

爬虫(一)
什么是爬虫?
就是一个应用程序,提取网络有效数据,为我所用。尤其是做一些资源网站,比如电影,小说网站,他们本身可能没有那么多的数据,所以需要到网络上的其他网站上寻找资源。注意,爬取到的数据只是浏览器能获取到的数据。
爬虫攻防的一些策略
(1)Robots协议
这个协议是没有强制限制,要真想要爬取这个网站的数据的话,也还是能获取。就是放一个文档在这里,告诉你哪些数据不能被爬取,防君子不防小人。
(2)在服务器加限制
因为正常我们在访问网站的时候不会频繁的刷新网页,但是爬虫在读取数据的时候短时间内会频繁调用,所以在服务器端如果检测到请求短时间内过多,就把你的IP限制一下,比如返回错误界面。
(3)限定必须登录才能获取数据;一般登录都是用的session,cookie,所以这样也还是能突破的,看下图:
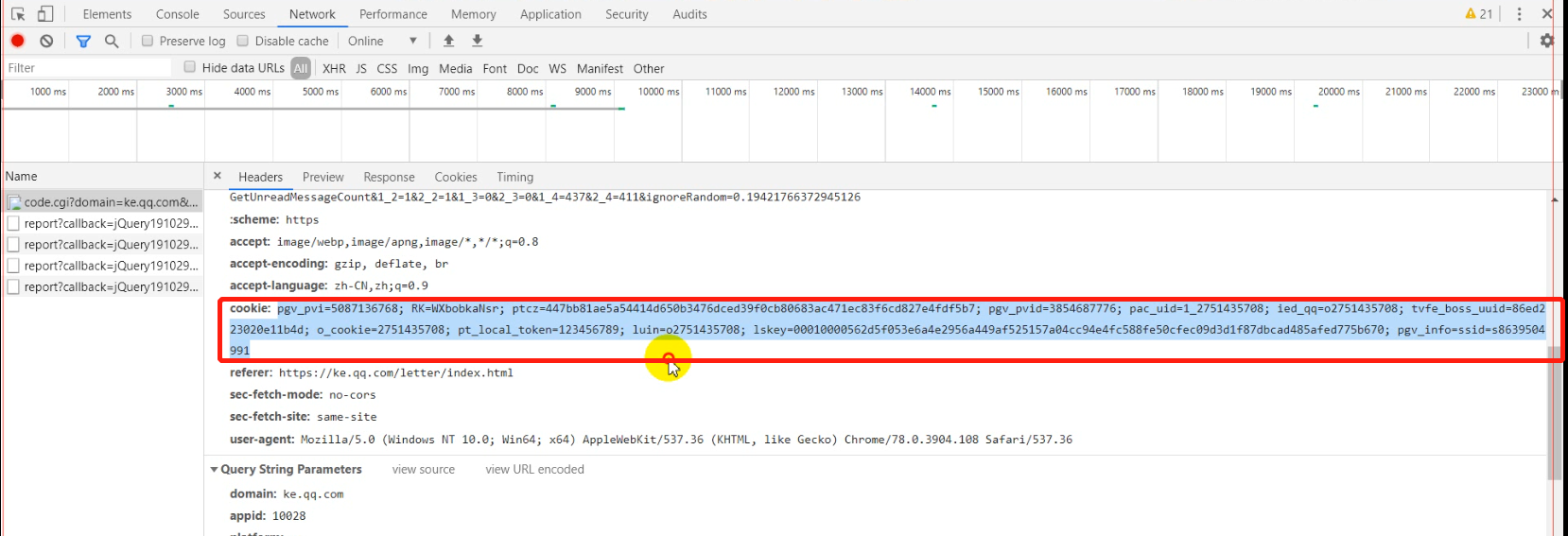
只要是模拟的请求的cookie的数据够真实,就能够突破。
(4)验证码,这种方式比较友好。当然也是能突破。
(5)js算法
看下面的截图,真实显示的值并不是浏览器获取到的值,这是他们自己的一套算法。

只要是http请求,没有绝对的安全,都是可以突破的。任何反爬虫策略都是可以突破的,只不过可能成本比较高。
爬虫步骤
(1)获取页面的html(通过模拟http请求)
这里我们通过httpwebrequest来模拟请求。模拟请求的时候一些相关的信息在这里也能看到:
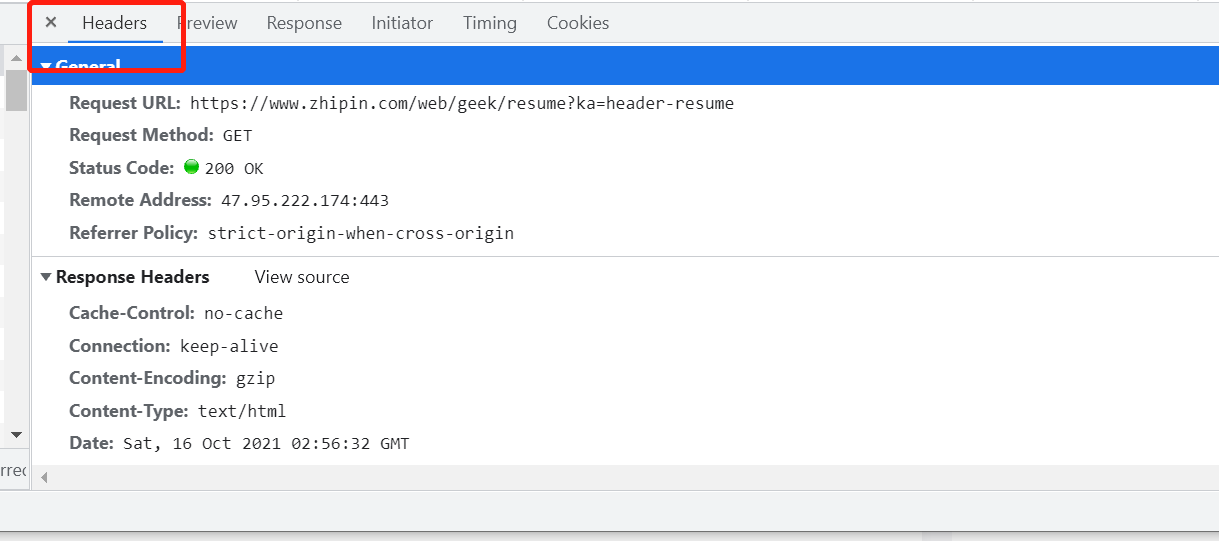
(2)筛选过滤有用信息
(3)汇总,数据入库
1


· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 字符编码:从基础到乱码解决
· 提示词工程——AI应用必不可少的技术