

课程笔记
1.如何下载基因组gff3文件
https://itol.embl.de/
ensembl plant -download-
2.提取cds序列
需要两个文件
①基因组序列文件:序列
②基因结构注释文件gff3:序列对应的结构
TBtools:GXF Sequences Extracter
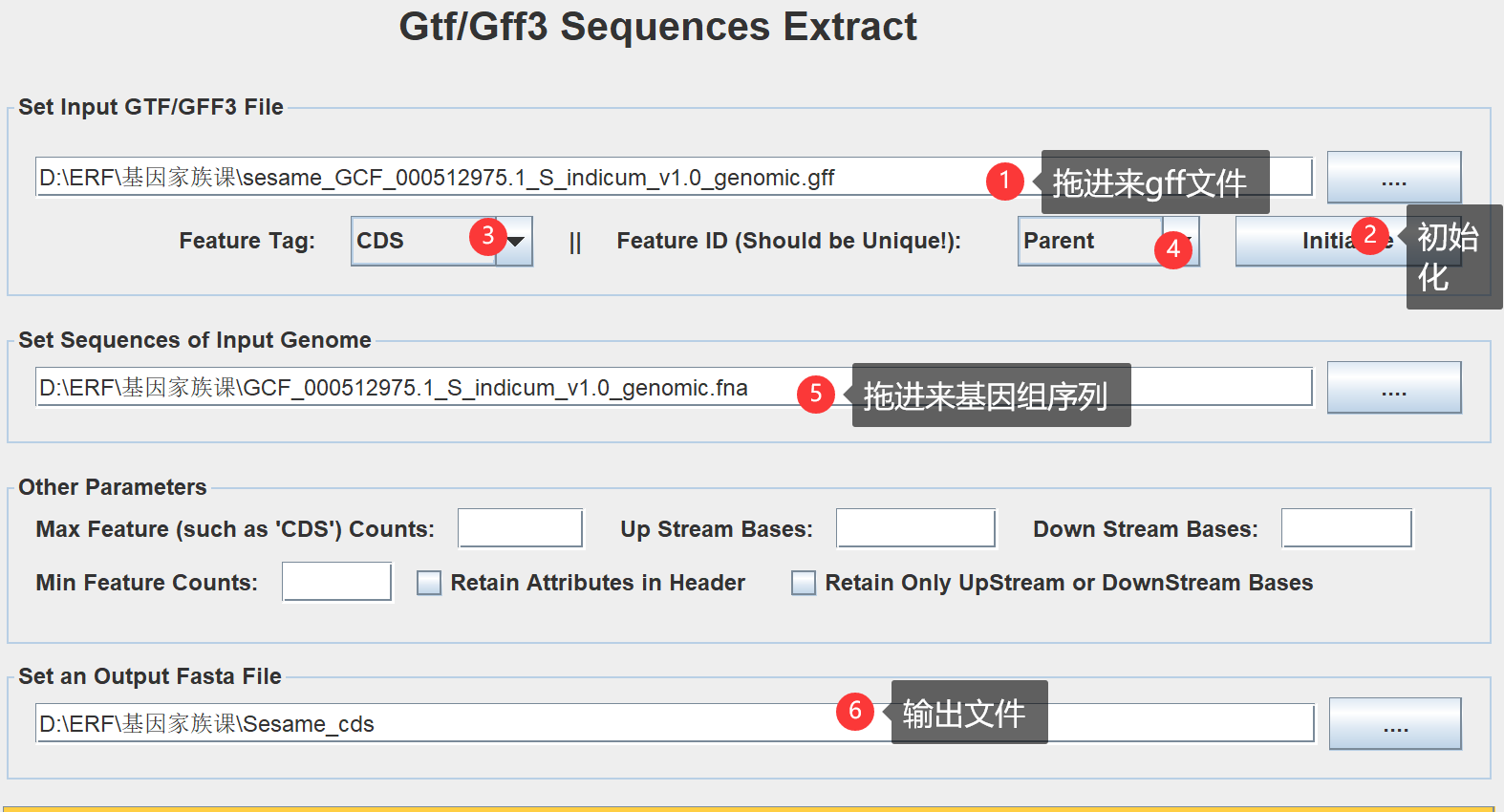
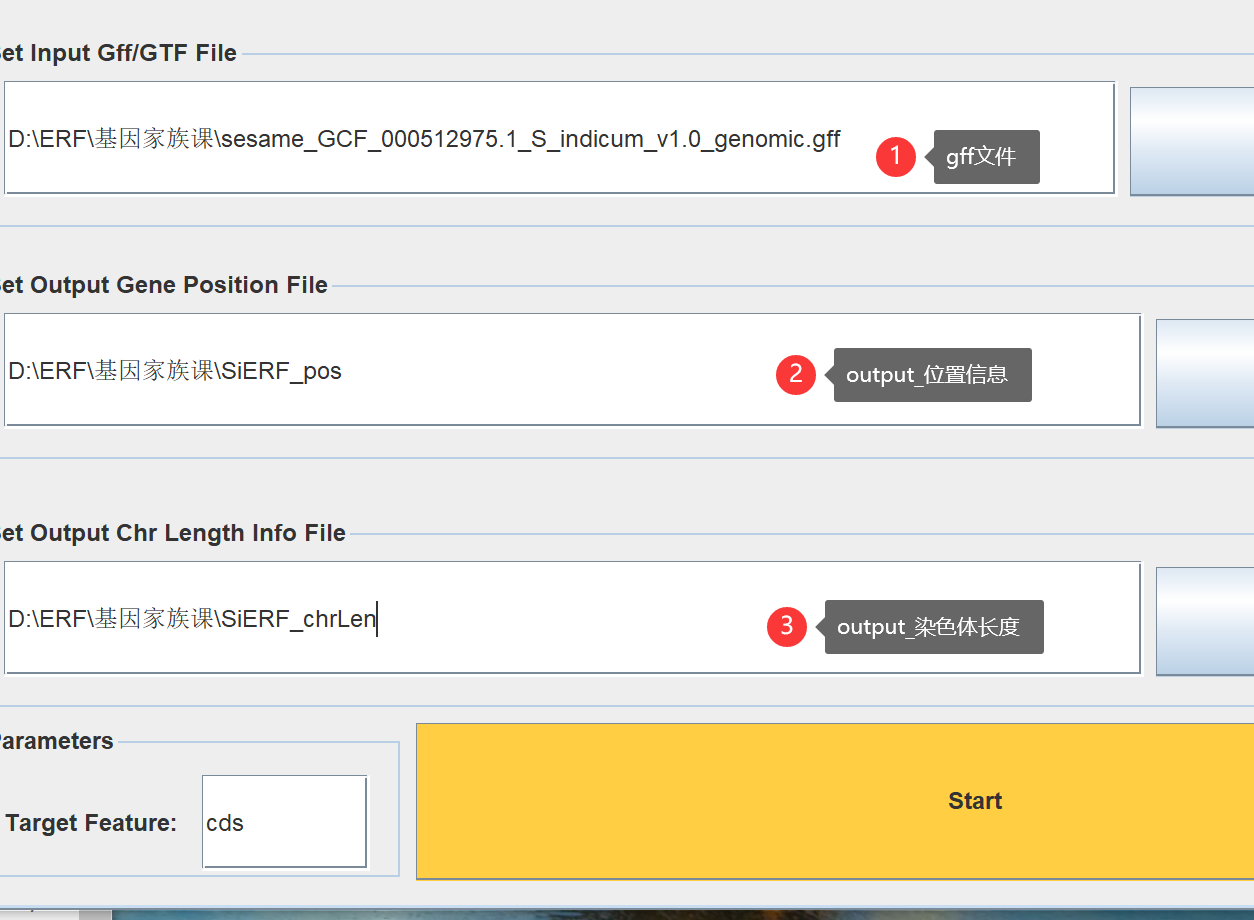
首先把gff文件拖进去,初始化,选择CDS、parent,拖进去基因组序列文件,输入输出文件位置。
