
JDBC
- 声明:此文是小白本人学习Spring所写,主要参考(搬运)了:【框架】--Spring - 随笔分类 - 唐浩荣 - 博客园 (cnblogs.com)
- 感谢此文所引用的文章的作者提供的优质学习资源,如有侵犯,请原作者联系我删除
1、JDBC的使用详解
1.1 JDBC的介绍
JDBC的全称是Java Data Base Connectivity(Java数据库连接)。是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问(例如MySQL,Oracle等),它由一组用Java语言编写的类和接口组成。JDBC提供了一种基准,据此可以构建更高级的工具和接口,使数据库开发人员能够编写数据库应用程序,JDBC实现了所有这些面向标准的目标并且具有简单、严格类型定义且高性能实现的接口。JDBC给数据库的连接搭建了桥梁,然后再根据不同的数据库厂商实现JDBC接口的驱动,就可以轻松的连接各种关系型数据库了。
注:JDBC是Java操作数据库的唯一方式,所以说JDBC非常的重要,尽管我们后面会学习框架,但是这是框架的底层必定都封装了JDBC的代码。
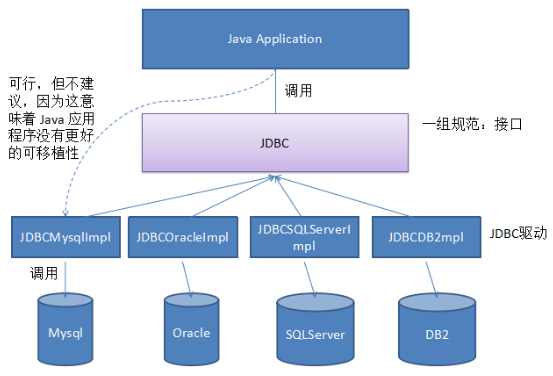
上面的图片是各种不同类型的数据库都有相应的实现,本文中的代码都是使用MySQL数据库实现的。所以我们需要MySQL的驱动,驱动下载网址:https://repo1.maven.org/maven2/mysql/mysql-connector-java/ (我选的是mysql-connector-java-5.1.48.jar)
1.2 JDBC常用接口
①、Driver接口
Driver接口由数据库厂家提供,作为java开发人员,只需要使用Driver接口就可以了。在编程中要连接数据库,必须先装载特定厂商的数据库驱动程序,不同的数据库有不同的装载方法。如:
- 装载MySql驱动:Class.forName("com.mysql.jdbc.Driver");
- 装载Oracle驱动:Class.forName("oracle.jdbc.driver.OracleDriver");
②、Connection接口
Connection与特定数据库的连接(会话),在连接上下文中执行sql语句并返回结果。DriverManager.getConnection(url, user, password)方法建立在JDBC URL中定义的数据库Connection连接上。
- 连接MySql数据库:
Connection conn = DriverManager.getConnection("jdbc:mysql://host:port/database", "user", "password"); - 连接Oracle数据库:
Connection conn = DriverManager.getConnection("jdbc:oracle:thin:@host:port:database", "user", "password"); - 连接SqlServer数据库:
Connection conn = DriverManager.getConnection("jdbc:microsoft:sqlserver://host:port; DatabaseName=database", "user", "password");
Connection中常用的方法:
createStatement():创建向数据库发送sql的statement对象。prepareStatement(sql):创建向数据库发送预编译sql的PrepareSatement对象。prepareCall(sql):创建执行存储过程的callableStatement对象。setAutoCommit(boolean autoCommit):设置事务是否自动提交。commit():在链接上提交事务。rollback():在此链接上回滚事务。
③、Statement接口
Statement用于执行静态SQL语句并返回它所生成结果的对象。Statement类有三种:
- Statement:由createStatement创建,用于发送简单的SQL语句(不带参数)。
- PreparedStatement :继承自Statement接口,由preparedStatement创建,用于发送含有一个或多个参数的SQL语句。PreparedStatement对象比Statement对象的效率更高,并且可以防止SQL注入,所以我们一般都使用PreparedStatement。
- CallableStatement:继承自PreparedStatement接口,由方法prepareCall创建,用于调用存储过程。
Statement中常用的方法:
execute(String sql):运行语句,返回是否有结果集executeQuery(String sql):运行select语句,返回ResultSet结果集。executeUpdate(String sql):运行insert/update/delete操作,返回更新的行数。addBatch(String sql):把多条sql语句放到一个批处理中。executeBatch():向数据库发送一批sql语句执行。
④、ResultSet接口
esultSet提供检索不同类型字段的方法,常用的有:
getString(int index)、getString(String columnName):获得在数据库里是varchar、char等类型的数据对象。getFloat(int index)、getFloat(String columnName):获得在数据库里是Float类型的数据对象。getDate(int index)、getDate(String columnName):获得在数据库里是Date类型的数据。getBoolean(int index)、getBoolean(String columnName):获得在数据库里是Boolean类型的数据。getObject(int index)、getObject(String columnName):获取在数据库里任意类型的数据。
ResultSet还提供了对结果集进行滚动的方法:
next():移动到下一行Previous():移动到前一行absolute(int row):移动到指定行beforeFirst():移动resultSet的最前面。afterLast():移动到resultSet的最后面。
1.3 JDBC创建步骤
JDBC创建步骤可以分为如下:导包—>加载驱动—>创建连接—>执行sql—>返回结果—>关闭连接
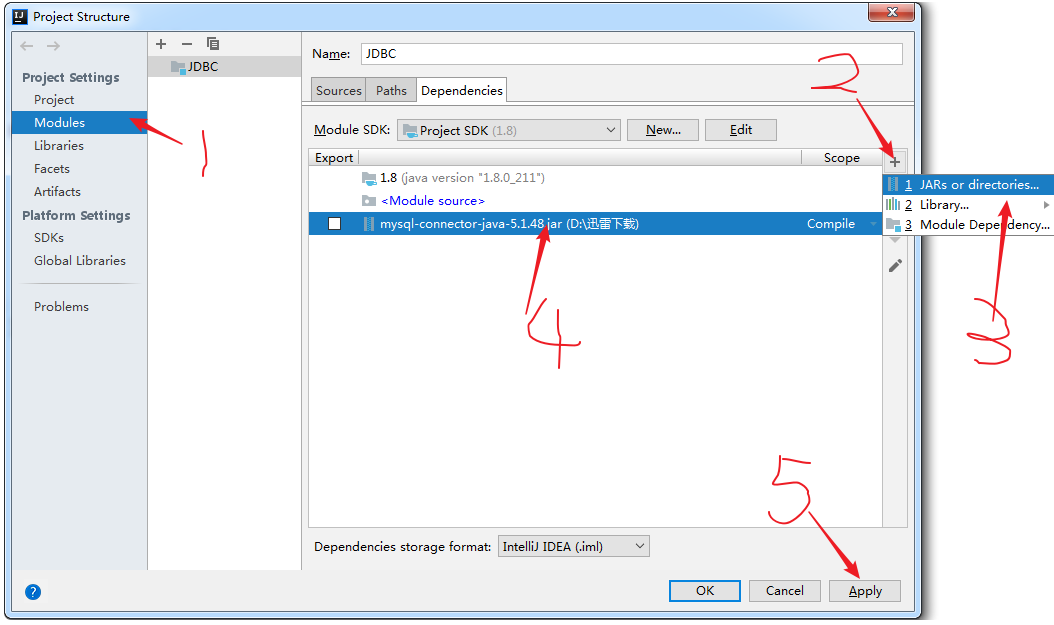
①、首先需要导入对应数据库的驱动包。
要访问MySQL时间就必须要用到MySQL驱动包(前面已经给出了链接),下载然后导入即可。本例用的是IDEA导入这个jar包。
导包步骤: 点击当前项目左上角File—>Project Structur—>Modules—>点击右边+号—>Jars Or directories
②、加载驱动
驱动的加载我们一般使用反射Class.forName(“com.mysql.jdbc.Driver”)来加载Driver这个类(因为它只会创建一次)。
也可以使用 DriverManager.registerDriver(new Driver())来加载,但这种方式会new两个Driver,从而造成资源浪费,所以不推荐使用这种方式。
try {
Class.forName("com.mysql.jdbc.Driver");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
注意:Class.forName是需要捕获ClassNotFoundException的。
③、建立连接
建立连接需要我们提供三个参数,分别是URL、USER、PASSWORD。
Connection conn = DriverManager.getConnection(url, user, password);
Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/mydb?characterEncoding=UTF-8","root","root");
它们各自的含义依次如下:
- 协议:jdbc
- 子协议:mysql
- 数据库服务端的IP地址:localhost或127.0.0.1
- 数据库端口:3306
- 连接的数据库名称:mydb
- 编码格式:?characterEncoding=UTF-8
- 数据库用户名:root
- 数据库密码:root (数据库密码是你安装时设置的密码)
try {
Class.forName("com.mysql.jdbc.Driver");
Connection con = DriverManager.getConnection("jdbc:mysql://localhost:3306/mydb?characterEncoding=UTF-8", "root", "root");
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
Connection的getConnection方法也需要捕获SQLException异常。
④、执行SQL语句(Statement和PreparedStatement)
- 使用Statement执行语句
Statement对象的获取可以使用createStatement()方法。当Statement对象创建之后,就可以执行SQL语句,完成对数据库的增删改查操作。
- 对于查询类的SQL语句使用:executeQuery(sql),sql是一个字符串sql语句,返回结果是一个结果集
