集合(Java总结一)
一、Queue
一个队列就是一个先入先出(FIFO)的数据结构
1、没有实现的阻塞接口的LinkedList: 实现了java.util.Queue接口和java.util.AbstractQueue接口
内置的不阻塞队列: PriorityQueue 和 ConcurrentLinkedQueue
PriorityQueue 和 ConcurrentLinkedQueue 类在 Collection Framework 中加入两个具体集合实现。
PriorityQueue 类实质上维护了一个有序列表。加入到 Queue 中的元素根据它们的天然排序(通过其 java.util.Comparable 实现)或者根据传递给构造函数的 java.util.Comparator 实现来定位。
ConcurrentLinkedQueue 是基于链接节点的、线程安全的队列。并发访问不需要同步。因为它在队列的尾部添加元素并从头部删除它们,所以只要不需要知道队列的大 小,对公共集合的共享访问就可以工作得很好。
ConcurrentLinkedQueue
1)常用方法
*offer():将指定的元素插入队列的尾部。
*poll() :获取并移除队列的头,如果队列为空则返回null。
*peek():获取表头元素但不移除队列的头,如果队列为空则返回null。
*remove(Object obj):移除队列已存在的元素,返回true,如果元素不存在,返回false。
*add(E e):将指定元素插入队列末尾,成功返回true,失败返回false(此方法非线程安全的方法,不推荐使用)。
2)特点
*调用size()方法的时候,需要遍历队列,通常使用isEmpty()。
*不允许插入null元素,会抛出空指针异常。
*是无界的,所以使用时,一定要注意内存溢出的问题。即对并发不是很大中等的情况下使用,不然占用内存过多或者溢出,对程序的性能影响很大,甚至是致命的。
2、实现阻塞接口的:
java.util.concurrent 中加入了 BlockingQueue 接口和五个阻塞队列类。BlockingQueue是双缓冲队列。BlockingQueue内部使用两条队列,允许两个线程同时向队列一个存储,一个取出操作。在保证并发安全的同时,提高了队列的存取效率。
它实质上就是一种带有一点扭曲的 FIFO 数据结构。不是立即从队列中添加或者删除元素,线程执行操作阻塞,直到有空间或者元素可用。
五个队列所提供的各有不同:
* ArrayBlockingQueue :一个由数组支持的有界队列。
* LinkedBlockingQueue :一个由链接节点支持的可选有界队列。
* PriorityBlockingQueue :一个由优先级堆支持的无界优先级队列。
* DelayQueue :一个由优先级堆支持的、基于时间的调度队列。
* SynchronousQueue :一个利用 BlockingQueue 接口的简单聚集(rendezvous)机制。

二,Set
Set:注重独一无二的性质,该体系集合可以知道某物是否已近存在于集合中,不会存储重复的元素
用于存储无序(存入和取出的顺序不一定相同)元素,值不能重复。
对象的相等性
引用到堆上同一个对象的两个引用是相等的。如果对两个引用调用hashCode方法,会得到相同的结果,如果对象所属的类没有覆盖Object的hashCode方法的话,hashCode会返回每个对象特有的序号(java是依据对象的内存地址计算出的此序号),所以两个不同的对象的hashCode值是不可能相等的。
如果想要让两个不同的Person对象视为相等的,就必须覆盖Object继下来的hashCode方法和equals方法。
1、HashSet
哈希表结构,基于HashMap实现,新增元素相当于HashMap的key,value默认为一个固定的Object。
具有如下特点:
-
不允许出现重复因素;
-
允许插入Null值;
-
元素无序(添加顺序和遍历顺序不一致);
-
线程不安全,若2个线程同时操作HashSet,必须通过代码实现同步;
2、TreeSet
底层结构为红黑树(特殊的二叉查找树,算法的规则: 左小右大)。
允许自定义排序,通过实现Comparator方法,重写equals方法
结果返回大于0时,方法前面的值大于方法中的值;
结果返回等于0时,方法前面的值等于方法中的值;
结果返回小于0时,方法前面的值小于方法中的值;具有如下特点:
-
对插入的元素进行排序,是一个有序的集合(主要与HashSet的区别);
-
底层使用红黑树结构,而不是哈希表结构;
-
允许插入Null值;
-
不允许插入重复元素;
-
线程不安全;
三、List
LinkedList和ArrayList的实现方式不同,可以在不同的场景下使用不同的List
ArrayList是由数组实现的,方便查找,返回数组下标对应的值即可,适用于多查找的场景
LinkedList由链表实现,插入和删除方便,适用于多次数据替换的场景
四、Map
https://zhuanlan.zhihu.com/p/21673805 美团技术博客
1、HashMap
最常用的Map,它根据键的HashCode 值存储数据。HashMap最多只允许一条记录的键为Null(多条会覆盖),非同步的。
HashMap计算hash对key的hashcode进行了二次hash,以获得更好的散列值,然后对table数组长度取摸。
4.1.1 底层结构
当链表数组的容量超过初始容量的0.75时,再散列将链表数组扩大2倍,把原链表数组的搬移到新的数组中
Entry类实际上是一个单向的链表结构,它具有Next指针,可以连接下一个Entry实体,以此来解决Hash冲突的问题。

