Hadoop全分布式集群环境配置
1 192.168.5.128 Master.Hadoop
2 192.168.5.129 Slave1.Hadoop
3 192.168.5.130 Slave2.Hadoop
3 配置SSH (实现三台服务器能够无密码互联)
以Maste.Hadoop这台服务器为例,输入如下命令:
1 ssh-keygen -t dsa -P '' -f .ssh/id_dsa
这个命令会在.ssh目录下产生两个文件id_dsa及id_dsa.pub,相当于现实中的锁和钥匙,把后者追加到授权的key中去,输入:
1 cat id_dsa.pub >> authorized_keys
这样就可以实现无密码ssh自登陆,可以试试命令:ssh localhost,如果登陆成功后输入exit退出
完成以上操作后分别按照相同的步骤分别在Slave1.Hadoop和Slave2.Hadoop服务器上产生对应的锁和钥匙,现在以Slave1.Hadoop服务器为例,输入如下命令
1 ssh-keygen -t dsa -P '' -f .ssh/id_dsa
在Slave1.Hadoop服务器上产生对应的锁和钥匙,然后把产生的id_dsa.pub通过命令传输到Master.Hadoop服务器上,命令如下:
1 scp .ssh/id_dsa.pub root@192.168.5.128:.ssh/id_dsa.pub.Slave1
Slave2.Hadoop执行上述相同的步骤,把产生id_dsa.pub传输到Master.Hadoop服务器上的id_dsa.pub.Slave2
现在在Master.Hadoop服务器上将id_dsa.pub.Slave1和id_dsa.pub.Slave2文件中的内容追加到授权的key中,命令如下:
1 cat .ssh/id_dsa.pub.Slave1 >> authorized_keys
2 cat .ssh/id_dsa.pub.Slave2 >> authorized_keys
完成以上操作后,现在通过命令把Master.Hadoop服务器上的授权key分别传输到Slave1.Hadoop和Slave2.Hadoop服务器上,命令如下:
1 scp .ssh/authorized_keys root@192.168.5.129:.ssh/authorized_keys
2 scp .ssh/authorized_keys root@192.168.5.130:.ssh/authorized_keys
完成以上步骤以后通过ssh Slave1.Hadoop,ssh Slave2.Hadoop,你会发现三台服务器之间都可以实现无密码互联了,进行这样设置的目的是为了能够在Master.Hadoop服务器上能够维护其他节点的相关信息,方便系统维护
4 配置Hadoop
现在仍旧以Master.Hadoop服务器为例,配置Hadoop集群的masters和slaves,修改Hadoop的配置文件masters,vi/masters,然后在文件中输入Master.Hadoop保存退出,修改slaves,vi/slaves,去掉文件中的localhost,按照如下方式输入如下内容:
1 Slave1.Hadoop
2 Slave2.Hadoop
保存退出,Hadoop的masters和slaves配置完毕
现在修改Hadoop集群运行需要的配置配置主要的配置文件有四个分别是core-site.xml,hdfs-site.xml,mapred-site.xml和yarn-site.xml,这几个文件的配置相对较简单,可以根据具体的业务要求参考Hadoop相关资料进行修改,本文就不做赘述了,直接上配置文件
core-site.xml
1 <?xml version="1.0" encoding="UTF-8"?>
2 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
3 <!--
4 Licensed under the Apache License, Version 2.0 (the "License");
5 you may not use this file except in compliance with the License.
6 You may obtain a copy of the License at
7
8 http://www.apache.org/licenses/LICENSE-2.0
9 Unless required by applicable law or agreed to in writing, software
10 distributed under the License is distributed on an "AS IS" BASIS,
11 WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 See the License for the specific language governing permissions and
13 limitations under the License. See accompanying LICENSE file.
14 -->
15
16 <!-- Put site-specific property overrides in this file. -->
17 <configuration>
18
19 <property>
20 <name>hadoop.tmp.dir</name>
21 <value>/usr/hadoop-2.8.1/data</value>
22 #记住该位置,为防止找不到该文件位置以及hadoop namenode -format不成功,每次在应在/opt新建一个hadoop目录
23 </property>
24 <property>
25 <name>fs.defaultFS</name>
26 <value>hdfs://Master.Hadoop:9000</value>
27 </property>
28 </configuration>
hdfs-site.xml
1 <?xml version="1.0" encoding="UTF-8"?>
2 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
3 <!--
4 Licensed under the Apache License, Version 2.0 (the "License");
5 you may not use this file except in compliance with the License.
6 You may obtain a copy of the License at
7
8 http://www.apache.org/licenses/LICENSE-2.0
9
10 Unless required by applicable law or agreed to in writing, software
11 distributed under the License is distributed on an "AS IS" BASIS,
12 WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 See the License for the specific language governing permissions and
14 limitations under the License. See accompanying LICENSE file.
15 -->
16
17 <!-- Put site-specific property overrides in this file. -->
18
19 <configuration>
20 <property>
21 <name>dfs.replication</name>
22 <value>2</value>
23 </property>
24 <property>
25 <name>dfs.namenode.name.dir</name>
26 <value>file:/usr/hadoop-2.8.1/data/hdfs/namenode</value>
27 <final>true</final>
28 </property>
29 <property>
30 <name>dfs.datanode.data.dir</name>
31 <value>file:/usr/hadoop-2.8.1/data/hdfs/datanode</value>
32 <final>true</final>
33 </property>
34 <property>
35 <name>dfs.namenode.secondary.http-address</name>
36 <value>Master.Hadoop:9001</value>
37 </property>
38 <property>
39 <name>dfs.webhdfs.enabled</name>
40 <value>true</value>
41 </property>
42 <property>
43 <name>dfs.permissions</name>
44 <value>false</value>
45 </property>
46 </configuration>
mapred-site.xml
1 <?xml version="1.0"?>
2 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
3 <!--
4 Licensed under the Apache License, Version 2.0 (the "License");
5 you may not use this file except in compliance with the License.