- 对于更新类(插入、删除、更新)的语句使用:executeUpdate(sql),sql是一个字符串sql语句,返回结果是一个整数(受影响的行数)
Class.forName("com.mysql.jdbc.Driver");
Connection con = DriverManager.getConnection("jdbc:mysql://localhost:3306/mydb?characterEncoding=UTF-8", "root", "root");
Statement statement = con.createStatement();
//添加数据
String insert_sql="insert into t_user(username,password) values ('张三',123456)";
int count = statement.executeUpdate(insert_sql);
System.out.println("受影响行数:"+count);
在Statement中是可以使用字符串拼接的方式,该方式存在句法复杂,容易犯错等缺点,字符串拼接方式的SQL语句是非常繁琐的,中间有很多的单引号和双引号的混用,极易出错。
而且使用Statement有一个极大的缺点,会导致SQL注入。当SQL语句的 where 条件后面带有 or 1=1 的条件时,数据库会认为是true可以执行的,所以外界可以对数据库进行删、改操作,这样的数据库如同虚设。
所以一般不推荐使用Statement(如果是处理批量数据则推荐使用它),并且它在实际过程中使用的非常的少。而是使用后面的PreparedStatement。
下面的例子是典型的SQL注入,这样会将数据库中的所有数据全部删除。
Class.forName("com.mysql.jdbc.Driver");
Connection con = DriverManager.getConnection("jdbc:mysql://localhost:3306/mydb?characterEncoding=UTF-8", "root", "root");
Statement statement = con.createStatement();
//删除数据
String id="1 or 1=1";
String delete_sql="delete from t_user where id="+id;
int count = statement.executeUpdate(delete_sql);
System.out.println("受影响行数:"+count);
- 使用PreparedStatement执行语句
PreparedStatement继承自Statement接口,它的实例对象可以通过调用preparedStatement(sql)方法来获取,注意它是直接传入了一条SQL语句。与Statement不同的是PrepareStatement中的SQL使用了占位符(也可以执行没有占位符的SQL语句)。?在SQL中就起到占位符的作用。这种方式除了避免了Statement拼接字符串的繁琐之外,还能够提高性能。每次SQL语句都是一样的,Java类就不会再次编译,这样能够显著提高性能。
然后再逐一给占位符填入数据,填入数据使用PreparedStatement实例的setXXX(int parameterIndex, String x)方法,其中第一个参数时索引位置,第二个是传入数据。
Connection con=null;
PreparedStatement ps=null;
try {
Class.forName("com.mysql.jdbc.Driver");
con = DriverManager.getConnection("jdbc:mysql://localhost:3306/mydb?characterEncoding=UTF-8", "root", "root");
String sql="insert into t_user(username,password) values (?,?)";
ps=con.prepareStatement(sql);
ps.setString(1,"李四");
ps.setString(2,"123456");
int count = ps.executeUpdate();
System.out.println("受影响行数:"+count);
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
注意PreparedStatement中的索引是从 1开始的,而不是从0。
⑤、返回结果
当执行了查询操作后,会返回一个结果集,返回结果是一个结果集,它有一个光标指向结果的每一行,最开始它不指向结果,第一次执行next()后,它指向第一行结果,继续执行next(),他会继续指向下一行。next的返回结果是布尔值,它可以用来判断是否有下一行。ResultSet中常用的方法在前面第二点已经给出来了,可自行划上去瞄一眼。
- 而对于每一行结果,可以使用getXXX方法(XXX代表某一基本数据类型)来获取某一列的结果,getXXX方法的参数可以为字段名,也可以为索引号(从1开始)
Connection con=null;
PreparedStatement ps=null;
ResultSet rs=null;
try {
Class.forName("com.mysql.jdbc.Driver");
con = DriverManager.getConnection("jdbc:mysql://localhost:3306/mydb?characterEncoding=UTF-8", "root", "root");
String sql="select * from t_user where username like ?";//查询SQL
ps= con.prepareStatement(sql);
ps.setString(1,"张"+"%");//查询条件
rs = ps.executeQuery();//执行查询操作,并返回数据
while (rs.next()){
int id=rs.getInt(1);//用索引
String username=rs.getString("username");//用字段名
String password=rs.getString("password");
System.out.print("编号:"+id+";");
System.out.print("姓名:"+username+";");
System.out.print("密码:"+password+";");
System.out.println();
}
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
⑥、关闭连接
当程序对数据库的操作完成后,切记一定要关闭连接,因为数据库连接非常的耗资源。顺序是后创建的先关闭,这些对象通常是ResultSet, Statement和Connection。
而且还要在关闭语句中加try catch已经以防止前面关闭出错,导致后面的关闭不了。
}finally {
if (rs!=null){
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (ps != null) {
try {
ps.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (con != null) {
try {
con.close();
} catch (SQLException e) {
}
}
}
注意:为确保资源释放代码能运行,资源释放代码最好放在finally语句中。
⑦、JDBC操作数据库完整代码
public class JDBCTest {
public static void main(String[] args) {
Connection con = null;
PreparedStatement ps = null;
ResultSet rs = null;
try {
//1、加载驱动
Class.forName("com.mysql.jdbc.Driver");
String url = "jdbc:mysql://localhost:3306/test?characterEncoding=UTF-8";
String username = "root";
String password = "root";
//2、创建链接
con = DriverManager.getConnection(url, username, password);
String sql = "select * from t_user where username like ?";//查询SQL
//3、预编译处理,用来执行SQL
ps = con.prepareStatement(sql);
ps.setString(1, "张" + "%");//查询条件
//4、执行SQL,并且获取结果集
rs = ps.executeQuery();
// 5、遍历 数据
while (rs.next()) {
int id = rs.getInt(1);//用索引
String name = rs.getString("username");//用字段名
String pwd = rs.getString("password");
System.out.print("编号:" + id + ";");
System.out.print("姓名:" + name + ";");
