
一、先介绍下什么是RFM模型
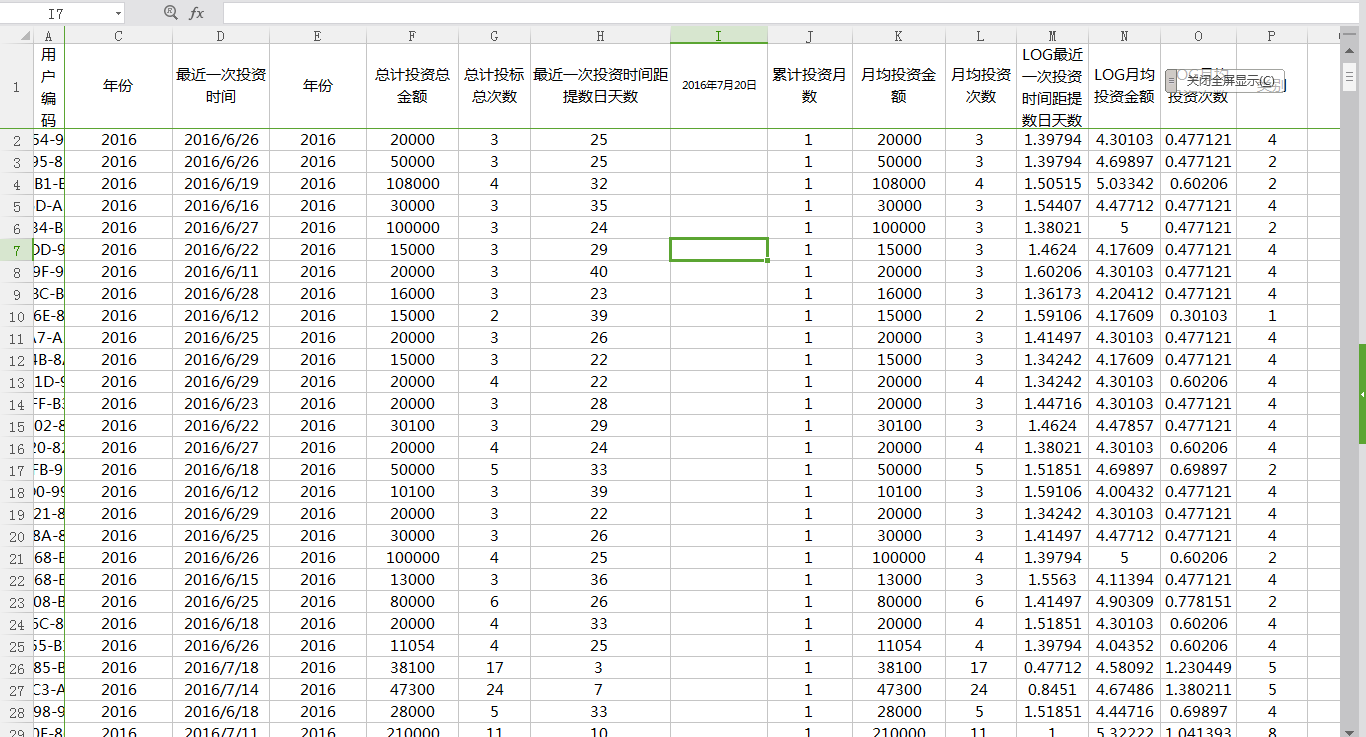
根据RFM模型,我们现在的目标是寻找那三个指标。
①最近一次消费。这里我们可以将最近一次投资时间与提数日做减法(这里选择了2016年7月20日为提数日),然后用DATEDIF这个隐形函数来计算“最近一次投资时间距离提数日天数”,记得要+上1.
