


集合
1.Comparable接口
* 所有可“排序”的类都可以通过实现java.lang.Comparable接口来实现,该接口中的唯一方法:
public int compareTo(Object obj);
该方法如果
返回 0,表示 this == obj
返回正数,表示 this > obj
返回负数,表示 this < obj
* 可“排序”的类通过Comparable接口的compareTo方法来确定该类对象的排序方式。
2.Comparator接口
1. 在实现类中重写compare方法
@Override
public int compareTo(Student o) {
return this.id - o.id;
}
2. 通过构造匿名内部类实现比较方法

TreeSet<Student> treeSet = new TreeSet<Student>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o1.id - o2.id;
}
});
TreeSet<Student> set2 = new TreeSet<Student>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
//o1 外面的
//o2 是里面的
if(o1.score == o2.score){
return 0;
}
return o1.score > o2.score ? -1 : 1;
}
});
注意,一个是compareTo,一个是compare,只能用给TreeSet
3.Map接口
* Map接口的实现类常用的有:
* HashMap:HashMap内部对“键”用Set进行散列存放。所以根据“键”去取“值”的效率很高
* TreeMap:TreeMap内部使用红黑树结构对“key”进行排序存放,所以放入TreeMap中的“key-value”对的“key”必须是可“排序”的
* Hashtable (并不常用)
4.Map.Entry接口
* Map.Entry是Map中内部定义的一个接口,专门用来保存key->value的内容
5.map遍历方法
* 第一种遍历
Set<Integer> keySet = map2.keySet();
for(Integer integer : keySet){
System.out.println("key:" + integer + " value:" + map2.get(integer));
}
* 第二种遍历
Set<Map.Entry<Integer, String>> entrys = map2.entrySet();
for(Map.Entry<Integer, String> entry : entrys){
System.out.println("key:" + entry.getKey() +
" value:" + entry.getValue());
}
6.set
* Set接口的实现类
* HashSet:散列存放
* TreeSet:有序存放
* LinkedHashSet
* set 集合是一个不可以重复的集合?
【解答】原理:它底层是一个Map -- key -value 对, key 跟 value 一一对应,其中,key 是不能重复的
* set 进行存储的时候,
1. 如果是添加同一个对象(即把同一个对象添加多次),那么set只添加一次,不管hashcode equals 方法的结果是啥 其结果是由它底层的map决定,因为key只能唯一
2. 如果添加的不是同个对象,那么先调用 hashcode方法,获取hashcode值 ,如果 hascode 一样,那么就调用equals方法,如果返回时true表示元素不可以存入,反之则可以
得出的结果:实际开发中,如果需要将自定义的类添加入set中,一样重写hashcode 跟 equals
* TreeSet
* 添加进去的元素,不管添加顺序怎样子的,输出结果,都是一样的
* 添加进去的元素,不能重复,如果重复,取其中一个 (由set的特性决定)
* LinkedHashSet:元素最终打印的顺序跟添加的顺序一样
7.HashSet
存储原理:
* 根据每个对象的哈希码值(调用hashCode()获得)用固定的算法算出它的存储索引,把对象存放在一个叫散列表的相应位置(表元)中:
* 如果对应的位置没有其它元素,就只需要直接存入。
* 如果该位置有元素了,会将新对象跟该位置的所有对象进行比较(调用equals()),以查看是否已经存在了:还不存在就存放,已经存在就直接使用。
* 取对象时:
* 根据对象的哈希码值计算出它的存储索引,在散列表的相应位置(表元)上的元素间进行少量的比较操作就可以找出它。
特点及使用技巧:
* HashSet不保存元素的加入顺序。
* HashSet 接口存、取、删对象都有很高的效率。
* 对于要存放到HashSet集合中的对象,对应的类一定要重写equals()和hashCode(Object obj)方法以实现对象相等规则。
* HashSet根据元素的哈希码进行存放,取出时也可以根据哈希码快速找到
8.iterator迭代器接口的使用方法
**所有实现了Collection接口的集合类都有一个iterator()方法用以返回一个实现了Iterator接口的对象**。
Iterator it = coll.iterator();
9.遍历
* 第一种:普通for循环
for(int i = 0; i < list.size(); i++){
System.out.print(list.get(i) + " ");
}
System.out.println();
* 第二种:增强的for循环
**增强for循环,只能用于循环遍历,无法进行修改(添加 删除)**
for(String str : list){
System.out.print(str + " ");
}
System.out.println();
* 第三种:迭代循环
//获取迭代器
Iterator<String> iterator = list.iterator();
for(;iterator.hasNext(); ){
System.out.print(iterator.next() + " ");
}
/*while(iteratro.hasNext()){
System.out.print(iterator.next() + " ");
}*/
10.总结
###List
* list集合中可以放置重复元素
#####ArrayList
* 底层是一个默认长度为10的数组, list.size超10个之后,会动态(size * 1.5 + 1)拓展底层那个数组
* 如果系统需要频繁的查询元素,获取元素使用ArrayList 进行元素存储
* 如果系统需要频繁的添加 删除 建议使用LinkedList
* ArrayList 是一个线程不安全的(不同步) 集合
####LinkedList
* 底层是一个双向链表
* 如果系统需要频繁的添加 删除使用LinkedList
* 如果系统需要频繁的查询元素,建议使用 ArrayList
* LinkedList 是一个线程不安全的(不同步) 集合
####Vector
* 老版本的Arraylist
* 跟ArrayList是一样的,唯一区别是vector 线程安全的,Arraylist线程不安全的
>运用场景:
* 由Arraylist 跟 linkedlist特证决定:
* 频繁的查询元素,用Arraylist 从数据库 获取数据,加工成 Arraylist
* 频繁的添加 删除 ,用linkedlist
###set
* 不能放置重复元素
#####HashSet
* 底层是一个Map,因为map的key要求是唯一,所以这造就HashSet不能重复放置元素
* 注意点:自定义类必须重写 hashcode 跟 equals方法,如果不重写,只能通过==进行判断。
* 获取值的时候,通过查hash表,然后对比值
#####TreeSet
* 特点跟HashSet 一样
* 底层实现一个红黑树结构存储方式,所以它带排序功能
* 注意:添加进去的元素,必须得可排序的 怎么实现呢?
* 方法1、自定义的类实现 Comparable 接口,进而重写 CompareTo方法
* 方法2、new TreeSet 自己添加一个比较器(Comparator 接口,实现compare方法)
>使用场景:
* 数据添加的数据需要不重复 HashSet TreeSet 一般选HashSet,但是如果数据还需要排序时选用TreeSet
###总结:
* 如果数据关注是否重复,选用set,反之选用List
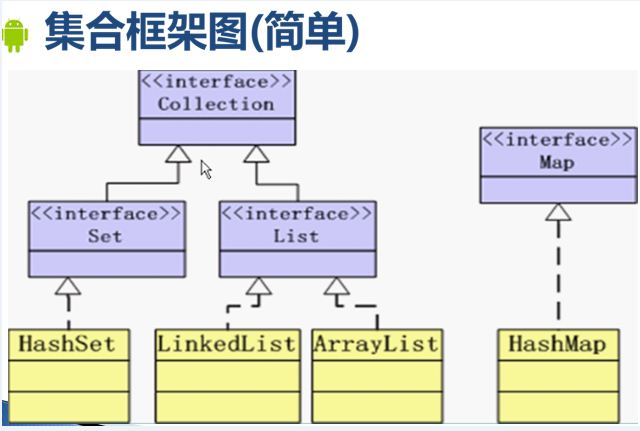
11.最后附图一张


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 25岁的心里话
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现