Spring
声明:此文是小白本人学习Spring所写,主要参考(搬运)了:【框架】--Spring - 随笔分类 - 唐浩荣 - 博客园 (cnblogs.com)
以及:
- 浅谈IOC--说清楚IOC是什么_ivan820819的博客-CSDN博客_ioc
- IOC 的理解与解释 - NancyForever - 博客园 (cnblogs.com)
- 代理模式与AOP_九州殊口二的博客-CSDN博客_aop和代理的区别
- JDK动态代理(介绍理解,如何实现)_TxCode的博客-CSDN博客_jdk动态代理
- JDK动态代理(介绍理解,如何实现)_TxCode的博客-CSDN博客_jdk动态代理
- AOP之动态代理_生椰打铁的博客-CSDN博客_aop动态代理
- 切入点表达式的写法详解_咸鸭蛋白的博客-CSDN博客_切入点表达式详解
感谢此文所引用的文章的作者提供的优质学习资源,如有侵犯,请原作者联系我删除
- 1、Spring框架介绍
- 2、Spring的入门案例
- 3、IoC控制反转/DI依赖注入
- 4、Spring IoC容器的设计与实现
- 5、Spring IoC容器的初始化过程
- 6、基于XML的方式装配Bean
- 7、基于注解的方式装配Bean
- 8、通过@Configuration和@Bean注解注册Bean
- 9、注解@Scope @DependsOn @Lazy @ImportResource的使用
- 10、AOP相关理论介绍
- 11、基于AspectJ注解实现AOP
- 12、基于XML的方式实现AOP
- 13、Spring中对事务的支持
- 14、使用注解驱动单元测试
- 15、Spring 整合 MyBatis
- 16、优化Spring配置
- 附:设计模式简介
1、Spring框架介绍
1.1 Spring简介
Spring的英文翻译为春天,可以说是给Java程序员带来了春天,因为它极大的简化了开发。
由此我们可以得出一个公式:Spring = 春天 = Java程序员的春天 = 简化开发
Spring是一个开放源代码的设计层面框架,是于2003年兴起的一个轻量级Java开发框架。Spring是为了解决企业应用开发复杂性而创建的,它解决的是业务逻辑层和其他各层之间松耦合的问题,因此他将面向接口编程的思想贯穿了整个系统应用。其主要优势之一是分层架构,分层架构允许使用者选择使用哪一个组件,同时为J2EE应用程序开发提供集成的框架。Spring使用基本的JavaBean来完成以前只可能由EJB完成的事情。然而,Spring的用途不仅限于服务器端的开发。从简单性、可测试性和松耦合的角度来说,任何Java应用程序都可以从中受益。
简单的来说,Spring是一个分层的JavaSE/EE full-stack(一站式) 轻量级开源框架。
Spring 的理念:不去重新发明轮子。其核心是控制反转(IOC)和面向切面(AOP)。
1.2 Spring的组成模块
Spring框架包含的功能大约由20个小功能组成。这些模块按组可分为核心容器(Core Container)、数据访问/集成(Data Access/Integration)、Web、面向切面编程(AOP和Aspects)、设备(Instrumentation)、消息(Messaging)和测试(Test)。
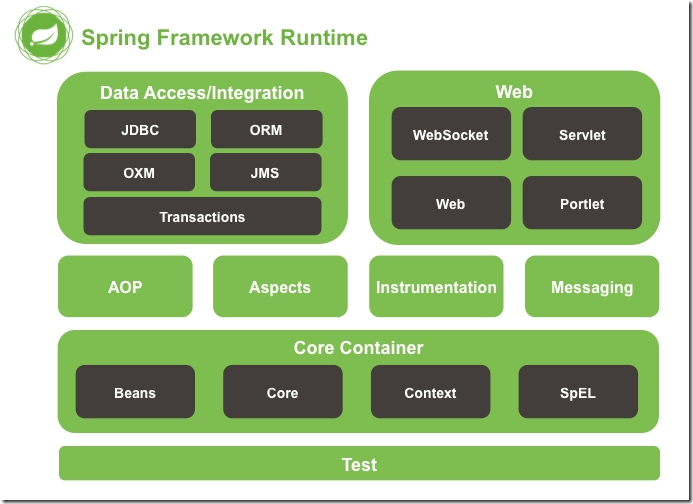
下面对各个模块进行详细介绍:
-
核心容器(Core Container)——Beans、Core、Context、Expression
该层由4个模块组成:spring-beans spring-core spring-context spring-expression(spring expression Language,SpEl) 。它们对应的jar包如下:
- spring-core:该模块是依赖注入IoC与DI的最基本实现。
- spring-beans:该模块是Bean工厂与bean的装配。
- spring-context:该模块构架于核心模块之上,扩展了BeanFactory,为它添加了Bean生命周期控制、框架事件体系以及资源加载透明化等功能。ApplicationContext是该模块的核心接口,他的超类是BeanFactory。与BeanFactory不同,ApplicationContext容器实例化之后会自动对所有的单例Bean进行实例化与依赖关系的装配,使之处于待用状态。
- spring-context-indexer:该模块是 Spring 的类管理组件和 Classpath 扫描。
- spring-context-support:该模块是对 Spring IOC 容器的扩展支持,以及 IOC 子容器。
- spring-expression:该模块是Spring表达式语言块是统一表达式语言(EL)的扩展模块,可以查询、管理运行中的对象,同时也方便的可以调用对象方法、操作数组、集合等。
-
数据访问与集成(Data Access/Integration)——Jdbc、Orm、Oxm、Jms、Transactions
该层由spring-jdbc、spring-tx、spring-orm、spring-jms 和 spring-oxm 5 个模块组成。它们对应的jar包如下:
- spring-jdbc:该模块提供了 JDBC抽象层,它消除了冗长的 JDBC 编码和对数据库供应商特定错误代码的解析。
- spring-tx:该模块支持编程式事务和声明式事务,可用于实现了特定接口的类和所有的 POJO 对象。编程式事务需要自己写beginTransaction()、commit()、rollback()等事务管理方法,声明式事务是通过注解或配置由 spring 自动处理,编程式事务粒度更细。
- spring-orm:该模块提供了对流行的对象关系映射 API的集成,包括 JPA、JDO 和 Hibernate 等。通过此模块可以让这些 ORM 框架和 spring 的其它功能整合,比如前面提及的事务管理。
- spring-oxm:该模块提供了对 OXM 实现的支持,比如JAXB、Castor、XML Beans、JiBX、XStream等。
- spring-jms:该模块包含生产(produce)和消费(consume)消息的功能。从Spring 4.1开始,集成了 spring-messaging 模块。
-
Web——Web、Webmvc、WebFlux、Websocket
该层由 spring-web、spring-webmvc、spring-websocket 和 spring-webflux 4 个模块组成。它们对应的jar包如下:
- spring-web:该模块为 Spring 提供了最基础 Web 支持,主要建立于核心容器之上,通过 Servlet 或者 Listeners 来初始化 IOC 容器,也包含一些与 Web 相关的支持。
- spring-webmvc:该模块众所周知是一个的 Web-Servlet 模块,实现了 Spring MVC(model-view-Controller)的 Web 应用。
- spring-websocket:该模块主要是与 Web 前端的全双工通讯的协议。
- spring-webflux:该模块是一个新的非堵塞函数式 Reactive Web 框架,可以用来建立异步的,非阻塞,事件驱动的服务,并且扩展性非常好。
-
面向切面编程——AOP,Aspects
该层由spring-aop和spring-aspects 2个模块组成。它们对应的jar包如下:
- spring-aop:该模块是Spring的另一个核心模块,是 AOP 主要的实现模块。
- spring-aspects:该模块提供了对 AspectJ 的集成,主要是为 Spring AOP提供多种 AOP 实现方法,如前置方法后置方法等。
-
设备(Instrumentation)——Instrmentation
spring-instrument:该模块是基于JAVA SE 中的"java.lang.instrument"进行设计的,应该算是 AOP的一个支援模块,主要作用是在 JVM 启用时,生成一个代理类,程序员通过代理类在运行时修改类的字节,从而改变一个类的功能,实现 AOP 的功能。
-
消息(Messaging)——Messaging
spring-messaging:该模块是从 Spring4 开始新加入的一个模块,主要职责是为 Spring 框架集成一些基础的报文传送应用。
-
测试(Test)——Test
spring-test:该模块主要为测试提供支持的,通过 JUnit 和 TestNG 组件支持单元测试和集成测试。它提供了一致性地加载和缓存 Spring 上下文,也提供了用于单独测试代码的模拟对象(mock object)。
1.3 Spring的核心
Spring的核心是控制反转(IOC)和面向切面编程(AOP)
注意:有人认为控制反转包括IOC和DI,但实质上他们是一样的,控制反转(IOC)和依赖注入(DI)是从不同角度描述同一件事情,是指通过引入IOC容器,利用依赖注入的方式,实现对象之间的解耦合。其中IOC是一个更广泛的概念,而DI则更为具体。
-
IOC(Inversion of Contorl 控制反转)或DI(Dependency Injection 依赖注入)
-
IOC:说简单点就是当我们使用对象调用一个方法或者类时,不再由我们主动去创建这个类的对象,控制权交给spring框架;说复杂点就是资源(组件)不再由使用资源双方进行管理,而是由不使用资源的第三方统一管理。这样带来的好处:①资源的集中管理,实现资源的可配置和易管理;②降低了使用资源双方的依赖程度,即耦合度。
IOC,即“控制反转”,是一种设计思想而非技术,它能指导我们如何设计出松耦合、更优良的程序。在Java开发中,Ioc意味着将你设计好的对象交给容器控制,而不是传统的在你的对象内部直接控制。
●谁控制谁,控制什么:传统Java SE程序设计,我们直接在对象内部通过new进行创建对象,是程序主动去创建依赖对象,从而导致类与类之间高耦合,难于测试;而IoC是有专门一个容器来创建这些对象,即由Ioc容器来控制对象的创建;谁控制谁?当然是IoC 容器控制了对象;控制什么?那就是主要控制了外部资源获取(不只是对象包括比如文件等)。
●为何是反转,哪些方面反转了:有反转就有正转,传统应用程序是由
我们自己在对象中主动控制去直接获取依赖对象,也就是正转;而反转则是由容器来帮忙创建及注入依赖对象;为何是反转?因为由容器帮我们查找及注入依赖对象,对象只是被动的接受依赖对象,所以是反转;哪些方面反转了?依赖对象的获取被反转了。对象A获得依赖对象B的过程,由主动行为变为了被动行为,控制权颠倒过来了,这就是“控制反转”这个名称的由来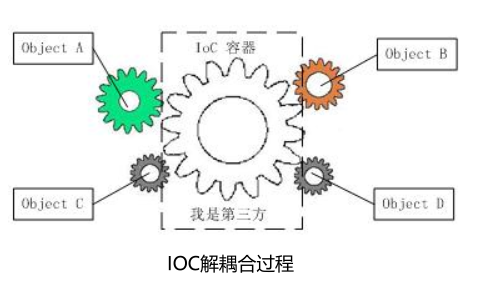
具体可以参考:
①浅谈IOC--说清楚IOC是什么_ivan820819的博客-CSDN博客_ioc
②IOC 的理解与解释 - NancyForever - 博客园 (cnblogs.com)
IoC对编程带来的最大改变不是从代码上,而是从思想上,发生了“主从换位”的变化。应用程序原本是老大,要获取什么资源都是主动出击,但是在IoC/DI思想中,应用程序就变成被动的了,被动的等待IoC容器来创建并注入它所需要的资源了。
IoC很好的体现了面向对象设计法则之一—— 好莱坞法则:“别找我们,我们找你”;即由IoC容器帮对象找相应的依赖对象并注入,而不是由对象主动去找。
-
DI(依赖注入):所谓依赖注入,就是由IOC容器在运行期间,动态地将某种依赖关系注入到对象之中。
●谁依赖于谁:当然是应用程序依赖于IoC容器;
●为什么需要依赖:应用程序需要IoC容器来提供对象需要的外部资源;
●谁注入谁:很明显是IoC容器注入应用程序某个对象,应用程序依赖的对象;
●注入了什么:就是注入某个对象所需要的外部资源(包括对象、资源、常量数据)。
-
-
AOP(Aspect Oriented Programming面向切面编程)
AOP:简单的说就是我们可以再不修改源码的情况下,对程序的方法进行增强;复杂的说就是,将涉及到诸多业务流程的通用功能抽取并单独封装,形成独立的切面,在合适的时机将这些切面横向的切入到业务流程指定的范围中。即系统级的服务从代码中解耦合出来。
例如:将日志记录,性能统计,安全控制,事务处理,异常处理等代码从业务逻辑代码中划分出来。允许你把遍布应用各处的功能分离出来形成可重用组件。提高程序的可重用性,同时提高了开发的效率。
1.3 Spring的优缺点
- 优点:
- 方便解耦,简化开发:通过Spring提供的IoC容器,我们可以将对象之间的依赖关系交由Spring进行控制,避免硬编码所造成的过度程序耦合。有了Spring,用户不必再为单实例模式类、属性文件解析等这些很底层的需求编写代码,可以更专注于上层的应用。
- AOP编程的支持:通过Spring提供的AOP功能,方便进行面向切面的编程,许多不容易用传统OOP实现的功能可以通过AOP轻松应付。
- 声明事务的支持:在Spring中,我们可以从单调烦闷的事务管理代码中解脱出来,通过声明式方式灵活地进行事务的管理,提高开发效率和质量。
- 方便程序的测试:可以用非容器依赖的编程方式进行几乎所有的测试工作,在Spring里,测试不再是昂贵的操作,而是随手可做的事情。例如:Spring对Junit4支持,可以通过注解方便的测试Spring程序。
- 方便集成各种优秀框架:Spring不排斥各种优秀的开源框架,相反,Spring可以降低各种框架的使用难度,Spring提供了对各种优秀框架(如Struts,Hibernate、Hessian、Quartz)等的直接支持。
- 轻量级的框架:从大小与开销两方面而言Spring都是轻量的。现在完整的Spring5框架只有82MB。并且Spring所需的处理开销也是微不足道的。
- 非入侵式的框架:Spring框架是一个非入侵式的框架,就是我们的系统使用了Spring,但系统完全不依赖于Spring的特定类。
- 降低Java EE API的使用难度:Spring对很多难用的Java EE API(如JDBC,JavaMail,远程调用等)提供了一个薄薄的封装层,通过Spring的简易封装,这些Java EE API的使用难度大为降低。
- Java 源码是经典学习范例:Spring的源码设计精妙、结构清晰、匠心独运,处处体现着大师对Java设计模式灵活运用以及对Java技术的高深造诣。Spring框架源码无疑是Java技术的最佳实践范例。如果想在短时间内迅速提高自己的Java技术水平和应用开发水平,学习和研究Spring源码将会使你收到意想不到的效果。
- 缺点
- 不易拆分:spring框架整合其它框架都是黏在一起,后面拆分的话就不容易拆分了。
- 有更好的替代品:对比新出的springboot,他已经逐渐占领了市场。
- 配置繁琐:随着系统工程的增大,系统与第三方的配置文件会大量增加,这也是Spring最致命的地方,人称:“配置地狱”。
1.4 Spring的拓展
Spring框架经过这么多年的发展,它已经衍生出了一个非常庞大的体系,有SpringBoot、SpringCloud等等。如下图所示:
2、Spring的入门案例
详见:Spring详解(二)----Spring的入门案例HelloSpring - 唐浩荣 - 博客园 (cnblogs.com)
在上一章内容中,详细的介绍了什么是Spring,Spring的历史与发展和Spring的一些特点。所以这一章来创建一个Spring的入门案例HelloSpring。
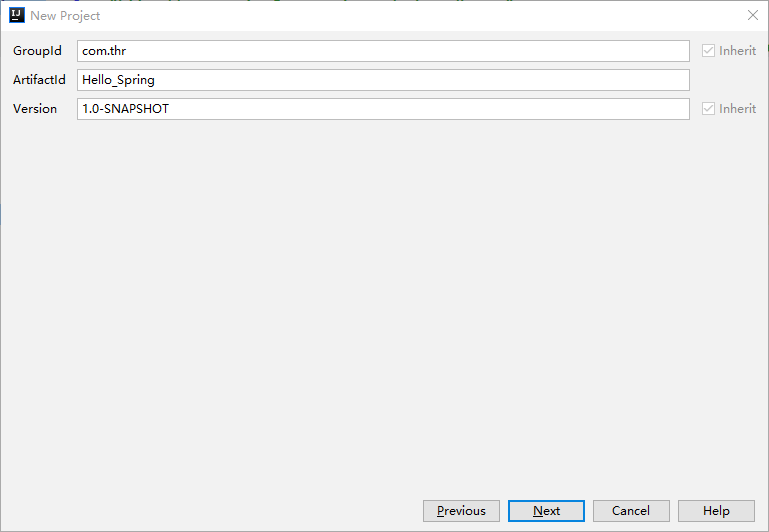
2.1 创建项目
首先创建一个名称为Hello_Spring的Maven项目。
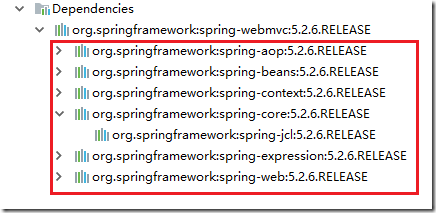
2.2 导入依赖
然后在pom.xml中导入spring依赖,暂时只导入一个,如下:
<!-- https://mvnrepository.com/artifact/org.springframework/spring-webmvc -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>5.2.6.RELEASE</version>
</dependency>
因为这个依赖会自动关联很多jar,如下图:
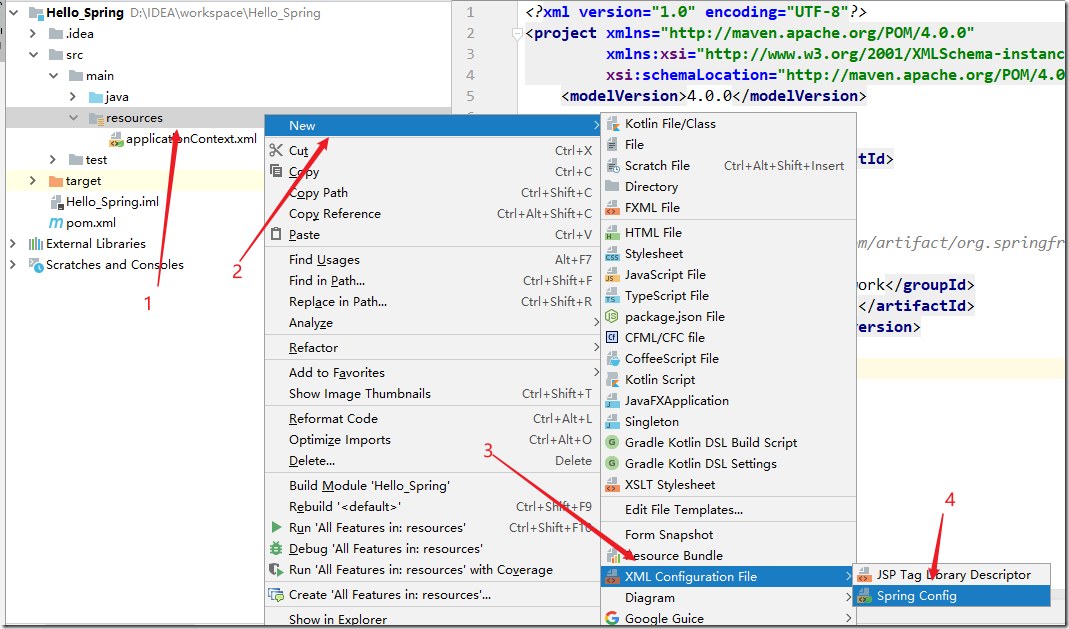
2.3 创建Spring配置文件
在src/mian/resources目录下创建一个applicationContext.xml文件。
【右击resources—>New—>选择XML Configuration File—>Spring Config】
注意:前提是要导入Spring的依赖,否则不会有Spring Config。
2.4 创建接口HelloSpring
在src/main/java目录下创建一个HelloSpring接口,并且定义一个sayHello()方法,代码如下所示。
package com.thr;
/**
* @author tanghaorong
* @desc HelloSpring接口
*/
public interface HelloSpring {
void sayHello();
}
2.5 创建接口实现类
实现上面创建的HelloSpring接口,并在方法中编写一条输出语句,代码如下所示。
package com.thr;
/**
* @author tanghaorong
* @desc HelloSpring实现类
*/
public class HelloSpringImpl implements HelloSpring {
@Override
public void sayHello() {
System.out.println("Hello Spring");
}
}
2.6 配置applicationContext.xml
接下来配置我们在src/main/resources目录中创建的applicationContext.xml文件。
因为这是一个Spring入门的例子,所以用 xml 配置文件的方式来配置对象实例,我们要创建的对象实例要定义在 xml 的<bean>标签中。
其中<bean>标签表示配置一个对象实例。<bean>标签常用的两个参数 id 和 class ,id表示标识符(别名),class 表示对象实例类的全限定名。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> <!-- bean definitions here -->
<!--将指定类配置给Spring,让Spring创建其对象的实例-->
<!--id:标识符(别名) class:需要实例化的类路径-->
<bean id="helloSpring" class="com.thr.HelloSpringImpl"></bean>
</beans>
这样HelloSpringImpl的实例对象就由Spring给我们创建了,名称为helloSpring,当然我们也可以创建多个对象实例,如下:
<bean id="helloSpring" class="com.thr.HelloSpringImpl"></bean>
<bean id="helloSpring1" class="com.thr.HelloSpringImpl"></bean>
<bean id="helloSpring2" class="com.thr.HelloSpringImpl"></bean>
2.7 配置测试类
在src/test/java下,创建测试类TestHelloSpring,代码如下:
package com.thr;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
/**
* @author tanghaorong
* @desc 测试类
*/
public class TestHelloSpring {
public static void main(String[] args) {
//传统方式:new 对象() 紧密耦合
HelloSpring helloSpring = new HelloSpringImpl();
helloSpring.sayHello();
//Spring方式:XML解析+反射+工厂模式
//1.初始化Spring容器,加载配置文件
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("applicationContext.xml");
//2.通过容器获取helloSpring实例,getBean()方法中的参数是bean标签中的id
HelloSpring helloSpring1 = (HelloSpring) applicationContext.getBean("helloSpring");
//3.调用实例中的方法
helloSpring1.sayHello();
}
}
因为这里是测试使用,所以需要初始化Spring容器,并且加载配置文件,实际开发中这一步不需要。
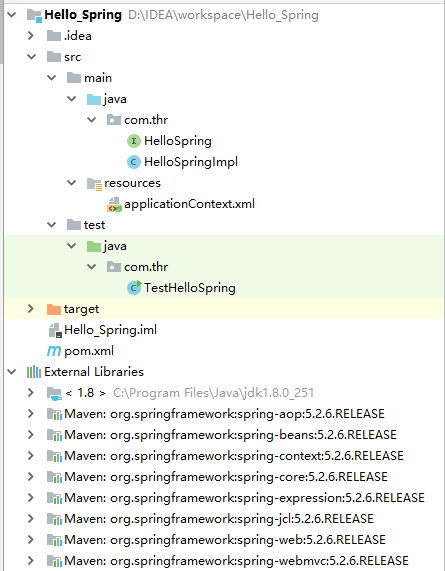
2.8 项目整体目录结构
以上全部创建完成后,项目的整体目录结构如下图:
2.9 运行测试
运行的结果会打印两遍Hello Spring,第一步是传统 new对象的方式,第二种是使用Spring IOC的方式,结果如下图:
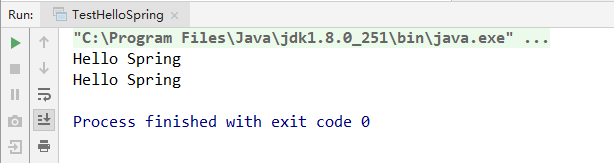
可以发现两种方式都创建了HelloSpring的对象实例,但是Spring IOC方式更加方便,而且低耦合,这样更有利于后期的维护。
这篇文章只是一个简单的入门案例,所以例子非常简单,也希望大家多多指点,谢谢!
3、IoC控制反转/DI依赖注入
IoC和AOP这些概念并不是Spring提出来的,它们在Spring出来之前就已经存在了,只是之前更多的是偏向于理论,没有产品很好的实现,直到Spring框架将这些概念进行了很好的实现。
3.1 什么是IoC(控制反转)
IoC是Spring最核心的点,并且贯穿始终。IoC并不是一门技术,而是一种设计思想。在Spring框架中实现控制反转的是Spring IoC容器,其具体实现就是由容器来控制对象的生命周期和业务对象之间的依赖关系,而不是像传统方式(new对象)中由代码来直接控制。程序中所有的对象都会在Spring IoC容器中登记,告诉容器你是个什么,你需要什么,然后IoC容器会在系统运行到适当的时候,把你要的对象主动给你,同时也把你交给其它需要你的对象。也就是说控制对象生存周期的不再是引用它的对象,而是由Spring IoC容器来控制所有对象的创建、销毁。对于某个具体的对象而言,以前是它控制其它对象,现在是所有对象都被Spring IoC容器所控制,所以这叫控制反转。
控制反转最直观的表达就是,IoC容器让对象的创建不用去new了,而是由Spring自动生产,使用java的反射机制,根据配置文件在运行时动态的去创建对象以及管理对象,并调用对象的方法。控制反转的本质是控制权由应用代码转到了外部容器(IoC容器),控制权的转移即是所谓的反转。控制权的转移带来的好处就是降低了业务对象之间的依赖程度,即实现了解耦。即然控制反转中提到了反转,那么肯定有正转,正转和反转有什么区别呢?我曾经在博客上看到有人在面试的时候被问到Spring IoC知识点:什么是反转、正转?
- 正转:如传统应用程序是由
我们自己在对象中主动控制去直接获取依赖对象- 反转:反转则是由容器来帮忙创建及注入依赖对象,对象只是被动的接受依赖对象
- 哪些方面反转了?依赖对象的获取被反转了。
3.2 什么是DI(依赖注入)
DI是IoC(控制反转)的一个别名。在早些年,软件开发教父Martin·Fowler在一篇文章中提到将IoC改名为 DI。

IoC和DI其实是同一个概念,只是从不同的角度描述罢了(IoC是一种思想,而DI则是一种具体的技术实现手段)。简单的说:IoC是目的(创建对象),DI是手段(怎么获取外部对象)
依赖注入:即应用程序在运行时依赖IoC容器来动态注入对象需要的外部资源。
●谁依赖于谁:当然是应用程序依赖于IoC容器;
●为什么需要依赖:应用程序需要IoC容器来提供对象需要的外部资源;
●谁注入谁:很明显是IoC容器注入应用程序某个对象,应用程序依赖的对象;
●注入了什么:就是注入某个对象所需要的外部资源(包括对象、资源、常量数据)。
综上所述,所谓Spring IoC/DI,就是Spring容器来负责对象的生命周期和对象之间依赖关系的理念/途径。
3.3 对Spring IoC的理解
依赖关系处理的方式由两种:主动创建对象、被动创建对象
-
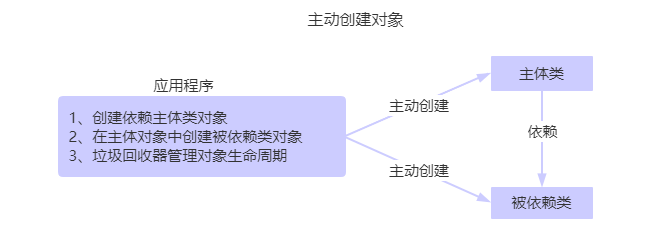
主动创建对象
我们知道,在传统的Java项目中,如果需要在一个对象中内部调用另一个对象的方法,最常用的就是在主体类中使用
new 对象的方式。当然我们也可以使用简单工厂模式来实现,就是在简单工厂模式中,我们的被依赖类由一个工厂方法创建,依赖主体先调用被依赖对象的工厂方法,接着主动基于工厂访问被依赖对象,但这种方式任然存在问题,即依赖主体与被依赖对象的工厂之间存在着耦合。//简单工厂模式 CategoryDao categoryDao = (CategoryDao)ObjectFactory.getInstance("categoryDao"); categoryService.insert(categoryName);主动创建对象的程序思想图如下所示:
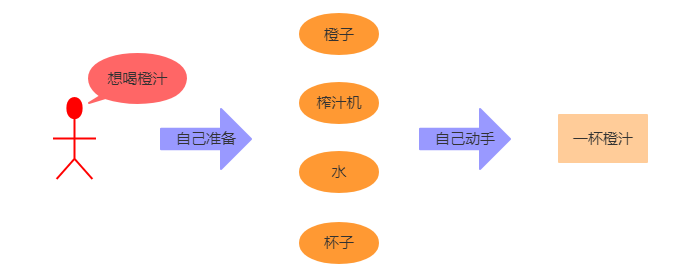
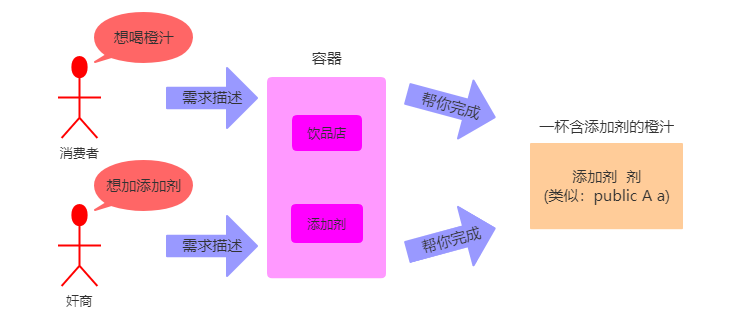
举例:例如我们平时想要喝一杯柠檬汁,在不去饮品店购买的情况下,那么我们自己想要的得到一杯橙汁的想法是这样的:买果汁机、买橙子,买杯子,然后准备水。这些都是你自己"主动"完成的过程,也就是说一杯橙汁需要你自己创造。如下图所示:
-
被动创建对象
由于主动创建对象的方式是很难避免耦合问题,所以通过思考总结有人通过容器来统一管理对象,然后逐渐引起了大家的注意,进而开启了被动创建对象的思潮。也正是由于容器的引入,使得应用程序不需要再主动去创建对象了,可见获取对象的过程被反转了,从主动获取变成了被动接受,这也是控制反转的过程。被动创建对象的程序思想图如下所示:

举例:在饮品店如此盛行的今天,不会还有人自己在家里制作饮品、奶茶吧!所以我们的首选肯定是去外面购买或者是外卖。那此时我们只需要描述自己需要什么饮品即可(加冰热糖忽略),不需要在乎我们的饮品是怎么制作的。而这些正是由别人"被动"完成的过程,也就是说一杯饮品需要别人被动创造。如下图所示:
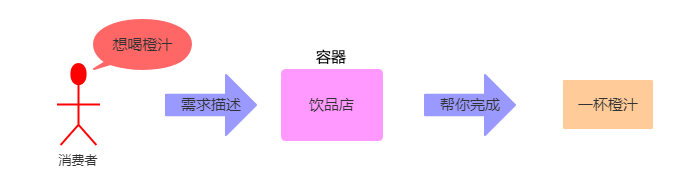
通过上图的例子我们可以发现,我们得到一杯橙汁并没有由自己"主动"去创造,而是通过饮品店创造的,然而也完全达到了你的要求,甚至比你创造的要好上那么一些。
上面的例子只能看出不需要我们自己创建对象了,那万一它还依赖于其它对象呢?那么对象之间要相互调用呢?我们要怎么来理解呢?下面接着举例。
假如这个饮品店的商家是一个奸商,为了节约成本,它们在饮品中添加添加剂,举例如下图所示:
在主体对象依赖其它对象的时候,对象之间的相互调用通过注入的方式来完成,所以下面我们介绍IOC中的三种注入方式。
3.4 IoC的三种注入方式
对IoC模式最有权威的总结和解释,应该是软件开发教父
Martin Fowler的那篇文章"Inversion of Control Containers and the Dependency Injection pattern",上面已经给出了链接,这里再说一遍:https://martinfowler.com/articles/injection.html。在这篇文章中提到了三种依赖注入的方式,即构造方法注入(constructor injection),setter方法注入(setter injection)以及接口注入(interface injection)。
3.4.1 构造函数注入
构造函数注入,顾名思义就是被注入对象可以通过在其构造方法中声明依赖对象的参数列表,让外部(通常是IoC容器)知道它需要哪些依赖对象。
IoC Service Provider会检查被注入对象的构造方法,取得它所需要的依赖对象列表,进而为其注入相应的对象。同一个对象是不可能被构造两次的。因此,被注入对象的构造乃至整个生命周期,应该是由IoC Service Provider来管理的。
构造方法注入方式比较直观,对象被构造完成后,即进入就绪状态,马上就可以使用。这就好比你刚进酒吧的门,服务生已经将你喜欢的啤酒摆上了桌面一样。坐下就可马上享受一份清凉与惬意。
//首先把需要注入的类写成属性,然后使用构造方法。实现代码如下: public class B { private A a; public B(A a){ this.a == a; } }//接着在配置文件中 //在constructor-arg子元素中,index用于指定参数的索引,name用于指定参数名,ref用于引用已声明的bean对象,value用于指定普通类型常量值。 <!--按构造器参数名称注入--> <bean id="aa" class="com.study.jyl.A"></bean> <bean id="bb" class="com.study.jyl.B"> <constructor-arg name="a" ref="aa"></constructor-arg> </bean> <!--按构造器参数下标注入--> <bean id="aa" class="com.study.jyl.A"></bean> <bean id="bb" class="com.study.jyl.B"> <constructor-arg index=0 ref="aa"></constructor-arg> </bean>
3.4.2 set方法注入
可分为:值类型属性和引用类型属性(value=" " 、ref=" ")
对于JavaBean对象来说,通常会通过setXXX()和getXXX()方法来访问对应属性。这些setXXX()方法统称为setter方法,getXXX()当然就称为getter方法。通过setter方法,可以更改相应的对象属性,通过getter方法,可以获得相应属性的状态。所以,当前对象只要为其依赖对象所对应的属性添加setter方法,就可以通过setter方法将相应的依赖对象设置到被注入对象中。
setter方法注入虽不像构造方法注入那样,让对象构造完成后即可使用,但相对来说更宽松一些,可以在对象构造完成后再注入。这就好比你可以到酒吧坐下后再决定要点什么啤酒,可以要百威,也可以要大雪,随意性比较强。如果你不急着喝,这种方式当然是最适合你的。
//把需要注入的类写成属性,给它设置一个set方法。实现代码如下: public class B { private A a; public void setA(A a){ this.a == a; } }//接着在配置文件中类A注入到类B里面去 <bean id="aa" class="com.study.jyl.A"></bean> <bean id="bb" class="com.study.jyl.B"> <!--property子元素中,name属性用于声明对象属性名, value属性用于指定普通值类型常量, ref属性用于引用已声明的复杂类型bean对象,通常是另一个bean的id--> <property name="a" ref="aa"></property> </bean>
3.4.3 接口注入(基本已经淘汰)
相对于前两种注入方式来说,接口注入没有那么简单明了。被注入对象如果想要IoC ServiceProvider为其注入依赖对象,就必须实现某个接口。这个接口提供一个方法,用来为其注入依赖对象。IoC Service Provider最终通过这些接口来了解应该为被注入对象注入什么依赖对象。
3.4.4 三种注入方式的比较
| 注入方式 | 描述 |
|---|---|
| setter方法注入 | 因为方法可以命名,所以setter方法注入在描述性上要比构造方法注入好一些。 另外,setter方法可以被继承,允许设置默认值,而且有良好的IDE支持。缺点当然就是对象无法在构造完成后马上进入就绪状态。 |
| 构造方法注入 | 这种注入方式的优点就是,对象在构造完成之后,即已进入就绪状态,可以 马上使用。缺点就是,当依赖对象比较多的时候,构造方法的参数列表会比较长。而通过反射构造对象的时候,对相同类型的参数的处理会比较困难,维护和使用上也比较麻烦。而且在Java中,构造方法无法被继承,无法设置默认值。对于非必须的依赖处理,可能需要引入多个构造方法,而参数数量的变动可能造成维护上的不便。 |
| 接口注入 | 从注入方式的使用上来说,接口注入是现在不甚提倡的一种方式,基本处于“退役状态”。因为它强制被注入对象实现不必要的接口,带有侵入性。而构造方法注入和setter方法注入则不需要如此 |
3.5 IoC的使用举例
IOC的实例讲解部分我们任然使用上面橙汁的例子,假如奸商为了节约成本,所以使用了添加剂,那么可以理解为饮品店的橙汁依赖于添加剂,在实际使用中我们要将添加剂对象注入到橙汁对象中。下面我通过这几种方式来讲解对IOC容器实例的应用:
- 原始方式
- 构造函数注入
- setter方法注入
- 接口注入
首先我们先分别创建橙汁OrangeJuice类和添加剂Additive类。
创建OrangeJuice类,代码如下:
/**
* @author tanghaorong
* @desc 橙汁类
*/
public class OrangeJuice {
public void needOrangeJuice(){
System.out.println("消费者点了一杯橙汁(无添加剂)...");
}
}
创建添加剂Additive类,代码如下:
/**
* @author tanghaorong
* @desc 添加剂类
*/
public class Additive {
public void addAdditive(){
System.out.println("奸商在橙汁中添加了添加剂...");
}
}
3.5.1 原始方式
最原始的方式就是没有IOC容器的情况下,我们要在主体对象中使用new的方式来获取被依赖对象。我们看一下在主体类中的写法,添加剂类一直不变:
public class OrangeJuice {
public void needOrangeJuice(){
//创建添加剂对象
Additive additive = new Additive();
//调用加入添加剂方法
additive.addAdditive();
System.out.println("消费者点了一杯橙汁(有添加剂)...");
}
}
创建测试类:
public class Test {
public static void main(String[] args) {
OrangeJuice orangeJuice = new OrangeJuice();
orangeJuice.needOrangeJuice();
}
}
运行结果如下:
通过上面的例子可以发现,原始方式的耦合度非常的高,如果添加剂的种类改变了,那么整杯橙汁也需要改变。
3.5.2 构造函数注入
构造器注入,顾名思义就是通过构造函数完成依赖关系的注入。首先我们看一下spring的配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> <!-- bean definitions here -->
<!--将指定类都配置给Spring,让Spring创建其对象的实例,一个bean对应一个对象-->
<bean id="additive" class="com.thr.Additive"></bean>
<bean id="orangeJuice" class="com.thr.OrangeJuice">
<!--通过构造函数注入,ref属性表示注入另一个对象-->
<constructor-arg ref="additive"></constructor-arg>
</bean>
</beans>
使用构造函数方式注入的前提必须要在主体类中创建构造函数,所以我们再来看一下,构造器表示依赖关系的写法,代码如下所示:
public class OrangeJuice {
//引入添加剂参数
private Additive additive;
//创建有参构造函数
public OrangeJuice(Additive additive) {
this.additive = additive;
}
public void needOrangeJuice(){
//调用加入添加剂方法
additive.addAdditive();
System.out.println("消费者点了一杯橙汁(有添加剂)...");
}
}
创建测试类:
public class Test {
public static void main(String[] args) {
//1.初始化Spring容器,加载配置文件
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("applicationContext.xml");
//2.通过容器获取实例对象,getBean()方法中的参数是bean标签中的id
OrangeJuice orangeJuice = (OrangeJuice) applicationContext.getBean("orangeJuice");
//3.调用实例中的方法
orangeJuice.needOrangeJuice();
}
}
运行结果如下:

可以发现运行结果和原始方式一样,但是将创建对象的权利交给Spring之后,橙汁和添加剂之间的耦合度明显降低了。此时我们的重点是在配置文件中,而不在乎程序本身,即使添加剂类型发生改变,我们只需修改配置文件即可,不需要修改程序代码。
3.5.3 set方法注入
setter注入在实际开发中使用的非常广泛,因为它可以在对象构造完成后再注入,这样就更加直观,也更加自然。我们来看一下spring的配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> <!-- bean definitions here -->
<!--将指定类都配置给Spring,让Spring创建其对象的实例,一个bean对应一个对象-->
<bean id="additive" class="com.thr.Additive"></bean>
<bean id="orangeJuice" class="com.thr.OrangeJuice">
<!--通过setter注入,ref属性表示注入另一个对象-->
<property name="additive" ref="additive"></property>
</bean>
</beans>
关于配置文件中的一些元素如
接着我们再来看一下,setter表示依赖关系的写法:
public class OrangeJuice {
//引入添加剂参数
private Additive additive;
//创建setter方法
public void setAdditive(Additive additive) {
this.additive = additive;
}
public void needOrangeJuice(){
//调用加入添加剂方法
additive.addAdditive();
System.out.println("消费者点了一杯橙汁(有添加剂)...");
}
}
测试类和运行的结果和构造器注入的方式是一样的,所以这里就不展示了。
3.5.4 接口注入
接口注入,就是主体类必须实现我们创建的一个注入接口,该接口会传入被依赖类的对象,从而完成注入。
由于Spring的配置文件只支持构造器注入和setter注入,所有这里不能使用配置文件,此时仅仅起到帮我们创建对象的作用。spring的配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> <!-- bean definitions here -->
<!--将指定类都配置给Spring,让Spring创建其对象的实例,一个bean对应一个对象-->
<bean id="additive" class="com.thr.Additive"></bean>
<bean id="orangeJuice" class="com.thr.OrangeJuice"></bean>
</beans>
创建一个接口如下:
//创建注入接口
public interface InterfaceInject {
void injectAdditive(Additive additive);
}
主体类实现接口并且初始化添加剂参数:
//实现InterfaceInject
public class OrangeJuice implements InterfaceInject {
//引入添加剂参数
private Additive additive;
//实现接口方法,并且初始化参数
@Override
public void injectAdditive(Additive additive) {
this.additive = additive;
}
public void needOrangeJuice(){
//调用加入添加剂方法
additive.addAdditive();
System.out.println("消费者点了一杯橙汁(有添加剂)...");
}
}
创建测试类:
public class Test {
public static void main(String[] args) {
//1.初始化Spring容器,加载配置文件
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("applicationContext.xml");
//2.通过容器获取实例对象,getBean()方法中的参数是bean标签中的id
OrangeJuice orangeJuice = (OrangeJuice) applicationContext.getBean("orangeJuice");
Additive additive = (Additive) applicationContext.getBean("additive");
//通过接口注入,调用注入方法并且将Additive对象注入
orangeJuice.injectAdditive(additive);
//3.调用实例中的方法
orangeJuice.needOrangeJuice();
}
}
由于接口注入方式它强制被注入对象实现了不必要的接口,具有很强的侵入性,所以这种方式已经被淘汰了。
3.6 属性注入的特殊写法(特殊数据类型)
创建一个bean对象定义一下不同数据类型的属性:
public class SpecialDiBean {
private String specialCharacter1; // 特殊字符值 1
private String specialCharacter2; // 特殊字符值 2
private List<String> list; // List 类型
private String[] array; // 数组类型
private Set<String> set; // Set 类型
private Map<String, String> map; // Map 类型
private Properties props; // Properties 类型
private String emptyValue; // 注入空字符串值
private String nullValue = "init value"; // 注入 null 值
//省略 get、set 和 toString 方法
}
注入特殊字符(XML中的特殊字符)
<bean id="entity" class="com.bjpowernode.common.SpecialBean">
<!-- 使用<![CDATA[]]>标记处理 XML 特 殊字符 -->
<property name="specialCharacter1">
<value><![CDATA[P&G]]></value>
</property>
<!-- 把 XML 特殊字符替换为预实体引用 -->
<property name="specialCharacter2">
<value>P&G</value>
</property>
</bean>
xml中的5个预定义实体引用:
< |
< | 小于 |
|---|---|---|
> |
> | 大于 |
& |
& | 和号 |
' |
' | 单引号 |
" |
" | 引号 |
3.6.1 注入集合类型的属性
<!-- 注入 List 类型 -->
<property name="list">
<list>
<!-- 定义 List 中的元素 -->
<value>足球</value>
<value>篮球</value>
</list>
</property>
<!-- 注入数组类型 -->
<property name="array">
<list> <!-- 定义数组中的元素 -->
<value>足球</value>
<value>篮球</value>
</list>
</property>
<!-- 注入 Set 类型 -->
<property name="set">
<set><!-- 定义 Set 或数组中的元素 -->
<value>足球</value>
<value>篮球</value>
</set>
</property>
<!-- 注入 Map 类型 -->
<property name="map">
<map><!-- 定义 Map 中的键值对 -->
<entry>
<key>
<value>football</value>
</key>
<value>足球</value>
</entry>
<entry>
<key>
<value>basketball</value>
</key>
<value>篮球</value>
</entry>
</map>
</property>
<!-- 注入 Properties 类型 -->
<property name="props">
<props><!-- 定义 Properties 中的键值对 -->
<prop key="football">足球</prop>
<prop key="basketball">篮球</prop>
</props>
</property>
3.6.2 注入 null 和空字符串
<!-- 注入空字符串值 -->
<property name="emptyValue">
<value></value>
</property>
<!-- 注入 null 值 -->
<property name="nullValue">
<null/>
</property>
3.7 总结IoC带来的好处
IoC的思想最核心的地方在于,资源不由使用资源的双方管理,而由不使用资源的第三方管理。
第一,资源集中管理,实现资源的可配置和易管理
第二,降低了使用资源双方的依赖程度,也就是我们说的耦合度
其实IoC对编程带来的最大改变不是从代码上,而是从思想上,发生了“主从换位”的变化。应用程序原本是老大,要获取什么资源都是主动出击,但是在IoC/DI思想中,应用程序就变成被动的了,被动的等待IoC容器来创建并注入它所需要的资源了。IoC很好的体现了面向对象设计法则之一好莱坞法则:“别找我们,我们找你”;即由IoC容器帮对象找相应的依赖对象并注入,而不是由对象主动去找
4、Spring IoC容器的设计与实现
4.1 Spring IoC容器的设计
在Spring中实现控制反转的是IoC容器,所以对于 IoC 来说,最重要的就是容器。因为容器管理着 Bean 的生命周期,控制着 Bean 的依赖注入。那么, 在Spring框架中是如何设计容器的呢?我们来看一下:Spring IoC 容器的设计主要是基于以下两个接口:
- 实现BeanFactory接口的简单容器
- 实现ApplicationContext接口的高级容器
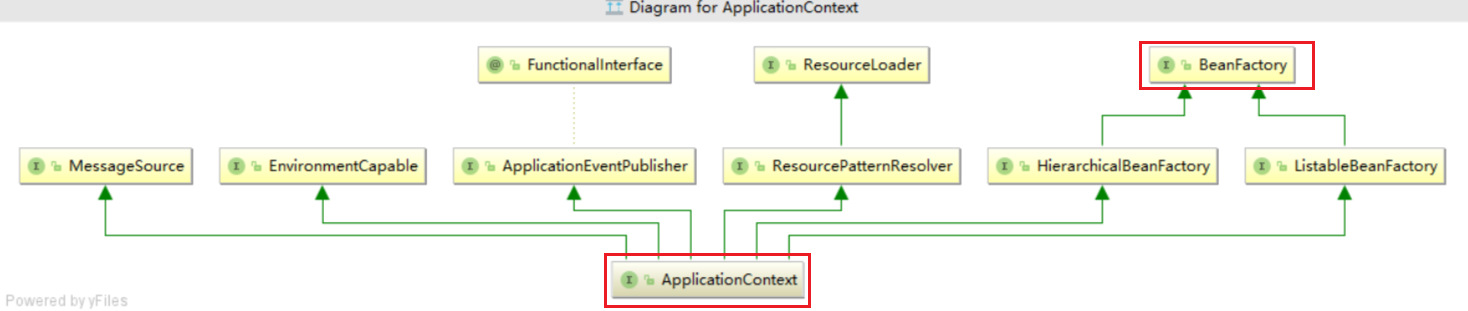
通过上面的图片我们可以发现ApplicationContext是BeanFactory的子接口。其中BeanFactory是Spring IoC容器的最底层接口,它只提供了IOC容器最基本的功能,给具体的IOC容器的实现提供了规范,所以我们称它为简单容器。它主要是负责配置、生产和管理bean,其内部定义了对单个bean的获取,对bean的作用域判断,获取bean类型,获取bean别名等功能。而ApplicationContext扩展(继承)了BeanFactory,所以ApplicationContext包含BeanFactory的所有功能,同时它又继承了MessageSource、ListableBeanFactory、ResourceLoader、ApplicationEventPublisher等接口,这样ApplicationContext为BeanFactory赋予了更高级的IOC容器特性,我们称它为高级容器。在实际应用中,一般不使用 BeanFactory,通常建议优先使用ApplicationContext(BeanFactory一般供代码内部使用)。
注意:上面两个重要的类都是接口,既然是接口那总得有具体的实现类吧,那是由哪个类来具体实现IOC容器的呢?答:在BeanFactory子类中有一个DefaultListableBeanFactory类,它实现了包含基本Spirng IoC容器所具有的重要功能,我们开发时不论是使用BeanFactory系列还是ApplicationContext系列来创建容器基本都会使用到DefaultListableBeanFactory类。在平时我们说BeanFactory提供了IOC容器最基本的功能和规范,但真正可以作为一个可以独立使用的IOC容器还是DefaultListableBeanFactory,因为它真正实现了BeanFactory接口中的方法。所以DefaultListableBeanFactory 是整个Spring IOC的始祖,在Spring中实际上把它当成默认的IoC容器来使用。但是暂时我们不深入了解,只需知道有这么个东西即可。
4.2 BeanFactory和ApplicationContext的区别
通过上面的介绍我们知道,BeanFactory和ApplicationContext是Spring IOC容器的两大核心接口,它们都可以当做Spring的容器。其中ApplicationContext是BeanFactory的子接口,那么它们两者之间的区别在哪呢?下面我们来学习一下:
-
提供的功能不同
BeanFactory:是Spring里面最底层的接口,它只提供了IOC容器最基本的功能,给具体的IOC容器的实现提供了规范。包含了各种Bean的定义,读取bean配置文档,管理bean的加载、实例化,控制bean的生命周期,维护bean之间的依赖关系等。
ApplicationContext:它作为BeanFactory的子接口,除了提供BeanFactory所具有的功能外,还提供了更完整的框架功能。我们看一下ApplicationContext类结构:
public interface ApplicationContext extends EnvironmentCapable, ListableBeanFactory, HierarchicalBeanFactory, MessageSource, ApplicationEventPublisher, ResourcePatternResolver { }ApplicationContext额外提供的功能有:
- 支持国际化(MessageSource)
- 统一的资源文件访问方式(ResourcePatternResolver)
- 提供在监听器中注册bean的事件(ApplicationEventPublisher)
- 同时加载多个配置文件
- 载入多个(有继承关系)上下文 ,使得每一个上下文都专注于一个特定的层次,比如应用的web层(HierarchicalBeanFactory)
-
启动时状态不同
BeanFactroy采用的是延迟加载形式来注入Bean的,即只有在使用到某个Bean时(调用getBean()),才对该Bean进行加载实例化。这样,我们就不能发现一些存在的Spring的配置问题。如果Bean的某一个属性没有注入,BeanFacotry加载后,直至第一次使用调用getBean方法才会抛出异常。
ApplicationContext,它是在容器启动时,一次性创建了所有的Bean。这样,在容器启动时,我们就可以发现Spring中存在的配置错误,这样有利于检查所依赖属性是否注入。 ApplicationContext启动后预载入所有的单实例Bean,通过预载入单实例bean ,确保当你需要的时候,你就不用等待,因为它们已经创建好了。相对于基本的BeanFactory,ApplicationContext 唯一的不足是占用内存空间。当应用程序配置Bean较多时,程序启动较慢。
-
BeanFactory通常以编程的方式被创建,ApplicationContext还能以声明的方式创建,如使用ContextLoader。
-
BeanFactory和ApplicationContext都支持BeanPostProcessor、BeanFactoryPostProcessor的使用,但两者之间的区别是:BeanFactory需要手动注册,而ApplicationContext则是自动注册。
4.3 BeanFactory容器的设计原理
我们知道,BeanFactory接口提供了使用IOC容器的基本规范,在这个基础上,Spring还提供了符合这个IOC容器接口的一系列容器的实现供开发人员使用,我们以DefaultListableBeanFactory的子类XmlBeanFactory的实现为例,来说明简单IOC容器的设计原理,下面的图为BeanFactory——>XmlBeanFactory设计的关系,相关接口和实现类的图如下:
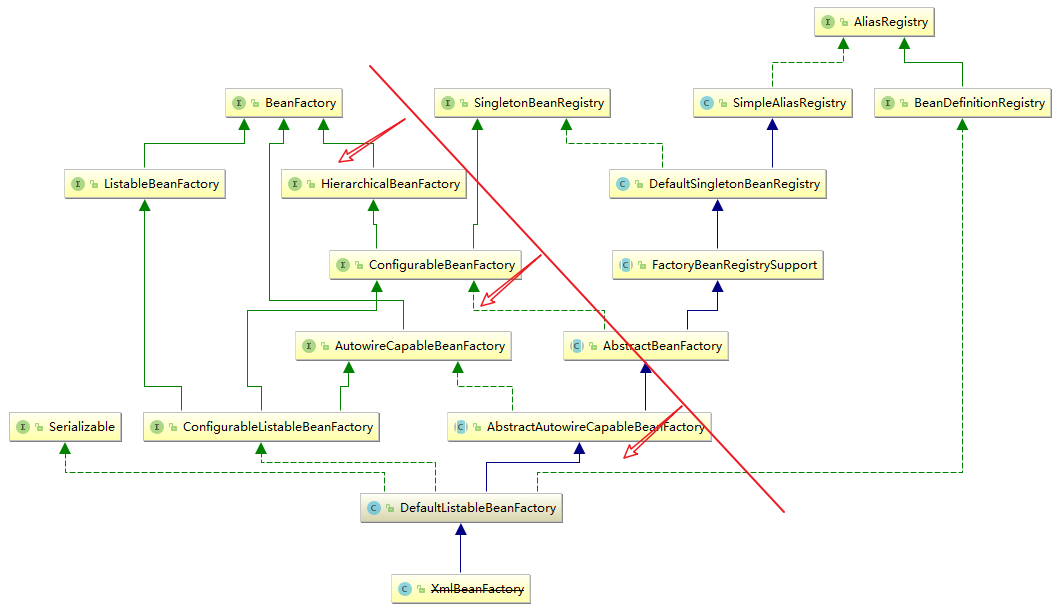
可以发现它的体系很庞大,下面简单介绍一下图片中左边重要的接口和类:
- BeanFactory接口:是Spring IOC容器的最底层接口,提供了容器的基本规范,如获取bean、是否包含bean、是否单例与原型、获取bean类型和bean别名的方法。
- HierarchicalBeanFactory:提供父容器的访问功能,它内部定义了两个方法。
- ListableBeanFactory:提供了列出工厂中所有的Bean的方法 定义了容器内Bean的枚举功能(枚举出来的Bean不会包含父容器)。
- AutowireCapableBeanFactory:在BeanFactory基础上实现对已存在实例的管理,主要定义了集成其它框架的功能。一般应用开发者不会使用这个接口,所以像ApplicationContext这样的外观实现类不会实现这个接口,如果真想用可以通过ApplicationContext的getAutowireCapableBeanFactory接口获取。
- ConfigurableBeanFactory:定义了BeanFactory的配置功能。
- ConfigurableListableBeanFactory:继承了上述的所有接口,增加了其他功能:比如类加载器、类型转化、属性编辑器、BeanPostProcessor、作用域、bean定义、处理bean依赖关系、bean如何销毁等功能。
- DefaultListableBeanFactory:实现上述BeanFactory接口中所有功能。它还可以注册BeanDefinition。
- XmlBeanFactory :在Spring3.1之前使用,后面被标记为Deprecated,继承自DefaultListableBeanFactory,增加了对Xml文件解析的支持。
通过上面的图片可以发现XmlBeanFactory是BeanFactory体系中的最底层的实现类,我们知道BeanFactory的实现主要是由DefaultListableBeanFactory类完成,而XmlBeanFactory又继承了DefaultListableBeanFactory类,所以说BeanFactory实现的最底层是XmlBeanFactory,这个类是Rod Johnson大佬在2001年就写下的代码,可见这个类应该是Spring的元老类了。由于那个时候没有使用注解,都是使用XML文件来配置Spring,所以XmlBeanFactory继承DefaultListableBeanFactory的目的就很明显,我们从XmlBeanFactory这个类的名字上就可以猜到,它是一个与XML相关的BeanFactory,没错,XmlBeanFactory在父类的基础上增加了对XML文件解析的支持,也就是说它是一个可以读取XML文件方式定义BeanDefinition的IOC容器。
注意:这里说一下BeanDefinition:在Spring中BeanDefinition非常的重要,从字面意思就知道它跟Bean的定义有关。它是对 IOC容器中管理的对象依赖关系的数据抽象,是IOC容器实现控制反转功能的核心数据结构,控制反转功能都是围绕对这个BeanDefinition的处理来完成的,这些BeanDefinition就像是容器里裝的水一样,有了这些基本数据,容器才能够发挥作用。简单来说,BeanDefinition在Spring中是用来描述Bean对象的,它本身并不是一个Bean实例,而是包含了Bean实例的所有信息,比如类名、属性值、构造器参数、scope、依赖的bean、是否是单例类、是否是懒加载以及其它信息。其实就是将Bean实例定义的信息存储到这个BeanDefinition相应的属性中,后面Bean对象的创建是根据BeanDefinition中描述的信息来创建的,例如拿到这个BeanDefinition后,可以根据里面的类名、构造函数、构造函数参数,使用反射进行对象创建。也就是说 IOC容器可以有多个BeanDefinition,并且一个BeanDefinition对象对应一个<bean>标签中的信息。
当然BeanDefinition的最终目的不只是用来存储Bean实例的所有信息,而是为了可以方便的进行修改属性值和其他元信息,比如通过BeanFactoryPostProcessor进行修改一些信息,然后在创建Bean对象的时候就可以结合原始信息和修改后的信息创建对象了。
我们先来看一下使用XmlBeanFactory的方式创建容器,即使XmlBeanFactory已经过时了,但是有必要还是说一说。(以上一章橙汁和添加剂的栗子来举例)
//创建XmlBeanFactory对象,并且传入Resource
XmlBeanFactory xmlBeanFactory = new XmlBeanFactory(new ClassPathResource("applicationContext.xml"));
//调用getBean方法获取实例对象
OrangeJuice orangeJuice = (OrangeJuice) xmlBeanFactory.getBean("orangeJuice");
orangeJuice.needOrangeJuice();
可以发现这里的XmlBeanFactory构造函数中的参数是ClassPathResource类,而ClassPathResource类实现了Resource接口,这个Resource接口是定义资源文件的位置。在Spring框架中,如果我们需要读取Xml文件的信息,我们就需要知道这个文件在哪,也就是指定这个文件的来源。要让Spring知道这个来源,我们需要使用Resource类来完成。Resource类是Spring用来封装IO操作的类,通过Resoruce类实例化出一个具体的对象,比如ClasspathResource构造参数传入Xml文件名,然后将实例化好的Resource传给BeanFactory的构造参数来加载配置、管理对象,这样Spring就可以方便地定位到需要的BeanDefinition信息来对Bean完成容器的初始化和依赖注入过程,也就是说Spring的配置文件的加载少不了Resource这个类。在XmlBeanFactory中对Xml定义文件的解析通过委托给 XmlBeanDefinitionReader 来完成,我们可以在XmlBeanFactory中看到。
上面说了XmlBeanFactory已经淘汰不用了,那现在肯定有更好的方式来处理,我们先来分析一下XmlBeanFactory源码:
@Deprecated
public class XmlBeanFactory extends DefaultListableBeanFactory {
private final XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(this);
public XmlBeanFactory(Resource resource) throws BeansException {
this(resource, null);
}
public XmlBeanFactory(Resource resource, BeanFactory parentBeanFactory) throws BeansException {
super(parentBeanFactory);
this.reader.loadBeanDefinitions(resource);
}
}
通过XmlBeanFactory的源码我们可以发现,在 XmlBeanFactory 中,初始化了一个 XmlBeanDefinitionReader对象,它的功能是读取Xml文件,将Bean的xml配置文件转换为多个BeanDefinition对象的工具类,一个BeanDefinition对象对应一个<bean>标签中的信息。XmlBeanFactory 中额外还定义了两个构造函数,可以看到第一个构造函数调用了第二个,所以重点看第二个,首先是调用了父类构造函数,然后执行loadBeanDefinition()方法,这个方法就是具体加载了BeanDefinition的操作,我们可以将这段代码抽取出来。所以下面我们我们以编程的方式使用DefaultListableBeanFactory,从中我们可以看到IOC容器使用的一些基本过程,对我们了解IOC容器的工作原理是非常有帮助的,因为这个编程式使用IOC容器过程,很清楚的揭示了在IOC容器实现中那些关键的类,可以看到他们是如何把IOC容器功能解耦的,又是如何结合在一起为IOC容器服务的,DefaultListableBeanFactory方式创建容器如下:
//创建ClassPathResource对象,BeanDefinition的定义信息
ClassPathResource resource = new ClassPathResource("applicationContext.xml");
//创建一个DefaultListableBeanFactory对象,XmlBeanFactory 继承了这个类
DefaultListableBeanFactory factory = new DefaultListableBeanFactory();
/*创建一个载入IOC容器配置文件的读取器,这里使用XMLBeanFactory中使用的XmlBeanDefinitionReader读取器来载入XML文件形式的BeanDefinition,通过一个回到配置给BeanFactory*/
XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(factory);
/*从定义好的资源位置读入配置信息,具体的解析过程有XmlBeanDefinitionReader来完成,
完成整个载入和注册Bean定义后需要的IOC容器就建立起来了,这个时候就可以直接使用IOC容器了*/
reader.loadBeanDefinitions(resource);
//获取实例对象并调用方法
OrangeJuice orangeJuice = (OrangeJuice) factory.getBean("orangeJuice");
orangeJuice.needOrangeJuice();
/*applicationContext.xml部分配置
<bean id="additive" class="com.thr.Additive"></bean>
<bean id="orangeJuice" class="com.thr.OrangeJuice">
<property name="additive" ref="additive"/>
</bean>
*/
总结:这样我们就可以通过Factory独享来使用DefaultListableBeanFactory这个IOC容器了,在使用IOC容器时 需要以下几个步骤:
- 创建IOC配置文件的Resource抽象资源,这个抽象资源包含了BeanDefinition的定义信息。
- 创建一个BeanFactory,这里使用DefaultListableBeanFactory。
- 创建一个载入BeanDefinition的读取器,这里使用XmlBeanDefinitionReader来载入XML文件形式的BeanDefinition,通过一个回调配置给BeanFactory。
- 从定义好的资源位置读取配置信息,具体的解析过程由 XmlBeanDefinitionReader来完成,完成整个载入和注册Bean定义后,需要的IOC容器就建立起来了,这个时候就可以使用IOC容器了。
关于DefaultListableBeanFactory方式创建容器更加详细的介绍可以参考:https://blog.csdn.net/csj941227/article/details/85050632
4.4 BeanFactory的详细介绍
BeanFactory 接口位于 IOC容器设计的最底层,它提供了 Spring IOC容器最基本的功能,给具体的IOC容器的实现提供了规范。为此,我们来看看该接口中到底提供了哪些功能和规范(也就是接口中的方法),BeanFactory 接口中的方法如下图所示:
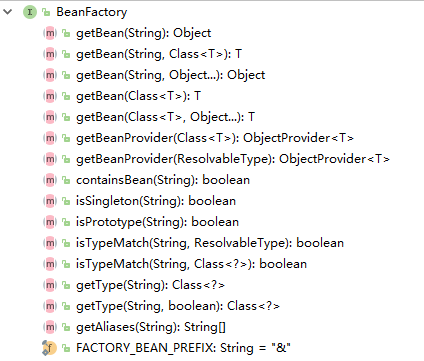
可以看到这里定义的只是一系列的接口方法,通过这一系列的BeanFactory接口,可以使用不同的Bean的检索方法,很方便的从IOC容器中得到需要的Bean,从而忽略具体的IOC容器的实现,从这个角度看的话,这些检索方法代表的是最为基本的容器入口。其具体的方法有:5个获取实例的方法(getBean的重载方法);2个获取Bean的提供者;4个判断的方法(判断是否存在,是否为单例、原型,名称类型是否匹配);2个获取类型的方法和1个获取别名的方法。
下面我们来看BeanFactory 具体的介绍:
public interface BeanFactory {
//用户使用容器时,可以使用转义符“&”来得到FactoryBean本身
String FACTORY_BEAN_PREFIX = "&";
//获取Bean
Object getBean(String name) throws BeansException;
<T> T getBean(String name, Class<T> requiredType) throws BeansException;
Object getBean(String name, Object... args) throws BeansException;
<T> T getBean(Class<T> requiredType) throws BeansException;
<T> T getBean(Class<T> requiredType, Object... args) throws BeansException;
//获取bean的提供者(对象工厂)
<T> ObjectProvider<T> getBeanProvider(Class<T> requiredType);
<T> ObjectProvider<T> getBeanProvider(ResolvableType requiredType);
//判断是否包含指定名字的bean
boolean containsBean(String name);
//获取指定名字的Bean是否是Singleton类型的Bean,对于Singleton属性,用户可以在BeanDefinition中指定
boolean isSingleton(String name) throws NoSuchBeanDefinitionException;
//获取指定名字的Bean是否是Prototype类型的,与Singleton属性一样也可以在BeanDefinition中指定
boolean isPrototype(String name) throws NoSuchBeanDefinitionException;
//指定名字的bean是否和指定的类型匹配
boolean isTypeMatch(String name, ResolvableType typeToMatch);
boolean isTypeMatch(String name, Class<?> typeToMatch) throws NoSuchBeanDefinitionException;
//获取指定名字的Bean的Class类型
Class<?> getType(String name) throws NoSuchBeanDefinitionException;
//获取指定名字的Bean的所有别名,这些别名是用户在BeanDefinition中定义的
String[] getAliases(String name);
}
正是由于BeanFactory是 Spring IoC 最底层的设计,其所有关于 Spring IoC 的容器将会遵守它所定义的方法。所以其内部定义的方法也极其重要,我们只有先搞清楚这个接口中的每一个方法,才能更好的理解IOC容器,下面我们对BeanFactory接口中的方法方法进行介绍。(同样以前面橙汁和添加剂的栗子来举例)如下:
(1)、常量部分:FACTORY_BEAN_PREFIX = "&"
它的作用是如果在使用beanName获取Bean时,在BeanName前添加这个前缀(”&BeanName”), 那么使用这个BeanName获得的Bean实例是其所在FactoryBean的实例,也就是实现 FactoryBean 接口的那个类的Bean实例。
关于BeanFactory和FactoryBean的区别可以参考:https://blog.csdn.net/wangbiao007/article/details/53183764
(2)、getBean部分(重要):该方法表示获取bean实例
①、根据名字获取bean:getBean(String name)
Object obj = (obj)factory.getBean("beanName");
注意:这种方法不太安全,IDE 不会检查其安全性(关联性),所以我们必须强制转换类型。
②、根据类型获取bean:getBean(Class<T> requiredType)
Object obj = factory.getBean(Bean.class);
注意:要求在 Spring 中只配置了一个这种类型的实例,否则报错。(如果有多个,那 Spring 就懵了,不知道该获取哪一个)
③、根据名字和类型获取bean(推荐):getBean(String name, Class<T> requiredType)
Object obj = factory.getBean("beanName",Bean.class);
这种方式解决上面两个方法的问题,所以推荐使用这个方法。
④、根据名称、类型和给定的构造函数参数或者工厂方法参数构造对象获取bean
使用Bean名称寻找对应的Bean,使用给定的构造函数参数或者工厂方法参数构造对象并返回,会重写Bean定义中的默认参数。
Object getBean(String name, Object... args) throws BeansException
使用Bean类型寻找属于该类型的Bean,用给定的构造函数参数或工厂方法参数构造对象并返回,会重写Bean定义中的默认参数。
<T> T getBean(Class<T> requiredType, Object... args) throws BeansException
注意:该两个方法只适用于prototype的Bean,默认作用域的Bean不能重写其参数。
(3)、getBeanProvider部分:该方法表示获取bean的提供者(对象工厂)
getBeanProvider方法用于获取指定bean的提供者,可以看到它返回的是一个ObjectProvider,其父级接口是ObjectFactory。首先来看一下ObjectFactory,它是一个对象的实例工厂,只有一个方法:
T getObject() throws BeansException;
调用这个方法返回的是一个对象的实例。此接口通常用于封装一个泛型工厂,在每次调用的时候返回一些目标对象新的实例。ObjectFactory和FactoryBean是类似的,只不过FactoryBean通常被定义为BeanFactory中的服务提供者(SPI)实例,而ObjectFactory通常是以API的形式提供给其他的bean。简单的来说,ObjectFactory一般是提供给开发者使用的,FactoryBean一般是提供给BeanFactory使用的。
ObjectProvider继承ObjectFactory,特为注入点而设计,允许可选择性的编程和宽泛的非唯一性的处理。在Spring 5.1的时候,该接口从Iterable扩展,提供了对Stream的支持。该接口的方法如下:
// 获取对象的实例,允许根据显式的指定构造器的参数去构造对象
T getObject(Object... args) throws BeansException;
// 获取对象的实例,如果不可用,则返回null
T getIfAvailable() throws BeansException;
T getIfAvailable(Supplier<T> defaultSupplier) throws BeansException;
void ifAvailable(Consumer<T> dependencyConsumer) throws BeansException;
// 获取对象的实例,如果不是唯一的或者没有首先的bean,则返回null
T getIfUnique() throws BeansException;
T getIfUnique(Supplier<T> defaultSupplier) throws BeansException;
void ifUnique(Consumer<T> dependencyConsumer) throws BeansException;
// 获取多个对象的实例
Iterator<T> iterator();
Stream<T> stream();
Stream<T> orderedStream()
这些接口是分为两类,
- 一类是获取单个对象,
getIfAvailable()方法用于获取可用的bean(没有则返回null),getIfUnique()方法用于获取唯一的bean(如果bean不是唯一的或者没有首选的bean返回null)。getIfAvailable(Supplier<T> defaultSupplier)和getIfUnique(Supplier<T> defaultSupplier),如果没有获取到bean,则返回defaultSupplier提供的默认值,ifAvailable(Consumer<T> dependencyConsumer)和ifUnique(Consumer<T> dependencyConsumer)提供了以函数式编程的方式去消费获取到的bean。 - 另一类是获取多个对象,stream()方法返回连续的Stream,不保证bean的顺序(通常是bean的注册顺序)。orderedStream()方法返回连续的Stream,预先会根据工厂的公共排序比较器进行排序,一般是根据org.springframework.core.Ordered的约定进行排序。
(4)、其它部分是一些工具性的方法
containsBean(String name):通过名字判断是否包含指定bean的定义 。isSingleton(String name)isPrototype(String name):判断是单例和原型(多例)的方法。(注意:在默认情况下,isSingleton为 ture,而isPrototype为 false )。如果isSingleton为true,其意思是该 Bean 在容器中是作为一个唯一单例存在的。而isPrototype则相反,如果判断为真,意思是当你从容器中获取 Bean,容器就为你生成一个新的实例。isTypeMatch:判断给定bean的名字是否和类型匹配 。getType(String name):根据bean的名字来获取其类型的方法 (按 Java 类型匹配的方式 )。getAliases(String name):根据bean的名字来获取其别名的方法。
(5)、ResolvableType参数介绍
或许你已经注意到了,有两个方法含有类型是ResolvableType的参数,那么ResolvableType是什么呢?假如说你要获取泛型类型的bean:MyBean,根据Class来获取,肯定是满足不了要求的,泛型在编译时会被擦除。使用ResolvableType就能满足此需求,代码如下:
ResolvableType type = ResolvableType.forClassWithGenerics(MyType.class, TheType.class);
ObjectProvider<MyType<TheType>> op = applicationContext.getBeanProvider(type);
MyType<TheType> bean = op.getIfAvailable()
简单的来说,ResolvableType是对Java java.lang.reflect.Type的封装,并且提供了一些访问该类型的其他信息的方法(例如父类, 泛型参数,该类)。从成员变量、方法参数、方法返回类型、类来构建ResolvableType的实例。
4.5 ApplicationContext容器的设计原理
我们知道ApplicationContext容器是扩展BeanFactory容器而来,在BeanFactory的基本让IoC容器功能更加丰富。如果说BeanFactory是Sping的心脏(提供了IOC容器的基本功能),那么ApplicationContext就是完整的身躯了(提供了更加高级的功能)。所以我们来看一下ApplicationContext和它的基础实现类的体系结构图,如下所示:
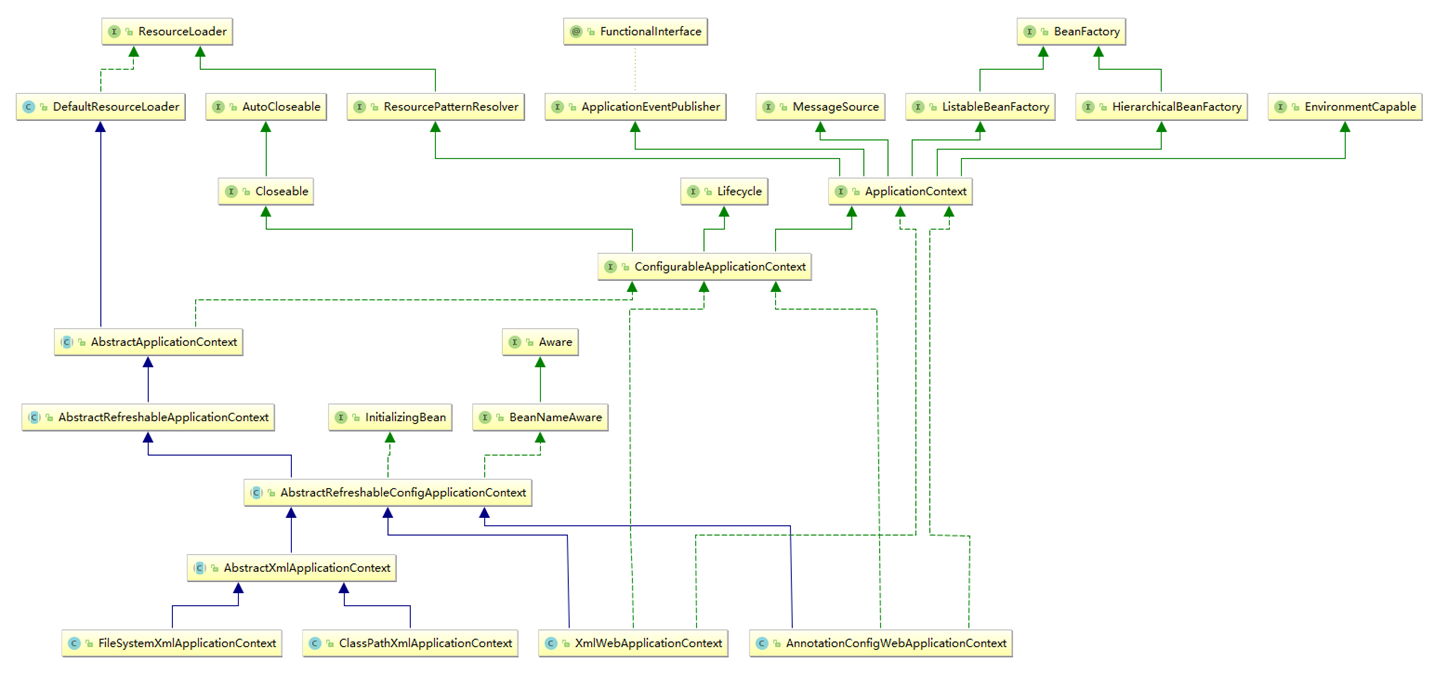
这也太复杂了,看到这么复杂是不是就不想看了?别急,我们暂时只看最下面一排即可。可以看到ClassPathXmlApplicationContext这个类我们比较熟悉,因为在第二章Spring的入门案例中我们已经使用过ClassPathXmlApplicationContext这个类了。所以在ApplicationContext容器中,我们以常用的ClassPathXmlApplicationContext的实现为例来说明ApplicationContext容器的设计原理。使用classpath路径下的xml配置文件加载bean的方式如下:
ApplicationContext context=new ClassPathXmlApplicationContext("applicationContext.xml");
下面对此代码进行分析,追踪源码来介绍它的设计原理如下所示:
首先是new了ClassPathXmlApplicationContext对象,并且构造参数传入了一个xml文件,我们进入其构造方法(核心)如下:
public ClassPathXmlApplicationContext(String configLocation) throws BeansException {
this(new String[] {configLocation}, true, null);
}
上面的参数configLocation表示的是Spring配置文件的路径,可以发现后面又调用了内部另一个构造方法如下:
public ClassPathXmlApplicationContext(String[] configLocations, boolean refresh, @Nullable ApplicationContext parent) throws BeansException {
// 1.初始化父类
super(parent);
// 2.设置本地的配置信息
setConfigLocations(configLocations);
// 3.完成Spring IOC容器的初始化
if (refresh) {
refresh();
}
}
首先初始化了父类,就是一直到父类AbstractApplicationContext中,将ApplicationContext的环境属性设置给本类的环境属性,包括一些profile,系统属性等。
然后设置本地的配置文件信息,这里调用其父类AbstractRefreshableConfigApplicationContext 的 setConfigLocations 方法,该方法主要处理ClassPathXmlApplicationContext传入的字符串中的占位符,即解析给定的路径数组(这里就一个),setConfigLocations 方法源码如下:
public void setConfigLocations(@Nullable String... locations) {
if (locations != null) {
Assert.noNullElements(locations, "Config locations must not be null");
this.configLocations = new String[locations.length];
for (int i = 0; i < locations.length; i++) {
//循环取出每一个path参数,在此处就一个applicationContext.xml
this.configLocations[i] = resolvePath(locations[i]).trim();
}
}
else {
this.configLocations = null;
}
}
setConfigLocations方法除了处理ClassPathXmlApplicationContext传入的字符串中的占位符之外,其实还有一个作用:创建环境对象ConfigurableEnvironment。
详细可以参考:https://blog.csdn.net/boling_cavalry/article/details/80958832
当本地配置文件解析完成之后,就可以准备实现容器的各个功能了。
然后调用了refresh()方法,这个方法非常非常非常重要,它算是ApplicationContext容器最核心的部分了,因为这个refresh过程会牵涉IOC容器启动的一系列复杂操作,ApplicationContext的refresh()方法里面操作的不只是简单 IoC容器,而是高级容器的所有功能(包括 IoC),所以你说这个方法重不重要。而对于不同的高级容器的实现,其操作都是类似的(比如FileSystemXmlApplicationContext),因此将其具体的操作封装在父类 AbstractApplicationContext 中,在其子类中仅仅涉及到简单的调用而已。所以我们来看看AbstractApplicationContext类,可以看到refresh方法的源码如下(AbstractApplicationContext.refresh() 源码脉络):
//AbstractApplicationContext.refresh()方法
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
// Prepare this context for refreshing.
//刷新上下文环境
prepareRefresh();
// Tell the subclass to refresh the internal bean factory.
//这里是在子类中启动 refreshBeanFactory() 的地方,获得新的BeanFactory,解析XML、Java类,并加载BeanDefinition
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// Prepare the bean factory for use in this context.
//准备bean工厂,以便在此上下文中使用
prepareBeanFactory(beanFactory);
try {
// Allows post-processing of the bean factory in context subclasses.
//设置 beanFactory 的后置处理
postProcessBeanFactory(beanFactory);
// Invoke factory processors registered as beans in the context.
//调用 BeanFactory 的后处理器,这些处理器是在Bean 定义中向容器注册的
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
//注册Bean的后处理器,在Bean创建过程中调用
registerBeanPostProcessors(beanFactory);
// Initialize message source for this context.
//对上下文中的消息源进行初始化
initMessageSource();
// Initialize event multicaster for this context.
//初始化上下文中的事件机制
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
//初始化其他特殊的Bean
onRefresh();
// Check for listener beans and register them.
//检查监听Bean并且将这些监听Bean向容器注册
registerListeners();
// Instantiate all remaining (non-lazy-init) singletons.
//实例化所有的(non-lazy-init)单件
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
//发布容器事件,结束Refresh过程
finishRefresh();
}
catch (BeansException ex) {
if (logger.isWarnEnabled()) {
logger.warn("Exception encountered during context initialization - " +
"cancelling refresh attempt: " + ex);
}
// Destroy already created singletons to avoid dangling resources.
destroyBeans();
// Reset 'active' flag.
cancelRefresh(ex);
// Propagate exception to caller.
throw ex;
}
finally {
// Reset common introspection caches in Spring's core, since we
// might not ever need metadata for singleton beans anymore...
//重置Spring公共的缓存
resetCommonCaches();
}
}
}
对上面refresh方法中调用的各个方法详细的介绍:
- prepareRefresh() :为刷新准备上下文,主要设置状态量(是否关闭,是否激活),记录启动时间,初始化属性资源占位符、校验必填属性是否配置及初始化用于存储早期应用事件的容器。
- obtainFreshBeanFactory():主要用于获取一个新的BeanFactory,如果BeanFactory已存在,则将其销毁并重建,默认重建的BeanFactory为AbstractRefreshableApplicationContext;此外此方法委托其子类从XML中或基于注解的类中加载BeanDefinition。
- prepareBeanFactory():配置BeanFactory使其具有一个上下文的标准特征,如上下文的类加载器、后处理程序(post-processors,如设置如总感知接口)。
- postprocessBeanFactory():在应用上下文内部的BeanFactory初始化结束后对其进行修改,在所有的BeanDefinition已被加载但还没有实例化bean, 此刻可以注册一些特殊的BeanPostFactory,如web应用会注册ServletContextAwareProcessor等。
- invokeBeanFactoryPostProcessors():调用注册在上下文中的BeanFactoryPostProcessor,如果有顺序则按顺序调用,并且一定再单列对象实例化之前调用。
- registerBeanPostProcessors():实例化并注册BeanPostProcessor,如果有显式的顺序则按照顺序调用一定在所有bean实例化之前调用。
- initMessageSource():初始化MessageSource,如果当前上下文没有定义则使用其父类的,如果BeanFactory中不能找到名称为messageSource中的bean, 则默认使用DelegatingMessageSource。
- initApplicationEventMulticaster():初始化ApplicationEventMulticaster,如果上下文没有定义则默认使用SimpleApplicationEventMulticaster,此类主要用于广播ApplicationEvent。
- onRefresh() :在一些特定的上下文子类中初始化特定的bean,如在Webapp的上下文中初始化主题资源。
- registerListeners():添加实现了ApplicationListener的bean作为监听器,它不影响非bean的监听器;还会使用多播器发布早期的ApplicationEvent。
- finishBeanFactoryInitialization():实例化所有非延迟加载的单例,完成BeanFactory的初始化工作。
- finishRefresh():完成上下文的刷新工作,调用LifecycleProcessor的onFresh()及发布的ContextRefreshEvent事件。
- resetCommonCaches():重置Spring公共的缓存,如:ReflectionUtils、ResolvableType、CachedIntrospectionResults的缓存CachedIntrospectionResults的缓存。
上述各个方法的详细介绍可以参考:https://blog.csdn.net/boling_cavalry/article/details/81045637
ApplicationContext的设计原理暂时就介绍到这里吧!!!下面来介绍一下ApplicationContext容器中常用的一些实现类。
4.6 ApplicationContext的详细介绍
对于ApplicationContext高级容器的详细介绍我们就不看它的的源码了,主要来介绍一下它的具体实现类,因为平时我们在开发中使用它的实现类比较多。ApplicationContext的中文意思为“应用上下文”,它继承自BeanFactory,给IOC容器提供更加高级的功能,所以我们称它为高级容器,ApplicationContext接口有以下常用的实现类,如下所示:
| 实现类 | 描述 |
|---|---|
| ClassPathXmlApplicationContext | 从系统类路径classpath下加载一个或多个xml配置文件,适用于xml配置的方式 |
| FileSystemXmlApplicationContext | 从系统磁盘下加载一个或多个xml配置文件(必须有访问权限) |
| XmlWebApplicationContext | 从web应用下加载一个或多个xml配置文件,适用于web应用的xml配置方式 |
| AnnotationConfigApplicationContext | 从Java注解的配置类中Spring的ApplicationContext容器。使用注解避免使用application.xml进行配置。相比XML配置,更加便捷 |
| AnnotationConfigWebApplicationContext | 专门为web应用准备的用于读取注解创建容器的类 |
下面详细介绍各个实现类的使用方式:
(1)、ClassPathXmlApplicationContext:从系统类路径classpath下加载一个或多个xml配置文件,找到并装载完成ApplicationContext的实例化工作。例如:
ApplicationContext ctx = new ClassPathXmlApplicationContext("applicationContext.xml");
(2)、FileSystemXmlApplicationContext:从系统磁盘下加载一个或多个xml配置文件(必须有访问权限)。也就是读取系统磁盘指定路径的xml文件。例如:
ApplicationContext ac = new FileSystemXmlApplicationContext("c:/applicationContext.xml");
它与ClassPathXmlApplicationContext的区别在于读取Spring配置文件的方式,FileSystemXmlApplicationContext不在从类路径下读取配置文件,而是通过制定参数从系统磁盘读取,前提是有访问权限。
(3)、XmlWebApplicationContext:从web应用下加载一个或多个xml配置文件,适用于web应用的xml配置方式。
在Java项目中提供ClassPathXmlApplicationContext类手工实例化ApplicationContext容器通常是不二之选,但是对于Web项目就不行了,Web项目的启动是由相应的Web服务器负责的,因此,在Web项目中ApplicationContext容器的实例化工作最好交由Web服务器来完成。Spring为此提供了以下两种方式:
- org.springframework.web.context.ContextLoaderListener
- org.springframework.web.context.ContexLoaderServlet(此方法目前以废弃)
ContextLoaderListener方式只适用于Servlet2.4及以上规范的Servlet,并且需要Web环境。我们需要在web.xml中添加如下配置:
<!--从类路径下加载Spring配置文件,classpath特指类路径下加载-->
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:applicationContext.xml</param-value>
</context-param>
<!--以Listener的方式启动spring容器-->
<listener>
<listener-class>
org.springframework.web.context.ContextLoaderListener
</listener-class>
</listener>
当Spring容器启动后就可以在项目中获取对应的实例了。例如:
@WebServlet("/MyServlet")
public class MyServlet {
public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
//创建XmlWebApplicationContext对象,但这时并没有初始化容器
XmlWebApplicationContext context = new XmlWebApplicationContext();
// 指定配置文件路径
context.setConfigLocation("application.xml");
// 需要指定ServletContext对象
context.setServletContext(request.getServletContext());
// 初始化容器
context.refresh();
//获取实例
Additive additive = (Additive) context.getBean("additive");
additive.addAdditive();
}
}
(4)、AnnotationConfigApplicationContext:从Java注解的配置类中加载Spring的ApplicationContext容器。使用注解避免使用application.xml进行配置。相比XML配置,更加便捷。
创建一个AppConfig配置类(OrangeJuice和Additive类参考上一章内容)。例如:
@Configuration
public class AppConfig {
@Bean(name = "orangeJuice")
public OrangeJuice orangeJuice(){
OrangeJuice orangeJuice = new OrangeJuice();
return orangeJuice;
}
@Bean(name = "additive")
public Additive additive(){
Additive additive = new Additive();
return additive;
}
}
注意:@Configuration和@Bean注解的介绍和理解
- @Configuration可理解为用spring的时候xml里面的标签。
- @Bean可理解为用spring的时候xml里面的标签,默认name为方法名。
使用AnnotationConfigApplicationContext获取Spring容器实例。代码如下:
//创建AnnotationConfigApplicationContext对象,此时并没有初始化容器
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext();
//将AppConfig中的配置注册至容器中
context.register(AppConfig.class);
// 初始化容器
context.refresh();
//获取实例对象
OrangeJuice orangeJuice = (OrangeJuice) context.getBean("orangeJuice");
Additive additive = (Additive) context.getBean("additive");
orangeJuice.setAdditive(additive);
orangeJuice.needOrangeJuice();
(5)、AnnotationConfigWebApplicationContext:专门为web应用准备的用于读取注解创建容器的类。
如果是Web项目使用@Configuration的java类提供配置信息的配置 web.xml 配置修改如下:
<!--通过指定context参数,让Spring使用AnnotationConfigWebApplicationContext启动容器
而非XmlWebApplicationContext。默认没配置时是使用XmlWebApplicationContext-->
<context-param>
<param-name>contextClass</param-name>
<param-value> org.springframework.web.context.support.AnnotationConfigWebApplicationContext
</param-value>
</context-param>
<!--指定标注了@Configuration的类,多个可以用逗号分隔-->
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>com.thr.AppConfig</param-value>
</context-param>
<!--监听器将根据上面的配置使用AnnotationConfigWebApplicationContext
根据contextConfigLocation指定的配置类启动Spring容器-->
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
</listener>
4.7 ApplicationContext容器扩展功能详解介绍
前面在介绍BeanFactory和ApplicationContext的区别是生成了一张图如下:
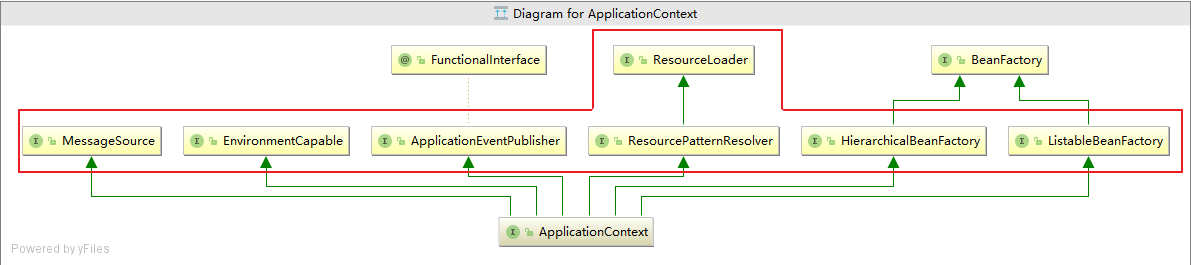
我们知道ApplicationContext容器正是因为继承了红框中的这些接口,使用才让ApplicationContext容器有了更加高级的功能。所以下面来详细介绍红框中各个接口:
(1)、ListableBeanFactory——可将Bean逐一列出的工厂
ListableBeanFactory接口能够列出工厂中所有的bean,下面是该接口的源码:
/**
* ListableBeanFactory源码介绍
*/
public interface ListableBeanFactory extends BeanFactory {
//判断是否包含给定名字的bean的定义
boolean containsBeanDefinition(String beanName);
//获取工厂中bean的定义的数量
int getBeanDefinitionCount();
//获取工厂中所有定义了的bean的名字(包括子类)
String[] getBeanDefinitionNames();
//获取指定类型的bean的名字(includeNonSingletons为false表示只取单例Bean,true则不是;
//allowEagerInit为true表示立刻加载,false表示延迟加载。 注意:FactoryBeans都是立刻加载的。)
String[] getBeanNamesForType(ResolvableType type);
String[] getBeanNamesForType(ResolvableType type, boolean includeNonSingletons, boolean allowEagerInit);
String[] getBeanNamesForType(@Nullable Class<?> type);
String[] getBeanNamesForType(@Nullable Class<?> type, boolean includeNonSingletons, boolean allowEagerInit);
//根据指定的类型来获取所有的bean名和bean对象的Map集合(包括子类)
<T> Map<String, T> getBeansOfType(@Nullable Class<T> type) throws BeansException;
<T> Map<String, T> getBeansOfType(@Nullable Class<T> type, boolean includeNonSingletons, boolean allowEagerInit)
throws BeansException;
//根据注解类型,获取所有有这个注解的bean名称
String[] getBeanNamesForAnnotation(Class<? extends Annotation> annotationType);
//根据注解类型,获取所有有这个注解的bean名和bean对象的Map集合
Map<String, Object> getBeansWithAnnotation(Class<? extends Annotation> annotationType) throws BeansException;
//根据bean名和注解类型查找所有指定的注解(会考虑接口和父类中的注解)
@Nullable
<A extends Annotation> A findAnnotationOnBean(String beanName, Class<A> annotationType)
throws NoSuchBeanDefinitionException;
}
上面的这些方法都不考虑祖先工厂中的bean,只会考虑在当前工厂中定义的bean。
(2)、HierarchicalBeanFactory——分层的Bean工厂
HierarchicalBeanFactory接口定义了BeanFactory之间的分层结构,ConfigurableBeanFactory中的setParentBeanFactory方法能设置父级的BeanFactory,下面列出了HierarchicalBeanFactory中定义的方法:
/**
* HierarchicalBeanFactory源码介绍
*/
public interface HierarchicalBeanFactory extends BeanFactory {
//获取本Bean工厂的父工厂
@Nullable
BeanFactory getParentBeanFactory();
//本地的工厂是否包含指定名字的bean
boolean containsLocalBean(String name);
}
这两个方法都比较直接明了,getParentBeanFactory方法用于获取父级BeanFactory。containsLocalBean用于判断本地的工厂是否包含指定的bean,忽略在祖先工厂中定义的bean。
(3)、MessageSource——消息的国际化
在前面也提到过MessageSource,它主要用于消息的国际化,下面是该接口的源码:
// 获取消息
String getMessage(String code, Object[] args, String defaultMessage, Locale locale);
String getMessage(String code, Object[] args, Locale locale) throws NoSuchMessageException;
String getMessage(MessageSourceResolvable resolvable, Locale locale) throws NoSuchMessageException;
以上的三个方法都是用于获取消息的,第一个方法提供了默认消息,第二个接口如果没有获取到指定的消息会抛出异常。第三个接口中的MessageSourceResolvable参数是对代码、参数值、默认值的一个封装。
(4)、ApplicationEventPublisher
ApplicationEventPublisher接口封装了事件发布功能,提供Spring中事件的机制。接口中的方法定义如下:
// 发布事件
void publishEvent(ApplicationEvent event);
void publishEvent(Object event);
第一个方法用于发布特定于应用程序事件。第二个方法能发布任意的事件,如果事件不是ApplicationEvent,那么会被包裹成PayloadApplicationEvent事件。
(5)、EnvironmentCapable
EnvironmentCapable提供了访问Environment的能力,该接口只有一个方法:
Environment getEnvironment();
Environment表示当前正在运行的应用的环境变量,它分为两个部分:profiles和properties。它的父级接口PropertyResolver提供了property的访问能力。
(6)、ResourceLoader和ResourcePatternResolver
首先来看一下ResourceLoader,听名字就知道该接口是用来加载资源的策略接口(例如类路径或者文件系统中的资源)。该接口中的源码如下:
/**
* ResourceLoader源码介绍
*/
public interface ResourceLoader {
//用于从类路径加载的伪URL前缀:" classpath:"。
String CLASSPATH_URL_PREFIX = ResourceUtils.CLASSPATH_URL_PREFIX;
//根据指定的位置获取资源
Resource getResource(String location);
//获取该资源加载器所使用的类加载器
ClassLoader getClassLoader();
}
该接口只有简单明了的两个方法,一个是用来获取指定位置的资源,一个用于获取资源加载器所使用的类加载器。
Resource是从实际类型的底层资源(例如文件、类路径资源)进行抽象的资源描述符。再看下Resource的源码:
/**
* Resource源码介绍
*/
public interface Resource extends InputStreamSource {
boolean exists(); // 资源实际上是否存在
boolean isReadable(); // 资源是否可读
boolean isOpen(); // 检查资源是否为打开的流
boolean isFile(); // 资源是否为文件系统上的一个文件
URL getURL() throws IOException; // 获取url
URI getURI() throws IOException; // 获取URI
File getFile() throws IOException; // 获取文件
ReadableByteChannel readableChannel() throws IOException; // 获取ReadableByteChannel
long contentLength() throws IOException; // 资源的内容的长度
long lastModified() throws IOException; // 资源的最后修改时间
// 相对于当前的资源创建一个新的资源
Resource createRelative(String relativePath) throws IOException;
String getFilename(); // 获取资源的文件名
String getDescription(); // 获取资源的描述信息
}
Resource的父级接口为InputStreamSource,可以简单的理解为InputStream的来源,其内部只有一个方法,如下:
// 获取输入流
InputStream getInputStream() throws IOException;
接下来在来看一下ResourcePatternResolver,该接口用于解析一个位置模式(例如Ant风格的路径模式),该接口也只有一个方法,如下:
// 将给定的位置模式解析成资源对象
Resource[] getResources(String locationPattern) throws IOException;
至此BeanFactory和ApplicationContext容器的设计已经全部介绍完了。
5、Spring IoC容器的初始化过程
5.1 前言
上一章介绍了Spring IOC容器的设计与实现,同时也讲到了高级容器ApplicationContext中有个refresh()方法,执行了这个方法标志着 IOC 容器正式启动,简单来说,IOC 容器的初始化是由refresh()方法来启动的。而在Spring IOC 容器启动的过程中,会将Bean解析成Spring内部的BeanDefinition结构。不管是通过xml配置文件的<Bean>标签,还是通过注解配置的@Bean,它最终都会被解析成一个BeanDefinition信息对象,最后我们的Bean工厂就会根据这份Bean的定义信息,对Bean进行实例化、初始化等等操作。
从上可知BeanDefinition这个对象对Spring IoC容器的重要之处,并且IOC的初始化都是围绕这个BeanDefinition来进行的。所以了解好了它,能让我们更大视野的来看Spring管理Bean的一个过程,也能透过现象看本质。所以这里再次强调一次BeanDefinition对象的作用:简单来说,BeanDefinition在Spring中是用来描述Bean对象的,它本身并不是一个Bean实例,而是包含了Bean实例的所有信息,比如类名、属性值、构造器参数、scope、依赖的bean、是否是单例类、是否是懒加载以及其它信息。其实就是将Bean实例定义的信息存储到这个BeanDefinition相应的属性中,后面Bean对象的创建是根据BeanDefinition中描述的信息来创建的,例如拿到这个BeanDefinition后,可以根据里面的类名、构造函数、构造函数参数,使用反射进行对象创建。也就是说 IOC容器可以有多个BeanDefinition,并且一个BeanDefinition对象对应一个<bean>标签中的信息。当然BeanDefinition的最终目的不只是用来存储Bean实例的所有信息,而是为了可以方便的进行修改属性值和其他元信息,比如通过BeanFactoryPostProcessor进行修改一些信息,然后在创建Bean对象的时候就可以结合原始信息和修改后的信息创建对象了。
5.2 IoC容器的初始化步骤
我们知道,在refresh()之后IOC 容器的启动会经过一段很复杂的过程,我们暂时不要求全部了解清楚,但是现在大体了解一下 Spring IoC 初始化的过程还是必要的。这对于理解 Spring 的一系列行为是很有帮助的。IOC 容器初始化包括BeanDefinition的Resource定位、载入和注册三个基本过程,如果我们了解如何编程式的使用 IOC 容器(编程式就是使用DefaultListableBeanFactory来创建容器),就可以清楚的看到Resource定义和载入过程的接口调用,在下面的内容中,我们将会详细分析这三个过程的实现。
IOC 容器的初始化包括的三个过程介绍如下:
- Resource定位过程:这个Resource定位指的是BeanDefinition的资源定位,就是对开发者的配置文件(Xml)进行资源的定位,并将其封装成Resource对象。它由ResourceLoader通过统一的Resource接口来完成,这个Resource对各种形式的BeanDefinition的使用都提供了统一接口。比如:在文件系统中的Bean定义信息可以使用FileSystemResource来进行抽象。在类路径中的Bean定义信息可以使用ClassPathResource来进行抽象等等。这个定位过程类似于容器寻找数据的过程,就像用水捅装水先要把水找到一样。
- BeanDefinition的载入:这个载入过程是将Resource 定位到的信息,表示成IoC容器内部的数据结构,而这个容器内部的数据结构就是BeanDefinition。
- BeanDefinition的注册:这个注册过程把上面载入过程中解析得到的BeanDeftnition向IoC容器进行注册。注册过程是通过调用BeanDefinitionRegistry接口的实现来完成的。在IoC容器内部将BeanDefinition注人到一个HashMap中去,IoC容器就是通过这个HashMap来持有这些BeanDefinition数据的。
注意:Bean的定义和初始化在 Spring IoC 容器是两大步骤,它是先定义,然后再是初始化和依赖注入。所以当Spring做完了以上 3 步后,Bean 就在 Spring IoC 容器中被定义了,而没有被初始化,更没有完成依赖注入,所以此时仍然没有对应的 Bean 的实例,也就是没有注入其配置的资源给 Bean,也就是它还不能完全使用。对于初始化和依赖注入,Spring Bean 还有一个配置选项——【lazy-init】,其含义就是:是否默认初始化 Spring Bean。在没有任何配置的情况下,它的默认值为default,实际值为 false(默认非懒加载),也就是 Spring IoC 容器默认会自动初始化 Bean。如果将其设置为 true(懒加载),那么只有当我们使用 Spring IoC 容器的 getBean 方法获取它时,它才会进行 Bean 的初始化,完成依赖注入。
5.3 BeanDefinition的Resource定位
在Spring框架中,如果想要获取系统中的配置文件,就必须通过Resource接口的实现来完成,Resource是Sping中用于封装I/O操作的接口。例如我们前面在以编程的方式使用DefaultListableBeanFactory时,首先是定义一个Resource来定位容器使用的BeanDefinition,这里使用的是Resource的实现类ClassPathResource,这时Spring会在类路径中去寻找以文件形式存在BeanDefinition。
ClassPathResource resource = new ClassPathResource("beans.xml");
但是这里的Resource并不能由 DefaultListableBeanFactory 直接使用,而是需要通过Spring中的 BeanDefinitionReader 来对这些信息进行处理。在这里,我们也可以看到使用 ApplicationContext 相对于直接使用 DefaultListableBeanFactory 的好处,因为在ApplicationContext中,Spring已经为我们提供了一系列加载不同Resource的读取器实现,而在 DefaultListableBeanFactory 只是一个纯粹的IOC容器,需要为它配置配置特定的读取器才能完成这些功能,当然了 利和弊 是共存的,使用 DefaultListableBeanFactory 这样更底层的IOC容器,能提高定制IOC容器的的灵活性。
常用的Resource资源类型如下:
- FileSystemResource:以文件的绝对路径方式进行访问资源,效果类似于Java中的File;
- ClassPathResourcee:以类路径的方式访问资源,效果类似于this.getClass().getResource("/").getPath();
- ServletContextResource:web应用根目录的方式访问资源,效果类似于request.getServletContext().getRealPath("");
- UrlResource:访问网络资源的实现类。例如file: http: ftp:等前缀的资源对象;
- ByteArrayResource: 访问字节数组资源的实现类。
回到我们经常使用的ApplicationContext上来,它给我们提供了一系列加载不同Resource的读取器实现,例如ClassPathXmlApplicationContext、FileSystemXmlApplicationContext以及XmlWebApplicationContext等等,简单的从这些类的名字上分析,可以清楚的看到他们可以提供哪些不同的Resource读入功能,比如:ClassPathXmlApplicationContext可以从 classpath载入Resource,FileSystemXmlApplicationContext可以从文件系统中载入Resource,XmlWebApplicationContext可以在Web容器中载入Resource等。
我们通常喜欢拿ClassPathXmlApplicationContext来举例,所以这里用它来分析ApplicationContext是如何来完成BeanDefinition的Resource定位,首先来看一下ClassPathXmlApplicationContext的整继承体系:
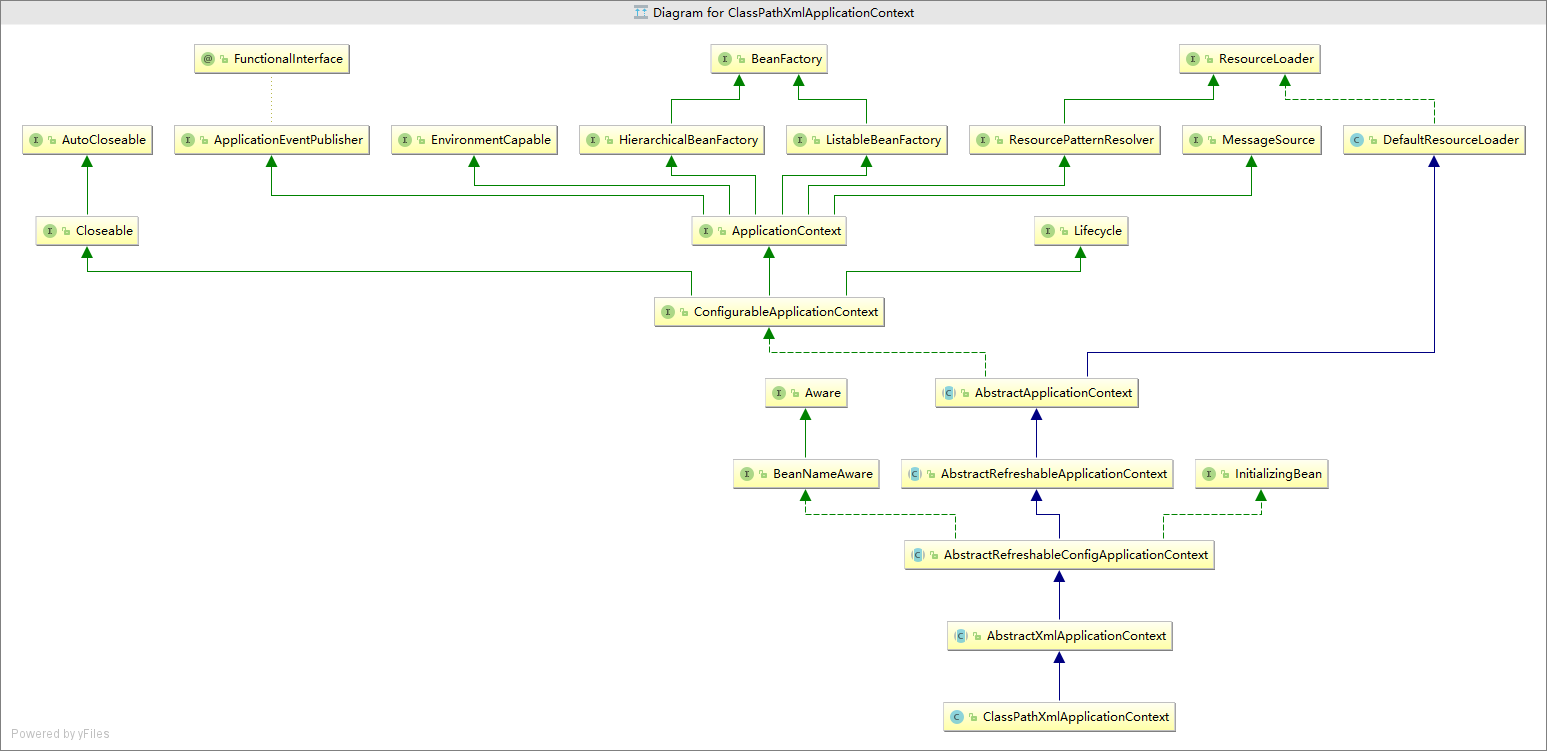
通过上面的图片并且查看继承关系可知,ClassPathXmlApplicationContext继承了AbstractApplicationContext,所以该实现类具备了读取Resource定义的BeanDefinition的能力。因为AbstractApplicationContext的基类是DefaultResourceLoader。而且其它的类如FileSystemXmlApplicationContext、XmlWebApplicationContext等等都如出一辙。也是通过DefaultResourceLoader读取Resource。
下面我们再来看一下ClassPathXmlApplicationContext的顺序图。通过这个顺序图可以清晰的看到IOC容器的初始化阶段所调用的各个方法。
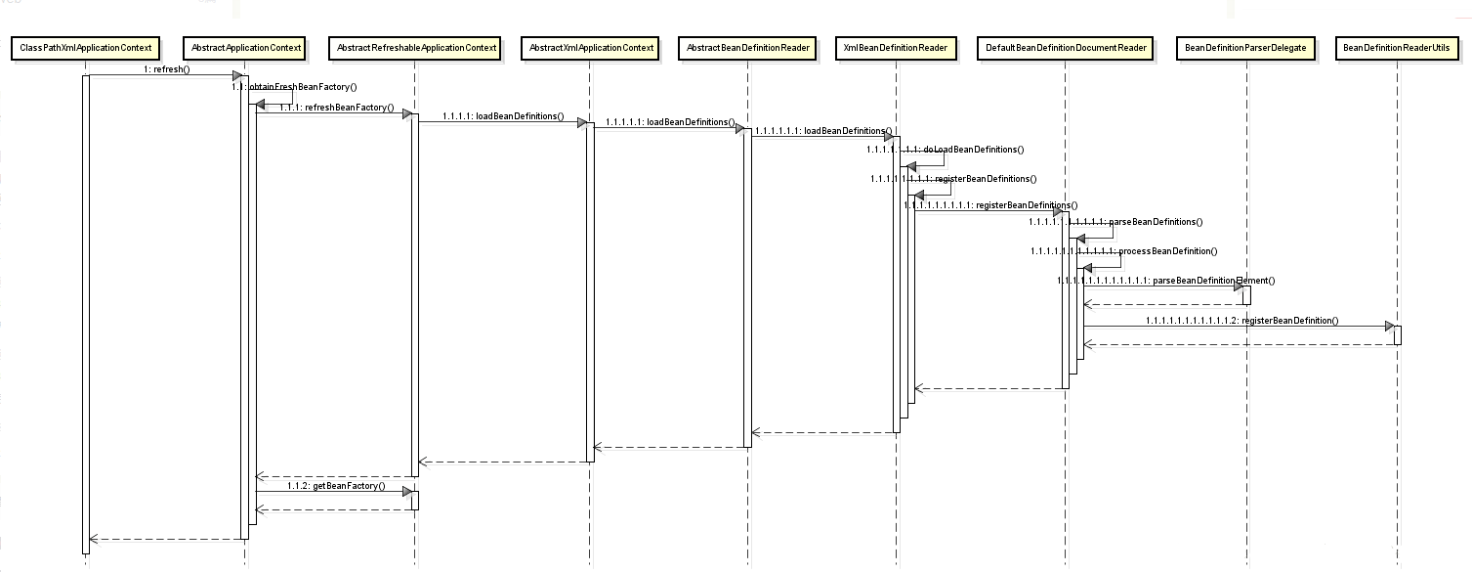
那么接下来我们从ClassPathXmlApplicationContext这个类来分析Spring的IoC容器是如何一步一步完成定位的:
①、我们知道IOC容器的启动是从refresh()方法开始的,所以我们先从refresh()方法开始:ClassPathXmlApplicationContext类中调用的refresh()方法是其继承的基类 AbstractApplicationContext中的实现,所以先跟踪AbStractApplicationContext中的refresh()方法:
注意:在refresh()中我们先重点看obtainFreshBeanFactory()这个方法,这是IoC容器初始化的入口。
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
//刷新上下文环境
prepareRefresh();
//我们先着重看这个方法 这是初始化容器的地方,是在子类中启动refreshBeanFactory()
//并且在这里获得新的BeanFactory,解析XML、Java类,并加载BeanDefinition
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
//准备bean工厂,以便在此上下文中使用
prepareBeanFactory(beanFactory);
try {
//设置 beanFactory 的后置处理
postProcessBeanFactory(beanFactory);
//调用 BeanFactory 的后处理器,这些处理器是在Bean 定义中向容器注册的
invokeBeanFactoryPostProcessors(beanFactory);
//注册Bean的后处理器,在Bean创建过程中调用
registerBeanPostProcessors(beanFactory);
//对上下文中的消息源进行初始化
initMessageSource();
//初始化上下文中的事件机制
initApplicationEventMulticaster();
//初始化其他特殊的Bean
onRefresh();
//检查监听Bean并且将这些监听Bean向容器注册
registerListeners();
//实例化所有的(non-lazy-init)单件
finishBeanFactoryInitialization(beanFactory);
//发布容器事件,结束Refresh过程
finishRefresh();
}
catch (BeansException ex) {
if (logger.isWarnEnabled()) {
logger.warn("Exception encountered during context initialization - " +
"cancelling refresh attempt: " + ex);
}
destroyBeans();
cancelRefresh(ex);
throw ex;
}
finally {
//重置Spring公共的缓存
resetCommonCaches();
}
}
}
②、然后点击obtainFreshBeanFactory()这个方法,它还在AbstractApplicationContext中实现,这个obtainFreshBeanFactory()很关键,这里面有 IoC的Resource定位和载入。
protected ConfigurableListableBeanFactory obtainFreshBeanFactory() {
refreshBeanFactory();
return getBeanFactory();
}
进来后发现其调用refreshBeanFactory和getBeanFactory方法,表示重新获取一个新的BeanFactory实例。
③、继续跟踪refreshBeanFactory()方法,点击进入。
protected abstract void refreshBeanFactory() throws BeansException, IllegalStateException;
可以看到这里只是定义了抽象方法,既然是抽象的方法,那么肯定有具体的实现,那这个具体初始化IOC容器的实现在哪呢?在AbstractApplicationContext中没有做具体实现。我们从前面的继承图可知,AbstractApplicationContext还有很多子类,所以肯定是交给其子类完成,实现解耦,让初始化IOC容器变得更加灵活。
所以我们从其子类AbstractRefreshableApplicationContext中找到实现的refreshBeanFactory()方法。
protected final void refreshBeanFactory() throws BeansException {
//这里判断,如果存在了BeanFactory,则销毁并关闭该BeanFactory
if (hasBeanFactory()) {
destroyBeans();
closeBeanFactory();
}
try {
//这里的创建新的BeanFactory,对于DefaultListableBeanFactory前面一章已经介绍了很多了,应该都知道它的作用
DefaultListableBeanFactory beanFactory = createBeanFactory();
beanFactory.setSerializationId(getId());
customizeBeanFactory(beanFactory);
//载入Bean ,抽象方法,委托子类AbstractXmlApplicationContext实现
//后面会看到一系列重载的loadBeanDefinitions方法
loadBeanDefinitions(beanFactory);
synchronized (this.beanFactoryMonitor) {
this.beanFactory = beanFactory;
}
}
catch (IOException ex) {
throw new ApplicationContextException("I/O error parsing bean definition source for " + getDisplayName(), ex);
}
}
上面的代码主要分为这么几个步骤:
-
-
首先判断BeanFactory是否存在,如果存在(不为NULL),则销毁关闭该BeanFactory。也就是清除跟Bean有关的Map或者List等属性集合,并且将BeanFactory设置为null,序列化Id设置为null。
-
然后创建一个新的DefaultListableBeanFactory(这个类是Spring Bean初始化的核心类),所以我们看下创建DefaultListableBeanFactory的地方:createBeanFactory(),这个方法 是在AbstractRefreshableApplicationContext中实现,所以AbstractApplicationContext 让我们可以充分自由的实例化自己想初始化的原始IOC容器。
protected DefaultListableBeanFactory createBeanFactory() { //getInternalParentBeanFactory 获取当前容器已有的父亲容器,来作为新容器的父容器,这个方法是在AbstractApplicationContext中实现的。 return new DefaultListableBeanFactory(getInternalParentBeanFactory()); } -
最后对新建的BeanFactory进行设置,包括bean序列化Id的设置、bean的特殊设置,bean载入操作。然后将beanFactory赋值给本类的beanFactory属性。注意:customizeBeanFactory(beanFactory)里面只做了两件事:一个是设置bean是否允许覆盖,另一个是设置bean是否允许循坏使用。
-
④、跟踪loadBeanDefinitions(beanFactory)方法。
protected abstract void loadBeanDefinitions(DefaultListableBeanFactory beanFactory)
throws BeansException, IOException;
这个方法的具体实现是由子类AbstractXmlApplicationContext具体实现的。所以我们知道了该怎么去找这个loadBeanDefinitions的具体实现了吧。
protected void loadBeanDefinitions(DefaultListableBeanFactory beanFactory) throws BeansException, IOException {
//创建一个xml配置读写器用于解析xml文件中定义的bean
XmlBeanDefinitionReader beanDefinitionReader = new XmlBeanDefinitionReader(beanFactory);
//设置BeanDefinitionReader 的相关属性
//1.设置 Environment,即环境,与容器的环境一致
beanDefinitionReader.setEnvironment(this.getEnvironment());
//2.设置 ResourceLoader,即资源加载器,具体加载资源的功能,这个加载器很重要,后面会用到
// 这里传一个this进去,因为ApplicationContext是实现了ResourceLoader接口
beanDefinitionReader.setResourceLoader(this);
//3.设置 EntityResolver,即实体解析器,这里用于解析资源加载器加载的资源内容
beanDefinitionReader.setEntityResolver(new ResourceEntityResolver(this));
//这个方法默认实现是空的,允许用户自定义实现读取器的定制化,需要实现接口,可以设置xml解析完成校验,定制化解析器等
initBeanDefinitionReader(beanDefinitionReader);
// 这里开始就是 加载、获取BeanDefinition资源定位,并且是载入模块的开始了
loadBeanDefinitions(beanDefinitionReader);
}
⑤、继续跟踪loadBeanDefinitions(beanDefinitionReader)方法,这个方法在AbstractXMLApplicationContext中有实现,我们看下。
protected void loadBeanDefinitions(XmlBeanDefinitionReader reader) throws BeansException, IOException {
//以Resource的方式获取所有定位到的resource资源位置(用户定义)
//但是现在不会走这条路,因为配置文件还没有定位到,也就是没有封装成Resource对象。
Resource[] configResources = getConfigResources();
if (configResources != null) {
reader.loadBeanDefinitions(configResources);//载入resources
}
//以String的方式获取所有配置文件的位置(容器自身)
String[] configLocations = getConfigLocations();
if (configLocations != null) {
reader.loadBeanDefinitions(configLocations);//载入resources
}
}
这里主要是获取到用户定义的resource资源位置以及获取所以本地配置文件的位置。
⑥、进入第二个reader.loadBeanDefinitions(configLocations)方法。从这里开始就是BeanDefinitionReader模块的实现了,也就是ApplicationContext上下文将BeanDefinition的定位加载工作交付到了XmlBeanDefinitionReader。这个方法是由XmlBeanDefinitionReader的基类AbstractBeanDefinitionReader来实现的。
public int loadBeanDefinitions(String... locations) throws BeanDefinitionStoreException {
Assert.notNull(locations, "Location array must not be null");
int count = 0;
//循坏加载配置文件
for (String location : locations) {
count += loadBeanDefinitions(location);
}
return count;
}
这里就是循环加载xml配置文件的路径,然后返回总个数。
⑦、下面我们继续跟踪loadBeanDefinitions(loaction)这个方法,它是还在AbstractBeanDefinitionReader的类中实现。
public int loadBeanDefinitions(String location) throws BeanDefinitionStoreException {
return loadBeanDefinitions(location, null);
}
⑧、继续跟踪上面代码中的 loadBeanDefinitions(location, null)。
进入到loadBeanDefinitions(String location, Set
public int loadBeanDefinitions(String location, @Nullable Set<Resource> actualResources) throws BeanDefinitionStoreException {
//这里取到ResourceLoader对象(其实DefaultResourceLoader对象)
ResourceLoader resourceLoader = getResourceLoader();
if (resourceLoader == null) {
throw new BeanDefinitionStoreException(
"Cannot load bean definitions from location [" + location + "]: no ResourceLoader available");
}
//这里对Resource的路径模式进行解析,比如我们设定的各种Ant格式的路径定义,得到需要的Resource集合,
//这些Resource集合指定我们已经定义好的BeanDefinition信息,可以是多个文件。
if (resourceLoader instanceof ResourcePatternResolver) {
try {
//把字符串类型的xml文件路径,形如:classpath*:user/**/*-context.xml,转换成Resource对象类型,
//其实就是用流的方式加载配置文件,然后封装成Resource对象
Resource[] resources = ((ResourcePatternResolver) resourceLoader).getResources(location);
//加载Resource资源中的Bean,然后返回加载数量,这个loadBeanDefinitions就是Bean的载入了
int count = loadBeanDefinitions(resources);
if (actualResources != null) {
Collections.addAll(actualResources, resources);
}
if (logger.isTraceEnabled()) {
logger.trace("Loaded " + count + " bean definitions from location pattern [" + location + "]");
}
return count;
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(
"Could not resolve bean definition resource pattern [" + location + "]", ex);
}
}
else {
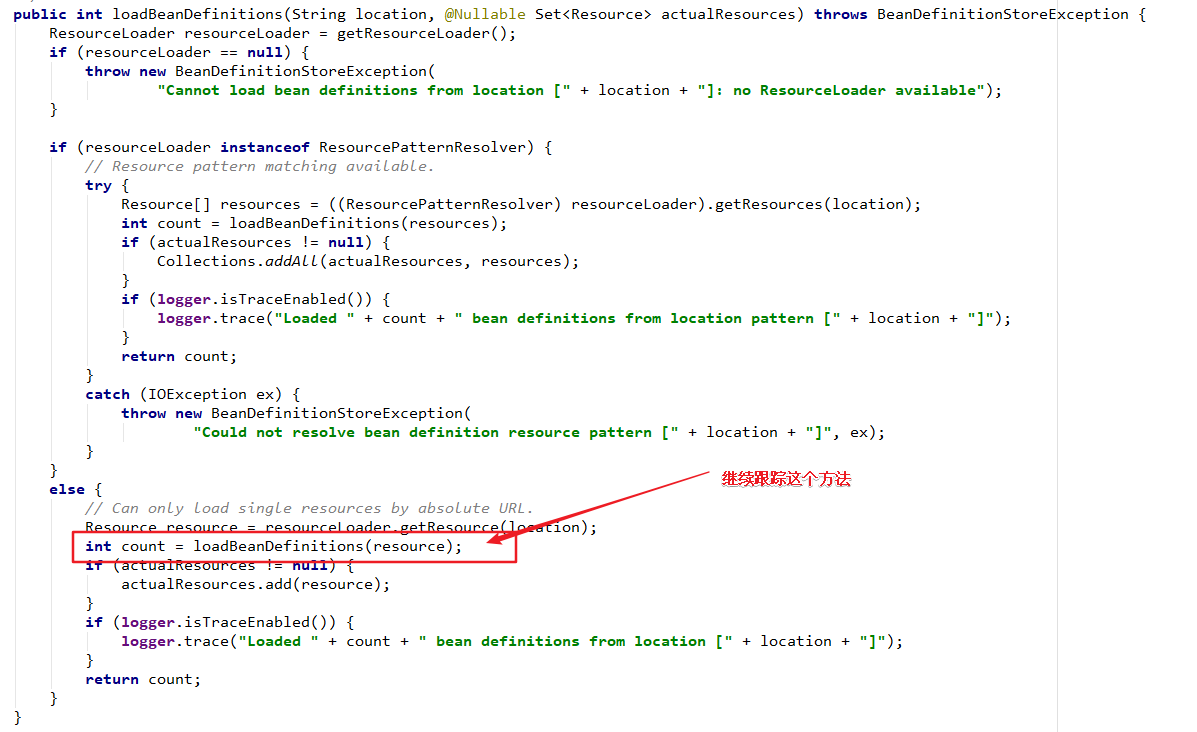
// Can only load single resources by absolute URL.
// 调用DefaultResourceLoader的getResource(String)方法来获取资源定位,然后封装成Resource对象,这里只能加载一个资源
Resource resource = resourceLoader.getResource(location);
//循环加载所有的资源,返回总数,这个loadBeanDefinitions就是Bean的载入了
int count = loadBeanDefinitions(resource);
if (actualResources != null) {
//对于成功找到的Resource定位,都会添加到这个传入的actualResources参数中
actualResources.add(resource);
}
if (logger.isTraceEnabled()) {
logger.trace("Loaded " + count + " bean definitions from location [" + location + "]");
}
return count;
}
}
这个方法中主要将xml配置文件加载到内存中并封装成为Resource对象。但是它是怎么操作的呢?在上述代码中,loadBeanDefinitions()方法中可能调用ResourcePatternResolver或DefaultResourceLoader中的getResource()方法,这两个类一个是继承、一个是实现ResourceLoader。其中ResourcePatternResolver用于解析资源文件的策略接口,其特殊的地方在于,它应该提供带有*号这种通配符的资源路径。DefaultResourceLoader用于用来加载资源,并且具体实现了ResourceLoader中的方法。而在第④步的时候,在实例化XmlBeanDefinitionReader的时候已经设置ResourceLoader,并且ResourceLoad为ApplicationContext,然后也设置了ResourcePatternResolver。所以XmlBeanDefinitionReader有了加载资源和解析资源的功能。
⑨、所以我们直接来看getResource()方法,DefaultResourceLoader中的 getResource(String)实现。
public Resource getResource(String location) {
Assert.notNull(location, "Location must not be null");
//看有没有自定义的ProtocolResolver,如果有则先根据自定义的ProtocolResolver解析location得到Resource
for (ProtocolResolver protocolResolver : getProtocolResolvers()) {
Resource resource = protocolResolver.resolve(location, this);
if (resource != null) {
return resource;
}
}
//根据路径是否匹配"/"或"classpath:"来解析得到ClassPathResource
if (location.startsWith("/")) {
return getResourceByPath(location);
}
else if (location.startsWith(CLASSPATH_URL_PREFIX)) {
return new ClassPathResource(location.substring(CLASSPATH_URL_PREFIX.length()), getClassLoader());
}
else {
try {
//这里处理带有URL标识的Resource定位
URL url = new URL(location);
return (ResourceUtils.isFileURL(url) ? new FileUrlResource(url) : new UrlResource(url));
}
catch (MalformedURLException ex) {
//如果既不是classPath 也不是URL标识的Resource定位(那其实就是自己实现的了).则把getResource的重任交给getResourceByPath来完成,
//这个方法是一个protected方法,默认的实现是得到一个ClassPathContextResource,这个方法常常会用子类来实现也就是FileSystemXMLApplicationContext
return getResourceByPath(location);
}
}
}
通过上述代码可以看到,getResource最后又调用了子类实现的getResourceByPath方法或是子类传递过来的字符串,从而实现Resource定位。使得整个Resource定位过程就说得通了。总结起来就是,Resource资源通过最外层的实现类传进来的字符串或者直接调用getResourceByPath方法,来获取bean资源路径。
对上面的代码进行四步来进行介绍:
-
第一步:首先看有没有自定义的ProtocolResolver,如果有则先根据自定义的ProtocolResolver解析location得到Resource(默认ProtocolResolver是空的,后面我们会说)
for (ProtocolResolver protocolResolver : getProtocolResolvers()) { Resource resource = protocolResolver.resolve(location, this); if (resource != null) { return resource; } }这里的protocolResolvers是DefaultResourceLoader类中的成员变量,而这个成员变量是ProtocolResolver类型的Set集合。
-
第二步:再根据路径是否匹配"/"或"classpath:"来解析得到ClassPathResource。
if (location.startsWith("/")) { return getResourceByPath(location); } else if (location.startsWith(CLASSPATH_URL_PREFIX)) { return new ClassPathResource(location.substring(CLASSPATH_URL_PREFIX.length()), getClassLoader()); } -
第三步:最后处理带有URL标识的Resource定位,加载得到一个UrlResource,如果都不是这些类型,则交给getResourceByPath来完成。
else { try { // Try to parse the location as a URL... URL url = new URL(location); return (ResourceUtils.isFileURL(url) ? new FileUrlResource(url) : new UrlResource(url)); } catch (MalformedURLException ex) { // No URL -> resolve as resource path. return getResourceByPath(location); } } -
第四步:上面的getResourceByPath()方法会根据路径加载Resource对象
protected Resource getResourceByPath(String path) { return new ClassPathContextResource(path, getClassLoader()); }上面方法返回的是一个ClassPathContextResource对象,通过这个对象Spring就可以进行相关的I/O操作了。
因为对ProtocolResolver这个类不是很熟悉,所以我去了解了一下,ProtocolResolver翻译过来就是"协议解析器",这个接口类里就只有一个方法,方法如下:
Resource resolve(String location, ResourceLoader resourceLoader);我们在第一步的时候调用了ProtocolResolver的resolve方法,如果你要使用ProtocolResolver。我们可以自定义一个类实现ProtocolResolver接口,然后实现该resolve方法,就可以解析特定的location得到Resoure。是的,ProtocolResolver是解析location的自定义拓展类,有了它我们才能随意传入不同格式的location,然后根据对应的格式去解析并获得我们的Resource即可。
关于DefaultResourceLoader和ProtocolResolver的区别:
- DefaultResourceLoader类的作用是加载Resource
- ProtocolResolver是解析location获取Resource的拓展
默认情况下,DefaultResourceLoader类中的protocolResolvers成员变量是一个空的Set,即默认情况下是没有ProtocolResolver可以去解析的,只能走ClassPath和URL两种方式获得Resource。
至此我们的Resource定位已经全部完成了。饶了这么远就是为了拿到这个Resource对象,拿到这个对象后,就可以通过AbstractBeanDefinitionReader流操作来实现Resource的载入,最后通过AbstractApplicationContext的registerListeners来进行注册。这就是IoC容器的初始化过程。所以下面我们来介绍一下Resource的载入工程。
5.4 BeanDefinition的载入
在完成对Resource定位分析之后,就可以通过获取的Resource对象进行BeanDefinition的载入了。对IOC容器来说,这个载入过程,相当于把定义的bean在IOC容器中转化成一个Spring内部表示的数据结构的过程,也就是将其转化为BeanDefinition,IOC容器对Bean的管理和依赖注入功能的实现,是通过对其持有的BeanDefinition进行各种相关操作来完成的,这些BeanDefinition在IOC容器中通过一个HashMap来保持和维护。
我们继续跟踪AbstractBeanDefinitionReader中的loadBeanDefinitions方法,之前跟踪到的是如下图的loadBeanDefinitions方法。
①、继续跟到loadBeanDefinitions(resource)方法。
public int loadBeanDefinitions(Resource... resources) throws BeanDefinitionStoreException {
Assert.notNull(resources, "Resource array must not be null");
int count = 0;
// 将所有定位到的Resource资源全部加载,交给XmlBeanDefinitionReader实现的方法来处理这些resource
for (Resource resource : resources) {
count += loadBeanDefinitions(resource);
}
return count;
}
这里循环加载定位到Resource资源,这个方法跟前面循环加载资源路径类似,但加载的内容不一样。
②、然后点击进入loadBeanDefinitions(resource),进入之后我们可以发现,在BeanDefinitionReader接口定义了两个加载Resource资源的方法:
int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException;
int loadBeanDefinitions(Resource... resources) throws BeanDefinitionStoreException;
两个方法具体由BeanDefinitionReader接口的子类XmlBeanDefinitionReader 实现,其继承关系如下图所示。
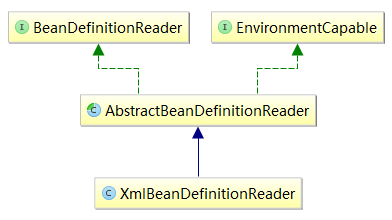
XmlBeanDefinitionReader主要用来将Bean的XML配置文件转换为多个BeanDefinition对象的工具类,所以它会将定位到的Resource资源进行处理。我们先来看上面两个实现的方法,大致过程是,先将resource包装为EncodeResource类型,然后继续进行处理,为生成BeanDefinition对象为后面做准备,我们在XmlBeanDefinitionReader类中找到实现的方法,其主要的两个方法的源码如下。
public int loadBeanDefinitions(Resource resource) throws BeanDefinitionStoreException {
//包装resource为EncodeResource类型
return loadBeanDefinitions(new EncodedResource(resource));
}
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
Assert.notNull(encodedResource, "EncodedResource must not be null");
if (logger.isTraceEnabled()) {
logger.trace("Loading XML bean definitions from " + encodedResource);
}
// 这里使用threadLocal来保证并发的同步
Set<EncodedResource> currentResources = this.resourcesCurrentlyBeingLoaded.get();
//先添加threadLocal,加载完之后finally中再移除threadLocal
if (!currentResources.add(encodedResource)) {
throw new BeanDefinitionStoreException(
"Detected cyclic loading of " + encodedResource + " - check your import definitions!");
}
// 通过resource对象得到XML文件内容输入流,并为I/O的InputSource做准备
try (InputStream inputStream = encodedResource.getResource().getInputStream()) {
InputSource inputSource = new InputSource(inputStream);
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
//这里就是具体读取Xml文件的方法
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(
"IOException parsing XML document from " + encodedResource.getResource(), ex);
}
finally {
currentResources.remove(encodedResource);
if (currentResources.isEmpty()) {
this.resourcesCurrentlyBeingLoaded.remove();
}
}
}
③、接着进入doLoadBeanDefinitions方法,这里就是具体读取Xml文件的方法,也是从指定xml文件中实际载入BeanDefinition的地方。当然了这肯定是在XmlBeanDefinitionReader中的方法了。
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
try {
//这里取得的是XML文件的Document对象,具体的解析过程是由DocumentLoader完成的,
//这里使用的DocumentLoader是DefaultDocumentLoader,在定义documentLoader对象时候创建的
Document doc = doLoadDocument(inputSource, resource);
//这里启动的是对BeanDefinition解析的详细过程,也就是将document文件的bean封装成BeanDefinition,并注册到容器
//启动对BeanDefinition解析的详细过程,这个解析会用到Spring的Bean配置规则,是我们下面详细讲解的内容
int count = registerBeanDefinitions(doc, resource);
if (logger.isDebugEnabled()) {
logger.debug("Loaded " + count + " bean definitions from " + resource);
}
return count;
}
catch () {
省略......
}
}
DefaultDocumentLoader这个类大致了解即可,感兴趣可自行百度。
④、下面我们主要关心的是Spring的BeanDefinition是怎么样按照Spring的Bean语义要求进行解析 并转化为容器内部数据结构的,这个过程是在registerBeanDefinitions(doc, resource)中完成的,具体的过程是BeanDefinitionDocumentReader来完成的,这个registerBeanDefinitions还对载入的Bean数量进行了统计,这个方法也是在 XmlBeanDefinitionReader 中自己实现的,
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
//这里得到的BeanDefinitionDocumentReader对象来对XML的BeanDefinition信息进行解析
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
//获取容器中bean的数量
int countBefore = getRegistry().getBeanDefinitionCount();
//具体的解析过程在这个方法中实现
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
return getRegistry().getBeanDefinitionCount() - countBefore;
}
注意:BeanDefinition的载入分成两部分,首先通过调用XML的解析器(XmlBeanDefinitionReader)得到document对象,但这些document对象并没有 按照Spring的Bean规则去进行解析,在完成通用XML解析之后才是按照Spring得 Bean规则进行解析的地方,这个按照Spring的Bean规则进行解析的过程是在documentReade中实现的,这里使用的documentReader是默认设置好的DefaultBeanDefinitionDocumentReader,创建的过程也是在XmlBeanDefinitionReader 中完成的,根据指定的默认方式如下:
private Class<? extends BeanDefinitionDocumentReader> documentReaderClass =
DefaultBeanDefinitionDocumentReader.class;
protected BeanDefinitionDocumentReader createBeanDefinitionDocumentReader() {
return BeanUtils.instantiateClass(this.documentReaderClass);
}
上面通过通过 XmlBeanDefinitionReader 类中的私有属性 documentReaderClass 获得一个 DefaultBeanDefinitionDocumentReader 实例对象,并且具体的解析过程在DefaultBeanDefinitionDocumentReader来实现,所以下面我们继续跟踪。
⑤、DefaultBeanDefinitionDocumentReader实现了BeanDefinitionDocumentReader接口,它的registerBeanDefinitions方法定义如下:
public void registerBeanDefinitions(Document doc, XmlReaderContext readerContext) {
this.readerContext = readerContext;
doRegisterBeanDefinitions(doc.getDocumentElement());
}
这里只是将 XML中的元素取了出来,但是具体的活还是 doRegisterBeanDefinitions(root)来实现的,do开头的方法才是真正干活的方法。
⑥、所以继续跟踪doRegisterBeanDefinitions(root)方法
protected void doRegisterBeanDefinitions(Element root) {
// 创建了BeanDefinitionParserDelegate对象
BeanDefinitionParserDelegate parent = this.delegate;
this.delegate = createDelegate(getReaderContext(), root, parent);
// 如果是Spring原生命名空间,首先解析 profile标签,这里不重要
if (this.delegate.isDefaultNamespace(root)) {
String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);
if (StringUtils.hasText(profileSpec)) {
String[] specifiedProfiles = StringUtils.tokenizeToStringArray(
profileSpec, BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS);
if (!getReaderContext().getEnvironment().acceptsProfiles(specifiedProfiles)) {
if (logger.isDebugEnabled()) {
logger.debug("Skipped XML bean definition file due to specified profiles [" + profileSpec +
"] not matching: " + getReaderContext().getResource());
}
return;
}
}
}
//解析BeanDefinition之前做的一些事情的接口触发
preProcessXml(root);
//主要看这个方法,标签具体解析过程
parseBeanDefinitions(root, this.delegate);
// 解析BeanDefinition之后可以做的一些事情的触发
postProcessXml(root);
this.delegate = parent;
}
在这个方法中,我们重点看“一类三法”,也就是BeanDefinitionParserDelegate类和preProcessXml、parseBeanDefinitions、postProcessXml三个方法。其中BeanDefinitionParserDelegate类非常非常重要(需要了解代理技术,如JDK动态代理、cglib动态代理等)。Spirng BeanDefinition的解析就是在这个代理类下完成的,此类包含了各种对符合Spring Bean语义规则的处理,比如
⑦、前面提到Document对象不能通过XmlBeanDefinitionReader,真正去解析Document文档树的是 BeanDefinitionParserDelegate完成的,这个解析过程是与Spring对BeanDefinition的配置规则紧密相关的,parseBeanDefinitions(root, delegate)方法如下:
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
if (delegate.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
// 遍历所有节点,做对应解析工作
// 如遍历到<import>标签节点就调用importBeanDefinitionResource(ele)方法对应处理
// 遍历到<bean>标签就调用processBeanDefinition(ele,delegate)方法对应处理
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
if (delegate.isDefaultNamespace(ele)) {
//默认标签解析
parseDefaultElement(ele, delegate);
}
else {
//自定义标签解析
delegate.parseCustomElement(ele);
}
}
}
}
else {
delegate.parseCustomElement(root);
}
}
这里有两种标签的解析:Spring原生标签和自定义标签,那来怎么区分这两种标签呢?如下:
- 默认标签:
<bean:/> - 自定义标签:
<context:component-scan/>
如果带有bean的就是Spring默认标签,否则就是自定义标签。但无论哪种标签在使用前都需要在Spring的xml配置文件里声明Namespace URI,这样在解析标签时才能通过Namespace URI找到对应的NamespaceHandler。
引入:xmlns:context=http://www.springframework.org/schema/contex http://www.springframework.org/schema/beans
⑧、上面的代码中先是isDefaultNamespace判断是不是默认标签,然后进入parseDefaultElement方法(自定义方法感兴趣可以自行百度):
private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) {
// 解析<import>标签
if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) {
importBeanDefinitionResource(ele);
}
// 解析<alias>标签
else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) {
processAliasRegistration(ele);
}
// 解析<bean>标签,最常用,过程最复杂
else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) {
processBeanDefinition(ele, delegate);
}
// 解析<beans>标签
else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) {
// recurse
doRegisterBeanDefinitions(ele);
}
}
这里面主要是对import、alias、bean标签的解析以及beans的字标签的递归解析。
⑨、这里针对常用的
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
//BeandefinitionHolder是BeanDefinition的封装,封装了BeanDefinition,bean的名字和别名,用它来完成向IOC容器注册,
//得到BeanDefinitionHodler就意味着BeanDefinition是通过BeanDefinitionParseDelegate对xml元素按照bean的规则解析得到的
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
if (bdHolder != null) {
bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
try {
// 这里是向IOC容器解析注册得到BeanDefinition的地方
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
}
catch (BeanDefinitionStoreException ex) {
getReaderContext().error("Failed to register bean definition with name '" +
bdHolder.getBeanName() + "'", ele, ex);
}
// 在BeanDefinition向Ioc容器注册完成后发送消息
getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
}
}
⑩、进入parseBeanDefinitionElement(Element ele)方法方法。
注意:parseBeanDefinitionElement(Element ele)方法会调用parseBeanDefinitionElement(ele, null)方法,需要强调一下的是parseBeanDefinitionElement(ele, null)方法中产生了一个抽象类型的BeanDefinition实例,这也是我们首次看到直接定义BeanDefinition的地方,这个方法里面会将
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele) {
return parseBeanDefinitionElement(ele, null);
}
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele, @Nullable BeanDefinition containingBean) {
// 获取id和name属性
String id = ele.getAttribute(ID_ATTRIBUTE);
String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);
// 获取别名属性,多个别名可用,;隔开
List<String> aliases = new ArrayList<>();
if (StringUtils.hasLength(nameAttr)) {
String[] nameArr = StringUtils.tokenizeToStringArray(nameAttr, MULTI_VALUE_ATTRIBUTE_DELIMITERS);
aliases.addAll(Arrays.asList(nameArr));
}
String beanName = id;
if (!StringUtils.hasText(beanName) && !aliases.isEmpty()) {
beanName = aliases.remove(0);
if (logger.isTraceEnabled()) {
logger.trace("No XML 'id' specified - using '" + beanName +
"' as bean name and " + aliases + " as aliases");
}
}
// 检查beanName是否重复
if (containingBean == null) {
checkNameUniqueness(beanName, aliases, ele);
}
// 具体的解析封装过程还在这个方法里
AbstractBeanDefinition beanDefinition = parseBeanDefinitionElement(ele, beanName, containingBean);
if (beanDefinition != null) {
if (!StringUtils.hasText(beanName)) {
try {
if (containingBean != null) {
beanName = BeanDefinitionReaderUtils.generateBeanName(
beanDefinition, this.readerContext.getRegistry(), true);
}
else {
beanName = this.readerContext.generateBeanName(beanDefinition);
// Register an alias for the plain bean class name, if still possible,
// if the generator returned the class name plus a suffix.
// This is expected for Spring 1.2/2.0 backwards compatibility.
String beanClassName = beanDefinition.getBeanClassName();
if (beanClassName != null &&
beanName.startsWith(beanClassName) && beanName.length() > beanClassName.length() &&
!this.readerContext.getRegistry().isBeanNameInUse(beanClassName)) {
aliases.add(beanClassName);
}
}
if (logger.isTraceEnabled()) {
logger.trace("Neither XML 'id' nor 'name' specified - " +
"using generated bean name [" + beanName + "]");
}
}
catch (Exception ex) {
error(ex.getMessage(), ele);
return null;
}
}
String[] aliasesArray = StringUtils.toStringArray(aliases);
return new BeanDefinitionHolder(beanDefinition, beanName, aliasesArray);
}
return null;
}
上面的解析过程可以看做根据xml文件对
⑪、下面再来多加一个点,看一下bean的具体解析。
public AbstractBeanDefinition parseBeanDefinitionElement(
Element ele, String beanName, @Nullable BeanDefinition containingBean) {
this.parseState.push(new BeanEntry(beanName));
// 获取class名称和父类名称
String className = null;
if (ele.hasAttribute(CLASS_ATTRIBUTE)) {
className = ele.getAttribute(CLASS_ATTRIBUTE).trim();
}
// 解析 parent 属性
String parent = null;
if (ele.hasAttribute(PARENT_ATTRIBUTE)) {
parent = ele.getAttribute(PARENT_ATTRIBUTE);
}
try {
// 创建GenericBeanDefinition对象
AbstractBeanDefinition bd = createBeanDefinition(className, parent);
// 解析bean标签的属性,并把解析出来的属性设置到BeanDefinition对象中
parseBeanDefinitionAttributes(ele, beanName, containingBean, bd);
bd.setDescription(DomUtils.getChildElementValueByTagName(ele, DESCRIPTION_ELEMENT));
//解析bean中的meta标签
parseMetaElements(ele, bd);
//解析bean中的lookup-method标签
parseLookupOverrideSubElements(ele, bd.getMethodOverrides());
//解析bean中的replaced-method标签
parseReplacedMethodSubElements(ele, bd.getMethodOverrides());
//解析bean中的constructor-arg标签
parseConstructorArgElements(ele, bd);
//解析bean中的property标签
parsePropertyElements(ele, bd);
// 解析子元素 qualifier 子元素
parseQualifierElements(ele, bd);
bd.setResource(this.readerContext.getResource());
bd.setSource(extractSource(ele));
return bd;
}
catch (ClassNotFoundException ex) {
error("Bean class [" + className + "] not found", ele, ex);
}
catch (NoClassDefFoundError err) {
error("Class that bean class [" + className + "] depends on not found", ele, err);
}
catch (Throwable ex) {
error("Unexpected failure during bean definition parsing", ele, ex);
}
finally {
this.parseState.pop();
}
return null;
}
上面的代码是具体生成BeanDefinition的地方,bean标签的解析步骤仔细理解并不复杂,就是将一个个标签属性的值装入到了BeanDefinition对象中,这里需要注意parseConstructorArgElements和parsePropertyElements方法,分别是对constructor-arg和property标签的解析,解析完成后分别装入了BeanDefinition对象的constructorArgumentValues和propertyValues中,而这两个属性在c和p标签的解析中还会用到,而且还涉及一个很重要的设计思想——装饰器模式。Bean标签解析完成后将生成的BeanDefinition对象、bean的名称以及别名一起封装到了BeanDefinitionHolder对象并返回,然后调用了decorateBeanDefinitionIfRequired进行装饰,后面具体的调用就不具体介绍了,想了解的可以自行百度。
5.5 BeanDefinition的注册
在完成了BeanDefinition的载入和解析后,就要对它进行注册。我们知道最终Bean配置会被解析成BeanDefinition并与beanName,Alias一同封装到BeanDefinitionHolder类中,然后返回这个对象,所以我们顺着BeanDefinitionHolder类创建的地方,也就是DefaultBeanDefinitionDocumentReader的processBeanDefinition()方法继续往下看。
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
//BeandefinitionHolder是BeanDefinition的封装,封装了BeanDefinition,bean的名字和别名,用它来完成向IOC容器注册,
//得到BeanDefinitionHodler就意味着BeanDefinition是通过BeanDefinitionParseDelegate对xml元素按照bean的规则解析得到的
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
if (bdHolder != null) {
bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
try {
// 这里是向IOC容器解析注册得到BeanDefinition的地方
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
}
catch (BeanDefinitionStoreException ex) {
getReaderContext().error("Failed to register bean definition with name '" +
bdHolder.getBeanName() + "'", ele, ex);
}
// 在BeanDefinition向Ioc容器注册完成后发送消息
getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
}
}
然后跟踪到BeanDefinitionReaderUtils的registerBeanDefinition()方法,这里会传入上一步的BeanDefinitionHolder对象,并且将BeanDefinition注册到IoC容器中。进入BeanDefinitionReaderUtils类的registerBeanDefinition方法如下。
public static void registerBeanDefinition(
BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
throws BeanDefinitionStoreException {
// 注册beanDefinition!!
String beanName = definitionHolder.getBeanName();
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
// 如果有别名的话也注册进去
String[] aliases = definitionHolder.getAliases();
if (aliases != null) {
for (String alias : aliases) {
registry.registerAlias(beanName, alias);
}
}
}
之后会调用BeanDefinitionRegistry接口的registerBeanDefinition( beanName, bdHolder.getBeanDefinition())方法,而对于IoC容器中最重要的一个类DefaultListableBeanFactory实现了该接口的方法。这个方法的主要目的就是将BeanDefinition存放至DefaultListableBeanFactory对象的beanDefinitionMap中,当初始化容器进行bean初始化时,在bean的生命周期分析里必然会在这个beanDefinitionMap中获取beanDefition实例。我们可以在DefaultListableBeanFactory中看到此Map的定义。
/** Map of bean definition objects, keyed by bean name. */
private final Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<>(256);
下面我们在来看一下这个方法是如将BeanDefinition存放至beanDefinitionMap中的,DefaultListableBeanFactory中实现的registerBeanDefinition( beanName, bdHolder.getBeanDefinition() )方法具体如下:
public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
throws BeanDefinitionStoreException {
Assert.hasText(beanName, "Bean name must not be empty");
Assert.notNull(beanDefinition, "BeanDefinition must not be null");
if (beanDefinition instanceof AbstractBeanDefinition) {
try {
((AbstractBeanDefinition) beanDefinition).validate();
}
catch (BeanDefinitionValidationException ex) {
throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,
"Validation of bean definition failed", ex);
}
}
//此处检查是不是有相同名字的Bean存在
//如果名字相同又不允许覆盖,就会抛出异常BeanDefinitionOverrideException
BeanDefinition existingDefinition = this.beanDefinitionMap.get(beanName);
if (existingDefinition != null) {
if (!isAllowBeanDefinitionOverriding()) {
throw new BeanDefinitionOverrideException(beanName, beanDefinition, existingDefinition);
}
else if (existingDefinition.getRole() < beanDefinition.getRole()) {
// e.g. was ROLE_APPLICATION, now overriding with ROLE_SUPPORT or ROLE_INFRASTRUCTURE
if (logger.isInfoEnabled()) {
logger.info("Overriding user-defined bean definition for bean '" + beanName +
"' with a framework-generated bean definition: replacing [" +
existingDefinition + "] with [" + beanDefinition + "]");
}
}
else if (!beanDefinition.equals(existingDefinition)) {
if (logger.isDebugEnabled()) {
logger.debug("Overriding bean definition for bean '" + beanName +
"' with a different definition: replacing [" + existingDefinition +
"] with [" + beanDefinition + "]");
}
}
else {
if (logger.isTraceEnabled()) {
logger.trace("Overriding bean definition for bean '" + beanName +
"' with an equivalent definition: replacing [" + existingDefinition +
"] with [" + beanDefinition + "]");
}
}
//存储Bean(Bean名字作为key,BeanDefinition作为value)
this.beanDefinitionMap.put(beanName, beanDefinition);
}
else {
if (hasBeanCreationStarted()) {
//注册的过程需要保证数据的一致性
synchronized (this.beanDefinitionMap) {
//将获取到的BeanDefinition放入Map中,容器操作使用bean时通过这个HashMap找到具体的BeanDefinition
//存储Bean(Bean名字作为key,BeanDefinition作为value)
this.beanDefinitionMap.put(beanName, beanDefinition);
List<String> updatedDefinitions = new ArrayList<>(this.beanDefinitionNames.size() + 1);
updatedDefinitions.addAll(this.beanDefinitionNames);
updatedDefinitions.add(beanName);
this.beanDefinitionNames = updatedDefinitions;
removeManualSingletonName(beanName);
}
}
else {
// Still in startup registration phase
this.beanDefinitionMap.put(beanName, beanDefinition);
this.beanDefinitionNames.add(beanName);
removeManualSingletonName(beanName);
}
this.frozenBeanDefinitionNames = null;
}
if (existingDefinition != null || containsSingleton(beanName)) {
resetBeanDefinition(beanName);
}
else if (isConfigurationFrozen()) {
clearByTypeCache();
}
}
当把所有的BeanDefinition(懒加载除外)都存入IOC容器中的HashMap后,注册就结束了。但是注意,以上仅仅是BeanDefinition的载入、载入和注册,Bean之间的依赖关系并不会在初始化的时候完成!后面还需要调用一系列方法才会完成初始化。
6、基于XML的方式装配Bean
6.1 什么是Bean的装配
注:我们知道,在Spring中,IOC容器是存放Bean的地方,所以如果我们要想使用Bean,那么就应该先装配Bean然后将其放入IOC容器中,这样才有的用,当然放入容器的步骤不需要我们操作,但是Bean的装配是需要我们来操作的。
Bean的装配说得简单点就是将对象以Bean的方式装配到Spring IoC容器中,也可以说是Bean的依赖注入。在Spring中提供了三种方法进行配置:
- 在Spring XML中配置Bean(通过Spring的XML配置文件来装配Bean,现在基本上不这么用了)
- 通过注解@Component+@Autowrited注解来自动装配Bean(常用)
- 通过注解@Configuration+@Bean在类中实现装配Bean(常用)。这种方式在SpringBoot中经常使用
在实际的工作中,这 3 种方式可能都会被用到,并且在学习和工作中常常混合使用,所以我们需要明确3种方式的优先级,也就是我们应该怎么选择使用哪种方式去把 Bean 装配到 Spring IoC 容器中。所以这里给出关于这 3 种方法优先级的建议(优先级从高到低):
- 于约定优于配置的原则,最优先的应该是选择 第二种方式。这样的好处是减少程序开发者的决定权,简单又不失灵活,所以这种方式在我们的实际开发中用的最多。
- 在没有办法使用自动装配原则的情况下应该优先考虑 第三种方式,这样的好处是避免 XML 置的泛滥,也更为容易 。这种场景典型的例子是 一个父类有多个子类,比如学生类有两个子类,一个男学生类和女学生类,通过 IoC 容器初始化一个学生类,容器将无法知道使用哪个子类去初始化,这个时候可以使用 Java 的注解配置去指定。
- 如果上述的两种方法都无法使用的情况下,那么只能选择 第一种方式了。这种方式的好处就是简单易懂,对于初学者非常友好。这种场景的例子是由于现实工作中常常用到第三方的类库,有些类并不是我们开发的,我们无法修改里面的代码,这个时候就通过 XML 方式配置使用了。
本章都是通过 XML 的方式来配置 Bean,这样会更好的理解。使用 XML 装配 Bean 需要定义对应的XML,这里需要引入对应的 XML 模式(XSD)文件,这些文件会定义配置 Spring Bean 的一些元素。