②消费频率。用月均投资次数来表示是最好的,计算出月均投资金额,用 总计投标总次数/累计投资月数,
③消费金额。用月均投资金额来表示是最好的,公式是 总计投资总金额/累计投资月数
有了以上三个数后,我们便凑齐RFM三个元素了,但三个元素的量纲需要减少下,可以用Z分数标准化,也可以用LOG(以10为底)来进行减少量纲。这里我用了对数化。
四、利用SPSS进行K-MEANS聚类分析
我们把LOG后的三个元素复制到SPSS上进行聚类分析,如下图
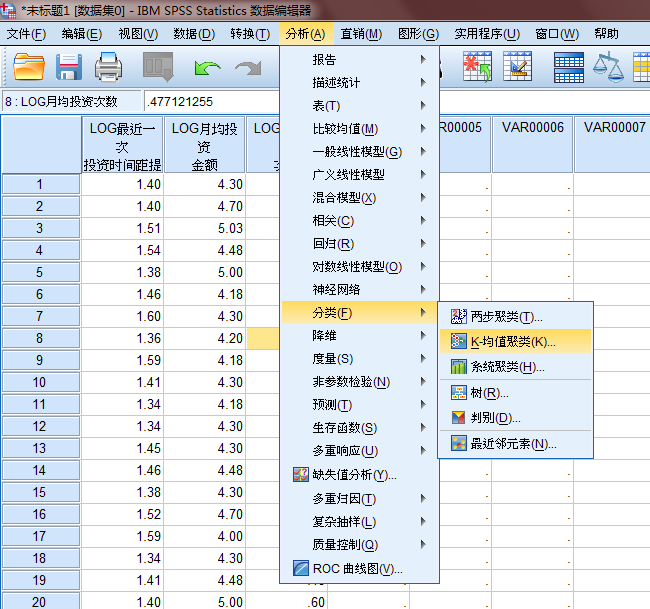
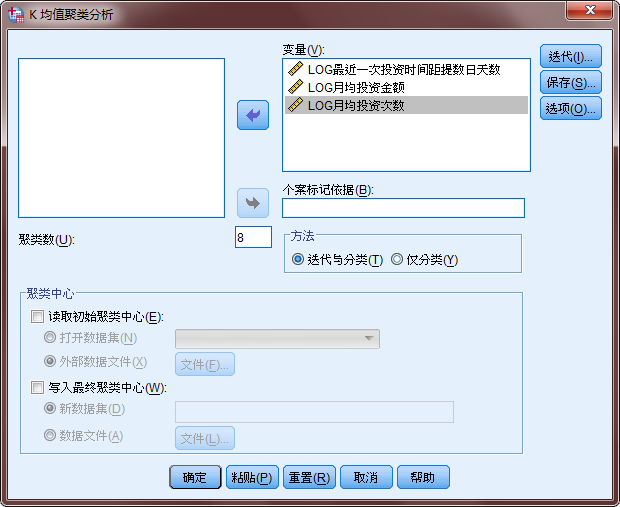
将三个数据全部载入,聚类数是8,因为RFM是将用户类型分成八类的
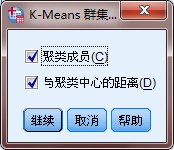
迭代信息不用改,保存信息将两个选项都勾选上,将选项信息里的统计量全勾选上
确定后可以仔细看看出现的图表,千万不要连图表都不会看就直接将结果复制粘贴了,这样很危险。不要做工具和模型的奴隶。
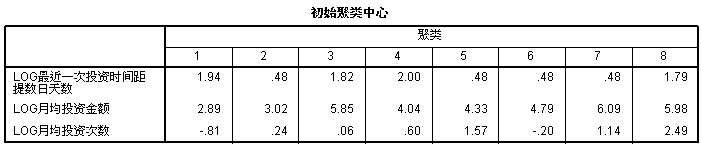
这里SPSS选了这八组数作为初始凝聚点
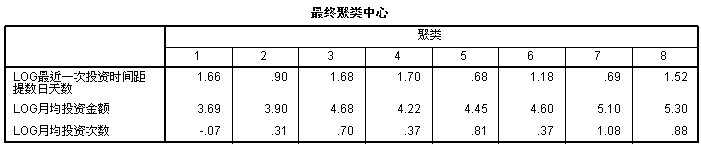
经过迭代后,形成了最终聚类中心,而这些聚类中心将会与其他除聚类中心以外的数据进行类间最小距离与类内最大距离的比较计算
