
JavaSE
声明:此文是小白本人学习Java所写,主要参考资料如下:
- 【Java】--Java 基础 - 随笔分类 - 唐浩荣 - 博客园 (cnblogs.com)
- 【Java】--Java IO流 - 随笔分类 - 唐浩荣 - 博客园 (cnblogs.com)
- 【Java】--并发编程 - 随笔分类 - 唐浩荣 - 博客园 (cnblogs.com)
- C/C++、Java、Python谁是编译型语言,谁是解释型语言? - 青山牧云人 - 博客园 (cnblogs.com)
- 类与类之间的关系 - 爱吃牛大 - 博客园 (cnblogs.com)
- java实现10种排序算法_努力努力再努力²的博客-CSDN博客_java排序算法
- 十大经典排序算法(Java实现)_Zandz_的博客-CSDN博客_经典排序算法(java实现)
- Java十大排序算法 - 寇拉斯 - 博客园 (cnblogs.com)
- 1.0 十大经典排序算法 | 菜鸟教程 (runoob.com)
- Java学习教程,Java基础教程(从入门到精通) (biancheng.net)
- Java面试题大全(2021版)_Java程序员-张凯的博客-CSDN博客_java面试题
- 2022版王道考研数据结构
- JavaSE零基础教程讲义
- Java基础入门(第3版) 黑马程序员
感谢此文所引用的文章的作者提供的优质学习资源,如有侵犯,请原作者联系我删除
- 1、Java概述及运行原理
- 2、标识符与关键字
- 3、字面量与变量
- 4、数据类型
- 5、运算符
- 6、控制语句
- 7、方法
- 8、认识面向对象
- 9、对象的创建和使用
- 10、this、static、super和final
- 11、代码块
- 12、面向对象三大特征
- 13、抽象类和接口
- 14、UML-类图
- 15、Object类
- 16、内部类
- 17、数组
- 18、常用类
- 19、正则表达式
- 20、异常处理
- 21、集合
- 22、泛型
- 23、IO流
- 24、多线程
- 25、反射
- 26、注解
- 27、Java8新特性
1、Java概述及运行原理
1.1 何为编程
什么是编程,我们具体的说应该是什么叫做编写程序,而为了搞清楚这个问题我们将从两个点入手,层层递进的剖析这个问题并给出答案。
- 首先,我们要搞清楚我们编程编写的是什么?是程序。而程序是为了完成特定的任务(比如:对数据的分析、计算),用某种语言编写的一系列指令的集合,即一组计算机能识别和执行的静态代码,静态对象。
- 第二,我们要知道我们为什么要编程,计算机是不懂我们人类的语言的,而为了让计算机帮助我们解决某个特定的问题就必须要用计算机能够理解的语言(比如说:汇编、C语言、C++、Java、python等)去告诉计算机,使得计算机能够根据人的指令一 步一步去工作,完成某种特定的任务
所以,编程就是让计算机为解决某个问题而使用某种程序设计语言编写程序代码,并终得到结果的过程。
程序、进程、线程、多线程:
- 程序:就是为了完成特定的任务,用某种语言编写的一系列指令的集合。即一组计算机能识别和执行的静态代码,静态对象。
- 进程:是指一个内存中运行的应用程序。进程是操作系统分配资源的最小单位,一个进程中可以包含多个线程。每个进程都有自己独立的一块内存空间,进程是一个动态的过程,它自身伴随着程序启动,运行,关闭的整个生命周期过程。比如在Windows系统中运行的QQ,Google Chrome等。
- 线程:是进程中的一个执行流程,是CPU调度和分派的最小单位,一个进程可以由多个线程组成,多个线程可以共享一个进程的内存空间。线程总是属于某个进程,线程没有自己的虚拟地址空间,与进程内的其他线程一起共享分配给该进程的所有资源。线程由CPU独立调度执行,在多核CPU环境下就允许多个线程同时运行。同样多线程也可以实现并发操作,每个请求分配一个线程来处理。
- 多线程:指的是一个程序(一个进程)在运行时产生了不止一个线程,产生的多个线程同时运行或交替运行,如果是单核CPU(现在哪还有这种CPU呀),也是交替运行,只不过要等一个线程运行完后才能运行下一个线程,因为在一个单位时间内,CPU只能执行一个线程任务,其实它是一种假的多线程。如果是多核CPU,才能发挥出多线程真正的效率。例如上面的Google浏览器就产生了很多个线程。多线程的作用一句话来说明:为了提高程序的效率(注意不是提高运行速度,宽带速度)。
1.2 什么是Java
Java是一门编程语言,由Sun公司在1990年创建的,于1995年公布于世(一般说java诞生于1995年),是一门面向对象的编程语言,不仅吸收了C++语言的各种优点,还摒弃了C++难以理解的多继承、指针等概念,因此Java语言具有强大和易用两个特征。Java 语言作为面向对象编程语言的代表,极好地实现了面向对象理论,允许程序员以优雅的思维方式进行复杂的编程。
1.3 Java三大板块
- JavaSE Java standard Edition Java基础
- 它允许开发和部署在桌面、服务器、嵌入式环境和实时环境中使用的Java应用程序。Java SE 包含了支持 JavaWeb 服务开发的类,并为Java EE和Java ME提供基础。(实时指的是计算机程序对外来信息能够以足够快的速度进行处理,并在被控对象允许的时间范围内做出快速反应)
- 主要做一般的 Java应用,比如应用软件/ QQ 之类的通信软件
- JavaEE Java Enterprise Edition Java企业版
- Java EE是在Java SE的基础上构建的,它提供 Web 服务、组件模型、 管理和通信 API,可以用来实现企业级的面向服务体系结构(service-oriented architecture,SOA)和 Web2.0应用程序。
- 主要做企业应用,比如公司网站,企业解决方案等
- JavaME Java Micro Edition Java微服务版
- Java ME 为在移动设备和嵌入式设备(比如手机、PDA、电视机顶盒和打印机)上运行的应用程序提供一个健壮且灵活的环境。
- 主要面向嵌入式等设备应用的开发,比如手机游戏等
1.4 Java语言特性
sun公司对Java的描述:Java is a simple,object-oriented,distributed,interpreted,robust,secure,architecture neutral,portable,high-performance,multihreaded,and dynamic language.
-
简单性
Java语言底层采用c++语言实现,但相对于c++来说,Java摒弃了c++难以理解的多继承、指针等概念(只支持单继承),在很多地方进行了简化。
-
面向对象
Java 中提供了封装、继承、多态等面向对象的机制
-
健壮性
在 C++程序当中的无用数据、垃圾数据需要编程人员手动释放,当忘记释放内存的时候,会导致内存使用率降低,影响程序的执行;Java语言引入了自动垃圾回收机制(GC机制),Java 程序启动了一个单独的垃圾回收线程,用于时刻监测内存使用情况,在特定的时机会回收/释放垃圾数据,防止大量无用数据导致内存使用率低,影响程序执行。
-
多线程
Java语言支持多个线程同时并发执行,同时也提供了多线程环境下的安全机制
-
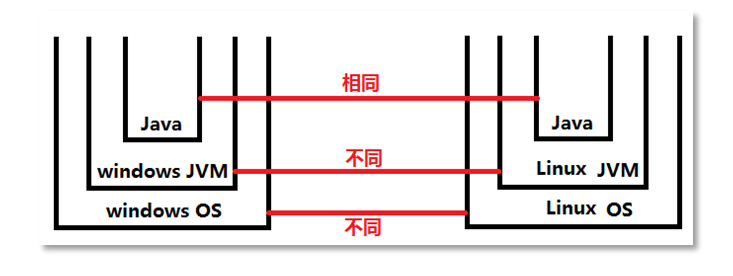
可移植性/跨平台
Java语言只需要编写/编译一次,即可处处运行。Java 代码既可以运行在 windows 的环境下,又可以运行在 Linux 的环境下,而不需要修改Java源程序。
功劳全在于“Java 虚拟机(Java Virtual Machine,简称JVM)”这种机制,实际上 Java 程序运行的时候并不是直接运行在操作系统上面的,而是在操作系统上先安装了一个 JVM,把 Java 程序放到了 JVM 当中运行,JVM屏蔽了各操作系统之间的差异,这样就完成了跨平台。但是,JVM 的出现虽然搞定了跨平台,同时也带来了一些问题,比如要想运行 Java 程序就必须先安装 JVM,没有 JVM,Java 程序是运行不了的。
1.5 JDK、JRE、JVM三者关系
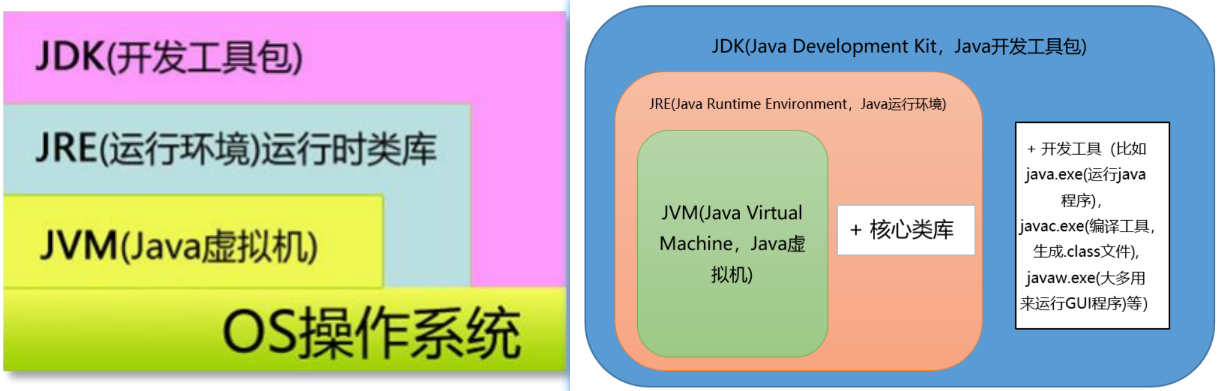
- JDK:(Java Development Kit) 是 Java 语言的软件开发工具包(SDK),JDK 安装之后,它会自带一个JRE,因为软件开发人
员编写完代码之后总是要运行的。注意:如果只是在这台机器上运行Java程序,则不需要安装JDK,只需要安装JRE即可 - JRE:JRE(Java Runtime Environment,Java 运行环境),运行 JAVA 程序所必须的环境的集合,包含 JVM 标准实现及 Java 核心类库。
- JVM:JVM 是 Java Virtual Machine(Java 虚拟机)的缩写,JVM 是一种用于计算设备的规范,它是一个虚构出来的计算机。Java 程序运行的时候并不是直接运行在操作系统上面的,而是在操作系统上先安装了一个 JVM,把 Java 程序放到了 JVM 当中运行,JVM屏蔽了各操作系统之间的差异,这样就完成了跨平台。不同的平台有各种不同的虚拟机
1.6 初步了解 Java 的加载与执行
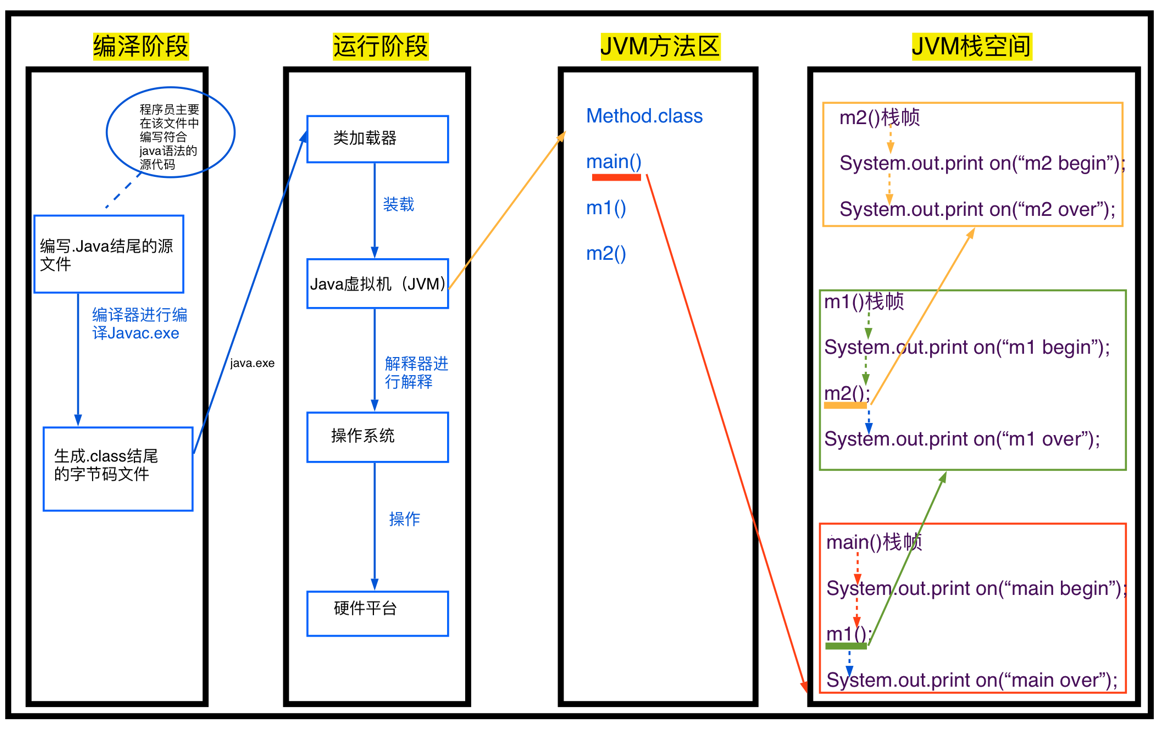
Java 程序加载与执行的过程:
Java 程序从开发到运行包括编译和运行两个阶段,这两个阶段可以在不同的操作系统中完成,例如在 windows 环境下进行编译,在 Linux 环境下运行,这是因为有 JVM 机制的存在,做到了一次编译到处运行(跨平台/可移植)。
编译阶段是把.java源文件,经过javac命令进行编译,最终变成扩展名为 .class字节码文件;之后再执行java命令,通过类加载器把class文件名中类信息加载到了虚拟机,虚拟机读取类信息,翻译成二进制,最终交给OS,然后OS调度相应硬件执行代码,最终在控制台输出结果。
注意:
- 一个 Java 源文件可能会编译生成多个 class 文件。
- Java 源文件中的源代码如果不符合 Java 的语法机制则编译时编译器会提示错误信息,并且无法生成 class 文件。反之则生成 class 文件,而 class 文件才是最终要执行的程序,此时将 Java 源文件删除是不会影响 Java 程序运行的(当然,我们也不必删除 java 源文件,因为在运行 class 文件之后,如果没有达到预期的运行效果,这个时候还需要将 Java 源代码修改,重新编译,以达到最终的运行效果)。
- 运行 Java 程序的前提是当前操作系统上已经安装了对应版本的 JVM(JVM 不是单独安装的,安装 JRE 即可,不同的操作系统需要安装不同版本的 JRE,不同版本的 JRE 对应不同版本的 JVM)。
1.7 什么是字节码
- 字节码:Java源代码经过虚拟机编译器编译后产生扩展名为.class的二进制文件,其中包含着虚拟机指令、程序和数据片段,并且这种类型的代码以一个字节8bit为最小单位存储,所以被称为字节码。它不面向任何特定的处理器,只面向虚拟机。
- 采用字节码的好处:Java语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以Java程序运行时比较高效,而且,由于字节码并不专对一种特定的机器,因此,Java程序无须重新编译便可在多种不同的计算机上运行。
机器码:由0,1组成的二进制代码,这种类型的代码即称为机器码,机器码是计算机可以直接执行的、速度最快的代码。
先看下java中的编译器和解释器:
Java中引入了虚拟机的概念,即在机器和编译程序之间加入了一层抽象的虚拟机器。这台虚拟的机器可以在任何平台上提供给编译程序一个的共同的接口。编译程序只需要面向虚拟机,生成虚拟机能够理解的代码,然后由解释器来将虚拟机代码转换为特定系统的机器码执行。在Java中,这种供虚拟机理解的代码叫做字节码(即扩展为.class的文件),它不面向任何特定的处理器,只面向虚拟机。每一种平台的解释器是不同的,但是实现的虚拟机是相同的。Java源程序经过编译器编译后变成字节码,字节码由虚拟机解释执行,虚拟机将每一条要执行的字节码送给解释器,解释器将其翻译成特定机器上的机器码,然后在特定的机器上运行,这就是上面提到的Java的特点的编译与解释并存的解释。
Java源代码-->编译器-->jvm可执行的Java字节码(即虚拟指令)-->jvm-->jvm中解释器-->机器可执行的二进制机器码-->程序运行。
1.8 编译型语言与解释型语言
1.8.1 编译型语言
-
定义:在程序运行之前,通过编译器将源程序一次性编译成机器码(可运行的二进制代码),生成一个可执行程序(比如 Windows 下的 .exe 文件),只要拥有这个可执行程序,就可以随时运行,不需要再重新编译,也就是“一次编译,无限次运行”。
-
特点:
-
优点
- 编译型语言的程序执行速度快、效率高。因为编译器一般会有预编译的过程对代码进行优化,并且编译只做一次,运行时不需要编译
- 编译型语言可以脱离开发环境运行,在运行的时候,我们只需要编译生成的可执行程序,此时就不再需要源代码和编译器
-
缺点:
-
可移植性差,编译型语言通常是不能跨平台的,也就是不能在不同的操作系统之间随意切换。
体现在两个方面:
- 可执行程序不能跨平台:不同操作系统对可执行文件的内部结构有着截然不同的要求,彼此之间也不能兼容。不能跨平台是天经地义,能跨平台反而才是奇葩。比如,你不能将 Windows 下的可执行程序拿到 Linux 下使用,也不能将 Linux 下的可执行程序拿到 macOS 下使用。
- 源代码不能跨平台:不同平台支持的函数、类型、变量等都可能不同,基于某个平台编写的源代码一般不能拿到另一个平台直接运行。比如:①在C语言中,要想让程序暂停,我们可以使用“睡眠”函数。在 Windows 平台下该函数是 Sleep() ,并以毫秒为时间单位,而在 Linux 平台下则是 sleep(), 以秒为单位;②虽然不同平台的C语言都支持 long 类型,但不同平台下 long 类型所占用的字节长度却不相同。例如 Windows 64 位平台下的 long 占用 4 个字节,Linux 64 位平台下的 long 却占用 8 个字节。
-
编译之后如果需要修改就需要整个模块重新编译
-
-
-
代表语言:C、C++、汇编语言
1.8.2 解释型语言
-
定义:解释型语言的源代码不是直接翻译成机器码,而是先翻译成中间代码,再由解释器对中间代码进行解释运行,不会生成可执行程序。在运行的时候才将源程序翻译成机器码,翻译一句,然后执行一句,直至结束。相比于编译型语言,解释型语言几乎都能跨平台,“一次编写,到处运行”。
-
特点:
-
优点
- 有良好的平台兼容性,可以跨平台运行。这里所说的跨平台,是指源代码跨平台,而非解释器跨平台。解释器用来将源代码转换成机器码,它本质上就是一个可执行程序,是绝对不能跨平台的。我们以 Python 为例,Python 官方针对不同平台(比如 Windows、macOS、Linux )开发了不同的解释器,这些解释器必须要遵守同样的语法,识别同样的函数,完成同样的功能。只有这样,同一份代码才能在不同平台上拥有相同的执行结果。
- 灵活:修改代码的时候直接修改就可以,可以快速部署,不用停机维护
-
缺点:
-
执行速度慢、效率低:由于每次执行程序都需要重新转换源代码,所以解释型语言的执行效率天生就低于编译型语言,甚至是数量级的差距。因此计算机的一些底层功能,或者关键算法,一般都使用 C/C++ 实现,只有在应用层面(比如网站开发、批处理、小工具等)才会使用解释型语言。
-
无法脱离开发环境运行:在运行解释型语言的时候,我们始终都需要源代码和解释器
例如,当我们说“下载一个程序(软件)”时,不同类型的语言有不同的含义:
- 对于编译型语言,我们下载到的是可执行文件,源代码被作者保留,所以编译型语言的程序一般是闭源的;
- 对于解释型语言,我们下载到的是所有的源代码,因为作者不给源代码就没法运行,所以解释型语言的程序一般是开源的。
-
-
-
代表语言:JavaScript、Python、PHP
1.8.3 Java是编译型语言还是解释型语言
关于Java是编译型语言还是解释型语言的说法不一。
-
有人认为,Java是半编译半解释型语言(混合型语言),因为这类语言将源代码先编译成一种中间文件(字节码文件),然后再将中间文件拿到虚拟机中执行。
-
有人认为,Java是解释型语言,因为Java代码编译后不能直接运行,它是解释运行在JVM上的
-
还有的人认为,如今编译型语言、解释性语言的分界线不再那么明显,应该避免把语言简单归类为“编译型”和“解释型”。
参考:C/C++、Java、Python谁是编译型语言,谁是解释型语言? - 青山牧云人 - 博客园 (cnblogs.com)
-
JAVA的第一道工序是javac编译,当然目标文件是BYTECODE(字节码)。后续可能有三种处理方式:
1. 运行时,BYTECODE由JVM逐条解释执行,
2. 运行时,部分代码可能由JIT翻译为目标机器指令(以method为翻译单位,还会保存起来,第二次执行就不用翻译了)直接执行;
3. RTSJ。继JAVAC之后执行AOT二次编译,生成静态的目标平台代码(典型的就是IBM WEBSHPERE REAL TIME)。有的时候,可能是以上三种方式同时在使用。至少,1和2是同时使用的,3需要程序员手工指定。
-
1.9 什么是Java程序的主类?应用程序和小程序的主类有何不同?
一个程序中可以有多个类,但只能有一个类是主类。在Java应用程序中,这个主类是指包含main()方法的类。而在Java小程序中,这个主类是一个继承自系统类JApplet或Applet的子类。应用程序的主类不一定要求是public类,但小程序的主类要求必须是public类。主类是Java程序执行的入口点。
1.10 Java应用程序与小程序之间有那些差别?
简单说应用程序是从主线程启动(也就是main()方法)。applet小程序没有main方法,主要是嵌在浏览器页面上运行(调用init()线程或者run()来启动),嵌入浏览器这点跟flash的小游戏类似。
1.11 Java和C++的区别
- 都是面向对象的语言,都支持封装、继承和多态
- Java不提供指针来直接访问内存,程序内存更加安全
- Java的类是单继承的,C++支持多重继承;虽然Java的类不可以多继承,但是接口可以多继承。
- Java有自动内存管理机制,不需要程序员手动释放无用内存
1.12 Java中的注释
定义:用于解释说明程序的文字
Java注释的分类
- 单行注释
格式: // 注释文字 - 多行注释
格式: /* 注释文字 */ - 文档注释
格式:/** 注释文字 */
Java注释的作用
在程序中,尤其是复杂的程序中,适当地加入注释可以增加程序的可读性,有利于程序的修改、调试和交流。注释的内容在程序编译的时候会被忽视,不会产生目标代码,注释的部分不会对程序的执行结果产生任何影响。
注意事项:多行和文档注释都不能嵌套使用。
2、标识符与关键字
2.1 标识符
标识符(identifier)是用来标识一个实体的一个符号,在不同的应用环境下有不同的含义。在编程语言中是用户编程使用的名字,用于给变量、常量、函数、语句块等命名,以建立起名称与使用之间的关系,标识符通常由字母和数字以及其它字符构成,是程序员自己规定的代表一定含义的任意合法符号,如类名、属性名、变量名等。
在Java源程序中,标识符可以用来标识:类名、接口名、变量名、方法名、常量名等
2.1.1 命名规则
- 标识符只能由数字、字母、下划线“_”、美元符号“$”组成,不能含有其它符号。
- 标识符不能以数字开头(建议不要以下划线开头、$结尾)
- Java关键字和保留字符(const、goto)不能作为标识符。
- 严格区分大小写
- 理论上没有长度限制
2.1.2 命名规范
- 见名知义
- 驼峰式命名
- 类名、接口名首字母大写
- 变量名、方法名首字母小写
- 常量名全部大写,可用_连接
2.2 关键字
关键字是一组有特定意义的单词,Java中所有的关键字都是小写的英文单词,如public\static\void等
常用关键字:
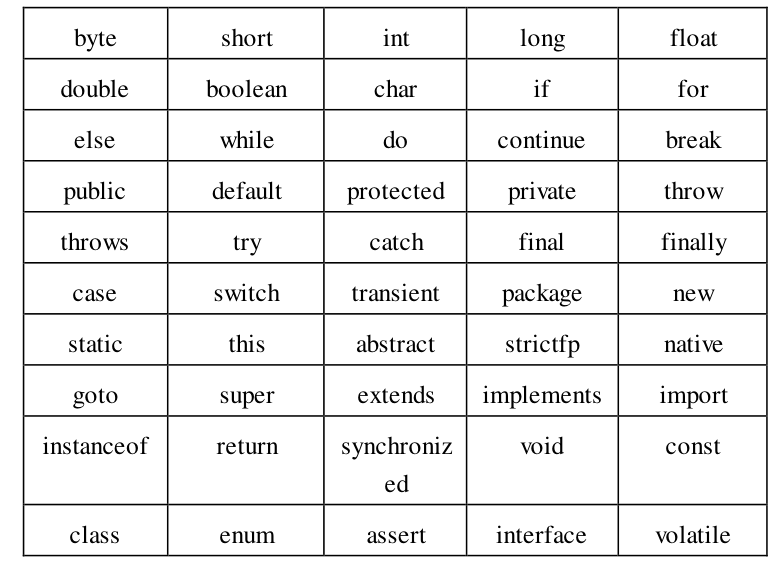
3、字面量与变量
3.1 字面量
-
字面量就是数据/数值,如123、true、“abc”、“中”,如你的体重是86kg、身高175cm。
-
字面量的分类
整数型、浮点型、字符型、布尔型、字符串型 ,其中字符型用单引号括起、字符串型用双引号
//找问题
public class Test1{
public static void main(String[] args){
System.out.println(abc);
// 程序无法编译,因为abc不上一个合法的字面量
}
}
3.2 变量概述
- 变量是内存中存储数据的最基本的单元,将数据(字面量)放到内存中,同时给这块内存空间取一个名字,这就是变量。
- 所谓变量:可变化的量。它的意思是变量中存储的数据不是一成不变的,是可以被改变的,
- 变量是有三要素组成的,分别是:数据类型、变量名、存储的值(即字面量)。
3.2.1 使用规则
- 数据类型 变量名 = 值(字面量)
- Java中的变量(局部变量)必须先声明再赋值,才能访问(静态变量有默认值)
- 同一个域,即同一个域{}中不能声明两个同名的变量。
3.2.2 变量分类
-
局部变量:在方法体中声明的变量以及方法的每一个参数都是局部变量
-
成员变量:在方法体外,类体内声明的变量称为成员变量
如果,成员变量使用static修饰声明,则为静态成员变量(简称静态变量)
如果,没有使用则称为实例成员变量(简称实例变量)
public class Test{
int x=20; //实例变量
static int y =20; //静态变量
public static void sum(int a,int b){ //局部变量
int firstNum=100; //局部变量
}
}
3.2.3 变量的作用域
出了大括号就不认识了;
//就近原则
public class Test{
static int a=100;
public static void main(String[] args){
int a=300;
System.out.println("a="+a);
m();
}
public static void m(){
System.out.println(a);
}
}
结果:a=300
100
说明:Java中采用的是就近原则,且是自上而下、从右到左的执行顺序,并且m()访问的是静态变量a
4、数据类型
软件的存在主要是进行数据的处理,现实生活中的数据有很多,所以编程语言对其进行了分门别类,然后就产生了数据类型,不同数据类型的数据会给其分配不同大小的空间进行存储。也就是说,数据类型作用就是决定程序运行阶段给该变量分配多大的内存空间。这就是数据类型的主要作用
Java 中的数据类型就包括两大类,一类是基本数据类型,另一类是引用数据类型
-
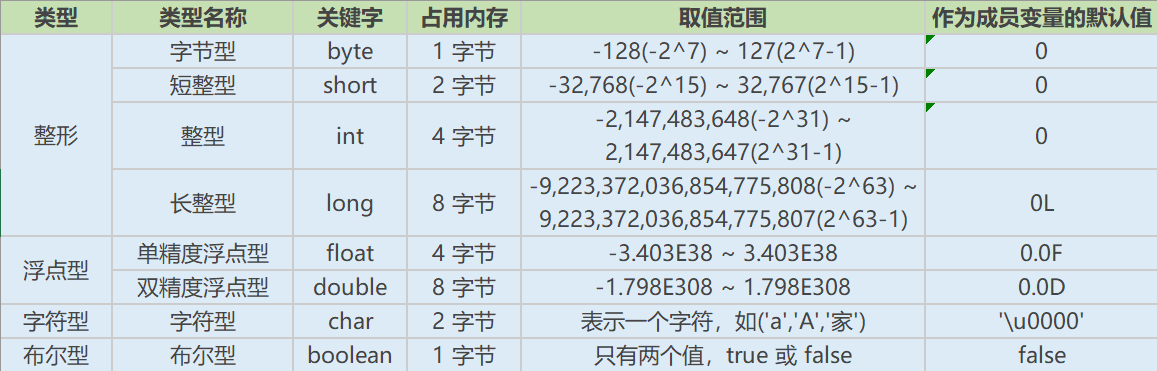
基本数据类型(4类8种):
-
整数型:byte、short、int、long
-
浮点型:float、double
-
字符型:char
-
布尔型:boolean
-
- 引用数据类型
- 类(class)
- 接口(interface)
- 数组([])
- 枚举
- 注解
编码
Java语言采用何种编码方案?有何特点?
Java语言采用Unicode编码标准,Unicode(标准码),它为每个字符制订了一个唯一的数值,因此在任何的语言,平台,程序都可以放心的使用。
notes:
👏switch 是否能作用在 byte 上,是否能作用在 long 上,是否能作用在 String 上?
在 Java 5 以前,switch(expr)中,expr 只能是 byte、short、char、int。从 Java5 开始,Java 中引入了枚举类型,expr 也可以是 enum 类型,从 Java 7 开始,expr 还可以是字符串(String),但是长整型(long)在目前所有的版本中都是不可以的。
👏用最有效率的方法计算 2 乘以 8
2 << 3(左移 3 位相当于乘以 2 的 3 次方,右移 3 位相当于除以 2 的 3 次方)
👏Math.round(11.5) 等于多少?Math.round(-11.5)等于多少
Math.round(11.5)的返回值是 12,Math.round(-11.5)的返回值是-11。四舍五入的原理是在参数上加 0.5 然后进行下取整。
👏float f=3.4;是否正确
不正确。3.4 是双精度数,将双精度型(double)赋值给浮点型(float)属于下转型(down-casting,也称为窄化)会造成精度损失,因此需要强制类型转换float f =(float)3.4; 或者写成 float f =3.4F;。
一个数据在赋值给一个变量的时候存在三种不同的情况:
- 第一种情况是类型一致,不存在类型转换;
- 第二种情况是小容量可以自动赋值给大容量,称为自动类型转换;
- 第三种情况是大容量不能直接赋值给小容量,大容量如果一定要赋值给小容量的话,必须添加强制类型转换符进行强制类型转换操作。不过需要注意的是,强制类型转换在使用的时候一定要谨慎,因为可能会导致精度损失,因为大杯水倒入小杯中,可能会导致水的溢出,不过这也不全都是,也可能精度不会损失,如果大杯中的水很少,这个时候倒入小杯中也可能是不溢出的。
👏short s1 = 1; s1 = s1 + 1;有错吗?short s1 = 1; s1 += 1;有错吗
对于 short s1 = 1; s1 = s1 + 1;由于 1 是 int 类型,因此 s1+1 运算结果也是 int型,需要强制转换类型才能赋值给 short 型。
而 short s1 = 1; s1 += 1;可以正确编译,因为 s1+= 1;相当于 s1 = (short(s1 + 1);其中有隐含的强制类型转换。
👏a=a+b与a+=b有什么区别吗?
+= 操作符会进行隐式自动类型转换,此处a+=b隐式的将加操作的结果类型强制转换为持有结果的类型,而a=a+b则不会自动进行类型转换
4.1 字符型
字符型 char 在 Java 语言中占用 2 个字节,char 类型的字面量必须使用半角的单引号括起来,取值范围为[0-65535], char 和 short 都占用 2 个字节,但是 char 可以取到更大的正整数,因为 char 类型没有负数。
public class CharTest01{
public static void main(String[] args){
char c = 'ab';
System.out.println(c);
}
}
编译器报错了,错误信息是“未结束的字符文字”,这是因为 Java 中有规定,字符型只能是单个字符,当编译器检测到'ab'的时候,左边以单引号开始,继续检测到 a字符,然后编译器会继续检查下一个字符是否为另一半单引号,结果不是,而是 b,所以编译器报错了。这也说明了 Java 中的字符只能是单个字符,不能是多个字符。
4.2 整数型
public class IntegerTypeTest06 {
public static void main(String[] args) {
byte b = 1;
System.out.println(b);
}
}
结果:编译通过
原因:因为在java 语言有这样一条规定,当一个整数型的字面量没有超出 byte,short,char 的取值范围,可以将该字面量直接赋值给 byte,short,char 类型的变量,如果超出范围则需要添加强制类型转换符。
小结:
- 第一,Java 中的整数型字面量有四种表示方式,但最常用的还是十进制;
- 第二,整数型字面量被当做 int 处理,如果想当做 long 处理,需要在后面添加 L 或 l;
- 第三,小容量转换为大容量被称为自动类型转换;
- 第四,大容量转换成小容量称为强制类型转换,强转时需要添加强制类型转换符,但要注意强转可能损失精度;
- 优先级:byte<short(char)<int<long<float<double <String
- 第五,当整数型字面量没有超出 byte、short、char 的取值范围,可直接赋值。
4.3 浮点型详解
在 java 语言中有这样的一条规定:只要是浮点型的字面量,例如 1.0、3.14 等默认会被当做 double 类型来处理,如果想让程序将其当做 float 类型来处理,需要在字面量后面添加 f/F。
5、运算符
5.1 算术运算符
注意:a++ 与++a
a++是先使用a,再自增;++a是先自增再使用
5.2 赋值运算符
注意:+=、-=、=、/=、%=
一般情况下,a+=b <====>a=a+b;
但a+=b并非完全等价于a=a+b
byte b=10;b=b+1;编译出错,强制转换数据类型后的b+1是int型,无法赋值给b(byte型)
byte b=10;b+=1; 编译通过,原因java 对于扩展类的赋值运算符进行了特殊的处理,所有的扩展赋值运算符,最终都不会改变运算的结果类型,实际上等同于b=(byte)(b+1);
5.3 关系运算符
注意:==不能用来判断字符串型 应该使用equals方法
5.4 逻辑运算符
与、或、非、异或、短路与、短路或
& | ! ^ && ||
注意:“逻辑与&”和“短路与&&”
1)逻辑与&:无论左边表达式结果是 true 还是 false,右边表达式一定会执行。
2)短路与&&:左边的表达式只要为 false,就会发生短路,右边表达式不再执行了。
3)短路或||:当左边为true时,就会发生短路,右边表达式不再执行了。
5.5 条件运算符
属于三目运算符
语法结构: 布尔表达式?表达式1:表达式2
5.6 字符串连接运算符
“+”运算符在 java 语言中有两个作用且遵循自左向右运算
1)对数字进行求和运算:两边的操作数都是数字
2)字符串连接运算:只要其中有一个操作数是字符串类型
6、控制语句
6.1 转向语句
6.1.1 break
用break语句可以使流程跳出switch语句体,也可以用break语句在循环结构终止本层循环体,从而提前结束本层循环
6.1.2 continue
continue语句的作用是跳过本次循环体中余下尚未执行的语句,立即进行下一次的循环
7、方法
7.1 概念
在Java中方法又叫method,在C语言中叫做函数,是一段可以完成某个特定功能的代码片段,而且可以重复调用
7.2 作用
可以解决代码的冗余,避免重复
[修饰符列表] 返回值类型 方法名(形式参数列表){
方法体;
}
//例如
public static void sumInt(int a,int b){
int c=a+b;
System.out.println(a+"+"+b+"="+c);
}
//public static 是修饰符列表;
//void 是返回值类型;
//sumInt 是方法名;
//(int a , int b)是形式参数列表,简称形参,每一个形参都是局部变量;
/*形参后面使用一对儿大括号括起来的是方法体,方法体是完成功能的核心代码,方法体中的代
码有执行顺序的要求,遵循自上而下的顺序依次逐行执行,不存在跳行执行的情况。*/
//又如
public static int sumInt(int a , int b){ //sumInt之前的int是返回值类型
int c = a + b;
return c;
}
[修饰符列表] 返回值类型 方法名 (形式参数列表) {
方法体;
}规则:
- [修饰符列表],此项是可选项,不是必须的,目前大家统一写成 public static
- 返回值类型,此项可以是 java 语言当中任何一种数据类型,包括基本数据类型,也包括所有的引用数据类型,当然,如果一个方法执行结束之后不准备返回任何数据,则返回值类型必须写 void。
- 方法名,此项需要是合法的标识符,开发规范中要求方法名首字母小写,后面每个单词首字母大写。
- 形式参数列表(int a, int b),此项又被称为形参,其实每一个形参都是“局部变量”,形参的个数为 0~N 个,如果是多个参数,则采用半角“,”进行分隔,形参中起决定性作用的是参数的数据类型。
- 方法体,由一对儿大括号括起来,在形参的后面,这个大括号当中的是实现功能的核心代码,方法体由 java 语句构成,方法体当中的代码只能遵循自上而下的顺序依次逐行执行,不能跳行执行,核心代码在执行过程中如果需要外部提供数据,则通过形参进行获取。
7.3 如何调用
语法格式是(前提是方法的修饰符列表中带有static关键字,静态方法,静态方法在类加载时就存在了,不需要依赖于其他对象):类名.方法名(实际参数列表)
- 有的情况下“类名.”是可以省略的
- 当a()方法在执行过程中调用b()方法的时候,并且a()方法和b()方法在同一个类的时候,此时的类名可以省略不写,否则不能省略。
当方法书写完毕后,如果要执行方法的结果,则必须放入main中 进行调用,得到结果
public class MethodTest {
public static void main(String[] args) {
MethodTest.sumInt(100, 200);
MethodTest.sumDouble(1.0, 2.0);
}
public static void sumInt(int x , int y){
System.out.println(x + "+" + y + "=" + (x + y));
}
public static void sumDouble(double a , double b){
System.out.println(a + "+" + b + "=" + (a + b));
}
}
7.4 方法中参数的分类
方法中参数的分类:
形式参数:方法定义时书写的参数为形式参数,简称形参
比如: public static void show(int x,int y) {} x,y为方法定义时写的形式参数
形式参数特点是:没有值
实际参数:发生在方法调用时,写的参数为实际参数,简称实参
- 实参和形参必须一一对应,所谓的一一对应就是,个数要一样,数据类型要对应相同
7.5 方法返回值详解
返回值类型可以是任何一种数据类型,包括基本数据类型,也包括引用数据类型,例如:byte,short,int,long,float,double,boolean,char,String,Student(自定义类,class类型)等
//错误示例1
public static int method1(){
return 1;
System.out.println("hello world!");
}
/*该程序编译出错,提 示 的 错 误 信 息 是 :“System.out.println("hello world!");”这行代码是无法访问的语句。在Java中一旦执行了带return的语句,此方法就会结束*/
//错误示例
public static int method1(){
boolean flag = true;
if(flag)
return 1;
}
/*编译报错,错误信息是“缺少返回语句,因为方法在声明的时候指定了返回值类型为int,Java语法则要求方法必须能够”百分之百的保证“在结束时返回int类型的数据,以上程序”return 1“,出现在if语句的分支中,对于编译器来说,它只知道”return 1 “有可能执行,也有可能不执行,所以编译器报错*/
//正确写法1
public static int method1(){
boolean flag = true;
if(flag)
return 1;
else
return 0;
}
//正确写法2
public static int method1(){
boolean flag = true;
if(flag)
return 1;
return 0;
}
/*以上代码可以编译通过!因为其必然会有个return语句执行。对于写法1来说,if...else语句必然会执行一个分支;对于写法2,两个return语句必然会执行其中之一*/
//错误示例
public static int method1(){
boolean flag = true;
if(flag){
return 1;
System.out.println("第 1 行");
}
System.out.println("第 2 行");
return 0;
System.out.println("第 3 行");
}
/*该程序编译出错,其中”第1行“、”第3行“没有机会执行,但”第2行是有机会执行的,总之return后面不能写任何代码“*/
//正确写法
public static int method1(){
boolean flag = true;
return flag ? 1 : 0;
}
//错误写法
public static void method2(){
return 10;
}
//该方法返回值是void,表明该方法结束时不能返回任何数据,而方法体却是返回int数据,前后说法不一致,编译器报错。
//正确写法
public static void method2(){
return;
}
/*当一个方法的返回值是void时,方法体中允许出现return语句,作用是终止方法的执行。当一个方法的返回值是void的时候,在方法执行过程中,如果满足了某个条件,没有办法往下执行的时候,可以用return*/
return与break的区别:break 用来终止循环,return 用来终止一个方法的执行
public static void main(String[] args) {
//可以编译也可以正常运行
sumInt(10 , 20);
int retValue = sumInt(100 , 200);
System.out.println("计算结果 = " + retValue);
/*编译报错,返回值类型是 int,不能采用 byte 接收*/
//byte retValue2 = sumInt(1 , 2);
}
public static int sumInt(int a , int b){
return a + b;
}
7.6 方法执行过程中内存的变化
代码片段被存储在什么位置?方法调用的时候,在哪里开辟内存空间?
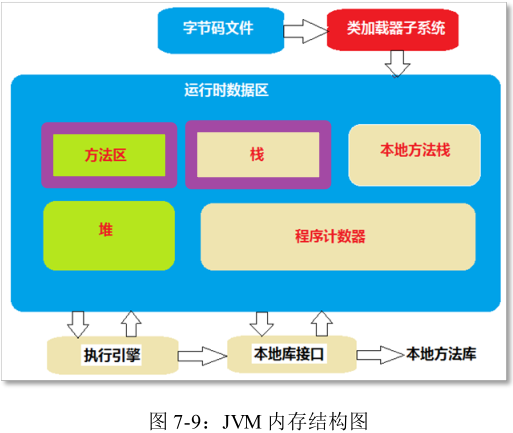
目前只看“方法区”和“栈”,方法区中存储类的信息(代码片段),方法在执行过程中需要的内存空间在栈中分配。
Java程序开始执行时先通过类加载器子系统找到硬盘上的字节码文件,然后将其加载到Java虚拟机的方法区内,开始调用main方法,main方法被调用的瞬间,会给main方法在“栈”内存中分配所属的活动空间(方法不去调用的话,只是把它的代码片段存储在方法区中,Java虚拟机是不会在栈内存中给该方法分配活动空间的),此时发生压栈动作,main方法的活动空间处于栈底。main方法最先被调用,那么也将是最后一个结束的,即main方法结束了,程序也就结束了。
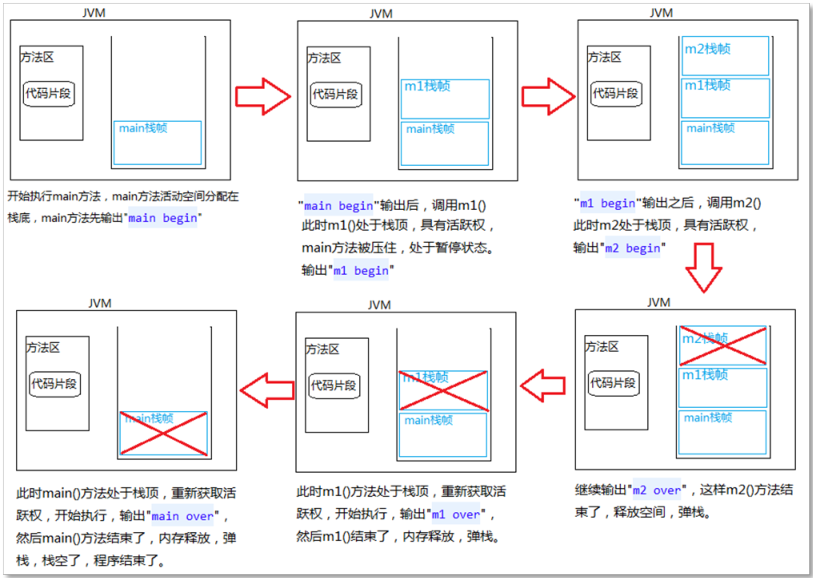
阅读一段代码,同时画出内存结构图,以及使用文字描述该程序的内存变化
public class MethodTest {
public static void main(String[] args) {
System.out.println("main begin");
m1();
System.out.println("main over");
}
public static void m1() {
System.out.println("m1 begin");
m2();
System.out.println("m1 over");
}
public static void m2() {
System.out.println("m2 begin");
System.out.println("m2 over");
}
}
内存变化过程:
类加载器将 .class 文件加载到方法区
7.7 方法重载/overload
-
概念:
- 方法重载是指在同一个类中定义多个同名的方法,但是要求每个方法具有不同的参数列表(参数类型、参数个数或参数的执行顺序不同),与方法的返回值类型和修饰符无关,方法重载通常用于创建完成一组任务相似但参数类型或参数个数不同的方法。调用方法时通过传递给他们的不同个数和类型的实参来决定使用哪个方法
-
何时使用
- 在同一个类中,如果多个功能是相似的,可以考虑将他们的方法名定义的一致
-
意义
- 方便记忆,减少执行难度
7.8 方法递归
-
概念:自己调用自己
-
递归调用会引发异常 StackOverFlowError
-
如何解决栈溢出:
- 输出时,限制输出次数
- java-x 调整栈大小
-
递归和循环应该首选循环结构
-
递归适用于:
- 数学运算
- 目录遍历
8、认识面向对象
拓展:
- C/C++
- C:过程版,不适合于应用程序开发。一般用来做OS开发:Linux
- C++:半面向对象,保留了C的指针,适合于各种应用程序、硬件开发:IOS
- Java:纯面向对象, java 底层是 C++语言实现的,适用于企业级开发:并发编程。手机开发如Android
- python:纯面向对象
8.1 面向过程与面向对象
8.1.1面向过程(步骤化)
概念
- 做一件事情,按照事情的先后顺序或因果关系来依次执行
- 面向过程(Procedure-Oriented)是一种以过程为中心的编程思想,简称OP,就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步步实现,使用的时候一个一个依次调用,注重步骤
特点
- 性能比面向对象高,因为类调用时需要实例化,开销比较大,比较消耗资源;比如单片机、嵌入式开发、Linux/Unix等一般采用面向过程开发,性能是最重要的因素。
- 缺点:没有面向对象易维护、易复用、易扩展,功能模块间联系过于紧密,这说明模块间耦合度过于高
8.1.2 面向对象(行为化)
概念
- 面向对(Object-Oriented)是一种以对象为中心的编程思想,简称OO,是把整个需求按照特点、功能划分,将这些存在共性的部分封装成类,类实例化后创建了对象,但不是为了完成某一个步骤,而是描述某个事物在解决问题的步骤中的行为。面向对象编程思想中关注点是“对象”或者“事物”
特点
- 易维护、易复用、易扩展,由于面向对象有封装、继承、多态性的特性,可以设计出低耦合的系统,使系统更加灵活、更加易于维护
- 性能比面向过程低

面向过程是具体化的、流程化的解决一个问题,你需要一步一步的分析,一步一步的实现。
面向对象是模型化的,你只需抽象出一个类,这是一个封闭的盒子,在这里你拥有数据也拥有解决问题的方法。需要什么功能直接使用就可以了,不必去一步一步的实现,至于这个功能是如何实现的,管我们什么事?我们会用就可以了。
面向对象的底层其实还是面向过程,把面向过程抽象成类,然后封装,方便我们使用的就是面向对象了。
8.1.3 举个例子谈谈对面向过程和面向对象的理解
例如我们设计一个桌球游戏(略过开球,只考虑中间过程)
A:面向过程方式思考:
把下述的步骤通过函数一步一步实现,这个需求就完成了。(只为演示概念,不细究逻辑问题)。
① palyer1 击球 —— ② 实现画面击球效果 —— ③ 判断是否进球及有效 —— ④ palyer2击球
⑤ 实现画面击球效果 —— ⑥ 判断是否进球及有效 —— ⑦ 返回步骤 1—— ⑧ 输出游戏结果
B:面向对象方式思考:
经过观察我们可以看到,其实在上面的流程中存在很多共性的地方,所以我们将这些共性部分全集中起来,做成一个通用的结构
- 玩家系统:包括 palyer1 和 palyer2
- 击球效果系统:负责展示给用户游戏时的画面
- 规则系统:判断是否犯规,输赢等
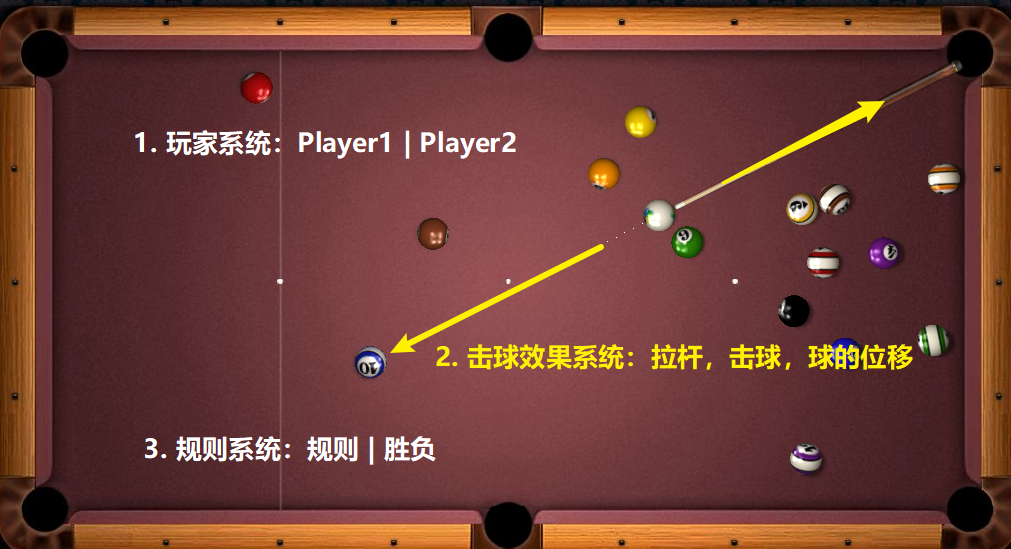
我们将繁琐的步骤,通过行为、功能,模块化,这就是面向对象,我们甚至可以利用该程序,分别快速实现8球和斯诺克的不同游戏(只需要修改规则、地图和球色即可,玩家系统,击球效果系统都是一致的)
8.1.4 OO与OP的不同
就好比蛋炒饭和盖浇饭。OO是一道蛋炒饭,蛋和饭混在一起炒,入味均匀,吃起来香,但如果你不喜欢吃鸡蛋,那只能全部倒掉,重新做一份;OP是一道盖浇饭,菜饭分离,就是入味不均,吃起来可能没有蛋炒饭香,但如果你不喜欢这个菜的话,只需要把菜换掉就好。
总的来说,就是上述中,OO、OP的概念、特点之间的不同。
8.2 类和对象的基本概念
-
类:是现实世界当中具有共同特征的事物进行抽象形成的模板或概念。在生活中并不是真实存在的,是抽象的,是人大脑思考总结的结果,里面会规定每个对象具有的特征和行为。
-
对象:是实际存在的个体。
类和对象的关系: 类是由多个具体的个体提取出共同特征,抽象形成的。一个类中可以实例化一个或多个对象。
-
实例(instan):是对象的另一种叫法
-
实例化:通过类产生对象的过程
-
抽象:从多个对象中提取共同的特征和行为的这个过程。
8.3 实例变量
- 是类中定义的变量,也可以叫成员变量。
- 实例变量是类中的特征,属性
- 实例变量可以有默认值。
- 实例变量在在产生对象时(new)初始化
- 实例变量是对象级别的变量 ,由对象所有,由对象调用,这些属性要想访问,必须先创建对象才能访问,不能直接通过类去访问,调用语法: 对象名.实例变量名
- 实例变量在初始化时,有默认值
9、对象的创建和使用
9.1 对象的创建和使用
如何从模板类中产生对象:语法: 模板类名 对象名(变量名)=new 模板类名(); 产生一个新的对象
如何取出模板类中的特征(属性):
语法: 对象名(变量名).模板类中的特征(属性);
此处的原点: . 代表引用,使用,调用
9.2 java虚拟机内存管理
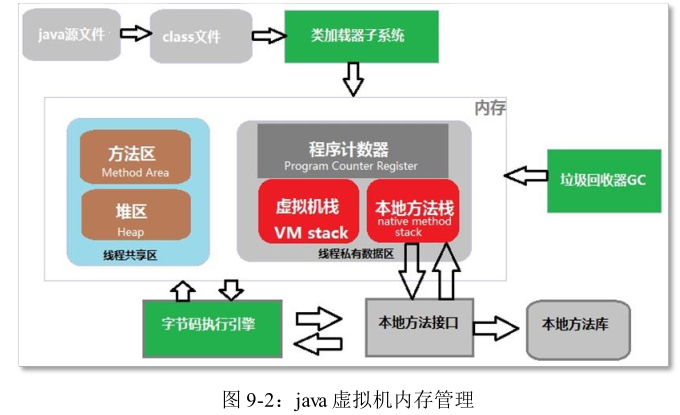
① 程序计数器:
- 概念:可以看做当前线程所执行的字节码的行号指示器。
- 特点:线程私有的内存
② java 虚拟机栈(重点):
- 概念:描述的是 java 方法执行的内存模型。(每个方法在执行的时候会创建一个栈帧,用于存储局部变量表,操作数栈,动态链接,方法出口等信息。每个方法从调用直至完成的过程,就对应一个栈帧从入栈到出栈的过程。)
- 特 点 : 线 程 私 有,生命周期和线程相同 。 这个区域 会 出 现 两种 异 常 :StackOverflowError 异常: 若线 程请求的深度大于虚拟机所允许的 深度 。OutOfMemoryError 异常:若虚拟机可以动态扩展,如果扩展是无法申请到足够的内存。
③ 本地方法栈:
- 概念:它与虚拟机栈所发挥的作用是相似的,区别是 java 虚拟机栈为执行 java 方法服务,而本地方法栈是为本地方法服务。
- 特点:线程私有,也会抛出两类异常:StackOverflowError 和 OutOfMemoryError。
④ java 堆(重点):
- 概念:是被所有线程共享的一块区域,在虚拟机启动时创建。
- 特点:线程共享,存放的是对象实例(所有的对象实例和数组),GC 管理的主要区域。可以处于物理上不连续的内存空间。
⑤ 方法区(重点):
- 概念:存储已被虚拟机加载的类信息、常量、静态变量,即时编译器编译后的代码等数据。
- 特点:线程共享的区域,抛出异常 OutOfMemory 异常:当方法区无法满足内存分配需求的时候。
对于 Student s1 = new Student()代码来说, s1 不是对象,是一个引用,对象实际上是在堆区当中,s1 变量持有这个对象的内存地址。
java 中没有指针的概念(指针是 C 语言当中的机制),所以 java 程序员没有权利直接操作堆内存,只能通过“引用”去访问堆内存中的对象,例如:s1.no、s1.name、s1.sex、s1.age。访问一个对象的内存,其实就是访问该对象的实例变量,而访问实例变量通常包括两种形式,要么就是读取数据,要么就是修改数据,例如:System.out.println(s1.no)这就是读取数据,s1.no= 100 这就是修改数据。
9.3 构造方法(constructor)
- 概念:构造方法也叫构造函数,也叫构造器,是一个与类同名的方法。是类中特殊的方法,通过调用构造方法来完成对象的创建,以及对象属性的初始化操作
- 语法:
[修饰符列表] 构造方法名(形式参数列表){构造方法体;}- 构造方法名和类名一样
- 构造方法用来创建对象,以及完成属性初始化操作
- 构造方法返回值不需要写,写上就报错,包括void也不能写
- 构造方法的返回值类型实际上是当前类的类型
- 一个类中可以定义多个构造方法,这些构造方法构成方法重载
- 作用:构造方法用来创建对象,以及完成属性初始化操作。是给本类中的属性赋值用的
- 构造方法何时调用:在new时,产生对象时调用。语法格式是:new 构造方法名(实际参数列表);
- 构造方法可以带参数并且支持方法重载
- 构造方法如果没有书写,则默认调用的是无参构造方法。
- 如果一个类中书写了带参构造方法,默认无参构造方法就会失效,必须手动书写出无参构造方法。建议程序员手动的将无参数构造方法写上,因为不写无参数构造方法的时候,这个默认的构造方法很有可能就不存在了,另外也是因为无参数构造方法使用的频率较高
- 一个构造方法中可不可以调用另外一个构造方法? 可以,调用不是按照实例方法调用规则进行,必须使用一个关键字来解决: this。
public class Date {
int year; //年
int month; //月
int day; //日
//构造方法(无参数构造方法)
public Date(){
System.out.println("Date 类无参数构造方法执行");
}
//构造方法(有参数构造方法)
public Date(int year1){
System.out.println("带有参数 year 的构造方法");
}
//构造方法(有参数构造方法)
public Date(int year1 , int month1){
System.out.println("带有参数 year,month 的构造方法");
}
//构造方法(有参数构造方法)
public Date(int year1 , int month1 , int day1){
System.out.println("带有参数 year,month,day 的构造方法");
}
}
/*******************************************************************/
public class DateTest {
public static void main(String[] args) {
System.out.println("main begin");
new Date();
new Date(2008);
new Date(2008 , 8);
new Date(2008 , 8 , 8);
System.out.println("main over");
}
}

构造方法虽然在返回值类型方面不写任何类型,但它执行结束之后实际上会返回该对象在堆内存当中的内存地址,这个时候可以定义变量接收对象的内存地址,这个变量就是之前所学的“引用”
如:Student s1=new Student();
public class DateTest {
public static void main(String[] args) {
System.out.println("main begin");
//new Date()调用构造方法创建了一个对象,并对属性进行初始化
//执行结束后,该对象返回堆内存,并定义了time1接收对象的内存地址
Date time1 = new Date();
System.out.println(time1);
Date time2 = new Date(2008);
System.out.println(time2);
Date time3 = new Date(2008 , 8);
System.out.println(time3);
Date time4 = new Date(2008 , 8 , 8);
System.out.println(time4);
System.out.println("main over");
}
}
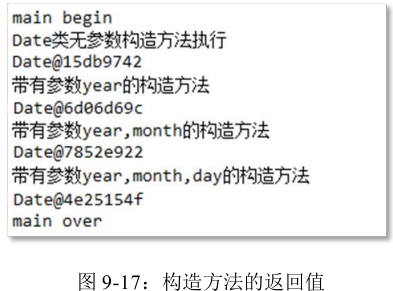
一定要注意,实例变量没有手动赋值的时候系统会默认赋值,但不管是手动赋值还是系统赋默认值,都是在构造方法执行的时候才会进行赋值操作,类加载的时候并不会初始化实例变量的空间,那是因为实例变量是对象级别的变量,没有对象,哪来实例变量,这也是为什么实例变量不能采用“类名”去访问的原因。
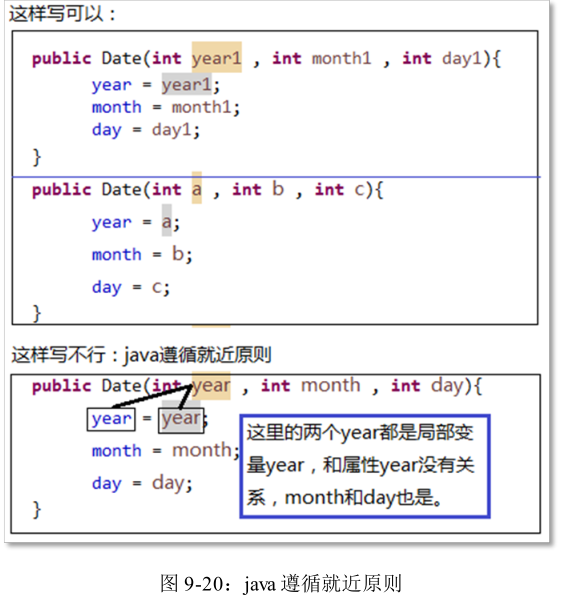
java遵循就近原则
9.4 方法调用时参数的传递问题
方法在调用的时候参数是如何传递的呢?其实在调用的时候参数传递给方法,这个过程就是赋值的过程,参数传递和“赋值规则”完全相同,只不过参数传递在代码上看不见“=”运算符。
public class AssignmentTest {
public static void main(String[] args) {
//基本数据类型
int a = 10;
int b = a; //a 赋值给 b,a 把什么给了 b?
//引用数据类型
Bird bird1 = new Bird("polly");
//bird1 赋值给 bird2,bird1 把什么给了 bird2?
Bird bird2 = bird1;
}
}
class Bird {
String name;
public Bird(){}
public Bird(String _name){
name = _name;
}
}
在以上程序当中,有两个疑问,第一个:a 赋值给 b,a 把什么给了 b?第二个:bird1 赋值给 bird2,bird1 把什么给了 bird2?
其实 a,b,bird1,bird2 就是 4 个普通的变量,唯一的区别只是 a 和 b 都是基本数据类型的变量,bird1 和 bird2 都是引用数据类型的变量(或者说都是引用),a 变量中保存的那个“值”是 10,bird1 变量中保存的那个“值”是 0x8888(java 对象内存地址)本质上来说 10 和 0x8888 都是“值”,只不过一个“值”是整数数字,另一个“值”是 java 对象的内存地址,大家不要把内存地址特化,
它也是一个普通的值。那么“赋值”是什么意思呢,顾名思义,赋值就是把“值”赋上去。a 赋值给 b,本质上不是把 a给了 b,而是把 a 变量中保存的“值 10”复制了一份给了 b。bird1 赋值给 bird2 本质上不是把 bird1给了 bird2,而是把 bird1 变量中保存的“值 0x8888”复制了一份给了 bird2。
“赋值”运算的时候实际上和变量的数据类型无关,无论是基本数据类型还是引用数据类型,一律都是将变量中保存的“值”复制一份,然后将复制的这个“值”赋上去。他们的区别在于,如果是基本数据类型则和堆内存当中的对象无关,如果是引用数据类型由于传递的这个值是 java 对象的内存地址,所以会导致两个引用指向同一个堆内存中的 java 对象,通过任何一个引用去访问堆内存当中的对象,此对象内存都会受到影响。
值传递和引用传递
- 值传递:指的是在方法调用时,传递的参数是按值的拷贝传递,传递的是值的拷贝,也就是说传递后就互不相关了。
- 引用传递:指的是在方法调用时,传递的参数是按引用进行传递,其传递的是引用的地址,也就是变量所对应的内存空间的地址。传递的是值的引用,也就是说传递前和传递后都指向同一个引用(也就是同一个内存空间)。
10、this、static、super和final
10.1 this
this是Java语言的一个关键字,是一个引用,存储在Java虚拟机内存的对象内部,this这个引用保存了当前对象的内存地址指向自身,任何一个堆内存的java对象都有一个this。
this指向当前对象,也可以说this代表“当前对象”,this可以用在实例方法以及构造方法中。
10.1.1 this在实例方法中使用
-
this不能出现在 static的方法当中
- 因为static方法在被调用时是不需要创建对象的,直接采用“类名”的方式调用,也就是说static方法的执行过程是不需要“当前对象”参与的,所以static方法中不能出现this。
-
this在实例方法中,指代的是当前类的对象
-
this在大部分的情况下可以省略,只有当在实例方法中区分局部变量和实例变量的时候不能省略
-
在 static 方法中不能访问类的非静态成员变量和非静态成员方法
-
因为非静态成员方法/变量都是必须依赖具体的对象才能够被调用
-
在 static 的方法中不能直接访问实例变量,要访问实例变量必须先自己创建一个对象,通过“引用”可以去访问,不能通过 this 访问,因为实例变量是对象级的变量,static方法在被调用时是不需要创建对象的, 而this又指代着当前对象,所以在 static 的方法中也不能直接访问实例变量
//错误写法,编译报错 错误:无法从静态上下文中引用非静态变量 public class ThisTest { int i = 10; public static void main(String[] args) { System.out.println(i); } } //正确写法 public class ThisTest { int i = 10; public static void main(String[] args) { //这肯定是不行的,因为 main 方法带有 static,不能用 this //System.out.println(this.i); //可以自己创建一个对象 ThisTest tt = new ThisTest(); //通过引用访问 System.out.println(tt.i); } } -
在 static 的方法中不能直接访问实例方法
//错误写法,编译报错 错误:无法从静态上下文中引用非静态方法 public class ThisTest { public static void main(String[] args) { doSome(); } public void doSome(){ System.out.println("do some..."); } } //正确写法 public class ThisTest { public static void main(String[] args) { ThisTest tt = new ThisTest(); tt.doSome(); } public void doSome(){ System.out.println("do some..."); } }
-
10.1.2 this在构造方法中使用
- 使用在构造方法第一行(只能出现在第一行),通过当前构造方法调用本类当中其它的构造方法,其目的是为了代码复用
- this(): 调用无参构造方法
- this(参数列表): 调用带参构造方法
public class Date {
private int year;
private int month;
private int day;
//业务要求,默认创建的日期为 1970 年 1 月 1 日
public Date(){
//System.out.println("..."); 如果加上这一句则报错 错误:对this的调用必须是构造器中的第一个语句
this(1970 , 1, 1);
}
public Date(int year,int month,int day){
this.year = year;
this.month = month;
this.day = day;
}
}
10.2 static
本小节转载自:夯实Java基础(七)----Static关键字 - 唐浩荣 - 博客园 (cnblogs.com)
10.2.1 static介绍
执行顺序:静态变量 > 静态代码块 > mian()方法 > 普通变量 > 构造代码块 > 构造方法 > 局部代码块
Java中static表示“全局”或者“静态”的意思,可以用来修饰成员变量、成员方法、代码块、内部类和导包。在Java中并不存在全局变量的概念,但是我们可以通过static来实现一个“伪全局”的概念,被static修饰的成员变量和成员方法独立于该类的任何对象。也就是说,它不依赖类特定的实例,被类的所有实例共享。只要这个类被加载了,Java虚拟机就能根据类名在运行时数据区的方法区内定找到他们。因此,static对象可以在它的任何对象创建之前访问,无需引用任何对象,所以被static修饰的成员变量和成员方法可以直接使用类名调用。
class Person{
private static int num=0;
public Person() {
num++;
}
public static void plus(){
System.out.println(Person.num);
}
public static void main(String[] args) {
new Person();
new Person();
Person.plus();
plus();
}
}
//结果:2、2
10.2.2 static变量
static修饰的成员变量称作静态变量,静态变量被所有的对象所共享,在内存中只有一个,它会随着类的加载而加载。另外主要:static是不允许用来修饰局部变量。
局部变量,有效范围很小,只能在方法体中访问,方法结束之后局部变量内存就释放了,在内存方面局部变量存储在栈当中
提到静态变量我们来看静态变量和非静态变量的区别:
- 静态变量(类变量):静态变量被所有的对象所共享,也就是说我们创建了一个类的多个对象,多个对象共享着一个静态变量,如果我们修改了静态变量的值,那么其他对象的静态变量也会随之修改。
- 非静态变量(实例变量):如果我们创建了一个类的多个对象,那么每个对象都有它自己该有的非静态变量。当你修改其中一个对象中的非静态变量时,不会引起其他对象非静态变量值得改变。
class Person{
private static int num;
private int num1;
public static void main(String[] args) {
Person p1 = new Person();
Person p2 = new Person();
Person.num=10;
p1.num1=11;
Person.num=100;
p2.num1=111;
System.out.println(Person.num);
System.out.println(p1.num);
System.out.println(p2.num);
System.out.println(p1.num1);
System.out.println(p2.num1);
}
}
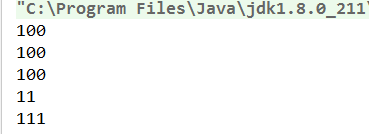
从运行结果来看,static变量的值是相同的,说明是共享的,而非静态变量他们的值则不相同,说明依赖于实例。虽然static修饰的变量它不依赖类特定的实例,但它毕竟也是类中的一个属性,也是可以通过类的实例来调用的,只不过属性的值是共享的而已。但是最好还是用类名调用。
10.2.3 static方法
static修饰的成员方法称作静态方法,这样我们就可以通过“类名. 方法名”进行调用。由于静态方法在类加载的时候就存在了,所以它不依赖于任何对象的实例就可以进行调用,因此对于静态方法而言,是没有当前对象的概念,即没有this、super关键字的。因为static方法独立于任何实例,因此static方法必须被实现,而不能是抽象的abstract。
并且由于独立于任何实例,在静态方法中不能访问类的非静态成员变量和非静态成员方法,因为非静态成员方法/变量都是必须依赖具体的对象才能够被调用。但是要注意的是,虽然在静态方法中不能访问非静态成员方法和非静态成员变量,但是在非静态成员方法中是可以访问静态成员方法/变量的。举个简单的例子:
class Person{
public static void main(String[] args) {
Person p=new Person();
p.show1();
}
public void show1(){
System.out.println("非静态方法show1()...");
show2();
show3();
}
public static void show2(){
System.out.println("静态方法show2()...");
//这里编译会报错Non-static method 'show1()' cannot be referenced from a static context
//show1();
}
public static void show3(){
System.out.println("静态方法show3()...");
show2();
}
}
10.2.4 static代码块
被static修饰的代码块也叫静态代码块,会随着JVM加载类的时候而加载这些静态代码块,并且会自动执行。它们可以有多个,可以存在于该类的任何地方。JVM会按照它们的先后顺序依次执行它们,而且每个静态代码块只会被初始化一次,不会进行多次初始化。示例:
public class Person{
static {
System.out.println("Person类静态块");
}
public Person() {
System.out.println("Person类构造器");
}
public static void main(String[] args) {
new Son();
System.out.println("-------");
new Son();
}
}
class Son extends Person{
static {
System.out.println("Son类静态块");
}
public Son() {
System.out.println("Son类构造器");
}
}
运行结果:

从运行结果分析:首先运行main()方法,然后JVM就会加载类,因为Son类继承了Person类,所以会先加载父类Person类,再去加载子类Son。
由于静态代码块会随着类的加载而加载,所以先输出父类中静态代码块内容"Person类静态块",加载完类之后执行main()方法内容,先new了第一个Son实例,子类Son开始加载,输出子类中静态代码块内容"Son类静态块",然后执行子类构造器,由于子类构造器中默认调用了super(),所以先输出父类构造器的内容,再输出子类构造器的内容。之后又new了第二个Son实例,却是输出的构造器的内容,说明static静态块只加载了一次。结论:静态代码块是先加载父类的静态代码块,然后再加载子类静态代码块,是随着类的加载而加载,而且只会加载一次。
补充:因为入口main()是个方法,也需要用类去调用,所以类的加载优先级>main()方法。
10.2.5 static内部类
static修饰内部类的用法很少,毕竟内部类用的就不是很多,一般在源码中才能看见。但是就是有这么一个特殊的用法是用static修饰内部类。普通类是不允许声明为静态的,只要内部类才可以,被static修饰的内部类可以直接作为一个普通类来使用,而不需先实例一个外部类。
static修饰内部类注意几点:
- 静态内部类只能访问外部类的静态成员,否则编译会报错。
- 不管是静态方法还是非静态方法都可以在非静态内部类中访问。
- 如果需要调用内部类的非静态方法,必须先new一个OuterClass的对象outerClass,然后通过outer。new生成内部类的对象,而static内部类则不需要。
简单举例:
public class OuterClass {
private static int num=6;
// 静态内部类
public static class InnerStaticClass{
public void print() {
System.out.println("静态内部类方法print()=="+num);
}
}
//非静态内部类
public class InnerClass{
public void display(){
System.out.println("非静态内部类方法display()=="+num);
show();
}
}
public void show(){
System.out.println("外部类的show()方法=="+num);
}
public static void main(String[] args) {
//非static对象实例
OuterClass outer = new OuterClass();
OuterClass.InnerClass innerClass = outer.new InnerClass();
innerClass.display();
//static对象实例
OuterClass.InnerStaticClass staticClass=new OuterClass.InnerStaticClass();
staticClass.print();
}
}
10.2.6 static导包
这个知识点非常的冷门,基本上很少的地方会用,我们只需要了解一下即可,用static修饰导包的格式是 import static 包名,static不能写在import前面,这样可以指定导入某个类中的指定静态资源,并且不需要使用类名.资源名,可以直接使用资源名。
来看一下案例:
import static java.lang.Math.*;
public class StaticTest {
public static void main(String[] args) {
System.out.println(sqrt(9));
System.out.println(abs(-12));
}
}
//结果:3、12
从上面的案例看出,使用import static我们导入了Math类下的所有静态资,所以我们就可以直接使用sqrt(9)、abs(-12)静态方法了。
这样在写代码的时候确实能省一点代码,但是会影响代码可读性,所以一般情况下不建议这么使用。
10.2.7 总结
static是非常重要的一个关键字,它的用法也很丰富,以下总结为:
- static可以用来修饰成员变量、成员方法、代码块、内部类和导包。
- 用来修饰成员变量,将其变为静态变量,从而实现所有对象对于该成员的共享,通过“类名.变量名”即可调用。
- 用来修饰成员方法,将其变为静态方法,可以直接使用“类名.方法名”的方式调用,常用于工具类。
- 静态方法中不能使用关键字this和super 。
- 静态块用法,将多个类成员放在一起初始化,使得程序更加规整,其中理解对象的初始化过程非常关键。
- 静态代码块是先加载父类的静态代码块,然后再加载子类静态代码块,而且只会加载一次。
- static修饰成员变量、成员方法、代码块会随着类的加载而加载。
- 静态导包用法,将类的方法直接导入到当前类中,从而直接使用“方法名”即可调用类方法,更加方便,但是代码的可读性降低。
10.3 super
建议:初学者学完封装、继承、多态之后再看本小节
严格地说,super并不是一个引用,他只是一个关键字,代表了当前对象中从父类继承过来的部分特征。
super 和 this 可以对比着学习:
-
this
-
this是一个引用,保存内存地址指向自己
-
this出现在实例方法中,谁调用这个实例方法,this就代表谁,this代表当前正在执行这个动作的对象
-
this不能出现在静态方法中
-
this大部分情况下可以省略,在方法中区分实例变量和局部变量的时候不能省略
-
“
this(实际参数列表)”出现在构造方法的第一行,通过当前的构造方法去调用本类当中的其他构造方法
-
-
super:
-
super并不是一个引用,他只是一个关键字,代表了当前对象中从父类继承过来的部分特征,而this指向一个独立的对象,换句话来说,super其实是this的一部分
-
super和this都可以用在实例方法中
-
super不能使用在静态方法中,因为super代表了当前对象的父类型特征,静态方法中没有 this,肯定也是不能使用 super 的。
-
super 也有这种用法:“
super(实际参数列表);”,这种用法是通过当前的构造方法调用父类的构造方法。
-
10.3.1 super在构造方法中使用
super(实际参数列表);语法表示调用父类的构造方法
这行代码和“this(实际参数列表)”都是只允许出现在构造方法第一行,所以这两行代码是无法共存的。
public class People {
String idCard;
String name;
boolean sex;
public People(){
}
public People(String idCard,String name,boolean sex){
this.idCard = idCard;
this.name = name;
this.sex = sex;
}
}
/*****************************************************************/
public class Student extends People{
//学号是子类特有的
int sno;
public Student(){
}
public Student(String idCard,String name,boolean sex,int sno){
this.idCard = idCard;
this.name = name;
this.sex = sex;
this.sno = sno;
}
}
//子类的构造方法
public Student(String idCard,String name,boolean sex,int sno){
//“super(实际参数列表);表示调用父类的构造方法
super(idCard,name,sex);
this.sno = sno;
}
- 当一个构造方法第一行没有显示的调用“
super(实际参数列表)”的话,系统默认调用父类的无参数构造方法“super()”。当然前提是“this(实际参数列表)”也没有显示的去调用(因为 super()和 this()都只能出现在构造方法第一行,所以不能并存)。
Object 类是所有类的父类
10.3.2 super在实例方法中使用
this大部分情况下都是可以省略的,只有在方法中区分局部变量和实例变量的时候不能省略。那super什么时候可以省略,什么时候不能省略呢?
父类和子类中有同名实例变量或者有同名的实例方法,如果想在子类中访问父类的实例变量或实例方法,super 不能省略
//书
public class Book {
//书名
String name;
//构造方法
public Book(){
super();
}
public Book(String name){
super();
this.name = name;
}
}
//纸质书
public class PaperBook extends Book {
//构造方法
public PaperBook(){
super();
}
public PaperBook(String name){
super();
this.name = name;
}
//打印书名
public void printName(){
System.out.println("this.name->书名 : " + this.name);
System.out.println("super.name->书名 : " + super.name);
}
}
public class BookTest {
public static void main(String[] args) {
PaperBook book1 = new PaperBook("零基础学 Java 卷 I");
book1.printName();
}
}
输出结构:

本例中,子类继承了父类的实例变量,当子类调用构造方法PaperBook(String name时, this.name = name;为name赋值,因为只有一个name,所以this.name和super.name指向的其实是同一个内存空间(因为变量name是同一个),所以他们的值相等。this.成员变量会先从本类声明的成员变量列表中查找,如果未找到,会去从父类继承的在子类中仍然可见的成员变量列表中查找
//纸质书
public class PaperBook extends Book {
//在子类中也定义了一个 name 属性
String name;
//构造方法
public PaperBook(){
super();
}
public PaperBook(String name){
super();
this.name = name;//这里的 this.name 代表子类的 name
}
//打印书名
public void printName(){
System.out.println("this.name->书名 : " + this.name);
System.out.println("super.name->书名 : " + super.name);
}
}
输出:

本例中,由于在子类 PaperBook 中定义了重名的变量 name 导致在当前对象中有两个 name,一个是从父类中继承过来的,一个是自己的,如果此时想访问父类中继承过来的 name 则必须使用 super.name,当直接访问 name 或者 this.name 都表示访问当前对象自己的 name
10.4 final
本小节转载自:夯实Java基础(九)----final关键字 - 唐浩荣 - 博客园 (cnblogs.com)
建议初学者学完面向对象三大特征之后再看
10.4.1 final简介
Java语言中的final关键字,想必大家都不是很陌生,平时使用最多的情况应该是结合Static关键字来定义常量,还有在面试的时候有一个常见的面试题就是:final、finally、finalize区别,那么下面就来了解final这个关键字的用法,其实这个关键字还是非常简单的。
final从字面意思是不可更改的,最终的意思,它可以用来修类、成员方法、变量(包括成员变量和局部变量)、参数。
- final类:表示不能被继承,没有子类, final类中的方法默认是final的;
- final方法:表示不能被重写,但可以被继承,可以被重载,这里很多人会弄混;
- final成员变量:表示常量,只能被赋值一次,赋值后值不再改变,变量是只读的。final变量经常和static关键字一起使用,作为常量。
- final参数(形参):表明该形参的值不能被修改,即不能被重新赋值了;
10.4.2 final修饰类
final修饰类,表示该类不能再被继承了。如果一个类中的功能是完整的,那么我们可以将该类用final来修饰,它不需要被继承来扩展别的功能了。我们最常用String、Integer、System等类就是用final修饰的,其不能再被其它类所继承。
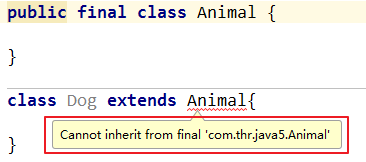
用final修饰类如果被继承了那么在编译的时候就会报错。
10.4.3 修饰方法
final修饰方法,表示这个方法不能被子类方法重写。如果你认为一个方法的功能已经足够完整了,不需要再去子类中扩展的话,我们可以声明此方法为final。比如Object类中getClass()方法就是final修饰的。
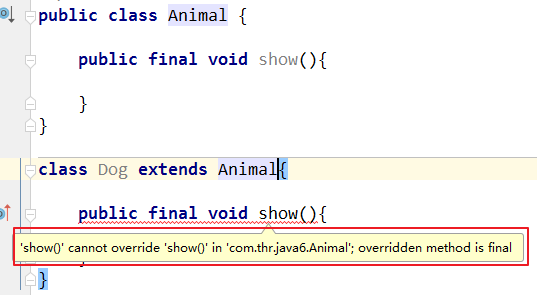
注意:类中所有的private方法都自动成为final。由于不能访问一个private方法,所以它绝对不会被覆盖。
10.4.4 修饰变量
对于一个final变量,如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能再让其指向另一个对象
final修饰变量表示是常量,一般都和static一起使用,用来定义全局常量。final无论修饰的是成员变量还是局部变量,都必须进行显式初始化。
public class FinalTest {
//显式初始化
final int AA = 11;
final int BB;
final int CC;
final int DD;
//构造代码块初始化
{
BB = 22;
}
//构造方法初始化
public FinalTest() {
CC = 33;
DD = 44;
}
public FinalTest(int CC, int DD) {
this.CC = CC;
this.DD = DD;
}
}
我们可以通过显式初始化、构造代码块初始化、构造方法初始化等只要能够初始化成功的方式对final修饰的变量进行初始化即可。前面都是final修饰基本数据类型的变量,如果final修饰引用变量会是怎么样,我们来看一下举例:
public class FinalTest {
public static void main(String[] args) {
final AA aa = new AA();
//这里在引用其他的对象就会报错Cannot assign a value to final variable 'aa'
//aa=new AA();
aa.i++;
System.out.println(aa.i);
}
}
class AA {
int i;
}
//运行结果:1
可以看到,虽然我们将引用变量用final修饰了,但是该对象的变量 i 我们还是可以进行修改,而这个变量的引用不能再指向另一个对象了。表明final修饰的是引用变量,就不能再指向其他对象,但是如果该对象内的变量不是final修饰的,其变量的值是可以进行修改的。
final关键字修改变量小结:对于一个final变量,如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能再让其指向另一个对象。
10.4.5修饰参数
final修饰参数准确的来说应该是修饰形参,表明该形参的值不能被修改。
public class FinalTest {
public void show(final int param) {
//编译报错:Cannot assign a value to final variable 'param'
//param=10;
System.out.println(param);
}
public static void main(String[] args) {
FinalTest f = new FinalTest();
f.show(5);
}
}
我在使用final修饰形参时,表明此形参是一个常量。当我们调用方法的时候,给形参进行赋值,一旦赋值以后,就只能在该方法使用,而且不能进行重新赋值操作,否则编译报错。如果形参是引用类型,则引用变量不能再指向其他对象,但是该对象的内容是可以改变的。
10.4.6 类的final变量和普通变量有什么区别?
参考链接:浅谈Java中的final关键字 - 平凡希 - 博客园 (cnblogs.com)
当用final作用于类的成员变量时,成员变量(注意是类的成员变量,局部变量只需要保证在使用之前被初始化赋值即可)必须在定义时或者构造器中进行初始化赋值,而且final变量一旦被初始化赋值之后,就不能再被赋值了。那么final变量和普通变量到底有何区别呢?下面请看一个例子:
public class Test {
public static void main(String[] args) throws Exception {
String a = "hello2";
final String b = "hello";
String d = "hello";
String c = b + 2;
String e = d + 2;
System.out.println((a == c));//true
System.out.println((a == e));//false
System.out.println(a.equals(c));//true
System.out.println(a.equals(e));//true
String aa = "hello" + 2;
System.out.println(a == aa);//true
final String bb = getHello();
System.out.println(a == bb);//false
}
private static String getHello(){
return "hello";
}
}
输出结果:true、false、true、true、true、false
这里面就是final变量和普通变量的区别了,当final变量是基本数据类型以及String类型时,如果在编译期间能知道它的确切值,则编译器会把它当做编译期常量使用。也就是说在用到该final变量的地方,相当于直接访问的这个常量,不需要在运行时确定。这种和C语言中的宏替换有点像。因此在上面的一段代码中,由于变量b被final修饰,因此会被当做编译器常量,所以在使用到b的地方会直接将变量b 替换为它的值"hello",所以b+2会被替换为"hello"+2,变量c这个形式的初始化会被编译器优化成"hello2"存在字符串常量池,而由于a已经被初始化为"hello2",这个字符串已经存在于常量池,所以直接返回其引用。而对于变量d的访问却需要在运行时通过链接来进行,b的值在编译时不确定,不能编译优化,所以d=b+"2",jvm会在堆中生成一个值为"hello2"的对象,返回引用给d。想必其中的区别大家应该明白了,不过要注意,只有在编译期间能确切知道final变量值的情况下,编译器才会进行这样的优化。
==与equals():
- ==比较的数值是否相等和对象地址是否相等。
- equals()方法比较的对象内容是否相等(前提是重写了父类的方法)。
- 一般除了自定义的类除外,大部分能够使用的类都重写了equals()方法。
比如下面的这段代码就不会进行优化:
public class Test {
public static void main(String[] args) {
String a = "hello2";
final String b = getHello();
String c = b + 2;
System.out.println((a == c));
}
public static String getHello() {
return "hello";
}
}
这段代码的输出结果为false。这里要注意一点就是:不要以为某些数据是final就可以在编译期知道其值,通过变量b我们就知道了,在这里是使用getHello()方法对其进行初始化,他要在运行期才能知道其值。
10.4.7 final、finally和finalize的区别
- final修饰符(关键字)。被final修饰的类,就意味着不能再派生出新的子类,不能作为父类而被子类继承。因此一个类不能既被abstract声明,又被final声明。将变量或方法声明为final,可以保证他们在使用的过程中不被修改。被声明为final的变量必须在声明时给出变量的初始值,而在以后的引用中只能读取。被final声明的方法也同样只能使用,即不能方法重写。
- finally是在异常处理时提供finally块来执行任何清除操作。不管有没有异常被抛出、捕获,finally块都会被执行。try块中的内容是在无异常时执行到结束。catch块中的内容,是在try块内容发生catch所声明的异常时,跳转到catch块中执行。finally块则是无论异常是否发生,都会执行finally块的内容,所以在代码逻辑中有需要无论发生什么都必须执行的代码,就可以放在finally块中。
- finalize是方法名。java技术允许使用finalize()方法在垃圾收集器将对象从内存中清除出去之前做必要的清理工作。这个方法是由垃圾收集器在确定这个对象没有被引用时对这个对象调用的。它是在object类中定义的,因此所有的类都继承了它。子类覆盖finalize()方法以整理系统资源或者被执行其他清理工作。finalize()方法是在垃圾收集器删除对象之前对这个对象调用的。
11、代码块
Java中代码块指的是使用”{}”括起来的代码,一共分为四种:
- 普通代码块:在类中方法的方法体中用{}括起来的代码,通常也叫局部代码块
- 构造代码块:类中用{}直接括起来的语句,每次创建对象都会被调用,并且先于构造函数执行
- 静态代码块:类中用static{}括起来的语句,jvm在加载类时执行,并且只执行一次,先于构造代码块块执行
- 同步代码块:类中synchronized(){}括起来的语句,在多线程环境下,对共享数据的读写操作是需要互斥进行的,否则会导致数据的不一致性。
11.1 普通代码块
普通代码块:也可以叫局部代码块,在方法、循环、判断等语句中出现的代码块就称为普通代码块。普通代码块和一般语句的执行顺序由他们在代码中出现的次序决定,先出现先执行。
public class CodeBlockTest {
public static void main(String[] args) {
int x = 1;
{
x = 10;//代码块与方法中的变量会冲突,若先在方法中定义变量,那么在后面的代码块中不能再定义同名的,只能用原变量名接收
System.out.println("普通代码块内的变量 x=" + x);
int y = 20;
System.out.println("普通代码块内的变量 y=" + y);
int z = 30;
System.out.println("普通代码块内的变量 z=" + z);
}
int y = 40;//如果先在代码块中定义变量,在方法中又可以重新定义一次
System.out.println("主方法内的变量 x=" + x);
System.out.println("主方法内的变量 y=" + y);
{
int z = 50;
System.out.println("普通代码块内的变量 z=" + z);
}
//Cannot resolve symbol 'z'
//System.out.println(z);
}
}
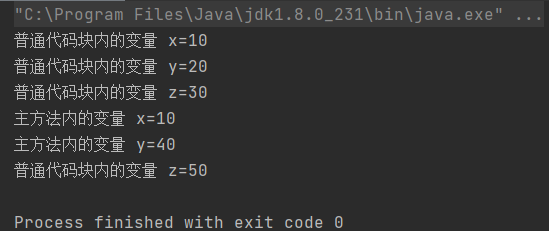
可以看到,代码块中与代码块中定义的变量互不干扰,但是代码块与方法中定义的变量则会冲突,如果先在方法中定义变量,那么在后面的代码块中不能再定义同名的,只能用原变量名接收,而先在代码块中定义变量,在方法中又可以重新定义一次,感兴趣的可以去研究一下。
11.2 构造代码块
直接在类中用"{}"定义且不加任何关键字的代码块称为构造代码块。构造代码块在创建对象时被调用,每次创建对象都会被调用,并且构造代码块的执行次序优先于类构造函数。如果存在多个构造代码块,执行顺序由他们在代码中出现的次序决定,先出现先执行。
构造代码块的作用:可以用来初始化实例变量和实例环境(即创建对象的必要条件),这样可以减少代码量,同时也可以增强程序的可读性。
public class CodeBlockTest {
{
System.out.println("构造代码块1...");
}
public CodeBlockTest() {
System.out.println("无参构造器...");
}
{
System.out.println("构造代码块2...");
}
public static void main(String[] args) {
new CodeBlockTest();
new CodeBlockTest();
}
}
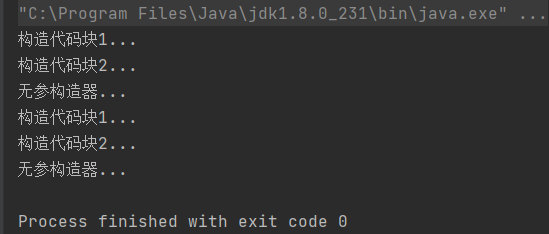
从运行结果容易看出,构造代码块中的语句比构造方法中语句先执行,即使将构造块写在构造方法后面也是一样的结果,事实上是这样子吗?
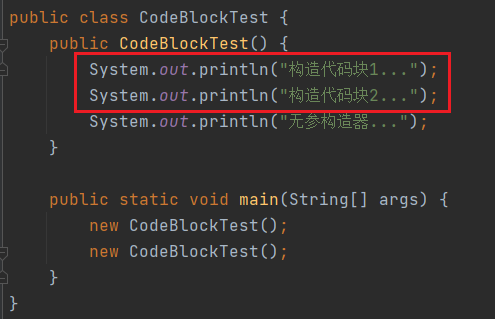
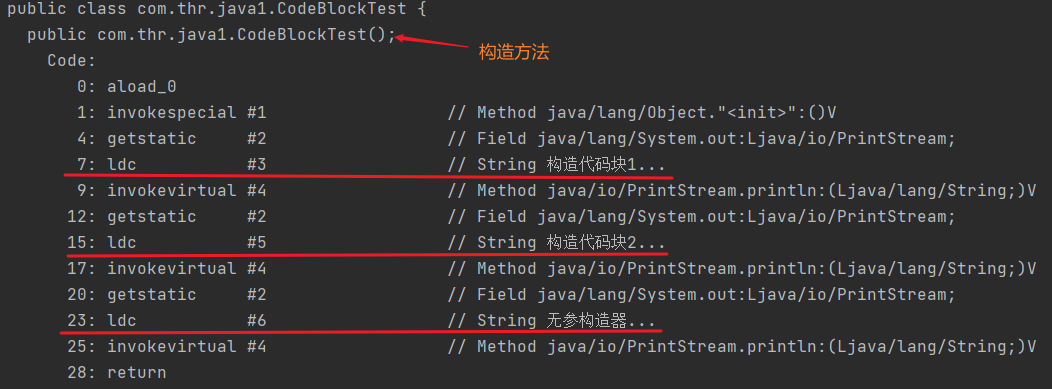
原理:其实构造代码块并不是真正的在构造方法之前执行的,而是在构造方法中执行的。JVM在编译的时候会把构造代码块插入到每个构造函数的最前面,构造代码块随着构造方法的执行而执行,如果某个构造方法调用了其他的构造方法,那么构造代码块不会插入到该构造方法中以免构造代码块执行多次。可以从编译后生成的class文件可以看出来。
或者直接查看代码的反编译文件:
11.3 静态代码块
在类中用static关键字修饰的代码块叫静态代码块。每个静态代码块只会执行一次,并且由于JVM在加载类时会加载静态代码块,所以静态代码块先于主方法执行。如果类中包含多个静态代码块,那么将按照"先定义的代码先执行,后定义的代码后执行"。
静态代码块的特点:
- 静态代码块不能存在于任何方法体内。
- 静态代码块不能直接访问实例变量和实例方法,需要通过类的实例对象来访问。
代码简单示例:
public class Person {
static {
System.out.println("Person类静态块");
}
public Person() {
System.out.println("Person类构造器");
}
}
class Son extends Person {
static {
System.out.println("Son类静态块");
}
public Son() {
System.out.println("Son类构造器");
}
}
class Main {
public static void main(String[] args) {
new Son();
System.out.println("-------");
new Son();
}
}
运行结果:
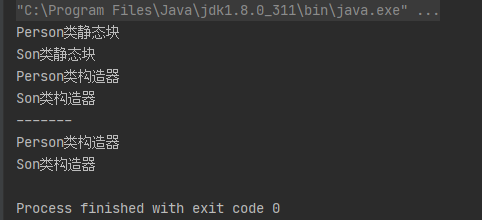
从运行结果分析:首先运行main()方法,然后JVM就会加载类,因为Son类继承了Person类,所以会先加载父类Person类,再去加载子类Son。
由于静态代码块会随着类的加载而加载,所以先输出父类中静态代码块内容"Person类静态块",加载完类之后执行main()方法内容,先new了第一个Son实例,子类Son开始加载,输出子类中静态代码块内容"Son类静态块",然后执行子类构造器,由于子类构造器中默认调用了super(),所以先输出父类构造器的内容,再输出子类构造器的内容。之后又new了第二个Son实例,却是输出的构造器的内容,说明static静态块只加载了一次。结论:静态代码块是先加载父类的静态代码块,然后再加载子类静态代码块,是随着类的加载而加载,而且只会加载一次。
补充:因为入口main()是个方法,也需要用类去调用,所以类的加载优先级>main()方法。
11.4 同步代码块
使用synchronized关键字修饰的普通代码块(其只能用在方法体内部)。其作用在多线程的环境下,对共享数据进行加锁, 从而实现线程同步,是一种多线程保护机制,但是注意同步代码块使用不当可能会造成“死锁”问题。具体使用请移至:Java多线程系列
public void show(){
synchronized (obj){
System.out.println("同步代码块");
}
}
11.5 代码块的执行顺序
上面讲述了四种代码块的基本信息,所以下面结合上面分析的各种情况结合在一起来看一下四种代码块的执行顺序。
public class CodeBlockTest {
static {
System.out.println("静态代码块...");
}
{
System.out.println("构造代码块...");
}
public CodeBlockTest() {
System.out.println("无参构造器...");
}
public void show() {
{
System.out.println("局部代码块...");
}
}
}
class Main {
public static void main(String[] args) {
System.out.println("main()方法运行");
new CodeBlockTest().show();
System.out.println("----------");
new CodeBlockTest().show();
}
}
打印结果:
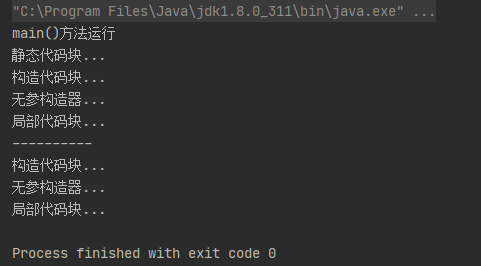
执行顺序(优先级从高到低):静态代码块 > mian()方法 > 构造代码块 > 构造方法 > 局部代码块。其中静态代码块只执行一次。构造代码块和局部代码块再每次创建对象是都会执行。
TIPS:如果加上变量的话:静态变量 > 静态代码块 > mian()方法 > 普通变量 > 构造代码块 > 构造方法 > 局部代码块
12、面向对象三大特征
12.1 封装
12.1.1 封装介绍
封装封装,见名知意,就是把东西包装隐藏起来,不被外界所看见。
- 像平时用的洗衣机,只需要按一下开关和洗涤模式就可以了。有必要了解洗衣机内部的结构吗?有必要碰电动机吗?
- 我们使用的电脑,内部有CPU、硬盘、键盘、鼠标等等,每一个部件通过某种连接方式一起工作,但是各个部件之间又是独立的
- 现实生活中,每一个个体与个体之间是有边界的,每一个团体与团体之间是有边界的,而同一个个体、团体内部的信息是互通的,只是对外有所隐瞒。
Java特性封装:
是指利用抽象数据类型将数据和基于数据的操作封装在一起,使其构成一个不可分割的独立实体,数据被保护在抽象数据类型的内部,尽可能地隐藏内部的细节,只保留一些对外接口使之与外部发生联系。系统的其他对象只能通过包裹在数据外面的已经授权的操作来与这个封装的对象进行交流和交互。也就是说用户是无需知道对象内部的细节(当然也无从知道),但可以通过该对象对外的提供的接口来访问该对象。类的某些信息隐藏在类的内部,不允许外部程序直接访问,而是通过该类提供的方法来对隐藏的信息向外暴露来进行操作和访问。封装可以被认为是一个保护屏障,防止该类的代码和数据被其他类随意访问。适当的封装可以让代码更容易理解与维护,也加强了代码的安全性。
简单的说,是指将对象的状态信息(包括属性和方法等)隐藏在对象内部,不允许外部程序直接访问对象内部信息,而是通过该类所提供的方法来实现对内部信息的操作和访问。
封装的好处(优点):
-
良好的封装能够增加内聚减少耦合。
- 高内聚:类的内部数据操作细节自己完成,不允许外部干涉;
- 低耦合:仅对外暴露少量的方法用于使用
内聚:度量一个模块内部各个元素彼此结合的紧密程度
耦合:度量模块之间互相连接的紧密程度
-
通过隐藏对象的属性来保护对象内部的状态,方便修改和实现。(隐藏信息、实现细节)。
-
提高了代码的可用性和可维护性,因为对象的行为可以被单独的改变或者是扩展(将变化隔离,类内部的结构可以自由修改,增加内部实现部分的可替换性)。
-
禁止对象之间的不良交互提高模块化(良好的封装能够减少耦合)。
-
可以对成员变量进行更精确的控制。
-
容易保证类内部数据间的一致性,从而提高软件的可靠性。
12.1.2 权限修饰符
提到Java的封装,那么肯定离不开四种权限修饰。Java的权限修饰符共有4种,分别为public,protected、缺省、private;权限修饰符可以使得数据在一定范围内可见或者隐藏。
权限修饰符共有4种,分别为public,protected、缺省、private;权限修饰符可以使得数据在一定范围内可见或者隐藏。
| 修饰符 | 当前类 | 同包(子类,非子类) | 非同包子类 | 非同包非子类 |
|---|---|---|---|---|
| private | √ | × | × | × |
| 缺省 | √ | √ | × | × |
| protected | √ | √ | √ | × |
| public | √ | √ | √ | √ |
这里protected需要注意一下,它的范围应该更大:被protected修饰的成员对于本包和其子类可见,具体参考:https://blog.csdn.net/asahinokawa/article/details/80777302
12.1.3 封装的引入
首先我们先来定义一个Person类,并且将其所有的属性用public修饰。代码如下所示:
public class Person {
public String name;//姓名
public int age;//年龄
public String sex;//性别
}
从上面的Person类可以看到,他的所有属性都是用public修饰的,我们在任何地方都可以直接给其属性赋值以及修改值;这就好像你的姓名,年龄,性别都是暴露在外面的,并且在哪里都可以被修改的,而如果Person类有更多的属性,如身份证、电话号码、家庭住址这种比较私密的属性暴露在外面那就不安全了,因为这些属性都是直接暴露在外面的,这就是没有封装的弊端。
我们创建一个Person的实例给他赋值:
Person person=new Person();
person.name="菜徐坤";
person.age=21;
person.sex="woman";
这里我们直接操作属性的值,而封装的思想则是指数据的隐藏,额外暴露接口来对属性进行操作,所以下面来看看怎么在Java中实现封装。
12.1..4 封装的实现
如果要使用封装,那么应该怎么操作? 我们只需将成员变量(field)私有化(用private修饰),并且提供公共(public)的get/set方法即可,我们把这种成员变量也称为属性(property)。
public class Person {
private String name;//姓名
private int age;//年龄
private String sex;//性别
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
}
在使用了封装之后,就不能再用Person类的实例来调用其属性了,会提示该属性是私有化的,不能调用,这样就保证了属性的隐蔽性。我们会提供属性public的getter和setter方法来对属性进行操作。
Person person=new Person();
person.setName("菜徐坤");
person.setAge(21);
person.setSex("woman");
如果你想将年龄设置成 person.setAge(500),你会发现也可以,但是这就不和常理了,人怎么可能活500岁,使用封装我们能够轻松解决这样的问题。我们只需在setAge方法里面添加一些条件即可,如下所示。
public class Person {
private String name;//姓名
private int age;//年龄
private String sex;//性别
public int getAge() {
return age;
}
public void setAge(int age) {
if (age>256 || age <0){
System.out.println("你输入的年龄有误!");
}else{
this.age = age;
}
}
/** 省略其他属性的setter、getter **/
}
12.2 继承
12.2.1 继承的概述
继承是Java面向对象的三大特征之一,是比较重要的一部分,与后面的多态有着直接的关系。继承很好理解,子承父业嘛!在Java中继承就是子类继承父类的一些特征和行为,使得子类对象(实例)具有父类相同的特征和行为,当然子类也可以有自己的特征与行为。
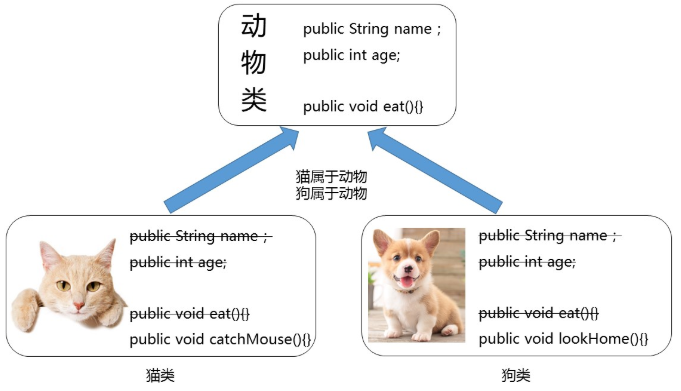
继承的目的:如果多个子类中存在相同的特征与行为,那么就可以将这些内容抽取到父类中,而父类中的一些特征和行为可以被子类继承下来使用,不再需要再在子类中重复定义了。这里以动物为例:Animal类是所有动物的父类,它应该有动物的一些共同特征和行为,而猫、狗等动物也都具有这些特征和行为,所有它们可以通过继承来实现。
如图所示:

将猫、狗类中的共同属性和行为抽取出来,
其中,多个类可以称为子类,也叫派生类;多个类抽取出来的这个类称为父类、超类(superclass)或者基类。
继承描述的是事物之间的所属关系,这种关系是:is-a 的关系。例如,图中猫属于动物,狗也属于动物。可见,父类更通用,子类更具体。我们通过继承,可以使多种事物之间形成一种关系体系。
①、Java继承的特点:
- Java只支持单继承 ,不支持多继承(如A继承B,A继承C),但支持多层继承(如A继承B,B继承C) 。
- 子类拥有父类非private的属性,方法。(其实子类继承父类后,仍然认为获取了父类的private结构,只是因为封装的影响,使得子类不能直接调用父类的结构而已)
- 子类可以拥有自己的属性和方法,即子类可以对父类进行扩展。
- 子类可以用自己的方式实现父类的方法。
- 提高了类之间的耦合性(继承的缺点,耦合度高就会造成代码之间的联系)。
②、继承的好处:
- 减少代码的冗余,提高代码的复用性。
- 便于功能的扩展。
- 为后面多态的使用提供了前提。
③、类的继承格式:
在Java中通过 extends 关键字来实现继承关系,形式如下:
[修饰符] class 父类 {
属性、方法
}
[修饰符] class 子类 extends 父类 {
属性、方法
}
④、类的继承举例:
/*
* 定义动物类Animal,做为父类
*/
public class Animal {
// 定义name属性
public String name;
// 定义age属性
public int age;
// 定义动物的吃东西方法
public void eat() {
System.out.println("动物具有吃的行为...");
}
}
//定义猫类Cat 继承 动物类Animal
class Cat extends Animal {
// 定义一个猫抓老鼠的方法catchMouse
public void catchMouse() {
System.out.println("猫抓老鼠");
}
}
//定义猫类Dog 继承 动物类Animal
class Dog extends Animal {
// 定义一个狗会看门的方法watchDoor
public void watchDoor() {
System.out.println("狗会看门");
}
}
//定义测试类
class Main {
public static void main(String[] args) {
// 创建一个猫类对象
Cat cat = new Cat();
// 为该猫类对象的name属性进行赋值
cat.name = "TomCat";
// 为该猫类对象的age属性进行赋值
cat.age = 3;
// 调用该猫继承来的eat()方法
cat.eat();
// 调用该猫的catchMouse()方法
cat.catchMouse();
Dog dog = new Dog();
dog.name = "JackDog";
dog.age = 2;
dog.eat();
dog.watchDoor();
}
}
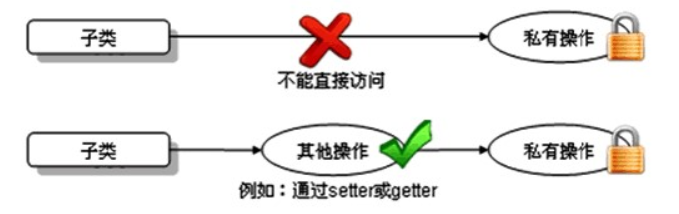
注意:我们知道,子类可以继承父类的所有属性和方法,并直接使用,但是私有(private)的例外,私有的属性不能直接访问(也可以理解为私有的属性不能被继承,官方文档中的说法);如果直接使用父类用private修饰的属性或方法在编译时就会报错。虽然子类不能直接进行访问父类的私有属性,但可以通过继承的getter/setter方法进行访问。如图所示:
既然提到Java的继承,肯定离不开this,super关键字和构造器的使用,下面来介绍一下。
12.2.2 构造器
构造器也叫构造方法,构造器的作用是用于创建并初始化对象。
当我们在使用new关键字创建对象时,如A a = new A(); 此时使用了无参构造器创建了一个对象,对象创建完成后它的成员变量也会被初始化,默认是相对数据类型的默认值。如果我们需要赋别的值,需要挨个为它们再赋值,太麻烦了。我们能不能在new对象时,直接为当前对象的某个或所有成员变量直接赋值呢。答案是可以使用有参的构造器。
注意:构造器只为实例变量初始化,不为静态类变量初始化
①、构造器的语法格式
构造器又称为构造方法或构造函数,那是因为它长的很像方法。但是和方法还有有所区别的。
[修饰符] 构造器名(){
// 实例初始化代码
}
[修饰符] 构造器名(参数列表){
// 实例初始化代码
}
构造器创建的注意事项:
- 构造器名必须与它所在的类名必须相同
- 它没有返回值,所以不需要返回值类型,甚至不需要void
- 如果你不提供构造器,系统会给出默认无参数构造器,并且该构造器的修饰符默认与类的修饰符相同
- 如果你提供了构造器,系统将不再提供无参数构造器,除非你自己定义。
- 构造器是可以重载的,既可以定义参数,也可以不定义参数。
- 构造器不能被继承,因为构造器的构造器名是与类的名称相同,如果子类能够继承父类的构造方法,那么在子类的构造方法中就有不同于子类名称的构造法;这与构造方法的定义不符;所以子类是不能继承父类的构造方法的;
- 构造器的修饰符只能是权限修饰符,不能被其他任何修饰
简单的举例代码如下:
public class Father {
private String name;
private int age;
// 无参构造
public Father() {}
// 有参构造
public Father(String name,int age) {
this.name = name;
this.age = age;
}
//getter,setter方法省略...
}
12.2.3 方法重载与重写
这里就给出它两的定义与区别,具体的可以去问度娘😂。
方法重载(Overload):指在同一个类中,允许存在一个以上的同名方法,只要它们的参数列表不同即可,与修饰符和返回值类型无关。
参数列表不同:指的是参数个数不同,数据类型不同,数据类型顺序不同。
方法重写(Override):子类中定义与父类中相同的方法,一般方法体不同,用于改造并覆盖父类的方法。当子类继承了父类的某个方法之后,发现这个方法并不能满足子类的实际需求,那么可以通过方法重写,覆盖父类的方法。
重写的具体规则如下:
- 必须保证父子类之间方法的名称相同,参数列表也相同。
- 子类方法的返回值类型必须与父类方法的返回值类型相同或者为父类方法返回值类型的子类类型。
- 子类方法的访问权限必须不能小于父类方法的访问权限。(public > protected > 缺省 > private)
- 子类方法 抛出的异常不能大于父被重写的异常
注意事项:
- 静态方法不能被重写,方法重写指的是实例方法重写,静态方法属于类的方法不能被重写,而是隐藏。
- 私有等在子类中不可见的方法不能被重写
- final方法不能被重写
12.2.4 this和super关键字
12.2.4.1 this关键字
①、this关键字的含义:表示当前对象的引用或正在创建的对象。可用于调用本类的属性、方法、构造器。
②、this使用位置:
- this在实例初始化相关的代码块和构造器中:表示正在创建的那个实例对象,即正在new谁,this就代表谁
- this在非静态实例方法中:表示调用该方法的对象,即谁在调用,this就代表谁。
- this不能出现在静态代码块和静态方法中
③、this使用格式:
(1) this.成员变量名:
- 当方法的局部变量与当前对象的成员变量重名时,就可以在成员变量前面加this.,如果没有重名问题,就可以省略this.
- this.成员变量会先从本类声明的成员变量列表中查找,如果未找到,会去从父类继承的在子类中仍然可见的成员变量列表中查找
(2) this.成员方法:
- 调用当前对象的成员方法时,都可以加"this.",也可以省略,实际开发中都省略
- 当前对象的成员方法,先从本类声明的成员方法列表中查找,如果未找到,会去从父类继承的在子类中仍然可见的成员方法列表中查找
(3) this()或this(实参列表):
- 只能调用本类的其他构造器
- 必须在构造器的首行
- 如果一个类中声明了n个构造器,则最多有 n - 1个构造器中使用了"this(【实参列表】)",否则会发生递归调用死循环
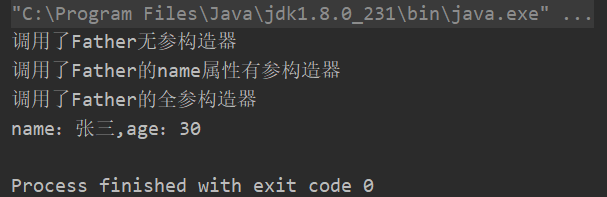
this关键字的简单举例如下所示(注:这里只举例this调用构造器,调用其它的下面会举例):
/**
* 通过this调用构造器测试
*/
public class Demo {
public static void main(String[] args) {
Father father = new Father("张三", 30);
father.show();
}
}
class Father {
public String name;
public int age;
//无参构造器
public Father() {
System.out.println("调用了Father无参构造器");
}
//name属性的有参构造器
public Father(String name) {
this();
this.name = name;
System.out.println("调用了Father的name属性有参构造器");
}
//全参构造器
public Father(String name, int age) {
this(name);
this.name = name;
this.age = age;
System.out.println("调用了Father的全参构造器");
}
// 定义show方法
public void show() {
System.out.println("name:" + this.name + ",age:" + this.age);
}
}
12.2.4.2 super关键字
①、super的含义:super是用于在当前类中访问父类的一个特殊关键字,可用于调用父类的属性、方法、构造器,它不是对象的引用。(区别this :super不能单独使用赋值给一个变量)
②、super使用的前提
- 通过super引用父类的xx,都是在子类中仍然可见的
- 不能在静态代码块和静态方法中使用super,因为super代表了当前对象的父类型特征,静态方法中没有 this,肯定也是不能使用 super 的
③、super的使用格式:
(1) super.成员变量:在子类中访问父类的成员变量,如果是当子类的成员变量与父类的成员变量重名时,必定是调用父类的成员变量。
(2) super.成员方法:在子类中调用父类的成员方法,如果是当子类重写了父类的成员方法时,必定是调用父类的成员方法。
(3) super()或super(实参列表):在子类的构造器首行,用于表示调用父类的哪个实例初始化方法
super() 和 this() 都必须是在构造方法的第一行,所以不能同时出现。
super关键字的简单举例:
public class Demo {
public static void main(String[] args) {
Son son = new Son();
son.show();
}
}
class Father {
String name = "Father";
int age = 40;
public Father() {
System.out.println("调用了父类的无参构造器");
}
public Father(String name, int age) {
this.name = name;
this.age = age;
}
public void show() {
System.out.println("父类的Show方法");
}
}
class Son extends Father {
String name = "Son";
int age = 20;
public Son() {
//调用父类构造器,可以省略,系统会默认添加
super();
}
public void show() {
System.out.println("子类的Show方法");
System.out.println("本类属性:" + this.name + "," + this.age);
//调用父类方法
super.show();
System.out.println("父类属性:" + super.name + "," + super.age);
}
}
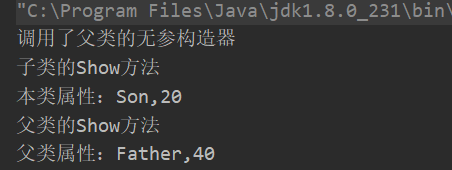
注意:这个默认调用父类的构造器(super())是有前提的:父类必须有默认构造器。如果父类没有默认构造器(父类写了有参的构造器,那么默认的无参构造器就会被隐藏),我们就要必须显示的使用super()来调用父类构造器,或者显示的写出父类的无参构造器,否则编译器会报错:无法找到符合父类形式的构造器。
12.2.4.3 this、super的小结
- 在使用this、super调用构造器的时候,this、super语句必须放在构造方法的第一行,否则编译会报错。
- 由于this、super关键字调用构造器的时候都必须出现在第一行,所以它两不能同时出现。
- 不能在子类中使用父类构造方法名来调用父类构造方法,因为父类的构造方法不被子类继承。
- 调用父类的构造方法的唯一途径是使用 super 关键字,如果子类中没显式调用,则编译器自动调用 super(),也就是说会一直调到Object类,因为Object是所有类的父类。
- 子类会默认使用super()调用父类默认构造器,如果父类没有默认构造器,则子类必须显式的使用super()来调用父类构造器。
- super和this都不能出现在静态方法和静态代码块中,因为super和this都是存在于对象中的
12.2.4.4 this、super的练习
①、父类,子类及子类方法中存在同名变量时
public class Test {
public static void main(String[] args) {
Son son = new Son();
System.out.println(son.a);//20
System.out.println(son.b);//11
son.test();
son.method(30);
son.fun(13);
}
}
class Father {
int a = 10;
int b = 11;
}
class Son extends Father {
int a = 20;
public void test() {
//子类与父类的属性同名,子类对象中就有两个a
System.out.println("父类的a:" + super.a);//10 直接从父类局部变量找
System.out.println("子类的a:" + this.a);//20 先从本类成员变量找
System.out.println("子类的a:" + a);//20 先找局部变量找,没有再从本类成员变量找
//子类与父类的属性不同名,是同一个b
System.out.println("b = " + b);//11 先找局部变量找,没有再从本类成员变量找,没有再从父类找
System.out.println("b = " + this.b);//11 先从本类成员变量找,没有再从父类找
System.out.println("b = " + super.b);//11 直接从父类局部变量找
}
public void method(int a) {
//子类与父类的属性同名,子类对象中就有两个成员变量a,此时方法中还有一个局部变量a
System.out.println("父类的a:" + super.a);//10 直接从父类局部变量找
System.out.println("子类的a:" + this.a);//20 先从本类成员变量找
System.out.println("局部变量的a:" + a);//30 先找局部变量
}
public void fun(int b) {
System.out.println("b = " + b);//13 先找局部变量
System.out.println("b = " + this.b);//11 先从本类成员变量找
System.out.println("b = " + super.b);//11 直接从父类局部变量找
}
}
②、父子类中找方法1
public class Test {
public static void main(String[] args) {
Son s = new Son();
System.out.println(s.getNum());//10 没重写,先找本类,没有,找父类
Daughter d = new Daughter();
System.out.println(d.getNum());//20 重写了,先找本类
}
}
class Father {
protected int num = 10;
public int getNum() {
return num;
}
}
class Son extends Father {
private int num = 20;
}
class Daughter extends Father {
private int num = 20;
public int getNum() {
return num;
}
}
③、父子类中找方法2
public class Test {
public static void main(String[] args) {
Son s = new Son();
s.test();
Daughter d = new Daughter();
d.test();
}
}
class Father {
protected int num = 10;
public int getNum() {
return num;
}
}
class Son extends Father {
private int num = 20;
public void test() {
System.out.println(getNum());//10 本类没有找父类
System.out.println(this.getNum());//10 本类没有找父类
System.out.println(super.getNum());//10 本类没有找父类
}
}
class Daughter extends Father {
private int num = 20;
public int getNum() {
return num;
}
public void test() {
System.out.println(getNum());//20 本类有,先找本类
System.out.println(this.getNum());//20 本类有,先找本类
System.out.println(super.getNum());//10 重写了,直接找父类
}
}
12.2.5 继承带来的问题
- 子类与父类存在严重的耦合关系。
- 继承破坏了父类的封装性。
- 子类继承父类的属性和方法,也就说明可以从子类中恶意修改父类的属性和方法。
所以能不使用继承关系就尽量不要使用继承。
12.2.6 何时使用继承
- 子类需要额外增加属性,而不仅仅是属性值的改变。
- 子类需要增加自己独有的行为方式(包括增加新的方法或重写父类的方法)。
12.3 多态
12.3.1 多态介绍
面向对象三大特征:封装、继承、多态。多态是Java面向对象最核心,最难以理解的内容。从一定角度来看,封装和继承几乎都是为多态而准备的。
多态就是指程序中定义的引用变量所指向的具体类型和通过该引用变量发出的方法调用在编译时并不确定,而是在程序运行期间才确定,即一个引用变量倒底会指向哪个类的实例对象,该引用变量发出的方法调用到底是哪个类中实现的方法,必须在由程序运行期间才能决定。因为在程序运行时才确定具体的类,这样,不用修改源程序代码,就可以让引用变量绑定到各种不同的类实现上,从而导致该引用调用的具体方法随之改变,即不修改程序代码就可以改变程序运行时所绑定的具体代码,让程序可以选择多个运行状态,这就是多态性。
比如有一种动物,藏在某个看不见得地方,你知道它是一种动物(静态绑定),但是不知道具体是哪种动物,只有等它发出叫声才能辨别(动态绑定),是猫——喵喵喵,是狗——旺旺旺,你一听就知道这是什么动物,对于不同的动物会有不同的结果,可以理解为多态。
简单地说就是:相同类型的变量调用同一个方法时呈现出多种不同的行为特征
产生原因:Java 允许把一个子类对象直接赋给一个父类引用变量,无须任何类型转换。当把一个子类对象赋给父类引用变量时,会出现编译类型和运行类型不一致的情况,此时调用子类和父类的同名方法时(这里的同名指的是子类重写了父类方法),总是表现出子类方法的行为特征。例如:B b = new A() 编译类型看左边,运行类型看右边,因此编译类型为 B,运行类型为 A,当 b 调用 A 和 B 的同名的方法时,运行的总是 A 中的方法。
Java引用类型有编译类型与运行类型:当两个类型不一致时,就出现了对象的多态性
- 编译类型:由声明该变量时使用的类型决定
- 运行类型:由实际赋给该变量的对象决定
Java多态也可以用一句话表示:父类的引用指向子类的对象。体现在程序中就是:同一个父类引用,引用不同的子类的对象(实例)
👏Java程序包括编译和运行阶段,所以Java的多态性也体现在2个层面:
- 编译阶段:静态绑定
- 编译时,编译器会去查看某一变量的类型是什么,然后会去该变量所属类中去查找相应的方法,如果有,则把这个变量和方法绑定上。
- 运行阶段:动态绑定
- 运行时,JVM会发现实际上在堆内存中指向的对象是哪个,然后就把该变量和实际指向的对象中的方法绑定上。
多态存在的三个必要条件:
- 继承:在多态中必须存在有继承关系的子类和父类。
- 重写:子类对父类中某些方法进行重新定义,在调用这些方法时就会调用子类的方法。
- 向上转型:在多态中需要将子类的引用赋给父类对象,只有这样该引用才能够具备技能调用父类的方法和子类的方法。
11.3.2 多态的实现
开头说了这么多Java多态的基本概念,那么到底用Java代码怎么体现出来呢?下面我们直接看代码。
//父类Animal
public class Animal {
public void eat() {
System.out.println("动物吃东西");
}
public void skill() {
System.out.println("动物有本领");
}
}
//Dog类
class Dog extends Animal {
public void eat() {
System.out.println("狗吃骨头");
}
public void skill() {
System.out.println("狗会看家");
}
}
//Cat类
class Cat extends Animal {
public void eat() {
System.out.println("猫吃鱼");
}
public void skill() {
System.out.println("猫会抓老鼠");
}
}
//测试类
public class AnimalTest {
public static void main(String[] args) {
Animal dog = new Dog();
dog.eat();
dog.skill();
Animal cat = new Cat();
cat.eat();
cat.skill();
}
}
运行结果:
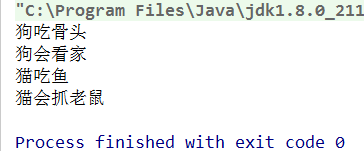
从上面的测试类来看,我们都是创建不同子类的对象,相同的父类引用,却表现出它们不同的特征,这就是体现了Java的多态性。
如果你认为这样还是不能体现多态的好处,我们在AnimalTest类中添加一个show()方法,来体会Java多态的好处。
如果Java中没有多态的特性会是什么样的,下面我们来看一下。
public class AnimalTest {
public static void main(String[] args) {
AnimalTest animalTest = new AnimalTest();
animalTest.show(new Animal());
animalTest.show(new Dog());
animalTest.show(new Cat());
}
public void show(Animal animal) {
animal.eat();
animal.skill();
}
public void show(Dog dog) {
dog.eat();
dog.skill();
}
public void show(Cat cat) {
cat.eat();
cat.skill();
}
}
可以发现在show()方法中的形参都传入了对象,而且重载3个相同的show()方法,如果我们有十个百个千个类需要传入方法,那么岂不是要重载上千个方法,可见这样代码的冗余非常的大,非常不利于代码的维护。
而如果有多态的话,只需写一个show()方法即可。
public class AnimalTest {
public static void main(String[] args) {
AnimalTest animalTest = new AnimalTest();
animalTest.show(new Animal());
animalTest.show(new Dog());
animalTest.show(new Cat());
}
public void show(Animal animal) {
animal.eat();
animal.skill();
}
}
从这里可以看出来多态的优点:
- 减少重复代码,使代码变得简洁(由继承保证)。
- 提高了代码的扩展性(由多态保证)。
但是也有缺点:子类单独定义的方法会丢失。后面的向上转型会介绍到。
多态其实是一种虚拟方法调用。在编译期间,只能调用父类中声明的方法,但是在运行期间,实际执行的是子类重写父类的方法。
总结为一句话:编译看左边,运行看右边(可能看到这句话会有点头晕,但是理解下面向上转型的概念就应该能够理解这句话了)。
12.3.3 向上转型
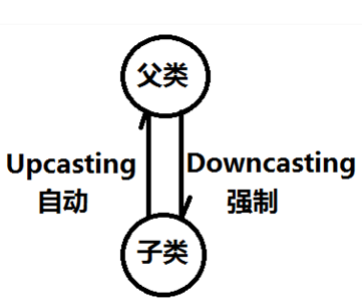
子类引用的对象转换为父类类型称为向上转型。通俗地说就是是将子类对象转为父类对象。此处父类对象也可以是接口。
我们用前面多态的例子举例,只是在子类中添加了它们自己的方法,父类中没有定义,如下。
public class Animal {
public void eat() {
System.out.println("动物吃东西");
}
public void skill() {
System.out.println("动物有本领");
}
}
class Dog extends Animal {
public void eat() {
System.out.println("狗吃骨头");
}
public void skill() {
System.out.println("狗会看家");
}
//新添加的方法
public void run() {
System.out.println("狗跑得快");
}
}
class Cat extends Animal {
public void eat() {
System.out.println("猫吃鱼");
}
public void skill() {
System.out.println("猫会抓老鼠");
}
//新添加的方法
public void life() {
System.out.println("猫有九条命");
}
}
//测试类
public class AnimalTest {
public static void main(String[] args) {
Animal dog = new Dog();//向上转型成Animal
dog.eat();
dog.skill();
//dog.run();//Cannot resolve method 'run()'
Animal cat = new Cat();//向上转型成Animal
cat.eat();
cat.skill();
//cat.life();//Cannot resolve method 'life()'
}
}
这里就产生了向上转型,Animal dog= new Dog();Animal cat= new Cat();将子类对象Dog和Cat转化为父类对象Animal。这个时候Animal这个引用调用的都是子类方法。再去调用子类单独的方法就会报错。如果非要调用也不是说不可以,那就要强转了。既然现在已经是父类了,那就强转为子类呗。
((Dog) dog).run();
((Cat) cat).life();
这样也可以调用。但是千万要注意,不能这样转,子类引用不能指向父类对象,Dog dog=(Dog)newAnimal();Cat cat = (Cat)new Animal();这样是绝对不行的。就好像儿子可以生出爸爸一样,这样不和常理。
如果在向上转型时,子类并没有重写父类的方法,那么调用的就是父类中的方法。
👏到此为止,也可以证明前面说的一个结论:向上转型会使子类单独定义的方法会丢失。
12.3.4 向下转型
与向上转型相对应的就是向下转型了。向下转型是把父类对象转为子类对象。这里我们就会想到,即然子类向上转型为了父类,而子类又继承了父类的属性和方法,为什么还要将父类转型为子类。是因为对象的多态性只适用于方法,而不适用于属性。所以当我们在使用多态的时候,就不能调用子类中的属性和特有的方法了,所以需要向下转型。(内存中实际上是加载了子类所特有的属性和方法,但是由于变量声明的是父类类型,导致在编译时只能调用父类中声明的属性和方法,子类特有的属性和方法不能调用)
我们还是使用向上转型那里的代码为例(Anima、Dog、Cat类):
public class AnimalTest {
public static void main(String[] args) {
Animal dog = new Dog();//Dog向上转型成Animal
Dog dog1 = (Dog) dog;//向下转型为Dog
dog1.eat();
dog1.skill();
Cat cat = (Cat) dog;//java.lang.ClassCastException: com.thr.java2.Dog cannot be cast to com.thr.java2.Cat
cat.eat();
cat.skill();
}
}
运行结果:
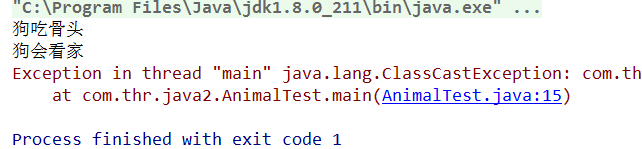
我们可以发现向下转型为Dog没有报错,但是转型为Cat却报错了,这个倒不难理解,因为开始向上转型本来是Dog,然后再变回Dog,总不能Dog变成Cat吧。所以会报类型转换错误。
向下转型注意事项
- 向下转型的前提是父类对象指向的是子类对象(也就是说,在向下转型之前,它得先向上转型)
- 向下转型只能转型为本类对象(猫是不能变成狗的)。
向下转型我们一般会使用 instanceof 关键字来判断:
使用方法:a instanceof A:判断对象a是否为对象A的实例,如果是,返回true,如果不是,则返回false。
public class AnimalTest {
public static void main(String[] args) {
AnimalTest test = new AnimalTest();
test.show(new Animal());
test.show(new Dog());
test.show(new Cat());
}
public void show(Animal animal) {
if (animal instanceof Dog) {
Dog dog = (Dog) animal;
dog.eat();
dog.skill();
dog.run();
}
}
}
运行结果:
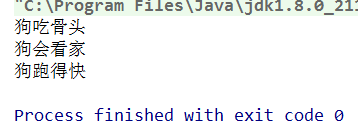
我们可以发现测试方法调用三次show方法,分别传入了Animal、Dog、Cat对象,由于show()方法只判断了Dog是否是该对象,所以Dog返回了true,输出了Dog的信息,而其他的返回了false,则没有输出然后信息。
12.3.5 经典案例
Java的多态和转型都了解以后,现在趁热打铁,来点网上多态非常经典的例题:来源:Java多态性理解,好处及精典实例
public class A {
public String show(D obj) {
return ("A and D");
}
public String show(A obj) {
return ("A and A");
}
}
public class B extends A {
public String show(B obj) {
return ("B and B");
}
public String show(A obj) {
return ("B and A");
}
}
public class C extends B {
}
public class D extends B {
}
public class Test {
public static void main(String[] args) {
A a1 = new A();
A a2 = new B();
B b = new B();
C c = new C();
D d = new D();
System.out.println("1--" + a1.show(b));
System.out.println("2--" + a1.show(c));
System.out.println("3--" + a1.show(d));
System.out.println("4--" + a2.show(b));
System.out.println("5--" + a2.show(c));
System.out.println("6--" + a2.show(d));
System.out.println("7--" + b.show(b));
System.out.println("8--" + b.show(c));
System.out.println("9--" + b.show(d));
}
}
运行的结果:

前面3个强行发现还能得到答案,但是从第4个之后就有点头晕。
我们来慢慢分析第4个:首先是子类B类向上转型为父类A,而子类B有重写了父类A中的show(A obj)方法,所以a2变量能调用的只有父类A类中的show(D obj)方法和子类B中的show(A obj)方法(此处不能调用子类B中的show(B obj)方法,因为子类B类向上转型为父类A会使子类单独定义的方法会丢失) ,而B是继承自A类的,D继承自B类,所以不可能调用show(D obj)方法,所以结果是4--B and A;剩下的依次类推。
当父类对象变量引用子类对象时,被引用对象的类型决定了调用谁的成员方法,引用变量类型决定可调用的方法。如果子类中没有覆盖该方法,那么会去父类中寻找。但是它仍然要根据继承链中方法调用的优先级来确认方法,该优先级为:this.show(O)、super.show(O)、this.show((super)O)、super.show((super)O)。
12.3.6 总结
- 通过上面对多态的学习,可以小结一下概念:
- Java多态也可以用一句话表示:父类的引用指向子类的对象。
- 运行时多态的前提:继承,重写,向上转型。
- 多态能够减少重复代码,使代码变得简洁;提高了代码的扩展性。
- 多态其实是一种虚拟方法调用。归结为一句话:编译看左边,运行看右边。
- 向上转型就是是将子类对象转为父类对象。
- 继承链中对象方法的调用的优先级:this.show(O)、super.show(O)、this.show((super)O)、super.show((super)O)。
13、抽象类和接口
13.1 本章前言
之前介绍了Java的三大特征有封装、继承、多态,这样说其实我们少讲了一个,那就是抽象性,在平时的教程中认为只有三种特征,因为它们把抽象放到继承里了,认为抽象类是继承的一种,这也使抽象性是否是Java的一大特征具有争议。而Java语言中对抽象概念定义的机制就是抽象类和接口,正由于它们才赋予Java强大的面向对象的功能。他们两者之间对抽象概念的支持有很大的相似,但是也有区别。所以接下来我们就来学习它们两的使用和区别。(如果在平时面试时遇到问Java有几大特征,我们就说封装、继承、多态这三特征即可)。
13.2 抽象类
在Java面向对象的概念中,我们知道所有的对象都是通过类来描绘的,类是对象的抽象,而对象是类的具体实例。类是抽象的,不占用内存,而对象是具体的,会占用内存空间。但是有时候并不是所有的类都是用来描绘对象的,如果一个类中没有包含足够的信息来描绘一个具体的对象,这样的类就是抽象类。
抽象类是用来描述一种类型应该具备的基本特征与功能,而具体如何去完成这些行为则由其子类通过方法重写来完成。简单举个例子:比如我们创建一个Animal类,然后用这个类来创建一个动物对象,但是我们并不知道这具体是哪一种动物,只知道动物的一些基本特征和行为,比如有吃喝拉撒睡等,此时这个Animal对象是抽象的。所以我们需要一个具体的类来描述该动物,如用狗、猫来对它进行特定的描述,才知道它具体是什么动物。在描述的同时,狗和猫的特征也是不一样的,比如猫喜欢吃鱼,而狗喜欢吃骨头,所以此时不应该在动物类中将这些特征体现出来,而是要在Animal类的子类中给出一个声明即可,也就是重写父类中的方法。
在Java中用abstract关键字来修饰的类就是抽象类,当然这个关键字也可以用来修饰方法,表明该方法是抽象方法。
『以下是抽象类的一些特点(非常重要!!!)』:
- 抽象类不能实例化,必须要由继承它的子类来创建实例。
- 抽象方法只有方法的声明,没有方法体。抽象类中的抽象方法必须要在子类中重写。
- 抽象类中既可以有抽象方法,也可以有普通方法,普通方法可不用重写。
- 抽象类中不一定包含抽象方法,但是有抽象方法的类必定是抽象类。
- 抽象类中可以有构造方法,是供子类创建对象时,初始化父类成员变量使用的。
- 抽象类的子类,必须重写抽象父类中所有的抽象方法,否则,编译无法通过而报错。除非该子类也是抽象类。
- 只要包含一个抽象方法的类,该类必须要定义成抽象类。
- abstract不能用来修饰属性、构造器等结构。
- abstract不能与final并列修饰同一个类。
- abstract不能与private、static、final或native并列修饰同一个方法。
- 抽象类:被
abstract所修饰的类。 - 抽象方法 :被
abstract所修饰的方法,它是没有方法体的方法。
①、抽象类的语法格式:
【权限修饰符】 abstract class 类名{
}
【权限修饰符】 abstract class 类名 extends 父类{
}
②、抽象方法的语法格式:
【其他修饰符】 abstract 返回值类型 方法名(【形参列表】);
注意:抽象方法没有方法体
③、抽象类的简单示例,代码如下所示:
public abstract class Animal {
//可以有属性
String name;
Integer age;
//抽象方法
public abstract void eat();
//普通方法
public void sleep() {
System.out.println("动物需要睡觉...");
}
//抽象类可以有构造器
public Animal() {
}
}
class Cat extends Animal {
@Override
public void eat() {
System.out.println("猫喜欢吃鱼...");
}
@Override
public void sleep() {
System.out.println("猫需要睡觉...");
}
}
class Dog extends Animal {
@Override
public void eat() {
System.out.println("狗喜欢吃骨头...");
}
@Override
public void sleep() {
System.out.println("狗需要睡觉...");
}
}
//测试类
class Main{
public static void main(String[] args) {
Animal a1 = new Dog();
a1.eat();
a1.sleep();
Animal a2 = new Cat();
a2.eat();
a2.sleep();
}
}
13.3 接口
在我们的生活中,也常常会接触到接口这个词,比如我们的电脑边上提供了USB接口插槽,只要其它设备也是遵循USB接口的规范,那么就可以互联,并正常通信。至于这个电脑、以及其他设备是哪个厂家制造的,内部是如何实现的,我们都无需关心。
这种设计是将规范和实现分离,这也正是Java接口的好处。Java的软件系统会有很多模块组成,那么各个模块之间也应该采用这种面向接口的低耦合设计,为系统提供更好的可扩展性和可维护性。
接口的本质是契约,标准规范 ,准确来说接口定义的就是一种规范。体现了现实世界中“如果你是/要...则必须能...”的思想。
- 例如:你能不能用USB接口进行连接,或是否具备USB通信功能,就看你是否遵循USB接口规范
- 例如:Java程序是否能够连接使用某种数据库产品,那么要看该数据库产品有没有实现Java设计的JDBC规范
接口的英文名称是 interface。接口是属于和类类型同等级别的结构,但是它不是类,却和类类型有着共同点,在接口中可以含有变量、方法。接口使用interface这个关键字来进行修饰。
接口:用interface关键字修饰的类。
接口中的变量:接口中的变量会被隐式地指定为public static final变量,并且只能是public static final变量,用private修饰会报编译错误。
接口中的方法:接口中的方法会被隐式地指定为public abstract方法,且只能是public abstract方法,如果用其他关键字,如private、protected、static、 final等修饰都会导致报编译错误。
接口的实现:使用implement关键字。
也就是说接口中的变量全都是常量,方法都是抽象方法(JDK1.8以前)。从这里可以隐约看出接口和抽象类的区别,接口是一种极度抽象的类型,它比抽象类更加“抽象”。
Java8中的接口:在jdk8之前,interface之中可以定义变量和方法,变量必须是public、static、final的,方法必须是public、abstract的。在jdk8及以后,允许我们在接口中定义static方法和default方法。
- default方法:必须用
default关键字修饰,而且可以被实现类重写,它只能通过接口实现类的对象来调用。 - static方法:只能通过接口名调用,不可以通过实现类的类名或者实现类的对象调用。
Java9中的接口:jdk9后接口中允许定义private的方法,用于服务于本接口其他方法。
①、接口的声明格式:
【修饰符】 interface 接口名{
//接口的成员
[public static final] 数据类型 变量名;//静态常量,默认修饰符public static final
[public abstract] 返回值类型 方法名(形参列表);//抽象方法,默认自带修饰符public abstract
default 方法名(形参列表){}//jdk8后,缺省方法,扩展方法,默认public修饰,实现类可以自行选择是否实现此方法
static void testStatic(){}//jdk8后,默认public修饰,通常定义服务于此接口的实现类的一些工具类方法
private void testPrivate(){}//jdk9后出现,服务于本接口其他方法。
}
接口的实现格式(接口可以多实现,类只能单继承):
修饰符 class 实现类名 implement 接口{
//重写接口中的方法
public 返回值类型 方法名(形参列表){
方法体
}
}
修饰符 class 实现类名 extends 父类 implements 接口名1,接口名2,...{
//重写接口和抽象类中的抽象方法
}
接口的一些特点(都非常重要!!!):接口定义的是多个类共同的公共行为规范,这些行为规范是与外部交流的通道,这就意味着接口里通常是定义一组公共方法。
- 接口没有构造方法,不能创建对象。
- 成员变量默认自带修饰符public static final,即为静态常量。
- 抽象方法默认自带修饰符public abstract(jdk8之前版本接口中方法只能是抽象方法)
- 接口是用来被实现的,其实现类必须重写它的所有抽象方法,除非实现类是个抽象类
- 接口可以多实现,一个类可以同时实现多个接口
- 接口可以继承接口,接口之间支持多继承
- 在JDK1.8时,接口中允许声明默认方法和静态方法:
- 公共的默认的方法:其中public 可以省略,建议保留,但是default不能省略
- 公共的静态的方法:其中public 可以省略,建议保留,但是static不能省略
- 在JDK1.9时,接口又增加了私有方法,用于服务于本接口其他方法
- 如果子类(或实现类)继承的父类和实现的接口中声明了同名的成员变量,那么在调用的时候会报错,模糊不清。
- 如果子类(或实现类)继承的父类和实现的接口中声明了同名同参数的方法,那么子类在没有重写该方法的情况下,默认调用父类中的同名同参数的方法。-->类优先原则。
- 如果实现类实现了多个接口(没有继承),而多个接口中定义了同名同参数的默认方法,那么在实现类没有重写此方法的情况下,会报错。-->接口冲突。这就需要我们在实现类中重写此方法。
- 如果需要调用父类中方法或接口中默认方法,父类使用
super.方法名,接口使用接口名.super.方法名。
这里讲的非常的细,其实我们只需要了解即可。
接口的简单举例,代码如下:
/**
* 定义接口
*/
public interface InterfaceDemo {
//接口成员变量(前面默认加了public static final)
int MAX_VALUES = 1000;
//接口抽象方法(前面默认加了public abstract)
void abstractMethod();
//接口默认方法(必须加default)
default void defaultMethod() {
System.out.println("接口default方法...");
}
//接口静态方法
static void staticMethod() {
System.out.println("接口static方法...");
}
}
//定义接口的实现类
class InterfaceImpl implements InterfaceDemo {
@Override
public void abstractMethod() {
System.out.println("重写接口中的abstract方法...");
}
@Override
public void defaultMethod() {
System.out.println("重写接口中的default方法...");
}
}
//定义测试类
class Main {
public static void main(String[] args) {
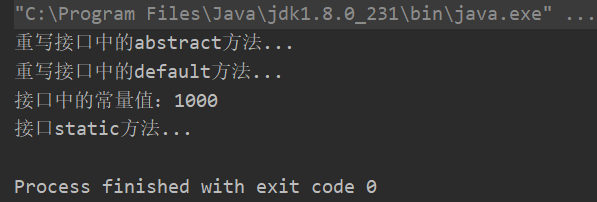
InterfaceImpl ifi = new InterfaceImpl();
ifi.abstractMethod();
ifi.defaultMethod();
System.out.println("接口中的常量值:" + InterfaceDemo.MAX_VALUES);
InterfaceDemo.staticMethod();
}
}
运行结果如下所示:
13.4 抽象类与接口的对比
抽象类和接口的主要区别:
- 从设计层面上:抽象类是对类的抽象,是一种模板设计,所以抽象类常用作当做模板类使用。接口是行为的抽象,是一种行为的规范。
- 从应用层面上:接口更多的是在系统架构设计方法发挥作用,主要用于定义模块之间的通信契约。而抽象类在代码实现方面发挥作用,可以实现代码的重用。
| 特点 | 抽象类 | 接口 |
|---|---|---|
| 继承限制 | 单继承 | 一个类可以实现多个接口,而且接口也可以继承多个接口 |
| 成员变量 | 有 | 只能是公共的静态的常量【public static final】(不写默认会加上) |
| 构造器 | 有 | 无 |
| 代码块 | 可以有 | 无 |
| 抽象方法 | 可以有 | 只能是公共的抽象方法【public abstract】 |
| 静态方法 | 可以有 | JDK1.8之后可以有公共的静态方法 |
| 默认方法 | 可以有 | JDK1.8之后可以有公共的默认方法,必须用default修饰 |
| 私有方法 | 可以有 | JDK1.9之后可以有私有方法 |
| 访问修饰符 | 抽象方法可以有public、protected和default | 接口方法默认修饰符是public,不可以使用其它修饰符 |
| 相同点 | 都不能直接实例化 | 都不能直接实例化 |
14、UML-类图
14.1 UML统一建模语言简介
在软件开发流程中,一般应先对软件开发的过程进行建模,把要做什么功能、如何去实现、达到什么样的程度这些基本问题分析清楚了,才去写代码实现。建模是对现实按照一定规则进行简化,但应该体现出现实事物的特点。通过软件建模可以把现实世界中的问题转化到计算机世界进行分析和实现,软件建模的实现过程就是需求-建模-编码的一个过程。
UML统一建模语言,United Modeling Language,是一种面向对象的可视化建模语言,通过图形符号描述现实系统的组成,通过建立图形之间的关系来描述整个系统模型。
14.2 类图
类图是面向对象系统建模中最常用的一种UML图,主要用来表示类与类之间的关系,包括泛化关系、关联关系、依赖关系和实现关系。
类图由三部分组成:类名、属性和方法。

- 表示private
+ 表示public
# 表示protected
- 属性表示为 属性名:类型
- 方法表示为 方法名(参数类型):返回值类型
14.3 类与类之间的关系
在面向对象设计模式中,类与类之间主要有6种关系,他们分别是:依赖、关联、聚合、组合、继承、实现。他们的耦合度依次增强。
1. 依赖(Dependence)
依赖关系的定义为:对于两个相对独立的对象,当一个对象负责构造另一个对象的实例,或者依赖另一个对象的服务时,这两个对象之间主要体现为依赖关系。定义比较晦涩难懂,但在java中的表现还是比较直观的:类A当中使用了类B,其中类B是作为类A的方法参数、方法中的局部变量、或者静态方法调用。类上面的图例中:People类依赖于Book类和Food类,Book类和Food类是作为类中方法的参数形式出现在People类中的。
也就是说,一个类A使用了另一个类B,表现在代码层面为类B作为参数被A在某个方法中使用。
2.关联(Association)
单向关联:
双向关联:
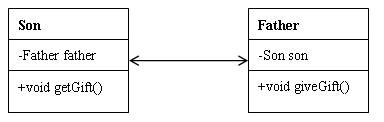
对于两个相对独立的对象,当一个对象的实例与另一个对象的一些特定实例存在固定的对应关系时,这两个对象之间为关联关系。关联关系分为单向关联和双向关联。在java中,单向关联表现为:类A当中使用了类B,其中类B是作为类A的成员变量;双向关联表现为:类A当中使用了类B作为成员变量,同时类B中也使用了类A作为成员变量。
也就是说,关系一般是长期的,平等的,可以是单向的也可以是双向的,变现在代码层为被关联的B以类属性的形式出现在关联类A中,也可能是关联类A引用了一个类型为被关联类B的全局变量。
3.聚合(Aggregation)
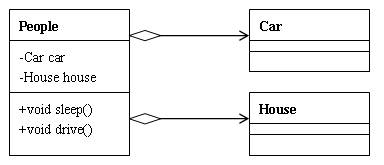
聚合关系是关联关系的一种,耦合度强于关联,他们的代码表现是相同的,仅仅是在语义上有所区别:关联关系的对象间是相互独立的,而聚合关系的对象之间存在着包容关系,他们之间是“整体-个体”的相互关系。也就是说,“has-a”
4.组合(Composition)
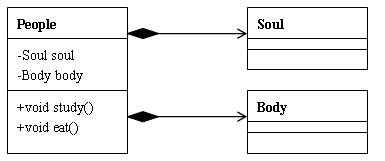
相比于聚合,组合是一种耦合度更强的关联关系。存在组合关系的类表示“整体-部分”的关联关系,“整体”负责“部分”的生命周期,他们之间是共生共死的;并且“部分”单独存在时没有任何意义。
也就是说,“contains-a”
5.继承(Generalization)
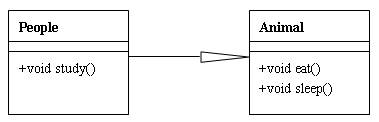
继承表示类与类(或者接口与接口)之间的父子关系。在java中,用关键字extends表示继承关系。UML图例中,继承关系用实线+空心箭头表示,箭头指向父类。
6.实现(Implementation)
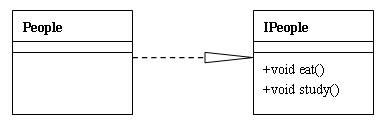
表示一个类实现一个或多个接口的方法。接口定义好操作的集合,由实现类去完成接口的具体操作。在java中使用implements表示。UML图例中,实现关系用虚线+空心箭头表示,箭头指向接口。
14.4 Java类中的 is-a、is-like-a、has-a
has-a
关联关系:聚合
凡是能够使用 has a 来描述的,统一以属性的方式存在
例如 Customer has a FoodMenu(顾客有一个食物菜单)
is-a
继承关系:继承
凡是满足is a的表达式都可以设置为继承
例如 Cat is a Animal(猫是一种动物)
is-like-a
实现关系:接口
满足 is like a 的表达式也是一种继承
实现关系通常是:类实现接口
但是在继承中,仅覆盖了父类方法即为Is-a;若在覆盖父类方法基础上有新增方法,则为Is-like-a。
15、Object类
Object类是Javajava.lang包下的核心类,是类层次结构的根
- Object 类是所有 Java 类的根基类
- 如果在类的声明中未使用 extends 关键字指明其基类,则默认基类为 Object 类
Object 类的常用方法
| 方法 | 说明 |
|---|---|
Class getClass() |
返回一个对象运行时的实例类 |
boolean equals(Object) |
比较两对象是否相等 |
int hashCode() |
返回该对象的散列码值 |
String toString() |
返回该对象的字符串表示 |
void finalize() |
当垃圾回收器确定不存在对该对象的更多引用时,对象垃圾回收器调用该方法 |
Object clone() |
创建与该对象的类相同的新对象 |
void notify() |
激活等待在该对象的监视器上的一个线程 |
void notifyAll() |
激活等待在该对象的监视器上的全部线程 |
void wait() |
在其他线程调用此对象的 notify() 方法或 notifyAll() 方法前,导致当前线程等待 |
其中,toString()、equals() 方法和 getClass() 方法在 Java 程序中比较常用。
15.1 toString()
返回该对象的字符串表示。通常 toString 方法会返回一个“以文本方式表示”此对象的字符串,Object 类的 toString 方法返回一个字符串,该字符串由类名加@标记和此对象哈希码的无符号十六进制表示组成,Object 类 toString 源代码如下:
getClass().getName() + '@' + Integer.toHexString(hashCode())
我们一般会重写此方法。
15.2 finalize
垃圾回收器(Garbage Collection),也叫 GC,垃圾回收器主要有以下特点:
- 当对象不再被程序使用时,垃圾回收器将会将其回收
- 垃圾回收是在后台运行的,我们无法命令垃圾回收器马上回收资源,但是我们可以告诉他,尽快回收资源(System.gc 和 Runtime.getRuntime().gc())
- 垃圾回收器在回收某个对象的时候,首先会调用该对象的
finalize方法 - GC 主要针对堆内存
- 单例模式的缺点
当垃圾收集器将要收集某个垃圾对象时将会调用 finalize,建议不要使用此方法,因为此方法的运行时间不确定,如果执行此方法出现错误,程序不会报告,仍然继续运行
15.3 ==与 equals 方法
15.3.1 前言
我们在学习Java的时候,看到==、equals()就认为比较简单,随便看了一眼就过了,其实你并没有深入去了解二者的区别。这个问题在面试的时候出现的频率比较高,而且据统计有85%的人理直气壮的答错。所以理解==、equals()的区别很有必要。·
15.3.2 ==运算符
==可以使用在基本数据类型变量和引用数据类型变量中。
- 如果比较的是基本数据类型变量:比较两个变量的数值是否相等(数据类型不一定要相等,只看值,因为会类型自动提升!);
- 如果比较的是引用数据类型变量:比较两个对象的地址值是否相等。
下面看一下案例:
public class Test {
public static void main(String[] args) {
int a=10;
int b=10;
double c=10.00;
System.out.println(a==b);//true
System.out.println(a==c);//true
String str1="123";
String str2="123";
System.out.println(str1==str2);//true
String str3=new String("123");
String str4=new String("123");
System.out.println(str3==str4);//false
}
}
结果为:true、true、true、false。前面两个为true的结果非常容易理解,但是第三个为true,第四个为false,而它们都是String引用类型,为什么不一样呢?
分析原因:
对于8种基本数据类型(byte,short,char,int,float,double,long,boolean)的值而言,它们都是存储在常量池中,而str1、str2的字符串 "123" 也同样在常量池中,而一个常量只会对应一个地址,因此不管是再多的数据都只会存储一个地址,所以所有他们的引用都是指向的同一块地址,因此基本数据类型和String常量是可以直接通过==来直接比较的。
而str3、str4分别在堆内存中创建的两个对象,地址值自然就不相同了。
15.3.3 equals()方法
equals()是一个方法,不是数据类型,所以他只适用于引用数据类型。
该方法主要用于比较两个对象的内容是否相等。其实这样的说法是不准确的。首先我们来看看在Object类中定义的equals方法:

可以看到,在Object类型的equals方法是直接通过==来比较的,和==是没有任何区别的。
那么为什么又要说equlas和==的区别呢?是因为所有的类都直接或间接地继承自java.lang.Object类,因此我们可以通过重写equals方法来实现我们自己想要的比较方法。
我们创建一个Person类来测试,先不重写父类的equals()方法:
public class Test {
public static void main(String[] args) {
Person person1=new Person("菜徐坤",21);
Person person2=new Person("菜徐坤",21);
System.out.println(person1.equals(person2));
}
}
class Person{
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
}
毫无疑问,输出的结果肯定是false,因为没有重写父类的equals()方法,从而调用了父类的,而父类的equals()方法是用==判断的。
然后我们重写父类的equals()方法:
public class Test {
public static void main(String[] args) {
Person person1=new Person("菜徐坤",21);
Person person2=new Person("菜徐坤",21);
System.out.println(person1.equals(person2));
}
}
class Person{
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
if (age != person.age) return false;
return name != null ? name.equals(person.name) : person.name == null;
}
}
重写之后输出就是true了,因为比较的对象的内容。
实际上,像String、Date、Math、File、包装类等大部分类都重写了Object的equals()方法。重写以后,就不是比较两个对象的地址值是否相同了,而是比较两个对象里面的内容是否相等。
下面我们来看一下String类重写的equals()方法:
/* @see #compareTo(String)
* @see #equalsIgnoreCase(String)
*/
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
可以看到重写的方法内用char[] 数组进行一个一个的比较,并不是用==进行比较,。
我们在重写equals()方法时必须要遵循如下几个规则:
- 自反性:x.equals(x)必须返回是true。
- 对称性:如果x.equals(y),返回时true,那么y.equals(x)也必定返回为true。
- 传递性:如果x.equals(y)返回的true,而且y.equals(z)返回是true,那么z.equals(x)返回的也是true。
- 一致性:如果x.equals(y)返回是true,只要x和y的内容一直不变,不管重复x.equals(y)多少次,返回都是true
- 任何情况下,x.equals(null),永远返回是false,x.equals(与x是不同类型的对象),也永远返回是false。
对于上面几个规则,我们在使用的过程中最好遵守,避免出现意想不到的错误。
15.3.4 小结
- ==比较的数值是否相等和对象地址是否相等。
- equals()方法比较的对象内容是否相等(前提是重写了父类的方法)。
- 一般除了自定义的类除外,大部分能够使用的类都重写了equals()方法。
16、内部类
16.1 内部类的概念
内部类顾名思义:将一个类定义在另一个类里面或者一个方法里面,这样的类称为内部类。对于很多Java初学者来说,内部类学起来真的是一头雾水,根本理解不清楚是个什么东西,包括我自己(我太菜了!哈哈),所以接下来我要好好地来研究一下。
我们来看下内部类的定义格式;
public class OuterClass {
//code
class InnerClass{
//code
}
}
这里的InnerClass就是一个内部类。无论在我们的学习中还是工作中,内部类用到的地方真的不是很多,一般都出现在源码中,但是我们还是要搞懂内部类,因为后面对我们阅读源码非常有帮助。而且随着后面我们编程能力的提高,自然而然会领悟到它的魅力所在,它能够让我们设计出更加优雅的程序结构。在使用内部类之前我们需要明白为什么要使用内部类,内部类能够为我们带来什么样的好处。
在《Think in java》中有这样一句话:使用内部类最吸引人的原因是:每个内部类都能独立地继承一个(接口的)实现,所以无论外围类是否已经继承了某个(接口的)实现,对于内部类都没有影响。
也就是说内部类拥有类的基本特征(可以继承父类,实现接口)。在我们程序设计中有时候会存在一些使用接口很难解决的问题,这个时候我们可以利用内部类提供的、可以继承多个具体的或者抽象的类的能力来解决这些程序设计问题。可以这样说,接口只是解决了部分问题,而内部类使得多重继承的解决方案变得更加完整。(注:内部类可以嵌套内部类,但是这极大的破换了代码的构,这里不推荐使用)
那我们来看一下使用内部类如何进行多继承,接口多继承就不举例了,因为接口本身就可以实现多继承。
class Father{
public String handsome(){
return "爸爸很帅气";
}
}
class Mother{
public String beautiful(){
return "妈妈很漂亮";
}
}
class Son{
//内部类继承了Father类
class MyFather extends Father{
//重写父类方法
public String handsome(){
return "我遗传了爸爸的帅气";
}
}
//内部类继承了Mother类
class MyMother extends Mother{
//重写父类方法
public String beautiful(){
return "我遗传了妈妈的漂亮";
}
}
}
public class Test {
public static void main(String[] args) {
Son son=new Son();
Son.MyFather myFather=son.new MyFather();
System.out.println(myFather.handsome());
Son.MyMother myMother=son.new MyMother();
System.out.println(myMother.beautiful());
}
}
运行结果:

从上面的举例代码可以看出,两个内部类分别继承了Father、Mother类,并且重写了父类的方法,这是内部类最重要的特性:内部类可以继承一个与外部类无关的类,保证了内部类的独立性,正是基于这一点,多重继承才会成为可能。
可以发现在创建内部类实例的时候,使用了.new这个特征,与以往我们创建实例不太相同。.new可以这样理解:根据外部类来创建内部类的对象实例。
Java中内部类可分为四种:成员内部类、局部内部类、匿名内部类、静态内部类。下面我们逐一介绍这四种内部类:
16.2 成员内部类
成员内部类是定义在类中的类。我们可以把成员内部类看成是外部类的一个成员,所以成员内部类可以无条件访问外部类的所有成员属性和成员方法,包括private成员和静态成员。但是外部类要访问内部类的成员属性和方法则需要通过内部类实例来访问。当成员内部类拥有和外部类同名的成员变量或者方法时,会优先访问的是成员内部类的成员,但是我们可以使用 .this(如果有继承可以使用super)来访问外部类的变量和方法。
在成员内部类中要注意两点:
- 成员内部类中不能存在任何static的变量和方法;
- 成员内部类是依附于外部类的,所以只有先创建了外围类才能够创建内部类(静态内部类除外)。
class OuterClass {
private String outerName = "tang_hao_outer";
private int outerAge = 22;
public OuterClass() {
}
// 成员方法
public void outerMethod() {
System.out.println("我是外部类的outerMethod方法");
}
// 外部类静态方法
public static void outerStaticMethod() {
System.out.println("我是外部类的outerStaticMethod静态方法");
}
// 定义返回内部类实例的方法,推荐使用该方法来换取内部类实例
public InnerClass getInnerClassInstance() {
return new InnerClass();
}
// 内部类
class InnerClass {
private String innerName = "tang_hao_Inner";
private int innerAge = 21;
public InnerClass() {
}
public void show() {
// 当名字和外部类一样时,默认调用内部类的成员属性
System.out.println("内部类变量:" + innerName);
System.out.println("内部类变量:" + innerAge);
// 当名字和外部类一样时,可以使用 。this来调用外部类属性
System.out.println("外部类变量:" + OuterClass.this.outerName);
System.out.println("外部类变量:" + OuterClass.this.outerAge);
// 访问外部类的方法
outerMethod();
outerStaticMethod();
}
}
}
public class Test {
public static void main(String[] args) {
// 普通方法创建实例
OuterClass outerClass = new OuterClass();
OuterClass.InnerClass innerClass = outerClass.new InnerClass();
innerClass.show();
System.out.println("-------------------");
// 调用外部类的getInnerClassInstance来创建内部类实例
OuterClass.InnerClass innerClassInstance = outerClass.getInnerClassInstance();
innerClassInstance.show();
}
}
运行结果:
从上面示例中,当内部类和外部类的变量和方法一样时,我们用了 .this来调用外部类的属性(静态除外,因为静态随类加载而加载,优于对象的创建),它可以理解为:产生一个指向外部类的引用。还有如果该内部类的构造函数无参数,强烈推荐使用类似getInnerClassInstance()这样的方法来获取成员内部类的实例对象。
16.3 局部内部类
局部内部类是定义在一个方法或者一个作用域里面的类,它和成员内部类的区别在于局部内部类的访问仅限于方法内或者该作用域内。注意:局部内部类就像是方法里面的一个局部变量一样,是不能有 public、protected、private 以及 static 修饰符的。
局部内部类一般都用于返回一个类或实现接口的实例。我们用Comparable接口为例:
class OuterClass {
// 创建返回一Comparable接口实例的方法
public Comparable getComparable() {
// 创建一个实现Comparable接口的内部类:局部内部类
class MyComparable implements Comparable {
@Override
public int compareTo(Object o) {
return 0;
}
}
// 返回实现Comparable接口的实例
return new MyComparable();
}
}
当我们创建外部类的实例调用getComparable()方法时,就可以轻松获取实现Comparable接口的实例了。
注意:局部内部类如果想用方法传入形参,该形参必须使用final声明(JDK8形参变为隐式final声明)。上面的例子如果是getComparable(Object o),那么这个形参前面就隐式加了final关键字。
16.4 匿名内部类
匿名内部类就是没有名字的内部类。它与局部内部类很相似,不同的是它没有类名,如果某个局部类你只需要用一次,那么你就可以使用匿名内部类。匿名内部类可以使你的代码更加简洁,你可以在定义一个类的同时对其进行实例化。
//创建一个接口
interface IPerson {
public void eat();
public void sleep();
}
public class OuterClass {
// 这里注意,局部内部类如果需要通过方法传入参数,该形参必须使用final声明(JDK8形参变为隐式final声明)
// 我用的JDK8,所以这里没有显式的加final,但是JVM会自动加
public static IPerson getInnerClassInstance(String eat, String sleep) {
return new IPerson() {
@Override
public void eat() {
System.out.println(eat);
}
@Override
public void sleep() {
System.out.println(sleep);
}
};// 这个分号要注意
}
public static void main(String[] args) {
IPerson person = OuterClass.getInnerClassInstance("吃饭", "睡觉");
person.eat();
person.sleep();
}
}
运行结果:吃饭、睡觉
我们知道在抽象类和接口中是不能被实例化的,但是在匿名内部类中我们却看见new了一个IPerson接口,这是怎么回事。这是因为匿名内部类是直接使用new来生成一个对象的引用,而在new对象时,系统会自动给抽象类或接口添加一个它们的实现类,当然这个引用是隐式的,我们看不见。我们自己拆分出来理解一下,注意这里是自己想出来的,运行时并不会有这些类存在:
class Farmer implements IPerson {
@Override
public void eat() {
System.out.println("农民吃饭");
}
@Override
public void sleep() {
System.out.println("农民睡觉");
}
}
一般我们创建抽象类或接口的实例是这样的:IPerson iPerson = new Farmer();这个可以叫做是非匿名对象非匿名类,而我们创建的是匿名内部类,所以这个实现类不能有名字,所以只好叫父类的名字,所以就看到了前面直接new了一个接口,其实是隐式的创建了实现类的对象。(不知道这样讲对不对,鄙人菜鸟一个,如果有什么不对的或理解错误的地方,欢迎指出,虚心接受!)
匿名内部类最常用的情况就是在多线程的实现上,因为要实现多线程必须继承Thread类或是继承Runnable接口。
在使用匿名内部类的过程中,我们需要注意如下几点:
- 使用匿名内部类时,我们必须是继承一个类或者实现一个接口,但是两者不可兼得,同时也只能继承一个类或者实现一个接口。
- 匿名内部类中是不能定义构造函数的。
- 匿名内部类中不能存在任何的静态成员变量和静态方法。
- 匿名内部类为局部内部类,所以局部内部类的所有限制同样对匿名内部类生效。
- 匿名内部类不能是抽象的,它必须要实现继承的类或者实现的接口的所有抽象方法。
16.5 静态内部类
静态内部类是指用static修饰的内部类。在前面Static关键字中提到了static关键字可以修饰内部类。我们知道普通类是不允许声明为静态的,只要内部类才可以,被static修饰的内部类它不依赖于外部类的实例。这是因为非静态内部类在编译完成之后会隐含地保存着一个引用,该引用是指向创建它的外部类。
static修饰内部类注意几点:
- 静态内部类可以不依赖于外部类的实例,但是要注意它们创建对象的区别。
- 静态内部类只能访问外部类的静态变量和静态方法,否则编译会报错。
- 非静态内部类中可以调用外部类的任何成员,不管是静态的还是非静态的。
- 如果需要调用内部类的非静态方法,必须先new一个OuterClass的对象outerClass,然后通过outer。new生成内部类的对象,而static内部类则不需要。
简单举例:
class OuterClass {
// 静态变量
private static int static_num = 66;
// 非静态变量
private int num = 99;
// 静态内部类
static class InnerStaticClass {
public void print() {
// 静态内部类只能访问外部类的静态变量和静态方法
System.out.println("静态内部类方法print()==" + static_num);
staticShow();
}
}
// 非静态内部类
class InnerClass {
public void display() {
// 非静态内部类中可以调用外部类的任何成员,不管是静态的还是非静态的
System.out.println("外部类静态变量==" + static_num);
System.out.println("外部类普通变量==" + num);
show();
System.out.println("非静态内部类方法display()==" + num);
}
}
public void show() {
System.out.println("外部类非静态show()方法");
}
public static void staticShow() {
System.out.println("外部类静态staticShow()方法");
}
}
public class Test {
public static void main(String[] args) {
// static对象实例
OuterClass.InnerStaticClass staticClass = new OuterClass.InnerStaticClass();
staticClass.print();
// 非static对象实例
OuterClass outerClass = new OuterClass();
OuterClass.InnerClass innerClass = outerClass.new InnerClass();
innerClass.display();
}
}
运行结果:

从上面的例子我们可以看到静态内部类和非静态内部类的区别。
参考文章链接:https://www.cnblogs.com/chenssy/p/3388487.html
17、数组
17.1 数组的介绍
数组(Array):就是多个相同类型的数据按照一定的顺序排列的集合。简单理解数组就是一个数据容器。
数组是编程中最常见的一种数据结构,可用于存储多个数据,每个数组元素存放一个数据,通常我们可以通过数组元素的索引来访问数组元素。包括为数组元素赋值和取出数组元素的值。
数组的相关概念:数组名,下标(或脚标、索引)(index),元素(element),数组的长度(length)。
数组的基本特性:
- 数组本身是引用数据类型,而数组中的元素可以是任何数据类型,包括基本数据类型和引用数据类型。
- 创建数组对象会在内存中开辟一整块连续的空间,而数组的引用是这块连续空间的首地址。
- 数组一旦初始化完成,数组在内存所占用的空间将被固定下来,因此数组的长度不可变。
- 数组可以直接通过下标的方式来调用,下标从0开始。
17.2 数组的声明与初始化
数组的声明
注:数组在使用之前需要先进行声明并初始化
16.2.1 数组的声明
数组的声明比较简单,和变量基本一样,只是多了个括号[]。数组的声明如下:
//推荐
元素的数据类型[] 数组的名称;
int[] age;
//不推荐
元素的数据类型 数组名[];
int age[];
16.2.2 数组的初始化
数组使用之前需要先初始化,什么是数组初始化?就是给数组分配内存空间,并给元素赋值。数组的初始化有两种:静态初始化和动态初始化。
①、静态初始化:定义数组的同时为数组分配内存空间,并赋值。程序员只给定数组元素的初始值,不指定数组长度,由系统决定数组的长度。
数据类型[] 数组名 = new 数据类型[]{元素1,元素2,元素3...};
int[] age =new int[]{1,2,3};
或
数据类型[] 数组名;
数组名 = new 数据类型[]{元素1,元素2,元素3...};
int[] age;
age = new int[]{1,2,3};
简化方式:
数据类型[] 数组名 = {元素1,元素2,元素3...};//必须在一个语句中完成,不能分开两个语句写
int[] age = {1,2,3};
②、动态初始化:初始化时候程序员只指定数组长度,由系统元素分配初始值(为对应类型的默认值,比如int默认赋值为0)。
数据类型 [] 数组名称 = new 数据类型 [数组长度]
int[] age =new int[3];
或
数据类型 数组名称[ ] = new 数据类型 [数组长度]
③、简单举例代码如下:
//声明一个元素为1,2,3的int型数组
int[] arr=new int[]{1,2,3};
int[] arr1={1,2,3};
//声明一个长度为3的数组
int[] arr2=new int[3];
④、错误写法:
//未指定数组长度
int [] arr1=new int[];
//数组前面[]不能写长度
int [5] arr2=new int[5];
//静态初始化不能写长度
int [] arr3=new int[3]{1,2,3};
上面的代码写法都是错误的,在编译时会报错。
17.3 数组元素的访问与遍历
①、访问数组元素以及给数组元素赋值
数组是存在下标索引的,索引的范围为[0,数组的length-1],通过下标可以获取指定位置的元素,数组下标是从0开始的,也就是说下标0对应的就是数组中第1个元素,可以很方便的对数组中的元素进行存取操作。格式为:数组名[索引]。
//声明一个长度为3的数组
int[] arr=new int[3];
//给arr第1个元素赋值1
arr[0]=1;
//给arr第2个元素赋值2
arr[1]=2;
//输出
System.out.println(arr[0]);
System.out.println(arr[1]);
上面的arr数组,我们只能赋值三个元素,也就是下标从0到2,如果你访问 arr[3] ,那么会报数组下标越界异常。
②、数组的遍历
数组遍历: 就是将数组中的每个元素分别获取出来,这就是遍历。遍历也是数组操作中的基石,数组有个 length 属性,是记录数组的长度的,我们可以利用length属性来遍历数组。语句为:数组名.length,返回int类型结果。由次可以推断出,数组的最大索引值为数组名.length-1。
//声明一个元素为1,2,3的int型数组
int[] arr=new int[]{1,2,3};
//遍历arr数组
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
// 使用增强for循环foreach进行遍历
for (int i : arr) {
System.out.println(i);
}
//使用Arrays.toSting(数组名)进行遍历
System.out.println(Arrays.toString(arr));
17.4 数组的内存图
众所周知,程序是运行在内存中的,而Java程序是运行在Java虚拟机(JVM)上的,那么JVM要运行程序,必须要对内存进行空间的分配和管理。JVM的内存是怎么划分的呢?为了提高运算效率,就对空间进行了不同区域的划分,因为每一片区域都有特定的处理数据方式和内存管理方式。
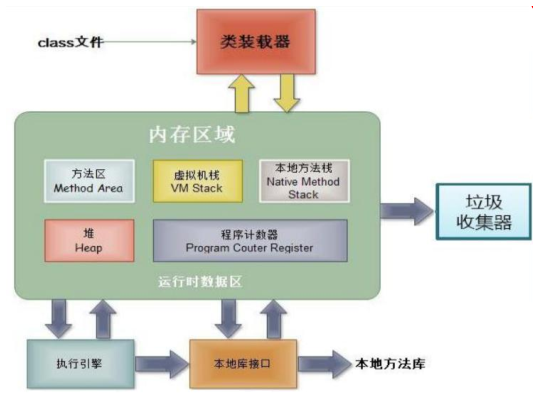

数组内存图分析:
public static void main(String[] args) {
int[] arr = new int[3];
int[] arr2 = new int[2];
System.out.println(arr);
System.out.println(arr2);
}
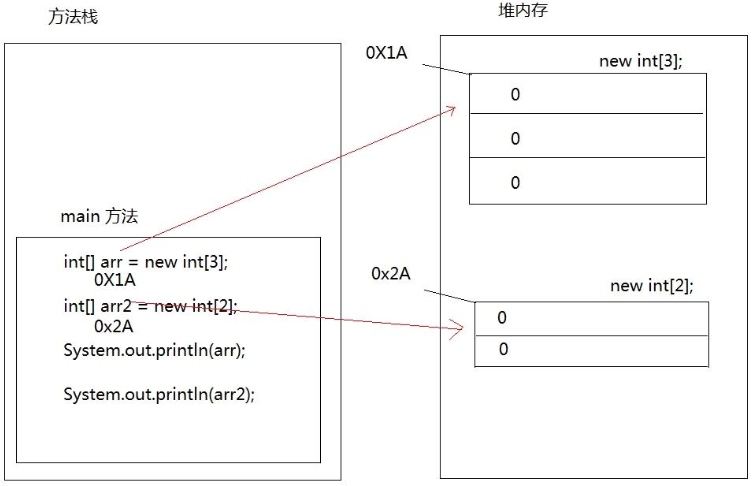
17.5 数组的使用举例
17.5.1 将数组元素反转
public class ArrayTest {
public static void main(String[] args) {
String[] str=new String[]{"AA","BB","CC","DD","EE","FF","GG"};
System.out.println("反转前:");
for (int i = 0; i < str.length; i++) {
System.out.print(str[i]+"\t");
}
for(int i=0;i<str.length/2;i++){
String temp=str[i];
str[i]=str[str.length-i-1];
str[str.length-i-1]=temp;
}
System.out.println();
System.out.println("反转后:");
for (int i = 0; i < str.length; i++) {
System.out.print(str[i]+"\t");
}
}
}
17.5.2 线性查找
public class ArrayTest1 {
public static void main(String[] args) {
String[] str=new String[]{"AA","BB","CC","DD","EE","FF","GG"};
String dest="BB";
boolean isFlag=true;
for (int i = 0; i < str.length; i++) {
if (dest.equals(str[i])){
System.out.println("找到了元素,位置在"+(i+1));
isFlag=false;
break;
}
}
if (isFlag) {
System.out.println("对不起,没有找到");
}
}
}
17.5.3 排序算法
👏本小节引用的博客及书籍:
- java实现10种排序算法_努力努力再努力²的博客-CSDN博客_java排序算法
- 十大经典排序算法(Java实现)_Zandz_的博客-CSDN博客_经典排序算法(java实现)
- Java十大排序算法 - 寇拉斯 - 博客园 (cnblogs.com)
- 1.0 十大经典排序算法 | 菜鸟教程 (runoob.com)
- 2022版王道考研数据结构
首先排序算法可以分为内部排序算法和外部排序算法:
排序算法可以分为内部排序和外部排序,内部排序是数据记录在内存中进行排序,而外部排序是因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存。常见的内部排序算法有:插入排序、希尔排序、选择排序、冒泡排序、归并排序、快速排序、堆排序、基数排序等。用一张图概括:
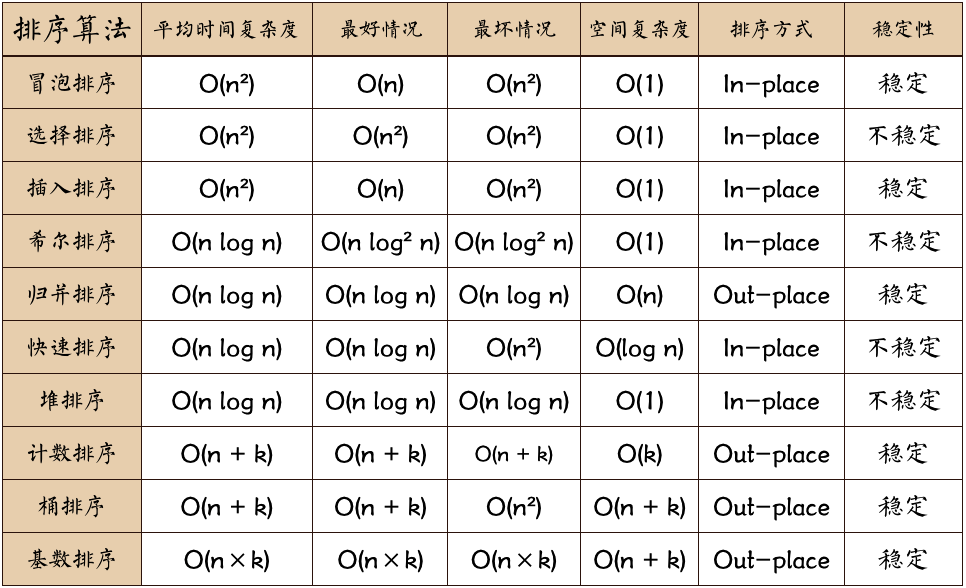
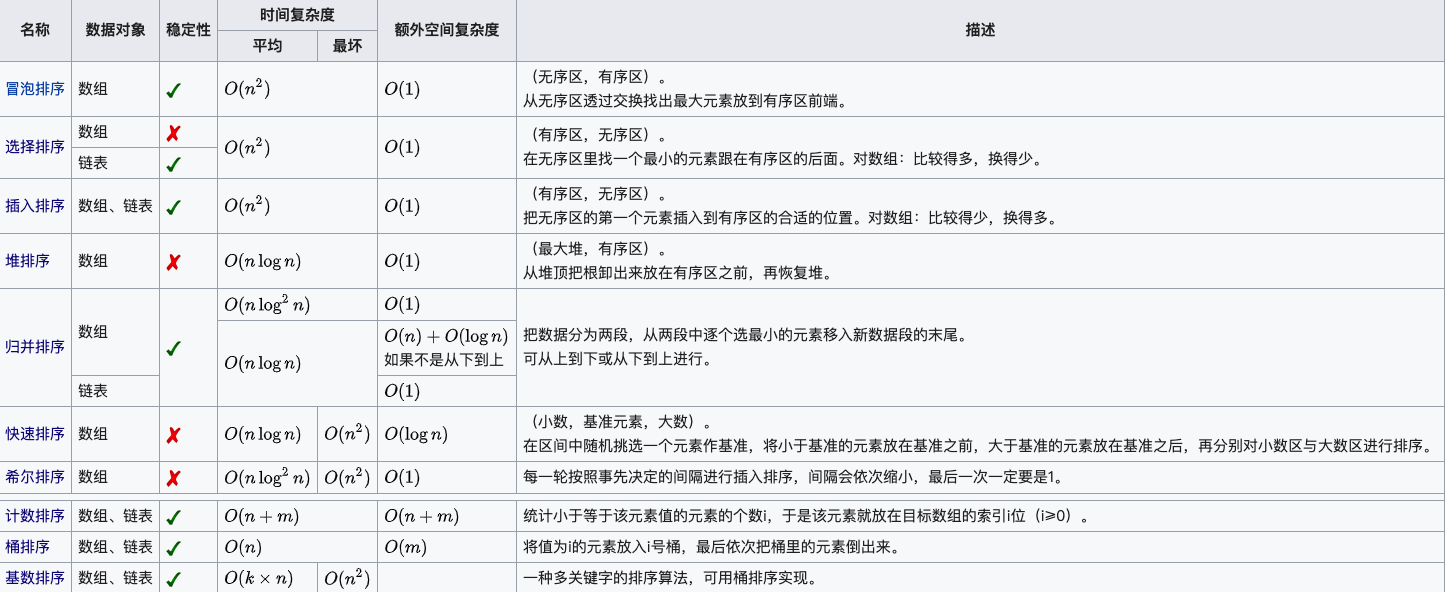
表中数据说明:
-
稳定:如果A原本在B前面,而A=B,排序之后A仍然在B的前面;
-
不稳定:如果A原本在B的前面,而A=B,排序之后A可能会出现在B的后面;
-
时间复杂度: 描述一个算法执行所耗费的时间;
-
空间复杂度:描述一个算法执行所需内存的大小;
-
n:数据规模;
-
k:“桶”的个数;
-
In-place:占用常数内存,不占用额外内存;
-
Out-place:占用额外内存。
该十种排序算法可分为如下所示的两大类
-
比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlog \loglogn),因此也称为非线性时间比较类排序。
-
非比较类排序:不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,以线性时间运行,因此也称为线性时间非比较类排序。
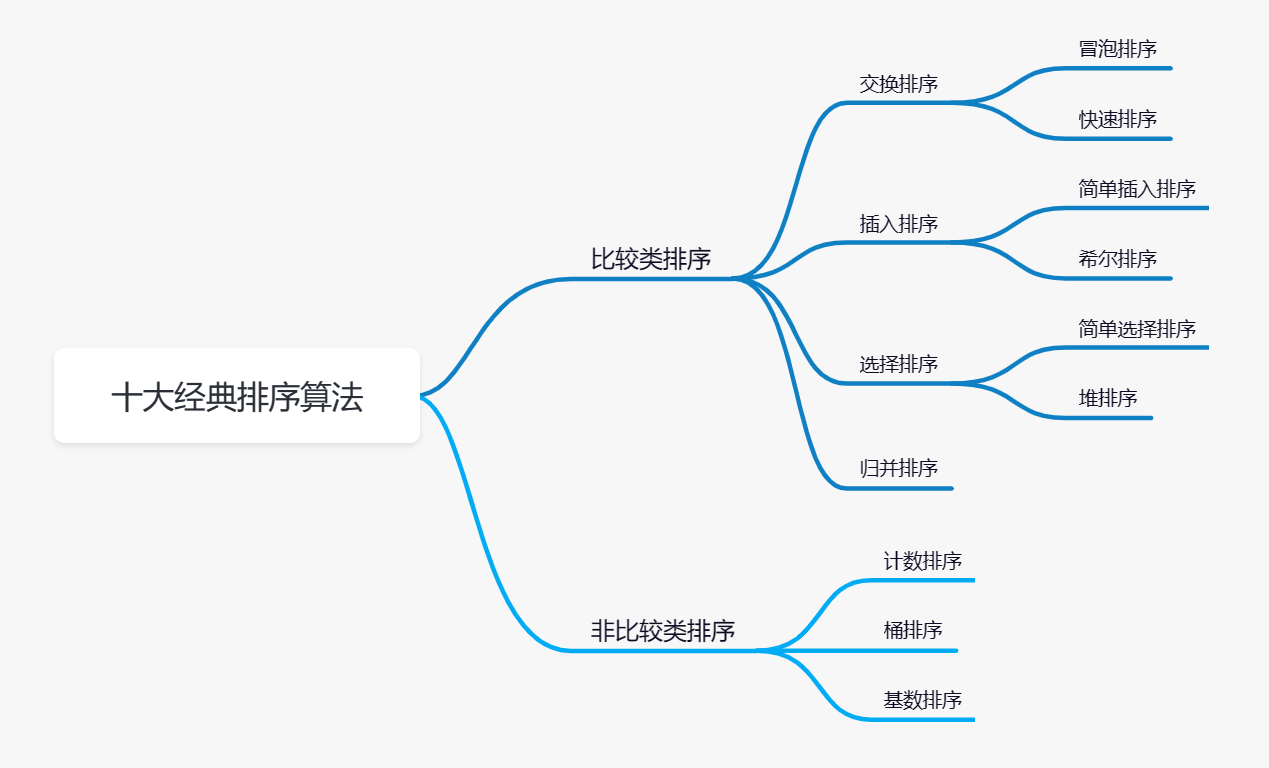
17.5.3.1 冒泡排序
冒泡排序(Bubble Sort)的基本思想是:对比相邻的元素值,如果满足条件就交换元素值,把较小的元素值移动到数组前面,把大的元素值移动到数组后面(也就是交换两个元素的位置),这样数组元素就像气泡一样从底部上升到顶部。
冒泡排序的算法比较简单,排序的结果稳定,但时间效率不太高。Java中的冒泡排序在双层循环中实现,其中外层循环控制排序轮数,总循环次数为要排序数组的长度减 1。而内层循环主要用于对比相邻元素的大小,以确定是否交换位置,对比和交换次数依排序轮数而减少。
public class BubbleSort {
public static void bubbleSort(int[] arr) {
for (int i = 0; i < arr.length; i++) {
boolean flag = true;
for (int j=0;j<arr.length-1-i;j++){ //第一趟,把最大的元素排在最后
if (arr[j]>arr[j+1]){
int temp=arr[j];
arr[j]=arr[j+1];
arr[j+1]=temp;
flag=false;
}
}
if (flag){
return;//本趟遍历后为发生交换,表示数组有序
}
}
}
}
数组无论在Java,C,C++,PHP等语言中都有着非常重要的地位,所以学好数组基础非常有必要。
17.5.3.2 快速排序
快速排序(Quicksort)是对冒泡排序的一种改进,是一种排序执行效率很高的排序算法。
快速排序的基本思想是:通过一趟排序,将要排序的数据分隔成独立的两部分,其中一部分的所有数据比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此使整个数据变成有序序列。
具体做法是:在待排序表L[1…n]中任取⼀个元素pivot作为枢轴(或基准,通常取⾸元素),通过⼀趟排序将待排序表划分为独⽴的两部分L[1…k-1]和L[k+1…n],使得L[1…k-1]中的所有元素⼩于pivot,L[k+1…n]中的所有元素⼤于等于pivot,则pivot放在了其最终位置L(k)上,这个过程称为⼀次“划分”。然后分别递归地对两个⼦表重复上述过程,直⾄每部分内只有⼀个元素或空为⽌,即所有元素放在了其最终位置上。
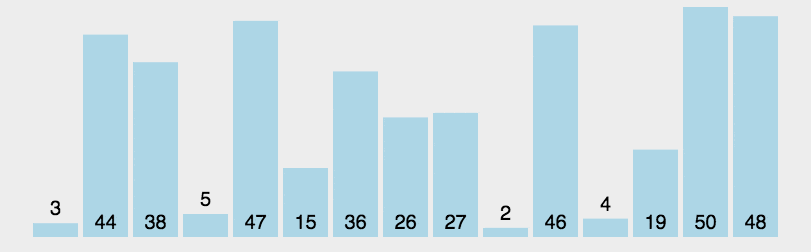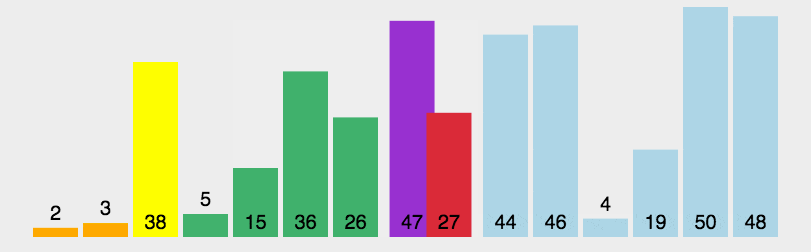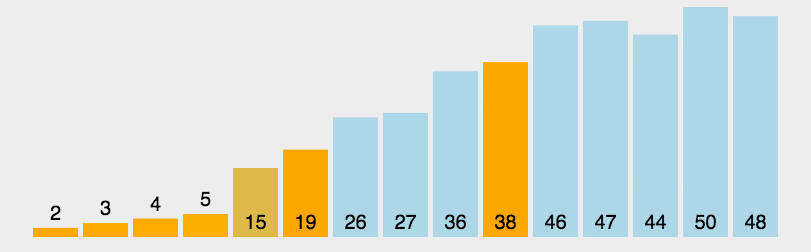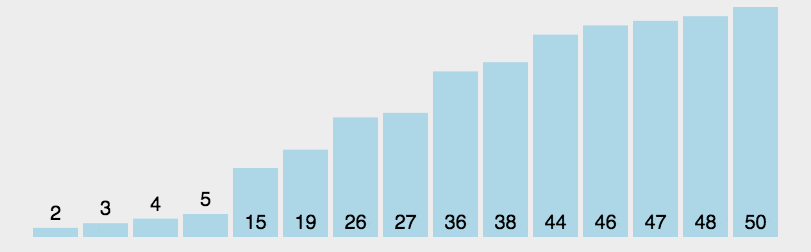
public class QuickSort {
public static void quickSort(int[] arr) {
sort(arr, 0, arr.length - 1);
}
private static void sort(int[] arr, int low, int high) {
if (low < high) {//递归跳出的条件
int pivotpos = partition(arr, low, high);//划分
sort(arr, low, pivotpos - 1);//划分左子表
sort(arr, pivotpos + 1, high);//划分右子表
}
}
//用第一个元素将待排序序列划分为左右两个部分
private static int partition(int[] arr, int low, int high) {
int pivot = arr[low];//用第一个元素作为枢轴
while (low<high){//用low、gigh搜索枢轴的最终位置
while (low<high && arr[high] >= pivot){
--high;
}
arr[low] = arr[high];//比枢轴小的元素移动到左端
while (low<high && arr[low] <= pivot){
++low;
}
arr[low] = arr[high];//比枢轴大的元素移动到右端
}
arr[low] = pivot;//枢轴元素存放到最终位置
return low;
}
}
17.5.3.2 选择排序
选择排序(Selection Sort)每⼀趟在待排序元素中选取关键字最小(或最大)的元素加⼊有序⼦序列
public class SelectionSort {
public static void selectionSort(int[] arr) {
int len = arr.length;
for (int i = 0; i < len - 1; i++) {//一共进行len-1趟
int min = i;//记录最小元素的位置
for (int j = i + 1; j < len; j++) {//在数组中选择最小的元素
if (arr[min] > arr[j]) {
min = j;//更新最小元素位置
}
}
if (min != i) {
int temp = arr[i];
arr[i] = arr[min];
arr[min] = temp;
}
}
}
}
17.5.4 查找算法
17.5.4.1 二分(折半)查找
二分查找,是一种在有序数组中查找某一特定元素的查找算法。
基本思路:用给定值k先与中间结点的关键字比较,中间结点把线形表分成两个子表,若相等则查找成功;若不相等,再根据k与该中间结点关键字的比较结果确定下一步查找哪个子表,这样递归进行,直到查找到或查找结束发现表中没有这样的结点。
/**
* 使用递归的二分查找
* title:recursionBinarySearch
* @param arr 有序数组
* @param key 待查找关键字
* @return 找到的位置
*/
public static int recursionBinarySearch(int[] arr,int key,int low,int high){
if(key < arr[low] || key > arr[high] || low > high){
return -1;
}
int middle = (low + high) / 2; //初始中间位置
if(arr[middle] > key){
//比关键字大则关键字在左区域
return recursionBinarySearch(arr, key, low, middle - 1);
}else if(arr[middle] < key){
//比关键字小则关键字在右区域
return recursionBinarySearch(arr, key, middle + 1, high);
}else {
return middle;
}
}
/**
* 不使用递归的二分查找
* title:recursionBinarySearch
* @param arr 有序数组
* @param key 待查找关键字
* @return 找到的位置
*/
public static int commonBinarySearch(int[] arr,int key){
int low = 0;
int high = arr.length - 1;
int middle = 0; //定义middle
if(key < arr[low] || key > arr[high] || low > high){
return -1;
}
while(low <= high){
middle = (low + high) / 2;
if(arr[middle] > key){
//比关键字大则关键字在左区域
high = middle - 1;
}else if(arr[middle] < key){
//比关键字小则关键字在右区域
low = middle + 1;
}else{
return middle;
}
}
return -1; //最后仍然没有找到,则返回-1
}
17.6 二维数组(理解)
二维数组:本质上就是数组的元素为一维数组的一个数组。意思就是一个一维数组存储的是另一个数组的地址值,而另一个数组才是真正用来存储值的。
6.1、二维数组的声明
声明语法格式为:
//推荐
元素的数据类型[][] 二维数组的名称;
//不推荐
元素的数据类型 二维数组名[][];
//不推荐
元素的数据类型[] 二维数组名[];
//声明一个二维数组
int[][] arr;
6.2、二维数组的初始化
①、静态初始化,程序员给定元素初始值,由系统决定数组长度。
//1.先声明,再静态初始化
元素的数据类型[][] 二维数组名;
二维数组名 = new 元素的数据类型[][]{
{元素1,元素2,元素3 。。。},
{第二行的值列表},
...
{第n行的值列表}
};
//2.声明并同时静态初始化
元素的数据类型[][] 二维数组名 = new 元素的数据类型[][]{
{元素1,元素2,元素3 。。。},
{第二行的值列表},
...
{第n行的值列表}
};
//3.声明并同时静态初始化的简化写法
元素的数据类型[][] 二维数组名 = {
{元素1,元素2,元素3 。。。},
{第二行的值列表},
...
{第n行的值列表}
};
如果是静态初始化,右边new 数据类型[][]中不能写数字,因为行数和列数,由{}的元素个数决定
简单的示例:
//声明二维数组
int[][] arr;
//静态初始化
arr = new int[][]{{1,2,3},{4,5,6},{7,8,9}};
//arr = new int[3][3]{{1,2,3},{4,5,6},{7,8,9}};//错误,静态初始化,右边new 数据类型[]中不能指定长度
//声明并同时初始化
int[][] arr = new int[][]{{1,2,3},{4,5,6},{7,8,9}};
//声明并同时初始化的简化写法
int[][] arr = {{1,2,3},{4,5,6},{7,8,9}};//声明与初始化必须在一句完成
public static void main(String[] args) {
//定义数组
int[][] arr = {{1,2,3},{4,5},{6}};
System.out.println(arr);
System.out.println(arr[0]);
System.out.println(arr[1]);
System.out.println(arr[2]);
System.out.println(arr[0][0]); //1
System.out.println(arr[1][0]); //4
System.out.println(arr[2][0]); //6
System.out.println(arr[0][1]); //2
System.out.println(arr[1][1]); //5
//越界
System.out.println(arr[2][1]); //错误
}
②、动态初始化(规则二维表)程序员指定数组的长度,后期再赋值(系统会先给定元素默认初始值)。
什么是规则二维表?规则二维表的每一行的列数是相同的。
//(1)确定行数和列数
元素的数据类型[][] 二维数组名 = new 元素的数据类型[m][n];
m:表示这个二维数组有多少个一维数组。或者说二维表一共有几行
n:表示每一个一维数组的元素有多少个。或者说每一行共有一个单元格
//此时创建完数组,行数、列数确定,而且元素也都有默认值
//(2)再为元素赋新值
二维数组名[行下标][列下标] = 值;
public static void main(String[] args) {
//定义一个二维数组
int[][] arr = new int[3][2];
//定义了一个二维数组arr
//这个二维数组有3个一维数组的元素
//每一个一维数组有2个元素
//输出二维数组名称
System.out.println(arr); //地址值 [[I@175078b
//输出二维数组的第一个元素一维数组的名称
System.out.println(arr[0]); //地址值 [I@42552c
System.out.println(arr[1]); //地址值 [I@e5bbd6
System.out.println(arr[2]); //地址值 [I@8ee016
//输出二维数组的元素
System.out.println(arr[0][0]); //0
System.out.println(arr[0][1]); //0
}
③、动态初始化(不规则二维表);不规则二维表:每一行的列数可能不一样。
//(1)先确定总行数
元素的数据类型[][] 二维数组名 = new 元素的数据类型[总行数][];
//此时只是确定了总行数,每一行里面现在是null
//(2)再确定每一行的列数,创建每一行的一维数组
二维数组名[行下标] = new 元素的数据类型[该行的总列数];
//此时已经new完的行的元素就有默认值了,没有new的行还是null
//(3)再为元素赋值
二维数组名[行下标][列下标] = 值;
public static void main(String[] args) {
//定义数组
int[][] arr = new int[3][];
System.out.println(arr); //[[I@175078b
System.out.println(arr[1][0]);//NullPointerException
System.out.println(arr[0]); //null
System.out.println(arr[1]); //null
System.out.println(arr[2]); //null
//动态的为每一个一维数组分配空间
arr[0] = new int[2];
arr[1] = new int[3];
arr[2] = new int[1];
System.out.println(arr[0]); //[I@42552c
System.out.println(arr[1]); //[I@e5bbd6
System.out.println(arr[2]); //[I@8ee016
System.out.println(arr[0][0]); //0
System.out.println(arr[0][1]); //0
//ArrayIndexOutOfBoundsException
//System.out.println(arr[0][2]); //错误
arr[1][0] = 100;
arr[1][2] = 200;
}
6.3、二维数组的遍历(两个for循环)
for(int i=0; i<二维数组名.length; i++){
for(int j=0; j<二维数组名[i].length; j++){
System.out.print(二维数组名[i][j]);
}
System.out.println();
}
6.4、二维数组的内存图分析
int[][] arr = {{1},{2,2},{3,3,3},{4,4,4,4},{5,5,5,5,5}};
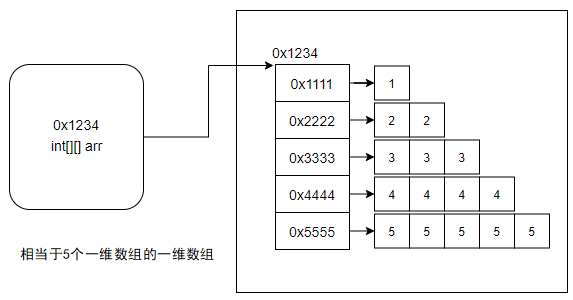
17.7 Arrays工具类
在java.util包下提供了一个叫Arrays的工具类,里面提供了很多静态方法来对数组进行操作,而且如下每一个方法都有各种重载形式,以下只列出int[]类型的,其他类型的数组类推:
static int binarySearch(int[] a, int key):要求数组有序,在数组中查找key是否存在,如果存在返回第一次找到的下标,不存在返回负数static int[] copyOf(int[] original, int newLength):根据original原数组复制一个长度为newLength的新数组,并返回新数组static int[] copyOfRange(int[] original, int from, int to):复制original原数组的[from,to)构成新数组,并返回新数组static boolean equals(int[] a, int[] a2):比较两个数组的长度、元素是否完全相同static void fill(int[] a, int val):用val填充整个a数组static void fill(int[] a, int fromIndex, int toIndex, int val):将a数组[fromIndex,toIndex)部分填充为valstatic void sort(int[] a):将a数组按照从小到大进行排序static void sort(int[] a, int fromIndex, int toIndex):将a数组的[fromIndex, toIndex)部分按照升序排列static String toString(int[] a):把a数组的元素,拼接为一个字符串,形式为:[元素1,元素2,元素3。。。]
示例代码:
import java.util.Arrays;
import java.util.Random;
public class Test {
public static void main(String[] args) {
int[] arr = new int[5];
//1、打印数组,输出地址值
System.out.println(arr); //[I@d716361
//2、toString;数组内容转为字符串
System.out.println("arr数组初始状态:" + Arrays.toString(arr));//arr数组初始状态:[0, 0, 0, 0, 0]
//3、fill
Arrays.fill(arr, 3);
System.out.println("arr数组现在状态:" + Arrays.toString(arr));//arr数组现在状态:[3, 3, 3, 3, 3]
//赋值操作
Random rand = new Random();
for (int i = 0; i < arr.length; i++) {
arr[i] = rand.nextInt(100);//赋值为100以内的随机整数
}
System.out.println("arr数组现在状态:" + Arrays.toString(arr));//arr数组现在状态:[42, 25, 50, 77, 21]
//4、copyOf
int[] arr2 = Arrays.copyOf(arr, 10);
System.out.println("新数组:" + Arrays.toString(arr2));//新数组:[42, 25, 50, 77, 21, 0, 0, 0, 0, 0]
//5、equals
System.out.println("两个数组的比较结果:" + Arrays.equals(arr, arr2));//两个数组的比较结果:false
//6、sort
Arrays.sort(arr);
System.out.println("arr数组现在状态:" + Arrays.toString(arr));//arr数组现在状态:[21, 25, 42, 50, 77]
}
}
结果:
18、常用类
18.1 String
18.1.1String的介绍
字符串无论是在Java语言中还是在其它语言中,都应该是用的最频繁、最多的,可见字符串对于我们来说是多么的重要,所以我们非常有必要去深入的了解一下。
String就代表字符串,在Java中字符串属于对象。我们刚刚接触Java时,在学习数据类型的时候应该提到过String。Java有基本数据类型和引用数据类型,而String就是一个引用数据类型,它是一个类,位于java.lang包下,既然它是一个类,那我们就来看看它的源码结构。

