


以前装Hadoop-3.1.2是跟着厦大林子雨的详细教程装的,所以遇到的问题不多,自己没怎么思考,导致跟着官网再装了一个Hadoop-2.9.2(为了装Hbase2.2.0)时装了两天,现在把遇到过的问题记下来以免以后再犯。
首先,安装软件首先看官网教程。但官网的教程是很简单的,比如Hadoop的安装。默认会创建hadoop用户;给hadoop权限;所有都在hadoop用户下操作(不然会出错);会更新apt;会解压;会配JAVA_HOME,会配置SSH免密登陆。但我是个小白啊,都不懂,因此查了很多资料。不过这些都是Linux基础,我现在得记住这些。
一、准备工作
(一)创建hadoop用户
1.1 创建可以登陆的 hadoop 用户,并自动建立用户的登入目录
sudo useradd -m hadoop
-m 是自动建立用户的登入目录,如果不输以新用户身份登入后会出错。
-s指定用户登入后所使用的shell。默认值为/bin/bash。(所以可以不指定)
其他详见useradd命令详解:
https://www.cnblogs.com/irisrain/p/4324593.html
1.2 设置密码,按提示输入两次密码
sudo passwd ${你想设的密码}
sudo是使得普通用户有root权限的命令,如果就是root没必要输。
1.3 可为 hadoop 用户增加管理员权限,方便部署
sudo adduser hadoop sudo
(二)更新apt
后续我们使用 apt 安装软件(比如ssh-server),如果没更新可能有一些软件安装不了。
sudo apt-get update
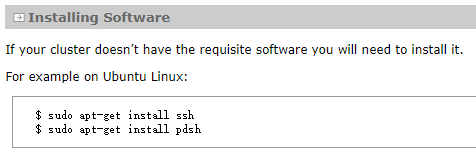
(三)安装SSH,配置免密登陆
厦大教程cf官网教程,厦大说下载ssh-server(首先要确保你的linux系统中已经安装了ssh,对于ubuntu系统一般默认只安装了ssh client,所以还需要我们手动安装ssh server)
而官网说安装ssh(why?I don‘t know,但我相信官网hhh)
所以安装过程是:
sudo apt-get install ssh
sudo apt-get install pdsh
配置免密登陆是:
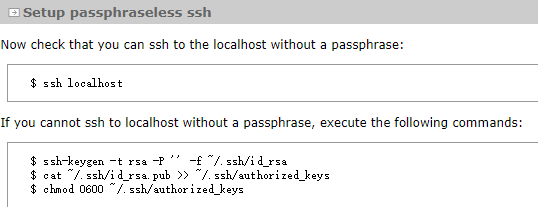
先check一下可不可以免密:
ssh localhost
如果不行,利用 ssh-keygen 生成密钥,并将密钥加入到授权中(参考官网)。
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys #加入授权 chmod 0600 ~/.ssh/authorized_keys #啥意思?

(四)安装Java环境
4.1 apt傻瓜式安装java
按班主任的操作好像是先查看 java -version ,或者 which java ,没有,系统提示apt-install headlessjava啥的,然后安装openjdk-8-jdk
apt install openjdk-8-jdk
不安11好像是因为这个在hadoop3上没有错,比较稳定。
4.2 编辑当前登录用户的环境变量配置文件
vim ~/.bashrc
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
JAVA_HOME指明JDK安装路径,此路径下包括lib,bin,jre等文件夹。如果你不记得自己的JAVA在哪里,可以输 whereis java ,再翻文件夹到第一个不是快捷键的就是你java的位置啦!
4.3 让环境变量立即生效
请执行如下代码:
source ~/.bashrc
4.4检验
执行上述命令后,可以检验一下是否设置正确:
用查看java -version等方式检验一下,至此,就成功安装了Java环境。下面就可以进入Hadoop的安装。
二、安装Hadoop
(一)下载Hadoop(假如是2.9.2,方法都是一样的,只是把名字改一下)
也可用ftp传,但很慢,清华镜像是个好东西!超级快!以后都用wget https://mirrors.tuna.tsinghua.edu.cn/apache 之类的。
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.9.2/hadoop-2.9.2.tar.gz
(二)解压
wget默认下载到登陆路径~也就是/home/user,linux下安装路径一般是/usr/local,所以解压到那里。
sudo tar -zxf ~/hadoop-2.9.2.tar.gz -C /usr/local
林子雨的教程里面把hadoop-2.9.2改名了(mv 成hadoop),但考虑到可能装多个hadoop我就不改名了哈。
但hadoop-2.9.2的权限得改,因为hadoop-2.9.2文件默认拥有者是root。
cd /usr/local/ #进入用户安装目录 sudo chown -R hadoop ./hadoop-2.9.2 # 修改文件权限(hadoop-2.9.2默认拥有者是root,这里我们让hadoop也成为拥有者)
chown详解:https://www.runoob.com/linux/linux-comm-chown.html
(三)检查
(每一步都要检查一下,不然就会像我一样经常重置系统哦!)
Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
cd /usr/local/hadoop-2.9.2 ./bin/hadoop version # 查看hadoop版本信息,成功显示则安装成功
(四)修改/usr/local/hadoop-2.9.2/etc/hadoop/hadoop-env.sh
uncomment export JAVA_HOME=${JAVA_HOME}或者修改为具体地址
三、单机配置standlone
默认就是,无需配置!我们可以运行运行grep例子
cd /usr/local/hadoop #进入用户安装目录 mkdir ./input cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件 ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+' cat ./output/* # 查看运行结果
结果出现一次,说明✔
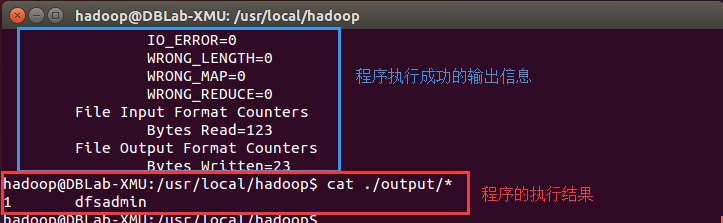
养成好习惯,删掉output,不然下次运行出错
rm -r ./output
四、伪分布式
(一)修改 ./ect/hadoop/core-site.xml
配置hdfs端口9000(默认是8020,但和Client连接的RPC端口冲突),让空空的configuration标签充实起来
可用 netstat -ntlp 查看所有使用端口
netstat -lent | grep 9000 查看9000端口
林子雨说可以配置tmp文件路径(默认为/tmp/hadoo-hadoop,重启时可能被系统清理掉),所以配吧配吧以免之后出错。(记住各种dir要根据自己安装的路径改一下啊)
<configuration> <property> <name>hadoop.tmp.dir</name> <!-- value不要直接ctrl c v,要看着自己安装目录改一下啊 --> <value>file:/usr/local/hadoop-2.9.2/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
(二)修改 ./ect/hadoop/hdfs-site.xml
hdfs-site中官网只配了replication(有几个备份),林子雨指定了 dfs.namenode.name.dir 和 dfs.datanode.data.dir
<configuration> <!--官网只配了replication--> <property> <name>dfs.replication</name> <value>1</value> </property> <!--林子雨还配了namenode和datanode的路径--> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop-2.9.2/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop-2.9.2/tmp/dfs/data</value> </property> </configuration>
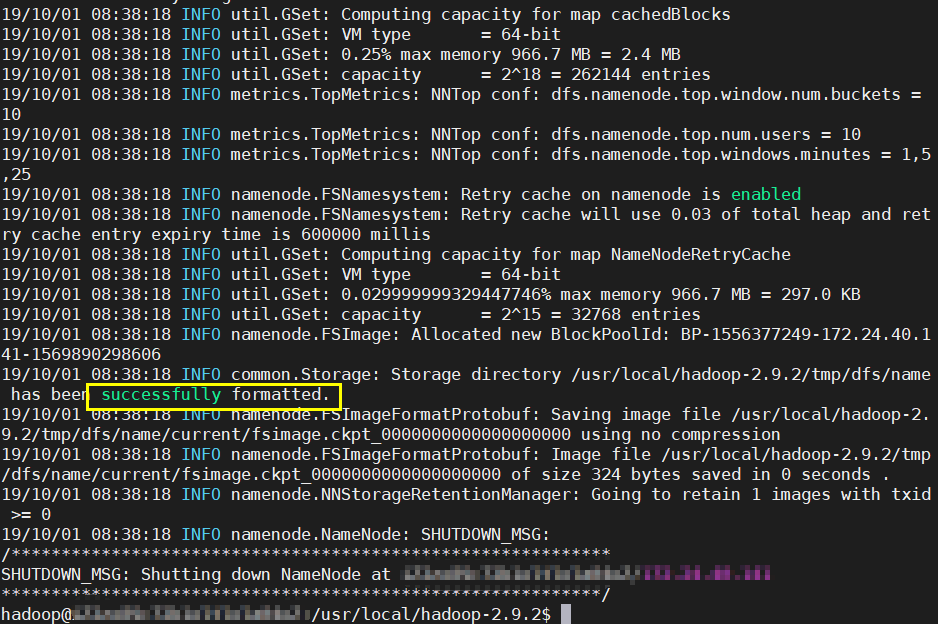
(三)执行 NameNode 的格式化
./bin/hdfs namenode -format
结果应该是“successfully formatted” ,若JAVA_HOME报错,改./etc/hadoop/hadoop-env.sh中JAVA_HOME为具体地址
(四)启动
终于可以启动了,是不是很激动!