System.out.print("密码:" + pwd + ";");
System.out.println();
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (rs != null) {
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (ps != null) {
try {
ps.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (con != null) {
try {
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
}
1.4 自定义JDBCUtil工具
前面Jdbc的基本使用使用已经讲得差不多了,但如果我们经常要创建连接,关闭连接的话,那么每次都要写重复的代码,显然这样非常的麻烦,为了避免这种情况,编写了一个JdbcUtil工具类,如下。
db.properties文件,用于放置驱动名称,连接数据库地址,数据库账号和密码。(db.properties要放在src或者默认会加载的目录下,不要放在包下面了)
#MySQL连接配置
mysqlDriver=com.mysql.jdbc.Driver
mysqlURL=jdbc:mysql://localhost:3306/mydb?characterEncoding=utf8&useSSL=false
mysqlUser=root
mysqlPwd=root
创建JdbcUtil工具类,代码如下:
public class JdbcUtil {
static Properties pros = null; //读取和处理资源文件中的信息
static { //加载JdbcUtil类的时候调用db.properties文件
pros = new Properties();
try {
pros.load(JdbcUtil.class.getClassLoader().getResourceAsStream("db.properties"));
} catch (IOException e) {
e.printStackTrace();
}
}
//创建连接
public static Connection getConnection() {
try {
Class.forName(pros.getProperty("mysqlDriver"));
return DriverManager.getConnection(
//获取properties文件中对应key的value
pros.getProperty("mysqlURL"),
pros.getProperty("mysqlUser"),
pros.getProperty("mysqlPwd"));
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
//关闭资源(如果没有传入null即可)
public static void close(Connection con, PreparedStatement ps, ResultSet rs) {
//ResultSet关闭
if (rs != null) {
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
//Statement关闭
if (ps != null) {
try {
ps.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
//Connection关闭
if (con != null) {
try {
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
JdbcUtil的简单示例:
public static void main(String[] args) {
Connection con = null;
PreparedStatement ps = null;
ResultSet rs = null;
//调用JdbcUtil来创建连接
con = JdbcUtil.getConnection();
String sql = "select * from t_user";
try {
ps = con.prepareStatement(sql);
rs = ps.executeQuery();
while (rs.next()) {
System.out.print("编号:" + rs.getInt(1) + ";");
System.out.print("姓名:" + rs.getString(2) + ";");
System.out.print("密码:" + rs.getString(3) + ";");
System.out.println();
}
} catch (Exception e) {
e.printStackTrace();
} finally {
JdbcUtil.close(con, ps, rs);
}
}
1.5 JDBC的事务(重要)
5.1、事务的基本概念
事务是若干个SQL语句构成的一个操作序列,这些操作表示一个完整的功能,并且需要保证功能的完整性,因此要求在该事务中要求所有的sql要么都执行,要么都不执行,是一个不可分割的整体单位。
5.2、事务的四个基本要素(ACID)
- 原子性(Atomicity):事务是一个不可分割的整体,所有操作要么全做,要么全不做;只要事务中有一个操作出错,回滚到事务开始前的状态的话,那么之前已经执行的所有操作都是无效的,都应该回滚到开始前的状态。
- 一致性(Consistency):事务开始前和结束后,数据库的完整性约束没有被破坏 。比如A向B转账,不可能A扣了钱,B却没收到。
- 隔离性(Isolation):同一时间,只允许一个事务请求同一数据,不同的事务之间彼此没有任何干扰。比如A正在从一张银行卡中取钱,在A取钱结束前,B不能向这张卡转账。
- 持久性(Durability):事务一旦被提交后,事务对数据库的所有更新将被永远保存到数据库,不能回滚。
5.3、事务并发产生的问题
- 脏读:事务A读取了事务B更新并且未提交的数据,然后B回滚操作,那么A读取到的数据是脏数据
- 不可重复读:事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果不一致。
- 幻读:事务A从一个表中读取了一个字段,然后B在该表中插入/删除了一些新的行。 之后, 如果 A 再次读取同一个表, 就会多/少几行,就好像发生了幻觉一样,这就叫幻读。
5.4、事务的隔离级别
由于数据库事物可以并发执行,而并发操作可能会带来数据的不一致性,包括脏读、不可重复读、幻读等。数据库为了避免数据不一致问题提供了隔离级别来让我们有针对性地选择事务的隔离级别。
SQL标准定义了4种隔离级别(从低到高),分别对应可能出现的数据不一致的情况:
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交(read-uncommitted) | 是 | 是 | 是 |
| 不可重复读(read-committed) | 否 | 是 | 是 |
| 可重复读(repeatable-read) | 否 | 否 | 是 |
| 串行化(serializable) | 否 | 否 | 否 |
4种隔离级别的描述:
- 读未提交(read-uncommitted):允许A事务读取其他事务未提交和已提交的数据
- 不可重复读(read-committed):只允许A事务读取其他事务已提交的数据
- 可重复读(repeatable-read):确保事务可以多次从一个字段中读取相同的值。在这个事务持续期间,禁止其他事务对这个字段进行更新;注意:mysql中使用了MVCC多版本控制技术,在这个级别也可以避免幻读。
- 串行化(serializable):确保事务可以从一个表中读取相同的行,相同的记录。在这个事务持续期间,禁止其他事务对该表执行插入、更新、删除操作(效率非常低,基本不用)
- 查看当前mysql连接的隔离级别:
select @@tx_isolation;
- 查看全局的隔离级别:
select @@global.tx_isolation;
- 设置当前 mysql连接的隔离级别:
set tx_isolation ='read-uncommitted';
set tx_isolation ='read-committed';
set tx_isolation ='repeatable-read';
更详细的事物隔离级别:理解事务的4种隔离级别
5.5、JDBC事务原理
JDBC中的事物分为两种: 自动事务和手动事务。注意这两者有一定的区别需要记住。
①、自动事务(默认)con.setAutoCommit(true):
在自动事务的情况下,只要SQL语句是正确的,执行的过程中没有发生异常、错误,就会提交到是数据库中,一般情况下没有指定的话就是默认为自动事务,实际上没有设定过的数据库就是自动事务,也就是说我们平时的数据库操作都是自动事务,所以自动事务会出现数据残留现象。
②、手动事务con.setAutoCommit(false):
在手动事务的情况下,需要自己调用提交或回滚来接结束事务,不然事务处理不会结束,手动事务有自定义的好处,而且能够自己判断语句的操作结果是否是自己想要的,如果不是自己想要的就可以进行回滚,是自己想要的操作结果才提交,自动事务则只要语句没出错都会进行提交。在大部分情况下,使用手动事务要多一些,因为使用自动事务的话语句没出错就自动把操作结果提交了,当SQL语句里的值写错了,或者操作结果不是正确的,就没办法进行回滚了,这些情况下SQL语句不会报错。