从上面的图可以看出,String类是用final修饰的,表明它不能再被继承了。同时还实现了序列化(Serializable)、比较排序(Comparable)、字符序列(CharSequence)这三个接口,表明字符串可以被序列化、可以用于比较排序。关于实现了CharSequence接口下面有讲到。我们还可以看到String类中定义了一个char型数组value[ ],这个是用于存储字符串的内容,并且使用final修饰的,表明这个是常量。所以字符串一旦被初始化,就不可以被改变,表示String是不可变性,这就导致每次对String的操作都会生成新的String对象。
以上可以得出字符串的一些特点:
- 字符串的一个重要特点就是字符串不可变。这种不可变性是通过内部的
private final char[]字段,以及没有任何修改char[]的方法实现的。修改一个字符串变量值,相当于新生成一个字符串对象。 - 上面这个字符数组
private final char value[];也是字符串对象的内部存储形式。所以"abc"等效于char[] data={ 'a' , 'b' , 'c' }。
JDK1.9之前使用的是char[] value数组,JDK1.9之后改成了byte[]数组
- 字符串字面量也是一个String类的实例,存储在字符串常量池中,相同的字符串字面量表示的对象在内存中只有一份。
- 字符串String类型本身是final声明的,意味着我们不能继承String,也就意味着我们不能去重写他的方法。
18.1.2 CharSequence接口介绍
关于String实现CharSequence接口这里,我去百度一下,介绍如下:
CharSequence是一个接口,表示char值的一个可读序列。此接口对许多不同种类的char序列提供统一的自读访问。此接口不修改该equals和hashCode方法的常规协定,因此,通常未定义比较实现 CharSequence 的两个对象的结果。他有几个实现类:CharBuffer、String、StringBuffer、StringBuilder。
CharSequence与String都能用于定义字符串,但CharSequence的值是可读可写序列,而String的值是只读序列。
对于一个抽象类或者是接口类,不能使用new来进行赋值,但是可以通过以下的方式来进行实例的创建:
CharSequence cs="hello";
CharSequence的使用简单实例:
public class StringTest {
public static void main(String[] args) {
String str = "String";
StringBuffer sBuffer = new StringBuffer("StringBuffer");
StringBuilder sBuilder = new StringBuilder("StringBuilder");
show(str);
show(sBuffer);
show(sBuilder);
}
//如果参数类型为String则不能接收StringBuffer和StringBuilder
public static void show(CharSequence cs) {
System.out.println(cs);
}
}
运行的结果如下所示:
可能是这样理解的吧,CharSequence是一个接口,本身是没有什么读写意义的。String只是它的一个实现类,虽然String是只读,但是CharSequence的实现类还有StringBuffer,StringBuilder这些可写的,所以用CharSequence作为参数可以接收String,StringBuffer,StringBuilder这些类型。
此处参考链接:https://blog.csdn.net/a78270528/article/details/46785949
18.1.3 String字符串创建
字符串的创建比较简单,创建String的实例有两种方式,一种是直接给String的变量赋值,另一种是使用String的构造器创建实例。那么这两种方式创建的实例有什么区别呢?区别就是前者会创建一个对象,而后者会创建两个对象,这个后面讨论。下面是String中的构造方法:
public String():初始化新创建的 String对象,以使其表示空字符序列。String(String original): 初始化一个新创建的String对象,使其表示一个与参数相同的字符序列;换句话说,新创建的字符串是该参数字符串的副本。public String(char[] value):通过当前参数中的字符数组来构造新的String。public String(char[] value,int offset, int count):通过字符数组的一部分来构造新的String。public String(byte[] bytes):通过使用平台的默认字符集解码当前参数中的字节数组来构造新的String。public String(byte[] bytes,String charsetName):通过使用指定的字符集解码当前参数中的字节数组来构造新的String。
上述字符串构造器简单代码示例:
//字符串常量对象,推荐
String str = "hello";
// 无参构造,不推荐
String str1 = new String();
//创建"hello"字符串常量的副本,不推荐
String str2 = new String("hello");
//通过字符数组构造
char chars[] = {'a', 'b', 'c','d','e'};
String str3 = new String(chars);
String str4 = new String(chars,0,3);
// 通过字节数组构造
byte bytes[] = {97, 98, 99 };
String str5 = new String(bytes);
String str6 = new String(bytes,"GBK");
然后再来分析一下直接给String的变量赋值和使用String的构造器创建实例分别创建了几个对象,这里好像也是面试的时候经常问的一个问题 ,举例代码如下:
public class StringTest {
public static void main(String[] args) {
//方式一:直接赋值
String s1 = "abc";
String s2 = "abc";
//方式二:new+构造器
String s3 = new String("abc");
String s4 = new String("abc");
System.out.println(s1 == s2);//true
System.out.println(s1 == s3);//false
System.out.println(s3 == s4);//false
System.out.println(s1.equals(s3));//true
}
}
运行结果一目了然,String的值是常量,它的值是放在方法区的处理池中,而常量池中相同的值在只会存在一份。我们知道==比较的地址,equal()比较的是内容,s1和s2指向同一个引用,所以地址相同,而s3和s4它们分别创建了两个对象,地址值显然不同。
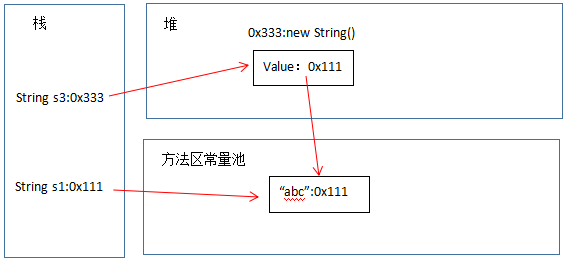
通过这个图我们也容易分析出创建实例时创建了几个对象。
String s1 = "abc"创建对象的过程:首先检查常量池中是否存在内容为"abc"的字符串,如果有,则不再创建对象,直接让s1变量指向该字符串的引用,如果没有则在常量池中创建"abc"对象然后让s1引用该对象。
String s3 = new String("abc")创建实例的过程:首先在堆创建一个String的对象,并让s3引用指向该对象,然后再到常量池中查看是否存在内容为"abc"字符串对象,如果存在,则将String对象中的value引用指向常量对象,将new出来的字符串对象与字符串常量池中的对象联系起来,如果不存在,则在字符串常量池中创建一个内容为"abc"的字符串对象,并将堆中的String对象与之联系起来。
18.1.4 String字符串拼接
字符串的拼接有三种方式:
- 直接使用"
+"; - 使用
concat()方法; - 使用
append()方法。
这里我主要来讨论一下"+"问题,举例:
注:如果都能做对说明已经掌握的很好了👍
这里先给出String字符串拼接的一些结论(重要!!!):
- 常量与常量的拼接结果必定是常量,它们是在常量池中完成,因为常量在编译阶段就可以确定下来,在编译阶段就会自动拼接完成。
- 只要涉及到有变量的(非常量),结果都是在堆内存中完成的,因为变量只有在运行阶段才可以确定。
- 直接赋值
String str="a"与构造器new String("a")创建的字符串必定不会相等。 - 如果拼接后的结果调用了
intern()方法,则返回值就是在常量池中。 - 字符串只有值传递,没有引用传递。
(1)、直接给String赋值的拼接举例:
@Test
public void test1() {
String s1 = "Hello";
String s2 = "World";
String s3 = "HelloWorld";
String s4 = "Hello" + "World";
String s5 = s1 + "World";
String s6 = "Hello" + s2;
String s7 = s1 + s2;
String s8 = s7.intern();
System.out.println("(1)" + (s3 == s4));
System.out.println("(2)" + (s3 == s5));
System.out.println("(3)" + (s3 == s6));
System.out.println("(4)" + (s3 == s7));
System.out.println("(5)" + (s3 == s8));
System.out.println("(6)" + (s5 == s6));
System.out.println("(7)" + (s5 == s7));
System.out.println("(8)" + (s6 == s7));
}
运行结果如下图所示:
(2)、直接赋值与使用构造方法创建字符串的拼接方式:
@Test
public void test2() {
String str1 = "1";
String str2 = "2";
String str3 = new String("1");
final String str4 = "2";
final String str5 = new String("2");
String str6 = "12";
String str7 = "1" + "2";
String str8 = str1 + "2";
String str9 = str1 + str2;
String str10 = str3 + str4;
String str11 = "1" + str4;
String str12 = "1" + str5;
String str13 = (str1 + str2).intern();
System.out.println("(1)" + (str1 == str3));
System.out.println("(2)" + (str2 == str4));
System.out.println("(3)" + (str4 == str5));
System.out.println("(4)" + (str6 == str7));
System.out.println("(5)" + (str6 == str8));
System.out.println("(6)" + (str6 == str9));
System.out.println("(7)" + (str6 == str10));
System.out.println("(8)" + (str6 == str11));
System.out.println("(9)" + (str6 == str12));
System.out.println("(10)" + (str6 == str13));
}
运行结果如下图所示:
(3)、字符串的值传递:
@Test
public void test3() {
String str1 = "hello";
String str2 = new String("hello");
char[] ch = new char[]{'h', 'e', 'l', 'l', 'o'};
String str3 = new String(ch);
change(str1, str2, ch, str3);
System.out.println("str1 = " + str1);
System.out.println("str2 = " + str2);
System.out.println("ch = " + String.valueOf(ch));
System.out.println("str3 = " + str3);
}
public static void change(String str1, String str2, char[] arr, String str3) {
str1 = "change";
str2 = "change";
str3 = "change";
arr[0] = 'c';
arr[1] = 'h';
arr[2] = 'a';
arr[3] = 'n';
arr[4] = 'g';
}
运行结果如下图所示:
18.1.5 String字符串中常用的方法
String中的常用方法我们需要熟练的掌握, 这样平时做一些字符串的常规操作就可以快速知道,而不用去查找API了。
①、常规:
int length():返回字符串的长度: return value.lengthboolean isEmpty():判断是否是空字符串:return value.length == 0String trim():返回字符串的副本,忽略前导空白和尾部空白String concat(String str):将指定字符串连接到此字符串的结尾。 等价于用“+”String toLowerCase():使用默认语言环境,将 String 中的所有字符转换为小写String toUpperCase():使用默认语言环境,将 String 中的所有字符转换为大写char[] toCharArray():将字符串转为char型数组。
②、比较:
boolean equals(Object obj):比较字符串的内容是否相同boolean equalsIgnoreCase(String anotherString):与equals方法类似,忽略大小写int compareTo(String anotherString):比较两个字符串的大小boolean matches(String regex):判断此字符串是否匹配给定的正则表达式。
③、查找:
char charAt(int index): 返回某索引处的字符return value[index]int indexOf(String str):返回指定子字符串在此字符串中第一次出现处的索引。注:indexOf和lastIndexOf方法如果未找到都是返回-1int indexOf(String str, int fromIndex):返回指定子字符串在此字符串中第一次出现处的索引,从指定的索引开始int lastIndexOf(String str):返回指定子字符串在此字符串中最右边出现处的索引int lastIndexOf(String str, int fromIndex):返回指定子字符串在此字符串中最后一次出现处的索引,从指定的索引开始反向搜索boolean endsWith(String suffix):测试此字符串是否以指定的后缀结束boolean startsWith(String prefix):测试此字符串是否以指定的前缀开始boolean startsWith(String prefix, int toffset):测试此字符串从指定索引开始的子字符串是否以指定前缀开始boolean contains(CharSequence s):当且仅当此字符串包含指定的 char 值序列时,返回 true
④、替换:
String replace(char oldChar, char newChar):返回一个新的字符串,它是通过用 newChar 替换此字符串中出现的所有 oldChar 得到的。String replace(CharSequence target, CharSequence replacement):使用指定的字面值替换序列替换此字符串所有匹配字面值目标序列的子字符串。String replaceAll(String regex, String replacement):使用给定的 replacement 替换此字符串所有匹配给定的正则表达式的子字符串。String replaceFirst(String regex, String replacement):使用给定的 replacement 替换此字符串匹配给定的正则表达式的第一个子字符串。
⑤、截取:
String substring(int beginIndex):返回一个新的字符串,它是此字符串的从beginIndex开始截取到最后的一个子字符串。String substring(int beginIndex, int endIndex):返回一个新字符串,它是此字符串从beginIndex开始截取到endIndex(不包含)的一个子字符串。
⑥、切片:
String[] split(String regex):根据给定正则表达式的匹配拆分此字符串。String[] split(String regex, int limit):根据匹配给定的正则表达式来拆分此字符串,最多不超过limit个,如果超过了,剩下的全部都放到最后一个元素中。
⑦、其它
boolean matches(String regex):用于配置正则表达式String trim():去除字符串前后的空格,返回一个新的对象static String valueOf(int i):将各种基本数据类型转为字符串public native String intern():如果字符串常量池中已经包含一个等于此String对象的字符串,则返回代表池中这个字符串的String对象;否则,将此String对象包含的字符添加到常量池中,并返回此String对象的引用
如果还想学习更多的方法,可以自行去看String的API或者源码。
18.1.6 StringBuffer和StringBuilder
StringBuffer和StringBuilder十分相似,它们都代表可变的字符序列,可以对字符序列进行增删改查操作,此时不会产生新的对象,而且它两内部的方法也是一样的。那么String、StringBuffer和StringBuilder的区别是什么。
- String(JDK1.0):字符串常量,不可变字符序列,线程安全,效率低。
- StringBuffer(JDK1.0):字符串变量,可变字符序列,线程安全,效率低。
- StringBuilder(JDK5.0):字符串变量,可变字符序列,线程不安全,效率高。
👏为什么说String和StringBuffer是线程安全,StringBuilder是线程不安全呢?
- 因为String是final修饰的常量,它是不可变的字符串,所有的操作都是不可能改变它的值,所以线程是安全的。再通过看StringBuffer和StringBuilder的源码,可以很明显发现,StringBuffer是线程安全的,因为其下的所有方法都加上了synchronized。而StringBuilder则没有加这个关键字。
它们之间常用的方法:
StringBuffer append(xxx):用于进行字符串的拼接cahr charAt(int index):返回char在指定索引在这个序列值。StringBuffer delete(int start,int end):删除指定位置的内容StringBuffer deleteCharAt(int index):删除char在这个序列中的指定位置。StringBuffer replace(int start,int end,String str):把[start,end)位置上的元素替换为strvoid sedtCharAt(int n,char ch):将指定索引位置的字符改成chStringBuffer insert(int offset,xxx):在指定位置插入xxxStringBuffer reverse():将字符序列反转int indexOf(String str):返回指定子字符串第一次出现的字符串内的索引。int lastIndexOf(String str):返回指定子字符串最右边出现的字符串内的索引。String subString(int start,int end):返回一个新的 String,其中包含此序列中当前包含的字符的子序列。
18.1.7 String、StringBuffer和StringBuilder三者效率对比
String、StringBuffer和StringBuilder涉及可变序列与不可变序列、线程是否安全情况,这些因素必然影响到它们之间的运行效率,所以我们来比较一下他们之间的运行效率。
简单代码示例:
public class StringTest {
public static void main(String[] args) {
long startTime = 0L;
long endTime = 0L;
String text = " ";
StringBuffer buffer = new StringBuffer("");
StringBuilder builder = new StringBuilder("");
//String
startTime = System.currentTimeMillis();
for (int i = 0; i < 50000; i++) {
text = text + i;
}
endTime = System.currentTimeMillis();
System.out.println("String执行时间:" + (endTime - startTime));
//StringBuffer
startTime = System.currentTimeMillis();
for (int i = 0; i < 50000; i++) {
buffer.append(String.valueOf(i));
}
endTime = System.currentTimeMillis();
System.out.println("StringBuffer执行时间:" + (endTime - startTime));
//StringBuilder
startTime = System.currentTimeMillis();
for (int i = 0; i < 50000; i++) {
builder.append(String.valueOf(i));
}
endTime = System.currentTimeMillis();
System.out.println("StringBuilder执行时间:" + (endTime - startTime));
}
}
运行结果可能需要等个5-8秒,运行结果如下:

我们多次运行的结果也大致相同,所以运行效率为:StringBuilder > StringBuffer > String。String如此的慢是因为它是字符串常量,在创建对象后是不可改变的,然而每次改变String类型的值都会在常量池中新建一个常量对象,所以非常耗时间。而StringBuffer和StringBuilder的可变的字符序列,它们只是在原有内容发生了改变,并没有新创建对象。所以经常改变内容的字符串最好不要用 String类型,推荐使用StringBuffer,因为每次生成对象都会对系统性能产生影响,特别当内存中无引用对象多了以后, JVM 的 GC 就会开始工作,性能就会降低。
18.1.8 String字符串小结
通过上面的学习,我们简单小结一下:
- String:不可变字符串,应该是线程安全的,因为它是不可变的字符串,适用于少量字符串操作的情况。
- StringBuffer:可变字符串,线程安全,适用多线程下在字符缓冲区进行大量操作的情况。
- StringBuilder:可变字符串,线程不安全,适用于单线程下在字符缓冲区进行大量操作的情况。
18.2 包装类
18.2.1 包装类简介
我们都知道Java是面向对象编程语言,包含了8种基本数据类型,但是这8种基本数据类型并不支持面向对象的特征,它们既不是类,也不能调用方法,它们仅是关键字。这在实际使用时存在很多的不便,比如int类型需要转换成字符串,是非常麻烦的,为了解决这个不足,然后就出现了包装类。
包装类顾名思义,就是将这些基本数据类型封装在类中,并且提供丰富的方法来对数据进行操作。这样八个类和基本数据类型对应的类统称为包装类(Wrapper Class)。
Java中的包装类提供了将基本数据类型转换为对象,以及将对象转换为基本数据类型的机制。
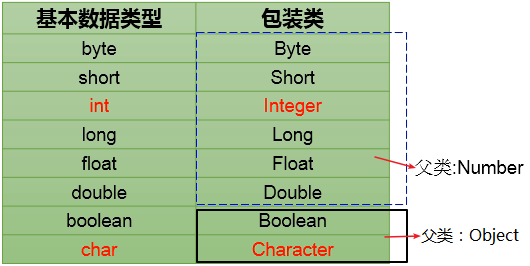
其中Byte,Short,Integer,Float,Double,Long都属于Number子类。Character ,Boolean属于Object子类。它们的默认值都是NULL。
包装类的特点:
- 所有包装类都是类,是可以实例化的
- 所有包装类都是final类型,因此不能创建他们的子类。
- 包装类是不可变类,一个包装类的对象自创建后,他所包含的基本类型数据就不能被改变。
包装类有以下用途:
- 集合不允许存放基本数据类型,所以可以用包装类来代替
- 包含了每种基本类型的相关属性,如最大值,最小值,所占位数等
- 作为基本数据类型对应的类类型,提供了一系列实用的对象操作,如类型转换,进制转换等
18.2.2 装箱和拆箱
什么是装箱和拆箱?
- 装箱:将基本数据类型变为包装类对象。
- 拆箱:将包装类中包装的基本数据类型取出转为基本数据类型。
在 Java 1.5 之前,开发人员如果想要将基本数据类型和包装类进行转换,则需要手动进行装拆箱,比如说:
Integer a = new Integer(10); // 手动装箱
int b = a.intValue(); // 手动拆箱
[1]、装箱可以通过调用包装类的构造器来实现(以Integer为例,其它同理):
| 构造方法 | 描述 |
|---|---|
Integer(int value) |
构造一个新分配的 Integer 对象,它表示指定的 int 值 |
Integer(String s) |
构造一个新分配的 Integer 对象,它表示 String 参数所指示的 int 值(必须是纯数字) |
注:如果传递的字符串,必须是基本类型的字符串,否则会抛出异常,例如:"100" 正确、"a" 抛异常。
[2]、装箱也可通过包装类的静态方法来实现(其它同理):
| 静态方法 | 描述 |
|---|---|
static Integer valueOf(int i) |
返回一个表示指定的 int 值的 Integer 实例 |
static Integer valueOf(String s) |
返回保存指定的 String 的值的 Integer 对象 |
[3]、拆箱(包装类>>>基本类型的数据)通过调用包装类的xxxValue()方法实现:
| 成员方法 | 描述 |
|---|---|
int intValue() |
以 int 类型返回该 Integer 的值 |
18.2.3 自动装箱和自动拆箱
理解了上面的装箱和拆箱后,那么自动装箱和拆箱也就好理解了,就是全自动完成咯,不需要开发人员手动来完成!!!
在JDK1.5之后,为了减少开发人员的工作,Java提供了自动装箱和自动拆箱功能。
Integer a = 21; // 自动装箱
int b = a; // 自动拆箱
/*
* ArrayList集合无法直接存储整数,可以存储Integer包装类
*/
ArrayList<Integer> list = new ArrayList<>();
list.add(1); //-->自动装箱 list.add(new Integer(1));
int a = list.get(0); //-->自动拆箱 list.get(0).intValue();
由于出现了自动装箱和自动拆箱功能,所以基本数据类型和包装类之间的相互转换变得非常简单,再也不用去调用繁琐的方法了。
自动装箱和自动拆箱的原理:
Integer a = 21; // 自动装箱
int b = a; // 自动拆箱
将上面自动装拆箱的代码反编译class文件之后得到如下内容:

将上面反编译后的代码转为我们可以看得懂的代码就是:
当执行到
Integer a = 21;这句代码时,系统为我们执行了:Integer a = Integer.valueOf(21);自动进行装箱当执行到
int b = a;这句代码时,系统为我们执行了:int b = a.intValue();自动进行拆箱
通过上面可以发现:自动装箱和自动拆箱的原理也需要同调用指定的方法来实现,只不过这个步骤不再用开发人员手动完成,而是由编译器自动帮我们完成,这就是所谓的自动装箱和拆箱。
18.2.4 基本数据类型、包装类、字符串之间的转换
虽然上面已经介绍了自动装箱和自动拆箱,但是下面还是简单举例:
[1]、基本数据类型>>>>>包装类(装箱):调用包装类的构造器
@Test
public void test1(){
Integer i1=new Integer(10);
System.out.println("i1结果:"+i1);
Integer i2=new Integer("10");
System.out.println("i2结果:"+i2);
//Integer i3=new Integer("10abc"); 必须是纯数字,java.lang.NumberFormatException: For input string: "10abc"
//System.out.println(i3);
Double d1=new Double(12.3);
Double d2=new Double("12.3");
System.out.println("d1结果:"+d1);
System.out.println("d1结果:"+d2);
Boolean b1=new Boolean(true);
Boolean b2=new Boolean("TrUe");
Boolean b3=new Boolean("TrUe123");
System.out.println("b1结果:"+b1);
System.out.println("b2结果:"+b2);
System.out.println("b3结果:"+b3);
}
运行结果:
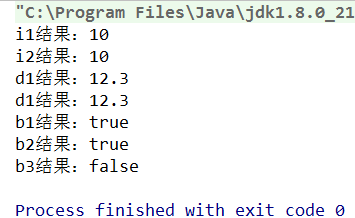
从运行的结果来看,通过调用包装类构造器可以将基本数据类型转为包装类,但是传入的参数必须合法,否则就像Integer那样会报错。可以看见Boolean包装类传入的字符串是忽略大写的,这是因为构造器中调用了parseBoolean(String s)方法,然后这个方法内部又调用了String方法的equalsIgnoreCase(String anotherString)方法,所以传入字符串会忽略大小写。而且你传入的是非法字符串它并不会报错,只是返回了false,这里需要注意一下。
[2]、包装类>>>>>基本数据类型(拆箱):调用包装类的xxxValue()方法
@Test
public void test2(){
Integer integer = new Integer(10);
int i=integer.intValue();
System.out.println(i+1);
Double aDouble = new Double(10.11);
double d=aDouble.doubleValue();
System.out.println(d+1);
Boolean aBoolean = new Boolean(false);
boolean b=aBoolean.booleanValue();
System.out.println(b);
}
运行结果:
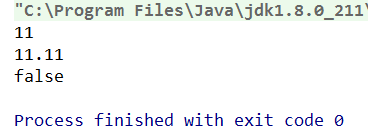
包装类转换为基本数据类型是非常简单的,只需要调用正确的方法即可,其他的包装类也是同样的道理。
[3]、由于出现了自动拆箱和自动装箱,基本数据类型和包装类就可以看成一个整体。
基本数据类型、包装类>>>>>字符串:调用String重载的valueOf(Xxx xxx)
@Test
public void test3(){
int num=10;
//方式1:连接运算
String str1=num+"";
System.out.println("str1结果"+str1);
//方式2:调用String的valueOf(Xxx xx)方法
String str2=String.valueOf(15);
System.out.println("str2结果"+str2);
Integer integer=new Integer(21);
String str3=String.valueOf(integer);
System.out.println("str3结果"+str3);
}
运行结果:
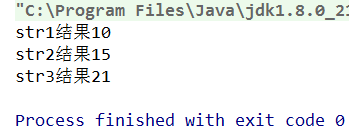
[4]、字符串>>>>>基本数据类型、包装类:调用包装类中的parseXxx()方法
@Test
public void test5(){
String str1="211";
int num=Integer.parseInt(str1);
System.out.println(num);
//运行报错,ava.lang.NumberFormatException: For input string: "211abc"
//String str2="211abc";
//int num1=Integer.parseInt(str2);
String str3="truetrue";
boolean b=Boolean.parseBoolean(str3);
System.out.println(b);
}
运行结果:211、false。
无论怎样转换,数据的格式必须是正确的,否则就会报错,boolean特殊点,返回的是false。
最后它们三者的转换可以详细归结为:
1、基本数据类型与包装类之间转换:直接使用自动装箱和自动拆箱。
2、基本数据类型、包装类转换为字符串:调用String的valueOf(Xxx xxx)方法。
3、字符串转换为基本数据类型、包装类:调用包装类的parseXxx()方法。
另外包装类中还有丰富的方法可供大家调用,如需学习可以自行查看包装类的API。
18.2.5 Integer经典面试题
以下是一道关于Integer包装类非常经典的面试题,如下:
@Test
public void test6(){
Integer a=127;
Integer b=127;
System.out.println(a == b);
Integer c=128;
Integer d=128;
System.out.println(c == d);
}
运行结果:
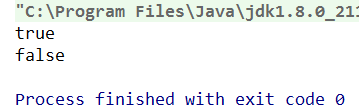
运行的结果肯定会有很大的疑问?同样是两个int型自动装箱为包装类进行比较,为什么127比较返回是true,而128比较则返回了false。这是为什么呢?答:这与Java的Integer类的设计有关,查看Integer类的源代码,如下所示。
上面已经知道了在自动装箱的过程中,编译器自动调用了valueOf()方法,所以先进入这个方法一探究竟:
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
通过上面的字段代码可知,进来先先判断 i 的范围,如满足条件,则直接从IntegerCache缓存中返回值,否则通过调用包装类的构造方法创建一个对象然后返回值。所以下面重点进入IntegerCache这个类。
private static class IntegerCache {
static final int low = -128; // 缓存最小值
static final int high; // 缓存最大值
static final Integer cache[]; // 缓存对象
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
//将最大范围赋给high变量
high = h;
//定义长度为256的Integer数组
cache = new Integer[(high - low) + 1];
int j = low;
//执行初始化,创建-128~127的Integer实例,并放入cache[]数组中
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache.high >= 127;
}
private IntegerCache() {}
}
从上面代码可以看出,Integer类中定义了一个IntegerCache内部类,内部类中定义了一个静态常量的Integer cache [ ]数组,而这个数组存储了从-128~127之间的整数自动装箱成Integer实例,如果我们使用自动装箱的方式,给Integer包装类赋值时,范围在-128~127之间,就可以直接使用数组中的元素,因为-128--127之间的同一个整数自动装箱成Integer实例时,永远是引用cache数组的同一个数组元素。而如果超出了这个范围,自动装箱需要再重新new对象,所以就出现了程序中的运行结果。
18.2.6 包装类小结
- 包装类的默认值都是NULL。
- 基本数据类型、包装类、字符串之间的转换可以归结为:
- 基本数据类型与包装类之间转换:直接使用自动装箱和自动拆箱。
- 基本数据类型、包装类转换为字符串:调用String的valueOf(Xxx xxx)方法。
- 字符串转换为基本数据类型、包装类:调用包装类的parseXxx()方法。
- Integer类中默认存放值的范围是-128~127之间。
18.3 System类和Runtime类
18.3.1 System类
System类对读者来说并不陌生,因为在之前所学知识中,需要打印结果时,使用的都是“System.out.println();”语句,这句代码中就使用了System类。System类定义了一些与系统相关的属性和方法,它所提供的属性和方法都是静态的,因此,想要引用这些属性和方法,直接使用System类调用即可。
System类的常用方法如下表所示。
| 方法声明 | 功能描述 |
|---|---|
static void exit(int status) |
该方法用于终止当前正在运行的Java虚拟机,其中参数status表示状态码,若状态码非0,则表示异常终止 |
static void gc() |
运行垃圾回收器,并对垃圾进行回收 |
static native long currentTimeMillis() |
返回以毫秒为单位的当前时间 |
static void arraycopy(Object src,int srcPos,Obiect dest,int destPos,int length) |
从src引用的指定源数组拷贝到dest引用的数组,拷贝从 指定的位置开始,到目标数组的指定位置结束 |
static Properties getProperties() |
取得当前的系统属性 |
static String getProperty(String key) |
获取指定键描述的系统属性 |
1.getProperties()方法
System类的getProperties()方法用于获取当前系统的全部属性,该方法会返回一个Properties对象,其中封装了系统的所有属性,这些属性是以键值对形式存在的。
package cn.itcast.chapter05.example09;
import java.util.*;
/**
* System类的getProperties()方法
*/
public class Example09 {
public static void main(String[] args) {
// 获取当前系统属性
Properties properties = System.getProperties();
// 获得所有系统属性的key,返回Enumeration对象
Enumeration propertyNames = properties.propertyNames();
while (propertyNames.hasMoreElements()) {
// 获取系统属性的键key
String key = (String) propertyNames.nextElement();
// 获得当前键key对应的值value
String value = System.getProperty(key);
System.out.println(key + "--->" + value);
}
}
}
2.currentTimeMillis()
currentTimeMillis()方法返回一个long类型的值,该值表示当前时间与1970年1月1日0点0分0秒之间的时间差,单位是毫秒,通常也将该值称作时间戳。
package cn.itcast.chapter05.example10;
/**
* 计算程序在进行求和操作时所消耗的时间
*/
public class Example10 {
public static void main(String[] args) {
long startTime = System.currentTimeMillis();// 循环开始时的当前时间
int sum = 0;
for (int i = 0; i < 100000000; i++) {
sum += i;
}
long endTime = System.currentTimeMillis();// 循环结束后的当前时间
System.out.println("程序运行的时间为:" + (endTime - startTime) + "毫秒");
}
}
3.arraycopy(Object src,int srcPos,Object dest,int destPos,int length)
arraycopy()方法用于将一个数组中的元素快速拷贝到另一个数组。其中的参数具体作用如下:
- src:表示源数组。
- dest:表示目标数组。
- srcPos:表示源数组中拷贝元素的起始位置。
- destPos:表示拷贝到目标数组的起始位置。
- length:表示拷贝元素的个数。
package cn.itcast.chapter05.example11;
/**
* 数组元素的拷贝
*/
public class Example11 {
public static void main(String[] args) {
int[] fromArray = { 101, 102, 103, 104, 105, 106 }; // 源数组
int[] toArray = { 201, 202, 203, 204, 205, 206, 207 }; // 目标数组
System.arraycopy(fromArray, 2, toArray, 3, 4); // 拷贝数组元素
// 打印目标数组中的元素
for (int i = 0; i < toArray.length; i++) {
System.out.println(i + ": " + toArray[i]);
}
}
}
18.3.2 Runtime类
Runtime类用于表示虚拟机运行时的状态,它用于封装JVM虚拟机进程。每次使用java命令启动虚拟机都对应一个Runtime实例,并且只有一个实例,因此该类采用单例模式进行设计,对象不可以直接实例化。若想在程序中获得一个Runtime实例,只能通过以下方式:Runtime run = Runtime.getRuntime();
案例代码
由于Runtime类封装了虚拟机进程,因此,在程序中通常会通过该类的实例对象来获取当前虚拟机的相关信息。
package cn.itcast.chapter05.example12;
/**
* Runtime类的使用
*/
public class Example12 {
public static void main(String[] args) {
Runtime rt = Runtime.getRuntime(); // 获取
System.out.println("处理器的个数: " + rt.availableProcessors() + "个");
System.out.println("空闲内存数量: " + rt.freeMemory() / 1024 / 1024 + "M");
System.out.println("最大可用内存数量: " + rt.maxMemory() / 1024 / 1024 + "M");
}
}
案例代码
Runtime类中提供了一个exec()方法,该方法用于执行一个dos命令,从而实现和在命令行窗口中输入dos命令同样的效果。例如,通过运行“notepad.exe”命令打开一个Windows自带的记事本程序
package cn.itcast.chapter05.example13;
import java.io.IOException;
/**
* 使用exec()方法打开记事本
*/
public class Example13 {
public static void main(String[] args) throws IOException {
Runtime rt = Runtime.getRuntime(); // 创建Runtime实例对象
rt.exec("notepad.exe"); // 调用exec()方法
}
}
打开记事本并在3秒后自动关闭
package cn.itcast.chapter05.example14;
/**
* 打开的记事本并在3秒后自动关闭
*/
public class Example14 {
public static void main(String[] args) throws Exception {
Runtime rt = Runtime.getRuntime(); // 创建一个Runtime实例对象
Process process = rt.exec("notepad.exe");// 得到表示进程的Process对象
Thread.sleep(3000); // 程序休眠3秒
process.destroy(); // 杀掉进程
}
}
Runtime.getRuntime().availableProcessors(); // 获取CPU核心数
Runtime.getRuntime().maxMemory(); // 获取应用被分配的最大内存
18.4 Math类
本小节引用自:Java Math类的常用方法 (biancheng.net)
18.4.1 Math类的常用方法
java中的 +、-、*、/ 和 % 等基本算术运算符不能进行更复杂的数学运算,例如,三角函数、对数运算、指数运算等。于是 Java 提供了 Math 工具类来完成这些复杂的运算。
在 Java 中 Math 类封装了常用的数学运算,提供了基本的数学操作,如指数、对数、平方根和三角函数等。Math 类位于 java.lang 包,它的构造方法是 private 的,因此无法创建 Math 类的对象,并且 Math 类中的所有方法都是类方法,可以直接通过类名来调用它们。
下面详细介绍该类的常量及数学处理方法。
18.4.1.1 静态常量
Math 类中包含 E 和 PI 两个静态常量,正如它们名字所暗示的,它们的值分别等于 e(自然对数)和 π(圆周率)。
例 1
调用 Math 类的 E 和 PI 两个常量,并将结果输出。代码如下:
System.out.println("E 常量的值:" + Math.E);
System.out.println("PI 常量的值:" + Math.PI);
执行上述代码,输出结果如下:
E 常量的值:2.718281828459045
PI 常量的值:3.141592653589793
18.4.1.2 求最大值、最小值和绝对值
在程序中常见的就是求最大值、最小值和绝对值问题,如果使用 Math 类提供的方法可以很容易实现。这些方法的说明如表 1 所示。
| 方法 | 说明 |
|---|---|
| static int abs(int a) | 返回 a 的绝对值 |
| static long abs(long a) | 返回 a 的绝对值 |
| static float abs(float a) | 返回 a 的绝对值 |
| static double abs(double a) | 返回 a 的绝对值 |
| static int max(int x,int y) | 返回 x 和 y 中的最大值 |
| static double max(double x,double y) | 返回 x 和 y 中的最大值 |
| static long max(long x,long y) | 返回 x 和 y 中的最大值 |
| static float max(float x,float y) | 返回 x 和 y 中的最大值 |
| static int min(int x,int y) | 返回 x 和 y 中的最小值 |
| static long min(long x,long y) | 返回 x 和 y 中的最小值 |
| static double min(double x,double y) | 返回 x 和 y 中的最小值 |
| static float min(float x,float y) | 返回 x 和 y 中的最小值 |
例 2
求 10 和 20 的较大值、15.6 和 15 的较小值、-12 的绝对值,代码如下:
public class Test02 {
public static void main(String[] args) {
System.out.println("10 和 20 的较大值:" + Math.max(10, 20));
System.out.println("15.6 和 15 的较小值:" + Math.min(15.6, 15));
System.out.println("-12 的绝对值:" + Math.abs(-12)); }
}
该程序的运行结果如下:
10和20的较大值:20
15.6和15的较小值:15.0
-12的绝对值:12
18.4.1.3 求整运算
Math 类的求整方法有很多,详细说明如表 2 所示。
| 方法 | 说明 |
|---|---|
| static double ceil(double a) | 返回大于或等于 a 的最小整数 |
| static double floor(double a) | 返回小于或等于 a 的最大整数 |
| static double rint(double a) | 返回最接近 a 的整数值,如果有两个同样接近的整数,则结果取偶数 |
| static int round(float a) | 将参数加上 1/2 后返回与参数最近的整数 |
| static long round(double a) | 将参数加上 1/2 后返回与参数最近的整数,然后强制转换为长整型 |
例 3
下面的实例演示了 Math 类中取整函数方法的应用:
import java.util.Scanner;
public class Test03 {
public static void main(String[] args) {
Scanner input = new Scanner(System.in);
System.outprintln("请输入一个数字:");
double num = input.nextDouble();
System.out.println("大于或等于 "+ num +" 的最小整数:" + Math.ceil(num));
System.out.println("小于或等于 "+ num +" 的最大整数:" + Math.floor(num));
System.out.println("将 "+ num +" 加上 0.5 之后最接近的整数:" + Math.round(num));
System.out.println("最接近 "+num+" 的整数:" + Math.rint(num));
}
}
执行结果如下:
请输入一个数字:
99.01
大于或等于 99.01 的最小整数:100.0
小于或等于 99.01 的最大整数:99.0
将 99.01 加上 0.5 之后最接近的整数:100
最接近 99.01 的整数:99.0
18.4.1.4 三角函数运算
Math 类中包含的三角函数方法及其说明如表 3 所示。
| 方法 | 说明 |
|---|---|
| static double sin(double a) | 返回角的三角正弦值,参数以孤度为单位 |
| static double cos(double a) | 返回角的三角余弦值,参数以孤度为单位 |
| static double asin(double a) | 返回一个值的反正弦值,参数域在 [-1,1],值域在 [-PI/2,PI/2] |
| static double acos(double a) | 返回一个值的反余弦值,参数域在 [-1,1],值域在 [0.0,PI] |
| static double tan(double a) | 返回角的三角正切值,参数以弧度为单位 |
| static double atan(double a) | 返回一个值的反正切值,值域在 [-PI/2,PI/2] |
| static double toDegrees(double angrad) | 将用孤度表示的角转换为近似相等的用角度表示的角 |
| staticdouble toRadians(double angdeg) | 将用角度表示的角转换为近似相等的用弧度表示的角 |
在表 3 中,每个方法的参数和返回值都是 double 类型,参数以弧度代替角度来实现,其中 1 度等于 π/180 弧度,因此平角就是 π 弧度。
例 4
计算 90 度的正弦值、0 度的余弦值、1 的反正切值、120 度的弧度值,代码如下:
public class Test04 {
public static void main(String[] args) {
System.out.println{"90 度的正弦值:" + Math.sin(Math.PI/2));
System.out.println("0 度的余弦值:" + Math.cos(0));
System.out.println("1 的反正切值:" + Math.atan(l));
System.out.println("120 度的弧度值:" + Math.toRadians(120.0));
}
}
在上述代码中,因为 Math.sin() 中的参数的单位是弧度,而 90 度表示的是角度,因此需要将 90 度转换为弧度,即 Math.PI/180*90,故转换后的弧度为 Math.PI/2,然后调用 Math 类中的 sin() 方法计算其正弦值。
该程序的运行结果如下:
90 度的正弦值:1.0
0 的余弦值:1.0
1 的反正切值:0.7853981633974483
120 度的弧度值:2.0943951023931953
18.4.1.5 指数运算
指数的运算包括求方根、取对数及其求 n 次方的运算。在 Math 类中定义的指数运算方法及其说明如表 4 所示。
| 方法 | 说明 |
|---|---|
| static double exp(double a) | 返回 e 的 a 次幂 |
| static double pow(double a,double b) | 返回以 a 为底数,以 b 为指数的幂值 |
| static double sqrt(double a) | 返回 a 的平方根 |
| static double cbrt(double a) | 返回 a 的立方根 |
| static double log(double a) | 返回 a 的自然对数,即 lna 的值 |
| static double log10(double a) | 返回以 10 为底 a 的对数 |
例 5
使用 Math 类中的方法实现指数的运算,main() 方法中的代码如下:
public class Test05 {
public static void main(String[] args) {
System.out.println("4 的立方值:" + Math.pow(4, 3));
System.out.println("16 的平方根:" + Math.sqrt(16));
System.out.println("10 为底 2 的对数:" + Math.log1O(2));
}
}
该程序的运行结果如下:
4 的立方值:64.0
16 的平方根:4.0
10 为底 2 的对数:0.3010299956639812
18.4.2 random()和Random类
java中要生成一个指定范围之内的随机数字有两种方法:一种是调用 Math 类的 random() 方法,一种是使用 Random 类。
Random 类提供了丰富的随机数生成方法,可以产生 boolean、int、long、float、byte 数组以及 double 类型的随机数,这是它与 random() 方法最大的不同之处。 random() 方法只能产生 double 类型的 0~1 的随机数。
Random 类位于 java.util 包中,该类常用的有如下两个构造方法。
- Random():该构造方法使用一个和当前系统时间对应的数字作为种子数,然后使用这个种子数构造 Random 对象。
- Random(long seed):使用单个 long 类型的参数创建一个新的随机数生成器。
18.4.2.1 Random 类
Random 类提供的所有方法生成的随机数字都是均匀分布的,也就是说区间内部的数字生成的概率是均等的,在表 1 中列出了 Random 类中常用的方法。
| 方法 | 说明 |
|---|---|
| boolean nextBoolean() | 生成一个随机的 boolean 值,生成 true 和 false 的值概率相等 |
| double nextDouble() | 生成一个随机的 double 值,数值介于 [0,1.0),含 0 而不包含 1.0 |
| int nextlnt() | 生成一个随机的 int 值,该值介于 int 的区间,也就是 -231~231-1。如果 需要生成指定区间的 int 值,则需要进行一定的数学变换 |
| int nextlnt(int n) | 生成一个随机的 int 值,该值介于 [0,n),包含 0 而不包含 n。如果想生成 指定区间的 int 值,也需要进行一定的数学变换 |
| void setSeed(long seed) | 重新设置 Random 对象中的种子数。设置完种子数以后的 Random 对象 和相同种子数使用 new 关键字创建出的 Random 对象相同 |
| long nextLong() | 返回一个随机长整型数字 |
| boolean nextBoolean() | 返回一个随机布尔型值 |
| float nextFloat() | 返回一个随机浮点型数字 |
| double nextDouble() | 返回一个随机双精度值 |
例 1
下面编写一个 Java 程序,演示如何使用 Random 类提供的方法来生成随机数。具体代码如下:
import java.util.Random;
public class Test06 {
public static void main(String[] args) {
Random r = new Random();
double d1 = r.nextDouble(); // 生成[0,1.0]区间的小数
double d2 = r.nextDouble() * 7; // 生成[0,7.0]区间的小数
int i1 = r.nextInt(10); // 生成[0,10]区间的整数
int i2 = r.nextInt(18) - 3; // 生成[-3,15)区间的整数
long l1 = r.nextLong(); // 生成一个随机长整型值
boolean b1 = r.nextBoolean(); // 生成一个随机布尔型值
float f1 = r.nextFloat(); // 生成一个随机浮点型值
System.out.println("生成的[0,1.0]区间的小数是:" + d1);
System.out.println("生成的[0,7.0]区间的小数是:" + d2);
System.out.println("生成的[0,10]区间的整数是:" + i1);
System.out.println("生成的[-3,15]区间的整数是:" + i2);
System.out.println("生成一个随机长整型值:" + l1);
System.out.println("生成一个随机布尔型值:" + b1);
System.out.println("生成一个随机浮点型值:" + f1);
System.out.print("下期七星彩开奖号码预测:");
for (int i = 1; i < 8; i++) {
int num = r.nextInt(9); // 生成[0,9]区间的整数
System.out.print(num);
}
}
}
本实例每次运行时结果都不相同,这就实现了随机产生数据的功能。该程序的运行结果如下:
生成的[0,1.0]区间的小数是:0.8773165855918825
生成的[0,7.0]区间的小数是:6.407083074782282
生成的[0,10]区间的整数是:5
生成的[-3,15]区间的整数是:4
生成一个随机长整型值:-8462847591661221914
生成一个随机布尔型值:false
生成一个随机浮点型值:0.6397003
下期七星彩开奖号码预测:0227168
18.4.2.2 Math 类的 random() 方法
Math 类的 random() 方法没有参数,它默认会返回大于等于 0.0、小于 1.0 的 double 类型随机数,即 0<=随机数<1.0。对 random() 方法返回的数字稍加处理,即可实现产生任意范围随机数的功能。
下面使用 random() 方法实现随机生成一个 2~100 偶数的功能。具体代码如下:
public class Test07 {
public static void main(String[] args) {
int min = 2; // 定义随机数的最小值
int max = 102; // 定义随机数的最大值
// 产生一个2~100的数
int s = (int) min + (int) (Math.random() * (max - min));
if (s % 2 == 0) {
// 如果是偶数就输出
System.out.println("随机数是:" + s);
} else {
// 如果是奇数就加1后输出
System.out.println("随机数是:" + (s + 1));
}
}
}
由于 m+(int)(Math.random()n) 语句可以获取 m~m+n 的随机数,所以 2+(int)(Math. random()(102-2)) 表达式可以求出 2~100 的随机数。在产生这个区间的随机数后还需要判断是否为偶数,这里使用了对 2 取余数,如果余数不是零,说明随机数是奇数,此时将随机数加 1 后再输出。
该程序的运行结果如下:
随机数是:20
18.4.3 数字格式化
数字的格式在解决实际问题时使用非常普遍,这时可以使用 DedmalFormat 类对结果进行格式化处理。例如,将小数位统一成 2 位,不足 2 位的以 0 补齐。
DecimalFormat 是 NumberFormat 的一个子类,用于格式化十进制数字。DecimalFormat 类包含一个模式和一组符号,
常用符号的说明如表 1 所示。
| 符号 | 说明 |
|---|---|
| 0 | 显示数字,如果位数不够则补 0 |
| # | 显示数字,如果位数不够不发生变化 |
| . | 小数分隔符 |
| - | 减号 |
| , | 组分隔符 |
| E | 分隔科学记数法中的尾数和小数 |
| % | 前缀或后缀,乘以 100 后作为百分比显示 |
| ? | 乘以 1000 后作为千进制货币符显示。用货币符号代替。如果双写,用国际货币符号代替; 如果出现在一个模式中,用货币十进制分隔符代替十进制分隔符 |
下面编写一个Java程序,演示如何使用 DecimalFormat 类将数字转换成各种格式,实现代码如下。
import java.text.DecimalFormat;
import java.util.Scanner;
public class Test08 {
public static void main(String[] args) {
// 实例化DecimalFormat类的对象,并指定格式
DecimalFormat df1 = new DecimalFormat("0.0");
DecimalFormat df2 = new DecimalFormat("#.#");
DecimalFormat df3 = new DecimalFormat("000.000");
DecimalFormat df4 = new DecimalFormat("###.###");
Scanner scan = new Scanner(System.in);
System.out.print("请输入一个float类型的数字:");
float f = scan.nextFloat();
// 对输入的数字应用格式,并输出结果
System.out.println("0.0 格式:" + df1.format(f));
System.out.println("#.# 格式:" + df2.format(f));
System.out.println("000.000 格式:" + df3.format(f));
System.out.println("###.### 格式:" + df4.format(f));
}
}
执行上述代码,输出结果如下所示:
请输入一个float类型的数字:5487.45697
0.0 格式:5487.5
#.# 格式:5487.5
000.000 格式:5487.457
###.### 格式:5487.457
请输入一个float类型的数字:5.0
0.0 格式:5.0
#.# 格式:5
000.000 格式:005.000
###.### 格式:5
18.4.4 BigInteger类和BigDecimal类
在 Java 中提供了用于大数字运算的类,即 java.math.BigInteger 类和 java.math.BigDecimal 类。这两个类用于高精度计算,其中 BigInteger 类是针对整型大数字的处理类,而 BigDecimal 类是针对大小数的处理类。
18.4.4.1 BigInteger 类
如果要存储比 Integer 更大的数字,Integer 数据类型就无能为力了。因此,Java 中提供 BigInteger 类来处理更大的数字。
BigInteger 类型的数字范围较 Integer 类型的数字范围要大得多。BigInteger 支持任意精度的整数,也就是说在运算中 BigInteger 类型可以准确地表示任何大小的整数值。
除了基本的加、减、乘、除操作之外,BigInteger 类还封装了很多操作,像求绝对值、相反数、最大公约数以及判断是否为质数等。
要使用 BigInteger 类,首先要创建一个 BigInteger 对象。BigInteger 类提供了很多种构造方法,其中最直接的一种是参数以字符串形式代表要处理的数字。这个方法语法格式如下:
BigInteger(String val)
这里的 val 是数字十进制的字符串。例如,要将数字 5 转换为 BigInteger 对象,语句如下:
BigInteger bi = new BigInteger("5")
注意:这里数字 5 的双引号是必需的,因为 BigInteger 类构造方法要求参数是字符串类型。
创建 BigInteger 对象之后,便可以调用 BigInteger 类提供的方法进行各种数学运算操作,表 1 列出了 BigInteger 类的常用运算方法。
| 方法名称 | 说明 |
|---|---|
| add(BigInteger val) | 做加法运算 |
| subtract(BigInteger val) | 做减法运算 |
| multiply(BigInteger val) | 做乘法运算 |
| divide(BigInteger val) | 做除法运算 |
| remainder(BigInteger val) | 做取余数运算 |
| divideAndRemainder(BigInteger val) | 做除法运算,返回数组的第一个值为商,第二个值为余数 |
| pow(int exponent) | 做参数的 exponent 次方运算 |
| negate() | 取相反数 |
| shiftLeft(int n) | 将数字左移 n 位,如果 n 为负数,则做右移操作 |
| shiftRight(int n) | 将数字右移 n 位,如果 n 为负数,则做左移操作 |
| and(BigInteger val) | 做与运算 |
| or(BigInteger val) | 做或运算 |
| compareTo(BigInteger val) | 做数字的比较运算 |
| equals(Object obj) | 当参数 obj 是 Biglnteger 类型的数字并且数值相等时返回 true, 其他返回 false |
| min(BigInteger val) | 返回较小的数值 |
| max(BigInteger val) | 返回较大的数值 |
编写一个 Java 程序,将用户输入的数字作为 BigInteger 对象,然后调用该对象的各种方法实现加、减、乘、除和其他运算,并输出结果。具体实现代码如下:
import java.math.BigInteger;
import java.util.Scanner;
public class Test09 {
public static void main(String[] args) {
Scanner input = new Scanner(System.in);
System.out.println("请输入一个整型数字:");
// 保存用户输入的数字
int num = input.nextInt();
// 使用输入的数字创建BigInteger对象
BigInteger bi = new BigInteger(num + "");
// 计算大数字加上99的结果
System.out.println("加法操作结果:" + bi.add(new BigInteger("99")));
// 计算大数字减去25的结果
System.out.println("减法操作结果:" + bi.subtract(new BigInteger("25")));
// 计算大数字乘以3的结果
System.out.println("乘法橾作结果:" + bi.multiply(new BigInteger("3")));
// 计算大数字除以2的结果
System.out.println("除法操作结果:" + bi.divide(new BigInteger("2")));
// 计算大数字除以3的商
System.out.println("取商操作结果:" + bi.divideAndRemainder(new BigInteger("3"))[0]);
// 计算大数字除以3的余数
System.out.println("取余操作结果:" + bi.divideAndRemainder(new BigInteger("3"))[1]);
// 计算大数字的2次方
System.out.println("取 2 次方操作结果:" + bi.pow(2));
// 计算大数字的相反数
System.out.println("取相反数操作结果:" + bi.negate());
}
}
上述代码将用户输入的整型数字保存到 num 变量中,由于 BigInteger 类的构造方法只接收字符串类型的参数,所以使用“new BigInteger(num+"")”代码来创建 BigInteger 对象。接下来的代码演示了如何调用 BigInteger 类提供的运算方法,运行效果下所示。
请输入一个整型数字:
125
加法操作结果:224
减法操作结果:100
乘法橾作结果:375
除法操作结果:62
取商操作结果:41
取余操作结果:2
取 2 次方操作结果:15625
取相反数操作结果:-125
18.4.4.2 BigDecimal 类
BigInteger 和 BigDecimal 都能实现大数字的运算,不同的是 BigDecimal 加入了小数的概念。一般的 float 和 double 类型数据只能用来做科学计算或工程计算,但由于在商业计算中要求数字精度比较高,所以要用到 BigDecimal 类。BigDecimal 类支持任何精度的浮点数,可以用来精确计算货币值。
BigDecimal 常用的构造方法如下。
- BigDecimal(double val):实例化时将双精度型转换为 BigDecimal 类型。
- BigDecimal(String val):实例化时将字符串形式转换为 BigDecimal 类型。
BigDecimal 类的方法可以用来做超大浮点数的运算,像加、减、乘和除等。在所有运算中,除法运算是最复杂的,因为在除不尽的情况下,末位小数的处理方式是需要考虑的。
下面列出了 BigDecimal 类用于实现加、减、乘和除运算的方法。
BigDecimal add(BigDecimal augend) // 加法操作
BigDecimal subtract(BigDecimal subtrahend) // 减法操作
BigDecimal multiply(BigDecimal multiplieand) // 乘法操作
BigDecimal divide(BigDecimal divisor,int scale,int roundingMode ) // 除法操作
其中,divide() 方法的 3 个参数分别表示除数、商的小数点后的位数和近似值处理模式。
表 2 列出了 roundingMode 参数支持的处理模式。
| 模式名称 | 说明 |
|---|---|
| BigDecimal.ROUND_UP | 商的最后一位如果大于 0,则向前进位,正负数都如此 |
| BigDecimal.ROUND_DOWN | 商的最后一位无论是什么数字都省略 |
| BigDecimal.ROUND_CEILING | 商如果是正数,按照 ROUND_UP 模式处理;如果是负数,按照 ROUND_DOWN 模式处理 |
| BigDecimal.ROUND_FLOOR | 与 ROUND_CELING 模式相反,商如果是正数,按照 ROUND_DOWN 模式处理; 如果是负数,按照 ROUND_UP 模式处理 |
| BigDecimal.ROUND_HALF_ DOWN | 对商进行五舍六入操作。如果商最后一位小于等于 5,则做舍弃操作,否则对最后 一位进行进位操作 |
| BigDecimal.ROUND_HALF_UP | 对商进行四舍五入操作。如果商最后一位小于 5,则做舍弃操作,否则对最后一位 进行进位操作 |
| BigDecimal.ROUND_HALF_EVEN | 如果商的倒数第二位是奇数,则按照 ROUND_HALF_UP 处理;如果是偶数,则按 照 ROUND_HALF_DOWN 处理 |
编写一个 Java 程序,演示如何使用 BigDecimal 类提供的方法对数字执行运算,并输出结果。具体实现代码如下:
import java.math.BigDecimal;
import java.util.Scanner;
public class Test10 {
public static void main(String[] args) {
Scanner input = new Scanner(System.in);
System.out.println("请输入一个数字:");
// 保存用户输入的数字
double num = input.nextDouble();
// 使用输入的数字创建BigDecimal对象
BigDecimal bd = new BigDecimal(num);
// 计算大数字加上99.154的结果
System.out.println("加法操作结果:" + bd.add(new BigDecimal(99.154)));
// 计算大数字减去-25.157904的结果
System.out.println("减法操作结果:" + bd.subtract(new BigDecimal(-25.157904)));
// 计算大数字乘以3.5的结果
System.out.println("乘法操作结果:" + bd.multiply(new BigDecimal(3.5)));
// 计算大数字除以3.14的结果,并保留小数后2位
System.out.println("除法操作结果(保留 2 位小数):" + bd.divide(new BigDecimal(3.14), 2, BigDecimal.ROUND_CEILING));
// 计算大数字除以3.14的结果,并保留小数后5位
System.out.println("除法操作结果(保留 5 位小数):" + bd.divide(new BigDecimal(3.14), 5, BigDecimal.ROUND_CEILING));
}
}
上述代码将用户输入的数字保存到 num 变量中,然后调用“newBigDecimal(num)”方法来创建 BigDecimal 对象。接下来的代码演示了如何调用 BigDecimal 类提供的运算方法,运行效果如下所示。
请输入一个数字:
100
加法操作结果:199.15399999999999636202119290828704833984375
减法操作结果:125.157903999999998490011421381495893001556396484375
乘法操作结果:350.0
除法操作结果(保留 2 位小数):31.85
除法操作结果(保留 5 位小数):31.84714
18.5 日期类
18.5.1 日期的处理
18.5.1.1 Date类
Date 类表示系统特定的时间戳,可以精确到毫秒。Date 对象表示时间的默认顺序是星期、月、日、小时、分、秒、年。
1. 构造方法
Date 类有如下两个构造方法。
- Date():此种形式表示分配 Date 对象并初始化此对象,以表示分配它的时间(精确到毫秒),使用该构造方法创建的对象可以获取本地的当前时间。
- Date(long date):此种形式表示从 GMT 时间(格林尼治时间)1970 年 1 月 1 日 0 时 0 分 0 秒开始经过参数 date 指定的毫秒数。
这两个构造方法的使用示例如下:
Date date1 = new Date(); // 调用无参数构造函数
System.out.println(date1.toString()); // 输出:Wed May 18 21:24:40 CST 2016
Date date2 = new Date(60000); // 调用含有一个long类型参数的构造函数
System.out.println(date2); // 输出:Thu Jan 0108:01:00 CST 1970
Date 类的无参数构造方法获取的是系统当前的时间,显示的顺序为星期、月、日、小时、分、秒、年。
Date 类带 long 类型参数的构造方法获取的是距离 GMT 指定毫秒数的时间,60000 毫秒是一分钟,而 GMT(格林尼治标准时间)与 CST(中央标准时间)相差 8 小时,也就是说 1970 年 1 月 1 日 00:00:00 GMT 与 1970 年 1 月 1 日 08:00:00 CST 表示的是同一时间。 因此距离 1970 年 1 月 1 日 00:00:00 CST 一分钟的时间为 1970 年 1 月 1 日 00:01:00 CST,即使用 Date 对象表示为 Thu Jan 01 08:01:00 CST 1970。
2. 常用方法
Date 类提供了许多与日期和事件相关的方法,其中常见的方法如表 1 所示。
| 方法 | 描述 |
|---|---|
| boolean after(Date when) | 判断此日期是否在指定日期之后 |
| boolean before(Date when) | 判断此日期是否在指定日期之前 |
| int compareTo(Date anotherDate) | 比较两个日期的顺序 |
| boolean equals(Object obj) | 比较两个日期的相等性 |
| long getTime() | 返回自 1970 年 1 月 1 日 00:00:00 GMT 以来,此 Date 对象表示的毫秒数 |
| String toString() | 把此 Date 对象转换为以下形式的 String: dow mon dd hh:mm:ss zzz yyyy。 其中 dow 是一周中的某一天(Sun、Mon、Tue、Wed、Thu、Fri 及 Sat) |
例 1
下面使用一个实例来具体演示 Date 类的使用。假设,某一天特定时间要去做一件事,而且那个时间已经过去一分钟之后才想起来这件事还没有办,这时系统将会提示已经过去了多 长时间。具体的代码如下:
import java.util.Date;
import java.util.Scanner;
public class Test11 {
public static void main(String[] args) {
Scanner input = new Scanner(System.in);
System.out.println("请输入要做的事情:");
String title = input.next();
Date date1 = new Date(); // 获取当前日期
System.out.println("[" + title + "] 这件事发生时间为:" + date1);
try {
Thread.sleep(60000);// 暂停 1 分钟
} catch (InterruptedException e) {
e.printStackTrace();
}
Date date2 = new Date();
System.out.println("现在时间为:" + date2);
if (date2.before(date1)) {
System.out.println("你还有 " + (date2.getTime() - date1.getTime()) / 1000 + " 秒需要去完成【" + title + "】这件事!");
} else {
System.out.println("【" + title + "】事情已经过去了 " + (date2.getTime() - date1.getTime()) / 1000 + " 秒");
}
}
}
在该程序中,分别使用 Date 类的无参数构造方法创建了两个 Date 对象。在创建完第一个 Date 对象后,使用 Thread.sleep() 方法让程序休眠 60 秒,然后再创建第二个 Date 对象,这样第二个 Date 对象所表示的时间将会在第一个 Date 对象所表示时间之后,因此“date2.before(date1)”条件表达式不成立,从而执行 else 块中的代码,表示事情已经发生过。
运行该程序,执行结果如下所示。
请输入要做的事情:
收快递
【收快递】这件事发生时间为:Fri Oct 12 11:11:07 CST 2018
现在时间为:Fri Oct 12 11:12:07 CST 2018
【收快递】事情已经过去了 60 秒
18.5.1.2 Calendar 类
Calendar 类是一个抽象类,它为特定瞬间与 YEAR、MONTH、DAY_OF—MONTH、HOUR 等日历字段之间的转换提供了一些方法,并为操作日历字段(如获得下星期的日期) 提供了一些方法。
创建 Calendar 对象不能使用 new 关键字,因为 Calendar 类是一个抽象类,但是它提供了一个 getInstance() 方法来获得 Calendar类的对象。getInstance() 方法返回一个 Calendar 对象,其日历字段已由当前日期和时间初始化。
Calendar c = Calendar.getInstance();
当创建了一个 Calendar 对象后,就可以通过 Calendar 对象中的一些方法来处理日期、时间。Calendar 类的常用方法如表 2 所示。
| 方法 | 描述 |
|---|---|
| void add(int field, int amount) | 根据日历的规则,为给定的日历字段 field 添加或减去指定的时间量 amount |
| boolean after(Object when) | 判断此 Calendar 表示的时间是否在指定时间 when 之后,并返回判断结果 |
| boolean before(Object when) | 判断此 Calendar 表示的时间是否在指定时间 when 之前,并返回判断结果 |
| void clear() | 清空 Calendar 中的日期时间值 |
| int compareTo(Calendar anotherCalendar) | 比较两个 Calendar 对象表示的时间值(从格林威治时间 1970 年 01 月 01 日 00 时 00 分 00 秒至现在的毫秒偏移量),大则返回 1,小则返回 -1,相等返回 0 |
| int get(int field) | 返回指定日历字段的值 |
| int getActualMaximum(int field) | 返回指定日历字段可能拥有的最大值 |
| int getActualMinimum(int field) | 返回指定日历字段可能拥有的最小值 |
| int getFirstDayOfWeek() | 获取一星期的第一天。根据不同的国家地区,返回不同的值 |
| static Calendar getInstance() | 使用默认时区和语言坏境获得一个日历 |
| static Calendar getInstance(TimeZone zone) | 使用指定时区和默认语言环境获得一个日历 |
| static Calendar getInstance(TimeZone zone, Locale aLocale) | 使用指定时区和语言环境获得一个日历 |
| Date getTime() | 返回一个表示此 Calendar 时间值(从格林威治时间 1970 年 01 月 01 日 00 时 00 分 00 秒至现在的毫秒偏移量)的 Date 对象 |
| long getTimeInMillis() | 返回此 Calendar 的时间值,以毫秒为单位 |
| void set(int field, int value) | 为指定的日历字段设置给定值 |
| void set(int year, int month, int date) | 设置日历字段 YEAR、MONTH 和 DAY_OF_MONTH 的值 |
| void set(int year, int month, int date, int hourOfDay, int minute, int second) | 设置字段 YEAR、MONTH、DAY_OF_MONTH、HOUR、 MINUTE 和 SECOND 的值 |
| void setFirstDayOfWeek(int value) | 设置一星期的第一天是哪一天 |
| void setTimeInMillis(long millis) | 用给定的 long 值设置此 Calendar 的当前时间值 |
Calendar 对象可以调用 set() 方法将日历翻到任何一个时间,当参数 year 取负数时表示公元前。Calendar 对象调用 get() 方法可以获取有关年、月、日等时间信息,参数 field 的有效值由 Calendar 静态常量指定。
Calendar 类中定义了许多常量,分别表示不同的意义。
- Calendar.YEAR:年份。
- Calendar.MONTH:月份。
- Calendar.DATE:日期。
- Calendar.DAY_OF_MONTH:日期,和上面的字段意义完全相同。
- Calendar.HOUR:12小时制的小时。
- Calendar.HOUR_OF_DAY:24 小时制的小时。
- Calendar.MINUTE:分钟。
- Calendar.SECOND:秒。
- Calendar.DAY_OF_WEEK:星期几。
例如,要获取当前月份可用如下代码:
int month = Calendar.getInstance().get(Calendar.MONTH);
如果整型变量 month 的值是 0,表示当前日历是在 1 月份;如果值是 11,则表示当前日历在 12 月份。
使用 Calendar 类处理日期时间的实例如下:
Calendar calendar = Calendar.getInstance(); // 如果不设置时间,则默认为当前时间
calendar.setTime(new Date()); // 将系统当前时间赋值给 Calendar 对象
System.out.println("现在时刻:" + calendar.getTime()); // 获取当前时间
int year = calendar.get(Calendar.YEAR); // 获取当前年份
System.out.println("现在是" + year + "年");
int month = calendar.get(Calendar.MONTH) + 1; // 获取当前月份(月份从 0 开始,所以加 1)
System.out.print(month + "月");
int day = calendar.get(Calendar.DATE); // 获取日
System.out.print(day + "日");
int week = calendar.get(Calendar.DAY_OF_WEEK) - 1; // 获取今天星期几(以星期日为第一天)
System.out.print("星期" + week);
int hour = calendar.get(Calendar.HOUR_OF_DAY); // 获取当前小时数(24 小时制)
System.out.print(hour + "时");
int minute = calendar.get(Calendar.MINUTE); // 获取当前分钟
System.out.print(minute + "分");
int second = calendar.get(Calendar.SECOND); // 获取当前秒数
System.out.print(second + "秒");
int millisecond = calendar.get(Calendar.MILLISECOND); // 获取毫秒数
System.out.print(millisecond + "毫秒");
int dayOfMonth = calendar.get(Calendar.DAY_OF_MONTH); // 获取今天是本月第几天
System.out.println("今天是本月的第 " + dayOfMonth + " 天");
int dayOfWeekInMonth = calendar.get(Calendar.DAY_OF_WEEK_IN_MONTH); // 获取今天是本月第几周
System.out.println("今天是本月第 " + dayOfWeekInMonth + " 周");
int many = calendar.get(Calendar.DAY_OF_YEAR); // 获取今天是今年第几天
System.out.println("今天是今年第 " + many + " 天");
Calendar c = Calendar.getInstance();
c.set(2012, 8, 8); // 设置年月日,时分秒将默认采用当前值
System.out.println("设置日期为 2012-8-8 后的时间:" + c.getTime()); // 输出时间
上面的示例代码演示了 Calendar 类中的方法与常量的结合使用,从而完成处理日期的操作。
例 2
下面使用 Calendar 类来实现日历的打印功能,代码实现如下:
import java.util.Calendar;
public class CalendarDemo {
public static void main(String[] args) {
Calendar calendar = Calendar.getInstance();
calendar.set(2016, 5, 1); // 实际的calendar对象所表示的日期为2016年6月1日
// 判断2016年6月1日为一周中的第几天
int index = calendar.get(Calendar.DAY_OF_WEEK) - 1;
char[] title = { '日', '一', '二', '三', '四', '五', '六' }; // 存放曰历的头部
int daysArray[][] = new int[6][7];// 存放日历的数据
int daysInMonth = 31; // 该月的天数
int day = 1; // 自动增长
for (int i = index; i < 7; i++) {
// 填充第一周的日期数据,即日历中的第一行
daysArray[0][i] = day++;
}
for (int i = 1; i < 6; i++) {
// 填充其他周的日历数据,控制行
for (int j = 0; j < 7; j++) {
// 如果当前day表示的是本月最后一天,则停止向数组中继续赋值
if (day > daysInMonth) {
i = 6;
break;
}
daysArray[i][j] = day++;
}
}
System.out.println("------------------2016 年 6 月--------------------\n");
for (int i = 0; i < title.length; i++) {
System.out.print(title[i] + "\t");
}
System.out.print("\n");
// 输出二元数组daysArray中的元素
for (int i = 0; i < 6; i++) {
for (int j = 0; j < 7; j++) {
if (daysArray[i][j] == 0) {
if (i != 0) {
// 如果到月末,则完成显示日历的任务,停止该方法的执行
return;
}
System.out.print("\t");
continue;
}
System.out.print(daysArray[i][j] + "\t");
}
System.out.print("\n");
}
}
}
该程序看似复杂其实很简单。因为 Calendar 类所表示的时间月份是 set() 方法中表示月份的参数值 +1,因此 Calendar 类的实际时间为 2016 年 6 月 1 日。在下面的代码中分别获取 6 月 1 日为本周中的第几天,以便在相应的星期下开始输出 6 月份的日历。程序中的 daysArray 是一个二元数组,该二元数组控制了日历的格式输出,第一个子数组控制日历的行,第二个子数组控制曰历的列,即可输出二元数组中的每一个元素。
运行程序,执行结果如下所示。
------------------2016 年 6 月--------------------
日 一 二 三 四 五 六
1 2 3 4
5 6 7 8 9 10 11
12 13 14 15 16 17 18
19 20 21 22 23 24 25
26 27 28 29 30 31
18.5.2 日期格式化
格式化日期表示将日期/时间格式转换为预先定义的日期/时间格式。例如将日期“Fri May 18 15:46:24 CST2016” 格式转换为 “2016-5-18 15:46:24 星期五”的格式。
在 Java中,可以使用 DateFormat 类和 SimpleDateFormat 类来格式化日期,下面详细介绍这两个格式化日期类的使用。
18.5.2.1 DateFormat 类
DateFormat 是日期/时间格式化子类的抽象类,它以与语言无关的方式格式化并解析日期或时间。日期/时间格式化子类(如 SimpleDateFormat)允许进行格式化(也就是日期→文本)、解析(文本→日期)和标准化日期。
在创建 DateFormat 对象时不能使用 new 关键字,而应该使用 DateFormat 类中的静态方法 getDateInstance(),示例代码如下:
DateFormat df = DateFormat.getDatelnstance();
在创建了一个 DateFormat 对象后,可以调用该对象中的方法来对日期/时间进行格式化。DateFormat 类中常用方法如表 1 所示。
| 方法 | 描述 |
|---|---|
| String format(Date date) | 将 Date 格式化日期/时间字符串 |
| Calendar getCalendar() | 获取与此日期/时间格式相关联的日历 |
| static DateFormat getDateInstance() | 获取具有默认格式化风格和默认语言环境的日期格式 |
| static DateFormat getDateInstance(int style) | 获取具有指定格式化风格和默认语言环境的日期格式 |
| static DateFormat getDateInstance(int style, Locale locale) | 获取具有指定格式化风格和指定语言环境的日期格式 |
| static DateFormat getDateTimeInstance() | 获取具有默认格式化风格和默认语言环境的日期/时间 格式 |
| static DateFormat getDateTimeInstance(int dateStyle,int timeStyle) | 获取具有指定日期/时间格式化风格和默认语言环境的 日期/时间格式 |
| static DateFormat getDateTimeInstance(int dateStyle,int timeStyle,Locale locale) | 获取具有指定日期/时间格式化风格和指定语言环境的 日期/时间格式 |
| static DateFormat getTimeInstance() | 获取具有默认格式化风格和默认语言环境的时间格式 |
| static DateFormat getTimeInstance(int style) | 获取具有指定格式化风格和默认语言环境的时间格式 |
| static DateFormat getTimeInstance(int style, Locale locale) | 获取具有指定格式化风格和指定语言环境的时间格式 |
| void setCalendar(Calendar newCalendar) | 为此格式设置日历 |
| Date parse(String source) | 将给定的字符串解析成日期/时间 |
格式化样式主要通过 DateFormat 常量设置。将不同的常量传入到表 1 所示的方法中,以控制结果的长度。DateFormat 类的常量如下。
- SHORT:完全为数字,如 12.5.10 或 5:30pm。
- MEDIUM:较长,如 May 10,2016。
- LONG:更长,如 May 12,2016 或 11:15:32am。
- FULL:是完全指定,如 Tuesday、May 10、2012 AD 或 11:l5:42am CST。
使用 DateFormat 类格式化曰期/时间的示例如下:
// 获取不同格式化风格和中国环境的日期
DateFormat df1 = DateFormat.getDateInstance(DateFormat.SHORT, Locale.CHINA);
DateFormat df2 = DateFormat.getDateInstance(DateFormat.FULL, Locale.CHINA);
DateFormat df3 = DateFormat.getDateInstance(DateFormat.MEDIUM, Locale.CHINA);
DateFormat df4 = DateFormat.getDateInstance(DateFormat.LONG, Locale.CHINA);
// 获取不同格式化风格和中国环境的时间
DateFormat df5 = DateFormat.getTimeInstance(DateFormat.SHORT, Locale.CHINA);
DateFormat df6 = DateFormat.getTimeInstance(DateFormat.FULL, Locale.CHINA);
DateFormat df7 = DateFormat.getTimeInstance(DateFormat.MEDIUM, Locale.CHINA);
DateFormat df8 = DateFormat.getTimeInstance(DateFormat.LONG, Locale.CHINA);
// 将不同格式化风格的日期格式化为日期字符串
String date1 = df1.format(new Date());
String date2 = df2.format(new Date());
String date3 = df3.format(new Date());
String date4 = df4.format(new Date());
// 将不同格式化风格的时间格式化为时间字符串
String time1 = df5.format(new Date());
String time2 = df6.format(new Date());
String time3 = df7.format(new Date());
String time4 = df8.format(new Date());
// 输出日期
System.out.println("SHORT:" + date1 + " " + time1);
System.out.println("FULL:" + date2 + " " + time2);
System.out.println("MEDIUM:" + date3 + " " + time3);
System.out.println("LONG:" + date4 + " " + time4);
运行该段代码,输出的结果如下:
SHORT:18-10-15 上午9:30
FULL:2018年10月15日 星期一 上午09时30分43秒 CST
MEDIUM:2018-10-15 9:30:43
LONG:2018年10月15日 上午09时30分43秒
该示例主要介绍了 DateFormat 类中方法与常量的结合使用,通过使用 DateFomat 类可以对日期进行不同风格的格式化。
18.5.2.2 SimpleDateFormat 类
如果使用 DateFormat 类格式化日期/时间并不能满足要求,那么就需要使用 DateFormat 类的子类——SimpleDateFormat。
SimpleDateFormat 是一个以与语言环境有关的方式来格式化和解析日期的具体类,它允许进行格式化(日期→文本)、解析(文本→日期)和规范化。SimpleDateFormat 使得可以选择任何用户定义的日期/时间格式的模式。
SimpleDateFormat 类主要有如下 3 种构造方法。
- SimpleDateFormat():用默认的格式和默认的语言环境构造 SimpleDateFormat。
- SimpleDateFormat(String pattern):用指定的格式和默认的语言环境构造 SimpleDateF ormat。
- SimpleDateFormat(String pattern,Locale locale):用指定的格式和指定的语言环境构造 SimpleDateF ormat。
SimpleDateFormat 自定义格式中常用的字母及含义如表 2 所示。
| 字母 | 含义 | 示例 |
|---|---|---|
| y | 年份。一般用 yy 表示两位年份,yyyy 表示 4 位年份 | 使用 yy 表示的年扮,如 11; 使用 yyyy 表示的年份,如 2011 |
| M | 月份。一般用 MM 表示月份,如果使用 MMM,则会 根据语言环境显示不同语言的月份 | 使用 MM 表示的月份,如 05; 使用 MMM 表示月份,在 Locale.CHINA 语言环境下,如“十月”;在 Locale.US 语言环境下,如 Oct |
| d | 月份中的天数。一般用 dd 表示天数 | 使用 dd 表示的天数,如 10 |
| D | 年份中的天数。表示当天是当年的第几天, 用 D 表示 | 使用 D 表示的年份中的天数,如 295 |
| E | 星期几。用 E 表示,会根据语言环境的不同, 显示不 同语言的星期几 | 使用 E 表示星期几,在 Locale.CHINA 语 言环境下,如“星期四”;在 Locale.US 语 言环境下,如 Thu |
| H | 一天中的小时数(0~23)。一般用 HH 表示小时数 | 使用 HH 表示的小时数,如 18 |
| h | 一天中的小时数(1~12)。一般使用 hh 表示小时数 | 使用 hh 表示的小时数,如 10 (注意 10 有 可能是 10 点,也可能是 22 点) |
| m | 分钟数。一般使用 mm 表示分钟数 | 使用 mm 表示的分钟数,如 29 |
| s | 秒数。一般使用 ss 表示秒数 | 使用 ss 表示的秒数,如 38 |
| S | 毫秒数。一般使用 SSS 表示毫秒数 | 使用 SSS 表示的毫秒数,如 156 |
编写 Java 程序,使用 SimpleDateFormat 类格式化当前日期并打印,日期格式为“xxxx 年 xx 月 xx 日星期 xxx 点 xx 分 xx 秒”,具体的实现代码如下:
import java.text.SimpleDateFormat;
import java.util.Date;
public class Test13 {
public static void main(String[] args) {
Date now = new Date(); // 创建一个Date对象,获取当前时间
// 指定格式化格式
SimpleDateFormat f = new SimpleDateFormat("今天是 " + "yyyy 年 MM 月 dd 日 E HH 点 mm 分 ss 秒");
System.out.println(f.format(now)); // 将当前时间袼式化为指定的格式
}
}
该程序的运行结果如下:
今天是 2018 年 10 月 15 日 星期一 09 点 26 分 23 秒
18.6 枚举类
18.6.1 枚举类简介
枚举:指的是仅容许特定数据类型值的有限集合。例如我们日常生活中星期一到星期日这七天就是一个特定的有限集合,一年四季的春夏秋冬也同样是的,它们都是枚举。枚举和我们数学中的集合非常相似,例如我们定义一个Season={Spring、Summer、Autumn、Winner}这样的集合,当我们要从集合中取出数据时,只能从集合中取出已经存在的数据,否则是肯定获取不到的。
枚举类:顾名思义:类的对象是有限和固定的集合。枚举类是JDK1.5中才出现的新特性,它是一种特殊的数据类型,在Java中用enum关键字来修饰,enum的全称是enumeration。所有被enum修饰的类都会默认的继承自java.lang.Enum这个类,而不是Object类。有些人并不推荐使用枚举类,而有些人则推荐使用,认为使用枚举类更加的方便。这里就要说上一句仁者见仁智者见智吧。然而在实际开发中枚举类用的还是比较的多的,用来定义各种状态。
另可参考:一篇文章彻底读懂Java枚举Enum类(案例详解) - Java辰兮 - 博客园 (cnblogs.com)
枚举是一个引用类型,是一个规定了取值范围的变量类型。
枚举变量不能使用其他的数据,只能使用枚举中常量赋值。提高程序安全性;
枚举 里面定义的 就相当于是已经生成且固定的对象,你可以直接使用;
枚举中的变量,其实就是一个当前类型的静态常量。
比如说:英雄联盟里面,有很多职业,比如说”战士“、”法师“、”射手“……等职业。我们就可以定义一个叫”职业“的枚举类型;后台再其它地方哪里需要直接引用即可;
18.6.2 枚举类的定义
上面提到了枚举类是JDK1.5才有的新特性,那么在没有枚举之前是怎么来定义的?
public class SeasonDemo {
public static final int SPRING = 0;
public static final int SUMMER = 1;
public static final int AUTUMN = 2;
public static final int WINTER = 3;
public static void main(String[] args) {
System.out.println(SeasonDemo.SPRING);
System.out.println(SeasonDemo.SUMMER);
System.out.println(SeasonDemo.AUTUMN);
System.out.println(SeasonDemo.WINTER);
System.out.println("---------------");
show(SeasonDemo.SPRING);
show(123);
}
public static void show(int season) {
System.out.println(season);
}
}
结果:
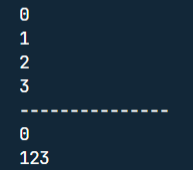
上述在没有枚举类之前我们使用public static final修饰的全局常量来表示枚举,虽然这样可以达到效果,但是也会存在缺陷。
- 类型不安全1:上述如果存在定义int值相同的变量的情况,那么混淆的几率还是很大的,而编译器不会提出任何警告,所以枚举类出现后基本上就不再推荐这种写法了。
- 类型不安全2:若一个方法中要求传入season这个参数,使用常量的话,形参就是int类型,而开发者可以传入任何int类型的值,但是如果是枚举类型的话,就只能传入枚举类中包含的对象。
- 代码复杂:如果我们定义时是这样定义常量的
public static final int SPRING=1。而我们要的结果是输出SPRING这个字符串,那么我们还要在方法中进行大量if else 判断,如下所示。
if (season==0){
System.out.println("SPRING");
}
......
上面大致分析了一下在没有枚举类之前是如何来定义伪枚举的,并且总结有这种方式的缺陷。而上面的问题在枚举类出现之后也算得到了解决。所以话不多说,直接上代码示例来感受一下吧:
//枚举类型,使用关键字enum
public enum Season {
SPRING, SUMMER, AUTUMN, WINNER;
}
从上面的代码可以发现,使用枚举后代码量减少了很多,相当简洁。所以使用枚举类的好处:枚举类会让代码更加直观,类型更安全,代码量更少。但是要注意:在枚举类中声明枚举变量时,最前面不能含有任何变量,方法,构造器等内容,也就是说枚举变量必须声明在第一行。多个对象之间需要用逗号隔开,如果枚举变量中没有参数,那么最后的分号可以省略。最后再来看看枚举类的简单使用:
//枚举类型,使用关键字enum
public enum Season {
SPRING, SUMMER, AUTUMN, WINNER;
public static void main(String[] args) {
Season spring = Season.SPRING;//也就是说,Season.SPRING就是SPRING
System.out.println(spring);//SPRING
show(Season.SUMMER);//SUMMER
//show("enum"); 编译时就会报错
}
public static void show(Season season) {
System.out.println(season);
}
}
枚举的使用非常的简单,像上述代码那样,我们可以直接使用枚举类名称 . 对象名称来引用枚举的值,这便是枚举类型的最简单的使用。
18.6.3 在switch语句中的使用
在之前的switch语法中只支持int和char类型的数据,但是随着枚举类型的出现,enum类型也可以在switch中使用了,看一下怎么在switch语句中使用。
枚举在switch中使用比较简单,只需了解有这么个情况就OK了。
//枚举类型,使用关键字enum
public enum Season {
SPRING, SUMMER, AUTUMN, WINNER;
}
class EnumTest {
public static void main(String[] args) {
show(Season.SPRING);
show(Season.SUMMER);
show(Season.AUTUMN);
show(Season.WINNER);
}
public static void show(Season season) {
switch (season) {
case SPRING:
System.out.println("春天");
break;
case SUMMER:
System.out.println("夏天");
break;
case AUTUMN:
System.out.println("秋天");
break;
case WINNER:
System.out.println("冬天");
break;
}
}
}
错误用例:
An enum switch case label must be the unqualified name of an enumeration constant
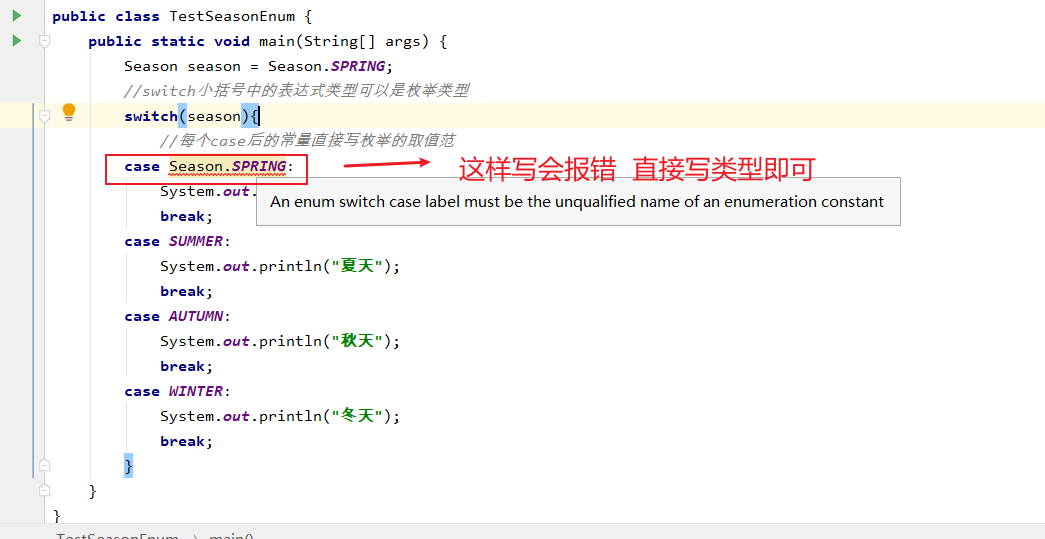
注意,在switch中,不能使用枚举类名称,因为编译器会根据switch()的类型来判定每个枚举类型,在case中必须直接给出与()相同类型的枚举选项,而不能再有类型。
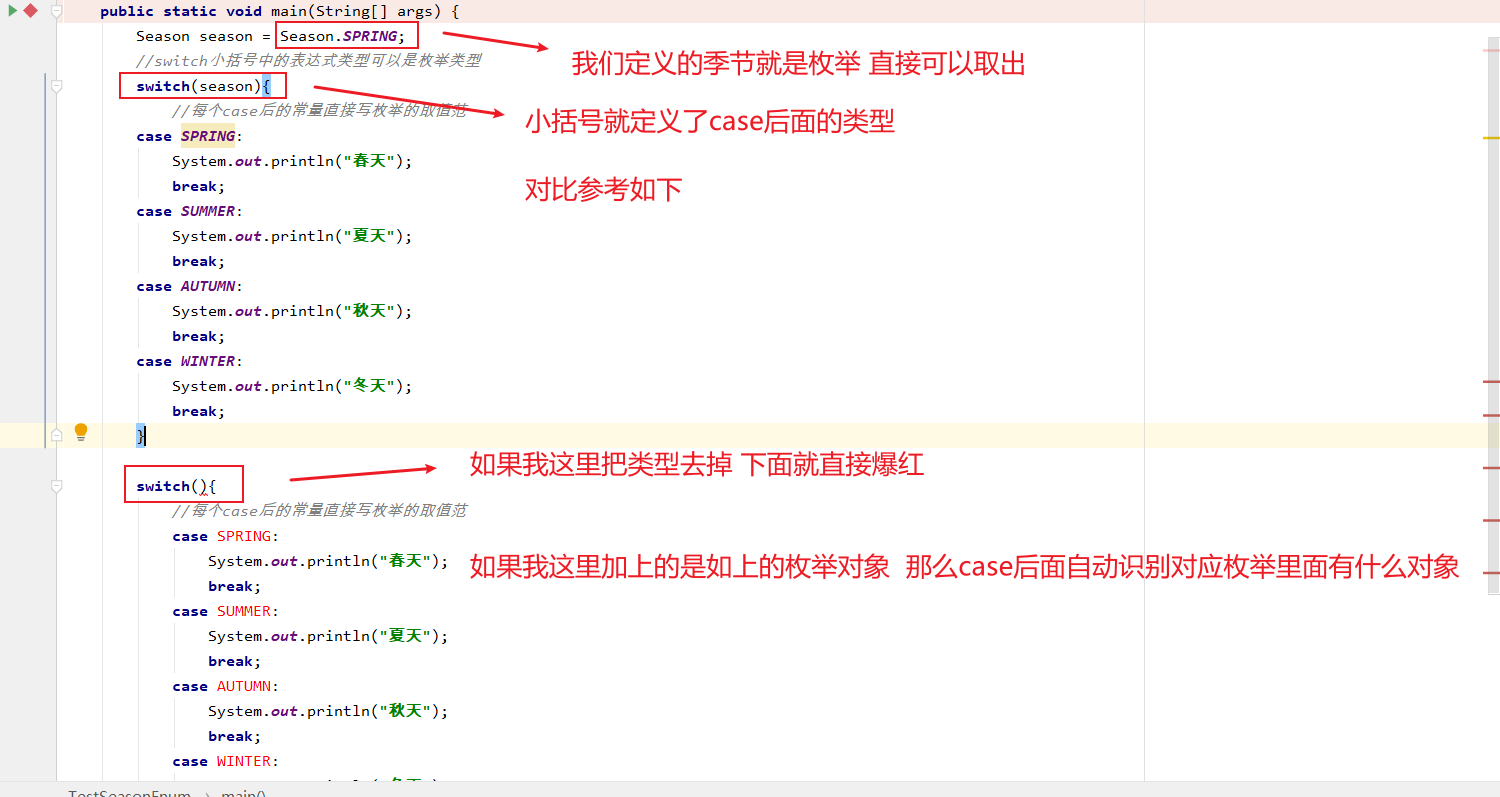
18.6.4 枚举类中常用方法
即然所有的枚举类都是继承自java.lang.Enum这个类,那么每个枚举类都必定有可用的方法。这里只例举比较常用方法:
Season.valueOf(String name)方法:返回具有指定名称的指定枚举类型的枚举常量(区分大小写),如果没有则报错。Season.values()方法:返回枚举类中包括所有枚举对象的数组。该方法可以很方便地遍历枚举值。枚举类变量.name()方法:返回当前枚举类对象的名称。它和toString()方法是一模一样的。枚举类变量.ordinal()方法:返回此枚举常数的序数(其枚举声明中的位置,其中初始常数的序数为零)。枚举类变量.toString()方法:返回当前枚举类对象的名称,等同于name()方法。
常用方法的举例:
public enum Season {
SPRING, SUMMER, AUTUMN, WINNER;
}
class EnumTest {
public static void main(String[] args) {
//Season.valueOf()
Season season1 = Season.valueOf("SPRING");
System.out.println(season1);
System.out.println("-------------");
//Season.values()
Season[] values = Season.values();
for (Season season2:values){
System.out.println(season2);
}
System.out.println("-------------");
//name()
System.out.println(Season.SUMMER.name());
//ordinal()
System.out.println(Season.SUMMER.ordinal());
//toString()
System.out.println(Season.SUMMER.toString());
}
}
输出结果:
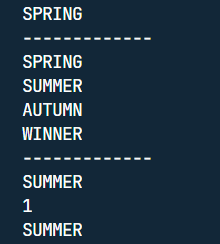
还有一些其他的方法就不介绍了,有些应该都知道,而有些则不常用。有感兴趣的话可以自己去看看官方API或者源码,都比较的简单。
18.6.5 枚举类的原理
上面已经了解了枚举类型的定义与简单使用后,那我们定义枚举类型后,到底发生了什么呢?所以现在有必要来了解一下枚举类型的基本实现原理。实际上在使用关键字enum创建枚举类型并编译后,编译器会为我们生成一个相关的类,这个类继承了Java API中的java.lang.Enum类,也就是说通过关键字enum创建枚举类型在编译后事实上也是一个类类型而且该类继承自java.lang.Enum类。所以先来了解一下Enum的源码:
public abstract class Enum<E extends Enum<E>>
implements Comparable<E>, Serializable {
// 内部定义的属性和方法省略......
}
接下来对前面定义的Season编译生成的class文件进行反编译,可以通过:javap -p Season.class 来得到反编译后的结果:

我们看到,对与枚举类,有很多值的注意的点:
- 枚举类在经过编译后确实是生成了一个扩展了java.lang.Enum的类
- 枚举类是final的,因此我们无法再继承它了,并且编译器会自动为枚举类默认继承了java.lang.Enum抽象类,而Java只支持单继承,
- 我们定义的每个枚举值都是该类中的一个成员,且成员的类型仍然是Season类型
- 枚举类中被默认增加了许多静态方法,例如values()等
为了进一步了解每个方法中的操作,我们使用javap -p -c Season.class每个方法中的字节码:
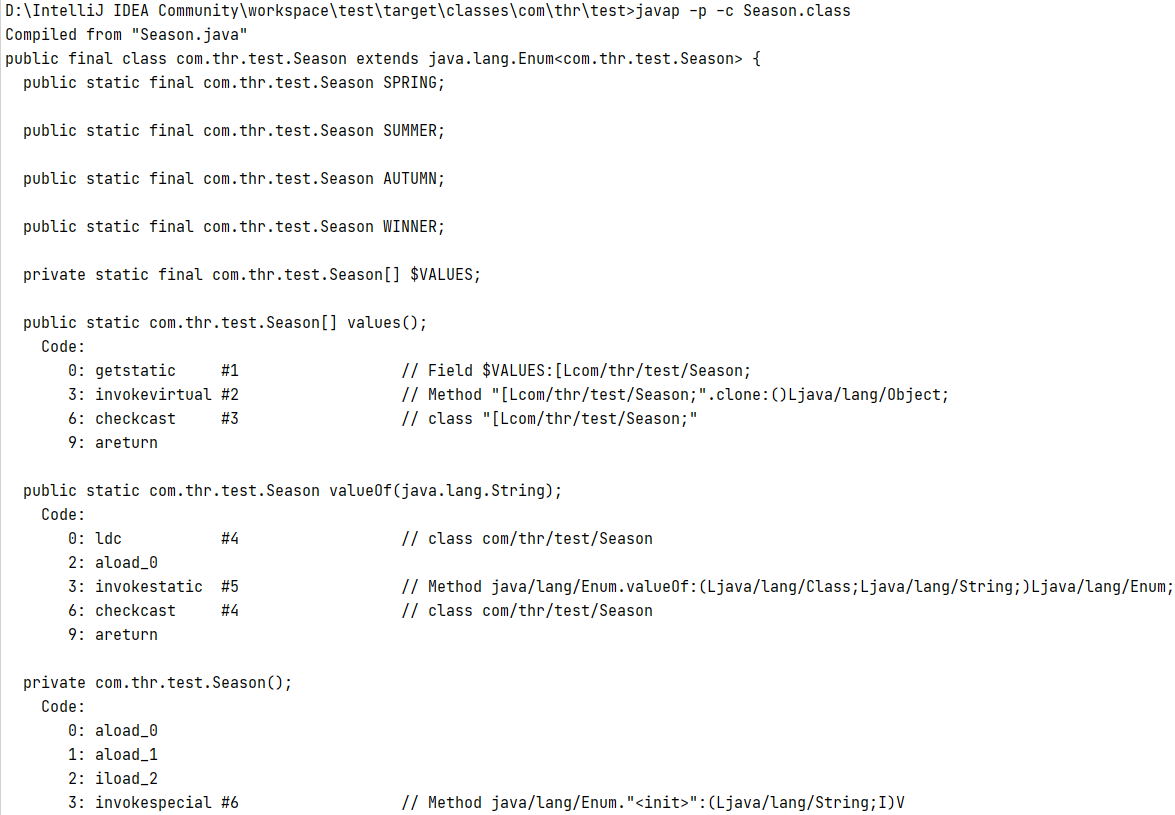
由于打印的太多,所以只截取了部分,根据字节码,我们还原其操作代码,大致如下:
public final class com.thr.test.Season extends java.lang.Enum<com.thr.test.Season>{
public static final com.thr.test.Season SPRING;
public static final com.thr.test.Season SUMMER;
public static final com.thr.test.Season AUTUMN;
public static final com.thr.test.Season WINTER;
private static final com.thr.test.Season[] $VALUES;
public static com.thr.test.Season values(){
retrun (Season[])$VALUES.clone();
}
public static com.thr.test.Season valueOf(String s){
retrun (Season)Enum.valueOf(java/lang/String, s);
}
private com.thr.test.Season(String s, int i){
super(s,i);
}
static {
SPRING = new Season("SPRING", 0);
SUMMER = new Season("SUMMER", 1);
SUMMER = new Season("AUTUMN", 2);
WINTER = new Season("WINTER", 3);
$VALUES = (new Season[] {
SPRING, SUMMER, SUMMER, WINTER
});
}
}
通过这里我们可以看到,在类的static操作中,编译器帮助我们生成每个枚举值的对象。
18.6.6 给枚举变量添加自定构造器
在前面的分析中,我们都是基于简单枚举类型来定义的,并没有在枚举类中定义变量、方法、构造器等结构。实际上枚举类和普通类有着相同的特征,除了不能使用继承之外(因为编译器会自动为我们继承Enum抽象类,而Java只支持单继承,并且枚举类是final的),我们完全可以把枚举类当成普通类,下面来感受一下吧。
public enum Season {
SPRING("春暖花开"),
SUMMER("夏日炎炎"),
AUTUMN("秋高气爽"),
WINNER("冬暖夏凉");//此时的分号不能省略
private String name;
//系统默认构造器是private,而且必须是private的,用public则会报错
Season(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
class Test{
public static void main(String[] args) {
for (Season season:Season.values()){
System.out.println(season.name()+","+season.getName());
}
}
}
程序运行结果:

通过上述可知,虽然枚举类中可以普通类一样声明变量、成员方法、构造器。但是我们必须注意到以下几点:
- 枚举类变量必须放在第一行,如果枚举类变量有构造器,那么分号必须加上,否则可以省略。
- 枚举类的构造器必须是private的,系统会自动设置为private,我们也可以自己加上,但是不能用public等修饰符,否则会报错。
18.6.7 枚举类中定义抽象方法
枚举类即然和普通类一样,那么枚举类中就允许定义抽象类和接口,接口下一节讲。但是需要注意的是每个枚举变量都需要重写该方法,否则编译会报错。继续用上面的例子,只是在其中添加了一个抽象方法。
public enum Season {
SPRING("春暖花开"){
public String show(){
return "SPRING";
}
},
SUMMER("夏日炎炎"){
public String show(){
return "SUMMER";
}
},
AUTUMN("秋高气爽"){
public String show(){
return "AUTUMN";
}
},
WINNER("冬暖夏凉"){
public String show(){
return "WINNER";
}
};//此时的分号不能省略
private String name;
//系统默认构造器是private,而且必须是private的,用public则会报错
Season(String name) {
this.name = name;
}
//定义抽象方法
public abstract String show();
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
class Test{
public static void main(String[] args) {
for (Season season:Season.values()){
System.out.println(season.name()+","+season.getName()+",枚举变量方法返回值:"+season.show());
}
}
}
程序运行结果:

通过这种方式就可以轻而易举地定义每个枚举变量的不同行为方式。而且调用枚举变量中方法有两种方式,一种是枚举变量名称.方法,另一种是枚举类名.枚举变量.方法(如Season.SPRING.show());
18.6.8 枚举类实现接口
虽然枚举类不能再继承其他的类了,但是它还是能够实现接口的,举例:
interface Behaviour{
String show();
}
public enum Season implements Behaviour{
SPRING("春暖花开"),
SUMMER("夏日炎炎"),
AUTUMN("秋高气爽"),
WINNER("冬暖夏凉");//此时的分号不能省略
private String name;
//系统默认构造器是private,而且必须是private的,用public则会报错
Season(String name) {
this.name = name;
}
@Override
public String show() {
return this.name;
}
}
class Test{
public static void main(String[] args) {
for (Season season:Season.values()){
System.out.println(season.show());
}
}
}
这样使用起来还是比较的简单的。在枚举类中使用接口还有一个功能就是对一组数据进行分类,此时就可以利用接口来组织枚举。比如一年四季中包含的节气:
public interface Season {
enum Spring implements Season{
//立春,雨水,清明
SPRING_BEGINS,RAIN,TOMB_SWEEPING
}
enum Summer implements Season{
//夏至,芒种,小暑,大暑
SUMMER_BEGINS,GRAIN_INE_EAR,SLIGHT_HEAD,GREAT_HEAD
}
enum AUTUMN implements Season{
//立秋,寒露,霜降
AUTUMN_BEGINS,COLD_DEW,FROST
}
enum WINTER implements Season{
//立冬,小雪,大雪,冬至
WINTER_BEGINS,LIGHT_SNOW,HEAVY_SNOW,WINTER_SOLSTICE_FESTIVAL
}
}
class Test{
public static void main(String[] args) {
//遍历Spring
Season.Spring[] values = Season.Spring.values();
for (Season season:values){
System.out.println(season);
}
}
}
//运行结果:
//SPRING_BEGINS
//RAIN
//TOMB_SWEEPING
通过上面这种方式我们可以很方便地组织枚举,同时还确保了具体类型属于春夏秋冬,而春夏秋冬则属于季节Season。
18.6.9 EnumSet和EnumMap的应用
EnumSet和EnumMap这两个都是关于枚举集合方面的知识,所以暂时不深入学习,仅用示例来简单了解一下。但是要清楚一点EnumSet是保证集合中的元素不重复。而EnumMap中的 key是enum类型,而value则可以是任意类型。
18.6.9.1 EnumSet
关于EnumSet先来看看EnumSet的继承体系图:
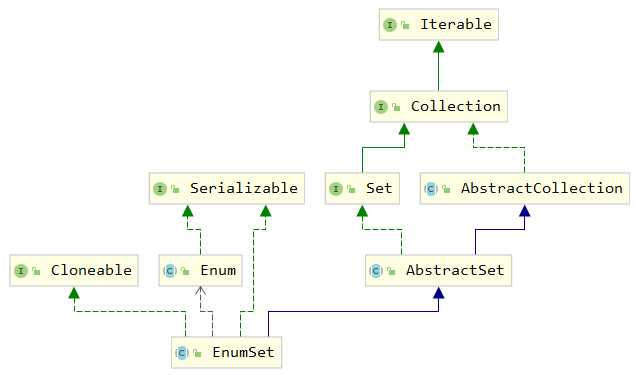
可以发现EnumSet实现了Set接口,所以它有Set相关的特性,它相比于HashSet,它有以下优点:
- 消耗较少的内存
- 效率更高,因为是位向量实现的。
- 可以预测的遍历顺序(enum 常量的声明顺序)
- 拒绝加 null
EnumSet就是Set的高性能实现,它的要求就是存放必须是同一枚举类型。EnumSet的常用方法:
- allof():创建一个包含指定枚举类里所有枚举值的EnumSet集合
- range():获取某个范围的枚举实例
- of():创建一个包括参数中所有枚举元素的EnumSet集合
- complementOf():初始枚举集合包括指定枚举集合的补集
/**
* EnumSet枚举
*/
public class EnumTest {
public static void main(String[] args) {
EnumSet<Season> set1, set2, set3, set4;
set1 = EnumSet.of(Season.SPRING, Season.SUMMER, Season.AUTUMN);
set2 = EnumSet.complementOf(set1);
set3 = EnumSet.allOf(Season.class);
set4 = EnumSet.range(Season.SUMMER, Season.WINNER);
System.out.println("Set 1: " + set1);
System.out.println("Set 2: " + set2);
System.out.println("Set 3: " + set3);
System.out.println("Set 4: " + set4);
}
}
运行结果:
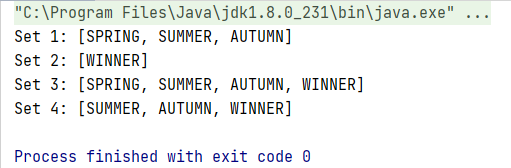
18.6.9.2 EnumMap
EnumMap的继承体系图如下:
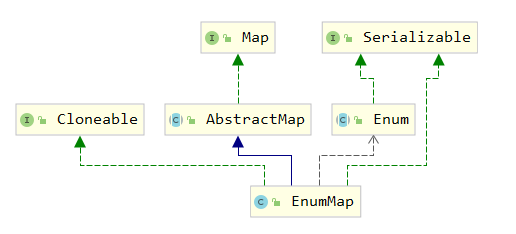
显然可以发现,EnumMap也实现了Map接口,它相比于HashMap,它有以下优点:
- 消耗较少的内存
- 效率更高
- 可以预测的遍历顺序
- 拒绝 null
EnumMap就是Map的高性能实现。它的常用方法跟HashMap是一致的,唯一约束是枚举相关。
/**
* EnumMap枚举
*/
public class EnumTest {
public static void main(String[] args) {
EnumMap<Season, String> map = new EnumMap<Season, String>(Season.class);
map.put(Season.SPRING, "春暖花开");
map.put(Season.SUMMER, "夏日炎炎");
map.put(Season.AUTUMN, "秋高气爽");
map.put(Season.WINNER, "冬暖夏凉");
System.out.println(map);
System.out.println(map.get(Season.SPRING));
//遍历map有很多种方式,这里是map遍历的一种方式,这种方式是最快的
for (EnumMap.Entry<Season, String> entry : map.entrySet()) {
System.out.println(entry.getKey() + "," + entry.getValue());
}
}
}
程序运行结果:
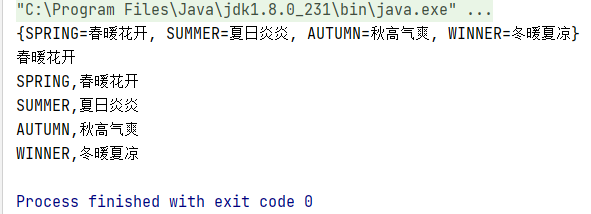
参考资料: 深入理解Java枚举类型(enum)
19、正则表达式
19.1 正则表达式概述
正则表达式,又称规则表达式,它的英文叫Regular Expression,在代码中常简写为regex、regexp等。它是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
19.2 为什么要用正则表达式
首先我们先来做一道题目:判断一个字符串是否由数字组成。代码示例如下:
public class Test {
public static void main(String[] args) {
//定义字符串
String str = "123456";
//转成char数组
char[] chars = str.toCharArray();
boolean flag = true;
//遍历判断
for (int i = 0; i < chars.length; i++) {
if (chars[i] < '0' || chars[i] > '9') {
flag = false;
}
}
if (flag) {
System.out.println("是由数字组成的字符串!");
} else {
System.out.println("不是由数字组成的字符串!");
}
}
}
通过这个例子可以发现,这种写法很轻松就可以得出想要的结果,但是如果我们要判断更加复杂一点的语句就麻烦了,如:电话号码、电子邮箱、网址等。再用这种方式完成就需要写很多的代码,这样就使得代码的可读性降低了。而如果使用正则表达式来匹配就会简洁很多,所以下面我们来学习Java正则表达式的使用。将上面的代码用正则表达式来验证:
public class Test {
public static void main(String[] args) {
//定义字符串
String str = "123456";
//定义正则表达式;(匹配一次或多次数字);注意:在Java中\(反斜杠)必须要使用转义字符 \\ 来表示
String regex ="\\d+";
System.out.println(str.matches(regex));//返回true
}
}
19.3 正则表达式语法大全
注意:在Java正则表达式中(反斜杠)必须要使用转义字符 \ 来表示。在JavaScript中,则必须以/^开头,$/结尾。例如:
- Java:
1[358]\\d{9}匹配电话号码为1开头,第二个位置只能为3|5|8,其它位为任意数字 - JavaScript:
/^1[358]\d{9}$/同上
| 字符 | 描述 |
|---|---|
| * | 将下一字符标记为特殊字符、文本、反向引用或八进制转义符。例如,"n"匹配字符"n"。"\n"匹配换行符。序列"\\"匹配"\","\("匹配"("。 |
| ^ | 匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,^ 还会与"\n"或"\r"之后的位置匹配。 |
| $ | 匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与"\n"或"\r"之前的位置匹配。 |
| ***** | 零次或多次匹配前面的字符或子表达式。例如,zo* 匹配"z"和"zoo"。* 等效于 {0,}。 |
| + | 一次或多次匹配前面的字符或子表达式。例如,"zo+"与"zo"和"zoo"匹配,但与"z"不匹配。+ 等效于 {1,}。 |
| ? | 零次或一次匹配前面的字符或子表达式。例如,"do(es)?"匹配"do"或"does"中的"do"。? 等效于 {0,1}。 |
| {*n*} | n 是非负整数。正好匹配 n 次。例如,"o{2}"与"Bob"中的"o"不匹配,但与"food"中的两个"o"匹配。 |
| {*n*,} | n 是非负整数。至少匹配 n 次。例如,"o{2,}"不匹配"Bob"中的"o",而匹配"foooood"中的所有 o。"o{1,}"等效于"o+"。"o{0,}"等效于"o*"。 |
| {*n*,*m*} | m 和 n 是非负整数,其中 n <= m。匹配至少 n 次,至多 m 次。例如,"o{1,3}"匹配"fooooood"中的头三个 o。'o{0,1}' 等效于 'o?'。注意:您不能将空格插入逗号和数字之间。 |
| ? | 当此字符紧随任何其他限定符(*、+、?、{n}、{n,}、{n,m})之后时,匹配模式是"非贪心的"。"非贪心的"模式匹配搜索到的、尽可能短的字符串,而默认的"贪心的"模式匹配搜索到的、尽可能长的字符串。例如,在字符串"oooo"中,"o+?"只匹配单个"o",而"o+"匹配所有"o"。 |
| . | 匹配除"\r\n"之外的任何单个字符。若要匹配包括"\r\n"在内的任意字符,请使用诸如"[\s\S]"之类的模式。 |
| (pattern) | 匹配 pattern 并捕获该匹配的子表达式。可以使用 $0…$9 属性从结果"匹配"集合中检索捕获的匹配。若要匹配括号字符 ( ),请使用"("或者")"。 |
| (?:pattern) | 匹配 pattern 但不捕获该匹配的子表达式,即它是一个非捕获匹配,不存储供以后使用的匹配。这对于用"or"字符 (|) 组合模式部件的情况很有用。例如,'industr(?:y|ies) 是比 'industry |
| (?=pattern) | 执行正向预测先行搜索的子表达式,该表达式匹配处于匹配 pattern 的字符串的起始点的字符串。它是一个非捕获匹配,即不能捕获供以后使用的匹配。例如,'Windows (?=95|98|NT|2000)' 匹配"Windows 2000"中的"Windows",但不匹配"Windows 3.1"中的"Windows"。预测先行不占用字符,即发生匹配后,下一匹配的搜索紧随上一匹配之后,而不是在组成预测先行的字符后。 |
| (?!pattern) | 执行反向预测先行搜索的子表达式,该表达式匹配不处于匹配 pattern 的字符串的起始点的搜索字符串。它是一个非捕获匹配,即不能捕获供以后使用的匹配。例如,'Windows (?!95|98|NT|2000)' 匹配"Windows 3.1"中的 "Windows",但不匹配"Windows 2000"中的"Windows"。预测先行不占用字符,即发生匹配后,下一匹配的搜索紧随上一匹配之后,而不是在组成预测先行的字符后。 |
| x|y | food' 匹配"z"或"food"。'(z|food' 匹配"z"或"food"。'(z|f)ood' 匹配"zood"或"food"。 |
| [*xyz*] | 字符集。匹配包含的任一字符。例如,"[abc]"匹配"plain"中的"a"。 |
| [^xyz] | 反向字符集。匹配未包含的任何字符。例如,"[^abc]"匹配"plain"中"p","l","i","n"。 |
| [a-z] | 字符范围。匹配指定范围内的任何字符。例如,"[a-z]"匹配"a"到"z"范围内的任何小写字母。 |
| [^a-z] | 反向范围字符。匹配不在指定的范围内的任何字符。例如,"[^a-z]"匹配任何不在"a"到"z"范围内的任何字符。 |
| \b | 匹配一个字边界,即字与空格间的位置。例如,"er\b"匹配"never"中的"er",但不匹配"verb"中的"er"。 |
| \B | 非字边界匹配。"er\B"匹配"verb"中的"er",但不匹配"never"中的"er"。 |
| \cx | 匹配 x 指示的控制字符。例如,\cM 匹配 Control-M 或回车符。x 的值必须在 A-Z 或 a-z 之间。如果不是这样,则假定 c 就是"c"字符本身。 |
| \d | 数字字符匹配。等效于 [0-9]。 |
| \D | 非数字字符匹配。等效于 [^0-9]。 |
| \f | 换页符匹配。等效于 \x0c 和 \cL。 |
| \n | 换行符匹配。等效于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等效于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等。与 [ \f\n\r\t\v] 等效。 |
| \S | 匹配任何非空白字符。与[^ \f\n\r\t\v]等效。 |
| \t | 制表符匹配。与 \x09 和 \cI 等效。 |
| \v | 垂直制表符匹配。与 \x0b 和\cK 等效。 |
| \w | 匹配任何字类字符,包括下划线。与"[A-Za-z0-9_]"等效。 |
| \W | 与任何非单词字符匹配。与"[^A-Za-z0-9_]"等效。 |
| \xn | 匹配 n,此处的 n 是一个十六进制转义码。十六进制转义码必须正好是两位数长。例如,"\x41"匹配"A"。"\x041"与"\x04"&"1"等效。允许在正则表达式中使用 ASCII 代码。 |
| \num | 匹配 num,此处的 num 是一个正整数。到捕获匹配的反向引用。例如,"(.)\1"匹配两个连续的相同字符。 |
| \n | 标识一个八进制转义码或反向引用。如果 n 前面至少有 n 个捕获子表达式,那么 n 是反向引用。否则,如果 n 是八进制数 (0-7),那么 n 是八进制转义码。 |
| \nm | 标识一个八进制转义码或反向引用。如果 nm 前面至少有 nm 个捕获子表达式,那么 nm 是反向引用。如果 nm 前面至少有 n 个捕获,则 n 是反向引用,后面跟有字符 m。如果两种前面的情况都不存在,则 nm 匹配八进制值 nm,其中 n 和 m 是八进制数字 (0-7)。 |
| \nml | 当 n 是八进制数 (0-3),m 和 l 是八进制数 (0-7) 时,匹配八进制转义码 nml。 |
| \un | 匹配 n,其中 n 是以四位十六进制数表示的 Unicode 字符。例如,\u00A9 匹配版权符号 (©)。 |
19.4 Pattern和Matcher类
在Java中用来操作正则表达式的是Pattern和Matcher类,它们都属于java.util.regex包下:
- Pattern 类:Pattern类用于创建一个正则表达式,也可以说是创建一个匹配模式,它的构造方法是私有的,所以不可以直接创建,可以通过两个静态方法创建:
compile(String regex)和compile(String regex,int flags),其中regex是正则表达式,flags为可选模式(如:Pattern.CASE_INSENSITIVE 忽略大小写)。 - Matcher 类:Matcher 对象是对输入字符串进行解释和匹配操作的引擎。与Pattern 类一样,Matcher 也没有公共构造方法。你需要调用 Pattern 对象的 matcher 方法来获得一个 Matcher 对象。
由于在实际开发工作中,为了方便我们很少直接使用Pattern类或Matcher类,而是使用String类下的方法,所以这里只简单的介绍一下Pattern和Matcher类。
/**
* 测试Pattern和Matcher
*/
public class TestPatternMatcher {
public static void main(String[] args) {
String str = "1234567abc";
//匹配任何字类字符(包括下划线),至少5次;与"[A-Za-z0-9_]{5,}"等效。
String regex = "\\w{5,}";
//编译正则表达式
Pattern pat = Pattern.compile(regex);
//获取Matcher对象
Matcher mat = pat.matcher(str);
//进行匹配,结果返回boolean
System.out.println(mat.matches());
}
}
关于更多关于Pattern和Matcher的使用可以自行去百度搜索。下面来介绍一下String中如何来处理正则表达式的,
String类下用来处理正则表达式的方法如下(常用):
- 验证:public boolean matches(String regex)
- 分割:public String[] split(String regex)
- 替换:public String replaceAll(String regex, String replacement)
①、验证功能:public boolean matches(String regex)
案例:判断输入的手机号是否为13、15或者18开头的电话号码
public class Demo {
public static void main(String[] args) {
//定义键盘输入流
Scanner sc = new Scanner(System.in);
System.out.println("请输入手机号:");
String s = sc.nextLine();
//要求:电话号码为1开头,第二个位置只能为3|5|8,其它位为任意数字
String regex = "1[358]\\d{9}";
//通过String的matches()方法进行验证
boolean flag = s.matches(regex);
System.out.println("flag:" + flag);
}
}
注意:String类中的matches(regex)方法其实就是调用了Pattern和Matcher类中的方法。


②、分割功能:public String[] split(String regex)
public class Demo {
public static void main(String[] args) {
String str = "Tom:30|Jerry:20|Bob:25";
String regex = "\\|";
//Pattern pat = Pattern.compile(regex);
//String[] arr = pat.split(str);
String[] arr = str.split(regex);
for (String s : arr) {
System.out.println(s);
}
}
}
③、替换功能:public String replaceAll(String regex,String replacement)
public class Demo {
public static void main(String[] args) {
String str = "12Y34h56dAd7";
String regex = "[a-zA-Z]+";
//Pattern pat = Pattern.compile(regex);
//Matcher mat = pat.matcher(str);
//System.out.println(mat.replaceAll("-"));
System.out.println(str.replaceAll(regex, "-"));
}
}
19.5 正则表达式大全(常用)
以下正则表达式引用自:https://blog.csdn.net/zpz2411232428/article/details/83549502
一、校验数字的表达式
1 数字:^[0-9]*$
2 n位的数字:^\d{n}$
3 至少n位的数字:^\d{n,}$
4 m-n位的数字:^\d{m,n}$
5 零和非零开头的数字:^(0|[1-9][0-9]*)$
6 非零开头的最多带两位小数的数字:^([1-9][0-9]*)+(.[0-9]{1,2})?$
7 带1-2位小数的正数或负数:^(\-)?\d+(\.\d{1,2})?$
8 正数、负数、和小数:^(\-|\+)?\d+(\.\d+)?$
9 有两位小数的正实数:^[0-9]+(.[0-9]{2})?$
10 有1~3位小数的正实数:^[0-9]+(.[0-9]{1,3})?$
11 非零的正整数:^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$
12 非零的负整数:^\-[1-9][]0-9"*$ 或 ^-[1-9]\d*$
13 非负整数:^\d+$ 或 ^[1-9]\d*|0$
14 非正整数:^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$
15 非负浮点数:^\d+(\.\d+)?$ 或 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$
16 非正浮点数:^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或 ^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$
17 正浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$
18 负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$
19 浮点数:^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$
二、校验字符的表达式
1 汉字:^[\u4e00-\u9fa5]{0,}$
2 英文和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$
3 长度为3-20的所有字符:^.{3,20}$
4 由26个英文字母组成的字符串:^[A-Za-z]+$
5 由26个大写英文字母组成的字符串:^[A-Z]+$
6 由26个小写英文字母组成的字符串:^[a-z]+$
7 由数字和26个英文字母组成的字符串:^[A-Za-z0-9]+$
8 由数字、26个英文字母或者下划线组成的字符串:^\w+$ 或 ^\w{3,20}$
9 中文、英文、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$
10 中文、英文、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$
11 可以输入含有^%&',;=?$\"等字符:[^%&',;=?$\x22]+
12 禁止输入含有~的字符:[^~\x22]+
三、特殊需求表达式
1 Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$
2 域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.?
3 InternetURL:[a-zA-z]+://[^\s]* 或 ^https://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$
4 手机号码:^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$
5 电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$
6 国内电话号码(0511-4405222、021-87888822):\d{3}-\d{8}|\d{4}-\d{7}
7 身份证号:
15或18位身份证:^\d{15}|\d{18}$
15位身份证:^[1-9]\d{7}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}$
18位身份证:^[1-9]\d{5}[1-9]\d{3}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{4}$
8 短身份证号码(数字、字母x结尾):^([0-9]){7,18}(x|X)?$ 或 ^\d{8,18}|[0-9x]{8,18}|[0-9X]{8,18}?$
9 帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
10 密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$
11 强密码(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
12 日期格式:^\d{4}-\d{1,2}-\d{1,2}
13 一年的12个月(01~09和1~12):^(0?[1-9]|1[0-2])$
14 一个月的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$
15 钱的输入格式:
16 1.有四种钱的表示形式我们可以接受:"10000.00" 和 "10,000.00", 和没有 "分" 的 "10000" 和 "10,000":^[1-9][0-9]*$
17 2.这表示任意一个不以0开头的数字,但是,这也意味着一个字符"0"不通过,所以我们采用下面的形式:^(0|[1-9][0-9]*)$
18 3.一个0或者一个不以0开头的数字.我们还可以允许开头有一个负号:^(0|-?[1-9][0-9]*)$
19 4.这表示一个0或者一个可能为负的开头不为0的数字.让用户以0开头好了.把负号的也去掉,因为钱总不能是负的吧.下面我们要加的是说明可能的小数部分:^[0-9]+(.[0-9]+)?$
20 5.必须说明的是,小数点后面至少应该有1位数,所以"10."是不通过的,但是 "10" 和 "10.2" 是通过的:^[0-9]+(.[0-9]{2})?$
21 6.这样我们规定小数点后面必须有两位,如果你认为太苛刻了,可以这样:^[0-9]+(.[0-9]{1,2})?$
22 7.这样就允许用户只写一位小数.下面我们该考虑数字中的逗号了,我们可以这样:^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$
23 8.1到3个数字,后面跟着任意个 逗号+3个数字,逗号成为可选,而不是必须:^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$
24 备注:这就是最终结果了,别忘了"+"可以用"*"替代如果你觉得空字符串也可以接受的话(奇怪,为什么?)最后,别忘了在用函数时去掉去掉那个反斜杠,一般的错误都在这里
25 xml文件:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$
26 中文字符的正则表达式:[\u4e00-\u9fa5]
27 双字节字符:[^\x00-\xff] (包括汉字在内,可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1))
28 空白行的正则表达式:\n\s*\r (可以用来删除空白行)
29 HTML标记的正则表达式:<(\S*?)[^>]*>.*?|<.*? /> (网上流传的版本太糟糕,上面这个也仅仅能部分,对于复杂的嵌套标记依旧无能为力)
30 首尾空白字符的正则表达式:^\s*|\s*$或(^\s*)|(\s*$) (可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式)
31 腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始)
32 中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字)
33 IP地址:\d+\.\d+\.\d+\.\d+ (提取IP地址时有用)
参考链接:https://blog.csdn.net/weixin_43860260/article/details/91417485
20、异常处理
20.1 异常处理概述
在Java程序执行过程中, 总是会发生不被期望的事件, 阻止程序按照程序员预期正常运行, 这就是Java程序出现的异常。
异常处理是基于面向对象的一种运行错误处理机制,通过对异常问题的封装,实现对用户的非法操作、参数设置异常,硬件系统异常,网络状态改变异常等运行态中可能出现的异常信息的处理机制。
如果某个方法不能按照正常的途径完成任务,就可以通过另一种路径退出方法。在这种情况下会抛出一个封装了错误信息的对象。此时,这个方法会立刻退出同时不返回任何值。另外,调用这个方法的其他代码也无法继续执行,异常处理机制会将代码执行交给异常处理器来处理,这就是Java异常的处理。Java为我们提供了非常完美的异常处理机制,我们看下面的图。
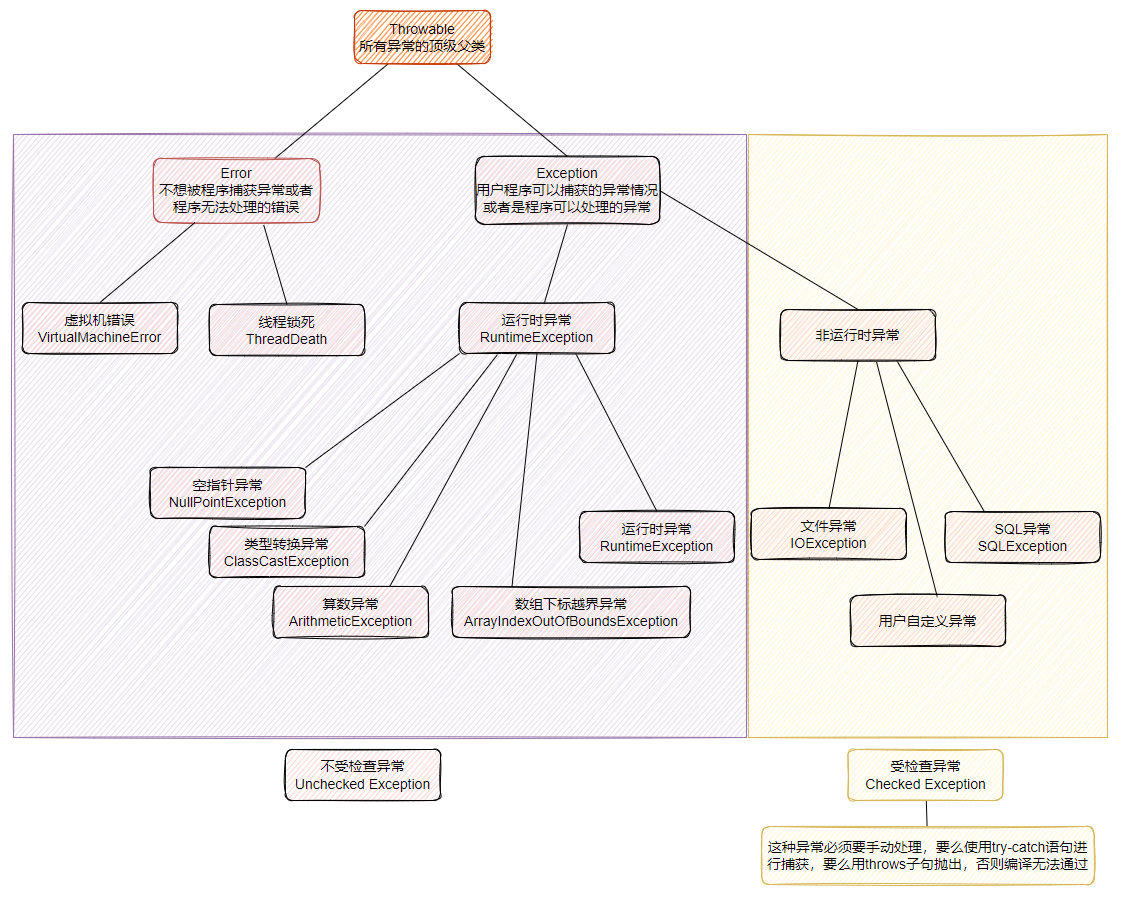
从图的结构我们可以知道,所有的异常都是继承自Throwable,有两个子类Error和Exception,它们分别表示错误和异常。下面来看看Throwable、Error与Exception 的具体描述:
-
Throwable:它是 Java 语言中所有异常的超类。Throwable 包含了其线程创建时线程执行堆栈的快照,它提供了 printStackTrace() 等接口用于获取堆栈跟踪数据等信息。Throwable 包含两个子类:Error(错误)和 Exception(异常),它们通常用于指示发生了异常情况。
-
Error:表示程序中无法处理的错误,说明运行应用程序中出现了严重的错误。比如VirtualMachineError(虚拟机运行错误)、OutOfMemoryError(内存不足错误)、ThreadDeath(线程锁死)、StackOverflowError(栈溢出错误)等。当这些异常发生时, Java虚拟机一般会选择线程终止。
-
Exception:是程序本身可以处理的异常。这种异常它们又分为两大类RunTimeException(运行时异常)和非RunTimeException(非运行时异常),在程序中我们应当尽可能去处理这些异常。
- RunTimeException(运行时异常):表示 JVM 在运行期间可能出现的异常。这种异常Java 编译器不会检查它,当程序中可能出现这类异常时,倘若既"没有通过 throws 声明抛出它",也"没有用 try-catch 语句捕获它",还是会编译通过。当遇到异常时会由 Java 虚拟机自动抛出并自动捕获(就算我们没写异常捕获语句运行时也会抛出错误!!),此类异常的出现绝大数情况是代码本身有问题应该从逻辑上去解决并改进代码。
- 非RunTimeException(非运行时异常):这种异常首先 Java 编译器会检查它。如果程序中出现此类异常,比如 ClassNotFoundException(没有找到指定的类异常),IOException(IO 流异常),要么通过 throws 进行声明抛出,要么通过 try-catch 进行捕获处理,否则不能通过编译。在程序中,通常不会自定义该类异常,而是直接使用系统提供的异常类。该异常我们必须手动在代码里添加捕获语句来处理该异常。
-
CheckException:受检查异常,它发生在编译阶段。所有CheckException都是需要在代码中处理的,所以这对我们在编码时是非常有帮助的。它们的发生是可以预测的,是可以合理的处理。要么使用try-catch-finally语句进行捕获,要么用throws子句抛出,否则编译就会报错。在Exception中,除了RuntimeException及其子类以外,其他都是都是CheckedException。
-
UncheckedException:不受检查异常,它发生只有在运行期间。所有是无法预先捕捉处理的,主要是由于程序的逻辑错误所引起的。Error也是UncheckedException,也是无法预先处理的,它们都难以排查。所以在我们的程序中应该从逻辑角度出发,尽可能避免这类异常的发生。
既然有些时候错误和异常不可避免,那么我们可以在程序设计中认真的考虑,设计出更加高质量的代码,这样即使产生了异常,也能尽量保证程序朝着有利方向发展。
20.2 Java常见的异常
在Java中异常的种类非常的多,所以我们就列出比较常见的异常。
Error异常:
- OutOfMemoryError:内存不足错误。当可用内存不足以让Java虚拟机分配给一个对象时抛出该错误。
- StackOverflowError:堆栈溢出错误。当一个应用递归调用的层次太深而导致堆栈溢出时抛出该错误。
- VirtualMachineError:虚拟机错误。用于指示虚拟机被破坏或者继续执行操作所需的资源不足的情况。
- ThreadDeath:线程结束。当调用Thread类的stop方法时抛出该错误,用于指示线程结束。
- UnknownError:未知错误。用于指示Java虚拟机发生了未知严重错误的情况。
Exception中出现的异常:
RunTimeException子类:
- NullPointerException:空指针异常。
- ArrayIndexOutOfBoundsException:数组索引越界异常。
- ClassCastException:类型转换异常类。
- NumberFormatException:字符串转换为数字抛出的异常。
- ArithmeticException:算术条件异常。如:整数除零等。
- NegativeArraySizeException:数组长度为负异常。
- ArrayStoreException:数组中包含不兼容的值抛出的异常。
- SecurityException:安全性异常。
- IllegalArgumentException:非法参数异常。
- NoSuchMethodException:方法未找到异常。
非RunTimeException子类:
- IOException:输入输出流异常。
- EOFException:文件已结束异常。
- SQLException:操作数据库异常。
- ClassNotFoundException:找不到类异常。
- 自定义Exception:用户自己定义的异常。
20.3 异常处理的机制
在 Java 应用程序中,异常处理机制为:捕获异常,抛出异常,声明异常。
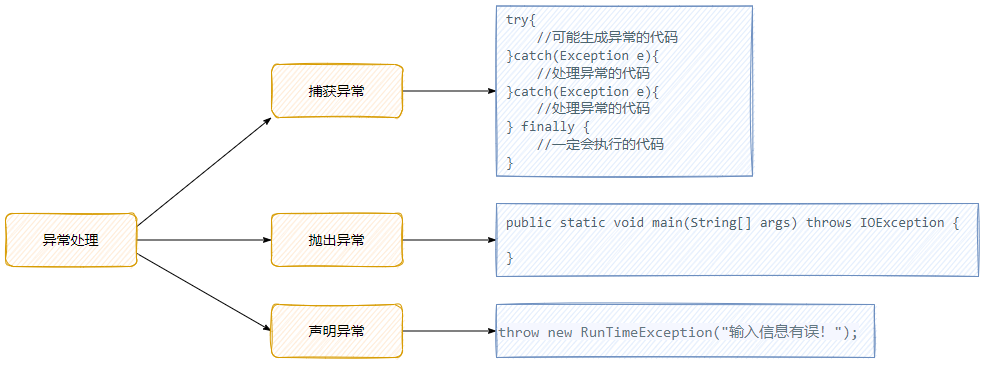
接下来先来学习怎么用try-catch-finally语句来捕获异常。
20.4 捕获处理 try-catch-finally
先看一下try-catch-finally语句的格式:
try{
//可能生成异常的代码
}catch(Exception e){
//处理异常的代码
}catch(Exception e){
//处理异常的代码
} finally {
//一定会执行的代码
}
用一个整数除以零为例,来使用try-catch-finally捕获异常:
public class Main {
public static void main(String[] args) {
int i = 10;
try {
int j = i / 0;//会出现异常的地方
System.out.println(j);
} catch (Exception e) {
e.printStackTrace();
System.out.println("代码出现了异常...");
} finally {
System.out.println("一定会执行...");
}
}
}
运行结果:
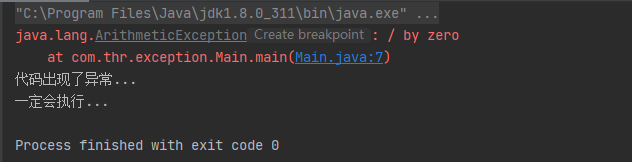
我们知道任何数是不可以除零,这个地方一定会抛出异常,所以我们用try-catch给它包起来,当真的出现异常之后就可以将其捕获打印出来。从结果可以看出来,当程序遇到异常时会终止程序的运行(即后面的代码不在执行),控制权交由异常处理机制处理。由catch捕获异常后,再执行catch中的语句。然后再执行finally中一定会执行的语句(finally语句块一般都是去释放占用的资源)。
TIPS:在一个 try-catch 语句块中可以捕获多个异常类型,并对不同类型的异常做出不同的处理
private static void tryCatchTest(String filePath) {
try {
// code
} catch (FileNotFoundException | UnknownHostException e) {
// handle FileNotFoundException or UnknownHostException
} catch (IOException e){
// handle IOException
}
}
注:同一个 catch 也可以捕获多种类型异常,用 | 隔开,但是一般都不会这么干,因为可能会造成分不清是哪个异常导致的错误。
从上面的例子我们会不会认为try-catch-finally捕获异常非常的简单,然而它们真的非常简单吗?再来看下面这个例子。
public class TryTest {
public static void main(String[] args) {
System.out.println(test());
}
private static int test() {
int num = 10;
try {
System.out.println("try");
return num += 80;
} catch (Exception e) {
System.out.println("error");
} finally {
if (num > 20) {
System.out.println("finally num>20 : " + num);
}
System.out.println("finally");
}
return num;
}
}
运行结果:
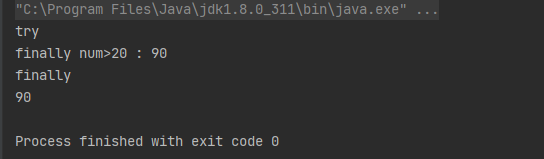
看到这样的结果一定会非常的懵逼,你可以自己先思考一下,后面会介绍try-catch-finally中有无return的执行顺序。
20.5 抛出异常 throws+异常类型(异常链)
throws是在声明在方法的后面使用,表示此方法不处理异常,而交给方法调用者进行处理,然后一直将异常向上一级抛给调用者,而调用者可以选择捕获或者抛出,如果所有方法(包括main)都选择抛出。那么最终将会抛给JVM,由JVM来打印出信息(异常链)。
package com.thr.exception;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
public class ThrowsTest {
public static void method1() throws IOException {
File file = new File("hello.txt");
FileInputStream fis = new FileInputStream(file);
int data = fis.read();
while (data != -1) {
System.out.println(data);
data = fis.read();
}
fis.close();
}
public static void method2() throws IOException {
method1();
}
public static void main(String[] args) throws IOException {
method2();
}
}
//结果;java.io.FileNotFoundException: hello.txt (系统找不到指定的文件。)
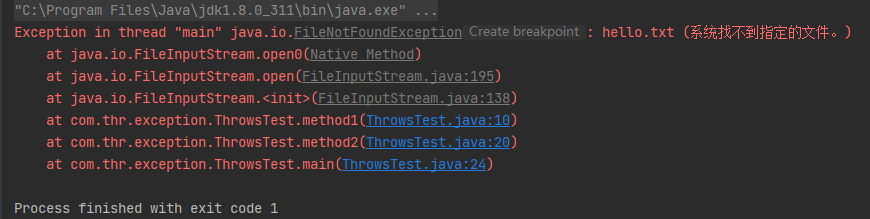
上面代码的异常信息最终由JVM打印,同样我们也可以对异常进行捕获。
public static void main(String[] args) {
try {
method2();
} catch (IOException e) {
e.printStackTrace();
}
}
通过使用throws+异常类型(异常链),我们可以提高代码的可理解性、系统的可维护性。
20.6 定义异常 throw (手动抛出异常)
使用throw是允许我们在程序中手动抛出异常的,那么这就操蛋了,我们都巴不得不出现任何异常,这咋还得自己来抛出异常呢!这是因为有些地方确实需要抛出异常,我们简单举例来看:
public class ThrowTest {
public void show(int age) throws Exception {
if (age > 0 && age < 256) {
System.out.println(age);
} else {
//System.out.println("输入年龄有误!");
throw new Exception("输入年龄有误!");
}
System.out.println(age);
}
public static void main(String[] args) {
ThrowTest test = new ThrowTest();
try {
test.show(500);
} catch (Exception e) {
e.printStackTrace();
}
}
}
上面的例子中如果我们使用System.out.println("输入年龄有误!");输出信息,然而它仅仅是一个输出的功能,并不会终止后面代码的执行,所以这时我们就可以选择手动抛出异常来终止代码的运行。
20.7 自定义异常
上面介绍了几种异常的处理机制,但是那些异常都是Java本身经定义好的,在实际开发中一般都会自己定义一些异常,这样可以更加方便的处理异常。那么我们自己怎么定义异常呢?Java是允许让用户自己定义异常的,但是一定要注意的是:在我们自定义异常时,一定要是Throwable的子类,如果是检查异常就要继承自Exception,如果是运行异常就要继承自RuntimeException。
package com.thr.exception;
//自定义异常,继承Exception
public class MyException extends Exception {
private static final long serialVersionUID = 1L;
private String errorCode;
private String errorMessage;
//定义无参构造方法
public MyException() {
}
// 定义有参构造方法
public MyException(String errorMessage) {
super(errorMessage);
this.errorMessage = errorMessage;
}
public MyException(String errorCode, String errorMessage) {
super(errorMessage);
this.errorCode = errorCode;
this.errorMessage = errorMessage;
}
}
class Main {
public void show(int i) throws Exception {
if (i >= 0) {
System.out.println(i);
} else {
throw new MyException("不能为负数...");
}
}
public static void main(String[] args) {
Main main = new Main();
try {
main.show(-5);
} catch (Exception e) {
e.printStackTrace();
}
}
}
运行结果:
20.8 try-catch-finally的执行顺序
对于try-catch-finally的执行顺序在我们的日常编码中可能不会用到,但是可能会出现在你笔试中,所以我们还是需要了解一下。
情况一:try、finally中没有return
public class TryTest1 {
public static void main(String[] args) {
System.out.println("main:" + test());
}
private static int test() {
int num = 10;
try {
num = 20;
} finally {
num = 30;
}
return num;
}
}
这种情况比较好理解:输出结果就是 30。
情况二:try中有return,finally中没有return
public class TryTest2 {
public static void main(String[] args) {
System.out.println("main:" + test());
}
private static int test() {
int num = 10;
try {
return num += 20;
} finally {
System.out.println("finally--" + num);
}
}
}
输出结果如下:
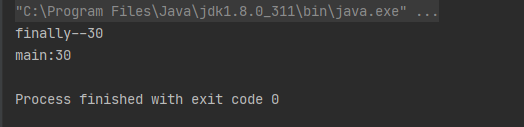
特别注意:try中有return的情况下,在执行到return的时候会保留好要返回的值,先去执行finally中的操作,然后才会返回来执行return。
分析:当代码执行到return num += 20;的时候,JVM会将计算好的结果存储起来,此时并没有直接返回,因为之前说过,finally中代码一定是会执行,那么随后会去执行finally中的代码,执行完之后再将结果返回,此时num的值为30.
情况三:try和finally中均有return
public class TryTest4 {
public static void main(String[] args) {
System.out.println(test());
}
private static int test() {
int num = 10;
try {
num += 20;
return 10;
} finally {
System.out.println("finally--" + num);
return num;
}
}
}
输出结果如下:
分析:和上面的一样,当遇到try中的return时,计算好结果后会去执行finally中的代码。但是此时finally中有return,所以finally中的return语句先于try中的return语句执行,因而try中的return被”覆盖“掉了,不再执行。
情况四:finally中改变返回值num
public class TryTest5 {
public static void main(String[] args) {
System.out.println(test());
}
private static int test() {
int num = 10;
try {
return num += 20;
} catch (Exception e) {
System.out.println("catch-error");
} finally {
System.out.println("finally-" + num);
num = 100;
System.out.println("finally-" + num);
}
return num;
}
}
输出结果如下:
分析:如果前面几个理解了,那么这个也非常的简单,主要还是上面特别注意中的那句话。代码中虽然在finally中改变了返回值num,但因为finally中没有return该num的值,因此在执行完finally中的语句后,test()函数会得到try中返回的num的值,而try中的num的值依然是程序进入finally代码块前保留下来的值,因此得到的返回值为 30。
情况五:将num的值包装在Num类中
下面在来看看当值被包装在一个对象中的情况。
public class TryTest {
public static void main(String[] args) {
System.out.println(test().num);
}
private static Num test() {
Num number = new Num();
try {
return number;
} catch (Exception e) {
System.out.println("catch-error");
} finally {
System.out.println("finally-" + number.num);
number.num = 100;
System.out.println("finally-" + number.num);
}
return number;
}
}
class Num {
public int num = 10;
}
输出结果如下:
从结果中可以看出,这里在finally中改变了返回值num的值,打印的结果也是finally中改变后的值,这是因为此时是对象引用类类型了。我们在finally中改变的是对象引用中内部属性的值,而try中return的确是对象的引用,所以对象Num number = new Num();本身是没有发生改变的,只是对内部属性num的值发生了改变。
更细的可以参考这篇文章:[面试官太难伺候?一个try-catch问出这么多花样](面试官太难伺候?一个try-catch问出这么多花样 (qq.com))
对于含有return语句的情况,这里我们可以简单地总结如下:
- 特别注意:try中有return的情况下,在执行到return的时候会保留好要返回的值,先去执行finally中的操作,然后才会返回来执行return。
- 如果try-finally没有return语句,那么值是什么就返回什么。
- 如果try有return语句,且finally中也有return语句,则finally中return会将try中的return语句”覆盖“掉,直接执行finally中的return语句,得到返回值,这样便无法得到try之前保留好的返回值。
- 如果try有return语句,且finally中没有return语句,也没有改变要返回值,则执行完finally中的语句后,会接着执行try中的return语句,返回之前保留的值。
- 如果try有return语句,且finally中没有return语句,但是改变了要返回的值,这里有点类似与引用传递和值传递的区别,分以下两种情况,:
- 如果return的数据是基本数据类型或文本字符串,则在finally中对该基本数据的改变不起作用,try中的return语句依然会返回进入finally块之前保留的值。
- 如果return的数据是引用数据类型,而在finally中对该引用数据类型的属性值的改变起作用,try中的return语句返回的就是在finally中改变后的该属性的值。
20.9 try-with-resource的介绍
try-with-resources语句是一种声明了一种或多种资源的try语句。资源是指在程序用完了之后必须要关闭的对象。try-with-resources语句保证了每个声明了的资源在语句结束的时候都会被关闭。JAVA 7 提供了更优雅的方式来实现资源的自动释放,自动释放的资源需要是实现了 AutoCloseable 接口的类。任何实现了java.lang.AutoCloseable接口的对象,和实现了java.io.Closeable接口的对象,都可以当做资源使用。
在Java SE7之前,你可以用finally代码块来确保资源一定被关闭,无论try语句正常结束还是异常结束。下面的例子用finally代码块代:
static String readFirstLineFromFileWithFinallyBlock(String path) throws IOException {
BufferedReader br = new BufferedReader(new FileReader(path));
try {
return br.readLine();
} finally {
if (br != null) br.close();
}
}
而在Java SE7之后就可以使用try-with-resource简写的方式来处理资源的释放。
static String readFirstLineFromFile(String path) throws IOException {
try (BufferedReader br = new BufferedReader(new FileReader(path))) {
return br.readLine();
}
}
当try 代码块退出时,会自动调用 br.close 方法,和把 br.close 方法放在 finally 代码块中不同的是,若 br.close 抛出异常,则会被抑制,抛出的仍然为原始异常。被抑制的异常会由 addSusppressed 方法添加到原来的异常,如果想要获取被抑制的异常列表,可以调用 getSuppressed 方法来获取。
20.10 关于throw 和 throws 的区别
我们发现throws和throw这两个关键字非常的相似,来看看它们的区别是什么:
- throws:该关键字用在方法声明上,用来声明一个方法可能产生的所有异常。该方法不做任何处理,而是一直将异常往上一级传递,由调用者继续抛出或捕获。它用在方法声明的后面,跟的是异常类名,可以跟多个异常类名,用逗号隔开,它表示的是向上抛出异常,由该方法的调用者来处理。如果一种没有处理异常,那么最终将会抛给JVM,最后由JVM打印出异常信息。
- throw:该关键字用在方法内部,用来抛出一种异常,它用在方法体内部,抛出的异常的对象名称。它表示抛出异常,由方法体内的语句处理。
21、集合
21.1 前言
集合在Java中的地位想必大家都知道,不用多BB了。无论是在我们现在的学习中还是在今后的工作中,集合这样一个大家族都无处不在,无处不用。在前面讲到的数组也是一个小的容器,但是数组不是面向对象对象的,它存在明显的缺陷,而集合恰好弥补了数组带来的缺陷。集合比数组更加灵活、更加实用。而且不同的集合框架可用于不同的场景。
我们简单来比较一下数组和集合区别:
- 数组能存放基本数据类型和对象,而集合类中只能存放对象。
- 数组容量固定无法动态改变,集合类容量可以动态改变。
- 数组无法判断其中实际存有多少元素,length只告诉了数组的容量,而集合的size()可以确切知道元素的个数。
- 集合有多种实现方式和不同适用场合,不像数组仅采用顺序表方式。
- 集合以类的形式存在,具有封装、继承、多态等类的特性,通过简单的方法和属性即可实现各种复杂操作,从而大大提高了软件的开发效率。
为了清晰的认识Java集合大家族,下面是整个Java集合的框架图:
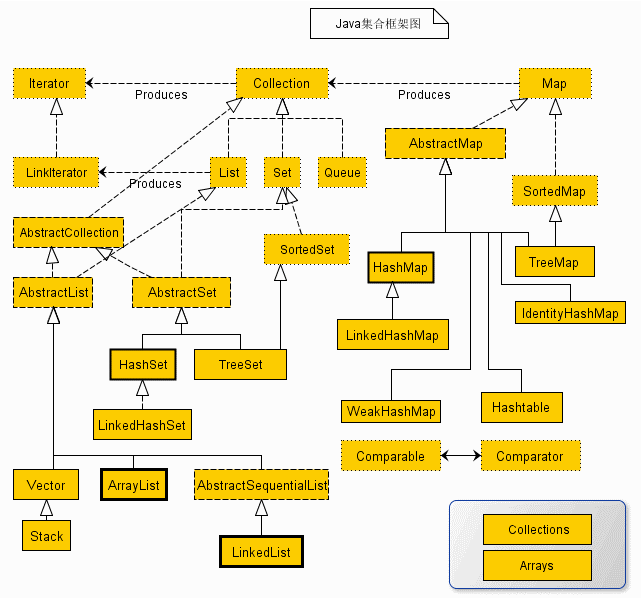
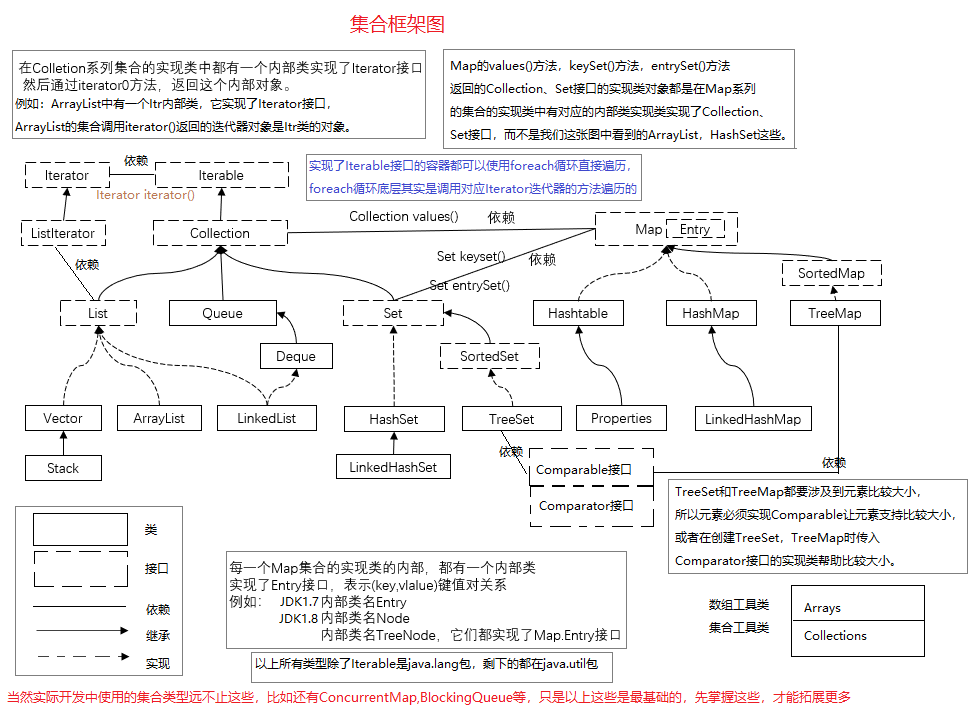
通过上面的图片可以看到集合大家族的成员以及他们之间的关系。发现这也太多了吧,不过不要太慌张。我们现在只需要抓住它们的主干即可,即Collection、Map和Iterator,额外的还有两个对集合操作的工具类Collections和Arrays。其中虚框表示的是接口或抽象类,实框是类,虚箭头是实现,实箭头是继承。然后把它们捋一捋给分个类就应该清楚了。
把上面捋一捋可以总结集合主要分为两大系列:Collection和Map,Collection 表示一组对象,Map表示一组映射关系或键值对。
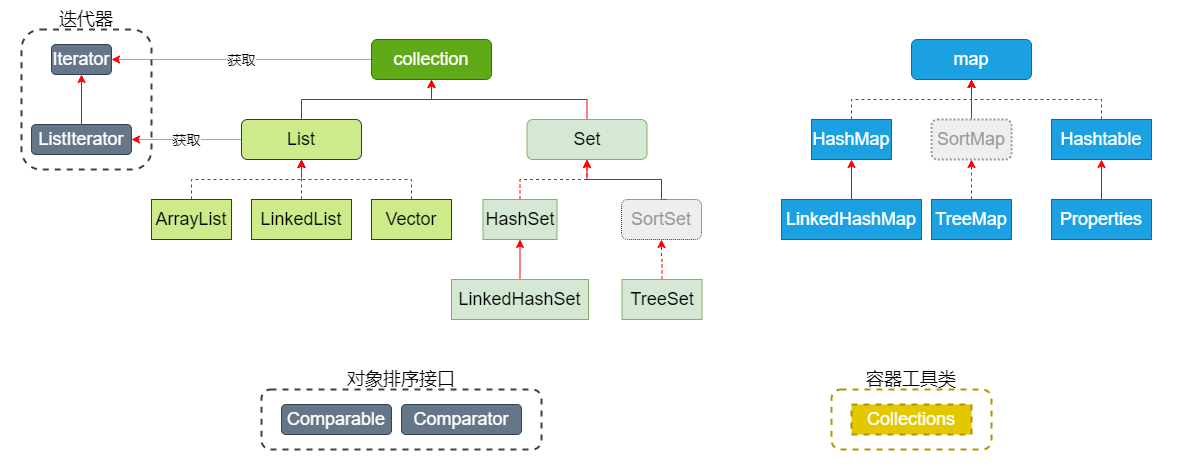
21.2 集合的分类
上面的Java集合框架图看起来比较的杂乱,所以我们对它们进行了分类处理,这样更加直观。
①、Collection接口:最基本的集合接口(单列数据)
- List接口:所有元素按照进入的先后顺序有序存储,可重复集合
- ArrayList:接口实现类,用数组实现,随机访问,增删慢,查询快,没有同步,线程不安全
- LinkedList:接口实现类,用双向链表实现, 插入删除快,查询慢, 没有同步,线程不安全
- Vector:接口实现类,用数组实现,它和ArrayList几乎一样,但是它是同步, 线程安全的(Vector几乎已经不用了)
- Stack:继承自Vector类,Stack具有后进先出的特点
- Set接口:不允许包含重复的值(可以有null,但是只有一个),无序,不可重复集合
- HashSet:使用hash表(数组)存储元素,无序,其底层是包装了一个HashMap去实现的,所以查询插入速度较快
- LinkedHashSet:继承HashSet类,它新增了一个重要特性,就是元素按照插入的顺序存储
- TreeSet:底层基于TreeMap实现的,它支持2种排序方式:自然排序(Comparable)和定制排序(Comparator)
- HashSet:使用hash表(数组)存储元素,无序,其底层是包装了一个HashMap去实现的,所以查询插入速度较快
- Queue接口:队列,它的特点是先进先出
②、Map接口:键值对的集合接口,不允许含有相同的key,有则输出一个key-value组合(双列数据)
- Hashtable:接口实现类,用hash表实现,不可重复key,key不能为null,同步,效率稍低,线程安全
- Properties:是Java 语言的配置文件所使用的类,以key=value 的 键值对的形式进行存储值。 key值不能重复。
- HashMap:接口实现类 ,用hash表实现,不可重复key,key可以为null,没有同步,效率稍高 ,线程不安全
- LinkedHashMap:双向链表和hash表实现,按照key的插入顺序存放
- WeakHashMap:和HashMap一样,但它的键是“弱键”,垃圾收集器会自动的清除没有在其他任何地方被引用的键值对
- TreeMap:用红黑树算法实现,它默认按照所有的key进行排序
- IdentifyHashMap:它是一个特殊的Map实现,它的内部判断key是否相等用的是 ==,而HashMap则更加复杂
简单完成分类之后我们就从集合的特点和区别来进行一 一讲解。
21.3 Collection接口
Collection是最基本的集合接口,它是单列数据集合。在JDK中不提供Collection接口的任何直接实现,它只提供了更具体的子接口(即继承自Collection接口),例如List列表,Set集合,Queue队列,然后再由具体的类来实现这些子接口。通过具体类实现接口之后它们的特征就得以凸显出来,有些集合中的元素是有序的,而其他的集合中的元素则是无序的;有些集合允许重复的元素,而其他的集合则不允许重复的元素;有些集合允许排序,而其他的集合则不允许排序。
既然Collection接口是集合的层次结构的根接口,那么必定有常用的方法,我们来看一下:
boolean add(E e):向集合中添加一个元素。集合更改则添加成功返回true,如果该集合不允许重复并且已经包含指定的元素,返回false。部分子类的add方法可能会限制添加到集合中的元素类型,或者不会将NULL添加到集合中。boolean addAll(Collection<? extends E> c):将指定集合中的所有元素添加到此集合中。在添加过程中如果被添加的集合发生了更改,addAll方法不具有幂等性。void clear():清空掉集合中的所有元素。boolean contains(Object o):如果集合中包含指定元素那么返回true。特别的,如果集合中也包含NULL元素的时候并且要查找的元素也是NULL的时候也返回true。boolean containsAll(Collection<?> c):如果该集合中包含指定集合中的所有元素的时候返回true。boolean isEmpty():如果集合中不包含元素返回true。Iterator iterator():返回在此集合的元素上进行迭代的迭代器。关于元素返回的顺序没有任何保证,除非此集合是某个能提供保证顺序的类实例。boolean remove(Object o):删除集合中的指定的元素。如果存在NULL,也删除。boolean removeAll(Collection<?> c):删除当前集合中所有等于指定集合中的元素。boolean retainAll(Collection<?> c):仅保留此集合中那些也包含在指定集合的元素。移除此集合中未包含在指定集合中的所有元素。int size():返回该集合中元素的个数。如果超过了Integer.MAX_VALUE,那么返回Integer.MAX_VALUE。Object[] toArray():返回包含此集合中所有元素的数组。T[] toArray():返回包含此集合中所有元素的数组; 返回的数组的运行时类型是指定数组的运行时类型。
21.4 Iterator接口
我们从上面Collection结构中可以看到其内部有一个iterator()方法,这个方法不是Collection中所特有的,而是重写了父类Iterable中的。因为Collection接口继承了java.lang.Iterable接口,而该接口中有一个iterator()方法。也就是说所有实现了Collection接口的集合类中都有iterator()方法,它用来返回实现了Iterator接口的迭代器对象。
介绍一下迭代的概念:迭代:即Collection集合元素的通用获取方式。在取元素之前先要判断集合中有没有元素,如果有,就把这个元素取出来,继续在判断,如果还有就再取出出来。一直把集合中的所有元素全部取出。这种取出方式专业术语称为迭代。
Iterator接口的内部结构比较简单,其内部只定义的四个方法,它们分别是:
boolean hasNext():如果迭代具有更多元素,则返回true。E next():返回迭代器中游标的下一元素。default void remove():从集合中删除此迭代器返回的最后一个元素。每次调用next后只能调用一次此方法,不能多次调用,否则会报错。如果在进行迭代时用调用此方法之外的其他方式修改了该迭代器所指向的集合,那么则迭代器的行为是不确定的。default void forEachRemaining(Consumer<? super E> action):对每个剩余元素执行给定的操作,直到所有元素都被处理或动作引发异常。如果指定了迭代的顺序,则按迭代的顺序执行。操作引发的异常将被转发给调用者。
接下来我们通过案例学习如何使用Iterator迭代集合中元素:
@Test
public void test() {
Collection collection = new ArrayList();
collection.add(123);
collection.add("AA");
collection.add('a');
collection.add(true);
collection.add(new String("ArrayList"));
//创建迭代器对象
Iterator iterator = collection.iterator();
//hasNext()、next()测试
while (iterator.hasNext()){
System.out.println(iterator.next());
}
System.out.println("-------remove()-------");
Iterator iterator1 = collection.iterator();
while (iterator1.hasNext()){
Object next = iterator1.next();
//iterator1.remove();不能在next()前先调用
if (next.equals(123)){
iterator1.remove();
//iterator1.remove();不能在next()后再次调
}
}
Iterator iterator2 = collection.iterator();
while (iterator2.hasNext()){
System.out.println(iterator2.next());
}
}
简易分析一下:当返回了Iterator对象之后可以理解为有一个指针,它指在第一个对象的上面(即123的上面,此时指针为空),当我们调用iterator.hasNext()的时候,判断是否还有下一个元素,如果有则返回true。然后调用iterator.next()使指针往下移并且返回下移以后集合位置上的元素,这样以此类推就输出了以上结果。
迭代器的实现原理:
我们在之前案例已经完成了Iterator遍历集合的整个过程。当遍历集合时,首先通过调用集合的iterator()方法获得迭代器对象,然后使用hashNext()方法判断集合中是否存在下一个元素,如果存在,则调用next()方法将元素取出,否则说明已到达了集合末尾,停止遍历元素。Iterator迭代器对象在遍历集合时,内部采用指针的方式来跟踪集合中的元素,为了能更好地理解迭代器的工作原理,接下来通过一个图例来演示Iterator对象迭代元素的过程:
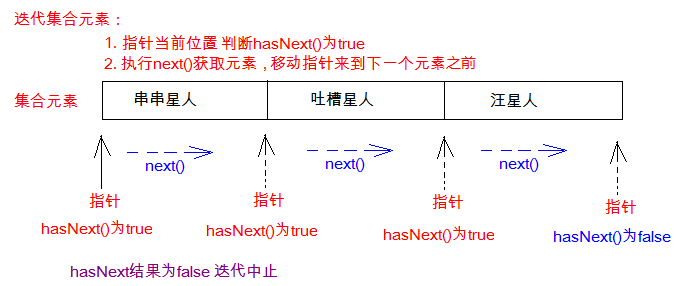
在调用Iterator的next方法之前,迭代器的索引位于第一个元素之前,指向第一个元素,当第一次调用迭代器的next方法时,返回第一个元素,然后迭代器的索引会向后移动一位,指向第二个元素,当再次调用next方法时,返回第二个元素,然后迭代器的索引会再向后移动一位,指向第三个元素,依此类推,直到hasNext方法返回false,表示到达了集合的末尾,终止对元素的遍历。
tips:在进行集合元素取出时,如果集合中已经没有元素了,还继续使用迭代器的next方法,将会发生java.util.NoSuchElementException没有集合元素的错误。
21.5 List接口
List接口直接继承了Collection接口,它对Collection进行了简单的扩充,从而让集合凸显出它们各自的特征。在List中所有元素的存储都是有序的,而且是可重复存储的。用户可以根据元素存储位置的索引来操作元素。实现了List接口的集合主要有以下几个:ArrayList、LinkedList、Vector和Stack。
了解:List集合它有一个特有的迭代器——ListIterator。Iterator的子接口ListIterator是专门给List集合提供的迭代元素的接口,它的内部对Iterator功能进行一些扩充。例如增加的方法有hasPrevious()、nextIndex()、previousIndex()等等。
List接口特点:
- List集合所有的元素是以一种线性方式进行存储的,例如,存元素的顺序是11、22、33。那么集合中,元素的存储就是按照11、22、33的顺序完成的
- 它是一个元素存取有序的集合。即元素的存入顺序和取出顺序有保证。
- 它是一个带有索引的集合,通过索引就可以精确的操作集合中的元素(与数组的索引是一个道理)。
- 集合中可以有重复的元素,通过元素的equals方法,来比较是否为重复的元素。
既然List接口直接继承了Collection接口,而且List是有序存储结构,那么List除了从Collection中继承的方法之外,必定会自己添加一些根据索引来操作集合元素的方法,我们来看一下:
void add(int index, E element):将指定的元素插入此列表中的指定位置(可选操作)。boolean addAll(int index, Collection<? extends E> c):将指定集合中的所有元素插入到此列表中的指定位置。E get(int index):返回此列表中指定位置的元素。int indexOf(Object o):返回此列表中指定元素的第一次出现的索引,如果此列表不包含元素,则返回-1。int lastIndexOf(Object o):返回此列表中指定元素的最后一次出现的索引,如果此列表不包含元素,则返回-1。E remove(int index):删除该列表中指定位置的元素(可选操作)。E set(int index, E element):用指定的元素(可选操作)替换此列表中指定位置的元素。List subList(int fromIndex, int toIndex):返回从fromIndex到toIndex位置上的子集合。
21.5.1 ArrayList
ArrayList应该是我们最常见的集合,同时也是List中最重要的一个。ArrayList的特点是:随机访问、查询快,增删慢,轻量级,线程不安全。它的底层是用Object数组实现的,我们可以把ArrayList看做是一个可改变大小的数组。随着越来越多的元素被添加到ArrayList中,其容量是动态增加的(初始化容量是10,增量是原来的1.5倍 int newCapacity = oldCapacity + (oldCapacity >> 1);)。
ArrList的特点:随机访问、查询快,增删慢,轻量级,线程不安全,初始化容量是10,增量是原来的1.5倍。
ArrayList源码分析总结(这里就不去看源码了,不是很难):
ArrayList底层实现:可变长的数组,有索引,查询效率高,增删效率低
构造方法:
new ArrayList():
jdk6中,空参构造直接创建10长度的数组
jdk7(新版)jdk8中,默认初始容量0,在添加第一元素时初始化容量为10
new ArrayList(int initialCapacity):
指定初始化容量,第一次直接扩容为initialCapacity大小
添加元素:add(E e);
-首次添加元素,初始化容量为10
-每次添加修改modCount属性值
-每次添加检查容量是否足够,容量不足时需要扩容,扩容大小为原容量的1.5倍
移除元素:remove(E e);
-每次成功移除元素,修改modCount值
-每次成功移除,需要移动元素以保证所以元素是连续存储的(删除操作效率低的原因)
21.5.2 LinkedList
LinkedList底层是通过双向链表实现的,所以它不能随机访问,而且需要查找元素必须要从开头或结尾(从靠近指定索引的一端)开始一个一个的找。使用双向链表则让增加、删除元素比较的方便,但查询变得困难。
所以LinkedList的特点是:查询慢,增删快,线程不安全。
由于LinkedList是双向链表实现的,所以它除了有List中的基本操作方法外还额外提供了一些方法在LinkedList的首部或尾部进行操作的方法(其实是继承Deque中的),如addXXX()、getXXX()、removeXXX()等等。同时,LinkedList还实现了Queue接口的子接口Deque,所以他还提供了offer(), peek(), poll()、pop()、push()等方法。我们简单来看一下:
void addFirst(E e):在该列表开头插入指定的元素。void addLast(E e):将指定的元素追加到此列表的末尾。E element():检索但不删除此列表的头(第一个元素)。E getFirst():返回此列表中的第一个元素。E getLast():返回此列表中的最后一个元素。boolean offer(E e):将指定的元素添加为此列表的尾部(最后一个元素)。boolean offerFirst(E e):在此列表的前面插入指定的元素。boolean offerLast(E e):在该列表的末尾插入指定的元素。E poll XXX():检索并删除此列表的头(第一个元素)。E peek XXX():检索但不删除此列表的头(第一个元素)。E pop():从此列表表示的堆栈中弹出一个元素。void push(E e):将元素推送到由此列表表示的堆栈上。E remove XXX():从列表中删除指定元素的第一个出现(如果存在)。
LinkedList底层结构:
源码中节点使用Node对象表示一个完整的元素节点:
private static class Node<E> {
E item;//数据元素
Node<E> next;//下一个元素节点
Node<E> prev;//上一个元素节点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
21.5.3 Vector
Vector和ArrayList几乎一样,它们都是通过Object数组来实现的。但是Vector是线程安全的,和ArrayList相比,Vector中很多方法是用synchronized关键字处理过来保证证数据安全,这就必然会影响其效率,所以你的程序如果不涉及到线程安全问题,那么推荐使用ArrayList集合。其实无论如何大家都会选择ArrayList的,因为Vector已经很少用了,几乎面临淘汰。
另外二者还有一个区别就是Vector和ArrayList的扩容策略不一样,Vector的扩容增量是原来容量的2倍,而ArrayList是原来的1.5倍。
21.5.4 Stack
Stack的名称是堆栈。它是继承自Vector这个类,这就意味着,Stack也是通过数组来实现的。Stack的特性是:先进后出(FILO, First In Last Out)。此外Stack中还提供5个额外的方法使得Vector得以被当作堆栈使用。我们来看一下这五个方法:
boolean empty():测试堆栈是否为空。Stack刚创建后就是空栈。E peek():查看此堆栈顶部的对象,而不从堆栈中删除它。E pop():出栈,删除此堆栈顶部的对象,并将该对象作为此函数的值返回。E push(E item):压栈,将元素推送到此堆栈的顶部。int search(Object o):返回一个对象在此堆栈上的基于1的位置。
21.6 Set接口
Set和List一样都是继承自Collection接口,但是Set和List的特点完全不一样。Set集合中的元素是无顺序的,且没有重复的元素。如果你试图将多个相同的对象添加到Set中,那么不好意思,它会立马阻止。 Set中会用equals()和hashCode()方法来判断两个对象是否相同,只要该方法的结果是true,Set就不会再次接收这个对象了。实现了Set接口主要有一下几个:HashSet、LinkedHashSet、TreeSet、EnumSet。Set中没有增加任何新的方法,用的都是继承自中Collection中的。
21.6.1 HashSet
HashSet是 按照哈希算法(hashCode)来存储集合中的对象,所以它是无序的,同时也不能保证元素的排列顺序。 其底层是包装了一个HashMap去实现的,所以其查询效率非常高。而且在增加和删除的时候由于运用hashCode的值来比较确定添加和删除元素的位置,所以不存在元素的偏移,效率也非常高。因此HashSet的查询、增加和删除元素的效率都是非常高的。但是HashSet增删的高效率是通过花费大量的空间换来的:因为空间越大,取余数相同的情况就越小。HashSet这种算法会建立许多无用的空间。使用HashSet接口时要注意,如果发生冲突,就会出现遍历整个数组的情况,这样就使得效率非常的低。
HashSet 集合判断两个元素相等的标准:
- 两个对象通过 hashCode() 方法比较相等,
- 并且两个对象的 equals() 方法返回值也相等。
因此,存储到HashSet的元素要重写hashCode和equals方法。
HashSet消除重复原则:
HashSet对于加入集合的这些对象,首先先获取这个对象的哈希码值(通过此对象调用hashCode()),HashSet会去看这些hashCode值是否相等,如果不相等,则hashSet认为是不同的对象,分别把它们加入集合;如果相等,则hashset则会去看每个对象的内容是否相同(调用equals()),如果每个对象的内容不相同,则hashset认为它们是不同的对象,分别加入集合 ;如果每个对象的内容相同,则hashset认为它们是相同的,执行消重加入。
HashSet使用简单举例:
@Test
public void test1() {
//创建HashSet的实例
HashSet<String> hashSet = new HashSet<>();
//添加了两个AA元素
hashSet.add("AA");
hashSet.add("AA");
hashSet.add("YYY");
hashSet.add("BB");
hashSet.add("HashSet");
//添加了两个CC元素
hashSet.add("CC");
hashSet.add("CC");
//使用增强for循坏
for (String s : hashSet) {
System.out.println("元素值:"+s+"--hash值:"+s.hashCode());
}
}
21.6.2 LinkedHashSet
LinkedHashSet继承自HashSet类,它不仅实现了哈希算法(hashCode),还实现了链表的数据结构,提供了插入和删除的功能。他有HashSet全部特性,但它新增了一个重要特性,就是元素按照插入的顺序存储。所以当遍历LinkedHashSet集合里的元素时,LinkedHashSet将会按元素的添加顺序来访问集合里的元素。正是因为多加了这样一种数据结构,所以它的效率较低,不建议使用,如果要求一个集合急要保证元素不重复,也需要记录元素的先后添加顺序,才选择使用LinkedHashSet。
LinkedHashSet使用简单举例:
@Test
public void test2() {
//创建LinkedHashSet实例
LinkedHashSet<String> linkedHashSet = new LinkedHashSet<>();
//无序添加元素
linkedHashSet.add("DD");
linkedHashSet.add("BB");
linkedHashSet.add("AA");
linkedHashSet.add("EE");
linkedHashSet.add("CC");
//遍历打印值
for (String s : linkedHashSet) {
System.out.println("元素值:"+s+",hash值:"+s.hashCode());
}
boolean b = linkedHashSet.add("GG");
System.out.println(b);
//删除GG元素
boolean gg = linkedHashSet.remove("GG");
System.out.println(gg);
}
21.6.3 TreeSet
TreeSet的底层是 基于TreeMap中实现的,都是基于红黑树实现的,红黑树是一种平衡二叉树,查询效率高于链表。它不仅能保证元素的唯一性,还能对元素按照某种规则进行排序。它继承了AbstractSet抽象类,实现了NavigableSet ,Cloneable,可序列化接口。而NavigableSet 又继承了SortedSet接口,此接口主要用于排序操作,即实现此接口的子类都属于排序的子类,有可排序的功能。TreeSet中的元素支持2种排序方式:自然排序或者定制排序,使用方式具体取决于我们使用的构造方法(默认使用自然排序)。
TreeSet特点:
- 元素唯一
- 实现排序(取出的元素是经过排序的)。
TreeSet是如何如何排序?如果TreeSet中的元素要实现元素唯一和排序,那么这些元素就必须是可以进行比较的,如何保证元素可比较呢?要么元素本身实现Comparable接口,从而实现可比较;要么给TreeSet容器传入一个实现了Comparator接口的比较器,使其可以对存入的元素进行比。
自然排序或者定制排序可以去参考博客:夯实Java基础(十五)——Java中Comparable和Comparator
Java提供的核心类很多都实现了Comparable接口比如常见的String类,包装类,日期类等
BigDecimal、BigInteger 以及所有的数值型对应的包装类:按它们对应的数值大小进行比较
Character:按字符的 unicode值来进行比较
Boolean:true 对应的包装类实例大于 false 对应的包装类实例
String:从第一个字符开始,比较每一个字符,如果字符都相同再比较长度。
Date、Time:比较毫秒值,后边的时间、日期比前面的时间、日期大
TreeSet使用简单举例(TreeSet传入实现Comparator实现类):
@Test
public void test3() {
//创建TreeSet实例、使用Comparator定制排序
TreeSet<Integer> treeSet = new TreeSet<>(new Comparator<Integer>() {
//排序方式为:降序
@Override
public int compare(Integer o1, Integer o2) {
if (o1 > o2) {
return -1;
} else if (o1 < o2) {
return 1;
} else {
return 0;
}
}
});
treeSet.add(22);
treeSet.add(44);
treeSet.add(11);
treeSet.add(33);
for (Integer integer : treeSet) {
System.out.println(integer);
}
}
21.6.4 EnumSet
EnumSet是专门为枚举类而设计的有序集合类,EnumSet中所有元素都必须是指定枚举类型的枚举值,在创建EnumSet时必须显式或隐式指定它对应的枚举类。
EnumSet使用简单举例:
@Test
public void test4(){
//EnumSet的简单使用
EnumSet<Season> seasons = EnumSet.allOf(Season.class);
//遍历
for (Season season : seasons) {
System.out.println(season);
}
}
//创建枚举类
enum Season {
SPRING,SUMMER,AUTUMN,WINNER;
}
21.7 Queue接口
Queue接口与List、Set是同一级别的,都继承了Collection接口。Queue表示的是队列,它的特点是:先进先出(FIFO,First-in-First-Out) 。
队列主要分为两大类:
一类是BlockingDeque阻塞队列(Queue的子接口),它的主要实现类包括ArrayBlockQueue、PriorityBlockingQueue. LinkedBlockingQueue。
另一类是Deque双端队列(也是Queue的子接口),支持在头部和尾部两端插入和移除元素,主要实现类包括:ArrayDeque、LinkedList。
Queue接口中包含的方法有:
booleab add(E e):插入指定的元素要队列中,并返回true或者false,如果队列数量超过了容量,则抛出IllegalStateException的异常。boolean offer(E e):插入指定的元素到队列,并返回true或者false,如果队列数量超过了容量,不会抛出异常,只会返回false。E remove():搜索并删除最顶层的队列元素,如果队列为空,则抛出一个Exception。E poll():搜索并删除最顶层的队列元素,如果队列为空,则返回null。E element():检索但不删除并返回队列中最顶层的元素,如果该队列为空,则抛出一个Exception。E peek(): 检索但不删除并返回最顶层的元素,如果该队列为空,则返回null。
对于BlockingDeque阻塞队列的详解可以参考这篇博客:BlockingQueue(阻塞队列)详解 ,写的非常不错。
21.8 Collection系列的集合小结
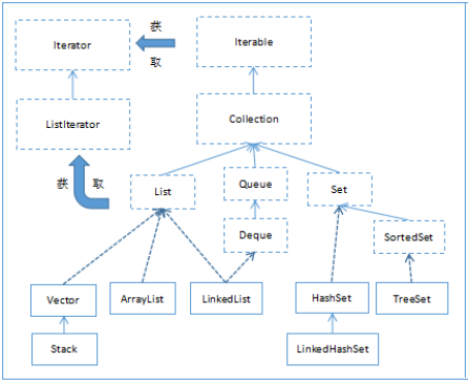
Collection:集合根接口,存储一组对象。
- List:接口,特点是,元素可重复,有序(存取顺序一致)
- ArrayList:底层结构为数组,查询快,增删慢,线程不安全
- LinkedList:底层结构为链表,查询慢,增删快
- Vector:底层结构为数组,线程安全,效率低,不推荐使用
- Set:接口,特点是,元素唯一
- HashSet:底层结构为Hash表,查询和增删效率都高
- TreeSet:底层结构为红黑树,查询效率高于链表,增删效率高于数组,元素实现排序
- LinkedHashSet:底层结构为hash表+链表,链表保证元素的有序
21.9 Map接口
Map接口与Collection接口是完全不同的。Map中保存的是具有“映射关系”的数据,即是由一系列键值对组成的集合,提供了key到value的映射,也就是说一个key对应一个value,其中key和value都可以是任何引用数据类型。但是Map中不能存在相同的key值,对于相同key值的Map对象会通过equals()方法来判断key值是否相等,只要该方法的结果是true,Map就不会再次接收这个对象了,当然value值可以相同。实现了Map接口的类主要的有以下几个:HashMap、Hashtable、LinkedHashMap、WeakHashMap、TreeMap、IdentifyHashMap、EnumMap。其中Map集合还和Set集合有着非常紧密的联系,因为很多Set集合中底层就是用Map来实现的。
我们来看一下Map键值对根接口中的方法:
void clear():删除该map集合中的所有键值对映射。boolean containsKey(Object key):检测map中有没有包含指定值为key的元素,如果有则返回true,否则返回false。boolean containsValue(Object value):检测map中有没有包含指定值为value的元素,如果有则返回true,否则返回false。Set<Map.Entry<K,V>> entrySet():返回map到一个Set集合中,以map集合中的Key=Value的形式返回到set中。V get(Object key):根据map集合中指定的key值来获取相应value值。Set keySet():返回map集合中所有key。V put(K key,V value):向map集合中添加key的值和value的值,当添加成功时返回null,否则返回value。void putAll(Map<? extends K,? extends V> m):把一个map集合合并到另一个map集合里。V remove(Object key):删除指定值为key的元素。int size():返回map集合中元素大小。Collection values():返回map集合中所有的value值到一个Collection集合。
21.9.1 Hashtable
Hashtable是一个古老的Map实现类,在JDK1.0就提供了,它继承自Dictionary类, 底层基于hash表结构+数组+链表实现实现,内部所有方法都是同步的,即线程很安全,但是效率低。 注意在Hashtable中key和value均不可为null。
21.9.2 HashMap
HashMap是Map集合中使用最多的,也是集合中最最最重要的一个类,它是Hashtable的一个轻量级版本,它是继承了Abstractmap类。JDK1.7 HashMap底层基于数组+链表;JDK1.8 HashMap是基于数组+链表+红黑树,当链表长度大于8时会将链表转化成红黑树。内部所有方法是不同步的,即线程不安全,但是效率高。在 HashtMap 中 key 和 value 均均可为 null。
JDK1.7 HashMap底层基于数组+链表,插入数据使用头插法(头插法多线程情况下可能死循环);
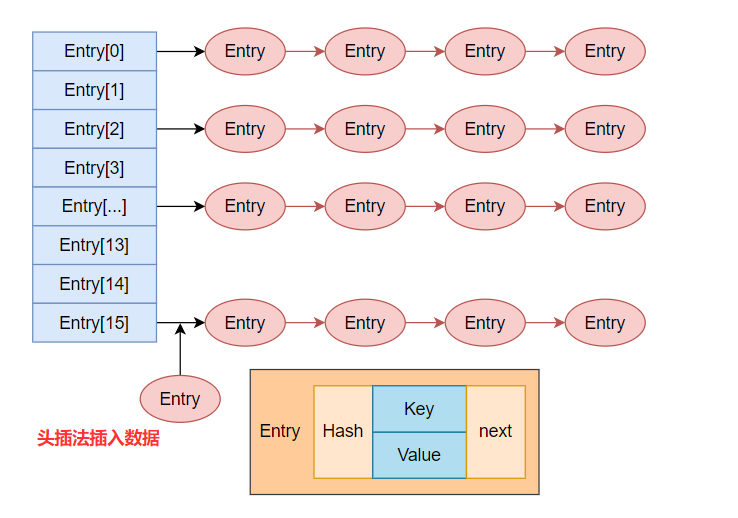
JDK1.8 HashMap是基于数组+链表+红黑树,当链表长度大于8时并且当容量大于64时会将链表转化成红黑树,插入数据使用尾插发。
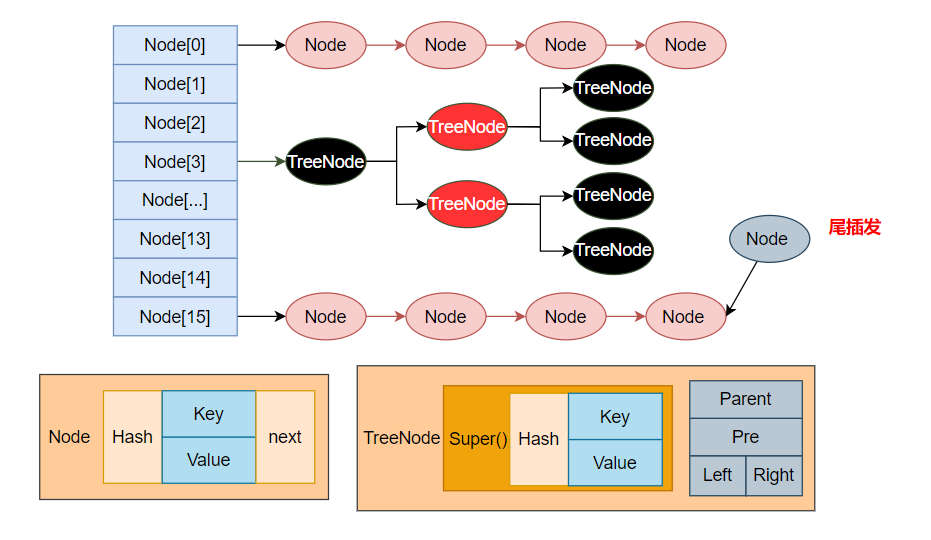
21.9.2.1 HashMap的特点
- 存储的元素为Key-Value的形式
- Key可以为null,Value也可以为null
- Key的值是唯一的
- 元素是无序的
- 线程不安全
21.9.2.2 HashMap的底层结构
- JDK 1.7 采用数组+链表的方式,插入元素使用头插法(头插法在多线程的情况下可能会造成死循环)。
- JDK 1.8 采用数组+链表+红黑树的方式,插入元素使用尾插法。
21.9.2.3 Hash算法
HashMap进行put一个新元素时,应该把新元素放到什么位置?如何计算这个新元素的位置?
这里通过源码可以发现有三步:
①、获取key的hashCode值
- 哈希值要尽量与key对象的每项数据相关,并且尽量唯一
②、哈希值进行高16位与低16位的异或运算
- 保证高低位都参与运算,为下一步准备
//对key进行二次hash计算
static final int hash (Object key){
int h;
//hash值进行高16异或低16位运算,为下一步取模运算做准备
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
③、模运算
- hash值& (length-1),结果为0到length-1范围的值,也就是整个数组的索引范围的值。
最终确定元素存入数组中的索引位置。以上算法目的是尽量保证每个元素均衡分布在数组中。
21.9.2.4扩容机制
如果链表太长,也会影响查询效率,所以JDK8后,引入了红黑树,以进一步提升查询效率。当链表长度达到8时(并且数组长度>=64),链表转为红黑树,当树节点数量降为6时再次退化成链表。当元素数量继续上升,红黑树节点数量还会不断增加,查询效率还是逐渐降低,这时会进行数组扩容,重新分布元素,以降低树的高度,提升查询效率。
- 如何扩容?
默认加载因子为0.75,容器中元素个数达到容器容量*0.75时,如16*0.75=12时,数组进行扩容,新容量为原来的2倍,这时会将所有元素重新计算哈希,重新分布元素位置。总之扩容很消耗性能,所以在预知元素个数的情况下,尽量指定合适容器容量,以减少扩容操作。
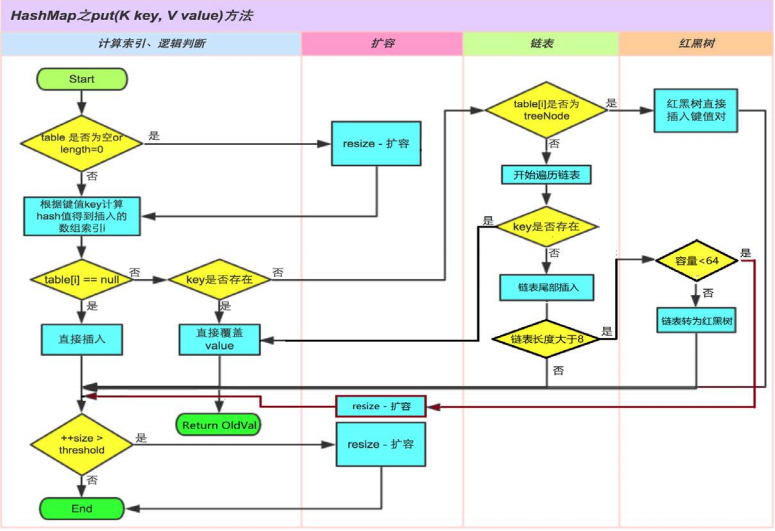
21.9.2.5 JDK1.8的HashMap简单总结
- 底层结构哈希表,数组+链表+红黑树,增删改查综合效率较高
- key是唯一,需要重写hashCode和equals
- 初始化容量,jdk8中第一次添加元素时,扩容容量为16,早期版本(jdk8之前)创建集合对象时初始化容量为16.
- 如果通过有参构造,指定初始容量为cap,实际初始容量为2的n次幂,并且大于等于cap。
- 当然元素个数达到临界值,即加载因子0.75*容量时,进行扩容,扩容为原来的2倍
- 链表大于8时,并且数组容量达到64,链表转为红黑树,链表小于6时,红黑树转为链表。(注意:当链表大于8时,而数组没有达到64则继续扩容数组至64为止)
- 采用尾插发插入元素
HashMap的使用简单举例:
@Test
public void test5(){
HashMap<String, String> map = new HashMap<>();
map.put("1","张三");
map.put("2","李四");
map.put("3","王五");
map.put("4","赵六");
map.put("5","孙琦");
Set<Map.Entry<String, String>> entrySet = map.entrySet();
for (Map.Entry<String, String> entry : entrySet) {
System.out.println("key="+entry.getKey()+",value = "+entry.getValue());
}
}
下面介绍一下Java中遍历Map集合的四种方式:
- 方法一(推荐):在for-each循环中使用entry来遍历,通过Map.entrySet遍历key和value,这是最常见的并且在大多数情况下也是最可取的遍历方式。在键值都需要时使用。
@Test
public void test5() {
HashMap<String, String> map = new HashMap<>();
map.put("1", "张三");
map.put("2", "李四");
Set<Map.Entry<String, String>> entrySet = map.entrySet();
for (Map.Entry<String, String> entry : entrySet) {
System.out.println("key=" + entry.getKey() + ",value = " + entry.getValue());
}
}