./sbin/start-dfs.sh #start-dfs.sh是个完整的可执行文件,中间没有空格
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable WARN 提示可以忽略,并不会影响正常使用。
(五)检查
输入 jps 查看是否成功,成功了应该有四个

不成功的话:
- 1.查看.log日志,百度
- 2.若Datanode没启动
# 针对 DataNode 没法启动的解决方法 ./sbin/stop-dfs.sh # 关闭 rm -r ./tmp # 删除 tmp 文件,注意这会删除 HDFS 中原有的所有数据 ./bin/hdfs namenode -format # 重新格式化 NameNode ./sbin/start-dfs.sh # 重启
(六)Web界面访问
我之前一直无法通过localhost访问,后来才想起我不是在本机我电脑是阿里云的云主机啊啊啊啊!!所以正确做法是:
6.1首先关闭防火墙
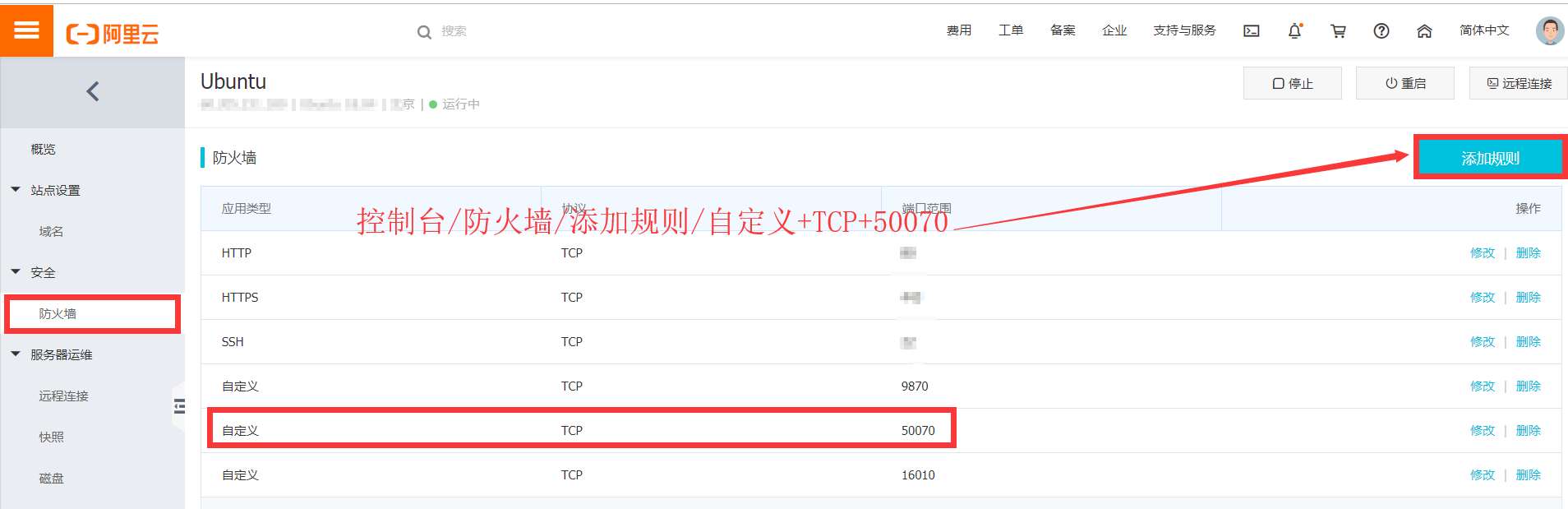
6.2 浏览器输入{你阿里云的公网ip}:50070
