CBAM: 卷积块注意模块
CBAM: Convolutional Block Attention Module
论文地址:https://arxiv.org/abs/1807.06521
简介:我们提出了卷积块注意模块 (CBAM), 一个简单而有效的注意模块的前馈卷积神经网络。给出了一个中间特征映射, 我们的模块按照两个独立的维度、通道和空间顺序推断出注意力映射, 然后将注意力映射相乘为自适应特征细化的输入特征映射。因为 CBAM 是一个轻量级和通用的模块, 它可以无缝地集成到任何 CNN 架构只增加微不足道的间接开销, 可以集成到端到端的CNN里面去。通过对 ImageNet-1K、COCO、MS 检测和 VOC 2007 检测数据集的广泛实验, 我们验证了我们的 CBAM。我们的实验表明, 各种模型的分类和检测性能都有了一致的改进, 证明了 CBAM 的广泛适用性。这些代码和模型将公开提供。
2 相关工作
网络架构的构建,一直是计算机视觉中最重要的研究之一, 因为精心设计的网络确保了在各种应用中显著的性能提高。自成功实施大型 CNN以来, 已经提出了一系列广泛的体系结构。一种直观而简单的扩展方法是增加神经网络的深度如 VGG-NET、ResNet及其变体,如 WideResNet和 ResNeXt。GoogLeNet展现了增加网络的宽度对于结果的提升的帮助,典型的分类网络都在提升深度与宽度上下了很大功夫。
众所周知, 注意力在人的知觉中起着重要的作用。一个人并不是试图一次处理整个场景。相反, 人类注意部分场景, 并有选择地专注于突出部分, 以便更好地捕捉视觉结构。
最近, 有几次尝试加入注意处理, 以提高CNNs在大规模分类任务的性能。Residual attention network for image classification中使用 encoder-decoder 样式的注意模块的Residual attention network。通过细化特征映射,不仅网络性能良好, 而且对噪声输入也很健壮。我们不直接计算3d 的注意力映射, 而是分解了单独学习通道注意和空间注意的过程。对于3D 特征图, 单独的注意生成过程的计算和参数开销要小得多, 因此可以作为CNN的前置基础架构的模块使用。
