Java-Redis是如何保证高可用的?
Java-Redis是如何保证高可用的?
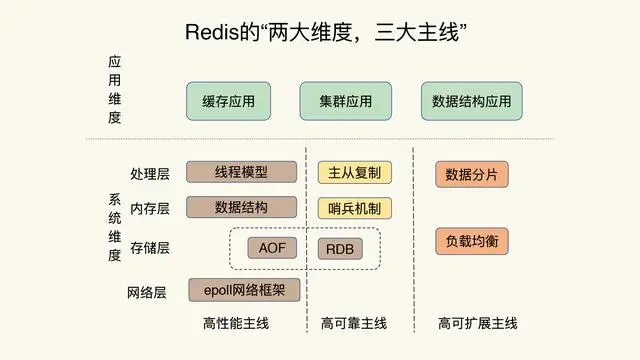
高性能
基于内存的存储
Redis是基于内存的存储系统,所有数据都保存在内存中,这使得Redis可以快速读取和写入数据。与传统的基于磁盘存储的系统相比,Redis的读写性能更高。
单线程的设计
是单线程的设计,所有的读写请求都由同一个线程处理,避免了多线程的锁竞争和上下文切换的开销,使得Redis的读写性能更高。
非阻塞的IO多路复用机制
采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络 IO 的时间消耗),且 Redis 在内存中操作数据的速度非常快,也就是说内存内的操作不会成为影响Redis性能的瓶颈。
在多路复用IO模型中,会有一个内核线程不断地去轮询多个 socket 的状态,只有当真正读写事件发送时,才真正调用实际的IO读写操作。因为在多路复用IO模型中,只需要使用一个线程就可以管理多个socket,系统不需要建立新的进程或者线程,也不必维护这些线程和进程,并且只有真正有读写事件进行时,才会使用IO资源,所以它大大减少来资源占用。
数据结构的优化
内置了多种数据结构,如字符串、列表、集合、有序集合等,这些数据结构都经过了优化,使得Redis可以快速进行读写操作。
持久化的设计