如果数据与某个凝聚中心的距离小于类间最小距离,则两个数据就合并,取他们的重心作为新的凝聚点,依次迭代下去。
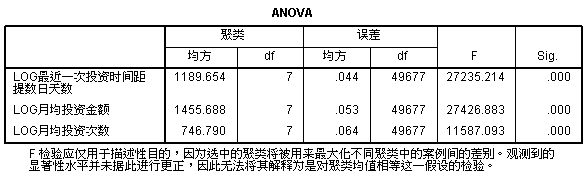
这是方差分析表(ANOVA),这里的方差分析判断用于聚类的变量是否对于聚类结果有贡献,方差分析检验结果越显著的变量,说明对聚类结果越有影响。对于不显著的变量,可以考虑从模型中剔除。这里我们可以看到P值真的很小很小,所以可以判断有显著差异。
把主要的几个表解释完了,现在可以返回到SPSS的数据表格中查看用户被分成了哪几类,我们可以看到:
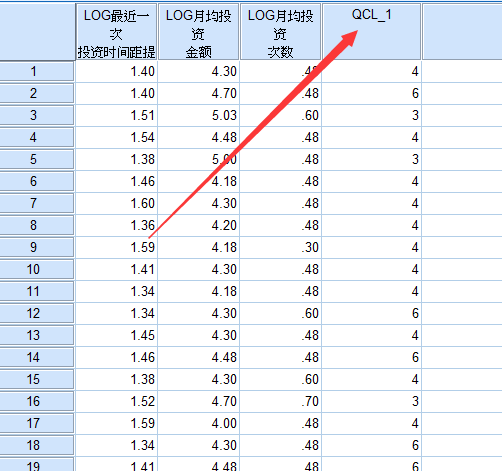
可以把分类那一列复制到Excel里
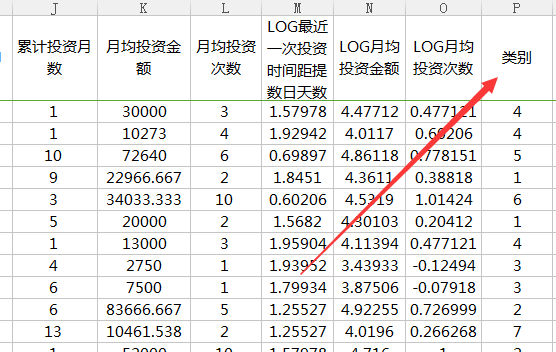
搞定后,就要开始对用户进行具体的分类了。
首先,在根据八大类,对各项指标值进行计算,这里一定要熟悉使用countifs、sumifs等函数,反正不要小看excel的各种小技巧,如$这样的锁定键。
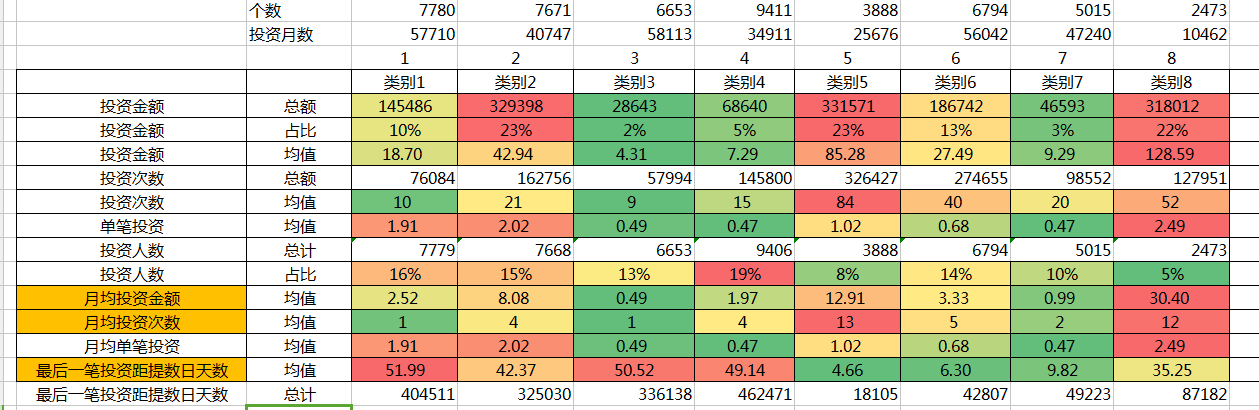
接下来,我们把八大类的R、F、M、投资金额占比、投资人数占比的数据再列出来,转置如下,做堆积图
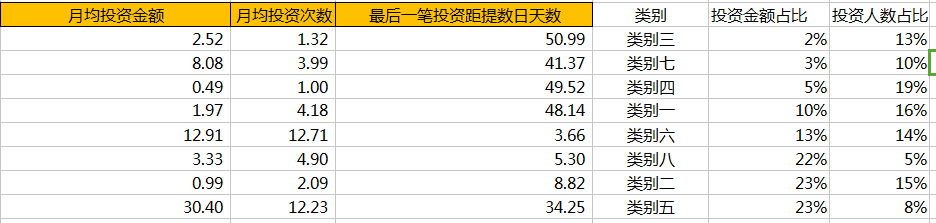
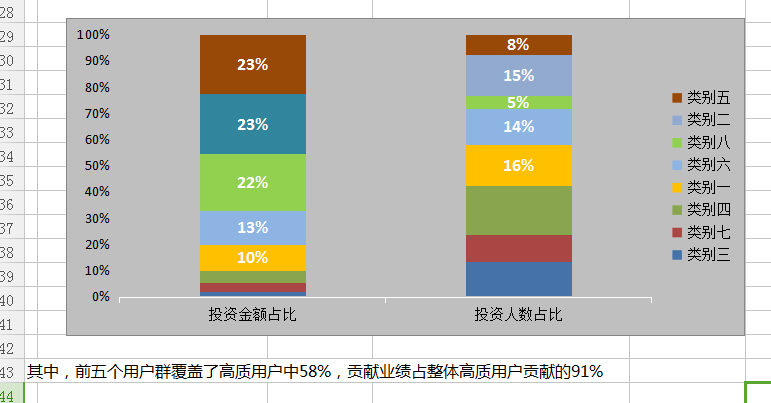
