
mysql数据库总结
1、mysql中innoDB和myisam的区别
1.innoDB支持事务,myisam不支持 2.innoDB支持行级锁,myisam支持表级锁 3.innoDB支持外键,myisam不支持 4.innoDB不支持全文索引,myisam支持
2、事务的隔离级别
读未提交 read uncommitted
第已提交 read committed
可重复读 repeatable read
串行 serializable
各隔离级别含义
Read Uncommitted:可以读取其他 session 未提交的脏数据。
Read Committed:允许不可重复读取,但不允许脏读取。提交后,其他会话可以看到提交的数据。
Repeatable Read: 禁止不可重复读取和脏读取、以及幻读(innodb 独有)。
Serializable: 事务只能一个接着一个地执行,但不能并发执行。
事务隔离级别最高。不同的隔离级别有不同的现象,并有不同的锁定/并发机制,隔离级别越高,数据库的并发性就越差。
数据库的4个特性和含义
数据库事务transanction正确执行的四个基本要素。ACID,原子性(Atomicity)、一致性(Correspondence)、隔离性(Isolation)、持久性(Durability)。
原子性:整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
一致性:在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。
隔离性:隔离状态执行事务,使它们好像是系统在给定时间内执行的唯一操作。如果有两个事务,运行在相同的时间内,执行 相同的功能,事务的隔离性将确保每一事务在系统中认为只有该事务在使用系统。
这种属性有时称为串行化,为了防止事务操作间的混淆,必须串行化或序列化请 求,使得在同一时间仅有一个请求用于同一数据。
持久性:在事务完成以后,该事务所对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。
索引
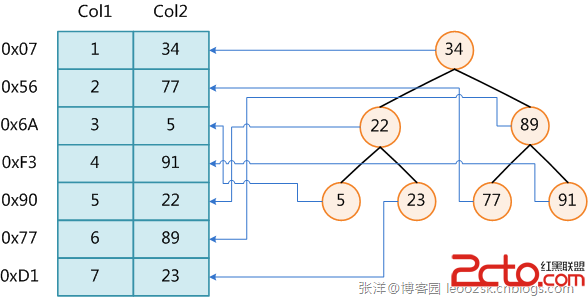
数据库索引,是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库表中数据。索引的实现通常使用B树及其变种B+树。
在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
为表设置索引要付出代价的:一是增加了数据库的存储空间,二是在插入和修改数据时要花费较多的时间(因为索引也要随之变动)。
图展示了一种可能的索引方式。左边是数据表,一共有两列七条记录,最左边的是数据记录的物理地址(注意逻辑上相邻的记录在磁盘上也并不是一定物理相邻的)。为了加快Col2的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找在O(log2n)的复杂度内获取到相应数据。
创建索引可以大大提高系统的性能。
第一,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
第二,可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
第三,可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
第四,在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
第五,通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
也许会有人要问:增加索引有如此多的优点,为什么不对表中的每一个列创建一个索引呢?因为,增加索引也有许多不利的方面。
第一,创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
第二,索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
第三,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
索引是建立在数据库表中的某些列的上面。在创建索引的时候,应该考虑在哪些列上可以创建索引,在哪些列上不能创建索引。一般来说,应该在这些列上创建索引:在经常需要搜索的列上,可以加快搜索的速度;在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构;在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度;在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
同样,对于有些列不应该创建索引。一般来说,不应该创建索引的的这些列具有下列特点:
第一,对于那些在查询中很少使用或者参考的列不应该创建索引。这是因为,既然这些列很少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度和增大了空间需求。
第二,对于那些只有很少数据值的列也不应该增加索引。这是因为,由于这些列的取值很少,例如人事表的性别列,在查询的结果中,结果集的数据行占了表中数据行的很大比例,即需要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度。
第三,对于那些定义为text, image和bit数据类型的列不应该增加索引。这是因为,这些列的数据量要么相当大,要么取值很少。
第四,当修改性能远远大于检索性能时,不应该创建索引。这是因为,修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。因此,当修改性能远远大于检索性能时,不应该创建索引。
根据数据库的功能,可以在数据库设计器中创建三种索引:唯一索引、主键索引和聚集索引。
唯一索引
唯一索引是不允许其中任何两行具有相同索引值的索引。
当现有数据中存在重复的键值时,大多数数据库不允许将新创建的唯一索引与表一起保存。数据库还可能防止添加将在表中创建重复键值的新数据。例如,如果在employee表中职员的姓(lname)上创建了唯一索引,则任何两个员工都不能同姓。 主键索引 数据库表经常有一列或列组合,其值唯一标识表中的每一行。该列称为表的主键。 在数据库关系图中为表定义主键将自动创建主键索引,主键索引是唯一索引的特定类型。该索引要求主键中的每个值都唯一。当在查询中使用主键索引时,它还允许对数据的快速访问。 聚集索引 在聚集索引中,表中行的物理顺序与键值的逻辑(索引)顺序相同。一个表只能包含一个聚集索引。
如果某索引不是聚集索引,则表中行的物理顺序与键值的逻辑顺序不匹配。与非聚集索引相比,聚集索引通常提供更快的数据访问速度。
优化
1.sql结构优化
1)应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。 2)应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如: select id from t where num is null 可以在num上设置默认值0,确保表中num列没有null值,然后这样查询: select id from t where num=0 3)很多时候用 exists 代替 in 是一个好的选择 4)用Where子句替换HAVING 子句 因为HAVING 只会在检索出所有记录之后才对结果集进行过滤
2.索引优化
根据情况创建合适的索引
3.表结构优化
1)范式优化: 比如消除冗余(节省空间。。) 2)反范式优化:比如适当加冗余等(减少join) 3)拆分表: 分区将数据在物理上分隔开,不同分区的数据可以制定保存在处于不同磁盘上的数据文件里。这样,当对这个表进行查询时,只需要在表分区中进行扫描,
而不必进行全表扫描,明显缩短了查询时间,另外处于不同磁盘的分区也将对这个表的数据传输分散在不同的磁盘I/O,一个精心设置的分区可以将数据传输对磁盘I/O竞争均匀地分散开。对数据量大的时时表可采取此方法。可按月自动建表分区。 4)拆分其实又分垂直拆分和水平拆分: 案例: 简单购物系统暂设涉及如下表: 1.产品表(数据量10w,稳定) 2.订单表(数据量200w,且有增长趋势) 3.用户表 (数据量100w,且有增长趋势) 以mysql为例讲述下水平拆分和垂直拆分,
mysql能容忍的数量级在百万静态数据可以到千万 垂直拆分:解决问题:表与表之间的io竞争 不解决问题:单表中数据量增长出现的压力 方案: 把产品表和用户表放到一个server上 订单表单独放到一个server上 水平拆分: 解决问题:单表中数据量增长出现的压力 不解决问题:表与表之间的io争夺 方案: 用户表通过性别拆分为男用户表和女用户表 订单表通过已完成和完成中拆分为已完成订单和未完成订单 产品表 未完成订单放一个server上 已完成订单表盒男用户表放一个server上 女用户表放一个server上(女的爱购物 哈哈)
4.服务器硬件优化
5.分享一篇对mysql的b+数索引总结的不错的文章

 浙公网安备 33010602011771号
浙公网安备 33010602011771号