

JAVA HASHMAP的原理分析
一网友发贴:map原理,它是如何快速查找key的.
还是来整体看一下HashMap的结构吧. 如下图所示(图没画好),方框代表Hash桶,椭图代表桶内的元素,在这里就是Key-value对所组成Map.Entry对像.
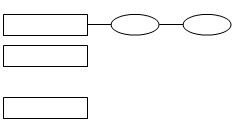
如果有多个元索被Hash函数定位到同一个桶内,我们称之为hash冲突,桶内的元素组成单向链表.让我们看一下hashMap JDK源码(因篇幅关系,删除了部分代码与注释,感兴可以查看JDK1.6源码):
 代码
代码

extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
{
static final int DEFAULT_INITIAL_CAPACITY = 16;
static final int MAXIMUM_CAPACITY = 1 << 30;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
transient Entry[] table;
transient int size;
int threshold;
final float loadFactor;
transient volatile int modCount;
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];
init();
}
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
private V getForNullKey() {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
}
先介绍一下负载因子(loadFactor)和容量(capacity)的属性。其实一个 HashMap 的实际容量就 因子*容量,其默认值是 16(DEFAULT_INITIAL_CAPACITY)×0.75=12; 这个很重要,当存入HashMap的对象超过这个容量时,HashMap 就会重新构造存取表.
最重要的莫过于Put与Get方法.
我们先看put. 这里先说一下,HashMap的hash函数是对key对像的hashCode进行hash,并把Null keys always map to hash 0.这里也正好证明了为什么基本类型(int之类) 不能做KEY值。
参考put方法源码,首选判断Key是否为null,若为NULL,刚从0号散列桶内去寻找key为null的Entry,找到则用新的Value替换旧的Value值,并返回旧值.反之把当前Entry放入0号桶,0号桶内的其他Entry链接到当前Entry后面(参考Entry的next属性).
如果是非NULL值,其实已经很简单,根把hash结果找到相应的hash桶(当前桶),遍历桶内链表,如果找到与当前KEY值相同Entry,则替抱该Entry的value值为当前value值。否则用当前key-value构建Entry对像,并入当前桶内,桶内元素链到新Entry后面.与NULL思路相同.
到这里get方法,就不用多说了,首先用key的hashCode 进行hash(参考HashMap的hash方法),用所得值定位桶号.遍历桶内链表,找到该KEY值的Entry对像,返回VALUE.反不到,则返回NULL,简单着呢.
回到网友贴子上来,如何快速查找KEY? hashMap通示计算得的HASH值快速定位到元素所在的桶,这样就排除了绝大部分元素,遍历其内的小链表就很快了.如果用链表把所有元素链起来,时间可想而知.
HashMap唯一高明之处在于他的Hash算法(不太明白):
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}.
另外 transient Entry[] table中的transient是什么意思,下一篇再说吧,欢迎拍砖.

