Python JSON数据解析、操作集合
JSON格式是网站和API使用的通用标准格式,现在主流的一些数据库(如PostgreSQL)都支持JSON格式。在本文中,我们将介绍如何使用Python处理JSON数据。首先,让我们先来看看JSON的定义。
-
内置模块:
json - 强大的解析模块:
demjson - 强大的查询模块:
定义
JSON或JavaScript Object Notation,是一种使用文本存储数据对象的格式。换句话说,它是一种数据结构,将对象用文本形式表示出来。尽管它来源自JavaScript,但它已成为传输对象的实际标准。
{ "name": "United States", "population": 23123124, "capital": "dasdasd", "languages": [ "English", "Spanish" ] }
在这个例子中,JSON数据看起来像一个Python字典。像字典一样,JSON以键值对的形式传递数据。
然而,JSON数据也可以是字符串、数字、布尔值或列表。
一、内置模块 json
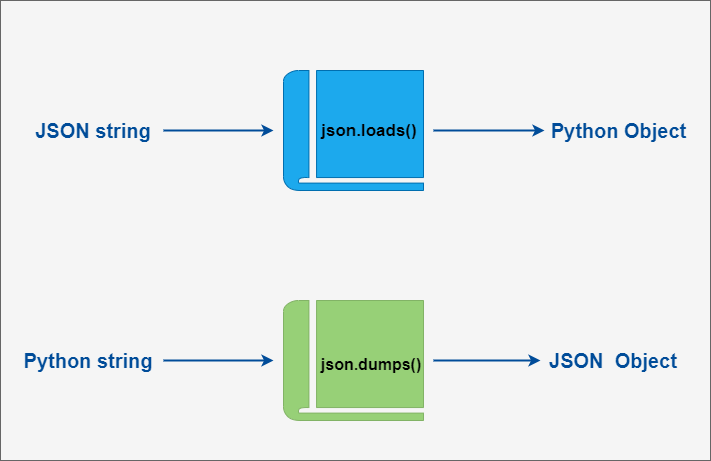
-
json.dumps(): 对数据进行编码。
-
json.loads(): 对数据进行解码。
使用方法
# Python 字典类型转换为 JSON 对象 data = { 'no' : 1, 'name' : [1,2,3,4], } json_str = json.dumps(data) # 将 JSON 对象转换为 Python 字典 data2 = json.loads(json_str)
1.1 将JSON字符串转换为Python类对象
类(class)对象不是JSON序列化对象。
import json class People(object): def __init__(self, name, age, gender): self.name = name self.age = age self.gender = gender people_obj = People("张三", 32, "男") print(json.dumps(people_obj)) # TypeError: Object of type People is not JSON serializable # 类型错误:People对象不可以JSON序列化
解决方案
要将对象转换为JSON,我们需要编写一个扩展JSONEncoder的新类。在这个类中,需要实现default()。此方法将具有返回JSON的自定义代码。
class PeopleEncoder(json.JSONEncoder): def default(self, obj): if isinstance(obj, People): # 处理People的序列化 return { "name": obj.name, "age": obj.age, "gender": obj.gender, } else: # 使用父类的序列化方法 super(PeopleEncoder, self).default(obj) # 使用 print(json.dumps(people_obj, cls=PeopleEncoder, ensure_ascii=False)) # {"name": "张三", "age": 32, "gender": "男"}
1.2 从JSON对象创建Python类对象 -- object_hook
使用object_hook
class People(object): def __init__(self, name, age, gender): self.name = name self.age = age self.gender = gender @staticmethod def object_hook(d): return People(**d) people_obj = People("张三", 32, "男") json_str = '{"name": "张三", "age": 32, "gender": "男"}' p = json.loads(json_str, object_hook=People.object_hook) print(type(p)) # <class '__main__.People'> print(p.name, p.age, p.gender) # 张三 32 男
二、demjson 解决多种疑难杂症
Demjson是 python 的第三方模块库,可用于编码和解码 JSON 数据,包含了 JSONLint 的格式化及校验功能。
安装
pip install demjson
使用
-
demjson.encode: 将 Python 对象编码成 JSON 字符串
-
demjson.decode: 将已编码的JSON 字符串解码为 Python 对象
该包功能相较于json而言具有格式化校验功能,支持js的多种格式的对象转字典
# 可以解析包含 ' 的字符串 d_s = """{"a":1, "b":2, 'c':3}""" d = demjson.decode(d_s) # 解析js的的特殊字符 js_obj = """{a:1,b:2}""" d2 = demjson.decode(js_obj) # 包含不规范的js字符串 undefined、null js_obj2 = '''{a:undefined,b:null}''' d3 = demjson.decode(js_obj)
三、jsonpath 快速处理dict的深度查询
-
JSONPath - 用于JSON的XPath
-
用来解析多层嵌套的json数据;JsonPath 是一种信息抽取类库,是从JSON文档中抽取指定信息的工具.