注:Map.Entry方法解释:Map.Entry是Map声明的一个内部接口,此接口为泛型,定义为Entry<K,V>。它表示Map中的一个实体(一个key-value对)
- 方法二:在for-each循环中遍历keys或values,如果只需要map中的键或者值,你可以通过keySet或values来实现遍历,而不是用entrySet。该方法比entrySet遍历在性能上稍好(快了10%),而且代码更加干净。
@Test
public void test5() {
HashMap<String, String> map = new HashMap<>();
map.put("1", "张三");
map.put("2", "李四");
//遍历map中的键
for(String key:map.keySet()){
System.out.println("key="+key);
}
//遍历map中的值
for(String value:map.values()){
System.out.println("value ="+value);
}
}
- 方法三:使用Iterator遍历
@Test
public void test5() {
HashMap<String, String> map = new HashMap<>();
map.put("1", "张三");
map.put("2", "李四");
Iterator<Map.Entry<String,String>> entries = map.entrySet().iterator();
while(entries.hasNext()){
Map.Entry<String,String> entry = entries.next();
System.out.println("key="+entry.getKey()+",value = "+entry.getValue());
}
}
该种方式看起来冗余却有其优点所在。首先,在老版本java中这是唯一遍历map的方式。另一个好处是,你可以在遍历时调用iterator.remove()来删除entries,另两个方法则不能。根据javadoc的说明,如果在for-each遍历中尝试使用此方法,结果是不可预测的。
从性能方面看,该方法类同于for-each遍历(即方法二)的性能。
- 方法四:通过键找值遍历,这个代码看上去更加干净;但实际上它相当慢且无效率。
@Test
public void test5() {
HashMap<String, String> map = new HashMap<>();
map.put("1", "张三");
map.put("2", "李四");
for (String key : map.keySet()) {
String value = map.get(key);
System.out.println("Key = " + key + ", Value = " + value);
}
}
结论:一般来讲使用entrySet的方式进行遍历是效率最高的,因为hashMap内部的存储结构就是基于Entry的数组,在用这种方式进行遍历时,只需要遍历一次即可。而使用其他方式的时间复杂度可以会提高,例如:keySet方式,每次都需要通过key值去计算对应的hash,然后再通过hash获取对应的结果值,因此效率较低。
21.9.3 LinkedHashMap
LinkedHashMap基于双向链表和数组实现,内部结构和HashMap类似,就是多加了一个双向链表结构。根据key的插入顺序进行存储。(注意和TreeMap对所有的key-value进行排序进行区分)
21.9.4 WeakHashMap
WeakHashMap与HashMap的用法基本相似。区别在于,HashMap的key保留了对实际对象的"强引用",这意味着只要该HashMap对象不被销毁,该HashMap所引用的对象就不会被垃圾回收。但WeakHashMap的key只保留了对实际对象的弱引用,这意味着如果WeakHashMap对象的key所引用的对象没有被其他强引用变量所引用,则这些key所引用的对象可能被垃圾回收,当垃圾回收了该key所对应的实际对象之后,WeakHashMap也可能自动删除这些key所对应的key-value对。
21.9.5 TreeMap
TreeMap底层是用红黑树算法实现,它实现SortMap接口,所以其内部元素默认按照所有的key进行排序。当然也支持2种排序方式:自然排序或者定制排序。其中TreeMap中的key不可null,而它非线程安全的。使用可以参考上面的TreeSet示例,使用方式差不多。
21.9.6 IdentifyHashMap
IdentityHashMap是一种可重复key的集合类。它和HashMap类似,所以我们一般都是拿IdentityHashMap和HashMap来进行比较,因为它们两者判断重复key的方式不一样。IdentifyHashMap中判断重复key相等的条件是:(k1= =k2),也就是说它只比较普通值是否相等,不比较对象中的内容。而HashMap中类判断重复key相等的条件是: (k1= =null?k2==null:k1.equals(k2))= =true),它不仅比较普通值,而且比对象中的内容是否相等。
IdentityHashMap的简单举例:
@Test
public void test6(){
//创建HashMap实例,添加Integer实例为key
HashMap hashMap=new HashMap();
hashMap.put(1,"hello");
hashMap.put(1,"hello");
hashMap.put(new Integer(2),"hello");
hashMap.put(new Integer(2),"hello");
hashMap.put(new Integer(2),"hello");
System.out.println("HashMap:"+hashMap.toString());
//创建IdentityHashMap实例,添加Integer实例为key
IdentityHashMap<Object, Object> identityHashMap = new IdentityHashMap<>();
identityHashMap.put(3,"world");
identityHashMap.put(3,"world");
identityHashMap.put(new Integer(4),"world");
identityHashMap.put(new Integer(5),"world");
identityHashMap.put(new Integer(4),"world");
System.out.println("IdentityHashMap:"+identityHashMap.toString());
}
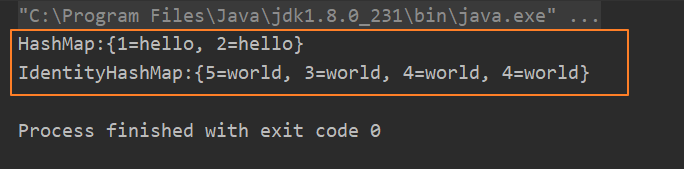
21.9.7 EnumMap
EnumMap这个类是专门为枚举类而设计的有键值对的集合类。集合中的所有键(key)都必须是单个同一个类型的枚举值,创建EnumMap时必须显式或隐式指定它对应的枚举类。当EnumMap创建后,其内部是以数组形式保存,所以这种实现形式非常紧凑高效。EnumMap根据key的自然顺序(即枚举值在枚举类中的定义顺序)来维护来维护key-value对的次序。可以通过keySet()、entrySet()、values()等方法来遍历EnumMap即可看到这种顺序。EnumMap不允许使用null作为key值,但允许使用null作为value。如果试图使用null作为key将抛出NullPointerException异常。如果仅仅只是查询是否包含值为null的key、或者仅仅只是使用删除值为null的key,都不会抛出异常。
EnumMap的代码示例如下:
@Test
public void test7(){
//EnumMap的简单使用
EnumMap<Season,String> map=new EnumMap<Season, String>(Season.class);
map.put(Season.SPRING,"春暖花开");
map.put(Season.SUMMER,"夏日炎炎");
map.put(Season.AUTUMN,"秋高气爽");
map.put(Season.WINNER,"冬暖夏凉");
//遍历map有很多种方式,这里是map遍历的一种方式,这种方式是最快的
for (EnumMap.Entry<Season,String> entry:map.entrySet()){
System.out.println(entry.getKey()+","+entry.getValue());
}
}
enum Season {
SPRING, SUMMER, AUTUMN, WINNER;
}
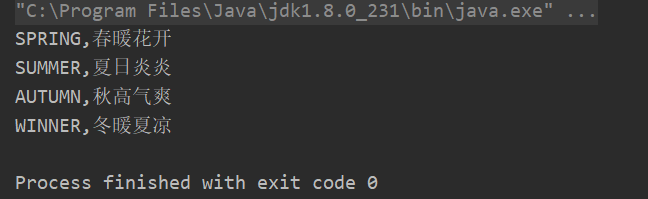
21.10 Collections工具类
Collections 是一个操作 Set、List 和 Map 等集合的工具类。Collections 中提供了一系列静态的方法对集合元素进行排序、查询和修改等操作,还提供了对集合对象设置不可变、对集合对象实现同步控制等方法(泛型被屏蔽掉了):
public static boolean addAll(Collection<? super T> c,T... elements)将所有指定元素添加到指定 collection 中。public static int binarySearch(List<? extends Comparable<? super T>> list,T key)在List集合中查找某个元素的下标,但是List的元素必须是T或T的子类对象,而且必须是可比较大小的,即支持自然排序的。而且集合也事先必须是有序的,否则结果不确定。public static int binarySearch(List<? extends T> list,T key,Comparator<? super T> c)在List集合中查找某个元素的下标,但是List的元素必须是T或T的子类对象,而且集合也事先必须是按照c比较器规则进行排序过的,否则结果不确定。public static <T extends Object & Comparable<? super T>> T max(Collection<? extends T> coll)在coll集合中找出最大的元素,集合中的对象必须是T或T的子类对象,而且支持自然排序public static T max(Collection<? extends T> coll,Comparator<? super T> comp)在coll集合中找出最大的元素,集合中的对象必须是T或T的子类对象,按照比较器comp找出最大者public static void reverse(List<?> list)反转指定列表List中元素的顺序。public static void shuffle(List<?> list)List 集合元素进行随机排序,类似洗牌public static <T extends Comparable<? super T>> void sort(List list)根据元素的自然顺序对指定 List 集合元素按升序排序public static void sort(List list,Comparator<? super T> c)根据指定的 Comparator 产生的顺序对 List 集合元素进行排序public static void swap(List<?> list,int i,int j)将指定 list 集合中的 i 处元素和 j 处元素进行交换public static int frequency(Collection<?> c,Object o)返回指定集合中指定元素的出现次数public static void copy(List<? super T> dest,List<? extends T> src)将src中的内容复制到dest中public static boolean replaceAll(List list,T oldVal,T newVal):使用新值替换 List 对象的所有旧值Collections 类中提供了多个 synchronizedXxx() 方法,该方法可使将指定集合包装成线程同步的集合,从而可以解决多线程并发访问集合时的线程安全问题Collections类中提供了多个unmodifiableXxx()方法,该方法返回指定 Xxx的不可修改的视图。
参考链接:
21.11 Java中Comparable和Comparator
21.11.1 前言
对于Java中的对象,我们只能使用基本运算符==、!=来判断一下地址是否相等,不能使用>、<来比较大小。但是在实际的开发中,我们需要对对象进行排序,也就是比较大小,那么应该如何实现呢?这就需要使用到Java中的两个常用的接口Comparable<T>和Comparator<T>来实现了。下面通过示例学习这两个接口的使用。
21.11.2 Comparable接口
Comparable是一个基于排序接口,它是自然排序。该接口中只有一个compareTo(Obj o)方法,用于给一个类的多个实例比较大小,进而完成排序。也就是说某个类实现了Comparable接口,就意味着该类支持排序。通过实现类重写compareTo(Obj o)方法,从而规定多个实例的自然顺序,然后使用Arrays.sort 或Collections.sort 方法对数组对象或List对象进行排序。
先 看看Comparable 接,它的定义如下:
public interface Comparable<T> {
public int compareTo(T o);
}
用String举一个简单的例子:
public class CompareTest {
public static void main(String[] args) {
String[] str=new String[]{"AA","EE","DD","CC","FF","BB"};
Arrays.sort(str);
System.out.println(Arrays.toString(str));
}
}
运行结果为:

可以发现,在使用Arrays.sort(str)之后就完成了排序,但是我们并没有调用compareTo(Obj o)方法。这是因为 String 源码中实现了Comparable接口并且重写了该接口的方法,在使用Arrays.sort(str)时sort方法内部间接的调用了String的compareTo(Obj o)方法,所以我们直接就看到了排序的结果。像String、包装类等都实现了Comparable接口,重写了compareTo方法,都清晰的给出了比较两个对象的方式,可以自行去看一下String重写的compareTo方法的源码。但是在重写compareTo(Obj o)方法时都需要遵循这三个规则:
①、如果比较者(即this当前对象)大于被比较者(即compareTo方法里面的形参)(即前者大于后者),则返回正整数。
②、如果比较者小于被比较者 (即前者小于后者),那么返回负整数。
③、如果比较者等于被比较者 (即前者等于后者),那么返回零。
自定义的类是无法排序的,但是通过实现Comparable接口之后就可以实现,然后通过Arrays.sort 或Collections.sort 方法排序。我们来看一个自己定义的类怎么使用Comparable接口进行排序:
public class Person implements Comparable{
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
//按名字排序
@Override
public int compareTo(Object o) {
if(o instanceof Person){
Person p= (Person) o;
//name是String类型,这里直接调用String的compareTo
if (this.name.compareTo(p.name)>0){
return 1;
}else if(this.name.compareTo(p.name)<0){
return -1;
}else{
return 0;
}
}else{
throw new RuntimeException("传入数据类型不一致...");
}
}
public static void main(String[] args) {
Person[] p=new Person[5];
p[0]=new Person("Jack",23);
p[1]=new Person("Marry",13);
p[2]=new Person("Tom",18);
p[3]=new Person("John",33);
p[4]=new Person("Thomas",41);
System.out.println("排序前------------");
for (Person person : p) {
System.out.print(person.getName()+":"+person.getAge()+"\n");
}
System.out.println("排序后------------");
Arrays.sort(p);
for (Person person : p) {
System.out.print(person.getName()+":"+person.getAge()+"\n");
}
}
}
运行结果为:
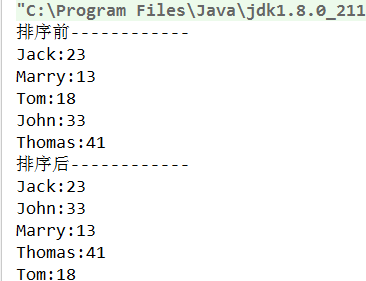
在Person类中实现了Comparable接口并且重写compareTo(Obj o)方法,然后我们按照名字排序,可以发现它默认的排序方式是升序,如果要降序则可以在返回值前面加一个负号。
21.11.3 Comparator接口
Comparator也是一个排序接口,它和Comparable功能是一样的,但是它是定制排序。怎么来理解定制排序呢?如果某个类没有实现Comparable接口,那么该类本身是不支持排序的,我们就可以使用Comparator来进行排序,或者我们自定义类实现了Comparable接口后,但是自定义类的代码不能再更改了,这时需要改变comparaTo(Obj o)方法中排序的方式,此时也可以选择定制排序Comparator。Comparator接口中有一个compare(T o1, T o2)方法,这个方法和compareTo(Obj o)类似,定义排序的规则是一样的:
o1>o2 (前者大于后者),返回值为正整数。
o1<o2 (前者小于后者),返回值为负整数。
o1=o2 (前者等于后者),返回值为零。
同样使用String简单举例:
public class CompareTest {
public static void main(String[] args) {
String[] str = new String[] { "AA", "EE", "DD", "CC", "FF", "BB" };
// 使用匿名内部类直接创建
Arrays.sort(str, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
if (o1.compareTo(o2) > 0) {
return 1;
} else if (o1.compareTo(o2) < 0) {
return -1;
} else {
return 0;
}
}
});
System.out.println(Arrays.toString(str));
}
}
我们知道接口是不能被实例化的,这里是匿名内部类的知识,可以自行去度娘寻找答案。
自定义类使用Comparator进行排序:
public class Person{
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public static void main(String[] args) {
Person[] p=new Person[5];
p[0]=new Person("Jack",23);
p[1]=new Person("Marry",13);
p[2]=new Person("Tom",18);
p[3]=new Person("John",33);
p[4]=new Person("Thomas",41);
System.out.println("排序前------------");
for (Person person : p) {
System.out.print(person.getName()+":"+person.getAge()+"\n");
}
System.out.println("排序后------------");
Arrays.sort(p, new Comparator<Person>() {
//按照年龄默认排序,如果年龄相同则按照名字默认排序
@Override
public int compare(Person o1, Person o2) {
if (o1 instanceof Person && o2 instanceof Person) {
if (o1.age > o2.age) {
return 1;
}else if (o1.age<o2.age){
return -1;
}else {
return o1.name.compareTo(o2.name);
}
}else{
throw new RuntimeException("传入数据类型不一致...");
}
}
});
for (Person person : p) {
System.out.print(person.getName()+":"+person.getAge()+"\n");
}
}
}
程序运行结果:
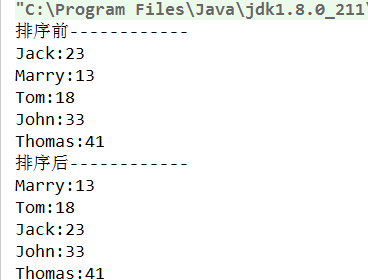
这样就使用Comparator定制排好序了。
21.11.4 小结
小结一下Comparable和Comparator的使用和区别:
- Comparable是排序接口,若一个类实现了Comparable接口,就意味着“该类支持排序”。而Comparator是比较器,我们若需要控制某个类的次序,可以建立一个“该类的比较器”来进行排序。
- Comparable是java.lang包下的,而Comparator是java.util包下的。
- Comparable可以看做是内部比较器,而Comparator是外部比较器。
- Comparable是自然排序,Comparator是定制排序。
- 如果某个类没有实现Comparable接口,而该类本身是不支持排序的,那么我们就可以使用Comparator来进行定制排序。
- 或者我们自定义类实现了Comparable接口后,但是自定义类的代码不能再更改了,这时需要改变compareTo(Obj o)方法中排序的方式,此时也可以选择定制排序Comparator。
这两种方法各有优劣:某个类实现了Comparable接口后,在任何地方都可以比较大小,但是有时候需要修改其比较的方式,则需要修原有的代码。而用Comparator的好处就是不需要修改原有代码, 而是另外实现一个比较器, 当某个自定义的对象需要作比较的时候,把比较器和对象一起传递过去就可以比大小了, 并且在Comparator 里面用户可以自己实现复杂的可以通用的逻辑,使其可以匹配一些比较简单的对象,那样就可以节省很多重复劳动了。
22、泛型
22.1 什么是泛型
Java 泛型(generics)是 JDK 5 中引入的一个新特性,也是非常重要的一个特性,泛型提供了编译时类型安全检测机制,该机制允许开发者在编译时检测到非法的类型。泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。这种参数类型可以用在类、接口和方法的创建中,分别称为泛型类、泛型接口、泛型方法。这个类型参数将在程序运行时确定。
我们可以把泛型理解为作用在类或者接口上面的标签。根据这个标签的类型传入规定的数据类型,否则就会出错,其中类型必须是类类型,不能是基本数据类型。例如我们国家中医存药的箱子,每个箱子上面都贴有一个标签,如果上面贴的是冬虫夏草,那么就只能放冬虫夏草,而和其他的药物混合放在一起就非常的乱,很容易出现错误。
泛型就是这样的道理,我们先来看下泛型最简单的使用吧:
ArrayList<String> list=new ArrayList<>();
list.add("Hello");
//只能放字符串,如果放数字编译报错
//list.add(666);
注意:Java1.7之后泛型可以简化,就是变量前面的参数类型必须要写,而后面的参数类型可以写出来,也可以省略不写。
22.2 为什么要泛型
简单举个例子,这个应该是网上最经典的例子:
//创建集合对象
ArrayList list=new ArrayList();
list.add("Hello");
list.add("World");
list.add(111);
list.add('a');
//遍历集合内容
for (int i = 0; i < list.size(); i++) {
String str= (String) list.get(i);
System.out.println(str);
}
上面程序运行结果毫无疑问会出现异常java.lang.ClassCastException: java.lang.Integer cannot be cast to java.lang.String,这就是没有泛型的弊端。因为上面的ArrayList中就可以存放任意类型(即Object类型),我们知道,所有的类型都可以用Object类型来示,而Object在类型转换方面很容易出现错误。也许有人会想可以先用Object类型代替String接收,然后再转成相对应的数据类型,这样是也可以的,但是万一在转换的时候某个数据类型看错了或者记错了,那么还不是会出现转换异常。就算运气好全部都对了,但是这种强制类型转换一大堆的代码,你的同事或者领导看了可能会拿刀来砍死你,非常不利于代码后期的维护。同时我们还能得出泛型带来的一些好处:
- 可以有效的防止类型转换异常的出现。
- 可以让代码更简洁,从而提高代码的可读性、可维护性和稳定性。
- 可以增强for循环遍历集合,进而提升性能,因为都是相同类型的。
- 可以解决类型安全编译警告。因为没有泛型时所有类型向上转型为Object类型,所以存在类型安全问题。
泛型它有三种使用方式,分别为:泛型类、泛型接口、泛型方法。我们接下来学习它们怎么使用。
22.3 泛型类
泛型类就是把泛型定义在类上,它的使用比较的简单。我们先来定义一个最普通的泛型类:
//定义泛型类,其中T表示一个泛型标识
public class Generic<T> {
private T key;
public Generic() {
}
public Generic(T key) {
this.key = key;
}
//这里不是泛型方法,它们是有区别的
public T getKey() {
return key;
}
public void setKey(T key) {
this.key = key;
}
}
泛型类的测试代码如下,我们只需在类实例化的时候传入想要的类型,然后泛型类中的T就会自动转换成该相应的类型。
public static void main(String[] args) {
//有参构造器初始化,传入String类型
Generic<String> generic = new Generic<>("Generic1...");
System.out.println(generic.getKey());//Generic1...
//无参构造器初始化,传入Integer类型
Generic<Integer> generic1 = new Generic<>();
generic1.setKey(123456);
int key = generic1.getKey();
System.out.println(key);//123456
}
然后我们再来看下泛型中泛型标识符,在上面这个泛型类中 T 表示的是任意类型,泛型中还有很多这样的标识,例如K表示键,V表示值,E表示集合,N表示数字类型等等。
在泛型类中还有两种特殊的使用方式,是关于继承的时候是否传入具体的参数。
①、当继承泛型类的子类明确传入泛型实参时:
//子类中明确传入泛型参数类型
class SubGeneric extends Generic<String>{
}
//测试类
class Test{
public static void main(String[] args) {
SubGeneric subGeneric = new SubGeneric();
//调用继承自父类的属性
subGeneric.setKey("SubGeneric...");
String key = subGeneric.getKey();
System.out.println(key);
}
}
可以得出子类在继承了带泛型的父类时,明确的指明了传入的参数类型,那么子类在实例化时,不需要再指明泛型,用的是父类的类型。
②、当继承泛型类的子类没有明确传入泛型实参时:
//子类没有明确传入泛型参数类型
class SubGeneric<T> extends Generic<T>{
private T value;
public T getValue() {
return value;
}
public void setValue(T value) {
this.value = value;
}
}
class Test{
public static void main(String[] args) {
SubGeneric<Integer> subGeneric = new SubGeneric<>();
//调用继承自父类的属性
subGeneric.setKey(123456);
int key = subGeneric.getKey();
System.out.println(key);
//调用子类自己的属性
SubGeneric<String> subGeneric1=new SubGeneric<>();
subGeneric1.setValue("SubGeneric...");
String value = subGeneric1.getValue();
System.out.println(value);
}
}
当子类没有明确指明传入的参数类型时,那么在子类实例化时,都是根据子类中传入的类型来确定的父类的类型。如果父类和子类中有一个明确,另一个没有明确或者两者明确的类型不一样,那么它们的类型会自动提升为Object类型。如下:
//一个明确,一个不明确
class SubGeneric<T> extends Generic<String>{
private T value;
}
22.4 泛型接口
泛型接口和泛型类的定义和使用几乎相同,只是在语句上面有些不同罢了,所以这里就不多说什么了。直接来看一下例子:
//定义一个泛型接口
public interface IGeneric<T> {
public T show();
}
class Test implements IGeneric<String>{
@Override
public String show() {
return "hello";
}
}
泛型接口实现类中是否明确传入参数和泛型类是一样的,所以就不说了,可以参考泛型类。
22.5 泛型方法
前面介绍了泛型类和泛型接口,它们两者的使用相对来说比较的简单,然后我们再来看一下泛型方法,泛型方法比它们两者稍微复杂一点点。在前面的泛型类中我们也看到了方法中有用到泛型,它的格式是这样的:
//这里不是泛型方法,它们是有区别的
public T getKey() {
return key;
}
但是它并不是泛型方法。泛型方法的中的返回值必须是用 <泛型标识> 来修饰(包括void),只有声明了<T>的方法才是泛型方法,这里<T>表明该方法将使用泛型标识T,此时才可以在方法中使用泛型标识T。而单独只用一个泛型标识 T 来表示会报错(这里的意思是,如果只用一个泛型标识 T 来表示返回值,并且该方法所在的类中没有使用<T>),系统无法解析它是什么。当然我们也可以使用其他的泛型标识符如:K、V、E、N等。
泛型方法的声明格式如下:
//这里的泛型标识 T 与泛型类中的 T 没有任何关系
public <T> T show(T t){
return t;
}
注意:泛型方法的泛型与所属的类的泛型没有任何关系。我们可以举例说明:
public class GenericMethod<T> {
// 注意这不是泛型方法,只是普通方法
public T getKey(T t) {
return t;
}
// 这里的泛型标识 T 与泛型类中的 T 没有任何关系
public <T> T show(T t) {
return t;
}
// 用这个与上面进行区分会更好理解,泛型类中 泛型标识T 与泛型方法中 泛型标识U 是没有关系的
public <U> U show1(U t) {
return t;
}
}
class Test {
public static void main(String[] args) {
//实例化泛型类,传入String类型
GenericMethod<String> genericMethod = new GenericMethod<>();
//调用方法,传入数字,返回Integer类型
Integer show = genericMethod.show(123456);
System.out.println(show);//123456
//调用方法,传入字符,字符类型
Character a = genericMethod.show('a');
System.out.println(a);//a
Integer show1 = genericMethod.show1(123);
System.out.println(show1);//123
}
}
在测试类中,创建类的实例时,泛型传入的是String类型,而在调用方法的时候,分别传入了数字类型和字符类型。
至此我们得出结论:泛型方法是在调用方法的时候由方法的形参来决定泛型方法的具体类型,它与泛型类中的泛型无关,所以泛型方法可以是静态的;
public class StaticGenerator<T> {
....
....
/**
* 如果在类中定义使用泛型的静态方法,需要添加额外的泛型声明(将这个方法定义成泛型方法)
* 即使静态方法要使用泛型类中已经声明过的泛型也不可以。
* 如:public static void show(T t){..},此时编译器会提示错误信息:
"StaticGenerator cannot be refrenced from static context"
*/
public static <T> void show(T t){
}
}
22.6 泛型在继承方面的体现(兼容性)
如果某个类继承了另一个类,那么它们之间的转换就会变得简单,例如Integer继承Number:
Number number=123;
Integer integer=456;
number=integer;//可以赋值
Number[] numbers=null;
Integer[] integers=null;
numbers=integers;//可以赋值
上面这么做完全可以,但是把它们用在泛型中却不是这么一回事了。
List<Number> list1=null;
List<Integer> list2=null;
//编译报错,不兼容的类型
//list1=list2;
这是因为Integer继承自Number类,但是List<Integer>并不是继承自List<Number>的,它们两是都继承自Object这个根父类。看到下面这张图片可能会更好的理解(图片引用自https://blog.csdn.net/whdalive/article/details/81751200)
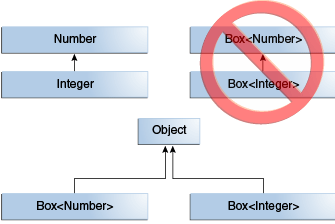
这里用这样一段话来概括:虽然类A是类B的父类,但是G<A>和G<B>它们之间不具备任何子父类关系,二者都是并列关系,唯一的关系就是都继承自Object这个根父类。
再来看一下另一种情况:带泛型的类(接口)与另一个类(接口)有继承(实现)的关系。
举例:在集合中,ArrayList <E>实现List <E> , List <E>扩展Collection <E> 。 因此ArrayList <String>是List <String>的子类型,List <String>是Collection <String>的子类型。 所以只要不改变类型参数,就会在类型之间保留子类型关系。
Collection<String> collection=null;
List<String> list=null;
ArrayList<String> arrayList=null;
collection=list;
list=arrayList;
这里其实就是普通的继承(实现),类似于Integer继承在Number类一样。图片如下:
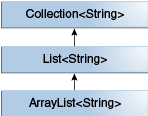
参考文章:https://blog.csdn.net/whdalive/article/details/81751200
22.7 泛型中通配符
我们在定义泛型类,泛型方法,泛型接口的时候经常会碰见很多不同的通配符,比如 T,E,K,V 等等,这些通配符又都是什么意思呢?
22.7.1 常用的 T,E,K,V,?
本质上这些个都是通配符,没啥区别,只不过是编码时的一种约定俗成的东西。比如上述代码中的 T ,我们可以换成 A-Z 之间的任何一个 字母都可以,并不会影响程序的正常运行,但是如果换成其他的字母代替 T ,在可读性上可能会弱一些。通常情况下,T,E,K,V,?是这样约定的:
- ?表示不确定的 java 类型
- T (type) 表示具体的一个java类型
- K V (key value) 分别代表java键值中的Key Value
- E (element) 代表Element
在上面的一节中讲了Integer是Number的一个子类,而List<Integer>和List<Number>二者都是并列关系,它们之间毫无关系,唯一的关系就是都继承自Object这个根父类。那么问题来了,我们在使用List<Number>作为方法的形参时,能否传入List<Integer>类型的参数作为实参呢?其实这个时候答案已经很明显了,是不能的。所以这时候就可以用到通配符了。
在没有使用通配符的情况下我们的代码要这样写:
public class Generic {
public static void main(String[] args) {
List<Number> list1=new ArrayList<>();
list1.add(1);
list1.add(2);
List<Integer> list2=new ArrayList<>();
list2.add(3);
list2.add(4);
show(list1);
//报错说不能应用Integer类型
//show(list2);
}
public static void show(List<Number> list){
System.out.println(list.toString());//[1, 2]
}
}
如果还想要支持Integer类型则需要添加新的方法:
public static void show1(List<Integer> list){
System.out.println(list.toString());//[1, 2]
}
这样就会导致代码大量的冗余,非常不利于阅读。所以此时就需要泛型的通配符了,格式如下:
public static void show(List<?> list){
System.out.println(list.toString());//[1, 2][3, 4]
}
当我们使用了通配符之后,就能轻松解决以上问题了。在Java泛型中用 ? 号用来表示通配符,?号通配符表示当前可以匹配任意类型,任意的Java类都可以匹配。但是在使用通配符之后一定要注意:该对象中的有些方法任然可以调用,而有些方法则不能调用了。例如:
public static void show(List<?> list){
//list.add(66);//不能使用add()
list.add(null);//唯独能添加的只有null
Object remove = list.remove(0);//可以使用remove()
System.out.println(remove);
Object get = list.get(0);//可以使用get()
System.out.println(get);
System.out.println(list.toString());
}
这是因为只有调用的时候才知道List<?>通配符中的具体类型是什么。所以对于上面的list而言,如果调用add()方法,那么我们并不知道要添加什么样的类型,所以会报错。而remove()和get()方法都是根据索引来操作的,它们都是数字类型,所以它是可以被调用的。
通配符还有两种扩展的用法:
22.7.2 通配符上限
List<? extends ClassName>,它表示的是传入的参数必须是ClassName的子类(包括该父类),
类似于数学中(∞,ClassName],然后简单举例说明:
public static void main(String[] args) {
List<Number> list1=new ArrayList<>();
list1.add(1);
List<Integer> list2=new ArrayList<>();
list2.add(2);
List<Object> list3=new ArrayList<>();
list3.add(3);
show(list1);//传入Number类型
show(list2);//传入Integer类型
//show(list3);//传入Object类型,报错说不能应用Object类型,因为这里最大只能用到Number类型
}
public static void show(List<? extends Number> list){
System.out.println(list.toString());
}
22.7.3 通配符下限
List<? super ClassName>,它表示的是传入的参数必须是ClassName的父类(包括该子类),类似于数学中[ClassName,∞)
public static void main(String[] args) {
List<Number> list1=new ArrayList<>();
list1.add(1);
List<Integer> list2=new ArrayList<>();
list2.add(2);
List<Object> list3=new ArrayList<>();
list3.add(3);
show(list1);//传入Number类型
//show(list2);//传入Integer类型,报错说不能应用Integer类型,因为此时最小只能用到Number类型
show(list3);//传入Object类型,
}
public static void show(List<? super Number> list){
System.out.println(list.toString());
}
23、IO流
23.1 IO流简单介绍
23.1.1 什么是IO
我们在生活中一定遇到这样的情况,比如我们在编辑某个文件的时候,一时忘记了按 Ctrl+S 键,但是此时电脑恰好出现意外情况,就会导致我们的文件白白编辑了,如果文件不重要倒还好,如果是重要文件你估计会非常的气愤。之所以一旦出现意外情况我们编辑的文件就没了呢?这是因为我们编辑的新文件还保存在内存中,没有将数据保存至硬盘中,那么我们应该通过 Ctrl+S 将数据从内存存储至硬盘中。我们把这种数据的传输,可以看做是一种数据的流动,按照流动的方向,以内存为基准,分为输入Input 和输出Output ,即流向内存是输入流,流出内存的输出流,统称为 IO流。 Java中I/O操作主要是指使用java.io包下的内容,进行输入、输出操作。输入也叫做读取数据,输出也叫做作写出数据。

23.1.2 流的概念和作用
流:代表任何有能力产出数据的数据源对象或者是有能力接受数据的接收端对象
流的本质:数据传输,根据数据传输特性将流抽象为各种类,方便更直观的进行数据操作。
作用:为数据源和目的地建立一个输送通道
23.1.3 IO流的分类
①、根据数据流向不同分为:输入流和输出流。
输入:读取外部数据(磁盘、光盘等存储设备的数据)到程序(内存)中。如InputStream,Reader
输出:把程序(内存)中的内容输出到磁盘、光盘等存储设备中。如OutputStream、Writer
②、根据处理数据类型的不同分为:字节流和字符流。
字节流:可以用于读写二进制文件及任何类型文件。
字符流:可以用于读写文本文件。
字节流和字符流的区别
字符流的由来: Java中字符是采用Unicode标准,一个字符是16位,即一个字符使用两个字节来表示。为此,JAVA中引入了处理字符的流。因为数据编码的不同,从而有了对字符进行高效操作的流对象。本质其实就是基于字节流读取时,去查了指定的码表。
两者的区别:(1字符 = 2字节 、 1字节(byte) = 8位(bit) 、 一个汉字占两个字节长度)
- 读写单位不同:字节流以字节为单位,字符流以字符为单位,根据码表映射字符,一次可能读多个字节。
- 处理对象不同:字节流能处理所有类型的数据(如图片、avi等),而字符流只能处理字符类型的数据。
- 缓存不同:字节流在操作的时候本身是不会用到缓冲区的,是文件本身的直接操作的;而字符流在操作的时候下后是会用到缓冲区的,是通过缓冲区来操作文件。
总结:优先选用字节流。因为硬盘上的所有文件都是以字节的形式进行传输或者保存的,包括图片等内容。字符只是在内存中才会形成的,所以在开发中,字节流使用广泛。除非处理纯文本数据(如TXT文件),才优先考虑使用字符流,除此之外都使用字节流。
③、根据功能的不同分为:节点流和处理流。
节点流:可以从或向一个特定的地方(节点)读写数据。如FileInputStream,FileReader。
处理流:是对一个已存在的流的连接和封装,通过所封装的流的功能调用实现数据读写。如BufferedReader。处理流的构造方法总是要带一个其他的流对象做参数。一个流对象经过其他流的多次包装,称为流的链接。
节点流是直接作用在文件上的流,可以理解为一个管道,文件在管道中传输。
处理流是作用在已有的节点流基础上,是包在节点流的外面的管道(可多层),其目的是让管道内的流可以更快的传输。
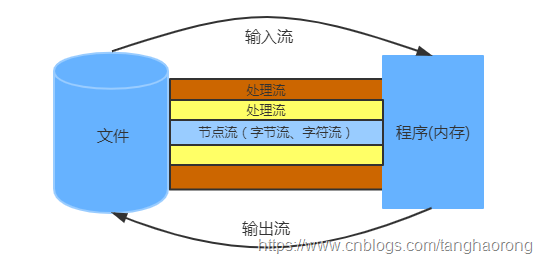
Java的IO模型设计非常优秀,它使用装饰模式(Decorator Pattern)[这篇博文详细说明了什么是装饰者模式 传送门 ],这种设计是也称为包装模式(Wrapper Pattern),其使用一种对客户端透明的方式来动态地扩展对象的功能,它是通过继承扩展功能的替代方案之一。在现实生活中你也有很多装饰者的例子,例如:人需要各种各样的衣着,不管你穿着怎样,但是,对于你个人本质来说是不变的,充其量只是在外面加上了一些装饰,有,“遮羞的”、“保暖的”、“好看的”、“防雨的”.....。例如:您需要一个具有缓冲的文件输入流,则应当组合使用FileInputStream和BufferedInputStream,而流的本身是不变的。
23.1.4 IO流中的基类
四个基本的抽象流类型,所有的流都继承这四个。

下图是Java IO流的整体架构图,后面的博客会详细的讲解这些流使用:
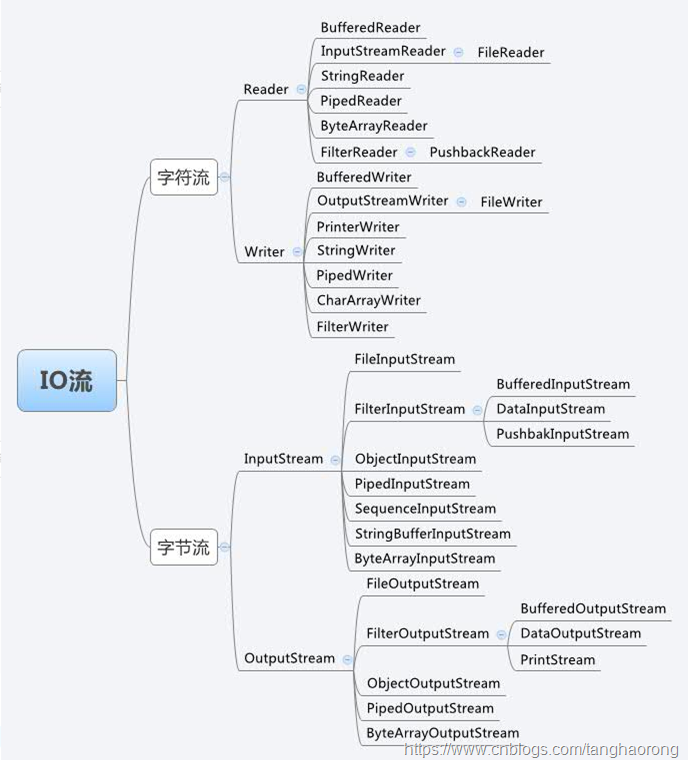
当看到上面这张图的时候会感到很懵逼,因为这么多的类在使用时是选择字节流输入输出还是选择字符流输入输出呢?其实并不难。
- 如果你要将磁盘光盘中的数据读到程序中,那就选择输入流,反之则是输出流。
- 如果你要传输的是音频视频数据,那就肯定是字节流。如果单独是纯文本文件(如TXT),那就字符流。其实所有数据都可以使用字节流,只是效率高低问题。
- 如上面两个都确定了,就可以选出一个合适的节点流,然后再根据你的需求是否需要额外功能(比如是否需要转换流、高效流等)。
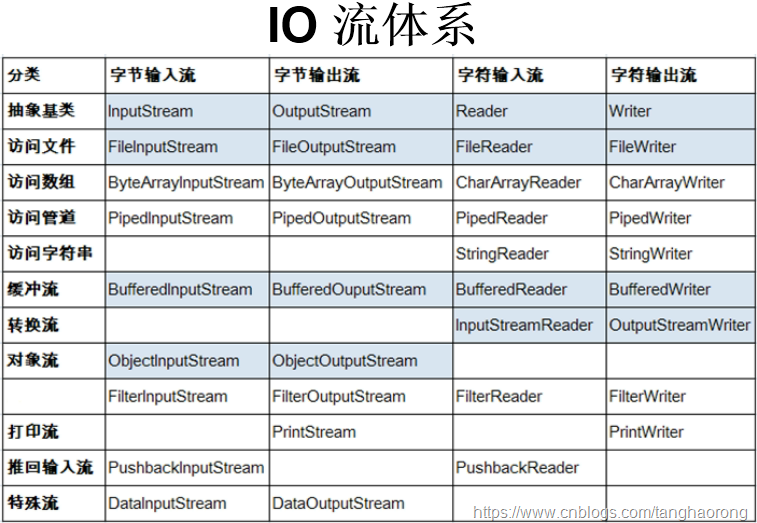
23.1.5 IO流常用到的五类一接口
Java IO流中所有的接口和类都放在java.io这个包下。其中最重要的就是5个类和一个接口。5个类指的是File、OutputStream、InputStream、Writer、Reader;一个接口指的是Serializable。如掌握了这些IO的核心使用方法,那么就能把Java IO流玩弄于股掌之中,将它放在手中任意盘它。
它们的详细介绍如下:
①. File(文件特征与管理):File类是对文件系统中文件以及文件夹进行封装的对象,可以通过对象的思想来操作文件和文件夹。 File类保存文件或目录的各种元数据信息,包括文件名、文件长度、最后修改时间、是否可读、获取当前文件的路径名,判断指定文件是否存在、获得当前目录中的文件列表,创建、删除文件和目录等方法。
②. InputStream(二进制格式操作):抽象类,基于字节的输入操作,是所有输入流的父类。定义了所有输入流都具有的共同特征。
③. OutputStream(二进制格式操作):抽象类。基于字节的输出操作。是所有输出流的父类。定义了所有输出流都具有的共同特征。
④. Reader(文件格式操作):抽象类,基于字符的输入操作。
⑤. Writer(文件格式操作):抽象类,基于字符的输出操作。
⑥. RandomAccessFile(随机文件操作):一个独立的类,直接继承至Object.它的功能丰富,可以从文件的任意位置进行存取(输入输出)操作。
⑦. Serializable(序列化操作):是一个空接口,为对象提供标准的序列化与反序列化操作。
23.1.6 Java IO流对象介绍
23.1.6.1 字节输入流InputStream

根据上图介绍各个类的作用:
-
InputStream:字节输入流基类,是所有的字节输入流的父类,它是一个抽象类。
-
FileInputSream:文件输入流。它通常用于对文件进行读取操作。
-
FilterInputStream :过滤流。作用是为基础流提供一些额外的功能。装饰者模式中处于装饰者,具体的装饰者都要继承它,所以在该类的子类下都是用来装饰别的流的,也就是处理类。
- BufferedInputStream:缓冲流。对处理流进行装饰,增强,内部会有一个缓存区,用来存放字节,每次都是将缓存区存满然后发送,而不是一个字节或两个字节这样发送。效率更高。
- DataInputStream:数据输入流。它是用来装饰其它输入流,它“允许应用程序以与机器无关方式从底层输入流中读取基本 Java 数据类型”。
- PushbakInputStream:回退输入流。java中读取数据的方式是顺序读取,如果某个数据不需要读取,需要程序处理。PushBackInputStream就可以将某些不需要的数据回退到缓冲中。
-
ObjectInputStream:对象输入流。用来提供对“基本数据或对象”的持久存储。通俗点讲,也就是能直接传输对象(反序列化中使用)。
-
PipedInputStream:管道字节输入流。它和PipedOutputStream一起使用,能实现多线程间的管道通信。
-
SequenceInputStream:合并输入流。依次将多个源合并成一个源。
-
StringBufferInputStream:字符相关流。已经过时不多说。
-
ByteArrayInputStream:字节数组输入流,该类的功能就是从字节数组(byte[])中进行以字节为单位的读取,也就是将资源文件都以字节的形式存入到该类中的字节数组中去,我们拿也是从这个字节数组中拿。
23.1.6.2 字节输出流OutputStream

根据上图介绍各个类的作用:
-
OutputStream:字节输出流基类,是所有的字节输出流的父类,它是一个抽象类。
-
FileOutputStream:文件输出流。该类实现了一个输出流,将数据输出到文件。
-
FilterOutputStream :过滤流。用来封装其它的输出流,并为它们提供额外的功能(序列化中使用)。它主要包括BufferedOutputStream, DataOutputStream和PrintStream。
- BufferedOutputStream:缓冲输出流。给输出流提供缓冲功能。
- DataOutputStream:是用来装饰其它输出流,将DataOutputStream和DataInputStream输入流配合使用,“允许应用程序以与机器无关方式从底层输入流中读写基本 Java 数据类型”。
- PrintStream:是用来装饰其它输出流。它能为其他输出流添加了功能,使它们能够方便地打印各种数据值表示形式。
-
ObjectOutputStream:对象输出流。该类将实现了序列化的对象序列化后写入指定地方。
-
PipedOutputStream:管道字节输出流。它和PipedInputStream一起使用,能实现多线程间的管道通信,是管道的发送端。
-
ByteArrayOutputStream:字节数组输出流。该类实现了一个输出流,其数据被写入由byte数组充当的缓冲区,缓冲区会随着数据的不断写入而自动增长。
23.1.6.3 字符输入流Reader
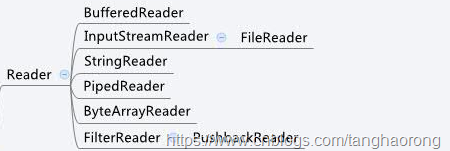
根据上图介绍各个类的作用:
-
Reader:是所有的输入字符流的父类,它是一个抽象类。
-
InputStreamReader:是一个连接字节流和字符流的桥梁,它将字节流转变为字符流。
- FileReader 可以说是一个达到此功能、常用的工具类,在其源代码中明显使用了将FileInputStream 转变为Reader 的方法。我们可以从这个类中得到一定的技巧。Reader 中各个类的用途和使用方法基本和InputStream 中的类使用一致。后面会有Reader 与InputStream 的对应关系。
-
CharReader、StringReader 是两种基本的介质流,它们分别将Char 数组、String中读取数据。
-
PipedReader 是从与其它线程共用的管道中读取数据。
-
FilterReader 是所有自定义具体装饰流的父类,其子类PushbackReader 对Reader对象进行装饰,会增加一个行号。
- BufferedReader是一个装饰器,它和其子类LineNumberReader负责装饰其它Reader对象。
23.1.6.4 字符输出流Writer
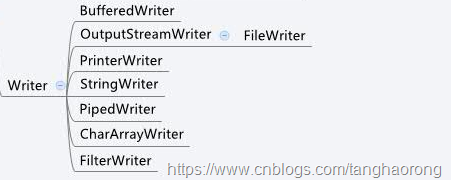
根据上图介绍各个类的作用:
-
Writer:是所有的输出字符流的父类,它是一个抽象类。
-
OutputStreamWriter:是OutputStream 到Writer 转换的桥梁
- FileWriter 其实就是一个实现此功能的具体类(具体可以研究一SourceCode)。功能和使用和OutputStream 极其类似。
-
PrintWriter 和PrintStream 极其类似,功能和使用也非常相似。
-
PipedWriter 是向与其它线程共用的管道中写入数据,
-
CharArrayWriter、StringWriter 是两种基本的介质流,它们分别向Char 数组、String 中写入数据。
-
BufferedWriter 是一个装饰器为Writer 提供缓冲功能。
如果博客对你有一点点帮助的话,哪怕只有一点点,能否动一下靓仔靓女的手指点个赞。

23.2 File类
在上一章博客中简单的介绍了Java IO流的一些特征。也就是对文件的输入输出,既然至始至终都离不开文件,所以Java IO流的使用得从File这个类讲起。
File类的描述:File类是文件和目录路径名的抽象表示形式,主要用于文件和目录的创建、查找和删除等操作。即Java中把文件或者目录(文件夹)都封装成File对象。也就是说如果我们要去操作硬盘上的文件或者目录只要创建File这个类即可。
不过要注意的是File类只是对文件的操作类,只能对文件本身进行操作,不能对文件内容进行操作。
23.2.1 File类的属性(字段)
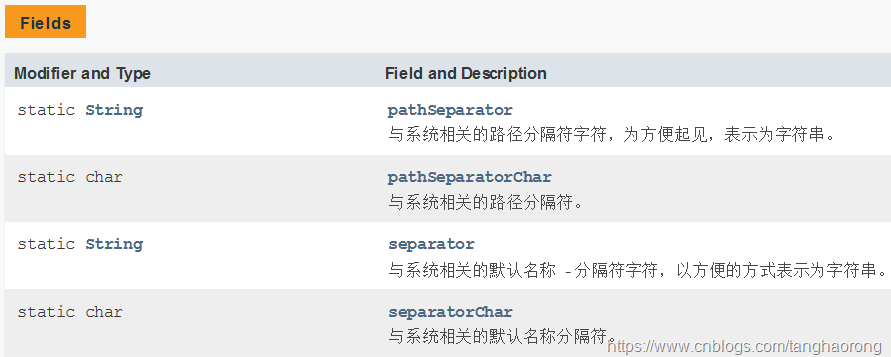
从上图的API可以发现File中包括两种分隔符,路径分隔符和名称分隔符,而且分别还有两种形式Char型和String型。其中
File.pathSeparator 指的是分隔连续多个路径字符串的分隔符。在UNIX系统上,这个字符是’:’ ; 在Microsoft Windows系统上是’;’ 。
File.separator 指的是用来分隔同一个路径字符串中的目录的分隔符。在UNIX系统上,该字段的值为’/’; 在Microsoft Windows系统上是’\’ 。
我们都知道由于不同的操作系统之间会导致分隔符的不同,所以使用它们的作用主要就是屏蔽各个平台之间的分隔符差异。
//在Windows系统下输出
System.out.println(File.pathSeparator);// 输出;
System.out.println(File.separator);// 输出\
//简单测试一下,调用的方法后面会讲
File file1 = new File("D:\\IO\\hello.txt");//这里两个\\是Java中的转义字符
File file2 = new File("D:"+File.separator+"IO"+File.separator+"hello.txt");
System.out.println(file1.getAbsolutePath());
System.out.println(file2.getAbsolutePath());
输出的结果都是:D:\IO\hello.txt
23.2.2 File类的构造方法
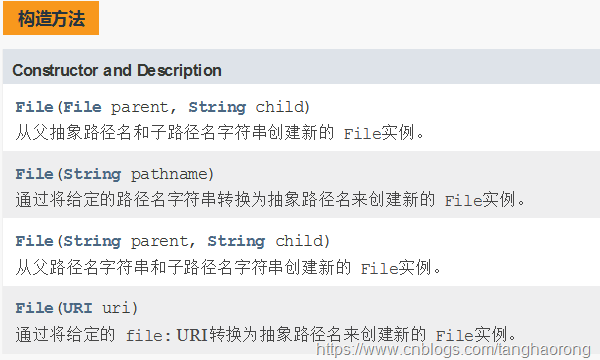
上图的构造方法使用举例如下:
package com.thr;
import java.io.File;
/**
* @author Administrator
* @date 2020-02-20
* @desc File构造方法举例
*/
public class Demo {
public static void main(String[] args) {
//File(String parent, String child)
//从父路径名字符串和子路径名字符串创建新的File实例。
File f1 = new File("D:","IO\\hello.txt");
System.out.println(f1); //输出 D:\IO\hello.txt
//File(String pathname)
//通过将给定的路径名字符串转换为抽象路径名来创建新的File实例。
//不用Java分隔符
File f2=new File("D:\\IO\\hello.txt");
//使用Java分隔符
File f3 = new File("D:"+File.separator+"IO"+File.separator+"hello.txt");
System.out.println(f2); //输出 D:\IO\hello.txt
System.out.println(f3); //输出 D:\IO\hello.txt
//File(File parent, String child)
//从父抽象路径名和子路径名字符串创建新的 File实例。
File f4 = new File("D:");
File f5 = new File(f4,"IO\\hello.txt");
System.out.println(f5); //输出 D:\IO\hello.txt
}
}
小贴士:
- 一个File对象代表硬盘中实际存在的一个文件或者目录。
- 无论该路径下是否存在文件或者目录,都不影响File对象的创建。
23.2.3 File类的常用方法
23.2.3.1 获取文件的相关信息
String getAbsolutePath():获取绝对路径名字符串。String getName():获取文件或目录的名称。String getPath():获取路径名字符串。String getParent():获取路径名父目录的路径名字符串;如果此路径名没有指定父目录,则返回 null。Long lastModified():获取最后一次修改的时间(返回毫秒)。Long length():获取文件的长度,如果表示目录则返回值未指定。
以上方法测试的代码如下【测试以自己的电脑文件夹为准】:
package com.thr;
import java.io.File;
import java.io.IOException;
/**
* @author Administrator
* @date 2020-02-20
* @desc File常用方法举例
*/
public class Demo1 {
public static void main(String[] args) {
//路径带文件
File f1 = new File("D:\\IO\\hello.txt");
System.out.println("文件绝对路径:"+f1.getAbsolutePath());
System.out.println("文件名称:"+f1.getName());
System.out.println("文件路径(字符串):"+f1.getPath());
System.out.println("文件父路径:"+f1.getParent());
System.out.println("文件最后修改时间(ms):"+f1.lastModified());
System.out.println("文件长度:"+f1.length());
System.out.println("------------");
//路径不带文件,纯目录
File f2 = new File("D:\\IO");
System.out.println("目录绝对路径:"+f2.getAbsolutePath());
System.out.println("目录名称:"+f2.getName());
System.out.println("目录路径(字符串):"+f2.getPath());
System.out.println("目录父路径:"+f2.getParent());
System.out.println("目录最后修改时间(ms):"+f2.lastModified());
System.out.println("目录长度:"+f2.length());
}
}
运行结果:
文件绝对路径:D:\IO\hello.txt
文件名称:hello.txt
文件路径(字符串):D:\IO\hello.txt
文件父路径:D:\IO
文件最后修改时间(ms):1582207195168
文件长度:9
------------
目录绝对路径:D:\IO
目录名称:IO
目录路径(字符串):D:\IO
目录父路径:D:\
目录最后修改时间(ms):1582206503515
目录长度:0
注意:绝对路径和相对路径的区别
- 绝对路径:是一个完整的路径,以盘符开头,例如 D://IO//hello.txt。
- 相对路径:是相较于当前路径,不以盘符开头,例如 //hello.txt。
23.2.3.2 判断功能
Boolean isDirectory():判断此路径是否为一个目录Boolean isFile():判断是否为一个文件Boolean exists():判断文件或目录是否存在Boolean canExecute():判断文件是否可执行Boolean canRead():判断文件是否可读Boolean canWrite():判断文件是否可写Boolean isHidden():判断是否为隐藏文件
以上方法测试的代码如下:
package com.thr;
import java.io.File;
import java.io.IOException;
/**
* @author Administrator
* @date 2020-02-20
* @desc File常用方法举例
*/
public class Demo2 {
public static void main(String[] args) throws IOException {
File f1 = new File("D:\\IO\\hello.txt");
//路径带文件
System.out.println("是否为目录:"+f1.isDirectory());
System.out.println("是否为文件"+f1.isFile());
System.out.println("是否存在"+f1.exists());
System.out.println("是否可执行"+f1.canExecute());
System.out.println("是否可读"+f1.canRead());
System.out.println("是否可写"+f1.canWrite());
System.out.println("是否隐藏"+f1.isHidden());
System.out.println("------------");
File f2 = new File("D:\\IO");
//路径不带文件,纯目录
System.out.println("是否为目录:"+f2.isDirectory());
System.out.println("是否为文件"+f2.isFile());
System.out.println("是否存在"+f2.exists());
System.out.println("是否可执行"+f2.canExecute());
System.out.println("是否可读"+f2.canRead());
System.out.println("是否可写"+f2.canWrite());
System.out.println("是否隐藏"+f2.isHidden());
}
}
23.2.3.3 新建和删除
Boolean createNewFile():创建文件,如果文件存在则不创建,返回false,反之返回true。Boolean mkdir():创建文件目录。如果此文件目录存在则不创建,如果此文件目录的上层目录不存在就不创建。Boolean mkdirs(): 创建文件目录。如果上层文件目录不存在也会创建。Boolean delete():删除的文件或目录。如果目录下有文件或目录则不会删除。
以上方法测试的代码如下:
package com.thr;
import java.io.File;
import java.io.IOException;
/**
* @author Administrator
* @date 2020-02-20
* @desc File常用方法举例
*/
public class Demo3 {
public static void main(String[] args) throws IOException {
//创建文件
File f1 = new File("D:\\IO\\hi.txt");
if (!f1.exists()) {
f1.createNewFile();
System.out.println("创建成功...");
}else{
System.out.println("创建失败...");
}
//mkdir创建文件目录,目标目录不存在,上层目录存在
File f2 = new File("D:\\IO\\IO1");
boolean mkdir = f2.mkdir();
if (mkdir){
System.out.println("创建目录成功...");
}else{
System.out.println("创建目录失败...");
}
//mkdirs创建文件目录,上层目录不存在存在
File f3 = new File("D:\\IO1\\IO1");
boolean mkdirs = f3.mkdirs();
if (mkdirs){
System.out.println("创建目录成功...");
}else{
System.out.println("创建目录失败...");
}
//删除文件或目录
/* boolean delete = f1.delete();
System.out.println(delete);
boolean delete1 = f2.delete();
System.out.println(delete1);
boolean delete2 = f3.delete();
System.out.println(delete2);*/
}
}
23.2.3.4 文件的获取
String[] list():返回一个字符串数组,获取指定目录下的所有文件或者目录名称的数组。File[] listFiles():返回一个抽象路径名数组,获取指定目录下的所有文件或者目录的File数组。
以上方法测试的代码如下:为了方便测试我在IO目录下添加了其他目录。
package com.thr;
import java.io.File;
import java.io.IOException;
/**
* @author Administrator
* @date 2020-02-20
* @desc File常用方法举例
*/
public class Demo4 {
public static void main(String[] args) {
File file = new File("D:\\IO");
//list()方法
String[] list = file.list();
for (String s : list) {
System.out.println(s);
}
System.out.println("----------");
//listFiles()方法
File[] files = file.listFiles();
for (File f : files) {
System.out.println(f.toString());
}
}
}
运行结果:
hello.txt
hi.txt
IO1
IO2
IO3
IO4
IO5
IO6
----------
D:\IO\hello.txt
D:\IO\hi.txt
D:\IO\IO1
D:\IO\IO2
D:\IO\IO3
D:\IO\IO4
D:\IO\IO5
D:\IO\IO6
23.2.3.5 重命名文件
Boolean renameTo(File dest):把文件重命名到指定路径。
注意:要使用这个方法其原文件(即TXT文件或其它文件)一定要存在,而且指定路径不能存在与重命名名字相同的文件,否则永远返回false。
package com.thr;
import java.io.File;
/**
* @author Administrator
* @date 2020-02-20
* @desc renameTo方法测试
*/
public class Demo5 {
public static void main(String[] args) {
File file1 = new File("D:\\IO\\hello.txt");
File file2 = new File("D:\\test\\hi.txt");
boolean renameTo = file1.renameTo(file2);
System.out.println(renameTo);
}
}
23.3 字节流InputStream和OutPutStream
我们都知道在计算机中,无论是文本、图片、音频还是视频,所有的文件都是以二进制(字节)形式存在的,IO流中针对字节的输入输出提供了一系列的流,统称为字节流。字节流是程序中最常用的流。在JDK中,提供了两个抽象类InputStream和OutputStream,它们是字节流的顶级父类,所有的字节输入流都继承自InputStream,所有的字节输出流都继承自OutputStream。既然二者是抽象类,那么就不能实例化,都是依赖于具体继承它们的子类去实现。但二者抽象类中也包含它们各自的方法,如果我们先了解清楚抽象类中每一个方法的含义,那么对于后续具体的子类将会有非常大的帮助。
23.3.1 字节输入流InputStream
InputStream是所有字节输入流的父类,定义了所有字节输入流都具有的共同特征。其内部提供的方法如下:
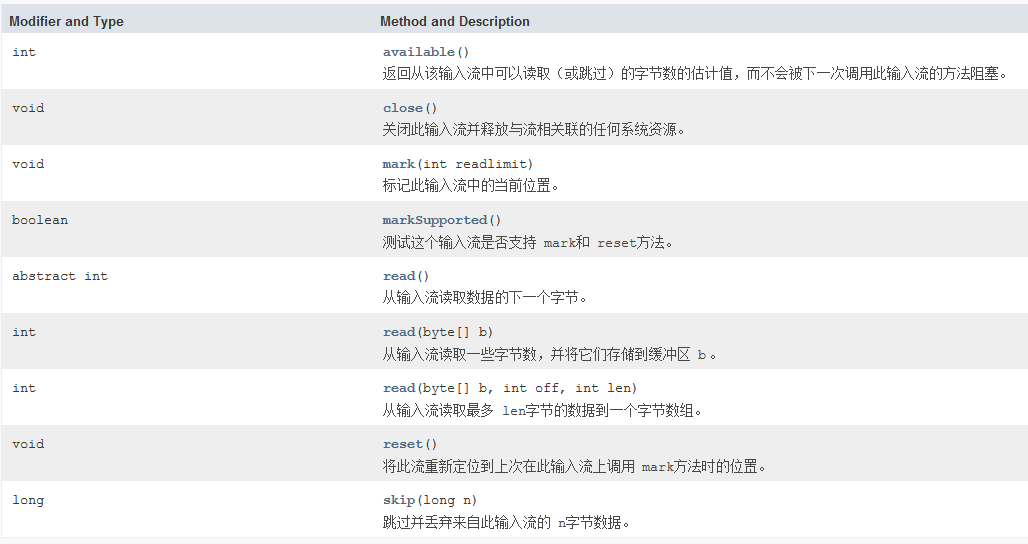
上图中的三个read()方法都是用来读数据的。
int read():每次读取一个字节,返回读取到的字节。int read(byte[] b):每次读取 b 数组长度的字节数,然后返回读取的字节的个数 [注意与read() 方法的区别],读到末尾时返回-1。int read(byte[] b,int off,int len):每次读取 b 数组长度的字节数,从数组b 的索引为off 的位置开始,长度为len个字节。
小贴士:close方法,当完成流的操作时,必须调用此方法,释放系统资源。
其中InputStream的实现类FileInputStream是专门用于读取文件中的数据,通过它将目标设备上的数据读入到程序。
FileInputStream的构造方法:
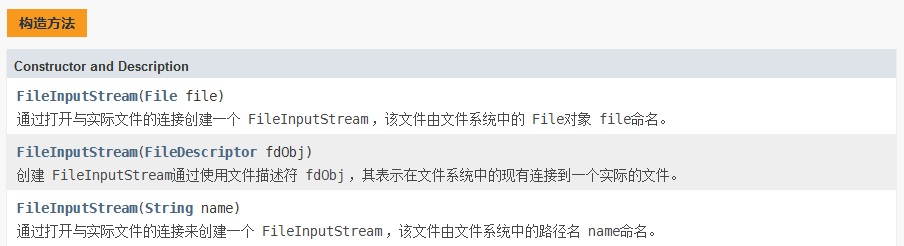
FileInputStream(File file): 通过打开与实际文件的连接来创建一个 FileInputStream ,该文件由文件系统中的 File对象 file命名。FileInputStream(String name): 通过打开与实际文件的连接来创建一个 FileInputStream ,该文件由文件系统中的路径名 name命名。
FileInputStream读入文件举例(读取的hello.txt文件内容是 ABCDEFGH):
package com.thr;
import java.io.*;
/**
* @author Administrator
* @date 2020-02-21
* @desc 字节输入流FileInputStream
*/
public class FileInputStreamTest {
public static void main(String[] args) {
//定义输入流
FileInputStream fis =null;
try {
//1、创建文件对象
File file = new File("D:\\IO\\hello.txt");
//2、创建输入流对象
fis = new FileInputStream(file);
//用定义字节数组,作为装字节数据的容器
byte[] buffer =new byte[5];
int len;//记录每次读取的字节个数
//System.out.println(fis.read(buffer));
while ((len=fis.read(buffer))!=-1){
//转成String型,否则输出ASCII码
String str=new String(buffer,0,len);
System.out.println(str);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//释放资源
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
运行结果:
ABCDE
FGH
如果我们在读取的hello.txt文件中添加几个中文字,再次用同样的代码来运行看一下会发生什么情况(hello.txt内容为 ABCDEFGH中国人):
运行结果的截图:
可以发现运行的结果出现了乱码,这是因为每次读取五个字符,而一个utf-8的中文则占了3个字节,而第二次读取的时候【中】这个字的字节数并没有读完,而【国】字全部读完了,所以【中】和【人】字都出现了乱码而【国】没有出现乱码。这里画个图好理解一点。

为了避免可能出现的乱码,要么把 byte[] 数组容量增大,要么就使用字符输入输出流来处理(对于纯文本最好使用字符流)。
23.3.2 字节输出流OutputStream
OutputStream是所有字节输出流的父类,定义了所有字节输出流都具有的共同特征。其内部提供的方法如下:
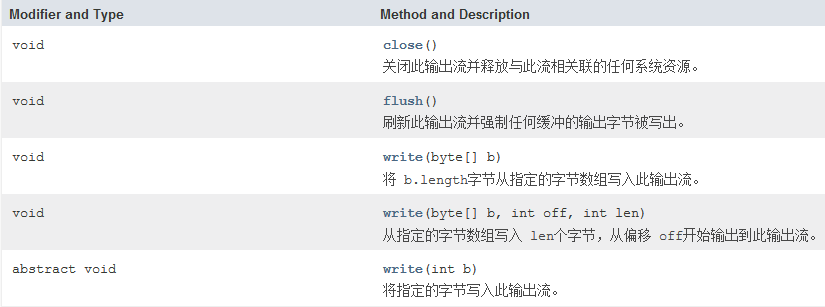
上图中的三个write()方法都是用来写数据的。
void write(int b):把一个字节写入到文件中。void write(byte[] b):把数组b 中的所有字节写入到文件中。void write(byte[] b,int off,int len):把数组b 中的字节从 off 索引开始的 len 个字节写入到文件中。
其中OutputStream的实现类FileOutputStream是门用于读出文件中的数据,通过它将数据从程序输出到目标设备。
FileOutputStream的构造方法:
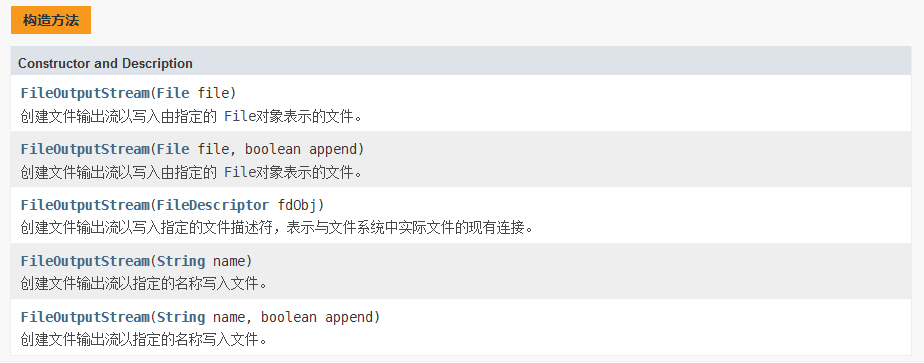
FileOutputStream(File file):创建文件输出流以写入由指定的 File对象表示的文件。FileOutputStream(String name): 创建文件输出流以指定的名称写入文件。FileOutputStream(String name,boolean append): 创建文件输出流以指定的名称写入文件,每次输出文件是否继续拼接。
FileOutputStream输出文件举例:
package com.thr;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* @author Administrator
* @date 2020-02-21
* @desc 字节输出流FileOutputStream
*/
public class FileOutputStreamTest {
public static void main (String[] args) {
//定义字节输出流
FileOutputStream fos =null;
try {
//1、创建文件对象
File file = new File("D:\\IO\\hello.txt");
//2、创建输出流对象
fos = new FileOutputStream(file);
fos.write(97);
//后面的 \r\n表示回车换行
fos.write("中国人!\r\n".getBytes());
//从索引2开始输出4个字节
fos.write("ABCDEFGH".getBytes(),2,4);
} catch (IOException e) {
e.printStackTrace();
} finally {
//释放资源
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
运行后结果是: a中国人!CDEF 。而如果我们多次运行测试代码会发现,每次运行完程序之后文件大小并没有改变,说明每次运行都创建了一次新的输出流对象,每次都清空目标文件中的数据。那么要如何才能保留目标文件中数据,还能继续追加新数据呢?其实很简单,如下两个FileOutputStream构造方法:
public FileOutputStream(File file, boolean append)public FileOutputStream(String name, boolean append)
这两个构造方法,第二个参数中都需要传入一个boolean类型的值,true表示追加数据,false表示不追加也就是清空原有数据。
23.3.3 字节流拷贝文件
在应用程序中,IO流通常都是成对出现的,即输入流和输出流一起使用。而文件的拷贝就需要通过输入流来读取文件中的数据,通过输出流将数据写入文件。
package com.thr;
import java.io.*;
/**
* @author Administrator
* @date 2020-02-21
* @desc 将文件从D盘拷贝到C盘
*/
public class FileInputOutputStreamTest {
public static void main(String[] args) {
//定义输入流
FileInputStream fis =null;
//定义输出流
FileOutputStream fos=null;
//idea的try-catch快捷键Ctrl+Alt+T
try {
//创建文件对象
File f1 = new File("D:\\IO\\1.jpg");
File f2 = new File("C:\\2.jpg");
//创建输入输出流对象
fis = new FileInputStream(f1);
fos = new FileOutputStream(f2);
//定义读取的大小
byte [] bytes = new byte[1024];
int len;
//读取并且读出
while((len=fis.read(bytes))!=-1){
fos.write(bytes, 0, len);
}
System.out.println("拷贝成功...");
} catch (IOException e) {
e.printStackTrace();
} finally {
//释放
try {
fis.close();
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
23.4 字符流Reader和Writer
前面一章介绍了字节流的使用,提到了字节流在处理 utf-8 编码的中文可能会出现乱码的情况(其他编码的中文同样会出现乱码),所以Java针对这一情况提供了字符流。
但是字符流只能处理字符,不能用来处理 .jpg;.mp3;.mp4;.avi;.doc;.ppt等二进制文件,这些只能通过字节流来处理。所以对于纯文本的文件,强烈推荐使用字符输入输出流。
字符流的本质其实就是基于字节流在读取时去查了指定的码表。
23.4.1 字符输入流Reader
Reader是所有字符输入流的父类,定义了所有字符输入流都具有的共同特征。其内部提供的方法如下:
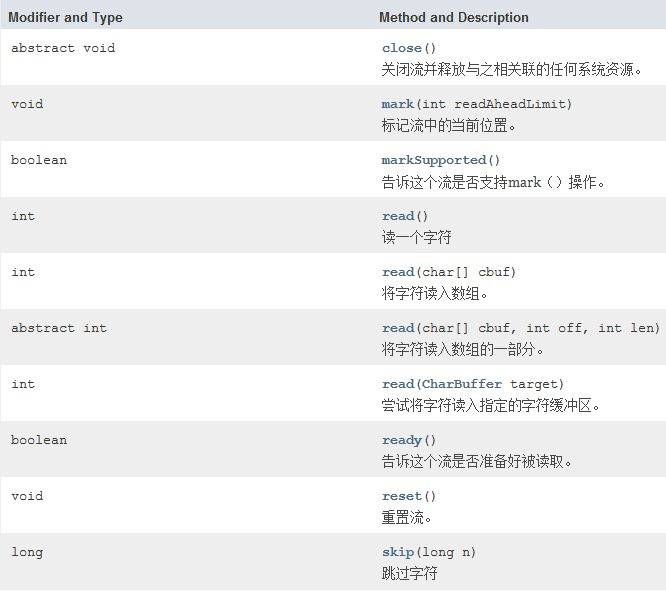
上图中重载的三个read()方法都是用来读数据的。
int read():每次读取一个字符,并把它转换为 0~65535 的整数,然后返回读取到的字符。读到末尾返回-1。(为了提高 I/O 操作的效率,建议尽量使用下面两种read()方法)int read(char[] cbuf):将读取到的多个字符存储到 cbuf 中,然后返回读取的字符,读到末尾时返回-1。int read(char[] cbuf,int off,int len):将读取到的多个字符存储进字符数组 cbuf,从索引 off 开始,长度为len字符,返回结果为读取的字符数.
其中Reader的实现类FileReader是专门用于读取文件中的数据,通过它将目标设备上的数据读入到程序。
FileReader读入文件举例(读取的hello.txt文件内容是:你好,我是中国人!):
package com.thr;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
/**
* @author Administrator
* @date 2020-02-23
* @desc 字符输入流FileReader
*/
public class FileReaderTest {
public static void main(String[] args) {
//定义输入流
FileReader fr =null;
try {
//1、创建文件对象
File file = new File("D:\\IO\\hello.txt");
//2、创建输入流对象
fr = new FileReader(file);
//循环读取,读取到末尾返回-1
int len ;//记录每次读取的字节个数
while((len = fr.read())!=-1){
System.out.print((char)len);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
//释放资源
try {
fr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
运行结果:
你好,我是中国人!
23.4.2 字符输出流Writer
Writer是所有字符输出流的父类,定义了所有字符输出流都具有的共同特征。其内部提供的方法如下:
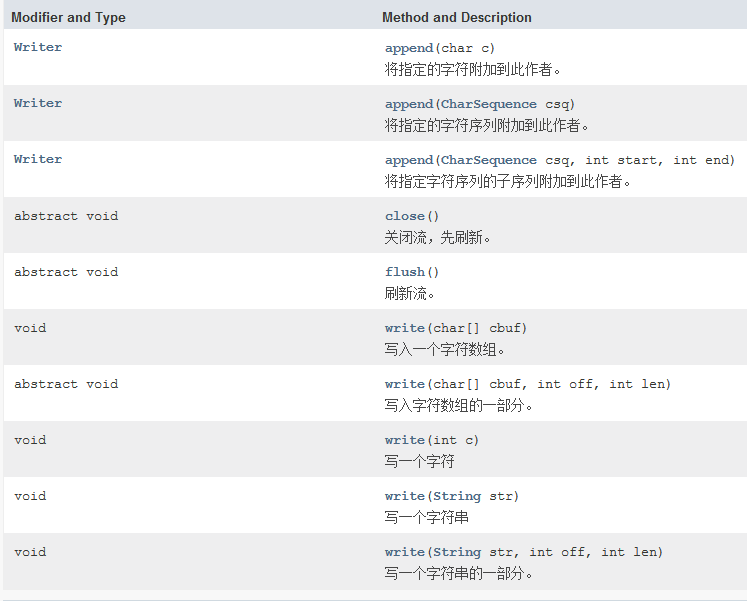
上图中重载的五个write()方法都是用来写数据的。
void write(int c):把一个字符写入到文件中。void write(char[] cbuf):把cbuf字符数组写入到文件中。void write(char[] cbuf,int off,int len):把部分字符数组写入到文件中,从 cbuf 数组的 off 索引开始,写入len个字符。void write(String str):把一个字符串写入到文件中。void write(String str,int off,int len):把部分字符串写入到文件中,从 字符串的 off 索引开始,写入len个字符。
其中Writer的实现类FileWriter是门用于读出文件中的数据,通过它将数据从程序输出到目标设备。
FileWriter输出文件举例:
package com.thr;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
/**
* @author Administrator
* @date 2020-02-23
* @desc 字符输出流FileWriter
*/
public class FileWriterTest {
public static void main(String[] args) {
//定义输出流
FileWriter fw =null;
try {
//1、创建文件对象
File file = new File("D:\\IO\\a.txt");
//2、创建输出流对象,保留原来的数据,在文件后面追加
fw = new FileWriter(file,true);
//write():写出一个字符(utf-8编码)
fw.write(20200223);
fw.write("\r\n");//回车换行
//write(char[] buffer):把cbuf字符数组写入到文件中。
fw.write("我是中国人".toCharArray());
fw.write("\r\n");
//write(char[] cbuf,int off,int len):把部分字符数组写入到文件中,从 cbuf 数组的 off 索引开始,写入len个字符。
fw.write("我是中国人".toCharArray(),1,4);
fw.write("\r\n");
//write(String str):把一个字符串写入到文件中。
fw.write("中国人");
fw.write("\r\n");
//write(String str,int off,int len):把部分字符串写入到文件中,从 字符串的 off 索引开始,写入len个字符。
fw.write("你好,我是中国人\n",3,6);
} catch (IOException e) {
e.printStackTrace();
} finally {
//释放资源
try {
fw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
注意:如果字符输出流不调用close()方法关闭资源,数据只是保存到缓冲区,并不会保存到文件(这一点与FileOutputStream不同,即使它不调用close()方法依然会写入到文件中)。
这里就得介绍一下flush()这个方法。
flush()和close()方法的区别:
flush():将流中的缓冲区缓冲的数据刷新到目的地中,刷新后,流还可以继续使用。
close():关闭资源,但在关闭前会将缓冲区中的数据先刷新到目的地,否则丢失数据,然后在关闭流。流不可以使用。
而当我们亲自去使用flush()方法的时候会产生一个疑问,就算我们在close()之前不加flush()方法也不会影响文件的写出呀,那为什么还要用这个方法呢?先看一下下面的代码吧:
package com.thr;
import java.io.FileWriter;
import java.io.IOException;
/**
* @author Administrator
* @date 2020-02-24
* @desc flush方法的使用
*/
public class WriterFlushTest {
public static void main(String[] args) {
//定义输出流
FileWriter fw = null;
//其实该步就是在明确数据要存放的目的地
try {
fw=new FileWriter("D:\\flush.txt");
fw.write("介");//调用write方法,将字符串写入到流中(使用write其实并没有将字符串直接写入到指定文件,而是存放在流中)
fw.flush();//这一步才是将上一步write的所写的字符串冲刷到指定的文件(在指定的文件打开后有字符串存在了)
fw.write("绍");
fw.flush();
fw.write("flush方法");
fw.flush();
fw.close();//close()是一定要做的(其实close方法中调用了flush方法)
fw.write("CCC");//close后若再write,会提示IO异常Stream closed
} catch (IOException e) {
e.printStackTrace();
}
}
}
小声BB:我认为flush()方法可有可无,它就是将缓冲区的数据强制写入到文件中,因为在调用完write()方法后数据并没有写入到文件中,而是保存在流中,此时我们可以调用flush()方法,也可以在最后用close()方法来将数据写入文件,因为在close()的时候,也会进行一次flush的,因此close之前其实可以不用专门做flush的。但是在某些情况下,数据量较大的时候,在写的过程中,可以进行阶段性的flush。(话说我也不知道这样做会有什么好处……)
23.4.3 字符流拷贝文件
package com.thr;
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
/**
* @author Administrator
* @date 2020-02-23
* @desc 拷贝文本文件
*/
public class FileReaderWriterTest {
public static void main(String[] args) {
//定义输入流
FileReader fr =null;
//定义输出流
FileWriter fw =null;
try {
//创建读入文件对象
File f1 = new File("D:\\IO\\hello.txt");
//创建读出文件对象
File f2 = new File("C:\\a.txt");
fr = new FileReader(f1);
fw = new FileWriter(f2);
//循环读取,读取到末尾返回-1
char chars[] = new char[1024];
int len ;//记录每次读取的字节个数
while((len = fr.read(chars))!=-1){
fw.write(chars,0,len);
}
System.out.println("拷贝成功...");
} catch (IOException e) {
e.printStackTrace();
} finally {
//释放资源
try {
fr.close();
fw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
23.5 缓冲流
缓冲流也叫高效流,是处理流的一种,即是作用在流上的流。其目的就是加快读取和写入数据的速度。
缓冲流本身并没有IO功能,只是在别的流上加上缓冲效果从而提高了效率。当对文件或其他目标频繁读写或操作效率低,效能差时。这时使用缓冲流能够更高效的读写信息。因为缓冲流先将数据缓存起来,然后一起写入或读取出来。所以说,缓冲流还是很重要的,在IO操作时加上缓冲流提升性能。
Java IO流中对应的缓冲流有以下四个:
字节缓冲流:BufferedInputStream、BufferedOutputStream
字符缓冲流:BufferedReader、BufferedWriter
23.5.1 字节缓冲流
构造方法:
输入流:
BufferedInputStream(InputStream in):创建一个新的字节缓冲输入流,传入的参数是InputStream类型,缓冲区默认大小为8129。BufferedInputStream(InputStream in, int size):创建一个指定缓冲区大小的字节缓冲输入流。
输出流:
BufferedOutputStream(OutputStream out):创建一个新的字节缓冲输出流,传入的参数是OutputStream ,以将数据写入指定的基础输出流。BufferedOutputStream(OutputStream out, int size):创建一个指定缓冲区大小的的字节缓冲输出流,以将具有指定缓冲区大小的数据写入指定的基础输出流。
构造方法举例代码如下:
//字节缓冲输入输出流,此种方法默认缓冲区大小8192
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("D:\\IO\\hello.txt"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("D:\\IO\\hello.txt"));
//自定义缓冲区大小
BufferedInputStream bis1 = new BufferedInputStream(new FileInputStream("D:\\IO\\hello.txt"),10240);
BufferedOutputStream bos1 = new BufferedOutputStream(new FileOutputStream("D:\\IO\\hello.txt"),10240);
前面就说缓冲流可以加快读取和写入数据的速度,所以现在就来比较一下使用普通流和使用缓冲流的效率对比(拷贝一个886MB大小的视频):
普通流代码示例:
package com.thr;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
/**
* @author Administrator
* @date 2020-02-26
* @desc 普通流测试
*/
public class BufferedDemo {
public static void main(String[] args) {
//定义流
FileInputStream fis = null;
FileOutputStream fos = null;
try {
//开始时间
long start = System.currentTimeMillis();
//创建流对象
fis = new FileInputStream("D:\\IO\\1.mp4");
fos = new FileOutputStream("D:\\IO\\2.mp4");
//读写操作
int len;
byte[] buffer = new byte[1024];
while ((len=fis.read(buffer))!=-1){
fos.write(buffer,0,len);
}
//结束时间
long end = System.currentTimeMillis();
System.out.println("完成,共耗时:"+(end-start)+"ms");
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
fos.close();
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
//完成,共耗时:5165ms
缓冲流代码示例:
package com.thr;
import java.io.*;
/**
* @author Administrator
* @date 2020-02-26
* @desc 缓冲流测试
*/
public class BufferedDemo1 {
public static void main(String[] args) {
//定义缓冲流
BufferedInputStream bis = null;
BufferedOutputStream bos = null;
try {
//开始时间
long start = System.currentTimeMillis();
//创建缓冲流对象,注意参数传的FileXXX,而不文件目录
bis = new BufferedInputStream(new FileInputStream("D:\\IO\\1.mp4"));
bos = new BufferedOutputStream(new FileOutputStream("D:\\IO\\3.mp4"));
//读写操作
int len;
byte[] buffer = new byte[1024];
while ((len=bis.read(buffer))!=-1){
bos.write(buffer,0,len);
}
//结束时间
long end = System.currentTimeMillis();
System.out.println("完成,共耗时:"+(end-start)+"ms");
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
bos.close();
bis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
//完成,共耗时:1658ms
我们可以看出缓冲流大概只用了三分之一的时间就完成了同样的工作。
23.5.2 字符缓冲流
构造方法
输入流:
BufferedReader(Reader in):创建一个新的字符缓冲输入流,传入的参数是Reader类型,缓冲区默认大小为8129。BufferedReader(Reader in, int sz):创建一个指定大小缓冲区的字符缓冲输入流。
输出流:
BufferedWriter(Writer out):创建一个新的字符缓冲输出流,传入的参数是Writer类型,缓冲区默认大小为8129。BufferedWriter(Writer out, int sz):创建一个指定大小缓冲区的字符缓冲输出流。
构造方法举例代码如下:
//字符缓冲输入输出流,此种方法默认缓冲区大小为defaultCharBufferSize = 8192;
BufferedReader br = new BufferedReader(new FileReader("D:\\IO\\hello.txt"));
BufferedWriter bw = new BufferedWriter(new FileWriter("D:\\IO\\hello.txt"));
//自定义缓冲区大小
BufferedReader br1 = new BufferedReader(new FileReader("D:\\IO\\hello.txt"),10240);
BufferedWriter bw1 = new BufferedWriter(new FileWriter("D:\\IO\\hello.txt"),10240);
字符缓冲流和字节缓冲流的使用大致一样,只是两者处理的东西不一样。但是在字符缓冲流中它有两个独特的方法。
BufferedReader:public String readLine():读一行数据。 读取到最后返回null。BufferedWriter:public void newLine():换行,该方法内部调用了lineSeparator,它表示的换行符。
两个方法使用举例:
package com.thr;
import java.io.*;
/**
* @author Administrator
* @date 2020-02-26
* @desc ReadLine和newLine的使用
*/
public class BufferedTest {
public static void main(String[] args) {
BufferedReader br = null;
BufferedWriter bw = null;
try {
br = new BufferedReader(new FileReader("D:\\IO\\hello.txt"));
bw = new BufferedWriter(new FileWriter("D:\\IO\\hi.txt"));
//1、普通字符数组方式
/* int len;
char[] buffer = new char[1024];
while ((len=br.read(buffer))!=-1){
bw.write(buffer,0,len);
}
System.out.println("拷贝完成...");*/
//2、使用readLine和newLine的方式
String data;
while ((data=br.readLine())!=null){//不再是-1,因为返回的String类型
//每次读取一行数据
bw.write(data);//这样输出来的文件是没有换行的,所以要在后面加上newLine()方法用来换行
bw.newLine();
}
System.out.println("拷贝完成...");
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally {
if (bw!=null){
try {
bw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (br!=null){
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
23.6 转换流(字节流和字符流之间的转换)
转换流也是一种处理流,它提供了字节流和字符流之间的转换。在Java IO流中提供了两个转换流:InputStreamReader 和 OutputStreamWriter,这两个类都属于字符流。其中InputStreamReader将字节输入流转为字符输入流,继承自Reader。OutputStreamWriter是将字符输出流转为字节输出流,继承自Writer。
众所周知,计算机中存储的数据都是二进制的数字,我们在电脑屏幕上看到的文字信息是将二进制转换之后显示的,两者之间存在编码与解码的过程,其互相转换必须遵循某种规则,即编码和解码都遵循同一种规则才能将文字信息正常显示,如果编码跟解码使用了不同的规则,就会出现乱码的情况。
- 编码:字符、字符串(能看懂的) ------> 字节(看不懂的)
- 解码:字节(看不懂的) ------> 字符、字符串(能看懂的)
上面说的编码与解码的过程需要遵循某种规则,这种规则就是不同的字符编码。我们在刚刚学习编程的时候最早接触就是ASCII码,它主要是用来显示英文和一些符号,到后面还有接触到别的编码规则常用的有:gb2312,gbk,utf-8等。它们分别属于不同的编码集。
我们需要明确的是字符编码和字符集是两个不同层面的概念。
- encoding是charset encoding的简写,即字符集编码,简称编码。
- charset是character set的简写,即字符集。
编码是依赖于字符集的,一个字符集可以有多个编码实现,就像代码中的接口实现依赖于接口一样。
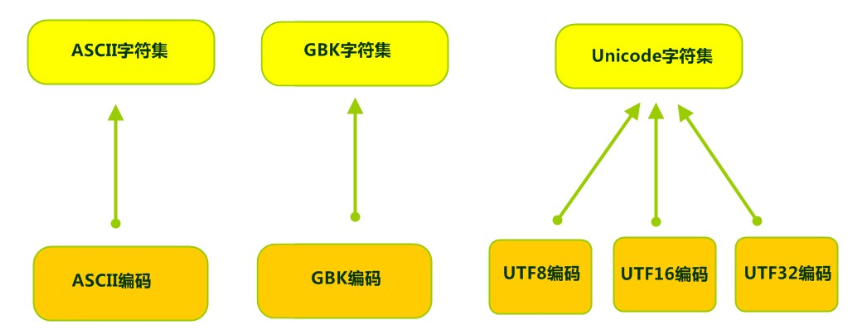
转换流的原理是:字符流 = 字节流 + 编码表。在转换流中选择正确的编码非常的重要,因为指定了编码,它所对应的字符集自然就指定了,否则很容易出现乱码,所以编码才是我们最终要关心的。
转换流的特点:其是字符流和字节流之间的桥梁。
可对读取到的字节数据经过指定编码转换成字符
可对读取到的字符数据经过指定编码转换成字节
那么何时使用转换流?
当字节和字符之间有转换动作时
流操作的数据需要编码或解码时