会形成2个文件,一个是格式化的序列TBtools.fa,一个是索引TBtools.fa.fai

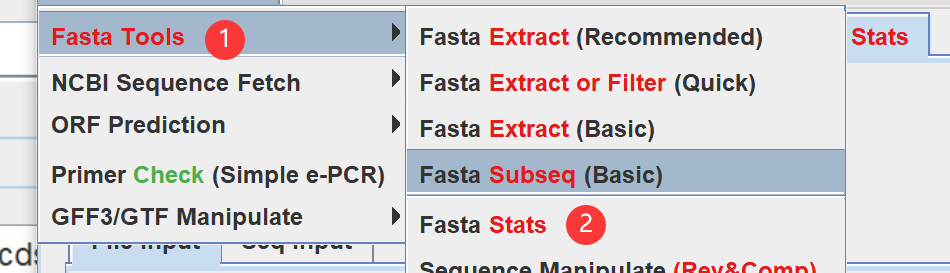
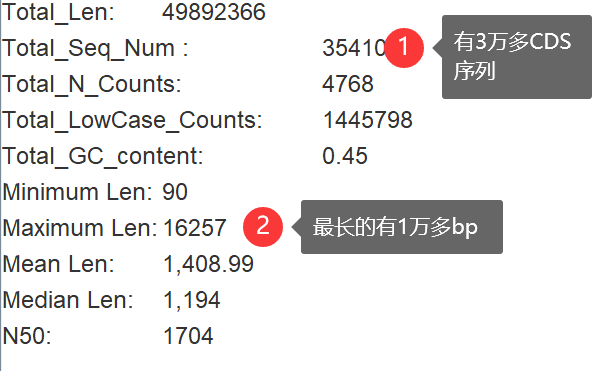
3.查看CDS有多少个基因:Fasta Tools-Fasta Stats,然后把cds文件拖进来。
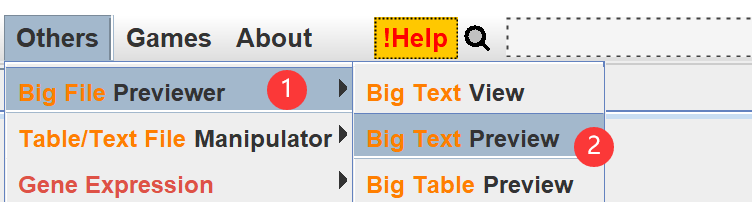
