
第一次个人编程作业
| 这个作业属于课程 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-12 |
| 作业要求| https://edu.cnblogs.com/campus/gdgy/CSGrade22-12/homework/13220 |
| 作业目标 | 实现论文查重的功能并进行代码功能测试,改进代码质量|
第一次个人编程作业
作业链接:https://github.com/2024shuid/anni2022/tree/main/3122004909
一、 模块设计
- 类:总共为4个,分别是Files类,getDistance类,getSimHash类,MainCheck类,函数:一共7个,分别为Files下的 read(),write(),getDistance下的getHammingDistance(),getSimilarity(),getSimHash下的getHsah(),simHash()函数,MainCheck下的main()。
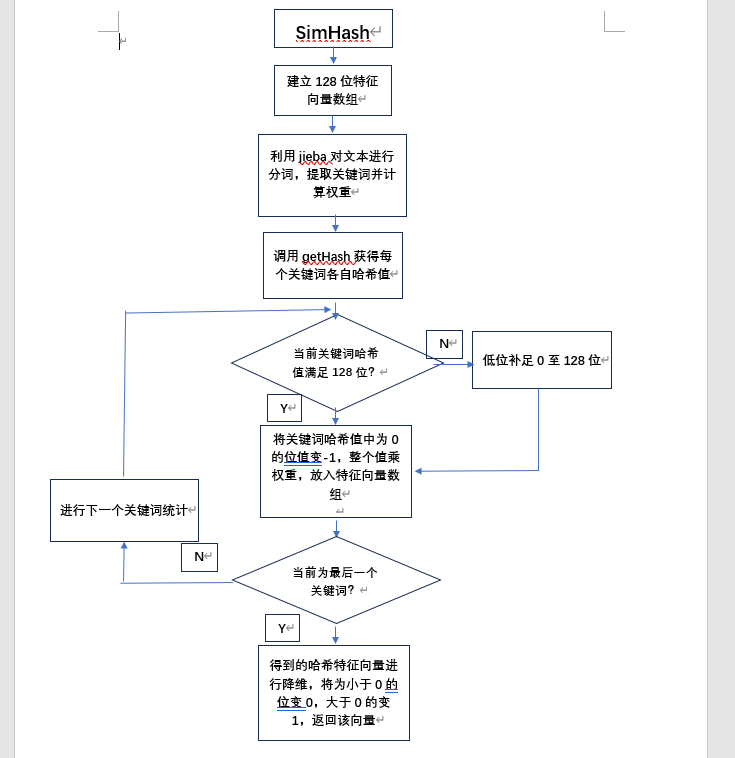
关系:(1)main函数调用read函数读取文件,调用simHash函数计算文本哈希特征向量,调用getSimilarity函数计算两文本的相似度,调用write函数将结果写入文件;(2)simHash函数调用getHash函数获得关键词转化的哈希值进行统计并返回值;(3) getSimilarity函数调用getDistance函数计算两文本的海明距离,进行相似度计算; - 关键函数流程图
![]()
- 算法关键:通过jieba分词并计算关键词权重后,将关键词按MD5转化为哈希值,并低位补0至128位数,将所有关键词按位根据权重分配后相加在一起,最后向量降维得到文本的特征向量,最后比较两个文本的向量得到海明距离,再由此计算相似度。
