
这个Scrapy框架搞了我好久,功夫不负有心人,差不多懂整个思维逻辑了,下面是我爬的代码,不详细介绍了
要自己找资料慢慢体会,多啃啃就懂的啦。
这个框架及真的很好用,很快,很全,上次用Request只爬了200多,这次差不多800.很nice哦!!
其实不用太懂这个原理,懂用这个框架就好了,反正也不是做爬虫工程师~想懂原理自己去看Scrapy的源代码
下面是Spider里的那个文件:
Setting:
其他不用改
ITEMS:
import scrapy from scrapy.item import Item, Field class Lagou2Item(scrapy.Item): name = Field() location = Field() position = Field() exprience = Field() money = Field()
SPIDER里的代码:
import scrapy import os import re import codecs import json import sys from scrapy import Spider from scrapy.selector import Selector from lagou2.items import Lagou2Item from scrapy.http import Request from scrapy.http import FormRequest from scrapy.utils.response import open_in_browser class LgSpider(scrapy.Spider): name = 'lg' #allowed_domains = ['www.lagou.com'] start_urls = ['http://www.lagou.com/'] custom_settings = { "DEFAULT_REQUEST_HEADERS": { 'Accept': 'application/json, text/javascript, */*; q=0.01', 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8', 'Host': 'www.lagou.com', 'Origin': 'https://www.lagou.com', 'Referer': 'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?px=default&city=%E5%85%A8%E5%9B%BD', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36', 'X-Anit-Forge-Code': '0', 'X-Anit-Forge-Token': 'None', 'X-Requested-With': 'XMLHttpRequest' }, "ITEM_PIPELINES": { 'lagou2.pipelines.LagouPipeline': 300 } } def start_requests(self): #修改city参数更换城市 url = "https://www.lagou.com/jobs/positionAjax.json?px=default&needAddtionalResult=false&city=全国" requests = [] for i in range(1, 60): #修改kd参数更换关键字 formdata = {'first':'false', 'pn':str(i), 'kd':'数据分析'} request = FormRequest(url, callback=self.parse_model, formdata=formdata) requests.append(request) print(request) return requests def parse_model(self, response): print(response.body.decode()) jsonBody = json.loads(response.body.decode()) results = jsonBody['content']['positionResult']['result'] items=[] for result in results: item = Lagou2Item() item['name'] = result['companyFullName'] item['location'] = result['city'] item['position'] = result['positionName'] item['exprience'] = result['workYear'] item['money'] = result['salary'] items.append(item) return items
PIPELINES:
from scrapy import signals import json import codecs from openpyxl import Workbook class LagouPipeline(object): def __init__(self): self.workbook = Workbook() self.ws = self.workbook.active self.ws.append(['公司名称', '工作地点', '职位名称', '经验要求', '薪资待遇']) # 设置表头 #self.file = codecs.open('lagou2.json', 'w', encoding='utf-8') def process_item(self, item, spider): line = [item['name'], item['location'], item['position'], item['exprience'], item['money']] # 把数据中每一项整理出来 self.ws.append(line) self.workbook.save('lagou2.xlsx') # 保存xlsx文件 #line = json.dumps(dict(item), ensure_ascii=False) + "\n" #self.file.write(line) return item def spider_closed(self, spider): self.file.close()
结果:
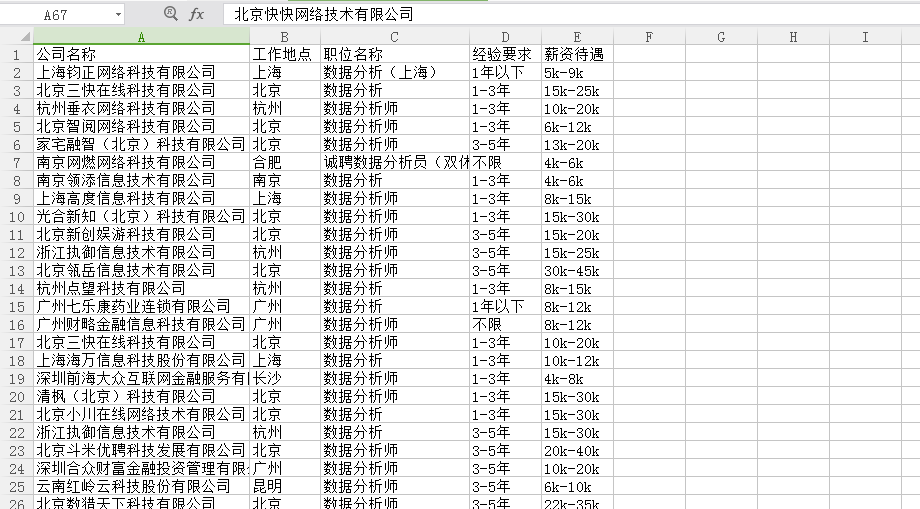

我们开始可视化把:在jupyter notebook里操作
import pandas as pd #数据框操作 import numpy as np import matplotlib.pyplot as plt #绘图 import matplotlib as mpl #配置字体 from pyecharts import Geo #地理图 import xlrd import re
mpl.rcParams['font.sans-serif'] = ['SimHei'] #这个是绘图格式,不写这个的话横坐标无法变成我们要的内容 #配置绘图风格 plt.rcParams['axes.labelsize'] = 8. plt.rcParams['xtick.labelsize'] = 12. plt.rcParams['ytick.labelsize'] = 12. plt.rcParams['legend.fontsize'] =10. plt.rcParams['figure.figsize'] = [8.,8.]