23.6.1 InputStreamReader
InputStreamReader是字节流到字符流的桥梁:它读取字节,并使用指定的字符集将其解码为字符。它的字符集可以由名称指定,也可以接受平台的默认字符集。
构造方法:
InputStreamReader(InputStream in):创建一个默认字符集字符输入流。InputStreamReader(InputStream in, String charsetName):创建一个指定字符集的字符流。
构造方法示例代码:
InputStreamReader isr1 = new InputStreamReader(new FileInputStream("D:\\IO\\utf8.txt"));
InputStreamReader isr2 = new InputStreamReader(new FileInputStream("D:\\IO\\utf8.txt"),"UTF-8");
InputStreamReader读入不同编码举例(读入的文件编码是UTF-8):
package com.thr;
import java.io.*;
/**
* @author Administrator
* @date 2020-02-27
* @desc InputStreamReader
*/
public class InputStreamReaderTest {
public static void main(String[] args) {
//定义转换流
InputStreamReader isr = null;
InputStreamReader isr1 = null;
try {
//创建流对象,默认编码方式
isr = new InputStreamReader(new FileInputStream("D:\\IO\\utf8.txt"));
//创建流对象,指定GBK编码
isr1 = new InputStreamReader(new FileInputStream("D:\\IO\\utf8.txt"),"GBK");
//默认方式打印
int len;
char[] buffer = new char[1024];
while ((len=isr.read(buffer))!=-1){
System.out.println(new String(buffer,0,len));
}
//GBK编码方式打印
int len1;
char[] buffer1 = new char[1024];
while ((len1=isr1.read(buffer1))!=-1){
System.out.println(new String(buffer1,0,len1));
}
System.out.println("成功...");
} catch (IOException e) {
e.printStackTrace();
} finally {
//释放资源,先使用的后关闭
if (isr1!=null){
try {
isr1.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (isr!=null){
try {
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
//运行结果:
--UTF-8
武汉加油
中国加油
齐心协力
战胜疫情
--GBK
锘挎姹夊姞娌�
涓浗鍔犳补
榻愬績鍗忓姏
鎴樿儨鐤儏
可以发现,UTF-8编码没有出现乱码,而GBK编码出现了乱码,这是因为是在IDEA编辑器下打印的,我的IDEA编辑器设置的默认编码是UTF-8。而UTF-8的编码集是Unicode,GBK的编码集是GBK,两者并没有通过转换,所以GBK编码在Unicode集上打印出现了乱码。
23.6.2 OutputStreamWriter
OutputStreamWriter是字符流通向字节流的桥梁:用指定的字符集将字符编码为字节。它的字符集可以由名称指定,也可以接受平台的默认字符集。
构造方法:
OutputStreamWriter(OutputStream in): 创建一个使用默认字符集的字符流。OutputStreamWriter(OutputStream in, String charsetName): 创建一个指定字符集的字符流。
构造方法示例代码:
OutputStreamWriter isr1 = new OutputStreamWriter(new FileOutputStream("D:\\IO\\gbk.txt"));
OutputStreamWriter isr2 = new OutputStreamWriter(new FileOutputStream("D:\\IO\\gbk1.txt") , "GBK");
OutputStreamWriter读出不同编码举例:
package com.thr;
import java.io.*;
/**
* @author Administrator
* @date 2020-02-27
* @desc OutputStreamWriter
*/
public class OutputStreamReaderTest {
public static void main(String[] args) {
//定义转换流
OutputStreamWriter osw = null;
OutputStreamWriter osw1 = null;
try {
osw = new OutputStreamWriter(new FileOutputStream("D:\\IO\\gbk.txt"));
osw1 = new OutputStreamWriter(new FileOutputStream("D:\\IO\\gbk1.txt"),"GBK");
//以默认格式写出
osw.write("武汉加油,中国加油");
//以GBK格式写出
osw1.write("武汉加油,中国加油");
System.out.println("成功...");
} catch (IOException e) {
e.printStackTrace();
} finally {
//释放资源,先使用的后关闭
if (osw1!=null){
try {
osw1.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (osw!=null){
try {
osw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
我们运行完后发现并没有乱码,这是因为Windows系统默认支持了UTF-8和GBK字符集。可以将输出的路径改为当前项目下 new FileOutputStream(“gbk.txt”);然后用Idea打开就可以看成差别来了。
23.6.3 转换文件编码
将UTF-8编码的文本文件,转换为GBK编码的文本文件。
1、指定UTF-8编码的转换流,读取文本文件。
2、使用GBK编码的转换流,写出文本文件。
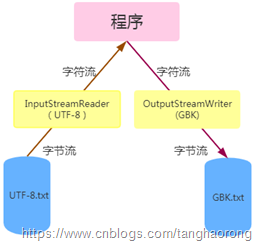
package com.thr;
import java.io.*;
/**
* @author Administrator
* @date 2020-02-27
* @desc 将读入UTF-8文件转换为GBK
*/
public class ConversionStreamTest {
public static void main(String[] args) {
//定义转换流
InputStreamReader isr = null;
OutputStreamWriter osw = null;
try {
//创建流对象,指定GBK编码
isr = new InputStreamReader(new FileInputStream("D:\\IO\\utf8.txt"),"UTF-8");
osw = new OutputStreamWriter(new FileOutputStream("gbk.txt"),"GBK");
int len;
char[] buffer = new char[1024];
while ((len=isr.read(buffer))!=-1){
osw.write(buffer,0,len);
}
System.out.println("成功...");
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//释放资源
if (osw!=null){
try {
osw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (isr!=null){
try {
isr.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
23.7 对象流(序列化与反序列化)
对象流的主要用作是对Java对象的序列化和反序列化的操作。在Java IO流中提供了两个对象流:ObjectInputStream和ObjectOutputStream,这两个类都属于字节流。其中ObjectOutputStream将Java对象以字节序列的形式写出到文件,实现对象的永久存储,它继承自OutputStream。ObjectInputStream是将之前使用ObjectOutputStream序列化的字节序列恢复为Java对象,它继承自InputStream。
23.7.1 序列化与反序列化
序列化 : 把Java对象转换成字节序列的过程。
反序列化:把序列化成字节序列的数据恢复为Java对象的过程。
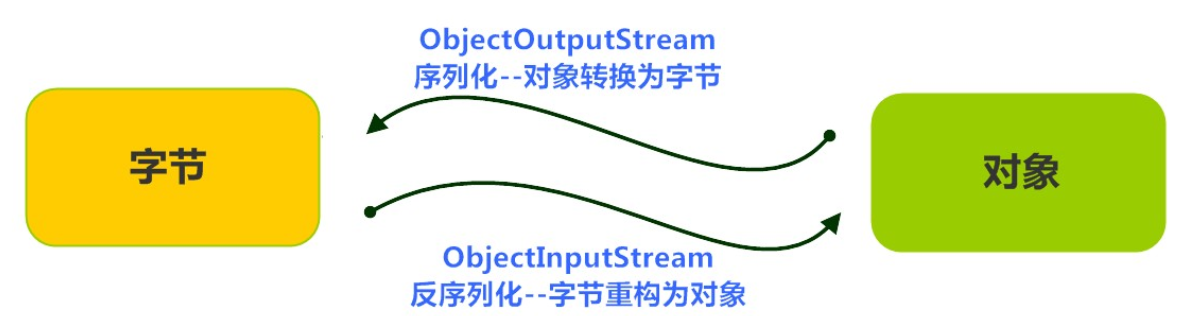
23.7.2 为什么需要序列化?
①、把对象的字节序列永久地保存到硬盘上:对于一个存在JVM中的对象来说,其内部的状态只是保存在内存中。当JVM退出之后,内存资源也就被释放,Java对象的内部状态也就丢失了。而在很多情况下,对象内部状态是需要被持久化的,将运行中的对象状态保存下来(最直接的方式就是保存到文件系统中),在需要的时候可以还原,即使是在Java虚拟机退出的情况下。
②、在网络上传送对象的字节序列:对象序列化机制是Java内建的一种对象持久化方式,可以很容易实现在JVM中的活动对象与字节数组(流)之间进行转换,使用得Java对象可以被存储,可以被网络传输,在网络的一端将对象序列化成字节流,经过网络传输到网络的另一端,可以从字节流重新还原为Java虚拟机中的运行状态中的对象。
23.7.3 ObjectOutputStream类
ObjectOutputStream代表对象输出流,即序列化,将Java对象以字节序列的形式写出到文件,实现对象的永久存储。
它的 writeObject(Object obj) 方法可对指定的obj参数对象进行序列化。
首先需要明确的一点是:一个对象要想序列化,该对象必须要实现Serializable接口,否则会抛出NotSerializableException异常,Serializable接口是一个标记接口,它内部没有任何方法,和Cloneable接口是一样的。
下面定义一个Person类,并且实现Serializable接口:
package com.thr;
import java.io.Serializable;
/**
* @author Administrator
* @date 2020-02-28
* @desc Person对象
*/
public class Person implements Serializable {
private int id;
private String name;
private int age;
public Person() {
}
public Person(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
//getter、setter、toString方法省略(自己测试需要加上)
}
序列化操作:
package com.thr;
import java.io.*;
/**
* @author Administrator
* @date 2020-02-28
* @desc 使用ObjectOutputStream序列化对象
*/
public class ObjectOutputStreamTest {
public static void main(String[] args) {
//定义对象流
ObjectOutputStream oos = null;
try {
//创建对象流
oos = new ObjectOutputStream(new FileOutputStream("D:\\IO\\person.txt"));
//序列化对象
oos.writeObject(new Person(10001,"张三",20));
oos.writeObject(new Person(10002,"李四",21));
//刷新缓冲区
oos.flush();
System.out.println("序列化成功...");
} catch (IOException e) {
e.printStackTrace();
}finally {
//释放资源
if (oos!=null){
try {
oos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
序列化之后打开的文件我们是看不懂的,因为它是字节序列文件,只有计算机懂。所以接下来需要将它反序列化成我们能看懂的。
23.7.4 ObjectInputStream类
ObjectOutputStream代表对象输入流,即反序列化,将之前使用ObjectOutputStream序列化的字节序列恢复为Java对象。
它的readObject()方法读取指定目录下的序列化对象。
反序列化操作:
package com.thr;
import java.io.*;
/**
* @author Administrator
* @date 2020-02-28
* @desc 使用ObjectInputStream反序列化对象
*/
public class ObjectInputStreamTest {
public static void main(String[] args) {
//定义对象流
ObjectInputStream ois = null;
try {
//创建对象输入流对象
ois = new ObjectInputStream(new FileInputStream("D:\\IO\\person.txt"));
//反序列化对象
Person person1 = (Person) ois.readObject();
Person person2 = (Person) ois.readObject();
System.out.println(person1);
System.out.println(person2);
System.out.println("反序列化成功...");
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} finally {
if (ois!=null){
try {
ois.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
在使用ObjectInputStream反序列化时需要注意一点:
①、在完成序列化操作后,如果对序列化对象进行了修改,比如增加某个字段,那么我们再进行反序列化就会抛出InvalidClassException异常,这种情况叫不兼容问题。
解决的方法是:在对象中手动添加一个 serialVersionUID 字段,用来声明一个序列化版本号,之后再怎么添加属性也能进行反序列化,凡是实现Serializable接口的类都应该有一个表示序列化版本标识符的静态变量。
public class Person implements Serializable {
//序列化版本号
private static final long serialVersionUID = 5687485987455L;
private int id;
private String name;
private int age;
//getter、setter、toString、构造方法省略(自己测试需要加上)
}
注意:ObjectInputStream和ObjectOutputStream不能序列化transient修饰的成员变量。
Transient 关键字
transient修饰符仅适用于变量,不适用于方法和类。在序列化时,如果我们不想序列化特定变量以满足安全约束,那么我们应该将该变量声明为transient。执行序列化时,JVM会忽略transient变量的原始值并将默认值保存到文件中。因此,transient意味着不要序列化。
假如Person类中的age属性不需要序列化,在age属性上添加transient关键字。private transient int age;
package com.thr;
import java.io.*;
/**
* @author Administrator
* @date 2020-02-29
* @desc transient的使用
*/
public class Test {
public static void main(String[] args) {
serialization(new Person(10001, "赵六", 20));
deserialization();
}
//序列化
public static void serialization(Person person){
ObjectOutputStream oos = null;
try {
//创建输出对象流
oos = new ObjectOutputStream(new FileOutputStream("D:\\IO\\object.txt"));
//序列化对象
oos.writeObject(person);
oos.flush();
System.out.println("序列化成功...");
} catch (IOException e) {
e.printStackTrace();
} finally {
//释放资源
try {
if (oos!=null){
oos.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
//反序列化
public static void deserialization (){
ObjectInputStream ois = null;
try {
//创建输入对象流
ois = new ObjectInputStream(new FileInputStream("D:\\IO\\object.txt"));
//反序列化对象
Person person = (Person) ois.readObject();
System.out.println(person);
System.out.println("反序列化成功...");
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} finally {
try {
ois.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
运行的结果为:Person{id=10001, name='赵六', age=0},可以发现,尽管age属性没有序列化,但是它是有默认值的。
23.8 其他流的使用
在前面几章博客中介绍的流是需要我们理解和掌握的,其实在Java IO包下面还有很多不同种类的流,但是用的不是非常多,所以这里就汇总简单举个例子。
这些流包括:数组流、字符串流、打印流、数据流、合并流、管道流、回退流、随机存储文件流。
23.8.1 数组(内存)流
数组流:就是将数据都以数组的方式存入该类中的字节或字符数组中,然后取数据也是从这个数组中取。
数组流分为:字节数组流和字符数组流。
- 字节数组流:ByteArrayInutStream 和 ByteArrayOutputStream
- 字符数组流:CharArrayReader 和 CharArrayWriter
23.8.1.1 字节数组流
package com.thr.other;
import java.io.*;
/**
* @author Administrator
* @date 2020-02-29
* @desc 字节数组流
*/
public class ByteArrayStreamTest {
public static void main(String[] args) throws IOException {
//程序——>字节数组(内存)
ByteArrayOutputStream bos = new ByteArrayOutputStream();
byte[] bytes = "中国牛逼".getBytes();
System.out.println(bytes.length);//因为UTF-8下的中文占3个字节,所以长度为12
bos.write(bytes);
//将数据放在temp数组中
byte[] temp = bos.toByteArray();
System.out.println(new String(temp,0,temp.length));
//字节数组(内存)——>程序
ByteArrayInputStream bis = new ByteArrayInputStream(temp);//将上面temp数组中字节拿到程序中来
byte[] buffer = new byte[20];
int len=-1;
while ((len=bis.read(buffer))!=-1){
System.out.println(new String(buffer,0,len));
}
//释放资源
bis.close();
bos.close();
//bos.write(1);
}
}
其实字节数组流中的流可以不调用close()方法,因为它内部定义的是一个空方法,没有做任何操作。即使关闭流后仍可调用其他方法,而不会产生任何IOException。
23.8.1.2 字符数组流
package com.thr.other;
import java.io.*;
/**
* @author Administrator
* @date 2020-02-29
* @desc 字符数组流
*/
public class CharArrayStreamTest {
public static void main(String[] args) throws IOException {
//程序——>字符数组(内存)
CharArrayWriter caw = new CharArrayWriter();
caw.write("中国牛逼");
//将数据放在temp缓冲区数组中
char[] temp = caw.toCharArray();
System.out.println(temp);
//字符数组(内存)——>程序
CharArrayReader car = new CharArrayReader(temp);//将上面temp数组中字节拿到程序中来
char[] buffer = new char[20];
int len=-1;
while ((len=car.read(buffer))!=-1){
System.out.println(new String(buffer,0,buffer.length));
}
//释放资源
car.close();
caw.close();
}
}
23.8.2 字符串流
字符串流:以一个字符串为数据源,来构造一个字符流。StringWriter内部其实调用了StringBuffer来拼接字符串。
字符串流有两个类:StringReader和StringWriter。
package com.thr.other;
import java.io.*;
/**
* @author Administrator
* @date 2020-02-29
* @desc 字符串流
*/
public class StringStreamTest {
public static void main(String[] args) throws IOException {
StringWriter sw = new StringWriter();
sw.write("中国牛逼!");
sw.write("中国加油!");
String string = sw.toString();
System.out.println(string);//中国牛逼!中国加油!
StringReader sr = new StringReader(string);
char[] buffer = new char[20];
int len;
while ((len=sr.read(buffer))!=-1){
System.out.println(new String(buffer,0,len));
}
//释放资源
sr.close();
sw.close();
}
}
关闭字符串流无效。此类中的方法在关闭该流后仍可调用方法,而不会产生任何IOException。
23.8.3 打印流
打印流:实现将任何数据类型的数据格式转为字符串输出。它是输出信息最为方便的类。
打印流分为两种:字节打印流PrintStream、字符打印流PrintWriter。它们的内部提供了提供了一系列重载的print()和println()方法,用于多种数据类型的输出。我们最先接触的system.out中的print()和println()方法都是PringStream中的。注意:System.out.println();其实等价于 PrintStream ps = System.out; ps.println()。
打印流的一些特点:
- 不负责数据源,只负责数据目的
- 不会抛出IOException,但是可能抛出其他异常
- 有自动flush功能
字节打印流举例:
package com.thr.other;
import java.io.*;
/**
* @author Administrator
* @date 2020-02-29
* @desc 字节打印流
*/
public class PrintStreamTest {
public static void main(String[] args) throws IOException {
//打印流输出基本数据类型、字符串
PrintStream ps1 = new PrintStream("D:\\IO\\print.txt");
ps1.println(666);
ps1.println(123.456);
ps1.println(123456789L);
ps1.println("中国牛逼");
ps1.close();
//打印流输出目的是流对象
FileOutputStream fos = new FileOutputStream("D:\\IO\\print1.txt");
PrintStream ps2 = new PrintStream(fos,true);//加个true表示开启自动flush功能
ps2.print("China Niubility");
ps2.close();
//打印流复制文本
BufferedReader br=new BufferedReader(new FileReader("D:\\IO\\print.txt"));
PrintWriter pw=new PrintWriter(new FileWriter("D:\\IO\\printofcopy.txt"),true);
String line =null;
while((line=br.readLine())!=null){
pw.println(line);
}
pw.close();
br.close();
}
}
由于字符打印流和字节打印流的用法基本一致,这里就不多举例了。
23.8.4 数据流
数据流:可以很方便的将Java基本数据类型(八大基本数据类型)和String类型的数据写入到文件中。作用就是:保留数据的同时也保留了数据类型,方便后期获取数据类型而不需要强转。
数据流有两个类:DataInputStream和DataOutStream,这两个类中分别定义了writeXXX()和readXXX()方法用来写出或写入特定的数据类型。
数据流写出并读取数据,其中注意的两点:
- 先写出再读取:因为用DataOutputStream写出的数据,必须用DataInputStream来读写。
- 写出的数据和读取的数据顺序必须保持一致,否则会抛出异常EOFException。
package com.thr.other;
import java.io.*;
/**
* @author Administrator
* @date 2020-02-29
* @desc 数据流写入写出数据
*/
public class DataStreamTest {
public static void main(String[] args) {
wirteData();//写出数据
readData();//读取数据
}
public static void wirteData() {
//定义数据流
DataOutputStream dos = null;
try {
//创建数据输出流对象
dos = new DataOutputStream(new FileOutputStream("D:\\IO\\data.txt"));
//写出数据
dos.writeUTF("张三");
dos.writeInt(20);
dos.writeBoolean(true);
dos.writeDouble(99999999.99);
} catch (IOException e) {
e.printStackTrace();
} finally {
if (dos!=null){
try {
dos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
public static void readData() {
//定义数据流
DataInputStream dis = null;
try {
//创建数据输入流对象
dis = new DataInputStream(new FileInputStream("D:\\IO\\data.txt"));
//写入数据
String name = dis.readUTF();
int age = dis.readInt();
boolean isMale = dis.readBoolean();
double money = dis.readDouble();
//打印
System.out.println("name:"+name);
System.out.println("age:"+age);
System.out.println("isMale:"+isMale);
System.out.println("money:"+money);
} catch (IOException e) {
e.printStackTrace();
}
}
}
23.8.5 合并流
合并流(SequenceInputStream):就是将两个输入流合并成一个输入流。读取的时候是先读第一个,读完了再读下面一个流。
package com.thr.other;
import java.io.*;
/**
* @author Administrator
* @date 2020-02-29
* @desc 合并流
*/
public class SequenceInputStreamTest {
public static void main(String[] args) {
//定义流
SequenceInputStream sis = null;
FileOutputStream fos = null;
try {
//创建合并流对象
sis = new SequenceInputStream(new FileInputStream("D:\\IO\\1.txt"), new FileInputStream("D:\\IO\\2.txt"));
//创建输出流对象
fos = new FileOutputStream("D:\\IO\\3.txt");
//声明byte数组用于存储从输入流读取到的数据
byte[] by = new byte[1024];
//该变量纪录每次读取到的字符个数
int len = 0;
//读取输入流中的数据
while((len = sis.read(by))!=-1){
//输出从输入流中读取到的数据
fos.write(by, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
}finally {
//释放资源
if (sis!=null){
try {
sis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (fos!=null){
try {
fos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
23.8.6 回退流
回退流:在JAVA IO中所有的数据都是采用顺序的读取方式,即对于一个输入流来讲都是采用从头到尾的顺序读取的,如果在输入流中某个不需要的内容被读取进来,则只能通过程序将这些不需要的内容处理掉,为了解决这样的处理问题,在JAVA中提供了一种回退输入流可以把读取进来的某些数据重新回退到输入流的缓冲区之中。
回退流有两个类:PushbackInputStream、PushbackReader
使用InputStream 要使用read() 方法不断读取,是采用顺序的读取方式。
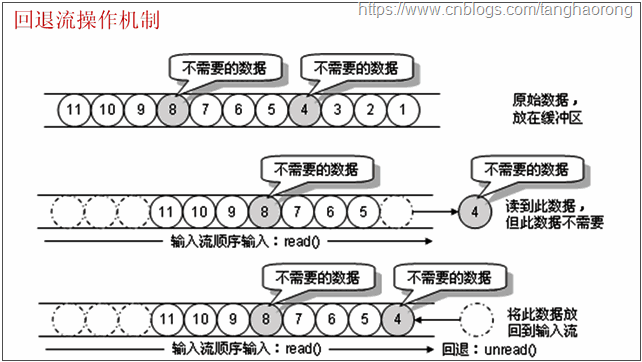
回退操作同样分为字节流和字符流,本教程还是以字节流为准。
PushbackInputStream类的常用方法
public PushbackInputStream(InputStream in)构造方法 将输入流放入到回退流之中。public int read() throws IOException普通 读取数据。public int read(byte[] b,int off,int len) throws IOException普通方法 读取指定范围的数据。public void unread(int b) throws IOException普通方法 回退一个数据到缓冲区前面。public void unread(byte[] b) throws IOException普通方法 回退一组数据到缓冲区前面。public void unread(byte[] b,int off,int len) throws IOException普通方法 回退指定范围的一组数据到缓冲区前面。
对于回退操作来说,提供了三个unread()的操作方法,这三个操作方法与InputStream类中的read()方法是一一对应的。
内存中使用ByteArrayInputStream,把内容设置到内存之中。
程序代码如下:
package com.thr.other;
import java.io.*;
/**
* @author Administrator
* @date 2020-02-29
* @desc 回退流
*/
public class PushInputStreamTest{
public static void main(String args[]) throws Exception { // 所有异常抛出
String str = "www.pornhub.com;www.xvideos.com" ; // 定义"老司机"字符串
PushbackInputStream push = null ; // 定义回退流对象
ByteArrayInputStream bai = null ; // 定义内存输入流
bai = new ByteArrayInputStream(str.getBytes()) ;// 实例化内存输入流
push = new PushbackInputStream(bai) ; // 从内存中读取数据
System.out.print("读取之后的数据为:") ;
int temp = 0 ;
while((temp=push.read())!=-1){ // 读取内容
if(temp=='.'){ // 判断是否读取到了“.”
push.unread(temp) ; //放回到缓冲区之中
temp = push.read() ; //再读一遍
System.out.print("(退回"+(char)temp+")") ;
}else{
System.out.print((char)temp) ; //输出内容
}
}
}
}
运行结果: 读取之后的数据为:www(退回.)pornhub(退回.)com;www(退回.)xvideos(退回.)com。
此处参考博客:https://blog.csdn.net/hanshileiai/article/details/6719647
23.8.7 管道流
管道流:是用来在多个线程之间进行信息传递的流。
管道流分为:字节流管道流和字符管道流。(它们必须成双成对的使用)
- 字节管道流:PipedOutputStream 和 PipedInputStream。
- 字符管道流:PipedWriter 和 PipedReader。
其中 PipedOutputStream、PipedWriter可以理解为写入者、生产者、发送者,PipedInputStream、PipedReader可以理解为读取者、消费者、接收者。
一个PipedInputStream对象必须和一个PipedOutputStream对象进行连接而产生一个通信管道, PipedOutputStream可以向管道中写入数据,PipedInputStream可以从管道中读取PipedOutputStream写入的数据。
字节管道流:PipedOutputStream、PipedInputStream
package com.thr.other;
import java.io.*;
/**
* @author Administrator
* @date 2020-02-29
* @desc 字节管道流
*/
public class PipeStreamTest {
public static void main(String[] args) {
try {
Sender sender = new Sender(); // 创建线程对象Sender
Receiver receiver = new Receiver(); // 创建线程对象Receiver
PipedOutputStream out = sender.getOutputStream(); // 写入
PipedInputStream in = receiver.getInputStream(); // 读出
out.connect(in); // 将输出发送到输入
sender.start();// 启动线程
receiver.start();
}
catch(IOException e) {
e.printStackTrace();
}
}
}
//写入数据的线程,发送端
class Sender extends Thread {
private PipedOutputStream out = new PipedOutputStream();
public PipedOutputStream getOutputStream() {
return out;
}
public void run() {
try {
String s = new String("Receiver,你好!");
out.write(s.getBytes());
out.close();
}
catch(IOException e) {
e.printStackTrace();
}
}
}
//读取数据的线程,接收端
class Receiver extends Thread {
private PipedInputStream in = new PipedInputStream();
public PipedInputStream getInputStream() {
return in;
}
public void run() {
try {
String s = null;
byte[] b = new byte[1024];
int len = in.read(b);
s = new String(b, 0, len);
System.out.println("收到了以下信息:" + s);
in.close();
}
catch(IOException e) {
e.printStackTrace();
}
}
}
注意:当点进去PipedInputStream的源码可以发现,其内部包含一个缓冲区,其默认值为DEFAULT_PIPE_SIZE = 1024个字节,这就意味着 通过PipedOutputStream写入的数据会保存到对应的 PipedInputStream的内部缓冲区。如果对应的 PipedInputStream输入缓冲区已满,再次企图写入PipedOutputStream的线程都将被阻塞,直至出现读取PipedInputStream的操作从缓冲区删除数据。
对于字符管道流,这里就不分析了,因为字符管道流原理跟字节管道流一样,只不过底层一个是 byte 数组存储 一个是 char 数组存储的。
23.7.8 随机存储文件流
随机存储文件流(RandomAccessFile):RandomAccessFile是一个非常特殊的流,它虽然声明在java.io包下,但是它是直接继承自java.lang.Object类的。并且它实现了DataInput和DataOutput这两个接口,表明这个类既可以读也可以写数据。但是和其他输入/输入流不同的是,程序可以直接跳到文件的任意位置来读写数据。 因为RandomAccessFile可以自由访问文件的任意位置,所以如果我们希望只访问文件的部分内容,那就可以使用RandomAccessFile类。
RandomAccessFile类的构造方法如下所示:
RandomAccessFile(File file , String mode):创建随机存储文件流,文件属性由参数File对象指定RandomAccessFile(String name , String mode):创建随机存储文件流,文件属性由指定名称的文件读取。
这两个构造方法均涉及到一个String类型的参数mode,它决定随机存储文件流的操作模式,其中mode值及对应的含义如下:
- “
r”:以只读的方式打开,调用该对象的任何write(写)方法都会导致IOException异常。 - “
rw”:以读、写方式打开,支持文件的读取或写入。若文件不存在,则创建之。 - “
rws”:以读、写方式打开,与“rw”不同的是,还要求对文件内容或元数据的每个更新都同步写入到底层设备。这里的“s”表示synchronous(同步)的意思 - “
rwd”:以读、写方式打开,与“rw”不同的是,还要对文件内容的每次更新都同步更新到潜在的存储设备中去。使用“rwd”模式仅要求将文件的内容更新到存储设备中,而使用“rws”模式除了更新文件的内容,还要更新文件的元数据(metadata),因此至少要求1次低级别的I/O操作
接下来简单举例:
package com.thr.other;
import java.io.*;
/**
* @author Administrator
* @date 2020-02-29
* @desc 随机存储流
*/
public class RandomAccessFileTest {
public static void main(String[] args) throws IOException {
//随机流读数据--r
RandomAccessFile raf1 = new RandomAccessFile("D:\\IO\\RAF.txt", "r");
byte[] buffer1 = new byte[1024];
int len1;
while ((len1=raf1.read(buffer1))!=-1){
System.out.println(new String(buffer1,0,len1));
};
//随机流写数据--rw
RandomAccessFile raf2 = new RandomAccessFile("D:\\IO\\RAF1.txt", "rw");
byte[] buffer2 = new byte[1024];
int len2;
while ((len2=raf1.read(buffer2))!=-1){//注意这里是raf1,因为从RAF.txt读取数据,输出到RAF1.txt中
raf2.write(buffer2,0,len2);
};
raf1.close();
raf2.close();
}
}
RandomAccessFile还有一个特殊的地方是它包含了一可以从超大的文本中快速定位我们的游标,用于标记当前读写处的位置。当前读写n个字节后,文件指示器将指向这n个字节后面的下一个字节处。除此之外,RandomAccessFile是可以自由的移动记录指针,即可以向前移动,也可以向后移动。RandomAccessFile包含了以下两个方法来操作文件的记录指针:
long getFilePointer():返回文件记录指针的当前位置 。void seek(long pos):将文件记录指针定位到pos位置。
①、使用RandomAccessFile实现从指定位置读取文件的功能。
package com.thr.other;
import java.io.*;
/**
* @author Administrator
* @date 2020-02-29
* @desc 随机存储流中的游标方法使用示例
*/
public class RandomAccessFileMethodTest1 {
public static void main(String[] args) {
RandomAccessFile raf=null;
try {
raf=new RandomAccessFile("D:\\IO\\test.txt","r");
// 获取 RandomAccessFile对象文件指针的位置,初始位置为0
System.out.print("输入内容:"+raf.getFilePointer());
//移动文件记录指针的位置
raf.seek(2);
byte[] b=new byte[1024];
int len=0;
//循环读取文件
while((len=raf.read(b))>0){
//输出文件读取的内容
System.out.print(new String(b,0,len));
}
}catch (IOException e){
e.printStackTrace();
}finally {
try {
raf.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
②、使用RandomAccessFile实现向文件中追加内容的功能
package com.thr.other;
import java.io.*;
/**
* @author Administrator
* @date 2020-02-29
* @desc 随机存储流中的游标方法使用示例
*/
public class RandomAccessFileMethodTest2 {
public static void main(String[] args)throws IOException {
RandomAccessFile raf=null;
File file=null;
try {
// 以读写的方式打开一个RandomAccessFile对象
raf=new RandomAccessFile("D:\\IO\\test.txt","rw");
//将记录指针移动到该文件的最后
raf.seek(raf.length());
//向文件末尾追加内容
raf.writeUTF("【这是追加内容】");
}catch (IOException e){
e.printStackTrace();
}finally {
raf.close();
}
}
}
③、使用RandomAccessFile实现向文件指定位置插入内容的功能
注:RandomAccessFile不能向文件的指定位置插入内容,如果直接将文件记录指针移动到中间某位置后开始输出,则新输出的内容会覆盖文件原有的内容,如果需要向指定位置插入内容,程序需要先把插入点后面的内容写入缓存区,等把需要插入的数据写入到文件后,再将缓存区的内容追加到文件后面。
package com.thr.other;
import java.io.*;
/**
* @author Administrator
* @date 2020-02-29
* @desc 随机存储流中的游标方法使永示例
*/
public class RandomAccessFileMethodTest3 {
public static void main(String[] args)throws IOException {
insert("D:\\IO\\test.txt",10,"【插入指定位置指定内容】");
}
/**
* 插入文件指定位置的指定内容
* @param filePath 文件路径
* @param pos 插入文件的指定位置
* @param insertContent 插入文件中的内容
* @throws IOException
*/
public static void insert(String filePath,long pos,String insertContent)throws IOException{
RandomAccessFile raf=null;
File tmp= File.createTempFile("temp",null);
tmp.deleteOnExit();
try {
// 以读写的方式打开一个RandomAccessFile对象
raf = new RandomAccessFile(new File(filePath), "rw");
//创建一个临时文件来保存插入点后的数据
FileOutputStream fileOutputStream = new FileOutputStream(tmp);
FileInputStream fileInputStream = new FileInputStream(tmp);
//把文件记录指针定位到pos位置
raf.seek(pos);
raf.seek(pos);
//------下面代码将插入点后的内容读入临时文件中保存-----
byte[] buffer = new byte[64];
//用于保存实际读取的字节数据
int len = 0;
//使用循环读取插入点后的数据
while ((len = raf.read(buffer)) != -1) {
//将读取的内容写入临时文件
fileOutputStream.write(buffer, 0, len);
}
//-----下面代码用于插入内容 -----
//把文件记录指针重新定位到pos位置
raf.seek(pos);
//追加需要插入的内容
raf.write(insertContent.getBytes());
//追加临时文件中的内容
while ((len = fileInputStream.read(buffer)) != -1) {
//将读取的内容写入临时文件
raf.write(buffer, 0, len);
}
}catch (Exception e){
throw e;
}
}
}
上面的程序使用File类的createTempFile方法创建了一个临时文件(该文件将在JVM退出后被删除),用于保存被插入点后面的内容。程序先将文件中插入点后的内容读入临时文件中,然后重新定位到插入点,将需要插入的内容添加到文件后面,最后将临时文件的内容添加到文件后面,通过这个过程就可以向指定文件,指定位置插入内容。每次运行上面的程序,都会看到test.txt文件中多了一行内容。
24、多线程
24.1 多线程的基本概念
24.1.1 程序、进程、线程、多线程
Java多线程的知识现在是面试或笔试中经常会问的问题,主要是考察面试者对并发是否有所了解。当然这一系列Java多线程只是入门,并不涉及到很深入的并发编程知识。我们在学习Java多线程之前需要先了解以下几个概念。
①、程序(program)
程序这个词现在应该无人不知,无人不晓,因为大家每天都在使用程序。但是如果你在面试的时候,别人问你一句:你知道什么是程序吗?如果程序是什么都不知道还敢说自己是一名程序员。程序:就是为了完成特定的任务,用某种语言编写的一系列指令的集合。即一组计算机能识别和执行的静态代码,静态对象。
②、进程(process)
进程:是指一个内存中运行的应用程序。进程是操作系统分配资源的最小单位,一个进程中可以包含多个线程。每个进程都有自己独立的一块内存空间,进程是一个动态的过程,它自身伴随着程序启动,运行,关闭的整个生命周期过程。比如在Windows系统中运行的QQ,Google Chrome等。
我们可在电脑屏幕底部的任务栏,右键打开任务管理器查看当前任务的进程和线程:
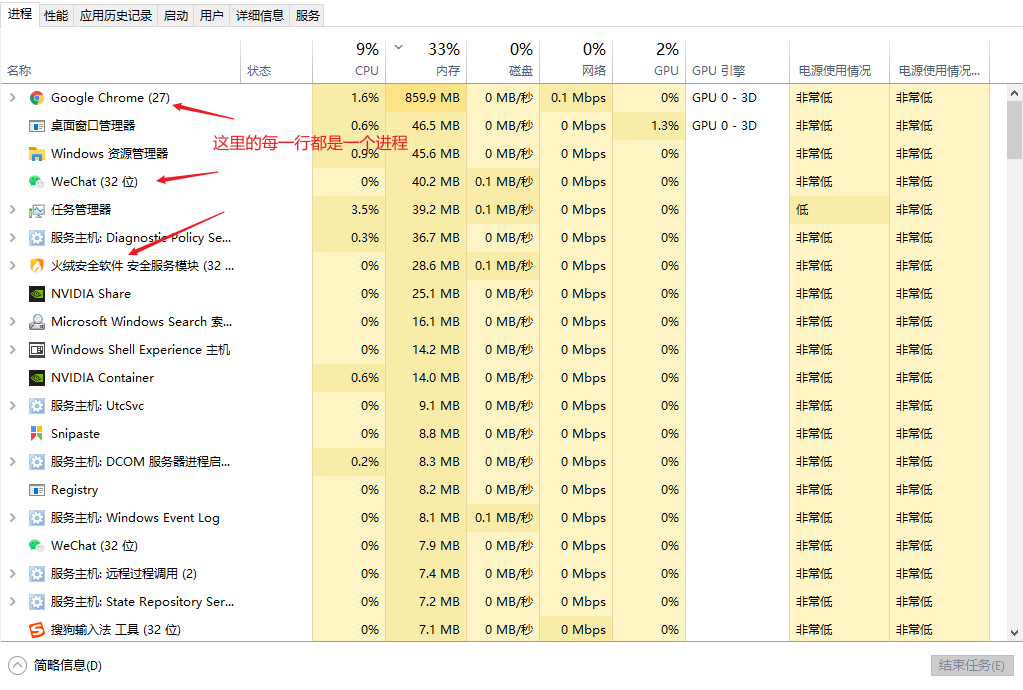
③、线程(thread)
线程是进程中的一个执行流程,是CPU调度和分派的最小单位,一个进程可以由多个线程组成,多个线程可以共享一个进程的内存空间。比如下图的Google Chrome进程中运行的多个线程。线程总是属于某个进程,线程没有自己的虚拟地址空间,与进程内的其他线程一起共享分配给该进程的所有资源。线程由CPU独立调度执行,在多核CPU环境下就允许多个线程同时运行。同样多线程也可以实现并发操作,每个请求分配一个线程来处理。
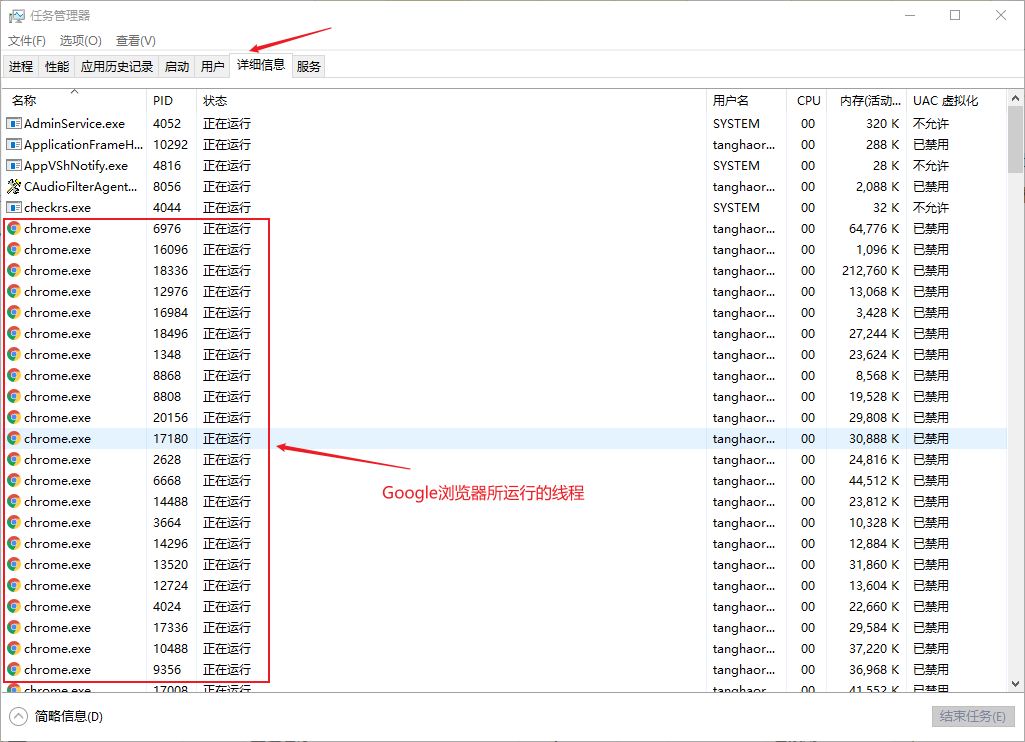
④、多线程
多线程:指的是一个程序(一个进程)在运行时产生了不止一个线程,产生的多个线程同时运行或交替运行,如果是单核CPU(现在哪还有这种CPU呀),也是交替运行,只不过要等一个线程运行完后才能运行下一个线程,因为在一个单位时间内,CPU只能执行一个线程任务,其实它是一种假的多线程。如果是多核CPU,才能发挥出多线程真正的效率。例如上面的Google浏览器就产生了很多个线程。多线程的作用一句话来说明:为了提高程序的效率(注意不是提高运行速度,宽带速度)。
24.1.2 并行与并发
并行:是指同一时刻内CPU处理了两个或多个任务,是真正的同时。例如多个人同时做不同的事。
并发:是指同一时间间隔内CPU执行了两个或多个任务。例如抢红包,秒杀商品,多个人做同一件的事。
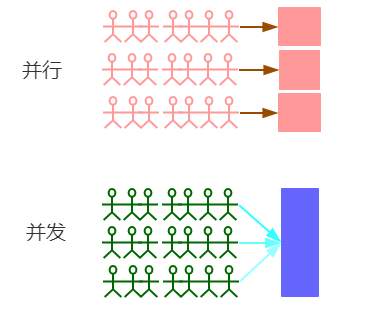
由此可见:并行是针对进程的,并发是针对线程的。
所以在多线程编程实践中,一般都称多线程并发编程而不是多线程并行编程。
24.1.3 进程和线程的区别
进程:
- 进程是指一个内存中运行的应用程序
- 进程可以产生多个线程,但至少有一个线程
- 进程作为资源分配的单位,系统在运行时会为每个进程分配独立的内存空间。所以进程中的数据存放空间是独立的(堆空间和方法区内存)
线程:
- 线程是一条执行路径,是进程中的一个执行流程,是CPU调度和分派的基本单位,一个进程可以由多个线程组成
- 线程总是属于某个进程。线程消耗的资源比进程小的多。
- 线程作为调度和执行的单位,每个线程拥有独立的运行栈和程序计数器(PC)。
- 同一个进程中的线程共享其它进程中的内存和资源。因为堆内存和方法区内存是共享的,而栈内存是独立的不共享,每个线程有自己独立的栈。
这样虽然使得线程的通信更加简单、高效,但是当一进程中的多个线程同时访问相同的资源时就可能会带来安全隐患。出现数据不一致的现象,此时需要使用到后面讲到的同步机制。
由于创建一个线程的开销比创建一个进程的开销小的多,那么我们在开发多任务运行的时候,通常考虑创建多线程,而不是创建多进程。
24.1.4 使用多线程的优点
- 提高程序的响应,增加用户的体验。
- 最大限度的利用CPU的空闲时间来处理其他任务。
- 提高程序的效率。注意:它不是提高运行速度,而是提高CPU的使用率,从而使程序的运行效率加快了。
- 系统创建进程需要为该进程重新分配系统资源,创建线程的代价则小的多,因此多任务并发时,多线程效率高。
24.1.5 Java中的主线程
在运行的Java程序中至少包含了两个线程,一个主线程是main()方法线程,另外一个是垃圾回收机制线程。每当使用Java命令执行一个类时,都会启动一个JVM,并且加载对应的class文件,而每一个JVM在操作系统中启动了一个main()方法的主线程,Java 本身具备了垃圾的收集机制,所以在 Java 运行时至少会启动两个线程。当代码执行时,JVM会从main方法开始执行我们的程序代码,一直把main方法的代码执行结束。如果在执行过程遇到循环时间比较长的代码,那么在循环之后的其他代码是不会被马上执行的。如下代码演示:
package com.thr;
/**
* @author Administrator
* @date 2020-03-12
* @desc Java主线程
*/
public class Demo {
//调用main方法,启动主线程
public static void main(String[] args) {
new Person("张三").show();
new Person("李四").show();
new Person("王五").show();
}
}
class Person{
private String name;
public Person(String name) {
this.name = name;
}
public void show(){
for (int i = 0; i < 100000; i++) {
System.out.println("name="+name+",i="+i);
}
}
}
在上述代码中show()方法中的循环执行次数很多,这时 匿名对象.show();下面的代码是依次按顺序从上往下执行,并且在输出窗口也可以看到按顺序不停的输出 name=XXX,i=值 这样的语句。那为什么会这样呢?原因是:JVM启动后,必然有一个执行路径(线程)从main方法开始的,一直执行到main方法结束为止,这个线程在Java中称之为主线程。当程序的主线程执行时,如果遇到了循环而导致程序在指定位置停留时间过长,则无法马上执行下面的程序,需要等待循环结束后能够执行。
那么,能否实现一个主线程负责执行其中一个循环,再由另一个线程负责其他代码的执行,最终实现多部分代码同时执行的效果?是能够实现同时执行,通过Java中的多线程技术来解决该问题。
24.2 创建多线程的两种方式
多线程的创建有以下三种方式:
- 继承Thread类,重写run方法
- 实现Runnable接口,重写run方法
- 匿名内部类
其实还可以使用JDK1.5之后的Callable类和线程池的方式创建,但是该系列只是Java多线程入门,而且我也对线程池的使用不是很了解,所以就没有写它们了。但是好像上面的这些方式都用的不多,都是使用线程池创建线程。(哈哈,只能怪自己太菜,菜是原罪啊,还得继续加油,欧力给)
24.2.1 继承Thread类
使用Thread类创建线程的步骤:
- 创建一个继承自Thread类的子类。
- 重写Thread类的run()方法。
- 创建Thread类的子类对象。
- 通过子类对象调用start()方法。
package com.thr;
/**
* @author Administrator
* @date 2020-03-13
* @desc 继承Thread类
*/
//1、创建一个继承自Thread类的子类
class MyThread extends Thread{
//2、重写Thread类的run()方法
@Override
public void run() {
for (int i = 0; i < 1000; i++) {
System.out.println(Thread.currentThread().getName()+":"+i);
}
}
}
public class ThreadDemo {
public static void main(String[] args) {
//3、创建Thread类的子类对象
MyThread t1 = new MyThread();
MyThread t2 = new MyThread();
//4、通过子类对象调用start()方法
t1.start();
t2.start();
}
}
运行结果如下:
从上面的运行结果可以看出:线程是一个子任务,创建的线程是交替执行的。这是线程调度的结果,Java的线程调度策略是优先级抢占式调度,首先让优先级高的线程大概率能够使用CPU资源,如果线程的优先级相同,那么CPU会随机调度(线程随机性),上面的代码都是默认的优先级,创建的两个线程同时在抢占CPU的资源,那么谁能抢占到的CPU资源就执行。所以输出的结果是随机的,我们是不能干涉的。
注意:不要将run()和start()这两者给搞混了。
run()和start()方法区别:
- start():首先启动当前线程,然后再由JVM去调用该线程的run()方法。
- run():仅仅是封装被线程执行的代码,直接调用是普通方法,并不会启动线程。
还有需要注意一点的是:如果该线程已经调用了start()方法,则不能再次调用该方法了,否则会抛出IllegalThreadStateException异常。解决办法就是重新创建一个Thread子类的实例调用start()方法。
24.2.2实现Runnable接口
使用Runnable接口创建线程的步骤:
- 创建一个实现Runnable接口的类。
- 实现类去实现Runnable接口中的抽象方法run()。
- 创建实现类的对象。
- 创建一个Thread类,将实现类的对象传入到Thread类的构造器中。
- 通过Thread类的对象调用start()方法。
package com.thr;
/**
* @author Administrator
* @date 2020-03-13
* @desc 实现Runnable接口
*/
//1、创建一个实现了Runnable接口的类
class MyThread implements Runnable{
//2、实现Runnable接口的抽象run()方法
@Override
public void run() {
for (int i = 0; i < 1000; i++) {
System.out.println(Thread.currentThread().getName()+":"+i);
}
}
}
public class RunnableDemo {
public static void main(String[] args) {
//3、创建实现类对象
MyThread m = new MyThread();
//4、创建一个Thread类,将实现类的对象传入到Thread类的构造器中。
Thread t1 = new Thread(m);
Thread t2 = new Thread(m);
//5、通过Thread类的对象调用start()方法。
t1.start();
t2.start();
}
}
既然有这两种方式实现对线程,那么我们使用哪一种呢???
答:一般使用的是实现Runnable接口方式开发多线程,因为Java只能单继承却可以实现多个接口。
24.2.3 匿名内部类
Thread匿名内部类
package com.thr;
/**
* @author Administrator
* @date 2020-03-13
* @desc Thread类的匿名内部方式
*/
public class ThreadDemo {
public static void main(String[] args) {
//创建一个打印1000以内的所有偶数的线程
new Thread(){
@Override
public void run() {
for (int i = 0; i < 1000; i++) {
if (i % 2 == 0){
System.out.println(Thread.currentThread().getName()+":"+i);
}
}
}
}.start();
//创建一个打印1000以内的所有奇数的线程
new Thread(){
@Override
public void run() {
for (int i = 0; i < 1000; i++) {
if (i % 2 != 0){
System.out.println(Thread.currentThread().getName()+":"+i);
}
}
}
}.start();
}
}
Runnable作为参数传入Thread类的匿名内部方式。
package com.thr;
/**
* @author Administrator
* @date 2020-03-13
* @desc Runnable作为参数传入Thread类的匿名内部方式
*/
public class RunnableDemo1 {
public static void main(String[] args) {
//创建一个打印1000以内的所有偶数的线程
new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 1000; i++) {
if (i % 2 == 0){
System.out.println(Thread.currentThread().getName()+":"+i);
}
}
}
}).start();
//创建一个打印1000以内的所有奇数的线程
new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 1000; i++) {
if (i % 2 != 0){
System.out.println(Thread.currentThread().getName()+":"+i);
}
}
}
}).start();
}
}
24.3 线程的生命周期
我们知道JVM的线程调度策略是优先级抢占式调度。即是指能够大概率的让优先级高的线程抢占到CPU资源(注意并不是优先高的先执行,执行是随机的,只是抢占的概率会大很多,后面的线程优先级会有举例),如果线程的优先级相同,那么就随机选择一个线程,使其占用CPU资源。所以当一个线程创建并且启动之后,它不会一直处于执行状态,那么线程在未取得CPU资源时是处于就绪状态,也会因为某些原因导致线程进入阻塞状态。所以线程状态会多次在运行、就绪和阻塞之间来回切换。
24.3.1 线程的生命周期
24.3.1.1 传统线程模型的五种线程状态
传统线程模型中把线程的生命周期描述为五种状态:新建(New)、就绪(Runnable)、运行(Running)、阻塞(Blocked)、死亡(Dead)。CPU需要在多条线程之间切换,于是线程状态会多次在运行、阻塞、就绪之间切换。
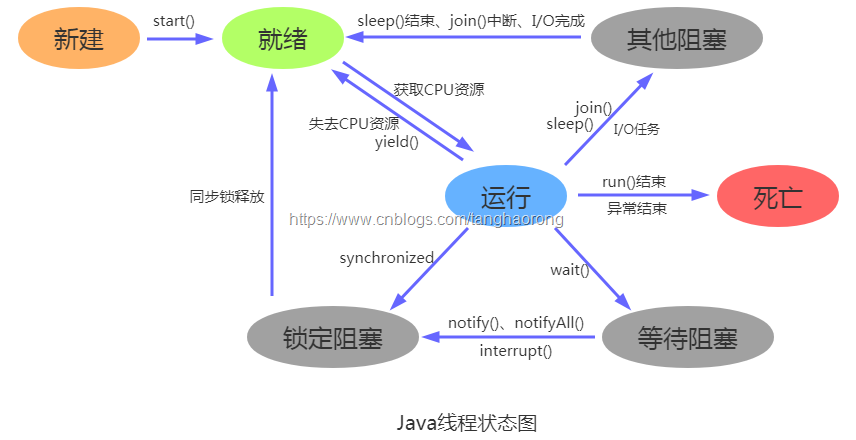
通过上面的图各种状态一目了然,线程的生命周期包含的5个阶段:新建、就绪、运行、阻塞、死亡。
- 新建(new Thread):当创建Thread类的一个实例(对象)时,此线程进入新建状态(未被启动)。例如:Thread t1=new Thread()。
- 就绪(runnable):就是Thread实例调用了start()方法后,线程已经被启动,这时候线程处于等待CPU分配资源阶段,谁先抢的CPU资源,谁开始执行。例如:t1.start()。
- 运行(running):当就绪的线程被调度并获得CPU资源时,便进入运行状态,run方法定义了线程的操作和功能。
- 阻塞(blocked):线程在运行状态的时候,可能因为某些原因导致运行状态的线程变成了阻塞状态。
- 死亡(dead):如果线程正常执行完毕后或线程被提前强制性的终止或出现异常导致结束,那么线程就要被销毁,释放资源。分为自然终止和异常终止。
其中值得一提的是阻塞(Blocked)这个状态:线程在Running的过程中可能会遇到各种阻塞(Blocked)情况,如下:
- 等待阻塞:调用运行线程的wait()方法,虚拟机会把该线程放入等待池(wait blocked pool)。如需将阻塞状态下的线程唤醒,可调用notify或者notifyAll()方法,线程被唤醒被放到锁定池(lock blocked pool ),释放同步锁使线程回到就绪行状态(Runnable)。
- 锁定(同步)阻塞:运行线程获取对象的同步锁时,该锁已被其他线程获得,虚拟机会把该线程放入锁定池(lock blocked pool )。
- 其他阻塞:调用运行线程的sleep()方法、join()方法或线程发出I/O请求时,进入阻塞状态。
24.3.1.2 JDK定义的六种线程状态(了解)
在java.lang.Thread类内部定义了一个枚举类用来描述线程的六种状态:
public enum State {
NEW,//新建
RUNNABLE,//可运行
BLOCKED,
WAITING,
TIMED_WAITING,
TERMINATED;//终止
}
跟传统线程模型中的线程状态不同的是:
-
枚举类中没有区分
就绪和运行状态,而是定义成了一种状态Runnable。- 因为对于Java对象来说,只能标记为可运行,至于什么时候运行,不是JVM来控制的了,是OS来进行调度的,而且时间非常短暂,因此对于Java对象的状态来说,无法区分。只能我们人为的进行想象和理解。
-
传统模型中的阻塞状态在枚举类的定义中又细分为了三种状态的:
BLOCKED、WAITING、TIMED_WAITING。BLOCKED:是指互有竞争关系的几个线程,其中一个线程占有锁对象时,其他线程只能等待锁。只有获得锁对象的线程才能有执行机会。TIMED_WAITING:当前线程执行过程中遇到Thread类的sleep或join,Object类的wait,LockSupport类的park方法,并且在调用这些方法时,设置了时间,那么当前线程会进入TIMED_WAITING,直到时间到,或被中断。WAITING:当前线程执行过程中遇到遇到Object类的wait,Thread类的join,LockSupport类的park方法,并且在调用这些方法时,没有指定时间,那么当前线程会进入WAITING状态,直到被唤醒。- 通过Object类的wait进入
WAITING状态的要有Object的notify/notifyAll唤醒; - 通过Condition的await进入
WAITING状态的要有Conditon的signal方法唤醒; - 通过LockSupport类的park方法进入
WAITING状态的要有LockSupport类的unpark方法唤醒 - 通过Thread类的join进入
WAITING状态,只有调用join方法的线程对象结束才能让当前线程恢复;
- 通过Object类的wait进入
说明:当从WAITING或TIMED_WAITING恢复到Runnable状态时,如果发现当前线程没有得到监视器锁,那么会立刻转入BLOCKED状态。
24.3.2 线程中常用方法
线程中常用方法:
(1)、Thread类中的方法:
currentThread():返回对当前正在执行的线程对象的引用。getId():返回此线程的标识符。getName():返回此线程的名称。setName(String name):设置此线程的名称。getPriority():返回此线程的优先级。setPriority(int newPriority):设置此线程的优先级。isDaemon():判断这个线程是否是守护线程。setDaemon(boolean on):将此线程标记为 daemon线程或用户线程。isAlive():判断当前线程是否存活。interrupt():将当前线程置为中断状态。sleep(long millis):使当前运行的线程进入睡眠状态,睡眠时间至少为指定毫秒数,此时线程处于阻塞状态。yield():放弃当前的CPU资源,从运行状态进入就绪状态,让其它的线程去占用CPU资源。(注:放弃的时间不确定,可能一会就会重新获得CPU资源)。join():表示等待这个线程结束,即在一个线程中调用other.join(),将等待other线程结束后才继续本线程。
(2)、Object类中的方法:
wait():让当前线程进入等待阻塞状态,直到其他线程调用了此对象的notify()或notifyAll()方法后,当前线程才被唤醒进入就绪状态。
notify():唤醒在此对象监控器(锁)上等待的单个线程。notifyAll():唤醒在此对象监控器(锁)上等待的所以线程。
注:wait()、notify()、notifyAll()都依赖于同步锁,而同步锁是对象持有的,且每个对象只有一个,所以这些方法定义在Object类中,而不是Thread类中(这三个方法非常重要,后面会详细介绍)。
(3)、yield()、sleep()、wait()比较:
wait():让线程从运行状态进入等待阻塞状态,并且会释放它所持有的同步锁。sleep():让线程从运行状态进入阻塞状态,不会释放它所持有的同步锁。yield():让线程从运行状态进入就绪状态,不会释放它所持有的同步锁。
24.4 线程的调度与控制
通常我们的计算机只有一个 CPU,CPU 在某一个时刻只能执行一条指令,线程只有得到 CPU时间片,也就是使用权,才可以执行指令。在单 CPU 的机器上线程不是并行运行的,只有在多个 CPU 上线程才可以并行运行。Java 虚拟机要负责线程的调度,取得CPU 的使用权,目前有两种调度模型:分时调度模型和抢占式调度模型,Java 使用抢占式调度模型。
分时调度模型:所有线程轮流使用 CPU 的使用权,平均分配每个线程占用 CPU 的时间片
抢占式调度模型:优先级高的线程获取 CPU 的时间片相对多一些,如果线程的优先级相同,那么会随机选择一个
24.4.1 线程的优先级
上面就说到过JVM的调度是根据优先级高低来抢占CPU资源的,那么我们怎么给一个线程设置优先级呢?接下来介绍:
线程的优先级分为1~10个级别,下面的这三是Thread类中给我定义好的三个静态常量:
- 最高优先级——MAX_PRIORITY:10
- 最低优先级——MIN _PRIORITY:1
- 默认优先级——NORM_PRIORITY:5
我们可以打开Thread类的源码查看到这三个常量,如下图:
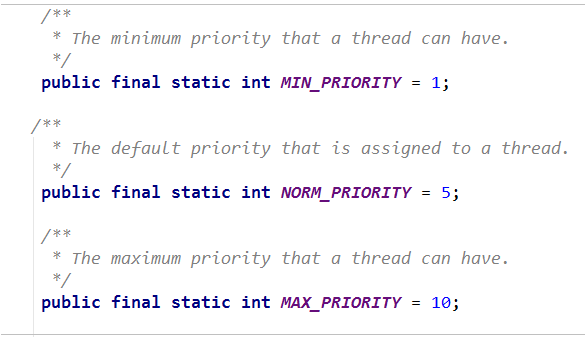
设置优先级的方法:
getPriority():获取线程的优先级。setPriority(int p):设置线程的优先级,参数是一个整数,范围是1~10之间,也可以使用Thread类提供的三个静态常量。
说明:高优先级的线程要抢占低优先级线程CPU的执行权。但是只是从概率上讲,高优先级的线程高概率的情况下被执行。并不意味着只有当高优先级的线程执行完以后,低优先级的线程才执行。
简单举例:
package com.thr;
/**
* @author Administrator
* @date 2020-03-16
* @desc 设置线程的优先级
*/
class MyThread implements Runnable{
@Override
public void run() {
for (int i = 0; i < 1000; i++) {
System.out.println(Thread.currentThread().getName()+":"+i);
}
}
}
public class RunnableDemo {
public static void main(String[] args) {
MyThread m = new MyThread();
Thread t1 = new Thread(m);
Thread t2 = new Thread(m);
//给两个不同的线程设置一个最高优先级,一个最低优先级,看看运行结果
t1.setPriority(Thread.MAX_PRIORITY);
t2.setPriority(Thread.MIN_PRIORITY);
//t1.setPriority(9);也可以使用数字取值范围为1~~10
t1.start();
t2.start();
}
}
运行结果:

从运行的结果可以说明,并不是优先级高的线程先执行完后,低优先级的线程才执行,只是高优先级的线程可以大概率获得CPU资源。
24.4.2 守护线程
Java中线程分为两类:用户线程(User Thread)和守护线程(Daemon Thread)。
用户线程和守护线程的区别在于:
- 用户线程:运行在前台,执行具体的任务,如程序的主线程、连接网络的子线程等都是用户线程
- 守护线程:运行在后台,为其他前台线程服务.也可以说守护线程是JVM中非守护线程的 “佣人”。
- 用户线程是独立存在的,不会因为其他用户线程退出而退出。
- 守护线程是依赖于用户线程,用户线程退出了,守护线程也就会退出,典型的守护线程如垃圾回收线程。
守护线程举例:
package com.thr;
/**
* @author Administrator
* @date 2020-03-16
* @desc 守护线程
*/
class MyThread implements Runnable{
@Override
public void run() {
for (int i = 0; i < 1000; i++) {
System.out.println(Thread.currentThread().getName()+":"+i);
}
}
}
public class RunnableDemo {
public static void main(String[] args) {
MyThread m = new MyThread();
Thread t = new Thread(m);
t.setDaemon(true);//将t线程设置为守护线程
t.start();
System.out.println("main线程结束...");
}
}
运行结果如下:
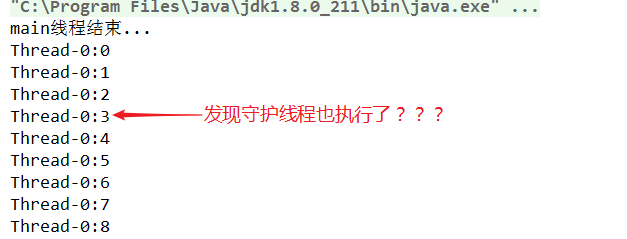
唉唉唉!你看看,用户线程main方法明明都结束了,但是守护线程t还是执行了,这是为什么?是因为在main线程运行完成退出的一瞬间,守护线程获取到CPU资源,从而使守护线程执行了一小段,但是当main线程真正退出之后,这个线程也就彻底消失了。如果你要效果明显一点就在for循环中加一个sleep()即可。
守护线程注意点:
- 如果Java没有设置线程为守护线程,那么它就是用户线程。
- 正在运行的常规线程不能设置为守护线程。
- thread.setDaemon(true)必须在thread.start()之前设置,否则会抛出一个IllegalThreadStateException异常。
- 在Daemon线程中产生的新线程也是Daemon的(这里要和linux的区分,linux中守护进程fork()出来的子进程不再是守护进程)
24.4.3 线程睡眠sleep
线程睡眠就是调用sleep方法让当前正在执行的线程暂停一段时间,并进入阻塞状态。当时间到了之后就进入就绪状态而不是执行状态。下面使用代码举例:
package com.thr;
/**
* @author Administrator
* @date 2020-03-16
* @desc 线程睡眠sleep
*/
class MyThread implements Runnable{
@Override
public void run() {
for (int i = 0; i < 100; i++) {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+":"+i);
}
}
}
public class RunnableDemo {
public static void main(String[] args) {
MyThread m = new MyThread();
Thread t1 = new Thread(m);
Thread t2 = new Thread(m);
try {
//注意:这里用别 t1 线程对象调用sleep方法,但是它不是睡眠 t1 线程,而是睡眠的main线程,因为sleep方法只能让当前运行的线程睡眠
//而此时运行的正是main主线程,所以即使用其它线程对象调用sleep方法,依然是睡眠主线程。
t1.sleep(5000);//睡眠5秒
} catch (InterruptedException e) {
e.printStackTrace();
}
t1.start();
t2.start();
}
}
运行的结果会发现先等主线程睡眠了5秒,然后其它线程才开始执行。所以最好不要用线程的实例对象调用sleep方法,因为它睡眠的始终是当前正在运行的线程,而不是睡眠调用它的线程对象,它只对正在运行状态的线程对象有效。sleep方法也是一个静态方法,所以推荐使用Thread.sleep()方式调用。
24.4.4 线程让步yeild
线程让步就是调用yeild方法让当线程自己让出 CPU 资源,从运行状态进入就绪状态,让其它的线程去占用CPU资源。由于线程是进入就绪状态,所以完全有可能马上重新获取到CPU资源。这个方法开发中会很少使用该方法,该方法主要运用于调试或测试,它可能有助于多线程竞争条件下的错误重现现象。
yeild方法与sleep方法有点相似,yeild也可以让当前正在执行的线程暂停,让出cpu资源给其他的线程,只是yeild方法不能指点暂停时间的长度,并且yield方法暂停线程后直接进入就绪状态,不会进入到阻塞状态。实际上,当某个线程调用了yield()方法暂停之后,优先级与当前线程相同,或者优先级比当前线程更高的就绪状态的线程更有可能获得CPU资源的机会,当然,这只是有可能,因为CPU的调度是随时的,我们干涉不了的。使用代码举例如下:
package com.thr;
/**
* @author Administrator
* @date 2020-03-16
* @desc 线程让步yeild
*/
class MyThread implements Runnable{
@Override
public void run() {
for (int i = 0; i < 100; i++) {
if (i % 5 == 0){
Thread.yield();//run方法中调用yeild方法
}
System.out.println(Thread.currentThread().getName()+":"+i);
}
}
}
public class RunnableDemo {
public static void main(String[] args) {
MyThread m = new MyThread();
Thread t1 = new Thread(m);
Thread t2 = new Thread(m);
//设置线程优先级
t1.setPriority(10);
t2.setPriority(1);
t1.start();
t2.start();
for (int i = 0; i < 100; i++) {
System.out.println("主线程执行了:"+i+"次");
}
}
}
关于sleep()方法和yield()方的区别如下:
-
sleep方法暂停当前线程后,会进入阻塞状态,只有当睡眠时间到了,才会转入就绪状态;而yield方法调用后 ,是直接进入就绪状态,完全可能马上又被调度到运行状态。
-
sleep 方法会给其他线程运行的机会,但是不考虑其他线程优先级的问题;而yield 方法会优先给更高优先级的线程运行机会。
-
sleep方法声明抛出了InterruptedException,所以调用sleep方法的时候要捕获该异常,或者显示声明抛出该异常。而yield方法则没有声明抛出任务异常。
24.4.5 线程合并join
线程合并就是调用join方法让几个并行的线程合并为一个单线程执行。join()的作用是让“主线程”等待“子线程”结束之后才能继续运行(注意这个主线程不是main线程的意思,是指当前运行的线程)。其实join不能简单的理解为合并,因为join底层实际是通过wait()来实现的,它的目的是让当前线程一直等待,然后让子线程执行。
wait()的作用是让当前线程等待进入阻塞状态。但是我们的join方法是由子线程来调用的,但是等待阻塞的却是“主线程“,而不是“子线程”!这里肯定会产生一个问题:为什么是“子线程”调用的join方法(子线程也就间接调用了wait()),那么为什么等待的不是子线程,而是主线程,这个问题后面解释。
先来看一下 join代码举例如下:
package com.thr;
/**
* @author Administrator
* @date 2020-03-16
* @desc 线程合并join
*/
class MyThread implements Runnable{
@Override
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println(Thread.currentThread().getName()+":"+i);
}
}
}
public class RunnableDemo {
public static void main(String[] args) {
MyThread m = new MyThread();
Thread t1 = new Thread(m);
Thread t2 = new Thread(m);
t1.start();
t2.start();
//这里是main主线程的循环
for (int i = 1; i < 10; i++) {
System.out.println("主线程执:"+i);
if (i == 5){
try {
//当i==5时,在main主线程中调用t1、t2的join方法,让main主线程处于等待阻塞状态,等t1、t2执行完了,main主线程才有执行的机会
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}
运行结果如下图:

我们可以点进join()的源码查看:

再点入到join(long millis)方法中:
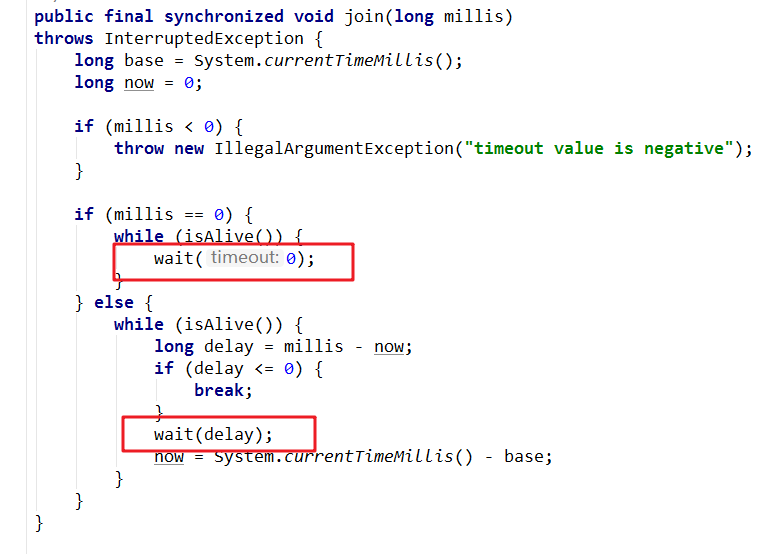
简单说明:从源码中,我们可以发现。当millis==0时,会进入while(isAlive())循环。即只要子线程是活的,主线程就不停的等待。
问题:son.join()被调用的地方是发生在主线程中,但是调用join()是通过子线程son。那么被调用join中对应的wait(0)也应该是让子线程son等待才对。那为什么等待的不是子线程,而是主线程呢?
回答:wait()的作用是让当前线程等待进入阻塞状态,而这里的“当前线程”是指当前在CPU上运行的线程。虽然是调用子线程的wait()方法,但是它是在“主线程”中去调用的。所以,等待的是主线程,而不是“子线程”!这一点和前面讲的sleep()方法是一样的道理,它只对正在运行状态的线程对象有效。
24.5 线程的同步(线程安全问题)
24.5.1 线程安全问题
线程安全问题产生的主要原因有两个:存在共享资源和多个线程共同操作共享数据。就是当多个线程同时操作同一个可共享的资源时导致出现的一些不必要的问题,此时就出现了线程的安全问题,这个时候就需要使用到线程同步。
这里通过一个非常经典的案例卖票来演示线程安全问题(三个窗口总共卖100张票):
package com.thr;
class Ticket implements Runnable{
//定义100张票(临界资源)
private int ticket = 100;
@Override
public void run() {
while (ticket > 0) {
try {
Thread.sleep(10);//让效果明显一点加个sleep
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "卖出了一张票,票号为:" + ticket );
ticket--;
}
}
}
public class RunnableDemo {
public static void main(String[] args) {
//创建一个ticket对象
Ticket ticket = new Ticket();
Thread t1 = new Thread(ticket,"窗口1");
Thread t2 = new Thread(ticket,"窗口2");
Thread t3 = new Thread(ticket,"窗口3");
t1.start();
t2.start();
t3.start();
}
}
运行结果如下图:
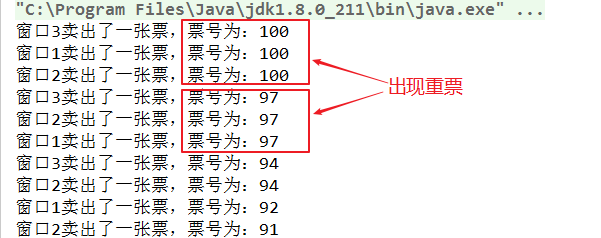

从运行的结果可以发现:上面卖的票出现了问题:
- 卖的票出现了重复的票。
- 卖的票出现错误的票 0、-1。
其实,出现上面的原因都是由全局变量ticket引起的,因为只创建了一个Ticket实例对象,所以多个线程共享这一个全局变量ticket=100。假如窗口1和窗口2这两个线程,在某一时刻,窗口1和窗口2线程都读取到了ticket=100,那么可能会发生这种情况:窗口1打印100然后减减,然后窗口2也打印了100再减减(这是重票,错票同理)。此时这个就是线程安全问题,即多个线程同时访问一个共享数据(也称临界资源)时,会导致程序运行结果并不是想看到的结果。
所以为了避免产生线程安全问题提供了三种解决方法:
1、同步代码块(synchronize)
2、同步方法
3、锁机制(Lock)
24.5.2 同步代码块
同步代码块的格式:
synchronized(锁对象) {
线程安全问题的代码
}
当在某个线程中执行这段代码块时,该线程会获取我们指定的对象的锁,从而使得其他线程无法同时访问该代码块。
在使用同步代码块时注意:
- 同步代码块的锁对象,可以是非null的任意对象。
- 必须保证多个线程使用的锁对象必须是同一个。
使用上面线程安全问题的例子举例:
class Ticket implements Runnable{
//定义100张票(临界资源)
private int ticket = 100;
private Object object = new Object();
@Override
public void run() {
//1、synchronized (obj):获取自定义对象的锁,可以是Java非NULL的所有对象
//2、synchronized (this):获取当前对象锁,此时的this为Ticket ticket = new Ticket();对象
//3、synchronized (Ticket.class):获取当前类对象锁,Class clazz=Ticket.class
synchronized (object) {
while (ticket > 0) {
try {
Thread.sleep(10);//让效果明显一点加个sleep
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "卖出了一张票,票号为:" + ticket);
ticket--;
}
}
}
}
在main方法中的代码不变,运行之后的结果就不会再出现重票错票的情况了。
24.5.3 同步方法
同步方法的格式:
修饰符 synchronized 返回值类型 方法名称(参数列表) {
方法体
}
这种方式就是把操作共享资源的代码抽取出来,放到一个用synchronize关键字修饰的方法中。
(1)、同步非静态方法:
还是以上面线程安全问题的例子举例:
class Ticket implements Runnable{
//定义100张票(临界资源)
private int ticket = 100;
@Override
public void run() {
sell();
}
//定义同步方法
public synchronized void sell(){
while (ticket > 0) {
try {
Thread.sleep(10);//让效果明显一点加个sleep
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + "卖出了一张票,票号为:" + ticket);
ticket--;
}
}
}
运行结果同样不会出现问题,不过要注意的是此时的锁对象不再是任意对象了,此时的锁对象是this,也就是说谁调用了方法,那么this就是谁,而由于当前就创建了一个Ticket ticket = new Ticket();实例对象,所以此时的this就是ticket实例的锁对象。
注意:不能直接用 synchronized 来修饰 run() 方法,因为这样做就是第一个线程进来之后拿到锁对象,一直执行完所有操作才出来,其它线程一直等待第一个线程执行完,这样你创建的多个线程就没有任何意义了。
(2)、同步静态方法:
同步静态方法和同步方法很像,就是在同步方法前面加了个static关键字,添加之后的锁对象就不再是this了,而是类对象(ClassName.class)。我们在使用静态同步方法时,共享数据也要加上static,因为只有static成员才能访问static成员。
一般情况下,不使用static锁:因为JVM编译的时候,static是存到方法区,方法区是垃圾回收机制不会回收的。
最后总结synchronize关键字修饰不同地方的锁对象(非常重要!!!):
- 修饰代码块,指定加锁对象,对给定对象加锁,线程进入同步代码前要获得给定对象的锁,这个锁可以是实例锁,也可是类对象锁。
- 修饰实例方法,作用于当前实例加锁,线程进入同步代码前要获得当前实例的锁,即this锁。
- 修饰静态方法,作用于当前类对象加锁,线程进入同步代码前要获得当前类对象的锁,即 类.class锁。
同步的原理:当多个线程同时对一个共享数据进行操作时,只有一个线程能够拿到锁对象,因为一个对象只有一把锁,当一个线程获取了该对象的锁之后,其他线程是无法获取该锁对象的,所以只能等待拿到锁对象的线程运行完释放过后,其它线程才能访问,这样便实现了线程对临界区的互斥访问,保证了共享数据安全。这也就是锁的竞争问题,也是死锁产生的条件。
24.5.4 死锁(DeadLock)
线程的同步虽然能够解决线程安全问题,但是它满足了互斥条件,而这是产生死锁的必要条件,所以是有可能出现死锁的。
就举一个生活中的例子:某天,2个人一起吃饭但是只有一双筷子(规定只有一双筷子才能吃饭)。就在某一时刻,一个人拿起了左边的筷子,另一个人拿起右边的筷子,此时2个人都同时占用一个资源,它们都在等待对方吃完把筷子拿过来,但是没有人放筷子都想吃饭呢,这样就一直僵持着,谁也无法吃饭,就形成了死锁。
线程死锁产生的原因:多个线程分别占用对方需要的同步资源不放弃,都在等对方放弃自己需要的同步资源,从而形成了死锁。
产生死锁的必要条件:
- 互斥条件:某资源只能被一个进程使用,其他进程请求该资源时,只能等待,直到资源使用完毕后释放资源。
- 请求和保持条件:当进程因请求资源而阻塞时,对已获得的资源保持不放。
- 不剥夺条件:进程已获得的资源在未使用完之前,不能剥夺,只能在使用完时由自己释放。
- 环路等待条件:在发生死锁时,必然存在一个进程--资源的环形链。
产生死锁的一个例子:
package com.thr;
/**
* @author Administrator
* @date 2020-03-25
* @desc 死锁举例
*/
public class DeadLockDemo {
private static Object o1=new Object();
private static Object o2=new Object();
public static void main(String[] args) {
//线程1
new Thread(new Runnable() {
@Override
public void run() {
synchronized (o1){
//System.out.println("111");
try {
Thread.sleep(500);
} catch (Exception e) {
e.printStackTrace();
}
synchronized (o2){
System.out.println("222");
}
}
}
}).start();
//线程2
new Thread(new Runnable() {
@Override
public void run() {
synchronized (o2){
//System.out.println("333");
try {
Thread.sleep(500);
} catch (Exception e) {
e.printStackTrace();
}
synchronized (o1){
System.out.println("444");
}
}
}
}).start();
}
}
通过运行结果发现,死锁出现后,不会出现任何异常,不会输出任何提示,但程序也不会终止,所有线程都处于阻塞状态,无法继续。
上面程序分析:首先是线程1启动,先获取到o1锁,然后睡眠500毫秒,在睡眠过程中,线程2会启动,然后获取o2锁,睡眠500毫秒。当线程1睡眠结束后,需要获取o2锁才能继续执行完成,而此时的o2已经被线程2获取锁定了,线程2获取o1同理。所以此时线程1和线程2相互等待,都需要等待对方释放锁对象才能继续执行,从而产生死锁。
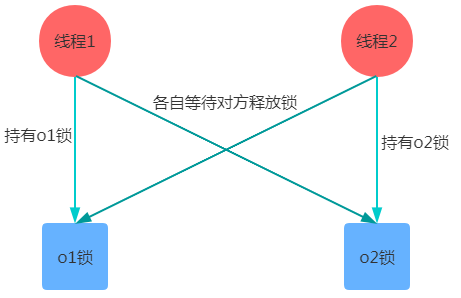
那么怎么来预防死锁的产生呢?
可以通过破坏死锁产生的4个必要条件来预防死锁,由于资源互斥是资源使用的固有特性是无法改变的,所以只需破坏其他3个即可。
- 破坏”请求与保持条件“:第一种方法静态分配,即每个进程在开始执行时就申请他所需要的全部资源。第二种是动态分配,即每个进程在申请所需要的资源时他本身不占用系统资源。
- 破坏“不可剥夺”条件:一个进程不能获得所需要的全部资源时便处于等待状态,等待期间他占有的资源将被隐式的释放重新加入到 系统的资源列表中,可以被其他的进程使用,而等待的进程只有重新获得自己原有的资源以及新申请的资源才可以重新启动,执行。
- 破坏“循环等待”条件:采用资源有序分配其基本思想是将系统中的所有资源顺序编号,将紧缺的,稀少的采用较大的编号,在申请资源时必须按照编号的顺序进行,一个进程只有获得较小编号的进程才能申请较大编号的进程。
24.5.5 锁机制(Lock)
在Java多线程中,可以使用synchronized关键字来实现线程之间的同步互斥。而在Java5中又新增了一个java.util.concurrent包来支持同步,使用其中的ReentrantLock类也同样能够达到同样的效果,而且比synchronize更加的灵活。ReentrantLock类是可重入、互斥的的,它实现了Lock接口。
其中有两个非常重要的方法:
- lock()方法:上锁
- unlock()方法:释放锁
使用ReentrantLock同步举例:
package com.thr;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
class Ticket implements Runnable{
//定义100张票(临界资源)
private static int ticket = 100;
//创建一个锁对象
private Lock lock =new ReentrantLock();
@Override
public void run() {
try {
//获取锁
lock.lock();
while (ticket > 0) {
System.out.println(Thread.currentThread().getName() + "卖出了一张票,票号为:" + ticket);
ticket--;
}
} catch (Exception e) {
e.printStackTrace();
} finally {
//释放锁
lock.unlock();
}
}
}
public class RunnableDemo {
public static void main(String[] args) {
//创建一个ticket对象
Ticket ticket = new Ticket();
Thread t1 = new Thread(ticket,"窗口1");
Thread t2 = new Thread(ticket,"窗口2");
Thread t3 = new Thread(ticket,"窗口3");
t1.start();
t2.start();
t3.start();
}
}
为了安全起见释放锁最好放在finally语句中。
synchronized与Lock的区别:
- synchronized当线程执行完毕或者抛出异常的话,会自动释放锁(相当于汽车中的自动挡)。
- Lock锁需要手动的启动同步(lock()),在结束同步是也需要手动的实现(unlock())(相当于汽车中的手动挡)。
优先使用顺序:Lock>同步代码块>同步方法
24.6 线程之间的通信(生产者与消费者模型)
24.6.1 什么是线程通信
线程通信:就是指多个线程在处理同一个资源,但是需要处理的动作(任务)不同,此时我们就需要使用到线程的通信来解决多线程之间对同一资源的使用和操作。
本文介绍的线程通信使用到三种方式:
- 使用等待通知机制控制线程通信(synchronized + wait + notify)
- 使用Condition控制线程通信(Lock + Condition + await + signal)
- 使用阻塞队列控制线程通信(BlockingQueue)
由于在线程通信中生产者-消费者模型是最经典的经典问题之一,所有下面就都用生产者与消费者来举例。它就像我们学习Java语言中的Hello World一样经典。
我们这里的生产者-消费者模型为:
生产者Producer不停的生产资源,将其放在仓库(缓冲池)中,也就是下面代码中的Resource,仓库最大容量为10,然后消费者不停的从仓库(缓冲池)中取出资源。当仓库(缓冲池)已装满时,生产者线程就需要停止自己的生产操作,使自己处于等待阻塞状态,并且放弃锁,让其它线程执行。因为如果生产者不释放锁的话,那么消费线程就无法消费仓库中的资源,这样仓库资源就不会减少,而且生产者就会一直无限等待下去。因此,当仓库已满时,生产者必须停止并且释放锁,这样消费者线程才能够执行,等待消费者线程消费资源,然后再通知生产者线程生产资源。同样地,当仓库为空时,消费者也必须等待,等待生产者通知它仓库中有资源了。这种互相通信的过程就是线程间的通信(协作)。
24.6.2 使用等待通知机制控制线程通信(synchronized + wait + notify)
在Java线程通信中,等待通知机制是最传统的方式,就是在一个线程进行了规定操作后,该线程就进入等待状态(wait), 等待其它线程执行完它们的指定代码过后,再将之前等待的线程唤醒(notify)。等待通知机制中使用到wait()、notify()和notifyAll()这三个方法,它们都属于Object这个类中,由于所有的类都从Object继承而来,因此,所有的类都拥有这些共有方法可供使用。而且,由于他们都被声明为final,因此在子类中不能覆写任何一个方法。
我们来看看这个三个方法的介绍:
wait():让当前的线程进入等待阻塞状态,直到其它线程调用此对象的 notify()方法或notifyAll()方法才唤醒。notify():唤醒在此对象监视器(锁)上等待的单个线程(随机唤醒)。notifyAll():唤醒在此对象监视器(锁)上等待的所有线程。
后下面详细说明一下各个方法在使用中需要注意的几点:
首先这三个方法必须在同步方法或同步块中调用,而且必须由同步监视器(锁对象)来调用,并且它们的同步监视器(锁对象)必须一致。
1、wait()
public final void wait() throws InterruptedException , IllegalMonitorStateException
该方法用来将当前线程置入休眠(阻塞)状态,直到接到通知或被中断为止。在调用wait()之前,线程必须要获得该对象的对象级别锁,即只能在同步方法或同步块中调用wait()方法。进入wait()方法后,当前线程释放锁。在从wait()返回前,线程与其他线程竞争重新获得锁。如果调用wait()时,没有持有适当的锁,则抛出IllegalMonitorStateException。
2、notify()
public final native void notify() throws IllegalMonitorStateException
该方法也要在同步方法或同步块中调用,即在调用前,线程也必须要获得该对象的对象级别锁,如果调用notify()时没有持有适当的锁,也会抛出IllegalMonitorStateException。
该方法用来通知那些可能等待该对象的对象锁的其他线程。如果有多个线程等待,则线程规划器任意挑选出其中一个wait()状态的线程来发出通知,并使它等待获取该对象的对象锁,但不惊动其他同样在等待被该对象notify的线程们。当第一个获得了该对象锁的wait线程运行完毕以后,它会释放掉该对象锁,此时如果该对象没有再次使用notify语句,则即便该对象已经空闲,其他wait状态等待的线程由于没有得到该对象的通知,会继续阻塞在wait状态,直到这个对象发出一个notify或notifyAll。这里需要注意:它们等待的是被notify或notifyAll,而不是锁。这与下面的notifyAll()方法执行后的情况不同。
特别注意:当在同步中调用wait()方法时,执行该代码的线程会立即放弃它在对象上的锁。然而在调用notify()时,并不意味着这时线程会放弃该对象锁,而是要等到程序运行完synchronized代码块后,当前线程才会释放锁,wait所在的线程也才可以获取该对象锁。
3、notifyAll()
public final native void notifyAll() throws IllegalMonitorStateException
该方法与notify()方法的工作方式相同,重要的一点差异是:
notifyAll使所有原来在该对象上wait的线程统统退出wait的状态(即全部被唤醒,不再等待notify或notifyAll,但由于此时还没有获取到该对象锁,因此还不能继续往下执行),变成等待获取该对象上的锁,一旦该对象锁被释放(notifyAll线程退出调用了notifyAll的synchronized代码块的时候),他们就会去竞争。如果其中一个线程获得了该对象锁,它就会继续往下执行,在它退出synchronized代码块,释放锁后,其它的已经被唤醒的线程将会继续竞争获取该锁,一直进行下去,直到所有被唤醒的线程都执行完毕。
上面BB了这么多,下面举一个生产者-消费者的栗子应该就明白了:
package com.thr;
/**
* @author Administrator
* @date 2020-04-02
* @desc synchronized+wait+notify线程通信举例(生产者消费者模型)
*/
public class ProducerConsumerWaitNotify {
public static void main(String[] args) {
Resource resource = new Resource();
//创建3个生产者线程
Thread t1 = new Thread(new Producer(resource),"生产线程1");
Thread t2 = new Thread(new Producer(resource),"生产线程2");
Thread t3 = new Thread(new Producer(resource),"生产线程3");
//创建2个消费者线程
Thread t4 = new Thread(new Consumer(resource),"消费线程1");
Thread t5 = new Thread(new Consumer(resource),"消费线程2");
//生产者线程启动
t1.start();
t2.start();
t3.start();
//消费者线程启动
t4.start();
t5.start();
}
}
/**
* 共享资源(仓库)
*/
class Resource{
//当前资源数量
private int num = 0;
//最大资源数量
private int size = 10;
//生产资源
public synchronized void add(){
if (num < size){
num++;
System.out.println("生产者--" + Thread.currentThread().getName() +
"--生产一件资源,当前资源池有" + num + "个");
notifyAll();
}else{
try {
wait();
System.out.println("生产者--"+Thread.currentThread().getName()+"进入等待状态,等待通知");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
//消费资源
public synchronized void remove(){
if (num > 0){
num--;
System.out.println("消费者--" + Thread.currentThread().getName() +
"--消耗一件资源," + "当前线程池有" + num + "个");
notifyAll();
}else{
try {
wait();
System.out.println("消费者--" + Thread.currentThread().getName() + "进入等待状态,等待通知");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
/**
* 生产者线程
*/
class Producer implements Runnable{
//共享资源对象
private Resource resource;
public Producer(Resource resource) {
this.resource = resource;
}
@Override
public void run() {
while (true){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
resource.add();
}
}
}
/**
* 消费者线程
*/
class Consumer implements Runnable{
//共享资源对象
private Resource resource;
public Consumer(Resource resource) {
this.resource = resource;
}
@Override
public void run() {
while (true){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
resource.remove();
}
}
}
运行的结果如下:
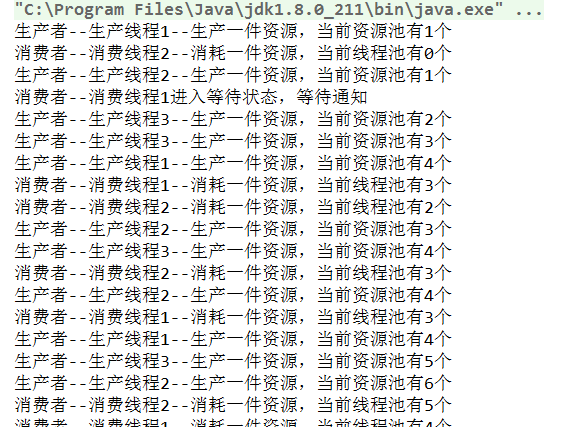
实际上生产者-消费者模型中更应该加一个"仓库”,因为该模型离开了“仓库”生产者消费者模型就显得没有说服力了。而对于此模型,应该明确一下几点:
- 生产者仅仅在仓库未满时候生产,仓库满则停止生产。
- 消费者仅仅在仓库有产品时候才能消费,仓库空则等待。
- 当消费者发现仓库没产品可消费时候会通知生产者生产。
- 生产者在生产出可消费产品时候,应该通知等待的消费者去消费。
再来比较一下sleep() 和 wait()的异同?
相同点:都可以使得当前的线程进入阻塞状态。
不同点:
- 声明的位置不同:Thread类中声明sleep() , Object类中声明wait()。
- 调用的要求不同:sleep()可以在任何需要的场景下调用。 wait()必须使用在同步代码块或同步方法中。
- 是否释放同步监视器:如果两个方法都使用在同步代码块或同步方法中,sleep()不会释放锁,wait()会释放锁。
- 如何唤醒:sleep()自动唤醒,wait()需要手动调用notify()和notifyAll()。
24.6.3 使用Condition控制线程通信(Lock + Condition + await + signal)
Condition是在Java 1.5中才出现的,它是一个接口,其内部基本的方法就是await()、signal()和signalAll()方法。它的作用就是用来代替传统的Object类中的wait()、notify()实现线程间的通信。相比使用Object的wait()、notify(),使用Condition的await()、signal()这种方式实现线程间协作更加安全和高效,因此通常来说比较推荐使用Condition。但是需要注意的是Condition依赖于Lock接口,它必须在Lock实例中使用,否则会抛出IllegalMonitorStateException。也就是说调用Condition的await()和signal()方法,必须在lock.lock()和lock.unlock之间才可以使用。
- Conditon中的await()对应Object的wait();
- Condition中的signal()对应Object的notify();
- Condition中的signalAll()对应Object的notifyAll()。
Condition对象的生成代码如下:
Lock lock = new ReentrantLock();
Condition condition = lock.newCondition();
使用Condition控制线程通信举例:
package com.thr;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
/**
* @author Administrator
* @date 2020-04-03
* @desc Lock + Condition + await + signal举例
*/
public class ProducerConsumerCondition {
public static void main(String[] args) {
//创建ReentrantLock和Condition对象
Lock lock = new ReentrantLock();
Condition producerCondition = lock.newCondition();
Condition consumerCondition = lock.newCondition();
Resource resource = new Resource(lock,producerCondition,consumerCondition);
//创建3个生产者线程
Thread t1 = new Thread(new Producer(resource),"生产线程1");
Thread t2 = new Thread(new Producer(resource),"生产线程2");
Thread t3 = new Thread(new Producer(resource),"生产线程3");
//创建2个消费者线程
Thread t4 = new Thread(new Consumer(resource),"消费线程1");
Thread t5 = new Thread(new Consumer(resource),"消费线程2");
//生产者线程启动
t1.start();
t2.start();
t3.start();
//消费者线程启动
t4.start();
t5.start();
}
}
/**
* 共享资源(仓库)
*/
class Resource{
//当前资源数量
private int num = 0;
//最大资源数量
private int size = 10;
//定义lock和condition
private Lock lock;
private Condition producerCondition;
private Condition consumerCondition;
//初始化
public Resource(Lock lock, Condition producerCondition, Condition consumerCondition) {
this.lock = lock;
this.producerCondition = producerCondition;
this.consumerCondition = consumerCondition;
}
//生产资源
public void add(){
lock.lock();//获取锁
try {
if (num < size){
num++;
System.out.println("生产者--" + Thread.currentThread().getName() +
"--生产一件资源,当前资源池有" + num + "个");
//唤醒等待的消费者
consumerCondition.signalAll();
//notifyAll();
}else{
//让生产者线程等待
producerCondition.await();
//wait();
System.out.println("生产者--"+Thread.currentThread().getName()+"进入等待状态,等待通知");
}
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
lock.unlock();//释放锁
}
}
//消费资源
public void remove(){
lock.lock();//获取锁
try {
if (num > 0){
num--;
System.out.println("消费者--" + Thread.currentThread().getName() +
"--消耗一件资源," + "当前线程池有" + num + "个");
//唤醒等待的生产者
producerCondition.signalAll();
//notifyAll();
}else{
//让消费者线程等待
consumerCondition.await();
//wait();
System.out.println("消费者--" + Thread.currentThread().getName() + "进入等待状态,等待通知");
}
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
lock.unlock();//释放锁
}
}
}
/**
* 生产者线程
*/
class Producer implements Runnable{
//共享资源对象
private Resource resource;
public Producer(Resource resource) {
this.resource = resource;
}
@Override
public void run() {
while (true){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
resource.add();
}
}
}
/**
* 消费者线程
*/
class Consumer implements Runnable{
//共享资源对象
private Resource resource;
public Consumer(Resource resource) {
this.resource = resource;
}
@Override
public void run() {
while (true){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
resource.remove();
}
}
}
实现的效果跟上面wait和notify是一样的。
24.6.4 使用BlockingQueue控制线程通信(BlockingQueue)
BlockingQueue也是在Java 1.5中才出现的,是一个接口,它继承了Queue接口。BlockingQueue的底层实际上是使用了Lock和Condition来实现的,它帮我们搞好了一切(已经帮我们调用了lock、unlock、await和signal方法),我们只需调用BlockingQueue中合适的方法即可,所以使用BlockingQueue可以很轻松的实现线程通信。
BlockingQueue具有的特征:如果该队列已满,当生产者线程试图向BlockingQueue中放入元素时,则线程被阻塞。如果队列已空,消费者线程试图从BlockingQueue中取出元素时,则该线程阻塞。
BlockingQueue提供如下两个支持阻塞的方法:
put(E e):尝试把元素放入BlockingQueue的尾部,如果该队列的元素已满,则阻塞该线程。take():尝试从BlockingQueue的头部取出元素,如果该队列的元素已空,则阻塞该线程。
BlockingQueue既然继承了Queue接口,那当然当然也可以使用Queue接口中的方法,这些方法归纳起来可以分为如下三组:
- 在队列尾部插入元素,包括
add(E e)、offer(E e)、put(E e)方法,当该队列已满时,这三个方法分别会抛出异常、返回false、阻塞队列。 - 在队列头部删除并返回删除的元素。包括
remove()、poll()、和take()方法,当该队列已空时,这三个方法分别会抛出异常、返回false、阻塞队列。 - 在队列头部取出但不删除元素。包括
element()和peek()方法,当队列已空时,这两个方法分别抛出异常、返回false。
BlockingQueue最终会有四种状况,抛出异常、返回特殊值(常常是 true / false)、阻塞、超时,下表总结了这些方法:
| 位置 | 抛出异常 | 返回特殊值 | 阻塞 | 超时 |
|---|---|---|---|---|
| 插入 | add(e) | offer(e) | put(e) | offer(e,time,unit) |
| 移除 | remove() | poll() | take() | poll(time,unit) |
| 检查 | element() | peek() | 不可用 | 不可用 |
BlockingQueue是个接口,它有如下5实现类:
- ArrayBlockingQueue(数组阻塞队列):基于数组实现的有界BlockingQueue队列,按FIFO(先进先出)原则对元素进行排序,创建其对象必须明确大小。
- LinkedBlockingQueue(链表阻塞队列):基于链表实现的BlockingQueue队列,按FIFO(先进先出)原则对元素进行排序,建其对象如果没有明确大小,默认值是Integer.MAX_VALUE。
- PriorityBlockingQueue(优先级阻塞队列):它并不是按FIFO(先进先出)原则对元素进行排序,该队列调用remove()、poll()、take()等方法提取出元素时,是根据对象(实现Comparable接口)的本身大小来自然排序或者Comparator来进行定制排序的。不懂排序的可以查看这篇博客:夯实Java基础(十五)——Java中Comparable和Comparator
- SynchronousQueue(同步阻塞队列):它是一个特殊的BlockingQueue,其内部同时只能够容纳单个元素。如果该队列已有一元素的话,尝试向队列中插入一个新元素的线程将会阻塞,直到另一个线程将该元素从队列中抽走。同样,如果该队列为空,试图向队列中抽取一个元素的线程将会阻塞,直到另一个线程向队列中插入了一条新的元素。
- DelayQueue(延迟阻塞队列):它也是一个特殊的BlockingQueue,底层基于PriorityBlockingQueue实现,不过,DelayQueue要求集合元素都实现Delay接口(该接口里只有一个long getDelay()方法), DelayQueue根据集合元素的getDalay()方法的返回值进行排序。
使用BlockingQueue控制线程通信举例:
package com.thr;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
/**
* @author Administrator
* @date 2020-04-03
* @desc BlockingQueue线程通信举例
*/
public class ProducerConsumerBlockingQueue {
public static void main(String[] args) {
Resource resource = new Resource();
//创建3个生产者线程
Thread t1 = new Thread(new Producer(resource),"生产线程1");
Thread t2 = new Thread(new Producer(resource),"生产线程2");
Thread t3 = new Thread(new Producer(resource),"生产线程3");
//创建2个消费者线程
Thread t4 = new Thread(new Consumer(resource),"消费线程1");
Thread t5 = new Thread(new Consumer(resource),"消费线程2");
//生产者线程启动
t1.start();
t2.start();
t3.start();
//消费者线程启动
t4.start();
t5.start();
}
}
/**
* 共享资源(仓库)
*/
class Resource{
//定义一个链表队列,最大容量为10
private BlockingQueue<Integer> blockingQueue = new LinkedBlockingQueue(10);
//生产资源
public void add(){
try {
blockingQueue.put(1);
System.out.println("生产者--" + Thread.currentThread().getName() +
"--生产一件资源,当前资源池有" + blockingQueue.size() + "个");
} catch (Exception e) {
e.printStackTrace();
}
}
//消费资源
public void remove(){
try {
blockingQueue.take();
System.out.println("消费者--" + Thread.currentThread().getName() +
"--消耗一件资源," + "当前线程池有" + blockingQueue.size() + "个");
} catch (Exception e) {
e.printStackTrace();
}
}
}
/**
* 生产者线程
*/
class Producer implements Runnable{
//共享资源对象
private Resource resource;
public Producer(Resource resource) {
this.resource = resource;
}
@Override
public void run() {
while (true){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
resource.add();
}
}
}
/**
* 消费者线程
*/
class Consumer implements Runnable{
//共享资源对象
private Resource resource;
public Consumer(Resource resource) {
this.resource = resource;
}
@Override
public void run() {
while (true){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
resource.remove();
}
}
}
24.7 Callable、Future和线程池(ThreadPoolExecutor)的基础学习
本文介绍另外两种创建多线程的方式,这两种方式我们在实际中会用的多一点,尤其是线程池。而在前面文章中我们讲述了创建线程最基本的两种方式:一种是直接继承Thread,另外一种就是实现Runnable接口。但是这两种方式创建线程有一个缺陷,那就是无法获取到线程运行后的结果,因为这两个方式都是重写了 run()方法,而run()方法是用void修饰的。所以后来就有了Callable和Future这两个接口,它们能够获取线程执行的结果。
24.7.1 Callable介绍
Callable是在JDK1.5中出现的接口,它和Runnable接口很相似,所以可以认为:Callable接口是Runnable接口的增强版,因为Runnable有的功能Callable都有,而且还能获取任务执行的结果。所以下面来看一下Callable和Runnable接口的对比:
先来看一下Runnable接口的源码:
public interface Runnable {
public abstract void run();
}
Callable接口的源代码:
public interface Callable<V> {
V call() throws Exception;
}
可以很明显的看出它们二者的区别:
- Callable使用的是call(),而Runnable中使用的是run()。
- Callable的call()可以抛出异常,而Runnable的run()不会抛出异常。
- Callable能接受一个泛型,然后在call()中返回一个这个类型的值。而Runnable的run()没有返回值。
- 补充:Callable不能直接替换Runnable,因为Thread类的构造方法根本没有Callable。
上面说Callable是可以返回任务执行结果的,而获取返回结果需使用到Future。所以下面要介绍一下Future。
24.7.2 Future介绍
Future也是一个接口,通过它可以获得任务执行的返回值。该接口的内部源码如下:
public interface Future<V> {
boolean cancel(boolean mayInterruptIfRunning);
boolean isCancelled();
boolean isDone();
V get() throws InterruptedException, ExecutionException;
V get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException;
}
可以发现在Future接口中声明了5个方法,下面依次解释每个方法的作用:
cancel(boolean mayInterruptIfRunning):用来取消任务,如果取消任务成功则返回true,如果取消任务失败则返回false。参数mayInterruptIfRunning表示是否允许取消正在执行却没有执行完毕的任务,如果设置true,则表示可以取消正在执行过程中的任务。如果任务已经完成,则无论mayInterruptIfRunning为true还是false,此方法肯定返回false,即如果取消已经完成的任务会返回false;如果任务正在执行,若mayInterruptIfRunning设置为true,则返回true,若mayInterruptIfRunning设置为false,则返回false;如果任务还没有执行,则无论mayInterruptIfRunning为true还是false,肯定返回true。isCancelled():表示任务是否被取消成功,如果在任务正常完成前被取消成功,则返回 true。isDone():表示任务是否已经完成,若任务完成,则返回true;get():用来获取执行结果,这个方法会产生阻塞,阻塞的线程为调用get()方法的线程,会一直等到任务执行完毕返回结果,之后阻塞的主线程才能够往后执行。get(long timeout, TimeUnit unit):用来获取执行结果,如果在指定时间内,还没获取到结果,就会抛出TimeoutException异常(慎用这个方法,因为有很多坑)。
下面是Future接口中在java.util.concurrent包下类的结构图:
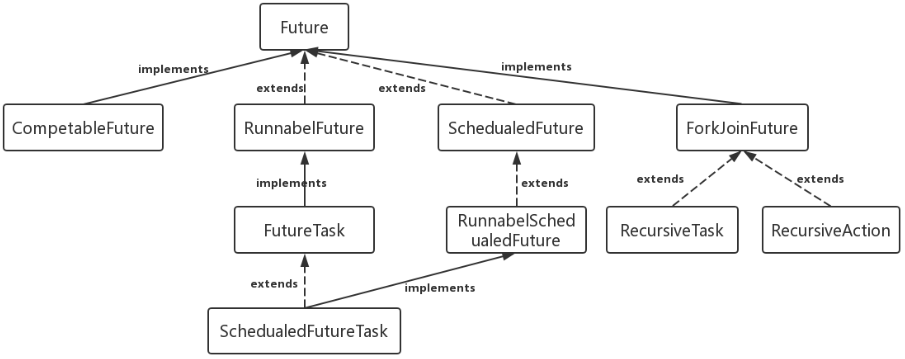
由于Future只是一个接口,所以是无法直接用来创建对象使用的,所以真正获取结果用到的是FutureTask这个类。
『FutureTask』
通过上面的图片发现FutureTask类是实现了RunnableFuture接口,而这个接口又继承了Future接口,我们具体点开其源码来看。
public class FutureTask<V> implements RunnableFuture<V>{
code...
}
打开RunnableFuture接口的实现:
public interface RunnableFuture<V> extends Runnable, Future<V> {
void run();
}
可以看出RunnableFuture继承了Runnable和Future接口,而FutureTask实现了RunnableFuture接口。所以它既可以作为Runnable被线程执行,又可以作为Future得到Callable的返回值。
上面说了这么多,接下来使用Callable+FutureTask创建线程并获取执行结果的一个栗子如下:
- 创建一个实现Callable接口的类。
- 重写call方法,将线程要执行的操作定义在call()中。
- 创建Callable接口实现类的对象。
- 创建FutureTask对象,并将上面Callable接口实现类的对象传入FutureTask构造器中。
- 将FutureTask的对象作为参数传入Thread类的构造器中,创建Thread类对象,并且启动线程。
- 获取Callable中call方法的返回值。
package com.thr;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
/**
* @author Administrator
* @date 2020-04-09
* @desc Callable+Future创建并获取线程执行结果
*/
//1、创建一个实现Callable接口的类
class MyCallable implements Callable<Integer>{
//2、重写call方法,将线程要执行的操作定义在call()中
@Override
public Integer call() throws Exception {
int num=0;
for (int i = 1; i <= 100; i++) {
num+=i;
}
return num;
}
}
public class CallableFutureDemo {
public static void main(String[] args) {
//3、创建Callable接口实现类的对象
MyCallable callable = new MyCallable();
//4、创建FutureTask对象,并将上面Callable接口实现类的对象传入FutureTask构造器中
FutureTask<Integer> task = new FutureTask<Integer>(callable);
//5、将FutureTask的对象作为参数传入Thread类的构造器中,创建Thread类对象,并且启动线程
new Thread(task).start();
try {
//6、获取Callable中call方法的返回值,调用get()时,main线程会阻塞,知道任务线程返回结果
Integer integer = task.get();
System.out.println(integer);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
关于FutureTask的一些小结:
- 在主线程中需要执行比较耗时的操作时,但又不想阻塞主线程时,可以把这些作业交给Future对象在后台完成。
- 当主线程将来需要时,就可以通过Future对象获得后台作业的计算结果或者执行状态。
- 一般FutureTask多用于耗时的计算,主线程可以在完成自己的任务后,再去获取结果。
- 仅在计算完成时才能检索结果;如果计算尚未完成,则阻塞 get 方法。
- 一旦计算完成,就不能再重新开始或取消计算。
- get方法而获取结果只有在计算完成时获取,否则会一直阻塞直到任务转入完成状态,然后会返回结果或者抛出异常。
- get()只会计算一次,并且会导致主线程阻塞,所以get()方法一般发在最后。
我们知道Callable用于产生结果,Future用于获取结果。不过Callable和Future一般都和线程池搭配使用,所以下面再来简单介绍一下线程池的使用。
24.7.3 线程池的介绍
在前面的文章中介绍了Thread、Runnable和Callable这三种方式创建线程,我们在创建少量线程的时候使用它们是非常的简单方便的,但是如果我们需要创建成百上千的线程时,那么岂不是要创建成百上千个线程对象,调用成百上千的start()方法,可见这样是非常浪费时间、消耗资源和降低程序效率的,因为线程的创建和销毁需要耗费大量的系统资源。那为了解决这一问题出现了线程池。
线程池顾名思义,就是由很多线程构成的池子。在有任务的时候随时取用线程,当任务完成后又将线程放回池中。
所以合理利用线程池能够带来三个好处。
- 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
- 提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
线程池的创建一般用Executors这个工具类来创建,常见的有以下四种方式:
- newFixedThreadPool(int nThreads):创建一个固定线程数目的线程池,超出的线程处理数量的任务会在队列中等待。
- newSingleThreadExecutor():创建一个单线程化的线程池。它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
- newCacheThreadPool():创建一个可缓存的线程池。如果现有任务没有线程来处理,则创建一个新线程并添加到缓存池中。如果有被使用完但是还没销毁的线程,就复用该线程。如果有线程60s未被使用的话就会从缓存中移出并终止(销毁)。因此,长时间保持空闲的线程池不会使用任何资源。
- newScheduledThreadPool(int corePoolSize):创建一个大小无限的支持定时及周期性的任务执行的线程池,多数情况下可用来替代Time类。
『一般不推荐使用Executors的方式来创建线程池,因为可能会出现OOM(Out Of Memory,内存溢出)的情况,下面我们依次详细的分析这四个方式:』
①、Executors.newFixedThreadPool(int nThread)
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());
}
可以发现最后一行使用了LinkedBlockingQueue,泛型是Runnable类型,这里的队列是用来存放线程任务的。我们再来看看这个LinkedBlockingQueue部分源码:
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
last = head = new Node<E>(null);
}
在上一章博客中提过LinkedBlockingQueue是链表实现的有界阻塞队列,其capacity是可以选择进行设置的,如果不设置的话,将是一个无边界的阻塞队列,队列的最大长度为Integer.MAX_VALUE。而上面newFixedThreadPool的源码中,我们可以很清晰的看到LinkedBlockingQueue是没有指定capacity的。所以此时LinkedBlockingQueue就是一个无边界队列,对于一个无边界队列来说,是可以不断的向队列中加入任务的,这种情况下就有可能因为队列中等待的线程数太多而导致OOM。
下面我们来一个简单的例子,模拟一下使用Executors导致OOM的情况:
首先将JVM参数调一下:-Xmx8m –Xms8m
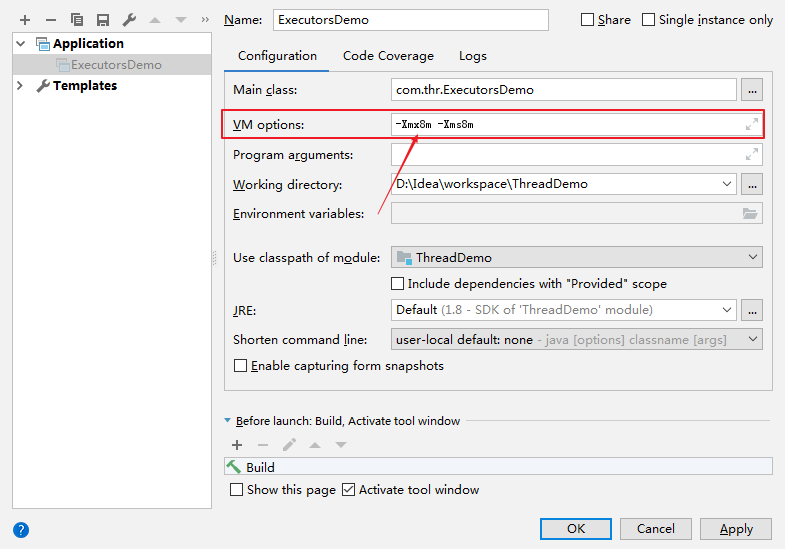
示例代码如下:
package com.thr;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* @author Administrator
* @date 2020-04-11
* @desc Excutors出现OOM举例
*/
public class ExecutorsDemo {
private static ExecutorService service = Executors.newFixedThreadPool(15);
public static void main(String[] args) {
for (int i = 0; i < Integer.MAX_VALUE; i++) {
service.execute(new SubThread());
}
}
}
class SubThread implements Runnable {
@Override
public void run() {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
//do nothing
}
}
}
运行结果:

②、Executors.newSingleThreadExexutor()
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>()));
}
可以发现还是使用阻塞队列LinkedBlockingQueue,所以问题是一样的。
③、Executors.newCacheThreadPool()
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>());
}
可以发现ThreadPoolExecutor对象中的第二个参数为Integer.MAX_VALUE,而这个位置参数的意思为线程池最大线程数。所以还是会出现OOM的情况。
④、Executors.newScheduleThreadPool()
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
public class ScheduledThreadPoolExecutor
extends ThreadPoolExecutor
implements ScheduledExecutorService {
code...
}
通过上面三段代码可以发现newScheduleThreadPool()方法返回了ScheduledThreadPoolExecutor对象,而它又继承了ThreadPoolExecutor类,并且调用的是父类的构造器,而构造器中的第二个参数为Integer.MAX_VALUE,所以还是同样的问题。
newScheduleThreadPool()的简单案例(由于前面三个的使用非常的简单,所有就不举例了) 代码如下:
[1]、延迟执行,线程在延迟5秒后执行。
/**
* newScheduleThreadPool()的简单案例
*/
public class ExecutorDemo {
public static void main(String[] args) {
// 创建一个定时处理任务的线程池
ScheduledExecutorService executorService = Executors.newScheduledThreadPool(10);
// 设置延迟5秒执行,时间到了就会执行线程
executorService.schedule(() -> {
System.out.println("newScheduledThreadPool---延迟5秒后打印");
}, 5, TimeUnit.SECONDS);
// 释放资源
executorService.shutdown();
}
}
[2]、定期执行,表示延迟5秒后每3秒执行一次。特别注意:线程池不能关闭
/**
* newScheduleThreadPool()的简单案例
*/
public class ExecutorDemo {
public static void main(String[] args) {
// 创建一个定时处理任务的线程池
ScheduledExecutorService executorService = Executors.newScheduledThreadPool(10);
// 设置延迟5秒,然后没过3秒打印一次
executorService.scheduleAtFixedRate(() -> {
System.out.println("newScheduledThreadPool---延迟5秒后每过3秒打印一次");
}, 5,3, TimeUnit.SECONDS);
// 注意这里不能释放资源
//executorService.shutdown();
}
}
这就是使用Executors工具类创建线程池的缺陷所在,在《阿里巴巴开发手册》中是不建议使用这种方式创建线程池的,而是推荐使用new ThreadPoolExecutor构造函数来创建线程池。如果你细心一点会发现上面四种方式中其实最终都是使用ThreadPoolExecutor这个类,所以这个类才是线程池的核心,我们只有彻底了解这个类才能真正的理解线程池。

24.7.4 ThreadPoolExecutor
上面既然说推荐使用ThreadPoolExecutor来创建线程池,那么先来看一下ThreadPoolExecutor的内容。在ThreadPoolExecutor类中提供了四个构造器,由于前三个构造器其实都是调用了第四个构造器来完成初始化的,所以这里就列出第四个构造器:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
可以发现构造器有7个参数,这7个参数特别的重要,下面分别解释下构造器中各个参数的含义:
-
corePoolSize:核心池的大小。在创建了线程池后,默认情况下,线程池中并没有任何线程,而是等待有任务到来才创建线程去执行任务。除非调用了prestartAllCoreThreads()或者prestartCoreThread()方法,从这2个方法是预创建线程的意思,即在没有任务到来之前就创建corePoolSize个线程或者一个线程。所以在默认情况下,创建了线程池后,线程池中的线程数为0,当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到缓存队列当中,例如LinkedBlockingQueue,如果缓存队列中存放的任务满了,则会继续创建新的线程来执行任务,直到创建maximumPoolSize个线程为止,也就是下面要定义的参数。
-
maximumPoolSize:线程池最大线程数,这个参数也是一个非常重要的参数,它表示在线程池中最多能创建多少个线程,所以它的数值肯定是不能小于corePoolSize的,从源码中也可以看到,如果这样做在运行时会抛出异常:IllegalArgumentException。
-
keepAliveTime:空闲线程的存活时间。就是当线程的数量大于corePoolSize时,如果等待了keepAliveTime时长还没有任务可执行,则线程终止(前提是线程池中的线程数必须大于corePoolSize时,keepAliveTime才会起作用,否则是没用的),直到线程池中的线程数不超过corePoolSize。但是如果调用了allowCoreThreadTimeOut(boolean)方法,在线程池中的线程数不大于corePoolSize时,keepAliveTime参数也会起作用,直到线程池中的线程数为0。
-
unit
:它为参数keepAliveTime的时间单位,它在TimeUnit类中有7种静态属性可取。
- 天:TimeUnit.DAYS;
- 小时:TimeUnit.HOURS;
- 分钟:TimeUnit.MINUTES;
- 秒:TimeUnit.SECONDS;
- 毫秒:TimeUnit.MILLISECONDS;
- 微妙:TimeUnit.MICROSECONDS;
- 纳秒:TimeUnit.NANOSECONDS;
-
workQueue
:一个阻塞队列,用来存储等待执行的任务,这个参数的选择也很重要,会对线程池的运行过程产生重大影响,一般来说,这里的阻塞队列有以下几种选择:
- ArrayBlockingQueue:是一个基于数组结构的有界阻塞队列,此队列按FIFO(先进先出)原则对元素进行排序,可以指定缓存队列的大小。
- LinkedBlockingQueue:一个基于链表结构的无界阻塞队列,此队列按FIFO(先进先出)原则对元素进行排序,吞吐量通常要高于ArrayBlockingQueue,所以这个比较常用,静态工厂方法Executors.newFixedThreadPool()使用了这个队列。
- SynchronousQueue:它没有容量,是无缓冲等待队列,是一个不存储元素的阻塞队列,会直接将任务交给消费者,必须等队列中的添加元素被消费后才能继续添加新的元素,否则插入操作一直处于阻塞状态。拥有公平(FIFO)和非公平(LIFO,SynchronousQueue默认)两种策略模式,非公平模式很容易出现饥渴的情况,即可能有某些生产者或者是消费者的数据永远都得不到处理。但是它的吞吐量通常要高于LinkedBlockingQueue,静态工厂方法Executors.newCachedThreadPool使用了这个列。
- PriorityBlockingQueue:一个具有优先级的无限阻塞队列(优先级的判断通过构造函数传入的Compator对象来决定)。但需要注意的是PriorityBlockingQueue并不会阻塞数据生产者,而只会在没有可消费的数据时,阻塞数据的消费者。因此使用的时候要特别注意,生产者生产数据的速度绝对不能快于消费者消费数据的速度,否则时间一长,会最终耗尽所有的可用堆内存空间。
- 注:其中ArrayBlockingQueue和PriorityBlockingQueue使用较少,一般使用LinkedBlockingQueue和SynchronousQueue。
-
threadFactory:线程工厂,它用于创建新的线程。threadFactory创建的线程也是采用new Thread()方式,threadFactory创建的线程名都具有统一的风格:pool-m-thread-n(m为线程池的编号,n为线程池内的线程编号)。
-
handler
:线程饱和策略或拒绝策略。当线程池和队列都满了,再加入的任务会执行此策略,它有四种策略。
- AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。线程池默认的拒绝策略。如何使用
new ThreadPoolExecutor.AbortPolicy()。 - DiscardPolicy:也是丢弃任务,但是不抛出异常。
- DiscardOldestPolicy:丢弃队列最前面的任务,也就是队列头的元素,然后重新尝试执行任务(重复此过程)。如果此时阻塞队列使用PriorityBlockingQueue优先级队列,将会导致优先级最高的任务被抛弃。
- CallerRunsPolicy:既不抛弃任务也不抛出异常,而是由调用线程的主线程来处理该任务。换言之就是由调用线程池的主线程自己来执行任务(例如:是有main线程启动的线程池,当触发次策略时,多余的任务就会交由main线程来执行),因此在执行任务的这段时间里主线程无法再提交新任务,从而使线程池中工作线程有时间将正在处理的任务处理完成,所以对性能和效率必然是极大的损耗。
- AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。线程池默认的拒绝策略。如何使用
上面既然介绍完了线程池构造方法中的各个参数,那么再来介绍线程池的工作流程:
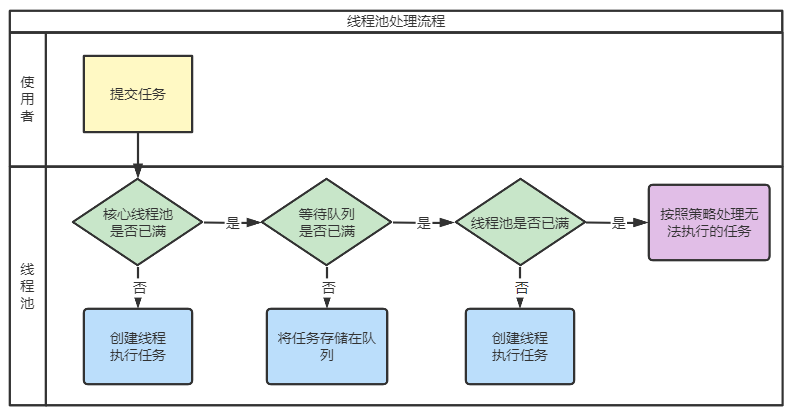
- 当线程池中的线程个数小于corePoolSize,每次提交一个新任务到线程池时,都会创建一个新的工作线程来执行任务,直到当前线程数等于corePoolSize;
- 当线程池中的线程个数等于corePoolSize,继续提交的任务被保存到阻塞队列中,等待被执行;
- 当线程池中的线程个数等于corePoolSize时,并且队列也满了(有界队列),这个时候再来新的任务,就会继续创建新的线程去处理(非核心线程),直到线程池中的线程数达到maximumPoolSize。这个时候创建的线程,当线程空闲下来的时候经过keepAliveTime的时间就会被销毁;
- 当线程池中的线程数达到maximumPoolSize时,这个时候再来新的任务,就由饱和策略来处理提交的任务;
注:如果存储任务的队列满了,并且线程数量大于corePoolSize,小于maximumPoolSize,此时创建的线程会优先执行新来的任务,之后在执行队列中的。
我们在打开ThreadPoolExecutor类的代码可以看到,ThreadPoolExecutor继承了AbstractExecutorService,我们来看一下AbstractExecutorService的实现:
public abstract class AbstractExecutorService implements ExecutorService {
protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) { };
protected <T> RunnableFuture<T> newTaskFor(Callable<T> callable) { };
public Future<?> submit(Runnable task) {};
public <T> Future<T> submit(Runnable task, T result) { };
public <T> Future<T> submit(Callable<T> task) { };
private <T> T doInvokeAny(Collection<? extends Callable<T>> tasks,boolean timed, long nanos)
throws InterruptedException, ExecutionException, TimeoutException {
};
public <T> T invokeAny(Collection<? extends Callable<T>> tasks)
throws InterruptedException, ExecutionException {
};
public <T> T invokeAny(Collection<? extends Callable<T>> tasks,long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException {
};
public <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks)
throws InterruptedException {
};
public <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit)
throws InterruptedException {
};
}
AbstractExecutorService是一个抽象类,它实现了ExecutorService接口。我们接着看ExecutorService接口的实现:
public interface ExecutorService extends Executor {
void shutdown();
boolean isShutdown();
boolean isTerminated();
boolean awaitTermination(long timeout, TimeUnit unit)
throws InterruptedException;
<T> Future<T> submit(Callable<T> task);
<T> Future<T> submit(Runnable task, T result);
Future<?> submit(Runnable task);
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks)
throws InterruptedException;
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks,long timeout, TimeUnit unit)
throws InterruptedException;
<T> T invokeAny(Collection<? extends Callable<T>> tasks)
throws InterruptedException, ExecutionException;
<T> T invokeAny(Collection<? extends Callable<T>> tasks,long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}
而ExecutorService又是继承了Executor接口,我们看一下Executor接口的实现:
public interface Executor {
void execute(Runnable command);
}
所以到这里,大家应该明白了ThreadPoolExecutor、AbstractExecutorService、ExecutorService和Executor几个之间的关系了。
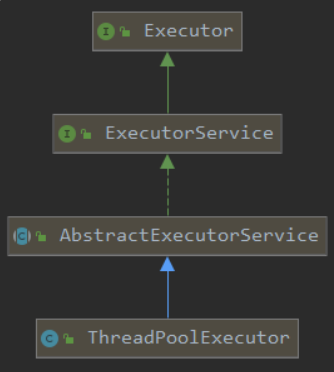
Executor是一个线程池顶层接口,在它里面只声明了一个方法execute(Runnable),返回值为void,参数为Runnable类型,它就是用来执行传进去的任务的,但没有返回值;
然后ExecutorService接口继承了Executor接口,并声明了一些方法:submit、invokeAll、invokeAny以及shutdown等;
抽象类AbstractExecutorService实现了ExecutorService接口,基本实现了ExecutorService中声明的所有方法;
然后ThreadPoolExecutor继承了类AbstractExecutorService。
在ThreadPoolExecutor类中有几个非常重要的方法:
- execute(Runnable command):用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功。
- submit(Callable task)/submit(Runnable task):用于提交需要返回值的任务。线程池会返回一个future类型的对象,通过这个future对象可以判断任务是否执行成功,并且可以通过future的get()方法来获取返回值,get()方法会阻塞当前线程直到任务完成,而使用get(long timeout,TimeUnit unit),在指定的时间内会等待任务执行,超时则抛出超时异常,等待时候会阻塞当前线程。
- shutdown():不会立即终止线程池,而是要等所有任务缓存队列中的任务都执行完后才终止,但再也不会接受新的任务。
- awaitTermination(long timeout, TimeUnit unit):用于设定超时时间及单位。当等待超过设定时间时,会监测ExecutorService是否已经关闭,若关闭则返回true,否则返回false。一般情况下会和shutdown方法组合使用。
- shutdownNow():立即终止线程池,并尝试打断正在执行的任务,并且清空任务缓存队列,返回尚未执行的任务。
所以通过上面的讲解大家应该知道创建线程池的正确姿势了吧:
ExecutorService es = new ThreadPoolExecutor(5,,20,0L,TimeUnit.MILLISECONDS,new LinkedBlockingQueue<>(10));
最后简单的举个创建线程池的例子吧:
package com.thr;
import java.util.concurrent.*;
/**
* @author Administrator
* @date 2020-04-11
* @desc 使用自定义参数ThreadPoolExecutor创建线程池
*/
public class ExecutorServiceDemo {
public static void main(String[] args) {
//定义线程池参数
ExecutorService es = new ThreadPoolExecutor(5, 20,0L,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(10));
//创建Callable和Future对象
MyCallable myCallable = new MyCallable();
Future<Integer> future = es.submit(myCallable);
try {
//获取结果并打印
Integer num = future.get();
System.out.println(num);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}finally {
//关闭线程池
es.shutdown();
}
}
}
class MyCallable implements Callable<Integer>{
@Override
public Integer call() throws Exception {
int sum=0;
for (int i = 1; i <= 100; i++) {
sum+=i;
}
return sum;
}
}
当然除了自己定义ThreadPoolExecutor外。还有其他方法。比如各种开源工具如Guava等。这里推荐使用Guava提供的ThreadFactoryBuilder来创建线程池。因为当我们需要给新创建的线程取名字、或者设置为守护线程、错误处理器等操作时,它的好处就体现出来了。简单举例:(注意使用Guava需要引入包)
public class ThreadFactoryBuilderTest {
public static void main(String[] args) {
ThreadFactory threadFactory = new ThreadFactoryBuilder().setNameFormat("线程名称-%s").build();
// 创建一个线程对象
Thread newThread = threadFactory.newThread(()->{
});
System.out.println(newThread.getName());
}
}
参考资料:
- https://www.cnblogs.com/dolphin0520/p/3949310.html
- https://www.cnblogs.com/dolphin0520/p/3932921.html
- https://zhuanlan.zhihu.com/p/32867181
25、反射
25.1 反射的概述
[1]、什么是反射
Java反射机制是指程序在运行状态中,对于任何一个类,我们都能够知道这个类的所有的属性和方法(包括private、protected等)。对于任何一个对象,我们都能够对它的属性和方法进行调用。我们把这种动态获取对象信息和调用对象方法的功能称之为反射机制。
Oracle 官方对反射的解释是:
Reflection enables Java code to discover information about the fields, methods and constructors of loaded classes, and to use reflected fields, methods, and constructors to operate on their underlying counterparts, within security restrictions.
The API accommodates applications that need access to either the public members of a target object (based on its runtime class) or the members declared by a given class. It also allows programs to suppress default reflective access control.
简而言之,通过反射,我们可以在运行时获得程序或程序集中每一个类型的成员和成员的信息。程序中一般的对象的类型都是在编译期就确定下来的,而 Java 反射机制可以动态地创建对象并调用其属性,这样的对象的类型在编译期是未知的。所以我们可以通过反射机制直接创建对象,即使这个对象的类型在编译期是未知的。
反射的核心是 JVM 在运行时才动态加载类或调用方法/访问属性,它不需要事先(写代码的时候或编译期)知道运行对象是谁。重点:是运行时而不是编译时
Java 反射主要提供以下功能:
- 在运行时判断任意一个对象所属的类;
- 在运行时构造任意一个类的对象;
- 在运行时判断任意一个类所具有的成员变量和方法(通过反射甚至可以调用private方法);
- 在运行时调用任意一个对象的成员变量和方法
- 在运行时获取泛型信息
- 在运行时处理注解
- 生成动态代理
- ......
[2]、反射的理解
所谓有反射就有正射,在理解反射这个概念之前,我们先来理解Java中的“正射”。
正射:就是当需要使用到某一个类的时候,必定先会去了解这是一个什么类,是用来做什么的,有怎么样的功能。之后我们才对这个类进行实例化,之后再使用这个类的实例化对象进行操作。
Person person = new Person();
person.getName();
反射:就是在运行时才知道要操作的类是什么,并且可以在运行时获取类的完整构造,并调用对应的方法。
Class<?> personClazz = Class.forName("com.thr.reflect.Person");
Field field = personClazz.getDeclaredField("name");
Constructor<?> constructor = personClazz.getConstructor();
Method method = personClazz.getMethod("doHomework", String.class);
Object instance = personClazz.newInstance();
method.invoke(instance,"English");
[3]、反射的主要用途
在我们日常的生产环境中,很少会直接使用到反射,所以很多人都认为反射在实际的 Java 开发应用中并不广泛,其实不然,反射最重要的用途就是开发各种通用框架,反射是框架设计的灵魂。当我们在使用大部分Java框架的时候,基本上都用到了反射,到后面会学习到框架的知识,其实框架的组成结构可以理解为这个公式:框架=反射+注解+设计模式,其中反射就是框架的灵魂所在。所以反射在Java的学习中非常重要。对与框架开发人员来说,反射虽小但作用非常大,它是各种容器实现的核心。而对于一般的开发者来说,不深入框架开发则用反射用的就会少一点,不过了解一下框架的底层机制有助于丰富自己的编程思想,也是很有益的。
[4]、反射机制的优缺点
- 优点:可以实现动态创建对象和编译,体现出很大的灵活性。
- 缺点:对性能有影响。使用反射基本上是一种解释操作,可以告诉 JVM,希望做什么,并且满足要求。这类操作总是慢于,直接执行相同的操作。
[5]、Java反射API中常用的四个类
| 类 | 描述 |
|---|---|
| java.lang.Class | 代表一个类 |
| java.lang.reflect.Field | 代表类的成员变量(成员变量也称为类的属性) |
| java.lang.reflect.Method | 代表类的方法 |
| java.lang.reflect.Constrctor | 代表类的构造方法 |
25.2 如何获取Class对象
关于Class的介绍:Class类是用来描述类的类,它是一个十分特殊的类,没有构造方法。Class对象的加载过程如下:当程序运行时,我们编写的每一个类都会被编译生成 类名.class 文件,当我们我们new对象或者类加载器加载的时候,JVM就会加载我们的 类名.class 文件并且加载到内存中,即当一个类加载完成之后,在堆内存的方法区中就生成了一个该类唯一的Class对象(一个类只会对应一个Class对象,绝对不会产生第二个),这个Class对象就包含了完整的类的结构信息,用于表示该类的所有信息。
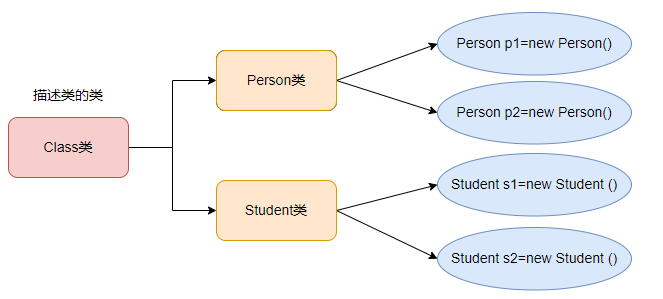
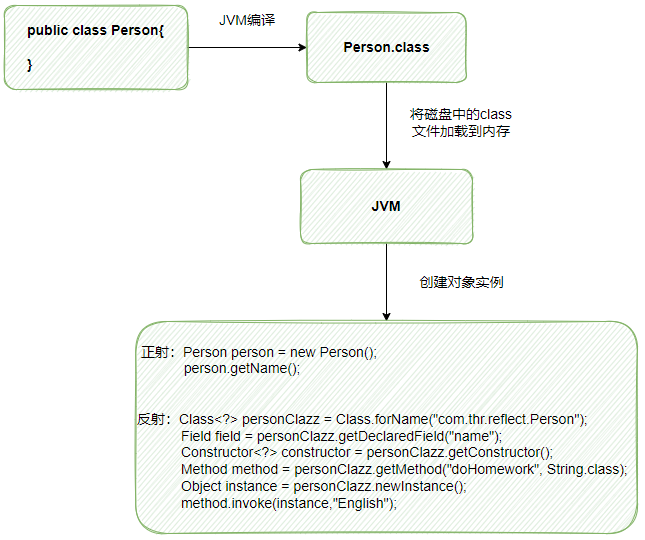
既然反射机制一定会用到Class这个类,那么就必须先获取它,先看下哪些对象可以获取Class。注意:Class并不是只有普通类或接口才能获取,其中基本数据类型、数组、枚举、注解、void等都可以获取其Class对象,甚至Class这个类本身也可以获取Class对象
Class<Object> c1 = Object.class;
Class<String> c2 = String.class;
Class<Integer> c3 = int.class;
Class<int[]> c4 = int[].class;
Class<int[][]> c5 = int[][].class;
Class<ElementType> c6 = ElementType.class;
Class<Override> c7 = Override.class;
Class<Class> c8 = Class.class;
Class<Void> c9 = void.class;
// 数组
int arr[]=new int[10];
int arr1[]=new int[100];
Class<? extends int[]> c10 = arr.getClass();
Class<? extends int[]> c11 = arr1.getClass();
//只要元素类型和维度相同,就是同一个Class
System.out.println(c10==c11);
TIPS:反射这里所有举例都用Person类来作为演示,所以先创建一个Person类,后面会一直用这个。
public class Person {
// public公共的成员变量
public String name;
// default成员变量
int age;
// private私有的成员变量
private String address;
// public默认构造方法
public Person() {
}
// private私有有参构造方法
private Person(String name, int age) {
this.name = name;
this.age = age;
}
// public公共全参构造方法
public Person(String name, int age, String address) {
this.name = name;
this.age = age;
this.address = address;
}
// public公共方法
public void doHomework(String subject) {
System.out.println("公共方法..." + subject);
}
// private私有方法
private void sleep() {
System.out.println("私有方法...");
}
//getter,setter,toString省略...
}
获取Class对象四种方式
- 通过Object类中的
getClass方法获取。这种方式要先创建类的对象,这样再使用反射就多此一举了,不推荐。 - 通过
类名 .class直接获取。这种方式需要导入相应类的包,依赖性较强,不推荐。 - 使用Class类中静态方法
forName(String className)获取。所以这种方式最常用。 - 使用
类加载器ClassLoader来获取。这种方式了解即可,用的很少,一般用来加载properties文件。
代码演示如下:
/**
* 获取Class对象的四种方式
*/
public class Reflection1 {
public static void main(String[] args) throws ClassNotFoundException {
//1、第一种方式:getClass
Person person = new Person();
Class<? extends Person> clazz1 = person.getClass();
System.out.println("getClass获取:" + clazz1);
//2、第二种方式:类名.class
Class<Person> clazz2 = Person.class;
System.out.println("类名.class获取:" + clazz2);
//3、第三种方式:Class.forName()
Class<?> clazz3 = Class.forName("com.thr.reflect.Person");
System.out.println("forName()方法获取:" + clazz3);
//4、第四种方式:类加载器ClassLoader,常用来加载properties配置文件
ClassLoader classLoader = Reflection1.class.getClassLoader();
Class<?> clazz4 = classLoader.loadClass("com.thr.reflect.Person");
System.out.println("类加载器ClassLoader获取:" + clazz4);
//可以发现返回都是true,说明引用的同一个对象
System.out.println("----------------------");
System.out.println(clazz1 == clazz2);
System.out.println(clazz1 == clazz3);
System.out.println(clazz1 == clazz4);
}
}
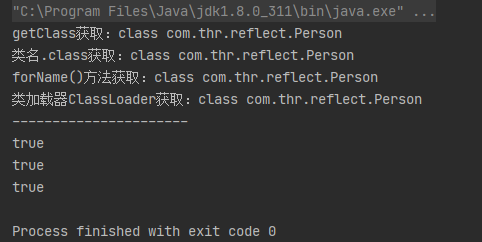
这四种方式推荐使用Class类中的静态方法forName(String className)来获取。但无论使用哪种方式获取,结果都是同一个类。
25.3 Class类中常用的方法
Class代表一个类,在运行的Java应用程序中表示类或接口。在Class类中提供了很多有用的方法,这里简单的列举一些。
1、获得类相关的方法:
asSubclass(Class<U> clazz):把传递的类的对象转换成代表其子类的对象Cast:把对象转换成代表类或是接口的对象getClassLoader():获得类的加载器getClasses():返回一个数组,数组中包含该类中所有公共类和接口类的对象getDeclaredClasses():返回一个数组,数组中包含该类中所有类和接口类的对象forName(String className):根据类名返回类的对象getName():获得类的完整路径名字newInstance():创建类的实例,它调用的是此类的默认构造方法(没有默认无参构造器会报错)getPackage():获得类的包getSimpleName():获得类的名字getSuperclass():获得当前类继承的父类的名字getInterfaces():获得当前类实现的类或是接口
2、获得类中属性相关的方法:
getField(String name):获得类中公有(public)的属性/字段,私有的属性它无法访问,能访问从其它类继承来的公有属性。getFields():获得所有公有的属性对象。getDeclaredField(String name):能获取类中所有的属性,与public,private,protect无关,不能访问从其它类继承来的属性。getDeclaredFields():获得所有属性对象。
注意:getXxx()与getDeclaredXxx()的区别:getXxx()只能访问类中声明为公有的内容,私有的内容它无法访问。getDeclaredXxx():能获取类中所有的字段,与public,private,protect无关。
3、获得类中注解相关的方法:
getAnnotation(Class<A> annotationClass):返回该类中与参数类型匹配的公有注解对象getAnnotations():返回该类所有的公有注解对象getDeclaredAnnotation(Class<A> annotationClass):返回该类中与参数类型匹配的所有注解对象getDeclaredAnnotations():返回该类所有的注解对象
4、获得类中构造器相关的方法:
getConstructor(Class...<?> parameterTypes):获得该类中与参数类型匹配的公有构造方法getConstructors():获得该类的所有公有构造方法getDeclaredConstructor(Class...<?> parameterTypes):获得该类中与参数类型匹配的构造方法getDeclaredConstructors():获得该类所有构造方法
5、获得类中方法相关的方法:
getMethod(String name, Class...<?> parameterTypes):获得该类某个公有的方法getMethods():获得该类所有公有的方法getDeclaredMethod(String name, Class...<?> parameterTypes):获得该类某个方法getDeclaredMethods():获得该类所有方法
6、类中其他重要的方法:
isAnnotation():如果是注解类型则返回trueisAnnotationPresent(Class<? extends Annotation> annotationClass):如果是指定类型注解类型则返回trueisAnonymousClass():如果是匿名类则返回trueisArray():如果是一个数组类则返回trueisEnum():如果是枚举类则返回trueisInstance(Object obj):如果obj是该类的实例则返回trueisInterface():如果是接口类则返回trueisLocalClass():如果是局部类则返回trueisMemberClass():如果是内部类则返回true
Class类中的方法有很多,这里只列举了部分,需要学习更多的可以自行去查看Class的API文档。
25.4 获取构造器
获取类中的构造器用到的是Constructor类,构造器的获取比较的简单,获的类中构造器相关的方法如下所示:
getConstructor(Class...<?> parameterTypes):获得该类中与参数类型匹配的公共(public)构造方法getConstructors():获得该类的所有公共(public)构造方法getDeclaredConstructor(Class...<?> parameterTypes):获得该类中与参数类型匹配的构造方法getDeclaredConstructors():获得该类所有构造方法
简单演示一下:
package com.thr.reflect;
import java.lang.reflect.Constructor;
/**
* 获取类中的构造器,并且创建对象的实例
*/
public class Reflection2 {
public static void main(String[] args) throws Exception {
//获取Person的Class对象
Class<?> clazz = Class.forName("com.thr.reflect.Person");
//1、获取public的构造器
Constructor<?>[] constructors = clazz.getConstructors();
for (Constructor<?> constructor : constructors) {
System.out.println(constructor);
}
System.out.println("-----------------------");
//2、获取所有的构造器
Constructor<?>[] declaredConstructors = clazz.getDeclaredConstructors();
for (Constructor<?> declaredConstructor : declaredConstructors) {
System.out.println(declaredConstructor);
}
System.out.println("-----------------------");
//3、使用反射创建实例,默认构造器
Constructor<?> constructor = clazz.getConstructor();
System.out.println(constructor.getName());
Object o = constructor.newInstance();
Person p = (Person) o;
System.out.println(p.toString());
//4、有参构造器创建实例
Constructor<?> constructor1 = clazz.getConstructor(String.class, int.class, String.class);
Object o1 = constructor1.newInstance("张三", 20, "China");
Person p1 = (Person) o1;
System.out.println(p1.toString());
}
}
25.5 通过反射创建对象
通过反射创建类对象主要有两种方式:
- 第一种:通过 Class 对象的
newInstance()方法。 - 第二种:通过 Constructor 对象的
newInstance(Object ... initargs)方法
package com.thr.reflect;
import java.lang.reflect.Constructor;
/**
* 通过反射创建类对象
*/
public class Demo {
public static void main(String[] args) throws Exception {
//获取Person的Class对象
Class<Person> clazz = Person.class;
//1、通过Class对象的newInstance()方法,只能使用默认的无参数构造方法
Person person = clazz.newInstance();
System.out.println(person);
System.out.println("-----------------");
//2、通过Constructor对象的newInstance(Object...initargs)方法,通过无参构造器创建
Constructor<Person> constructor = clazz.getConstructor();
Person person1 = constructor.newInstance();
System.out.println(person1);
System.out.println("-----------------");
//3、通过Constructor对象的newInstance(Object...initargs)方法,通过有参的构造器创建
Constructor<Person> constructor1 = clazz.getConstructor(String.class, int.class, String.class);
Person person2 = constructor1.newInstance("张三", 20, "深圳");
System.out.println(person2);
System.out.println("-----------------");
}
}
25.6 获取成员变量
在我们正常创建对象的实例时,其内部的私有元素是不能访问的,但是使用反射则可以轻易的获取,前面创建的Person类中属性、方法和构造器都有被private关键字所修饰。所以接下来演示一下怎么获取成员变量、方法和构造器。
获取属性使用到的是Field这个类,它内部的方法主要是获取、设置某个属性的方法,例如:getXXX()、setXXX();获得类中成员变量相关的方法如下:
getField(String name):获得某个公有的属性对象getFields():获得所有公有的属性对象getDeclaredField(String name):获得某个属性对象getDeclaredFields():获得所有属性对象
package com.thr.reflect;
import java.lang.reflect.Constructor;
import java.lang.reflect.Field;
/**
* 通过反射获取类的成员变量
*/
public class Reflection3 {
public static void main(String[] args) throws Exception {
//获取Person的Class对象
Class<?> clazz = Class.forName("com.thr.reflect.Person");
//1、通过反射获取所有public的成员变量,private、protected、default是不能获取到的
Field[] fields1 = clazz.getFields();
for (Field field : fields1) {
System.out.println(field.getName());
}
System.out.println("------------------------");
//2、通过反射单个获取public成员变量
Field name = clazz.getField("name");
System.out.println(name);
Field age = clazz.getDeclaredField("age");
System.out.println(age);
Field address = clazz.getDeclaredField("address");
System.out.println(address);
System.out.println("------------------------");
//3、通过反射获取所有变量,包括private、protected、default。
Field[] fields = clazz.getDeclaredFields();
for (Field field : fields) {
//4、获取成员变量名字
System.out.println("成员变量名:"+field.getName());
//5、获取权限修饰:0是default、1是public、2是private、4是protected。或者使用Modifier.toString(modifiers)输出
int modifiers = field.getModifiers();
System.out.println("权限修饰符:"+modifiers);
//6、获取成员变量数据类型
Class<?> type = field.getType();
System.out.println("数据类型:"+type);
System.out.println("---------------");
}
//4、获取成员变量并且给其赋值
//获取无参构造
Constructor<?> constructor = clazz.getConstructor();
//通过constructor对象进行实例化
Object o = constructor.newInstance();
//获取Class所对应的类型中某个公共的成员变量
Field addressField = clazz.getDeclaredField("address");
//这里必须设置为true,否则会报错java.lang.IllegalAccessException
//setAccessible(true)的作用是:忽略Class对象所对应的类型中成员的访问权限
addressField.setAccessible(true);
addressField.set(o, "中国深圳");
System.out.println(o.toString());
}
}
25.7 获取方法并且调用
获取方法用到的是Method类,内部方法也是一些getXXX()和setXXX的方法,这些方法就不演示了,和上面获取Field大同小异,可以参考上面的例子。
获得类中方法相关的方法:
getMethod(String name, Class...<?> parameterTypes):获得该类某个公有的方法getMethods():获得该类所有公有的方法,包括继承父类的方法getDeclaredMethod(String name, Class...<?> parameterTypes):获得该类某个方法getDeclaredMethods():获得该类所有方法,包括私有的,不包括继承父类的方法
需要注意的一点是:如果需要通过反射来调用方法,那么就需要使用到下面这个方法:
invoke(Object obj, Object... args):传递object对象及参数然后调用该对象所对应的方法。
/**
* 通过反射获取类的方法并且调用
*/
public class Reflection5 {
public static void main(String[] args) throws Exception {
//获取Person的Class对象
Class<?> clazz = Class.forName("com.thr.reflect.Person");
Object obj = clazz.newInstance();
Method doHomework = clazz.getDeclaredMethod("doHomework", String.class);
doHomework.invoke(obj, "English");
Method sleep = clazz.getDeclaredMethod("sleep");
//setAccessible(true):忽略Class对象所对应的类型中成员的访问权限,这里必须要设置,否则会报错
sleep.setAccessible(true);
sleep.invoke(obj);
}
}
25.8 获取注解
获得类中注解相关的方法:
getAnnotation(Class<A> annotationClass):返回该类中与参数类型匹配的公有注解对象getAnnotations():返回该类所有的公有注解对象getDeclaredAnnotation(Class<A> annotationClass):返回该类中与参数类型匹配的所有注解对象getDeclaredAnnotations():返回该类所有的注解对象isAnnotationPresent(Class<?extends Annotation> annotationClass):判断该程序元素上是否包含指定类型的注解,存在则返回true,否则返回false.
为了测试注解这里创建了三个自定义注解,分别是作用在类、属性、方法上面的注解。
定义作用于类上面的MyAnnotation注解 (需要注意的是@Retention必须要设置为RUNTIME类型,否则是获取不到的):
//作用于类上面的注解
@Target({ElementType.TYPE, ElementType.FIELD, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)//这里必须定义为RUNTIME
public @interface MyAnnotation {
String[] value() default "";
}
定义作用于属性上面的AttributeAnnotation注解:
//作用于属性上的注解
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)//这里必须定义为RUNTIME
public @interface AttributeAnnotation {
String value();
}
定义作用于方法上面的MethodAnnotation注解:
//作用于方法上的注解
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)//这里必须定义为RUNTIME
public @interface MethodAnnotation {
String value();
}
然后将上面创建的三个自定义注解作用到指定的位置:
@MyAnnotation(value = "MyAnnotation")
class AnnotationReflect {
@AttributeAnnotation(value = "AttributeAnnotation")
String str;
@MethodAnnotation(value = "MethodAnnotation_show")
public void show() {
System.out.println("MethodAnnotation_show");
}
@MethodAnnotation(value = "MethodAnnotation_display")
public void display() {
System.out.println("MethodAnnotation_display");
}
}
最后就是测试了:
public class AnnotationReflectMain {
public static void main(String[] args) throws NoSuchFieldException {
// 1、获取类上面的注解
boolean annotationPresent = AnnotationReflect.class.isAnnotationPresent(MyAnnotation.class);
System.out.println(annotationPresent);
if (annotationPresent) {
MyAnnotation myAnnotation = AnnotationReflect.class.getAnnotation(MyAnnotation.class);
System.out.println("class-annotation:" + Arrays.toString(myAnnotation.value()));
}
// 2、获取单个属性中的注解
Field str = AnnotationReflect.class.getDeclaredField("str");
AttributeAnnotation attributeAnnotation = str.getAnnotation(AttributeAnnotation.class);
if (attributeAnnotation != null) {
System.out.println("attribute-annotation:" + attributeAnnotation.value());
}
// 3、获取多个方法中的注解
Method[] declaredMethods = AnnotationReflect.class.getDeclaredMethods();
for (Method declaredMethod : declaredMethods) {
MethodAnnotation methodAnnotation = declaredMethod.getAnnotation(MethodAnnotation.class);
if (methodAnnotation != null) {
System.out.println("method-annotation:" + methodAnnotation.value());
}
}
}
}
其实后面还有获取父类、泛型、接口、所在包等等其他的就不多说了,其实都是大同小异,理解了上面这些,后面这些应该也会了。
参考链接:
26、注解
26.1 注解概述
从JDK5.0开始,Java增加对元数据(MetaData)的支持,也就是注解(Annotation)。其实我们早就已经接触过注解了,例如我们经常在Java代码中可以看到 “@Override”,“@Test”等等这样的东西,它们就是Java中的注解。注解可以像修饰符一样使用,可以用于修饰包、类、构造器、方法、成员变量、参数、局部变量的声明。
我们需要注意的是,注解与注释是有一定区别的,注解就是代码里面的特殊标记,这些标记可以在编译,类加载,运行时被读取,并执行相应的处理。通过注解开发人员可以在不改变原有代码和逻辑的情况下在源代码中嵌入补充信息。而注释则是用以说明某段代码的作用,或者说明某个类的用途、某个方法的功能和介绍,以及该方法的参数和返回值的数据类型及意义等等。
26.2 Java内置注解
在JavaSE部分,注解的使用往往比较简单,Java中提供了5个内置注解,它们分别是:
①、@Override:标注该方法是重写父类中的方法。
这个注解一个是我们见得最多的一个了,提示这个方法是重写于父类的方法。
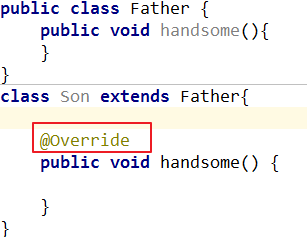
②、@Deprecated:标记某个功能已经过时,用于定义过时的类、方法、成员变量等。
这个注解想必大家应该都有碰到过,在使用Date日期类的时候,里面有大量过时的方法,我们来定义一个Date类来调用一个方法。

这个getDay()方法就是过时的,我们点击进去看一下这个方法的源码:

果然这个方法是用@Deprecated修饰过的。同时也可以发现我们在调用过时元素时,编译器在编译阶段遇到这个注解时会发出提醒警告,告诉开发者正在调用一个过时的元素,当然如果不想看到警告我们可以抑制它的出现。
③、@SuppressWarnings:抑制编译器警告。
上面说到用@Deprecated修饰过的元素在调用时会有警告,我们可以用@SuppressWarnings注解来抑制警告的出现。

可以发现左边的警告没有了。@SuppressWarnings这个注解中参数非常的多,这里介绍几个常见的参数:
- all:抑制所有警告。
- deprecation:抑制过期方法警告。
- null:忽略对null的操作。
- unchecked:抑制没有进行类型检查操作的警告。
- unused:抑制没被使用过的代码的警告。
如果需要了解更多的可以去查看官方文档。
④、@FunctionaInterface:指定接口必须为函数式接口。
这个注解是Java8出现的新特性。这个函数式接口的意思就是接口中有一个且仅有一个抽象方法,但是可以有多个非抽象方法,如果不定义或定义多个抽象方法就会报错。
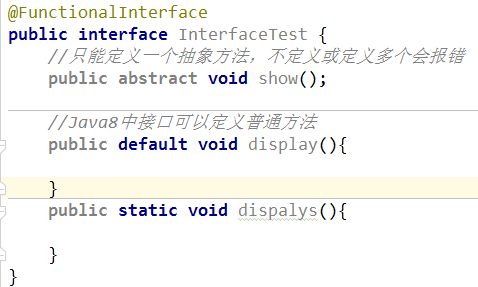
正式因为JDK 8中lambda表达式的引入,使得函数式接口在Java中变得越来越流行。因为这些特殊类型的接口可以用lambda表达式、方法引用或构造函数引用轻松替换。
⑤、@SafeVarargs:抑制"堆污染警告"。
这个注解是在Java7中引入,主要目的是处理可变长参数中的泛型,此注解告诉编译器:在可变长参数中的泛型是类型安全的。可变长参数是使用数组存储的,而数组和泛型不能很好的混合使用。因为数组元素的数据类型在编译和运行时都是确定的,而泛型的数据类型只有在运行时才能确定下来,因此当把一个泛型存储到数组中时,编译器在编译阶段无法检查数据类型是否匹配,因此会给出警告信息。
我们来看下面这个示例:
public class Test {
@SafeVarargs//这里告诉编译器类型安全,不让有警告。其实方法体内容类型不安全
public static void show(List<String>...lists){
Object[] arry=lists;
List<Integer> intList=Arrays.asList(11,22,33);
arry[0]=intList;//这里就是堆污染,这里没有警告,是因为只针对于可变长参数泛型
String str=lists[0].get(0);//java.lang.ClassCastException
}
public static void main(String[] args) {
List<String> list1=Arrays.asList("AA","BB","CC");
List<String> list2=Arrays.asList("DD","EE","DD");
show(list1,list2);
}
}
通过上述的示例,我们将intList赋给array[0],array[0]的类型是List<String>,但是储引用到实际为List<Integer>类型的值,这个无效的引用被称为堆污染。由于直到运行时才能确定此错误,因此它会在编译时显示为警告,这里没有警告,是因为只针对于可变长参数泛型,并在运行时出现ClassCastException。
注意:@SafeVarargs注解只能用在参数长度可变的方法或构造方法上,且方法必须声明为static或final,否则会出现编译错误。
26.3 自定义注解
我们在享受注解给我们带来方便地同时,我们自己应该要知道怎么去定义注解。注解的自定义非常的简单,通过 @interface关键字进行定义,可以发现这个关键字和接口interface很相似,就在前面加了一个 @符号,但是它和接口没有任何关系。自定义注解还需要注意的一点是:所有的自定义注解都自动继承了java.lang.annotation.Annotation这个接口。自定义注解的格式:
public @interface 注解名 {
//属性
}
同样我们可以在注解中定义属性,它的定义有点类似于方法,但又不是方法,在注解中是不能声明普通方法的。注解的属性在注解定义中以无参数方法的形式来声明,其方法名定义了属性的名字,其返回值定义了该属性的类型,我们称为配置参数。它们的类型只能是八种基本数据类型、String类型、Class类型、enum类型、Annotation类型以上所有类型的数组。例如:
//定义了一个MyAnnotation注解
public @interface MyAnnotation {
String[] value();
}
@MyAnnotation(value = "hello")
class Test{
}
上面注解代码中,定义了一个String的value数组。然后我们在使用的时候,就可以使用 属性名称=“xxx” 的形式赋值。
注解中属性还可以有默认值,默认值需要用 default 关键值指定。比如:.
//定义了一个MyAnnotation注解
public @interface MyAnnotation {
String id();
String[] value() default {"AA","BB"};
}
@MyAnnotation(id="one")
class Test{
}
上面定义了 id 属性没有默认值,而value属性中则设置了默认值,所以在使用注解的时候只需给 id 属性赋值即可,value可以不用写。
通过以上形式自定义的注解暂时都还没有任何实用的价值,因为自定义注解必须配上注解的信息处理流程(使用反射)才有意义。如何让注解真真的发挥作用,主要就在于注解处理方法,所以接下来我们将学习元注解和注解的反射。
26.4 元注解
元注解就是用来修饰其他注解的注解。我们随便点进一个注解的源码都可以发现有元注解。
Java5.0中定义了4个标准的元注解类型,它们被用来提供对其它注解类型作说明:
- @Retention
- @Target
- @Documented
- @Inherited
而Java8.0中又增加了一个新的元注解类型:
- @Repeatable
所以接下来我们将逐个分析它们的作用和使用方法。
1、@Retention:用于指定该Annotation的生命周期。
这个元注解只能用于修饰一个Annotation定义,它的内部包含了一个RetentionPolicy枚举类型的属性,而这个枚举类中定义了三个枚举实例,SOURCE、CLASS、RUNTIME。它们各个值的意思如下:
- RetentionPolicy.SOURCE:在源文件中有效(即源文件保留),在编译器进行编译时它将被丢弃忽视。
- RetentionPolicy.CLASS:在class文件中有效(即class保留),当Java程序运行时,它并不会被加载到 JVM 中,只保留在class文件中。这个是默认值。
- RetentionPolicy.RUNTIME:在运行时有效(即运行时保留),当Java程序运行时,注解会被加载进入到 JVM 中,所以我们可以使用反射获取到它们。

比较典型的是@SuppressWarnings注解,如果我们用 javap -c去反编译它是看到这个注解的,因为在编译的时候就已经被丢弃了。
②、@Target:用于指定该Annotation能够用在哪些地方。
@Target内部定义了一个枚举类型的数组ElementType[] value(),在ElementType这个枚举类中参数有很多,我们来看一下:
- TYPE:用于描述类、接口(包括注解类型) 或enum声明
- FIELD:用于描述域即类成员变量
- METHOD:用于描述方法
- PARAMETER:用于描述参数
- CONSTRUCTOR:用于描述构造器
- LOCAL_VARIABLE:用于描述局部变量
- ANNOTATION_TYPE:由于描述注解类型
- PACKAGE:用于描述包
- TYPE_PARAMETER:1.8版本开始,描述类、接口或enum参数的声明
- TYPE_USE:1.8版本开始,描述一种类、接口或enum的使用声明
③、@Document:表示Annotation可以被包含到javadoc中去。默认情况下javadoc是不包含注解的。
由于这个比较简单所以不细说。
④、@Inherited:被它修饰的Annotation将具有继承性。
@Inherited修饰过的Annotation其子类会自动具有该注解。在实际应用中,使用情况非常少。
⑤、@Repeatable:用于指示它修饰的注解类型是可重复的。
这个注解是在Java8中新出的特性,说到这个可重复注解可能有点不理解。我们通过示例来理解一下:
先定义一个MyAnnotation注解:
@Inherited
@Documented
@Repeatable(MyAnnotations.class)
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE,ElementType.FIELD,ElementType.METHOD,ElementType.PARAMETER})
public @interface MyAnnotation {
String value() default "Hello";
}
这里需要说明@Repeatable(MyAnnotations.class),它表示在同一个类中@MyAnnotation注解是可以重复使用的,重复的注解被存放至@MyAnnotations注解中。
然后再定义一个MyAnnotations注解:
@Inherited
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE,ElementType.FIELD,ElementType.METHOD,ElementType.PARAMETER})
public @interface MyAnnotations {
MyAnnotation[] value();
}
这个MyAnnotations注解里面的属性必须要声明为要重复使用注解的类型数组MyAnnotation[] value();,而且相应的生命周期和使用地方都需要同步。否则就会编译报错!
进行测试:
@MyAnnotation(value = "World")
@MyAnnotation(value = "World")
public class Test{
}
而在Java8之前没有@Repeatable注解是这样写的:
@MyAnnotations({@MyAnnotation(value = "World"),@MyAnnotation(value = "World")})
public class Test{
}
26.5 注解处理器(使用反射)
以上讲的所以注解的定义都只是一个形式,实际上还并没有什么可使用的价值,而注解的核心就是使用反射来获取到它们,所以下面我们要来学习注解处理器(使用反射)的使用。
下面参考:https://www.cnblogs.com/peida/archive/2013/04/26/3038503.html
java.lang.reflect 包下主要包含一些实现反射功能的工具类,实际上,java.lang.reflect 包所有提供的反射API扩充了读取运行时Annotation信息的能力。当一个Annotation类型被定义为RUNTIME的注解后,该注解才能是运行时可见,当class文件被装载时被保存在class文件中的Annotation才会被虚拟机读取。
AnnotatedElement 接口是所有程序元素(Class、Method和Constructor)的父接口,所以程序通过反射获取了某个类的AnnotatedElement对象之后,程序就可以调用该对象的如下四个个方法来访问Annotation信息:
- 方法1:
<T extends Annotation> T getAnnotation(Class<T> annotationClass): 返回改程序元素上存在的、指定类型的注解,如果该类型注解不存在,则返回null。 - 方法2:
Annotation[] getAnnotations():返回该程序元素上存在的所有注解。 - 方法3:
boolean is AnnotationPresent(Class<?extends Annotation> annotationClass):判断该程序元素上是否包含指定类型的注解,存在则返回true,否则返回false. - 方法4:
Annotation[] getDeclaredAnnotations():返回直接存在于此元素上的所有注释。与此接口中的其他方法不同,该方法将忽略继承的注释。(如果没有注释直接存在于此元素上,则返回长度为零的一个数组。)该方法的调用者可以随意修改返回的数组;这不会对其他调用者返回的数组产生任何影响。
一个简单的注解处理器:
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)//这里必须定义为RUNTIME
public @interface MyAnnotation {
String id();
String[] value() default {"AA","BB"};
}
@MyAnnotation(id = "hello")
class Test{
public static void main(String[] args) {
boolean annotationPresent = Test.class.isAnnotationPresent(MyAnnotation.class);
System.out.println(annotationPresent);
if ( annotationPresent ) {
MyAnnotation myAnnotation = Test.class.getAnnotation(MyAnnotation.class);
System.out.println("id:"+myAnnotation.id());
System.out.println("value:"+ Arrays.toString(myAnnotation.value()));
}
}
}
程序运行结果:
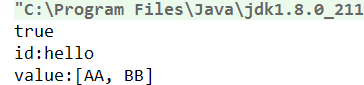
上面的例子只是作用在类上面的注解,如果要作用在属性、方法等上面的注解我们应该怎么获取呢?
定义作用于类上面的MyAnnotation注解:
//作用于类上面的注解
@Target({ElementType.TYPE, ElementType.FIELD, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)//这里必须定义为RUNTIME
public @interface MyAnnotation {
String[] value() default "";
}
定义作用于属性上面的AttributeAnnotation注解:
//作用于属性上的注解
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)//这里必须定义为RUNTIME
public @interface AttributeAnnotation {
String value();
}
定义作用于方法上面的MethodAnnotation注解:
//作用于方法上的注解
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)//这里必须定义为RUNTIME
public @interface MethodAnnotation {
String value();
}
然后就是测试了:
@MyAnnotation(value = "MyAnnotation")
class Test{
@AttributeAnnotation(value = "AttributeAnnotation")
String str;
@MethodAnnotation(value = "MethodAnnotation_show")
public void show(){
System.out.println("MethodAnnotation_show");
}
@MethodAnnotation(value = "MethodAnnotation_display")
public void display(){
System.out.println("MethodAnnotation_display");
}
public static void main(String[] args) {
//获取类上面的注解
boolean annotationPresent = Test.class.isAnnotationPresent(MyAnnotation.class);
System.out.println(annotationPresent);
if ( annotationPresent ) {
MyAnnotation myAnnotation = Test.class.getAnnotation(MyAnnotation.class);
System.out.println("class-annotation:"+Arrays.toString(myAnnotation.value()));
}
try {
//获取单个属性中的注解
Field str = Test.class.getDeclaredField("str");
AttributeAnnotation attributeAnnotation = str.getAnnotation(AttributeAnnotation.class);
if (attributeAnnotation!=null){
System.out.println("attribute-annotation:"+attributeAnnotation.value());
}
//获取多个方法中的注解
Method[] declaredMethods = Test.class.getDeclaredMethods();
for (Method declaredMethod : declaredMethods) {
MethodAnnotation methodAnnotation = declaredMethod.getAnnotation(MethodAnnotation.class);
if (methodAnnotation!=null){
System.out.println("method-annotation:"+methodAnnotation.value());
}
}
} catch (NoSuchFieldException e) {
e.printStackTrace();
}
}
}
程序运行结果:

小弟菜鸟只能领悟这么多了,如果有错误或者需要补充的地方欢迎大家留言指出。谢谢!!!
27、Java8新特性
27.1 日期处理类
27.1.1 Java 8新日期介绍
Java8之前处理日期一直是Java程序员比较头疼的问题,从Java 8之后,Java API中添加了许多关于日期的新特性,其中一个最常见也是最实用的便是日期处理的类。
java.time.LocalDate:只对年月日做出处理java.time.LocalTime:只对时分秒纳秒做出处理java.time.LocalDateTime:同时可以处理年月日和时分秒
它们是一种更为高效的日期类,比起Date的复杂具有相当高的简洁性,吸取了企业级别的joda.time时间处理的优点,避免了传统的Date和Calendar复合起来计算的难处。Java8 新的日期类都位于com.java.time包下,所以首先来看一下java.time这个包下的类结构图:
可以看到除了有四个包:chrono、format、temporal、zone之外,最外层还有一些日期、时间类,这些也是平时比较常用的。而那四个包就用的比较少了,所以先简略介绍下这四个包的用途。
[1]:chrono
chrono包提供历法相关的接口与实现。Java中默认使用的历法是ISO 8601日历系统,它是世界民用历法,也就是我们所说的公历。平年有365天,闰年是366天。闰年的定义是:非世纪年,能被4整除;世纪年能被400整除。为了计算的一致性,公元1年的前一年被当做公元0年,以此类推。此外chrono包提供了四种其他历法,每种历法有自己的纪元(Era)类、日历类和日期类,分别是:
- 泰国佛教历:ThaiBuddhistEra、ThaiBuddhistChronology和ThaiBuddhistDate;
- 民国历:MinguoEra、MinguoChronology和MinguoDate;
- 日本历:JapaneseEra、JapaneseChronology和JapaneseDate
- 伊斯兰历:HijrahEra、HijrahChronology和HijrahDate:
每个纪元类都是一个枚举类,实现Era接口。Era表示的是一个时间线的分割,比如Java默认的ISO历法中的IsoEra,就包含两个枚举量:BCE和CE,前者表示“公元前”,后者表示“公元”;再比如MinguoEra,包含了两个枚举量:BEFORE_ROC和ROC,ROC的意思是Republic of China,也即新中国,前者表示的就是新中国之前,也即民国,后者表示新中国;所以中国的历法用了“Minguo”这个名字。每种历法的日历系统的实现都是依赖于其纪元的。每个日历类都实现了抽象类AbstractChronology,其中定义了从时间、id、地域设置获取具体日历系统的接口和实现,以及获取特定日历系统下的时间的方法。定义了纪元和日历系统之后,日期类自然就确定好了,每种历法的日期类提供的接口并无大的不同,在实际开发中应用的比较少,也不是本篇的重点,暂且略过。
[2]:format
format包提供了日期格式化的方法。format包中定义了时区名称、日期解析和格式化的各种枚举,以及最为重要的格式化类DateTimeFormatter。需要注意的是,format包类中的类都是final的,都提供了线程安全的访问。在DateTimeFormatter类中提供了ofPattern的静态方法来获得一个DateTimeFormatter,但细看其实现,其实还是调用的DateTimeFormatterBuilder的静态方法:DateTimeFormatterBuilder.appendPattern(pattern).toFormatter();所以我们在实际格式化日期和时间的时候,是两种方式都可以使用的。
[3]:temporal
temporal包中定义了整个日期时间框架的基础:各种时间单位、时间调节器,以及在年月日时分秒中用到的各种属性。Java8中的日期时间类都是实现了temporal包中的时间单位(Temporal)、时间调节器(TemporalAdjuster)和各种属性的接口,所以在后面的日期的操作方法中都是以最基本的时间单位和各种属性为参数的。
[4]:zone
这个包没啥多说的,就是定义了时区转换的各种方法。
而在 java.time 包下比较常用的主要包含下面几个主要的类:
Instant:时间戳
Duration:持续时间,时间差
LocalDate:只包含日期,比如:2016-10-20
LocalTime:只包含时间,比如:23:12:10
LocalDateTime:包含日期和时间,比如:2016-10-20 23:14:21
Period:时间段
ZoneOffset:时区偏移量,比如:+8:00
ZonedDateTime:带时区的时间
Clock:时钟,比如获取目前美国纽约的时间
以及java.time.format包中的
DateTimeFormatter:时间格式化
下面我们通过例子来看如何使用java8新的日期时间库。
27.1.2 Java 8日期/时间类
Java 8日期/时间类主要有三个:LocalDate、LocalTime、LocalDateTime
- LocalDate:表示一个IOS格式(yyyy-MM-hh)的日期,它是不包含具体时间的日期。例如:2014-01-14。它可以用来存储生日、周年纪念日、入职日期等。
- LocalTime:表示一个时间,它是不含日期的时间。
- LocalDateTime:表示日期和时间,它包含了日期及时间,不过还是没有偏移信息或者说时区,这是一个最常用的类之一。
它们三者共同特点:
- 相比于前面的Date和Calendar,他们是线程安全的;
- 它们是不可变的日期时间对象;
常用方法:由于LocalDate的API与LocalTime、LocalDateTime大都是通用的,所有后面两个的就不展示了。方法使用举例:
创建日期/时间对象
| 方法 | 描述 |
|---|---|
| now() 、 now(Zoneld zone) | 静态方法,根据当前时间创建对象 、 指定时区的对象 |
| of() | 静态方法,根据指定日期,时间创建对象,即自定义日期/时间 |
// 创建日期/时间对象
@Test
public void testCreateDate() {
//now():获取当前日期
LocalDate localDate = LocalDate.now();
LocalTime localTime = LocalTime.now();
LocalTime localTime1 = LocalTime.now().withNano(0); // 这个是不带毫秒的
LocalDateTime localDateTime = LocalDateTime.now();
System.out.println("日期:" + localDate);
System.out.println("时间:" + localTime);
System.out.println("时间不带毫秒:" + localTime1);
System.out.println("日期时间:" + localDateTime);
//of():设置指定的年月日时分秒,没有偏移量
System.out.println("-----------");
LocalDateTime localDateTime2 = LocalDateTime.of(2020, 04, 04, 18, 48, 56);
System.out.println("of()-设置的时间为:" + localDateTime2);
}
获取年、月、日信息
| 方法 | 描述 |
|---|---|
| get(TemporalField field) | 配合ChronoField枚举获取指定的年月日,例如:ChronoField.YEAR |
| getYear() | 获取日期的年份 |
| getMonth() | 获得月份,返回枚举值(如:January) |
| getMonthValue() | 获得月份,返回数字(1-12) |
| getHour()、getMinute()、getSecond() | 获得当前日期的时、分、秒 |
| getDayOfMonth() | 获得月份天数(1-31) |
| getDayOfYear() | 获取年份天数(1-366) |
| getDayOfWeek() | 获得星期几 |
@Test
public void getDateInfo() {
LocalDateTime localDateTime = LocalDateTime.now();
//get():获取相关的属性
System.out.println("年份为:" + localDateTime.get(ChronoField.YEAR));
System.out.println("月份为:" + localDateTime.get(ChronoField.MONTH_OF_YEAR));
System.out.println("这年的第几天:" + localDateTime.get(ChronoField.DAY_OF_YEAR));
//getXXX():获取相关的属性
System.out.println("这年的第几天:" + localDateTime.getDayOfYear());
System.out.println("这月的第几天:" + localDateTime.getDayOfMonth());
System.out.println("这周的星期几:" + localDateTime.getDayOfWeek());
System.out.println("月份为:" + localDateTime.getMonth());
System.out.println("月份为:" + localDateTime.getMonthValue());
System.out.println("小时为:" + localDateTime.getHour());
}
日期的修改
| 方法 | 描述 |
|---|---|
| withYear() | 将年份修改为指定的值并且返回新的对象 |
| withMonth() | 将月份修改为指定的值并且返回新的对象 |
| withDayOfMonth() | 将月份修改为指定的值并且返回新的对象 |
| withDayOfYear() | 将年份修改为指定的值并且返回新的对象 |
| withHour() | 将小时修改为指定的值并且返回新的对象 |
| withMinute() | 将分钟修改为指定的值并且返回新的对象 |
| withSecond() | 将秒数修改为指定的值并且返回新的对象 |
| with() | 根据指定的参数修改,还可以配合TemporalAdjuster提供更加强大的日期修改功能,下面会介绍 |
@Test
public void testWith() {
LocalDateTime localDateTime = LocalDateTime.now();
//withXXX:设置相关的属性,修改后返回了新的对象,体现了不可变性
LocalDateTime localDateTime2 = localDateTime.withYear(2001);
System.out.println("当前的时间:" + localDateTime);
System.out.println("修改年份后:" + localDateTime2);
LocalDateTime localDateTime3 = localDateTime.withDayOfMonth(22);
System.out.println("当前的时间:" + localDateTime);
System.out.println("修改月份后:" + localDateTime3);
LocalDateTime localDateTime4 = localDateTime.withHour(14);
System.out.println("当前的时间:" + localDateTime);
System.out.println("修改小时后:" + localDateTime4);
// 修改为2222
LocalDateTime withYear = localDateTime.with(ChronoField.YEAR, 2222);
System.out.println(withYear);
// 修改为这年的第15天
LocalDateTime withDay = localDateTime.with(ChronoField.DAY_OF_YEAR, 15);
System.out.println(withDay);
}
日期的计算-加减
| 方法 | 描述 |
|---|---|
| plusHours() | 向当前对象添加几小时 |
| plusDays() | 向当前对象添加几天 |
| plusWeeks() | 向当前对象添加几周 |
| plusMonths() | 向当前对象添加几个月 |
| plusYears() | 向当前对象添加几年 |
| minusHours() | 从当前对象减去几小时 |
| minusDays() | 从当前对象减去几天 |
| minusWeeks() | 从当前对象减去几周 |
| minusMonths() | 从当前对象减去几月 |
| minusYears() | 从当前对象减去几年 |
| plus(long amountToAdd, TemporalUnit unit) | 根据TemporalUnit 参数相加 |
| minus(long amountToSubtract, TemporalUnit unit) | 根据TemporalUnit 参数相减 |
@Test
public void testPlusAndMinus() {
LocalDateTime localDateTime = LocalDateTime.now();
//plusXXX:增加相关属性
LocalDateTime localDateTime5 = localDateTime.plusDays(10);
System.out.println("当前时间:" + localDateTime);
System.out.println("加10天之后:" + localDateTime5);
LocalDateTime localDateTime6 = localDateTime.plusYears(2);
System.out.println("当前时间:" + localDateTime);
System.out.println("加2年之后:" + localDateTime6);
//minusXXX:减少相关属性
LocalDateTime localDateTime7 = localDateTime.minusDays(10);
System.out.println("当前时间:" + localDateTime);
System.out.println("减10天之后:" + localDateTime7);
LocalDateTime localDateTime8 = localDateTime.minusYears(2);
System.out.println("当前时间:" + localDateTime);
System.out.println("减2年之后:" + localDateTime8);
//增加一年-plus(long amountToAdd, TemporalUnit unit)
localDateTime = localDateTime.plusYears(1);
localDateTime = localDateTime.plus(1, ChronoUnit.YEARS);
//减少一个月-minus(long amountToSubtract, TemporalUnit unit)
localDateTime = localDateTime.minusMonths(1);
localDateTime = localDateTime.minus(1, ChronoUnit.MONTHS);
}
注:ChronoUnit 枚举表示日期周期单位的标准集合,它实现了TemporalUnit类
日期的判断
| 方法 | |
|---|---|
| isLeapYear() | 判断是否为闰年 |
| isEqual() | 检查日期是否与指定日期相等 |
| isBefore() | 检查日期是否在指定日期前面 |
| isAfter() | 检查日期是否在指定日期后面 |
@Test
public void judgeDate() {
LocalDate localDate = LocalDate.now();
boolean leapYear = localDate.isLeapYear();
System.out.println("是否是闰年:" + leapYear);
LocalDate date = LocalDate.of(2019, 1, 23);
boolean equal = date.isEqual(localDate);
System.out.println("日期是否相等:" + equal);
boolean before = date.isBefore(localDate);
boolean after = date.isAfter(localDate);
System.out.println("否在指定日期前面:" + before);
System.out.println("否在指定日期后面:" + after);
}
LocalDate ,LocalTime 和 LocalDateTime 之间的互相转换
/**
* LocalDate ,LocalTime,LocalDateTime 互相转换
*/
@Test
public void testDateConvert() {
String date = "2020-07-12";
String time = "15:51:30";
LocalDate localDate = LocalDate.parse(date);
LocalTime localTime = LocalTime.parse(time);
System.out.println(localDate);
System.out.println(localTime);
LocalDateTime localDateTime = LocalDateTime.of(2020, 7, 13, 16, 01, 30, 888);
LocalDateTime localDateTime1 = LocalDateTime.of(localDate, localTime);
//localDateTime-->LocalDate,LocalTime
LocalDate localDate1 = localDateTime.toLocalDate();
LocalTime localTime1 = localDateTime.toLocalTime();
// LocalDate,LocalTime --> LocalDateTime
LocalDateTime localDateTime2 = localDate.atTime(16, 2, 30);
LocalDateTime localDateTime3 = localTime.atDate(localDate);
}
Java日期与旧的日期之间的转换
此处来自:Convert between Date to LocalDateTime - HowToDoInJava
虽然Java8 的日期非常好用,但有时候还是需要转换为Date,二者的相互转换并不是一步到位那么简单,所以,还是需要记录一下转换的api
Date 转 LocalDateTime
Date todayDate = new Date();
LocalDateTime ldt = todayDate.toInstant()
.atZone( ZoneId.systemDefault() )
.toLocalDateTime();
System.out.println(ldt);
//2019-05-16T19:22:12.773
LocalDateTime 转 Date
LocalDateTime localDateTime = LocalDateTime.now();
Date date = Date.from( localDateTime.atZone( ZoneId.systemDefault()).toInstant());
System.out.println(date);
//Thu May 16 19:22:37 CST 2019
为了方便直接封装至一个DateUtils工具类中:
import java.time.Instant;
import java.time.LocalDate;
import java.time.LocalDateTime;
import java.time.ZoneId;
import java.util.Date;
public class DateUtils {
public static Date asDate(LocalDate localDate) {
return Date.from(localDate.atStartOfDay().atZone(ZoneId.systemDefault()).toInstant());
}
public static Date asDate(LocalDateTime localDateTime) {
return Date.from(localDateTime.atZone(ZoneId.systemDefault()).toInstant());
}
public static LocalDate asLocalDate(Date date) {
return Instant.ofEpochMilli(date.getTime()).atZone(ZoneId.systemDefault()).toLocalDate();
}
public static LocalDateTime asLocalDateTime(Date date) {
return Instant.ofEpochMilli(date.getTime()).atZone(ZoneId.systemDefault()).toLocalDateTime();
}
}
27.1.3 瞬时(Instant)
Instant类:时间线上的一个瞬时点,表示一个时间戳。设计初衷是为了便于机器使用,不提供人类意义上的时间单位,获取当前时刻的时间戳;它只是简单的从1970年1月1日0时0分0秒(UTC)开始的秒数。常用方法:
| 方法 | 描述 |
|---|---|
| now() | 静态方法,返回默认的UTC时区的Instant类的对象 |
| atOffset(ZoneOffset offset) | 将此瞬间与偏移组合起来创建一个OffsetDateTime |
| toEpochMilli() | 返回1970-01-01 00:00:00到当前的毫秒数,即时间戳 |
| ofEpochMilli(long epochMilli) | 静态方法,返回在1970-01-01 00:00:00基础加上指定毫秒数之后的Instant类的对象 |
| ofEpochSecond(long epochSecond) | 静态方法,返回在1970-01-01 00:00:00基础加上指定秒数之后的Instant类的对象 |
@Test
public void testInstant() {
//now():获取标准时间,即本初子午线的时间,没有偏移量
Instant instant = Instant.now();
System.out.println(instant);
//atOffset:添加偏移量,北京在东八区,时区加八即为北京时间
OffsetDateTime offsetDateTime = instant.atOffset(ZoneOffset.ofHours(8));
System.out.println(offsetDateTime);
//toEpochMilli:获取1970-01-01 00:00:00 开始的毫秒;类似Date的getTime
long epochMilli = instant.toEpochMilli();
System.out.println(epochMilli);
//ofEpochMilli:通过给定的毫秒数,获取Instant实例;类似Date(long millis)
Instant ofEpochMilli = Instant.ofEpochMilli(1562384592201L);
System.out.println(ofEpochMilli);
}
27.1.4 日期间隔(Period)/持续时间(Duration)
Java 8 中还引入的两个与日期相关的新类:Period 和 Duration。两个类分别表示时间量或两个日期之间的差,两者之间的差异为:Period基于日期值,而Duration基于时间值。
@Test
public void testDuration() {
//Duration
LocalTime time1 = LocalTime.of(15, 7, 50);
LocalTime time2 = LocalTime.of(17, 8, 53);
LocalDateTime dateTime1 = LocalDateTime.of(2020, 5, 12, 14, 22, 28);
LocalDateTime dateTime2 = LocalDateTime.of(2024, 5, 12, 14, 22, 28);
Instant instant1 = Instant.ofEpochSecond(1);
Instant instant2 = Instant.now();
Duration d1 = Duration.between(time1, time2);
Duration d2 = Duration.between(dateTime1, dateTime2);
Duration d3 = Duration.between(instant1, instant2);
System.out.println("LocalTime持续秒数:" + d1.getSeconds());
System.out.println("LocalDateTime持续秒数:" + d2.getSeconds());
System.out.println("Instant持续秒数" + d3.getSeconds());
}
@Test
public void testPeriod() {
//Period
LocalDate date1 = LocalDate.of(2020, 7, 6);
LocalDate date2 = LocalDate.of(2025, 9, 10);
Period period = Period.between(date1, date2);
System.out.println("相差年数:" + period.getYears());
System.out.println("相差月数:" + period.getMonths());
System.out.println("相差天数:" + period.getDays());
System.out.println("总月数:" + period.toTotalMonths());
}
27.1.5 日期校正器TemporalAdjusters
TemporalAdjusters一般配合with()方法来使用。有的时候,你需要对日期进行一些更加 复杂的操作,比如,将日期调整到下个周日、下个工作日,或者是本月的最后一天。这时,你可以使用重载版本的with方法,向其传递一个提供了更多定制化选择的TemporalAdjusters对象, 更加灵活地处理日期。对于最常见的用例,日期和时间API已经提供了大量预定义的 TemporalAdjusters。你可以通过TemporalAdjusters类的静态工厂方法访问它们,如下所示:
下面是TemporalAdjusters类中的方法:
| 方法 | 描述 |
|---|---|
| dayOfWeekInMonth(int ordinal,DayOfWeek dayOfWeek) | 返回一个新的日期,它的值为同一个月中每一周的第几天 |
| firstDayOfMonth() | 返回一个新的日期,它的值为当月的第一天 |
| firstDayOfNextMonth() | 返回一个新的日期,它的值为下月的第一天 |
| firstDayOfNextYear() | 返回一个新的日期,它的值为明年的第一天 |
| firstDayOfYear() | 返回一个新的日期,它的值为当年的第一天 |
| firstInMonth(DayOfWeek dayOfWeek) | 返回一个新的日期,它的值为同一个月中,第一个符合星期几要求的值 |
| lastDayOfMonth() | 返回一个新的日期,它的值为当月的最后一天 |
| lastDayOfNextMonth() | 返回一个新的日期,它的值为下月的最后一天 |
| lastDayOfNextYear() | 返回一个新的日期,它的值为明年的最后一天 |
| lastDayOfYear() | 返回一个新的日期,它的值为今年的最后一天 |
| lastInMonth(DayOfWeek dayOfWeek) | 返回一个新的日期,它的值为同一个月中,最后一个符合星期几要求的值 |
| next(DayOfWeek dayOfWeek)、previous(DayOfWeek dayOfWeek) | 返回一个新的日期,并将其值设定为日期调整后或者调整前,第一个符合指定星期几要求的日期 |
| nextOrSame(DayOfWeek dayOfWeek)、previousOrSame(DayOfWeek dayOfWeek) | 返回一个新的日期,并将其值设定为日期调整后或者调整前,第一个符合指定星期几要求的日期,如果该日期已经符合要求,直接返回该对象 |
方法使用举例:
@Test
public void testTemporalAdjusters(){
//dayOfWeekInMonth:返回这个月第二周星期二的日期
LocalDate localDate1=LocalDate.of(2020,9,15);
LocalDate localDate2 = localDate1.with(TemporalAdjusters.dayOfWeekInMonth(2, DayOfWeek.TUESDAY));
System.out.println("默认时间:"+localDate1);
System.out.println("更改时间:"+localDate2);
//firstDayOfMonth():这个月第一天
System.out.println("---------");
LocalDate localDate3=localDate1.with(TemporalAdjusters.firstDayOfMonth());
System.out.println("默认时间:"+localDate1);
System.out.println("更改时间:"+localDate3);
//lastDayOfMonth():这个月最后一天
System.out.println("---------");
LocalDate localDate4=localDate1.with(TemporalAdjusters.lastDayOfMonth());
System.out.println("默认时间:"+localDate1);
System.out.println("更改时间:"+localDate4);
//nextOrSame():获取周2时间,如果当前时间刚好是星期2,那么就返回当前时间
System.out.println("---------");
LocalDate localDate5 = localDate1.with(TemporalAdjusters.nextOrSame(DayOfWeek.TUESDAY));
System.out.println("默认时间:"+localDate1);
System.out.println("更改时间:"+localDate5);
}
运行结果:
27.1.6 Java 8的Clock时钟类
Java 8增加了一个Clock时钟类用于获取当时的时间戳,或当前时区下的日期时间信息。以前用到System.currentTimeInMillis()和TimeZone.getDefault()的地方都可用Clock替换。
package com.shxt.demo02;
import java.time.Clock;
public class Demo10 {
public static void main(String[] args) {
// Returns the current time based on your system clock and set to UTC.
Clock clock = Clock.systemUTC();
System.out.println("Clock : " + clock.millis());
// Returns time based on system clock zone
Clock defaultClock = Clock.systemDefaultZone();
System.out.println("Clock : " + defaultClock.millis());
}
}
27.1.7 Java 8日期解析和格式化(DateTimeFormatter)
之前格式化有 SimpleDateFormat 和 DateFormat,但是它们两者都是线程不安全的!啥情况下会有这样的问题呢?如果我们为了实现日期转换这样的工具,每次都new一个对象,但是用完了就不用了,就造成了浪费,为此我们会将它写成单例的,但是单例的同时,一个对象供多个线程使用的时候,就会出现线程安全的问题。这个时候就需要这个新的jdk8出的 DateTimeformatter 这个类。
该类提供了三种格式化方法:
- 预定义的标准格式。如:DateTimeFormatter.ISO_DATE_TIME;
- 本地化相关的格式。如:DateTimeFormatter.ofLocalizedDate(FormatStyle.MEDIUM);
- 自定义的格式。如:DateTimeFormatter.ofPattern(“yyyy-MM-dd hh:mm:ss”);
// 日期格式化
//预定义的标准格式
@Test
public void test() {
LocalDateTime now = LocalDateTime.now();
//预定义的标准格式
DateTimeFormatter df = DateTimeFormatter.ISO_DATE_TIME;//2019-08-06T16:38:23.756
//DateTimeFormatter df1 = DateTimeFormatter.ISO_DATE;//2019-08-06
//格式化操作
String str = df.format(now);
System.out.println(str);
}
//本地化相关的格式
@Test
public void test1() {
LocalDateTime now = LocalDateTime.now();
//本地化相关的格式
//DateTimeFormatter df = DateTimeFormatter.ofLocalizedDateTime(FormatStyle.LONG);//2019年8月6日 下午04时40分03秒
DateTimeFormatter df = DateTimeFormatter.ofLocalizedDateTime(FormatStyle.SHORT);//19-8-6 下午4:40
//格式化操作
String str = df.format(now);
System.out.println(str);
}
//自定义的格式
@Test
public void test2() {
LocalDateTime now = LocalDateTime.now();
//自定义的格式
DateTimeFormatter df = DateTimeFormatter.ofPattern("yyyy年MM月dd日 HH时mm分ss秒 SSS毫秒 E 是这一年的D天");
//格式化操作
String str = df.format(now);
System.out.println(str);
}
27.1.6.1 由字符串(String)转为日期
//把字符串解析为日期对象
@Test
public void test3() {
//1.默认的格式调用parse进行解析
String date = "2020-12-12";
LocalDate localDate = LocalDate.parse(date);
System.out.println(localDate);
//2.自定义的匹配格式(年月日)
String date1 = "2020.12.12";
DateTimeFormatter dtf = DateTimeFormatter.ofPattern("yyyy.MM.dd");
//--解析操作
LocalDate localDate1 = LocalDate.parse(date1, dtf);
System.out.println(localDate1);
//--注:上面的解析操作等价于下面
TemporalAccessor accessor = dtf.parse(date1);
LocalDate localDate2 = LocalDate.from(accessor);
System.out.println(localDate2);
//3.有年月日和时间
String datetime = "2020/12/24 18--15--56";
DateTimeFormatter dtf1 = DateTimeFormatter.ofPattern("yyyy/MM/dd HH--mm--ss");
LocalDateTime localDateTime = LocalDateTime.parse(datetime, dtf1);
System.out.println(localDateTime);
}
27.1.6.2 由日期转为字符串(String)
- 如果是LocalDate这种标准格式的,直接toString就可以了。
- 如果是LocalTime这种格式的,toString会附带纳秒值21:06:30.760163, 这个时候你可以使用日期格式器,或者这样 LocalTime time = LocalTime.now().withNano(0),把纳秒直接清0。
- 如果是LocalDateTime,这个时候是需要一个日期转换器的。才能由时间+日期->想要的时间。
//把日期对象转换为字符串
@Test
public void test4() {
//1.LocalDate如果是默认的标准格式(yyyy-MM-dd),则直接调用toString,
// 如果不是则需要使用DateTimeFormatter进行格式匹配,然后调用dtf的format()
LocalDate now = LocalDate.now();
System.out.println(now.toString());
//2.LocalTime的默认格式
LocalTime localTime = LocalTime.now().withNano(0);
System.out.println(localTime.toString());
//3.LocalDateTime格式,这里使用自定义的格式匹配进行匹配
DateTimeFormatter dtf = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
LocalDateTime localDateTime = LocalDateTime.now();
String result = localDateTime.format(dtf);
System.out.println(result);
}
27.1.8 Java 8 处理不同时区的时间
Java 8对时区处理的优化也是Java8中日期时间API的一大亮点,不仅分离了日期和时间,也把时区分离出来了。现在有一系列单独的类如ZoneId来处理特定时区,ZoneDateTime类来表示某时区下的时间。这在Java 8以前都是 GregorianCalendar类来做的。下面这个例子展示了如何把本时区的时间转换成另一个时区的时间。
@Test
public void testZone() {
// 查看当前的时区
ZoneId defaultZone = ZoneId.systemDefault();
System.out.println(defaultZone); //Asia/Shanghai
// 获取所有合法的“区域/城市”字符串
Set<String> zoneIds = ZoneId.getAvailableZoneIds();
// 查看美国纽约当前的时间
ZoneId america = ZoneId.of("America/New_York");
LocalDateTime shanghaiTime = LocalDateTime.now();
LocalDateTime americaDateTime = LocalDateTime.now(america);
System.out.println(shanghaiTime); //2019-11-06T15:20:27.996
System.out.println(americaDateTime); //2019-11-06T02:20:27.996 ,可以看到美国与北京时间差了13小时
// 带有时区的时间 由两部分构成,LocalDateTime和ZoneId
ZonedDateTime americaZoneDateTime = ZonedDateTime.now(america);
System.out.println(americaZoneDateTime); //2019-11-06T02:23:44.863-05:00[America/New_York]
// ZoneOffset,它是以当前时间和世界标准时间(UTC)/格林威治时间(GMT)的偏差来计算
ZoneOffset zoneOffset = ZoneOffset.of("+09:00");
LocalDateTime localDateTime = LocalDateTime.now();
OffsetDateTime offsetDateTime = OffsetDateTime.of(localDateTime, zoneOffset);
}
27.1.9 Java 8新日期小结
这次主要学习了Java8中新的日期处理类
- LocalDate、LocalTime、LocalDateTime处理日期时间都非常的方便,而且它们是线程安全的,
- 新版的日期和时间API中,日期和时间对象是不可变的。
- LocalDate日期是一个便于使用的日期类,线程安全,Date类比较复杂,时间计算麻烦。
- DateTimeFormatter的使用也安全,方便。以后用它来代替SimpleDateFormat
- TemporalAdjuster 让你能够用更精细的方式操纵日期,不再局限于一次只能改变它的 一个值,并且你还可按照需求定义自己的日期转换器
- JDBC的TimeStamp类和LocalDateTime的转换也很方便,提供了相应的方法。
- 使用的时候,日期必须是标准的yyyy-MM-dd格式,比如1月必须写成01,不然会报错。
27.2 Lambda表达式
27.2.1 本篇前言
Java 8于 2014 年发布到现在已经有5年时间了,经过时间的验证,毫无疑问,Java 8是继Java 5(发布于2004年)之后的又一个非常重要的版本。因为Java 8里面出现了非常多新的特征,这些特征主要包含语言、编译器、库、工具和JVM等方面,具体如下:
- Lambda表达式 👉 传送门👈
- Stream API 👉 传送门👈
- 方法引用/构造器引用 👉 传送门👈
- 新的日期处理类 👉 传送门👈
- 函数式接口 👉 传送门👈
- 接口中允许定义默认方法
- Optional类 👉 传送门👈
- 重复注解、类型注解、通用类型推断
- 新的编译工具:jjs、jdeps
- JVM中的PermGen被Metaspace取代
- 新的Nashron引擎,允许在JVM上允许JS代码
- ……
以上最值得我们学习的应该就是Lambda表达式、Stream API和新的日期处理类。并不是说其他的就不用去学了,还是有必要去了解一下的,而这三个(Lambda、Stream、新的日期)对我们来说很重要所以必须学习,因为在实际的工作中非常常用。
27.2.2 Lambda表达式简介
Lambda表达式本质上是一个匿名函数(方法),它没有方法名,没有权限修饰符,没有返回值声明。它看起来就是一个箭头->从左边指向右边。我们可以把Lambda表达式理解为一段可以传递的代码(将代码像数据一样进行传递),它的核心思想是将面向对象中的传递数据变成传递行为。
Lambda表达式的出现就是为了简化匿名内部类,让匿名内部类在方法中作为参数的使用更加方便。所以使用Lambda表达式可以让我们的代码更少,看上去更简洁,代码更加灵活。而Lambda表达式作为一种更紧凑的代码风格,使得Java的语言表达能力得到了提升。但也有它的缺点所在,如果Lambda表达式用的不好的话,调试运行和后期维护非常的麻烦,尤其是调试的时候,debug模式都不会进去。
Lambda表达式对接口的要求:Lambda只能接受函数式接口(@FunctionalInterface),而函数式接口规定接口中只能有一个需要被实现的方法,意思就是只能有一个抽象方法,但不是规定接口中只能有一个方法,也可以有其它的方法,jdk8接口中可以定义普通方法,但是必须用default关键字修饰。
总结下来Lambda表达式的特点就是:
- 匿名:没有一个确定的名称
- 函数:lambda不属于一个特定的类,但是却有参数列表、函数主体、返回类型、异常列表
- 传递:可以作为参数传递给方法、或者存储在变量中
- 简洁:不需要写很多模板代码
- 接口:必须为函数式接口(@FunctionalInterface)
27.2.3 Lambda表达式语法
Lambda表达式在Java语言中引入了一个新的语法元素和操作符。这个操作符为->,该操作符被称为Lambda操作符或箭头操作符,它将Lambda分为两个部分:
- 左侧:指定了Lambda表达式所需要的所有参数。
- 右侧:指定了Lambda体,即Lambda表达式所要执行的功能。
Java8中的Lambda表达式的基本语法结构如下,当然,这里只是简单的Lambda 表达式的应用。后面还有使用多个简单Lambda 表达式组成的复合 Lambda 表达式。例如: 函数复合、谓词复合、比较器复合等各种形式的组合起来的Lambda表达式。对于初学者而言刚刚看到这种写法肯定是非常懵逼的,所以不要心急,慢慢来:
| 描述 | 格式 |
|---|---|
| 无参数,无返回值 void | () -> System.out.print(“Lambda…”) ; |
| 有一个参数,但无返回值 void | (String s) -> System.out.print(“Lambda…”) ; |
| 有参数,但是参数数据类型省略,由编译器推断,称为"类型推断" | (s) –> System.out.print(“Lambda…”) ; |
| 若只有一个参数,方法的括号可以省略,如果多个参数则必须写上 | s–> System.out.print(“Lambda…”) ; |
| 有参数,且有返回值,如果显式返回语句时就必须使用花括号“{}” | (s,t) –> s+t ;或 (s,t) –> {return s+t;}; |
| 如果有两个或两个以上的参数,并且有多条语句则需要加上“{}”,一条执行语句可以省略。 | (s,t) –> { System.out.print(s) ; System.out.print(t) ; return s+t; }; |
到目前为止,我们对Lambda表达式有了基本的认识,而前面讲了那么多的理论,就是为了接下来快乐的写代码时光,用几个简单的例子来让我们好好理解一下Lambda表达式的使用,看看Lambda是怎么来消灭冗余的匿名内部类的:
/**
* lambda表达式举例
* @author tanghaorong
*/
public class LambdaTest {
public static void main(String[] args) {
//1、创建线程举例
//普通写法(匿名内部类)
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("Ordinary Writing");
}
}); thread.start();
//Lambda写法。无参无返回void
Thread thread1 = new Thread(() -> System.out.println("Lambda Writing"));
thread1.start();
//2、排序举例
//普通写法,默认升序
List<Integer> list = Arrays.asList(26, 65, 13, 79, 6, 123);
list.sort(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return Integer.compare(o1, o2);
}
}); System.out.println(list.toString());
//Lambda表达式写法。有参有返回,“类型推断”
list.sort((o1, o2) -> Integer.compare(o1, o2)); System.out.println(list.toString());
//3、遍历list集合
//普通写法
list.forEach(new Consumer<Integer>() {
@Override
public void accept(Integer integer) {
System.out.println(integer);
}
});
//Lambda表达式写法。遍历List集合,forEach方法中的参数是Consumer<? super T> action
//其中Consumer是Java8新的新出现的函数式接口,下面会讲到函数式接口
list.forEach(alist -> System.out.println(alist));
}
}
注意:要使用Lambda表达式的前提是函数式接口,所以接下来学习一下函数式接口。
27.2.4 函数式接口介绍
函数式接口(Functional Interface)也是Java8中的新特征。函数式接口的定义:只允许有一个抽象方法的接口,那么它就是一个函数式接口,这样接口就可以被隐式转换为Lambda表达式。但是为了避免后来人给这个接口添加函数后,导致该接口有多个函数,就不再是函数式接口了,所以官方给我们提供了一个注解@FunctionalInterface,该注解会检查它是否是一个函数式接口,所以如果我们需要自定义一个函数式接口的话,可以在接口类的上方声明@FunctionalInterface。注意:函数式接口虽然规定只能有一个抽象方法,但是同时可以有多个非抽象方法(Java8中接口可以定义普通方法)。简单的举个定义函数式接口的例子,代码如下:
/**
* 自定义函数式接口注解
* @author tanghaorong
*/
@FunctionalInterface
public interface MyInterface {
/**
* 抽象方法
*/
void method();
//void method1();再定义一个会提示:找到多个抽象方法
/**
* 默认方法,必须用default修饰
*/
default void defaultMethod() {
System.out.println("默认方法...");
}
/**
* 静态方法方法
*/
static void staticMethod() {
System.out.println("静态方法...");
}
}
上面的例子可以很容易的转换成如下Lambda表达式:
MyInterface myInterface = () -> System.out.println("MyInterface...");
我需要注意的一点是,接口中的默认方法和静态方法并不会破坏函数式接口的定义,既不会影响到Lambda表达式。同时也正因为Lambda表达式的引入,所以函数式接口也变得流行起来。其实早在Java8之前就有很多接口是函数式接口,只是在Java8才正式提出之一特性,例如:
- java.lang.Runnable
- java.util.concurrent.Callable
- java.util.Comparator
- java.io.FileFilter
- ……
除了以上这些,在Java 8中还增加了一个新的包:java.util.function。它们里面包含了常用的函数式接口,该包下定义的函数式接口非常多,主要有四大类,下面介绍。
27.2.5 四大类型接口