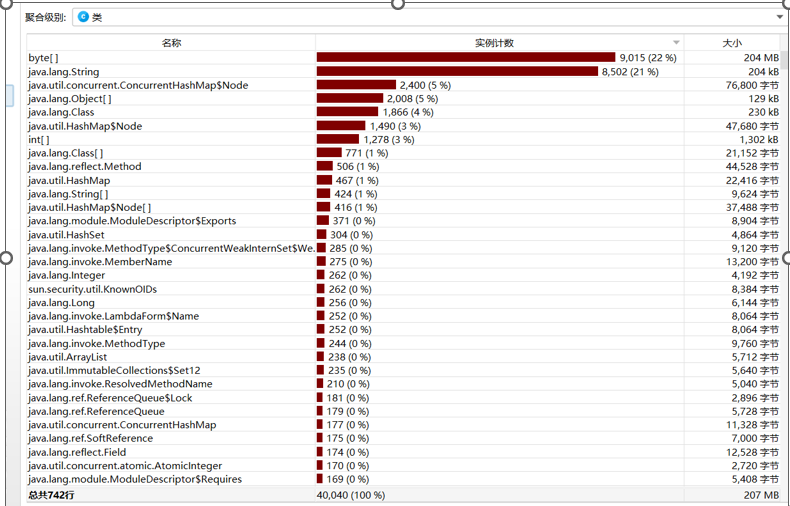
二、 性能改进 - 性能分析图&消耗最大函数
![]()
可以得知,消耗最大函数便是使用数组存储每个关键词的128位哈希向量值并加权合并的getSimHash函数。 - 改进思路
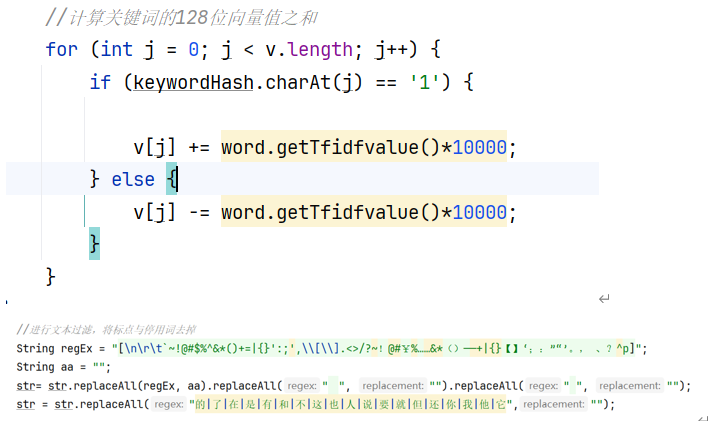
鉴于计算的速度和量级,将原本分词得到关键词的权重由原本的通过循环i值划分的0-10权重,变为在分词后,利用jieba提供的的TF-IDF算法得出文本关键词的权重,直接与自身哈希值相乘即可。还有对文本进行预处理,将标点与停用词删去,使得算法更加快捷,增加文本查重准确率
![]()
三、 部分单元测试
1. 测试思路
对每一个函数进行单元测试,进行正常的函数测试,当然还有可能出错的测试,例如main函数如果传入参数不规范,读写函数则进行能正常与非正常读写,计算文本关键词函数则考虑空文本等情况。
部分代码:
![]()
![]()
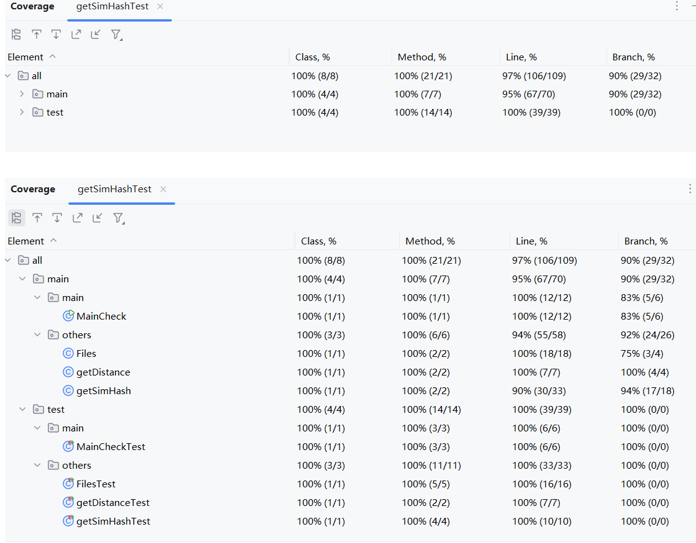
2. 测试覆盖率
![]()
四、 部分异常处理
异常错误场景与各异常设计目标
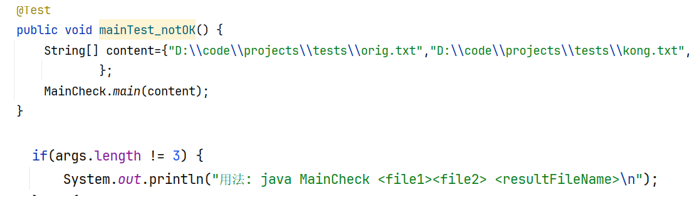
(1) main函数传入参数不规范——给予出错提醒,正确传入参数
![]()


(2) 传入文本中有空文件——输出文本为空异常


(3) 无法写入——抛出异常
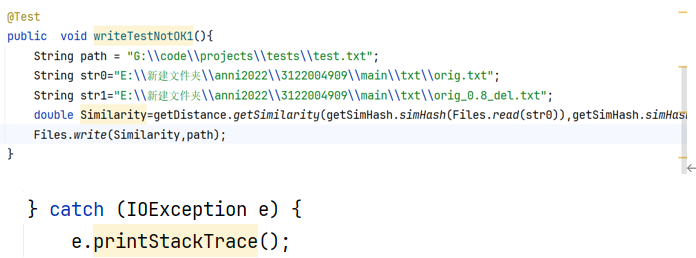
(4) 找不到该读取文本——抛出异常

(5) 得到相似值不足两位小数——保留
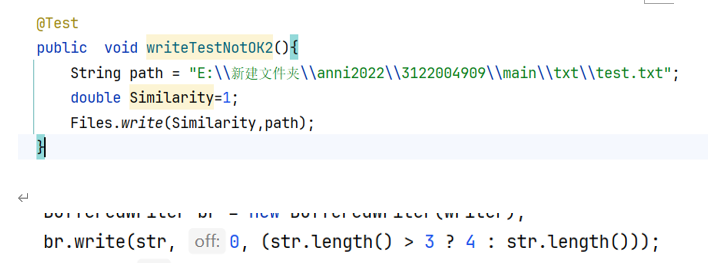
