onehot编码解释
什么是One-Hot编码?
One-Hot编码,又称为一位有效编码,主要是采用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。
One-Hot编码是分类变量作为二进制向量的表示。这首先要求将分类值映射到整数值。然后,每个整数值被表示为二进制向量,除了整数的索引之外,它都是零值,它被标记为1。
One-Hot编码的工作示例
如果我们有 ‘red’,‘red’,‘green’ 编码为0的“红色”标签将用二进制向量[1,0]表示,其中第0个索引被标记为值1。然后,编码为1的“绿色”标签将用一个二进制向量[0,1],其中第一个索引被标记为1 整数编码[0],[0],[1] one hot 编码 [1, 0] [1, 0] [0, 1]
One-Hot编码的作用
One hot 编码进行数据的分类更准确,许多机器学习算法无法直接用于数据分类。数据的类别必须转换成数字,对于分类的输入和输出变量都是一样的
在模型训练的过程中不同的值使得同一特征在样本中的权重可能发生变化 (1000比1对模型的影响更大)
我们可以直接使用整数编码,需要时重新调整。这可能适用于在类别之间存在自然关系的问题,例如温度“冷”(0)和”热“(1)的标签。
当没有关系时,可能会出现问题,一个例子可能是标签的“狗”和“猫”。
在这些情况下,我们想让网络更具表现力,为每个可能的标签值提供概率式数字。这有助于进行问题网络建模。当输出变量使用one-hot编码时,它可以提供比单个标签更准确的一组预测。
将离散型特征进行one-hot编码的作用,是为了让距离计算更合理,但如果特征是离散的,并且不用one-hot编码就可以很合理的计算出距离,那么就没必要进行one-hot编码,比如,该离散特征共有1000个取值,我们分成两组,分别是400和600,两个小组之间的距离有合适的定义,组内的距离也有合适的定义,那就没必要用one-hot 编码
离散特征进行one-hot编码后,编码后的特征,其实每一维度的特征都可以看做是连续的特征。就可以跟对连续型特征的归一化方法一样,对每一维特征进行归一化。比如归一化到[-1,1]或归一化到均值为0,方差为1
基于树的方法是不需要进行特征的归一化,例如随机森林,bagging 和 boosting等。基于参数的模型或基于距离的模型,都是要进行特征的归一化。
语义分割中的onehot编码

语义分割中label往往如图中所显示
实际上变为onehot编码为:
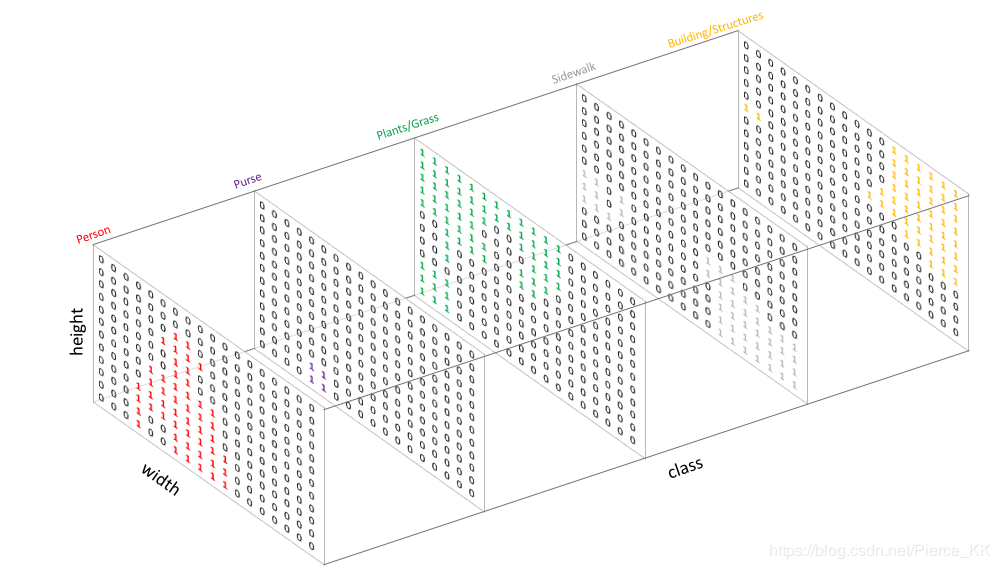
为每一个可能的类创建一个输出通道
最终通过取每个像素点在各个 channel 的 argmax 可以得到最终的预测分割图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号