

SqlServer全文索引
关系型数据库的尴尬事儿
1.=
2.<>
3.Like
用户在关系型数据库查询字符串"中华人名共和国 "的时候,其实无法绝对准确的指定关键字;因为在关系型数据库中要想查某个字符串在文本中是否存在,用的是like,但是like有很大的局限性,比如:

上图是全部数据,比如我们查中华人民共和国,但是如果用户不小心输入了一个空格,或者输错了,那就会查不出数据:
SELECT * FROM [dbo].[Company] where name like '%中华 人名共和国%' SELECT * FROM [dbo].[Company] where name like '%中华是大V人名共和国%'
这样查出的数据为空。
其实用户还是希望能给我一些结果,不是关键字不精确,就直接没有结果! 这种需求其实存在! 如果我们把关键字(一句话),做个拆分;拆分成各种词语,通过这些词语去匹配;
Lucence.Net
先说明一点,这里的索引和数据库中的索引没有一点关系,是完全不同的2个东西,互不干涉。
全文检索的工具包,不是应用,只是个类库,完成了全文检索的功能 就是把数据拆分;存起来; 查询时:拆分;匹配;结果。 Lucence之前是爱Java里面,后来在.Net中出现;lucence.Net
Lucence.Net大型搜索引擎系统、电商系统必备的;
首先需要下载对应文件:http://lucenenet.apache.org/download/version-3.html
进去之后点击源码下载:
下载解压之后在下面路径里找到项目:

打开项目,右边红框中的就存在Lucence.Net的七大对象类:
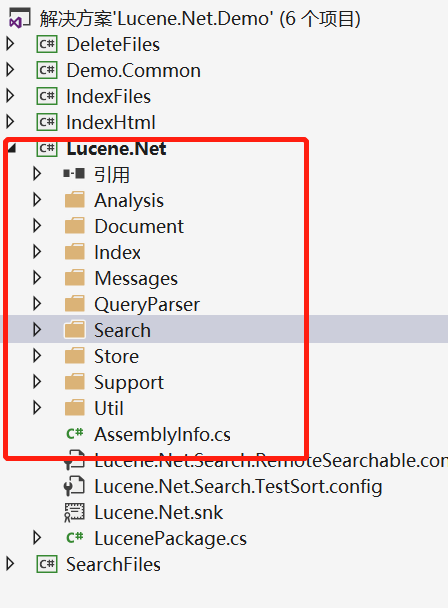
在这里就能直接看到Luncence.Net中的一些源码了,不想看的话直接在NuGet中下载Lucence.Net.dll就可以直接用了。
Lucence.Net七大对象
Analysis(读音[əˈnæləsɪs]):分词器,负责把字符串拆分成原子,包含了标准分词,Lucence默认直接空格拆分, 但是国内项目中一般用的是盘古中文分词,在项目中直接引用PanGu.Lucene.Analyzer.dll就可以
Document:数据结构,定义存储数据的格式。将数据库中的数据拿出来按照这个数据格式来存储。
Index:索引的读写类 因为按照Document类格式存储在索引中,所以需要Index这个类来进行读写。
QueryParser:查询解析器,负责解析查询语句
Search:负责各种查询类,命令解析后得到就是查询类
(1) TermQuery (单元查询)
数据库中的数据是一行一行的存储的,将数据存储在索引中是以Document文档的形式存储,每一个行对应着一个文档,文档里面也存储了多个字段。
比如我要查找字段title为张三的数据: new Term("title","张三")
(2)BoolenQuery:在单元查询的基础上加了and or的关系
使用形式:new Term(“title”,“张三”) and new Term(“title”,“李四”) ;
结果:title:张三 + title:李四
new Term("title","张三") or new Term("title","李四")
结果:title:张三 title:李四 (中间是空格)
(3) WildcardQuery
WildcardQuery:通配符
new Term(“title”,“张?”) 表示查找匹配以“张”字开头的数据
(4)PrefixQuery:前缀查询
以xx开头 ,title:张*
就是比如说
(6)FuzzyQuery:近似查询,
比如输入了ibhone,和iphone近似,所以不止是能匹配ibhone,也能匹配到iphone, title:ibhone~
(7)RangeQuery:范围查询
[1,100] 开区间,不包含2边
{1,100} 闭区间,包含2边
在按照价格时间等范围查询的时候可以用
Store:索引存储类,负责文件夹等等 Util:常见工具类库
Lucence.Net 一进一出
1.建立索引需要获取数据源,分词-保存到硬盘、也可以保存在内存
2.索引查找
就是说把数据库中的数据生成索引保存到硬盘或者内存中,之后需要数据的时候也可以通过索引来查找。
代码实践:
首先从数据库查询数据,生成索引,并保存到硬盘中