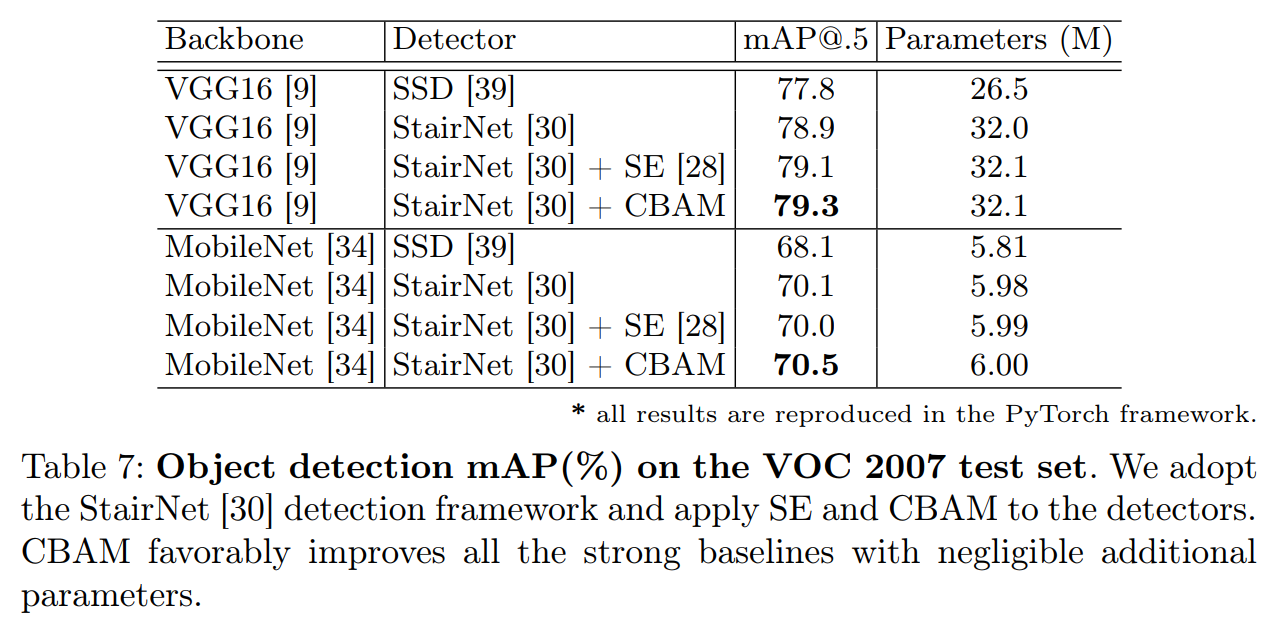
Squeeze-and-excitation networks引入一个紧凑模块来利用通道间的关系。在他们的压缩和激励模块中, 他们使用全局平均池功能来计算通道的注意力。然而, 我们表明, 这些都是次优特征, 以推断良好的通道注意, 我们使用最大池化的特点。然而,他们也错过了空间注意力机制, 在决定 "Where"。在我们的 CBAM 中, 我们利用一个有效的体系结构来开发空间和通道的注意力, 并通过经验验证, 利用两者都优于仅使用通道的注意作为。此外, 我们的实验表明, 我们的模块在检测任务 (MS COCO和 VOC2017)上是有效的。特别是, 我们通过将我们的模块放在VOC2007 测试集中的现有的目标检测器结合实现了最先进的性能。
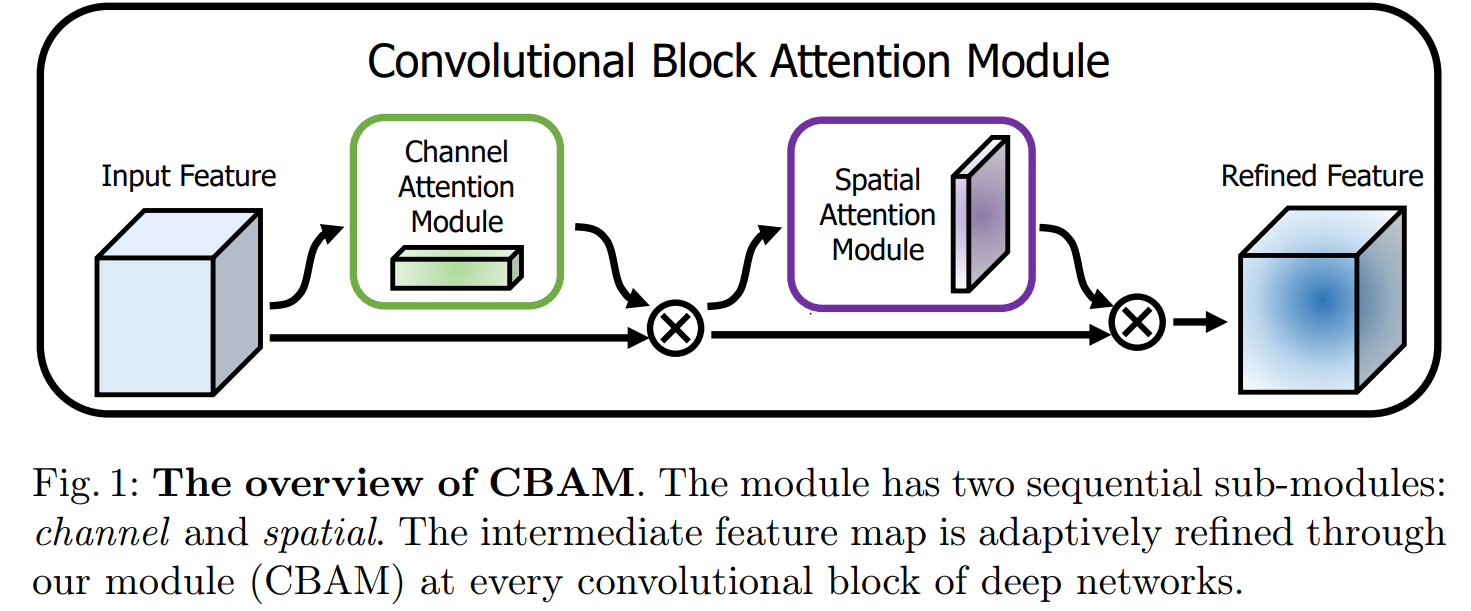
3 Convolutional Block Attention Module
给定一个中间特征映射F∈RC xHxW作为输入, CBAM的1维通道注意图Mc ∈RC ×1×1 和2D 空间注意图Ms ∈R1×HxW 如图1所示。总的注意过程可以概括为:
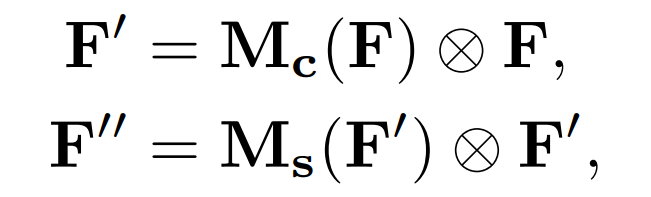
![]() 表示逐元素相乘。在相乘过程中,注意值被广播。相应地,通道注意值被沿着空间维度广播,反之亦然。F’’是最终输出。
表示逐元素相乘。在相乘过程中,注意值被广播。相应地,通道注意值被沿着空间维度广播,反之亦然。F’’是最终输出。
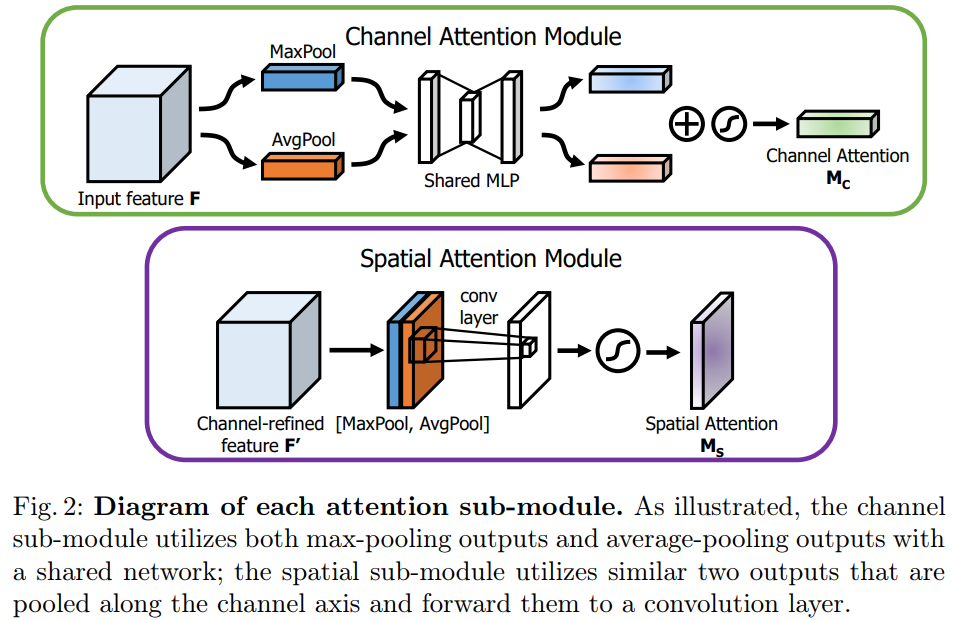
3.1 Channel attention module