首先我们来看一下自动提交事物的例子,我们把这两次添加数据看成是一次事务:
public class Demo1 {
public static void main(String[] args) {
Connection con = null;
PreparedStatement ps = null;
try {
con = JdbcUtil.getConnection();
//默认自动提交事务,这段可以省略
con.setAutoCommit(true);
ps = con.prepareStatement("insert into t_user(username,password) values(?,?)");
ps.setString(1, "张三");
ps.setString(2, "123456");
ps.executeUpdate();
System.out.println("添加第一条...");
//这里多添加一个占位符用来报错
ps = con.prepareStatement("insert into t_user(username,password) values(?,?,?)");
ps.setString(1, "李四");
ps.setString(2, "654321");
ps.executeUpdate();
System.out.println("添加第二条...");
} catch (SQLException e) {
e.printStackTrace();
} finally {
JdbcUtil.close(con, ps, null);
}
}
}
自动提交事物的代码运行完成之后的数据库如下:
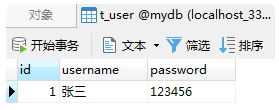
发现第一条添加成功了,而第二因为出错没有添加成功,所以自动提交事物会导致正确的SQL语句依然会执行,从而造成数据的残留。(不推荐使用)
注意:mysql中默认情况下,一个sql独占一个事务,且自动提交,从上面就可以看得出来
手动事物代码示例如下,注意它们的步骤:
- 获取Connection
- 设置autocommit(false)
- 需要执行的sql语句
- 提交事物,commit(提交事务的代码一定要在执行完指定的若干条SQL语句的后面)
- 出错,rollback
- 关闭连接
开启事务,提交事务和回滚事务都是使用的Connection对象。
public class Demo2 {
public static void main(String[] args) {
Connection con = null;
PreparedStatement ps = null;
try {
con = JdbcUtil.getConnection();
//关闭自动事物,改为手动提交事务
con.setAutoCommit(false);
ps = con.prepareStatement("insert into t_user(username,password) values(?,?)");
ps.setString(1, "张三");
ps.setString(2, "123456");
ps.executeUpdate();
System.out.println("添加第一条...");
//这里多添加一个占位符用来报错
ps = con.prepareStatement("insert into t_user(username,password) values(?,?,?)");
ps.setString(1, "李四");
ps.setString(2, "654321");
ps.executeUpdate();
System.out.println("添加第二条...");
con.commit();//提交事物
} catch (SQLException e) {
e.printStackTrace();
try {
con.rollback();//回滚
} catch (SQLException e1) {
e1.printStackTrace();
}
} finally {
JdbcUtil.close(con, ps, null);
}
}
}
运行之后的数据库:
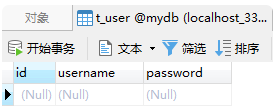
可以发现后面的SQL出现了异常,而前面的数据并没有加入到数据库中,说明整个事物都回滚了。
注意:如果开启了手动提交事物而不调用commit、rollback方法默认是会回滚的。
1.6 JDBC其他操作(了解)
1、批量处理(建议使用Statement)
/**
* @author Administrator
* @date 2020-02-15
* @desc 批处理
*/
public class Demo3 {
public static void main(String[] args) {
Connection con = null;
PreparedStatement ps = null;
//开始时间
long start = System.currentTimeMillis();
try {
//创建连接
con = JdbcUtil.getConnection();
con.setAutoCommit(false);//关闭自动事物
//预编译SQL
ps = con.prepareStatement("insert into t_user(username,password) values (?,?)");
for (int i = 1; i <= 10000; i++) { //添加一万条数据
ps.setObject(1, "张三" + i);
ps.setObject(2, i);
ps.addBatch();
}
ps.executeBatch();
con.commit();//提交事物
long end = System.currentTimeMillis();
System.out.println("耗时:" + (end - start) + " ms");
} catch (SQLException e) {
e.printStackTrace();
try {
con.rollback();//回滚
} catch (SQLException e1) {
e1.printStackTrace();
}
} finally {
try {
con.setAutoCommit(true);
} catch (SQLException e) {
e.printStackTrace();
}
JdbcUtil.close(con, ps, null);
}
}
}
2、获取自增主键
/**
* @author Administrator
* @date 2020-02-15
* @desc 获取自动生成主键
*/
public class Demo4 {
public static void main(String[] args) {
Connection con = null;
PreparedStatement ps = null;
ResultSet rs = null;
try {
con = JdbcUtil.getConnection();
String sql = "insert into t_user(username) values(?)";
ps = con.prepareStatement(sql, Statement.RETURN_GENERATED_KEYS);
ps.setString(1, "张三");//在插入username时数据库会自动生成id
ps.executeUpdate();
//获取自动生成的主键
rs = ps.getGeneratedKeys();
if (rs.next()) {
System.out.println(rs.getInt(1));
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
JdbcUtil.close(con, ps, rs);
}
}
}
为了测试接下来的数据,给数据库表添加了一些字段,如下:
CREATE TABLE `t_user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`password` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`regDate` date NULL DEFAULT NULL,
`regDateTime` timestamp(0) NULL DEFAULT NULL,
`info` text CHARACTER SET utf8 COLLATE utf8_general_ci NULL,
`image` longblob NULL,
PRIMARY KEY (`id`) USING BTREE
)
3、处理日期时间(Date和TimeStamp)
/**
* @author Administrator
* @date 2020-02-15
* @desc 处理日期时间
*/
public class Demo5 {
public static void main(String[] args) {
Connection con = null;
PreparedStatement ps = null;
ResultSet rs = null;
try {
con = JdbcUtil.getConnection();
//插入
ps = con.prepareStatement(
"insert into t_user(username,password,regDate,regDateTime)values(?,?,?,?)"