6 You may obtain a copy of the License at
7
8 http://www.apache.org/licenses/LICENSE-2.0
9
10 Unless required by applicable law or agreed to in writing, software
11 distributed under the License is distributed on an "AS IS" BASIS,
12 WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 See the License for the specific language governing permissions and
14 limitations under the License. See accompanying LICENSE file.
15 -->
16
17 <!-- Put site-specific property overrides in this file. -->
18
19 <configuration>
20
21 <property>
22 <name>mapreduce.framework.name</name>
23 <value>yarn</value>
24 </property>
25 <property>
26 <name>mapreduce.jobhistory.address</name>
27 <value>Master.Hadoop:10020</value>
28 </property>
29 <property>
30 <name>mapreduce.jobhistory.webapp.address</name>
31 <value>Master.Hadoop:19888</value>
32 </property>
33 </configuration>
yarn-site.xml
1 <?xml version="1.0"?>
2 <!--
3 Licensed under the Apache License, Version 2.0 (the "License");
4 you may not use this file except in compliance with the License.
5 You may obtain a copy of the License at
6
7 http://www.apache.org/licenses/LICENSE-2.0
8
9 Unless required by applicable law or agreed to in writing, software
10 distributed under the License is distributed on an "AS IS" BASIS,
11 WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 See the License for the specific language governing permissions and
13 limitations under the License. See accompanying LICENSE file.
14 -->
15
16 <configuration>
17 <property>
18 <name>yarn.nodemanager.aux-services</name>
19 <value>mapreduce_shuffle</value>
20 </property>
21 <property>
22 <name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
23 <value>org.apache.hadoop.mapred.ShuffleHandler</value>
24 </property>
25 <property>
26 <name>yarn.resourcemanager.address</name>
27 <value>Master.Hadoop:8032</value>
28 </property>
29 <property>
30 <name>yarn.resourcemanager.scheduler.address</name>
31 <value>Master.Hadoop:8030</value>
32 </property>
33 <property>
34 <name>yarn.resourcemanager.resource-tracker.address</name>
35 <value>Master.Hadoop:8031</value>
36 </property>
37 <property>
38 <name>yarn.resourcemanager.admin.address</name>
39 <value>Master.Hadoop:8033</value>
40 </property>
41 <property>
42 <name>yarn.resourcemanager.webapp.address</name>
43 <value>Master.Hadoop:8088</value>
44 </property>
45 <!-- Site specific YARN configuration properties -->
46 </configuration>
完成以上操作后Master.Hadoop服务器上的Hadoop配置就基本完成了,现在通过命令将Hadoop这个目录分别传输到Slave1.Hadoop,Slave2.Hadoop服务器上,命令如下:
1 scp /usr/hadoop-2.8.1 root@Slave1.Hadoop:/usr/hadoop-2.8.1
2 scp /usr/hadoop-2.8.1 root@Slave2.Hadoop:/usr/hadoop-2.8.1
文件传输完成后,Hadoop全分布式集群就配置完成了
5 测试部署的集群
先在Master.Hadoop上通过如下命令进行初始化
1 cd /usr/hadoop-2.8.1/bin2 ./hadoop namenode -format
完成上述初始化以后,启动Master.Hadoop上的Hadoop集群,命令如下
1 cd /usr/hadoop-2.8.1/sbin
2 ./start-all.sh
启动后会看到如下信息:
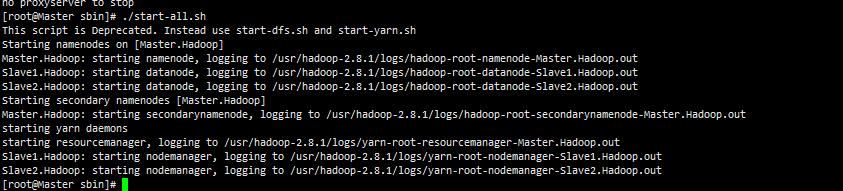
集群启动的同时会同时启动Slave1.Hadoop,Slave2.Hadoop上对应的节点,现在通过jps命令查看集群信息
在Master.Hadoop服务器上jps如果能看到如下进程信息,就说明我们的Hadoop全分布式集群部署成功了!!!
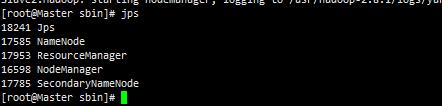
Slave1.Hadoop
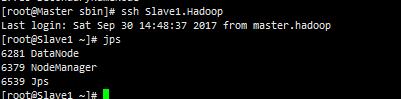
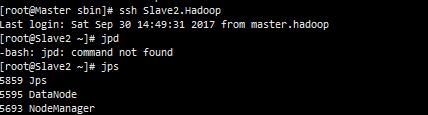
Slave2.Hadoop
posted on 2017-09-30 16:07 anqli_java 阅读(546) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号