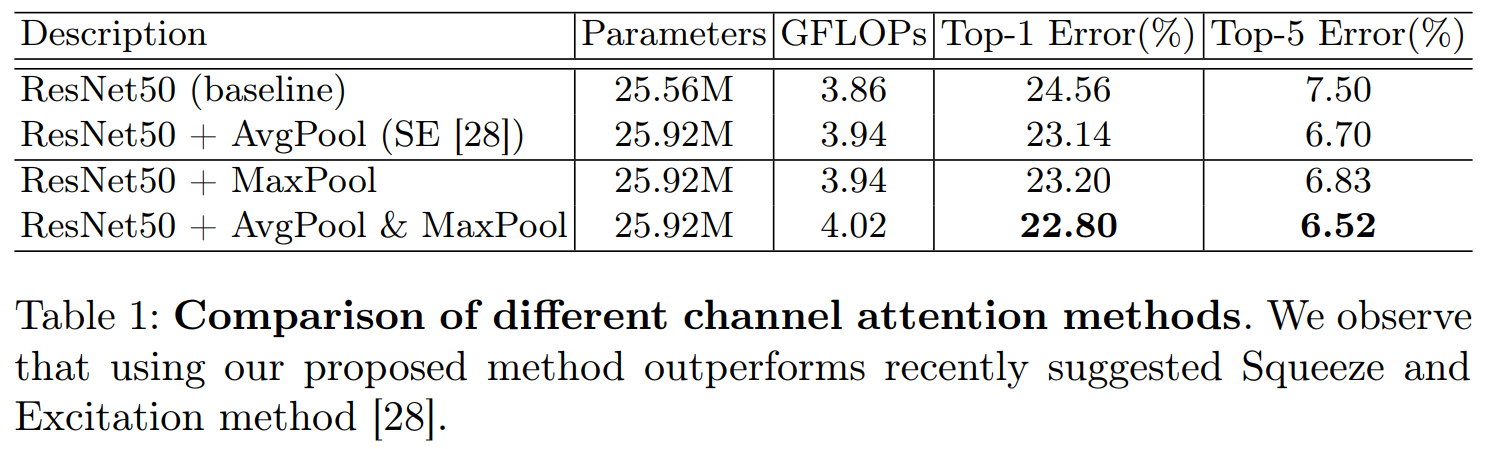
我们利用特征的通道间关系, 生成了通道注意图。当一个特征图的每个通道被考虑作为特征探测器, 通道注意聚焦于 ' what ' 是有意义的输入图像。为了有效地计算通道的注意力, 我们压缩了输入特征图的空间维数。为了聚焦空间信息,我们同时使用平均池化和最大池化。我们的实验证实, 同时使用这两种功能大大提高了网络的表示能力。下面将描述详细操作。
我们首先使用平均池化和最大池化操作来聚合特征映射的空间信息, 生成两个不同的空间上下文描述符:Fcavg 和Fcmax , 分别表示平均池化和最大池化。两个描述符然后送到一个共享网络, 以产生我们的通道注意力图 Mc ∈ Rc×1×1。共享网络由多层感知机(MLP) 和一个隐藏层组成。为了减少参数开销, 隐藏的激活大小被设置为 rc/c++×1×1, 其中 r 是压缩率。在将共享网络应用于每个描述符之后, 我们使用逐元素求和合并输出特征向量。简而言之, 频道的注意力被计算为:
Mc(f) = σ(MLP(AvgPool(f)) + MLP(MaxPool(f)))
= σ(W1(W0(Fcavg)) + W1(W0(Fcmax)))
σ是sigmoid function,W0 ∈ RC/r × C, W1 ∈ RC × C/r
W0 ,W1 是多层感知机的权重,共享输入和W0 的RELU激活函数。
3.2 Spatial attention module
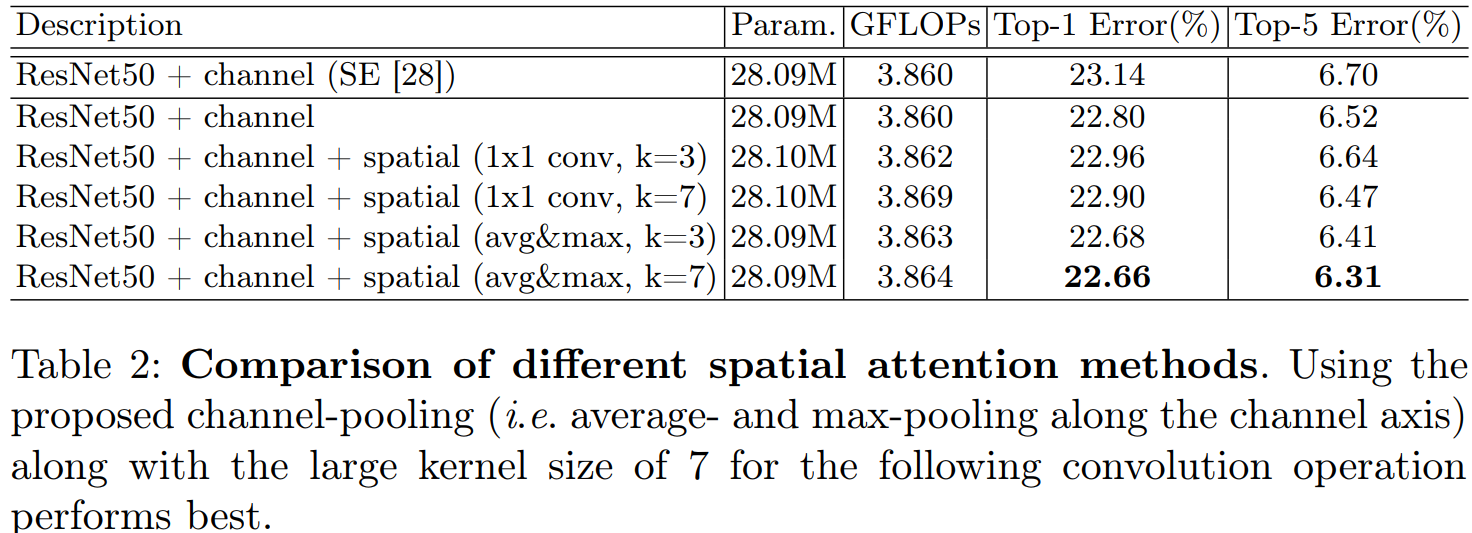
我们利用特征间的空间关系, 生成空间注意图。与通道注意力不同的是, 空间注意力集中在 "where" 是一个信息的部分, 这是对通道注意力的补充。为了计算空间注意力, 我们首先在通道轴上应用平均池和最大池运算, 并将它们连接起来以生成一个有效的特征描述符。在串联特征描述符上, 我们应用7×7的卷积生成空间注意图的层Ms (F) ∈RH×W 。我们描述下面的详细操作.