);
ps.setString(1, "张三");
ps.setString(2, "123456");
ps.setDate(3, new Date(System.currentTimeMillis()));//日期
ps.setTimestamp(4, new Timestamp(System.currentTimeMillis()));//日期和时间
ps.executeUpdate();
//查询
ps = con.prepareStatement("select * from t_user");
rs = ps.executeQuery();
while (rs.next()) {
System.out.println(rs.getString("username") + "--" +
rs.getString("password") + "--" +
rs.getDate("regDate") + "--" +
rs.getTimestamp("regDateTime"));
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
JdbcUtil.close(con, ps, rs);
}
}
}
4、存取文本文件(.txt文件)
CLOB(Character Large Object)用于存储大文本(mysql中无clob,存储大文本采用的是Text)
在MySQL中相关的类型:
- TINYTEXT 最大长度为255(2[1]-1)字符的TEXT列。
- TEXT 最大长度为65535(2[2]-1)字符的TEXT列。
- MEDIUMTEXT 最大长度为16777215(2[3]-1)字符的TEXT列。
- LONGTEXT 最大长度为4GB(2[4]-1)字符的TEXT列。
/**
* @author Administrator
* @date 2020-02-15
* @desc CLOB处理文本
*/
public class Demo6 {
public static void main(String[] args) {
Connection con = null;
PreparedStatement ps = null;
ResultSet rs = null;
Reader r = null;
try {
con = JdbcUtil.getConnection();
//插入
ps = con.prepareStatement("insert into t_user(username,info)values(?,?)");
ps.setString(1, "张三");
//将文本文件内容直接输入到数据库中
ps.setClob(2, new FileReader(new File("D:/1.txt")));
//将程序中的字符串输入到数据库中的CLOB字段中
//ps.setClob(2, new BufferedReader(new InputStreamReader(new ByteArrayInputStream("我是张三".getBytes()))));
ps.executeUpdate();
System.out.println("插入成功...");
//查询
ps = con.prepareStatement("select * from t_user");
rs = ps.executeQuery();
System.out.println("查询成功...");
while (rs.next()) {
Clob c = rs.getClob("info");
r = c.getCharacterStream();
int temp = 0;
while ((temp = r.read()) != -1) {
System.out.print((char) temp);
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
JdbcUtil.close(con, ps, rs);
}
}
}
5、存取二进制文件(图片,视频),注:实际开发中永远不可能将图片或视频存储在数据库中。
BLOB(Binary large Object)用于大量存储二进制文件,在MySQL中相关的类型:
- TINYBLOB 最大长度为255(2[5]-1)字符的BLOB列。
- BLOB 最大长度为65535(2[6]-1)字符的BLOB列。
- MEDIUMBLOB 最大长度为16777215(2[7]-1)字符的BLOB列。
- LONGBLOB 最大长度为4GB(2[8]-1)字符的BLOB列。
/**
* @author Administrator
* @date 2020-02-15
* @desc BLOB 处理二进制文件
*/
public class Demo7 {
public static void main(String[] args) {
Connection con = null;
PreparedStatement ps = null;
ResultSet rs = null;
InputStream is = null;
OutputStream os = null;
try {
con = JdbcUtil.getConnection();
//插入
ps = con.prepareStatement("insert into t_user(username,image)values(?,?)");
ps.setString(1, "张三");
ps.setBlob(2, new FileInputStream("C:/1.jpg"));
ps.executeUpdate();
System.out.println("插入成功...");
//查询
ps = con.prepareStatement("select * from t_user where id=?");
rs = ps.executeQuery();
System.out.println("查询成功...");
while (rs.next()) {
Blob b = rs.getBlob("image");
is = b.getBinaryStream();
os = new FileOutputStream("D:/2.jpg");
int temp = 0;
while ((temp = is.read()) != -1) {
os.write(temp);
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
JdbcUtil.close(con, ps, rs);
}
}
}
2、数据库连接池的使用
2.1 连接池的介绍
我们知道,在前面JDBC的知识中我们在连接数据库的时候,每次创建连接完成操作后再关闭连接。如果当一个程序有大量访问数据库操作的时候,此时就要不停的建立连接,关闭连接。而建立一个数据库连接是一件非常耗时(消耗时间)耗力(消耗资源)的事情,极大的浪费数据库的资源,并且极易造成数据库服务器内存溢出、拓机。之所以会这样,是因为连接到数据库服务器需要经历几个漫长的过程:建立物理通道(例如套接字或命名管道),与服务器进行初次握手,分析连接字符串信息,由服务器对连接进行身份验证,运行检查以便在当前事务中登记等等。我们先不管为什么会有这样的机制,存在总是有它的道理。既然新建一条连接如此痛苦,那么为什么不重复利用已有的连接呢?所以就有了数据库连接池。
数据库连接池:用来负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个。
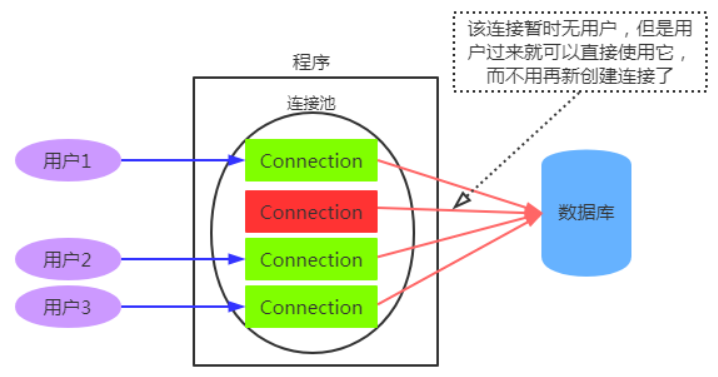
数据库连接池在初始化时将创建一定数量的数据库连接放到连接池中,这些数据库连接的数量是由最小数据库连接数来设定的。无论这些数据库连接是否被使用,连接池都将一直保证至少拥有这么多的连接数量。连接池的最大数据库连接数量限定了这个连接池能占有的最大连接数,当应用程序向连接池请求的连接数超过最大连接数量时,这些请求将被加入到等待队列中。
数据库连接池的最小连接数和最大连接数的设置要考虑到以下几个因素:
- 最小连接数:是连接池一直保持的数据库连接,所以如果应用程序对数据库连接的使用量不大,将会有大量的数据库连接资源被浪费。
- 最大连接数:是连接池能申请的最大连接数,如果数据库连接请求超过次数,后面的数据库连接请求将被加入到等待队列中,这会影响以后的数据库操作。
- 最小连接数与最大连接数差距:那么最先连接请求将会获利,之后超过最小连接数量的连接请求等价于建立一个新的数据库连接.不过,这些大于最小连接数的数据库连接在使用完不会马上被释放,他将被放到连接池中等待重复使用或是空间超时后被释放。
现在市面上常用的开源数据库连接池有DBCP、C3P0、Druid和Hikari连接池等等。其中DBCP和C3P0好像已经淘汰了,用的最多的是后面两个:Druid和Hikari连接池。
2.2 连接池的原理
我们早期对数据的操作是这样的:①、加载数据库驱动程序;②、通过 jdbc 建立数据库连接;③、访问数据库,执行 sql 语句;④、断开数据库连接。但是这种方式对于大量请求存在很多问题。因为每次web请求都会建立一次数据库连接,而建立连接是一个费时的过程。所以为了保障网站的正常使用,应该对其进行妥善管理。其实我们查询完数据库后,不要关闭连接,而是暂时存放起来,当别人使用时,把这个连接给他们使用。就避免了一次建立数据库连接和断开的操作时间消耗。