/// <summary> /// 初始化索引 /// /// 生成索引主要是为解决查询问题 如果查询频繁的 且要求 支持全文索引 就都生成; /// (1)找到要存储的数据,创建存储的路径 /// (2)创建index写入对象 /// (3)遍历数据库中的数据,放入到Document结构中,然后Document结构的数据保存到索引中。 /// (4)最终数据都保存到硬盘中 /// </summary> public static void InitIndex() {
List<CourseEntity> courseList = GetList(); //(1)这是声明生成的索引所要存储的位置 TestIndexPath是一个写死的完整的物理路径,实际开发中可以动态生成,不需要写死 FSDirectory directory = FSDirectory.Open(StaticConstant.TestIndexPath);//文件夹 using (IndexWriter writer = new IndexWriter(directory, new PanGuAnalyzer(), true, IndexWriter.MaxFieldLength.LIMITED))//索引写入器 { //(2)将得到的数据写入索引中, foreach (CourseEntity course in courseList) { //之所以又加了一个这个for就是为了增大数据量,因为目前测试的数据不大,实际业务中肯定不能多这一行 for (int k = 0; k < 10; k++) { //数据必须是以Document这种数据结构来存储 Document doc = new Document();//一条数据 //Field.Store.YES 就是表示是将此数据存到硬盘中,这里没有将id设置成yes是因为id值没有什么拆分的必要,就是一个int值,NOT_ANALYZES表示不进行分词,但是进行索引。 doc.Add(new Field("id", course.Id.ToString(), Field.Store.NO, Field.Index.NOT_ANALYZED));//一个字段 列名 值 是否保存值 是否分词 doc.Add(new Field("title", course.Title, Field.Store.YES, Field.Index.ANALYZED)); doc.Add(new Field("url", course.Url, Field.Store.NO, Field.Index.NOT_ANALYZED)); doc.Add(new Field("imageurl", course.ImageUrl, Field.Store.NO, Field.Index.NOT_ANALYZED)); doc.Add(new Field("content", "this is lucene working,powerful tool " + k, Field.Store.YES, Field.Index.ANALYZED)); doc.Add(new NumericField("price", Field.Store.YES, true).SetDoubleValue((double)(course.Price + k))); //doc.Add(new NumericField("time", Field.Store.YES, true).SetLongValue(DateTime.Now.ToFileTimeUtc())); doc.Add(new NumericField("time", Field.Store.YES, true).SetIntValue(int.Parse(DateTime.Now.ToString("yyyyMMdd")) + k)); writer.AddDocument(doc);//写进去 } } writer.Optimize();//优化 就是合并 } }
生成索引之后,在对应的路径下生成索引文件,如下面:

从索引中查询一个简单的数据:
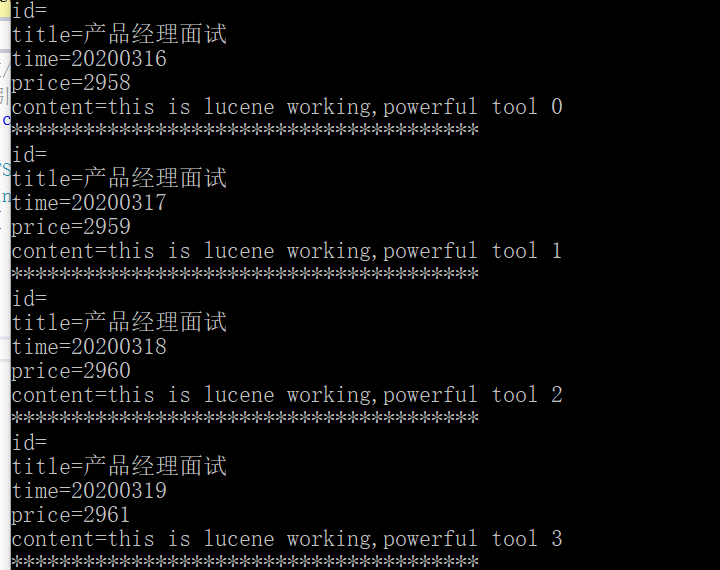
public static void Show() { FSDirectory dir = FSDirectory.Open(StaticConstant.TestIndexPath); IndexSearcher searcher = new IndexSearcher(dir);//查找器 { //查找title列中包含"产品"2个字的数据,内部其实会对传入的字符串"产品"做拆分, TermQuery query = new TermQuery(new Term("title", "产品"));//包含 //找到对应的10000数据,放到TopDocs对象中 TopDocs docs = searcher.Search(query, null, 10000);// foreach (ScoreDoc sd in docs.ScoreDocs) { Document doc = searcher.Doc(sd.Doc); Console.WriteLine("***************************************"); Console.WriteLine(string.Format("id={0}", doc.Get("id"))); Console.WriteLine(string.Format("title={0}", doc.Get("title"))); Console.WriteLine(string.Format("time={0}", doc.Get("time"))); Console.WriteLine(string.Format("price={0}", doc.Get("price"))); Console.WriteLine(string.Format("content={0}", doc.Get("content"))); } Console.WriteLine("1一共命中了{0}个", docs.TotalHits); } }
结果:
写法二,使用QueryParser解析器来解析一段带有空格的查询文本
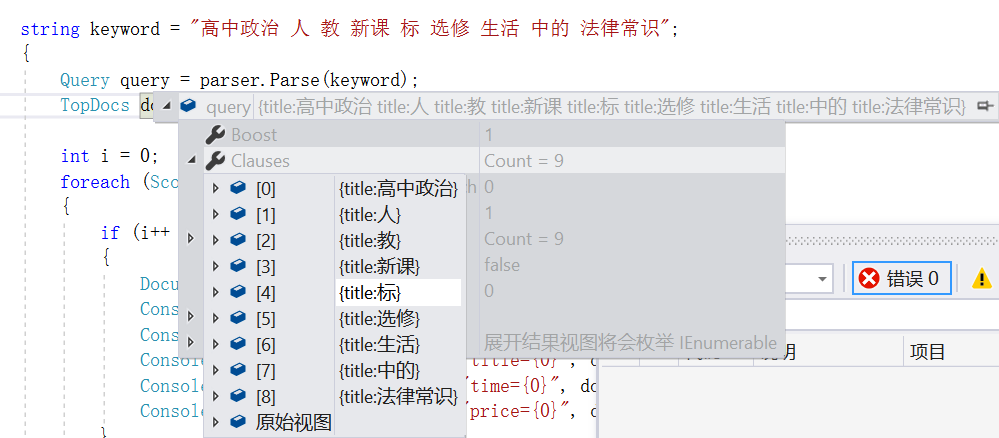
//使用PanGuAnalyzer盘古分词的解析器parser,对title列进行查询 QueryParser parser = new QueryParser(Lucene.Net.Util.Version.LUCENE_30, "title", new PanGuAnalyzer());//解析器 { string keyword = "高中政治 人 教 新课 标 选修 生活 中的 法律常识"; { Query query = parser.Parse(keyword); TopDocs docs = searcher.Search(query, null, 10000);//找到的数据 int i = 0; foreach (ScoreDoc sd in docs.ScoreDocs) { if (i++ < 1000) { Document doc = searcher.Doc(sd.Doc); Console.WriteLine("***************************************"); Console.WriteLine(string.Format("id={0}", doc.Get("id"))); Console.WriteLine(string.Format("title={0}", doc.Get("title"))); Console.WriteLine(string.Format("time={0}", doc.Get("time"))); Console.WriteLine(string.Format("price={0}", doc.Get("price"))); } } Console.WriteLine($"一共命中{docs.TotalHits}"); }
下图是在运行中得到的query对象,可以看到将这段文本拆分出了9个,只有索引文件中存在下面中文本的任意一个,都可以被检索出来。是或而不是并且。
结果:
*************************************** id= title=【逆向思维】在整个淘宝营销中的决定作用 time=20200317 price=6353 *************************************** *************************************** id= title=第8讲 交换小房子中的数 time=20200316 price=6203 ***************************************
如果存在过滤条件,排序的情况写法:
QueryParser parser = new QueryParser(Lucene.Net.Util.Version.LUCENE_30, "title", new PanGuAnalyzer());//解析器 { string keyword = "高中政治 人 教 新课 标 选修 生活 中的 法律常识"; { Query query = parser.Parse(keyword); //做一个时间范围查询,因为之前生成索引的时候就将时间变成了 Numeric类型 NumericRangeFilter<int> timeFilter = NumericRangeFilter.NewIntRange("time", 20200101, 20201231, true, true);//过滤 SortField sortPrice = new SortField("price", SortField.DOUBLE, false);//降序 SortField sortTime = new SortField("time", SortField.INT, true);//升序 Sort sort = new Sort(sortTime, sortPrice);//排序 哪个前哪个后 //根据过滤条件查询数据,并且可以排序 TopDocs docs = searcher.Search(query, timeFilter, 10000, sort);//找到的数据 int i = 0; foreach (ScoreDoc sd in docs.ScoreDocs) { if (i++ < 1000) { Document doc = searcher.Doc(sd.Doc); Console.WriteLine("***************************************"); Console.WriteLine(string.Format("id={0}", doc.Get("id"))); Console.WriteLine(string.Format("title={0}", doc.Get("title"))); Console.WriteLine(string.Format("time={0}", doc.Get("time"))); Console.WriteLine(string.Format("price={0}", doc.Get("price"))); } } Console.WriteLine("3一共命中了{0}个", docs.TotalHits); } }
一定要记住一件事,基于Lucence.Net查询,肯定是做不到实时的,因为数据量很大的话,光生成索引就要好长时间。
啊


· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 字符编码:从基础到乱码解决
· 提示词工程——AI应用必不可少的技术