预览一下:big file previewer-big text preview :以ATG开始,以TAG/TGA中止。
4.把cds翻译成蛋白:拖进去fasta格式的cds,输入蛋白输出路径。
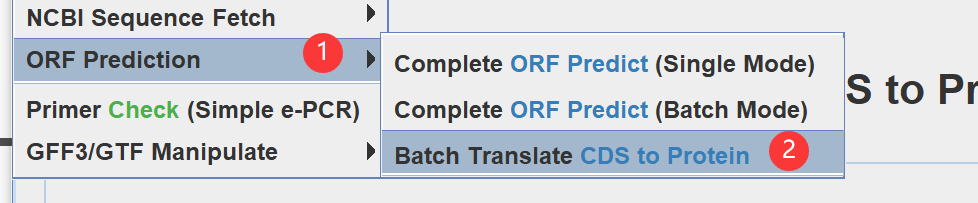
5.简化蛋白ID
基因家族分析
1.PlantTFDB网站:转录因子数据库。

2.Tair-browse-gene family下载基因家族序列
利用tair下载拟南芥的ERF蛋白序列,把122序列号复制到①中

复制基因到下面的框-直接get sequence,复制序列到txt文档,打开fasta stats查看。
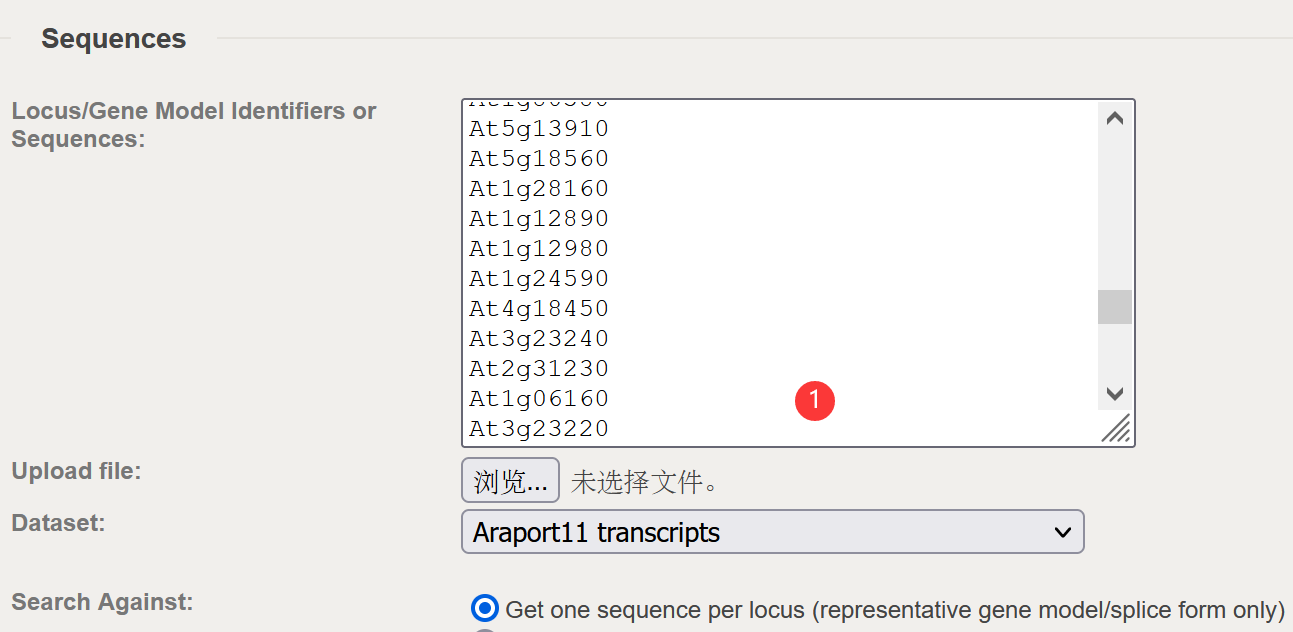
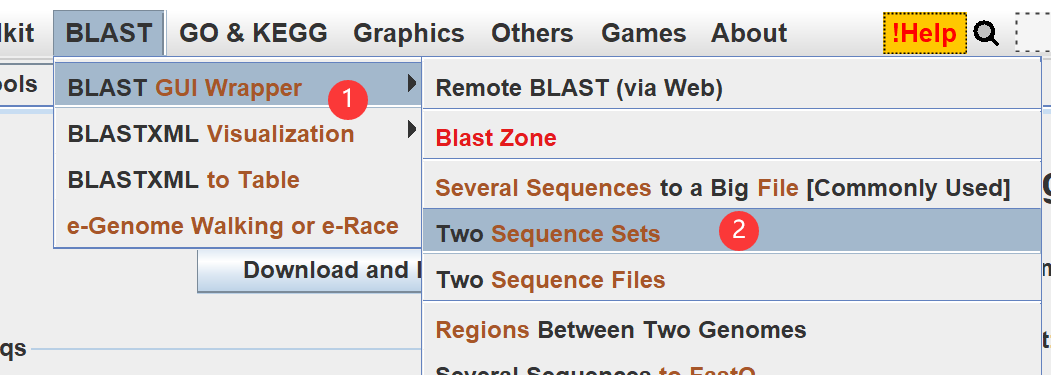
3.blast:two sequence file
文件:
①122个拟南芥的蛋白序列
②目标物种的蛋白序列:用cds翻译的蛋白序列
③输入.tab文件
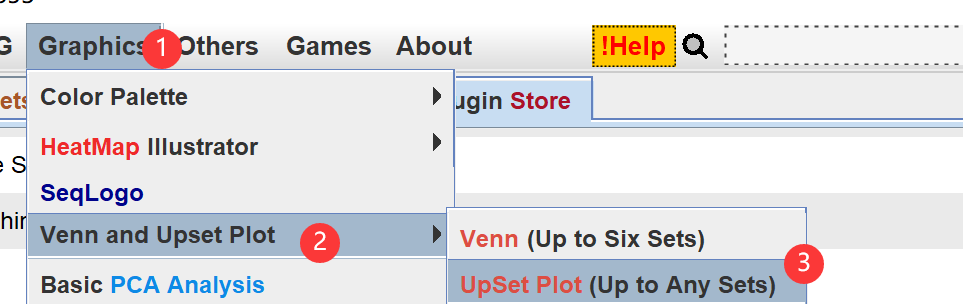
用excel打开,选择第二列序列复制到upsetprot去冗余,双击柱状图,复制序列名称。
