
初入scrapy
安装:pip install scrapy -i https://pypi:tuna.tsinghua.edu.cn/simple
测试验证安装结果: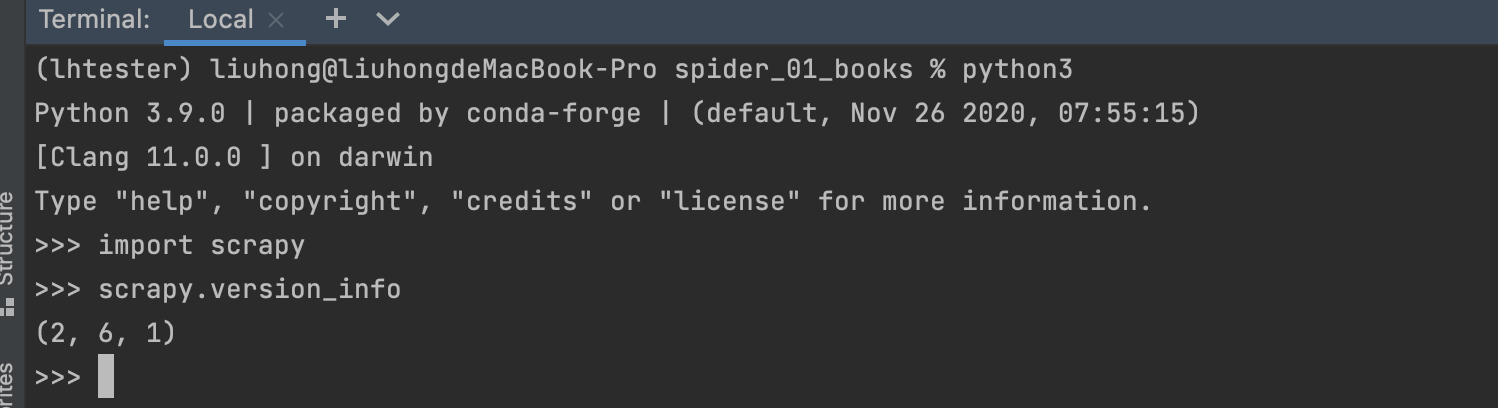
创建一个项目:在shell中使用scrapyard startproject name
使用pycharm工具打开
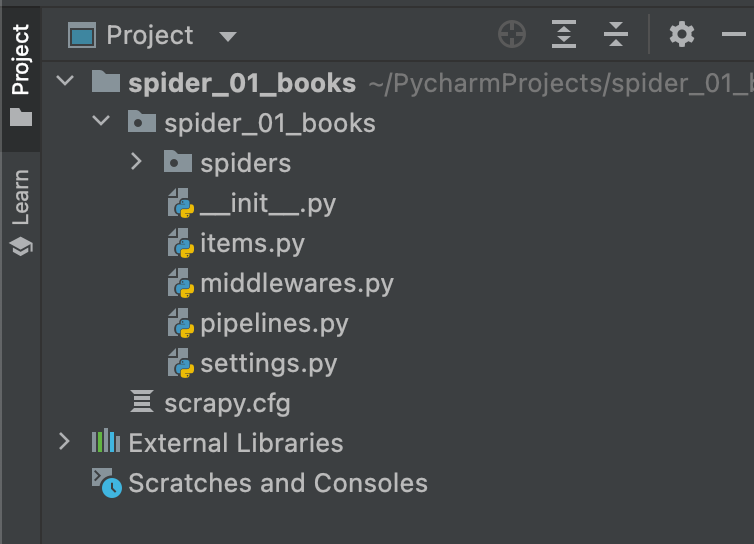
1.scrapy.cfg :scrapy项目的配置文件,其内定义了项目的配置文件路径/部署相关信息等内容。
2.items.py :定义item数据结构,所有item的定义都可以放在这里。
3.pipelines :定义 item Pipeline(管道) 的实现,所有item Pipline的实现都可以放在这里。
4.settings.py: 定义项目的全局配置
5.middlewares.py:定义Spider Middlewares (spider 中间件)和Downloader Middlewares(下载中间件)的实现
6.spider:其内包含一个个Spider的实现,每个Spider都有一个文件
实现spider:
进入项目并创建爬虫类:
scrapy genspider bookstoscrape books.toscrape.com

编辑bookstoscrape
import scrapy
class BookstoscrapeSpider(scrapy.Spider):
"""爬虫类,继承spider"""
#爬虫名称--每一个爬虫的唯一标识
name = 'bookstoscrape'
#允许爬爬取的域名
allowed_domains = ['books.toscrape.com']
#初始爬取的URL
start_urls = ['http://books.toscrape.com/']
#解析下载
def parse(self, response):
#提取数据
#每一本书的信息在<article class="product_pod">中,使用xpath()方法找到所有的article元素,并依次迭代
for book in response.xpath('//article[@class="product_pod"]'):
#书名信息在article>h3 >a元素的title属性中
#例如:<a href="catalogue/a-light-in-the-attic_1000/index.html" title="A Light in the Attic">A Light in the ...</a>
name = book.xpath('./h3/a/@title').extract_first()