我们使用两个池化操作来聚合功能映射的通道信息, 生成两个2维映射:Fsavg∈R1×HxW 和Fsmax∈R1×HxW 每个通道都表示平均池化和最大池化。然后通过一个标准的卷积层连接和卷积混合, 产生我们的2D 空间注意图。简而言之, 空间注意力被计算为:
Ms (f) = σ( f7×7( AvgPool(f) ; MaxPool(F)] )))
= σ(f7×7 (Fsavg; Fsmax])),
σ是sigmoid function, f7×7 是7×7的卷积。
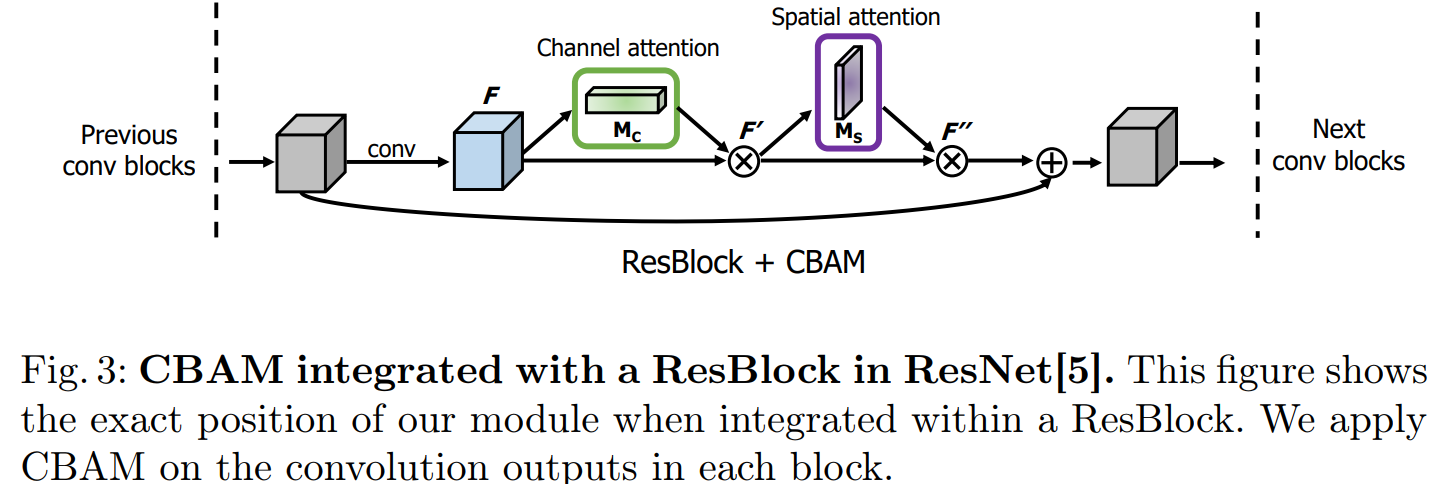
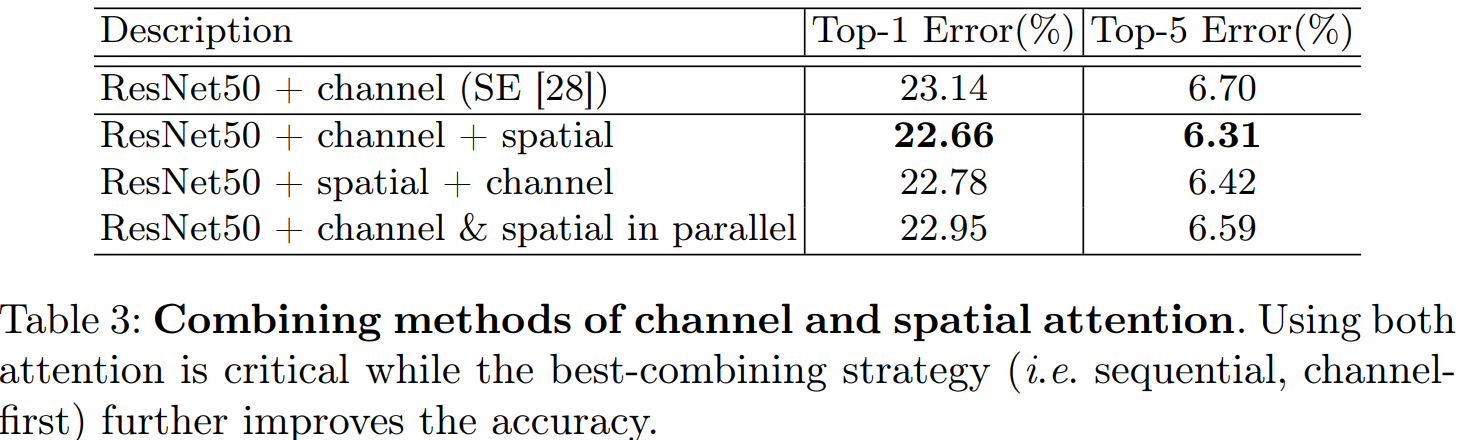
通过实验我们发现串联两个注意力模块的效果要优于并联。通道注意力放在前面要优于空间注意力模块放在前面。
4实验
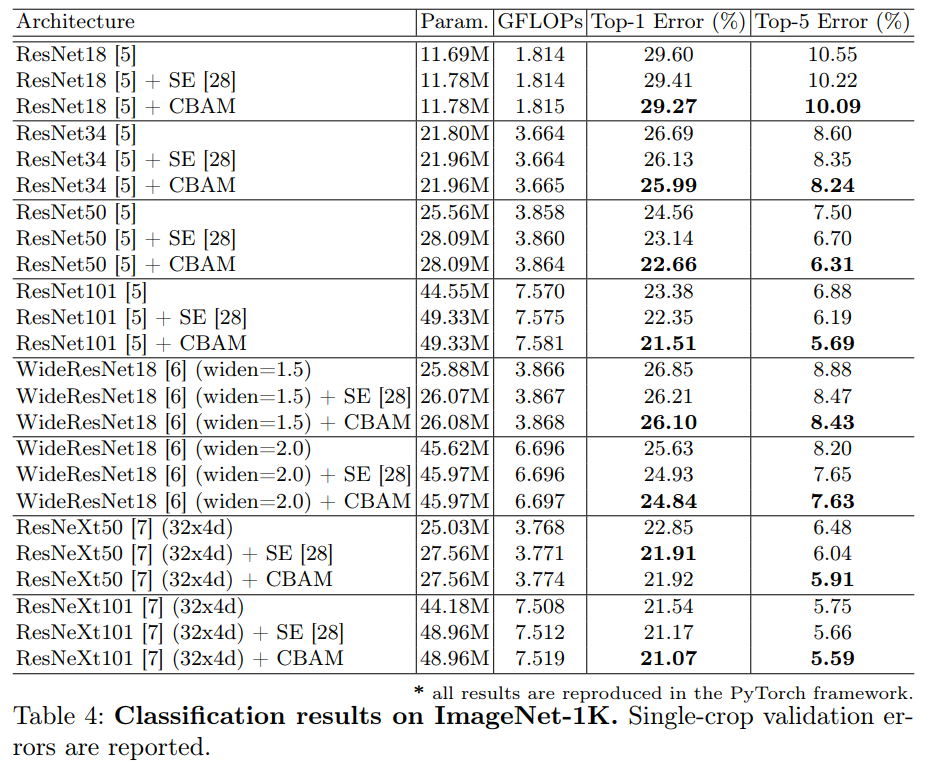
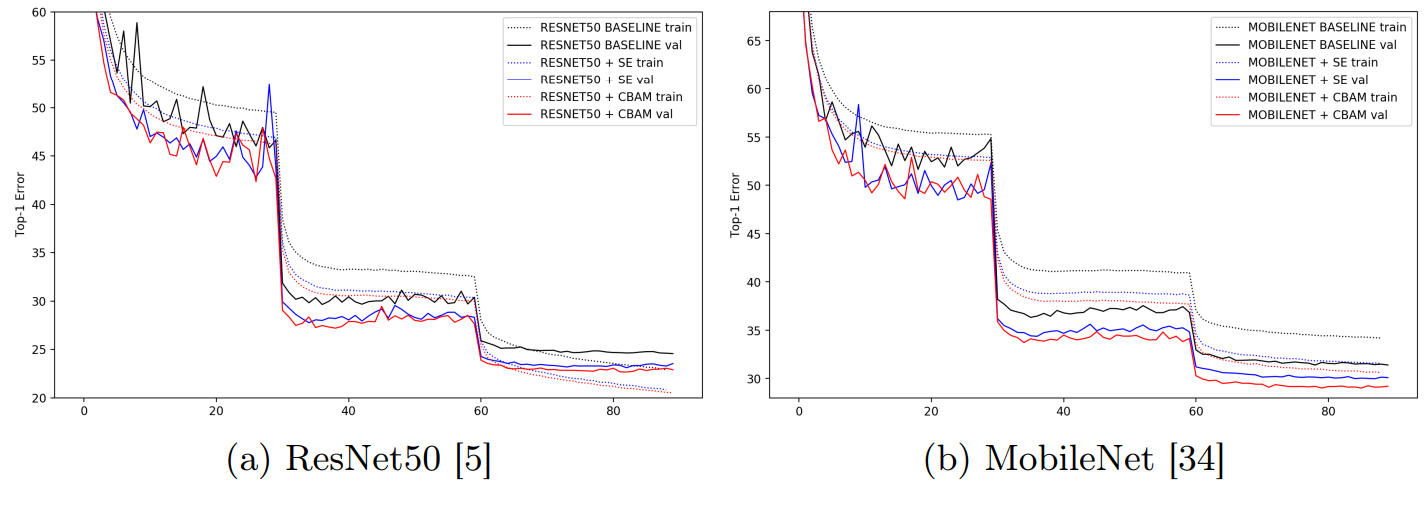
在本小节中,我们凭实验证明了我们的设计选择的有效性。 在这次实验中,我们使用ImageNet-1K数据集并采用ResNet-50作为基础架构。 ImageNet-1K分类数据集[1]由1.2组成用于训练的百万个图像和用于1,000个对象类的验证的50,000个图像
我们采用相同的数据增强方案进行训练和测试时间进行单一作物评估,大小为224×224。 学习率从0.1开始,每30个时期下降一次。 我们训练网络90迭代。
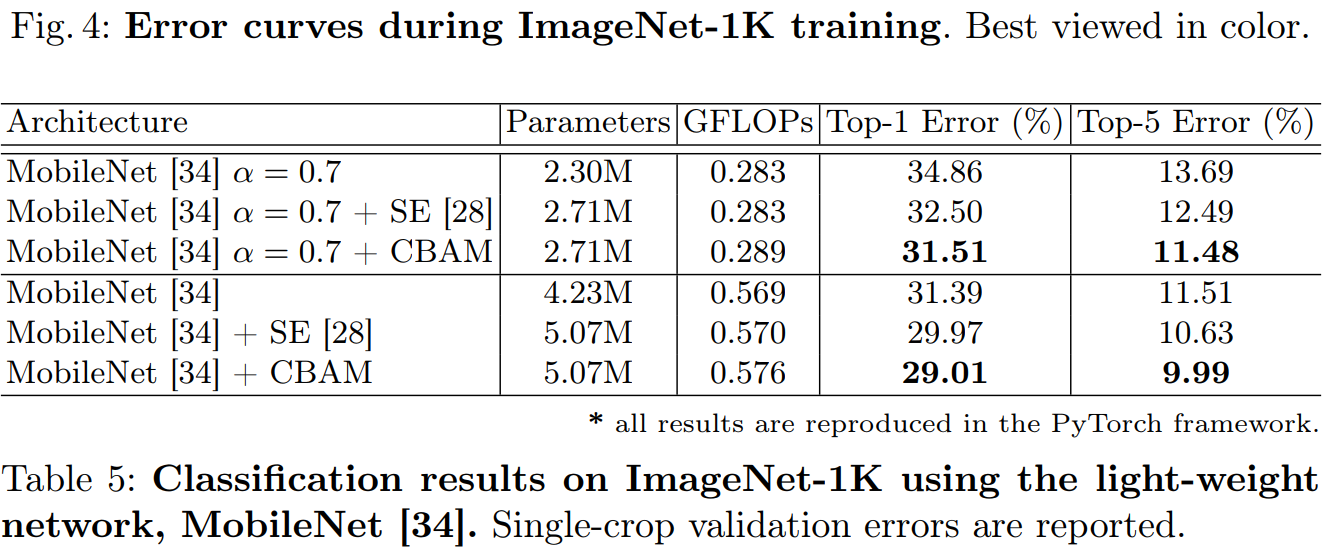
4.1 通道注意力和空间注意力机制实验
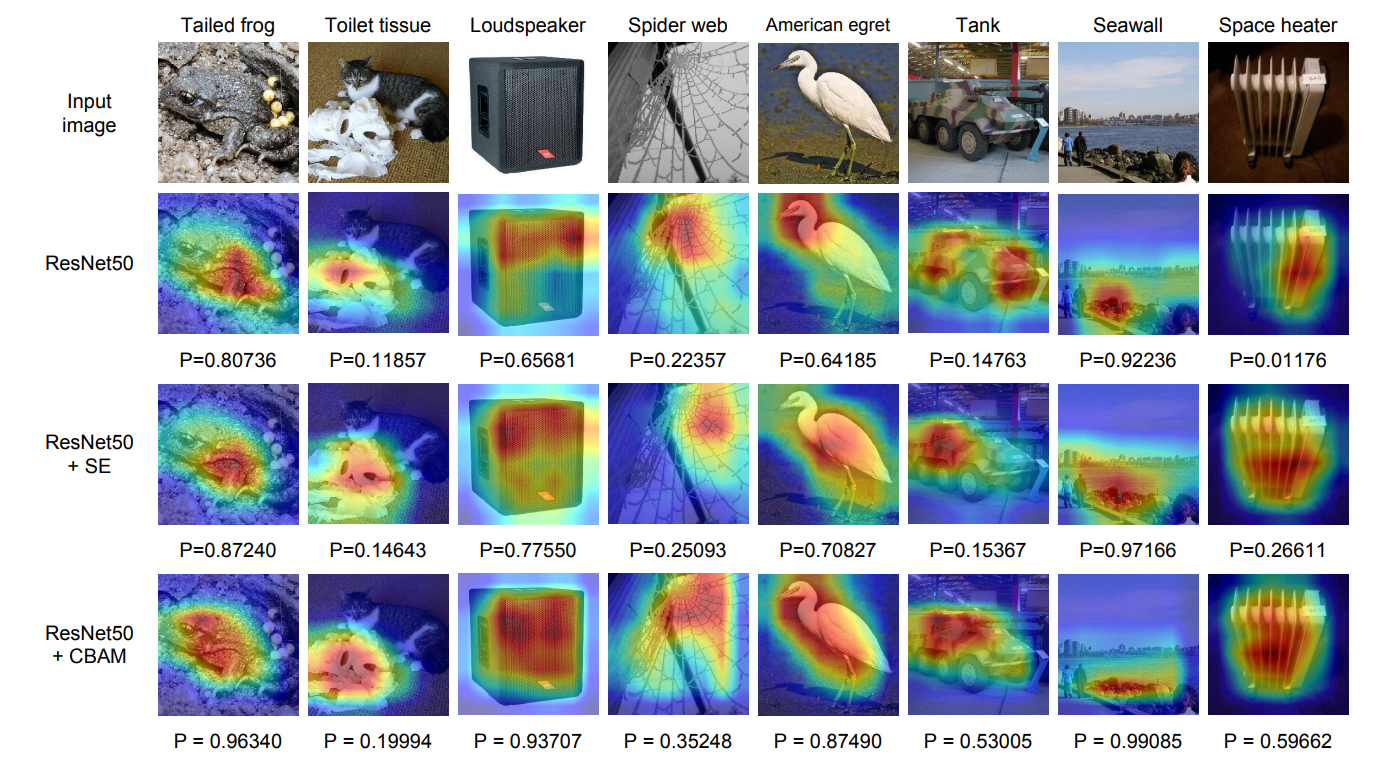
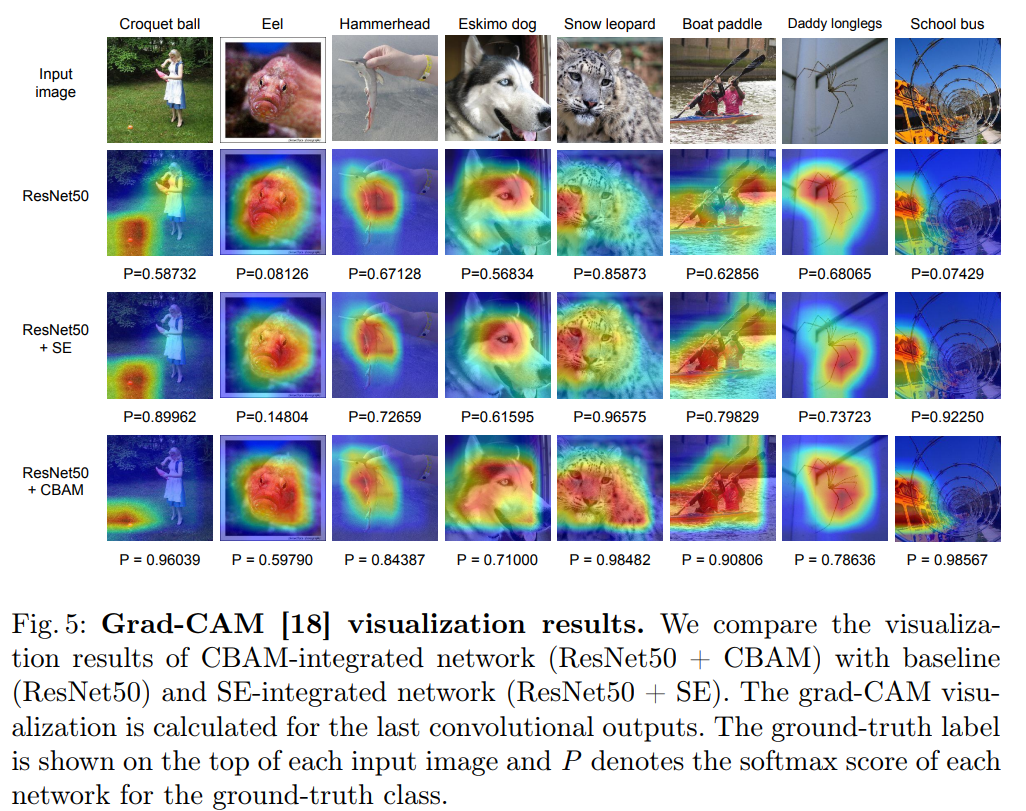
4.2我们使用Grad-CAM进行网络可视化
4.3 CBAM在目标检测的结果

5总结
作者提出了一种提高 CNN 网络表示的新方法--卷积瓶颈注意模块 (CBAM)。作者将基于注意力的特征细化成两个不同的模块、通道和空间结合起来, 实现了显著的性能改进, 同时保持了小的开销。对于通道的关注,使用最大池化和平均池化,最终模块 (CBAM) 学习了如何有效地强调或压缩提取中间特征。为了验证它的有效性, 我们进行了广泛的实验与并证实, CBAM 优于所有基线上的三不同的基准数据集: ImageNet-1K, COCO, 和 VOC 2007。此外, 我们可视化模块如何准确推断给定的输入图像。CBAM 或许会成为各种网络体系结构的重要组成部分。
附上cbam的代码:
pytorch_resnet50
1 from collections import OrderedDict 2 import math 3 import torch 4 import torch.nn as nn 5 # import torchvision.models.resnet 6 class CBAM_Module(nn.Module): 7 8 def __init__(self, channels, reduction): 9 super(CBAM_Module, self).__init__() 10 self.avg_pool = nn.AdaptiveAvgPool2d(1) 11 self.max_pool = nn.AdaptiveMaxPool2d(1) 12 self.fc1 = nn.Conv2d(channels, channels // reduction, kernel_size=1, 13 padding=0) 14 self.relu = nn.ReLU(inplace=True) 15 self.fc2 = nn.Conv2d(channels // reduction, channels, kernel_size=1, 