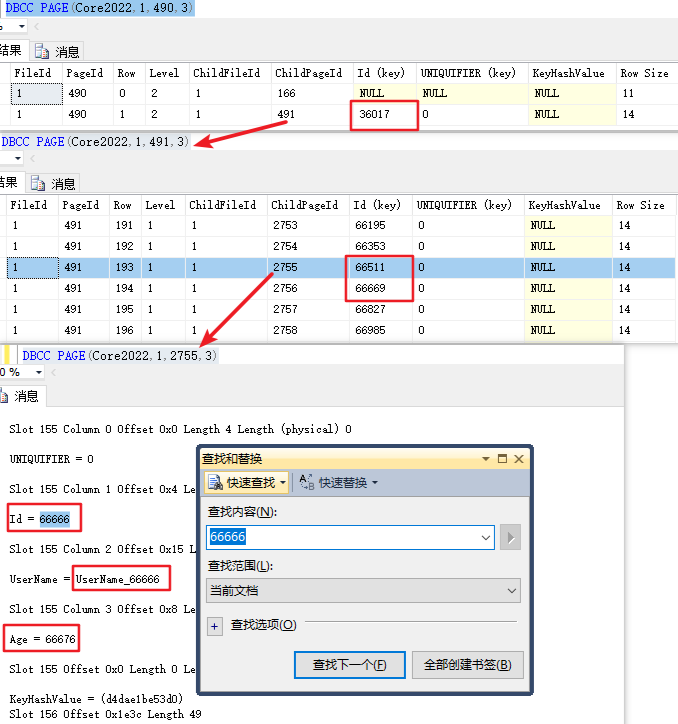
对上图进行解释
拿着 66666 从根节点指向的数据页开始找
66666 > 36017 所以就跳转到 491 这个数据页
66511 < 66666 ≤ 66669 所以就跳转到 2755 这个数据页
因为 2755 这个数据页已经是叶子节点了,直接在里面搜索 66666
就找到了这一行数据
SET STATISTICS IO ON SELECT * FROM Org_User WHERE Id = 66666

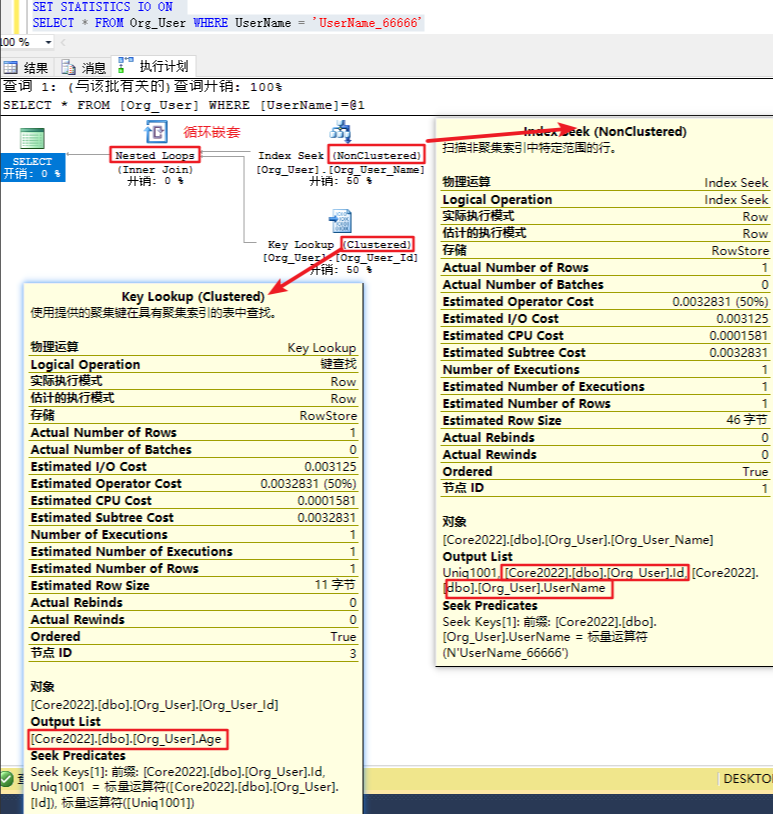
回表

因为这条SQL返回的字段是 Select *
非聚集索引里面没有 Age 这个字段
因此根据 UserName_66666 从非聚集索引中找到这条数据之后,根据 Id 到聚集索引里面在查一次,找到 Age 这个字段
覆盖索引

Select Id,UserName 非聚集索引里面这两个字段都有,所以就没有必要在查询聚集索引了
举一个例子
SET STATISTICS IO ON SELECT * FROM [Org_User] WHERE Id >= 1 AND Id <= 10 SELECT * FROM [Org_User] WHERE Id IN (1,2,3,4,5,6,7,8,9,10) -- 上面这两个SQL只有在 Id 为 Int 类型的时候才等价,在等价的前提下 -- 第一个SQL的效率要远超于第二个SQL /* SET STATISTICS IO ON (开启后输出的内容) (10 行受影响) 表 'Org_User'。扫描计数 1,逻辑读取 3 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 (10 行受影响) 表 'Org_User'。扫描计数 10,逻辑读取 30 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 很明显 第一个SQL只有3次逻辑读,而第二个有30次逻辑读 */
只有搞明白了索引运行的逻辑,结合执行计划等工具,才能搞明白什么情况下那些SQL更好
谣言:
COUNT(*) 和 COUNT(列) 谁快,谁慢
首先这两种写法都不等价 COUNT(*) 是所有的数据 COUNT(列) NULL值不参与运算,所以如果COUNT的某一列中包含了NULL值算出来的数据可能就有问题了
查询速度
COUNT(*) 更块
COUNT(列) 会受偏移量和字段中数据的大小影响
(通过 SET STATISTICS TIME ON 可以非常简单的得出结论)
SQL语句 大表写前面,小表写后面
当前数据库都会对SQL进行优化,所以无所谓谁在前,谁在后
IN 与 EXISTS 谁好谁坏
当前数据库都会对SQL进行优化,所以无所谓谁好,谁坏
这些坑人的谣言还有很多,有些在老版本的数据库是对的,在当前的数据库中已经过时了。
