
Mybatis
- 声明:此文是小白本人学习Spring所写,主要参考(搬运)了:【框架】--MyBatis - 随笔分类 - 唐浩荣 - 博客园 (cnblogs.com)
- 感谢此文所引用的文章的作者提供的优质学习资源,如有侵犯,请原作者联系我删除
- 1、Mybatis的介绍
- 2、Mybatis的第一个入门实例
- 3、Mybatis全局配置文件详解
- 4、SQL映射文件详解(XxxMapper.xml)
- 5、通过Mapper接口(动态代理)加载映射文件(推荐)
- 6、通过注解映射实现Mybatis实例
- 7、动态SQL
- 8、高级映射之一对一映射
- 9、高级映射之一对多映射
- 10、高级映射之多对多映射
- 11、延迟加载
- 12、Mybatis缓存
- 13、Mybatis逆向工程
- 14、Mybatis的分页
- 15、Mybatis简易整合Spring框架
- 16、Mybatis运行原理
- 17、SqlSession下的四大对象
- 18、Mybatis中使用的9种设计模式
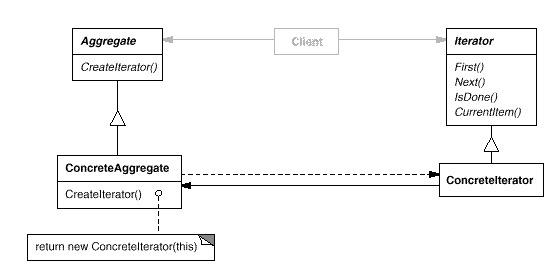
1、Mybatis的介绍

1.1 什么是Mybatis
MyBatis本是Apache的一个开源项目iBatis,2010年这个项目由Apache Software Foundation迁移到了Google Code,并且改名为MyBatis,也就是从3.0版本开始 iBatis改名为MyBatis。并且于2013年11月迁移到Github,地址:https://github.com/mybatis/mybatis-3。iBATIS一词来源于“internet”和“abatis”的组合,是一个基于Java的持久层框架。iBATIS提供的持久层框架包括SQL Maps和Data Access Objects(DAOs)
MyBatis 是一款优秀的持久层框架,它支持自定义 SQL、存储过程以及高级映射。MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。
用一句话来形容什么Mybatis:MyBatis 是一个可以自定义 SQL、存储过程和高级映射的持久层框架。
1.2 基本概念
Mybatis是一个基于Java的持久层 / ORM框架(对象关系映射Object Relational Mapping,简称ORM),所以我们在学习之前,先来了解一下如下基本概念。
-
什么是“持久化”
持久(Persistence),即把数据(如内存中的对象)保存到可永久保存的存储设备中(如磁盘)。持久化的主要应用是将内存中的数据存储在关系型的数据库中,当然也可以存储在磁盘文件中、XML数据文件中等,但是一般都会存放在关系型数据库中如:MySQL、Oracle等。
-
什么是“持久层”
持久层(Persistence Layer),即专注于实现数据持久化应用领域的某个特定系统的一个逻辑层面,将数据使用者和数据实体相关联。比如我们的pojo层、Dao层和Service层的关联。
-
什么是“ORM”
ORM即Object-Relationl Mapping,意思为对象关系映射。它用于实现面向对象编程语言的类型和关系型数据库类型之间的相互转换。简单的说,ORM是通过描述对象和数据库之间映射的元数据,将程序中的对象与关系数据库相互映射,到时候我们在具体的操作数据库的时候,就不需要再去和复杂的SQL语句打交道,只要像平时操作对象一样操作它就可以了 。但是从前面的描述可知,我们的Mybatis是需要与SQL打交道的,所以我们认为Mybatis是一个半自动化的ORM框架。
在Java中典型的ORM中有:
- JPA:JPA全称Java Persistence API,即Java持久化API,是sun公司推出的一套基于ORM的规范,内部由一系列的接口和抽象类构成。JPA通过JDK 5.0注解或XML描述
对象-关系表的映射关系,是Java自带的框架。 - Hibernate:全自动的ORM框架,强大、复杂、笨重、学习成本较高。Hibernate除了作为ORM框架之外,它也是一种JPA实现。
- Mybatis:半自动的ORM框架,强大,简单,灵活,学习成本较低。Mybatis提供了自定义SQL,这样开发者将主要精力放在SQL上就行了。
之所以要做持久化和使用ORM设计,因为持久化解决了数据的存储问题,ORM解决的主要是对象关系的映射的问题。在目前的企业应用系统设计中,都是以MVC为主要的系统架构模式(MVC即 Model(模型)- View(视图)- Control(控制))。MVC 中的 Model 包含了复杂的业务逻辑和数据逻辑,以及数据存取机制等(如 JDBC的连接、SQL生成和Statement创建、还有ResultSet结果集的读取等)。将这些复杂的业务逻辑和数据逻辑分离,以将系统的紧耦合关系转化为松耦合关系(即解耦合),是降低系统耦合度迫切要做的,也是持久化要做的工作。MVC 模式实现了架构上将表现层(即View)和数据处理层(即Model)分离的解耦合,持久化的设计则实现了数据处理层内部的业务逻辑和数据逻辑分离的解耦合。 而 ORM 作为持久化设计中的最重要也最复杂的技术,也是目前业界热点技术。
一般情况下,一个持久化类和一个表对应,类的每个实例对应表中的一条记录,类的每个属性对应表的每个字段。可以用下面这样一张图来表示:

下面我们将关系数据中的表记录映射成为对象,以对象的形式展现,这样程序员可以把对数据库的操作转化为对对象的操作。
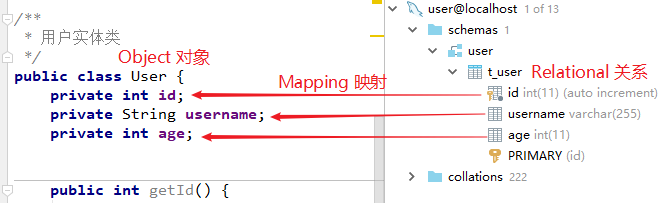
因此ORM的目的是为了方便开发人员以面向对象的思想来实现对数据库的操作。
ORM的方法论基于三个核心原则:
- 简单:以最基本的形式建模数据。
- 传达性:数据库结构被任何人都能理解的语言文档化。
- 精确性:基于数据模型创建正确标准化了的结构。
1.3 为什么使用Mybatis
我们以前在没有ORM框架的情况下,如果你要开发一个Web应用程序的话,你就必须要使用传统的JDBC代码来操作数据库,我们除了需要自己提供 SQL 外,还必须操作 Connection、Statment、ResultSet等,不仅如此,为了访问不同的表,不同字段的数据,我们需要些很多雷同模板化的代码,而这些代码写起来往往是重复的,写起来又繁琐又枯燥。
我们下面来分析一下使用传统JDBC的缺陷,先看如下代码:
public class SqlConnection {
public static void main(String[] args) {
//定义数据库连接
Connection con = null;
//定义数据库语句
PreparedStatement ps = null;
//定义返回结果集
ResultSet rs= null;
try {
//加载数据库驱动
Class.forName("com.mysql.cj.jdbc.Driver");
//定义MySQL URL,因为这里有的长所以在这里定义了
String url = "jdbc:mysql://localhost:3306/user?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf-8";
//获取连接
con = DriverManager.getConnection(url,"root","root");
//定义SQL语句,?表示占位符
String sql = "select * from t_user where username = ?";
//获取编译处理的statement
ps = con.prepareStatement(sql);
//设置SQL参数
ps.setString(1,"唐浩荣");
//执行SQL语句查询,并且返回结果集
rs = ps.executeQuery();
//遍历结果集
while (rs.next()){
System.out.println(rs.getInt("id")+
"--"+rs.getString("username")+
"--"+rs.getInt("age"));
}
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}finally {
//关闭数据库连接(三个写一起方便0.0)
try {
rs.close();
ps.close();
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
通过上面的一段JDBC连接数据代码,我们看有哪些不好的地方:
- 在创建Connection对象的时候,存在硬编码问题。也就是直接把连接数据库的信息写死,如果需要连接不同的数据库则要更改配置,不方便后期维护。
- 在使用PreparedStatement对象执行SQL语句的时候同样存在硬编码问题。将SQL语句硬编码到Java代码中,如果SQL语句修改,需要重新编译Java代码,不利于系统维护。
- 向PreparedStatement中设置参数,对占位符号位置和设置参数值,硬编码在Java代码中,不利于系统维护。
- 从ResutSet中遍历结果集数据时,存在硬编码,将获取表的字段进行硬编码,如果表的字段修改了则代码也需要修改,不利于系统维护。
- 每次在进行一次数据库连接后都会创建和关闭数据库连接,频繁的开启/关闭数据连接会造成数据库资源浪费,影响数据库性能。
- 缓存做的很差,如果存在数据量很大的情况下,这种方式性能特别低。
所以通过上面的分析,我们知道为什么要使用Mybatis了吧。在使用了 MyBatis 之后,只需要提供 SQL 语句就好了,其余的诸如:建立连接、操作Statment、ResultSet,处理 JDBC 相关异常等等都可以交给 MyBatis 去处理,我们的关注点于是可以就此集中在 SQL 语句上,关注在增删改查这些操作层面上。并且 MyBatis 支持使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 POJOs(Plain Old Java Objects,即普通的 Java对象)映射成数据库中的记录。
简单的说一下Mybatis相对JDBC的优势:
- Mybatis是把连接数据库的信息都是写在配置文件中,因此不存在硬编码问题,方便后期维护。
- Mybatis执行的SQL语句都是通过配置文件进行配置,不需要写在Java代码中。
- Mybatis的连接池管理、缓存管理等让连接数据库和查询数据效率更高。
1.4 Mybatis的特点及优缺点
特点:
- MyBatis 是支持定制化 SQL、存储过程以及高级映射的优秀的持久层框架。
- MyBatis 封装了底层 JDBC API 的调用细节,并能自动将结果集转换成 Java Bean 对象,大大简化了 Java 数据库编程的重复工作。
- MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。
- MyBatis 可以使用简单的XML或注解用于配置和原始映射,将接口和Java的实体映射成数据库中的记录。
- MyBatis 把 SQL语句从 Java 源程序中独立出来,放在单独的 XML 文件中编写,给程序的维护带来了很大便利。
- MyBatis 需要程序员自己去编写 SQL语句,程序员可以结合数据库自身的特点灵活控制 SQL语句,因此能够实现比 Hibernate 等全自动 ORM框架更高的查询效率,能够完成复杂查询。
优点:
- 简单易学,Mybatis本身就很小且简单,整个源代码大概5MB左右。并且没有任何第三方依赖,简单实用只要几个Jar包+配置几个SQL映射文件,而且有官方中文文档,可以通过官方文档轻松学习。
- 使用灵活,易于上手和掌握。相比于JDBC需要编写的代码更少,减少了50%以上的代码量。
- 提供XML标签,支持编写动态SQL,满足不同的业务需求。
- SQL写在XML里,便于统一管理和优化,同时也解除SQL与程序代码的耦合。使系统的设计更清晰,更易维护,更易单元测试。SQL和代码的分离,提高了可维护性。
- 提供映射标签,支持对象与数据库的ORM字段关系映射。
- 提供对象关系映射标签,支持对象关系组建维护。
缺点:
- SQL语句的编写工作量较大,尤其在表、字段比较多的情况下,对开发人员编写SQL的能力有一定的要求。
- SQL语句依赖于数据库,导致数据库不具有好的移植性,不可以随便更换数据库。
总体来说,MyBatis 是一个非常优秀和灵活的数据持久化框架,适用于需求多变的互联网项目,也是当前主流的 ORM 框架。
1.5 Mybatis和Hibernate的区别
Mybatis和Hibernate都是一款非常受欢迎的持久化框架,那么Mybatis和Hibernate二组之间有哪些区别呢?
下面我们来看一下,因为这个问题面试很可能会问到。
①、开发方面:
- Hibernate 属于全自动 ORM 映射工具,使用 Hibernate 查询关联对象或者关联集合对象时,可以根据对象关系模型直接获取,所以它是全自动的。
- Mybatis 属于半自动 ORM 映射工具,Mybatis 在查询关联对象或关联集合对象时,需要手动编写 SQL来完成,所以,称之为半自动 ORM 映射工具。不过 Mybatis 可以通过 XML 或注解方式灵活配置要运行的 SQL语句,并将Java 对象和 SQL语句映射生成最终执行的 SQL,最后将 SQL执行的结果再映射生成Java 对象。
②、底层方面:
- Hibernate的底层则是 JPA 规范的实现。
- Mybatis的底层封装了 JDBC 的代码。
③、SQL优化方面:
- Hibernate 自动生成SQL,有些语句较为繁琐,会多消耗一些性能。
- Mybatis 手动编写SQL,可以避免不需要的查询,提高系统性能。
④、学习成本方面:
- Hibernate 的学习门槛高,要精通门槛更高,而且怎么设计 O/R 映射,在性能和对象模型之间如何权衡,以及怎样用好 Hibernate 需要具有很强的经验和能力才行。
- Mybatis的学习门槛低,简单易学,程序员只需要把重心放在写原生态 SQL 上即可,可严格控制 SQL执行性能,灵活度高,非常适合对关系数据模型要求不高的软件开发,例如互联网软件、企业运营类软件等,因为这类软件需求变化频繁,一但需求变化要求成果输出迅速。
⑤、对象管理方面
- Hibernate 是完整的对象/关系映射的框架,对象/关系映射能力极强,开发工程中,无需过多关注底层实现,只要去管理对象即可;而且数据库无关性好,对于关系模型要求高的软件(例如需求固定的定制化软件)如果用 Hibernate 开发可以节省很多代码,提高效率。
- Mybatis 需要自行管理 映射关系;而且Mybatis 无法做到数据库无关性,如果需要实现支持多种数据库的软件则需要自定义多套 SQL映射文件,工作量大。
⑥日志系统方面:
- Hibernate日志系统非常健全,涉及广泛,包括:SQL记录、关系异常、优化警告、缓存提示、脏数据警告等。
- Mybatis则除了基本记录功能外,功能薄弱很多。
⑦、缓存方面
- 相同点:
Hibernate和Mybatis的二级缓存除了采用系统默认的缓存机制外,都可以通过实现你自己的缓存或为其他第三方缓 存方案,创建适配器来完全覆盖缓存行为。
- 不同点:
Hibernate的二级缓存配置在SessionFactory生成的配置文件中进行详细配置,然后再在具体的表-对象映射中配置那种缓存。如果使用二级缓存时如果出现脏数据,系统会报出错误并提示。
MyBatis的二级缓存配置都是在每个具体的表-对象映射中进行详细配置,这样针对不同的表可以自定义不同的缓存机制。并且Mybatis可以在命名空间中共享相同的缓存配置和实例,通过Cache-ref来实现。
⑧、各一句话总结它们:
- Mybatis:小巧、方便、高效、简单、直接、半自动化。比喻:机械工具,使用方便,拿来就用,但工作还是要自己来作,不过工具是活的,怎么使由我决定。
- Hibernate:强大、方便、高效、复杂、间接、全自动化。比喻:智能机器人,但研发它(学习、熟练度)的成本很高,工作都可以拜托他了,但仅限于它能做的事。
最后,不管你使用哪个持久化框架,它们都有它们各自的特点。总之,按照用户的需求在有限的资源环境下只要能做出维护性、扩展性良好的软件架构都是好架构,所以框架只有适合才是最好。
参考链接:MyBatis与Hibernate区别。
1.6 MyBatis的重要组件
Mybatis封装了JDBC的代码,我们来分析Mybatis给我们的一些重要组件。
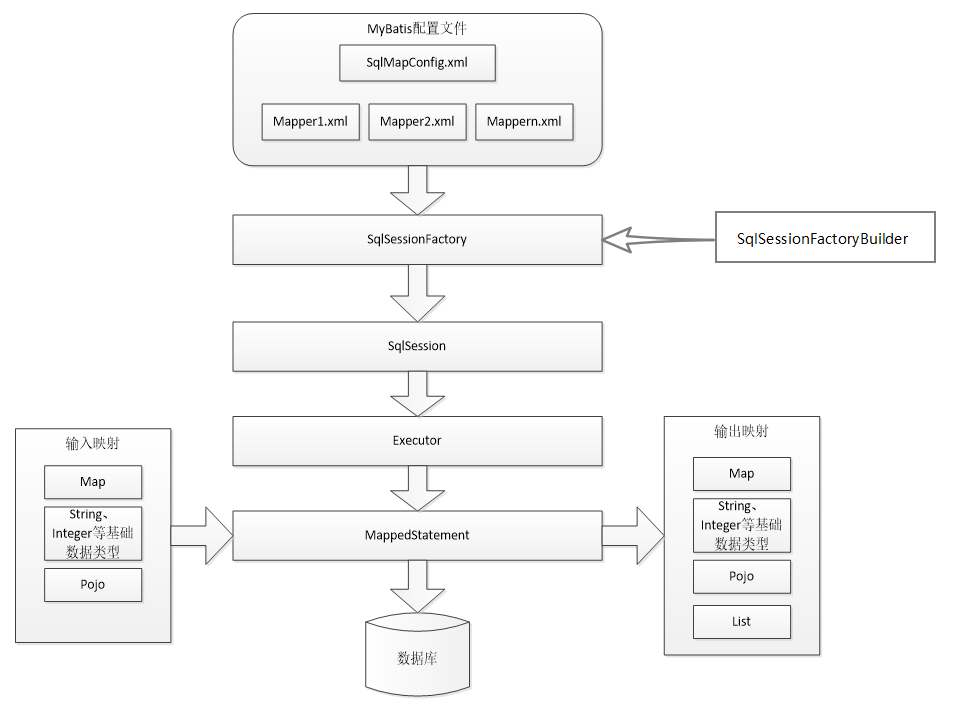
我们从上往下看,MyBatis 中的一些重要组件如下::
- Mybatis的配置文件:SqlMapConfig.xml是Mybatis的全局配置文件,主要配置数据源、事务、加载映射文件等,它的名称可以是任意(最好见名知意)。Mapper.xml主要是配置Statement的相关信息,如SQL语句。
- SqlSessionFactoryBuilder:会根据XML配置或是Java配置来生成SqlSessionFactory对象。采用建造者模式(简单来说就是分步构建一个大的对象,例如建造一个大房子,采用购买砖头、砌砖、粉刷墙面的步骤建造,其中的大房子就是大对象,一系列的建造步骤就是分步构建)。
- SqlSessionFactory:用于生成SqlSession,可以通过 SqlSessionFactory.openSession() 方法创建 SqlSession 对象。使用工厂模式(简单来说就是我们获取对象是通过一个类,由这个类去创建我们所需的实例并返回,而不是我们自己通过new去创建)。
- SqlSession:相当于JDBC中的 Connection对象,可以用 SqlSession 实例来直接执行被映射的 SQL 语句,也可以获取对应的Mapper。
- Executor:MyBatis 中所有的 Mapper 语句的执行都是通过 Executor 执行的。(Mapper:由XML文件和Java接口组成,根据XML中配置的映射信息执行对应的SQL语句并返回执行结果。)
- Mapper接口:数据操作接口也就是通常说的 DAO 接口,要和 Mapper 配置文件中的方法一一对应,也就是必须和Mapper.xml中的增删改查标签Id一致。
- Mapper配置:用于组织具体的查询业务和映射数据库的字段关系,可以使用 XML 格式(Mapper.xml)或 Java 注解格式来实现。
- MappedStatement:作用是封装了Statement的相关信息,包括SQL语句、输入参数和输出结果等等。
1.7 MyBatis 执行流程简单说明
- 首先是加载Mybatis的全局配置文件,随后会加载SQL 映射文件或者是注解的相关 SQL 内容。
- 创建会话工厂,MyBatis 通过读取配置文件的信息来构造出会话工厂(SqlSessionFactory)。
- 创建会话,根据会话工厂,MyBatis 就可以通过它来创建会话对象(SqlSession),会话对象是一个接口,该接口中包含了对数据库操作的增、删、改、查方法。
- 创建执行器,因为会话对象本身不能直接操作数据库,所以它使用了一个叫做数据库执行器(Executor)的接口来帮它执行操作。
- 封装 SQL 对象,在这一步,执行器将待处理的 SQL 信息封装到一个对象中(MappedStatement),该对象包括 SQL 语句、输入参数映射信息(Java 简单类型、HashMap 或 POJO)和输出结果映射信息(Java 简单类型、HashMap 或 POJO)。
- 操作数据库,拥有了执行器和 SQL 信息封装对象就使用它们访问数据库了,最后再返回操作结果,结束流程。
2、Mybatis的第一个入门实例
2.1 本章前言
在上一章简单介绍了什么是Mybatis,它封装的有哪些重要的组件以及它的使用步骤,所以这一章就来编写一个Mybatis的入门实例。首先说明一点:MyBatis 的使用分为三个版本:
- 基于原生接口的XML版本。
- 基于Mapper接口的XML版本。
- 基于Java 注解版本。
一般推荐基于 Mapper 接口和基于 Java 注解的方式,因为这两种方式在实际开发中我们更加常用。但是现在这里只是刚刚入门,所以就用原生接口的XML版本来创建一个Mybatis的入门实例。看看如何实现对数据库的基本操作,其步骤如下。
2.2创建一个数据库
由于Mybatis是对数据库的操作,所以首先得先创建一个数据库和一个表,数据库命名为mybatis,表命名为t_user。这里针对MySQL数据库。SQL脚本如下:
DROP TABLE IF EXISTS `t_user`;
CREATE TABLE `t_user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`age` int(11) NULL DEFAULT NULL,
`sex` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`address` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 8 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of t_user
-- ----------------------------
INSERT INTO `t_user` VALUES (1, '奥利给', 18, '男', '上海');
INSERT INTO `t_user` VALUES (2, '蔡徐坤', 18, '男', '北京');
INSERT INTO `t_user` VALUES (3, '黄飞鸿', 42, '男', '大清');
INSERT INTO `t_user` VALUES (4, '十三姨', 18, '女', '大清');
INSERT INTO `t_user` VALUES (5, '梁宽', 42, '男', '大清');
INSERT INTO `t_user` VALUES (6, '马保国', 33, '男', '深圳');
INSERT INTO `t_user` VALUES (7, '纳兰元述', 42, '男', '大清');
2.3 创建Maven工程
在Eclipse或IDEA中创建一个Maven项目。
然后导入pom依赖,如下:
<dependencies>
<!-- Mybatis -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.6</version>
</dependency>
<!-- mysql驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.21</version>
</dependency>
<!-- 日志处理 -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<!-- 单元测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
2.4 编写User实体类
创建一个User实体类,这里省略了getter、setter和toString方法,需自己加上。
/**
* 用户实体类
*/
public class User {
private Integer id;
private String username;
private Integer age;
private String sex;
private String address;
//getter、setter、toString方法省略......
}
2.5 创建Mybatis全局配置文件
然后在resources目录中,创建Mybatis的全局配置文件mybatis-config.xml。它是mybatis核心配置文件,配置文件内容为数据源、事务管理和指定映射配置文件的位置。代码如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!-- 配置环境.-->
<environments default="development">
<!-- id属性必须和上面的default一致 -->
<environment id="development">
<!--配置事务的类型-->
<transactionManager type="JDBC"></transactionManager>
<!--dataSource 元素使用标准的 JDBC 数据源接口来配置 JDBC 连接对象源 -->
<!--type: POOLED 使用数据库的连接池-->
<dataSource type="POOLED">
<!--配置连接数据库的4个基本信息-->
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/user?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf-8"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</dataSource>
</environment>
</environments>
</configuration>
对mybatis-config.xml中配置项的简单说明:
environments:配置当前的环境,default属性有development和work两种选择,默认是development开发模式,work是工作模式。environment:配置每个environment定义的环境,可以配置多个运行环境,但是每个SqlSessionFactory实例只能选择一个运行环境。其id属性也有development和work两种选择,并且必须和上面的default属性一致。如果配置了两个相同的environment,Mybatis会用后面的覆盖掉前面的。transactionManager:配置事务管理器类型,type属性中有JDBC和MANAGED两种,一次只能配置一个。- JDBC使用JdbcTransactionFactory工厂生成的JdbcTransaction对象实现,以JDBC的方式进行数据库的提交、回滚等操作,它依赖于从数据源得到的连接来管理事务范围。
- MANAGED使用ManagedTransactionFactory工厂生成的ManagedTransaction对象实现,它的提交和回滚不需要任何操作,而是把事务交给容器进行处理,默认情况下会关闭连接,如果不希望默认关闭,只要将其中的closeConnection属性设置为false即可。
dataSource:配置数据源类型,type属性有UNPOOLED、POOLED和JNDI三种选择:- UNPOOLED(UnpooledDataSourceFactory):采用非数据库池的管理方式,每次请求都会新建一个连接,并用完后关闭它,所以性能不是很高。该方式适用于只有小规模数量并发用户的简单应用程序上。
- POOLED(PooledDataSourceFactory):采用连接池的概念将数据库链接对象Connection组织起来,可以在初始化时创建多个连接,使用时直接从连接池获取,避免了重复创建连接所需的初始化和认证时间,从而提升了效率,所以这种方式比较适合对性能要求高的应用中。在开发或测试环境中经常用到此方式。
- JNDI(JndiDataSourceFactory):数据源JNDI的实现是为了能在如EJB或应用服务器这类容器中使用,容器可以集中或在外部配置数据源,然后放置一个JNDI上下文的引用。在生产环境中优先考虑这种方式。
property:dataSource中的property元素就是数据库相关的配置信息。
2.6 编写SQL映射配置文件(重要)
我们在目录resources--->mapper(mapper目录自行创建)下创建一个UserMapper.xml文件。Mybatis中所有数据库的操作都会基于该映射文件配置的SQL语句,在这个配置文件中可以配置任何类型的SQL语句。框架会根据配置文件中的参数配置,完成对SQL语句输入输出参数的映射配置。
注意事项 (非常重要!非常重要!非常重要!):
| 相关属性 | 描述 |
|---|---|
| namespace | 表示命名空间,用来设定当前Mapper配置文件的唯一标识,将来在Java程序中通过namespace属性的值来定位到这个配置文件,namespace属性值设置的方式:名字可以随便取,但是推荐以相对应的Mapper接口的全类名,例如com.thr.mapper.UserMapper |
| id | SQL映射语句的唯一标识,称为statement的id,将SQL语句封装到mappedStatement对象中,所以将id称为statement的id |
| parameterType | 指定输入参数的类型 |
| resultType | 指定输出结果类型。Mybatis将sql查询结果的一行记录数据映射为resultType指定类型的对象。如果有多条数据,则分别进行映射,并把对象放到List容器中,后面会还会介绍resultMap,推荐使用它 |
#{value} |
#{value}表示SQL语句的占位符,相当于JDBC中的”?”它会自动进行java类型和jdbc类型转换, #{value}里面参数写啥都可以,但是不要空着,如#{Id},#{name}。#{value}可以接收简单类型值或pojo属性值。 如果parameterType传输单个简单类型值,#{}括号中可以是value或其它名称。#{value}可以有效防止SQL注入 |
${value} | ${value}表示拼接SQL字符串,将接收到的参数在不进行jdbc类型转换的情况下拼接在SQL语句中,${value}里面必须要写参数,不然会报错。${}可以接收简单类型值或pojo属性值,如果parameterType传输单个简单类型值,${}括号中只能是value。使用${value}会造成 SQL注入,所以尽量不要使用它 |
文件代码如下所示:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- mapper标签是当前配置文件的根标签 -->
<!-- namespace属性:表示命名空间,用来设定当前Mapper配置文件的唯一标识,将来在Java程序中通过namespace属性的值来定位到这个配置文件 -->
<!-- namespace属性值设置的方式:名字可以随便取,但是推荐以相对应的Mapper接口的全类名,例如com.thr.mapper.UserMapper -->
<mapper namespace="com.thr.mapper.UserMapper">
<!-- 查询所有用户 -->
<select id="selectAllUser" resultType="com.thr.entity.User">
select * from t_user;
</select>
<!-- 通过Id查询一个用户 -->
<select id="selectUserById" parameterType="int" resultType="com.thr.entity.User">
select * from t_user where id = #{id};
</select>
<!-- 模糊查询,根据username字段查询用户-->
<select id="selectUserByName" parameterType="int" resultType="com.thr.entity.User">
select * from t_user where username like '%${value}%';
</select>
<!-- 添加用户-->
<insert id="insertUser" parameterType="com.thr.entity.User">
insert into t_user(username, age, sex, address)
values (#{username}, #{age}, #{sex}, #{address});
</insert>
<!-- 根据Id更新用户 -->
<update id="updateUser" parameterType="com.thr.entity.User">
update t_user set username = #{username},
age = #{age},sex = #{sex},address = #{address} where id = #{id}
</update>
<!-- 根据Id删除用户 -->
<delete id="deleteUser" parameterType="int">
delete from t_user where id = #{id}
</delete>
</mapper>
2.7 加载映射文件
将上面创建的UserMapper.xml文件添加至全局配置文件mybatis-config.xml下。
<!--指定映射配置文件的位置,这个映射配置文件指的是每个业务独立的配置文件-->
<mappers>
<mapper resource="mapper/UserMapper.xml"/>
</mappers>
2.8 导入日志文件
导入日志文件,在resources目录中创建log4j.properties文件,并且导入如下配置(如果log报错则以管理员的方式启动Eclipse或IDEA)。
# Set root category priority to INFO and its only appender to CONSOLE.
#log4j.rootCategory=INFO, CONSOLE debug info warn error fatal
log4j.rootCategory=debug, CONSOLE, LOGFILE
# Set the enterprise logger category to FATAL and its only appender to CONSOLE.
log4j.logger.org.apache.axis.enterprise=FATAL, CONSOLE
# CONSOLE is set to be a ConsoleAppender using a PatternLayout.
log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender
log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout
log4j.appender.CONSOLE.layout.ConversionPattern=%d{ISO8601} %-6r [%15.15t] %-5p %30.30c %x - %m\n
# LOGFILE is set to be a File appender using a PatternLayout.
log4j.appender.LOGFILE=org.apache.log4j.FileAppender
log4j.appender.LOGFILE.File=D:/axis.log
log4j.appender.LOGFILE.Append=true
log4j.appender.LOGFILE.layout=org.apache.log4j.PatternLayout
log4j.appender.LOGFILE.layout.ConversionPattern=%d{ISO8601} %-6r [%15.15t] %-5p %30.30c %x - %m\n
log4j.rootLogger=debug, stdout,logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.err
log4j.appender.stdout.layout=org.apache.log4j.SimpleLayout
log4j.logger.java.sql.ResultSet=INFO
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File =d:/mylog.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d{yyyy-MM-dd HH\:mm\:ss} %l %F %p %m%n
2.9 编写测试代码
最后创建一个MybatisTest的测试类,其源代码如下所示:
注意:使用JDBC的事务管理在进行增删改操作时,需要进行提交事务,也就是sqlSession.commit(),否则数据不会操作成功。
/**
* Mybatis的测试
*/
public class MybatisTest {
//定义 SqlSession
SqlSession sqlSession = null;
@Before
public void getSqlSession() {
//加载 mybatis 全局配置文件
InputStream is = MybatisTest.class.getClassLoader().getResourceAsStream("mybatis-config.xml");
//创建 SqlSessionFactory 对象
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(is);
//根据 sqlSessionFactory 产生 session
sqlSession = sqlSessionFactory.openSession();
}
//查询所有用户数据
@Test
public void testSelectAllUser() {
/**
* 注意:这个字符串由 UserMapper.xml 文件中的两个部分构成(namespace + id)
* <mapper namespace="com.thr.mapper.UserMapper">中 namespace 的值
* <select id="selectAllUser" > 中的 id 值
* 这样Mybatis才能找到需要的SQL
*/
String statement = "com.thr.mapper.UserMapper.selectAllUser";
List<User> listUser = sqlSession.selectList(statement);
for (User user : listUser) {
System.out.println(user);
}
sqlSession.close();
}
//根据Id查询一个用户数据
@Test
public void testSelectUserById() {
String statement = "com.thr.mapper.UserMapper.selectUserById";
User user = sqlSession.selectOne(statement, 1);
System.out.println(user);
sqlSession.close();
}
//模糊查询:根据 user 表的username字段
@Test
public void testSelectUserByName() {
String statement = "com.thr.mapper.UserMapper.selectUserByName";
List<User> listUser = sqlSession.selectList(statement, "三");
for (User user : listUser) {
System.out.println(user);
}
sqlSession.close();
}
//添加一个用户数据
@Test
public void testInsertUser() {
String statement = "com.thr.mapper.UserMapper.insertUser";
User user = new User();
user.setUsername("张三");
user.setAge(34);
user.setSex("男");
user.setAddress("中国深圳");
int i = sqlSession.insert(statement, user);
System.out.println( (i>0)? "添加成功!":"添加失败!");
//提交插入的数据
sqlSession.commit();
sqlSession.close();
}
//根据Id修改用户数据
@Test
public void testUpdateUser(){
//如果设置的 id不存在,那么数据库没有数据更改
String statement = "com.thr.mapper.UserMapper.updateUser";
User user = new User();
user.setId(3);
user.setUsername("王红");
user.setAge(26);
user.setSex("女");
user.setAddress("中国上海");
int i = sqlSession.update(statement, user);
System.out.println( (i>0)? "修改成功!":"修改失败!");
//提交数据
sqlSession.commit();
sqlSession.close();
}
//根据Id删除用户数据
@Test
public void testDeleteUser(){
String statement = "com.thr.mapper.UserMapper.deleteUser";
int i = sqlSession.delete(statement, 4);
System.out.println( (i>0)? "删除成功!":"删除失败!");
sqlSession.commit();
sqlSession.close();
}
}
3、Mybatis全局配置文件详解
3.1 全局配置文件
前面我们看到的Mybatis全局文件并没有全部列举出来,所以这一章我们来详细的介绍一遍,Mybatis的全局配置文件并不是很复杂,它的所有元素和代码如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration> <!--配置-->
<properties/> <!--属性-->
<settings/> <!--全局配置参数-->
<typeAliases/> <!--类型别名-->
<typeHandlers/> <!--类型处理器-->
<objectFactory/><!--对象工厂-->
<plugins/><!--插件-->
<environments default=""><!--环境配置-->
<environment id=""><!--环境变量-->
<transactionManager type=""/><!--事务管理器-->
<dataSource type=""/><!--数据源-->
</environment>
</environments>
<databaseIdProvider type=""/><!--数据库厂商标识-->
<mappers/><!--映射器-->
</configuration>
注意:Mybatis的配置文件的顺序是严格按照从上至下的顺序声明,不颠倒顺序,如果颠倒了它们的顺序,那么Mybatis在启动阶段就会产生异常,导致程序无法运行。
3.2 properties属性
properties的作用是引用java属性文件中的配置信息,比如:加载连接数据库的各种属性的配置文件。
mybatis提供了三种方式使用properties属性:
- property子元素(不推荐):就是在properties属性中增加子属性property,从而设置一些配置的key-value。
- properties文件:就是直接使用properties引入外部配置文件,相当于将子属性抽取成一个独立的外部文件引入,例如db.properties。
- 程序代码传递参数:就是通过代码的方式设置该配置相关的信息,如数据库配置文件中的用户名和密码一般是密文,但是连接数据库时需要对配置进行解密,此时就只能通过程序代码的方式配置了。
3.2.1 property子元素(不推荐)
以上一章的例子为基础,使用property子元素将数据库的连接配置信息进行改写,如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<properties>
<!--property子元素定义-->
<property name="database.driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="database.url" value="jdbc:mysql://localhost:3306/user?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf-8"/>
<property name="database.username" value="root"/>
<property name="database.password" value="root"/>
</properties>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"></transactionManager>
<dataSource type="POOLED">
<!--配置连接数据库的4个基本信息-->
<property name="driver" value="${database.driver}"/>
<property name="url" value="${database.url}"/>
<property name="username" value="${database.username}"/>
<property name="password" value="${database.password}"/>
</dataSource>
</environment>
</environments>
</configuration>
这种配置方式时有缺点的,虽然这样定义一次可以到处引用,但是如果配置项很多,那么就会让配置文件显得很庞大,所以使用这种方式显然不是一个很好的选择,为了解决这个缺点,我们可以使用下面的配置方式,也就是使用properties文件的方式。
3.2.2 properties文件
使用properties文件的方式在我们的开发中是比较常用,主要的这种方式简单,方便日后的维护和修改。首先将上述配置中的所有property属性提取到一个叫做 databse.properties 的配置文件中,如下代码所示:
#数据库连接配置
database.driver=com.mysql.cj.jdbc.Driver
database.url=jdbc:mysql://localhost:3306/user?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf-8
database.username=root
database.password=root
然后在Mybatis配置文件中使用<properties>元素的resource属性来引入properties文件。
<properties resource="database.properties" />
这样就相当于将 database.properties 中的所有配置都加载到MyBatis的配置文件中了,然后再按照 ${database.username} 的方式引入properties文件的属性参数即可。但是这种使用方式也存在它的缺点,当外部配置文件中的值需要加密时,如连接数据库的用户名和密码,无法在配置文件中进行解密,所以只能通过程序代码传递的方式,就是要介绍的第三种,如下。
3.2.3 程序代码传递参数
在真实的开发环境中,数据库的用户名和密码对开发人员和其他人员是保密的。而运维人员为了数据保密,一般都会把数据库的用户名和密码进行加密处理,会把加密后的数据配置到properties文件中。所以开发人员就必须用解密后的用户名和密码连接数据库,不可能用加密的数据进行连接。此时就需要使用到此种方式来对配置文件进行解密。其实这种方式一般会和第二种配合使用,作用对特殊配置进行覆盖或重写,以上面的database.properties为例,在使用到数据库配置信息时对配置中的用户名和密码进行解密。这里举个MyBatis中获取SqlSessionFactory的例子,代码如下:
public static SqlSessionFactory getSqlSessionFactoryByXml() {
synchronized (Lock) {
if (null != sqlSessionFactory) {
return sqlSessionFactory;
}
String resource = "mybatis-config.xml";
InputStream inputStream;
InputStream is = null;
try {
// 加载数据库配置文件
is = Resources.getResourceAsStream("database.properties");
Properties properties = new Properties();
properties.load(is);
// 获取加密信息
String username= properties.getProperty("database.username");
String password= properties.getProperty("database.password");
// 解密用户名和密码,并重置属性
properties.setProperty("database.username", CyperTool.decodeByBase64(username));
properties.setProperty("database.password", CyperTool.decodeByBase64(password));
// 读取mybatis配置文件
inputStream = Resources.getResourceAsStream(resource);
// 通过SqlSessionFactoryBuilder类的builder方法进行构建,并使用程序传递的方式覆盖原有属性
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream, properties);
} catch (IOException e) {
e.printStackTrace();
return null;
}
return sqlSessionFactory;
}
}
我们为了保证数据的准确性,加了synchronized锁。首先使用Resources对象读取了database.properties配置文件,然后获取了它原来配置的用户和密码,进行解密操作,最后使用SqlSessionFactoryBuilder的build方法,传递多个properties参数来完成。这将覆盖之前加密的配置,这样就可以连接数据库了,同时也能满足因为人员对数据库的用户名和密码的安全要求。
3.3 settings属性
settings是MyBatis中最复杂的配置,它能深刻影响MyBatis底层的运行,但是大部分情况下使用默认值便可以运行,所以在大部分情况下不需要大量配置,只需要修改一些常用的规则即可。常用规则有自动映射、驼峰命名映射、级联规则、是否启动缓存、执行器类型等。
<settings>
<!--缓存配置的全局开关:如果这里设置成false,那么即便在映射器中配置开启也无济于事 -->
<setting name="cacheEnabled" value="true" />
<!--延时加载的全局开关 -->
<setting name="lazyLoadingEnabled" value="false" />
<!-- 是否允许单一语句返回多结果集 -->
<setting name="multipleResultSetsEnabled" value="true" />
<!-- 使用列标签代替列名,需要兼容驱动 -->
<setting name="useColumnLabel" value="true" />
<!-- 允许JDBC自动生成主键,需要驱动兼容。如果设置为true,则这个设置强制使用自动生成主键,尽管一些驱动不能兼容但仍能正常工作 -->
<setting name="useGeneratedKeys" value="false" />
<!-- 指定MyBatis该如何自动映射列到字段或属性:NONE表示取消自动映射;PARTIAL表示只会自动映射,没有定义嵌套结果集和映射结果集;FULL会自动映射任意复杂的结果集,无论是否嵌套 -->
<setting name="autoMappingBehavior" value="PARTIAL" />
<!-- 指定发现自动映射目标未知列(或未知属性类型)的行为。NONE: 不做任何反应WARNING: 输出警告日志FAILING: 映射失败 (抛出 SqlSessionException) -->
<setting name="autoMappingUnknownColumnBehavior" value="WARNING" />
<!-- 配置默认的执行器:SIMPLE是普通的执行器;REUSE会重用预处理语句;BATCH会重用语句并执行批量更新 -->
<setting name="defaultExecutorType" value="SIMPLE" />
<!--设置超时时间:它决定驱动等待数据库响应的秒数,任何正整数-->
<setting name="defaultStatementTimeout" value="25"/>
<!--设置数据库驱动程序默认返回的条数限制,此参数可以重新设置,任何正整数 -->
<setting name="defaultFetchSize" value="100" />
<!-- 允许在嵌套语句中使用分页(RowBounds) -->
<setting name="safeRowBoundsEnabled" value="false" />
<!-- 是否开启自动驼峰命名规则,即从a_example到aExample的映射 -->
<setting name="mapUnderscoreToCamelCase" value="true" />
<!-- 本地缓存机制,防止循环引用和加速重复嵌套循环 -->
<setting name="localCacheScope" value="SESSION" />
<!-- 当没有为参数提供特定JDBC类型时,为空值指定JDBC类型。某些驱动需要指定列的JDBC类型,多数情况直接用一般类型即可,如NULL/VARCHAR/OTHER -->
<setting name="jdbcTypeForNull" value="OTHER" />
<!-- 指定触发延迟加载的方法,如equals/clone/hashCode/toString -->
<setting name="lazyLoadTriggerMethods" value="equals" />
</settings>
3、typeAlianses属性
typeAlianses属性就是起个别名,是为了在映射文件中更方便的编写输入参数类型和输出结果类型,因为平时的输入输出映射的全限定名显得很长,在使用过程中不是很方便,所以MyBatis中允许我们使用一种简写的方式来代替全限定名,这样可以提高我们的开发效率。
别名分为系统别名和自定义别名,系统别名就是系统默认给我们起的别名,例如我们在输入一个数值型的参数是,可以直接写parameterType=”int”,这是因为系统将Integer的Java类型起的别名为int。
我们可以通过Mybatis的官方文档来查看:mybatis – MyBatis 3 | 配置。
而自定义别名是自己定义的名称,后面会介绍如何使用。
3.3.1 系统定义的别名
Mybatis本身给我们定义了大量的别名,包括有基本数据类型,包装类、对象型、集合和Map等等。系统定义的别名是通过TypeAliasRegistry类来定义的,所以我们既可以通过这个对象获取系统中已经定义好的别名,也能自定义别名,先通过一段代码来获取系统中都预定义了哪些别名。
/**
* 获取系统别名配置
*/
public static void getTypeAlias() {
try {
InputStream stream = getResourceAsStream("mybatis-config.xml");
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(stream);
SqlSession sqlSession = factory.openSession();
//获取TypeAliasRegistry对象
TypeAliasRegistry typeAliasRegistry = sqlSession.getConfiguration().getTypeAliasRegistry();
Map<String, Class<?>> tarMap = typeAliasRegistry.getTypeAliases();
int i =0;
for (String key : tarMap.keySet()) {
//这个++i统计数量
System.out.println(++i+"*****"+tarMap.get(key).getSimpleName()+"*****"+key);
}
System.out.println("系统定义的别名个数为:"+i);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
getTypeAlias();
}
输出结果就不贴出来了,有点长,可以自行运行。通过运行结果可以发现系统自定义的别名一共有72个(这72个别名的使用不区分大小写)。所以我们可以使用别名代替冗长的全限定名,比如在MyBatis的映射文件中,我们设置一个SQL语句的参数类型或返回类型的时候,如果这个类型是字符串,我们完全可以用string代替java.lang.String。但是这就会有一个问题,我怎么知道哪个类型的别名是什么呢?在不知道的情况下有两种方式可以知道:
- 保险的方法:将系统别名打印出来,或者找官方文档查询;
- 寻规律:其实从上面的结果可以发现一个规律,就是如果类名以大写开头,则只要将大写变为小写就是该类的别名;而如果类名本来就是小写,只需要在小写前面加上下划线即可。
3.3.2 自定义别名
我们在平时的开发中,系统中会有大量的类,比如User类,需要对其进行反复的使用,而这些类系统并没有给我们取别名,难道我们要反复的编写很长的全限定名吗?NO,Mybatis给我们提供了用户自定义别名的规则,我们可以通过配置文件、包扫描或者注解进行注册。下面来介绍一下如何使用:
①、使用配置文件的typeAliases属性
<!--配置别名-->
<typeAliases>
<!--对类单独进行别名设置 -->
<typeAlias alias="user" type="com.thr.pojo.User"></typeAlias>
<typeAlias alias="student" type="com.thr.pojo.Student"></typeAlias>
</typeAliases>
这样我们就为两个类定义好了别名,但是这种方式有个缺点,如果多个类需要配置别名时就显得很麻烦,所以这种方式显然不行。
②、通过package自动扫描
<!--配置别名-->
<typeAliases>
<!-- 对包进行扫描,可以批量进行别名设置,设置规则是:获取类名称,将其第一个字母变为小写 -->
<package name="com.thr.pojo1"/>
<package name="com.thr.pojo2"/>
<package name="com.thr.pojo3"/>
</typeAliases>
这种方式会为扫描到的包下的所有类起一个别名,别名的命名规则为,将类名的第一个字母变为小写作为别名,比如com.thr.pojo.User变为别名为user。但是使用这种方式还有缺点,就是如果两个不同的包下出现了同名的类,那么在扫描的时候就会出现异常(通常不会出现这种情况)。这个时候可以通过注解@Alians("user1")来进行区分。
③、通过注解
这种方式比较简单,只要在对应包下的对应类上面使用注解@Alias("别名")即可,如下:
package com.thr.pojo1;
import org.apache.ibatis.type.Alias;
@Alias("user1")
public class User {
省略......
}
这样就能够避免因为避免重复而导致扫描失败的问题。
3.4 typeHandlers属性(了解)
typeHandlers叫类型处理器,在JDBC中,需要在PreparedStatement中设置预编译SQL所需的参数。在执行SQL后,会根据结果集ResultSet对象得到数据库的数据,需要将数据库中的类型和java中字段的类型进行转换一样,这些操作在MyBatis中通过typeHandler来实现。在typeHandler中,包含有javaType和jdbcType两种类型,其中javaType用来定义Java类型,jdbcType用来定义数据库类型,那么typeHandler的作用就是承担javaType和jdbcType两种类型的转换,如下图所示。
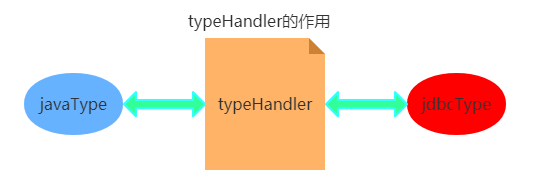
MyBatis中的typeHandlers存在系统定义的和自定义两种,MyBatis会根据javaType和jdbcType来决定采用哪个typeHandler来处理这些转换规则,而且系统定义的能满足大部分需求,但是有些情况是不够用的,比如我们的特殊转换规则,枚举类型,这时我们就需要自定义的typeHandlers了。下面分别介绍这两种typeHandler的使用。
3.4.1 系统定义的typeHandler
Mybatis内部定义了许多有用的typeHandler,我们可以参考Mybatis的官方文档查看:https://mybatis.org/mybatis-3/zh/configuration.html#typeHandlers,也可以自己通过程序代码进行打印,代码如下:
/**
* 获取类型处理器
*/
public static void getTypeHandlers() {
//SqlSession代码省略......
TypeHandlerRegistry typeHandlerRegistry = sqlSession.getConfiguration().getTypeHandlerRegistry();
Collection<TypeHandler<?>> handlers = typeHandlerRegistry.getTypeHandlers();
System.out.println(handlers.size());
int i = 0;
for (TypeHandler<?> typeHandler : handlers) {
System.out.println(++i+"*****"+typeHandler.getClass().getName());
}
}
执行结果就不列出来了,Mybatis一共定义了39个类型处理器。在大部分情况下我们不需要显示的声明JavaType和jdbcType,因为Mybatis会自动探测到。
在Mybatis中typeHandler都需要实现接口org.apache.ibatis.type.TypeHandler,所以我们来看看这个接口长啥样。源代码如下:
public interface TypeHandler<T> {
void setParameter(PreparedStatement var1, int var2, T var3, JdbcType var4) throws SQLException;
T getResult(ResultSet var1, String var2) throws SQLException;
T getResult(ResultSet var1, int var2) throws SQLException;
T getResult(CallableStatement var1, int var2) throws SQLException;
}
简单介绍一下内部定义了内容:
- 其中T表示泛型,专指JavaType,比如我们需要String类型的参数,那么实现类就是可以写成
implement TypeHandler<String>。 - setParameter方法,是使用typeHandler通过PreparedStatement对象进行设置SQL参数的时候使用的具体方法,其中
i是请查收在SQL的下标,parameter是参数,jdbcType为数据库类型。 - 其中三个getResult的方法,它的作用是从JDBC结果集中获取数据进行转换,要么使用列名,要么使用下标来获取数据库的数据,其中最后一个方法是存储过程专用的方法。
既然学习了TypeHandler接口,那么接着来学习它的实现了BaseTypeHandler类。源代码如下(只贴出少量):
public abstract class BaseTypeHandler<T> extends TypeReference<T> implements TypeHandler<T> {
......
public void setParameter(PreparedStatement ps, int i, T parameter, JdbcType jdbcType) throws SQLException {
......
}
public T getResult(ResultSet rs, String columnName) throws SQLException {
......
}
public T getResult(ResultSet rs, int columnIndex) throws SQLException {
......
}
public T getResult(CallableStatement cs, int columnIndex) throws SQLException {
......
}
public abstract void setNonNullParameter(PreparedStatement var1, int var2, T var3, JdbcType var4) throws SQLException;
public abstract T getNullableResult(ResultSet var1, String var2) throws SQLException;
public abstract T getNullableResult(ResultSet var1, int var2) throws SQLException;
public abstract T getNullableResult(CallableStatement var1, int var2) throws SQLException;
}
简单分析一下:
- setParameter方法,当参数parameter和jdbcType同时为空时,Mybatis将抛出异常。如果能获取jdbcType,则会继续空设置;如果参数不为空,那么他将使用setNonNullParameter方法设置参数。
- getResult方法,非空结果集是通过getNullableResult方法获取的。如果判断为空,则返回null。
- getNullableResult方法用于存储过程。
在Mybatis中使用最多的typeHandler为StringTypeHandler。它用于字符串的转换,所以我们来学习一下。源代码如下:
public class StringTypeHandler extends BaseTypeHandler<String> {
public StringTypeHandler() {
}
public void setNonNullParameter(PreparedStatement ps, int i, String parameter, JdbcType jdbcType) throws SQLException {
ps.setString(i, parameter);
}
public String getNullableResult(ResultSet rs, String columnName) throws SQLException {
return rs.getString(columnName);
}
public String getNullableResult(ResultSet rs, int columnIndex) throws SQLException {
return rs.getString(columnIndex);
}
public String getNullableResult(CallableStatement cs, int columnIndex) throws SQLException {
return cs.getString(columnIndex);
}
}
从上述代码可以看出它继承了BaseTypeHandler<String>类,并且实现了BaseTypeHandler的4个抽象方法,方法如下:
- setNonNullParameter:这个方法是用来将javaType转换成jdbcTpe。
- getNullableResult:这个方法用来将从结果集根据列名称获取到的数据的jdbcType转换成javaType。
- getNullableResult:这个方法用来将从结果集根据列索引获取到的数据的jdbcType转换成javaType。
- getNullableResult:这个方法用在存储过程中。
这里Mybatis把JavaType和jdbcType进行互换,那么他们是怎么进行注册的呢?在Mybatis中采用TypeHandlerRegistry类对象的register方法来进行则。
public TypeHandlerRegistry(Configuration configuration) {
......
this.register((Class)Boolean.class, (TypeHandler)(new BooleanTypeHandler()));
this.register((Class)Boolean.TYPE, (TypeHandler)(new BooleanTypeHandler()));
this.register((JdbcType)JdbcType.BOOLEAN, (TypeHandler)(new BooleanTypeHandler()));
this.register((JdbcType)JdbcType.BIT, (TypeHandler)(new BooleanTypeHandler()));
......
}
这样就是实现了用代码的形式注册typeHandler。但是注意,自定义的typeHandler一般不会使用代码进行注册,而是通过配置或者扫描,使用下面我们来学习如何自定义typeHandler。
3.4.2 自定义typeHandler
我们知道在大部分场景下,Mybatis的typeHandler都能应付,但是有时候也会不够用,比如枚举类型,这个时候就需要自定义typeHandler来进行处理了。从系统定义的typeHandler可以知道,要实现typeHandler就需要去实现接口typeHandler或者实现baseTypeHandler。
下面我们使用实现TypeHandler接口的方式创建一个MyTypeHandler,用来完成javaType中的String类型与jdbcType中的类型之间的转化。
public class MyTypeHandler implements TypeHandler<String> {
Logger log = Logger.getLogger(MyTypeHandler.class);
@Override
public void setParameter(PreparedStatement ps, int i, String parameter, JdbcType jdbcType) throws SQLException {
log.info("设置string参数:"+parameter);
ps.setString(i,parameter);
}
@Override
public String getResult(ResultSet rs, String columnName) throws SQLException {
String result = rs.getString(columnName);
log.info("读取string参数1:"+result);
return result;
}
@Override
public String getResult(ResultSet rs, int columnIndex) throws SQLException {
String result = rs.getString(columnIndex);
log.info("读取string参数2:"+result);
return result;
}
@Override
public String getResult(CallableStatement cs, int columnIndex) throws SQLException {
String result = cs.getString(columnIndex);
log.info("读取string参数3:"+result);
return result;
}
}
我们定义的泛型为String则表示我们要把数据库类型的数据转化为String类型,然后实现设置参数和获取结果集的方法。但是这个时候还没有启动typeHandler。还需要在配置文件中配置一下。
<typeHandlers>
<typeHandler jdbcType="VARCHAR" javaType="string"
handler="com.typeHandler.MyTypeHandler"/>
</typeHandlers>
配置完成之后系统才会读取它,这样就注册完毕了,当JavaType和jdbcType能与MyTypeHandler对应的时候,它就会启动MyTypeHandler。我们有两种方式来使用自定义的typeHandler。
<!-- 模糊查询,根据username字段查询用户-->
<select id="selectUserByName" parameterType="string" resultType="user">
select * from t_user
where username like concat ('%',#{username,typeHandler=com.typeHandler.MyTypeHandler},'%');
</select>
或者:
<select id="selectUserByName" parameterType="string" resultType="user">
select * from t_user where username like concat ('%',#{username,javaType=string,jdbcType=VARCHAR},'%');
</select>
注意,要么指定了与自定义typeHandler一致的jdbcType和JavaType,要么直接使用typeHandler指定的具体实现类。在一些因为数据库返回为空导致无法判定采用哪个typeHandler来处理,而又没有注册对应的JavaType的typeHandler是,Mybatis无法找到使用哪个typeHandler来转换数据。