4.1.2、JDK1.8以后 HashMap采用数组+链表+红黑树实现

当链表长度超过阈值(8)时,将链表转换为红黑树。在性能上进一步得到提升。
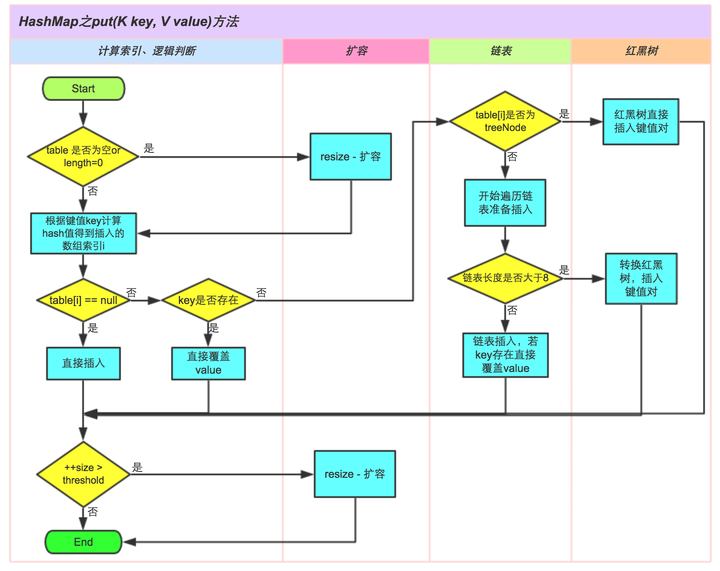
4.1.3 put操作
2、TreeMap
能够把它保存的记录根据键(key)排序,默认是按升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。TreeMap不允许key的值为null。非同步的。
3、Hashtable
与 HashMap类似,不同的是:key和value的值均不允许为null;它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了Hashtale在写入时会比较慢。
4、LinkedHashMap
保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的.在遍历的时候会比HashMap慢。key和value均允许为空,非同步的。
4.4.1底层原理
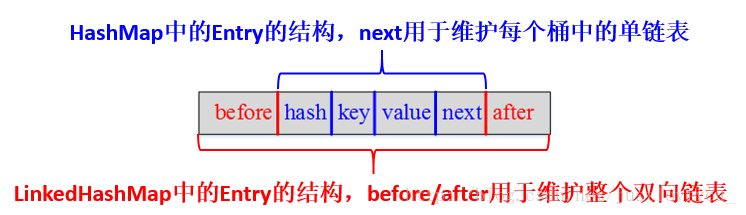

4.4.2LinkedHashMap和LRU算法
使用LinkedHashMap实现LRU的必要前提是将accessOrder标志位设为true以便开启按访问顺序排序的模式。我们可以看到,无论是put方法还是get方法,都会导致目标Entry成为最近访问的Entry,因此就把该Entry加入到了双向链表的末尾:get方法通过调用recordAccess方法来实现;
put方法在覆盖已有key的情况下,也是通过调用recordAccess方法来实现,在插入新的Entry时,则是通过createEntry中的addBefore方法来实现。这样,我们便把最近使用的Entry放入到了双向链表的后面。多次操作后,双向链表前面的Entry便是最近没有使用的,这样当节点个数满的时候,删除最前面的Entry(head后面的那个Entry)即可,因为它就是最近最少使用的Entry。
优化15条
 浙公网安备 33010602011771号
浙公网安备 33010602011771号