16 padding=0) 17 self.sigmoid_channel = nn.Sigmoid() 18 self.conv_after_concat = nn.Conv2d(2, 1, kernel_size = 3, stride=1, padding = 1) 19 self.sigmoid_spatial = nn.Sigmoid() 20 21 def forward(self, x): 22 # Channel attention module:(Mc(f) = σ(MLP(AvgPool(f)) + MLP(MaxPool(f)))) 23 module_input = x 24 avg = self.avg_pool(x) 25 mx = self.max_pool(x) 26 avg = self.fc1(avg) 27 mx = self.fc1(mx) 28 avg = self.relu(avg) 29 mx = self.relu(mx) 30 avg = self.fc2(avg) 31 mx = self.fc2(mx) 32 x = avg + mx 33 x = self.sigmoid_channel(x) 34 # Spatial attention module:Ms (f) = σ( f7×7( AvgPool(f) ; MaxPool(F)] ))) 35 x = module_input * x 36 module_input = x 37 avg = torch.mean(x, 1, keepdim=True) 38 mx, _ = torch.max(x, 1, keepdim=True) 39 x = torch.cat((avg, mx), 1) 40 x = self.conv_after_concat(x) 41 x = self.sigmoid_spatial(x) 42 x = module_input * x 43 return x 44 45 46 class Bottleneck(nn.Module): 47 """ 48 Base class for bottlenecks that implements `forward()` method. 49 """ 50 def forward(self, x): 51 residual = x 52 53 out = self.conv1(x) 54 out = self.bn1(out) 55 out = self.relu(out) 56 57 out = self.conv2(out) 58 out = self.bn2(out) 59 out = self.relu(out) 60 61 out = self.conv3(out) 62 out = self.bn3(out) 63 64 if self.downsample is not None: 65 residual = self.downsample(x) 66 67 out = self.se_module(out) + residual 68 out = self.relu(out) 69 70 return out 71 72 class CBAMResNetBottleneck(Bottleneck): 73 """ 74 ResNet bottleneck with a CBAM_Module. It follows Caffe 75 implementation and uses `stride=stride` in `conv1` and not in `conv2` 76 (the latter is used in the torchvision implementation of ResNet). 