Java-研究HashMap的源码
Java-研究HashMap的源码
持续更新中...
JDK版本:17
类注释
基于哈希表的Map接口实现。此实现提供了所有可选的映射操作,并允许null值和null键。 ( HashMap类大致相当于Hashtable ,只不过它是不同步的并且允许 null。)该类不保证映射的顺序;特别是,它不保证顺序随着时间的推移保持不变。
此实现为基本操作( get和put )提供恒定时间性能,假设散列函数将元素正确地分散在存储桶中。迭代集合视图所需的时间与HashMap实例的“容量”(桶的数量)加上其大小(键值映射的数量)成正比。因此,如果迭代性能很重要,那么不要将初始容量设置得太高(或负载因子太低),这一点非常重要。
HashMap实例有两个影响其性能的参数:初始容量和负载因子。容量是哈希表中桶的数量,初始容量就是创建哈希表时的容量。负载因子是衡量哈希表在其容量自动增加之前允许达到的满度的指标。当哈希表中的条目数超过负载因子与当前容量的乘积时,哈希表将被重新哈希(即重建内部数据结构),使得哈希表的桶数大约为两倍。
作为一般规则,默认负载因子 (0.75) 在时间和空间成本之间提供了良好的权衡。较高的值会减少空间开销,但会增加查找成本(反映在HashMap类的大多数操作中,包括get和put )。在设置其初始容量时应考虑映射中的预期条目数及其负载因子,以尽量减少重新哈希操作的次数。如果初始容量大于最大条目数除以负载因子,则不会发生重新哈希操作。
如果要在HashMap实例中存储许多映射,那么创建一个足够大的容量将允许更有效地存储映射,而不是让它根据需要执行自动重新哈希来增长表。请注意,使用具有相同hashCode()的多个键肯定会降低任何哈希表的性能。为了减轻影响,当键是Comparable时,此类可以使用键之间的比较顺序来帮助打破联系。
请注意,此实现不是同步的。如果多个线程同时访问哈希图,并且至少有一个线程在结构上修改了该图,则必须进行外部同步。 (结构修改是添加或删除一个或多个映射的任何操作;仅更改与实例已包含的键关联的值不是结构修改。)这通常是通过在自然封装映射的某个对象上进行同步来完成的。如果不存在这样的对象,则应使用Collections.synchronizedMap方法“包装”映射。最好在创建时完成此操作,以防止意外地不同步访问地图:
Map m = Collections.synchronizedMap(new HashMap(...));
此类的所有“集合视图方法”返回的迭代器都是快速失败的:如果在创建迭代器后的任何时间对映射进行结构修改,除了通过迭代器自己的remove方法之外的任何方式,迭代器都会抛出ConcurrentModificationException 。因此,面对并发修改,迭代器会快速而干净地失败,而不是在未来不确定的时间冒任意、非确定性行为的风险。
请注意,迭代器的快速失败行为无法得到保证,因为一般来说,在存在不同步并发修改的情况下不可能做出任何硬保证。快速失败迭代器会尽力抛出ConcurrentModificationException 。因此,编写依赖于此异常来确保其正确性的程序是错误的:迭代器的快速失败行为应该仅用于检测错误。
默认参数
初始容量DEFAULT_INITIAL_CAPACITY:16
初始容量选择 16 是基于对哈希表性能和内存利用率的一种平衡考虑。
- 哈希函数的工作方式: 在 HashMap 中,元素的存储位置是通过哈希函数计算得到的哈希码映射到数组中的槽位。选择一个容量是2的幂次方,有助于通过位运算快速计算哈希值对数组长度取模,以确定元素在数组中的位置。
- 减小哈希冲突的概率: 选择一个容量是2的幂次方,有助于分布键值对到数组槽位的均匀性。这可以降低哈希冲突的概率,即不同键计算得到相同槽位的可能性。
- 内存利用率: 16 是一个相对较小的初始容量,适用于刚开始存储少量元素的情况。这有助于节省内存,因为初始时不会分配过多的数组空间。随着元素的逐渐增加,HashMap 会根据加载因子(默认为 0.75)进行扩容,以维持性能。
- 性能考虑: 初始容量为 16 也是为了提高性能。较小的初始容量可以在初始化时更快地创建哈希表,并且在开始时,元素分布在相对较小的数组中,从而更容易实现均匀的哈希码分布。
为什么容量必须是2的幂次方?
因为在resize()中需要对桶(链表或红黑树)内的节点进行分裂,根据node的
hash&table.length 的结果(0或1)分裂成两个桶,tab[index]存储结果为0的桶,tab[index + bit]存储结果为1的桶,这样既完成了扩容,又保证查询时计算索引tab[(n - 1) & (hash = hash(key))]的正确性。
最大容量MAXIMUM_CAPACITY:2<<30 = 230 = 1073741824 ≈ 10亿
为什么是2的30次方?
数组索引是使用
int 类型表示的,而2^31 是int 类型的最大正整数值。由于数组的长度需要是2的幂次方,因此
<span style="font-weight: bold;" data-type="strong">2^30</span> 是小于 <span style="font-weight: bold;" data-type="strong">2^31</span> 的最大正整数的最大2次幂。这样做可以确保数组索引的正负范围都能够被充分利用。
加载因子DEFAULT_LOAD_FACTOR:0.75
为什么加载因子是0.75?