我们再来回顾一下,被Spring管理的对象统称为Bean,我们将这些对象让Spring去帮我们创建和管理,可以通过XML配置文件告诉Spring容器需要管理哪些Bean,Spring帮我们创建和组装好这些Bean对象;那么我们如何从Spring中获取想要的Bean对象呢,我们需要给Bean定义一个名称,Spring内部将这些名称和具体的Bean对象进行绑定,然后Spring容器可以通过这个的名称找对我们需要的对象,这个名称叫做Bean的名称,在一个Spring容器中需要是唯一的。这样我们就可以在里面定义对应的 Spring Bean了。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<!-- Spring Bean的配置XML文件 -->
<bean id="bean唯一标识" name="bean的名称" class="完整类型名称"/>
<import resource="引入其他bean xml配置文件" />
<alias name="bean标识" alias="别名" />
</beans>
标签介绍:
- beans元素:它是根元素,可以包含任意数量的import、bean、alias元素。
- bean元素:用来定义一个bean对象。其中属性 id和name都是用来作为bean的唯一标识,在Spring容器中必须唯一,否则会报错,用来让Spring找到这个Bean,class属性则是将哪个类装配为一个Bean。
- 补充--关于bean元素中 id和name的区别:
- 当id存在的时候,不管name有没有,取id为bean的名称
- 当id不存在,此时需要看name,name的值可以通过 ,;或者空格 分割,最后会按照分隔符得到一个String数组,数组的第一个元素作为bean的名称,其他的作为bean的别名
- 当id和name都存在的时候,id为bean名称,name用来定义多个别名
- 当id和name都不指定的时候,bean名称自动生成,Spring 将会采用“类全限定名#{number}“的格式生成编号。例如这里,如果没有声明 “id="user"的话,那么 Spring 为其生成的编号就是"com.thr.pojo.User#0”,当它第二次声明没有 id 属性的 Bean 时,编号就是"com.thr.pojo.User#1",后面以此类推。但是我们一般都会显示声明自定义的id,因为自动生成的id比较繁琐,不便于维护。
- alias元素:alias元素也可以用来给某个bean定义别名。
- import元素:当我们的系统比较大的时候,会分成很多模块,每个模块会对应一个bean xml文件,我们可以在一个总的bean xml中对其他bean xml进行汇总,相当于把多个bean xml的内容合并到一个里面了,可以通过import元素引入其他bean配置文件。
6.2 回顾依赖注入的三种方式
依赖注入有3种方式分别是:
- 构造器注入
- setter方法注入
- 接口注入
其中构造器注入和setter注入是最主要的方式,下面简单回顾一下,这样对的话理解Bean的装配会更加容易。
6.2.1 构造器注入
构造器注入:顾名思义就是被注入对象可以通过在其构造方法中声明依赖对象的参数列表,让外部(通常是IoC容器)知道它需要哪些依赖对象。
在大部分的情况下,我们都是通过类的构造方法来创建类对象, Spring 也可以采用反射的方式, 通过使用构造方法来完成注入,这就是构造器注入的原理。
首先要创建一个具体的类、构造方法并设置对应的参数,这里以User为例:
/**
* 用户实体类
*/
public class User {
private int userId;
private String userName;
private int userAge;
private String userPwd;
private String userAddress;
//getter、setter、toString方法省略......
//有参构造器
public User(int userId, String userName, int userAge,
String userPwd, String userAddress) {
this.userId = userId;
this.userName = userName;
this.userAge = userAge;
this.userPwd = userPwd;
this.userAddress = userAddress;
}
}
如果我们在实体类中创建了有参的构造器,而没有显示的创建无参构造器,那么是不能再通过无参的构造器创建对象了,为了使 Spring 能够正确创建这个对象,可以像如下Spring配置去做。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<!--将指定类都配置给Spring,让Spring创建其对象的实例,一个bean对应一个对象
如果类中创建了有参构造器,必须完成初始化-->
<bean id="user" class="com.thr.pojo.User">
<constructor-arg index="0" value="2020"/>
<constructor-arg index="1" value="菜逼唐"/>
<constructor-arg index="2" value="18"/>
<constructor-arg index="3" value="123456"/>
<constructor-arg index="4" value="地球中国"/>
</bean>
</beans>
constructor-arg元素用于定义类构造方法的参数,其中index 用于定义参数的位置(从0开始),而 value 则是设置值,通过这样的定义 Spring 便知道使用 哪个构造方法去创建对象了。虽然这样注入还是比较简单的,但是缺点也很明显,由于这里的参数比较少,所以可读性还是不错的,但是如果参数很多,那么这种构造方法就比较复杂了,这个时候应该考虑 setter 注入。
6.2.2 setter方法注入
setter方法注入:setter 注入是 Spring 中最主流的注入方式,它利用 Java Bean 规范所定义的 setter 方法来完成注入,灵活且可读性高。它消除了使用构造器注入时出现多个参数的可能性,首先可以把构造方法声明为无参数的,然后使用 setter 注入为其设置对应的值,其实也是通过 Java 反射技术得以现实的。这里去掉上面User类中的有参数的构造方法,然后做如下的Spring配置。
<bean id="user1" class="com.thr.pojo.User">
<property name="userId" value="2020"/>
<property name="userName" value="菜逼唐"/>
<property name="userAge" value="18"/>
<property name="userPwd" value="123456"/>
<property name="userAddress" value="地球中国"/>
</bean>
这样Spring就会通过反射调用没有参数的构造方法生成对象,同时通过反射对应的setter注入配置的值了。这种方式是Spring最主要的方式,在实际的工作中是最常用的,所以下面都是基于setter方法注入的举例。
6.2.3 接口注入
接口注入:接口注入是现在非常不提倡的一种方式,这种方式基本处于“退役状态”。因为它强制被注入对象实现不必要的接口,带有侵入性。而构造方法注入和setter方法注入则不需要如此,所以现在我们一般推荐使用构造器注入和setter注入。
6.3 装配简单类型值的Bean
这里先来讨论最简单的装配,比如基本的属性和对象,代码如下:
/**
* 用户实体类
*/
public class User {
private int userId;
private String userName;
private int userAge;
private String userPwd;
private String userAddress;
//女朋友
private GirlFriend girlFriend;
//getter、setter、toString方法省略......
}
GirlFriend实体:
/**
* GirlFriend实体
*/
public class GirlFriend {
private String girlName;
private int girlAge;
private String girlHeight;
//getter、setter、toString方法省略......
}
Spring的xml配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<!--实例化GirlFriend-->
<bean id="girlFriend" class="com.thr.pojo.GirlFriend">
<property name="girlName" value="王美丽"/>
<property name="girlAge" value="18"/>
<property name="girlHeight" value="170"/>
</bean>
<!--实例化User-->
<bean id="user1" class="com.thr.pojo.User">
<!--注入普通值:使用 value 属性-->
<property name="userId" value="2020"/>
<property name="userName" value="菜逼唐"/>
<property name="userAge" value="18"/>
<property name="userPwd" value="123456"/>
<property name="userAddress" value="地球中国"/>
<!--注入对象:使用 ref 属性-->
<property name="girlFriend" ref="girlFriend"/>
</bean>
</beans>
上面就是一个最简单最基本的配置Bean了,这里简单来解释一下:
- id 属性是标识符(别名),用来让Spring找到这个Bean,id属性不是一个必须的属性,如果我们没有声明它,那么 Spring 将会采用“全限定名#{number}“的格式生成编号。例如这里,如果没有声明 “id="user"的话,那么 Spring 为其生成的编号就是"com.thr.pojo.User#0”,当它第二次声明没有 id 属性的 Bean 时,编号就是"com.thr.pojo.User#1",后面以此类推。但是我们一般都会显示声明自定义的id,因为自动生成的id比较繁琐,不便于维护。
- class 属性显然就是一个类的全限定名 。
- property 元素是定义类的属性,其中的 name 属性定义的是属性的名称,而 value 是它的值,ref 是用来引入另一个Bean对象的。
简单来测试一下,测试代码如下:
public class SpringTest {
public static void main(String[] args) {
//1.初始化Spring容器,加载配置文件
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("applicationContext.xml");
//2.通过容器获取实例,getBean()方法中的参数是bean标签中的id
User user = applicationContext.getBean("user1", User.class);
//3.调用实例中的属性
System.out.println(user.getUserName()+"------"+user.getGirlFriend());
}
}
运行结果:

6.4 装配集合类型的Bean
有些时候我们需要装配一些复杂的Bean,比如 Set、Map、List、Array 和 Properties 等,所以我们将上面的User改一下,假如这个User是个“海王”呢?他有好几个GirlFriend。我们对User类添加了一些属性(记得更改setter、getter和tostring方法):
/**
* 用户实体类
*/
public class User {
private int userId;
private String userName;
private int userAge;
private String userPwd;
private String userAddress;
//女朋友
private GirlFriend girlFriend;
private List<GirlFriend> lists;
private Set<GirlFriend> sets;
private Map<String, GirlFriend> maps;
private Properties properties;
private String[] array;
//getter、setter、toString方法省略......
}
Spring的xml配置:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<!--实例化GirlFriend-->
<bean id="girlFriend1" class="com.thr.pojo.GirlFriend">
<property name="girlName" value="王美丽"/>
<property name="girlAge" value="18"/>
<property name="girlHeight" value="170"/>
</bean>
<bean id="girlFriend2" class="com.thr.pojo.GirlFriend">
<property name="girlName" value="杨美丽"/>
<property name="girlAge" value="19"/>
<property name="girlHeight" value="171"/>
</bean>
<bean id="girlFriend3" class="com.thr.pojo.GirlFriend">
<property name="girlName" value="李美丽"/>
<property name="girlAge" value="20"/>
<property name="girlHeight" value="172"/>
</bean>
<!--实例化User-->
<bean id="user2" class="com.thr.pojo.User">
<!--注入普通值:使用 value 属性-->
<property name="userId" value="2020"/>
<property name="userName" value="菜逼唐"/>
<property name="userAge" value="18"/>
<property name="userPwd" value="123456"/>
<property name="userAddress" value="地球中国"/>
<!--注入对象:使用 ref 属性-->
<property name="girlFriend" ref="girlFriend1"/>
<!--注入List集合-->
<property name="lists">
<list>
<ref bean="girlFriend1"/>
<ref bean="girlFriend2"/>
<ref bean="girlFriend3"/>
</list>
</property>
<!--注入Set集合-->
<property name="sets">
<set>
<ref bean="girlFriend1"/>
<ref bean="girlFriend2"/>
<ref bean="girlFriend3"/>
</set>
</property>
<!--注入Map集合-->
<property name="maps">
<map>
<entry key="正牌女友" value-ref="girlFriend1"/>
<entry key="备胎1" value-ref="girlFriend2"/>
<entry key="备胎2" value-ref="girlFriend3"/>
</map>
</property>
<!--注入Properties-->
<property name="properties">
<props>
<prop key="k1">v1</prop>
<prop key="k2">v2</prop>
</props>
</property>
<!--注入数组-->
<property name="array">
<array>
<value>value1</value>
<value>value2</value>
<value>value3</value>
</array>
</property>
</bean>
</beans>
对集合的装配进行总结:
- List 属性使用对应的
<list>元素进行装配,然后通过多个<value>元素设值,如果是bean则通过<ref>元素设值。 - Set 属性使用对应的
<set>元素进行装配,然后通过多个<value>元素设值,如果是bean则通过<ref>元素设值。 - Map 属性使用对应的
<map>元素进行装配,然后通过多个<entry>元素设值,entry 中包含一个键值对(key-value)的设置,普通值使用key和value,bean使用key-ref和value-ref设值。 - Properties 属性使用对应的
<properties>元素进行装配,通过多个<property>元素设值,只是 properties 元素有一个必填属性 key ,然后可以设置值 - 对于数组而言,可以使用
<array>设置值,然后通过多个<value>元素设值。
简单来测试一下,测试代码如下:
public class SpringTest {
public static void main(String[] args) {
//1.初始化Spring容器,加载配置文件
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("applicationContext.xml");
//2.通过容器获取实例,getBean()方法中的参数是bean标签中的id
User user = applicationContext.getBean("user2", User.class);
//3.调用实例中的属性
System.out.println("List集合:"+user.getLists());
System.out.println("Set集合:"+user.getSets());
System.out.println("Map集合:"+user.getMaps());
System.out.println("Properties:"+user.getProperties());
System.out.println("数组:");
String[] array = user.getArray();
for (String s : array) {
System.out.println(s);
}
}
}
运行结果:

6.5 命名空间装配 Bean (了解)
除了使用上述的的方法来装配Bean之外,Spring还提供了对应的命名空间的定义。
- c 命名空间:用于通过构造器注入的方式来配置 bean
- p 命名空间:用于通过setter的注入方式来配置 bean
- util 命名空间:工具类的命名空间,可以简化集合类元素的配置
下面来简单介绍。要使用它们首先得犹如对应的命名空间和XML模式(XSD)文件。
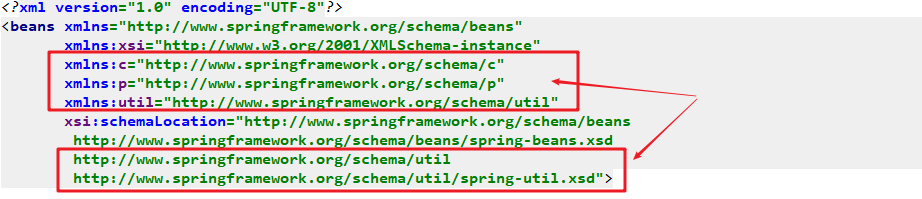
示例代码:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:c="http://www.springframework.org/schema/c"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:util="http://www.springframework.org/schema/util"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/util
http://www.springframework.org/schema/util/spring-util.xsd">
<!--c 命名空间 实例化GirlFriend,给GirlFriend显示的创建了一个无参和有参构造器-->
<bean id="girlFriend1" class="com.thr.pojo.GirlFriend" c:_0="王美丽" c:_1="18" c:_2="170"/>
<!--p 命名空间 实例化GirlFriend-->
<bean id="girlFriend2" class="com.thr.pojo.GirlFriend" p:girlName="杨美丽" p:girlAge="20" p:girlHeight="168"/>
<!--util 命名空间-->
<!--List集合-->
<util:list id="lists">
<ref bean="girlFriend1"/>
<ref bean="girlFriend2"/>
</util:list>
<!--Set集合-->
<util:set id="sets">
<ref bean="girlFriend1"/>
<ref bean="girlFriend2"/>
</util:set>
<!--Map集合-->
<util:map id="maps">
<entry key="第一个女友" value-ref="girlFriend1"/>
<entry key="第二个女友" value-ref="girlFriend2"/>
</util:map>
<!--Properties集合-->
<util:properties id="properties">
<prop key="k1">v1</prop>
</util:properties>
<!--实例化User-->
<bean id="user3" class="com.thr.pojo.User"
p:userId="2020"
p:userName="菜逼唐"
p:userAge="18"
p:userPwd="123456"
p:userAddress="地球中国"
p:girlFriend-ref="girlFriend1"
p:lists-ref="lists"
p:sets-ref="sets"
p:maps-ref="maps"
p:properties-ref="properties">
</bean>
</beans>
总结:
- c 命名空间:用于通过构造器注入的方式来配置 bean,c:_0 表示构造方法的第一个参数,c:_1 表示构造方法的第二个参数,以此类推。
- p 命名空间:用于通过setter的注入方式来配置 bean,p:属性名 表示为属性设值,p:list-ref 表示采用List属性,引用其上下文对应好的Bean,这里显然是util命名空间定义的List,Map和Set同理。
- util 命名空间:工具类的命名空间,可以简化集合类元素的配置。下表提供了 util-命名空间提供的所有元素:
| util元素 | 描述 |
|---|---|
<util:constant> |
引用某个类型的 public static 域,并将其暴露为 bean |
<util:list> |
创建一个 java.util.List 类型的 bean,其中包含值或引用 |
<util:map> |
创建一个 java.util.map 类型的 bean,其中包含值或引用 |
<util:properties> |
创建一个 java.util.Properties 类型的 bean |
<util:property-path> |
引用一个 bean 的属性(或内嵌属性),并将其暴露为 bean |
<util:set> |
创建一个 java.util.Set 类型的 bean,其中包含值或引用 |
6.6 Bean的自动装配
注意:Bean的自动装配只针对引用类型而言,什么意思呢?例如上面的User类中,需要用到GirlFriend这个类,所以此时可以就可以使用自动装配
6.6.1 自动装配的几种方式
上面介绍了在XML中如何手动来配置Bean,而在Spring 容器中给我们提供了完成 Bean之间的自动装配的功能(但是只针对对象类型的自动装配),这样的好处就是有助于减少编写一个大的基于 Spring 的应用程序的 XML 配置的数量,因为在稍微大一点的项目中,一个被引用的 Bean 的 ID 改变了,那么需要修改所有引用了它的 ID 。Spring框架默认是不支持自动装配的,可以使用Spring的配置文件中< bean >元素的 autowire 属性为一个 bean 定义指定自动装配模式。其中<bean>元素中的autowire属性有5个可选值,如下:
| 属性 | 描述 |
|---|---|
| no | 默认的设置,表示不启用自动装配,需要我们手动通过"ref"属性手动完成装配 |
| byName | 通过属性名称自动装配,如果一个JavaBean中的属性名称与Bean的id 相同,则自动装配这个Bean到JavaBean的属性中。Spring会查找该JavaBean中所有的set方法名,获得将set去掉并且首字母小写的字符串,然后去Spring容器中寻找是否有此字符串名称id 的Bean。如果有则就注入,如果没有则注入动作将不会执行 |
| byType | 通过属性类型自动装配。Spring会在容器中查找JavaBean中的属性类型与Bean的类型一致的Bean,并自动装配这个Bean到JavaBean的属性中,如果容器中包含多个这个类型的Bean,Spring将抛出异常。如果没有找到这个类型的Bean,那么注入动作将不会执行 |
| constructor | 类似于byType,也是通过类型自动装配,但是它是通过构造方法的参数类型来匹配。Spring会寻找与该JavaBean构造方法的各个参数类型相匹配的Bean,然后通过构造函数注入进来。如果在Spring容器中没有找一个构造函数参数类型的 Bean,则会报错 |
| autodetect | 表示在constructor和byType之间自动的选择注入方式(spring5.x已经没有了)。首先尝试通过 constructor 来自动装配,如果它不执行,则Spring 尝试通过 byType 来自动装配 |
| default | 由上级标签beans的default-autowire属性确定 |
6.6.2 简单举例代码
编写User代码:
/**
* 用户实体类
*/
public class User {
private int userId;
private String userName;
private int userAge;
private String userPwd;
private String userAddress;
//女朋友
private GirlFriend girlFriend;
public User() {
}
public User(int userId, String userName, int userAge, String userPwd,
String userAddress, GirlFriend girlFriend) {
this.userId = userId;
this.userName = userName;
this.userAge = userAge;
this.userPwd = userPwd;
this.userAddress = userAddress;
this.girlFriend = girlFriend;
}
//getter、setter、toString方法省略......
}
编写GirlFriend类代码:
/**
* GirlFriend实体
*/
public class GirlFriend {
private String girlName;
private int girlAge;
private String girlHeight;
//getter、setter、toString方法省略......
}
补充:Spring的xml配置文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<!--实例化GirlFriend-->
<bean id="girlFriend" class="com.thr.pojo.GirlFriend">
<property name="girlName" value="王美丽"/>
<property name="girlAge" value="18"/>
<property name="girlHeight" value="170"/>
</bean>
<!--实例化User-->
<bean id="user" class="com.thr.pojo.User" autowire="byType">
<!--注入普通值:使用 value 属性-->
<property name="userId" value="2020"/>
<property name="userName" value="菜逼唐"/>
<property name="userAge" value="18"/>
<property name="userPwd" value="123456"/>
<property name="userAddress" value="地球中国"/>
<!--这里本来是手动注入GirlFriend对象,但是现在让其自动注入,因为上面配置了 autowire="byType" -->
<!-- <property name="girlFriend" ref="girlFriend"/> -->
</bean>
</beans>
测试代码:
/**
* 测试代码
*/
public class SpringTest {
public static void main(String[] args) {
//1.初始化Spring容器,加载配置文件
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("applicationContext.xml");
//2.通过容器获取实例,getBean()方法中的参数是bean标签中的id
User user = applicationContext.getBean("user", User.class);
//3.调用实例中的属性
System.out.println(user.getUserName()+"-----"+user.getGirlFriend());
}
}
6.6.3 byName装配
byName装配是根据属性的名称自动装配,如果一个JavaBean中的属性名称与Bean的id 相同,则自动装配这个Bean到JavaBean的属性中。Spring会查找该JavaBean中所有的set方法名,获得将set去掉并且首字母小写的字符串,然后去Spring容器中寻找是否有此字符串名称id 的Bean。如果有则就注入,如果没有则注入动作将不会执行。
applicationContext.xml配置内容为:
运行测试代码,查看控制台输出:

可以发现根据名称自动配置成功了,User类中girlFriend属性自动找到了 id 为 girlFriend 的 Bean,而配置文件中如果没有定义 id 为 girlFriend 的 Bean则会自动装配失败,例如,修改xml中Bean id为girlFriend1,更改后如下所示:
再次运行测试代码,查看控制台输出:

可以发现如果没有找到这个bean,那么就不装配。
6.6.4 byType装配
byType装配表示通过属性类型自动装配。Spring会在容器中查找JavaBean中的属性类型与Bean的类型一致的Bean,并自动装配这个Bean到JavaBean的属性中,如果容器中包含多个这个类型的Bean,Spring将抛出异常。如果没有找到这个类型的Bean,那么注入动作将不会执行。
我们将前面Spring配置文件中的autowire属性修改为byType:
运行测试代码,查看控制台输出:

注意:使用byType首先需要保证同一类型的Bean在Spring容器中是唯一的,若不唯一则会产生歧义,Spring容器不知道选择哪个实例注入,所以后面会报异常。
假如这里出现了两个,那么 Spring 则不知道选择哪个,此时会报错:

运行测试代码,查看控制台输出:

所以,如果一旦选择了byType类型的自动装配,就必须确认配置文件中每个数据类型定义一个唯一的bean。
6.6.5 constructor装配
constructor装配类似于byType,也是通过类型自动装配,但是它是通过构造方法的参数类型来匹配。Spring会寻找与该JavaBean构造方法的各个参数类型相匹配的Bean,然后通过构造函数注入进来。如果在Spring容器中没有找一个构造函数参数类型的 Bean,则会报错。
applicationContext.xml配置内容为:
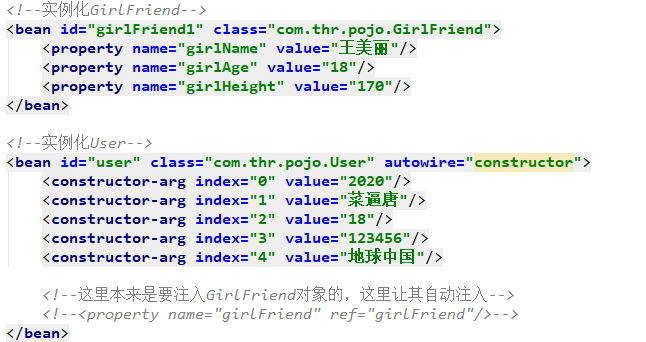
运行测试代码,查看控制台输出:

constructor自动装配具有和byType自动装配相同的局限性,就是当发现多个Bean匹配该JavaBean构造方法的类型时,Spring不知道用哪个Bean来装配,所以会导致装配失败。此外,如果一个JavaBean有多个构造方法,它们都满足自动装配的条件时,那么Spring也不会知道构造方法更适合使用,所以我们基本不会使用constructor装配。
6.6.6 default装配
default装配表示由父级标签beans的default-autowire属性来配置。如果beans标签上设置了default-autowire属性,那么default-autowire属性会统一配置当前beans中的所有bean的自动装配方式。

- 如果子标签
没有单独的设置autowire属性,那么将采用父标签的default-autowire属性的模式。 - 如果子标签
单独设置了autowire属性,则采用自己的模式。
6.6.7 Bean自动装配的补充
- [1]、上述的讲到byType和constructor装配是支持数组和强类型集合(即指定了集合元素类型)。如bean A有个属性定义是List
类型,Spring会在容器中查找所有类型为Foo的bean,注入到该属性。记住是Foo,不是List。另外如果集合是Map集合,那么Map的key必须是String类型,Spring会根据value的类型去匹配。例如有属性bean A中有一个属性为Map<String, Foo> p,容器中有bean B和C类型均为Foo,那么A实例化完成后,p属性的值为:{"B":B的实例对象,"C":C的实例对象}。 - [2]、虽然autowrie给我们带来配置的便利性,但是也有缺点,比如会导致bean的关系没那么显而易见,所以用autowire还是ref还是需要根据项目来决定。
- [3]、autowire-candidate:前面我们说到配置有autowire属性的bean,Spring在实例化这个bean的时候会在容器中查找匹配的bean对autowire bean进行属性注入,这些被查找的bean我们称为候选bean。作为候选bean,我凭什么就要被你用,老子不给你用。所以候选bean给自己增加了autowire-candidate="false"属性(默认是true),那么容器就不会把这个bean当做候选bean了,即这个bean不会被当做自动装配对象。同样,
标签可以定义default-autowire-candidate="false"属性让它包含的所有bean都不做为候选bean。我的地盘我做主。
7、基于注解的方式装配Bean
7.1 注解装配Bean介绍
通过前面的学习,我们已经知道如何通过XML的方式去装配Bean了,但是我们在实际的开发中,为了简化开发,更多的时候会使用到注解(annotation)的方式来装配Bean。因为注解可以大量减少繁琐的XML配置,并且注解的功能更为强大,它既能实现XML的功能,也提供了自动装配的功能,更加有利于开发,这就是“约定优于配置”原则,简称CoC(Convention over Configuration)。Spring提供了两种方式让Spring IOC容器发现Bean:
- 组件扫描:通过定义资源的方式,让Spring IOC容器扫描资源所在的包,从而装配Bean。
- 自动装配:通过注解自动找到依赖关系中所需要的Bean,即通过@Autowired或@Resource自动注入Bean对象。
所以在后面的学习中都会以注解为主。下面来学习下组件扫描和使用注解进行自动装配。
7.2 使用注解装配Bean
Spring提供了对Annotation(注解)技术的全面支持。Spring中定义了一系列的注解,常用的注解如表所示:
| 注解名称 | 描述 |
|---|---|
| @Component | 作用在类上的注解,可以使用此注解来描述Spring中的Bean,但是它是一个泛化的概念,仅仅表示一个组件,可以作用在任何层次。白话文描述:当某个类上用该注解修饰时,表示Spring 会把这个类扫描成一个Bean实例,等价于XML方式中定义的:<bean id="user" class="com.thr.spring.pojo.User">,此时可以直接简写成@Component(value = "user") 或者 @Component("user"),甚至直接写成@Component,如果不写括号里面的内容,默认以类名的首字母小写的形式作为 id 配置到容器中。 |
| @Repository | 通常用于对访问层DAO实现类进行标注,其功能与@Component相同,只是名字不同。 |
| @Service | 通常用于对业务层Service实现类进行标注,其功能与@Component相同,只是名字不同。 |
| @Controller | 通常用于对控制层Controller实现类进行标注,其功能与@Component相同,只是名字不同。 |
| @Autowired | 用于对Bean的属性变量、属性的setter()方法即构造方法进行标注,配合对应的注解处理完成Bean的自动装配工作。默认按照Bean的类型进行装配,说简单点就自动注入另一个对象,相当于<property name="" ref=""/> |
| @Resource(在Java11中被删除了) | 其作用于@Autowired一样,区别在于@Autowired默认按照Bean类型装配,而@Resource默认按照Bean实例名称进行装配。@Resource中有两个重要的属性:name和type。Spring将那么属性解析为Bean实例名称,type进行为Bean实例类型。若指定了name属性,则按照实例名称进行装配;若指定了type属性,则按照Bean类型进行装配;若都无法匹配,则抛出NoSuchBeanDefinitionException异常。这个注解在Java11中被删除了 |
| @Qualifier | 与@Autowired注解配合使用,会将默认的按Bean类型装配修改为按Bean的实例名称进行装配,Bean的实例名称由@Qualifier注解的参数指定。 |
| @Primary | 可以作用在类上,也可以配合@Bean作用在方法上,表示优先使用该注解标志的Bean。 |
| @Value | 相当于<property name="" value=""/>,这个注解表示注入一个值,但是这里只是一个简单值,如果是注入一个对象得用另一个注解(@Autowired 或者@Resource )。 |
使用注解装配Bean简单举例,来看之前的User类,并用@Component进行装配(或者@Repository、@Service、@Controller):
/**
* 用户实体类 用@Component注解将User类标注为一Bean
*
* @author tanghaorong
*/
@Data
@Component(value = "user")
public class User {
@Value(value = "2020")
private Integer userId;
@Value(value = "小唐")
private String userName;
@Value(value = "20")
private Integer userAge;
@Value(value = "123456")
private String userPwd;
@Value(value = "中国北京")
private String userAddress;
/**
* 装配对象属性这里下面介绍--使用注解自动装配
*/
private GirlFriend girlFriend;
}
GirlFriend实体对象:
/**
* GirlFriend实体对象
*/
@Data
@Component
public class GirlFriend {
private String girlName;
private Integer girlAge;
private String girlHeight;
}
然后在applicationContext.xml配置文件中引入组件扫描器(它的作用就是扫描哪里使用了@Component注解):
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
https://www.springframework.org/schema/context/spring-context.xsd">
<!-- bean definitions here -->
<!-- 组件自动扫描,指定注解扫描包路径 -->
<!-- base-package放的是包名,有多个包名中间用逗号隔开 -->
<context:component-scan base-package="com.thr.spring.pojo"/>
</beans>
注意:这里是要引入context的命名空间(idea会自动引入的):

测试代码:
/**
* Spring测试代码
*
* @author tanghaorong
*/
public class SpringRunTest {
public static void main(String[] args) {
//1.初始化Spring容器,加载配置文件
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("applicationContext.xml");
//2.通过容器获取实例,getBean()方法中的参数是bean标签中的id
User user = applicationContext.getBean("user", User.class);
//3.调用实例中的属性
System.out.println(user);
}
}
运行测试代码,查看控制台打印结果:

7.3 扫描组件注解@ComponentScan
上面我们在XML配置文件中配置了组件扫描: <context:component-scan base-package="com.thr.spring.pojo"/>,它的作用是自动扫描指定包路径下的组件,即:扫描指定包路径下用@Component、@Controller、@Service和@Repository注解修饰的类,存在就将其装配为Bean放入IOC容器中,我们也可以不在applicationContext.xml配置文件中配置组件扫描,而是直接使用注解扫描组件,所以我们将xml配置文件的配置去掉:
那么接下来要怎么做呢?这个时候我们需要重新创建一个类并且在类上添加@ComponentScan注解即可,意思是告诉 Spring 容器怎么扫描,就是指定扫描哪个包,如下:
package com.thr.spring.config;
import org.springframework.context.annotation.ComponentScan;
/**
* 组件扫描注解
*/
@ComponentScan(value = "com.thr.spring.*")
public class ScanBeanConfig {
}
代码目录结构:
上面的代码非常简单,但是需要注意的是:@ComponentScan注解如果不指定扫描哪个包的话,默认是扫描当前作用类的包路径 (这里是com.thr.spring.config),如果不在则扫描失败。然后就可以使用 Spring IOC 容器的实现类 AnnotationConfigApplicationContext 去生成Bean实例了,代码如下所示:
注意:AnnotationConfigApplicationContext 的参数必须是使用了@ComponentScan注解的那个类的Class对象,即将 ScanBeanConfig 作为参数传入。这样默认会扫描 ScanBeanConfig 类所在的包中的所有类,凡是类上有@Component、@Repository、@Service、@Controller任何一个注解的都会被注册到容器中。
/**
* Spring测试代码
*
* @author tanghaorong
*/
public class SpringRunTest {
public static void main(String[] args) {
//1.初始化Spring容器,通过注解加载
ApplicationContext applicationContext = new AnnotationConfigApplicationContext(ScanBeanConfig.class);
//2.通过容器获取实例
User user = applicationContext.getBean("user", User.class);
//3.调用实例中的属性
System.out.println(user);
}
}
这里可以看到使用了 AnnotationConfigApplicationContext 类去初始化 Spring IoC 容器,我们将@ComponentScan注解作用在 ScanBeanConfig 类上,所以它的配置项是 ScanBeanConfig类,这样 Spring IoC 就会根据注解的配置去解析对应的资源,来生成 IoC 容器了。但是这就有个弊端,一般来说我们的资源不会全部放在同一个包下,而对于 @ComponentScan 注解,它只是扫描所在包的 Java 类,这就意味着要进行全局扫描,这可怎么办呢?还好这个注解它有两个属性配置项basePackages和basePackageClasses:
- value:等价于basePackages。
- basePackages:表示扫描指定的包路径,可以是多个。
- basePackageClasses:表示扫描这些类所在的包及其子包中的类,可以配置多个。
这样我们就不用关心配置类是否和被扫描资源在同一个包下的问题了。然后我们来重构之前写的 ScanBeanConfig类来验证上面两个属性配置项,首先我们将ScanBeanConfig类移到另一个包下如com.thr.config,代码如下。
package com.thr.spring.config;
import com.thr.spring.pojo.User;
import org.springframework.context.annotation.ComponentScan;
/**
* 组件扫描注解(三选一)
*/
// @ComponentScan(basePackages = "com.thr.spring.*")
// @ComponentScan(value = "com.thr.spring.*")
@ComponentScan(basePackageClasses = User.class)
public class ScanBeanConfig {
}
如果有多个包或类,我们用大括号包起来然后在大括号里面用逗号隔开,简单举例:
@ComponentScan(basePackages = {"package1","package3","package4"})
@ComponentScan(basePackageClasses ={Class1.class,Class2.class,Class3.class})
这样 Spring 容器就能将一个类装配成Bean了。
7.4 使用@Autowired注解自动装配
上面提到使用@Value注解只能装配普通值,是不能装配对象的,所以下面我们来介绍使用注解自动装配对象,需要使用到@Autowired注解:
@Autowired:它默认是按byType进行匹配,可以用于修饰类成员变量(字段)、Setter 方法、构造函数,甚至普通方法,但是前提是方法必须有至少一个参数。
@Autowired注解并不是完全按照byType进行匹配。而是默认先按byType进行匹配,如果发现找到多个bean,则又按照byName方式进行匹配,如果还有多个,则报出异常。
我们在实际的开发中基本都会使用注解来对对象属性完成自动装配,因为这样可以减少配置的复杂度,所以@Autowired非常的重要!
-
作用于类的成员变量(字段 | Field)
注意:在IDEA编辑器中使用@Autowired作用于字段 (Field) 的时,IDEA会给出一个提示:Field injection is not recommended(意思是不再推荐使用字段注入),但是习惯了作用于字段,所以不必管它,如果你感觉不爽的话可以按照如下操作隐藏这个提示:
setting-->Editor-->inspections-->Spring-->Spring Core-->Code-->Filed injection warning去掉右边的小勾勾,Apply-->OK即可。具体为啥不推荐可以去百度一下。
然后创建的User类:
@Data @Component(value = "user") public class User { @Value(value = "2020") private Integer userId; @Value(value = "小唐") private String userName; @Value(value = "20") private Integer userAge; @Value(value = "123456") private String userPwd; @Value(value = "中国北京") private String userAddress; //这里使用@Autowired注解自动注入 @Autowired private GirlFriend girlFriend; }初始化用于注入的GirlFriend类:
@Data @Component public class GirlFriend { @Value("王美丽") private String girlName; @Value("18") private int girlAge; @Value("170") private String girlHeight; }测试代码如下:
/** * Spring测试代码 * * @author tanghaorong */ @ComponentScan(value = "com.thr.spring.*") public class SpringRunTest1 { public static void main(String[] args) { //1.初始化Spring容器,通过注解加载 ApplicationContext applicationContext = new AnnotationConfigApplicationContext(SpringRunTest1.class); //2.通过容器获取实例 User user = applicationContext.getBean("user", User.class); //3.调用实例中的属性 System.out.println(user); } }运行测试代码,查看控制台打印的结果:

-
作用于Setter方法
作用于Setter方法和作用于构造函数。这两种方式实现的效果和上面的效果是一模一样的。

-
作用于构造函数
注意:如果已经使用注解完成了初始化工作,那么则不能再创建该参数的构造方法了,比如我们使用了@Value注解初始化userName属性,那么则就不能再创建userName属性的构造方法了。
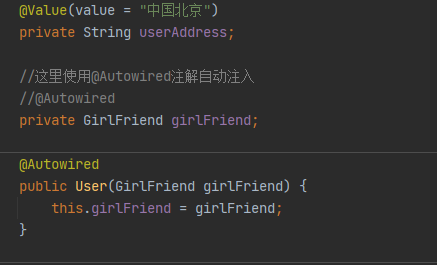
-
补充1:@Autowired注解中有个属性required,这个属性是一个boolean类型,为true(默认)表示注入bean的时候该bean必须存在,不然就会注入失败,但程序不报错 。为 false 表示注入bean的时候如果bean存在,就注入成功,如果没有就忽略跳过,启动时不会报错!但是不能直接使用,因为bean为NULL!
例如我将GirlFriend类的@Component注解给注释掉,并且把User类中的@Autowired注解的属性required设置为false。
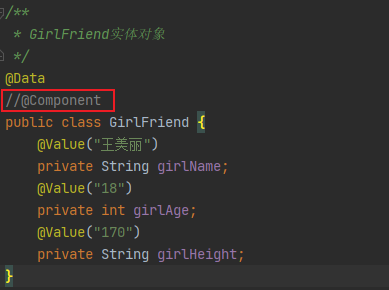
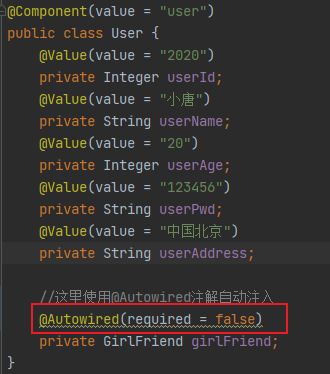
通过运行的结果可以发现注入失败了,但是不会报错,只是返回为null。