AOF 持久化:将写命令追加到文件中,定期将AOF文件重写,服务关闭时将AOF文件重写。AOF持久化的好处是可以保证数据不丢失,但是可能会导致写性能降低。
RDB 持久化:将数据快照存储到磁盘上,定期生成RDB文件,服务关闭时生成。RDB持久化的好处是可以快速恢复Redis的数据,但是可能会丢失一部分数据。
高可靠与高扩展
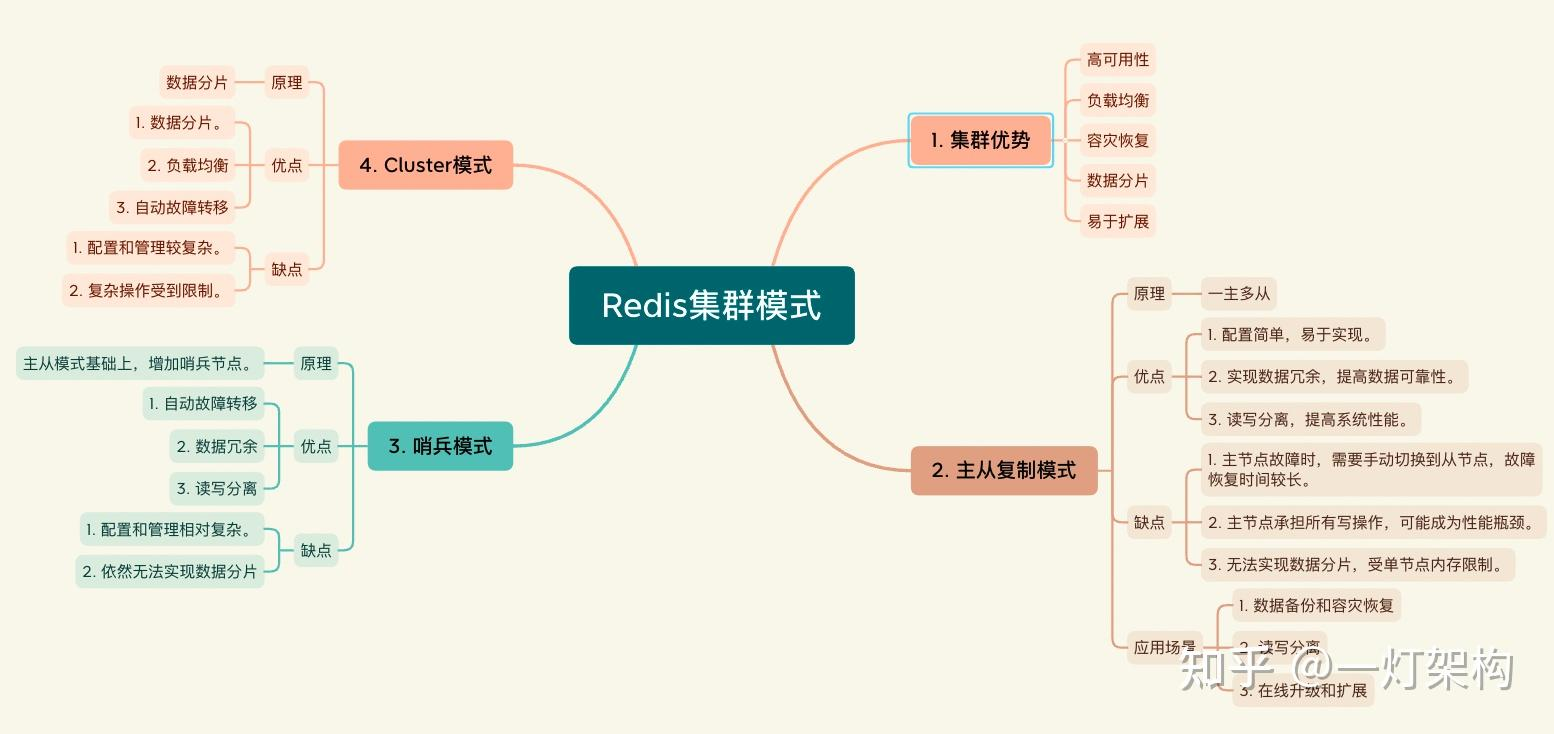
集群之间采用短连接的方式,客户端通过集群的负载均衡机制将请求分发到不同的节点。每个节点独立处理请求,然后返回结果给客户端。
在Redis集群中,客户端读取数据的过程涉及以下步骤:
- 连接到集群: 客户端首先需要连接到Redis集群。通常,客户端会连接到一个或多个集群节点,并从中选择一个作为起始节点。这个起始节点会告诉客户端关于整个集群拓扑的信息。
- 获取集群拓扑信息: 一旦连接到一个节点,客户端会向该节点发送
CLUSTER NODES命令,以获取整个集群的拓扑信息。这个信息包括集群中所有节点的IP地址、端口号、节点ID等。- 定位数据分片: 客户端通过哈希算法计算键的哈希值,然后根据哈希值定位数据所在的分片。Redis集群使用哈希槽(hash slot)来分片数据,每个分片包含一个或多个连续的哈希槽。
- 寻找负责的节点: 一旦确定了数据所在的分片,客户端需要找到负责该分片的节点。客户端会根据分片的哈希槽范围,找到负责该范围的节点。
