t 检验+R语言第九章方差分析+相关性图+主成分分析
用MASS包中的UScrime数据集
一、
1.独立样本的t检验
我们比较的对象是南方和非南方各州,因变量为监禁的概率。一个针对两组的独立样本t检验可以用于检验两个总体的均值相等的假设。

2 非独立样本的t检验

with(UScrime,t.test(U1,U2,paired=TRUE))

3.多于两组的情:使用方差分析(ANOVA)
二、
组间差异的非参数检验:结果变量在本质上就严重偏倚或呈现有序关系
4.两组的比较
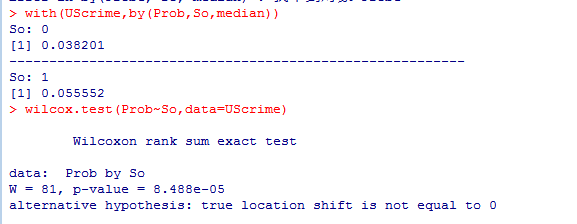
5.多于两组的比较
如果各组独立,则Kruskal—Wallis检验将是一种实用的方法。
states<-as.data.frame(cbind(state.region,state.x77))
kruskal.test(Illiteracy~state.region,data=states)

第八章回归
单因素方差
library(multcomp)
attach(cholesterol)
table(trt)
aggregate(response,by=list(trt),FUN=mean)
aggregate(response,by=list(trt),FUN=sd)
fit<-aov(response~trt)
summary(fit)

install.packages("gplots")
library(gplots)
plotmeans(response~trt,xlab="Treatment",ylab="Response",main="Mean Plot\nwith95% CI")
detach(cholesterol)

#多重比较(没做出来)
install.packages("multcomp")
library(multcomp)
par(mar=c(5,4,6,2))
tuk<-glht(fit,linfct=mcp(trt="Tukey"))
plot(cld(tuk,level=0.5),col="lightgrey')
TukeyHSD(fit)
install.packages("carData")
library(car)
qqplot(lm(response~trt,data=cholesterol),simulate=TRUE,main="Q-Q plot",labels=FALSE)
setwd("E:/rdata")
read.csv("土培11.csv")
a<-read.csv("土培11.csv")
head(a)

fit<-aov(根干重~根数,data=a)
summary(fit)

library(MASS)
attach(UScereal)
y<-cbind(calories,fat,sugars)#cbind()函数将三个因变量(卡路里、脂肪和糖)合并成一个矩阵
aggregate(y,by=list(shelf),FUN=mean)#aggregate()函数可获取货架的各个均值,cov()则输出各谷物间的方差和协方差。
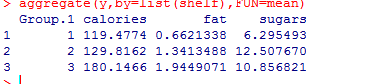
cov(y)

fit<-manova(y~shelf) #manova()函数能对组间差异进行多元检验。
summary(fit)

summary.aov(fit)
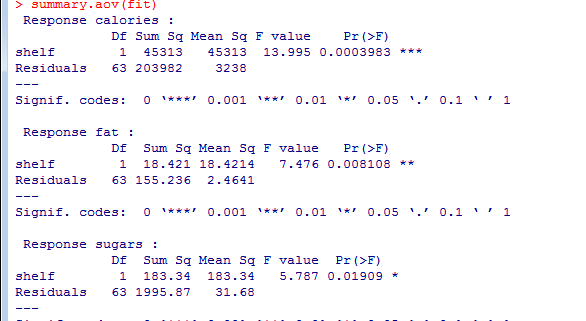
相关图
option(digits=2)
cor(mtcars)
install.packages("corrgram")
library(corrgram)
corrgram(mtcars,order=TRUE,lower.panel=panel.shade,
upper.panel=panel.pie,text.panel=panel.txt,
main="Correlogram of mtcars intercorrelations")
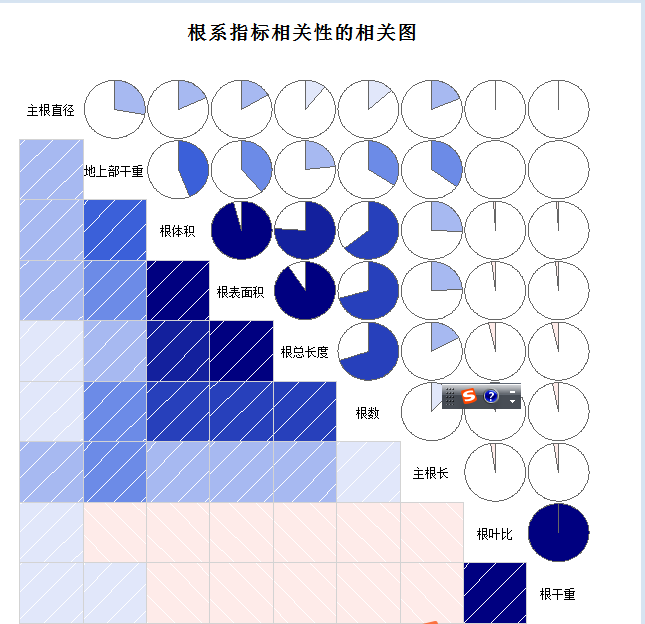
corrgram(a,order=TRUE,lower.panel=panel.shade,
upper.panel=panel.pie,text.panel=panel.txt,
main="根系指标相关性的相关图 ")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号