-
补充2:@Autowired注解并不是完全按照byType进行匹配。而是默认先按byType进行匹配,如果发现找到多个bean,则又按照byName方式进行匹配,如果还有多个,则报出异常。动手能力强的可以自己去实践一遍,我自己是去验证过的。
7.5 @Autowired自动装配的歧义性
由于@Autowired注解是根据类型来自动装配的,所以肯定会存在有多个相同类型的bean,而Spring IOC容器却不知要选择哪一个的情况,此时就产生了歧义性,那么我们怎么来解决呢?Spring中给我们提供了@Primary和@Qualifier这两个注解。
- @Primary:可以作用在类上,也可以配合@Bean作用在方法上,表示优先使用该注解标志的Bean。实际开发中不实用,所以就不介绍了。
- @Qualifier:表示当容器中存在多个相同类型的Bean时,使用这个注解可以根据Bean的名字来选择注入哪个Bean,推荐使用这种方式。
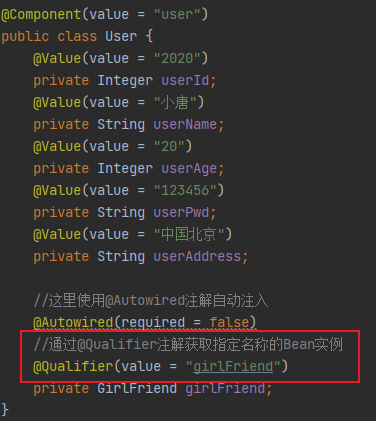
7.6 与@Autowired类似的注解@Resource
注意:这个注解在Java11中被删除了
@Resource 注解相当于@Autowired,它们两个都是用来实现依赖注入的。只是@AutoWried默认按byType自动注入,而@Resource默认按byName自动注入。而且@Resource只能处理setter注入(包括字段)。@Resource有两个重要属性,分别是name和type,其中name属性相当于@Qualifier,type相当于根据类型配置。Spring 将 name 属性解析为bean的名字,而type属性则被解析为bean的类型。所以如果使用name属性,则使用byName的自动注入策略,如果使用type属性则使用byType的自动注入策略。如果都没有指定,则通过反射机制使用byName自动注入策略。表面上我们说@Resource默认按byName自动注入,其实如果按名称查找不到匹配的bean时,最后会按byType进行自动注入,@Resource依赖注入时查找bean的规则如下:
- 如果不指定name属性,也不指定type属性,则自动按byName方式进行查找。如果没有找到符合的bean,则回退为一个原始类型进行进行查找,如果找到就注入。
- 只是指定了@Resource注解的name属性,则只能按name后的名字去bean元素里查找有与之相等的name属性的bean,如果找不到则会抛出异常。
- 只指定@Resource注解的type属性,则从上下文中找到类型匹配的唯一bean进行装配,找不到或者找到多个,都会抛出异常。
- 既指定了@Resource的name属性又指定了type,则从Spring上下文中找到唯一匹配的bean进行装配,找不到则抛出异常。
补充:但是我好像听说这个注解在Java11中被删除了,也不知道是不是真的,如果是真的还是慎用!然后我去查了一下JDK11的官方文档,确实JDK11将javax.annotation这个包移除了,如果想继续使用可以通过maven或者其他方式导入。
<dependency>
<groupId>javax.annotation</groupId>
<artifactId>javax.annotation-api</artifactId>
<version>1.3.2</version>
</dependency>
如果这个依赖无法使用,可以去maven仓库自行查找。
7.7 @Autowired和@Resource的区别
相同点:
- 二者均可以用来注入bean,都可以用在字段上或者方法上
不同点:
- @Autowired是属于Spring框架的,是 Spring 提供的注解;而@Resource属于J2EE,是 JDK 提供的注解。
- @Autowired默认按byType进行装配,可以结合@Qualifier使用按名称装配,如果发现找到多个bean,则又按照byName方式进行匹配,如果还有多个,则报出异常。
- @Resource默认按byName进行装配,名称可以通过name属性进行指定,如果没有指定name属性,则默认采用字段名进行查找,当找不到与名称匹配的bean时才按byType进行装配。但是需要注意的是,如果name属性一旦指定,就只会按照名称进行装配。
小结:@Autowired是按照先按 byType 后按 byName 进行匹配,@Resources是按照先按 byName 后按 byType进行匹配。
7.8 @Named/@Inject(了解)
这两个注解的是JSR-330的一部分,而Spring 是支持JSR-330的。这些注解在使用上和Spring的注解一样,只是想要导入额外的相关jar包。如下:
<!-- https://mvnrepository.com/artifact/javax.inject/javax.inject -->
<dependency>
<groupId>javax.inject</groupId>
<artifactId>javax.inject</artifactId>
<version>1</version>
</dependency>
- @Named 用来替代@Component 声明一个Bean
- @Inject 用来替代@Autowired来执行注入
实际上我们很少会使用这样的注解,只需知道有这个东西即可。
7.9 补充:@ComponentScan和@ComponentScans详解
这是@ComponentScan的官方介绍:
翻译一下的大致意思是:扫描组件注解可以与 @Configuration 类一起使用,并且该注解提供了与 Spring XML 的<context:component-scan>一样的功能,所以@ComponentScan是用于扫描注册Bean的一个注解,它会根据配置扫描路径下被@Component或者被其标注了的注解标注的类,比如@Controller、@Service、@Repository和@Configuration等。同时我们可以指定 basePackageClasses 或 basePackages(或其别名值)来定义要扫描的特定包,常用的方式是basePackages方式。 如果未定义特定的包,则会从声明此注解的类的包中进行扫描。
来看一下这个注解的详细定义:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@Documented
@Repeatable(ComponentScans.class)
public @interface ComponentScan {
/**
* 扫描包路径
* @ComponentScan(value = "spring.annotation.componentscan")
*/
@AliasFor("basePackages")
String[] value() default {};
/**
* 扫描包路径
*/
@AliasFor("value")
String[] basePackages() default {};
/**
* 指定扫描类所在的包
* @ComponentScan(basePackageClasses = {User.class, UserService.class})
*/
Class<?>[] basePackageClasses() default {};
/**
* 命名注册的Bean,可以自定义实现命名Bean,
* 1、@ComponentScan(value = "spring.annotation.componentscan",nameGenerator = MyBeanNameGenerator.class)
* MyBeanNameGenerator.class 需要实现 BeanNameGenerator 接口,所有实现BeanNameGenerator 接口的实现类都会被调用
* 2、使用 AnnotationConfigApplicationContext 的 setBeanNameGenerator方法注入一个BeanNameGenerator
* BeanNameGenerator beanNameGenerator = (definition,registry)-> String.valueOf(new Random().nextInt(1000));
* AnnotationConfigApplicationContext annotationConfigApplicationContext = new AnnotationConfigApplicationContext();
* annotationConfigApplicationContext.setBeanNameGenerator(beanNameGenerator);
* annotationConfigApplicationContext.register(MainConfig2.class);
* annotationConfigApplicationContext.refresh();
* 第一种方式只会重命名@ComponentScan扫描到的注解类
* 第二种只有是初始化的注解类就会被重命名
* 列如第一种方式不会重命名 @Configuration 注解的bean名称,而第二种就会重命名 @Configuration 注解的Bean名称
*/
Class<? extends BeanNameGenerator> nameGenerator() default BeanNameGenerator.class;
/**
* 用于解析@Scope注解,可通过 AnnotationConfigApplicationContext 的 setScopeMetadataResolver 方法重新设定处理类
* ScopeMetadataResolver scopeMetadataResolver = definition -> new ScopeMetadata(); 这里只是new了一个对象作为演示,没有做实际的逻辑操作
* AnnotationConfigApplicationContext annotationConfigApplicationContext = new AnnotationConfigApplicationContext();
* annotationConfigApplicationContext.setScopeMetadataResolver(scopeMetadataResolver);
* annotationConfigApplicationContext.register(MainConfig2.class);
* annotationConfigApplicationContext.refresh();
* 也可以通过@ComponentScan 的 scopeResolver 属性设置
*@ComponentScan(value = "spring.annotation.componentscan",scopeResolver = MyAnnotationScopeMetadataResolver.class)
*/
Class<? extends ScopeMetadataResolver> scopeResolver() default AnnotationScopeMetadataResolver.class;
/**
* 用来设置类的代理模式
*/
ScopedProxyMode scopedProxy() default ScopedProxyMode.DEFAULT;
/**
* 扫描路径 如 resourcePattern = **/*.class" 使用 includeFilters 和 excludeFilters 会更灵活
*/
String resourcePattern() default ClassPathScanningCandidateComponentProvider.DEFAULT_RESOURCE_PATTERN;
/**
* 指示是否应启用对带有{@code @Component},{@ code @Repository},
* {@ code @Service}或{@code @Controller}注释的类的自动检测。
*/
boolean useDefaultFilters() default true;
/**
* 对被扫描的包或类进行过滤,若符合条件,不论组件上是否有注解,Bean对象都将被创建
* @ComponentScan(value = "spring.annotation.componentscan",includeFilters = {
* @ComponentScan.Filter(type = FilterType.ANNOTATION, classes = {Controller.class, Service.class}),
* @ComponentScan.Filter(type = FilterType.ASSIGNABLE_TYPE, classes = {SchoolDao.class}),
* @ComponentScan.Filter(type = FilterType.CUSTOM, classes = {MyTypeFilter.class}),
* @ComponentScan.Filter(type = FilterType.ASPECTJ, pattern = "spring.annotation..*"),
* @ComponentScan.Filter(type = FilterType.REGEX, pattern = "^[A-Za-z.]+Dao$")
* },useDefaultFilters = false)
* useDefaultFilters 必须设为 false
*/
Filter[] includeFilters() default {};
/**
* 指定哪些类型不适合进行组件扫描。
* 用法同 includeFilters 一样
*/
Filter[] excludeFilters() default {};
/**
* 指定是否应注册扫描的Bean以进行延迟初始化。
* @ComponentScan(value = "spring.annotation.componentscan",lazyInit = true)
*/
boolean lazyInit() default false;
/**
* 用于 includeFilters 或 excludeFilters 的类型筛选器
*/
@Retention(RetentionPolicy.RUNTIME)
@Target({})
@interface Filter {
/**
* 要使用的过滤器类型,默认为 ANNOTATION 注解类型
* @ComponentScan.Filter(type = FilterType.ANNOTATION, classes = {Controller.class, Service.class})
*/
FilterType type() default FilterType.ANNOTATION;
/**
* 过滤器的参数,参数必须为class数组,单个参数可以不加大括号
* 只能用于 ANNOTATION 、ASSIGNABLE_TYPE 、CUSTOM 这三个类型
* @ComponentScan.Filter(type = FilterType.ANNOTATION, value = {Controller.class, Service.class})
* @ComponentScan.Filter(type = FilterType.ASSIGNABLE_TYPE, classes = {SchoolDao.class})
* @ComponentScan.Filter(type = FilterType.CUSTOM, classes = {MyTypeFilter.class})
*/
@AliasFor("classes")
Class<?>[] value() default {};
/**
* 作用同上面的 value 相同
* ANNOTATION 参数为注解类,如 Controller.class, Service.class, Repository.class
* ASSIGNABLE_TYPE 参数为类,如 SchoolDao.class
* CUSTOM 参数为实现 TypeFilter 接口的类 ,如 MyTypeFilter.class
* MyTypeFilter 同时还能实现 EnvironmentAware,BeanFactoryAware,BeanClassLoaderAware,ResourceLoaderAware 这四个接口
* EnvironmentAware
* 此方法用来接收 Environment 数据 ,主要为程序的运行环境,Environment 接口继承自 PropertyResolver 接口,详细内容在下方
* @Override
* public void setEnvironment(Environment environment) {
* String property = environment.getProperty("os.name");
* }
*
* BeanFactoryAware
* BeanFactory Bean容器的根接口,用于操作容器,如获取bean的别名、类型、实例、是否单例的数据
* @Override
* public void setBeanFactory(BeanFactory beanFactory) throws BeansException {
* Object bean = beanFactory.getBean("BeanName")
* }
*
* BeanClassLoaderAware
* ClassLoader 是类加载器,在此方法里只能获取资源和设置加载器状态
* @Override
* public void setBeanClassLoader(ClassLoader classLoader) {
* ClassLoader parent = classLoader.getParent();
* }
*
* ResourceLoaderAware
* ResourceLoader 用于获取类加载器和根据路径获取资源
* public void setResourceLoader(ResourceLoader resourceLoader) {
* ClassLoader classLoader = resourceLoader.getClassLoader();
* }
*/
@AliasFor("value")
Class<?>[] classes() default {};
/**
* 这个参数是 classes 或 value 的替代参数,主要用于 ASPECTJ 类型和 REGEX 类型
* ASPECTJ 为 ASPECTJ 表达式
* @ComponentScan.Filter(type = FilterType.ASPECTJ, pattern = "spring.annotation..*")
* REGEX 参数为 正则表达式
* @ComponentScan.Filter(type = FilterType.REGEX, pattern = "^[A-Za-z.]+Dao$")
*/
String[] pattern() default {};
}
}
从源码的定义上可以看出此注解可以用在任何类型上面,不过我们通常将其用在类上面。常用参数介绍:
- value:指定需要扫描的包,如:com.thr.spring.*
- basePackages:作用同value;value和basePackages不能同时存在设置,可二选一,表示要扫描的路径,如果为空,解析的时候会解析被@ComponentScan标注类的包路径
- basePackageClasses:指定一些类,Spring容器会扫描这些类所在的包及其子包中的类,与basePackages互斥
- nameGenerator:自定义bean名称生成器,在解析注册BeanDefinition的时候用到
- scopeResolver:类定义上的@Scope注解解析器,如果没有该注解默认单例
- scopedProxy:扫描到@Component组件是是否生成代理以及生成代理方式
- resourcePattern:扫描路径时规则,默认是:**/*.class,即会扫描指定包中所有的class文件
- useDefaultFilters:对扫描的类是否启用默认过滤器,默认为true,扫描@Component标注的类以及衍生注解标注的类,如果为false则不扫描,需要自己指定includeFilters
- includeFilters:自定义包含过滤器,用来配置被扫描出来的那些类会被作为组件注册到容器中,如果@Component扫描不到或者不能满足,则可以使用自定义扫描过滤器
- excludeFilters:自定义排除过滤器,和includeFilters作用刚好相反,用来对扫描的类进行排除的,被排除的类不会被注册到容器中
- lazyInit:表示扫描注册BeanDefinition后是否延迟初始化,默认false
TIPS:@ComponentScan工作的过程:Spring会扫描指定的包,且会递归下面子包,得到一批类的数组然后这些类会经过上面的各种过滤器,最后剩下的类会被注册到容器中所以玩这个注解,主要关注2个问题:第一个:需要扫描哪些包?通过 value、backPackages、basePackageClasses 这3个参数来控制;第二:过滤器有哪些?通过 useDefaultFilters、includeFilters、excludeFilters 这3个参数来控制过滤器,这两个问题搞清楚了,就可以确定哪些类会被注册到容器中。默认情况下,任何参数都不设置的情况下,此时,会将@ComponentScan修饰的类所在的包作为扫描包;默认情况下useDefaultFilters为true,这个为true的时候,Spring容器内部会使用默认过滤器,规则是:凡是类上有 @Repository、@Service、@Controller、@Component 这几个注解中的任何一个的,那么这个类就会被作为Bean注册到Spring容器中,所以默认情况下,只需在类上加上这几个注解中的任何一个,这些类就会自动交给spring容器来管理了。
而我们平时用的最多的就是basePackages,以及做一些定制化扫描时会用到includeFilters和excludeFilters,所以下面来看下。
7.9.1 value、basePackages和basePackageClasses的使用
- value:指定需要扫描的包,如:com.thr.spring.*
- basePackages:作用同value;value和basePackages不能同时存在设置,可二选一,表示要扫描的路径,如果为空,解析的时候会解析被@ComponentScan标注类的包路径
- basePackageClasses:指定一些类,Spring容器会扫描这些类所在的包及其子包中的类,与basePackages互斥
这些都是常规用法比较简单,所以不多说了,直接复用一下上面的代码ScanBeanConfig类,代码如下。
package com.thr.spring.config;
import com.thr.spring.pojo.User;
import org.springframework.context.annotation.ComponentScan;
/**
* 组件扫描注解(三选一)
*/
// @ComponentScan(basePackages = "com.thr.spring.*")
// @ComponentScan(value = "com.thr.spring.*")
@ComponentScan(basePackageClasses = User.class)
public class ScanBeanConfig {
}
如果有多个包或类,我们用大括号包起来然后在大括号里面用逗号隔开,简单举例:
@ComponentScan(basePackages = {"package1","package3","package4"})
@ComponentScan(basePackageClasses ={Class1.class,Class2.class,Class3.class})
7.9.2 includeFilters的使用
先来看一下includeFilters这个参数的定义:
Filter[] includeFilters() default {};
它是一个 Filter 类型的数组,多个Filter之间为或者关系,即满足任意一个就可以了,看一下 Filter 的代码:
@Retention(RetentionPolicy.RUNTIME)
@Target({})
@interface Filter {
FilterType type() default FilterType.ANNOTATION;
@AliasFor("classes")
Class<?>[] value() default {};
@AliasFor("value")
Class<?>[] classes() default {};
String[] pattern() default {};
}
可以看出Filter也是一个注解,参数有:
- type:过滤器的类型,是个枚举类型,5种类型
- ANNOTATION:通过注解的方式来筛选候选者,即判断候选者是否有指定的注解
- ASSIGNABLE_TYPE:通过指定的类型来筛选候选者,即判断候选者是否是指定的类型
- ASPECTJ:ASPECTJ表达式方式,即判断候选者是否匹配ASPECTJ表达式
- REGEX:正则表达式方式,即判断候选者的完整名称是否和正则表达式匹配
- CUSTOM:用户自定义过滤器来筛选候选者,对候选者的筛选交给用户自己来判断
- value:和参数classes效果一样,二选一
- classes:3种情况如下
- 当type=FilterType.ANNOTATION时,通过classes参数可以指定一些注解,用来判断被扫描的类上是否有classes参数指定的注解
- 当type=FilterType.ASSIGNABLE_TYPE时,通过classes参数可以指定一些类型,用来判断被扫描的类是否是classes参数指定的类型
- 当type=FilterType.CUSTOM时,表示这个过滤器是用户自定义的,classes参数就是用来指定用户自定义的过滤器,自定义的过滤器需要实现org.springframework.core.type.filter.TypeFilter接口
- pattern:2种情况如下
- 当type=FilterType.ASPECTJ时,通过pattern来指定需要匹配的ASPECTJ表达式的值
- 当type=FilterType.REGEX时,通过pattern来自正则表达式的值
案例1:扫描包含注解的类
我们自定义一个注解,让标注有这些注解的类自动注册到容器中,代码实现如下:首先在 com.thr.spring.annotation 包中自定义一个注解
package com.thr.spring.annotation;
import java.lang.annotation.*;
@Documented
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
public @interface MyBean {
}
然后创建一个类,使用上面创建的这个注解进行标注。
package com.thr.spring.service;
import com.thr.spring.annotation.MyBean;
@MyBean
public class Service1 {
}
再来一个类,处理使用Spring中的 @Compontent 标注。
package com.thr.spring.service;
import org.springframework.stereotype.Component;
@Component
public class Service2 {
}
最后再来一个扫描配置类,使用@CompontentScan标注。
package com.thr.spring.config;
import com.thr.spring.annotation.MyBean;
import com.thr.spring.pojo.User;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.FilterType;
@ComponentScan(value = "com.thr.spring.*",
includeFilters = {
@ComponentScan.Filter(type = FilterType.ANNOTATION, classes = MyBean.class)
})
public class ScanBeanConfig1 {
}
上面扫描了com.thr.spring包及其所有子包的类,并且额外指定了Filter的type为注解的类型,所以只要类上面有 @MyBean 注解的,都会被作为bean注册到容器中。
测试代码如下:
/**
* Spring测试代码
*
* @author tanghaorong
*/
public class SpringRunTest1 {
public static void main(String[] args) {
//1.初始化Spring容器,通过注解加载
ApplicationContext applicationContext = new AnnotationConfigApplicationContext(ScanBeanConfig1.class);
for (String beanName : applicationContext.getBeanDefinitionNames()) {
System.out.println(beanName + "->" + applicationContext.getBean(beanName));
}
}
}
运行输出结果:
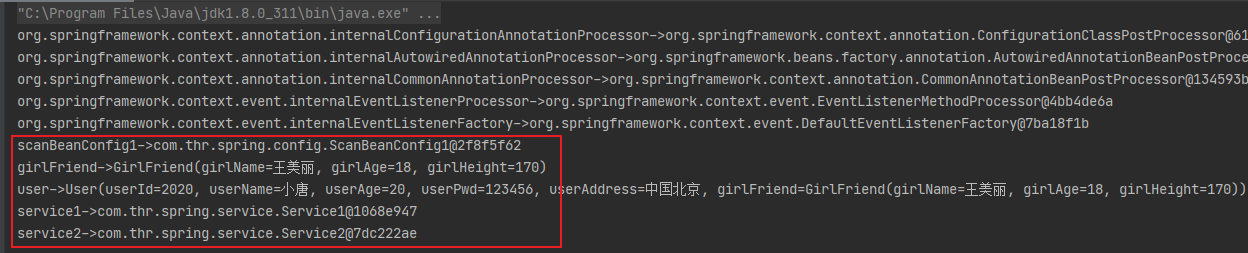
从运行结果可以发现:Service1上标注了 @MyBean 注解,被注册到容器了,但是 Service2 上没有标注 @MyBean 啊,怎么也被注册到容器了?并且可以发现User、Girlfriend、ScanBeanConfig1也都注册到容器了。
原因:Service2、User、Girlfriend上标注了 @Compontent 注解,而@CompontentScan注解中的 useDefaultFilters默认是 true ,表示也会启用默认的过滤器,而默认的过滤器会将标注有 @Component、@Repository、@Service、@Controller 这几个注解的类也注册到容器中。如果我们只想将标注有 @MyBean 注解的bean注册到容器,需要将默认过滤器关闭,即:useDefaultFilters=false,可以修改一下ScanBeanConfig1的代码如下:
@ComponentScan(value = "com.thr.spring.*",
useDefaultFilters = false, //不启用默认过滤器
includeFilters = {
@ComponentScan.Filter(type = FilterType.ANNOTATION, classes = MyBean.class)
})
public class ScanBeanConfig1 {
}
然后再次运行的到的输出结果为:
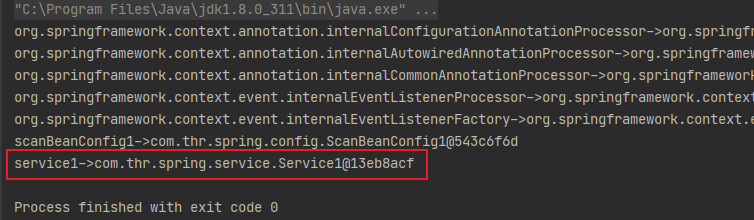
案例2:扫描包含指定类型的类
下面定义一个接口,让Spring来进行扫描,类型满足IService的都将其注册到容器中。
public interface IService {
}
创建两个上面IService接口实现类:
public class Service1 implements IService {
}
public class Service2 implements IService {
}
随后在来一个@CompontentScan标注的配置类,扫描配置类的意思是:被扫描的类满足 IService.class.isAssignableFrom(被扫描的类) 条件的都会被注册到Spring容器中。
@ComponentScan(value = "com.thr.spring.*",
useDefaultFilters = false, //不启用默认过滤器
includeFilters = {
@ComponentScan.Filter(type = FilterType.ASSIGNABLE_TYPE, classes = IService.class)
})
public class ScanBeanConfig2 {
}
测试代码:
/**
* Spring测试代码
*
* @author tanghaorong
*/
public class SpringRunTest2 {
public static void main(String[] args) {
//1.初始化Spring容器,通过注解加载
ApplicationContext applicationContext = new AnnotationConfigApplicationContext(ScanBeanConfig2.class);
for (String beanName : applicationContext.getBeanDefinitionNames()) {
System.out.println(beanName + "->" + applicationContext.getBean(beanName));
}
}
}
运行输出:

案例3:自定义Filter
首先来看看与自定义Filter有关的参数和相关的类,使用自定义过滤器的步骤:
- 设置@Filter中type的类型为:FilterType.CUSTOM
- 自定义过滤器类,需要实现接口:org.springframework.core.type.filter.TypeFilter
- 设置@Filter中的classses为自定义的过滤器类型
来看一下 TypeFilter 这个接口的定义
@FunctionalInterface
public interface TypeFilter {
boolean match(MetadataReader var1, MetadataReaderFactory var2) throws IOException;
}
可以发现它是一个函数式接口,包含一个match方法,方法返回boolean类型,有2个参数,都是接口类型的,下面介绍一下这2个接口。MetadataReader接口类元数据读取器,可以读取一个类上的任意信息,如类上面的注解信息、类的磁盘路径信息、类的class对象的各种信息,spring进行了封装,提供了各种方便使用的方法。看一下这个接口的定义:
public interface MetadataReader {
/**
* 返回类文件的资源引用
*/
Resource getResource();
/**
* 返回一个ClassMetadata对象,可以通过这个读想获取类的一些元数据信息,如类的class对象、
* 是否是接口、是否有注解、是否是抽象类、父类名称、接口名称、内部包含的之类列表等等,可以去看一下源
* 码
*/
ClassMetadata getClassMetadata();
/**
* 获取类上所有的注解信息
*/
AnnotationMetadata getAnnotationMetadata();
}
MetadataReaderFactory接口类元数据读取器工厂,可以通过这个类获取任意一个类的MetadataReader对象。源码:
public interface MetadataReaderFactory {
/**
* 返回给定类名的MetadataReader对象
*/
MetadataReader getMetadataReader(String className) throws IOException;
/**
* 返回指定资源的MetadataReader对象
*/
MetadataReader getMetadataReader(Resource resource) throws IOException;
}
自定义Filter案例
我们来个自定义的Filter,判断被扫描的类如果是 IService 接口类型的,就让其注册到容器中。
代码实现:在包com.thr.spring.filter下创建一个自定义的TypeFilter类
public class MyFilter implements TypeFilter {
@Override
public boolean match(MetadataReader metadataReader, MetadataReaderFactory
metadataReaderFactory) throws IOException {
Class<?> curClass = null;
try {
//当前被扫描的类
curClass = Class.forName(metadataReader.getClassMetadata().getClassName());
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
//判断curClass是否是IService类型
assert curClass != null;
return IService.class.isAssignableFrom(curClass);
}
}
随后在来一个@CompontentScan标注的配置类,注意:type为FilterType.CUSTOM,表示Filter是用户自定义的,classes为自定义的过滤器
@ComponentScan(value = "com.thr.spring.*",
useDefaultFilters = false, //不启用默认过滤器
includeFilters = {
@ComponentScan.Filter(type = FilterType.CUSTOM, classes = MyFilter.class)
})
public class ScanBeanConfig3 {
}
测试代码:
/**
* Spring测试代码
*
* @author tanghaorong
*/
public class SpringRunTest3 {
public static void main(String[] args) {
//1.初始化Spring容器,通过注解加载
ApplicationContext applicationContext = new AnnotationConfigApplicationContext(ScanBeanConfig3.class);
for (String beanName : applicationContext.getBeanDefinitionNames()) {
System.out.println(beanName + "->" + applicationContext.getBean(beanName));
}
}
}
运行输出:

7.9.3 excludeFilters的使用
excludeFilters参数用于配置排除的过滤器,满足这些过滤器的类不会被注册到容器中,用法上面和includeFilters用一样,所以就不演示了,可以参考includeFilters的用法。
7.9.4 @ComponentScans的使用
@ComponentScans注解可以一次声明多个 @ComponentScan 注释。也可以与 Java 8 对可重复注释的支持结合使用,在该方法中,可以简单地在同一方法上多次声明 @ComponentScan,从而隐式生成此容器注释。
我们先看 @ComponentScan 注解的源码,如下:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@Documented
@Repeatable(ComponentScans.class)
public @interface ComponentScan {
}
上面 @ComponentScan 注解源码上面使用了 @Repeatable 注解,表示该注解可以被 @ComponentScans 作为数组使用。
再来看看 @ComponentScans 注解源码,如下:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@Documented
public @interface ComponentScans {
ComponentScan[] value();
}
该注解的 value() 属性是一个 @ComponentScan 注解数组。
@ComponentScans案例
下面实例在 @ComponentScans 注解中声明了两个 @ComponentScan 注解,如下:
@ComponentScans({
@ComponentScan(basePackages = {
"com.thr.spring.controller1"
}, includeFilters = {
// 仅仅使用了 @RestController 注解声明的类
@ComponentScan.Filter(type = FilterType.ANNOTATION, classes = {Controller.class})
}, useDefaultFilters = false),
@ComponentScan(basePackages = {
"com.thr.spring.controller2"
}, excludeFilters = {
// 过滤使用了 @MyAnnotation 注解的类
@ComponentScan.Filter(type = FilterType.ANNOTATION, classes = {MyBean.class})
})
})
public class MyConfig {
}
上面实例中,第一个 @ComponentScan 注解将扫描 com.thr.spring.controller1 包及子包下面声明了 @Controller 注解的类;第二个 @ComponentScan 注解将过滤 com.thr.spring.controller2 包及子包下声明了 @MyBean 注解的类。
8、通过@Configuration和@Bean注解注册Bean
8.1 @Configuration注解
在Spring4以后,官方推荐使用 JavaConfig 来代替 application.xml 声明将Bean交给容器管理。在Spring Boot 中,JavaConfig 的使用完全代替了application.xml 实现了xml的零配置,所以下面来介绍下@Configuration和@Bean注解的使用。@Configuration与@Bean一般配合使用,作用主要用于在 Java 代码中实现 Spring 的配置,它的目的是代替Spring的xml配置文件。下面来简单介绍一下这两个注解:
- @Configuration:标注在类上,让这个类的功能等同于一个bean.xml配置文件(包含命名空间)。
@Configuration
public class BeanConfig {
}
上面代码类似于下面的xml:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<!-- bean definitions here -->
</beans>
如果要获取它们,我们可以使用AnnotationConfigApplicationContext 或 AnnotationConfigWebApplicationContext类进行扫描,并用于构建bean定义,初始化Spring容器。但是此时ConfigBean类中没有任何内容,相当于一个空的xml配置文件,此时我们要在ConfigBean类中注册bean,那么我们就要用到@Bean注解了。
8.2 @Bean注解
这个注解类似于bean.xml配置文件中的bean元素,用来在Spring容器中注册一个Bean。@Bean注解用在方法上,表示通过方法来定义一个Bean,默认将方法名称作为Bean名称,将方法返回值作为Bean对象,注册到Spring容器中。
@Configuration
public class BeanConfig {
@Bean
public User user() {
return new User();
}
}
上面代码类似于下面的xml:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<!-- bean definitions here -->
<bean id="user" class="com.thr.spring.pojo.User"/>
</beans>
@Bean注解的配置项中包含了一些属性,所以我们来看一下其源码:
@Target({ElementType.METHOD, ElementType.ANNOTATION_TYPE}) //@1
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface Bean {
@AliasFor("name")
String[] value() default {};
@AliasFor("value")
String[] name() default {};
@Deprecated
Autowire autowire() default Autowire.NO;
boolean autowireCandidate() default true;
String initMethod() default "";
String destroyMethod() default AbstractBeanDefinition.INFER_METHOD;
}
其中@Bean的配置项中包含的6个配置项含义:
- value:等同于下面的name属性
- name:相当于bean的id,
<bean id=" ">,它是一个字符串数组,允许配置多个 BeanName,如果不配置,则默认是方法名 - autowire:标志是否是一个引用的 Bean 对象,默认值是 Autowire.NO,这个参数上面标注了@Deprecated,表示已经过期了,不建议使用了
- autowireCandidate:是否作为其他对象注入时候的候选Bean
- initMethod:自定义初始化方法
- destroyMethod:自定义销毁方法
8.3 @Configuration与@Bean案例
下面是使用@Configuration与@Bean在Java代码中给容器之中添加Bean的代码案例:
[1]、首先创建一个User类,如下:
/**
* 用户实体类 用@Component注解将User类标注为一Bean
*
* @author tanghaorong
*/
@Data
public class User {
@Value(value = "2020")
private Integer userId;
@Value(value = "小唐")
private String userName;
@Value(value = "20")
private Integer userAge;
@Value(value = "123456")
private String userPwd;
@Value(value = "中国北京")
private String userAddress;
}
[2]、创建BeanConfig类,用来启动容器和注册Bean对象:
package com.thr.spring.config;
import com.thr.spring.pojo.User;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class BeanConfig {
//bean名称为方法默认值:user1
@Bean
public User user1() {
return new User();
}
//bean名称通过value指定了:user2Bean
@Bean("user2Bean")
public User user2() {
return new User();
}
//bean名称为:user3Bean,2个别名:[user3BeanAlias1,user3BeanAlias2]
@Bean({"user3Bean", "user3BeanAlias1", "user3BeanAlias2"})
public User user3() {
return new User();
}
}
[3]、测试代码(这里使用AnnotationConfigApplicationContext类来获取,它会将配置类中所有的Bean注册到Spring容器中):
/**
* Spring测试代码
*
* @author tanghaorong
*/
public class SpringRunTest {
public static void main(String[] args) {
//1.初始化Spring容器,通过注解加载
ApplicationContext applicationContext = new AnnotationConfigApplicationContext(BeanConfig.class);
//2.通过容器获取实例
User user1 = applicationContext.getBean("user1", User.class);
User user2Bean = applicationContext.getBean("user2Bean", User.class);
User user3Bean = applicationContext.getBean("user3Bean", User.class);
User user3BeanAlias1 = applicationContext.getBean("user3BeanAlias1", User.class);
User user3BeanAlias2 = applicationContext.getBean("user3BeanAlias2", User.class);
//3.调用实例中的属性
System.out.println("user1 = " + user1);
System.out.println("user2Bean = " + user2Bean);
System.out.println("user3Bean = " + user3Bean);
System.out.println("user3BeanAlias1 = " + user3BeanAlias1);
System.out.println("user3BeanAlias2 = " + user3BeanAlias2);
}
}
[4]、运行测试代码,查看控制台打印结果:
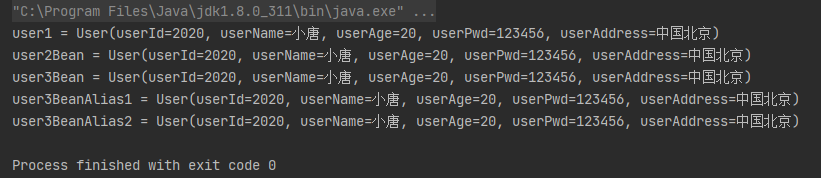
从上面的运行结果来看,Bean对象已经创建成功了。
8.4 去掉@Configuration注解会怎样
这里提出一个这样的问题:我们一般都是@Configuration和@Bean注解一起结合使用,如果不使用@Bean注解什么事情也没有,那么如果不加@Configuration注解,那能不能只通过@Bean注解注册Bean呢?下面来验证一下。
案例一:Bean之间是没有依赖关系的
实体对象User:
@Data
public class User {
@Value(value = "2020")
private Integer userId;
@Value(value = "小唐")
private String userName;
@Value(value = "20")
private Integer userAge;
@Value(value = "123456")
private String userPwd;
@Value(value = "中国北京")
private String userAddress;
}
配置类对象:
@Configuration
public class BeanConfig {
//bean名称为方法默认值:user1
@Bean
public User user1() {
return new User();
}
//bean名称通过value指定了:user2Bean
@Bean("user2Bean")
public User user2() {
return new User();
}
//bean名称为:user3Bean,2个别名:[user3BeanAlias1,user3BeanAlias2]
@Bean({"user3Bean", "user3BeanAlias1", "user3BeanAlias2"})
public User user3() {
return new User();
}
}
运行测试类
/**
* Spring测试代码
*
* @author tanghaorong
*/
public class SpringRunTest1 {
public static void main(String[] args) {
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(BeanConfig.class);
for (String beanName : context.getBeanDefinitionNames()) {
String[] aliases = context.getAliases(beanName);
//%s为占位符,相当于C语言中的%c %lf %d
System.out.printf("bean名称:%s,别名:%s,bean对象:%s%n",
beanName,
Arrays.asList(aliases),
context.getBean(beanName));
}
}
}
运行输出(部分截取):
有@Configuration注解的