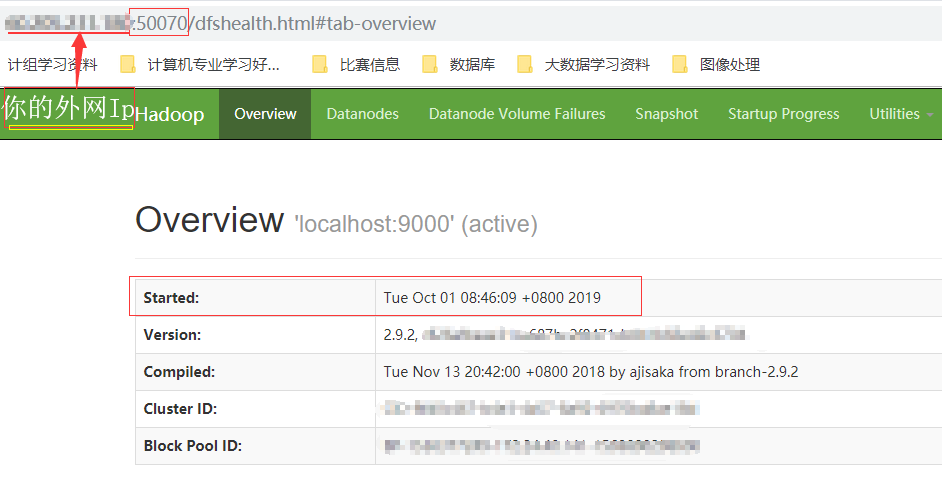
(Hadoop 2.*是50070,3.1.2是9870,具体自行查看官网)
(七)伪分布式例子
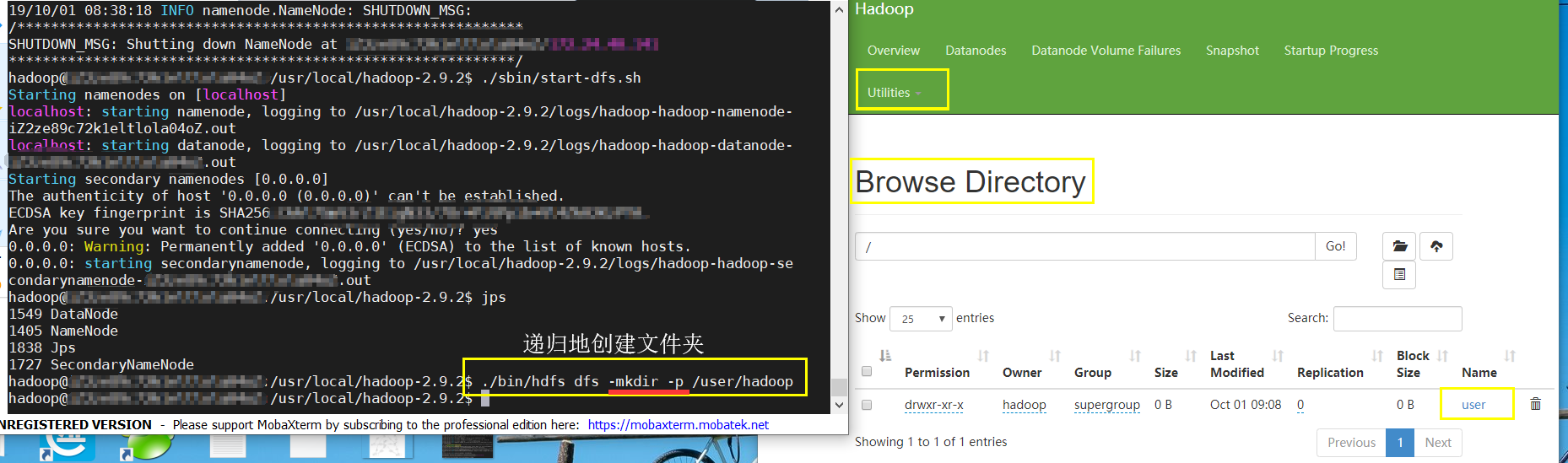
7.1创建用户目录
用户目录格式: /user/username
./bin/hdfs dfs -mkdir -p /user/hadoop
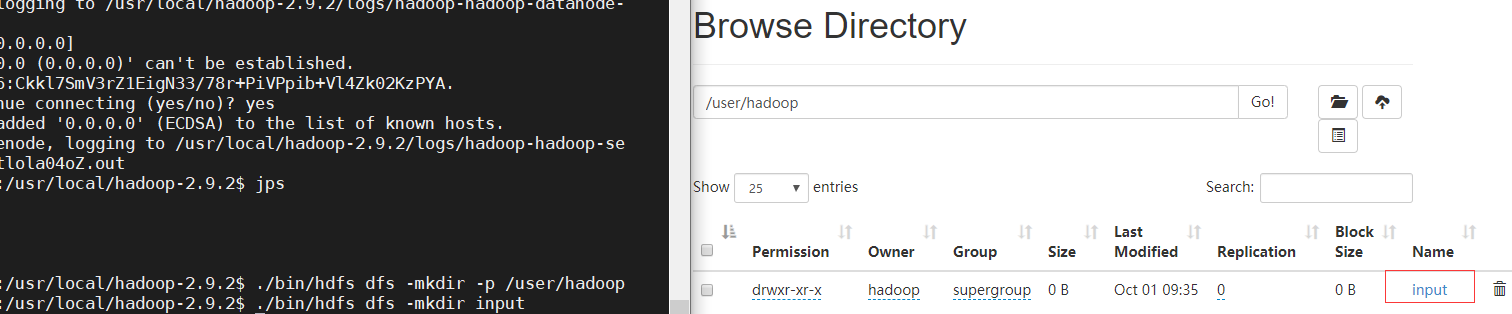
7.2input文件
将本地/usr/local/hadoop-2.9.2/ect/hadoop下的xml配置文件拷贝到分布式HDFS中用户目录下的input文件夹中
./bin/hdfs dfs -mkdir input
./bin/hdfs dfs -put ./etc/hadoop/*.xml input
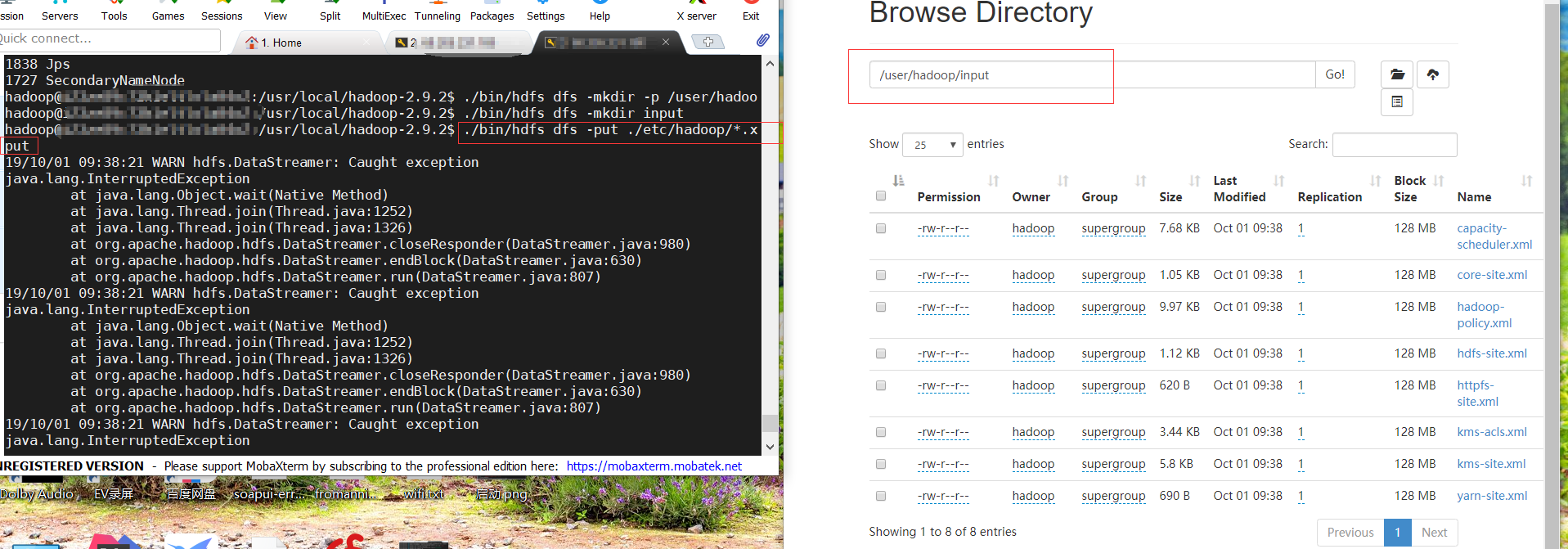
我在上传本地文件到HDFS时出现警告
WARN hdfs.DataStreamer: Caught exception java.lang.InterruptedException 但不影响上传,所以没管