77 """ 78 expansion = 4 79 80 def __init__(self, inplanes, planes, groups, reduction, stride=1, 81 downsample=None): 82 super(CBAMResNetBottleneck, self).__init__() 83 self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False, 84 stride=stride) 85 self.bn1 = nn.BatchNorm2d(planes) 86 self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, padding=1, 87 groups=groups, bias=False) 88 self.bn2 = nn.BatchNorm2d(planes) 89 self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False) 90 self.bn3 = nn.BatchNorm2d(planes * 4) 91 self.relu = nn.ReLU(inplace=True) 92 self.se_module = CBAM_Module(planes * 4, reduction=reduction) 93 self.downsample = downsample 94 self.stride = stride 95 96 97 98 class CABMNet(nn.Module): 99 100 def __init__(self, block, layers, groups, reduction, dropout_p=0.2, 101 inplanes=128, input_3x3=True, downsample_kernel_size=3, 102 downsample_padding=1, num_classes=1000): 103 super(CABMNet, self).__init__() 104 self.inplanes = inplanes 105 if input_3x3: 106 layer0_modules = [ 107 ('conv1', nn.Conv2d(3, 64, 3, stride=2, padding=1, 108 bias=False)), 109 ('bn1', nn.BatchNorm2d(64)), 110 ('relu1', nn.ReLU(inplace=True)), 111 ('conv2', nn.Conv2d(64, 64, 3, stride=1, padding=1, 112 bias=False)), 113 ('bn2', nn.BatchNorm2d(64)), 114 ('relu2', nn.ReLU(inplace=True)), 115 ('conv3', nn.Conv2d(64, inplanes, 3, stride=1, padding=1, 116 bias=False)), 117 ('bn3', nn.BatchNorm2d(inplanes)), 118 ('relu3', nn.ReLU(inplace=True)), 119 ] 120 else: 121 layer0_modules = [ 122 ('conv1', nn.Conv2d(3, inplanes, kernel_size=7, stride=2, 123 padding=3, bias=False)), 124 ('bn1', nn.BatchNorm2d(inplanes)), 125 ('relu1', nn.ReLU(inplace=True)), 126 ] 127 # To preserve compatibility with Caffe weights `ceil_mode=True` 128 # is used instead of `padding=1`. 