
用python解析word文件(二):table
太长了,我决定还是拆开三篇写。
(二)表格篇(table)(本篇)
选你所需即可。下面开始正文。
上一篇我们讲了用python-docx解析docx文件中的段落,也就是paragraph,不过细心的同学可能发现了,只有自然段是可以用paragraph处理的,如果word中有表格,根本读都读不到。这是正常的,因为表格在docx中是另一个类。
一个word文档中大概有这么几种类型的内容:paragraph(段落),table(表格),character(我也不知道该怎么叫,字符?)。我现在要解析的word文档中,基本都是段落和表格,所以character的具体内容我也没有特别关注。本文主要来讲一下如何从word中解析出表格,并在html中展示出来。
首先,很简单,使用
docx.tables
可以获得文档中的全部表格。跟excel中类似,word文档的表格也是分行(row)和列(column)的,读的方法是,对每一个table,先读出全部的rows,再对每一个row读出全部的column,这里的每行中的一列叫做一个单元格(cell),cell能做到的就跟一个paragraph类似了。如果用不着那么麻烦地获得表格的样式,就直接用
cell.text
获取单元格内容就好了。那么,一个二重循环,就获取到了table中的全部文字内容。
但是这是不够的。我的目的是要在html上展示出来。所以,需要在这一堆内容上添加html标签。具体的做法,我们来举个栗子吧。

不对,拿错了。应该是这样:
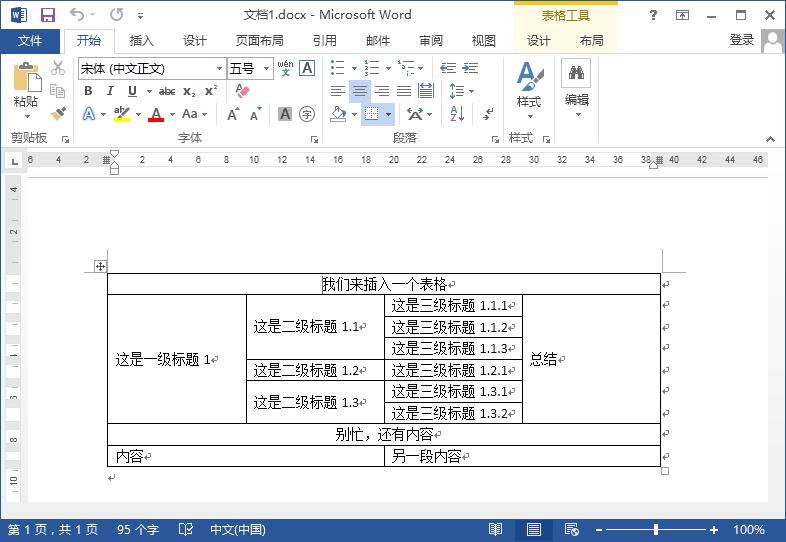
这是一个word中的table。按照上面的方法,我们可以写代码如下:
for t in docx.tables: # todo
但其实对于word中的table,并没有这么简单。有的时候,明明这一行只有一列,但是却读出多个值。那么,对于相邻的相同内容,就需要做去重处理。当然,这里的“去重”也不是list(set())这么简单的,因为一行中的所有列应当有顺序。所以,我们采用添加元素的方式:
_table_list = [] for i, row in enumerate(table.rows): # 读每行 row_content = [] for cell in row.cells: # 读一行中的所有单元格 c = cell.text if c not in row_content: row_content.append(c) # print(row_content) _table_list.append(row_content)