连接池的工作原理主要由三部分组成,分别为:①、连接池的建立;②、连接池中连接的使用管理;③、连接池的关闭。
①、连接池的建立。一般在系统初始化时,连接池会根据系统配置建立,并在池中创建了几个连接对象,以便使用时能从连接池中获取。连接池中的连接不能随意创建和关闭,这样避免了连接随意建立和关闭造成的系统开销。Java中提供了很多容器类可以方便的构建连接池,例如例如 Vector(线程安全类),LinkedList等
②、连接池的管理。连接池管理策略是连接池机制的核心,连接池内连接的分配和释放对系统的性能有很大的影响。其管理策略是:
- 当客户请求数据库连接时,首先查看连接池中是否有空闲连接,如果存在空闲连接,则将连接分配给客户使用;如果没有空闲连接,则查看当前所开的连接数是否已经达到最大连接数,如果没达到就重新创建一个连接给请求的客户;如果达到就按设定的最大等待时间进行等待,如果超出最大等待时间,则抛出异常给客户。
- 当客户释放数据库连接时,先判断该连接的引用次数是否超过了规定值,如果超过了就从连接池中删除该连接,并判断当前连接池内总的连接数是否小于最小连接数,若小于就将连接池充满;如果没超过就将该连接标记为开放状态,可供再次复用。该策略保证了数据库连接的有效复用,避免频繁的建立、释放连接所带来的系统资源开销。
③、连接池的关闭。当应用程序退出时,关闭连接池中所有的连接,释放连接池相关的资源,该过程正好与创建相反。
使用连接池的主要优点:
- 减少连接的创建时间。连接池中的连接是已准备好的,可以重复使用的,获取后可以直接访问数据库,因此减少了连接创建的次数和时间。
- 更快的系统响应速度。数据库连接池在初始化过程中,往往已经创建了若干数据库连接置于池中备用。此时连接的初始化工作均已完成。对于业务请求处理而言,直接利用现有可用连接,避免了数据库连接初始化和释放过程的时间开销,从而缩减了系统整体响应时间。
- 统一的连接管理。如果不使用连接池,每次访问数据库都需要创建一个连接,这样系统的稳定性受系统的连接需求影响很大,很容易产生资源浪费和高负载异常。连接池能够使性能最大化,将资源利用控制在一定的水平之下。连接池能控制池中的链接数量,增强了系统在大量用户应用时的稳定性。
2.3 DBCP连接池
DBCP:DBCP(DataBase connection pool)连接池是一个依赖Jakarta commons-pool对象池机制的数据库连接池,现在的版本是DBCP2,但是现在很久没有更新了。DBCP可以直接的在应用程序中使用。要使用DBCP数据源,需要应用程序应在系统中增加如下三个 jar 包(logging可以不要):
注意下载的是二进制包。
- commons-dbcp.jar:连接池的实现 。下载地址:http://commons.apache.org/proper/commons-dbcp/download_dbcp.cgi
- commons-pool.jar:连接池实现的依赖库。下载地址:http://commons.apache.org/proper/commons-pool/download_pool.cgi
- commons-logging.jar:连接池的日志。下载地址:http://commons.apache.org/proper/commons-logging/download_logging.cgi
下载后解压文件,将去导入到项目中去:
DBCP连接池的使用举例:
①、在src目录下加入dbcp的配置文件:dbcp.properties。
dbcp.properties的配置信息如下:
########DBCP配置文件##########
#驱动名
driverClassName=com.mysql.jdbc.Driver
#url
url=jdbc:mysql://localhost:3306/user?characterEncoding=utf8&useSSL=false
#用户名
username=root
#密码
password=root
#连接池的配置信息
#初始连接数,启动时创建的数量
initialSize=30
#最大活跃数 或 最大连接数(DBCP2中maxActive改成 maxTotal)
maxTotal=30
#最大空闲连接数
maxIdle=10
#最小空闲连接数
minIdle=5
#最长等待时间(毫秒),dbcp2由maxWait该成maxWaitMillis
maxWaitMillis=1000
想要了解更详细的配置信息可以参考:https://blog.csdn.net/brushli/article/details/80413461
②、测试DBCP数据源代码如下:
package com.dbcp;
import javax.sql.DataSource;
import java.io.IOException;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.Properties;
import org.apache.commons.dbcp2.BasicDataSourceFactory;
/**
* @author tanghaorong
* @date 2020-05-29
* @desc DBCP数据库连接池的使用
*/
public class DBCPTest {
public static void main(String[] args) {
//数据库连接对象
Connection con = null;
//数据库操作对象
PreparedStatement ps = null;
//数据库结果集对象
ResultSet rs = null;
//数据源对象
DataSource ds = null;
//properties配置文件对象
Properties properties = new Properties();
//读取dbcp.properties文件
InputStream in = DBCPTest.class.getClassLoader().getResourceAsStream("dbcp.properties");
try {
//从输入流中读取配置文件
properties.load(in);
//获取数据源,设置连接池参数。在createDataSource中设置连接池的参数
ds = BasicDataSourceFactory.createDataSource(properties);
//通过数据源来获取连接对象
con = ds.getConnection();
//编译并且执行SQL
ps = con.prepareStatement("select * from t_user");
rs = ps.executeQuery();
System.out.println("查询的数据为:");
//读取数据
while (rs.next()){
System.out.println(rs.getString(2)+":"+rs.getString(3));
}
} catch (IOException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
} finally {
//关闭连接
if (rs!=null){
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (ps!=null){
try {
ps.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (con!=null){
try {
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
}
2.4 C3P0连接池
C3P0:是一个开放源代码的JDBC连接池,它包括了实现JDBC3和JDBC2扩展规范说明的Connection 和Statement 池的DataSources 对象。虽然C3P0的功能简单易用,稳定性好这是它的优点,但是性能上的缺点却让它彻底淘汰了,因为现在的系统架构对性能的要是比较的高的,所以随着国内互联网大潮的涌起,性能有硬伤的c3p0彻底的退出了历史舞台。
要使用C3P0连接池,需要应用程序应在系统中增加如下两个 jar 包如下:
- c3p0-0.9.5.2.jar
- mchange-commons-0.2.12.jar
百度网盘下载链接:https://pan.baidu.com/s/1o9cBkMVb_kZmAksZjjoZYg 密码:c7pr
①、导入jar包之后新建一个c3p0-config.xml文件
注意:命名必须为c3p0-config.xml。必须放在src目录下,c3p0包会默认加载src目录下的c3p0-config.xml文件。
配置c3p0-config.xml文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<c3p0-config>
<!-- 默认读的c3p0配置文件,在代码中用“ComboPooledDataSource ds = new ComboPooledDataSource();”来获取 -->
<default-config>
<!--mysql数据库连接的各项参数-->
<property name="driverClass">com.mysql.jdbc.Driver</property>