129 layer0_modules.append(('pool', nn.MaxPool2d(3, stride=2, 130 ceil_mode=True))) 131 self.layer0 = nn.Sequential(OrderedDict(layer0_modules)) 132 self.layer1 = self._make_layer( 133 block, 134 planes=64, 135 blocks=layers[0], 136 groups=groups, 137 reduction=reduction, 138 downsample_kernel_size=1, 139 downsample_padding=0 140 ) 141 self.layer2 = self._make_layer( 142 block, 143 planes=128, 144 blocks=layers[1], 145 stride=2, 146 groups=groups, 147 reduction=reduction, 148 downsample_kernel_size=downsample_kernel_size, 149 downsample_padding=downsample_padding 150 ) 151 self.layer3 = self._make_layer( 152 block, 153 planes=256, 154 blocks=layers[2], 155 stride=2, 156 groups=groups, 157 reduction=reduction, 158 downsample_kernel_size=downsample_kernel_size, 159 downsample_padding=downsample_padding 160 ) 161 self.layer4 = self._make_layer( 162 block, 163 planes=512, 164 blocks=layers[3], 165 stride=2, 166 groups=groups, 167 reduction=reduction, 168 downsample_kernel_size=downsample_kernel_size, 169 downsample_padding=downsample_padding 170 ) 171 self.avg_pool = nn.AvgPool2d(7, stride=1) 172 self.dropout = nn.Dropout(dropout_p) if dropout_p is not None else None 173 self.last_linear = nn.Linear(512 * block.expansion, num_classes) 174 175 for m in self.modules(): 176 if isinstance(m, nn.Conv2d): 177 n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels 178 m.weight.data.normal_(0, math.sqrt(2. / n)) 179 elif isinstance(m, nn.BatchNorm2d): 180 m.weight.data.fill_(1) 181 m.bias.data.zero_() 182 183 # for m in self.modules(): 184 # if isinstance(m, nn.Conv2d): 185 # nn.init.kaiming_normal(m.weight.data) 