当要添加的元素跟行尾相同时不添加。结果是,上面的tables处理完后,是这样的一堆列表(上面代码中print的位置打印出的结果):
['我们来插入一个表格'] ['这是一级标题1', '这是二级标题1.1', '这是三级标题1.1.1', '总结'] ['这是一级标题1', '这是二级标题1.1', '这是三级标题1.1.2', '总结'] ['这是一级标题1', '这是二级标题1.1', '这是三级标题1.1.3', '总结'] ['这是一级标题1', '这是二级标题1.2', '这是三级标题1.2.1', '总结'] ['这是一级标题1', '这是二级标题1.3', '这是三级标题1.3.1', '总结'] ['这是一级标题1', '这是二级标题1.3', '这是三级标题1.3.2', '总结'] ['别忙,还有内容'] ['内容', '另一段内容']
不过在去重之后,是没法直接用的……表格是个方格,从整体上来说就是一个矩阵,只是有些位置合并了单元格而已,我们现在的二维数组各列可不是对齐的。所以接下来,需要进行填充处理。填充的方式并没有一腚之龟一定之规,这是因为我们并不知道表格的具体规则如何。好在我要填的表有几本规则:最多4列,如果某一行只有一个元素,就扩充为4个,如果有两个元素,就扩充为前两个元素一致,后两个一致,即[0,1]的列表变成[0,0,1,1]这种形式。没有一行三个元素的时候。我用了一个简单的函数对每行进行了处理,这样每一行都变成了4列,整个二维数组也变成了一个矩阵形式。
我的手动填充代码是这样的:
def _fill_blank(table): cols = max([len(i) for i in table]) new_table = [] for i, row in enumerate(table): new_row = [] [new_row.extend([i] * int(cols / len(row))) for i in row] print(new_row) new_table.append(new_row) return new_table
生成的结果是:
['我们来插入一个表格', '我们来插入一个表格', '我们来插入一个表格', '我们来插入一个表格'] ['这是一级标题1', '这是二级标题1.1', '这是三级标题1.1.1', '总结'] ['这是一级标题1', '这是二级标题1.1', '这是三级标题1.1.2', '总结'] ['这是一级标题1', '这是二级标题1.1', '这是三级标题1.1.3', '总结'] ['这是一级标题1', '这是二级标题1.2', '这是三级标题1.2.1', '总结'] ['这是一级标题1', '这是二级标题1.3', '这是三级标题1.3.1', '总结'] ['这是一级标题1', '这是二级标题1.3', '这是三级标题1.3.2', '总结'] ['别忙,还有内容', '别忙,还有内容', '别忙,还有内容', '别忙,还有内容'] ['内容', '内容', '另一段内容', '另一段内容']
像我这样有规律的表格可以这样做,如果表格毫无规律,就只能听天由命了。
那么,为什么要先去重,再扩充?真的不是吃饱了撑的吗?
原因是,我在我项目中要处理的表,一行里面最多有4列,第一行本来只有1列,结果我读出来了6列。至于为什么会这样,我也不清楚,只能说,用户对于word的用法是五花八门的,只要能做出来想要的样子,就完全没有规矩可言。鬼知道他们是不是把一个4个单元格拆成了6个,又合并成了1个。如果我直接使用6列的结果,是没办法做成html样式的table的。
做扩展的目的,主要是为了合并单元格。在html标签中,用rowspan和colspan来表示跨行和跨列。举个列子,如果一行是跨4列的,这一行应该是
<table border="1" align="center"> <tr align="center"><td colspan="4">Row One</td></tr> <tr align="center"><td>Row Two</td><td>Row Two</td><td>Row Two</td><td>Row Two</td></tr> </table>
形成这样一个表格:

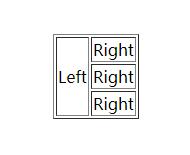
如果是跨行的,这一列应该是
<table border="1" align="center"> <tr><td rowspan="3">Left</td><td>Right</td></tr> <tr><td>Right</td></tr> <tr><td>Right</td></tr> </table>