<property name="jdbcUrl">jdbc:mysql://127.0.0.1:3306/user?characterEncoding=utf-8</property>
<property name="user">root</property>
<property name="password">root</property>
<!--配置数据库连接池的最小链接数、最大连接数、初始连接数-->
<property name="maxPoolSize">15</property>
<property name="minPoolSize">5</property>
<property name="initialPoolSize">5</property>
</default-config>
<!--按名称的配置文件,可用于配置其它数据库,比如oracle -->
<!--在代码中用“ComboPooledDataSource ds = new ComboPooledDataSource("mydb");”来获取
这样写就表示使用的是name为mydb的配置信息来创建数据源-->
<named-config name="mydb">
<property name="driverClass">com.mysql.jdbc.Driver</property>
<property name="jdbcUrl">jdbc:mysql://192.168.200.200:3306/user?characterEncoding=utf-8</property>
<property name="user">root</property>
<property name="password">root</property>
<property name="maxPoolSize">15</property>
<property name="minPoolSize">5</property>
<property name="initialPoolSize">5</property>
</named-config>
</c3p0-config>
②、测试c3p0连接池
package com.c3p0;
import com.mchange.v2.c3p0.ComboPooledDataSource;
import java.sql.*;
/**
* @author tanghaorong
* @date 2020-05-30
* @desc C3P0连接池的使用
*/
public class C3P0Test {
public static void main(String[] args) {
//数据库连接对象
Connection con = null;
//数据库操作对象
PreparedStatement ps = null;
//数据库结果集对象
ResultSet rs = null;
//创建数据库连接池对象,读取默认的
ComboPooledDataSource cpds = new ComboPooledDataSource();
//获取名称为mydb的配置文件内容
//ComboPooledDataSource cpds = new ComboPooledDataSource("mydb");
try {
//从数据库连接池中获取连接对象
con = cpds.getConnection();
ps = con.prepareStatement("select * from t_user");
rs = ps.executeQuery();
while (rs.next()){
System.out.println(rs.getString(2)+":"+rs.getString(3));
}
} catch (SQLException e) {
e.printStackTrace();
}finally {
//关闭连接
if (rs!=null){
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (ps!=null){
try {
ps.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (con!=null){
try {
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
}
2.5 HikariCP连接池
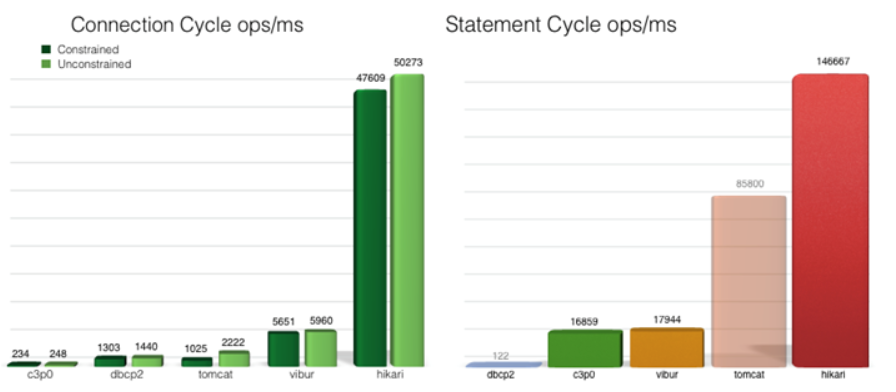
HikariCP连接池:HikariCP是由日本程序员开源的一个数据库连接池组件,代码非常轻量。它号称“性能杀手”(It’s Faster),所以其速度是非常的快,而且稳定性也很好。先来看下官网提供的数据:在i7CPU中,开启32个线程32个连接的情况下,进行随机数据库读写操作,HikariCP的速度是现在常用的C3P0数据库连接池的数百倍。在SpringBoot2.0中,官方也是推荐使用HikariCP。
那它是怎么做到如此强劲的呢?官网给出的说明如下:
- 字节码精简:优化代码,直到编译后的字节码最少,这样,CPU缓存可以加载更多的程序代码;
- 优化代理和拦截器:减少代码,例如HikariCP的Statement proxy只有100行代码;
- 自定义数组类型(FastStatementList)代替ArrayList:避免每次get()调用都要进行range check,避免调用remove()时的从头到尾的扫描;
- 自定义集合类型(ConcurrentBag):提高并发读写的效率;
其他缺陷的优化,比如对于耗时超过一个CPU时间片的方法调用的研究(但没说具体怎么优化)。
要使用HikariCP就需要导入对应的包,如下(HikariCP的jar包不好找,所以直接贴Maven坐标了):
<dependency>
<groupId>com.zaxxer</groupId>
<artifactId>HikariCP</artifactId>
<version>3.4.5</version>
</dependency>
使用HikariCP简单举例:
package com.hikaricp;
import com.zaxxer.hikari.HikariConfig;
import com.zaxxer.hikari.HikariDataSource;
import java.sql.*;
/**
* @author tanghaorong
* @date 2020-05-31
* @desc HikariCP连接池的使用
*/
public class HikariCPTest {
public static void main(String[] args) {
//数据库连接对象
Connection con = null;
//数据库操作对象
PreparedStatement ps = null;
//数据库结果集对象
ResultSet rs = null;
try {
//表示连接池的配置文件对象
HikariConfig hikariConfig = new HikariConfig();
//连接池的基本配置
hikariConfig.setJdbcUrl("jdbc:mysql://localhost:3306/user?characterEncoding=utf8&useSSL=false");
hikariConfig.setUsername("root");
hikariConfig.setPassword("root");
//连接池的配置信息
hikariConfig.setMaximumPoolSize(20);
hikariConfig.setMinimumIdle(15);
hikariConfig.setMaxLifetime(2000000);
hikariConfig.setConnectionTimeout(5000);
//创建连接池数据源对象
HikariDataSource ds = new HikariDataSource(hikariConfig);
con = ds.getConnection();
ps = con.prepareStatement("select * from t_user");
rs = ps.executeQuery();
while (rs.next()){
System.out.println(rs.getString(2)+":"+rs.getString(3));
}
} catch (SQLException e) {
e.printStackTrace();
}finally {
//关闭连接代码省略
}
}
}
关于HikariCP更多详细的配置信息可以参考:https://blog.csdn.net/Maskkiss/article/details/82115149
2.6 Druid连接池
Druid连接池想必大家都非常的熟悉,可能在座的大家都使用过,它是由阿里巴巴公司开发的一个开源项目。它支持所有JDBC兼容的数据库,包括Oracle、MySql、Derby、Postgresql、SQL Server、H2等。Druid除了提供性能卓越的连接池功能外,还集成了SQL监控,黑名单拦截等功能,用它自己的话说,Druid是“为监控而生”。其实Druid不仅是一个数据库连接池,还包含一个ProxyDriver、一系列内置的JDBC组件库、一个SQL Parser。所以Druid是Java语言中最好的数据库连接池是当之无愧的。