官方文档:http://goessner.net/articles/JsonPath
安装
pip install jsonpath
强大之处
import jsonpath res=jsonpath.jsonpath(dic_name,'$..key_name') # 查询字典中所有的key_name的值,返回列表
嵌套n层也能取到所有key_name信息,其中:“$”表示最外层的{},“..”表示模糊匹配,当传入不存在的key_name时,程序会返回false.
使用规则
- jsonpath表达式使用点注释
$.store.book[0].title
-
括号 -注释
$['store']['book'][0]['title']
jsonpath与xpath的联系
JSONPath语法元素与XPath对应的完整概述和并排比较。
| Xpath | JSONPath | 描述 |
|---|---|---|
| / | $ | 跟节点 |
| . | @ | 现行节点 |
| / | . or [] | 取子节点 |
| .. | n/a | 就是不管位置,选择所有符合条件的条件 |
| * | * | 匹配所有元素节点 |
| [] | [] | 迭代器标示(可以在里面做简单的迭代操作,如数组下标,根据内容选值等) |
| | | [,] | 支持迭代器中做多选 |
| [] | ?() | 支持过滤操作 |
| n/a | () | 支持表达式计算 |
| () | n/a | 分组,JsonPath不支持 |
实例演示
{ "store": {
"book": [
{ "category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{ "category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{ "category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{ "category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
}
}
jsonpath与xpath写法及其含义,帮助理解
| XPath的 | JSONPath | 结果 |
|---|---|---|
/store/book/author |
$.store.book[*].author |
商店里所有书籍的作者 |
//author |
$..author |
所有作者 |
/store/* |
$.store.* |
商店里的所有东西,都是一些书和一辆红色的自行车。 |
/store//price |
$.store..price |
商店里一切的价格。 |
//book[3] |
$..book[2] |
第三本书 |
//book[last()] |
$..book[(@.length-1)] $..book[-1:] |
最后一本书。 |
//book[position()<3] |
$..book[0,1] $..book[:2] |
前两本书 |
//book[isbn] |
$..book[?(@.isbn)] |
使用isbn number过滤所有书籍 |
//book[price<10] |
$..book[?(@.price<10)] |
过滤所有便宜10以上的书籍 |
//* |
$..* |
XML文档中的所有元素。JSON结构的所有成员。 |
python使用示例
jsonpath.jsonpath(匹配的字典,'jsonpath表达式') 如:res2= jsonpath.jsonpath(d,'$..name') #找d字典下面所有的name对应的值,返回一个列表
完整例子
shop={ "store": { "book": [ { "category": "reference", "author": "Nigel Rees", "title": "Sayings of the Century", "price": 8.95 }, { "category": "fiction", "author": "Evelyn Waugh", "title": "Sword of Honour", "price": 12.99 }, { "category": "fiction", "author": "Herman Melville", "title": "Moby Dick", "isbn": "0-553-21311-3", "price": 8.99 }, { "category": "fiction", "author": "J. R. R. Tolkien", "title": "The Lord of the Rings", "isbn": "0-395-19395-8", "price": 22.99 } ], "bicycle": { "color": "red", "price": 19.95 } }, "expensive": 10 } import jsonpath #商店里所有书籍的作者 author_list=jsonpath.jsonpath(shop,'$.store.book[*].author') print(author_list) #['Nigel Rees', 'Evelyn Waugh', 'Herman Melville', 'J. R. R. Tolkien'] #返回所有的作者 author_list2=jsonpath.jsonpath(shop,'$..author') print(author_list2) #['Nigel Rees', 'Evelyn Waugh', 'Herman Melville', 'J #商店里的所有东西 category_dx=jsonpath.jsonpath(shop,'$.store.*') print(category_dx) #商店里一切的价格 store_price_list=jsonpath.jsonpath(shop,'$.store..price') print(store_price_list) #[8.95, 12.99, 8.99, 22.99, 19.95] #第三本书 book_3=jsonpath.jsonpath(shop,'$..book[2]') print(book_3) #最后一本书 num=len(jsonpath.jsonpath(shop,'$..book'))-1 book_last=jsonpath.jsonpath(shop,f'$..book[{num}]') print(book_last) #前两本书 book_12=jsonpath.jsonpath(shop,f'$..book[0,1]') print(book_12) #过滤所有便宜10以上的书籍 book_lg10=jsonpath.jsonpath(shop,'$..book[?(@.price<10)]') print(book_lg10) #使用isbn number过滤所有书籍 book_lg10=jsonpath.jsonpath(shop,'$..book[?(@.isbn)]') print(book_lg10)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号