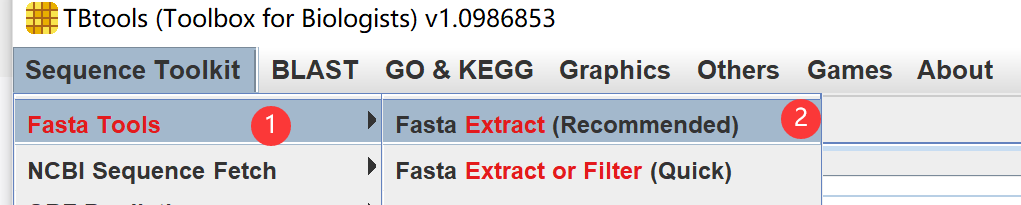
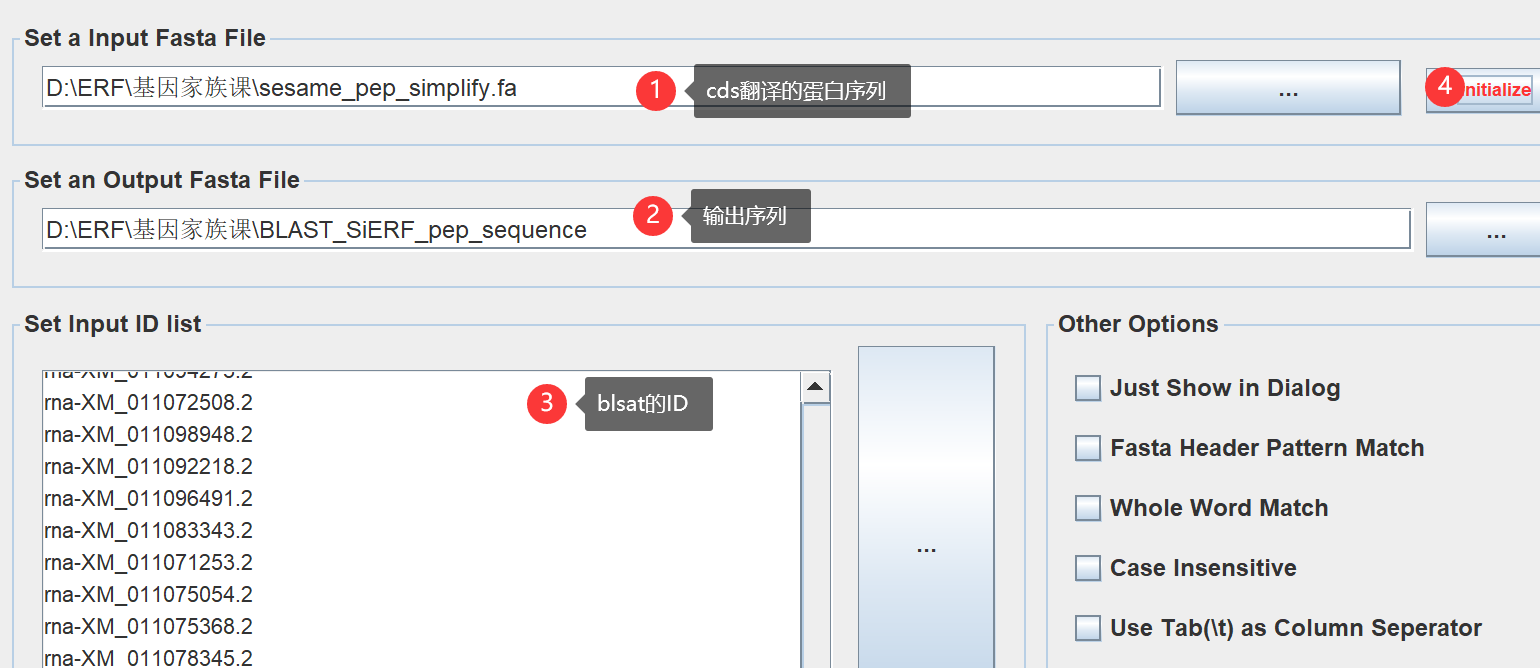
提取ID的蛋白序列
NCBI-Protein-Blast


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· winform 绘制太阳,地球,月球 运作规律
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· AI 智能体引爆开源社区「GitHub 热点速览」
· 写一个简单的SQL生成工具