有时候类很多的时候,我们还可以采用包扫描的方式。
<typeHandlers>
<package name="com.typeHandler"/>
</typeHandlers>
但是这样会无法指定jdbcType和JavaType,不过我们可以通过注解来处理它们,我们把MyTypeHandler类修改一些即可。
@MappedTypes(String.class)
@MappedJdbcTypes(JdbcType.VARCHAR)
public class MyTypeHandler implements TypeHandler<String> {
......
}
最后:在我们的日常开发中,一般都不需要定义,使用默认的就可以,除非是像枚举这种特殊类型就需要自己实现。
3.5 objectFacotry属性(了解)
objectFacotry表示为对象工厂。对象工厂我们只需了解即可,因为到时候与spring整合后,都会由spring来管理。
我们在使用MyBatis执行查询语句的时候,通常都会有一个返回类型,这个是在mapper文件中给sql增加一个resultType(或resultMap)属性进行控制。resultType和resultMap都能控制返回类型,只要定义了这个配置就能自动返回我想要的结果,于是我就很纳闷这个自动过程的实现原理,想必大多数人刚开始的时候应该也有和我一样的困惑和好奇,那么今天我就把自己的研究分享一下。在JDBC中查询的结果会保存在一个结果集中,其实MyBatis也是这个原理,只不过MyBatis在创建结果集的时候,会使用其定义的对象工厂DefaultObjectFactory来完成对应的工作。
详细可以参考: MyBatis配置文件(五)--objectFactory对象工厂 - bug改了我 - 博客园 (cnblogs.com)
MyBatis配置文件(五)--objectFactory对象工厂 - bug改了我 - 博客园 (cnblogs.com)
3.6 plugins属性(了解)
插件是Mybatis中最强大和灵活的组件,同时也是最复杂、最难使用的组件,并且它十分的危险,因为它将覆盖Mybatis底层对象的核心方法和属性。如果操作不当将产生非常严重的后果,甚至是摧毁Mybatis框架,所以我们在不了解Mybatis的底层结构的情况下,千万不要去碰这个插件属性。如果你想研究一下插件,那么前提是要清楚掌握Mybatis底层的结构和运行原理,否则将难以安全高效的使用它。而我们平时使用Mybatis的常规功能完全满足日常的开发,所以这里就不介绍了,有兴趣的可以自行去学习。
3.7 environments属性
environments属性表示的是运行环境,主要的作用是配置数据库的一些信息,我们可以配置多个数据库,但只能选择一个。它里面分为两个可配置的元素:事务管理器(transactionManager)、数据源(DataSource)。而在我们的日常开发中,这些都会交给Spring来管理,不用在全局配置中编写,这些会在后面Mybatis整合Spring中进行讲解。我们先来看看environments环境配置的配置代码吧。
<configuration>
<!-- 配置环境.-->
<environments default="development">
<!-- id属性必须和上面的default一致 -->
<environment id="development">
<!--配置事务的类型-->
<transactionManager type="JDBC"></transactionManager>
<!--dataSource 元素使用标准的 JDBC 数据源接口来配置 JDBC 连接对象源 -->
<dataSource type="POOLED">
<!--配置连接数据库的4个基本信息-->
<property name="driver" value="${database.driver}"/>
<property name="url" value="${database.url}"/>
<property name="username" value="${database.username}"/>
<property name="password" value="${database.password}"/>
</dataSource>
</environment>
</environments>
</configuration>
下面我们主要来详细介绍 transactionManager 和 DataSource 这两个元素。
3.7.1 transactionManager(事务管理)
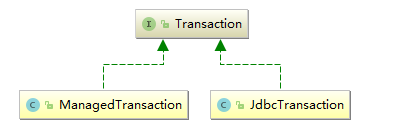
在MyBatis中,transactionManager提供了两个实现类,它们都需要实现接口Transaction,所以我们可以查看以下Transaction的源代码:
public interface Transaction {
Connection getConnection() throws SQLException;
void commit() throws SQLException;
void rollback() throws SQLException;
void close() throws SQLException;
Integer getTimeout() throws SQLException;
}
从上面的方法可知,它主要的工作就是提交(commit)、回滚(rollback)、关闭(close)数据库的事务。MyBatis中为Transaction接口提供了两个实现类,分别是 JdbcTransaction 和 ManagedTransaction。如下图所示:
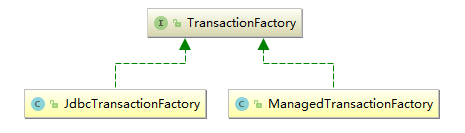
并且分别对应着 JdbcTransactionFactory 和 ManagedTransactionFactory 两个工厂,这两个工厂实现了 TransactionFactory 这个接口,当我们在配置文件中通过 transactionManager 的type属性配置事务管理器类型的时候,Mybatis就会自动从对应的工厂获取实例。我们可以把事务管理器配置成为以下两种方式:
<transactionManager type="JDBC"/>
<transactionManager type="MANAGED"/>
下面说一下这两者的区别:
- JDBC:使用JdbcTransactionFactory工厂生成的JdbcTransaction对象实现,以JDBC的方式进行数据库的提交、回滚等操作。
- MANAGED:使用ManagedTransactionFactory工厂生成的ManagedTransaction对象实现,它的提交和回滚不需要任何操作,而是把事务交给容器进行处理,默认情况下会关闭连接,如果不希望默认关闭,只要将其中的closeConnection属性设置为false即可。
<transactionManager type="MANAGED">
<property name="closeConnection" value="false"/>
</transactionManager>
在测试的过程中发现的最明显的区别就是,如果我使用JDBC的事务处理方式,当我向数据库中插入一条数据时,在调用完插入接口执行SQL之后,必须 执行sqlSession.commit();进行提交,否则虽然插入成功但是数据库中还是看不到刚才插入的数据;而使用MANAGED方式就不一样了,只需调用接口即可,无需手动提交。
当然除了使用默认的,我们还可以根据需要自定义一个事务管理器,需要以下三步:
第一步:创建一个自定义事务工厂MyTransactionFactory,需要实现TransactionFactory接口,代码如下:
/**
* 创建自定义事务工厂
*/
public class MyTransactionFactory implements TransactionFactory {
@Override
public void setProperties(Properties props) {
}
@Override
public Transaction newTransaction(Connection connection) {
//后面我们会创建这个类,它自定义的事务类
return new MyTransaction(connection);
}
@Override
public Transaction newTransaction(DataSource dataSource, TransactionIsolationLevel level, boolean b) {
return new MyTransaction(dataSource,level,b);
}
}
这里就实现了TransactionFactory所有定义的工厂方法了,这时还要一个自定义的事务类,下面我们来创建。
第二步:创建一个自定义事务类MyTransaction,用来实现Transaction接口,代码如下。
/**
* 定义自己的事务管理器,实现获取连接、提交、回滚、关闭数据库连接等操作
*/
public class MyTransaction extends JdbcTransaction implements Transaction {
public MyTransaction(Connection connection){
super(connection);
}
public MyTransaction(DataSource ds, TransactionIsolationLevel level,boolean desiredAutoCommit) {
super(ds,level,desiredAutoCommit);
}
@Override
public Connection getConnection() throws SQLException {
return super.getConnection();
}
@Override
public void commit() throws SQLException {
super.commit();
}
@Override
public void rollback() throws SQLException {
super.rollback();
}
@Override
public void close() throws SQLException {
super.close();
}
@Override
public Integer getTimeout() throws SQLException {
return super.getTimeout();
}
}
第三步:配置自定义事务管理器
<transactionManager type="com.transaction.MyTransactionFactory"/>
注意:这个地方配置的是自定义的工厂类,而不是事务管理类,因为mybatis是根据配置的工厂获取具体实例对象的。
3.7.2 DataSource(数据源)
在Mybatis中,数据库是通过PooledDataSourceFactory、UnpooledDataSourceFactory和JndiDataSourceFactory三个工厂类来提供,前两者分别产生PooledDataSource和UnpooledDataSource类对象,第三个则会根据JNDI的信息拿到外部容器实现的数据库连接对象,但是不管怎样,它们最后都会生成一个实现了DataSource接口的数据库连接对象。
因为有三种数据源,所以它们的配置信息如下:
<dataSource type="POOLED">
<dataSource type="UNPOOLED">
<dataSource type="JNDI">
下面介绍一下这三种数据源的意义:
①、UNPOOLED
UNPOOLED采用非数据库池的管理方式,每次请求都会新建一个连接,所以性能不是很高,使用这种数据源的时候,UNPOOLED类型的数据源可以配置以下属性:
- driver:数据库驱动名
- url:数据库连接URL
- username:用户名
- password:密码
- defaultTransactionIsolationLevel:默认的事务隔离级别,如果要传递属性给驱动,则属性的前缀为driver
②、POOLED
POOLED采用连接池的概念将数据库链接对象Connection组织起来,可以在初始化时创建多个连接,使用时直接从连接池获取,避免了重复创建连接所需的初始化和认证时间,从而提升了效率,所以这种方式比较适合对性能要求高的应用中。除了UNPOOLED中的配置属性之外,还有下面几个针对池子的配置:
- poolMaximumActiveConnections:任意时间都会存在的连接数,默认值为10
- poolMaxmumIdleConnections:可以空闲存在的连接数
- poolMaxmumCheckoutTime:在被强制返回之前,检查出存在空闲连接的等待时间。即如果有20个连接,只有一个空闲,在这个空闲连接被找到之前的等待时间就用这个属性配置。
- poolTimeToWait:等待一个数据库连接成功所需的时间,如果超出这个时间则尝试重新连接。
还有其他的一些配置,不详述了。
③、JNDI
JNDI数据源JNDI的实现是为了能在如EJB或应用服务器这类容器中使用,容器可以集中或在外部配置数据源,然后放置一个JNDI上下文的引用。这种数据源只需配置两个属性:
- initial_context:用来在InitialContext中寻找上下文。可选,如果忽略,data_source属性将会直接从InitialContext中寻找;
- data_source:引用数据源实例位置上下文的路径。当提供initial_context配置时,data_source会在其返回的上下文进行查找,否则直接从InitialContext中查找。
除了上述三种数据源之外,Mybatis还提供第三方数据源,如DBCP,但是需要我们自定义数据源工厂并进行配置,这一点暂时不做研究。
3.8 databaseIdProvider属性(了解)
databaseIdProvider元素主要是为了支持不同厂商的数据库,这个元素不常用。比如有的公司内部开发使用的数据库都是MySQL,但是客户要求使用Oracle,那麻烦了,因为Mybatis的移植性不如Hibernate,但是Mybatis也不会那么蠢,在Mybatis中我们可以使用databaseIdProvider这个元素实现数据库兼容不同厂商,即配置多中数据库。
下面以Oracle和MySQL两种数据库来介绍它们,要配置的属性如下:
<!--数据库厂商标示 -->
<databaseIdProvider type="DB_VENDOR">
<property name="Oracle" value="oracle"/>
<property name="MySQL" value="mysql"/>
<property name="DB2" value="d2"/>
</databaseIdProvider>
databaseIdProvider的type属性是必须的,不配置时会报错。上面这个属性值使用的是VendorDatabaseIdProvider类的别名。
property子元素是配置一个数据库,其中的name属性是数据库名称,value是我们自定义的别名,通过别名我们可以在SQL语句中标识适用于哪种数据库运行。如果不知道数据库名称,我们可以通过以下代码获取connection.getMetaData().getDatabaseProductName()来获取,代码如下:
/**
* 获取数据库名称
*/
public static void getDbInfo() {
SqlSession sqlSession = null;
Connection connection = null;
try {
InputStream stream = Resources.getResourceAsStream("mybatis-config.xml");
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(stream);
sqlSession = sqlSessionFactory.openSession();
connection = sqlSession.getConnection();
String dbName = connection.getMetaData().getDatabaseProductName();
String dbVersion = connection.getMetaData().getDatabaseProductVersion();
System.out.println("数据库名称是:" + dbName + ";版本是:" + dbVersion);
} catch (SQLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
我的输出结果是:数据库名称是:MySQL;版本是:5.7.28-log
然后下面我们就可以在自己的sql语句中使用属性databaseId来标示数据库类型了。配置如下:
<!-- 查询所有用户 -->
<select id="selectAllUser" resultType="com.thr.User" databaseId="oracle">
select * from t_user
</select>
注意:在上面的SQL中,我配置的databaseId是oracle,但是我的实际的数据库是mysql,结果最后肯定会报BindingException异常(但是我这个代码不知道为什么报的另一种异常,就很奇怪,百度了好久无果)。如果我们把databaseId=”oracle”换成mysql的,就能获取正确结果了。除上述方法之外,我们还可以不在SQL中配置databaseId,这样mybatis会使用默认的配置,也是可以成功运行的。
过上面的实践知道了:使用多数据库SQL时需要配置databaseIdProvider 属性。当databaseId属性被配置的时候,系统会优先获取和数据库配置一致的SQL,否则取没有配置databaseId的SQL,可以把它当默认值;如果还是取不到,就会抛出异常。
除了系统自定义的标识外,我们也可以自定义一个规则,需要实现MyBatis提供的DatabaseIdProvider接口,如下:
/**
* 自定义一个数据库标示提供类,实现DatabaseIdProvider接口
*/
public class MyDatabaseIdProvider implements DatabaseIdProvider {
private static final String DATABASE_TYPE_MYSQL = "MySQL";
private static final String DATABASE_TYPE_ORACLE = "Oracle";
private static final String DATABASE_TYPE_DB2 = "DB2";
//log4j的日志,别引入错了
private Logger log = Logger.getLogger(MyDatabaseIdProvider.class);
@Override
public void setProperties(Properties p) {
log.info(p);
}
@Override
public String getDatabaseId(DataSource dataSource) throws SQLException {
Connection conn = dataSource.getConnection();
String dbName = conn.getMetaData().getDatabaseProductName();
if(MyDatabaseIdProvider.DATABASE_TYPE_DB2.equals(dbName)){
return "db2";
} else if(MyDatabaseIdProvider.DATABASE_TYPE_MYSQL.equals(dbName)){
return "mysql";
} else if(MyDatabaseIdProvider.DATABASE_TYPE_ORACLE.equals(dbName)){
return "oracle";
} else {
return null;
}
}
}
然后在databaseIdProvider中做如下配置:
<!--数据库厂商标示 -->
<databaseIdProvider type="com.databaseidprovider.MyDatabaseIdProvider" />
property属性可以不做配置了,其它都一样。
3.9 mappers属性
mapper属性是用来加载映射文件的,也就是加载我们配置的SQL映射文件。它有四种方式加载:
- 用文件路径引入
- 使用URL方式引入
- 用类注册引入
- 用包名引入(推荐)
1、用文件路径引入
<mappers>
<mapper resource="com/thr/mapper/UserMapper.xml" />
<mapper resource="com/thr/mapper/StudentMapper.xml" />
<mapper resource="com/thr/mapper/TeacherMapper.xml" />
</mappers>
这种方式是相对路径,相对于项目目录下,所以得用 / 分开。
2、使用URL方式引入
<mappers>
<mapper url="D:/mappers/UserMapper.xml" />
<mapper url="D:/mappers/StudentMapper.xml" />
</mappers>
这种方式是绝对路径,就是从我们的磁盘读取映射文件,一般不会使用这种方式。
3、用类注册引入
<mappers>
<mapper class="com.thr.mapper.UserMapper" />
<mapper class="com.thr.mapper.StudentMapper" />
<mapper class="com.thr.mapper.TeacherMapper" />
</mappers>
这种方式使用Mapper接口的全限定名,不用管路径问题,让Mybatis自己通过全限定名去找映射文件。但是前提是Mapper接口的名称必须与映射文件的名称相同,并且要在同一个包名下,否则会找不到。比如:UserMapper.java(接口)—UserMapper.xml(映射文件)。关于Mapper接口对应的Mapper映射文件后面会详细介绍。
4、用包名引入(推荐)
<mappers>
<package name="com.thr.mapper"/>
</mappers>
推荐使用这种方式,表示引入该包下的所有mapper接口,这里引入了com.thr.mapper包下的所有接口文件,然后让Mybatis自己通过全限定名去找映射文件。
注意:这种方式的要求同样是Mapper接口和Mapper的映射文件的名称要相同,并且要放在相同的包名下,否则会导致找不到。
参考资料:
- 《Java EE 互联网轻量级框架整合开发》
- https://www.cnblogs.com/hellowhy/category/1304121.html
4、SQL映射文件详解(XxxMapper.xml)
4.1 映射器元素
映射器是Mybatis中最复杂并且是最重要的组件。它由一个接口和xml映射文件(或者注解)组成。在映射器中我们可以配置各类SQL、动态SQL、缓存、存储过程、级联等复杂的内容。并且通过简易的映射规则映射到指定的POJO或者其它对象上,映射器能有效的消除JDBC的底层代码。在Mybatis的应用程序开发中,映射器的开发工作量占全部工作量的80%,可见其重要性。
映射文件的作用是用来配置SQL映射语句,根据不同的SQL语句性质,使用不同的标签,其中常用的标签有:<select>、<insert>、<update>、<delete>。下面列出了SQL 映射文件的几个顶级元素(按照应被定义的顺序列出):
| 元素 | 描述 |
|---|---|
| cache | 该命名空间的缓存配置(会在缓存部分进行讲解) |
| cache-ref | 引用其它命名空间的缓存配置 |
| resultMap | 描述如何从数据库结果集中加载对象,它是最复杂也是最强大的元素 |
| parameterMap | 定义参数映射。此元素已被废弃,并可能在将来被移除!请使用行内参数映射parameType。所以本文中不会介绍此元素 |
| sql | 可被其它语句引用的可重用语句块 |
| select | 映射查询语句 |
| insert | 映射插入语句 |
| update | 映射更新语句 |
| delete | 映射删除语句 |
4.2 select元素
select元素表示 SQL 的 select 语句,用于查询,而查询语句是我们日常中用的最多的,使用的多就意味它有着强大和复杂的功能,所以我们先来看看select元素的属性有哪些(加粗为最常用的)。
| select元素中的属性 | 属性描述 |
|---|---|
| id | 在命名空间中唯一的标识符,可以被用来引用这条语句 |
| parameterType | 将会传入这条语句的参数类的完全限定名或别名。这个属性是可选的,因为 MyBatis 可以通过类型处理器(TypeHandler) 推断出具体传入语句的参数,默认值为未设置(unset) |
| parameterMap | 这是引用外部 parameterMap 的已经被废弃的方法。请使用内联参数映射和 parameterType 属性 |
| resultType | 从这条语句中返回的期望类型的类的完全限定名或别名。 注意如果返回的是集合,那应该设置为集合包含的类型,而不是集合本身。可以使用 resultType 或 resultMap,但不能同时使用 |
| resultMap | 外部 resultMap 的命名引用。结果集的映射是 MyBatis 最强大的特性,如果你对其理解透彻,许多复杂映射的情形都能迎刃而解。可以使用 resultMap 或 resultType,但不能同时使用 |
| flushCache | 将其设置为 true 后,只要语句被调用,都会导致本地缓存和二级缓存被清空,默认值:false |
| useCache | 将其设置为 true 后,将会导致本条语句的结果被二级缓存缓存起来,默认值:对 select 元素为 true |
| timeout | 这个设置是在抛出异常之前,驱动程序等待数据库返回请求结果的秒数。默认值为未设置(unset)(依赖驱动) |
| fetchSize | 这是一个给驱动的提示,尝试让驱动程序每次批量返回的结果行数和这个设置值相等。 默认值为未设置(unset)(依赖驱动) |
| statementType | STATEMENT,PREPARED 或 CALLABLE 中的一个。这会让 MyBatis 分别使用 Statement,PreparedStatement 或 CallableStatement,默认值:PREPARED |
| resultSetType | FORWARD_ONLY,SCROLL_SENSITIVE, SCROLL_INSENSITIVE 或 DEFAULT(等价于 unset) 中的一个,默认值为 unset (依赖驱动) |
| databaseId | 如果配置了数据库厂商标识(databaseIdProvider),MyBatis 会加载所有的不带 databaseId 或匹配当前 databaseId 的语句;如果带或者不带的语句都有,则不带的会被忽略 |
| resultOrdered | resultOrdered:这个设置仅针对嵌套结果 select 语句适用:如果为 true,就是假设包含了嵌套结果集或是分组,这样的话当返回一个主结果行的时候,就不会发生有对前面结果集的引用的情况。 这就使得在获取嵌套的结果集的时候不至于导致内存不够用。默认值:false |
| resultSets | 这个设置仅对多结果集的情况适用。它将列出语句执行后返回的结果集并给每个结果集一个名称,名称是逗号分隔的 |
看到有这么多的属性是不是有点害怕,但是在实际工作中用的最多的是id、parameterType、resultType、resultMap这四个。如果还要设置设置缓存的话,还会使用到flushCache和useCache,而其它的属性是不常用功能,反正我到现在还没有用过其它的。所以我们暂时熟练掌握id、parameterType、resultType、resultMap以及它们的映射规则就行,而flushCache和useCache会在后面的缓存部分进行介绍。
下面使用select元素来举一个例子,这个例子我们前面看到过,就是根据用户Id来查找用户的信息,代码如下:
<!-- 通过Id查询一个用户 -->
<select id="selectUserById" parameterType="int" resultType="com.thr.entity.User">
select * from t_user where id = #{id};
</select>
这条SQL语句非常的简单,但是现在的目的是为了举一个例子,看看在实际开发中如何使用映射文件,这个例子只是让我们认识select元素的常用属性及用法,而在以后的开发中我们所遇到的问题要比这条SQL复杂得多,可能有十几行甚至更长。
注意:没有设置的属性全都采用默认值,你不配置不代表这个属性没有用到。
4.3 insert元素
insert元素表示插入数据,它可以配置的属性如下。
| insert元素中的属性 | 属性描述 |
|---|---|
| id | 在命名空间中唯一的标识符,可以被用来引用这条语句 |
| parameterType | 将会传入这条语句的参数的类全限定名或别名。这个属性是可选的,因为 MyBatis 可以通过类型处理器(TypeHandler)推断出具体传入语句的参数,默认值为未设置(unset) |
| parameterMap | 用于引用外部 parameterMap 的属性,目前已被废弃。请使用行内参数映射和 parameterType 属性 |
| flushCache | 将其设置为 true 后,只要语句被调用,都会导致本地缓存和二级缓存被清空,默认值:(对 insert、update 和 delete 语句)true |
| timeout | 这个设置是在抛出异常之前,驱动程序等待数据库返回请求结果的秒数。默认值为未设置(unset)(依赖数据库驱动) |
| statementType | 可选 STATEMENT,PREPARED 或 CALLABLE。这会让 MyBatis 分别使用 Statement,PreparedStatement 或 CallableStatement,默认值:PREPARED |
| useGeneratedKeys | (仅适用于 insert 和 update)这会令 MyBatis 使用 JDBC 的 getGeneratedKeys 方法来取出由数据库内部生成的主键(比如:像 MySQL 和 SQL Server 这样的关系型数据库管理系统的自动递增字段),默认值:false |
| keyProperty | (仅适用于 insert 和 update)指定能够唯一识别对象的属性,MyBatis 会使用 getGeneratedKeys 的返回值或 insert 语句的 selectKey 子元素设置它的值,默认值:未设置(unset)。如果生成列不止一个,可以用逗号分隔多个属性名称。不能和keyColumn连用 |
| keyColumn | (仅适用于 insert 和 update)设置生成键值在表中的列名,在某些数据库(像 PostgreSQL)中,当主键列不是表中的第一列的时候,是必须设置的。如果生成列不止一个,可以用逗号分隔多个属性名称。不能和keyProperty连用 |
| databaseId | 如果配置了数据库厂商标识(databaseIdProvider),MyBatis 会加载所有不带 databaseId 或匹配当前 databaseId 的语句;如果带和不带的语句都有,则不带的会被忽略 |
下面是insert元素的简单应用,在执行完SQL语句后,会返回一个整数来表示其影响的记录数。代码如下:
<!-- 添加用户-->
<insert id="insertUser" parameterType="com.thr.entity.User">
insert into t_user(username, age ,sex ,address) values (#{username},#{age},#{sex},#{address});
</insert>
4.3.1 主键回填
在insert元素中,有一个非常重要且常用的属性——useGeneratedKeys,它的作用的主键回填,就是将当前插入数据的主键返回。例如上面的插入语句中,我们并没有插入主键 Id 列,因为在mysql数据库中将它设置为自增主键,数据库会自动为其生成对应的主键,所`以没必要插入这个列。但是有些时候我们还需要继续使用这个主键,用以关联其它业务,所以十分有必要获取它。比如在新增用户的时候,首先会插入用户的数据,然后插入用户和角色关系表,而插入用户时如果没办法取到用户的主键,那么就没有办法插入用户和角色关系表了,因此这个时候需要拿到对应的主键,以方便关联表的操作。
在JDBC中,使用Statement对象执行插入的SQL语句后,可以通过getGeneratedKeys方法来获取数据库生成的主键。而在insert元素中也设置了一个对应的属性useGeneratedKeys,它的默认值为false。当我们把这个属性设置为true时,还需要配置keyProperty或keyColumn(它二者不能同时使用),告诉系统把生成的主键放入哪个属性中,如果存在多个主键,就要用逗号隔开。
我们将上面xml配置文件中的insert语句进行更改,更改后代码如下:
<!-- 添加用户-->
<insert id="insertUser" parameterType="com.thr.entity.User" useGeneratedKeys="true" keyProperty="id">
insert into t_user(username, age ,sex ,address) values (#{username},#{age},#{sex},#{address});
</insert>
useGeneratedKeys设置为true表示将会采用jdbc的Statement对象的getGeneratedKeys方法返回主键,因为Mybatis的底层始终是jdbc的代码。设置keyProperty对于 id 表示用这个pojo对象的属性去匹配这个主键,它会将数据库返回的主键值赋值为这个pojo对象的属性。测试代码如下:
//添加一个用户数据
@Test
public void testInsertUser1(){
String statement = "com.thr.mapper.UserMapper.insertUser";
User user = new User();
user.setUsername("张三");
user.setAge(30);
user.setSex("男");
user.setAddress("中国北京");
sqlSession.insert(statement, user);
//提交插入的数据
sqlSession.commit();
sqlSession.close();
//输出返回的主键只
System.out.println("插入的主键值为:"+user.getId());
}
输出结果为:

通过结果可以发现我们已经获取到插入数据的主键了。
4.3.2 自定义主键
自定义主键,顾名思义就是我们自己定义返回的主键值。有时候我们的不想按照数据库自增的规则,例如每次插入主键+2,又或者随机生成数据。那么Mybatis对于这样的场景也提供了支持,它主要依赖于selectKey元素进行支持,它允许自定义键值的生成规则,如下代码:
<!-- 添加用户-->
<insert id="insertUser" parameterType="com.thr.entity.User">
<selectKey keyProperty="id" resultType="int" order="BEFORE">
select ROUND(RAND()*1000)
</selectKey>
insert into t_user(username, age ,sex ,address) values (#{username},#{age},#{sex},#{address});
</insert>
执行的流程是:首先通过select ROUND(RAND()*1000)得到主键值,然后将得到的值设置到 user 对象的 id 中,再最后进行 insert 操作。
下面再来介绍一下相关的标签:
keyProperty:将查询到的主键设置到parameterType 指定到对象的那个属性。select ROUND(RAND()*1000):得到一个随机主键的id值,ROUND()表示获取到小数点后几位(默认为0),RAND()*100表示获取[0 , 100 )之间的任意数字。resultType:指定select ROUND(RAND()*1000)的结果类型order:BEFORE,表示在SQL语句之前执行还是之后执行,可以设置为 BEFORE或AFTER。这里是BEFORE,则表示先执行select ROUND(RAND()*1000)。
测试运行结果为:

4.4 update和delete元素
update元素和delete元素在使用上比较简单,所以这里把它们放在一起论述。它们和insert元素的属性差不多,执行完后也会返回一个整数,用来表示该SQL语句影响了数据库的记录行数。它们二者的使用代码如下所示:
<!-- 根据Id更新用户 -->
<update id="updateUser" parameterType="com.thr.entity.User">
update t_user set username = #{username},age = #{age},sex = #{sex},address = #{address} where id = #{id}
</update>
<!-- 根据Id删除用户 -->
<delete id="deleteUser" parameterType="int">
delete from t_user where id = #{id}
</delete>
由于在使用上比较简单,所以就不做多介绍了,具体可以参考前面select和insert元素。
4.5 sql元素
sql元素是用来定义可重用的 sql代码片段,这样在字段比较多的时候,以便在其它语句中使用。
<!--定义sql代码片段-->
<sql id="userCols">
id,username,age,sex,address
</sql>
<!-- 查询所有用户 -->
<select id="selectAllUser" resultType="com.thr.entity.User">
select <include refid="userCols"/> from t_user
</select>
<!-- 添加用户-->
<insert id="insertUser" parameterType="com.thr.entity.User">
<selectKey keyProperty="id" resultType="int" order="BEFORE">
select ROUND(RAND()*1000)
</selectKey>
insert into t_user(<include refid="userCols"/>) values (#{id},#{username},#{age},#{sex},#{address});
</insert>
sql元素还支持变量的传递,这种方式简单了解即可,代码如下。
<!--定义sql代码片段-->
<sql id="userCols">
${alias}.id,${alias}.username,${alias}.age,${alias}.sex,${alias}.address
</sql>
<!-- 查询所有用户 -->
<select id="selectAllUser" resultType="com.thr.entity.User">
select <include refid="userCols">
<property name="alias" value="u"/>
</include>
from t_user u
</select>
在include元素中定义了一个命名为alias的变量,其值是表t_user的别名u,然后sql元素就能自动识别到对于表的变量名,例如u.id、u.username、u.age。这种方式对于多表查询很有用,但也用的不多。
4.6 输入映射parameterType
4.6.1 映射基本数据类型
即八大基本数据类型,比如int,boolean,long等类型
根据id查询一个用户:selectUserById,那么传入的就应该是int类型的值。所以使用别名int来映射传入的值。
<!-- 通过Id查询一个用户 -->
<select id="selectUserById" parameterType="int" resultType="com.thr.entity.User">
select * from t_user where id = #{id};
</select>
4.6.2 映射pojo类型
即普通的对象,比如user的javabean对象
添加用户:insertUser。这里传入的就是一个pojo类型。
<!-- 添加用户-->
<insert id="insertUser" parameterType="com.thr.entity.User">
insert into t_user(id,username,age,sex,address) values (#{id},#{username},#{age},#{sex},#{address});
</insert>
4.6.3 包装pojo类型
即内部属性为对象引用,集合等
那什么是包装pojo类型呢?比如如下的代码:
public class QueryVo {
//有个对象引用,可能是普通的pojo,也有可能是集合
private User user;
public User getUser() {
return user;
}
public void setUser(User user) {
this.user = user;
}
}
根据用户名和年龄查询用户信息:selectUserByUserNameAndAge。传入一个包装pojo类型,其内部有个属性是user的引用。
<!-- 通过username和age查询一个用户 -->
<select id="selectUserByUserNameAndAge" parameterType="com.thr.entity.QueryVo" resultType="com.thr.entity.User">
select * from t_user where username = #{user.username} and age = #{user.age};
</select>
测试代码:
@Test
public void testSelectUserByUserNameAndAge(){
String statement = "com.thr.mapper.UserMapper.selectUserByUserNameAndAge";
QueryVo vo = new QueryVo();
User user = new User();
user.setUsername("马保国");
user.setAge(30);
vo.setUser(user);
List<User> listUser = sqlSession.selectList(statement, vo);
for(User u : listUser){
System.out.println(u);
}
sqlSession.close();
}
注意:user.username这个属性的获取,因为QueryVO是一个包装pojo,其中有user的引用。而user中又有username的属性,那么这样一层层取过来用即可。
4.6.4 映射map集合
这个也很简单,理解了前面的,这个不难。就是通过map集合设置key和value的值,然后在映射文件中获取对应的key即可 #{key}。
<!-- 通过username和age查询一个用户 -->
<select id="selectUserByMap" parameterType="hashmap" resultType="com.thr.entity.User">
select * from t_user where username = #{username} and age = #{age};
</select>
测试代码:
@Test
public void testSelectUserByMap(){
String statement = "com.thr.mapper.UserMapper.selectUserByMap";
//创建HashMap对象
HashMap<String, Object> map = new HashMap<>();
//put值
map.put("username","马保国");
map.put("age",30);
List<User> listUser = sqlSession.selectList(statement, map);
for(User u : listUser){
System.out.println(u);
}
sqlSession.close();
}
注意:这里的hashmap使用的是别名,mybatis中内置了。
4.7 输出映射resultType
resultType为输出结果集类型,同样支持基本数据类型、pojo类型及map集合类型。SQL语句查询后返回的结果集会映射到配置标签的输出映射属性对应的Java类型上。
输出映射有两种配置,分别是resultType和resultMap,注意两者不能同时使用。
4.7.1 映射基本数据类型
<!-- 统计用户总数量 -->
<select id="countUsers" resultType="int">
select count(1) from t_user
</select>
4.7.2 映射pojo对象
<!-- 通过Id查询一个用户,resultType配置为PoJo类型 -->
<select id="selectUserById" parameterType="int" resultType="com.thr.entity.User">
select * from t_user where id = #{id};
</select>
4.7.3 映射pojo列表(映射多列数据)
映射单个pojo对象和映射pojo列表映射文件中的resultType都配置为pojo类型。区别只是返回单个对象是内部调用selectOne返回pojo对象,返回pojo列表时内部调用selectList方法。
<!-- 查询所有用户 -->
<select id="selectAllUser" resultType="com.thr.entity.User">
select * from t_user
</select>
4.7.4 映射hashmap
<!-- 查询所有用户, resultType为hashmap-->
<select id="selectAllUser" resultType="hashmap">
select * from t_user
</select>
测试代码:
//查询所有用户数据,通过HashMap
@Test
public void testSelectAllUser(){
String statement = "com.thr.mapper.UserMapper.selectAllUser";
List<HashMap<String, Object>> listUser = sqlSession.selectList(statement);
for (HashMap<String, Object> map: listUser) {
Iterator<Map.Entry<String, Object>> iterator = map.entrySet().iterator();
while (iterator.hasNext()){
Map.Entry<String, Object> entry = iterator.next();
System.out.println("key= "+entry.getKey()+" and value= "+entry.getValue());
}
}
sqlSession.close();
}
4.8 输出映射resultMap(重要)
我们在使用resultType的时候,前提是数据库表中的字段名和表对应实体类的属性名称一致才行(包括驼峰原则),但是在平时的开发中,表中的字段名和表对应实体类的属性名称往往不一定都是完全相同的,这样就会导致数据映射不成功,从而查询不到数据。那为了解决这个问题,我需要使用resultMap,通过resultMap将字段名和属性名作一个对应关系。
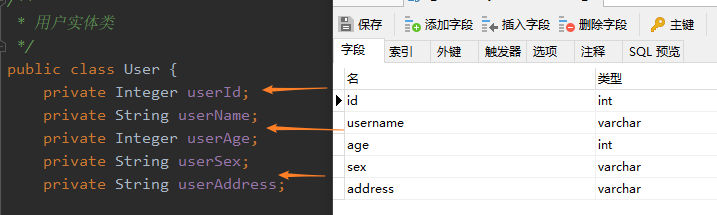
下面先来简单体验一下resultMap的使用,为了让例子更加好,我将数据库表User实体的属性进行了简单的修改,如下:
向表t_user中添加一些数据:
INSERT INTO `t_user` VALUES (1, '奥利给', 18, '男', '上海');
INSERT INTO `t_user` VALUES (2, '蔡徐坤', 18, '男', '北京');
INSERT INTO `t_user` VALUES (3, '黄飞鸿', 42, '男', '大清');
INSERT INTO `t_user` VALUES (4, '十三姨', 18, '女', '大清');
改完之后,数据库的字段与User实体的属性是不能在进行自动映射了。这种情况我们就可以使用resultMap进行映射。下面配置查询结果的列名和实体类的属性名的对应关系,修改xml配置文件。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.thr.mapper.UserMapper">
<!-- 配置查询结果的列名和实体类的属性名的对应关系 -->
<!--id:唯一标识,type:需要映射的java类型-->
<resultMap id="userMap" type="com.thr.entity.User">
<!-- 与主键字段的对应,property对应实体属性,column对应表字段 -->
<id property="userId" column="id"/>
<!-- 与非主键字段的对应,property对应实体属性,column对应表字段 -->
<result property="userName" column="username"/>
<result property="userAge" column="age"/>
<result property="userSex" column="sex"/>
<result property="userAddress" column="address"/>
</resultMap>
<!-- 查询所有用户,返回集为resultMap类型,resultMap的value上面配置的id=userMap要一致-->
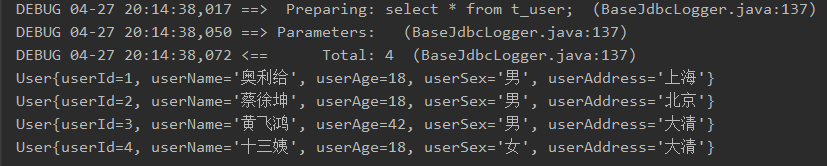
<select id="selectAllUser" resultMap="userMap">
select * from t_user
</select>
</mapper>
测试代码:
//查询所有用户数据
@Test
public void testSelectAllUser(){
String statement = "com.thr.mapper.UserMapper.selectAllUser";
List<User> listUser = sqlSession.selectList(statement);
for (User user : listUser) {
System.out.println(user);
}
sqlSession.close();
}
运行结果:
当然,还有一种方式可以不用resultMap元素,就是sql 查询取别名时与pojo属性一致即可,但是不推荐,这样sql的可读性差),举例代码如下。
<select id="selectAllUser" resultType="com.thr.entity.User">
select id userId,username userName,age userAge,sex userSex,address userAddress from t_user
</select>
resultMap元素中属性的简单介绍
额外,resultMap还有高级映射功能,还可以实现将查询结果映射为复杂类型的pojo类型,比如在查询结果映射对象中包括pojo和list实现一对一查询和一对多查询,这个会在后面单独进行详细的介绍,因为这个点非常非常非常重要,所以这里不多说。我们下面来详细介绍一下resultMap元素。
<resultMap id="" type="" extends="" autoMapping="">
<constructor><!--构造器注入属性值-->
<idArg/>
<arg/>
</constructor>
<id/><!--主键的映射规则-->
<result/><!--非主键的映射规则-->
<association/><!--高级映射-->
<collection /><!--高级映射-->
<discriminator>
<case/>
</discriminator><!--根据返回的字段的值封装不同的类型-->
</resultMap>
①、resultMap元素包含的属性:
- id:该封装规则的唯一标识。
- type:表示返回映射的类型,可以是基本数据类型、pojo和map类型。
- autoMapping:自动封装,如果数据库字段和javaBean的字段名一样,可以使用这种方式,但是不建议采取,还是老老实实写比较稳妥,如果非要使用此功能,那就在全局配置中加上mapUnderscoreToCamelCase=TRUE,它会使经典数据库字段命名规则翻译成javaBean的经典命名规则,如:a_column翻译成aColumn。
- extends:继承其他封装规则,和Java中的继承一样。
②、resultMap元素的子元素<constructor>
使用构造方法映射属性值,用的非常少。
<resultMap id="userConstructorMap" type="com.thr.entity.User">
<constructor>
<idArg column="id" name="userId" javaType="int"/>
<arg column="username" name="userName" javaType="string"/>
<arg column="age" name="userAge" javaType="int"/>
<arg column="sex" name="userSex" javaType="string"/>
<arg column="address" name="userAddress" javaType="string"/>
</constructor>
</resultMap>
③、resultMap元素的子元素<id>和<result>
<id>表示与主键字段的映射规则<result>表示与非主键字段的映射规则
它们二者的内部属性一致,如下:
- column:指定数据库字段名或者其别名(这个别名是数据库起的,如 username as name)
- property:指定javabean的属性名
- jdbcType:映射java的类型
- javaType:映射数据库类型
- typeHandler:数据库与Java类型匹配处理器(可以参考前面的TypeHandler部分)
④、<association>、<collection>和<discriminator>
<association>:高级映射一对一映射规则<collection>:高级映射一对多映射规则<discriminator>:负责根据返回的字段的值封装不同的类型
这些元素都是关于级联的问题比较复杂,所以这里就不探讨了,后面会介绍到。
5、通过Mapper接口(动态代理)加载映射文件(推荐)
5.1 本章前言
前面学习了基于原生接口的xml版本创建Mybatis实例,就是通过sqlSession对象调用其内部定义好的相对应的方法,包括增删改查方法,如selectOne、selectList、insert等等,但这种方式在实际中很少使用,不推荐。所以下面我们来学习一种在我们平时开发中最常用也是最实用的开发方式——通过Mapper接口(动态代理)加载映射文件。Mapper接口动态代理的方式需要程序员手动编写Mapper接口(相当于Dao接口),由Mybatis框架将根据接口定义创建接口的动态代理对象,代理对象的方法体实现Mapper接口中定义的方法。
下面就来学习这种方法创建一个Mybatis的实例。
5.2 创建数据库
创建数据库(mybatis)和表(t_user),SQL脚本如下:
DROP TABLE IF EXISTS `t_user`;
CREATE TABLE `t_user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`age` int(11) NULL DEFAULT NULL,
`sex` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`address` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 8 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of t_user
-- ----------------------------
INSERT INTO `t_user` VALUES (1, '奥利给', 18, '男', '上海');
INSERT INTO `t_user` VALUES (2, '蔡徐坤', 18, '男', '北京');
INSERT INTO `t_user` VALUES (3, '黄飞鸿', 42, '男', '大清');
INSERT INTO `t_user` VALUES (4, '十三姨', 18, '女', '大清');
INSERT INTO `t_user` VALUES (5, '梁宽', 42, '男', '大清');
5.3 创建Maven项目
在Eclipse或IDEA中创建一个Maven项目。
然后导入pom依赖,如下:
<dependencies>
<!-- Mybatis -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.6</version>
</dependency>
<!-- mysql驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.21</version>
</dependency>
<!-- 日志处理 -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<!-- 单元测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
5.4 编写User实体类
创建一个User实体类,这里省略了getter、setter和toString方法,需自己加上。
/**
* 用户实体类
*/
public class User {
private int userId;
private String userName;
private int userAge;
private String userSex;
private String userAddress;
//getter、setter、toString方法省略......
}
5.5 创建Mybatis全局配置文件
在resources目录中,创建Mybatis的全局配置文件mybatis-config.xml。代码如下:
注意:这里面配置了别名,扫描所有实体包,给实体类起个别名,别名就是小写字母的类名。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!--配置别名-->
<typeAliases>
<!-- 对包进行扫描,可以批量进行别名设置,设置别名的规则是:获取类名称,将其第一个字母变为小写 -->
<package name="com.thr.entity"/>
</typeAliases>
<!-- environments表示配置Mybatis的开发环境,可以配置多个环境,在众多具体环境中,使用default属性指定实际运行时使用的环境 -->
<environments default="development">
<!-- environment表示配置Mybatis的一个具体的环境 -->
<!-- id属性必须和上面的default一致 -->
<environment id="development">
<!--配置Mybatis的内置的事务管理器-->
<transactionManager type="JDBC"/>
<!--dataSource 元素使用标准的 JDBC 数据源接口来配置 JDBC 连接对象源 -->
<dataSource type="POOLED">
<!--配置连接数据库的4个基本信息-->
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mybatis?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf-8"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</dataSource>
</environment>
</environments>
</configuration>
5.6 编写Mapper接口
Mapper接口代码代码如下(命名不一定是XxxMapper,也可以是XxxDao等等):
/**
* UserMapper接口
*/
public interface UserMapper {
//查询所有用户
List<User> selectAllUser();
//根据id查询用户
User selectUserById(Integer id);
//根据用户名模糊查询用户列表
List<User> selectUserByName(String userName);
//添加用户
Integer insertUser(User user);
//修改用户信息
Integer updateUser(User user);
//删除用户
Integer deleteUser(Integer id);
}
5.7 编写SQL映射文件(非常重要)
在resources里创建目录:com/thr/mapper,然后在里面创建映射配置文件UserMapper.xml。注意:目录在创建时是斜杠(/)而不是点(.),如果用点(.)的话表示创建了一个名字为com.thr.mapper的文件,而不是com->thr->mapper的目录,到时候在加载映射文件的时候报错。
编写映射文件的注意事项如下(非常重要!非常重要!非常重要!):
- XML文件名的命名必须和Mapper接口名称相同,例如UserMapper.xml。
- SQL映射文件中命名空间namespace必须对应Mapper接口的全限定类名。
- 增删改查元素中的id与Mapper接口中的方法必须对应。
- parameterType的类型必须和Mapper接口方法的输入参数类型相同(有时可以省略)。
- resultType的类型必须和Mapper接口方法的输出参数类型相同。
映射文件的xml代码如下所示:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- mapper标签是当前配置文件的根标签 -->
<!-- namespace属性:表示命名空间,用来设定当前Mapper配置文件的唯一标识,将来在Java程序中通过namespace属性的值来定位到这个配置文件 -->
<!-- namespace属性值设置的方式:名字可以随便取,但是推荐以相对应的Mapper接口的全类名,例如com.thr.mapper.UserMapper -->
<mapper namespace="com.thr.mapper.UserMapper">
<!-- 配置查询结果的列名和实体类的属性名的对应关系 -->
<!--id:唯一标识,type:需要映射的java类型-->
<resultMap id="userMap" type="com.thr.entity.User">
<!-- 与主键字段的对应,property对应实体属性,column对应表字段 -->
<id property="userId" column="id"/>
<!-- 与非主键字段的对应,property对应实体属性,column对应表字段 -->
<result property="userName" column="username"/>
<result property="userAge" column="age"/>
<result property="userSex" column="sex"/>
<result property="userAddress" column="address"/>
</resultMap>
<!-- 查询所有用户 -->
<select id="selectAllUser" resultMap="userMap">
select * from t_user;
</select>
<!-- 通过Id查询一个用户 -->
<select id="selectUserById" parameterType="int" resultMap="userMap">
select * from t_user where id = #{id};
</select>
<!-- 模糊查询,根据username字段查询用户-->
<select id="selectUserByName" parameterType="int" resultMap="userMap">
select * from t_user where username like '%${value}%';
</select>
<!-- 添加用户-->
<insert id="insertUser" parameterType="com.thr.entity.User">
insert into t_user(username, age, sex, address)
values (#{userName}, #{userAge}, #{userSex}, #{userAddress});
</insert>
<!-- 根据Id更新用户 -->
<update id="updateUser" parameterType="com.thr.entity.User">
update t_user set username = #{userName},age = #{userAge},sex = #{userSex},address = #{userAddress} where id = #{userId}
</update>
<!-- 根据Id删除用户 -->
<delete id="deleteUser" parameterType="int">
delete from t_user where id = #{id}
</delete>
</mapper>
5.8 加载映射文件
将上面创建的UserMapper.xml文件添加至全局配置文件mybatis-config.xml下。
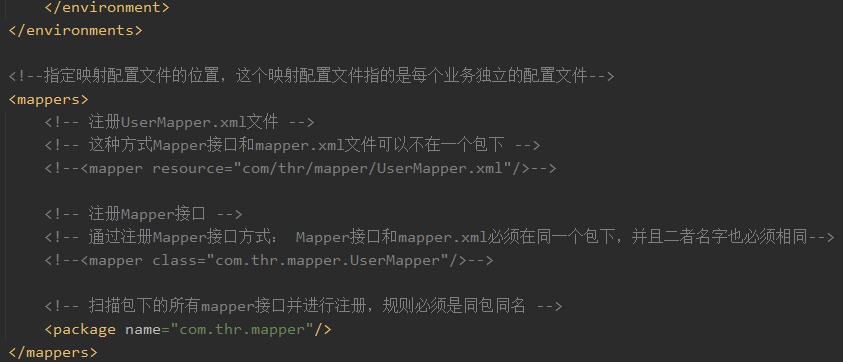
注意:通过注册Mapper接口或者包扫描的方式创建mapper.xml,它的位置必须和Mapper接口在相同的包或者相同目录下才能获取到对应的xml文件。
<mappers>
<!-- 注册UserMapper.xml文件 -->
<!-- 这种方式Mapper接口和mapper.xml文件可以不在一个包下 -->
<!--<mapper resource="com/thr/mapper/UserMapper.xml"/>-->
<!-- 注册Mapper接口 -->
<!-- 通过注册Mapper接口方式: Mapper接口和mapper.xml必须在同一个包下,并且二者名字也必须相同-->
<!-- <mapper class="com.thr.mapper.UserMapper"/> -->
<!-- 扫描包下的所有mapper接口并进行注册,规则必须是同包同名 -->
<package name="com.thr.mapper"/>
</mappers>
5.9 导入日志文件
导入日志文件,在resources目录中创建log4j.xml文件(这种方式打印的数据更加清晰),并且导入如下配置(如果log报错则以管理员的方式启动Eclipse或IDEA)。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE log4j:configuration SYSTEM "log4j.dtd">
<log4j:configuration xmlns:log4j="http://jakarta.apache.org/log4j/">
<appender name="STDOUT" class="org.apache.log4j.ConsoleAppender">
<param name="Encoding" value="UTF-8" />
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%-5p %d{MM-dd HH:mm:ss,SSS} %m (%F:%L) \n" />
</layout>
</appender>
<logger name="java.sql">
<level value="debug" />
</logger>
<logger name="org.apache.ibatis">
<level value="info" />
</logger>
<root>
<level value="debug" />
<appender-ref ref="STDOUT" />
</root>
</log4j:configuration>
5.10 编写测试文件
最后创建一个MybatisTest的测试类,其源代码如下所示:
/**
* Mybatis的测试
*/
public class MybatisTest {
//定义 SqlSession
private SqlSession sqlSession = null;
//定义 UserMapper对象
private UserMapper mapper = null;
@Before//在测试方法执行之前执行
public void getSqlSession(){
//1、加载 mybatis 全局配置文件
InputStream is = MybatisTest.class.getClassLoader().getResourceAsStream("mybatis-config.xml");
//2、创建SqlSessionFactory对象
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(is);
//3、根据 sqlSessionFactory 产生 session
sqlSession = sqlSessionFactory.openSession();
//4、创建Mapper接口的的代理对象,getMapper方法底层会通过动态代理生成UserMapper的代理实现类
mapper = sqlSession.getMapper(UserMapper.class);
}
@After//在测试方法执行完成之后执行,这里也有提交事务和关闭资源
public void destroy() throws IOException {
sqlSession.commit();
sqlSession.close();
}
//查询所有用户数据
@Test
public void testSelectAllUser(){
List<User> listUser = mapper.selectAllUser();
for (User user : listUser) {
System.out.println(user);
}
}
//根据Id查询一个用户数据
@Test
public void testSelectUserById(){
User user = mapper.selectUserById(1);
System.out.println(user);
}
//模糊查询:根据 user 表的username字段
@Test
public void testSelectUserByName(){
List<User> userList = mapper.selectUserByName("三");
for(User user : userList){
System.out.println(user);
}
}
//添加一个用户数据
@Test
public void testInsertUser(){
User user = new User();
user.setUserName("法外狂徒张三");
user.setUserAge(42);
user.setUserSex("男");
user.setUserAddress("中国监狱");
Integer i = mapper.insertUser(user);
System.out.println(i);
System.out.println( (i>0)? "添加成功!":"添加失败!");
}
//根据Id修改用户数据
@Test
public void testUpdateUser(){
//如果设置的 id不存在,那么数据库没有数据更改
User user = new User();
user.setUserId(3);
user.setUserName("梁宽");
user.setUserAge(42);
user.setUserSex("男");
user.setUserAddress("中国北京");
Integer i = mapper.updateUser(user);
System.out.println( (i>0)? "修改成功!":"修改失败!");
}
//根据Id删除用户数据
@Test
public void testDeleteUser(){
Integer i = mapper.deleteUser(3);
System.out.println( (i>0)? "删除成功!":"删除失败!");
}
}
6、通过注解映射实现Mybatis实例
6.1 本章前言
我们都知道注解能够帮我们减少大量的代码和配置,基本上每个人都喜欢用注解进行配置,包括我自己,因为实在太方便了。但是Mybatis是一个特例,因为Mybatis使用注解的话,如果SQL复杂点会导致可读性极差,所以Mybatis一般都不推荐使用注解实现,推荐使用基于Mapper接口的xml版本实现。通过注解映射实现Mybatis实例我们暂时只需简单了解即可。
6.2 创建数据库
创建数据库(mybatis)和表(t_user),完成创建数据库和表的操作后如下图所示:
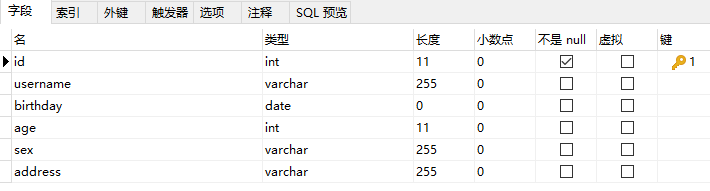
插入一些测试数据:
INSERT INTO `t_user` VALUES (1, '奥利给', '2002-04-28', 18, '男', '上海');
INSERT INTO `t_user` VALUES (2, '蔡徐坤', '2001-06-08', 18, '男', '北京');
INSERT INTO `t_user` VALUES (3, '马保国', '2004-11-12', 42, '男', '深圳');
INSERT INTO `t_user` VALUES (4, '十三姨', '1998-01-18', 18, '女', '大清');
6.3 创建Maven项目
在Eclipse或IDEA中创建一个Maven项目。
然后导入pom依赖,如下:
<dependencies>
<!-- Mybatis -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.6</version>
</dependency>
<!-- mysql驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.21</version>
</dependency>
<!-- 日志处理 -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<!-- 单元测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
6.4 创建User实体
创建一个User实体类,这里省略了getter、setter和toString方法,需自己加上。
/**
* 用户实体类
*/
public class User {
private int userId;
private String userName;
private int userAge;
private Date userBirthday;
private String userSex;
private String userAddress;
//getter、setter、toString方法省略......
}
6.5 创建Mybatis全局配置文件
在resources目录中,创建Mybatis的全局配置文件mybatis-config.xml。代码如下:
注意:这里面配置了别名,扫描所有实体包,给实体类起个别名,别名就是小写字母的类名。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!--配置别名-->
<typeAliases>
<!-- 对包进行扫描,可以批量进行别名设置,设置别名的规则是:获取类名称,将其第一个字母变为小写 -->
<package name="com.thr.entity"/>
</typeAliases>
<!-- environments表示配置Mybatis的开发环境,可以配置多个环境,在众多具体环境中,使用default属性指定实际运行时使用的环境 -->
<environments default="development">
<!-- environment表示配置Mybatis的一个具体的环境 -->
<!-- id属性必须和上面的default一致 -->
<environment id="development">
<!--配置Mybatis的内置的事务管理器-->
<transactionManager type="JDBC"/>
<!--dataSource 元素使用标准的 JDBC 数据源接口来配置 JDBC 连接对象源 -->
<dataSource type="POOLED">
<!--配置连接数据库的4个基本信息-->
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mybatis?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf-8"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</dataSource>
</environment>
</environments>
</configuration>
6.6 编写Mapper接口
Mapper接口代码如下(命名不一定是XxxMapper,也可以是XxxDao等等),当使用了注解的方式就不在需要XXXMapper.xml文件了。
/**
* UserMapper接口,使用注解配置
*/
public interface UserMapper {
//查询所有用户
@Select("select * from t_user")
@Results(id = "userMap",value = {
@Result(property = "userId", column = "id",id = true),
@Result(property = "userName", column = "username"),
@Result(property = "userAge", column = "age"),
@Result(property = "userBirthday", column = "birthday"),
@Result(property = "userSex", column = "sex"),
@Result(property = "userAddress", column = "address"),
})
List<User> selectAllUser();
//根据id查询用户
@Select("select * from t_user where id = #{id}")
@ResultMap("userMap")
User selectUserById(Integer id);
//根据用户名和地址模糊查询用户列表
@Select("select * from t_user where username like concat('%',#{userName},'%') and address like concat('%',#{userAddress},'%')")
@ResultMap("userMap")
List<User> selectUserByNameAndAddress(@Param("userName") String userName,@Param("userAddress") String userAddress);
//添加用户
@Insert("insert into t_user(username,age,birthday,sex,address) values " +
"(#{userName},#{userAge},#{userBirthday},#{userSex},#{userAddress});")
Integer insertUser(User user);
//修改用户信息
@Update("update t_user set username = #{userName},age = #{userAge}, birthday = #{userBirthday}," +
"sex = #{userSex},address = #{userAddress} where id = #{userId}")
Integer updateUser(User user);
//删除用户
@Delete("delete from t_user where id = #{id}")
Integer deleteUser(Integer id);
}
mybatis中一些常用注解介绍:
①、@Select()、@Insert()、@Update()、@Delete():基本增删改查注解
②、@Results():结果映射的列表,相当于resultMap标签,id表示结果映射的名字,value表示的是 @Result 的数组。注意:@Results需要和@Select配合使用,单独的@Results不会被识别。
③、@Result():在列和属性或字段之间的单独结果映射。属性有:id,column, property, javaType ,jdbcType ,typeHandler, one,many。
| 属性名 | 描述 |
|---|---|
| id | 是一个布尔值,表示是否为主键 |
| column | 数据库字段名或者其别名(这个别名是数据库起的,如 username as name) |
| property | 实体类属性名 |
| javaType | 映射java的类型 |
| jdbcType | 映射数据库类型 |
| typeHandler | 数据库与Java类型匹配处理器(可以参考前面的TypeHandler部分) |
| one | 属性是单独的联系,用来一对一操作, 和<association>相似 |
| many | 属性是对集合而言的,用来一对多操作 , 和 <collection>相似 |
④、@One:一对一注解。select属性必须是已映射语句的完全限定名(也就是接口的方法),它可以加载合适类型的实例。 fetchType会覆盖全局的配置参数lazyLoadingEnabled。
@Result(property = "property", column = "column", javaType = User.class,one=@One(select = "com.thr.mapper.XxxMapper.Method_Name",fetchType = FetchType.DEFAULT)),
⑤、@Many:一对多注解。select属性必须是已映射语句的完全限定名(也就是接口的方法),它可以加载合适类型的实例的集合,fetchType会覆盖全局的配置参数lazyLoadingEnabled。
@Result(property = "property", column = "column", javaType = User.class,many=@Many(select = "com.thr.mapper.XxxMapper.Method_Name",fetchType = FetchType.DEFAULT)),
⑥、@ResultMap():用来引用定义的结果映射的列表(@Results)。这使得注解的@Select可以复用那些定义在ResultMap中的内容。如果同一@Select注解中还存在@Results或者@ConstructorArgs,那么这两个注解将被此注解覆盖。
⑦、@Param():如果Mapper接口中的方法需要多个参数,,这个注解可以被应用于映射器的方法参数来给每个参数一个名字。否则,多参数将会以它们的顺序位置来被命名 (不包括任何 RowBounds 参数) 。比如:#{param1} , #{param2} 等(这是默认的)。使用 @Param("userName"),SQL参数就应该被命名为 #{userName}。
7.7 导入日志文件
导入日志文件,在resources目录中创建log4j.xml文件(这种方式打印的数据更加清晰),并且导入如下配置(如果log报错则以管理员的方式启动Eclipse或IDEA)。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE log4j:configuration SYSTEM "log4j.dtd">
<log4j:configuration xmlns:log4j="http://jakarta.apache.org/log4j/">
<appender name="STDOUT" class="org.apache.log4j.ConsoleAppender">
<param name="Encoding" value="UTF-8" />
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%-5p %d{MM-dd HH:mm:ss,SSS} %m (%F:%L) \n" />
</layout>
</appender>
<logger name="java.sql">
<level value="debug" />
</logger>
<logger name="org.apache.ibatis">
<level value="info" />
</logger>
<root>
<level value="debug" />
<appender-ref ref="STDOUT" />
</root>
</log4j:configuration>
7.8 编写测试代码
最后创建一个MybatisTest的测试类,其源代码如下所示:
/**
* Mybatis的测试
*/
public class MybatisTest {
//定义 SqlSession
private SqlSession sqlSession = null;
//定义 UserMapper对象
private UserMapper mapper = null;
@Before//在测试方法执行之前执行
public void getSqlSession(){
//1、加载 mybatis 全局配置文件
InputStream is = MybatisTest.class.getClassLoader().getResourceAsStream("mybatis-config.xml");
//2、创建SqlSessionFactory对象
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(is);
//3、根据 sqlSessionFactory 产生 session
sqlSession = sqlSessionFactory.openSession();
//4、创建Mapper接口的的代理对象,getMapper方法底层会通过动态代理生成UserMapper的代理实现类
mapper = sqlSession.getMapper(UserMapper.class);
}
@After//在测试方法执行完成之后执行
public void destroy() throws IOException {
sqlSession.commit();
sqlSession.close();
}
//查询所有用户数据
@Test
public void testSelectAllUser(){
List<User> listUser = mapper.selectAllUser();
for (User user : listUser) {
System.out.println(user);
}
}
//根据Id查询一个用户数据
@Test
public void testSelectUserById(){
User user = mapper.selectUserById(1);
System.out.println(user);
}
//模糊查询:根据username和address字段
@Test
public void testSelectUserByName(){
List<User> userList = mapper.selectUserByNameAndAddress("三","大");
for(User user : userList){
System.out.println(user);
}
}
//添加一个用户数据
@Test
public void testInsertUser(){
User user = new User();
user.setUserName("法外狂徒张三");
user.setUserAge(42);
user.setUserBirthday(new Date());
user.setUserSex("男");
user.setUserAddress("中国监狱");
Integer i = mapper.insertUser(user);
System.out.println(i);
System.out.println( (i>0)? "添加成功!":"添加失败!");
}
//根据Id修改用户数据
@Test
public void testUpdateUser(){
//如果设置的 id不存在,那么数据库没有数据更改
User user = new User();
user.setUserId(3);
user.setUserName("张红");
user.setUserAge(42);
user.setUserBirthday(new Date());
user.setUserSex("女");
user.setUserAddress("新疆");
Integer i = mapper.updateUser(user);
System.out.println( (i>0)? "修改成功!":"修改失败!");
}
//根据Id删除用户数据
@Test
public void testDeleteUser(){
Integer i = mapper.deleteUser(3);
System.out.println( (i>0)? "删除成功!":"删除失败!");
}
7、动态SQL
7.1 动态SQL介绍
在使用传统的JDBC来编写代码时,很多时候需要去拼接SQL,这是一件很麻烦的事情,因为有些查询需要许多的条件,比如在查询用户时,需要根据用户名,年龄,性别或地址等信息进行查询,当不需要用户名查询时却依然使用用户名作为条件查询就不合适了,而如果使用大量的Java进行判断,那么代码的可读性比较差,又或者在拼接的时候,不注意哪里少了或多了个空格、符号,都会导致错误。而Mybatis提供了对SQL语句动态拼接的能力,可以让我们在 xml 映射文件内,以标签的形式编写动态 SQL,完成逻辑判断和动态拼接 SQL的功能。大量的判断都可以在Mybatis的映射xml文件里面配置,以达到许多需要大量代码才能实现的功能,从而大大减少了代码量。
Mybatis动态SQL语句是基于OGNL表达式的,主要有以下几类:
- if 标签:简单的条件判断。
- where 标签:相当于where关键字,并且能智能的处理and or ,不必担心多余导致语法错误。
- set 标签:和where标签差不多,主要用于更新。
- trim 标签:插入包含prefix前缀、suffix后缀的内容,并且prefixOverrides去除第一个前缀内容,suffixOverrides去除结尾后缀内容。
- choose、when、otherwize 标签:相当于java 语言中的 switch 语法,与 jstl 中的choose 很类似。
- foreach 标签:用来对一个集合进行遍历,在使用 in 语句查询时特别有用。
- bind 标签:允许你在 OGNL 表达式以外创建一个变量,并将其绑定到当前的上下文。
本章我们以 User 表为例来说明:
7.2 if 标签
if 标签用来实现根据条件拼接sql语句,如果判断参数不为null,则拼接sql,否则不拼接。判断条件内容写在if标签的 test 属性中。示例如下:
<mapper namespace="com.thr.mapper.UserMapper">
<resultMap id="userMap" type="com.thr.pojo.User">
<id property="userId" column="id"/>
<result property="userName" column="username"/>
<result property="userAge" column="age"/>
<result property="userBirthday" column="birthday"/>
<result property="userSex" column="sex"/>
<result property="userAddress" column="address"/>
</resultMap>
<!--根据用户名和地址查询用户信息-->
<select id="selectUserByNameAndAddress" parameterType="user" resultMap="userMap">
select * from t_user where
<if test="userName!=null and userName!=''">
username = #{userName}
</if>
<if test="userAddress!=null and userAddress!=''">
and address = #{userAddress}
</if>
</select>
</mapper>
上述代码当参数userName和userAddress都不为 null 时,拼接出的SQL语句为:select * from t_user where username = ? and address = ? 。但是如果上面的SQL语句中传入的参数 userName 为null,则拼接出的sql语句为:select * from t_user where and address = ? ,可以明显看到 where and 是错误的语法,导致报错,又或者是传入的两个参数都为null,那么拼接出的sql语句为:select * from t_user where ,这明显也是错误的语法,要解决这个问题,需要用到where标签。
7.3 where 标签
<where>标签相当于SQL语句中的where关键字,而且where标签还有特殊的作用。作用如下:
- 自动向sql语句中添加where关键字
- 去掉第一个条件的and 或 or 关键字
上面的示例用where标签改写后示例如下:
<!--根据用户名和地址查询用户信息-->
<select id="selectUserByNameAndAddress" parameterType="user" resultMap="userMap">
select * from t_user
<where>
<if test="userName!=null and userName!=''" >
and username = #{userName}
</if>
<if test="userAddress!=null and userAddress!=''">
and address = #{userAddress}
</if>
</where>
</select>
SQL语句等价于:select * from t_user where username = ? and address = ?
7.4 set 标签
set标签的功能和 where 标签差不多,只是set 标签是用在更新操作的时候,作用如下:
- 自动向修改sql语句中添加set关键字
- 去掉最后一个条件结尾的逗号
使用set标签示例代码如下:
<!--修改用户名、年龄和地址-->
<update id="updateUser" parameterType="user">
update t_user
<set>
<if test="userName!=null and userName!=''">
username = #{userName},
</if>
<if test="userAge!=null and userAge!=''">
age = #{userAge},
</if>
<if test="userAddress!=null and userAddress!=''">
address = #{userAddress},
</if>
</set>
where id = #{userId}
</update>
可以发现最后一个修改条件多了一个逗号(,),但set标签帮我们去掉了,SQL语句等价于:update t_user SET username = ?, age = ?, address = ? where id = ?
7.5 trim 标签(了解)
trim 元素的主要功能是可以在自己包含的内容前加上某些前缀,也可以在其后加上某些后缀,与之对应的属性是 prefix 和 suffix;可以把包含内容的首部某些内容去除,也可以把尾部的某些内容去除,对应的属性是 prefixOverrides 和 suffixOverrides;正因为 trim 有这样的功能,它可以用来实现 where 和 set 一样的效果。
trim标签的属性:
- prefix:表示在trim标签内sql语句加上前缀
- suffix:表示在trim标签内sql语句加上后缀
- prefixOverrides:表示去除第一个前缀
- suffixOverrides:表示去除最后一个后缀
将前面where 标签示例用trim 标签代替:
<!--根据用户名和地址查询用户信息-->
<select id="selectUserByNameAndAddress" parameterType="user" resultMap="userMap">
select * from t_user
<!--<where>
<if test="userName!=null and userName!=''" >
and username = #{userName}
</if>
<if test="userAddress!=null and userAddress!=''">
and address = #{userAddress}
</if>
</where>-->
<!-- 插入prefix属性中指定的内容,并且移除首部所有指定在prefixOverrides属性中的内容-->
<trim prefix="where" prefixOverrides="and | or">
<if test="userName!=null and userName!=''" >
and username = #{userName}
</if>
<if test="userAddress!=null and userAddress!=''">
and address = #{userAddress}
</if>
</trim>
</select>
将前面set 标签示例用trim 标签代替:
<!--修改用户名、年龄和地址-->
<update id="updateUser" parameterType="user">
update t_user
<!--<set>
<if test="userName!=null and userName!=''">
username = #{userName},
</if>
<if test="userAge!=null and userAge!=''">
age = #{userAge},
</if>
<if test="userAddress!=null and userAddress!=''">
address = #{userAddress},
</if>
</set>-->
<!-- 插入prefix属性中指定的内容,并且移除尾部所有指定在suffixOverrides属性中的内容-->
<trim prefix="set" suffixOverrides=",">
<if test="userName!=null and userName!=''">
username = #{userName},
</if>
<if test="userAge!=null and userAge!=''">
age = #{userAge},
</if>
<if test="userAddress!=null and userAddress!=''">
address = #{userAddress},
</if>
</trim>
where id = #{userId}
</update>
7.6 choose、when、otherwise 标签
choose、when、otherwise标签是按顺序判断其内部 when 标签中的 test 条件出否成立,如果有一个成立,则choose结束,执行条件成立的SQL。当 choose 中所有 when 的条件都不满足时,则执行 otherwise 中的SQL,类似于Java中的switch…case…default语句。
示例代码如下:
<select id="selectUserByChoose" resultType="user" parameterMap="userMap">
select * from t_user
<where>
<choose>
<when test="userName!= null and userName!=''">
username=#{userName}
</when>
<when test="userAddress!= null and userAddress!=''">
and address=#{userAddress}
</when>
<otherwise>
and age=#{userAge}
</otherwise>
</choose>
</where>
</select>
- 如果username不为空,则只用username作为条件查询。SQL语句等价于:
select * from t_user where username = ? - 当username为空,而address不为空,用address作为条件进行查询。SQL语句等价于:
select * from t_user where address= ? - 当username和address都为空时,则要求以age作为条件查询。SQL语句等价于:
select * from t_user where age= ?
虽然这种场景有点不切实际,但是我们这里主要集中如何使用这三个标签来实现即可
7.7 foreach 标签(重要)
foreach 标签主要用于遍历集合。通常是用来构建 IN 条件语句,也可用于其他情况下动态拼接sql语句。
foreach标签有以下几个属性:
- collection:表示要遍历的集合元素,注意不要写#{}。
- item:表示每次遍历时生成的对象名(注:当传入Map对象或Map.Entry对象的集合时,index 是键,item是值)。
- index:表示在迭代过程中,每次迭代到的位置。
- open:表示开始遍历时要拼接的字符串。
- close:表示结束遍历时要拼接的字符串。
- sperator:表示在每次遍历时两个对象直接的连接字符串。
示例:如果现在有这样的需求:我们需要查询 t_user 表中 id 分别为1,2,4,5的用户。所对应的sql语句有这两条:select * from t_user where id=1 or id=2 or id=4 or id=5;和 select * from t_user where id in (1,2,4,5);。下面我们使用foreach标签来改写。
①、创建一个UserVo类,里面封装一个List<Integer> ids的属性,代码如下:
public class UserVo {
//封装多个id
private List<Integer> ids;
public List<Integer> getIds() {
return ids;
}
public void setIds(List<Integer> ids) {
this.ids = ids;
}
}
②、foreach 来改写 select * from t_user where id=1 or id=2 or id=4 or id=5;代码如下:
<select id="selectUserByListId" parameterType="userVo" resultMap="userMap">
select * from t_user
<where>
<!--加个括号
<foreach collection="ids" item="id" open="(" close=")" separator="or">
id=#{id}
</foreach>-->
<foreach collection="ids" item="id" separator="or">
id=#{id}
</foreach>
</where>
</select>
测试代码如下:
@Test
public void testSelectUserByListId(){
UserVo userVo = new UserVo();
List<Integer> ids = new ArrayList<>();
ids.add(1);
ids.add(2);
ids.add(4);
ids.add(5);
userVo.setIds(ids);
List<User> userList = mapper.selectUserByListId(userVo);
for (User user : userList) {
System.out.println(user);
}
}
运行结果:
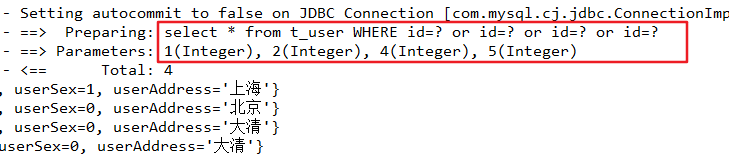
③、foreach 来改写 select * from t_user where id in (1,2,4,5);将上面的映射文件稍加修改:
<select id="selectUserByListId" parameterType="userVo" resultMap="userMap">
select * from t_user
<where>
<foreach collection="ids" item="id" open="id in (" close=")" separator=",">
#{id}
</foreach>
</where>
</select>
运行结果:
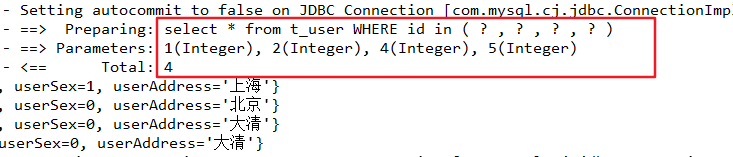
7.8 bind 标签(了解)
bind 标签允许你在 OGNL 表达式以外创建一个变量,并将其绑定到当前的上下文(可定义多个)。示例代码如下:
<!-- 模糊查询,根据username字段查询用户-->
<select id="selectUserByName" parameterType="string" resultMap="userMap">
<bind name="pattern" value="'%'+_parameter+'%'"/>
select * from t_user where username like #{pattern}
</select>
这里的_parameter代表的是传递进来的参数,它和通配符%连接后赋给了pattern,SQL语句等价于:select * from t_user where username like ?。这种方式无论是Mysql还是Oracle都可以使用这样的语句,提高了代码的可移植性。如果传递了多个参数,则可以定义多个bind 标签。
<select id="selectUserByNameAndAddress" parameterType="user" resultMap="userMap">
<bind name="pattern_username" value="'%'+userName+'%'"/>
<bind name="pattern_address" value="'%'+userAddress+'%'"/>
select * from t_user where username like #{pattern_username} and address like #{pattern_address}
</select>
8、高级映射之一对一映射
8.1 前言
在前面SQL映射文件的介绍中,说到resultMap元素中有两个标签是用来做关联查询操作的,也就是一对一,一对多,对应到Mybatis中的标签分别是association和collection标签。它们在实际的项目中,会经常用到关联表的查询,因为实际的项目中不可能是对单表的查询,经常会有一对一,一对多等情况,我们可以使用这两个标签来配合实现。在Java实体对象中,一对一属性使用包装对象来实现,一对多属性使用List或者Set来实现。
association和collection二者标签的内部属性基本是一致的,它们的属性介绍如下(红色标注表示常用):
- property:映射实体类属性名。
- column:映射数据库字段名或者其别名(这个别名是数据库起的,如 select username as name)。
- javaType:映射java类型。
- jdbcType:映射数据库类型。
- ofType:映射集合的类型(注意:javaType是用来指定pojo中属性的类型,而ofType指定的是映射到list集合属性中pojo的类型,也就是尖括号的泛型
private List<User> users)。 - select:用于加载复杂类型属性的映射语句的id (全限定名加方法,方法名后面无括号,例如:com.thr.mapper.UserMapper.selectAllUser),它会从 column 属性指定的列中检索数据,作为参数传递给目标 select 语句。 具体请参考下面的第二个例子。
- fetchType:延迟加载,lazy打开延迟加载,eager积极加载。指定属性后,将在映射中忽略全局配置参数 lazyLoadingEnabled,使用属性的值。
- resultMap:不使用嵌套模式,而是将此关联的嵌套结果集映射到一个外部的
<resultMap>标签中,然后通过 id 进行引入。 - resultSet:指定用于加载复杂类型的结果集名字。
- autoMapping:自动封装,如果数据库字段和javaBean的字段名一样,可以使用这种方式,但是不建议采取,还是老老实实写比较稳妥,如果非要使用此功能,那就在全局配置中加上mapUnderscoreToCamelCase=TRUE,它会使经典数据库字段命名规则翻译成javaBean的经典命名规则,如:a_column翻译成aColumn。
- columnPrefix:关联多张表查询时,为了使列明不重复,使用此功能可以减少开发量。
- foreignColumn:指定外键对应的列名,指定的列将与父类型中 column 的给出的列进行匹配。
- notNullColumn:不为空的列,如果指定了列,那么只有当字段不为空时,Mybatis才会真正创建对象,才能得到我们想要的值。
- typeHandler:数据库与Java类型匹配处理器(可以参考前面的TypeHandler部分)。
如果你想对这些属性有更加深入了解的话可以自行去参考Mybatis的官方文档,链接:https://mybatis.org/mybatis-3/zh/sqlmap-xml.html
8.2 案例分析
我们以典型的 员工(Employee)和部门(Department)为例:
- 一个员工只能在一个部门;Employee—>Department(一对一)
- 一个部门可以包含多个员工;Department—>Employee(一对多)
下面我们分别创建 员工表:t_employee 和 部门表:t_department:
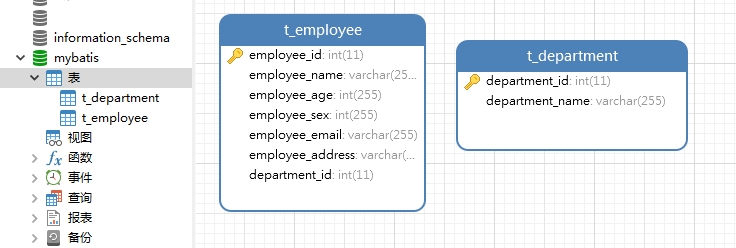
对应mysql的sql脚本如下:
-- ----------------------------
-- Table structure for t_department
-- ----------------------------
DROP TABLE IF EXISTS `t_department`;
CREATE TABLE `t_department` (
`department_id` int(11) NOT NULL AUTO_INCREMENT,
`department_name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`department_id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 8 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of t_department
-- ----------------------------
INSERT INTO `t_department` VALUES (1, '开发部');
INSERT INTO `t_department` VALUES (2, '人力资源部');
INSERT INTO `t_department` VALUES (3, '市场营销部');
INSERT INTO `t_department` VALUES (4, '财务部');
INSERT INTO `t_department` VALUES (5, '行政部');
INSERT INTO `t_department` VALUES (6, '监察部');
INSERT INTO `t_department` VALUES (7, '客服服务部');
-- ----------------------------
-- Table structure for t_employee
-- ----------------------------
DROP TABLE IF EXISTS `t_employee`;
CREATE TABLE `t_employee` (
`employee_id` int(11) NOT NULL AUTO_INCREMENT,
`employee_name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`employee_age` int(255) NULL DEFAULT NULL,
`employee_sex` int(255) NULL DEFAULT NULL,
`employee_email` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`employee_address` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`department_id` int(11) NULL DEFAULT NULL,
PRIMARY KEY (`employee_id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 10 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of t_employee
-- ----------------------------
INSERT INTO `t_employee` VALUES (1, '唐浩荣', 23, 1, '15477259875@163.com', '中国上海浦东区', 1);
INSERT INTO `t_employee` VALUES (2, '黄飞鸿', 32, 1, '86547547@qq.com', '大清广东', 2);
INSERT INTO `t_employee` VALUES (3, '十三姨', 18, 0, '520520520@gmail.com', '大清广东', 3);
INSERT INTO `t_employee` VALUES (4, '纳兰元述', 28, 1, '545627858@qq.com', '大清京师', 5);
INSERT INTO `t_employee` VALUES (5, '梁宽', 31, 1, '8795124578@qq.com', '大清广东', 7);
INSERT INTO `t_employee` VALUES (6, '蔡徐坤', 20, 0, '4257895124@gmail.com', '四川成都', 4);
INSERT INTO `t_employee` VALUES (7, '杨超越', 21, 0, '8746821252@qq.com', '中国北京', 7);
INSERT INTO `t_employee` VALUES (8, '马保国', 66, 1, '6666666666@qq.com', '广东深圳', 6);
INSERT INTO `t_employee` VALUES (9, '马牛逼', 45, 1, 'asdfg45678@163.com', '湖北武汉', 3);
注意:在MyBatis中主要有这两种方式实现关联查询:
- 嵌套结果:使用嵌套映射的方式来处理关联结果的子集。
- 分步查询:通过 select 属性来执行另外一个 SQL 映射语句来返回预期的复杂类型。select属性的规则是全限定名加方法名,例如:com.thr.mapper.UserMapper.selectAllUser,方法名后面无括号。
所以下面我们就通过代码来学习这两种方式实现Mybatis的关联查询。
8.3 嵌套结果
①、分别定义Employee和Department实体类
Employee实体类:
/**
* 员工实体类
*/
public class Employee {
//员工id
private Integer empId;
//员工名称
private String empName;
//员工年龄
private Integer empAge;
//员工性别
private Integer empSex;
//员工邮箱
private String empEmail;
//员工地址
private String empAddress;
//员工所属部门,和部门表构成一对一的关系,一个员工只能在一个部门
private Department department;
//getter、setter、toString方法和一些构造方法省略...
}
Department实体类:
/**
* 部门实体类
*/
public class Department {
//部门id
private Integer deptId;
//部门名称
private String deptName;
//getter、setter、toString方法和一些构造方法省略...
}
②、创建EmployeeMapper接口和EmployeeMapper.xml 文件
EmployeeMapper接口:
/**
* 员工Mapper接口
*/
public interface EmployeeMapper {
//查询所有数据
List<Employee> selectAll();
//根据员工id查询数据
Employee selectEmpByEmpId(@Param("id") Integer empId);
}
EmployeeMapper.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.thr.mapper.EmployeeMapper">
<resultMap id="employeeMap" type="com.thr.pojo.Employee">
<id property="empId" column="employee_id"/>
<result property="empName" column="employee_name"/>
<result property="empAge" column="employee_age"/>
<result property="empSex" column="employee_sex"/>
<result property="empEmail" column="employee_email"/>
<result property="empAddress" column="employee_address"/>
<!-- 一对一关联对象 -->
<association property="department" javaType="department">
<id property="deptId" column="department_id"/>
<result property="deptName" column="department_name"/>
</association>
</resultMap>
<!-- 查询所有数据-->
<select id="selectAll" resultMap="employeeMap">
SELECT * FROM
t_employee e,
t_department d
where
e.department_id=d.department_id
</select>
<!--根据员工id查询数据-->
<select id="selectEmpByEmpId" parameterType="int" resultMap="employeeMap">
SELECT * FROM
t_employee e,
t_department d
where
e.department_id=d.department_id
and e.employee_id= #{id}
</select>
</mapper>
③、创建数据库连接文件和日志文件
db.properties文件:
#数据库连接配置
database.driver=com.mysql.cj.jdbc.Driver
database.url=jdbc:mysql://localhost:3306/mybatis?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf-8
database.username=root
database.password=root
log4j.properties文件:
log4j.rootLogger=DEBUG, Console
#Console
log4j.appender.Console=org.apache.log4j.ConsoleAppender
log4j.appender.Console.layout=org.apache.log4j.PatternLayout
log4j.appender.Console.layout.ConversionPattern=%d [%t] %-5p [%c] - %m%n
log4j.logger.java.sql.ResultSet=INFO
log4j.logger.org.apache=INFO
log4j.logger.java.sql.Connection=DEBUG
log4j.logger.java.sql.Statement=DEBUG
log4j.logger.java.sql.PreparedStatement=DEBUG
④、注册 EmployeeMapper.xml 文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!--引入properties文件-->
<properties resource="db.properties"/>
<!--配置别名-->
<typeAliases>
<!-- 对包进行扫描,可以批量进行别名设置,设置规则是:获取类名称,将其第一个字母变为小写 -->
<package name="com.thr.pojo"/>
</typeAliases>
<!-- 配置环境.-->
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"></transactionManager>
<dataSource type="POOLED">
<property name="driver" value="${database.driver}"/>
<property name="url" value="${database.url}"/>
<property name="username" value="${database.username}"/>
<property name="password" value="${database.password}"/>
</dataSource>
</environment>
</environments>
<!--注册mapper,通过扫描的方式-->
<mappers>
<package name="com.thr.mapper"/>
</mappers>
</configuration>
⑤、编写测试代码
package com.thr.test;
import com.thr.mapper.EmployeeMapper;
import com.thr.pojo.Employee;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.io.InputStream;
import java.util.List;
/**
* 测试代码
*/
public class MybatisTest {
//定义 SqlSession
private SqlSession sqlSession = null;
//定义 EmployeeMapper对象
private EmployeeMapper mapper = null;
@Before//在测试方法执行之前执行
public void getSqlSession(){
//1、加载 mybatis 全局配置文件
InputStream is = MybatisTest.class.getClassLoader().getResourceAsStream("mybatis-config.xml");
//2、创建SqlSessionFactory对象
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(is);
//3、根据 sqlSessionFactory 产生 session
sqlSession = sqlSessionFactory.openSession();
//4、创建Mapper接口的的代理对象,getMapper方法底层会通过动态代理生成UserMapper的代理实现类
mapper = sqlSession.getMapper(EmployeeMapper.class);
}
@After//在测试方法执行完成之后执行
public void destroy() throws IOException {
sqlSession.commit();
sqlSession.close();
}
//查询所有数据
@Test
public void testSelectAll(){
List<Employee> employees = mapper.selectAll();
for (Employee employee : employees) {
System.out.println(employee);
}
}
//根据员工id查询数据
@Test
public void testSelectEmpByEmpId(){
Employee employee = mapper.selectEmpByEmpId(1);
System.out.println(employee);
}
}
⑥、运行结果
项目整体目录:
查询所有数据:

根据员工id查询数据:

8.4 分步查询
分步查询的这种方式是通过association标签中的select属性来完成,它需要执行另外一个 SQL 映射语句来返回预期的复杂类型,并且会从 column 属性指定的列中检索数据,作为参数传递给目标 select 语句。所以我们必须在关联的另一个Mapper接口中创建一个根据 id 查询数据的方法,并且表字段和实体属性如果不同还要进行映射。
①、更改EmployeeMapper.xml 文件,其它之前的文件都不变
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.thr.mapper.EmployeeMapper">
<resultMap id="employeeMap" type="com.thr.pojo.Employee">
<id property="empId" column="employee_id"/>
<result property="empName" column="employee_name"/>
<result property="empAge" column="employee_age"/>
<result property="empSex" column="employee_sex"/>
<result property="empEmail" column="employee_email"/>
<result property="empAddress" column="employee_address"/>
<!-- 一对一关联对象,注意:select方式需要加column属性,column属性会从当前查询出的指定列检索数据,
这里为t_employee表中的department_id,然后作为参数传递给目标的select语句-->
<association property="department" javaType="department" column="department_id"
select="com.thr.mapper.DepartmentMapper.selectDeptByDeptId"/>
</resultMap>
<!-- 查询所有数据-->
<select id="selectAll" resultMap="employeeMap">
SELECT * FROM t_employee
</select>
<!--根据员工id查询数据-->
<select id="selectEmpByEmpId" parameterType="int" resultMap="employeeMap">
SELECT * FROM t_employee where employee_id= #{id}
</select>
</mapper>
②、创建DepartmentMapper和DepartmentMapper.xml文件
DepartmentMapper接口:
/**
* 部门Mapper接口
*/
public interface DepartmentMapper {
//根据部门id查询数据
Department selectDeptByDeptId(@Param("id") Integer deptId);
}
DepartmentMapper.xml文件:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.thr.mapper.DepartmentMapper">
<resultMap id="departmentMap" type="com.thr.pojo.Department">
<id property="deptId" column="department_id"/>
<result property="deptName" column="department_name"/>
</resultMap>
<!--根据部门id查询-->
<select id="selectDeptByDeptId" parameterType="int" resultMap="departmentMap">
select * from t_department where department_id = #{id}
</select>
</mapper>
③、运行结果
查询所有数据:

根据员工id查询数据:

可以发现使用这种方式明显多执行了很多SQL语句,所以肯定会导致查询的效率变低,但是这种方式也有好处,那就是可以延迟加载。
9、高级映射之一对多映射
9.1 案例分析
继续接着上一章来,案例:一个部门可以包含多个员工;Department—>Employee(一对多)。一对多映射用到的resultMap标签中的collection子标签。它的属性和association标签基本一致,可以参考上一章的内容:链接 。下面我们就通过代码来实现一对多映射。
9.2 嵌套结果
①、分别定义Employee和Department实体类
Employee实体类:(不变,和上一章一样)
Department实体类(加入属性List<Employee> employees用于映射多个员工):
/**
* 部门实体类
*/
public class Department {
//部门id
private Integer deptId;
//部门名称
private String deptName;
//部门有哪些员工
private List<Employee> employees;
//getter、setter、toString方法和一些构造方法省略...
}
②、创建DepartmentMapper接口和DepartmentMapper.xml 文件
DepartmentMapper接口:
/**
* 部门Mapper接口
*/
public interface DepartmentMapper {
//查询所有数据
List<Department> selectAll();
//根据部门id查询数据,这个方法是上一章创建了的
Department selectDeptByDeptId(@Param("id") Integer deptId);
}
DepartmentMapper.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.thr.mapper.DepartmentMapper">
<resultMap id="departmentMap" type="com.thr.pojo.Department">
<id property="deptId" column="department_id"/>
<result property="deptName" column="department_name"/>
<!--一对多关联对象,ofType指定的是映射到list集合属性中pojo的类型,也就是尖括号的泛型-->
<collection property="employees" ofType="employee">
<id property="empId" column="employee_id"/>
<result property="empName" column="employee_name"/>
<result property="empAge" column="employee_age"/>
<result property="empSex" column="employee_sex"/>
<result property="empEmail" column="employee_email"/>
<result property="empAddress" column="employee_address"/>
</collection>
</resultMap>
<!-- 查询所有数据-->
<select id="selectAll" resultMap="departmentMap">
SELECT * FROM
t_employee e,
t_department d
WHERE
e.department_id=d.department_id
</select>
<!--根据部门id查询数据-->
<select id="selectDeptByDeptId" parameterType="int" resultMap="departmentMap">
SELECT * FROM
t_employee e,
t_department d
WHERE
e.department_id=d.department_id
and d.department_id = #{id}
</select>
</mapper>
③、创建数据库连接文件和日志文件(参考上一章)
④、注册 EmployeeMapper.xml 文件(参考上一章)
⑤、编写测试代码(稍微有一点点改动)
/**
* 测试代码
*/
public class MybatisTest {
//定义 SqlSession
private SqlSession sqlSession = null;
//定义 DepartmentMapper对象
private DepartmentMapper mapper = null;
@Before//在测试方法执行之前执行
public void getSqlSession(){
//1、加载 mybatis 全局配置文件
InputStream is = MybatisTest.class.getClassLoader().getResourceAsStream("mybatis-config.xml");
//2、创建SqlSessionFactory对象
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(is);
//3、根据 sqlSessionFactory 产生 session
sqlSession = sqlSessionFactory.openSession();
//4、创建Mapper接口的的代理对象,getMapper方法底层会通过动态代理生成DepartmentMapper的代理实现类
mapper = sqlSession.getMapper(DepartmentMapper.class);
}
@After//在测试方法执行完成之后执行
public void destroy() throws IOException {
sqlSession.commit();
sqlSession.close();
}
//查询所有数据
@Test
public void testSelectAll(){
List<Department> departments = mapper.selectAll();
for (Department department : departments) {
System.out.println(department);
}
}
//根据部门id查询数据
@Test
public void testSelectEmpByEmpId(){
Department department = mapper.selectDeptByDeptId(3);
System.out.println(department);
}
}
⑥、运行结果
查询所有数据:

通过运行结果可以发现,编号为3和7 部门下分别有多名员工。
根据部门id查询数据:

9.3 分步查询
使用分步查询的好处就是可以设置延迟加载,延迟加载后面会有介绍。
①、更改DepartmentMapper.xml 文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.thr.mapper.DepartmentMapper">
<resultMap id="departmentMap" type="com.thr.pojo.Department">
<id property="deptId" column="department_id"/>
<result property="deptName" column="department_name"/>
<!--一对多关联对象,ofType指定的是映射到list集合属性中pojo的类型,也就是尖括号的泛型
注意:这里的column属性首先是查询出t_department表的department_id,然后将它以参数的形式传递给select属性
中的EmployeeMapper.selectEmpByDeptId方法,进而查询出当前部门下的员工-->
<collection property="employees" ofType="employee" column="department_id"
select="com.thr.mapper.EmployeeMapper.selectEmpByDeptId">
</collection>
</resultMap>
<!-- 查询所有数据-->
<select id="selectAll" resultMap="departmentMap">
SELECT * FROM t_department
</select>
<!--根据部门id查询数据-->
<select id="selectDeptByDeptId" parameterType="int" resultMap="departmentMap">
SELECT * FROM t_department WHERE department_id = #{id}
</select>
</mapper>
特别注意:由于column属性是根据当前t_department表查询出的department_id作为参数,然后通过select属性传递给关联对象的方法,所以我们在查询员工表时,应该根据t_employee表中的字段department_id来查询,而不再是根据employee_id来查询,这一点一定要理解清楚,否则这里无法进行下去。所以我们需要在EmployeeMapper接口中创建一个根据部门id查询员工信息的方法。
②、分别在EmployeeMapper接口和EmployeeMapper.xml文件中添加如下代码:
EmployeeMapper接口:
/**
* 员工Mapper接口
*/
public interface EmployeeMapper {
//查询所有数据
List<Employee> selectAll();
//根据员工id查询数据
Employee selectEmpByEmpId(@Param("id") Integer empId);
//据据员工表的department_id查询员工数据,用于一对多的关联查询
Employee selectEmpByDeptId(@Param("id") Integer deptId);
}
EmployeeMapper.xml文件:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.thr.mapper.EmployeeMapper">
<resultMap id="employeeMap" type="com.thr.pojo.Employee">
<id property="empId" column="employee_id"/>
<result property="empName" column="employee_name"/>
<result property="empAge" column="employee_age"/>
<result property="empSex" column="employee_sex"/>
<result property="empEmail" column="employee_email"/>
<result property="empAddress" column="employee_address"/>
<!-- 一对一关联对象-->
<!--<association property="department" column="department_id" javaType="department"
select="com.thr.mapper.DepartmentMapper.selectDeptByDeptId"/>-->
</resultMap>
<!-- 查询所有数据-->
<select id="selectAll" resultMap="employeeMap">
SELECT * FROM t_employee
</select>
<!--根据员工id查询数据-->
<select id="selectEmpByEmpId" parameterType="int" resultMap="employeeMap">
SELECT * FROM t_employee where department_id= #{id}
</select>
<!--根据员工表的department_id查询员工数据,用于一对多的关联查询-->
<select id="selectEmpByDeptId" parameterType="int" resultMap="employeeMap">
SELECT * FROM t_employee where department_id= #{id}
</select>
</mapper>
这里需要注意的是:要注释掉一方中的关联映射,否则就会导致无限循环映射而导致报错。
③、测试代码
/**
* 测试代码
*/
public class MybatisTest {
//定义 SqlSession
private SqlSession sqlSession = null;
//定义 DepartmentMapper对象
private DepartmentMapper mapper = null;
@Before//在测试方法执行之前执行
public void getSqlSession(){
//1、加载 mybatis 全局配置文件
InputStream is = MybatisTest.class.getClassLoader().getResourceAsStream("mybatis-config.xml");
//2、创建SqlSessionFactory对象
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(is);
//3、根据 sqlSessionFactory 产生 session
sqlSession = sqlSessionFactory.openSession();
//4、创建Mapper接口的的代理对象,getMapper方法底层会通过动态代理生成UserMapper的代理实现类
mapper = sqlSession.getMapper(DepartmentMapper.class);
}
@After//在测试方法执行完成之后执行
public void destroy() throws IOException {
sqlSession.commit();
sqlSession.close();
}
//查询所有数据
@Test
public void testSelectAll(){
List<Department> departments = mapper.selectAll();
for (Department department : departments) {
System.out.println(department);
}
}
//根据部门id查询数据
@Test
public void testSelectDeptByDeptId(){
Department department = mapper.selectDeptByDeptId(3);
System.out.println(department);
}
}
④、运行结果
查询所有数据:
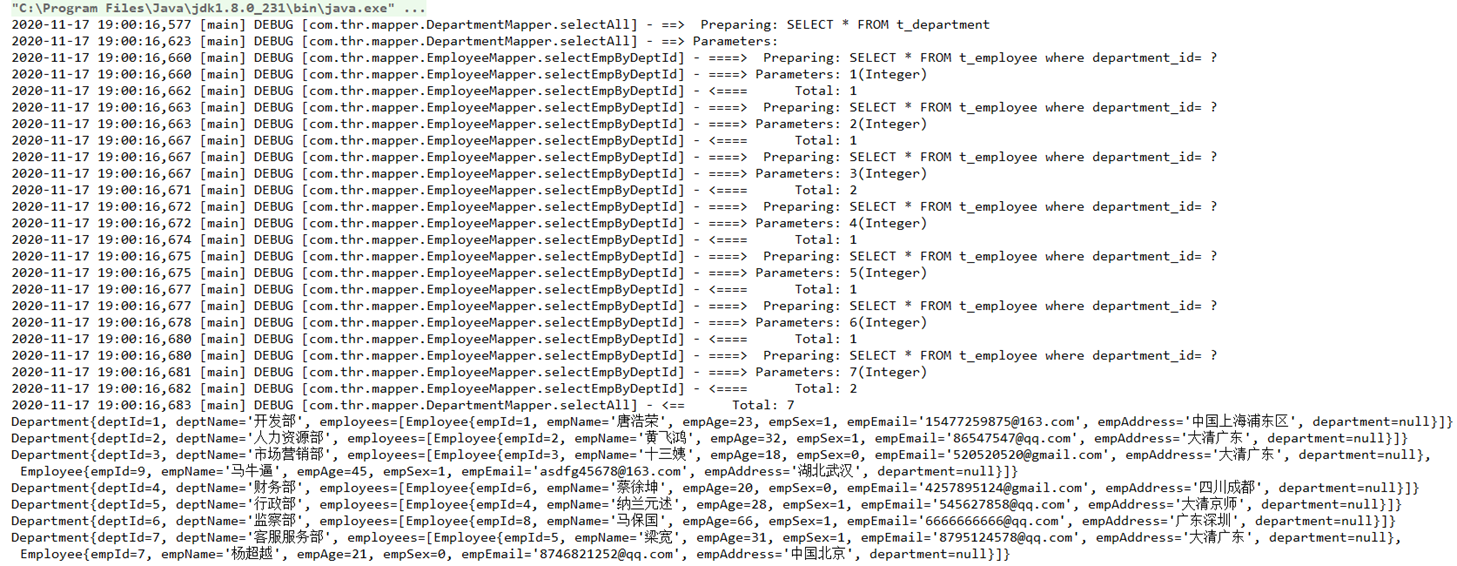
根据部门id查询数据:

10、高级映射之多对多映射
10.1 案例分析
多对多映射其实就是一个双向的一对多映射,因为两边都是一对多。多对多主要是关联关系要找好,然后根据关联去查询。
由于前面的案例员工和部门一方是一对一,一方是一对多,所以不能形成多对多的条件,我重新换了一个案例——用户和角色。
- 一个用户可以拥有多个角色,User—>Role(一对多)。
- 一个角色可以赋予多个用户,Role—>User(一对多)。
这样就是形成了一个双向的一对多,从而变成了多对多,其实前面掌握了一对多就已经完全足够了,我为了再巩固一下所以继续写了个多对多的例子。数据库表如下:

对应mysql的sql脚本如下:
-- ----------------------------
-- Table structure for t_role
-- ----------------------------
DROP TABLE IF EXISTS `t_role`;
CREATE TABLE `t_role` (
`roleId` int(11) NOT NULL AUTO_INCREMENT,
`roleName` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`remake` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`roleId`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 7 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of t_role
-- ----------------------------
INSERT INTO `t_role` VALUES (1, '管理员', '权限最大');
INSERT INTO `t_role` VALUES (2, '总经理', '公司老大');
INSERT INTO `t_role` VALUES (3, '项目经理', '项目好好搞,你们需求最多,工资最少!好好干哦');
INSERT INTO `t_role` VALUES (4, '销售经理', '销量就靠你们了,销量高,老板才能开上法拉利!');
INSERT INTO `t_role` VALUES (5, '仓库管理员', '仓库就归你管了,货不能出错!');
INSERT INTO `t_role` VALUES (6, '普通员工', '打工人,打工魂,打工都是人上人,加油!');
-- ----------------------------
-- Table structure for t_user
-- ----------------------------
DROP TABLE IF EXISTS `t_user`;
CREATE TABLE `t_user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`age` int(11) NULL DEFAULT NULL,
`birthday` date NULL DEFAULT NULL,
`sex` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`address` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 8 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of t_user
-- ----------------------------
INSERT INTO `t_user` VALUES (1, '唐浩荣', 18, '2020-11-10', '1', '上海');
INSERT INTO `t_user` VALUES (2, '蔡徐坤', 18, '2018-01-18', '0', '北京');
INSERT INTO `t_user` VALUES (3, '黄飞鸿', 42, '2020-11-12', '1', '大清');
INSERT INTO `t_user` VALUES (4, '十三姨', 18, '2020-11-10', '0', '大清');
INSERT INTO `t_user` VALUES (5, '梁宽', 42, '2020-11-10', '0', '大清');
INSERT INTO `t_user` VALUES (6, '马保国', 33, '2020-11-14', '1', '深圳');
INSERT INTO `t_user` VALUES (7, '纳兰元述', 42, '2020-11-12', '1', '大清');
-- ----------------------------
-- Table structure for t_user_role
-- ----------------------------
DROP TABLE IF EXISTS `t_user_role`;
CREATE TABLE `t_user_role` (
`ur_id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` int(11) NULL DEFAULT NULL,
`role_id` int(11) NULL DEFAULT NULL,
PRIMARY KEY (`ur_id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 10 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of t_user_role
-- ----------------------------
INSERT INTO `t_user_role` VALUES (1, 1, 2);
INSERT INTO `t_user_role` VALUES (2, 2, 4);
INSERT INTO `t_user_role` VALUES (3, 5, 1);
INSERT INTO `t_user_role` VALUES (4, 3, 3);
INSERT INTO `t_user_role` VALUES (5, 4, 6);
INSERT INTO `t_user_role` VALUES (6, 6, 6);
INSERT INTO `t_user_role` VALUES (7, 7, 4);
INSERT INTO `t_user_role` VALUES (8, 2, 5);
创建步骤分析:
- User表和Role表具有多对多关系,需要使用中间表(t_user_role)关联,中间表中包含各自的主键,在中间表中是外键;
- 建立两个实体类:用户实体类中包含对角色的集合引用,角色实体类中包含对用户的集合引用;
- 建立两个Mapper接口:用户的Mapper接口和角色的Mapper接口;
- 建立两个配置文件:用户的配置文件和角色的配置文件;
- 实现功能: 查询用户时,同时得到用户所包含的角色信息; 查询角色时,同时得到角色对应的用户信息;
- 编写测试代码并查看运行结果,能否查询出相应的数据;
10.2 用户到角色的多对多查询
①、查询所有数据的sql语句
SELECT * FROM t_user u,t_user_role ur,t_role r
WHERE u.id = ur.user_id AND ur.role_id = r.roleId ORDER BY id
运行结果如下:

②、编写User实体类和UserMapper接口
User实体类:
/**
* 用户实体类
*/
public class User {
private int userId;
private String userName;
private int userAge;
private Date userBirthday;
private int userSex;
private String userAddress;
//用户拥有的角色
private List<Role> roles;
//getter、setter、toString方法省略......
}
UserMapper接口:
/**
* UserMapperJ接口
*/
public interface UserMapper {
//查询所有用户信息
List<User> selectAllUser();
//根据用户id查询用户信息
User selectUserByUserId(@Param("id") Integer userId);
}
③、配置映射文件UserMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.thr.mapper.UserMapper">
<resultMap id="userMap" type="com.thr.pojo.User">
<id property="userId" column="id"/>
<result property="userName" column="username"/>
<result property="userAge" column="age"/>
<result property="userBirthday" column="birthday"/>
<result property="userSex" column="sex"/>
<result property="userAddress" column="address"/>
<!--一对多映射-->
<collection property="roles" ofType="role">
<id property="roleId" column="roleId"/>
<result property="roleName" column="roleName"/>
<result property="remake" column="remake"/>
</collection>
</resultMap>
<!-- 查询所有用户-->
<select id="selectAllUser" resultMap="userMap">
SELECT * FROM
t_user u,
t_user_role ur,
t_role r
WHERE
u.id = ur.user_id
AND
ur.role_id = r.roleId
ORDER BY id
</select>
<!--根据用户id查询用户信息-->
<select id="selectUserByUserId" resultMap="userMap">
SELECT * FROM
t_user u,
t_user_role ur,
t_role r
WHERE
u.id = ur.user_id
AND
ur.role_id = r.roleId
AND
u.id = #{id}
</select>
</mapper>
④、编写测试类
//查询所有用户信息
@Test
public void testSelectAllUser(){
List<User> userList = mapper.selectAllUser();
for (User user : userList) {
System.out.println(user);
}
}
//根据用户id查询用户信息
@Test
public void testSelectUserByUserId(){
User user = mapper.selectUserByUserId(2);
System.out.println(user);
}
⑤、运行结果
查询所有用户信息:

根据用户id查询用户信息:

10.3 角色到用户的多对多查询
①、查询所有数据的sql语句
SELECT * FROM t_user u,t_user_role ur,t_role r
WHERE u.id = ur.user_id AND ur.role_id = r.roleId ORDER BY roleID
运行结果如下:

②、编写Role实体类和RoleMapper接口
Role实体类:
/**
* 角色实体类
*/
public class Role {
private int roleId;
private String roleName;
private String remake;//备注
//该角色包含的用户
private List<User> users;
//getter、setter、toString方法省略......
}
RoleMapper接口:
/**
* 角色Mapper接口
*/
public interface RoleMapper {
//查询所有角色信息
List<Role> selectAllRole();
//根据角色id查询角色信息
Role selectRoleByRoleId(@Param("id") Integer roleId);
}
③、配置映射文件RoleMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.thr.mapper.RoleMapper">
<resultMap id="roleMap" type="com.thr.pojo.Role">
<id property="roleId" column="roleId"/>
<result property="roleName" column="roleName"/>
<result property="remake" column="remake"/>
<collection property="users" ofType="user">
<id property="userId" column="id"/>
<result property="userName" column="username"/>
<result property="userAge" column="age"/>
<result property="userBirthday" column="birthday"/>
<result property="userSex" column="sex"/>
<result property="userAddress" column="address"/>
</collection>
</resultMap>
<!-- 查询所有角色-->
<select id="selectAllRole" resultMap="roleMap">
SELECT * FROM
t_user u,
t_user_role ur,
t_role r
WHERE
u.id = ur.user_id
AND
ur.role_id = r.roleId
ORDER BY roleId
</select>
<!-- 根据角色id查询角色信息-->
<select id="selectRoleByRoleId" resultMap="roleMap">
SELECT * FROM
t_user u,
t_user_role ur,
t_role r
WHERE
u.id = ur.user_id
AND
ur.role_id = r.roleId
AND
r.roleId = #{id}
</select>
</mapper>
④、编写测试类
//查询所有角色信息
@Test
public void testSelectAllRole(){
List<Role> roleList = mapper.selectAllRole();
for (Role role : roleList) {
System.out.println(role);
}
}
//根据角色id查询角色信息
@Test
public void testSelectRoleByRoleId(){
Role role = mapper.selectRoleByRoleId(1);
System.out.println(role);
}
⑤、运行结果
查询所有角色信息:

根据用户id查询角色信息:

这一节的代码我给它放到了云盘上,有需要参考可以下载:链接:https://pan.baidu.com/s/1mCI74OpdqMlnIxcuiNp7TA ;提取码:s03n
11、延迟加载
11.1 N+1问题
N+1问题主要是针对分步查询,分步查询就是使用association或collection标签中的select属性来执行另外一个 SQL 映射语句来返回预期的复杂类型,例如:
<association property="department" javaType="department" column="department_id" select="com.thr.mapper.DepartmentMapper.selectDeptByDeptId"/>
在前面的代码中(分步查询),我们所有的级联都已经成功了,但是这样会引发性能问题,就是我们查询数据时,级联的数据也会跟着全部查询出来。但是如果我们暂时只需要部门的信息,而不需要级联对象中的信息,这就会使数据库多执行几条毫无意义的SQL,导致数据库资源的损耗和系统性能的下降。而如果有多重级联的话则会更加明显,假如现在有N个级联,本来我们只要查询主数据,只要一次查询就可以了,但是由于级联的关系,其级联的数据也会跟着查询出来,后面的SQL语句还会执行N次,这样就造成了N+1问题。
以前面员工和部门的例子举例:我们本来要的是部门数据,根据部门id查询部门信息,但是由于一个部门可以有多个员工,级联数据会跟着查询出来,假如现在有N个员工,那么查询的语句如下:
根据部门id查询
SELECT * FROM t_department WHERE department_id = #{id}
级联的查询(分步查询):
SELECT * FROM t_employee where department_id= 1
SELECT * FROM t_employee where department_id= 2
SELECT * FROM t_employee where department_id= 3
......
SELECT * FROM t_employee where department_id= n-1
SELECT * FROM t_employee where department_id= n
本来我们只需要部门的一条数据即可,但是查询了N+1次,这是不合理的。那么为了应对N+1问题,Mybatis提供了延迟加载功能
11.2 什么是延迟加载
延迟加载也叫做懒加载、惰性加载。就是我们希望一次性把常用的级联数据通过SQL直接查询出来,对于那些不想要的级联数据则不要取出,而是等待要用的时候才取出来。在mybatis中,resultMap可以实现高级映射(使用association、collection实现一对一及一对多映射),association、collection具备延迟加载功能。
11.3 如何开启延迟加载
开启延迟加载有两种方式:
①、全局配置延迟加载:这种方式就是给所有的级联配置延迟加载。Mybatis默认是不开启延迟加载的,需要我们去全局配置文件中打开延迟加载。

注意:这个aggressiveLazyLoading有点不好理解,下面会有介绍。
全局配置如下:
<settings>
<!-- 开启延迟加载,不配置默认关闭该特性-->
<setting name="lazyLoadingEnabled" value="true"></setting>
<setting name="aggressiveLazyLoading" value="false"/>
</settings>
②、fetchType属性为局部配置延迟加载:这种方式需要用到fetchType属性,主要解决全局配置的缺点,因为不是所有的地方都要使用到延迟加载,fetchType出现在级联元素association和collection中,它存在两个值:
- eager:立即加载对应的数据。
- lazy:延迟加载对应的数据。
11.4 全局配置实现延迟加载
以前面部门Department和员工Employee为例,一个部门可以包含多名员工的一对多关系。
①、创建员工和部门实体类:
员工实体类:
/**
* 员工实体类
*/
public class Employee {
//员工id
private Integer empId;
//员工名称
private String empName;
//员工年龄
private Integer empAge;
//员工性别
private Integer empSex;
//员工邮箱
private String empEmail;
//员工地址
private String empAddress;
//员工所属部门,和部门表构成一对一的关系,一个员工只能在一个部门
private Department department;
//getter、setter、toString方法和一些构造方法省略...
}
部门实体类:
/**
* 部门实体类
*/
public class Department {
//部门id
private Integer deptId;
//部门名称
private String deptName;
//部门有哪些员工,一对多关系
private List<Employee> employees;
//getter、setter、toString方法和一些构造方法省略...
}
②、创建员工和部门Mapper接口
EmployeeMapper:
/**
* 员工Mapper接口
*/
public interface EmployeeMapper {
//据据员工表的department_id查询员工数据,用于一对多的关联查询
Employee selectEmpByDeptId(@Param("id") Integer deptId);
}
DepartmentMapper:
/**
* 部门Mapper接口
*/
public interface DepartmentMapper {
//查询所有数据
List<Department> selectAll();
//根据部门id查询数据
Department selectDeptByDeptId(@Param("id") Integer deptId);
}
③、创建员工和部门SQL映射文件
EmployeeMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.thr.mapper.EmployeeMapper">
<resultMap id="employeeMap" type="com.thr.pojo.Employee">
<id property="empId" column="employee_id"/>
<result property="empName" column="employee_name"/>
<result property="empAge" column="employee_age"/>
<result property="empSex" column="employee_sex"/>
<result property="empEmail" column="employee_email"/>
<result property="empAddress" column="employee_address"/>
<!-- 一对一关联对象-->
<!--<association property="department" javaType="department" column="department_id"
select="com.thr.mapper.DepartmentMapper.selectDeptByDeptId"/>-->
</resultMap>
<!--根据员工表的department_id查询员工数据,用于一对多的关联查询-->
<select id="selectEmpByDeptId" parameterType="int" resultMap="employeeMap">
SELECT * FROM t_employee where department_id= #{id}
</select>
</mapper>
DepartmentMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.thr.mapper.DepartmentMapper">
<resultMap id="departmentMap" type="com.thr.pojo.Department">
<id property="deptId" column="department_id"/>
<result property="deptName" column="department_name"/>
<!--一对多关联对象,ofType指定的是映射到list集合属性中pojo的类型,也就是尖括号的泛型
注意:这里的column属性首先是查询出t_department表的department_id,然后将它以参数的形式传递给select属性
中的EmployeeMapper.selectEmpByDeptId方法,进而查询出当前部门下的员工-->
<collection property="employees" ofType="employee" column="department_id"
select="com.thr.mapper.EmployeeMapper.selectEmpByDeptId">
</collection>
</resultMap>
<!-- 查询所有数据-->
<select id="selectAll" resultMap="departmentMap">
SELECT * FROM t_department
</select>
<!--根据部门id查询数据-->
<select id="selectDeptByDeptId" parameterType="int" resultMap="departmentMap">
SELECT * FROM t_department WHERE department_id = #{id}
</select>
</mapper>
④、在Mybatis的配置文件中开启全局延迟加载
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!--引入properties文件-->
<properties resource="db.properties"/>
<!-- 全局配置参数,需要时再设置 -->
<settings>
<!-- 打开延迟加载的开关 -->
<setting name="lazyLoadingEnabled" value="true"/>
<setting name="aggressiveLazyLoading" value="false"/>
</settings>
<!--配置别名-->
<typeAliases>
<!-- 对包进行扫描,可以批量进行别名设置,设置规则是:获取类名称,将其第一个字母变为小写 -->
<package name="com.thr.pojo"/>
</typeAliases>
<!-- 配置环境-->
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"></transactionManager>
<dataSource type="POOLED">
<property name="driver" value="${database.driver}"/>
<property name="url" value="${database.url}"/>
<property name="username" value="${database.username}"/>
<property name="password" value="${database.password}"/>
</dataSource>
</environment>
</environments>
<!--注册mapper,通过扫描的方式-->
<mappers>
<package name="com.thr.mapper"/>
</mappers>
</configuration>
⑤、数据库连接和日志文件
db.properties:
#数据库连接配置
database.driver=com.mysql.cj.jdbc.Driver
database.url=jdbc:mysql://localhost:3306/mybatis?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf-8
database.username=root
database.password=root
log4j.properties:
log4j.rootLogger=DEBUG, Console
#Console
log4j.appender.Console=org.apache.log4j.ConsoleAppender
log4j.appender.Console.layout=org.apache.log4j.PatternLayout
log4j.appender.Console.layout.ConversionPattern=%d [%t] %-5p [%c] - %m%n
log4j.logger.java.sql.ResultSet=INFO
log4j.logger.org.apache=INFO
log4j.logger.java.sql.Connection=DEBUG
log4j.logger.java.sql.Statement=DEBUG
log4j.logger.java.sql.PreparedStatement=DEBUG
⑥、测试代码
/**
* 测试代码
*/
public class MybatisTest {
//定义 SqlSession
private SqlSession sqlSession = null;
//定义 DepartmentMapper对象
private DepartmentMapper mapper = null;
@Before//在测试方法执行之前执行
public void getSqlSession(){
//1、加载 mybatis 全局配置文件
InputStream is = MybatisTest.class.getClassLoader().getResourceAsStream("mybatis-config.xml");
//2、创建SqlSessionFactory对象
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(is);
//3、根据 sqlSessionFactory 产生 session
sqlSession = sqlSessionFactory.openSession();
//4、创建Mapper接口的的代理对象,getMapper方法底层会通过动态代理生成UserMapper的代理实现类
mapper = sqlSession.getMapper(DepartmentMapper.class);
}
@After//在测试方法执行完成之后执行
public void destroy() throws IOException {
sqlSession.commit();
sqlSession.close();
}
//查询所有数据
@Test
public void testSelectAll(){
List<Department> departments = mapper.selectAll();
for (Department department : departments) {
System.out.println(department.getDeptId()+"--"+department.getDeptName());
System.out.println("========");
//执行getEmployees()去查询员工信息,这里实现按需加载
//System.out.println(department.getEmployees());
}
}
//根据部门id查询数据
@Test
public void testSelectDeptByDeptId(){
Department department = mapper.selectDeptByDeptId(3);
System.out.println(department.getDeptId()+"--"+department.getDeptName());
System.out.println("========");
//执行getEmployees()去查询员工信息,这里实现按需加载
//System.out.println(department.getEmployees());
}
}
⑦、测试结果
(1)、只使用部门数据,这时候不需要查询员工信息


可以发现只查询了部门的信息。
(2)、需要使用员工数据,这时候因为需要获取员工数据所以要查询员工信息。


我们发现部门和员工数据都查询了,先是查询了部门的信息,然后我们又要获取员工的信息,所有后面再去查询员工的信息。
而我们在关闭延迟加载的查询时这样的,它直接给我们的数据全部都查询出来了,而不是等到我想要的时候才去查询。

11.5 fecthLazy实现局部延迟加载
fecthLazy实现局部延迟加载的方式配置非常简单,如下:
①、我们把Mybatis的全局配置文件中的开启延迟加载的配置删除或者注释
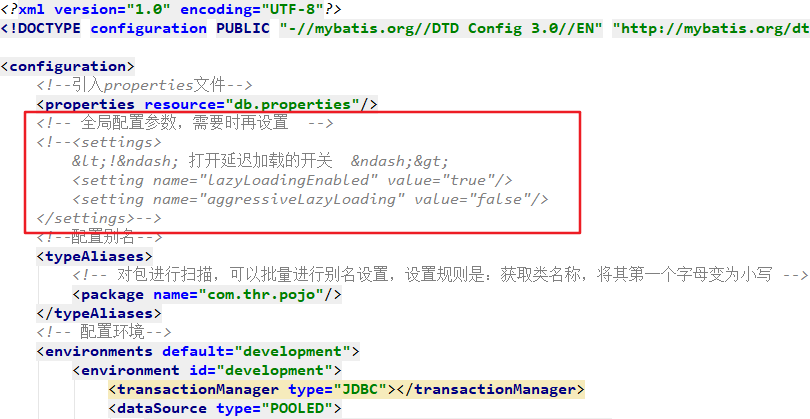
②、然后将我们需要设置为延迟加载的地方设置fecthLazy=lazy即可
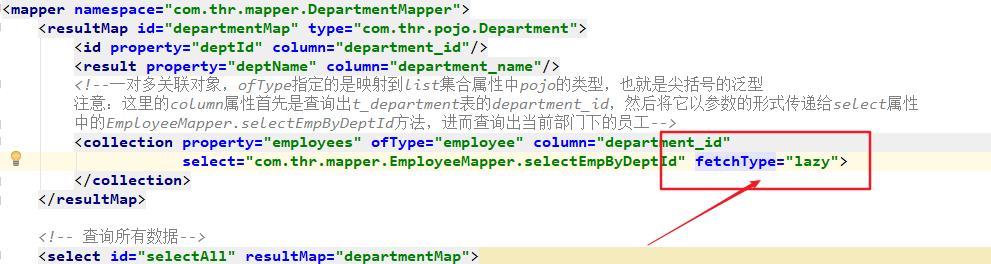
③、执行的结果和前面的测试结果是一样的,所以我们一般推荐使用这种方式,这种方式的好处就是我哪里想要延迟加载就设置哪里即可。
11.6 lazyLoadingEnabled和aggressiveLazyLoading的使用
-
lazyLoadingEnabled:主要控制延迟加载的开关。为true时表示开启延迟加载,false关闭。
-
aggressiveLazyLoading:true表示如果有延迟加载属性的对象在被调用时将会加载该对象的所有属性,false则表示每个属性会按需加载。
我们主要来学习一下aggressiveLazyLoading属性
(1)、aggressiveLazyLoading的属性为false,即每种属性按需加载,不调用就不加载。
运行测试方法:

运行结果:
可以看到只执行department的sql语句,并且只加载了调用的属性。
(2)、aggressiveLazyLoading设置为true:只要对这个类的任意操作将完整加载整个类的所有属性,即执行级联的SQL语句。运行同样的测试方法:
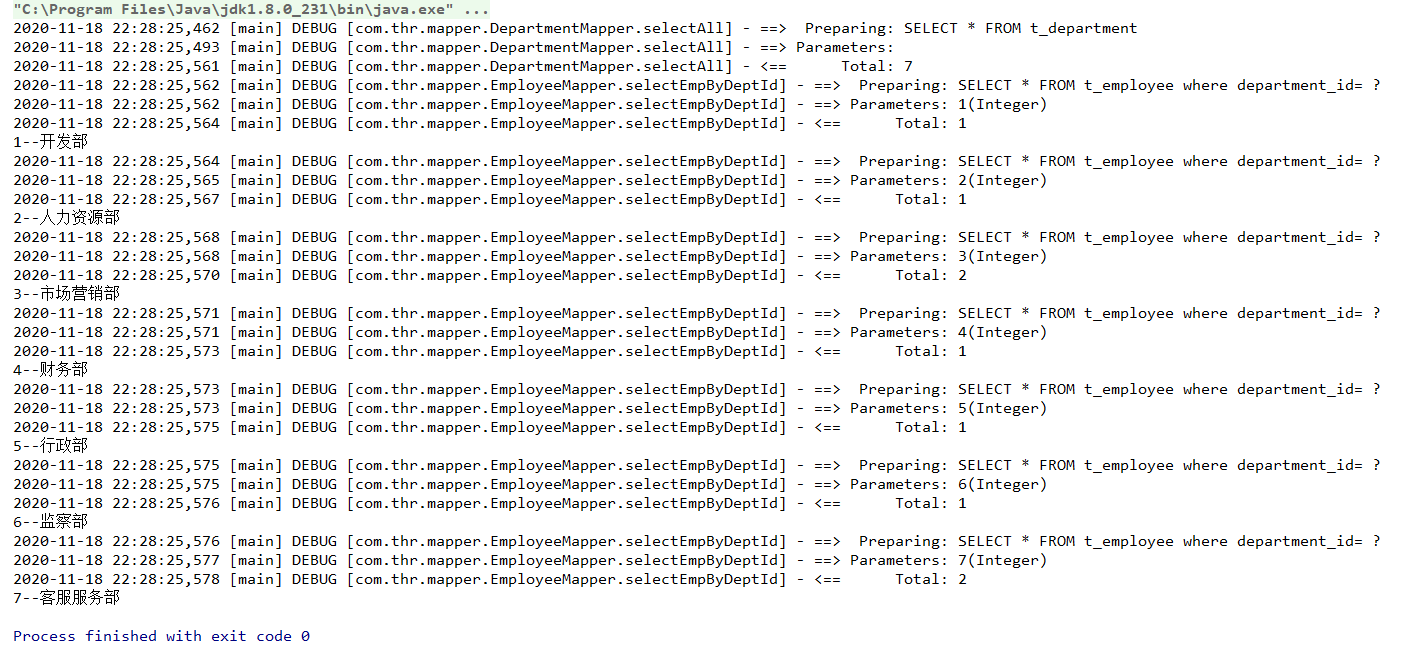
我们只调用了department对象中的getXxx方法,而并没有调用employee对象中的getXxx方法,但是mybatis却调用了查询员工SQL语句。
这下对这个属性有所了解了吧,如果没有看懂的可以去参考:https://blog.csdn.net/qq_42650817/article/details/103262158
12、Mybatis缓存
12.1 什么是Mybatis缓存
缓存就是将数据暂时存储在内存或硬盘中,当在查询数据时,如果缓存中有相同的数据就直接从缓存读取而不从数据库读取,从而减少Java应用与数据库的交互次数,这样就提升了程序的执行效率。比如查询 id = 1 的对象,第一次查询出对象之后会自动将该对象报存到缓存中,当下一次查询时,直接从缓存中去查找对象即可,无需再次访问数据库。
什么地方适用缓存:
- 适用缓存:经常查询并且不经常改变的数据,数据的正确与否对最终结果影响不大。
- 不适用缓存:经常改变的数据,数据的正确性与否对最终结果影响很大,比如:商品的库存,银行的存款,股市的牌价等等。
Mybatis提供了两种缓存,它们分别为:一级缓存和二级缓存。
- 一级缓存:指的是SqlSession对象级别的缓存。当我们执行查询后,查询的结果会同时存入到SqlSession为我们提供的一块区域中,该区域的结构是一个HashMap,不同的SqlSession的缓存区域是互相不受影响的。当我们再次查询同样的数据,Mybatis会先去SqlSession的缓存区域中查询是否有,有的话直接拿出来用,没有则去数据库查询。当SqlSession对象消失后(被flush或close),Mybatis的一级缓存也就消失了。(一级缓存默认是启动的,而且是一直存在的)
- 二级缓存:指的是Mapper对象(Namspace)级别的缓存(也可以说是SqlSessionFactory对象级别的缓存,由同一个SqlSessionFactory对象创建的SqlSession共享其缓存)。多个SqlSession去操作同一个Mapper的sql语句,多个SqlSession可以共用二级缓存,二级缓存是跨SqlSession的。(二级缓存Mybatis默认是关闭的,需要自己去手动配置开启或可以自己选择用哪个厂家的缓存来作为二级缓存)
一级缓存和二级缓存的区别:
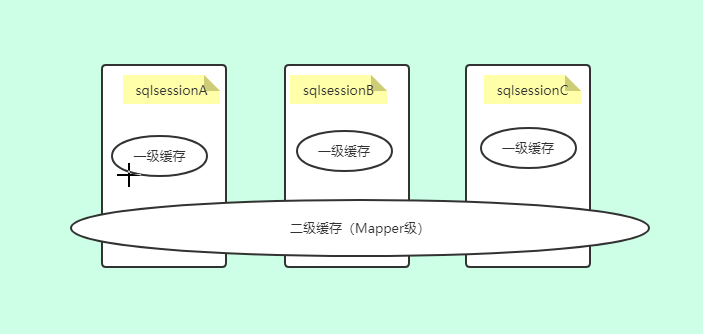
- 相同点:它们都是基于PerpetualCache 的 HashMap本地缓存,
- 不同点:一级缓存作用域为SqlSession,而二级缓存作用域为 Mapper(Namespace),并且可自定义存储源,如 Ehcache,Redis,Memcache等。
12.2 一级缓存
一级缓存是SqlSession对象级别的缓存,Mybatis会在SqlSession内部维护一个HashMap用于存储,缓存Key为hashcode+sqlid+sql,value则为查询的结果集,当执行查询时会先从缓存区域查找,如果存在则直接返回数据,否则从数据库查询,并将结果集写入缓存区。
一级缓存示例(以User举例):
①、创建User实体类:
/**
* 用户实体类
*/
public class User {
private int userId;
private String userName;
private int userAge;
private Date userBirthday;
private int userSex;
private String userAddress;
//getter、setter、toString方法省略......
}
②、编写UserMapper接口
/**
* UserMapper接口
*/
public interface UserMapper {
//查询所有用户
List<User> selectAllUser();
//根据id查询用户
User selectUserById(Integer id);
}
③、编写UserMapper.xml映射文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.thr.mapper.UserMapper">
<resultMap id="userMap" type="com.thr.pojo.User">
<id property="userId" column="id"/>
<result property="userName" column="username"/>
<result property="userAge" column="age"/>
<result property="userBirthday" column="birthday"/>
<result property="userSex" column="sex"/>
<result property="userAddress" column="address"/>
</resultMap>
<!-- 查询所有用户-->
<select id="selectAllUser" resultMap="userMap">
select * from t_user
</select>
<!--根据id查询用户-->
<select id="selectUserById" parameterType="int" resultMap="userMap">
select * from t_user where id = #{id}
</select>
</mapper>
④、编写数据库连接、日志和全局配置文件
数据库连接文件
#数据库连接配置
database.driver=com.mysql.cj.jdbc.Driver
database.url=jdbc:mysql://localhost:3306/mybatis?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf-8
database.username=root
database.password=root
日志文件
log4j.rootLogger=DEBUG, Console
#Console
log4j.appender.Console=org.apache.log4j.ConsoleAppender
log4j.appender.Console.layout=org.apache.log4j.PatternLayout
log4j.appender.Console.layout.ConversionPattern=%d [%t] %-5p [%c] - %m%n
log4j.logger.java.sql.ResultSet=INFO
log4j.logger.org.apache=INFO
log4j.logger.java.sql.Connection=DEBUG
log4j.logger.java.sql.Statement=DEBUG
log4j.logger.java.sql.PreparedStatement=DEBUG
mybatis-config.xml全局配置文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!--引入数据库配置文件-->
<properties resource="db.properties"/>
<!--配置别名-->
<typeAliases>
<package name="com.thr.pojo"/>
</typeAliases>
<!-- 配置环境.-->
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"></transactionManager>
<dataSource type="POOLED">
<property name="driver" value="${database.driver}"/>
<property name="url" value="${database.url}"/>
<property name="username" value="${database.username}"/>
<property name="password" value="${database.password}"/>
</dataSource>
</environment>
</environments>
<mappers>
<!-- 扫描包下的所有mapper接口并进行注册,规则必须是同包同名 -->
<package name="com.thr.mapper"/>
</mappers>
</configuration>
⑤、编写测试方法
//Mybatis的测试
public class MybatisTest {
//定义SqlSessionFactory
private SqlSessionFactory sqlSessionFactory = null;
//定义SqlSession
private SqlSession sqlSession = null;
@Before//在测试方法执行之前执行
public void getSqlSession(){
//1、加载 mybatis 全局配置文件
InputStream is = MybatisTest.class.getClassLoader().getResourceAsStream("mybatis-config.xml");
//2、创建SqlSessionFactory对象
sqlSessionFactory = new SqlSessionFactoryBuilder().build(is);
//3、根据 sqlSessionFactory 产生 session
sqlSession = sqlSessionFactory.openSession();
}
//查询所有用户数据
@Test
public void testSelectAllUser(){
//动态代理创建UserMapper对象
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
//第一次查询
List<User> listUser1 = mapper.selectAllUser();
for (User user1 : listUser1) {
System.out.println(user1);
}
System.out.println("--------------------------");
//第二次查询
List<User> listUser2 = mapper.selectAllUser();
for (User user : listUser2) {
System.out.println(user);
}
sqlSession.close();
}
//根据Id查询一个用户数据
@Test
public void testSelectUserById(){
//动态代理创建UserMapper对象
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
//第一次查询
User user1 = mapper.selectUserById(1);
System.out.println(user1);
System.out.println("--------------------------");
//第二次查询
User user2 = mapper.selectUserById(1);
System.out.println(user2);
sqlSession.close();
}
}
⑥、运行结果
查询所有数据:
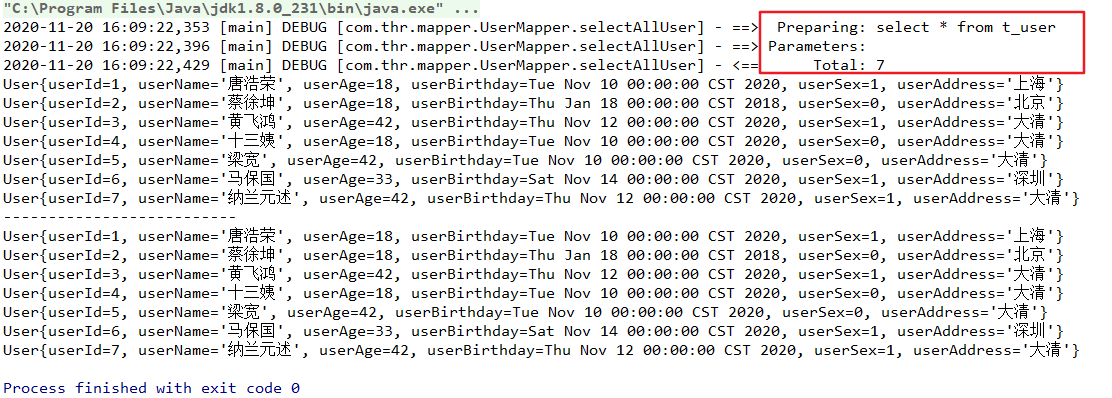
根据id查询一个用户数据:

通过上面的运行结果可以发现,第二次查询并没有执行SQL语句,但是却获得了数据,说明是直接从缓存中读取的数据。
12.3 一级缓存的清空
注意:这里的缓存清空是针对一级缓存而言的。
以下的两个操作会导致一级缓存的清空
①、执行了insert、update、delete的sql语句,又或者只执行了commit操作,都会导致一级缓存失效
注:添加、修改,删除操作不管有没有成功,只要你执行了增删改的SQL,缓存都会清空,即使没有通过commit方法提交,而二级缓存必须通过commit方法提交,才能清空缓存,因为二级缓存必须要在sqlSession关闭或者提交(commit)才能生效。
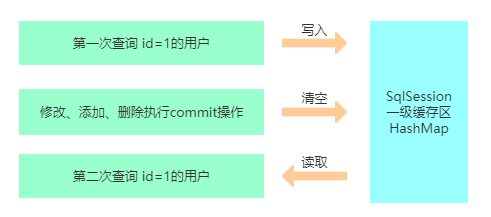
验证增删改是否成功:
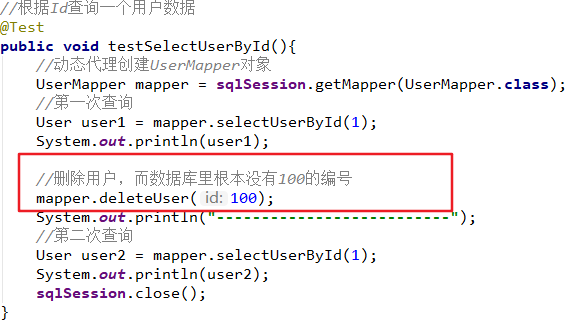

验证只执行commit()方法:
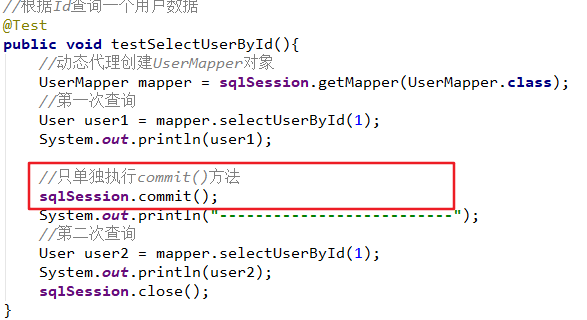

②、手动清空,通过sqlSession.clearCache
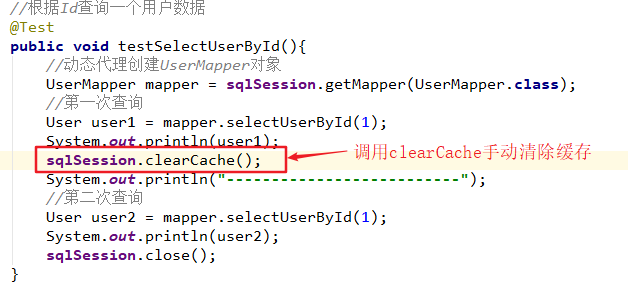
12.4 二级缓存
二级缓存是Mapper对象或sqlSessionFactory对象的缓存,由同一个sqlSessionFactory对象创建的SqlSession共享其缓存。当多个SqlSession去操作同一个Mapper的sql语句,多个SqlSession可以共用二级缓存,二级缓存是跨SqlSession的。(二级缓存Mybatis默认是关闭的,需要自己去手动配置开启或可以自己选择用哪个厂家的缓存来作为二级缓存)
//定义两个不同SqlSession,但有同一个sqlSessionFactory
SqlSession sqlSession1 = sqlSessionFactory.openSession();
SqlSession sqlSession2 = sqlSessionFactory.openSession();
二级缓存举例:
①、启用二级缓存,在mybatis的全局配置文件中加入如下配置
<!--开启二级缓存-->
<settings>
<setting name="cacheEnabled" value="true"/>
</settings>
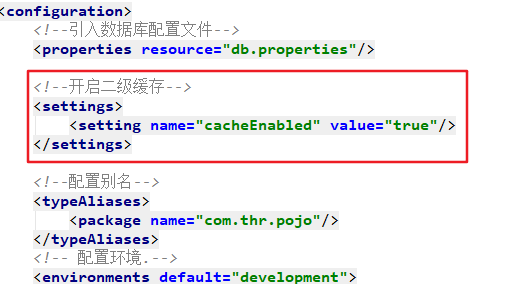
②、在UserMapper.xml配置文件中添加cache标签,让映射文件支持二级缓存
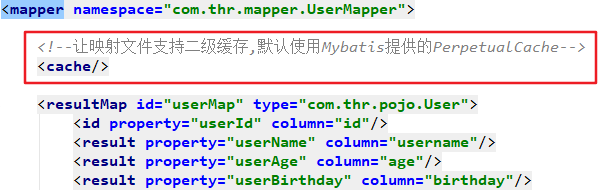
cache标签还可以配置其它参数,如:
<cache eviction="LRU" flushInterval="60000" size="512" readOnly="true" type=”xxxxx” />
cache标签属性介绍:
- eviction:缓存的回收策略,有四个策略,默认的是LRU 。LRU(Least Recently Used) — 最近最少使用,移除最长时间不被使用的对象;FIFO — 先进先出,按对象进入缓存的顺序来移除它们;SOFT — 软引用,移除基于垃圾回收器状态和软引用规则的对象;WEAK — 弱引用,更积极地移除基于垃圾收集器和弱引用规则的对象。
- flushInterval:缓存刷新间隔,就是多久清空一次,默认不清空,单位毫秒,在执行配置了flushCache标签的SQL时清空。
- size:缓存存放多少个元素,默认1024。
- readOnly:是否只读,默认为false。false:读写,mybatis觉得获取的数据可能会被修改,mybatis会利用序列化和反序列化的技术克隆一份新的数据给你,这样虽然安全,但速度相对慢。true:只读,mybatis认为所有从缓存中获取数据的操作都是只读操作,不会修改数据。mybatis为了加快获取数据,直接就会将数据在缓存中的引用交给用户 ,这样不安全,但是速度快。
- type:指定自定义缓存的全类名(实现Cache接口即可)。
③、实体对象实现序列化接口,使用Mybatis二级缓存需要将pojo对象实现java.io.Serializable接口,否则将出现序列化错误。
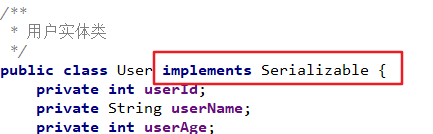
因为二级缓存有可能是存储在磁盘中,有文件的读写操作,所以映射的实体类要实现Serializable接口
④、编写UserMapper接口(参考一级缓存)。
⑤、编写UserMapper.xml配置文件(就多了个cache标签,其余参考一级缓存)。
⑥、编写测试方法
在编写测试代码时注意下面这句话非常重要:
注意:二级缓存在sqlSession关闭(sqlSession.close() )或者提交(sqlSession.commit() )时才会生效!主要是清空一级缓存,但是无法清空二级缓存。
//Mybatis的测试
public class MybatisTest1 {
//定义SqlSessionFactory
private SqlSessionFactory sqlSessionFactory = null;
@Before//在测试方法执行之前执行
public void getSqlSession(){
//1、加载 mybatis 全局配置文件
InputStream is = MybatisTest1.class.getClassLoader().getResourceAsStream("mybatis-config.xml");
//2、创建SqlSessionFactory对象
sqlSessionFactory = new SqlSessionFactoryBuilder().build(is);
}
//查询所有用户数据
@Test
public void testSelectAllUser(){
//定义两个不同SqlSession,但有同一个sqlSessionFactory
SqlSession sqlSession1 = sqlSessionFactory.openSession();
SqlSession sqlSession2 = sqlSessionFactory.openSession();
UserMapper mapper1 = sqlSession1.getMapper(UserMapper.class);
//第一次查询
List<User> listUser1 = mapper1.selectAllUser();
for (User user1 : listUser1) {
System.out.println(user1);
}
System.out.println("----------------");
//注意:二级缓存在sqlSession关闭或者提交才会生效!这里二选一
sqlSession1.close();
//sqlSession1.commit();
UserMapper mapper2 = sqlSession2.getMapper(UserMapper.class);
//第一次查询
List<User> listUser2 = mapper2.selectAllUser();
for (User user2 : listUser2) {
System.out.println(user2);
}
sqlSession2.close();
}
//根据Id查询一个用户数据
@Test
public void testSelectUserById(){
//定义两个不同SqlSession,但有同一个sqlSessionFactory
SqlSession sqlSession1 = sqlSessionFactory.openSession();
SqlSession sqlSession2 = sqlSessionFactory.openSession();
UserMapper mapper1 = sqlSession1.getMapper(UserMapper.class);
//第一次查询
User user1 = mapper1.selectUserById(1);
System.out.println(user1);
System.out.println("----------------");
//注意:二级缓存在sqlSession关闭或者提交才会生效!这里二选一
//sqlSession1.close();
sqlSession1.commit();
UserMapper mapper2 = sqlSession2.getMapper(UserMapper.class);
//第二次查询
User user2 = mapper2.selectUserById(1);
System.out.println(user2);
sqlSession1.close();
sqlSession2.close();
}
}
⑦、运行结果
(1)、在没有关闭sqlSession和提交commit的情况下运行:
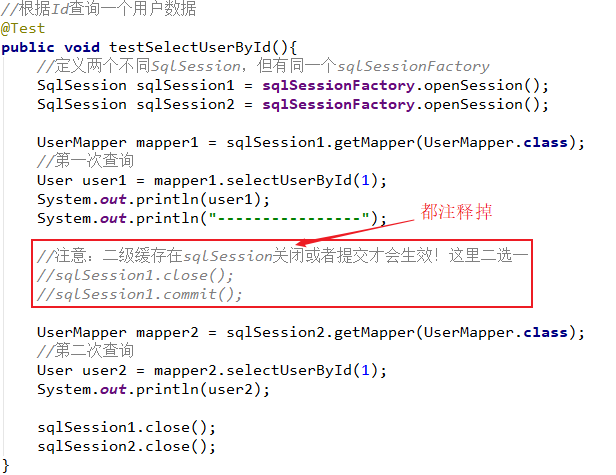