形成这样一个表格:
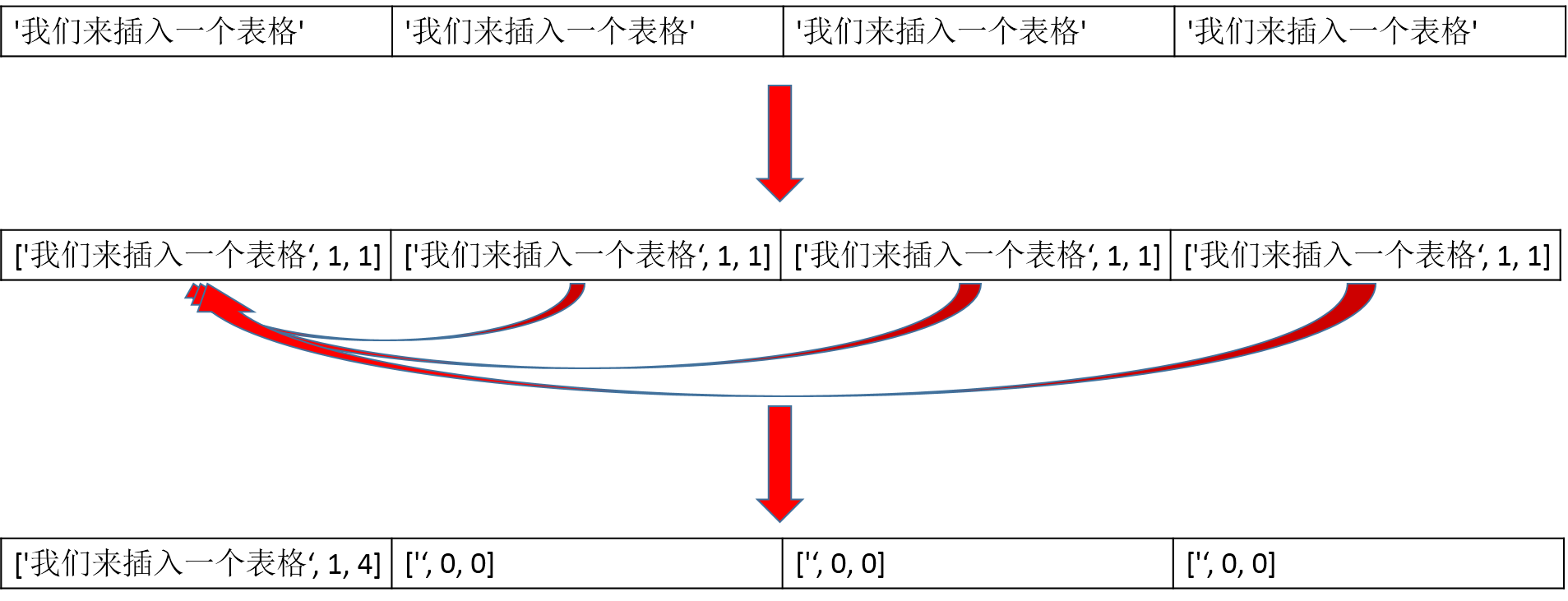
所以,我们的下一步工作就是数数。数清楚在一行中有多少个相同的列,合并到一起,整个矩阵中有多少个相同的行,合并到一起。所谓的合并,就是数量加到上一行/列上去,而本行为空。下图是算法的示意:
合并行:
合并列:
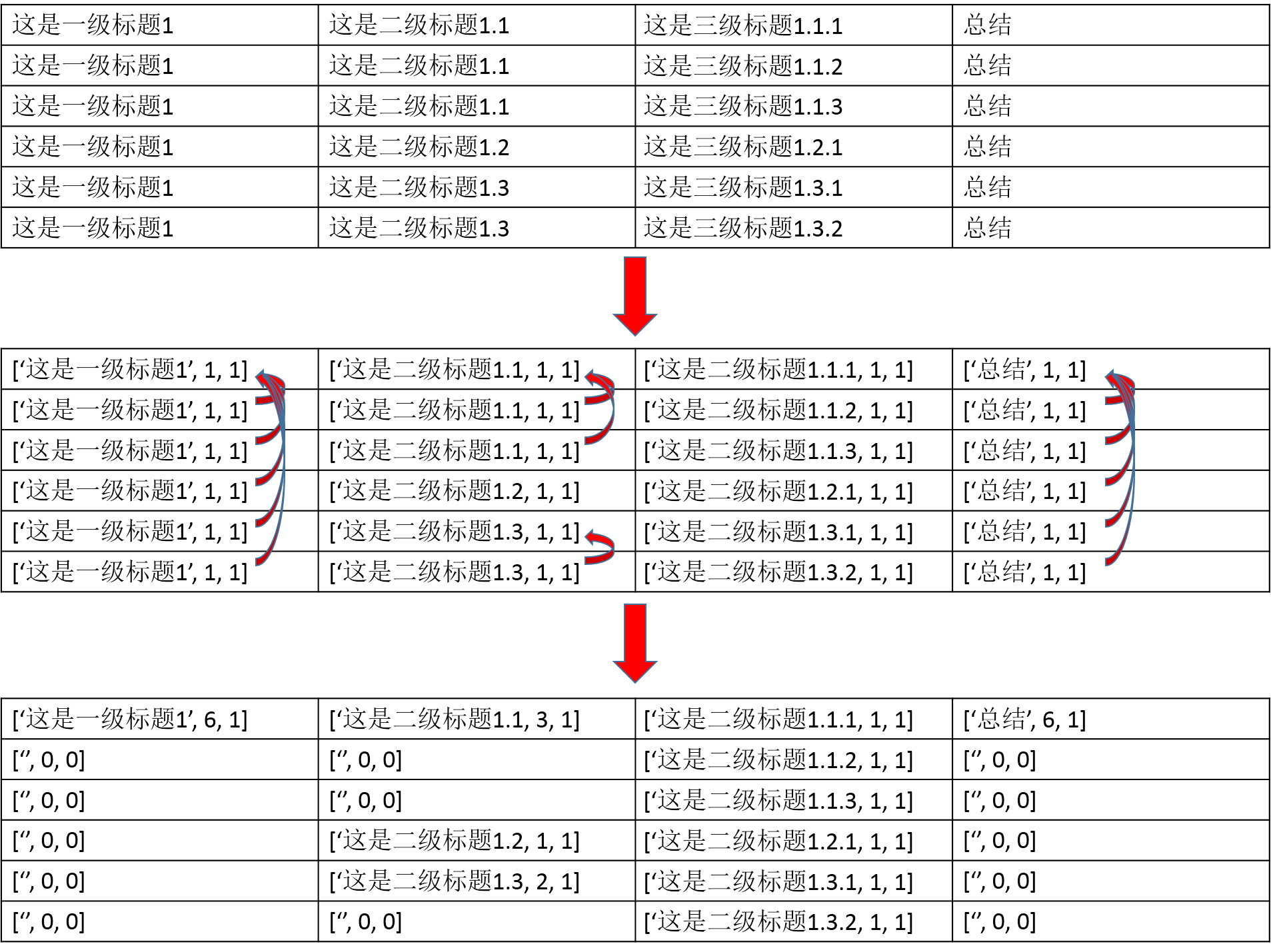
在这样一个二维数组中,每一个元素是一个三元组,第一个元素是表格中的文本内容,第二个元素是rowspan的数量,第三个元素是colspan的数量。如果本行/列跟上一个有内容的行/列内容相同,就把内容加到那一行/列中,本行/列为["", 0, 0];如果不同,则保留。
代码是酱婶的:
def _table_matrix(): if not table: return "" # 处理同一行的各列 temp_matrix = [] for row in table: if not row: continue col_last = [row[0], 1, 1] line = [col_last] for i, j in enumerate(row): if i == 0: continue if j == col_last[0]: col_last[2] += 1 line.append(["", 0, 0]) else: col_last = [j, 1, 1] line.append(col_last) temp_matrix.append(line) # 处理不同行 matrix = [temp_matrix[0]] last_row = [] for i, row in enumerate(temp_matrix): if i == 0: last_row.extend(row) continue new_row = [] for p, r in enumerate(row): if p >= len(last_row): break last_pos = last_row[p] if r[0] == last_pos[0] and last_pos[0] != "": last_row[p][1] += 1 new_row.append(["", 0, 0]) else: last_row[p] = row[p] new_row.append(r) matrix.append(new_row) return matrix