五、 最后结果
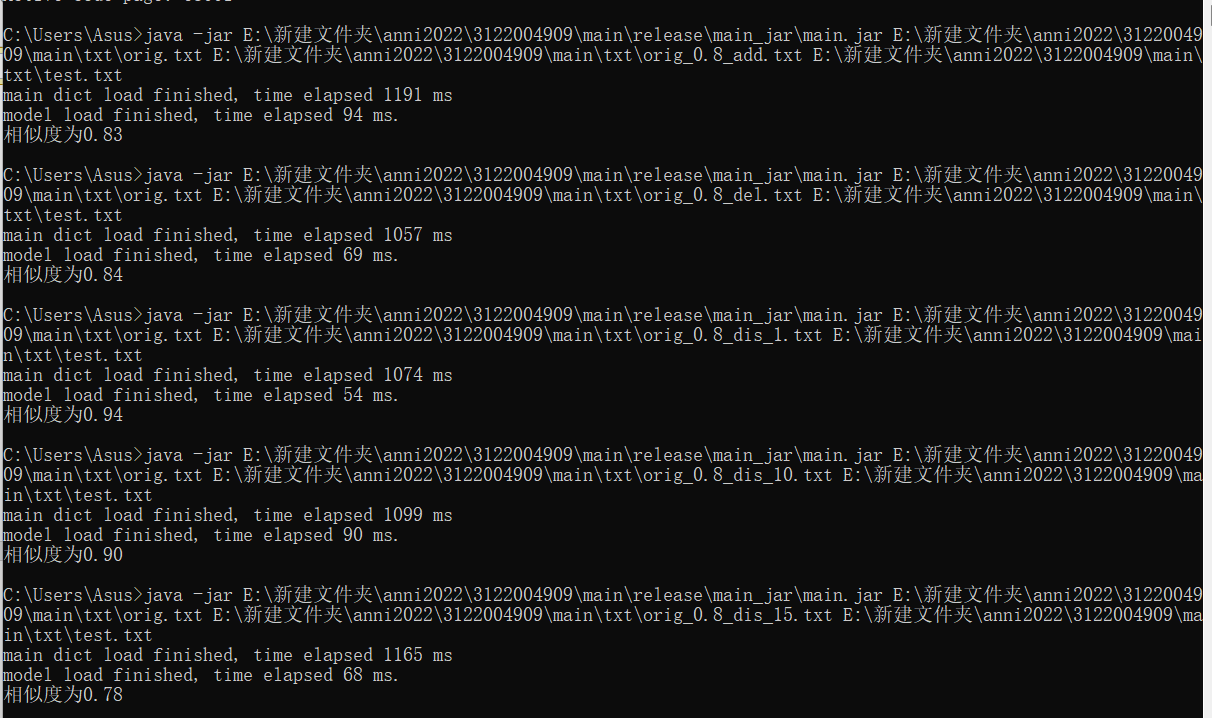
Add 相似度0.83
Del相似度0.83
Dis_1 相似度0.94
Dis_10 相似度0.90
Dis_15 相似度0.78
六、 PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟 |
|---|---|---|---|
| Planning | 计划 | 60 | 70 |
| Estimate | 估计这个任务需要多少时间 | 300 | 437 |
| Development | 开发 | 60 | 100 |
| Analysis | 需求分析 (包括学习新技术) | 80 | 110 |
| Design Spec | 生成设计文档 | 20 | 25 |
| Design Review | 设计复审 | 20 | 25 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 12 |
| Design | 具体设计 | 30 | 30 |
| Coding | 具体编码 | 60 | 70 |
| Code Review | 代码复审 | 24 | 33 |
| Test | 测试(自我测试,修改代码,提交修改 | 50 | 70 |
| Reporting | 报告 | 60 | 75 |
| Test Repor | 测试报告 | 20 | 20 |
| Size Measurement | 计算工作量 | 30 | 20 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 25 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号