可以从运行结果发现查询两次分别执行了两次SQL,并且缓存的命中率为0.0,说明没有缓存。
(2)、查询所有数据:
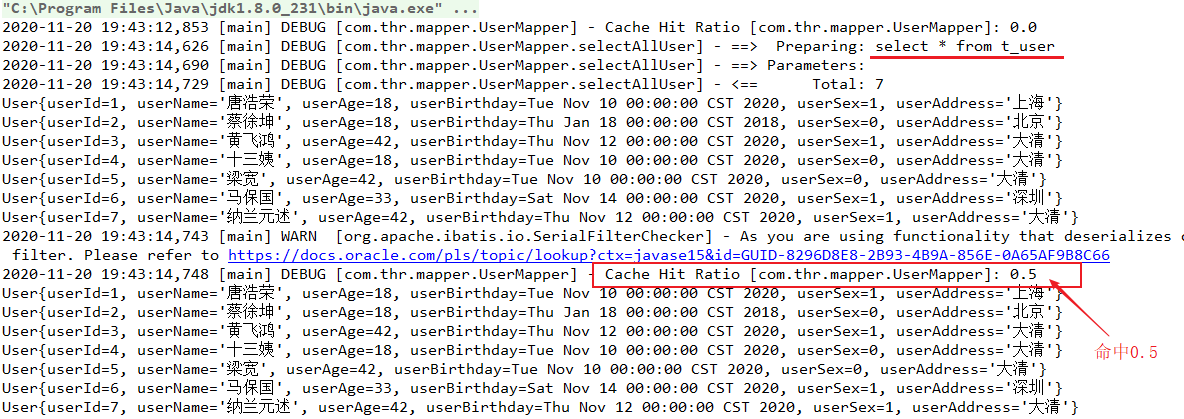
可以看到第二次查询后的缓存命中率为0.5,意思是我们查询了两次,其中有一条SQL语句是从缓存中查询的数据,这里也就是第二条,所以缓存的命中率为0.5。如果你再复制增加一条一样的语句,那么缓存的命中率会变为0.66666666。
(3)、根据id查询一个用户数据:
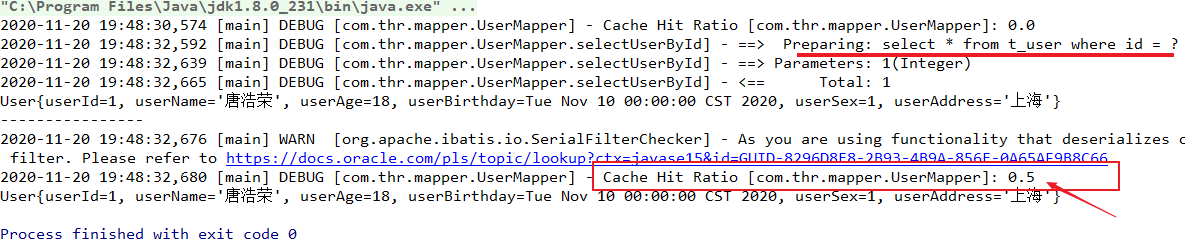
使用注解开启二级缓存
只需要在对应的Mapper接口上增加如下注解,就可以开启二级缓存,非常的方便。
@CacheNamespace(blocking = true)
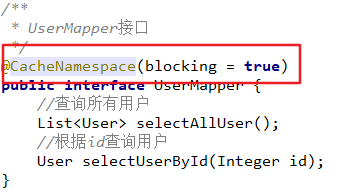
其它参数用逗号(,)隔开,比如:eviction、flushInterval、size等。
12.5 二级缓存的禁用与刷新(清空)
①、禁用二级缓存
useCache属性是用来禁用二级缓的,这个属性只有select标签有,它表示配置这个select是否使用二级缓存,默认为true,设置为false则表示禁止当前select使用二级缓存,即:

或者通过注解来禁用二级缓存,如下:
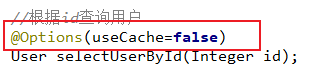
②、刷新(清空)二级缓存
flushCache属性是用来刷新二级缓存的,表示是否刷新(清空)缓存。
- 查询时默认为flushCache=false,因为查询时刷新缓存的话,就会导致一直去数据库查询,所以查询时必须要关闭;
- 增删改默认为flushCache=true,因为mybatis执行数据的增删改sql语句后,数据库与缓存数据可能已经不一致,如果不执行刷新缓存则可能出现脏读的情况,sql语句执行后,会同时清空一级缓存和二级缓存。
这个属性一般全部默认即可,不用管,因为你也管不了,查询时不可能设置为true刷新缓存吧,增删改也不可能设置为false禁止刷新缓存吧。

通过注解来清空二级缓存:

12.6 使用redis做二级缓存
我们知道Mybatis它是一个优秀的持久层框架,但是它不是一个缓存框架,所以说它本身的缓存机制不是很好,我们一般都是整合第三方的缓存框架,比如常见的缓存框架ehcache、redis、memcache等等。这里暂时以简单的redis缓存框架为例,因为redis是现在用的最多的。
如果我们想要使用第三方的缓存,就必须实现Mybatis提供的cache接口,它自己有一个默认的实现类PerpetualCache,我们来看一下cache接口。
public interface Cache {
String getId();
void putObject(Object key, Object value);
Object getObject(Object key);
Object removeObject(Object key);
void clear();
int getSize();
ReadWriteLock getReadWriteLock();
}
下面我们来实现如何使用redis做二级缓存,步骤如下:
①、redis的下载与安装参考链接(这里只以window版本为例):https://blog.csdn.net/WeiHao0240/article/details/100030637
②、添加maven包依赖
<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.3.0</version>
</dependency>
③、开启二级缓存
<settings>
<!--开启二级缓存-->
<setting name="cacheEnabled" value="true"/>
<!--日志-->
<setting name="logImpl" value="STDOUT_LOGGING" />
</settings>
④、编写序列化和反序列化工具类。
public class SerializableTools {
/**
* 反序列化
*
* @param bt
* @return
* @throws IOException
* @throws Exception
*/
public static Object byteArrayToObj(byte[] bt) throws Exception {
ByteArrayInputStream bais = new ByteArrayInputStream(bt);
ObjectInputStream ois = new ObjectInputStream(bais);
return ois.readObject();
}
/**
* 对象序列化
*
* @param obj
* @return
* @throws IOException
*/
public static byte[] ObjToByteArray(Object obj) throws IOException {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(obj);
return bos.toByteArray();
}
}
⑤、实现Mybatis二级缓存org.apache.ibatis.cache.Cache接口
public class RedisCache implements Cache {
// 初始化Jedis
private Jedis jedis = new Jedis("127.0.0.1", 6379);
/*
* MyBatis会把映射文件的命名空间作为
* 唯一标识cacheId,标识这个缓存策略属于哪个namespace
* 这里定义好,并提供一个构造器,初始化这个cacheId即可
*/
private String cacheId;
public RedisCache (String cacheId){
this.cacheId = cacheId;
}
/**
* 清空缓存
*/
@Override
public void clear() {
// 但这方法不建议实现
}
@Override
public String getId() {
return cacheId;
}
/**
* MyBatis会自动调用这个方法检测缓存
* 中是否存在该对象。既然是自己实现的缓存
* ,那么当然是到Redis中找了。
*/
@Override
public Object getObject(Object arg0) {
// arg0 在这里是键
try {
byte [] bt = jedis.get(SerializableTools.ObjToByteArray(arg0));
if (bt == null) { // 如果没有这个对象,直接返回null
return null;
}
return SerializableTools.byteArrayToObj(bt);
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
@Override
public ReadWriteLock getReadWriteLock() {
return new ReentrantReadWriteLock();
}
@Override
public int getSize() {
return Integer.parseInt(Long.toString(jedis.dbSize()));
}
/**
* MyBatis在读取数据时,会自动调用此方法
* 将数据设置到缓存中。这里就写入Redis
*/
@Override
public void putObject(Object arg0, Object arg1) {
/*
* arg0是key , arg1是值
* MyBatis会把查询条件当做键,查询结果当做值。
*/
try {
jedis.set(SerializableTools.ObjToByteArray(arg0), SerializableTools.ObjToByteArray(arg1));
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* MyBatis缓存策略会自动检测内存的大小,由此
* 决定是否删除缓存中的某些数据
*/
@Override
public Object removeObject(Object arg0) {
Object object = getObject(arg0);
try {
jedis.del(SerializableTools.ObjToByteArray(arg0));
} catch (IOException e) {
e.printStackTrace();
}
return object;
}
}
⑥、修改UserMapper.xml配置文件,通过type属型指定自定义二级缓存实现

⑦、启动Redis
然后额外cmd在打开一个窗口,测试一下是否成功。

⑧、运行代码
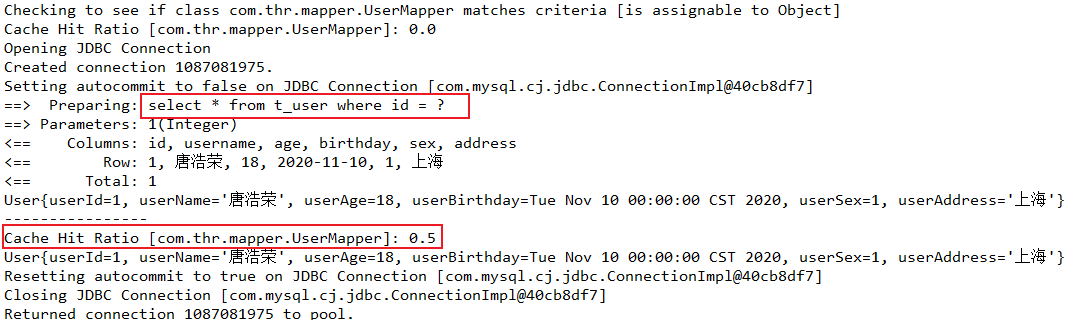
我们再次执行看一下会怎样:

可以发现所有的命中率都是1.0,说明了100%是从缓存中取的数据,而且是从redis中读取的。
这里参考的链接:https://blog.csdn.net/qq_36311372/article/details/79090070
13、Mybatis逆向工程
13.1 什么是逆向工程
Mybatis的逆向工程就是由代码生成器生成我们需要的代码和映射文件。我们在编写Mybatis程序时,基本都是围绕着pojo类,Mapper接口,Mapper.xml文件等文件来进行的。如果实际开发中数据库的表特别多,那么我们需要手动去写每一张表的pojo类,Mapper接口,Mapper.xml文件,这显然需要花费巨大的精力,而且可能由于表字段太多,哪里写错了都难以排除。所以我们在实际开发中,一般使用逆向工程方式来自动生成所需的文件,这也是企业中一种非常常见的方法。
注意:在使用逆向工程生成代码文件的时候,最好额外创建一个项目,不要在原来的项目中使用,因为如果你在原项目中有相同名字的文件,那么就会被新生成的文件所覆盖,导致之前写的代码没了,有一定的风险。所以实际开发中,我们一般新建一个项目,然后将生成的文件复制到自己的所需的工程中。
13.2 逆向工程生成代码
①、首先创建maven项目
项目整体目录:
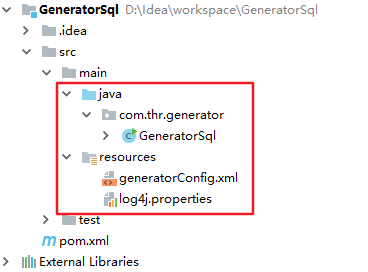
导入maven依赖:
<!-- Mybatis -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.6</version>
</dependency>
<!-- mysql驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.21</version>
</dependency>
<!-- 日志处理 -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<!-- 逆向工程 -->
<dependency>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-core</artifactId>
<version>1.4.0</version>
</dependency>
②、创建日志文件log4j.properties
# Set root category priority to INFO and its only appender to CONSOLE.
#log4j.rootCategory=INFO, CONSOLE debug info warn error fatal
log4j.rootCategory=debug, CONSOLE
# CONSOLE is set to be a ConsoleAppender using a PatternLayout.
log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender
log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout
log4j.appender.CONSOLE.layout.ConversionPattern=%d{ISO8601} %-6r [%15.15t] %-5p %30.30c %x - %m\n
③、创建generatorConfig.xml配置文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE generatorConfiguration
PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
"http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd">
<generatorConfiguration>
<!--targetRuntime="MyBatis3Simple"表示生成简易版本,这里创建原始版本,参数为MyBatis3-->
<context id="testTables" targetRuntime="MyBatis3">
<commentGenerator>
<!-- 是否去除自动生成的注释。true:是;false:否 -->
<property name="suppressAllComments" value="true" />
</commentGenerator>
<!--数据库连接的信息:驱动类、连接地址、用户名、密码 -->
<jdbcConnection driverClass="com.mysql.cj.jdbc.Driver"
connectionURL="jdbc:mysql://localhost:3306/mybatis?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf-8"
userId="root"
password="root">
</jdbcConnection>
<!-- 默认false,把JDBC DECIMAL和NUMERIC类型解析为Integer,为true时把JDBC DECIMAL 和
NUMERIC 类型解析为java.math.BigDecimal -->
<javaTypeResolver>
<property name="forceBigDecimals" value="false" />
</javaTypeResolver>
<!-- targetProject:POJO类生成的位置 -->
<javaModelGenerator targetPackage="com.thr.pojo"
targetProject="./src/main/java">
<!-- enableSubPackages:是否让schema作为包的后缀 -->
<property name="enableSubPackages" value="false" />
<!-- 从数据库返回的值被清理前后的空格 -->
<property name="trimStrings" value="true" />
</javaModelGenerator>
<!-- targetProject:mapper映射文件生成的位置 -->
<sqlMapGenerator targetPackage="com.thr.mapper"
targetProject="./src/main/resources">
<!-- enableSubPackages:是否让schema作为包的后缀 -->
<property name="enableSubPackages" value="false" />
</sqlMapGenerator>
<!-- targetPackage:mapper接口生成的位置 -->
<javaClientGenerator type="XMLMAPPER"
targetPackage="com.thr.mapper"
targetProject="./src/main/java">
<!-- enableSubPackages:是否让schema作为包的后缀 -->
<property name="enableSubPackages" value="false" />
</javaClientGenerator>
<!-- 指定生成哪些数据库表,要和数据库中对应,不能写错了,这里以t_user表为例,可以写多个;domainObjectName是要生成的实体类名称-->
<table schema="mybatis" tableName="t_user"/>
<!-- 有些表的字段需要指定java类型
<table schema="" tableName="">
<columnOverride column="" javaType="" />
</table> -->
</context>
</generatorConfiguration>
注意:serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf-8中的 & 要改成转义字符 & 这里传上来页面自动给转成了 &。

还有就是不同的数据库中不能含有相同的表,例如数据库A有t_user表,数据库B也有t_user表,那么到时候代码不知道生成哪个,而我恰好生成的是我们不需要的那个。啊?你说上面不是指定了数据库吗,怎么会到读取到其它数据库的表,不好意思,我试了不下十遍,最后我把其它数据库同名的表删除才成功的。如果你没有这种情况那更好咯。

④、创建逆向工程核心生成代码GeneratorSql.java
package com.thr.generator;
import org.mybatis.generator.api.MyBatisGenerator;
import org.mybatis.generator.config.Configuration;
import org.mybatis.generator.config.xml.ConfigurationParser;
import org.mybatis.generator.internal.DefaultShellCallback;
import java.io.File;
import java.util.ArrayList;
import java.util.List;
/**
* 逆向工程核心生成代码
*/
public class GeneratorSql {
public void generator() throws Exception {
List<String> warnings = new ArrayList<>();
boolean overwrite = true;
// 指定逆向工程配置文件
String file = GeneratorSql.class.getResource("/generatorConfig.xml").getFile();
File configFile = new File(file);
ConfigurationParser cp = new ConfigurationParser(warnings);
Configuration config = cp.parseConfiguration(configFile);
DefaultShellCallback callback = new DefaultShellCallback(overwrite);
MyBatisGenerator myBatisGenerator = new MyBatisGenerator(config, callback, warnings);
myBatisGenerator.generate(null);
}
// 执行main方法以生成代码
public static void main(String[] args) {
try {
GeneratorSql generatorSql = new GeneratorSql();
generatorSql.generator();
} catch (Exception e) {
e.printStackTrace();
}
}
}
⑤、运行逆向工程核心生成代码
运行上面的程序,如果控制台打印了如下日志,说明生成代码成功了。

然后我们再看项目就会发现生成了如下文件:
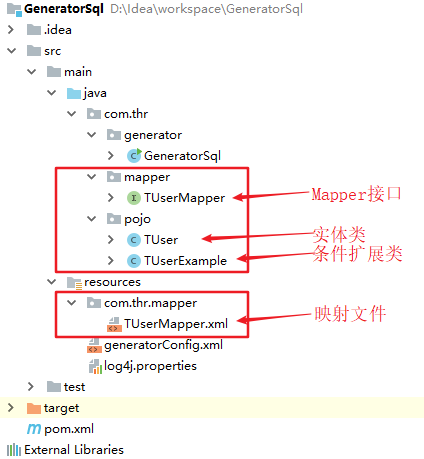
下面我们就来学习如何使用它们。
13.3 逆向工程举例
首先我们将上面生成的文件复制到目标项目中。在使用逆向工程举例之前,先来介绍生成的文件有哪些东西:
(1)、TUserMapper接口生成的方法介绍:
- long countByExample(TUserExample example):按条件计数
- int deleteByExample(TUserExample example):按条件删除
- int deleteByPrimaryKey(Integer id):按主键删除
- int insert(TUser record):插入数据(返回值为ID)
- int insertSelective(TUser record):插入数据,只插入值不为null的字段,内部动态sql判断
- List
selectByExample(TUserExample example):按条件查询,传入null表示查询所有 - TUser selectByPrimaryKey(Integer id):按主键查询
- int updateByExampleSelective(@Param("record") TUser record, @Param("example") TUserExample example):按条件更新值不为null的字段
- int updateByExample(@Param("record") TUser record, @Param("example") TUserExample example):按条件更新
- int updateByPrimaryKeySelective(TUser record):按主键更新值不为null的字段
- int updateByPrimaryKey(TUser record):按主键更新
测试不带条件的方法:
//Mybatis的测试
public class MybatisTest {
//定义 SqlSession
private SqlSession sqlSession = null;
//定义 TUserMapper对象
private TUserMapper mapper = null;
@Before//在测试方法执行之前执行
public void getSqlSession(){
//1、加载 mybatis 全局配置文件
InputStream is = MybatisTest.class.getClassLoader().getResourceAsStream("mybatis-config.xml");
//2、创建SqlSessionFactory对象
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(is);
//3、根据 sqlSessionFactory 产生session
sqlSession = sqlSessionFactory.openSession();
//4、创建Mapper接口的的代理对象,getMapper方法底层会通过动态代理生成TUserMapper的代理实现类
mapper = sqlSession.getMapper(TUserMapper.class);
}
@After//在测试方法执行完成之后执行
public void destroy() throws IOException {
sqlSession.commit();
sqlSession.close();
}
//查询所有用户信息
@Test
public void selectAllUser(){
List<TUser> tUsers = mapper.selectByExample(null);//传入null表示查询所有
for (TUser tUser : tUsers) {
System.out.println(tUser);
}
}
//根据用户id查询用户
@Test
public void selectByUserId(){
TUser tUser = mapper.selectByPrimaryKey(1);
System.out.println(tUser);
}
//添加用户信息
@Test
public void insertUser(){
TUser tUser = new TUser();
tUser.setUsername("凡尔赛");
tUser.setAge(18);
tUser.setBirthday(new Date());
tUser.setSex("0");
tUser.setAddress("漂亮国");
int i = mapper.insertSelective(tUser);
System.out.println(i>0?"添加成功":"添加失败");
}
//更新用户信息
@Test
public void updateUser(){
TUser tUser = new TUser();
tUser.setId(8);//这里要设置id才能修改成功,否则不知道修改哪一条数据
tUser.setUsername("川建国");
tUser.setAge(50);
tUser.setBirthday(new Date());
tUser.setSex("1");
tUser.setAddress("漂亮国");
int i = mapper.updateByPrimaryKeySelective(tUser);
System.out.println(i>0?"修改成功":"修改失败");
}
//删除用户信息
@Test
public void deleteUser(){
int i = mapper.deleteByPrimaryKey(8);
System.out.println(i>0?"删除成功":"删除失败");
}
}
(2)、TUserExample条件扩展类介绍:
上面的测试方法是不带条件的操作,那么接下来学习一下按条件如何进行增删改查操作,我们在逆向工程中已经生成了这个类TUserExample,这个类就是一个条件扩展类,里面定义了一系列方法用来做条件,比如:排序、去重、大于、小于、等于、模糊查询、数据在某某之间等等。
我们在TUserExample类中可以看到定义了一个内部类GeneratedCriteria,这个内部类就定义了一系列条件的方法,这些条件最后都会拼接在SQL中,但是我们一般不用它,都用它的子类Criteria来进行操作,Criteria继承了内部类GeneratedCriteria。
简单举例:
//Mybatis的测试
public class MybatisTest1 {
//定义 SqlSession
private SqlSession sqlSession = null;
//定义 UserMapper对象
private TUserMapper mapper = null;
@Before//在测试方法执行之前执行
public void getSqlSession(){
//1、加载 mybatis 全局配置文件
InputStream is = MybatisTest1.class.getClassLoader().getResourceAsStream("mybatis-config.xml");
//2、创建SqlSessionFactory对象
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(is);
//3、根据 sqlSessionFactory 产生session
sqlSession = sqlSessionFactory.openSession();
//4、创建Mapper接口的的代理对象,getMapper方法底层会通过动态代理生成UserMapper的代理实现类
mapper = sqlSession.getMapper(TUserMapper.class);
}
@After//在测试方法执行完成之后执行
public void destroy() throws IOException {
sqlSession.commit();
sqlSession.close();
}
//模糊查询用户信息
@Test
public void selectUserLike(){
TUserExample example = new TUserExample();
TUserExample.Criteria criteria = example.createCriteria();
//模糊条件
criteria.andUsernameLike("%三%");
/*sql语句相当于:select id, username, age, birthday, sex, address
from t_user WHERE ( username like ? )*/
List<TUser> tUsers = mapper.selectByExample(example);
for (TUser tUser : tUsers) {
System.out.println(tUser);
}
}
//查询年龄在18-30岁之间的用户信息
@Test
public void selectUserBetween(){
TUserExample example = new TUserExample();
TUserExample.Criteria criteria = example.createCriteria();
//Between条件
criteria.andAgeBetween(18,30);
example.or(criteria);
example.setDistinct(true);
/*sql语句相当于:select distinct id, username, age, birthday, sex, address
from t_user WHERE ( age between ? and ? ) or( age between ? and ? )*/
List<TUser> tUsers = mapper.selectByExample(example);
for (TUser tUser : tUsers) {
System.out.println(tUser);
}
}
//查询用户名A或B
@Test
public void selectUserOr(){
TUserExample example = new TUserExample();
TUserExample.Criteria criteria1 = example.createCriteria();
criteria1.andUsernameEqualTo("黄飞鸿");
TUserExample.Criteria criteria2 = example.createCriteria();
criteria2.andUsernameEqualTo("马保国");
//将criteria2条件拼接在 or 关键字字后面
example.or(criteria2);
/*sql语句相当于:select id, username, age, birthday, sex, address
from t_user WHERE ( username = ? ) or( username = ? )*/
List<TUser> tUsers = mapper.selectByExample(example);
for (TUser tUser : tUsers) {
System.out.println(tUser);
}
}
//根据用户名删除用户
@Test
public void deleteUserExample(){
TUserExample example = new TUserExample();
TUserExample.Criteria criteria = example.createCriteria();
criteria.andUsernameEqualTo("凡尔赛");
//sql语句相当于:delete from t_user WHERE ( username = ? )
int i = mapper.deleteByExample(example);
System.out.println(i>0?"删除成功":"删除失败");
}
}
至此Mybatis的逆向工程就全部介绍完成了,说难也不是特别难,只要一步步自己去实现,去理解一遍,是非常简单的,可能复杂一点的是那个XxxExample类,但如果自己多举几个例子也不难。
14、Mybatis的分页
14.1 前言
在前面学习mybatis的时候,会经常对数据进行增删改查操作,使用最多的是对数据库进行查询操作,但是前面都是简单的案例,所以查询的数据量不是很大,自然查询时没有任何压力,但是如果在实际的项目中,数据库的数据成千上万,如果还是这样一次性查询出所有数据,那么会导致数据可读性和数据库性能极差。所以我们往往使用分页进行查询,这样对数据库压力就在可控范围内。
这里介绍Mybatis的这几种分页方式:
- 原生SQL的Limit分页
- Mybatis自带的RowBounds分页
- 自定义拦截器插件进行分页
- 使用PageHelper插件分页
下面我们来简单学习一下。
14.2 原生Limit分页
原生Limit分页就是在编写sql语句时需要自己加上limit关键字,然后传入分页参数进行分页
例如:select * from t_user limit 0,3;
①、编写UserMapper接口
/**
* UserMapper接口
*/
public interface UserMapper {
//分页查询所有用户,通过原生limit
List<User> selectAllUserByLimit(Map map);
}
②、UserMapper.xml映射文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.thr.mapper.UserMapper">
<resultMap id="userMap" type="com.thr.pojo.User">
<id property="userId" column="id"/>
<result property="userName" column="username"/>
<result property="userAge" column="age"/>
<result property="userBirthday" column="birthday"/>
<result property="userSex" column="sex"/>
<result property="userAddress" column="address"/>
</resultMap>
<!-- 分页查询所有用户,通过原生limit -->
<select id="selectAllUserByLimit" resultMap="userMap">
select * from t_user limit #{start},#{size}
</select>
</mapper>
③、测试分页方法
//Mybatis的测试
public class MybatisTest2 {
//定义 SqlSession
private SqlSession sqlSession = null;
//定义 UserMapper对象
private UserMapper mapper = null;
@Before//在测试方法执行之前执行
public void getSqlSession(){
//1、加载 mybatis 全局配置文件
InputStream is = MybatisTest2.class.getClassLoader().getResourceAsStream("mybatis-config.xml");
//2、创建SqlSessionFactory对象
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(is);
//3、根据 sqlSessionFactory 产生session
sqlSession = sqlSessionFactory.openSession();
//4、创建Mapper接口的的代理对象,getMapper方法底层会通过动态代理生成UserMapper的代理实现类
mapper = sqlSession.getMapper(UserMapper.class);
}
@After//在测试方法执行完成之后执行
public void destroy() throws IOException {
sqlSession.commit();
sqlSession.close();
}
//分页查询所有用户信息,通过原生limit
@Test
public void selectAllUserByLimit(){
int currPage = 2;//当前页码
int pageSize = 3;//当前显示页记录数量
HashMap<String, Object> map = new HashMap<>();
//计算起始位置,注意:currPage和start别搞错了,一个表示当前页码,一个是从第几行读取记录
map.put("start",(currPage-1)*pageSize);
//页面显示记录数
map.put("size",pageSize);
System.out.println("当前页码为:第"+currPage+"页,页面显示记录数量:"+pageSize+"个");
List<User> userList = mapper.selectAllUserByLimit(map);
for (User user : userList) {
System.out.println(user);
}
}
}
④、运行结果

14.3 RowBounds分页
Mybatis内置了一个专门处理分页的类——RowBounds,我们使用它可以轻松完成分页。
RowBounds源代码如下:
package org.apache.ibatis.session;
public class RowBounds {
//默认值为0~~Java最大整数
public static final int NO_ROW_OFFSET = 0;
public static final int NO_ROW_LIMIT = Integer.MAX_VALUE;
public static final RowBounds DEFAULT = new RowBounds();
//偏移量,即从第几行开始读取
private final int offset;
//限制,即每页显示记录数量
private final int limit;
public RowBounds() {
this.offset = NO_ROW_OFFSET;
this.limit = NO_ROW_LIMIT;
}
public RowBounds(int offset, int limit) {
this.offset = offset;
this.limit = limit;
}
public int getOffset() {
return offset;
}
public int getLimit() {
return limit;
}
}
那么我们怎样来使用这个RowBounds分页呢?非常的简单。
①、定义接口方法
//分页查询所有用户,通过自带的RowBounds
List<User> selectAllUserByRowBounds(RowBounds rowBounds);
②、sql映射
<!-- 分页查询所有用户,通过自带的RowBounds -->
<select id="selectAllUserByRowBounds" resultMap="userMap">
select * from t_user
</select>
使用RowBounds分页我们可以不写在映射SQL中写limit关键字,到时候自动会给我们拼接。就两个字,方便!
③、测试方法
//分页查询所有用户信息,通过自带的RowBounds
@Test
public void selectAllUserByRowBounds(){
int currPage=2;//当前页码
int pageSize=3;//当前页显示记录数量
//注意:currPage和start别搞错了,一个表示当前页码,一个是从第几行读取记录
int start = (currPage-1)*pageSize;//计算从第几行读取记录
RowBounds rowBounds = new RowBounds(start,pageSize);
List<User> userList = mapper.selectAllUserByRowBounds(rowBounds);
for (User user : userList) {
System.out.println(user);
}
}
④、运行结果

RowBounds分页有一点好处就是处理数据量少时还可以,但是数据量大时,就不行好用了,此时一般都会实现拦截器来完成分页。
14.4 自定义拦截器插件分页
自定义拦截器插件分页 需要自己定义一个类实现Interceptor接口,这个接口是Mybatis提供的。任何分页插件想要对Mybatis进行分页就必须实现Interceptor接口,包括后面PageHelper分页插件。
①、创建MyPageInterceptor类
/**
* @Intercepts 表示是一个拦截器
* @Signature 拦截器的签名
* type 拦截的类型 四大对象之一( Executor,ResultSetHandler,ParameterHandler,StatementHandler)
* method 拦截的方法
*/
@Intercepts({@Signature(type=StatementHandler.class,method="prepare",args={Connection.class, Integer.class })})
public class MyPageInterceptor implements Interceptor {
//当前页码
private int currPage;
//每页显示的条目数
private int pageSize;
//数据库类型
private String dbType;
@Override
public Object intercept(Invocation invocation) throws Throwable {
System.out.println("plugin is running...");
//获取StatementHandler,默认是RoutingStatementHandler
StatementHandler statementHandler = (StatementHandler) invocation.getTarget();
//获取statementHandler包装类
MetaObject MetaObjectHandler = SystemMetaObject.forObject(statementHandler);
//分离代理对象链
while (MetaObjectHandler.hasGetter("h")) {
Object obj = MetaObjectHandler.getValue("h");
MetaObjectHandler = SystemMetaObject.forObject(obj);
}
while (MetaObjectHandler.hasGetter("target")) {
Object obj = MetaObjectHandler.getValue("target");
MetaObjectHandler = SystemMetaObject.forObject(obj);
}
//获取连接对象
//Connection connection = (Connection) invocation.getArgs()[0];
//object.getValue("delegate"); 获取StatementHandler的实现类
//获取查询接口映射的相关信息
MappedStatement mappedStatement = (MappedStatement) MetaObjectHandler.getValue("delegate.mappedStatement");
String mapId = mappedStatement.getId();
//statementHandler.getBoundSql().getParameterObject();
//拦截以.ByPage结尾的请求,分页功能的统一实现
if (mapId.matches(".+ByPage$")) {
//获取进行数据库操作时管理参数的handler
ParameterHandler parameterHandler = (ParameterHandler) MetaObjectHandler.getValue("delegate.parameterHandler");
//获取请求时的参数
Map<String, Object> paraObject = (Map<String, Object>) parameterHandler.getParameterObject();
//也可以这样获取
//paraObject = (Map<String, Object>) statementHandler.getBoundSql().getParameterObject();
//参数名称和在service中设置到map中的名称一致
currPage = (int) paraObject.get("currPage");
pageSize = (int) paraObject.get("pageSize");
String sql = (String) MetaObjectHandler.getValue("delegate.boundSql.sql");
//也可以通过statementHandler直接获取
//sql = statementHandler.getBoundSql().getSql();
//构建分页功能的sql语句
String limitSql;
sql = sql.trim();
limitSql = sql + " limit " + (currPage - 1) * pageSize + "," + pageSize;
//将构建完成的分页sql语句赋值个体'delegate.boundSql.sql',偷天换日
MetaObjectHandler.setValue("delegate.boundSql.sql", limitSql);
}
//调用原对象的方法,进入责任链的下一级
return invocation.proceed();
}
//获取代理对象
@Override
public Object plugin(Object o) {
//生成object对象的动态代理对象
return Plugin.wrap(o, this);
}
//设置代理对象的参数
@Override
public void setProperties(Properties properties) {
//如果项目中分页的pageSize是统一的,也可以在这里统一配置和获取,这样就不用每次请求都传递pageSize参数了。参数是在配置拦截器时配置的。
String limit1 = properties.getProperty("limit", "10");
this.pageSize = Integer.valueOf(limit1);
this.dbType = properties.getProperty("dbType", "mysql");
}
}
②、全局配置文件增加plugin设置(注意位置)
<!-- 配置自定义分页插件 -->
<plugins>
<plugin interceptor="com.thr.interceptor.MyPageInterceptor">
</plugin>
</plugins>
③、接口方法
//分页查询所有用户,通过原生自定义拦截器
List<User> selectAllUserByPage(Map map);
由于拦截器中设置了拦截以.ByPage结尾的方法,所以方法一定要命名正确,
④、sql映射
<!-- 分页查询所有用户,通过自定义拦截器 -->
<select id="selectAllUserByPage" resultMap="userMap">
select * from t_user
</select>
⑤、测试方法

14.6 PageHelper分页插件
PageHelper是一款非常优秀的分页插件,用的人非常多,详细的可以参考PageHelper的官方文档,讲的比较通俗易懂。链接:https://pagehelper.github.io/docs/howtouse/。 PageHelper分页其实也是自定义拦截器方式的一种第三方实现,它内部帮助我们实现了Interceptor的功能。所以实际上我们在执行查询方法之前,PageHelper分页插件同样是对我们的 sql 进行拦截,然后对分页参数进行拼接。
PageHelper的简单使用:
①、引入PageHelper依赖:
<!-- pagehelper分页插件 -->
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>5.2.0</version>
</dependency>
②、全局配置文件增加plugin设置(注意位置)
<!-- 配置分页插件 -->
<plugins>
<!-- PageHelper5版本配置 -->
<plugin interceptor="com.github.pagehelper.PageInterceptor"/>
</plugins>
③、接口方法
//分页查询所有用户,通过PageHelper
List<User> selectAllUserByPageHelper();
④、sql映射
<!-- 分页查询所有用户,通过PageHelper -->
<select id="selectAllUserByPageHelper" resultMap="userMap">
select * from t_user
</select>
⑤、测试方法
//分页查询所有用户信息,通过PageHelper
@Test
public void selectAllUserByPageHelper(){
int currPage = 2;//当前页码
int pageSize = 3;//当前页记录数量
//表示获取第2页,3条内容,默认会查询总数count
PageHelper.startPage(currPage,pageSize);
List<User> userList = mapper.selectAllUserByPageHelper();
for (User user : userList) {
System.out.println(user);
}
}
⑥、运行结果

以上只是PageHelper的简单介绍,还有更多的功能可以去参考官方文档,也可以自行百度学习。
15、Mybatis简易整合Spring框架
15.1 前言
前面的十几篇文章都单独的总结了Mybatis在开发中的相关技术,但在实际开发中一般都是和Spring进行整合开发的,而Spring框架相信大家已经非常熟悉了,通过Spring的IOC/DI,能帮助我们完成对象的创建,对象之间的依赖,并且管理对象的声明周期,而Spring的AOP也能帮助我们管理对象的事务。所以下面我们来实现Mybatis和Spring的整合,并在整合后进行简单的测试。
15.2 创建maven项目
①、项目整体目录
②、导入依赖
<!-- 添加Spring支持 -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>5.2.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
<version>5.2.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-tx</artifactId>
<version>5.2.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>5.2.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-aop</artifactId>
<version>5.2.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-aspects</artifactId>
<version>5.2.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>5.2.6.RELEASE</version>
</dependency>
<!-- Mybatis -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.6</version>
</dependency>
<!-- Mybatis-Spring -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
<version>2.0.3</version>
</dependency>
<!-- Mysql驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.21</version>
</dependency>
<!-- Druid数据库连接池 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.1</version>
</dependency>
<!-- 日志处理 -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<!-- 单元测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
15.3 编写实体类、Mapper接口以及Mapper.xml文件
①、User实体类
/**
* 用户实体类
*/
public class User implements Serializable {
private int userId;
private String userName;
private int userAge;
private Date userBirthday;
private int userSex;
private String userAddress;
//getter、setter、toString方法省略......
}
②、UserMapper接口
/**
* UserMapper接口
*/
public interface UserMapper {
//查询所有用户信息
List<User> selectAllUser();
}
③、UserMapper.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.thr.mapper.UserMapper">
<resultMap id="userMap" type="com.thr.pojo.User">
<id property="userId" column="id"/>
<result property="userName" column="username"/>
<result property="userAge" column="age"/>
<result property="userBirthday" column="birthday"/>
<result property="userSex" column="sex"/>
<result property="userAddress" column="address"/>
</resultMap>
<!-- 查询所有用户 -->
<select id="selectAllUser" resultMap="userMap">
select * from t_user
</select>
</mapper>
15.4 编写数据库连接文件和日志文件
①、db.properties
#数据库连接配置
database.driver=com.mysql.cj.jdbc.Driver
database.url=jdbc:mysql://localhost:3306/mybatis?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf-8
database.username=root
database.password=root
②、log4j.properties
log4j.rootLogger=DEBUG, Console
#Console
log4j.appender.Console=org.apache.log4j.ConsoleAppender
log4j.appender.Console.layout=org.apache.log4j.PatternLayout
log4j.appender.Console.layout.ConversionPattern=%d [%t] %-5p [%c] - %m%n
log4j.logger.java.sql.ResultSet=INFO
log4j.logger.org.apache=INFO
log4j.logger.java.sql.Connection=DEBUG
log4j.logger.java.sql.Statement=DEBUG
log4j.logger.java.sql.PreparedStatement=DEBUG
15.5 编写Mybatis全局配置文件mybatis-config.xml
这里几乎没什么可配置的,都整合到Spring的配置文件中去了。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<settings>
<!--开启日志-->
<setting name="logImpl" value="STDOUT_LOGGING" />
</settings>
</configuration>
15.6 编写Spring全局配置文件applicationContext.xml
在与Spring整合之前,我们都是在Mybatis的全局配置文件中管理数据源,并且sqlSessionFactory也是我们自己通过代码来完成注入的,但是现在与Spring整合了,这些操作都要交给Spring来管理了,所以下面我们来看一下applicationContext.xml 文件中的配置:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
https://www.springframework.org/schema/context/spring-context.xsd">
<!-- 加载classpath下的db.properties文件 -->
<context:property-placeholder location="classpath:db.properties"/>
<!-- 配置数据源 -->
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource">
<property name="driverClassName" value="${database.driver}" />
<property name="url" value="${database.url}" />
<property name="username" value="${database.username}" />
<property name="password" value="${database.password}" />
</bean>
<!-- 配置sqlSessionFactory,SqlSessionFactoryBean是用来产生sqlSessionFactory的 -->
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<!-- 加载上面配置好数据源 -->
<property name="dataSource" ref="dataSource" />
<!-- 加载mybatis的映射配置文件;XxxMapper.xml -->
<property name="mapperLocations" value="classpath:com/thr/mapper/*.xml" />
<!-- 加载mybatis的全局配置文件;mybatis-config.xml-->
<property name="configLocation" value="classpath:mybatis-config.xml"/>
<!-- 配置别名,使用包扫描,扫描com.thr.pojo包下的所有实体 -->
<property name="typeAliasesPackage" value="com.thr.pojo"/>
</bean>
<!-- 创建UserMapper接口的代理对象,这里是创建单个代理对象,不推荐这种方式,如果多个类就麻烦了
这里的org.mybatis.spring.mapper.MapperFactoryBean<T>类就是用来创建 Mapper代理对象的类 -->
<!--
<bean id="userMapper" class="org.mybatis.spring.mapper.MapperFactoryBean">
<property name="mapperInterface" value="com.thr.mapper.UserMapper"/>
<property name="sqlSessionFactory" ref="sqlSessionFactory"/>
</bean>
-->
<!-- 加载所在包名下的Mapper接口,并且为其创建代理对象,推荐 -->
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="com.thr.mapper" />
<!-- 可选,如果不写,Spring启动时候。容器中自动会按照类型去把SqlSessionFactory对象注入进来 -->
<property name="sqlSessionFactoryBeanName" value="sqlSessionFactory"></property>
</bean>
</beans>
15.7 编写测试代码与运行结果
①、测试代码
package com.thr.test;
import com.thr.mapper.UserMapper;
import com.thr.pojo.User;
import org.junit.Before;
import org.junit.Test;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import java.util.List;
public class UserMapperTest {
//创建ApplicationContext容器
private ApplicationContext applicationContext = null;
@Before
public void getApplicationContext() throws Exception {
//获取Spring容器
applicationContext = new ClassPathXmlApplicationContext("classpath:applicationContext.xml");
}
//查询所有用户
@Test
public void testSelectAllUser(){
//获取UserMapper对象
UserMapper userMapper = applicationContext.getBean("userMapper", UserMapper.class);
List<User> users = userMapper.selectAllUser();
for (User user : users) {
System.out.println(user);
}
}
}
②、运行结果
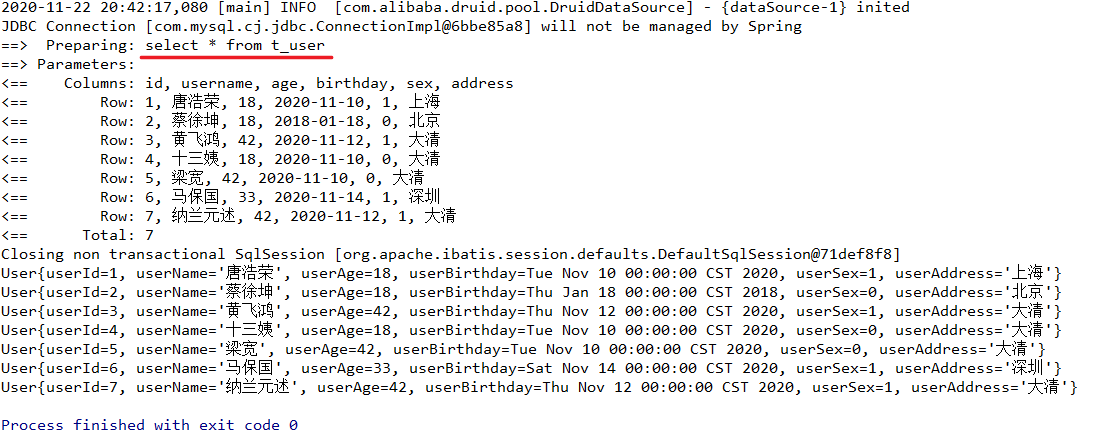
16、Mybatis运行原理
16.1 SqlSessionFactory的构建过程
16.1.1 写在前面
前面的一系列文章已经详细的介绍了Mybatis的各种使用方法,所以这章我们来更加深入的了解Mybatis,讲述一下Mybatis的内部解析与运行原理,但是这章所讲的只涉及基本的框架和核心代码,并不会面面俱到,所以本章中的一些细节将会被忽略掉,需要仔细研究的可以自行查阅相关书籍或者问度娘。虽然这章不可能让你对Mybatis的所有知识点都了解,但是当我们掌握了Mybatis的运行原理,就可以知道Mybatis是怎么运行的,也为后面大家阅读Mybatis源码奠定一点基础吧。
Mybatis的运行分为两大部分:
- SqlSessionFactory的创建过程,它主要是通过
XMLConfigBuilder将我们的配置文件读取并且缓存到Configuration对象中,然后通过Configuration来创建SqlSessionFactory对象。 - SqlSession的执行过程,这个过程是Mybatis中最复杂的,它包含了许多复杂的技术,包括反射技术和动态代理技术等,这是Mybatis底层架构的基础。
MyBatis的主要成员组件(成员):
在第一章的时候,简单的介绍了Mybatis的有哪些组件(成员),这里再次详细的介绍一下:
SqlSessionFactoryBuilder:会根据XML配置或是Java配置来生成SqlSessionFactory对象。采用建造者模式(简单来说就是分步构建一个大的对象,例如建造一个大房子,采用购买砖头、砌砖、粉刷墙面的步骤建造,其中的大房子就是大对象,一系列的建造步骤就是分步构建)。SqlSessionFactory:用于生成SqlSession,可以通过SqlSessionFactory.openSession()方法创建 SqlSession 对象。使用工厂模式(简单来说就是我们获取对象是通过一个类,由这个类去创建我们所需的实例并返回,而不是我们自己通过new去创建)。Configuration:MyBatis所有的配置信息都保存在Configuration对象之中,配置文件中的大部分配置都会存储到该类中。SqlSession:相当于JDBC中的 Connection对象,可以用 SqlSession 实例来直接执行被映射的 SQL 语句,也可以获取对应的Mapper。Executor:MyBatis 中所有的 Mapper 语句的执行都是通过 Executor 执行的,负责SQL语句的生成和查询缓存的维护 。StatementHandler:封装了JDBC Statement操作,负责对JDBC statement 的操作,如设置参数等。ParameterHandler:负责对用户传递的参数转换成JDBC Statement 所对应的数据类型。ResultSetHandler:负责将JDBC返回的ResultSet结果集对象转换成List类型的集合。TypeHandler:负责java数据类型和jdbc数据类型(也可以说是数据表列类型)之间的映射和转换。MappedStatement:作用是保存一个映射器节点<select|update|delete|insert>中的内容,主要用途是描述一条SQL语句。MappedStatement封装了Statement的相关信息,包括我们配置的SQL、SQL的id、缓存信息、resultMap、ParameterType、resultType、resultMap等重要配置内容等。Mybatis可以通过它来获取某条SQL配置的所有信息。它还有一个非常重要的属性是SqlSource。SqlSource:负责提供BoundSql对象的地方。作用就是根据上下文和参数解析生成真正的SQL,然后将信息封装到BoundSql对象中,并返回。我们在Mapper映射文件中定义的SQL,这个SQL可以有占位符和一系列参数的(如select * from t_user where id = #{id}),也可以是动态SQL的形式,这里的SqlSource就是用来将它解析为真正的SQL(如:select * from t_user where id = ?)。注意:SqlSource是一个接口,而不是一个实现类。对它而言有这么几个重要的实现类:DynamicSQLSource、ProviderSQLSource、RawSQLSource、StaticSQLSource。例如前面动态SQL就采用了DynamicSQLSource配合参数解析解析后得到的。它算是起到生成真正SQL语句的一个中转站吧。BoundSql:它是一个结果对象,它是通过SqlSource来获取的。作用是通过SqlSource对映射文件的SQL和参数联合解析得到的真正SQL和参数。什么意思呢?就是BoundSql包含了真正的SQL语句(由SqlSource生成的,如select * from t_user where id = ?),而且还包含了SQL语句增删改查的参数,而SqlSource是负责将映射文件中定义的SQL生成真正的SQL语句(算是映射文件中的SQL生成真正的SQL语句的中转站),这里搞得我有点昏