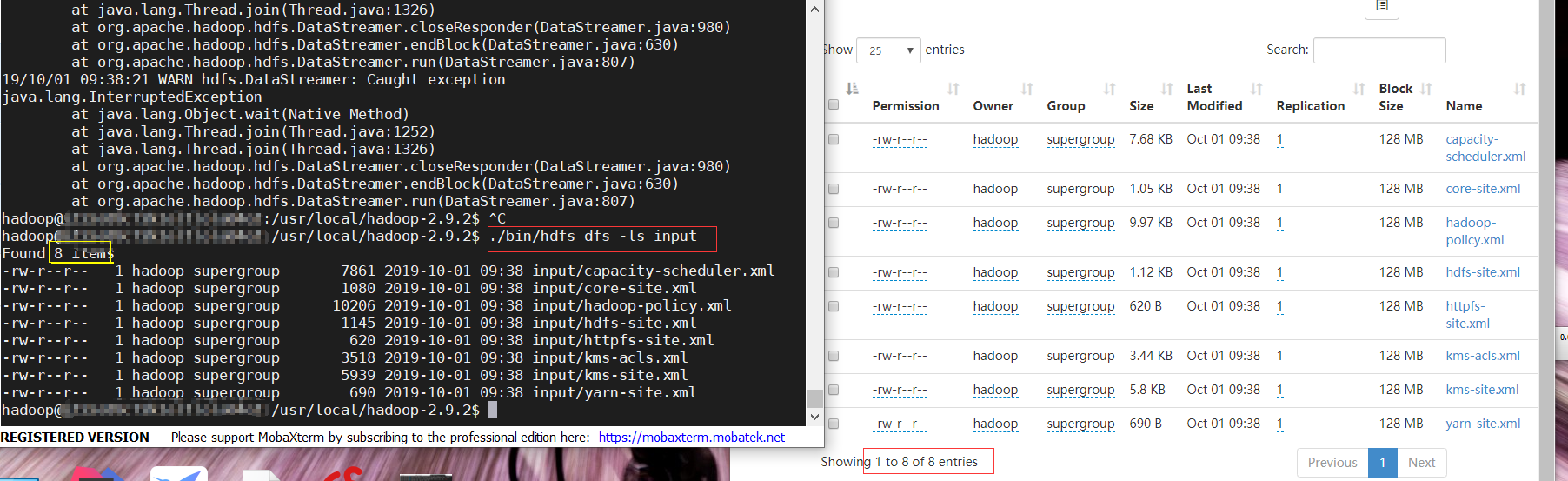
复制完成后,可以通过如下命令查看文件列表
./bin/hdfs dfs -ls input
7.3运行例子
伪分布式读取HDFS中的input信息,输出结果
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'
五、基本操作
hdfs的基本操作和单机模式相似,只是需要在hadoop安装目录下运行这个./bin/hdfs dfs
- -mkdir新建目录(-p递归地./bin/hdfs dfs -mkdir -p /user/hadoop)
- -get下载到本地(./bin/hdfs dfs -get output ./output)
- -cat显示查看文件内容(./bin/hdfs dfs -cat output/*)
- -put本地 目标地址(./bin/hdfs dfs -put ./etc/hadoop/*.xml input)
- -列出文件目录(./bin/hdfs dfs -ls input)
- -chmod 777 文件名(修改文件权限为所有人可读写)
- -rm 删除(-r递归的)
六、参考资料
http://hadoop.apache.org/docs/r2.9.2/hadoop-project-dist/hadoop-common/SingleCluster.html
http://dblab.xmu.edu.cn/blog/install-hadoop/
七、总结(敲重点!)
在阿里云Ubuntu实例上面装软件大概步骤就是
(1)在清华镜像上下载
wget http://mirrors.tuna.tsinghua.edu.cn/*
(2)解压
sudo tar -zxf ~/*.tar.gz -C /usr/local
(3)给hadoop(当前用户)这个文件夹的权限
sudo chown -R hadoop ./hadoop-2.9.2 # 修改文件权限(hadoop-2.9.2默认拥有者是root,这里我们让hadoop也成为拥有者)
(4)按照官网,按单机、伪分布一步步来,修改各种配置文件
(5)要访问web前关一下防火墙(控制台)
下面这是我安装hadoop的命令行:
希望我踩过的坑大家就不要踩了,最后,我想说老师说的对啊装软件还是要看官网以及各种英文网站。希望以后装软件快一点,加油!