为了便于记忆,这里对四大函数式接口的代表接口进行一个总结:
| 接口类型 | 函数式接口 | 参数类型 | 返回类型 | 方法 |
|---|---|---|---|---|
| 消费型接口 | Consumer |
T | void | void accept(T t) |
| 供给型接口 | Supplier |
无 | T | T get() |
| 判断型接口 | Predicate |
T | boolean | boolean test(T t) |
| 功能(函数)型接口 | Function<T, R> | T | R | R apply(T t) |
而下面则是所有关于java.util.function包下的相关接口,同时也会简单的举例。
27.2.5.1 消费型接口
消费型接口的抽象方法特点:有参数传入,无结果返回。
| 接口名 | 参数类型 | 返回类型 | 抽象方法 | 描述 |
|---|---|---|---|---|
| Consumer | T | void | void accept(T t) | 接收一个对象用于完成功能,不返回结果 |
| BiConsumer<T,U> | T,U | void | void accept(T t, U u) | 接收两个对象用于完成功能,不返回结果 |
| DoubleConsumer | double | void | void accept(double value) | 接收一个double值,不返回结果 |
| IntConsumer | int | void | void accept(int value) | 接收一个int值,不返回结果 |
| LongConsumer | long | void | void accept(long value) | 接收一个long值,不返回结果 |
| ObjDoubleConsumer | T,double | void | void accept(T t, double value) | 接收一个对象和一个double值,不返回结果 |
| ObjIntConsumer | T,int | void | void accept(T t, int value) | 接收一个对象和一个int值,不返回结果 |
| ObjLongConsumer | T,long | void | void accept(T t, long value) | 接收一个对象和一个long值,不返回结果 |
消费型接口的简单举例:
/**
* 消费型接口举例
* @author tanghaorong
*/
public class LambdaDemo {
public static void main(String[] args) {
//1、传入一个参数:Consumer<T> : void accept(T t);
Consumer<Integer> consumer = (a) -> System.out.println("消费型接口:" + a);
consumer.accept(1000);
//2、传入集合:Consumer<T> : void accept(T t);
List<String> list = Arrays.asList("hello", "world", "java", "html", "css");
list.forEach((s) -> {
System.out.println(s);
});
//3、传入两个参数:BiConsumer<T, U> : void accept(T t, U u);
HashMap<Integer, String> map = new HashMap<>(10);
map.put(1, "张三");
map.put(2, "李四");
map.put(3, "王五");
map.put(4, "赵六");
map.forEach((a, b) -> {
System.out.println(a + ":" + b);
});
}
}
27.2.5.2 供给型接口
这类接口的抽象方法特点:无参数传入,但是有返回值
| 接口名 | 参数类型 | 返回类型 | 抽象方法 | 描述 |
|---|---|---|---|---|
| Supplier | 无 | T | T get() | 供给一个T类型对象的结果 |
| BooleanSupplier | 无 | boolean | boolean getAsBoolean() | 供给一个boolean类型的结果 |
| DoubleSupplier | 无 | double | double getAsDouble() | 供给一个double类型的结果 |
| IntSupplier | 无 | int | int getAsInt() | 供给一个int类型的结果 |
| LongSupplier | 无 | long | long getAsLong() | 供给一个long类型的结果 |
供给型接口的简单举例:
/**
* 供给型接口举例
* @author tanghaorong
*/
public class LambdaDemo {
public static void main(String[] args) {
//Supplier<T> : T get();
Supplier<Double> supplier = () -> (Math.random() * 100);
Double d = supplier.get();
System.out.println("供给型接口:" + d);
Supplier<String> supplier1 = () -> "hello supplier";
String s = supplier1.get();
System.out.println("供给型接口:" + s);
}
}
27.2.5.3 判断型接口
判断型接口的抽象方法特点:有参传入,但是返回值类型是boolean结果。
| 接口名 | 参数类型 | 返回类型 | 抽象方法 | 描述 |
|---|---|---|---|---|
| Predicate | T | boolean | boolean test(T t) | 接收一个对象,断定并返回boolean类型结果 |
| BiPredicate<T,U> | T,U | boolean | boolean test(T t, U u) | 接收两个对象,断定并返回boolean类型结果 |
| DoublePredicate | double | boolean | boolean test(double value) | 接收一个double类型参数值,断定并返回boolean类型结果 |
| IntPredicate | int | boolean | boolean test(int value) | 接收一个int类型参数值,断定并返回boolean类型结果 |
| LongPredicate | long | boolean | boolean test(long value) | 接收一个long类型参数值,断定并返回boolean类型结果 |
判断型接口的简单举例:
/**
* 判断型接口举例
* @author tanghaorong
*/
public class LambdaDemo {
public static void main(String[] args) {
//1、Predicate<T> : boolean test(T t);
Predicate<String > predicate = (c) -> "predicate".equals(c);
boolean test = predicate.test("predicate");
System.out.println("断定型接口:" + test);
//2、BiPredicate<T,U> : boolean test(T t);
BiPredicate<String,String> biPredicate = (a, b) -> a.equals(b);
boolean test1 = biPredicate.test("hello", "biPredicate");
System.out.println("断定型接口:" + test1);
}
}
27.2.5.4 功能型接口
这类接口的抽象方法特点:既有参数传入又有结果值返回
| 接口名 | 参数类型 | 返回类型 | 抽象方法 | 描述 |
|---|---|---|---|---|
| Function<T,R> | T | R | R apply(T t) | 接收一个T类型对象,返回一个R类型对象结果 |
| UnaryOperator | T | T | T apply(T t) | 接收一个T类型对象,返回一个T类型对象结果 |
| DoubleFunction | double | R | R apply(double value) | 接收一个double值,返回一个R类型对象 |
| IntFunction | int | R | R apply(int value) | 接收一个int值,返回一个R类型对象 |
| LongFunction | long | R | R apply(long value) | 接收一个long值,返回一个R类型对象 |
| ToDoubleFunction | T | double | double applyAsDouble(T value) | 接收一个T类型对象,返回一个double |
| ToIntFunction | T | int | int applyAsInt(T value) | 接收一个T类型对象,返回一个int |
| ToLongFunction | T | long | long applyAsLong(T value) | 接收一个T类型对象,返回一个long |
| DoubleToIntFunction | double | int | int applyAsInt(double value) | 接收一个double值,返回一个int结果 |
| DoubleToLongFunction | double | long | long applyAsLong(double value) | 接收一个double值,返回一个long结果 |
| IntToDoubleFunction | int | double | double applyAsDouble(int value) | 接收一个int值,返回一个double结果 |
| IntToLongFunction | int | long | long applyAsLong(int value) | 接收一个int值,返回一个long结果 |
| LongToDoubleFunction | long | double | double applyAsDouble(long value) | 接收一个long值,返回一个double结果 |
| LongToIntFunction | long | int | int applyAsInt(long value) | 接收一个long值,返回一个int结果 |
| DoubleUnaryOperator | double | double | double applyAsDouble(double operand) | 接收一个double值,返回一个double |
| IntUnaryOperator | int | int | int applyAsInt(int operand) | 接收一个int值,返回一个int结果 |
| LongUnaryOperator | long | long | long applyAsLong(long operand) | 接收一个long值,返回一个long结果 |
| BiFunction<T,U,R> | T,U | R | R apply(T t, U u) | 接收一个T类型和一个U类型对象,返回一个R类型对象结果 |
| BinaryOperator | T,T | T | T apply(T t, T u) | 接收两个T类型对象,返回一个T类型对象结果 |
| ToDoubleBiFunction<T,U> | T,U | double | double applyAsDouble(T t, U u) | 接收一个T类型和一个U类型对象,返回一个double |
| ToIntBiFunction<T,U> | T,U | int | int applyAsInt(T t, U u) | 接收一个T类型和一个U类型对象,返回一个int |
| ToLongBiFunction<T,U> | T,U | long | long applyAsLong(T t, U u) | 接收一个T类型和一个U类型对象,返回一个long |
| DoubleBinaryOperator | double,double | double | double applyAsDouble(double left, double right) | 接收两个double值,返回一个double结果 |
| IntBinaryOperator | int,int | int | int applyAsInt(int left, int right) | 接收两个int值,返回一个int结果 |
| LongBinaryOperator | long,long | long | long applyAsLong(long left, long right) | 接收两个long值,返回一个long结果 |
功能型接口的简单举例:
/**
* 功能型接口举例
* @author tanghaorong
*/
public class LambdaDemo {
public static void main(String[] args) {
//1、Function<T, R> : R apply(T t);
Function<String, String> function = (b) -> b;
Object apply = function.apply("功能(函数)型接口");
System.out.println(apply);
//2、BiFunction<T, U, R>:R apply(T t, U u);
HashMap<Integer, Employee> map = new HashMap<>(10);
Employee p1 = new Employee(1, "张三", 8000.0);
Employee p2 = new Employee(2, "李四", 9000.0);
Employee p3 = new Employee(3, "王五", 10000.0);
Employee p4 = new Employee(4, "赵六", 11000.0);
map.put(p1.getId(), p1);
map.put(p2.getId(), p2);
map.put(p3.getId(), p3);
map.put(p4.getId(), p4);
map.forEach((k, v) -> System.out.println(k + ":" + v));
System.out.println("+++++++++++++++++++++++");
//将map中薪资低于10000的员工的薪资设置为10000
map.replaceAll((k, v) -> {
if (v.getSalary() < 10000) {
v.setSalary(10000.0);
}
return v;
});
map.forEach((k, v) -> System.out.println(k + ":" + v));
//3、UnaryOperator T apply(T t),注:xxxOperator结尾的接口都继承了Function接口
UnaryOperator<Integer> uoi = x -> x + 1;
System.out.println(uoi.apply(10));
UnaryOperator<String> uos = x -> x + "bb";
System.out.println(uos.apply("aa"));
}
}
/**
* 功能型接口举例时用到的实体类
*/
class Employee {
private Integer id;
private String name;
private Double salary;
//getter、setter和toString省略
public Employee(Integer id, String name, Double salary) {
this.id = id;
this.name = name;
this.salary = salary;
}
}
27.2.6 方法引用介绍
通过上面Lambda表达式的学习,如果你认为Lambda表达式已经让代码够简洁了,那么这里还有一个更加简洁的方法——方法引用。简单来说,方法引用就是进一步的简化Lambda表达式声明的一种语法糖。也正是因为方法引用实在太简洁了,所以学习方法引用前必须要对Lambda表达式非常的熟悉,否则学习方法引用会非常的吃力😱,你可能都不知道这是在干啥😂。
方法引用使用操作符::将对象或类的名字和方法名分隔开来。方法引用有好几种形式,它们的语法如下:
| 描述 | 格式 | 方法引用示例(后面不要写括号) | 等价的Lambda表达式 |
|---|---|---|---|
| 静态方法引用 | ClassName::staticMethodName | Integer::parseInt | (a) -> Integer.parseInt(a) |
| 实例方法引用 | instanceName::methodName | System.out::println 或 String::trim | (str) -> System.out.println(str) 或 (s) -> s.trim() |
| 类上的实例方法引用 | ClassName::methodName | String::equals 或 Person::getName | (x, y) -> x.equals(y) 或 (p) -> p.getName() |
| 父类上的实例方法引用 | super::methodName | super::toString | () -> super.toString() |
| 构造方法引用 | ClassName::new | Integer::new | (n) -> new String(n) |
| 数组构造方法引用 | TypeName[]::new | Integer[]::new | (n) -> new Integer[n] |
下面是关于这六种格式的举例:
①、静态方法引用。语法格式:ClassName::staticMethodName
//1、静态方法用——ClassName::staticMethodName
@Test
public void test1() {
// Lambda表达式写法
Function<String, Integer> function = (a) -> Integer.parseInt(a);
// 方法引用
Function<String, Integer> function1 = Integer::parseInt;
Integer integer = function1.apply("100");
System.out.println(integer);
// Lambda表达式
Comparator<Integer> comparator = (a, b) -> Integer.compare(a, b);
// 方法引用
Comparator<Integer> comparator1 = Integer::compare;
int result = comparator1.compare(100,10);
System.out.println(result);
// Lambda表达式
BiFunction<Double, Double, Double> biFunction = (x, y) -> Math.max(x, y);
System.out.println(biFunction.apply(11.1, 22.2));
System.out.println("-------------");
// 方法引用
BiFunction<Double, Double, Double> biFunction1 = Math::max;
System.out.println(biFunction1.apply(33.3, 44.4));
}
②、实例上的实例方法引用。语法格式:instanceName::methodName
//2、实例上的实例方法引用——instanceName::methodName
@Test
public void test2(){
Consumer<String> consumer = (str) -> System.out.println(str);
Consumer consumer1 = System.out::println;
Person person = new Person("tanghaorong", 20, "China");
Supplier supplier = () -> person.getName();
Supplier supplier1 = person::getName;
}
③、类上的实例方法引用。语法格式:ClassName::methodName
//3、类上的实例方法引用——ClassName::methodName
public void test3(){
BiPredicate<String, String> biPredicate = (x, y) -> x.equals(y);
BiPredicate<String, String> biPredicate1 = String::equals;
Function<Person, String> fun = (p) -> p.getName();
Function<Person, String> fun2 = Person::getName;
}
④、父类上的实例方法引用。语法格式:super::methodName
//4、父类上的实例方法引用——super::methodName
@Test
public void test4(){
Person person=new Person();
Supplier supplier = () -> super.toString();
Supplier supplier1 =super::toString;
}
⑤、构造方法引用。语法格式:ClassName::new
//5、构造方法引用——ClassName::new
@Test
public void test5() {
Function<String, String> function = (n) -> new String(n);
String apply = function.apply("Lambda构造方法");
System.out.println(apply);
Function<String, String> function1 = String::new;
String apply1 = function.apply("构造方法引用");
System.out.println(apply1);
}
⑥、数组构造方法引用。语法格式:TypeName[]::new
//6、数组构造方法引用——TypeName[]::new
@Test
public void test6() {
Function<Integer, Integer[]> function = (n) -> new Integer[n];
//Integer integer[]=new Integer[20];
Integer[] apply = function.apply(3);
apply[0] = 1;
for (Integer integer : apply) {
System.out.println(integer);
}
System.out.println("-----------------");
Function<Integer, Integer[]> function1 = Integer[]::new;
Integer[] apply1 = function1.apply(5);
apply1[0] = 11;
apply1[1] = 22;
for (Integer integer : apply1) {
System.out.println(integer);
}
}
27.2.6.1 方法引用解析
上面的例子看完后你现在的状态可能是这样的😂:

你先别激动,下面慢慢来解开你的疑惑。其实仔细一点可以发现它们都是有类似的规律,这里我总结了三点(其中第三点最重要):
- 必须能够使用Lambda表达式。
- Lambda表达式中右侧的
{}可以省略,即Lambda表达式的方法体只有一个语句。 - Lambda表达式中引用方法的参数个数、类型,返回值类型和函数式接口中的方法声明要一一对应。
当满足以上条件时,Lambda表达式就可以使用方法引用的简写方式了,下面再用简单例子来走一遍:
//System.out.println()简单举例
@Test
public void test() {
// Lambda表达式写法
Function<String, Integer> flb = (a) -> Integer.parseInt(a);
// 转成方法引用
Function<String, Integer> fmr = Integer::parseInt;
Integer integer = fmr.apply("100");
System.out.println(integer);
// Lambda表达式写法
Comparator<Integer> clb = (a, b) -> Integer.compare(a, b);
// 转成方法引用
Comparator<Integer> cmr = Integer::compare;
int result = cmr.compare(100,10);
System.out.println(result);
}
再次强调第三点:Lambda表达式中引用方法的参数个数、类型,返回值类型和函数式接口中的方法声明要一一对应才行。
首先分别来看下Function函数式接口中的apply方法和Integer类中parseInt这个方法,其中Function这个函数式接口的方法定义如下:
@FunctionalInterface
public interface Function<T, R> {
R apply(T t);
}
Integer类中的parseInt方法定义如下:
public static int parseInt(String s) throws NumberFormatException {
return parseInt(s,10);
}
我们将这两个方法进行对比可以发现Function中的 apply方法参数个数是 1 个,而parseInt方法的参数个数也是 1 个,所以参数个数对应上了。而 apply方法的参数类型是泛型,所以肯定能够与parseInt方法对应上。所以接下来再看它们的返回类型,其中apply方法的返回类型是泛型类型,所以肯定也能和 parseInt方法对应上。这样一来,就可以正确的接收Integer::parseInt的方法引用了,并可以调用Funciton的apply方法,这时候调用到的其实就是对应的 Integer.parseInt方法了。
所以现在可以举一反三,用这套标准套到 Integer::compare方法上,就不难理解为什么可以用Comparator<Integer>来接收了,其中Integer.compare方法定义如下:
public static int compare(int x, int y) {
return (x < y) ? -1 : ((x == y) ? 0 : 1);
}
两个参数参数类型都是 int,返回值类型也是 int。再来看下Comparator类中的compare方法。
@FunctionalInterface
public interface Comparator<T> {
int compare(T o1, T o2);
}
可以发现与Integer.compare方法是完全可以对应上的。
tips:其实只要参数类型、个数和返回值类型能够对上的话,那么只要满足要求的函数式接口都能接收。例如上面的compare,输入参数为两个int类型,并且返回的值为int类型的,它不仅可以用Comparator来接收,还可以用 BiFunction,ToIntBiFunction,IntBinaryOperator来接收,因为它们都是接收两个参数,返回一个Int类型,所以调用它们各自的方法都能正确的返回结果,完美接收。
最后来看Comparator和BiFunction,ToIntBiFunction,IntBinaryOperator这些函数式接口定义和其中对应的方法:
@FunctionalInterface
public interface Comparator<T> {
int compare(T o1, T o2);
}
@FunctionalInterface
public interface BiFunction<T, U, R> {
R apply(T t, U u);
}
@FunctionalInterface
public interface IntBinaryOperator {
int applyAsInt(int left, int right);
}
@FunctionalInterface
public interface IntBinaryOperator {
int applyAsInt(int left, int right);
}
举例对比:
// Lambda表达式
Comparator<Integer> comparator = (a, b) -> Integer.compare(a, b);
// 方法引用
Comparator<Integer> comparator1 = Integer::compare;
int result = comparator1.compare(100,10);
System.out.println(result);
// 其它类型进行接收
BiFunction<Integer,Integer,Integer> a = Integer::compare;
IntBinaryOperator b = Integer::compare;
ToIntBiFunction<Integer,Integer> c = Integer::compare;
可以发现用BiFunction,ToIntBiFunction,IntBinaryOperator来接收Integer::compare都能正确的匹配上,其实不仅仅是上面能够看得到接口,只要是满足前面所说的三点就都能够完美匹配。例如现在的Integer::compare只要是在某个函数式接口中声明了这样的方法:两个参数,参数类型是int或者泛型,并且返回值是int或者泛型的,都可以完美接收。
27.3 Stream API流
27.3.1 Stream流的简介
Java8 中除了引入了Lambda表达式、新的Date API之外,另外还有一最大亮点就是引入了 Stream API,这也是值得所有Java开发人员学习的一个知识点,因为它的功能非常的强大,解放了程序员操作集合(Collection)时的生产力,尤其是和前面学习的Lambda表达式、函数式接口、方法引用共同使用时,才能发挥出Stream最强大的威力。
Stream流是数据渠道,像一个高级的迭代器,用于操作数据源所生成的元素序列,即操作集合、数组等等。其中集合和 Stream 的区别是:集合讲的是数据,而 Stream 讲的是计算(处理数据的过程)。Stream的API全部都位于java.util.stream这样一个包下,它能够帮助开发人员从更高的抽象层次上对集合进行一系列操作,就类似于使用SQL执行数据库查询,在流的过程中,对流中的元素执行一些操作,比如“过滤掉长度大于 10 的字符串”、“获取每个字符串的首字母”等。而借助java.util.stream包,我们可以简明的声明性的表达集合,数组和其他数据源上可能的并行处理。实现从外部迭代到内部迭代的改变。它含有高效的聚合操作、大批量的数据处理,同时也内置了许多运算方式,包括筛选、排序、聚合等等。简单来说,用Stream来操作集合——减少了代码量,增强了可读性,提高运行效率。
注意:听到 Stream 这个词大家可能会联想到 Java IO 中的Stream,例如InputStream 和 OutputStream,但是 Java 8 新增的 Stream 和 Java IO中的 Stream 是完全不同的两个东西,没有半毛钱关系。本文要讲解的 Stream 是能够对集合对象进行各种串行或并发聚集操作,而Java IO流用来处理设备之间的数据传输,它们两者截然不同。
Stream的主要特点有:
- Stream本身并不存储数据,数据是存储在对应的collection(集合)里,或者在需要的时候才生成的。
- Stream不会修改数据源,总是返回新的stream。
- Stream的操作是延迟(lazy)执行的:仅当最终的结果需要的时候才会执行,即执行到终止操作为止。
27.3.2 Stream流与传统方式对比
首先先使用传统方式的方法来对集合进行一些操作,代码示例如下:
要求:从集合中遍历出前五个元素,并且过滤掉为“two”的字符串
public class StreamTest {
public static void main(String[] args) {
//创建集合
ArrayList<String> list = new ArrayList<>();
list.add("one");
list.add("two");
list.add("three");
list.add("four");
list.add("five");
list.add("six");
list.add("seven");
//遍历数据,只遍历5个
for (int i = 0; i < 5; i++) {
//过滤掉字符串——two
if (!(list.get(i).contains("two"))) {
System.out.println(list.get(i));
}
}
}
}
我相信像上面这样的代码估计每个Java开发人员分分钟都可以实现。但是呢!有时要处理的逻辑较为再复杂,那么此时代码量就会大量增加,所以再通过特定的条件进行筛选并且将结果输出。这样的代码中或多或少会有缺点的:
- 代码量一多,维护肯定更加困难。可读性也会变差。
- 难以扩展,要修改为并行处理估计会花费很大的精力。
- 每一次操作集合中所有的元素都需要通过循环来遍历。
- 如果需要筛选后的结果,那么还需要定义一个新的集合来存储结果。
下面展示了用 Stream 流来实现相同的功能,代码非常的简洁,即使处理较为复杂的逻辑也非常的方便,因为Stream给我们提供了大量方法。
//使用filter,limit,forEach方法
list.stream().filter(s->!s.contains("two")).limit(4).forEach(System.out::println);
最终两种方式的代码运行结果是一样的:
从上面使用 Stream 的情况下我们可以发现是Stream直接连接成了一个串,然后将stream过滤后的结果转为集合并返回输出。而至于转成哪种类型,这由JVM进行推断。整个程序的执行过程像是在叙述一件事,没有过多的中间变量,所以可以减小GC压力,提高效率。所以接下来开始探索Stream的功能吧。
27.3.3 Stream的三个步骤
Stream的原理是:将要处理的元素看做一种流,流在管道中传输,并且可以在管道的节点上进行处理,包括有过滤、筛选、去重、排序、映射等等。如果要想操作流,首先需要有一个数据源,可以是数组或者集合。元素在管道中经过中间操作的处理,每次操作都会返回一个新的流对象,方便进行链式操作,但原有的流对象会保持不变。最后由终止操作得到前面处理的结果。所以Stream的所有操作分为这三个部分:创建对象-->中间操作-->终止操作。
- 初始化操作:即创建Stream流的过程,我们要使用Stream流首先的创建流对象。
- 中间操作:一个中间操作链,可以有多个,每次返回一个新的流,它主要对数据源的数据进行处理。注:中间操作是延迟执行的(lazy),意思就是在终止操作开始的时候才中间操作才真正开始执行
- 终止操作,一个终止操作,只能有一个,每次执行完,这个流也就用完了,无法再执行下一个操作,此时会执行中间操作并且产生结果,因此只能放在最后。
Stream 提供的方法非常多,如下图:
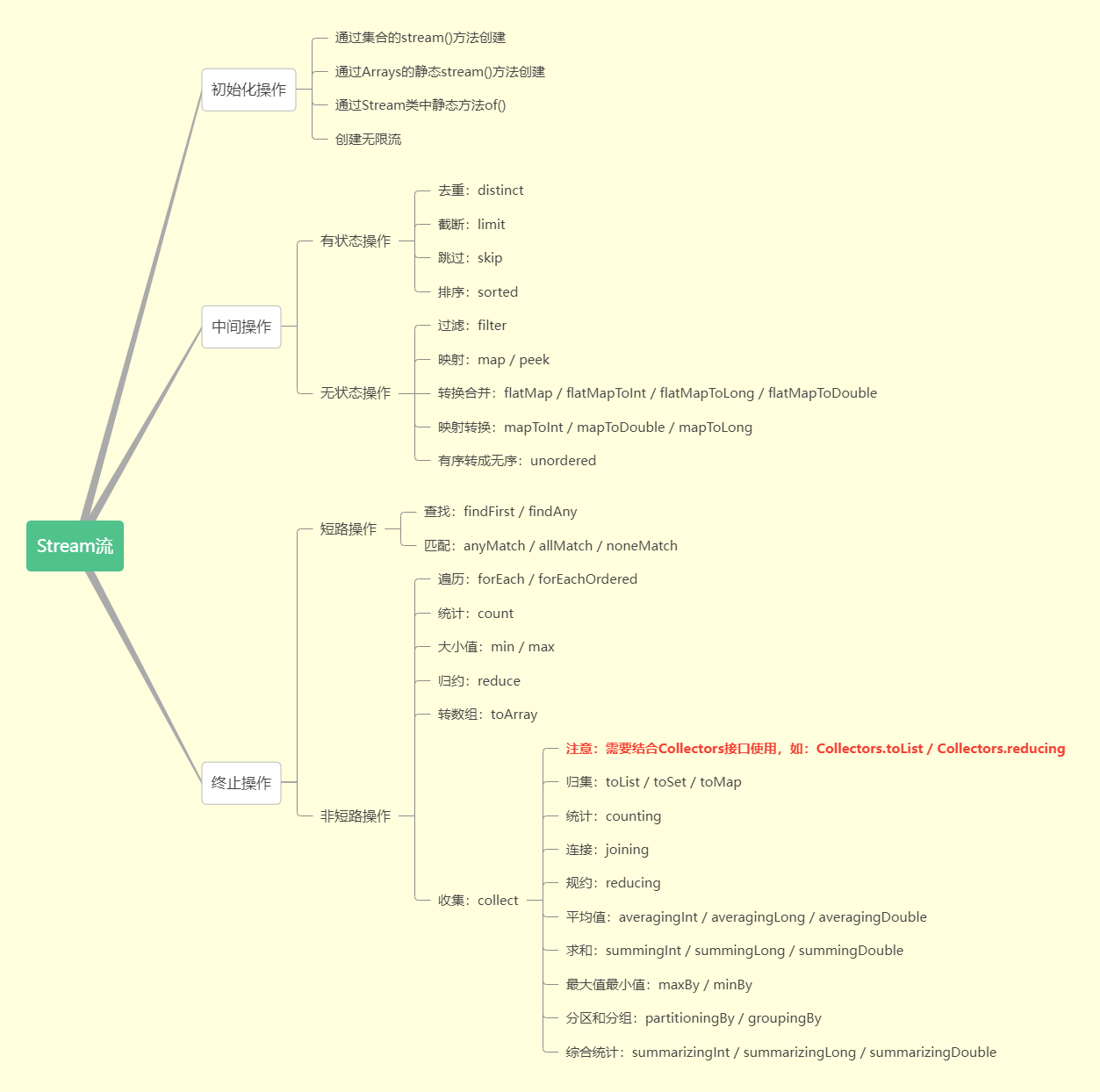
对于中间操作,又可以分为有状态的操作和无状态操作,具体如下:
- 有状态的操作是指当前元素的操作需要等所有元素处理完之后才能进行。
- 无状态的操作是指当前元素的操作不受前面元素的影响。
对于结束操作,又可以分为短路操作和非短路操作,具体如下:
- 短路操作是指不需要处理完全部的元素就可以结束。
- 非短路操作是指必须处理完所有元素才能结束。
27.3.4 Stream对象创建
[1]、使用Collection接口的扩展类,其中提供了两个获取流的方法:
default Stream<E> stream():返回一个数据流对象default Stream<E> parallelStream():返回一个并行流对象
//1、方法一:通过Collection
ArrayList<String> list=new ArrayList<>();
//获取顺序流,即有顺序的获取
Stream<String> stream = list.stream();
//获取并行流,即同时取数据,无序
Stream<String> stream1 = list.parallelStream();
[2]、通过数组,使用Arrays中的静态方法stream()获取数组流:
public static <T> Stream<T> stream(T[] array):返回一个流对象
//2、方法二:通过数组
String str[]=new String[]{"A","B","C","D","E"};
Stream<String> stream2 = Arrays.stream(str);
[3]、使用Stream类本身的静态方法of(),通过显式的赋来值创建一个流,它可以接受任意数量的参数:
public static<T> Stream<T> of(T... values):返回一个流
//3、方法三:通过Stream的静态方法of()
Stream<Integer> stream3 = Stream.of(1, 2, 3, 4, 5, 6);
[4]、创建无限流(迭代、生成)
public static<T> Stream<T> iterate(final T seed, final UnaryOperator<T> f)public static<T> Stream<T> generate(Supplier<T> s)
//4.、方式四:创建无限流(迭代、生成)
//迭代(需要传入一个种子,也就是起始值,然后传入一个一元操作)
Stream.iterate(2, (x) -> x * 2).limit(10).forEach(System.out::println);
//生成(无限产生对象)
Stream.generate(() -> Math.random()).limit(10).forEach(System.out::println);
以上的四种方式学习前三中即可,第四种不常用。除了上面这些额外还有其他创建Stream对象的方式,如Stream.empty():创建一个空的流、Random.ints():随机数流等等。
27.3.5 Stream中间操作
中间操作的所有操作会返回一个新的流,它暂时不会修改原始的数据源,因为中间操作是延迟执行的(lazy),并不会立马启动,需要等待终止操作才会执行。意思就是在终止操作开始的时候才中间操作才真正开始执行。中间操作主要有以下方法:

为了更好地举例,先创建一个Employee类,后面会使用该类:
public class Employee implements Serializable {
private static final long serialVersionUID = 4326842796835565390L;
/** 编号 */
private String empNo;
/** 名字 */
private String empName;
/** 年龄 */
private Integer age;
/** 性别 */
private Integer sex;
/** 地址 */
private String address;
/** 薪资 */
private Integer salary;
// 无参、全参、getter、setter、toString、hashCode 省略,请自行添加...
}
下面开始介绍流的中间操作的方法使用。
27.3.5.1 有状态操作
有状态的操作是指当前元素的操作需要等所有元素处理完之后才能进行。

[1]、distinct
去重 - distinct():去除流中重复的元素。
案例 :去掉字符串数组中的重复字符串
String[] array = {"a", "a", "b", "b", "c", "c", "d", "d", "e", "e"};
List<String> newList = Arrays.stream(array).distinct().collect(Collectors.toList());
System.out.println("newList:" + newList);
运行结果:
可以发现相同的元素被去除了,但是注意:使用 distinct 需要类中重写hashCode()和 equals()方法才可以使用,上面的String类中默认已经重写了。
[2]、limit
截断 - limit(long maxSize):从流中获取前 n 个元素。
案例:从数组中获取前 4 个元素
String[] array = { "a", "b", "c", "d", "e", "f", "g"};
List<String> newList = Arrays.stream(array).limit(4).collect(Collectors.toList());
System.out.println("newList:" + newList);
运行结果:
[3]、skip
跳过 - skip(long n):跳过流中前 n 个元素,若流中元素不足 n 个,则返回一个空流。它与 limit(n)互补。
案例 :从数组中获取第 4 个元素之后的元素
String[] array = { "a", "b", "c", "d", "e", "f", "g"};
List<String> newList = Arrays.stream(array).skip(4).collect(Collectors.toList());
System.out.println("newList:" + newList);
运行结果:
[4]、sorted
对流中的数据进行排序。分为默认排序和定制排序。
- sort() - 默认排序:将流中的元素按默认的顺序排序。
案例:对给定数组进行排序
String[] array = {"e", "b", "f", "d", "a", "g", "c"};
List<String> newList = Arrays.stream(array).sorted().collect(Collectors.toList());
System.out.println("newList:" + newList);
运行结果:
- sorted(Comparator<? super T> comparator) - 定制排序:按提供的比较符进行排序。
案例1:根据员工的薪资排序,并且输出员工的姓名
List<Employee> employees = new ArrayList<>();
employees.add(new Employee("1", "Jack", 23, 1, "深圳", 12000));
employees.add(new Employee("2", "Lucy", 19, 0, "上海", 7000));
employees.add(new Employee("3", "Tom", 28, 1, "北京", 32000));
employees.add(new Employee("4", "Alis", 24, 0, "纽约", 21000));
employees.add(new Employee("5", "Bob", 18, 1, "华盛顿", 5000));
List<String> nameList = employees.stream()
.sorted(Comparator.comparing(Employee::getSalary))
.map(Employee::getEmpName)
.collect(Collectors.toList());
System.out.println("按薪资排序输出员工姓名:" + nameList);
运行结果:
案例2:根据员工薪资排序,并且输出员工信息
List<Employee> employeeList = employees.stream()
.sorted((e1, e2) -> Integer.compare(e1.getSalary().compareTo(e2.getSalary()), 0))
.collect(Collectors.toList());
System.out.println("按薪资排序输出员工信息:\n" + employeeList);
注意这里的toString方法,前面加了个换行符'\n',不然都在一行不便观察结果:
@Override
public String toString() {
return "\nEmployee{" +
"empNo='" + empNo + '\'' +
", empName='" + empName + '\'' +
", age=" + age +
", sex=" + sex +
", address='" + address + '\'' +
", salary=" + salary +
'}';
}
运行结果:
27.3.5.2 无状态操作
无状态的操作是指当前元素的操作不受前面元素的影响。

[1]、filter
筛选 - filter(Predicate<? super T> predicate):按照一定的规则校验流中的元素,将符合条件的元素提取到新的流中的操作。即筛选出满足条件的数据。
案例1:筛选出数组中大于10的元素
Integer[] array = {4, 9, 3, 14, 5, 22, 19};
List<Integer> newList = Arrays.stream(array).filter(integer -> integer > 10).collect(Collectors.toList());
System.out.println("newList:" + newList);
运行结果:
案例2:筛选出年龄大于19岁并且薪资大于等于12000的员工信息
List<Employee> employees = new ArrayList<>();
employees.add(new Employee("1", "Jack", 23, 1, "深圳", 12000));
employees.add(new Employee("2", "Lucy", 19, 0, "上海", 7000));
employees.add(new Employee("3", "Tom", 28, 1, "北京", 32000));
employees.add(new Employee("4", "Alis", 24, 0, "纽约", 21000));
employees.add(new Employee("5", "Bob", 18, 1, "华盛顿", 5000));
List<Employee> employeeList = employees.stream()
.filter(employee -> employee.getAge() > 19)
.filter(employee -> employee.getSalary() >= 12000)
.collect(Collectors.toList());
System.out.println("按薪资排序输出员工姓名:" + employeeList);
运行结果:
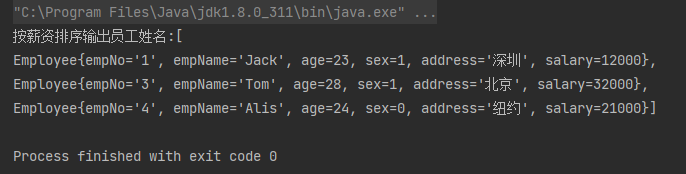
[2]、map
映射(转换) - map(Function<? super T, ? extends R> mapper):接收一个函数作为入参,将一个流的元素按照一定的映射规则映射到另一个流中,执行结果组成一个新的 Stream 返回。
案例1:对整数数组每个元素加 3
List<Integer> list = Arrays.asList(5, 2, 3, 1, 4);
List<Integer> newList = list.stream().map(x -> x + 3).collect(Collectors.toList());
System.out.println("newList:" + newList);
运行结果:

案例2:把字符串数组的每个元素转换为大写:
List<String> list = Arrays.asList("ab", "abc", "abcd", "abcde", "abcdef");
List<String> newList = list.stream().map(String::toUpperCase).collect(Collectors.toList());
System.out.println("newList:" + newList);
运行结果:
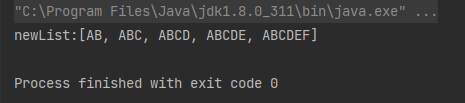
案例3:将薪资低于8000的员工全部增加1000。
List<Employee> employees = new ArrayList<>();
employees.add(new Employee("1", "Jack", 23, 1, "深圳", 12000));
employees.add(new Employee("2", "Lucy", 19, 0, "上海", 7000));
employees.add(new Employee("3", "Tom", 28, 1, "北京", 32000));
employees.add(new Employee("4", "Alis", 24, 0, "纽约", 21000));
employees.add(new Employee("5", "Bob", 18, 1, "华盛顿", 5000));
List<Employee> oldEmployeeList = employees.stream()
.filter(employee -> employee.getSalary() < 8000)
.collect(Collectors.toList());
System.out.println("旧集合中的数据:" + oldEmployeeList);
List<Employee> newEmployeeList = employees.stream()
.filter(employee -> employee.getSalary() < 8000)
.map(employee -> {
employee.setSalary(employee.getSalary() + 1000);
return employee;
}).collect(Collectors.toList());
System.out.println("新集合中的数据:" + newEmployeeList);
运行结果:
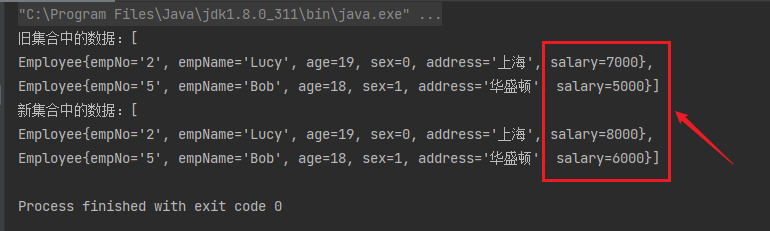
案例4:获取所有性别为男性的姓名
List<Employee> employees = new ArrayList<>();
employees.add(new Employee("1", "Jack", 23, 1, "深圳", 12000));
employees.add(new Employee("2", "Lucy", 19, 0, "上海", 7000));
employees.add(new Employee("3", "Tom", 28, 1, "北京", 32000));
employees.add(new Employee("4", "Alis", 24, 0, "纽约", 21000));
employees.add(new Employee("5", "Bob", 18, 1, "华盛顿", 5000));
List<String> nameList = employees.stream()
.filter(employee -> employee.getSex() == 1)
.map(Employee::getEmpName)
.collect(Collectors.toList());
System.out.println("获取所有性别为男性的姓名:" + nameList);
运行结果:
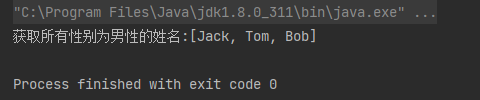
[3]、mapToXXX
- mapToInt:将元素转换成 int 类型,在 map方法的基础上进行封装。
- mapToLong:将元素转换成 Long 类型,在 map方法的基础上进行封装。
- mapToDouble:将元素转换成 Double 类型,在 map方法的基础上进行封装。
List<String> list = Arrays.asList("ab", "abc", "abcd", "abcde", "abcdef");
int[] newList = list.stream().mapToInt(r -> r.length()).toArray();
System.out.println("newList:" + Arrays.toString(newList));
运行结果:
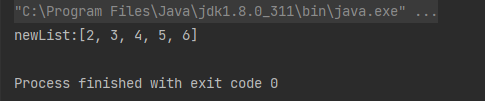
[4]、peek
返回由 stream 中元素组成的新 stream,用给定的函数作用在新 stream 的每个元素上。传入的函数是一个 Consumer 类型的,没有返回值,因此并不会改变原 stream 中元素的值。peek 主要用是 debug,可以方便地查看流处理结果是否正确。
案例:过滤出 stream 中长度大于 3 的字符串并转为大写:
Stream.of("one", "two", "three", "four")
.filter(e -> e.length() > 3)
.peek(e -> System.out.println("Filtered value: " + e))
.map(String::toUpperCase)
.peek(e -> System.out.println("Mapped value: " + e))
.collect(Collectors.toList());
运行结果:
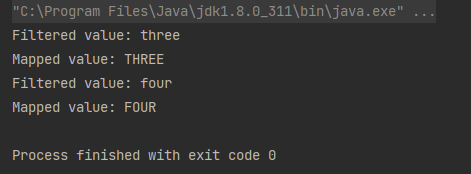
注:peek和map有点类似,所以来看一下它们之间的区别:
针对普通类型:
List<String> list = Arrays.asList("ab", "abc", "abcd", "abcde", "abcdef");
List<String> mapList = list.stream().map(String::toUpperCase).collect(Collectors.toList());
System.out.println("mapList:" + mapList);
List<String> list1 = Arrays.asList("ab", "abc", "abcd", "abcde", "abcdef");
List<String> peekList = list1.stream().peek(String::toUpperCase).collect(Collectors.toList());
System.out.println("peekList:" + peekList);
输出结果:
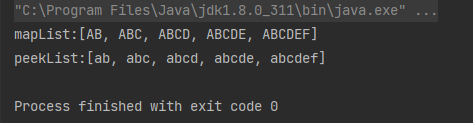
从结果可以看到使用map,流中的元素被转换成大写格式了。但是peek并没有被转换成大写格式。
解析:peek接收一个Consumer,而map接收一个Function。Consumer是没有返回值的,它只是对Stream中的元素进行某些操作,但是操作之后的数据并不返回到Stream中,所以Stream中的元素还是原来的元素。而Function是有返回值的,这意味着对于Stream的元素的所有操作都会作为新的结果返回到Stream中。
针对对象类型:
List<Employee> employees = new ArrayList<>();
employees.add(new Employee("1", "Jack", 23, 1, "深圳", 12000));
employees.add(new Employee("2", "Lucy", 19, 0, "上海", 7000));
employees.add(new Employee("3", "Tom", 28, 1, "北京", 32000));
employees.add(new Employee("4", "Alis", 24, 0, "纽约", 21000));
employees.add(new Employee("5", "Bob", 18, 1, "华盛顿", 5000));
// 简写
employees.stream().peek(employee -> {
employee.setEmpName("AAA");
}).forEach(System.out::println);
// 原生写法(通过看原生写法更好理解)
List<Employee> employeeList = employees.stream().peek(new Consumer<Employee>() {
@Override
public void accept(Employee employee) {
employee.setEmpName("AAA");
}
}).collect(Collectors.toList());
输出结果:
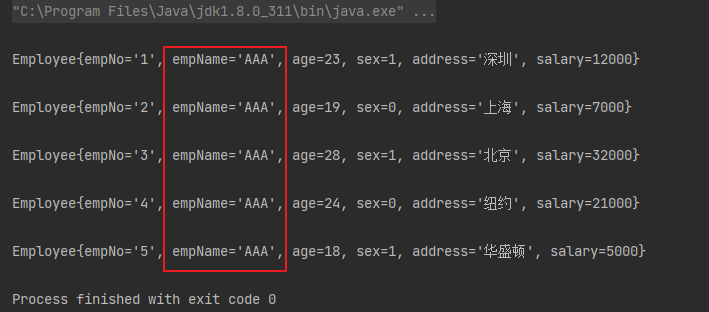
从结果可以看到如果是对象的话,实际的结果会被改变。这是因为我们操作的是对象的属性,只需改变属性值就成功了,并不需要返回,而此时原生的流中对象属性的值已经被改过了。
peek和map方法区别总结:
- 接收的参数不同:peek的入参为Consumer接口,没有返回值,而map的入参为Function接口,有返回值。
- 用途不全一样:peek一般用于打印,值修改等操作,而map一般用于更改流类型,例如List
转为List
注:一般推荐使用map即可。有些时候IDEA编译会提示你可将map操作转换成peek,但最好不要这么做。
[5]、flatMap
转换合并 - flatMap(Function<? super T, ? extends Stream<? extends R>> mapper):扁平化处理,将流中的每个值都转换成另一个流,然后把所有流组合成一个流并且返回。
它和map有点类似。flatMap在接收到Stream后,会将接收到的Stream中的每个元素取出来放入另一个Stream中,最后将一个包含多个元素的Stream返回。这是用在一些比较特别的场景下,当你的 Stream 是以下这几种结构的时候,需要用到 flatMap方法,用于将原有二维结构扁平化。
Stream<String[]>Stream<Set<String>>Stream<List<String>>
以上这三类结构,通过 flatMap方法,可以将结果转化为 Stream<String>这种形式,方便之后的其他操作。
案例1:针对Stream<String[]>举例 -- 把一个字符串数组转成另一个字符串数组:
List<String> list = Arrays.asList("h-e-l-l-o", "8-5-7");
List<String> listNew = list.stream().flatMap(s -> {
// 将每个元素转换成一个stream
String[] split = s.split("-");
Stream<String> s2 = Arrays.stream(split).distinct();
return s2;
}).collect(Collectors.toList());
System.out.println("处理前的集合:" + list);
System.out.println("处理后的集合:" + listNew);
输出结果:
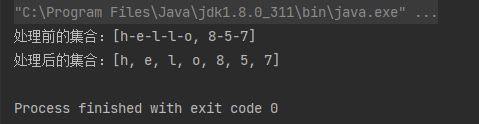
案例2:针对Stream<List
>举例 -- 把一个集合类型的集合转成另一个字符串数组:
List<List<String>> lists = new ArrayList<>();
lists.add(Arrays.asList("Sloane", "Gregory"));
lists.add(Arrays.asList("Farmer", "Just", "qq", "Roland"));
lists.add(Arrays.asList("Soldier", "Godly"));
List<String> collect4 = lists.stream().flatMap(Collection::stream)
.filter(str -> str.length() > 2)
.collect(Collectors.toList());
System.out.println(collect4);
输出结果:
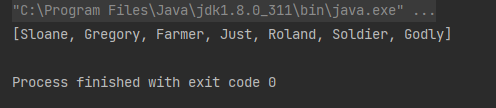
[6]、flatMapToXXX
- flatMapToInt:用法参考 flatMap,将元素扁平为 int 类型,在 flatMap方法的基础上进行封装。
- flatMapToLong:用法参考 flatMap,将元素扁平为 Long 类型,在 flatMap方法的基础上进行封装。
- flatMapToDouble:用法参考 flatMap,将元素扁平为 Double 类型,在 flatMap方法的基础上进行封装。
案例1:获取集合中字符串的长度
List<String> list = Arrays.asList("Stream", "IntStream", "List", "Arrays");
list.stream().flatMapToInt(str -> IntStream.of(str.length())).forEach(System.out::println);
输出结果:
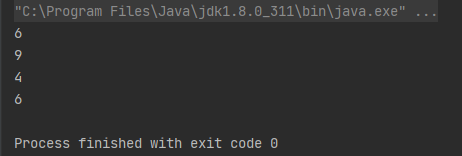
案例2:对给定的二维整数数组求和:
int[][] data = {{1,2},{3,4},{5,6}};
IntStream intStream = Arrays.stream(data).flatMapToInt(row -> Arrays.stream(row));
System.out.println(intStream.sum());
输出结果:

[7]、unordered
有序转成无序 - unordered():把一个有序的 Stream 转成一个无序 Stream。注:只在并行流中起作用,而且并行流在处理有序数据结构时,性能会有很大影响。
案例:把一个有序数组转成无序
List<String> list = Arrays.asList("a", "b", "c", "d", "ab", "abc", "abcd", "abcde", "abcdef");
list.parallelStream().unordered().forEach(System.out::println);
运行结果:
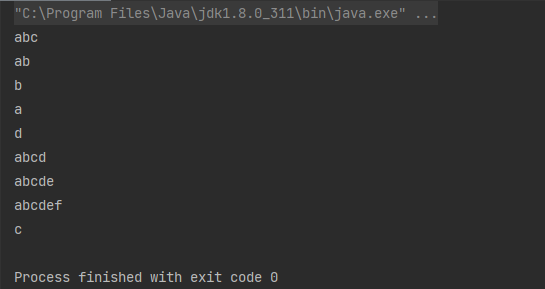
27.3.6 Stream终止操作
终止操作主要有以下方法如图,下面只介绍一下常用的方法。注意:Stream流只要进行了终止操作后,就不能再次使用了,再次使用得重新创建流。

27.3.6.1 短路操作
短路操作是指不需要处理完全部的元素就可以结束。

[1]、findFirst
查找 - findFirst():返回 Stream 中的第一个元素。
案例 1:找出数组中第一个字符串
String[] array = {"a", "b", "c", "d"};
String str = Arrays.stream(array).findFirst().get();
System.out.println("找出数组中第一个字符串:" + str);
运行结果:
案例 2:找出第一个年龄大于20岁的员工信息
List<Employee> employees = new ArrayList<>();
employees.add(new Employee("1", "Jack", 23, 1, "深圳", 12000));
employees.add(new Employee("2", "Lucy", 19, 0, "上海", 7000));
employees.add(new Employee("3", "Tom", 28, 1, "北京", 32000));
employees.add(new Employee("4", "Alis", 24, 0, "纽约", 21000));
employees.add(new Employee("5", "Bob", 18, 1, "华盛顿", 5000));
Employee employee1 = employees.stream().filter(employee -> employee.getAge() > 20).findFirst().orElse(null);
System.out.println("找出第一个年龄大于20岁的员工信息:" + employee1);
运行结果:

[2]、findAny
查找 - findAny():返回 Stream 中任何一个满足过滤条件的元素。注意:如果是串行情况下,一般都会返回第一个元素,并行情况下就不一定了。
案例:找出任何一个薪资高于 10000 的员工
Employee employee1 = employees.stream().filter(employee -> employee.getAge() > 20).findAny().orElse(null);
System.out.println("找出任何一个薪资高于 10000 的员工:" + employee1);
输出结果:

[3]、anyMatch
匹配 - anyMatch(Predicate<? super T> predicate):返回值为boolean,检查是否存在任意一个满足给定条件的元素。
案例:①、匹配是否存在薪资高于 20000 的员工。②、匹配是否存在薪资低于 3000 的员工。
boolean match1 = employees.stream().anyMatch(employee -> employee.getSalary() > 20000);
System.out.println("匹配是否存在薪资高于 20000 的员工:" + match1);
boolean match2 = employees.stream().anyMatch(employee -> employee.getSalary() < 3000);
System.out.println("匹配是否存在薪资低于 3000 的员工:" + match2);
运行结果:
[4]、allMatch
匹配 - allMatch(Predicate<? super T> predicate):返回值为boolean,检查是否至少匹配一个元素满足给定的条件,如果集合是空,则返回 true。
案例:①、匹配员工薪资是否都高于 3000。②、匹配员工薪资是否都高于 20000
boolean match1 = employees.stream().allMatch(employee -> employee.getSalary() > 3000);
System.out.println("匹配员工薪资是否都高于 3000:" + match1);
boolean match2 = employees.stream().allMatch(employee -> employee.getSalary() > 20000);
System.out.println("匹配员工薪资是否都高于 20000:" + match2);
运行结果:
[5]、noneMatch
匹配 - anyMatch(Predicate<? super T> predicate):返回值为boolean,检查是否没有元素能匹配给定的条件,如果集合是空,则返回 true。
案例:①、匹配是不是没有员工薪资在 40000 以上的。②、匹配是不是没有员工薪资在 10000 以下的
boolean match1 = employees.stream().noneMatch(employee -> employee.getSalary() > 40000);
System.out.println("匹配是不是没有员工薪资在 40000 以上的:" + match1);
boolean match2 = employees.stream().noneMatch(employee -> employee.getSalary() < 10000);
System.out.println("匹配是不是没有员工薪资在 10000 以下的:" + match2);
运行结果:
27.3.6.2 非短路操作
非短路操作是指必须处理完所有元素才能结束。

[1]、forEach
遍历 - forEach(Consumer<? super T> action):接收Lambda表达式,遍历流中的所有元素。
forEach上面已经用的够多的了这里就不说了。
[2]、forEachOrdered
遍历 - forEachOrdered(Consumer<? super T> action):按照给定集合中元素的顺序输出。主要使用场景是在并行流的情况下,按照给定的顺序输出元素。
案例:用并行流遍历一个数组并按照给定数组的顺序输出结果
List<Integer> array = Arrays.asList(5, 2, 3, 1, 4);
array.parallelStream().forEachOrdered(System.out :: println);
[3]、count / max / min
- count():返回流中总数量
- max(Comparator<? super T> comparator):返回流中最大值
- min(Comparator<? super T> comparator):返回流中最小值
案例1:总数、最大值、最小值
List<Integer> list = Arrays.asList(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
// 总数:count
Long count = list.stream().count();
// 最大值:max
Integer max = list.stream().max(Integer::compareTo).get();
// 最小值:min
Integer min = list.stream().min(Integer::compareTo).get();
案例2:分别获取年龄最大的员工和年龄最小的员工信息
// 获取最大年龄的员工信息
Optional<Employee> max = employees.stream().max(Comparator.comparingInt(Employee::getAge));
System.out.println("获取最大年龄的员工信息:"+max.get());
// 获取最小年龄的员工信息
Optional<Employee> min = employees.stream().min(Comparator.comparingInt(Employee::getAge));
System.out.println("获取最小年龄的员工信息:"+min.get());
运行结果:
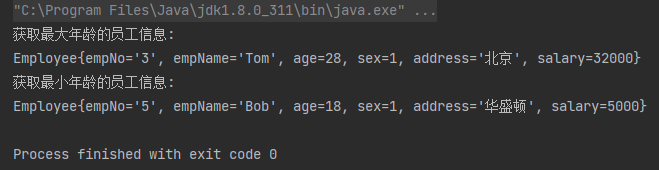
[4]、reduce
归约 - reduce:把一个流中的元素反复结合在一起,然后得到一个值。
Optional <T> reduce(BinaryOperator <T> accumulator):表示根据accumulator条件进行结合T reduce(T identity, BinaryOperator <T> accumulator):表示将identity作为起始值,然后根据accumulator条件进行结合
案例:从1累加到10
List<Integer> list = Arrays.asList(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
//1、Optional<T> reduce(BinaryOperator<T> accumulator);
Integer sum1 = list.stream().reduce(Integer::sum).get();
System.out.println("reduce1--" + sum1);
//2、T reduce(T identity, BinaryOperator<T> accumulator);
Integer sum2 = list.stream().reduce(0, Integer::sum);
System.out.println("reduce2--" + sum2);
//3、原生写法
Optional<Integer> sum3 = list.stream().reduce(new BinaryOperator<Integer>() {
@Override
public Integer apply(Integer integer1, Integer integer2) {
return Integer.sum(integer1, integer2);
}
});
System.out.println("reduce3--" + sum3.get());
运行结果:
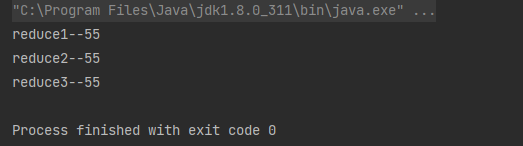
[5]、toArray
转数组 - toArray() / toArray(IntFunction<A[]> generator):返回包括给定 Stream 中所有元素的数组。
案例:把给定字符串流转化成数组
Stream<String> stream = Stream.of("ab", "abc", "abcd", "abcde", "abcdef");
String[] newArray1 = stream.toArray(str -> new String[5]);
String[] newArray2 = stream.toArray(String[]::new);
Object[] newArray3 = stream.toArray();
[6]、collect
收集 - collect(Collector<? super T, A, R> collector):将流转换为其他形式。它接收一个 Collector接口的实现,用于给Stream中元素做汇总的方法。由于这里主要跟Collectors接口有关,所以下面详细介绍。
27.3.7 Collectors的使用
Stream流与Collectors中的方法是非常好的搭档,通过组合来以更简单的方式来实现更加强大的功能,Collectors实用类提供了很多静态方法。

[1]、toList():将流转换成List。
案例:获取所有员工名称集合列表
List<Employee> employees = new ArrayList<>();
employees.add(new Employee("1", "Jack", 23, 1, "深圳", 12000));
employees.add(new Employee("2", "Lucy", 19, 0, "上海", 7000));
employees.add(new Employee("3", "Tom", 28, 1, "北京", 32000));
employees.add(new Employee("4", "Alis", 24, 0, "纽约", 21000));
employees.add(new Employee("5", "Bob", 18, 1, "华盛顿", 5000));
List<String> nameList = employees.stream().map(Employee::getEmpName).collect(Collectors.toList());
System.out.println("将流转换成List:" + nameList);
[2]、toSet():将流转换为Set。
案例:归纳不同薪资列表
List<Employee> employees = new ArrayList<>();
employees.add(new Employee("1", "Jack", 23, 1, "深圳", 12000));
employees.add(new Employee("2", "Lucy", 19, 0, "上海", 7000));
employees.add(new Employee("3", "Tom", 28, 1, "北京", 32000));
employees.add(new Employee("4", "Alis", 24, 0, "纽约", 21000));
employees.add(new Employee("5", "Bob", 18, 1, "华盛顿", 5000));
Set<Integer> salarySet = employees.stream().map(Employee::getSalary).collect(Collectors.toSet());
System.out.println("将流转换成Set:" + salarySet);
[3]、toMap():将流转换为Map。
案例:获取员工姓名对应的薪资集合
employees.add(new Employee("1", "Jack", 23, 1, "深圳", 12000));
employees.add(new Employee("2", "Lucy", 19, 0, "上海", 7000));
employees.add(new Employee("3", "Tom", 28, 1, "北京", 32000));
employees.add(new Employee("4", "Alis", 24, 0, "纽约", 21000));
employees.add(new Employee("5", "Bob", 18, 1, "华盛顿", 5000));
Map<String, Integer> toMap = employees.stream().collect(Collectors.toMap(Employee::getEmpName, Employee::getSalary));
System.out.println("将流转换成Map:" + toMap);
[4]、toCollection():将流转换为其他类型的集合。
TreeSet<String> toTreeSet = employees.stream().map(Employee::getEmpName).collect(Collectors.toCollection(TreeSet::new));
System.out.println("将流转换为其他类型的集合:" + toTreeSet);
[5]、counting():统计元素个数。
Long count = employees.stream().collect(Collectors.counting());
System.out.println("元素个数:" + count);
[6]、averagingInt() / averagingDouble() / averagingLong():求平均数。这三个方法都可以求平均数,不同之处在于传入得参数类型不同,但是返回值都为Double。
案例:求所有员工的平均年龄
/**
* Collectors.averagingInt()
* Collectors.averagingDouble()
* Collectors.averagingLong()
* 求平均数
*/
// 求所有员工的平均年龄
Double avgAge1 = employees.stream().collect(Collectors.averagingInt(employee -> employee.getAge()));
System.out.println("averagingInt()--求所有员工的平均年龄:" + avgAge1);
Double avgAge2 = employees.stream().collect(Collectors.averagingDouble(employee -> employee.getAge()));
System.out.println("averagingInt()--求所有员工的平均年龄:" + avgAge2);
Double avgAge3 = employees.stream().collect(Collectors.averagingLong(employee -> employee.getAge()));
System.out.println("averagingInt()--求所有员工的平均年龄:" + avgAge3);
运行结果:
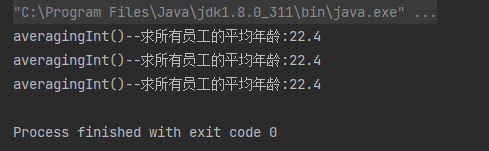
[7]、summingDouble() / summingDouble() / summingLong():求和。这三个方法都可以求和,不同之处在于传入得参数类型不同,返回值为Integer, Double, Long。
案例:求所有员工薪资总和。
/**
* Collectors.summingInt()
* Collectors.summingDouble()
* Collectors.summingLong()
* 求和
*/
// 求所有员工薪资总和。
Integer integer = employees.stream().collect(Collectors.summingInt(employee -> employee.getAge()));
System.out.println("summingInt()--求所有员工薪资总和:" + integer);
Double aDouble3 = employees.stream().collect(Collectors.summingDouble(employee -> employee.getAge()));
System.out.println("summingDouble()--求所有员工薪资总和:" + aDouble3);
Long aLong1 = employees.stream().collect(Collectors.summingLong(employee -> employee.getAge()));
System.out.println("summingLong()--求所有员工薪资总和:" + aLong1);
运行结果:
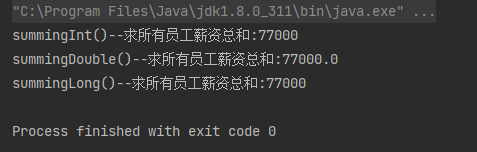
[8]、maxBy() / minBy():求最大值和最小值。
案例:①、获取薪资最高的员工信息。②、获取年龄小的员工信息
// 获取薪资最高的员工信息。
Optional<Integer> collect1 = employees.stream().map(Employee::getSalary).collect(Collectors.maxBy(Integer::compare));
System.out.println("获取薪资最高的员工信息:"+collect1.get());
// 获取年龄小的员工信息
Optional<Integer> collect2 = employees.stream().map(Employee::getAge).collect(Collectors.minBy(Integer::compare));
System.out.println("获取年龄小的员工信息:"+collect2.get());
运行结果:
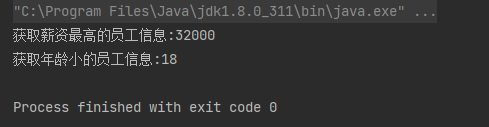
[9]、groupingBy():分组 ,返回一个map。
案例1:根据性别分组获取员工信息
List<Employee> employees = new ArrayList<>();
employees.add(new Employee("1", "Jack", 23, 1, "深圳", 12000));
employees.add(new Employee("2", "Lucy", 19, 0, "上海", 7000));
employees.add(new Employee("3", "Tom", 28, 1, "北京", 32000));
employees.add(new Employee("4", "Alis", 24, 0, "纽约", 21000));
employees.add(new Employee("5", "Bob", 18, 1, "华盛顿", 5000));
// 根据性别分组获取员工信息
Map<Integer, List<Employee>> map = employees.stream().collect(Collectors.groupingBy(Employee::getSex));
Set<Map.Entry<Integer, List<Employee>>> entrySet = map.entrySet();
for (Map.Entry<Integer, List<Employee>> entry : entrySet) {
System.out.println("key=" + entry.getKey() + ",value = " + entry.getValue());
}
运行结果:
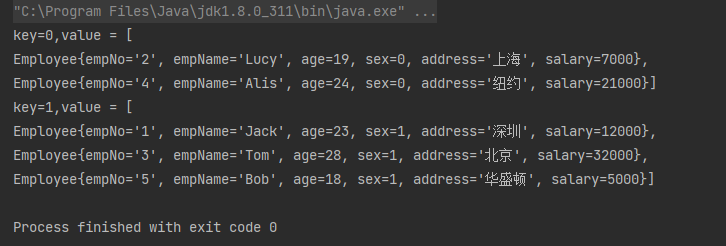
其中Collectors.groupingBy()还可以实现多级分组,如下:
案例2:根据性别分组然后得出每组的员工数量
//根据性别分组然后得出每组的员工数量,使用重载的groupingBy方法,第二个参数是分组后的操作
Map<String, Long> stringLongMap = employees.stream().collect(Collectors.groupingBy(Employee::getEmpName, Collectors.counting()));
System.out.println("groupingBy()多级分组-根据性别分组然后得出每组的员工数量:"+stringLongMap);
运行结果:

案例3:先按性别进行分组然后再按年龄分组
//先按性别进行分组然后再按年龄分组
Map<Integer, Map<Integer, List<Employee>>> integerMapMap = employees.stream().collect(Collectors.groupingBy(Employee::getSex, Collectors.groupingBy(Employee::getAge)));
System.out.println("groupingBy()多级分组-先按性别进行分组然后再按年龄分组:" + integerMapMap);
System.out.println("----遍历----");
//遍历
Iterator<Map.Entry<Integer, Map<Integer, List<Employee>>>> iterator = integerMapMap.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<Integer, Map<Integer, List<Employee>>> entry = iterator.next();
System.out.println("key=" + entry.getKey() + "--value=" + entry.getValue());
}
运行结果:
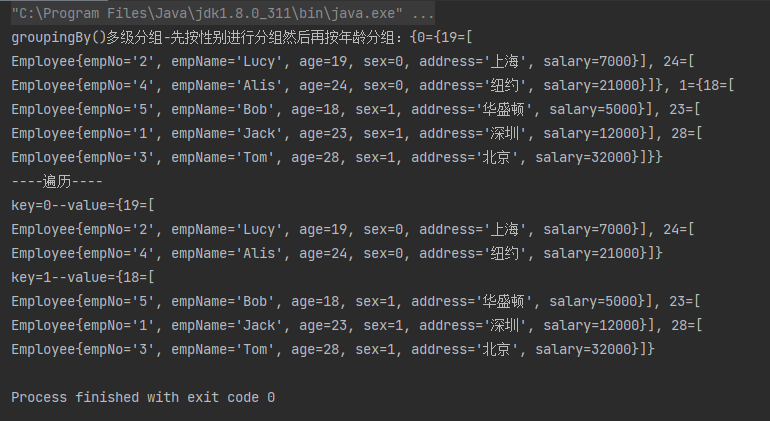
补充:分组之后我们获取的结果是一个对象的集合,但是如果有时候我们只需要对象中的某一个字段的数据呢,当然我们可以直接通过遍历的方式获取,但是Java也给我们提供了解决方案——Collectors.mapping()。
// 根据性别分组获取员工信息
Map<Integer, List<Employee>> map = employees.stream().collect(Collectors.groupingBy(Employee::getSex));
Set<Map.Entry<Integer, List<Employee>>> entrySet = map.entrySet();
for (Map.Entry<Integer, List<Employee>> entry : entrySet) {
System.out.println("key=" + entry.getKey() + ",value = " + entry.getValue());
}
System.out.println();
// 根据性别分组,并且只获取员工的名字
Map<Integer, List<String>> collect = employees.stream().collect(Collectors.groupingBy(Employee::getSex, Collectors.mapping(Employee::getEmpName, Collectors.toList())));
System.out.println(collect);
// 根据性别分组,并且只获取员工的名字,更换拼接方式
Map<Integer, String> collect1 = employees.stream().collect(Collectors.groupingBy(Employee::getSex, Collectors.mapping(Employee::getEmpName, Collectors.joining(";", "[", "]"))));
System.out.println(collect1);
运行结果:
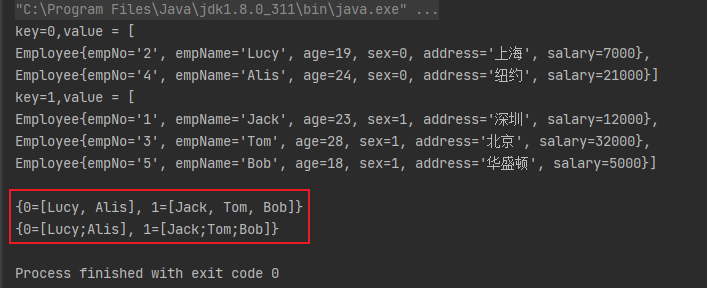
[10]、partitioningBy():分区 ,返回两个map。按true和false分成两个区。
案例:将员工按薪资是否高于8000分为两部分
List<Employee> employees = new ArrayList<>();
employees.add(new Employee("1", "Jack", 23, 1, "深圳", 12000));
employees.add(new Employee("2", "Lucy", 19, 0, "上海", 7000));
employees.add(new Employee("3", "Tom", 28, 1, "北京", 32000));
employees.add(new Employee("4", "Alis", 24, 0, "纽约", 21000));
employees.add(new Employee("5", "Bob", 18, 1, "华盛顿", 5000));
// 案例:将员工按薪资是否高于8000分为两部分
Map<Boolean, List<Employee>> part = employees.stream().collect(Collectors.partitioningBy(x -> x.getSalary() > 8000));
System.out.println("员工按薪资是否大于8000分组情况:" + part);
运行结果:
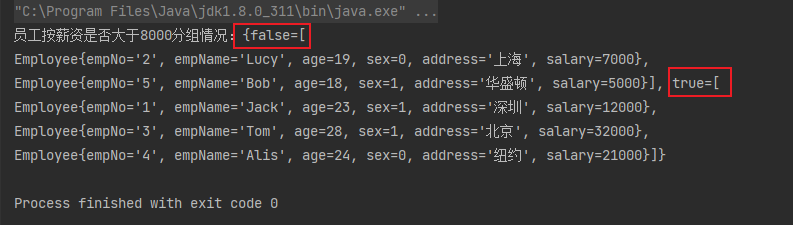
[11]、joining():拼接。按特定字符将数据拼接起来。
案例1:将字符串用 - 拼接
List<String> list = Arrays.asList("A", "B", "C");
String string = list.stream().collect(Collectors.joining("-"));
System.out.println("拼接后的字符串:" + string);
运行结果:
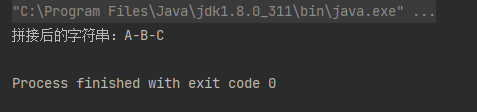
案例2:将所有员工的姓名用逗号分隔
String names = employees.stream().map(employee -> employee.getEmpName()).collect(Collectors.joining(","));
System.out.println("所有员工的姓名:" + names);
运行结果:
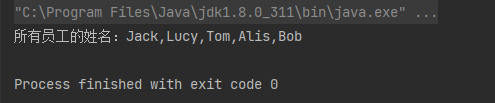
[12]、summarizingInt / summarizingLong / summarizingDouble:综合统计。返回的结果包含了总数,最大值,最小值,总和,平均值。
List<Integer> list = Arrays.asList(5, 2, 3, 1, 4);
IntSummaryStatistics statistics = list.stream().collect(Collectors.summarizingInt(r -> r));
System.out.println("综合统计结果:" + statistics.toString());
运行结果:

[13]、reducing:规约。前面已经介绍过了,这里的规约支持更强大的自定义规约
案例:数组中每个元素加 1 后求总和
List<Integer> list = Arrays.asList(5, 2, 3, 1, 4);
int listSum = list.stream().collect(Collectors.reducing(0, x -> x + 1, (sum, b) -> sum + b));
System.out.println("数组中每个元素加 1 后总和:" + listSum);
输出结果:

27.3.8 结束语
Java8中的Stream提供的功能非常强大,用它们来操作集合会让我们用更少的代码,更快的速度遍历出集合。而且在java.util.stream包下还有个类Collectors,它和stream是好非常好的搭档,通过组合来以更简单的方式来实现更加强大的功能。虽然上面介绍的都是Stream的一些基本操作,但是只要大家勤加练习就可以灵活使用,很快的可以运用到实际应用中。
27.3.9 Stream流的原理
这是我在微信公众看到的,觉得写的挺好的。
参考资料:
27.4 Optional 类
27.4.1 Optional概述
对于Java程序员来说,到目前为止出现次数最多的应该是NullPointerException,它是导致Java应用程序失败的最常见原因。之前处理空指针我们必须先通过条件去判断 (if...else,三元表达式),然后再确认是否有null值。但是在 Java 8 版本中,我们可以使用 Optional 类来解决null值判断问题,其借鉴Google Guava项目的Optional类而引入的一个同名Optional类,Guava通过使用检查空值的方式来防止代码污染,它鼓励程序员写更干净的代码。使用Optional类可以避免显式的null值判断 (null的防御性检查) ,避免null导致的NPE (NullPointerException)。
- Optional 类是 Java 8 版本才引入的一个特性,这个类主要是用来解决空指针异常。
- Optional 类是一个可以为null的容器对象,其内部提供了一些方法来处理对象可能为null的情况。例如:如果值存在则isPresent()方法会返回true,调用get()方法会返回该对象。
- Optional 是个容器:它可以保存类型T的值,或者仅仅保存null。Optional提供很多有用的方法,这样我们就不用显式进行空值检测。
首先我们来看一段代码示例:
public static String getName(Student student){
if (student==null){
return "null";
}
return student.getName();
}
这是一个获取学生姓名的方法,方法入参为一个Student对象,为了防止student对象为null, 做了防御性检查:如果值为null,返回"null"。
再看使用Optional对象的方法:
public static String getName(Student student){
Optional<Student> student1 = Optional.ofNullable(student);
if(student1.isPresent()){
return "null";
}
return student.getName();
}
改写成上面这种形式其实和上面的没有什么太大区别,因为它不是Optional最好的使用方式。
下面是Optional最优的方式:
public static String getName(Student student){
return Optional.ofNullable(student).map(s->s.getName()).orElse("null");
}
所以可以看到,Optional类在结合Lambda表达式能够让我们开发出的代码更简洁和优雅。
下面,我将简单的为大家介绍一下 Optional 以及怎么构建一个 Optional 对象和具体的 API 使用方法。
27.4.2 Optional对象的构建
构建Optional对象有三种方法,分别是:empty( )、of( )、ofNullable( )
然后我们看下这三个方法在Optional类的部分源码,如下所示:
public final class Optional<T> {
private static final Optional<?> EMPTY = new Optional<>();
private final T value;
private Optional() {
this.value = null;
}
public static<T> Optional<T> empty() {
@SuppressWarnings("unchecked")
Optional<T> t = (Optional<T>) EMPTY;
return t;
}
private Optional(T value) {
this.value = Objects.requireNonNull(value);
}
public static <T> Optional<T> of(T value) {
return new Optional<>(value);
}
public static <T> Optional<T> ofNullable(T value) {
return value == null ? empty() : of(value);
}
}
从上面可以看出,Optional类的两个构造方法都是private型的,因此类外部不能显示的使用new Optional()的方式来创建Optional对象,但是Optional类提供了三个静态方法empty()、of(T value)、ofNullable(T value)来创建Optinal对象。
1、empty():创建一个包装对象值为空的Optional对象
Optional<Student> optional1= Optional.empty();
2、of():创建包装对象值非空的Optional对象
Optional<String> optional2 = Optional.of("optional2");
3、ofNullable():创建包装对象值允许为空的Optional对象
Optional<Student> optional3 = Optional.ofNullable(null);
27.4.3 Optional类常用方法
1、 get()方法:如果在这个Optional中包含值,则返回实际值value,否则会抛出NoSuchElementException异常
简单看下get()方法的源码:
public T get() {
if (value == null) {
throw new NoSuchElementException("No value present");
}
return value;
}
可以看到,get()方法主要用于返回包装对象的实际值,但是如果包装对象值为null,会抛出NoSuchElementException异常。
2、isPresent()方法:如果值存在则方法会返回true,否则返回 false。
isPresent()方法的源码:
public boolean isPresent() {
return value != null;
}
可以看到,isPresent()方法用于判断包装对象的值是否非空。
3、 ifPresent()方法:如果存在值,则使用该值调用指定的使用者(Consumer),否则不执行任何操作。
ifPresent()方法的源码:
public void ifPresent(Consumer<? super T> consumer) {
if (value != null)
consumer.accept(value);
}
ifPresent()方法接受一个Consumer对象(消费函数),如果包装对象的值非空,运行Consumer对象的accept()方法,否则不做处理。示例如下:
public static void printName(Student student)
{
Optional.ofNullable(student).ifPresent(s -> System.out.println(s.getName()));
}
上述示例用于打印学生姓名,由于ifPresent()方法内部做了null值检查,调用前无需担心NPE问题。
特别注意:谨慎使用isPresent()和get()方法,尽量多使用下面的filter()、map()、orElse()等方法来发挥Optional的作用。因为使用isPresent()方法会像第一节实现的代码一样:
public static String getName(Student student){
Optional<Student> student1 = Optional.ofNullable(student);
if(student1.isPresent()){
return "null";
}
return student.getName();
}
这种用法不但没有减少null的防御性检查,而且增加了Optional包装的过程,违背了Optional设计的初衷,因此开发中要避免这种糟糕的使用。
4、filter()方法:如果值存在,并且这个值匹配给定的 predicate,返回一个Optional用以描述这个值,否则返回一个空的Optional。
filter()方法的源码:
public Optional<T> filter(Predicate<? super T> predicate) {
Objects.requireNonNull(predicate);
if (!isPresent())
return this;
else
return predicate.test(value) ? this : empty();
}
filter()方法接受参数为Predicate对象,用于对Optional对象进行过滤,如果符合Predicate的条件,返回Optional对象本身,否则返回一个空的Optional对象。举例如下:
public static void filterAge(Student student)
{
Optional.ofNullable(student).filter(s ->s.getAge() > 18).ifPresent(s -> System.out.println("The student age is more than 18."));
}
上述示例中,实现了年龄大于18的学生的筛选。
5、map()方法:如果有值,则对其执行调用映射函数得到返回值。如果返回值不为 null,则创建包含映射返回值的Optional作为map方法返回值,否则返回空Optional。
map()方法的源码:
public<U> Optional<U> map(Function<? super T, ? extends U> mapper) {
Objects.requireNonNull(mapper);
if (!isPresent())
return empty();
else {
return Optional.ofNullable(mapper.apply(value));
}
}
map()方法的参数为Function(函数式接口)对象,map()方法将Optional中的包装对象用Function函数进行运算,并包装成新的Optional对象(包装对象的类型可能改变)。举例如下:
public static Optional<Integer> getAge(Student student)
{
return Optional.ofNullable(student).map(s –> s.getAge());
}
上述代码中,先用ofNullable()方法构造一个Optional对象,然后用map()计算学生的年龄,返回Optional
6、flatMap()方法:如果值存在,返回基于Optional包含的映射方法的值,否则返回一个空的Optional
flatMap()方法的源码:
public<U> Optional<U> flatMap(Function<? super T, Optional<U>> mapper) {
Objects.requireNonNull(mapper);
if (!isPresent())
return empty();
else {
return Objects.requireNonNull(mapper.apply(value));
}
}
跟map()方法不同的是,入参Function函数的返回值类型为Optional类型,而不是U类型,这样flatMap()能将一个二维的Optional对象映射成一个一维的对象。
public static Optional<Integer> getAge(Student student)
{
return Optional.ofNullable(student).flatMap(s -> Optional.ofNullable(s.getAge()));
}
7、orElse()方法:如果存在该值,返回值, 否则返回 other。
orElse()方法的源码:
public T orElse(T other) {
return value != null ? value : other;
}
orElse()方法功能比较简单,即如果包装对象值非空,返回包装对象值,否则返回入参other的值(默认值)。
public static String getName(Student student)
{
return Optional.ofNullable(student).map(s –> s.getName()).orElse("Unkown");
}
8、orElseGet()方法:如果存在该值,返回值, 否则触发 other,并返回 other 调用的结果。
orElseGet()方法的源码:
public T orElseGet(Supplier<? extends T> other) {
return value != null ? value : other.get();
}
orElseGet()方法与orElse()方法类似,区别在于orElseGet()方法的入参为一个Supplier对象,用Supplier对象的get()方法的返回值作为默认值。如:
public static String getGender(Student student)
{
return Optional.ofNullable(student).map(s –> s.getGender()).orElseGet(() -> "Unkown");
}
9、orElseThrow()方法:如果存在该值,返回包含的值,否则抛出由 Supplier 继承的异常
orElseThrow()方法的源码:
public <X extends Throwable> T orElseThrow(Supplier<? extends X> exceptionSupplier) throws X {
if (value != null) {
return value;
} else {
throw exceptionSupplier.get();
}
}
orElseThrow()方法其实与orElseGet()方法非常相似了,入参都是Supplier对象,只不过orElseThrow()的Supplier对象必须返回一个Throwable异常,并在orElseThrow()中将异常抛出:
public static String getGender1(Student student)
{
return Optional.ofNullable(student).map(s –> s.getGender()).orElseThrow(() -> new RuntimeException("Unkown"));
}
orElseThrow()方法适用于包装对象值为空时需要抛出特定异常的场景。
27.4.4 Optional总结
总的来说,Optional类可以帮我们有效的处理null值,但是个人觉得不用函数式编程的话,感觉没什么体验,因为Optional实现的功能,有很多替代方案,if-else、三目等都可以;但Optional是用于函数式的一个整体中的一环,让函数式更流畅。所以如果你使用的是Java8,建议去了解一下。

