应课程需要写了几天爬虫,一开始使用requests+bs4的技术路线,但是速度不是很理想而且不能暂停,通过查阅资料,发现scrapy正是我需要的
做一下简短的记录:
首先应该毫不犹豫的scrapy startproject gnspider;scrapy genspider gnspider http://www.chinanews.com;
然后定义items文件,写下我们希望爬虫下载的内容
紧接着去测试gnspider能否请求到网页
gnspider的写法
1 class GnspiderSpider(scrapy.Spider): 2 3 name = “gnspider” 4 5 #从seed页开始,放入start_urls = [] 6 7 #seed页很多,则可以在def start_requests(self):重定义scrapy.Request(url),并返回由其组成的请求列表,即retuen [scrapy.Request(url),scrapy.Request(url),.....] 8 9 def parse(self,response): 10 11 #response是我们需要的网页的响应,我们通过css选择器或者xpath进行定位标签元素,这一步是最关键的,快速定位是必须的 12 response.css("div.content_list ul li div.dd_bt a::attr(href)").extract() #由于本科时了解过css,这里二话不说就用cssSelector,extract()是为了提取内容,结束提取则extract(),未结束则接着找标签。 13 14 response.css("div.left_zw p::text").extract() 15 16 content_list=response.xpath('//div[@id=\"artibody\"]/p/text()').extract() 17 18 big_urls=sel.xpath('//div[@id=\"tab01\"]/div/h3/a/@href').extract() #'http://news.sina.com.cn/guide' 19 big_titles=sel.xpath("//div[@id=\"tab01\"]/div/h3/a/text()").extract() 20 second_urls =sel.xpath('//div[@id=\"tab01\"]/div/ul/li/a/@href').extract() 21 second_titles=sel.xpath('//div[@id=\"tab01\"]/div/ul/li/a/text()').extract() 22 23 24 25 divs = response.xpath("//div[@id='J_ItemList']/div[@class='product']/div") 26 27 div.xpath("p[@class='productPrice']/em/@title")[0].extract() 28 29 div.xpath("p[@class='productTitle']/a/@title")[0].extract() 30 31 div.xpath("p[@class='productTitle']/a/@href")[0].extract() 32 33 34 35 