Druid 相对于其他数据库连接池的优点在于:
- 性能高。它比dbcp、c3p0的性能高很多很多,除了HikariCp。
- 提供了强大的监控特性,通过Druid提供的监控功能,可以清楚知道连接池和SQL的工作情况。
- 监控SQL的执行时间、ResultSet持有时间、返回行数、更新行数、错误次数、错误堆栈信息
- 方便扩展。Druid提供了Filter-Chain模式的扩展API,可以自己编写Filter拦截JDBC中的任何方法,可以在上面做任何事情,比如说性能监控、SQL审计、用户名密码加密、日志等等。
Druid与HikariCP的对比:因为HikariCP是性能之王,所以Hikari在性能上是完全秒杀阿里巴巴的Druid连接池的。对此,阿里的工程师也做了一定的回应,说Druid的性能稍微差点是锁机制的不同,并且Druid提供了更丰富的功能,两者的侧重点不一样。所以选择哪一款连接池就见仁见智了,不过两款都是开源产品,阿里的Druid有中文的开源社区,交流起来更加方便,并且经过阿里多个系统的实验,想必也是非常的稳定,而Hikari是SpringBoot2.0默认的连接池,全世界使用范围也非常广,对于大部分业务来说,使用哪一款都是差不多的,毕竟性能瓶颈一般都不在连接池。大家可根据自己的喜好自由选择。
Druid的使用:添加druid的依赖、数据库驱动:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.8</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.19</version>
</dependency>
①、纯Java代码方式
//数据源配置
DruidDataSource dataSource = new DruidDataSource();
dataSource.setUrl("jdbc:mysql://localhost:3306/user?characterEncoding=utf8&useSSL=false");
dataSource.setDriverClassName("com.mysql.cj.jdbc.Driver"); //这个可以缺省的,会根据url自动识别
dataSource.setUsername("root");
dataSource.setPassword("root");
//下面都是可选的配置
dataSource.setInitialSize(10); //初始连接数,默认0
dataSource.setMaxActive(30); //最大连接数,默认8
dataSource.setMinIdle(10); //最小闲置数
dataSource.setMaxWait(2000); //获取连接的最大等待时间,单位毫秒
dataSource.setPoolPreparedStatements(true); //缓存PreparedStatement,默认false
dataSource.setMaxOpenPreparedStatements(20); //缓存PreparedStatement的最大数量,默认-1(不缓存)。大于0时会自动开启缓存PreparedStatement
//获取连接
Connection connection = dataSource.getConnection();
String sql = "insert into t_user (username,password) values ('tom','123456')";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
preparedStatement.execute();
//关闭连接
connection.close();
②、配置文件方式
在项目中创建一个druid.properties的配置文件。
url=jdbc:mysql://localhost:3306/user?characterEncoding=utf8&useSSL=false
#这个可以缺省的,会根据url自动识别
driverClassName=com.mysql.cj.jdbc.Driver
username=root
password=abcd
##初始连接数,默认0
initialSize=10
#最大连接数,默认8
maxActive=30
#最小闲置数
minIdle=10
#获取连接的最大等待时间,单位毫秒
maxWait=2000
#缓存PreparedStatement,默认false
poolPreparedStatements=true
#缓存PreparedStatement的最大数量,默认-1(不缓存)。大于0时会自动开启缓存PreparedStatement
maxOpenPreparedStatements=20
测试代码如下:
public class DruidTest {
public static void main(String[] args) throws Exception {
//数据源配置
Properties properties=new Properties();
//通过当前类的class对象获取资源文件
InputStream is = DruidTest.class.getResourceAsStream("/druid.properties");
properties.load(is);
//返回的是DataSource,不是DruidDataSource
DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);
//获取连接
Connection connection = dataSource.getConnection();
String sql = "insert into t_user (username,password) values ('tom','123456')";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
preparedStatement.execute();
//关闭连接
connection.close();
}
}
③、与Spring整合
同样需要使用到上面的druid.properties配置文件,然后在Spring的配置文件配置如下:
<!--引入druid配置文件-->
<context:property-placeholder location="classpath:druid.properties" />
<!--druid连接池-->
<bean name="druidDataSource" class="com.alibaba.druid.pool.DruidDataSource">
<property name="url" value="${druid.url}" />
<property name="driverClassName" value="${druid.driverClassName}" />
<property name="username" value="${druid.username}" />
<property name="password" value="${druid.password}" />
<property name="initialSize" value="${druid.initialSize}"/>
<property name="maxActive" value="${druid.maxActive}" />
<property name="minIdle" value="${druid.minIdle}" />
<property name="maxWait" value="${druid.maxWait}" />
<property name="poolPreparedStatements" value="${druid.poolPreparedStatements}" />
<property name="maxOpenPreparedStatements" value="${druid.maxOpenPreparedStatements}" />
</bean>
测试Spring整合Druid连接池:
@@component
public class SpringWithDruid {
//注入Druid数据源
@Resource
private DruidDataSource dataSource;
public void add() throws SQLException {
//获取连接
Connection connection = dataSource.getConnection();
String sql = "insert into t_user (username,password) values ('tom','123456')";
PreparedStatement preparedStatement = connection.prepareStatement(sql);
preparedStatement.execute();
System.out.println(“执行成功…”);
//关闭连接
connection.close();
}
}
参考资料:https://blog.csdn.net/CrankZ/article/details/82874158