 。BoundSql有3个常用的属性:sql、parameterObject、parameterMappings,这里就不做讨论了,通过名字应该很容易理解它的用处。
。BoundSql有3个常用的属性:sql、parameterObject、parameterMappings,这里就不做讨论了,通过名字应该很容易理解它的用处。
以上主要组件(成员)在一次数据库操作中基本都会涉及。
注:图片来自《MyBatis 插件之拦截器(Interceptor)》我自己对其简单的加工了一下。
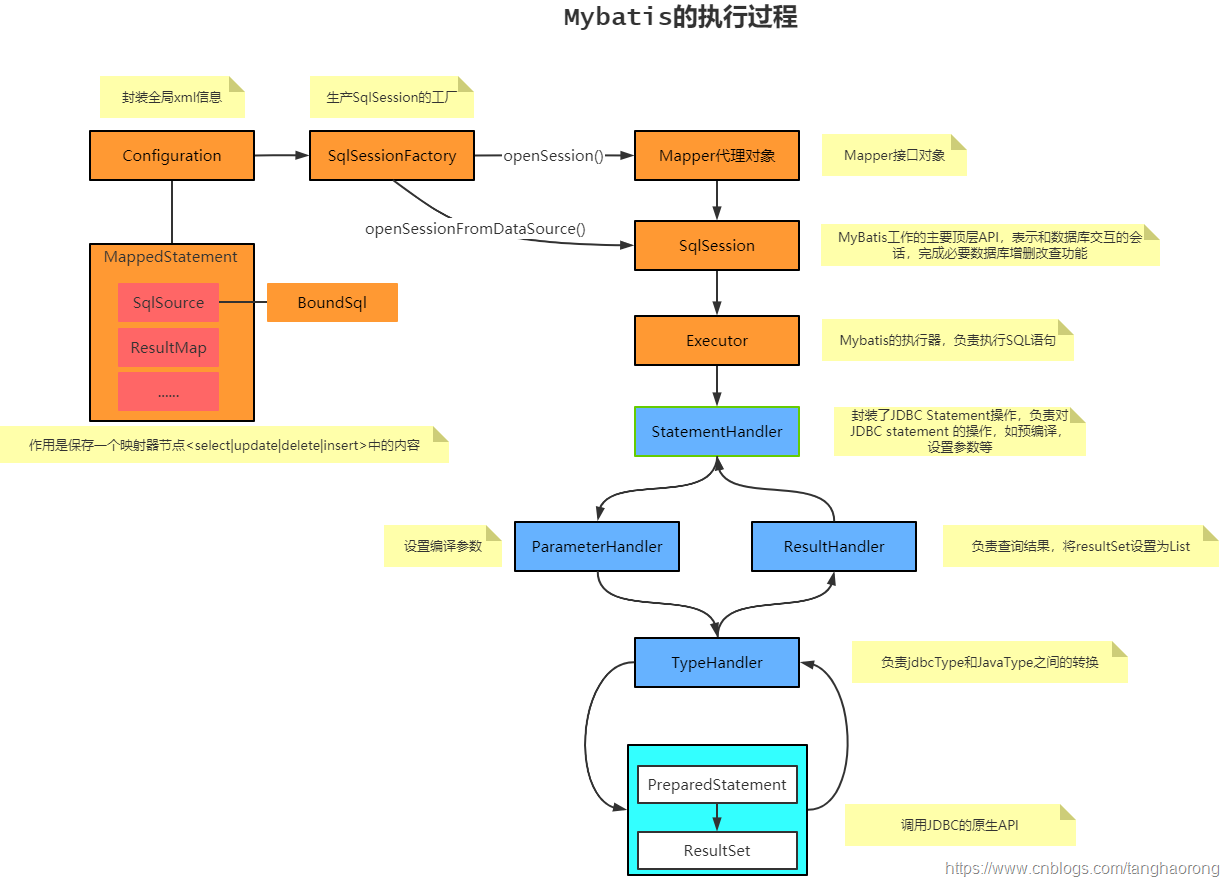
16.1.2 SqlSessionFactory的构建过程
SqlSessionFactory 是MyBatis的核心类之一, 其最重要的功能就是提供创建MyBatis的核心接口SqlSession,所以我们要先创建SqlSessionFactory,它是通过Builder(建造者)模式来创建的,所以在Mybatis中提供了SqlSessionFactoryBuilder类。其构建分为两步。
- 第 1 步: 通过 org.apache.ibatis.builder.xml.XMLConfigBuilder 解析配置的XML文件,读出所配置的参数,并将读取的内容存入org.apache.ibatis.session.Configuration类对象中。而Configuration采用的是单例模式,几乎所有的 MyBatis 配置内容都会存放在这个单例对象中,以便后续将这些内容读出。
- 第2步:使用Confinguration对象去创建SqlSessionFactory。MyBatis 中的 SqlSessionFactory 是一个接口,而不是一个实现类,为此MyBatis提供了一个默认的实现类org.apache.ibatis.session.defaults.DefaultSqlSessionFactory。在大部分情况下都没有必要自己去创建新的SqlSessionFactory 实现类,而是由系统创建。
这种创建的方式就是一种 Builder 模式,对于复杂的对象而言,使用构造参数很难实现。这时使用一个类(比如 Configuration)作为统领,一步步地构建所需的内容,然后通过它去创建最终的对象(比如 SqlSessionFactory),这样每一步都会很清晰,这种方式值得大家学习,并且在工作中使用。
下面我们就来学习一下SqlSessionFactory是如何构建的。程序入口代码如下:
//1、加载 mybatis 全局配置文件
InputStream is = MybatisTest.class.getClassLoader().getResourceAsStream("mybatis-config.xml");
//InputStream is = Resources.getResourceAsStream("mybatis-config.xml");
//2、创建SqlSessionFactory对象
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(is);
//3、根据 sqlSessionFactory 来创建sqlSession 对象
SqlSession sqlSession = sqlSessionFactory.openSession();
//4、创建Mapper接口的的代理对象,getMapper方法底层会通过动态代理生成UserMapper的代理实现类
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
①、首先会执行SqlSessionFactoryBuilder类中的build(InputStream inputStream)方法。
//最初调用SqlSessionFactoryBuilder类中的build
public SqlSessionFactory build(InputStream inputStream) {
//然后调用了重载方法
return build(inputStream, null, null);
}
②、上面的方法中调用了另一个重载的build方法。
//调用的重载方法
public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) {
try {
//XMLConfigBuilder是专门解析mybatis的配置文件的类
XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);
//又调用了一个重载方法。parser.parse()的返回值是Configuration对象,这是解析配置文件最核心的方法,非常重要!
return build(parser.parse());
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error building SqlSession.", e);
} finally {
ErrorContext.instance().reset();
try {
inputStream.close();
} catch (IOException e) {
// Intentionally ignore. Prefer previous error.
}
}
}
可以发现其内部定义了一个XMLConfigBuilder对象,然后通过这个对象调用自身的parse()方法对配置文件进行解析,这个parse()方法的返回值为Configuration对象,最后将返回的Configuration对象作为参数调用build()方法,从而完成SqlSessionFactory的创建。所以我们这里需要注意的就是这两行代码:XMLConfigBuilder对象和调用build(parser.parse())方法返回SqlSessionFactory。
(1)、XMLConfigBuilder从类名就可以看出,这是用来解析XML配置文件的类,其父类为BaseBuilder。我们来看一下这个类构造方法:
通过查看XMLConfigBuilder中构造方法的源码,可以得知XML配置文件最终是由org.apache.ibatis.parsing.XPathParser封装的XPath解析的。第一个构造方法通过XPathParser构造方法传入我们读取的XML流文件、Properites流文件和environment等参数得到了一个XpathParser实例对象parser,这里parser已包含全局XML配置文件解析后的所有信息,然后再将parser作为参数传给XMLConfigBuilder构造方法。其中XMLConfigBuilder 构造方法还调用了父类BaseBuilder的构造方法BaseBuilder(Configuration),这里传入了一个Configuration对象,用来初始化Configuration对象,我们来继续进入看一下:
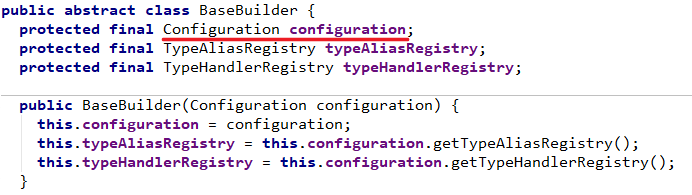
注意:这里的重点是创建了一个Configuration 对象,并且完成了初始化,这个Configuration是用来封装所有配置文件的类,所以非常非常重要!!!同时还初始化了别名和类型处理器,所以我们默认可以使用这些特性。额外这个父类BaseBuilder还包含了MapperBuilderAssistant, SqlSourceBuilder, XMLConfigBuilder, XMLMapperBuilder, XMLScriptBuilder, XMLStatementBuilder等子类,这些子类都是用来解析MyBatis各个配置文件,他们通过BaseBuilder父类共同维护一个全局的Configuration对象。只是XMLConfigBuilder的作用就是解析全局配置文件,调用BaseBuilder其他子类解析其他配置文件,生成最终的Configuration对象。
(2)、然后我们重点来看一下parse()方法,这是最核心的方法。进入parse.parse()方法:
public Configuration parse() {
//用于标识XMLConfigBuilder
if (parsed) {
throw new BuilderException("Each XMLConfigBuilder can only be used once.");
}
parsed = true;
//用于解析MyBatis全局配置文件<configuraction>标签中的相关配置
parseConfiguration(parser.evalNode("/configuration"));
return configuration;
}
注意:XMLConfigBuilder的 parsed 属性,默认值是false(上面的构造方法中可以看到),它是用来标识XMLConfigBuilder对象的。当创建了一个XMLConfigBuilder对象,并进行解析配置文件的时候,parsed的值就变成了true。如果第二次进行解析的时候就会抛出BuilderException异常,提示每个XMLConfigBuilder只能使用一次,从而确保了Configuration对象是单例的。因为Configuration对象是通过XMLConfigBuilder的parse()去解析的。
Configuration对象的具体解析是通过parseConfiguration(XNode root)方法来完成的。这个方法用于解析MyBatis 全局配置文件与SQL 映射文件中的相关配置,参数中"`/configuration" 就是对应全局配置文件中的
private void parseConfiguration(XNode root) {
try {
// issue #117 read properties first
propertiesElement(root.evalNode("properties"));
Properties settings = settingsAsProperties(root.evalNode("settings"));
loadCustomVfs(settings);
loadCustomLogImpl(settings);
typeAliasesElement(root.evalNode("typeAliases"));
pluginElement(root.evalNode("plugins"));
objectFactoryElement(root.evalNode("objectFactory"));
objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));
reflectorFactoryElement(root.evalNode("reflectorFactory"));
settingsElement(settings);
// read it after objectFactory and objectWrapperFactory issue #631
// 设置事务的相关配置与数据源
environmentsElement(root.evalNode("environments"));
databaseIdProviderElement(root.evalNode("databaseIdProvider"));
typeHandlerElement(root.evalNode("typeHandlers"));
// 解析<mappers>标签中的信息
mapperElement(root.evalNode("mappers"));
} catch (Exception e) {
throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
}
}
以上操作会把MyBatis 全局配置文件与SQL 映射文件中每一个节点的信息都读取出来,然后保存在Configuration单例中,Configuration分别对以下内容做出了初始化:properties 属性 ;typeAliases 类型别名;plugins 插件;objectFactory 对象工厂;settings 设置;environments 环境;databaseIdProvider 数据库厂商标识;typeHandlers 类型处理器;mappers 映射器等。这其中还涉及到了很多的方法,在这里就不一 一讲述了,大家可以自己进行查看。这里主要来看一下mappers映射器,因为我们需要频繁的访问它,因此它算是这里最重要的内容了吧。进入mapperElement(XNode parent):
private void mapperElement(XNode parent) throws Exception {
if (parent != null) {
// 遍历所有mappers节点下的所有元素
for (XNode child : parent.getChildren()) {
// 如是package引入的方式
if ("package".equals(child.getName())) {
String mapperPackage = child.getStringAttribute("name");
configuration.addMappers(mapperPackage);
// 如果是mapper引入的方式
} else {
String resource = child.getStringAttribute("resource");
String url = child.getStringAttribute("url");
String mapperClass = child.getStringAttribute("class");
// 如果是resource
if (resource != null && url == null && mapperClass == null) {
ErrorContext.instance().resource(resource);
InputStream inputStream = Resources.getResourceAsStream(resource);
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments());
mapperParser.parse();
// 如果是url
} else if (resource == null && url != null && mapperClass == null) {
ErrorContext.instance().resource(url);
InputStream inputStream = Resources.getUrlAsStream(url);
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, url, configuration.getSqlFragments());
mapperParser.parse();
// 如果是mapperClass
} else if (resource == null && url == null && mapperClass != null) {
Class<?> mapperInterface = Resources.classForName(mapperClass);
// 添加至Configuration对象中
configuration.addMapper(mapperInterface);
// 否则抛出异常
} else {
throw new BuilderException("A mapper element may only specify a url, resource or class, but not more than one.");
}
}
}
}
}
上面的代码遍历mappers标签下所有子节点,其中:
- 如果遍历到package子节点,是以包名引入映射器,则将该包下所有Class注册到Configuration的mapperRegistry中。
- 如果遍历到mapper子节点的class属性,是以class的方式引入映射器,则将制定的Class注册到注册到Configuration的mapperRegistry中。
- 如果遍历到mapper子节点的resource或者url属性,是通过resource或者url方式引入映射器,则直接对资源文件进行解析:
所以在通过resource或者url方式引入映射器的代码中,可以注意到定义了一个XMLMapperBuilder 类,然后调用了parse()方法,这目的就很明显了,如果遍历到是以mapper子节点的resource或者url属性方式引入的映射器,那么所有的Sql映射文件都是用XMLMapperBuilder 类的parse()方法来进行解析。
注意:其实到这里就已经可以不用往下看了,如果你想更加深入了解一下,那就继续往下滑吧!!!
我们先分别来看一下resource或者url属性方式引入映射器的构造方法(它两共用一个):
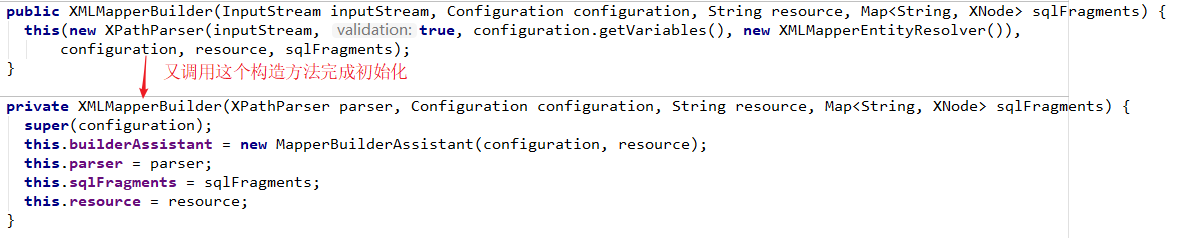
XPathParser将mapper配置文件解析成Document对象后封装到一个XPathParser对象,再将XPathParser对象作为参数传给XMLMapperBuilder构造方法并构造出一个XMLMapperBuilder对象,XMLMapperBuilder对象的builderAssistant字段是一个MapperBuilderAssistant对象,同样也是BaseBuilder的一个子类,其作用是对MappedStatement对象进行封装。
有了XMLMapperBuilder对象后,就可以进入解析mapper映射文件的过程,进入parse()方法:
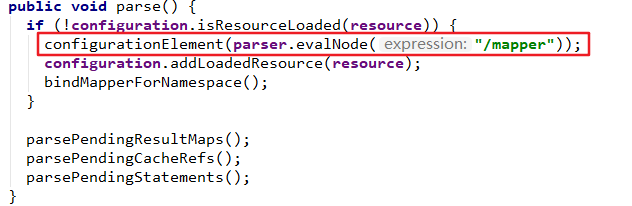
调用XMLMapperBuilder的configurationElement方法,对mapper映射文件进行解析
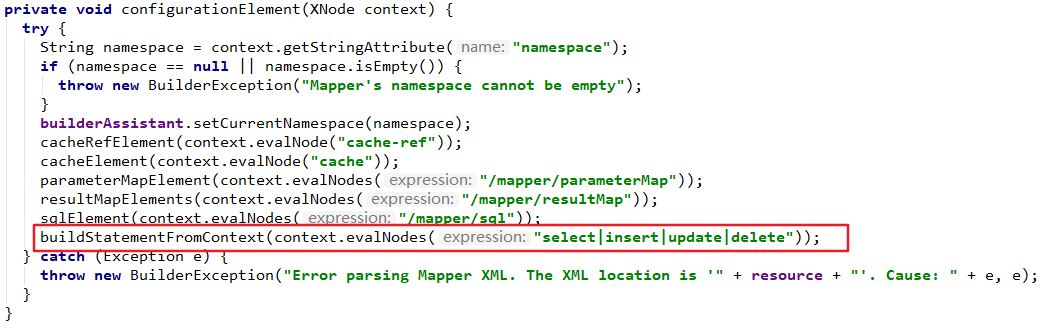
mapper映射文件必须有namespace属性值,否则抛出异常,将namespace属性保存到XMLMapperBuilder的MapperBuilderAssistant对象中,以便其他方法调用。
该方法对mapper映射文件每个标签逐一解析并保存到Configuration和MapperBuilderAssistant对象中,最后调用buildStatementFromContext方法解析select、insert、update和delete节点。
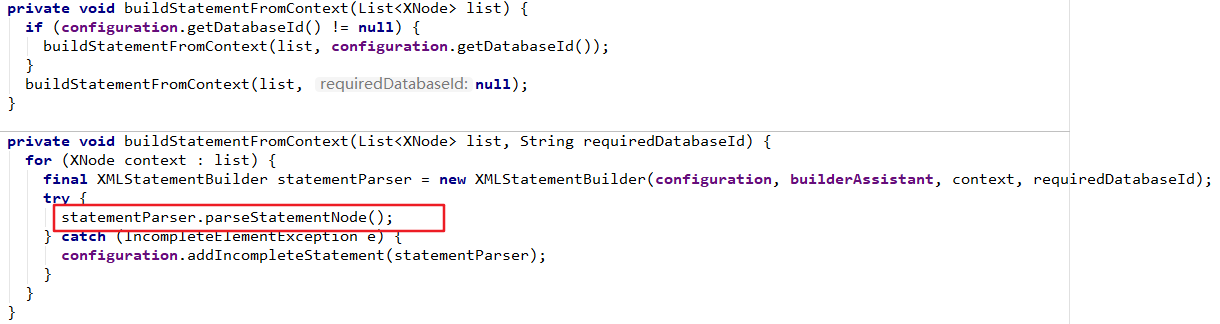
buildStatementFromContext方法中调用XMLStatementBuilder的parseStatementNode()方法来完成解析。


注意:解析所有的Sql语句会封装一个MappedStatement中,MappedStatement中包含了许多我们配置的SQL、SQL的id、缓存信息、resultMap、ParameterType、resultType、resultMap等重要配置内容。最重要的是它还有一个属性sqlSource。
通过上面的方法可以看到SQL语句封装到一个SqlSource对象,SqlSource是个接口,如果是动态SQL就创建DynamicSqlSource实现类,否则创建StaticSqlSource实现类。

SqlSource是MappedStatement的一个属性,它只是一个接口。它的主要作用是根据上下文和参数解析生成需要的Sql。
SqlSource接口中有一个getBoundSql方法,这个方法就是用来获取BoundSql的:

SqlSource接口中还有如下这几个重要的实现类:

BoundSql是一个结果集对象,也就是SqlSource通过对映射文件的SQL和参数解析得到的真正的SQL和参数。
注:MappedStatement、SqlSource和BoundSql在最上面已经详细的介绍了,自行滑到上面查看。
③、Mybatis的配置文件解析完成后,会将信息保存在Configuration对象中,之后通过XMLConfigBuilder类中的parse()方法返回,然后再将Configuration对象作为参数传递到build(Configuraction config)方法。进入这个build方法:
// SqlSessionFactoryBuilder另一个build方法
public SqlSessionFactory build(Configuration config) {
return new DefaultSqlSessionFactory(config);
}
可以看到最后接着返回一个DefaultSqlSessionFactory对象,DefaultSqlSessionFactory就是SqlSessionFactory的一个实现类,到这里SqlSessionFactory对象就完成了创建的全部过程。
SqlSessionFactory构建过程中的时序图:
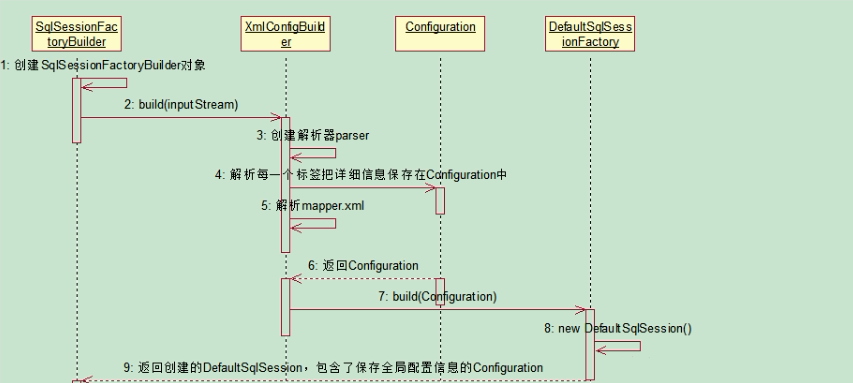
参考链接:
- 《Java EE 互联网轻量级框架整合开发》
- https://www.cnblogs.com/abcboy/p/9618419.html
- https://blog.csdn.net/codejas/article/details/79570068
- https://blog.csdn.net/qq_37776015/article/details/90249931
16.2 SqlSession的构建过程
16.2.1 SqlSession的构建过程
在上一章,详细的介绍了SqlSessionFactory的构建过程,它是用来获取SqlSession对象的,所以本章节就主要讲述SqlSession的构建过程。
程序代码的入口:
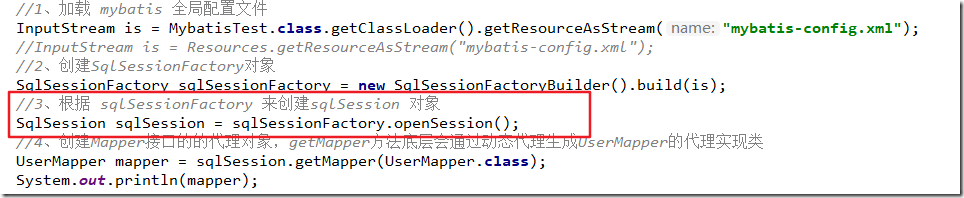
我们知道SqlSession对象是通过SqlSessionFactory的openSession()方法获取的,所以我们先来看一下SqlSessionFactory接口中的方法:
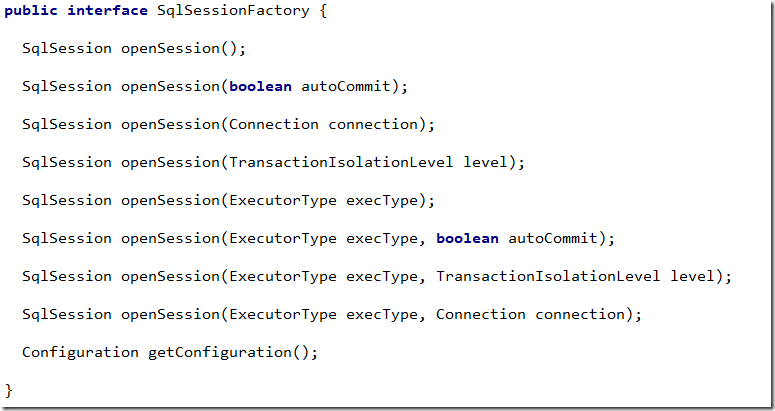
可以发现SqlSessionFactory接口提供一系列重载的openSession方法,其参数如下(这些参数的意义会在后面介绍):
- boolean autoCommit:是否开启JDBC事务的自动提交,默认为false。
- Connection:提供连接。
- TransactionIsolationLevel:定义事务隔离级别。
- ExecutorType:定义执行器类型。
SqlSessionFactory接口的实现类为DefaultSqlSessionFactory类。所以我们去DefaultSqlSessionFactory实现类中查看重写的openSession()方法:
//以无参的openSession()方法为例
public SqlSession openSession() {
return openSessionFromDataSource(configuration.getDefaultExecutorType(), null, false);
}
通过查看其它重写的方法,会发现最终都调用了openSessionFromDataSource方法,所以继续进入方法:
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
// 获取Configration全局配置中的environment的配置
final Environment environment = configuration.getEnvironment();
// 通过environment配置构建transactionFactory对象
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
// 从工厂中获取一个事务实例
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
// 通过configuration构建Executor执行器对象
final Executor executor = configuration.newExecutor(tx, execType);
// 返回SqlSession的默认实现类DefaultSqlSession
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
上面代码中有一行是通过configuration.newExecutor(tx,execType)来构建Executor执行器对象,这一步非常重要,因为MyBatis 中所有的 Mapper 语句的执行都是通过 Executor 来执行的,它负责SQL语句的生成和查询缓存的维护 。所以我们看一下它是怎么创建的,这里调用了Configuration类中newExecutor()方法。
// ====== Configuration 类中的方法 ======
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
// 定义Executor执行器
Executor executor;
// 判断执行器的类型,根据传入executorType参数
// BatchExecutor:批量执行器
// ReuseExecutor:会执行预处理的执行器
// SimpleExecutor:简单的执行器
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
// 如果没有配置,默认就为SimpleExecutor
executor = new SimpleExecutor(this, transaction);
}
//如果开启了二级缓存,则使用CachingExecutor 来包装executor,
//在查询之前都会先查询缓存中是否有对应的数据,包装的过程使用了装饰者模式
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
// 最后使用每个拦截器重新包装executor并返回
executor = (Executor) interceptorChain.pluginAll(executor);
//返回创建好的Executor执行器
return executor;
}
注意(这里了解就好):executor = (Executor) interceptorChain.pluginAll(executor);这个是Mybatis中的插件,它将构建一层层的代理对象,可以在执行真正的Executor的方法前,执行配置在插件中的方法对核心代码进行修改,所以不要轻易使用插件,这里用的是责任链模式。Mybatis在实例化Executor、ParameterHandler、ResultSetHandler、StatementHandler四大接口对象的时候都是调用interceptorChain.pluginAll() 方法插入进去的。其实就是循环执行拦截器链所有的拦截器的plugin() 方法。
Executor 对象创建完之后会以参数的形式传入DefaultSqlSession的构造方法中,从而完成SqlSession对象的创建并且返回。
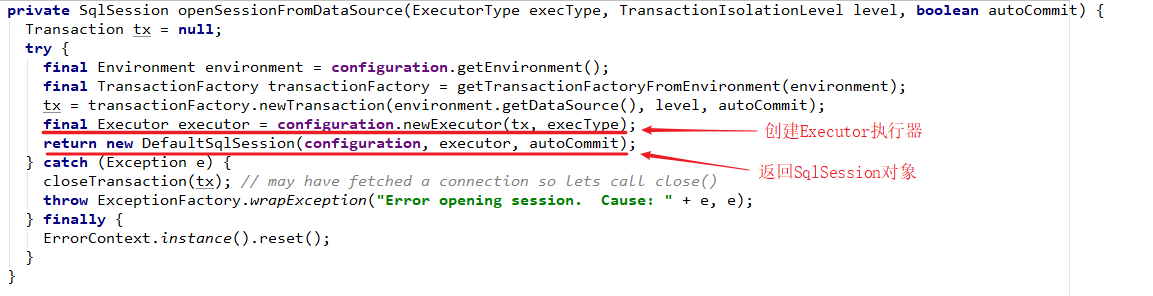
至此SqlSession对象的创建过程也就结束了。
SqlSession对象构建过程中的时序图:
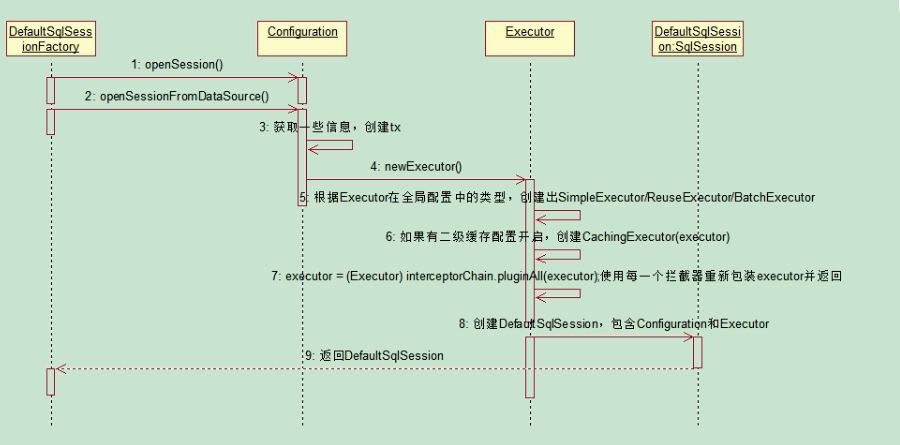
2、重载的openSession方法参数介绍
上面程序入口我们调用的是无参数的openSession()方法,那么其它重载的方法有什么用呢?这里来介绍一下有参方法中的参数含义,有四类分别为。
- boolean autoCommit:是否开启JDBC事务的自动提交,默认为false。
- Connection:提供连接。
- TransactionIsolationLevel:定义事务隔离级别。
- ExecutorType:定义执行器类型。
①、boolean autoCommit:是否自动提交事物,默认为false。
如果为true就自动提交事务,后面就不要写commit()方法提交了。
②、TransactionIsolationLevel :事务隔离级别类,它是一个枚举类型。
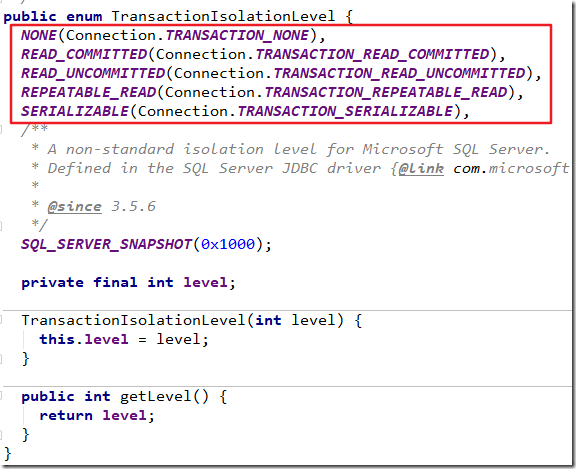
可以发现默认五种隔离级别:
- NONE(Connection.TRANSACTION_NONE):无隔离级别
- READ_COMMITTED(Connection.TRANSACTION_READ_COMMITTED):读取提交内容
- READ_UNCOMMITTED(Connection.TRANSACTION_READ_UNCOMMITTED):读取未提交内容
- REPEATABLE_READ(Connection.TRANSACTION_REPEATABLE_READ):可重复读
- SERIALIZABLE(Connection.TRANSACTION_SERIALIZABLE):可串行化
③、Connection:提供连接对象。
如果使用这种方式会优先使用这里面的数据库连接对象。如:

④、ExecutorType :执行器类型,它是一个枚举类型。
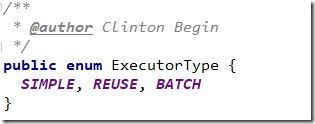
它主要用来判断使用哪种类型的执行器Executor,因为SqlSession是真正来执行Java与数据库交互的对象,提供了查询(query)、更新(update)等方法,主要有三种类型:
- SIMPLE:简易执行器,如果不配置类型,就是默认执行器
- REUSE:能过执行重用预处理语句的执行器
- BATCH:执行器重用语句和批量更新,批量专用的执行
在上面创建Executor执行器的代码中已经进行了判断。所以这里就不再多说了。

-----------------------------------------------------------------------------
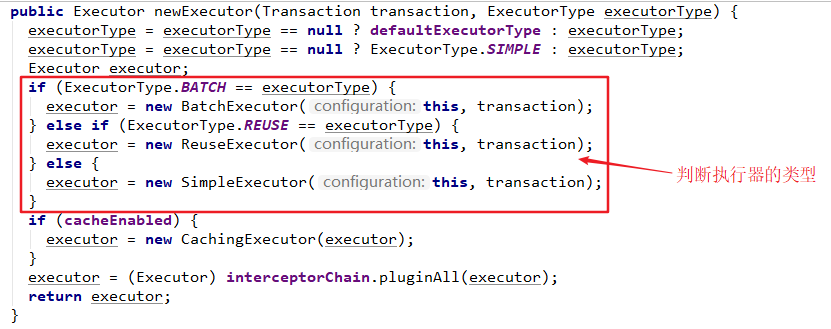
16.3 Mapper接口的动态代理过程
16.3.1 写在前面
前两章分别介绍了SqlSessionFactory和SqlSession的构建过程,然后就可以通过SqlSession来获取Mapper对象了,所以这章来学习Mapper接口是如何通过动态代理来创建对象的。
16.3.2 Mapper动态代理
①、程序入口:
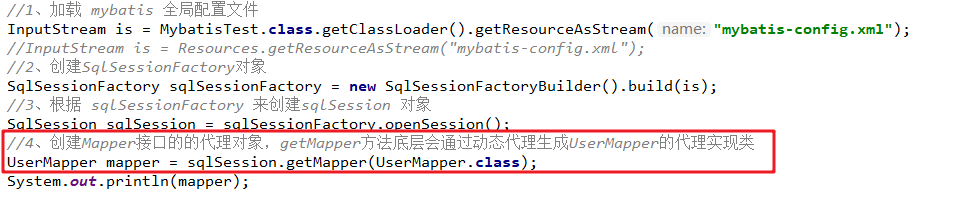
②、SqlSession的实现类为DefaultSqlSession,所以进入DeaultSqlSession类找到重写的getMapper()方法。

可以发现它明显是调用了Configuration对象中的getMapper()方法来获取对应的接口对象。
③、所以点击进入Configuration类找到对应的getMapper()方法。

可以发现这里也是将工作继续交到MapperRegistry的getMapper()的方法中,所以我们继续向下进行。
④、点击进入MapperRegistry类找到getMapper()方法。

上面的代码中MapperProxyFactory对象是通过knownMappers来获取的,它是一个HashMap,这个knownMapper的定义:
⑤、通过上面可以发现是使用MapperProxyFactory来生成代理类,所以进入MapperProxyFactory的newInstance()方法中。

注意:这里调用了两个newInstance()方法,上面的代码中进入后先调用第二个newInstance方法并创建MapperProxy代理对象,所以这里的重点是关注这个类。然后再去调用第一个newInstance方法并将创建好的MapperProxy代理对象传入进去,根据该对象创建代理类并返回。所以到这里已经得到需要的代理类了,但是我们的代理类所做的工作还得继续向下看MapperProxy类。
⑥、找到MapperProxy类,这个类非常重要。可以发现这个类实现了InvocationHandler接口,因为JDK的动态代理必须实现这个接口,只要类实现了InvocationHandler接口的类最终都会执行invoke()方法,所以我们重点关注重写的invoke()方法。
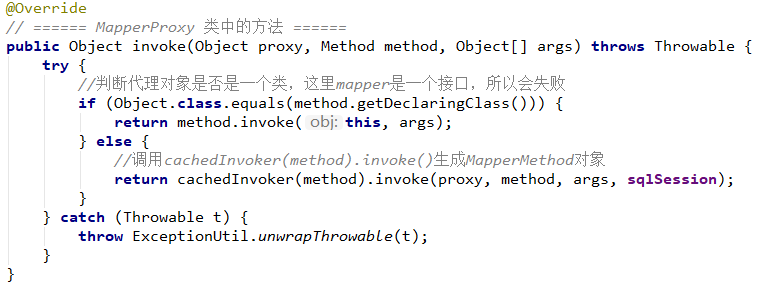
invoke()方法中首先判断代理对象是不是一个类,这里的Mapper代理对象是一个接口,不是一个类,所有会调用cachedInvoker(method).invoke()方法来生成MapperMethod对象,它是用来描述Mapper接口里面一个方法的内容的。有点类似于Spring中的BeanDefinition类。(MapperMethod对象下面会有介绍)。
下面我们来看看这个MapperMethod是如何生成的。它是调用了cachedInvoker(method).invoke()方法来生成的(注意:这里是一个方法链,先是调用了cachedInvoker(method),然后再调用的invoke()),cachedInvoker(method)这个方法就不仔细看了,它的返回值为MapperMethodInvoker对象,这个类是MapperProxy类中定义的一个内部接口,并且定义了内部实现类,我们重点要看的是调用invoke()方法,如下。
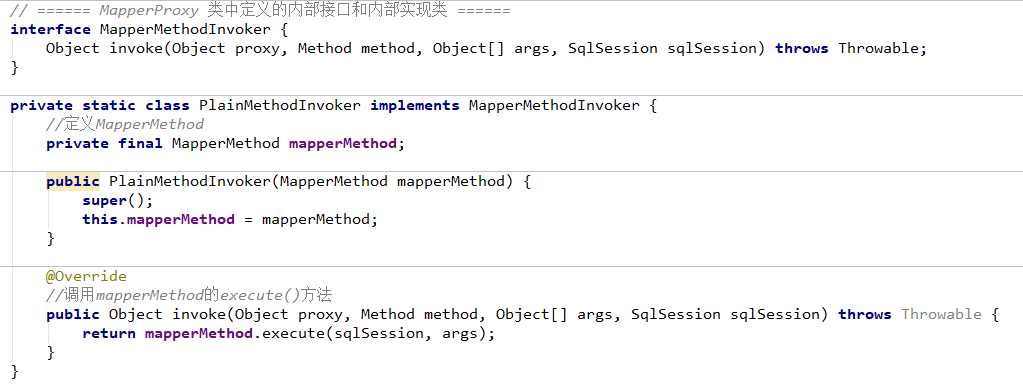
可以发现这里定义了MapperMethod对象,并且通过内部实现类重写的invoke()方法调用了mapperMethod.execute()方法,这个execute()方法是具体执行操作的方法,然后将结果返回。
⑦、所以我们来具体看看MapperMethod类。注意:我们首先需要知道这个MapperMethod类是干什么的?它用来描述Mapper接口里面一个方法的内容的,有点像Spring中的BeanDefinition。MapperMethod类是整个代理机制的核心类,它对SqlSession中的操作进行了封装使用,主要的功能是执行SQL的相关操作,例如执行sqlSession.selectList操作。该类里面定义了两个内部类分别为:SqlCommand(Sql命令)和MethodSignature(方法签名),其中SqlCommand听名字就知道是用来封装SQL命令的,是的,它是用来封装CRUD操作,也就是我们在xml中配置的操作的节点,每个节点都会生成一个MappedStatement类。另一个MethodSignature用来封装方法的参数以及返回类型。MapperMethod在初始化时会实例化两个组件SqlCommand(Sql命令)和MethodSignature(方法签名),必须同时给这两个组件提供参数:Mapper的接口路径(mapperInterface),待执行的方法(method),配置的Configuration。然后通过获取SqlCommand中的执行类型,MapperMethod才知道该Mapper接口将要执行什么样的操作。
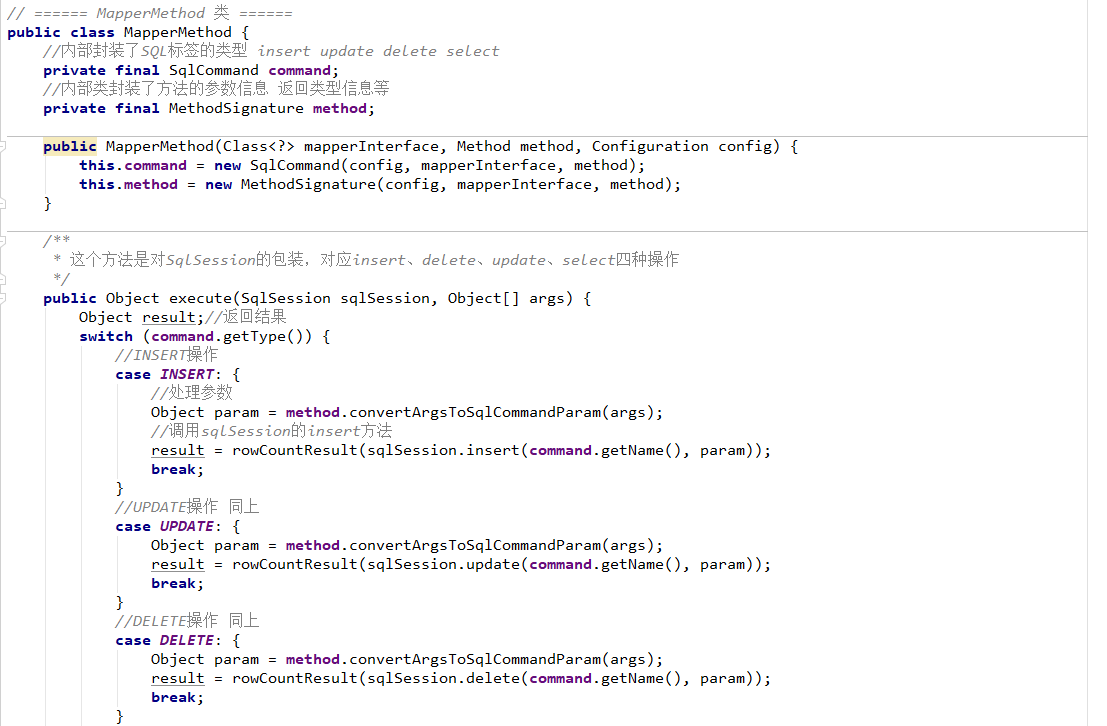
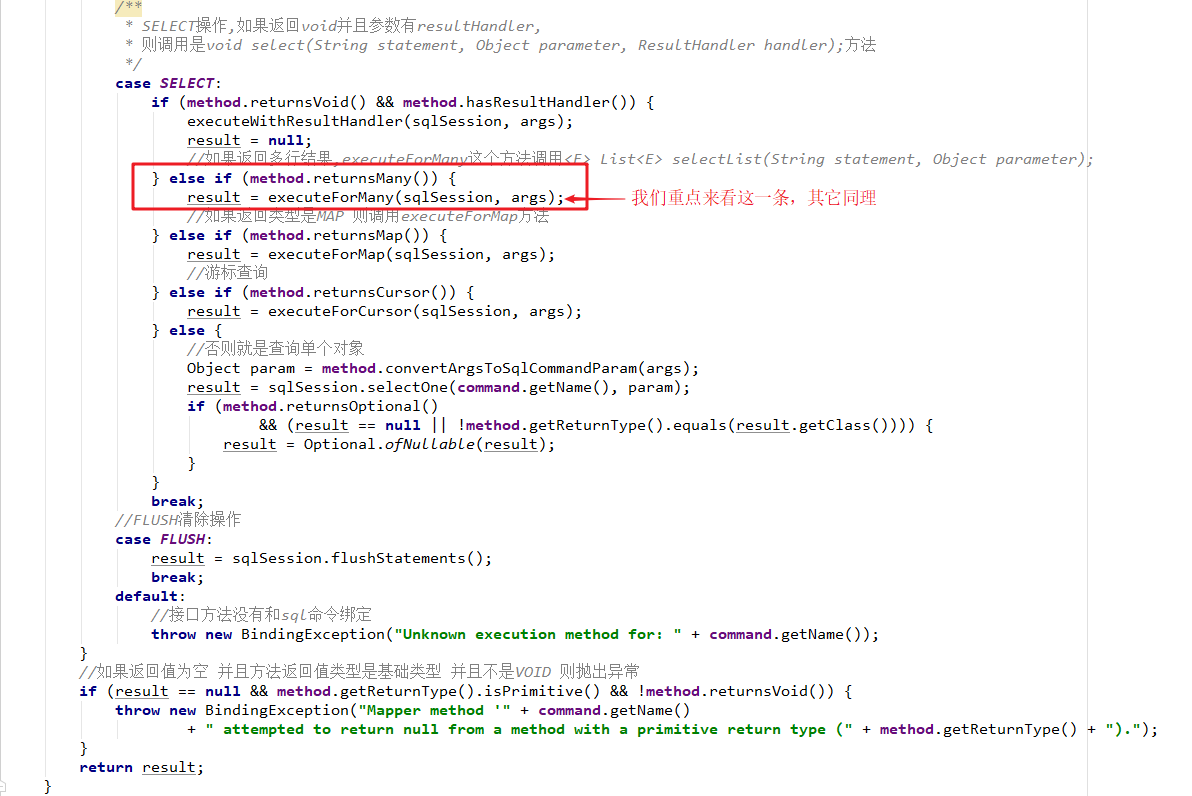
⑧、我们重点来看一下execute()方法中属性为SELECT时调用的executeForMany(SqlSession sqlSession, Object[] args)方法,这个方法表示查询多条数据。
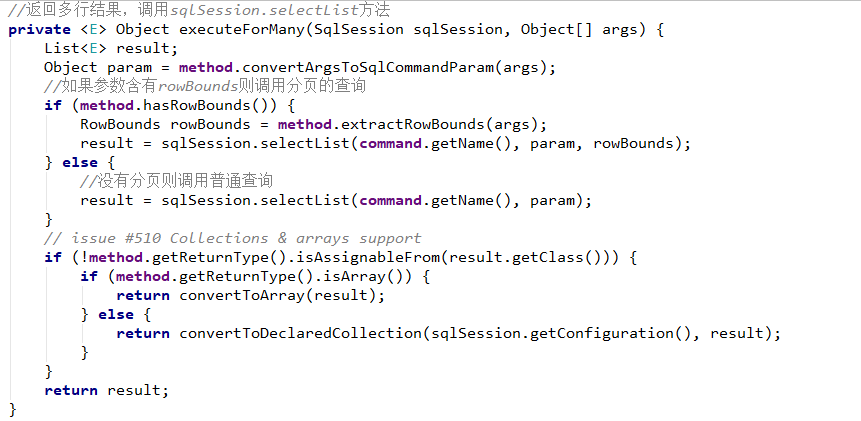
这是查询多条记录的一个方法,从上面的方法可以看到,虽然在SELECT操作中,是调用了MapperMethod中的方法,但本质上仍是通过Sqlsession下的selectList()方法实现的,而其它增删改查都是类似的。最后经过一大圈的代理又回到了原地,这就是整个动态代理的实现过程了。同时我们可以看到执行的参数是通过command.getName()来获取的,所以继续来跟踪command.getName()是怎么来的,这里是SQLCommand的内容。
⑨、MapperMethod的内部类——SqlCommand,它封装了具体执行的动作。
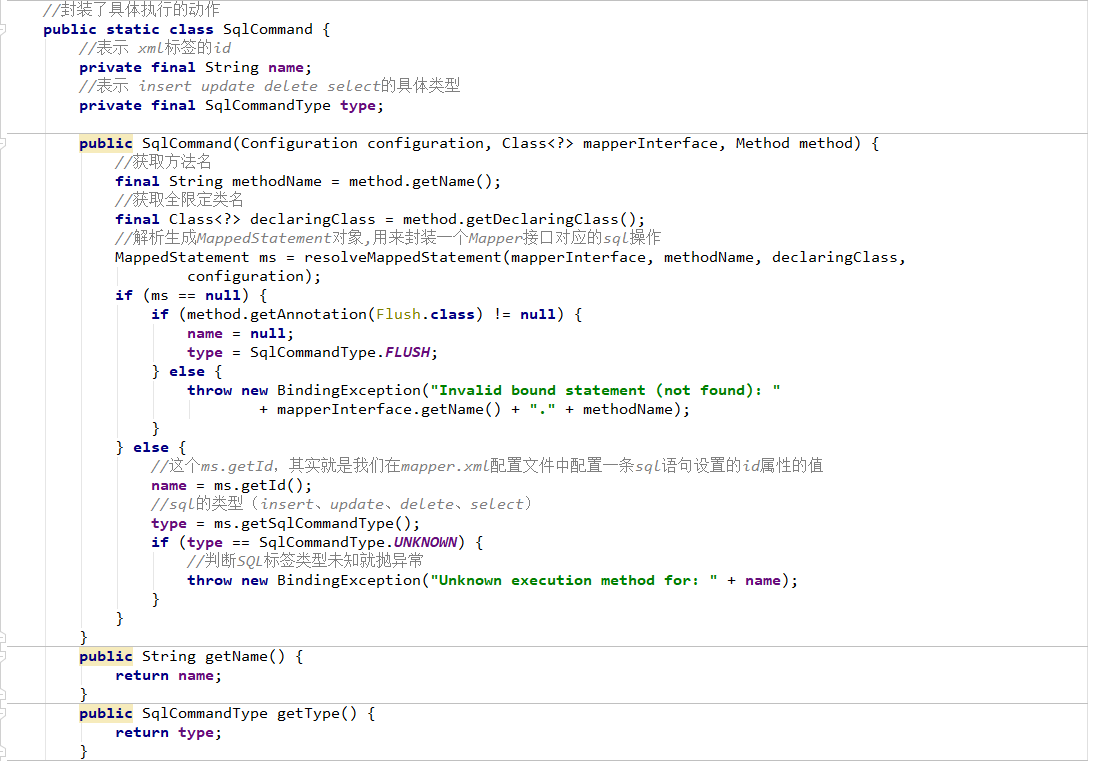
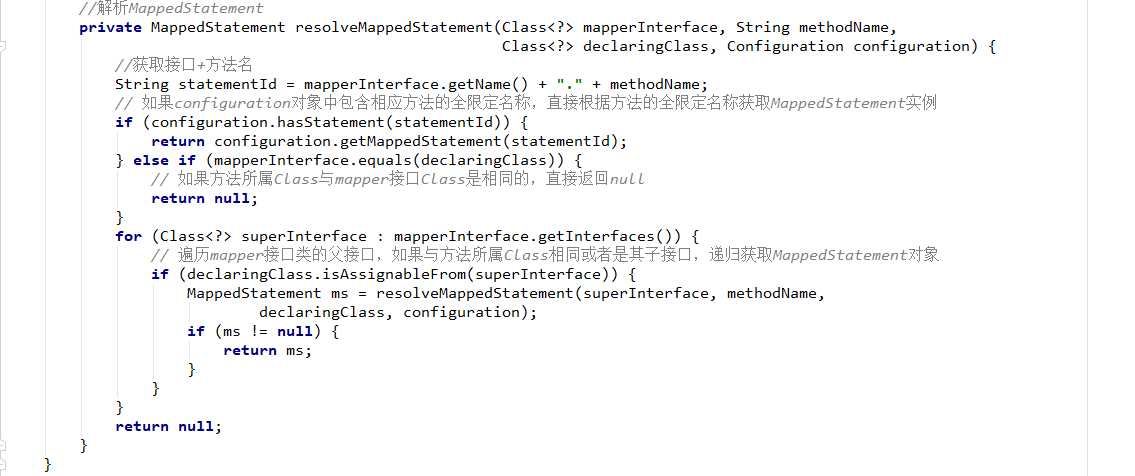
首先是获取了方法名和类名,然后调用了resolveMappedStatement()方法来解析生成MappedStatement对象。所以我们重点来看看这个解析的方法,进入方法后可以看到首先就是构建了statementId,注意到这个id是由接口名字+方法名字组成的。接着往下走,发现configuration.getMappedStatement(statementId);这句话,参数传入的是statementId,也就是说要找的MappedStatement并不是new出来的,而是通过statementId从Configuration类对象中get出来的。也就是说很早之前MappedStatement在很早之前就已经被初始化,并且放到Configuration对象里面,是的,我们的MappedStatement在SqlSessionFactory构建的时候就已经封装完成了,它包含了一条SQL语句的所有信息,MappedStatement本身是一个Map,它的可以为接口名字+方法名字组成的,所以这里我们可以根据statementId来获取MappedStatement对象。最后根据获取的MappedStatement对象来初始化name和type的值。
⑩、MapperMethod的内部类——MethodSignature,它主要封装了Mapper接口中方法的参数类型、返回值类型等信息。
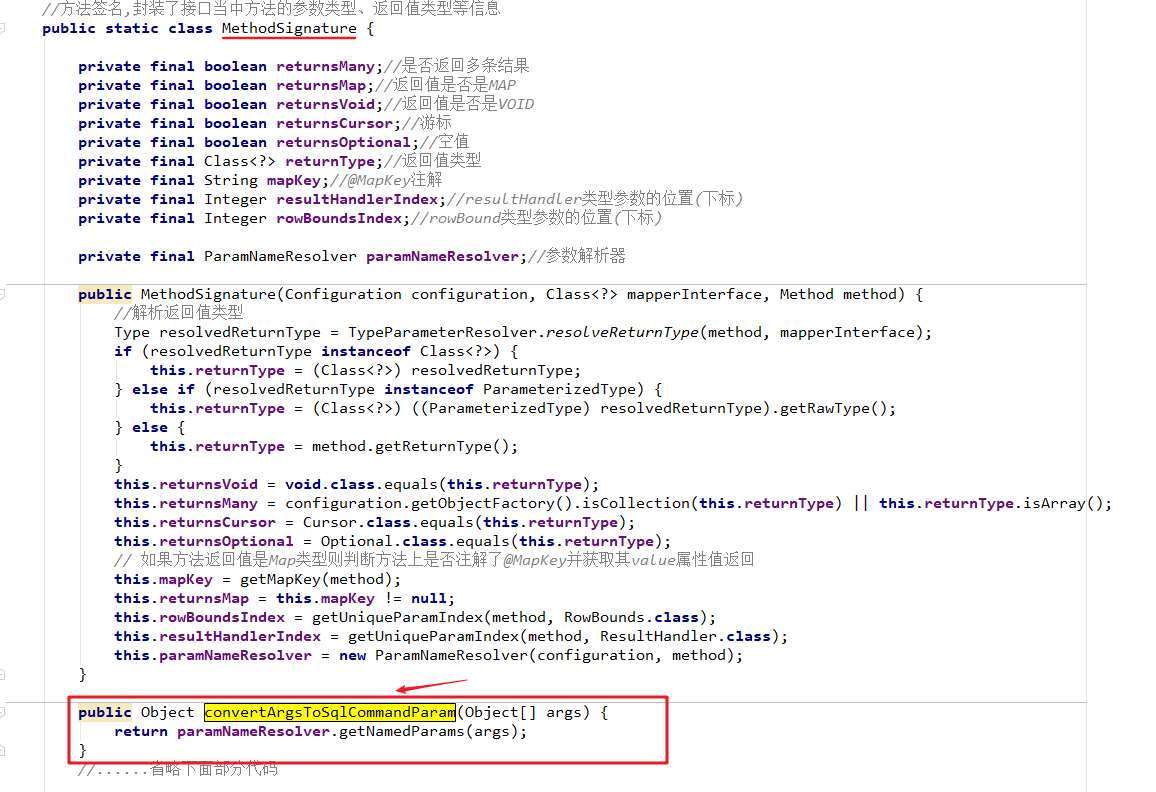
这里主要是对Mapper接口中的方法进行解析处理并且封装,它是通过参数解析器ParamNameResolver来完成的。
上面用到反射类Method中的很多方法,所以我们来简单掌握Method类常用的方法:
- getName():获取方法名
- getDeclaringClass:获取全限定类名
- getModifiers():获取权限修饰符
- getReturnType():获取返回类型
- getExceptionTypes():获取所有抛出的异常类型
- getParameterTypes():获取所有参数的类型
- getParameterAnnotations():获取方法中的所有注解
- getAnnotations():获取方法级别的注解
至此mapper的动态代理介绍完了。下面还介绍了Mapper接口中的方法参数是怎么来获取的,它是通过参数解析器(ParamNameResolver)来完成的,有兴趣可以了解一下。
⑪、在上述代码中经常能看见这样一句代码 method.convertArgsToSqlCommandParam(args); 这个方法是MethodSignature内部类中的,该方法主要的功能是获取@Param注解上的参数值。而实现方式便是通过参数解析器(ParamNameResolver),convertArgsToSqlCommandParam(args)方法实际上调用的是ParamNameResolver下的getNamedParams(args)方法。在分析该方法之前,先看看构造器都做了些什么操作。
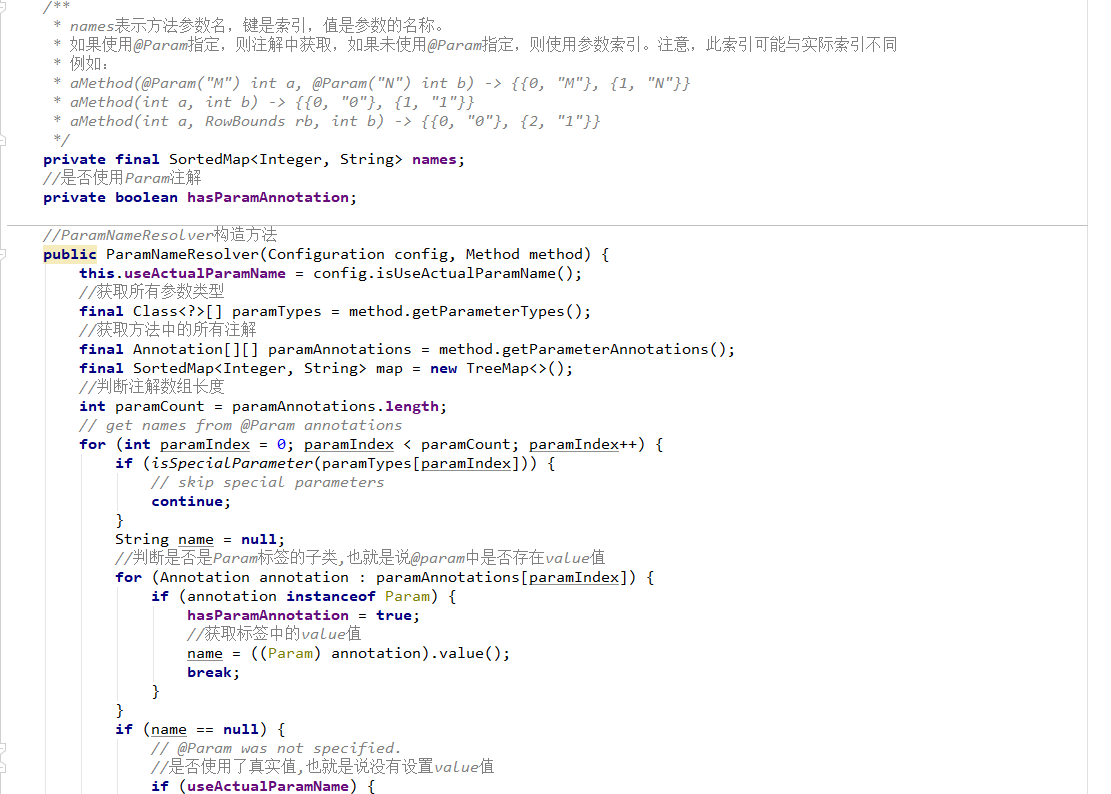