(1)加载因子越大,table空间利用率越高,冲突概率越大(
hash&table.length命中同一个桶),桶(链表或红黑树)内元素越多,性能越低。(2)加载因子越小,table空间利用率就越低,浪费的空间就越多,所以需要取一个平衡。
(3)HashMap在put时,元素命中的桶是完全随机的,而且符合泊松分布的条件:
如果以下假设成立,则泊松分布是一个合适的模型:^^ * k是某个时间间隔内事件发生的次数,k可以取值 0, 1, 2, ... 。 * 一个事件的发生不会影响第二个事件发生的概率。也就是说,事件是独立发生的。 * 事件发生的平均速率与任何事件的发生无关。为简单起见,通常假设该值是恒定的,但实际上可能会随时间而变化。 * 两个事件不可能在完全相同的时刻发生;相反,在每个非常小的子间隔,要么恰好发生一个事件,要么不发生任何事件。 如果这些条件成立,则k是泊松随机变量,并且k的分布是泊松分布。 (4)官方通过众多测试数据表明,当加载因子为0.75时,发生冲突(命中同一个桶)的平均概率为0.5。
(3)冲突的发生符合泊松分布,将0.5带入泊松公式后,得到以下公式,以及对应的同一个桶发生第N次冲突的概率图。
其中,X代表同一个桶发生的第几次冲突,Y代表同一个桶发生第X次冲突的概率;
经测算,值如下:
X Y 0 0.60653066 1 0.30326533 2 0.07581633 3 0.01263606 4 0.00157952 5 0.00015795 6 0.00001316 7 0.00000094 8 0.00000006 9 0.000000003265
不到千万分之一
(4)因此,加载因子为0.75时,空间利用率 和 冲突概率 (链表长度->桶内查询性能) 达到一个很好的平衡,此时HashMap的性能是最好的!
以下是代码注释中的原文:
作为一般规则,默认负载系数 (.75) 在时间和空间成本之间提供了良好的权衡。较高的值会降低空间开销,但会增加查找成本(反映在类的大多数操作 HashMap 中,包括 get 和 put)。在设置映射的初始容量时,应考虑映射中的预期条目数及其负载系数,以最大程度地减少重新散列操作的次数。如果初始容量大于最大条目数除以负载因子,则不会发生重新散列操作。
由于 TreeNodes 的大小大约是常规节点的两倍,因此我们仅在 bin 包含足够多的节点来保证使用时才使用它们(参见 TREEIFY_THRESHOLD)。当它们变得太小时(由于移除或调整大小),它们会被转换回普通垃圾箱。在具有良好分布的用户 hashCode 的用法中,很少使用树 bin。理想情况下,在随机哈希码下,bin 中节点的频率服从泊松分布 (http://en.wikipedia.org/wiki/Poisson_distribution),对于默认调整大小阈值 0.75,参数平均约为 0.5,尽管由于调整大小粒度而存在很大差异。忽略方差,列表大小 k 的预期出现次数为 (exp(-0.5) pow(0.5, k) factorial(k))。
0: 0.60653066
1: 0.30326533
2: 0.07581633
3: 0.01263606
4: 0.00157952
5: 0.00015795
6: 0.00001316
7: 0.00000094
8: 0.00000006
more(更多):不到千万分之一
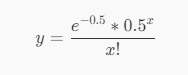
树化(转红黑树)阈值TREEIFY_THRESHOLD:8
使用树而不是箱列表的箱计数阈值。当将元素添加到至少具有这么多节点的 bin 时,bin 会转换为树。该值必须大于 2,并且至少应为 8,以便与树木移除中有关收缩后转换回普通箱的假设相吻合。
为什么是8?
因为根据上述中的泊松分布公式得出,树化(桶内元素个数大于等于8)的概率为千万分之六,这个概率就很小了。
非树化(转链表)阈值UNTREEIFY_THRESHOLD:6
在调整大小操作期间对(分割)bin 进行树形化的 bin 计数阈值。应小于 TREEIFY_THRESHOLD,且最多 6 个网格,以便在移除时进行收缩检测
最小树化阈值MIN_TREEIFY_CAPACITY:64
bin 可以树化的最小表容量。 (否则,如果 bin 中的节点太多,则表的大小将被调整。)应至少为 4 * TREEIFY_THRESHOLD 以避免调整大小和树化阈值之间的冲突。
重要属性
结构更新次数int modCount
用于遍历时检测结构是否被更改,若被更改就立刻抛出
ConcurrentModificationException异常!该 HashMap 在结构上被修改的次数 结构修改是指更改 HashMap 中的映射数量或以其他方式修改其内部结构(例如重新哈希)的次数。该字段用于使 HashMap 集合视图上的迭代器快速失败。 (请参阅并发修改异常)。瞬态 int modCount;
需调整大小的下一个阈值threshold
要调整大小的下一个大小值(容量 * 负载系数),默认是12。
初始化
/** * 使用默认初始容量 (16) 和默认负载因子 (0.75) 构造一个空HashMap 。 */ public HashMap() { this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted } /** * 构造一个具有指定初始容量和负载因子的空HashMap 。 * params: * initialCapacity – 初始容量 loadFactor – 负载系数 * return: * IllegalArgumentException – 如果初始容量为负或负载因子为非正数 */ public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; //这里使用算法来保证 threshold 永远是2的倍数 this.threshold = tableSizeFor(initialCapacity); } /** * 返回给定目标容量的2整数倍大小的幂 */ static final int tableSizeFor(int cap) { //将 `10000000000000000000000000000000` 右移 cap的二进制前导零个数 次,得到2的整倍数 int n = -1 >>> Integer.numberOfLeadingZeros(cap - 1); return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; }


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?