item["SHOP_NAME"] = div.xpath("li[1]/div/a/text()")[0].extract() 36 item["SHOP_URL"] = div.xpath("li[1]/div/a/@href")[0].extract() 37 item["COMPANY_NAME"] = div.xpath("li[3]/div/text()")[0].extract().strip() 38 item["COMPANY_ADDRESS"] = div.xpath("li[4]/div/text()")[0].extract().strip( 39 40 #对于每个链接进行请求,这里我想强调的是meta这个参数,可以帮助我们将一级页面上爬到的内容传递到二级页面上,通过response.meta这个字典进行传递,非常方便我们对item进行组装 41 42 for li in lis: 43 44 yield scrapy.Request(li,callback = self.parse_detail,meta={"cate":cate}) 45 46 47 48 49 50 def parse_detail(self,response): #解析二级页面 51 52 #经常我们爬取的是一个列表 53 54 str1 = “”.join(lis) #split方法中不带参数时,表示分割所有换行符、制表符、空格。 55 56 str1 = replace(" ","").replace("\u3000","") 57 58 return item
写gnspider的时候一定不要一口气写完,一定要一个函数一个函数的测,首先保证地址写对了,其次保证标签选对了,最后保证item组装好了,我把它称为爬虫三段式
既然爬到了内容就应该存下来留个纪念,通过pipelines定义存储方式,在这里使用文件存储
class MyspiderPipeline(object): # def open_spider(self,spider):#针对爬虫 # self.f = open('gn.txt','a') # def close_spider(self,spider): # self.f.close() def process_item(self, item, spider):#针对item self.f = open(cate[item["CATEGORY"]] + '.txt','a') #注意文件操作,防止乱码 line = str(dict(item)["CONTENT"]) + '\n' self.f.write(line) self.f.close() return item
最后别忘了在配置文件中启用pipelines
总结如下:
简单爬虫三步走,1.定义items,2.parse页面,3.pipelines定义存储方式
其中parse页面又分为三步1.写对网址,2.找到标签,3.组装item
scrapy还提供了暂停功能:开始爬虫时使用命令 scrapy crawl gnspider -s JOBDIR=supplement/auto
暂停时使用ctrl + c
再次启动时还使用命令 scrapy crawl gnspider -s JOBDIR=supplement/auto
当爬取大量数据时推荐写多个爬虫,同时进行,可使电脑资源发挥最大效果
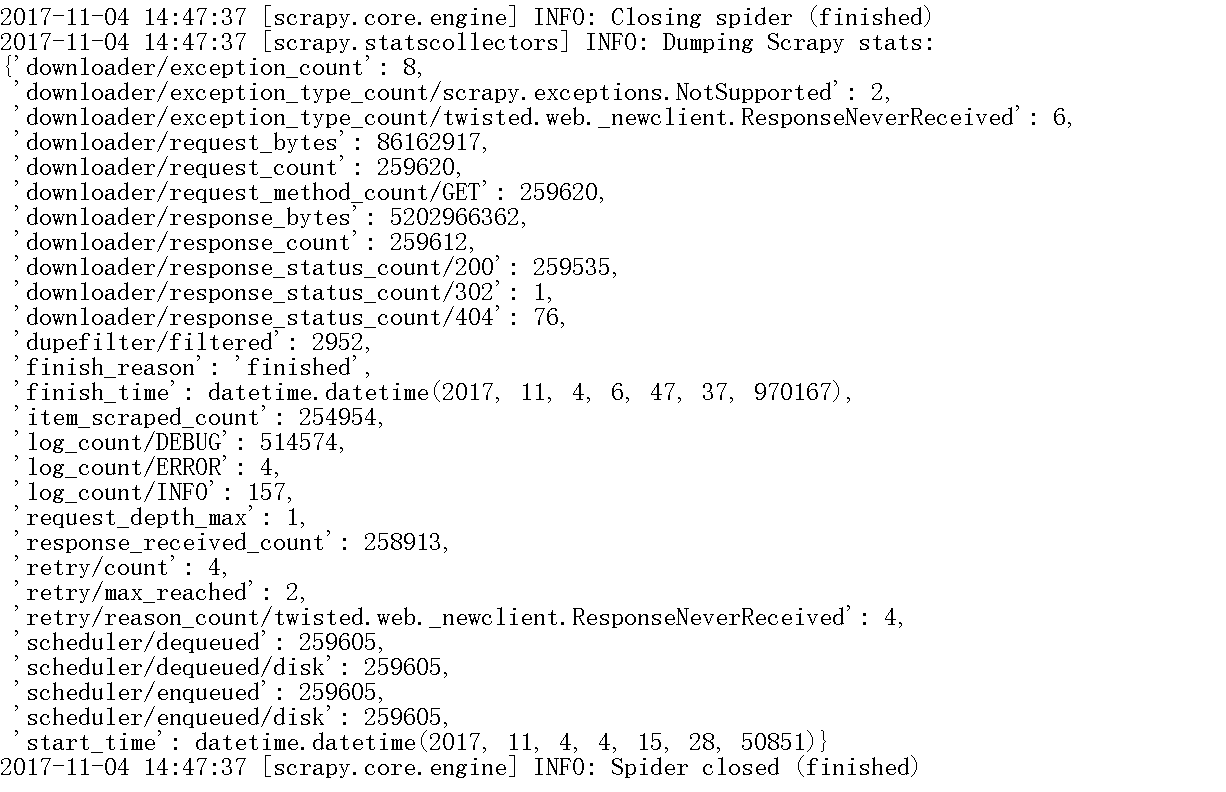
爬完结束提示信息如下