- 发起数据读取请求: 客户端向负责的节点发送读取请求。如果该节点不是主节点(可能是从节点),它可能会将客户端重定向到主节点。
- 从主节点读取数据: 如果需要,客户端会重新定向到主节点,并向主节点发送数据读取请求。主节点负责响应读请求,从自身存储的数据中获取并返回相应的值。
这是一个简化的描述,实际过程中还涉及了一些集群管理和故障处理的细节。需要注意的是,Redis集群的读操作通常是直接在主节点上执行的,而写操作则会被主节点同步到相应的从节点。这种方式既提高了读取性能,又保证了数据的一致性。
哨兵模式
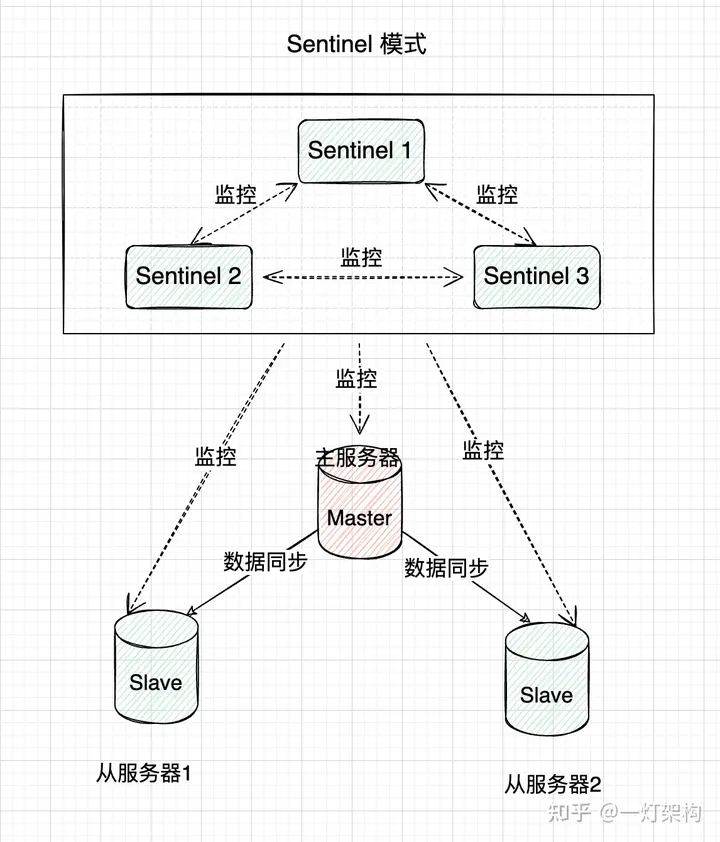
哨兵模式是在主从复制基础上加入了哨兵节点,实现了自动故障转移。哨兵节点是一种特殊的Redis节点,它会监控主节点和从节点的运行状态。当主节点发生故障时,哨兵节点会自动从从节点中选举出一个新的主节点,并通知其他从节点和客户端,实现故障转移。
Cluster模式
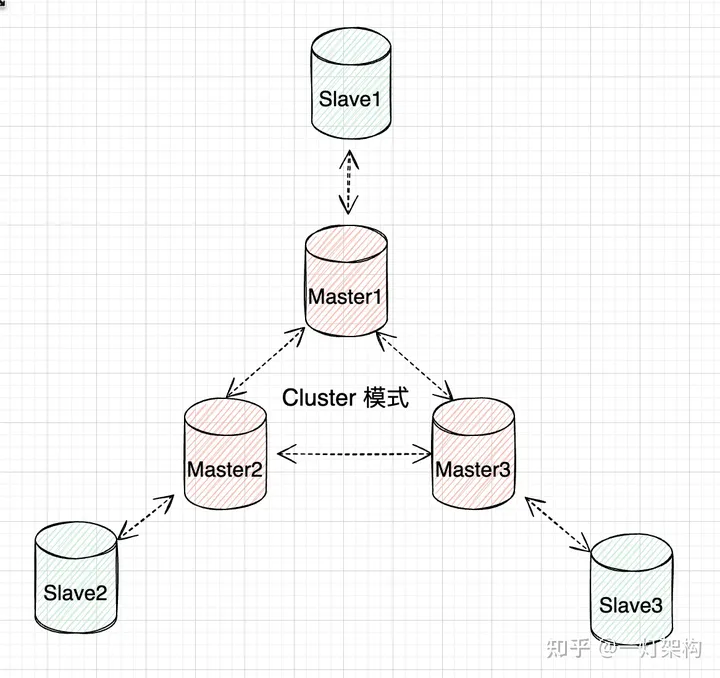
Cluster模式是Redis的一种高级集群模式,它通过数据分片和分布式存储实现了负载均衡和高可用性。在Cluster模式下,Redis将所有的键值对数据分散在多个节点上。每个节点负责一部分数据,称为槽位。通过对数据的分片,Cluster模式可以突破单节点的内存限制,实现更大规模的数据存储。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号