逻辑上会有一点点难读,在什么情况下数量加1,在哪里加1,需要比较细致地算,否则一定会乱。
最后这个数组出来之后,就可以转化html了。这个很简单,套上tr和td标签即可。代码如下:
def table2html(t): table = _fill_blank(t) matrix = _table_matrix(table) html = "" for row in matrix: tr = "<tr>" for col in row: if col[1] == 0 and col[2] == 0: continue td = ["<td"] if col[1] > 1: td.append(" rowspan=\"%s\"" % col[1]) if col[2] > 1: td.append(" colspan=\"%s\"" % col[2]) td.append(">%s</td>" % col[0]) tr += "".join(td) tr += "</tr>" html += tr return html
我没有套table标签,因为这个可以在页面上调一调样式。不必完全拘泥于word中的样子,也没办法完全按word来——如果一板一眼地按照word的方式设置,出来的html上的table肯定是错乱的,原因嘛,还是在于用户的使用习惯。
最后,要是在jinja模板中使用的话,记得把字符串传到页面上的时候加上safe过滤器。
{{ table|safe }}
出来的表格大概是这样的:
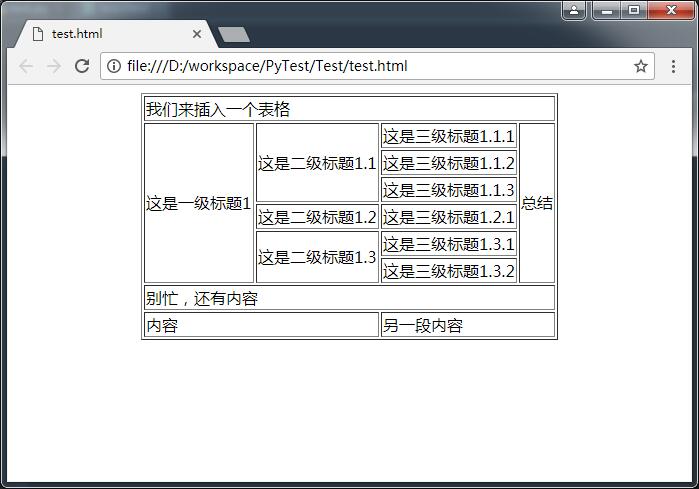
最后我们来对比一下word和table:
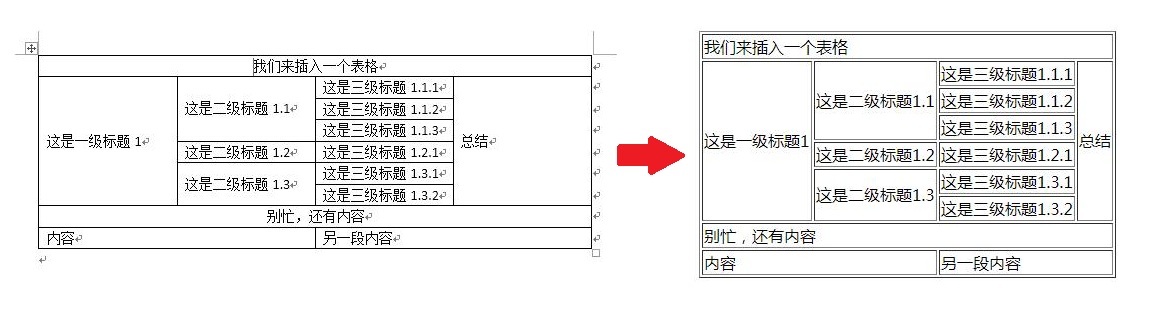
如果手工调整一下html table的样式,二者应该可以长得很像的,对吧?
好了,关于table,就介绍这么多。
本文原创自博客园文章,想了解python相关技巧,欢迎到我的博客踩踩~
地址:http://www.cnblogs.com/anpengapple/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号