186 # elif isinstance(m, nn.BatchNorm2d): 187 # m.weight.data.fill_(1) 188 # m.bias.data.zero_() 189 190 def _make_layer(self, block, planes, blocks, groups, reduction, stride=1, 191 downsample_kernel_size=1, downsample_padding=0): 192 downsample = None 193 if stride != 1 or self.inplanes != planes * block.expansion: 194 downsample = nn.Sequential( 195 nn.Conv2d(self.inplanes, planes * block.expansion, 196 kernel_size=downsample_kernel_size, stride=stride, 197 padding=downsample_padding, bias=False), 198 nn.BatchNorm2d(planes * block.expansion), 199 ) 200 201 layers = [] 202 layers.append(block(self.inplanes, planes, groups, reduction, stride, 203 downsample)) 204 self.inplanes = planes * block.expansion 205 for i in range(1, blocks): 206 layers.append(block(self.inplanes, planes, groups, reduction)) 207 208 return nn.Sequential(*layers) 209 210 def features(self, x): 211 x = self.layer0(x) 212 x = self.layer1(x) 213 x = self.layer2(x) 214 x = self.layer3(x) 215 x = self.layer4(x) 216 return x 217 218 def logits(self, x): 219 x = self.avg_pool(x) 220 if self.dropout is not None: 221 x = self.dropout(x) 222 x = x.view(x.size(0), -1) 223 x = self.last_linear(x) 224 return x 225 226 def forward(self, x): 227 x = self.features(x) 228 x = self.logits(x) 229 return x 230 231 232 233 234 def cbam_resnet50(num_classes=1000): 235 model = CABMNet(CBAMResNetBottleneck, [3, 4, 6, 3], groups=1, reduction=16, 236 dropout_p=None, inplanes=64, input_3x3=False, 237 downsample_kernel_size=1, downsample_padding=0, 238 num_classes=num_classes) 239 print(model) 240 return model 241 cbam_resnet50()
制作的PPT方便大家理解


 浙公网安备 33010602011771号
浙公网安备 33010602011771号