构造器同样需要两个入参,配置类和方法名,ParamNameResolver类下包含了两个属性字段GENERIC_NAME_PREFIX属性前缀和参数集合names,构造器会将Method中所有参数级别的注解全部解析出来方法有序参数集中,names中存储形式为<参数下标,参数名>,如果在注解上设置了参数名,则会直接获取注解的value值,如果没有使用@Param注解,则使用真实的参数名,注意:真实参数名其实是arg0,arg1....的形式展现的,在判断真实参数名时,Mybatis会检查JDK版本是否包含java.lang.reflect.Parameter类,不存在该类的化会抛出ClassNotFoundException异常。完成初始化后,就可以调用getNamedParams(args)方法了,如下代码所示,该方法使用了类中的names属性,从有序集合中取出所有的<参数索引,参数名>键值对>,随后填充到另外一个集合中,以<参数名,参数下标索引,>形式呈现,同时会保留一份<param+下标索引,参数下标>的键值对。
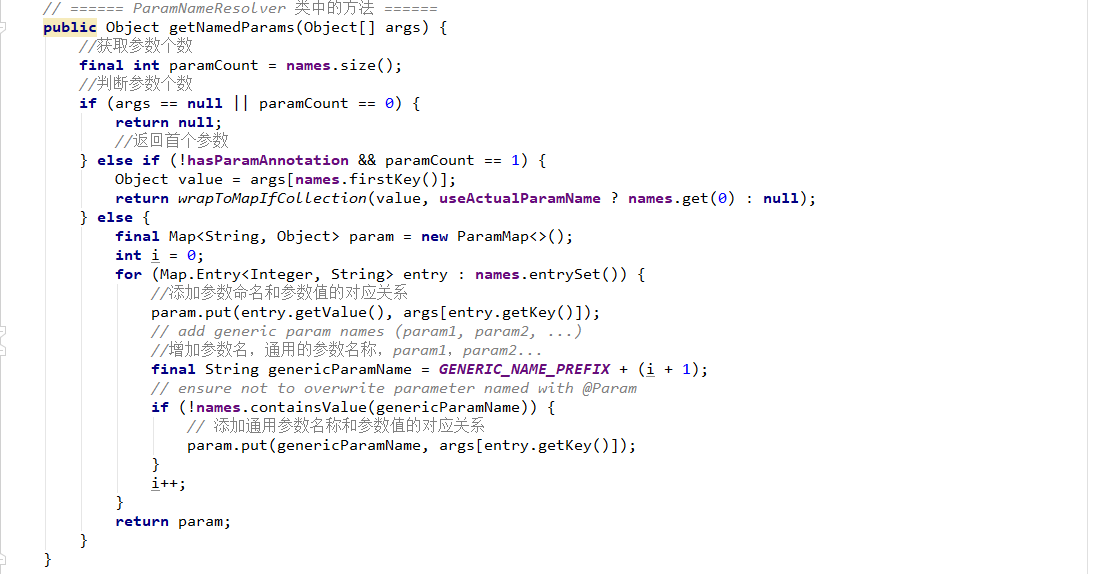
参考链接:
- 《Java EE 互联网轻量级框架整合开发》
- https://www.cnblogs.com/hopeofthevillage/p/11384848.html
- https://www.cnblogs.com/zsg88/p/7552600.html
- https://www.cnblogs.com/zhengzuozhanglina/p/11212200.html
17、SqlSession下的四大对象
17.1 SqlSession下的四大对象介绍
通过前面的分析,我们应该知道在Mybatis中的,首先是通过SqlSessionFactoryBuilder加载全局配置文件(包括SQL映射器),这些配置都会封装在Configuration中,其中每一条SQL语句的信息都会封装在MappedStatement中。然后创建SqlSession,这时还会初始化Executor执行器。最后通过调用sqlSession.getMapper()来动态代理执行Mapper中对应的SQL语句。而当一个动态代理对象进入到了MapperMethod的execute()方法后,它经过简单地判断就进入了SqlSession的delete、update、insert、select等方法,这里是真正执行SQL语句的地方。那么这些方法是如何执行呢?答:实际上SqlSession的执行过程是通过Executor、StatementHandler、ParameterHandler和ResultSetHandler来完成数据库操作和结果返回的,它们简称为四大对象:
- Executor:代表执行器,由它调度StatementHandler、ParameterHandler、ResultSetHandler等来执行对应的SQL,其中StatementHandler是最重要的。
- StatementHandler:作用是使用数据库的Statement(PreparedStatement)执行操作,它是四大对象的核心,起到承上启下的作用,许多重要的插件都是通过拦截它来实现的。
- ParameterHandler:是用来处理SQL参数的。
- ResultSetHandler:是进行数据集(ResultSet)的封装返回处理的,它非常的复杂,好在不常用。
这四个对象都是通过Mybatis的插件来完成的,在实例化Executor、StatementHandler、ParameterHandler、ResultSetHandler四大接口对象的时候都是调用interceptorChain.pluginAll() 方法插入进去的(Mybatis的插件实现原理可以参考:MyBatis 插件之拦截器(Interceptor)_M义薄云天的博客-CSDN博客_ibatis interceptor,MyBatis源码剖析 - MyBatis 插件之拦截器(Interceptor)实现原理_Ricky_Fung的博客-CSDN博客_ibatis interceptor )。下面依次分析这四大对象的生成和运作原理。
17.2 四大对象的生成和运作原理的引入
这里来分析一条查询SQL的执行过程:首先肯定是要构建SqlSessionFactory、SqlSession和动态代理Mapper对象的,前面已经介绍过了,所以不多说,主要来看具体是怎么样执行的。当动态代理对象获取MapperMethod对象后,通过其内部的execute()方法调用sqlSession.selectList()方法来真正执行SQL,所以继续从这里来跟踪代码:
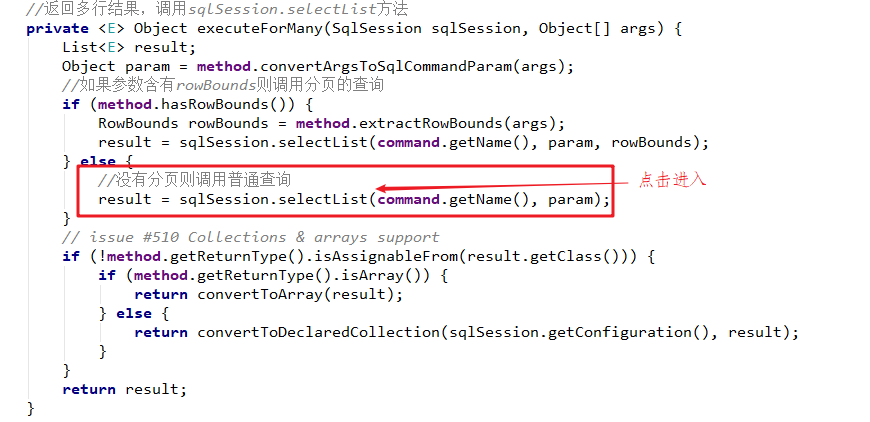
SqlSession的实现类为DefaultSqlSession,所以去DefaultSqlSession中查看selectList()方法:

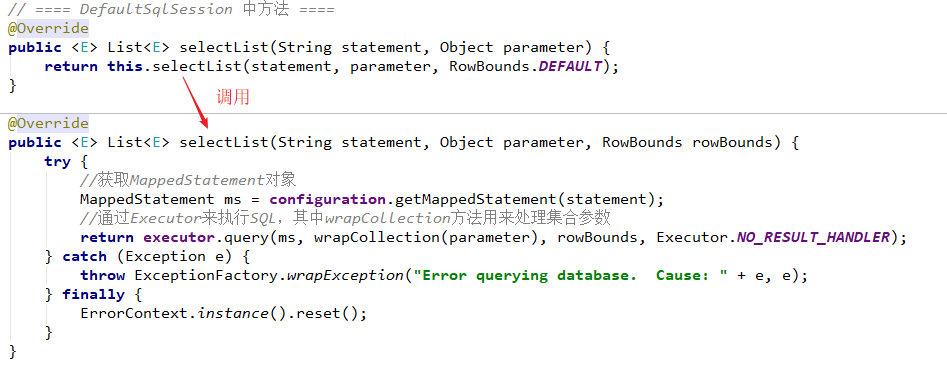
可以看到这里获取了MappedStatement对象,并且调用了executor对象的query()方法来执行SQL。所以我们来看看Executor类。
17.3 Executor对象
Executor表示执行器,它是真正执行Java和数据库交互的对象,所以它十分重要,每一个SqlSession都会拥有一个Executor对象,这个对象负责增删改查的具体操作,我们可以简单的将它理解为JDBC中Statement的封装版。。Executor的关系图如下:
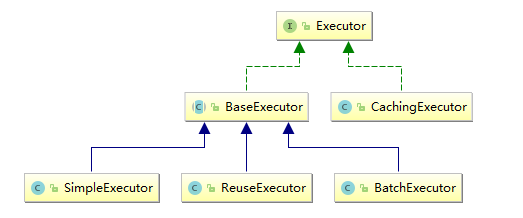
- BaseExecutor:是一个抽象类,采用模板方法的设计模式。它实现了Executor接口,实现了执行器的基本功能。
- SimpleExecutor:最简单的执行器,根据对应的SQL直接执行即可,不会做一些额外的操作;拼接完SQL之后,直接交给 StatementHandler 去执行。
- BatchExecutor:批处理执行器,用于将多个SQL一次性输出到数据库,通过批量操作来优化性能。通常需要注意的是批量更新操作,由于内部有缓存的实现,使用完成后记得调用flushStatements来清除缓存。
- ReuseExecutor :可重用的执行器,重用的对象是Statement,也就是说该执行器会缓存同一个sql的Statement,省去Statement的重新创建,优化性能。内部的实现是通过一个HashMap来维护Statement对象的。由于当前Map只在该session中有效,所以使用完成后记得调用flushStatements来清除Map。调用实现的四个抽象方法时会调用 prepareStatement()
- CachingExecutor:启用于二级缓存时的执行器;采用静态代理;代理一个 Executor 对象。执行 update 方法前判断是否清空二级缓存;执行 query 方法前先在二级缓存中查询,命中失败再通过被代理类查询。
我们来看看Mybatis是如何创建Executor的,其实在前面已经介绍过了,它是在Configuration类中完成的,这里不看可以跳过:
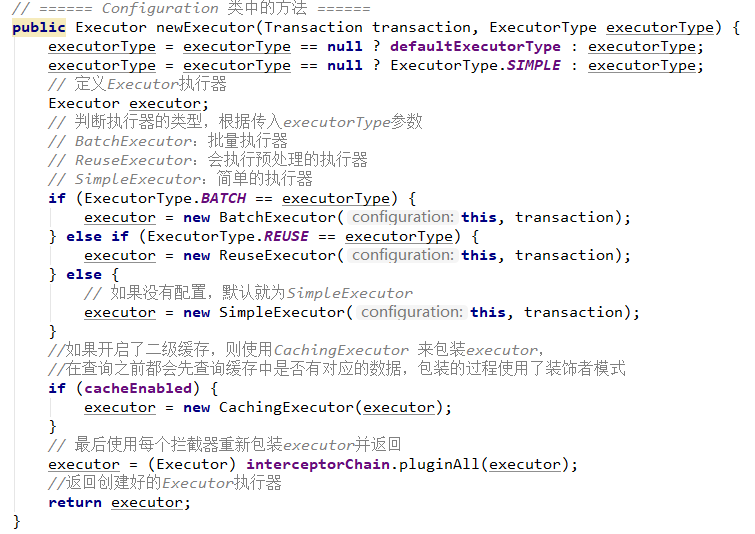
Executor对象会在MyBatis加载全局配置文件时初始化,它会根据配置的类型去确定需要创建哪一种Executor,我们可以在全局配置文件settings元素中配置Executor类型,setting属性中有个defaultExecutorType,可以配置如下3个参数:
- SIMPLE: 简易执行器,它没有什么特别的,默认执行器
- REUSE:是一种能够执行重用预处理语句的执行器
- BATCH:执行器重用语句和批量更新,批量专用的执行器
默认使用SimpleExecutor。而如果开启了二级缓存,则用CachingExecutor进行包装,SqlSession会调用CachingExecutor执行器的query()方法,先从二级缓存获取数据,当无法从二级缓存获取数据时,则委托给BaseExecutor的子类进行操作,CachingExecutor执行过程代码如下:
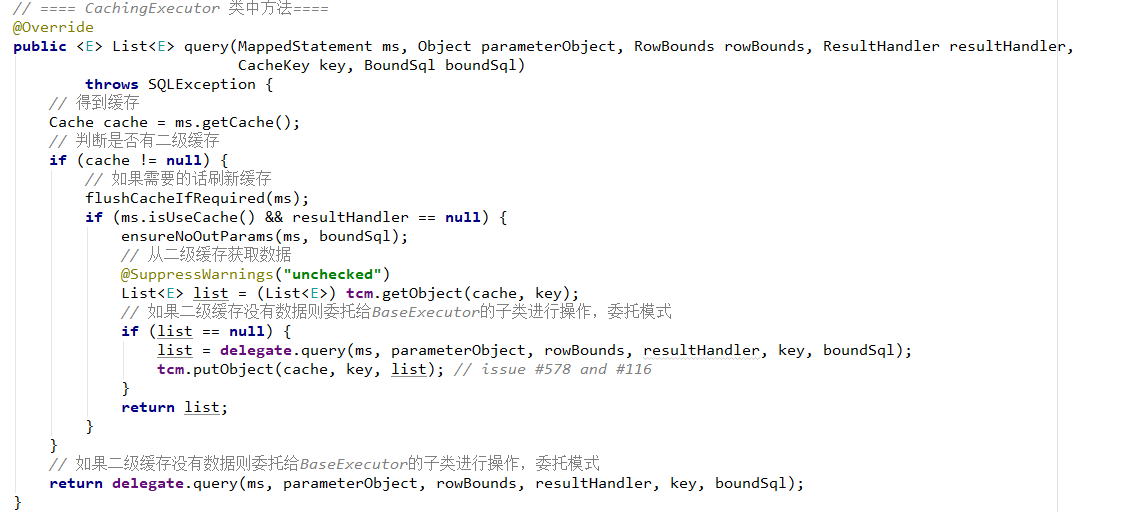
如果没有使用二级缓存并且没有配置其它的执行器,那么MyBatis默认使用SimpleExecutor,调用父类BaseExecutor的query()方法:
注意:query方法有两种形式,一种是直接查询;一种是从缓存中查询,下面来看一下源码:

当有一个查询请求访问的时候,如果开启了二级缓存,首先会经过Executor的实现类CachingExecutor,先从二级缓存中查询SQL是否是第一次执行,如果是第一次执行的话,那么就直接执行SQL语句,并创建缓存,如果第二次访问相同的SQL语句的话,那么就会直接从缓存中提取。如果没有开启二级缓存,是第一次执行,直接执行SQL语句,并创建缓存,再次执行则从一级缓存中获取数据,如下源代码所示:
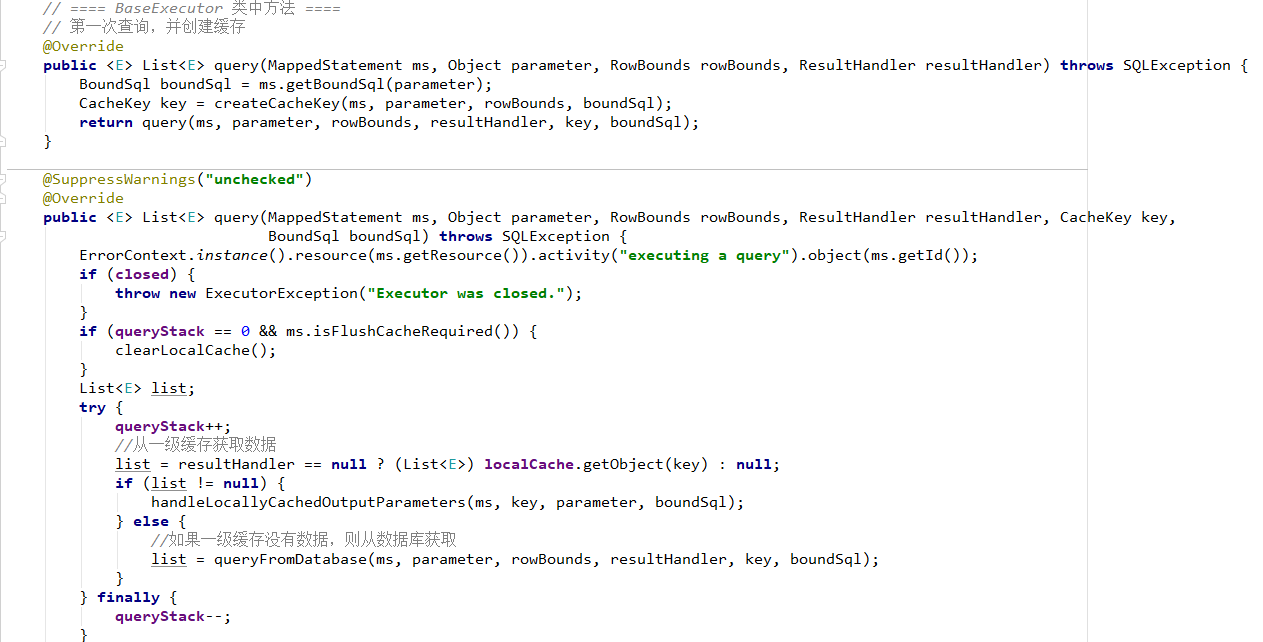

而如果一级缓存也没有数据,则调用queryFromDatabase()从数据库中获取数据:

在queryFromDatabase()方法中调用SimpleExecutor的 doQuery() 方法(注意:这里说是调用了SimpleExecutor的方法,但是还在BaseExecutor类中是因为SimpleExecutor继承了它,所以SimpleExecutor对象中也有这个方法,而doQuery()方法在子类SimpleExecutor实现的,所以说是调用SimpleExecutor的 doQuery() 方法。

 ),其方法代码如下:
),其方法代码如下:

这里显然是根据Configuration对象来构建StatementHandler,然后使用prepareStatement()方法对SQL编译和参数进行初始化。实现过程是:它调用了StatementHandler的prepare() 进行了预编译和基础的设置,然后通过StatementHandler的parameterize()来设置参数,这个parameterize()方法实际是通过ParameterHandler来对参数进行设置。最后使用 StatementHandler的query()方法,把ResultHandler传递进去,执行查询后再通过ResultSetHandler封装结果并将结果返回给调用者来完成一次查询,这样焦点又转移到了 StatementHandler 对象上。所以通过以上流程发现,MyBatis核心工作实际上是由Executor、StatementHandler、ParameterHandler和ResultSetHandler四个接口完成的,掌握这四个接口的工作原理,对理解MyBatis底层工作原理有很大帮助。
17.4 StatementHandler对象
StatementHandler是数据库会话器,顾名思义,数据库会话器就是专门处理数据库会话的,相当于JDBC中的Statement(PreparedStatement)。StatementHandler的关系图如下:
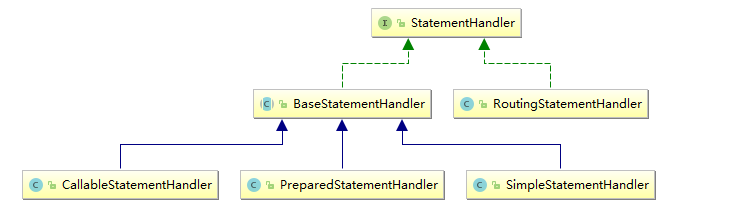
StatementHandler接口设计采用了适配器模式,其实现类RoutingStatementHandler根据上下文来选择适配器生成相应的StatementHandler。三个适配器分别是SimpleStatementHandler、PreparedStatementHandler和CallableStatementHandler。
- BaseStatementHandler: 是一个抽象类,它实现了StatementHandler接口,用于简化StatementHandler接口实现的难度,采用适配器设计模式,它主要有三个实现类SimpleStatementHandler、PreparedStatementHandler和CallableStatementHandler。
- SimpleStatementHandler: 最简单的StatementHandler,处理不带参数运行的SQL,对应JDBC的Statement
- PreparedStatementHandler: 预处理Statement的handler,处理带参数允许的SQL, 对应JDBC的PreparedStatement(预编译处理)
- CallableStatementHandler:存储过程的Statement的handler,处理存储过程SQL,对应JDBC的CallableStatement(存储过程处理)
- RoutingStatementHandler:RoutingStatementHandler根据上下文来选择适配器生成相应的StatementHandler。三个适配器分别是SimpleStatementHandler、PreparedStatementHandler和CallableStatementHandler。
StatementHandler 接口中的方法如下:

StatementHandler的初始化过程如下(它也是在Configuration对象中完成的):
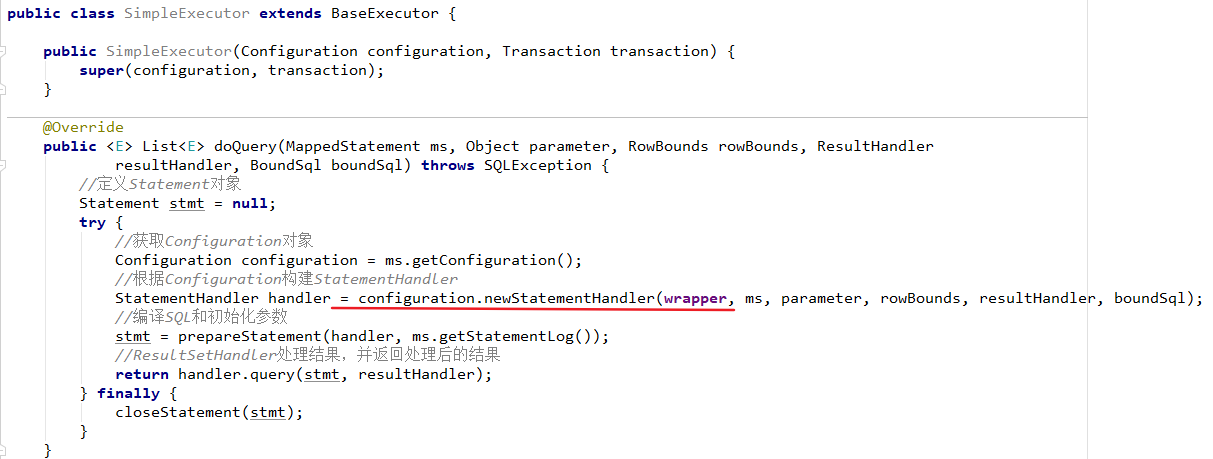
当调用到doQuery()方法时内部会通过configuration.newStatementHandler()方法来创建StatementHandler对象。

可以发现MyBatis生成StatementHandler代码中,创建的真实对象是一个RoutingStatementHandler的对象,而不是其它三个对象中的。但是RoutingStatementHandler并不是真实的服务对象,它是通过适配器模式来找到对应的StatementHandler来执行的。在初始化RoutingStatementHandler对象时,它会根据上下文环境来决定创建哪个具体的StatementHandler。RoutingStatementHandler 的构造方法如下:
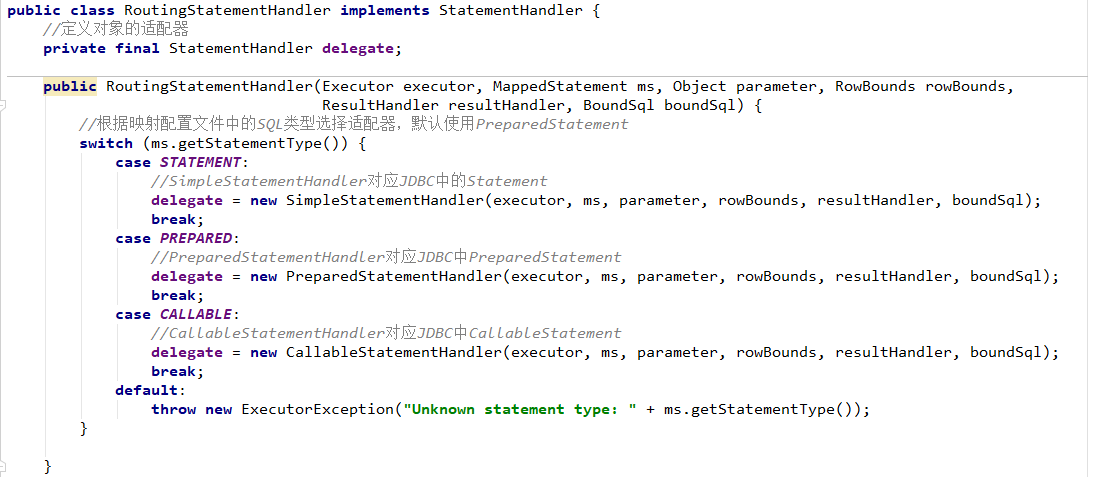
它内部定义了一个对象的适配器delegate,它是一个StatementHandler接口对象,然后构造方法根据配置来配置对应的StatementHandler对象。它的作用是给3个接口对象的使用提供一个统一且简单的适配器。此为对象的配适,可以使用对象配适器来尽可能地使用己有的类对外提供服务,可以根据需要对外屏蔽或者提供服务,甚至是加入新的服务。我们以常用的 PreparedStatementHandler 为例,看看Mybatis是怎么执行查询的。
继续跟踪到SimpleExecutor对象中的prepareStatement()方法:

可以发现Executor 执行查询时会执行 StatementHandler 的 prepare() 和 parameterize() 方法来对SQL进行预编译和参数的设置, 其中 PreparedStatementHandler 的 prepare 方法如下:
注意:这个 prepare 方法是先调用到 StatementHandler 的实现类 RoutingStatementHandler,再由RoutingStatementHandler 调用 BaseStatementHandler 中的 prepare 方法。

------------------------------------------------------------------------------------------------------------------------------------
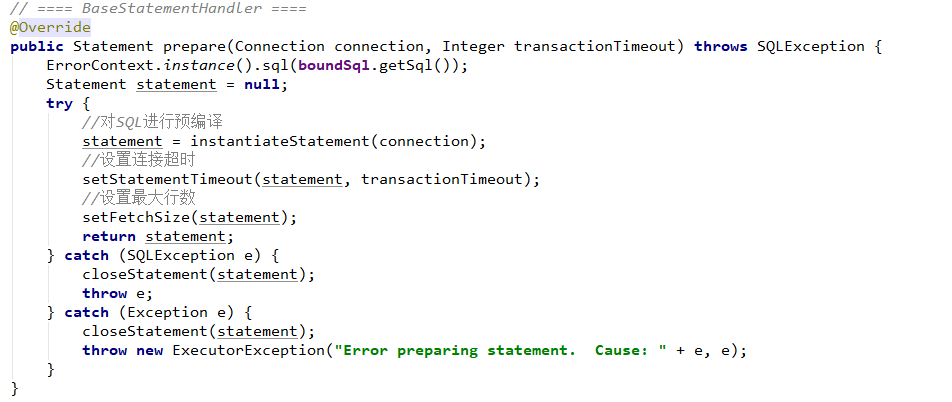
通过prepare()方法,可知其中最重要的方法就是 instantiateStatement() 方法了,因为它要完成对SQL的预编译。在得到 Statement 对象的时候,会去调用 instantiateStatement() 方法,这个方法位于 BaseStatementHandler 中,是一个抽象方法由子类去实现,实际执行的是三种 StatementHandler 中的一种,我们以 PreparedStatementHandler 中的为例:
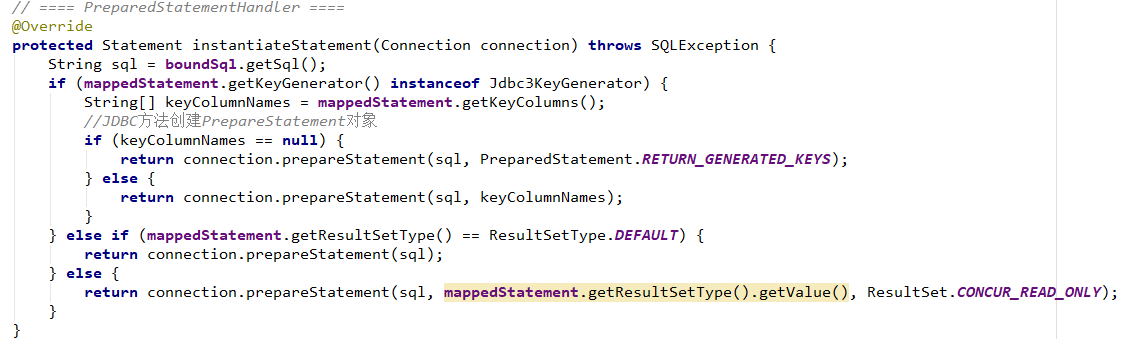
从上面的代码我们可以看到,instantiateStatement() 方法最终返回的也是Statement对象,所以经过一系列的调用会把创建好的 Statement 对象返回到 SimpleExecutor 简单执行器中,为后面设置参数的 parametersize 方法所用。也就是说,prepare 方法负责生成 Statement 实例对象,而 parameterize 方法用于处理 Statement 实例对应的参数。所以我们来看看parameterize 方法:

可以看到这里通过调用了ParameterHandler对象来设置参数,所以下面我们来介绍一下ParameterHandler对象。
17.5 ParameterHandler对象
ParameterHandler 是参数处理器,它的作用是完成对预编译的参数的设置,也就是负责为 PreparedStatement 的 SQL 语句参数动态赋值。ParameterHandler 相比于其他的组件就简单很多了,这个接口很简单只有两个方法:

这两个方法的含义为:
- getParameterObject: 用于获取参数对象。
- setParameters:用于设置预编译SQL的参数
ParameterHandler对象的创建,ParameterHandler参数处理器对象是在创建 StatementHandler 对象的同时被创建的,同样也是由 Configuration 对象负责创建:
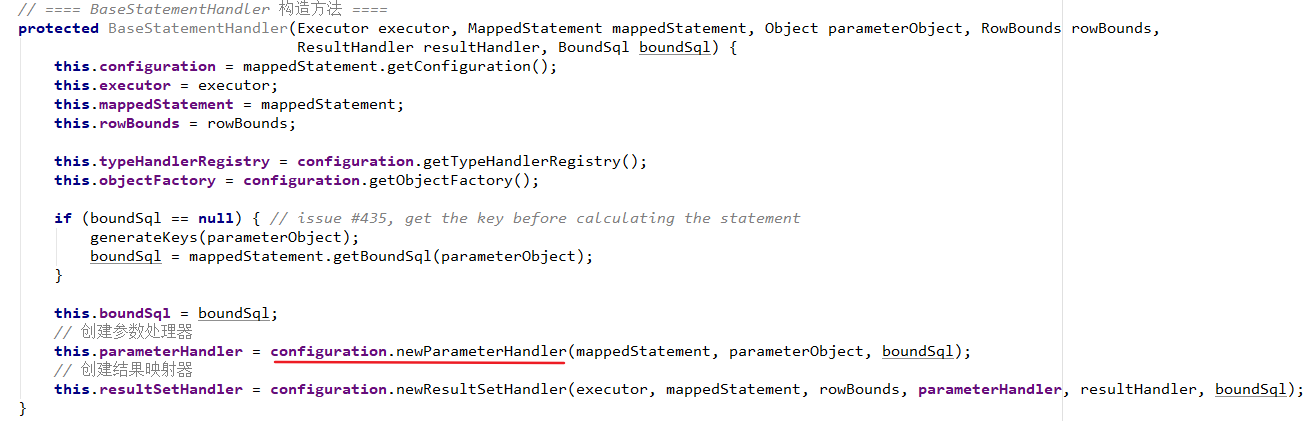
可以发现在创建 ParameterHandler 对象时,传入了三个参数分别是:mappedStatement、parameterObject、boundSql。mappedStatement保存了一个映射器节点<select|update|delete|insert>中的内容,包括我们配置的SQL、SQL的id、缓存信息、resultMap、ParameterType、resultType、resultMap等重要配置内容等。parameterObject表示读取的参数。boundSql表示要实际执行的SQL语句,它是通过SqlSource 对象来生成的,就是根据传入的参数对象,动态计算这个 BoundSql, 也就是 Mapper 文件中节点的计算,是由 SqlSource 完成的,SqlSource 最常用的实现类是 DynamicSqlSource。然后就我们进入newParameterHandler()方法中:

上面是在 Configuration 对象创建 ParameterHandler 的过程,它实际上是交由 LanguageDriver 来创建具体的参数处理器,LanguageDriver 默认的实现类是 XMLLanguageDriver,由它调用 DefaultParameterHandler 中的构造方法完成 ParameterHandler 的创建工作:
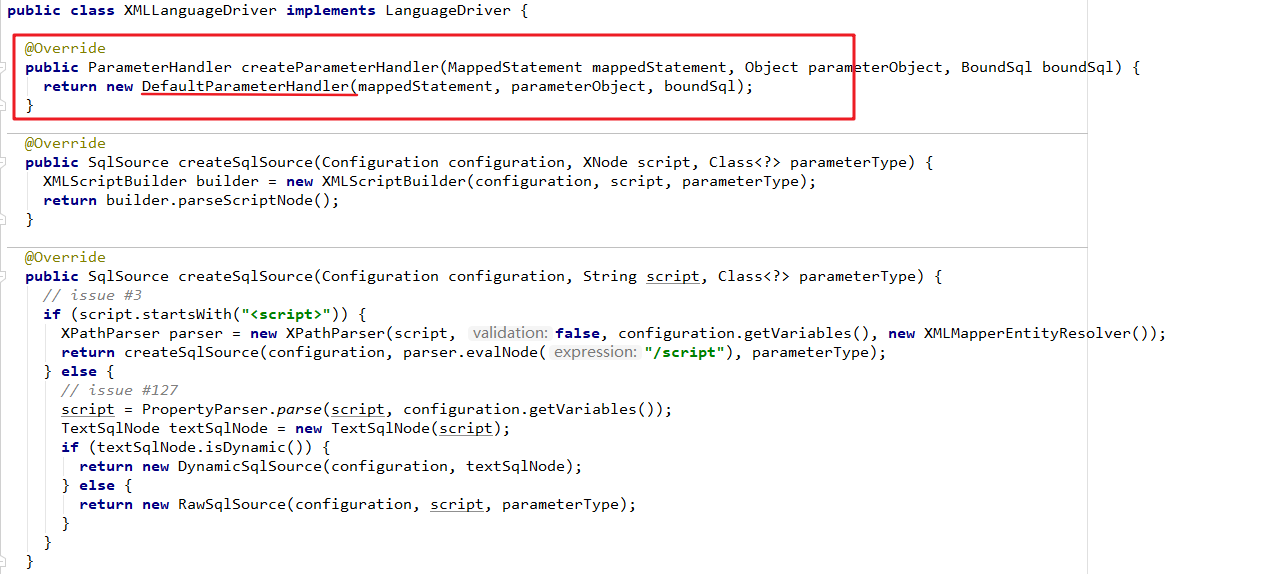
上面创建完成之后,该进行具体的解析工作,那么 ParameterHandler 如何解析SQL中的参数呢?ParameterHandler 由实现类DefaultParameterHandler执行,使用TypeHandler将参数对象类型转换成jdbcType,完成预编译SQL的参数设置,这是在setParameters()方法中完成的,setParameters()方法的实现如下:
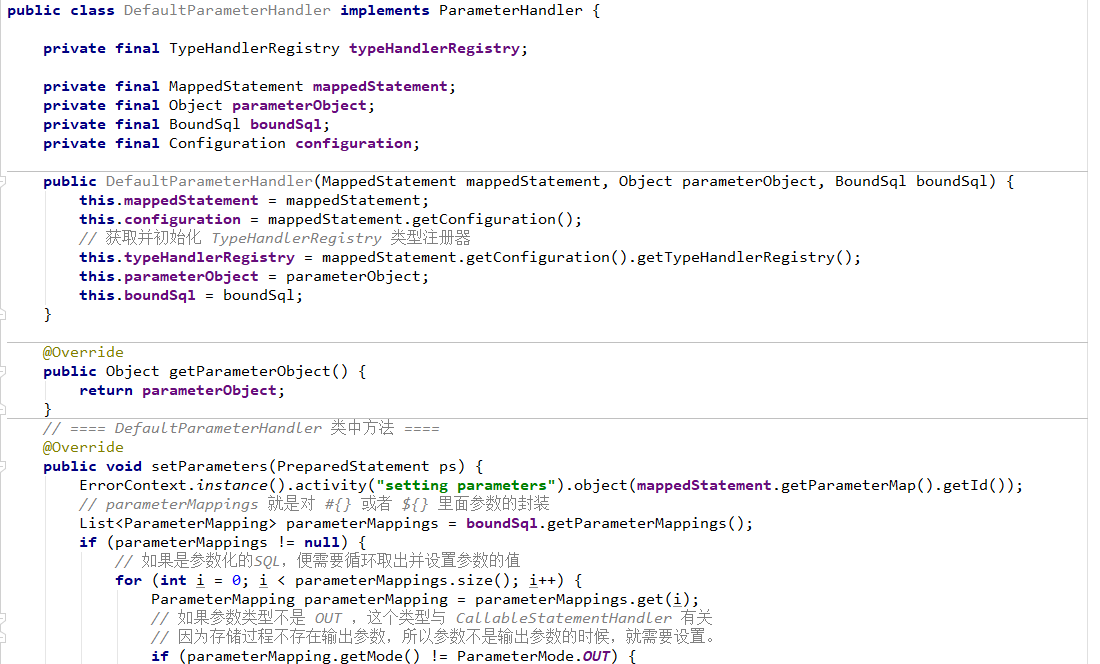
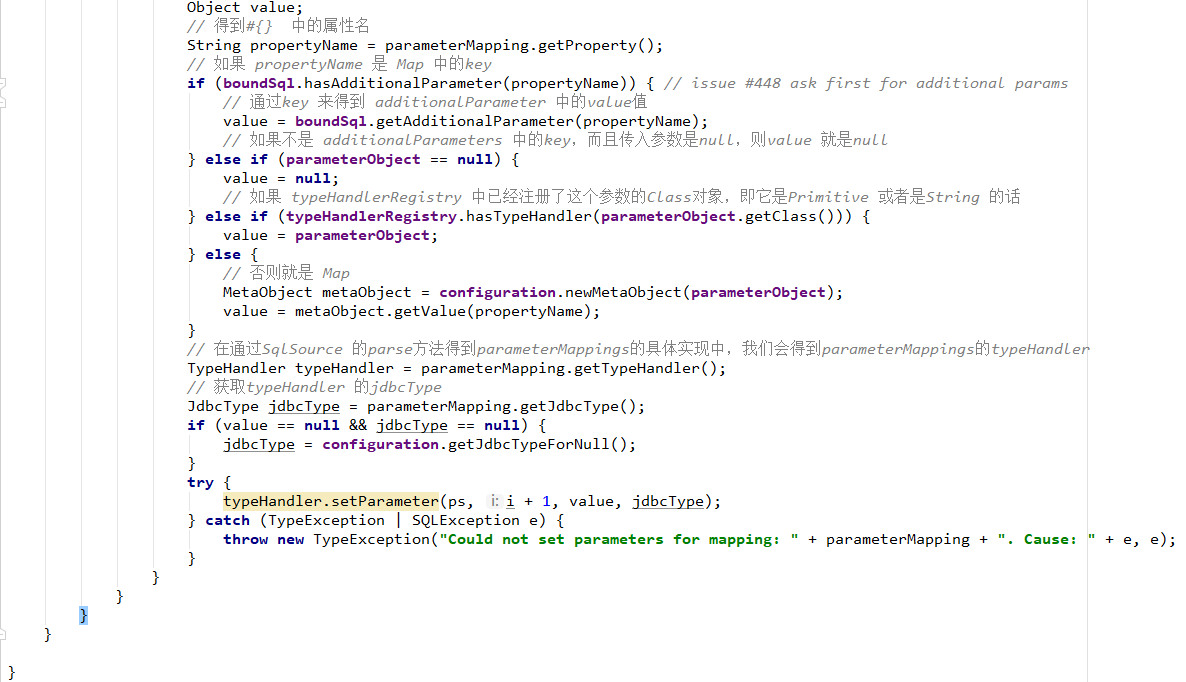
至此,我们的参数就处理完成了。一切都准备就绪之后就肯定可以执行了呗!在SimpleExecutor 的 doQuery()方法中最后会调用query()方法来执行SQL语句。并且把创建好的Statement和结果处理器以参数传入进去,我们进入query()方法:

可以看到这里执行了我们的SQL语句,然后对执行的结果进行处理,这里用到的是MyBatis 四大对象的最后一个神器也就是 ResultSetHandler,所以下面我们继续来介绍ResultSetHandler对象。
17.6 ResultSetHandler对象
ResultSetHandler 是结果处理器,它是用来组装结果集的。ResultSetHandler 接口的定义也挺简单的,只有三个方法:
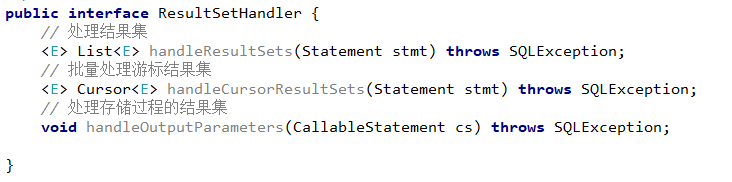
ResultSetHandler 对象的创建,ResultSetHandler 对象是在处理查询请求时创建 StatementHandler 对象同时被创建的,同样也是由 Configuration 对象负责创建,示例如下:
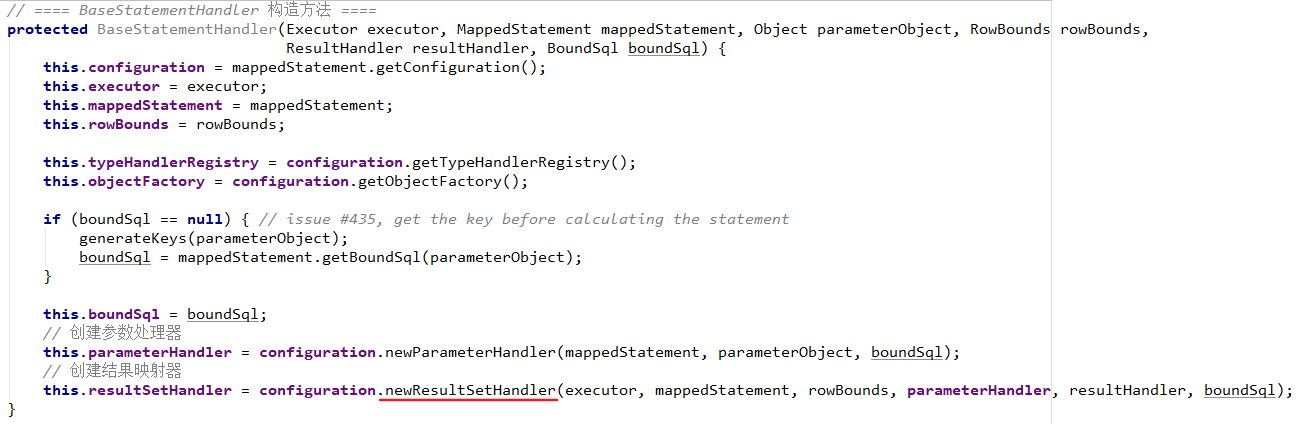
Configuration对象中的newResultSetHandler()方法:

ResultSetHandler 创建好之后就可以处理结果映射了。还记得在前面Executor的doQuery()方法中,我们最后是通过调用handler.query()方法来完成结果集的处理,如下:
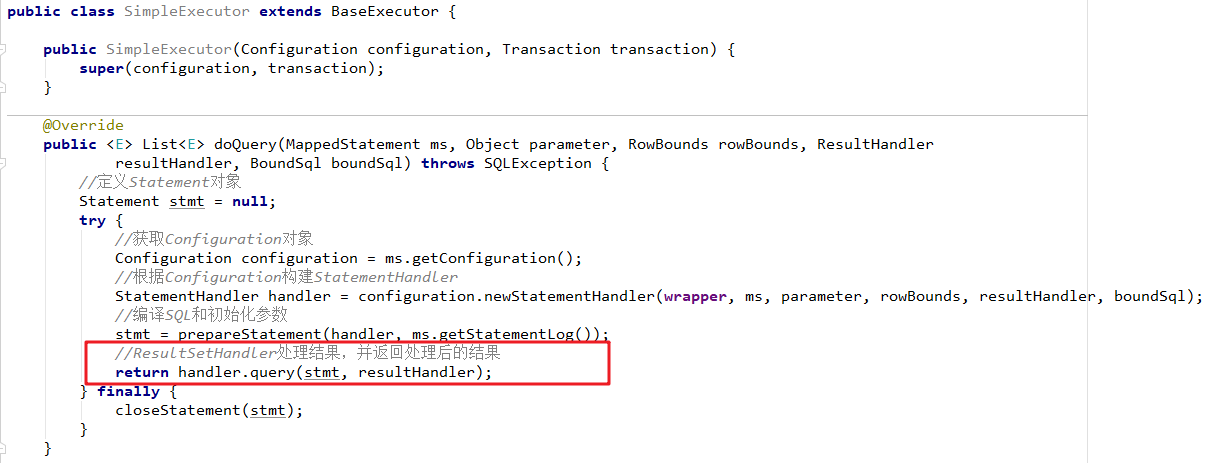
进入query()方法,它是在PreparedStatementHandler实现的:

ResultSetHandler接口只有一个默认的实现类是DefaultResultSetHandler,我们通过SELECT语句执行得到的结果集由其 handleResultSets() 方法处理,方法如下:
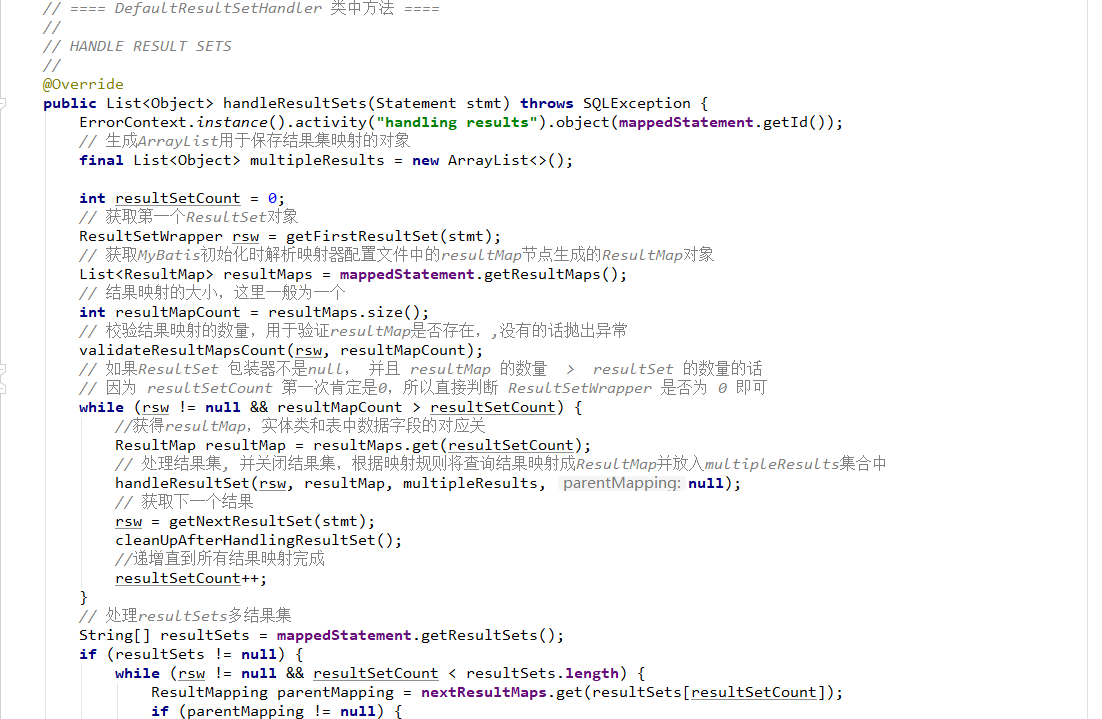

上面涉及的主要对象有:
ResultSetWrapper:结果集的包装器,主要针对结果集进行的一层包装。这个类中的主要属性有:
- ResultSet : Java JDBC ResultSet接口表示数据库查询的结果。 有关查询的文本显示了如何将查询结果作为java.sql.ResultSet返回。 然后迭代此ResultSet以检查结果。
- TypeHandlerRegistry: 类型注册器,TypeHandlerRegistry 在初始化的时候会把所有的 Java类型和类型转换器进行注册。
- ColumnNames: 字段的名称,也就是查询操作需要返回的字段名称
- ClassNames: 字段的类型名称,也就是 ColumnNames 每个字段名称的类型
- JdbcTypes: JDBC 的类型,也就是java.sql.Types 类型
ResultMap:负责处理更复杂的映射关系
multipleResults:用于封装处理好的结果集。其中的主要方法是 handleResultSet:

可以看到,handleResultSet() 方法中又分为:嵌套和不嵌套处理这两种方法,这里我们只管理不嵌套的处理,嵌套的虽然会比不嵌套复杂一点,但总体类似,差别并不大。

最后 handleResultSets() 方法返回的是 collapseSingleResultList(multipleResults) ,我们来看一下:

它是判断的 multipleResults 的数量,如果数量是 1 ,就直接取位置为0的元素,如果不是1,那就返回 multipleResults 的真实数量。
以上在 DefaultResultSetHandler 中处理完结果映射,并把上述得到的结果返回给调用的客户端,从而执行完成一条完整的SQL语句。结果集的处理就看到这里了,因为ResultSetHandler的实现非常复杂,它涉及了CGLIB或者JAVASSIST作为延迟加载,然后通过typeHandler和ObjectFactory解析组装结果在返回,由于实际工作需要改变它的几率不高加上他比较复杂,所以这里就不在论述了,有兴趣的可自行去百度信息。
17.8 小结
一条SQL语句在Mybatis中的执行过程小结:首先是创建Mapper的动态代理对象MapperProxy,然后将Mappe接口中的方法封装至MapperMethod对象,通过MapperMethod对象中的execute()方法来执行SQL,其本质是通过SqlSession下的方法来实现的,SQL语句的具体的执行则是通过SqlSession下的四大对象来完成。Executor先调用StatementHandler的prepare()方法预编译SQL,然后用parameterize()方法启用ParameterHandler设置参数,完成预编译,执行查询,update()也是这样的。如果是查询,MyBatis则会使用ResultSetHandler来封装结果并返回给调用者,从而完成查询。其执行的完整流程图如下:
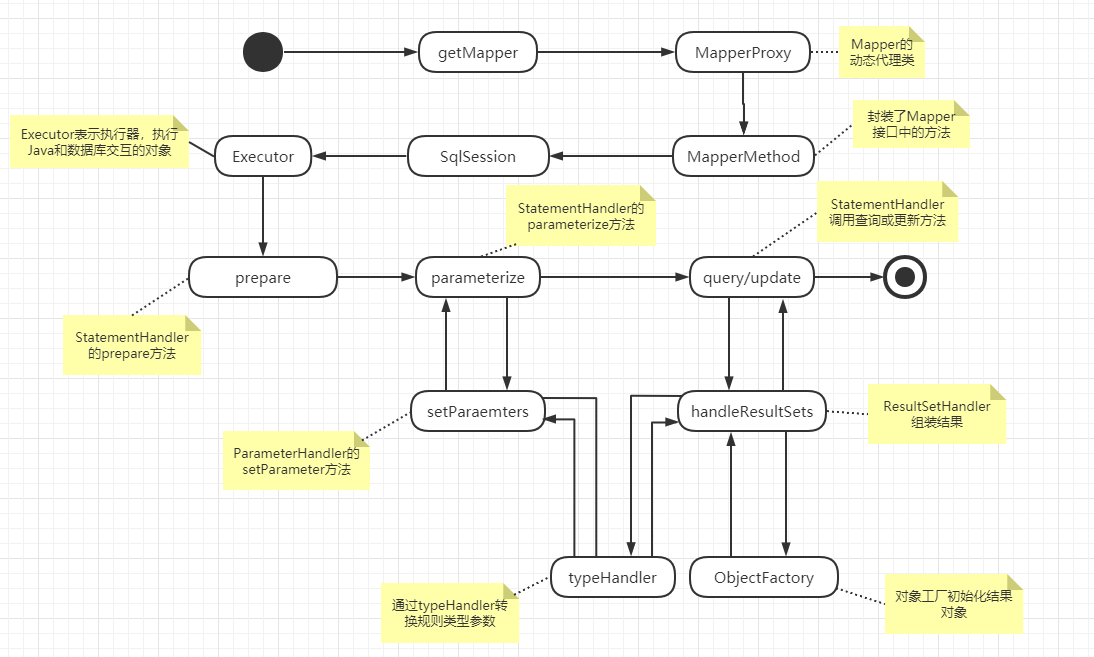
一个超级详细解析图 (图片来自 Mybatis:执行一个Sql命令的完整流程_qq_22423635的博客-CSDN博客):
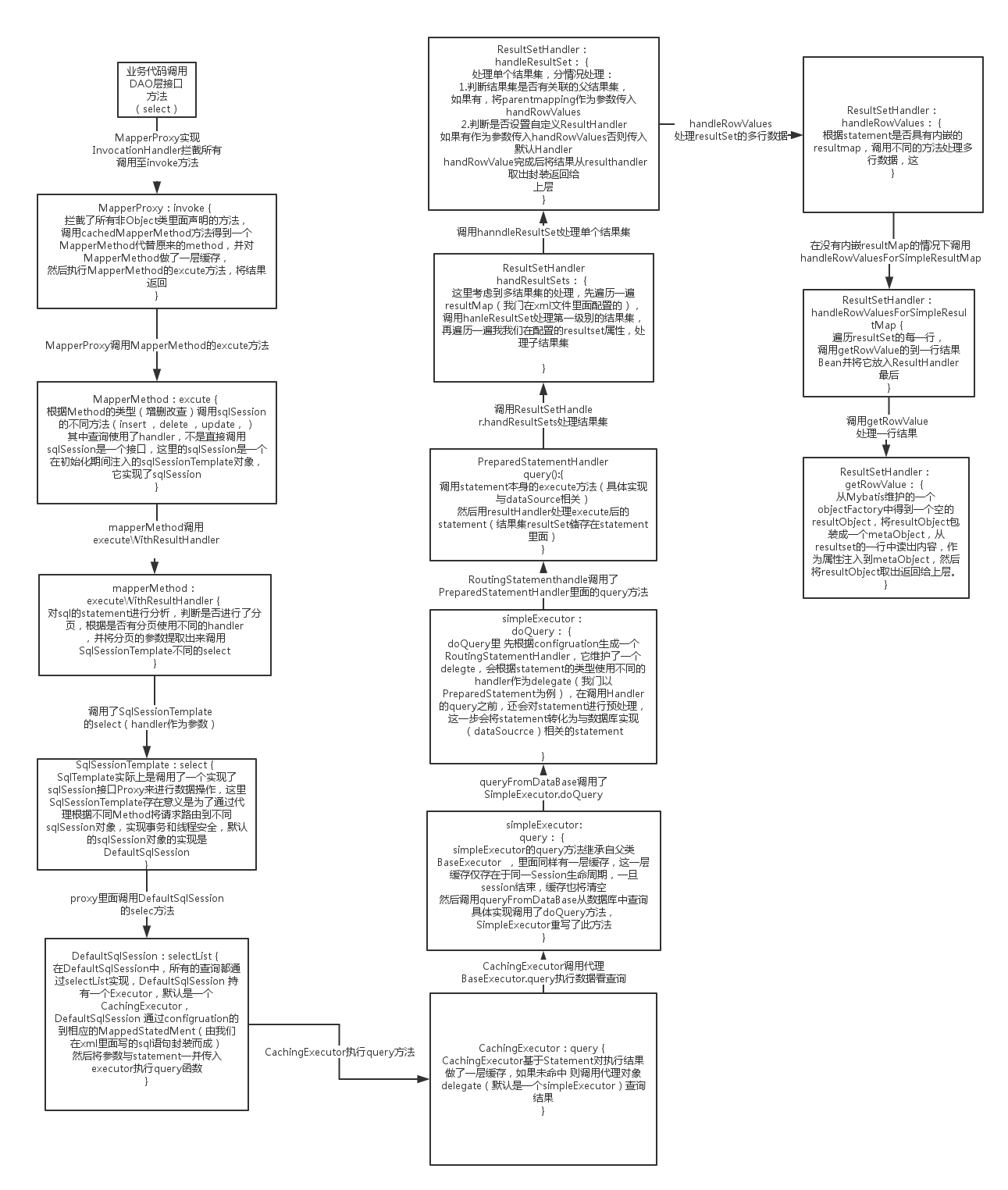
参考链接:
- 《Java EE 互联网轻量级框架整合开发》
- https://www.cnblogs.com/abcboy/p/9656302.html
- https://www.cnblogs.com/cxuanBlog/tag/MyBatis/
18、Mybatis中使用的9种设计模式
文章转载自:http://www.crazyant.net/2022.html
文章作者:蚂蚁学Python
18.1 前言
虽然我们都知道有26个设计模式,但是大多停留在概念层面,真实开发中很少遇到,Mybatis源码中使用了大量的设计模式,阅读源码并观察设计模式在其中的应用,能够更深入的理解设计模式。
Mybatis至少遇到了以下的设计模式的使用:
- Builder模式,例如SqlSessionFactoryBuilder、XMLConfigBuilder、XMLMapperBuilder、XMLStatementBuilder、CacheBuilder;
- 工厂模式,例如SqlSessionFactory、ObjectFactory、MapperProxyFactory;
- 单例模式,例如ErrorContext和LogFactory;
- 代理模式,Mybatis实现的核心,比如MapperProxy、ConnectionLogger,用的jdk的动态代理;还有executor.loader包使用了cglib或者javassist达到延迟加载的效果;
- 组合模式,例如SqlNode和各个子类ChooseSqlNode等;
- 模板方法模式,例如BaseExecutor和SimpleExecutor,还有BaseTypeHandler和所有的子类例如IntegerTypeHandler;
- 适配器模式,例如Log的Mybatis接口和它对jdbc、log4j等各种日志框架的适配实现;
- 装饰者模式,例如Cache包中的cache.decorators子包中等各个装饰者的实现;
- 迭代器模式,例如迭代器模式PropertyTokenizer;
接下来挨个模式进行解读,先介绍模式自身的知识,然后解读在Mybatis中怎样应用了该模式。
18.2 Builder模式
Builder模式的定义是将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。它属于创建类模式,一般来说,如果一个对象的构建比较复杂,超出了构造函数所能包含的范围,就可以使用工厂模式和Builder模式,相对于工厂模式会产出一个完整的产品,Builder应用于更加复杂的对象的构建,甚至只会构建产品的一个部分。
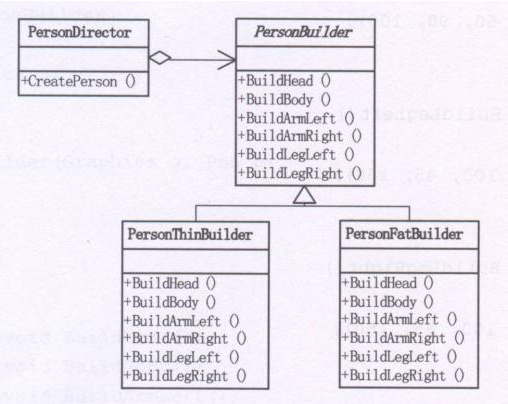
在Mybatis环境的初始化过程中,SqlSessionFactoryBuilder会调用XMLConfigBuilder读取所有的MybatisMapConfig.xml和所有的Mapper.xml文件,构建Mybatis运行的核心对象Configuration对象,然后将该Configuration对象作为参数构建一个SqlSessionFactory对象。
其中XMLConfigBuilder在构建Configuration对象时,也会调用XMLMapperBuilder用于读取Mapper文件,而XMLMapperBuilder会使用XMLStatementBuilder来读取和build所有的SQL语句。
在这个过程中,有一个相似的特点,就是这些Builder会读取文件或者配置,然后做大量的XpathParser解析、配置或语法的解析、反射生成对象、存入结果缓存等步骤,这么多的工作都不是一个构造函数所能包括的,因此大量采用了Builder模式来解决。
对于builder的具体类,方法都大都用build*开头,比如SqlSessionFactoryBuilder为例,它包含以下方法:
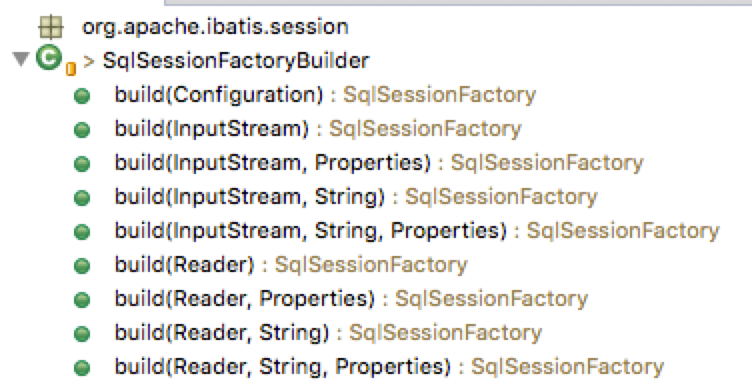
即根据不同的输入参数来构建SqlSessionFactory这个工厂对象。
18.3 工厂模式
在Mybatis中比如SqlSessionFactory使用的是工厂模式,该工厂没有那么复杂的逻辑,是一个简单工厂模式。
简单工厂模式(Simple Factory Pattern):又称为静态工厂方法(Static Factory Method)模式,它属于类创建型模式。在简单工厂模式中,可以根据参数的不同返回不同类的实例。简单工厂模式专门定义一个类来负责创建其他类的实例,被创建的实例通常都具有共同的父类。
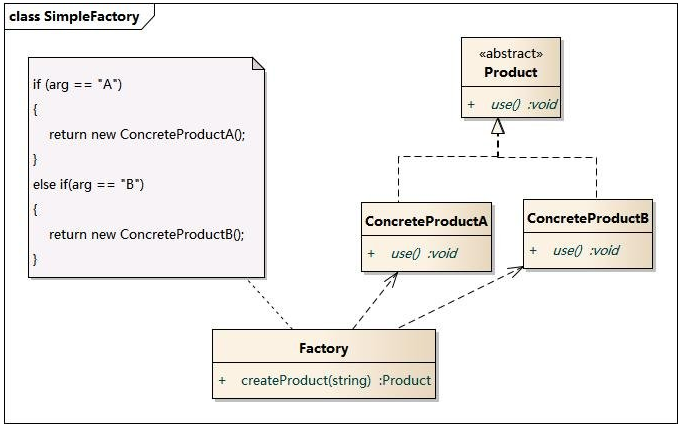
SqlSession可以认为是一个Mybatis工作的核心的接口,通过这个接口可以执行执行SQL语句、获取Mappers、管理事务。类似于连接MySQL的Connection对象。
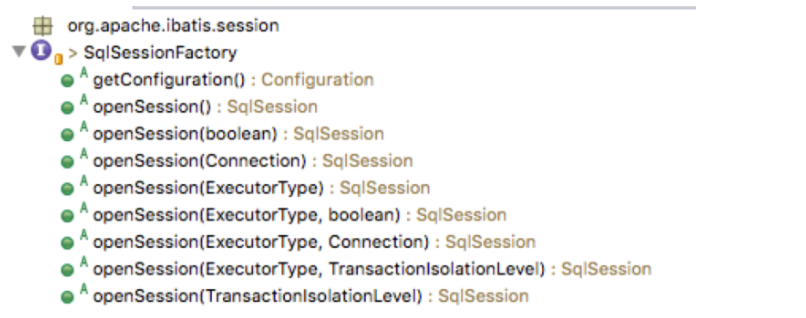
可以看到,该Factory的openSession方法重载了很多个,分别支持autoCommit、Executor、Transaction等参数的输入,来构建核心的SqlSession对象。
在DefaultSqlSessionFactory的默认工厂实现里,有一个方法可以看出工厂怎么产出一个产品:
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level,
boolean autoCommit) {
Transaction tx = null;
try {
final Environment environment = configuration.getEnvironment();
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
final Executor executor = configuration.newExecutor(tx, execType);
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call
// close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
这是一个openSession调用的底层方法,该方法先从configuration读取对应的环境配置,然后初始化TransactionFactory获得一个Transaction对象,然后通过Transaction获取一个Executor对象,最后通过configuration、Executor、是否autoCommit三个参数构建了SqlSession。
在这里其实也可以看到端倪,SqlSession的执行,其实是委托给对应的Executor来进行的。
而对于LogFactory,它的实现代码:
public final class LogFactory {
private static Constructor<? extends Log> logConstructor;
private LogFactory() {
// disable construction
}
public static Log getLog(Class<?> aClass) {
return getLog(aClass.getName());
}
这里有个特别的地方,是Log变量的的类型是Constructor<? extends Log>,也就是说该工厂生产的不只是一个产品,而是具有Log公共接口的一系列产品,比如Log4jImpl、Slf4jImpl等很多具体的Log。
18.4 单例模式
单例模式(Singleton Pattern):单例模式确保某一个类只有一个实例,而且自行实例化并向整个系统提供这个实例,这个类称为单例类,它提供全局访问的方法。
单例模式的要点有三个:一是某个类只能有一个实例;二是它必须自行创建这个实例;三是它必须自行向整个系统提供这个实例。单例模式是一种对象创建型模式。单例模式又名单件模式或单态模式。
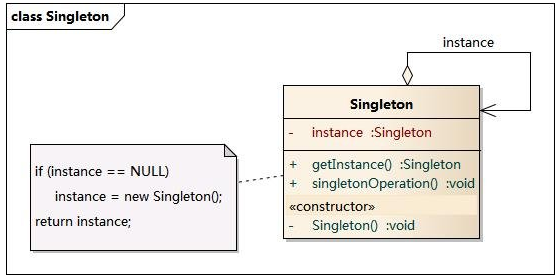
在Mybatis中有两个地方用到单例模式,ErrorContext和LogFactory,其中ErrorContext是用在每个线程范围内的单例,用于记录该线程的执行环境错误信息,而LogFactory则是提供给整个Mybatis使用的日志工厂,用于获得针对项目配置好的日志对象。
ErrorContext的单例实现代码:
public class ErrorContext {
private static final ThreadLocal<ErrorContext> LOCAL = new ThreadLocal<ErrorContext>();
private ErrorContext() {
}
public static ErrorContext instance() {
ErrorContext context = LOCAL.get();
if (context == null) {
context = new ErrorContext();
LOCAL.set(context);
}
return context;
}
构造函数是private修饰,具有一个static的局部instance变量和一个获取instance变量的方法,在获取实例的方法中,先判断是否为空如果是的话就先创建,然后返回构造好的对象。
只是这里有个有趣的地方是,LOCAL的静态实例变量使用了ThreadLocal修饰,也就是说它属于每个线程各自的数据,而在instance()方法中,先获取本线程的该实例,如果没有就创建该线程独有的ErrorContext。
18.5 代理模式
代理模式可以认为是Mybatis的核心使用的模式,正是由于这个模式,我们只需要编写Mapper.java接口,不需要实现,由Mybatis后台帮我们完成具体SQL的执行。
代理模式(Proxy Pattern) :给某一个对象提供一个代 理,并由代理对象控制对原对象的引用。代理模式的英 文叫做Proxy或Surrogate,它是一种对象结构型模式。
代理模式包含如下角色:
- Subject: 抽象主题角色
- Proxy: 代理主题角色
- RealSubject: 真实主题角色
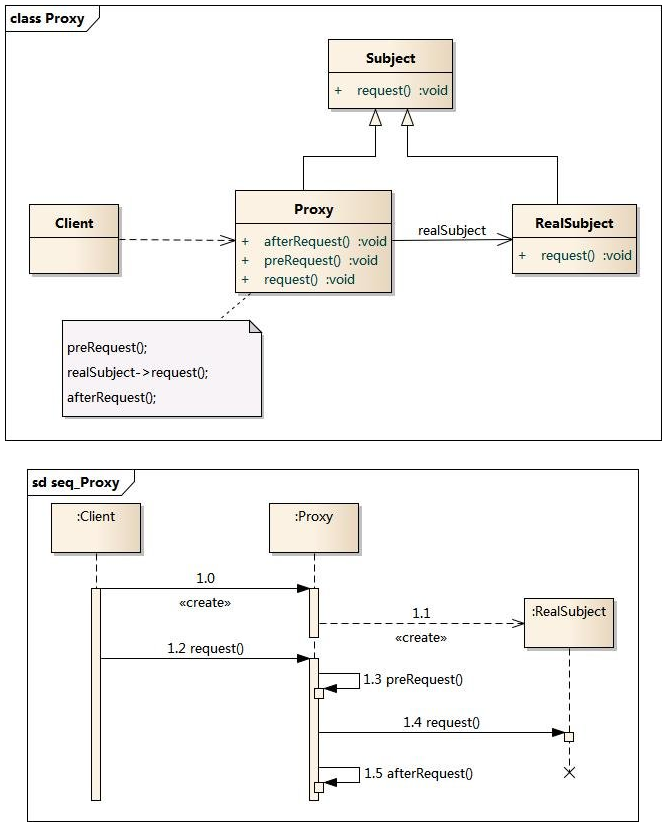
这里有两个步骤,第一个是提前创建一个Proxy,第二个是使用的时候会自动请求Proxy,然后由Proxy来执行具体事务;
当我们使用Configuration的getMapper方法时,会调用mapperRegistry.getMapper方法,而该方法又会调用mapperProxyFactory.newInstance(sqlSession)来生成一个具体的代理:
/**
* @author Lasse Voss
*/
public class MapperProxyFactory<T> {
private final Class<T> mapperInterface;
private final Map<Method, MapperMethod> methodCache = new ConcurrentHashMap<Method, MapperMethod>();
public MapperProxyFactory(Class<T> mapperInterface) {
this.mapperInterface = mapperInterface;
}
public Class<T> getMapperInterface() {
return mapperInterface;
}
public Map<Method, MapperMethod> getMethodCache() {
return methodCache;
}
@SuppressWarnings("unchecked")
protected T newInstance(MapperProxy<T> mapperProxy) {
return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[] { mapperInterface },
mapperProxy);
}
public T newInstance(SqlSession sqlSession) {
final MapperProxy<T> mapperProxy = new MapperProxy<T>(sqlSession, mapperInterface, methodCache);
return newInstance(mapperProxy);
}
}
在这里,先通过T newInstance(SqlSession sqlSession)方法会得到一个MapperProxy对象,然后调用T newInstance(MapperProxy
而查看MapperProxy的代码,可以看到如下内容(新版的mybatis源码中已经改了):
public class MapperProxy<T> implements InvocationHandler, Serializable {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
try {
if (Object.class.equals(method.getDeclaringClass())) {
return method.invoke(this, args);
} else if (isDefaultMethod(method)) {
return invokeDefaultMethod(proxy, method, args);
}
} catch (Throwable t) {
throw ExceptionUtil.unwrapThrowable(t);
}
final MapperMethod mapperMethod = cachedMapperMethod(method);
return mapperMethod.execute(sqlSession, args);
}
非常典型的,该MapperProxy类实现了InvocationHandler接口,并且实现了该接口的invoke方法。
通过这种方式,我们只需要编写Mapper.java接口类,当真正执行一个Mapper接口的时候,就会转发给MapperProxy.invoke方法,而该方法则会调用后续的sqlSession.cud>executor.execute>prepareStatement等一系列方法,完成SQL的执行和返回。
18.6 组合模式
组合模式组合多个对象形成树形结构以表示“整体-部分”的结构层次。
组合模式对单个对象(叶子对象)和组合对象(组合对象)具有一致性,它将对象组织到树结构中,可以用来描述整体与部分的关系。同时它也模糊了简单元素(叶子对象)和复杂元素(容器对象)的概念,使得客户能够像处理简单元素一样来处理复杂元素,从而使客户程序能够与复杂元素的内部结构解耦。
在使用组合模式中需要注意一点也是组合模式最关键的地方:叶子对象和组合对象实现相同的接口。这就是组合模式能够将叶子节点和对象节点进行一致处理的原因。
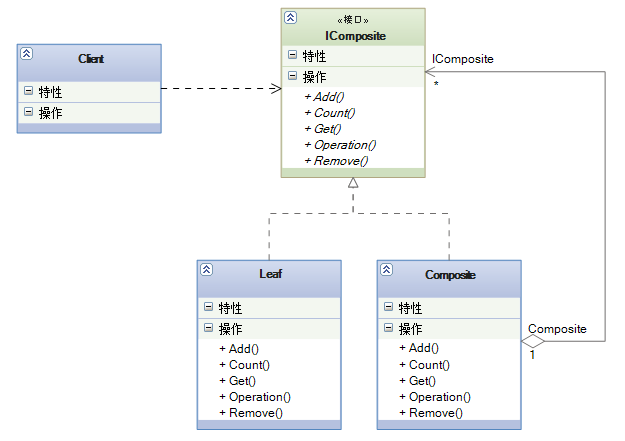
Mybatis支持动态SQL的强大功能,比如下面的这个SQL:
<update id="update" parameterType="org.format.dynamicproxy.mybatis.bean.User">
UPDATE users
<trim prefix="SET" prefixOverrides=",">
<if test="name != null and name != ''">
name = #{name}
</if>
<if test="age != null and age != ''">
, age = #{age}
</if>
<if test="birthday != null and birthday != ''">
, birthday = #{birthday}
</if>
</trim>
where id = ${id}
</update>
在这里面使用到了trim、if等动态元素,可以根据条件来生成不同情况下的SQL;
在DynamicSqlSource.getBoundSql方法里,调用了rootSqlNode.apply(context)方法,apply方法是所有的动态节点都实现的接口:
public interface SqlNode {
boolean apply(DynamicContext context);
}
对于实现该SqlSource接口的所有节点,就是整个组合模式树的各个节点:
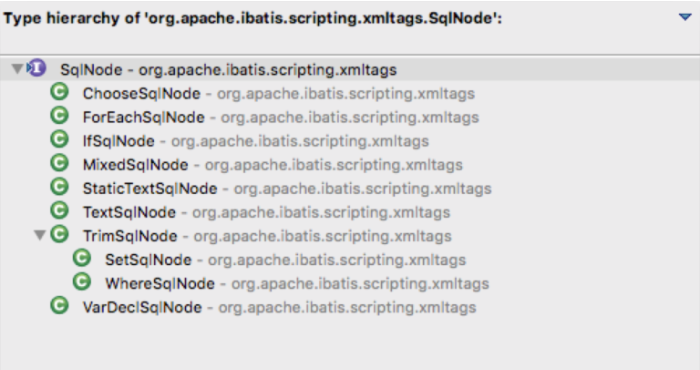
组合模式的简单之处在于,所有的子节点都是同一类节点,可以递归的向下执行,比如对于TextSqlNode,因为它是最底层的叶子节点,所以直接将对应的内容append到SQL语句中:
@Override
public boolean apply(DynamicContext context) {
GenericTokenParser parser = createParser(new BindingTokenParser(context, injectionFilter));
context.appendSql(parser.parse(text));
return true;
}
但是对于IfSqlNode,就需要先做判断,如果判断通过,仍然会调用子元素的SqlNode,即contents.apply方法,实现递归的解析。
@Override
public boolean apply(DynamicContext context) {
if (evaluator.evaluateBoolean(test, context.getBindings())) {
contents.apply(context);
return true;
}
return false;
}
18.7 模板方法模式
模板方法模式是所有模式中最为常见的几个模式之一,是基于继承的代码复用的基本技术。
模板方法模式需要开发抽象类和具体子类的设计师之间的协作。一个设计师负责给出一个算法的轮廓和骨架,另一些设计师则负责给出这个算法的各个逻辑步骤。代表这些具体逻辑步骤的方法称做基本方法(primitive method);而将这些基本方法汇总起来的方法叫做模板方法(template method),这个设计模式的名字就是从此而来。
模板类定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。
在Mybatis中,sqlSession的SQL执行,都是委托给Executor实现的,Executor包含以下结构:
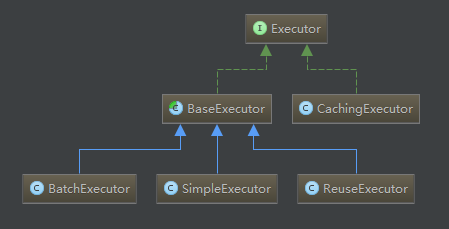
其中的BaseExecutor就采用了模板方法模式,它实现了大部分的SQL执行逻辑,然后把以下几个方法交给子类定制化完成:
protected abstract int doUpdate(MappedStatement ms, Object parameter) throws SQLException;
protected abstract List<BatchResult> doFlushStatements(boolean isRollback) throws SQLException;
protected abstract <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds,
ResultHandler resultHandler, BoundSql boundSql) throws SQLException;
该模板方法类有几个子类的具体实现,使用了不同的策略:
- 简单SimpleExecutor:每执行一次update或select,就开启一个Statement对象,用完立刻关闭Statement对象。(可以是Statement或PrepareStatement对象)
- 重用ReuseExecutor:执行update或select,以sql作为key查找Statement对象,存在就使用,不存在就创建,用完后,不关闭Statement对象,而是放置于Map<String, Statement>内,供下一次使用。(可以是Statement或PrepareStatement对象)
- 批量BatchExecutor:执行update(没有select,JDBC批处理不支持select),将所有sql都添加到批处理中(addBatch()),等待统一执行(executeBatch()),它缓存了多个Statement对象,每个Statement对象都是addBatch()完毕后,等待逐一执行executeBatch()批处理的;BatchExecutor相当于维护了多个桶,每个桶里都装了很多属于自己的SQL,就像苹果蓝里装了很多苹果,番茄蓝里装了很多番茄,最后,再统一倒进仓库。(可以是Statement或PrepareStatement对象)
比如在SimpleExecutor中这样实现update方法:
@Override
public int doUpdate(MappedStatement ms, Object parameter) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(this, ms, parameter, RowBounds.DEFAULT, null,
null);
stmt = prepareStatement(handler, ms.getStatementLog());
return handler.update(stmt);
} finally {
closeStatement(stmt);
}
}
17.8 适配器模式
适配器模式(Adapter Pattern) :将一个接口转换成客户希望的另一个接口,适配器模式使接口不兼容的那些类可以一起工作,其别名为包装器(Wrapper)。适配器模式既可以作为类结构型模式,也可以作为对象结构型模式。
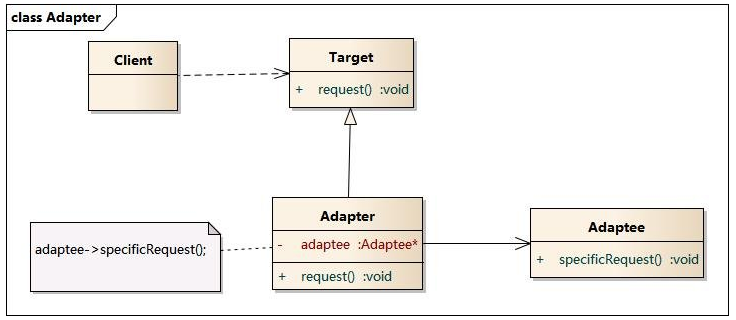
在Mybatsi的logging包中,有一个Log接口:
/**
* @author Clinton Begin
*/
public interface Log {
boolean isDebugEnabled();
boolean isTraceEnabled();
void error(String s, Throwable e);
void error(String s);
void debug(String s);
void trace(String s);
void warn(String s);
}
该接口定义了Mybatis直接使用的日志方法,而Log接口具体由谁来实现呢?Mybatis提供了多种日志框架的实现,这些实现都匹配这个Log接口所定义的接口方法,最终实现了所有外部日志框架到Mybatis日志包的适配:

比如对于Log4jImpl的实现来说,该实现持有了org.apache.log4j.Logger的实例,然后所有的日志方法,均委托该实例来实现。
public class Log4jImpl implements Log {
private static final String FQCN = Log4jImpl.class.getName();
private Logger log;
public Log4jImpl(String clazz) {
log = Logger.getLogger(clazz);
}
@Override
public boolean isDebugEnabled() {
return log.isDebugEnabled();
}
@Override
public boolean isTraceEnabled() {
return log.isTraceEnabled();
}
@Override
public void error(String s, Throwable e) {
log.log(FQCN, Level.ERROR, s, e);
}
@Override
public void error(String s) {
log.log(FQCN, Level.ERROR, s, null);
}
@Override
public void debug(String s) {
log.log(FQCN, Level.DEBUG, s, null);
}
@Override
public void trace(String s) {
log.log(FQCN, Level.TRACE, s, null);
}
@Override
public void warn(String s) {
log.log(FQCN, Level.WARN, s, null);
}
}
17.9 装饰者模式
装饰模式(Decorator Pattern) :动态地给一个对象增加一些额外的职责(Responsibility),就增加对象功能来说,装饰模式比生成子类实现更为灵活。其别名也可以称为包装器(Wrapper),与适配器模式的别名相同,但它们适用于不同的场合。根据翻译的不同,装饰模式也有人称之为“油漆工模式”,它是一种对象结构型模式。
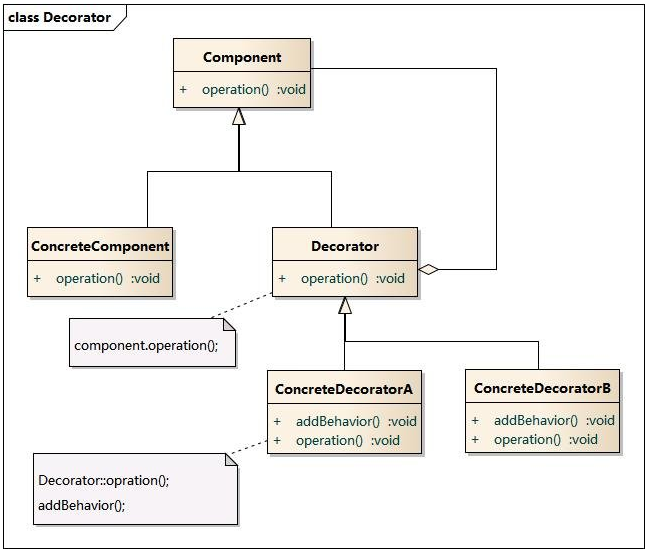
在mybatis中,缓存的功能由根接口Cache(org.apache.ibatis.cache.Cache)定义。整个体系采用装饰器设计模式,数据存储和缓存的基本功能由PerpetualCache(org.apache.ibatis.cache.impl.PerpetualCache)永久缓存实现,然后通过一系列的装饰器来对PerpetualCache永久缓存进行缓存策略等方便的控制。如下图:
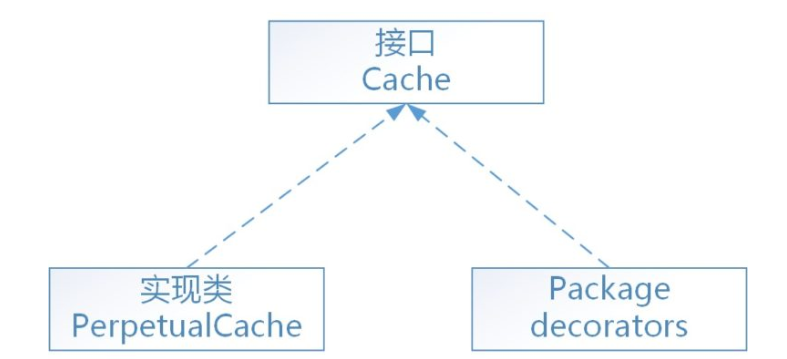
用于装饰PerpetualCache的标准装饰器共有8个(全部在org.apache.ibatis.cache.decorators包中):
- FifoCache:先进先出算法,缓存回收策略
- LoggingCache:输出缓存命中的日志信息
- LruCache:最近最少使用算法,缓存回收策略
- ScheduledCache:调度缓存,负责定时清空缓存
- SerializedCache:缓存序列化和反序列化存储
- SoftCache:基于软引用实现的缓存管理策略
- SynchronizedCache:同步的缓存装饰器,用于防止多线程并发访问
- WeakCache:基于弱引用实现的缓存管理策略
另外,还有一个特殊的装饰器TransactionalCache:事务性的缓存
正如大多数持久层框架一样,mybatis缓存同样分为一级缓存和二级缓存
- 一级缓存,又叫本地缓存,是PerpetualCache类型的永久缓存,保存在执行器中(BaseExecutor),而执行器又在SqlSession(DefaultSqlSession)中,所以一级缓存的生命周期与SqlSession是相同的。
- 二级缓存,又叫自定义缓存,实现了Cache接口的类都可以作为二级缓存,所以可配置如encache等的第三方缓存。二级缓存以namespace名称空间为其唯一标识,被保存在Configuration核心配置对象中。
二级缓存对象的默认类型为PerpetualCache,如果配置的缓存是默认类型,则mybatis会根据配置自动追加一系列装饰器。
Cache对象之间的引用顺序为:
SynchronizedCache–>LoggingCache–>SerializedCache–>ScheduledCache–>LruCache–>PerpetualCache
17.10 迭代器模式
迭代器(Iterator)模式,又叫做游标(Cursor)模式。GOF给出的定义为:提供一种方法访问一个容器(container)对象中各个元素,而又不需暴露该对象的内部细节。
Java的Iterator就是迭代器模式的接口,只要实现了该接口,就相当于应用了迭代器模式:
比如Mybatis的PropertyTokenizer是property包中的重量级类,该类会被reflection包中其他的类频繁的引用到。这个类实现了Iterator接口,在使用时经常被用到的是Iterator接口中的hasNext这个函数。
public class PropertyTokenizer implements Iterator<PropertyTokenizer> {
private String name;
private String indexedName;
private String index;
private String children;
public PropertyTokenizer(String fullname) {
int delim = fullname.indexOf('.');
if (delim > -1) {
name = fullname.substring(0, delim);
children = fullname.substring(delim + 1);
} else {
name = fullname;
children = null;
}
indexedName = name;
delim = name.indexOf('[');
if (delim > -1) {
index = name.substring(delim + 1, name.length() - 1);
name = name.substring(0, delim);
}
}
public String getName() {
return name;
}
public String getIndex() {
return index;
}
public String getIndexedName() {
return indexedName;
}
public String getChildren() {
return children;
}
@Override
public boolean hasNext() {
return children != null;
}
@Override
public PropertyTokenizer next() {
return new PropertyTokenizer(children);
}
@Override
public void remove() {
throw new UnsupportedOperationException(
"Remove is not supported, as it has no meaning in the context of properties.");
}
}
可以看到,这个类传入一个字符串到构造函数,然后提供了iterator方法对解析后的子串进行遍历,是一个很常用的方法类。
参考资料:
- 图说设计模式:http://design-patterns.readthedocs.io/zh_CN/latest/index.html
- 深入浅出Mybatis系列(十)—SQL执行流程分析(源码篇):http://www.cnblogs.com/dongying/p/4142476.html
- 设计模式读书笔记—–组合模式 http://www.cnblogs.com/chenssy/p/3299719.html
- Mybatis3.3.x技术内幕(四):五鼠闹东京之执行器Executor设计原本 http://blog.csdn.net/wagcy/article/details/32963235
- mybatis缓存机制详解(一)——Cache https://my.oschina.net/lixin91/blog/620068