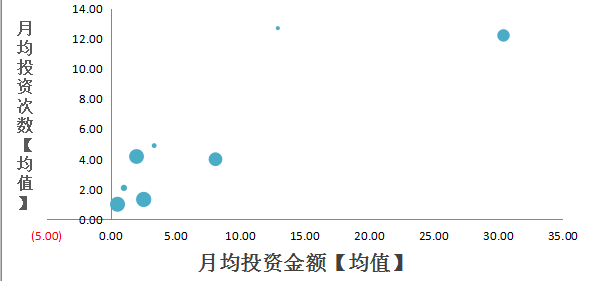
除此之外,我们还可以画出以月均投资金额为X值,月均投资次数为Y值,以最后一笔投资距提数日天数为面积画出气泡图
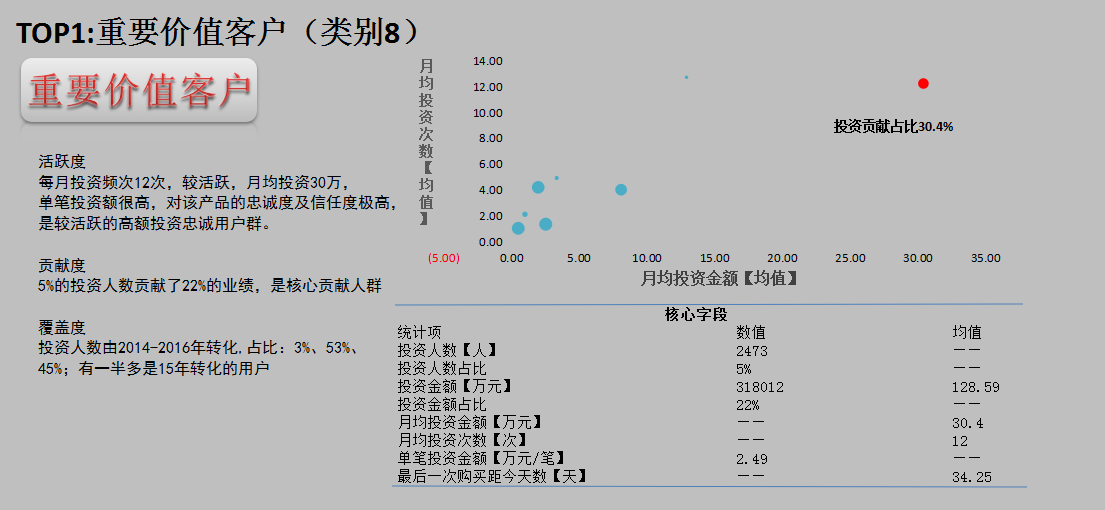
最后根据各项数值,来定义各类用户的类型,顺便做一下图表的美化。
八类客户我们可以分成: ①重要价值客户 ②重要唤回客户
③重要深耕客户 ④重要挽留客户
⑤潜力客户 ⑥新客户
⑦一般维持客户 ⑧流失客户
最好对活跃度、贡献度、覆盖度进行简单描述。覆盖度就是看注册时间和投资时间来比较
总结一下:RFM模型与K聚类相结合并不难,复杂的是对各类指标的理解和掌握。比如说我要怎么从那么多指标里挑出合适的三个指标作为我的R、F、M?对这些指标进行怎么样的处理才适合进行聚类运算?这些都是十分需要考虑的,不是你懂那个原理,懂那个模型就能解决的事情。还要对实际情况和业务进行深刻地理解,就是要多去实践,多了解当下的指标和业务,才能做出更好的判断。另外,还要必须对结果以外的数据做出深刻的解读,比如聚类分析后出现的方差分析表等等。其实我第一次做这个的时候,也是很多不懂,不懂的地方主要在于对指标的理解,还是问过老师很多次才知道这些指标什么意思,不过主要是自己上网找资料~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号