# extract_first():这个方法返回的是一个string字符串,是list数组里面的第一个字符串。
#书价信息在article><div class="product_price">的text中,例如:<p class="price_color">£51.77</p>
price= book.xpath('./div[2]/p[1]/text()').extract_first()[1:]
#书的评级在article>p 元素的class属性中。例如:<p class="star-rating Three">
rate = book.xpath('./p/@class').extract_first().split(" ")[1]
#返回单个图书对象
yield {
"name":name,
"price":price,
"rate":rate
}
#提取下一页的链接
#下一页的url在li.next >a 元素的href属性中
#例如:<li class="next"><a href="catalogue/page-2.html">next</a></li>
next_url= response.xpath('//li[@class="next"]/a/@href').extract_first()
#判断
if next_url:
#如果找到下一页的URl,则得到绝对路径,构造新的request对象
next_url = response.urljoin(next_url)
#返回新的request对象
yield scrapy.Request(next_url,callback=self.parse
在shell中运行爬虫:scrapy crawl bookstoscrape -o bookstoscrape.csv
crawl:表示启动爬虫
bookstoscrape:在bookstoscrape.py中BookstoscrapeSpider定义的name
-o:保存文件的路径,没有这个参数也能启动爬虫,只不过数据没有保存下来而已。
bookstoscrape.csv:文件名
我使用的是导出csv格式,也可以导出json和xml格式,json:scrapy crawl bookstoscrape -o bookstoscrape.jsonlines xml:scrapy crawl bookstoscrape -o bookstoscrape.xml
执行结果如下:
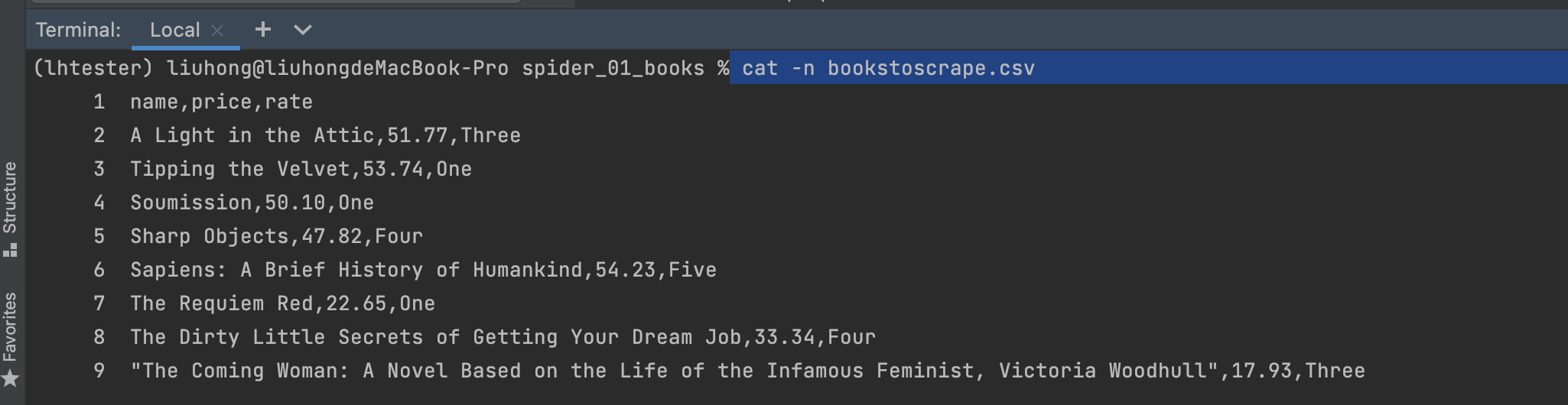
使用 cat -n bookstoscrape.csv 查看:
总结:
遇到lxml错误:
- lxml.etree.XPathEvalError: Unfinished literal
class写错了 - Python Xpath: lxml.etree.XPathEvalError: Invalid predicate
class少了一个冒号闭合