data = pd.read_excel(r'E:\\scrapyanne\\lagou2\\lagou2\\spiders\\lagou2.xlsx',encoding='gbk') #出现错误的话试试utf8,路径不能出现中文,会出现错误
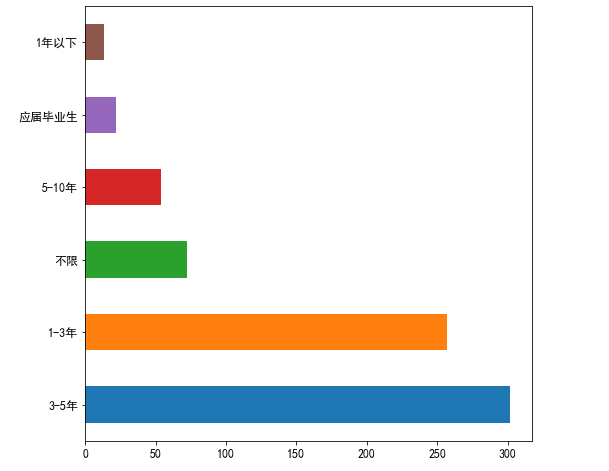
data['经验要求'].value_counts().plot(kind='barh') #绘制条形图 plt.show #显示图片
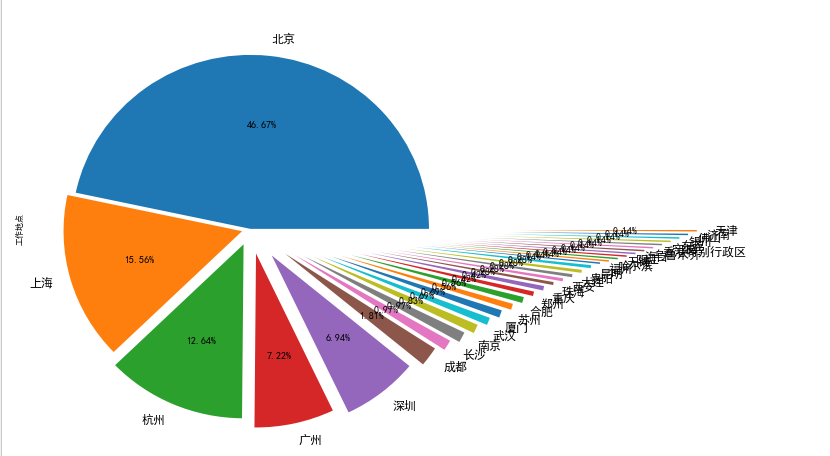
data['工作地点'].value_counts().plot(kind='pie',autopct='%1.2f%%',explode=np.linspace(0,1.5,32)) plt.show #显示图片
#从lambda一直到*1000,是一个匿名函数,*1000的原因是这里显示的是几K几K的,我们把K切割掉,只要数字,就*1000了 data2 = list(map(lambda x:(data['工作地点'][x],eval(re.split('k|K',data['薪资待遇'][x])[0])*1000),range(len(data))))
#再把data2框架起来 data3 = pd.DataFrame(data2) data3
#转化成geo所需要的故事,也是用匿名函数,在data3中,按照地区分组,然后根据地区来计算工资的平均值,将其变成序列后再分组 data4 = list(map(lambda x:(data3.groupby(0).mean()[1].index[x],data3.groupby(0).mean()[1].values[x]),range(len(data3.groupby(0)))))
#geo = Geo('主标题','副标题',字体颜色='白色',字体位置='中间',宽度=1200,高度=600,背景颜色=‘#404a59') geo = Geo("全国数据分析工资分布", "制作:风吹白杨的安妮", title_color="#fff", title_pos="center",width=1200, height=600, background_color='#404a59') #属性、数值对应的映射关系,attr是属性,value是该属性对应的数值,比如说北京对应15000,杭州对应10000 attr, value =geo.cast(data4) #这个是对地图进行设置,第一个参数设置为空值,我看别人这么设置我也这么设置了,下次查查为什么,第二个参数是属性,第三个为对应数值, #第四个参数是可视范围,把工资区间换算成了0到300. 第五个很容易出错,我之前安装完地图还是出错的原因就是没加上maptype=''china',一定要加上,第六个图例类型写上热力图, #第七个参数是地图文本字体颜色为白色,第八个是标识大小,第九个是否进行可视化=True. geo.add("", attr, value, visual_range=[0, 300],maptype='china',type='heatmap' ,visual_text_color="#fff", symbol_size=15, is_visualmap=True) geo

大功告成!!!!!!!!
有些特征没爬,比如说学历要求,不爬啦,累死咯!!!
那个漂亮的饼图我也琢磨出来啦~~!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号