无@Configuration注解的

对比得出:
- 对比最后3行,可以看出:有没有@Configuration注解,@Bean都会起效,都会将@Bean修饰的方法作为bean注册到容器中
- 两个内容的第一行有点不一样,被@Configuration修饰的bean最后输出的时候带有EnhancerBySpringCGLIB 的字样,而没有@Configuration注解的bean没有Cglib的字样;有EnhancerBySpringCGLIB 字样的说明这个Bean被cglib处理过的,变成了一个代理对象。
目前为止我们还是看不出二者本质上的区别,继续向下看。
案例二:Bean之间是有依赖关系的
public class User {
private GirlFriend girlFriend;
public User(GirlFriend girlFriend) {
this.girlFriend = girlFriend;
}
@Override
public String toString() {
return "User{" +
"girlFriend=" + girlFriend +
'}';
}
}
public class GirlFriend {
}
配置代码
@Configuration
public class BeanConfig1 {
@Bean
public GirlFriend girlFriend() {
System.out.println("调用了girlFriend创建方法");
return new GirlFriend();
}
@Bean
public User user1() {
System.out.println("调用了user创建方法一");
GirlFriend girlFriend = this.girlFriend();
return new User(girlFriend);
}
@Bean
public User user2() {
System.out.println("调用了user创建方法二");
GirlFriend girlFriend = this.girlFriend();
return new User(girlFriend);
}
}
运行测试类
/**
* Spring测试代码
*
* @author tanghaorong
*/
public class SpringRunTest1 {
public static void main(String[] args) {
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(BeanConfig.class);
for (String beanName : context.getBeanDefinitionNames()) {
String[] aliases = context.getAliases(beanName);
//%s为占位符,相当于C语言中的%c %lf %d
System.out.printf("bean名称:%s,别名:%s,bean对象:%s%n",
beanName,
Arrays.asList(aliases),
context.getBean(beanName));
}
}
}
运行输出(部分截取):
有@Configuration注解的
调用了girlFriend创建方法
调用了user创建方法一
调用了user创建方法二
bean名称:girlFriend,别名:[],bean对象:com.thr.spring.pojo.GirlFriend@564718df
bean名称:user1,别名:[],bean对象:User{girlFriend=com.thr.spring.pojo.GirlFriend@564718df}
bean名称:user2,别名:[],bean对象:User{girlFriend=com.thr.spring.pojo.GirlFriend@564718df}
没有@Configuration注解的
调用了girlFriend创建方法
调用了user创建方法一
调用了girlFriend创建方法
调用了user创建方法二
调用了girlFriend创建方法
bean名称:girlFriend,别名:[],bean对象:com.thr.spring.pojo.GirlFriend@76a3e297
bean名称:user1,别名:[],bean对象:User{girlFriend=com.thr.spring.pojo.GirlFriend@4d3167f4}
bean名称:user2,别名:[],bean对象:User{girlFriend=com.thr.spring.pojo.GirlFriend@ed9d034}
通过对比可以看出:
- 有@Configuration注解的,被@Bean修饰的方法都只被调用了一次,所有的GirlFriend都是同一个
- 没有@Configuration注解的,被@Bean修饰的方法都只被调用了一次,但是所有的GirlFriend都不是同一个
这是为什么呢?因为被@Configuration修饰的类,Spring容器中会通过cglib给这个类创建一个代理,代理会拦截所有被@Bean 修饰的方法,默认情况(Bean为单例)下确保这些方法只被调用一次,从而确保这些Bean是同一个Bean,即单例的。所以@Configuration修饰的类有cglib代理效果,默认添加的Bean都为单例。
到目前为止加不加@Configuration注解,有什么区别,大家估计比我都清楚了,简单总结:
- 不管@Bean所在的类上是否有@Configuration注解,都可以将@Bean修饰的方法作为一个Bean注册到Spring容器中
- @Configuration注解修饰的类,会被Spring通过cglib做增强处理,通过cglib会生成一个代理对象,代理会拦截所有被@Bean注解修饰的方法,可以确保一些Bean是单例的
9、注解@Scope @DependsOn @Lazy @ImportResource的使用
9.1 @Scope注解:指定Bean的作用域
@Scope可以用在类上和方法上,用来配置bean的作用域,等效于bean xml中的bean元素中的scope属性,xml代码:
先来看下@Scope注解的源码:
@Target({ElementType.TYPE, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface Scope {
@AliasFor("scopeName")
String value() default "";
@AliasFor("value")
String scopeName() default "";
ScopedProxyMode proxyMode() default ScopedProxyMode.DEFAULT;
}
参数介绍:value和scopeName效果一样,用来指定bean作用域名称,例如singleton单例模式;prototype原型模式(多例模式)
注解设置作用域: @Scope("prototype") 或者 @Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE)
常见的两种用法:
- 和@Compontent一起使用在类上
- 和@Bean一起标注在方法上
案例1:和@Compontent一起使用在类上
@Component
@Scope(ConfigurableBeanFactory.SCOPE_SINGLETON)
public class ServiceA {
}
上面定义了一个bean,作用域为单例的。直接使用ConfigurableBeanFactory接口中定义了几个作用域相关的常量。
案例2:和@Bean一起标注在方法上
@Bean标注在方法上,可以通过这个方法来向spring容器中注册一个bean,在此方法上加上@Scope可以指定这个bean的作用域,如:
@Configurable
public class BeanConfig2 {
@Bean
@Scope(ConfigurableBeanFactory.SCOPE_PROTOTYPE)
public ServiceA serviceA() {
return new ServiceA();
}
}
9.2 @DependsOn:指定当前Bean依赖的Bean
@DependsOn:可以用在任意类型和方法上,等效于bean xml中的bean元素中的depend-on属性。作用: 用于指定某个类的创建依赖的bean对象先创建。Spring中没有特定bean的加载顺序,使用此注解则可指定bean的加载顺序。。简单来说就是这个组件要依赖于另一个组件,也就是说被依赖的组件会比该组件先注册到IOC容器中。Spring在创建Bean的时候,如果Bean之间没有依赖关系,那么Spring容器很难保证Bean实例创建的顺序,如果想确保容器在创建某些Bean之前,需要先创建好一些其他的Bean,可以通过@DependsOn来实现(在基于注解配置中,是按照类中方法的书写顺序决定的),@DependsOn可以指定当前Bean依赖的Bean,通过这个可以确保@DependsOn指定的Bean在当前Bean创建之前先创建好。
先看一下其源码:
@Target({ElementType.TYPE, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface DependsOn {
String[] value() default {};
}
属性value:是一个string类型的数组,用来指定当前Bean需要依赖的Bean名称,可以确保当前容器在创建被@DependsOn标注的Bean之前,先将value指定的多个Bean先创建好。
@DependsOn常见的2种用法
- 和@Compontent一起使用在类上;
- 和@Bean一起标注在方法上;
案例1:和@Compontent一起使用在类上
下面定义3个bean:service1、service2、service3;service1需要依赖于其他2个service,需要确保容器在创建service1之前需要先将其他2个bean先创建好。
@DependsOn({"service2", "service3"})
@Component
public class Service1 {
public Service1() {
System.out.println("Create Service1 Success");
}
}
@Component
public class Service2 {
public Service2() {
System.out.println("create Service2 Success");
}
}
@Component
public class Service3 {
public Service3() {
System.out.println("create Service3 Success");
}
}
配置类,代码如下:
@ComponentScan(value = "com.thr.spring.*")
public class BeanConfig {
}
运行测试类,代码如下:
/**
* Spring测试代码
*
* @author tanghaorong
*/
public class SpringRunTest {
public static void main(String[] args) {
//1.初始化Spring容器,通过注解加载
ApplicationContext applicationContext = new AnnotationConfigApplicationContext(BeanConfig.class);
//2.通过容器获取实例
Service1 service1 = applicationContext.getBean(Service1.class);
}
}
运行输出结果
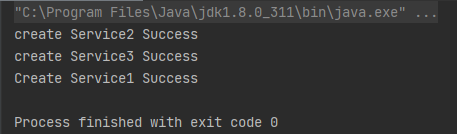
案例2:和@Bean一起标注在方法上
下面通过配置文件的方式来创建bean,如下:
@Configuration
public class BeanConfig1 {
@Bean
@DependsOn({"service2", "service3"})
public Service1 service1() {
return new Service1();
}
@Bean
public Service2 service2() {
return new Service2();
}
@Bean
public Service3 service3() {
return new Service3();
}
}
运行输出结果:
9.3 @Lazy注解:延迟加载
Spring IoC(ApplicationContext)容器一般都会在启动的时候实例化所有单实例 Bean。但是如果我们想要 Spring 在启动的时候延迟加载 Bean,即在调用某个 Bean 的时候再去初始化,那么就可以使用 @Lazy 注解。@Lazy等效于bean.xml中bean元素的lazy-init属性,可以实现bean的延迟初始化。所谓延迟初始化:就是使用到的时候才会去进行初始化。
来看一下其定义:
@Target({ElementType.TYPE, ElementType.METHOD, ElementType.CONSTRUCTOR,
ElementType.PARAMETER, ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface Lazy {
boolean value() default true;
}
参数介绍:value:boolean类型,用来配置是否应发生延迟初始化,默认为true。
@Lazy注解常用3种方式:
- 和@Compontent一起标注在类上,可以使这个类延迟初始化
- 和@Configuration一起标注在配置类上,可以让当前配置类中通过@Bean注册的bean延迟初始化
- 和@Bean一起使用,可以使当前bean延迟初始化
如果 @Component 或 @Bean 定义上不存在 @Lazy 注解,则会进行初始化。如果存在 @Lazy 注解且设置 value为true,则 @Bean或 @Component 定义的 Bean 将不会被初始化,直到被另一个 Bean 引用或从封闭的 BeanFactory 中显式检索。如果存在 @Lazy 且设置 value 为false,则将在执行启动单例初始化的Bean工厂启动时实例化Bean。
如果 @Configuration 类上存在 @Lazy 注解,则表明该 @Configuration 中的所有 @Bean 方法都应延迟初始化。如果在 @Lazy 注解的 @Configuration 类中的 @Bean方法上存在 @Lazy 注解且设置 value 为 false,则表明重写了“默认延迟”行为,并且应立即初始化Bean。
案例1:和@Compontent一起标注在类上
定义User实体类,代码如下:
@Data
@Component
@Lazy
public class User {
@Value(value = "2020")
private Integer userId;
@Value(value = "小唐")
private String userName;
@Value(value = "20")
private Integer userAge;
@Value(value = "123456")
private String userPwd;
@Value(value = "中国北京")
private String userAddress;
}
上面的User类使用到了@Lazy注解,默认值为true,所以它会被延迟初始化,在容器启动过程中不会被初始化,当从容器中查找这个bean的时候才会被初始化。
配置类,代码如下:
@ComponentScan(value = "com.thr.spring.pojo")
public class BeanConfig {
}
测试运行代码如下:
public class SpringRunTest {
public static void main(String[] args) {
//1.初始化Spring容器,通过注解加载
System.out.println("准备启动spring容器");
ApplicationContext applicationContext = new AnnotationConfigApplicationContext(BeanConfig.class);
System.out.println("spring容器启动完毕");
//2.通过容器获取实例
User user = applicationContext.getBean(User.class);
System.out.println(user);
}
}
运行输出结果:

案例2:和@Configuration一起标注在配置类上
@Lazy和@Configuration一起使用,此时配置类中所有通过@Bean方式注册的Bean都会被延迟初始化,看下面代码:
@Configuration
@Lazy
public class BeanConfig {
@Bean
public User user() {
return new User();
}
}
案例3:和@Bean一起标注在方法上
如果配置类上使用了@Lazy,此时会对当前类中所有@Bean标注的方法生效,但是某个配置方法上面也使用到了@Lazy,那么就以当前配置方法的为准,可以理解为就近原则,此时user2这个bean不会被延迟初始化,user这个bean会被延迟初始化。
@Configuration
@Lazy
public class BeanConfig {
@Bean
public User user() {
return new User();
}
@Bean
@Lazy(value = false)
public User user2() {
return new User();
}
}
9.4 @ImportResource注解:配置类中导入bean定义的配置文件
@ImportResource 注解用于导入 Spring 的配置文件,如:spring-mvc.xml、application-Context.xml。但遗憾的是 Spring Boot 里面没有Spring 配置文件,都是通过 Java 代码进行配置。如果我们自己编写了配置文件,Spring Boot 是不能自动识别,此时需要使用 @ImportResource 注解将自己的配置文件加载进来。
来看一下其定义:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.TYPE)
@Documented
public @interface ImportResource {
@AliasFor("locations")
String[] value() default {};
@AliasFor("value")
String[] locations() default {};
Class<? extends BeanDefinitionReader> reader() default
BeanDefinitionReader.class;
}
@ImportResource 注解的可选属性,如下:
- String[] locations:要导入的资源路径,如:classpath:spring-mvc.xml 从类路径加载 spring-mvc.xml 配置文件。
- String[] value:locations() 的别名
- Class<? extends BeanDefinitionReader> reader:在处理通过 value() 属性指定的资源时使用的 BeanDefinitionReader 实现。默认情况下,读取器将适应指定的资源路径:“.groovy” 文件将使用 GroovyBeanDefinitionReader 处理;然而,所有其他资源都将使用 XmlBeanDefinitionReader 进行处理。
示例代码
我们在 resources 目录下面创建一个 applicationContext.xml 文件,该文件中手动声明一个 Bean。applicationContext.xml 配置文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<!--实例化User-->
<bean id="user" class="com.thr.spring.pojo.User"/>
</beans>
定义User实体类,代码如下:
@Data
public class User {
@Value(value = "2020")
private Integer userId;
@Value(value = "小唐")
private String userName;
@Value(value = "20")
private Integer userAge;
@Value(value = "123456")
private String userPwd;
@Value(value = "中国北京")
private String userAddress;
}
配置类,代码如下:
@ImportResource(value = "classpath:applicationContext.xml")
public class BeanConfig {
}
测试运行代码如下:
public class SpringRunTest {
public static void main(String[] args) {
//1.初始化Spring容器,通过注解加载
ApplicationContext applicationContext = new AnnotationConfigApplicationContext(BeanConfig.class);
//2.通过容器获取实例
User user = applicationContext.getBean(User.class);
System.out.println(user);
}
}
运行输出结果:

10、AOP相关理论介绍
10.1 AOP的介绍
AOP为Aspect Oriented Programming的缩写,即面向切面编程(也叫面向方面),是一种可以通过预编译方式和运行期动态代理实现在不修改源代码的情况下给程序动态统一添加功能的一种技术。
| 编程思想 | 描述 |
|---|---|
| 面向对象编程(OOP) | 简化代码:把重复代码纵向抽取到父类,OOP的三大特征继承、封装、多态,它主要是为了实现编程的重用性、灵活性和扩展性,强调的是类之间的层次关系 |
| 面向接口编程 | 解耦:不同组件之间解耦,即使一个组件改变了也不会影响其它的 |
| 面向切面编程(AOP) | 简化代码:把方法中的重复代码横向抽取到切面中,它是对方法的增强 |
10.2 为什么学习AOP
下面来分析一下面向对象编程(OOP)的局限性。
例如这里有两个类,两个类的方法1中的内容是重复的,而方法2是不重复的,此时我们就可以将方法1中的代码抽取出来放入父类中,这是典型的面向对象编程思想。
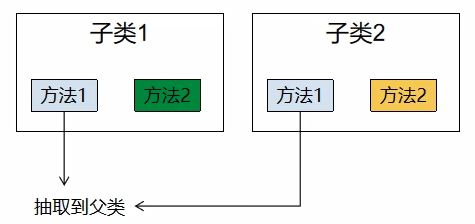
但是如果两个类的方法1中的内容只有部分是相同的,但是你又想将相同的方法抽取出来,这时再使用面向对象编程就无法实现了,因为相同的代码是存在于方法的内部,此时就可以使用AOP来实现了。
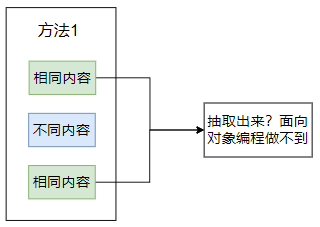
为了更好的理解OOP和AOP,下面简单举例说明:
①、定义一个简单的计算器类,内部功能为简单的加减乘除运算。
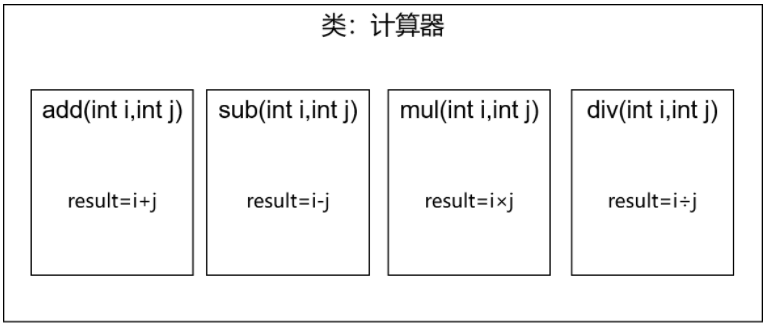
②、此时增加功能,给每个运算操作的前后都打印一下日志。
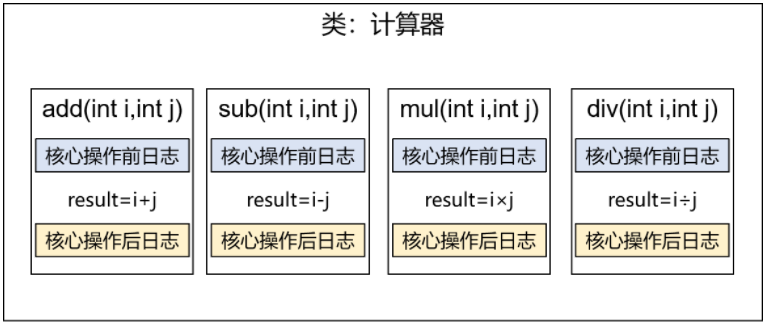
这样附加功能后,代码存在明显的问题:
- 代码会变得非常臃肿
- 核心逻辑的代码和非核心逻辑的代码混杂在一起,不利于开发和维护
- 将来不管是核心代码还是非核心代码想要升级或调试bug,都非常不便
而且这种情况也不能将相同的代码抽取出来放在父类中,但是可以用到AOP思想来解决。
③、使用AOP思想来解决上述问题,将不同的方法中相同的逻辑代码横向抽取出来,在使用时通过代理类织入到指定位置就能够完成特定的功能。
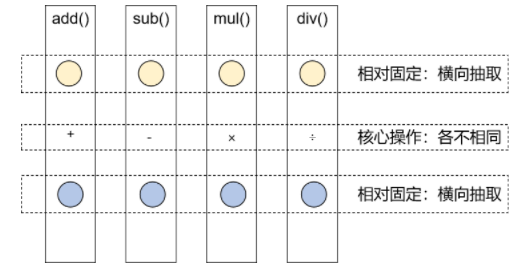
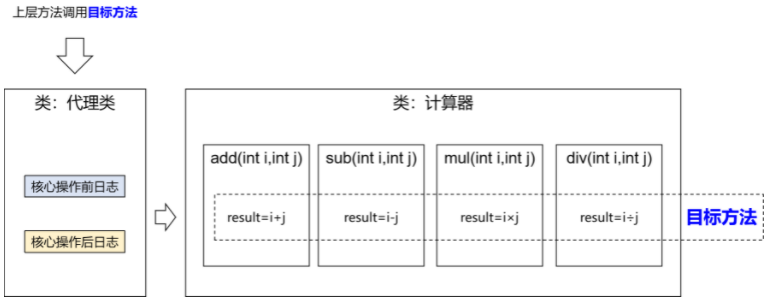
OOP与AOP对比
①相同点
- 都可以简化代码
②不同点
- 面向对象:纵向抽取
- 面向切面:横向抽取
AOP的总结:把『围绕』着目标代码的固定代码『抽取』出来,『封装』成固定的解决方案,哪里需要,套哪里。
10.3 AOP的应用场景
- 日志记录
- 事务处理
- 缓存处理
- 权限校验
- 性能统计
- 计数
- ......
10.4 AOP的实现原理(理论)
😃此小节,引用的博客
- 代理模式与AOP_九州殊口二的博客-CSDN博客_aop和代理的区别
- JDK动态代理(介绍理解,如何实现)_TxCode的博客-CSDN博客_jdk动态代理
- Java 动态代理作用是什么? - 知乎 (zhihu.com)
- AOP之动态代理_生椰打铁的博客-CSDN博客_aop动态代理
10.4.1 代理模式
AOP的实现原理:基于动态代理完成,这个几乎人尽皆知。
代理模式是二十三种设计模式中的一种,属于结构型模式。它的作用就是通过提供一个代理类,让我们在调用目标方法的时候,不再是直接对目标方法进行调用,而是通过代理类间接调用。让不属于目标方法核心逻辑的代码从目标方法中剥离出来。调用目标方法时先调用代理对象的方法,减少对目标方法的调用和打扰。
代理一词拆开来看就是代为受理,那显然是要涉及到请求被代理的委托方,提供代理的代理方,以及想要通过代理来实际联系委托方的客户三个角色。举个生活中很常见的例子,各路的明星都会有个自己的经纪人来替自己打点各种各样的事情,这种场景下,明星本身是委托方,经纪人是代理方,明星把自己安排演出、出席见面会的时间安排权利委托给经纪人,这样当各个商家作为客户想要请明星来代言时,就只能通过经纪人来进行。这样明星本身不用暴露身份,而经济人也可以在沟通中告知商家明星出席活动时要吃什么饭,做什么车的一些要求,省去了明星自己操心这些鸡毛蒜皮小事儿。另一方面,当经纪人也可以给多个明星提供服务,这样商家只接触一个经纪人,可以联系到不同的明星,找个适合自己公司的人选。
通过上面的例子,代理模式的优点就显而易见了:
优点一:可以隐藏委托类的实现;
优点二:可以实现客户与委托类间的解耦,委托类只负责自己的本职工作。代理方在不修改委托类代码的情况下能够做一些额外的处理。
aop也就是面向切面编程,其运用的就是动态代理模式,这可以让被代理的对象专注于完成自己的本职工作,而代理对象可以进行工作前的日志记录,时间计算,在工作之后进行日志记录,收尾工作等附加的功能,需要正式做工作的时候就交给被代理去做。就像插了两个刀到这个被代理的对象前后。所以形象的叫做面向切面编程。
根据代理的创建时期,代理模式分为静态代理和动态代理。
- 静态:由程序员创建代理类或特定工具自动生成源代码再对其编译,在程序运行前代理类的 .class 文件就已经存在了。
- 动态:在程序运行时,运用反射机制动态创建而成。
10.4.2 静态代理
背景:
假设现在项目经理有一个需求:在项目现有所有类的方法前后打印日志。
第一种想法:在方法前后插入日志记录信息
很显然这种实现方式有明显的不足,这种切入式的代码(Cross-cutting),会使得被代理的对象拥有了本该不属于他的职责,要在执行任务的同时记录日志。
试想一下,如果程序中的代码到处都是这种日志需求,那么我们的就必须在到处都加上这些日志代码,想必那是很大的工作量,而且当我们需要修改的时候,将会变得更加复杂,维护起来变得困难,所以我们自然想到封装,由于很多对象都需要日志记录这种需求,我们何不把日志行为分离出来。
这时候就可以代理模式解决这个问题,代理又分为静态代理(Static proxy)和动态代理(Dynamic proxy)
我们首先用静态代理来实现这个需求。
1.在静态代理模式中,代理与被代理对象必须实现同一个接口,代理专注于实现日志记录需求,并在合适的时候,调用被代理对象,这样被代理对象就可以专注于执行业务逻辑。

2.在创建代理对象时,通过构造器塞入一个目标对象,然后在代理对象的方法内部调用目标对象同名方法,并在调用前后打印日志。也就是说,代理对象 = 增强代码 + 目标对象(原对象)。有了代理对象后,就不用原对象了
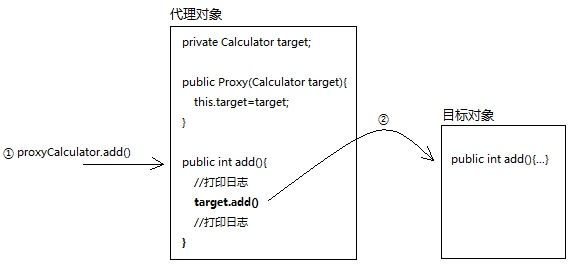
我们来实现下
首先创建一个代理与被代理对象共同实现的接口
public interface IHello {
public void hello(String name) ;
}
然后专注于业务逻辑实现的被代理对象HelloSpeaker实现上面这个接口
public class HelloSpeaker implements IHello {
@Override
public void hello(String name) {
System.out.println("Hello, " + name);
}
}
可以看到,在这个类中没有日志记录的代码,其只需要专注于实现业务功能,而记录日志的工作则可以交给代理对象来实现,代理对象也要实现Ihello接口:
public class HelloProxy implements IHello {
private final Logger logger = Logger.getLogger(this.getClass().getName());
private IHello helloObject;
public HelloProxy(IHello helloObject) {
this.helloObject = helloObject;
}
public void hello(String name) {
// 日志服务
log("hello method starts....");
// 逻辑
helloObject.hello(name);
try {
Thread.sleep(100); //为了让输出有序
} catch (InterruptedException e) {
e.printStackTrace();
}
// 日志服务
log("hello method ends....");
}
private void log(String msg) {
logger.log(Level.INFO, msg);
}
}
我们可以看到在hello方法的实现中,前后插入了日志记录的方法。
下面我们就测试一下
public class ProxyDemo {
public static void main(String[] args) {
IHello proxy = new HelloProxy(new HelloSpeaker());
proxy.hello("Justin");
}
}
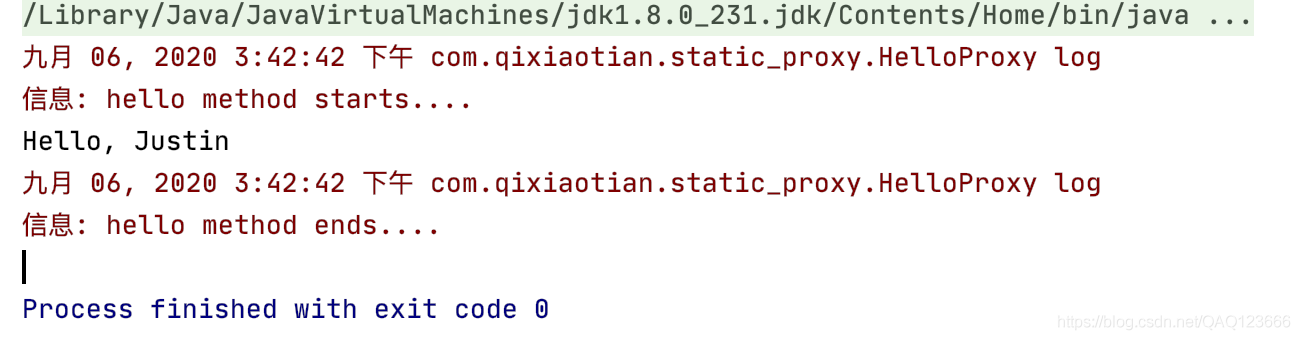
程序中执行hello方法的是代理对象,实例化代理对象的时候,必须传入被代理对象,而且声明代理对象的时候,必须使用代理对象和被代理对象共同实现的接口,以便实现多态。
代理对象将代理真正执行hello方法的被代理对象来执行hello,并在执行的前后加入日志记录的操作这样就可以使业务代码专注于业务实现。
优缺点:
优点:
- 静态代理可以做到在不修改目标对象的前提下,拓展目标对象的功能
- 实现简单,容易理解
缺点:
- 代理类和委托类实现了相同的接口,代理类通过委托类实现了相同的方法。这样就出现了大量的代码重复。如果接口增加一个方法,除了所有实现类需要实现这个方法外,所有代理类也需要实现此方法。增加了代码维护的复杂度。
- 代理对象只服务于一种类型的对象,如果要服务多类型的对象。势必要为每一种对象都进行代理,静态代理在程序规模稍大时就无法胜任了。
10.4.3 从静态代理到动态代理
复习对象的创建,很多初学Java的朋友眼中创建对象的过程
实际上可以换个角度,也说得通
所谓的Class对象,是Class类的实例,而Class类是描述所有类的,比如Person类,Student类
可以看出,要创建一个实例,最关键的就是得到对应的Class对象。只不过对于初学者来说,new这个关键字配合构造方法,实在太好用了,底层隐藏了太多细节,一句 Person p = new Person();直接把对象返回给你了。我自己刚开始学Java时,也没意识到Class对象的存在。
分析到这里,貌似有了思路:
能否不写代理类,而直接得到代理Class对象,然后根据它创建代理实例(反射)。
Class对象包含了一个类的所有信息,比如构造器、方法、字段等。如果我们不写代理类,这些信息从哪获取呢?苦思冥想,突然灵光一现:代理类和目标类理应实现同一组接口。之所以实现相同接口,是为了尽可能保证代理对象的内部结构和目标对象一致,这样我们对代理对象的操作最终都可以转移到目标对象身上,代理对象只需专注于增强代码的编写。还是上面这幅图:
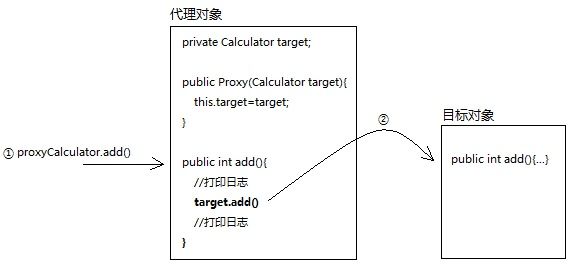
所以,可以这样说:接口拥有代理对象和目标对象共同的类信息。所以,我们可以从接口那得到理应由代理类提供的信息。但是别忘了,接口是无法创建对象的,怎么办?
10.4.4 JDK动态代理
静态代理会产生很多静态类,所以我们要想办法可以通过一个代理类完成全部的代理功能,这就引出了动态代理。
JDK原生动态代理
代理对象,不需要实现接口,但是目标对象要实现接口,否则不能用动态代理
代理对象的生成,是通过 JDK 的 API(反射机制),动态的在内存中构建代理对象
在 Java 中要想实现动态代理机制,需要 java.lang.reflect.InvocationHandler 接口和 java.lang.reflect.Proxy 类的支持
JDK提供了java.lang.reflect.InvocationHandler接口和java.lang.reflect.Proxy类,这两个类相互配合,入口是Proxy,所以我们先聊它。
Proxy有个静态方法:getProxyClass(ClassLoader, interfaces),只要你给它传入类加载器和一组接口,它就给你返回代理Class对象。
用通俗的话说,getProxyClass()这个方法,会从你传入的接口Class中,“拷贝”类结构信息到一个新的Class对象中,但新的Class对象带有构造器,是可以创建对象的。打个比方,一个大内太监(接口Class),空有一身武艺(类信息),但是无法传给后人。现在江湖上有个妙手神医(Proxy类),发明了克隆大法(getProxyClass),不仅能克隆太监的一身武艺,还保留了小DD(构造器)
所以,一旦我们明确接口,完全可以通过接口的Class对象,创建一个代理Class,通过代理Class即可创建代理对象。
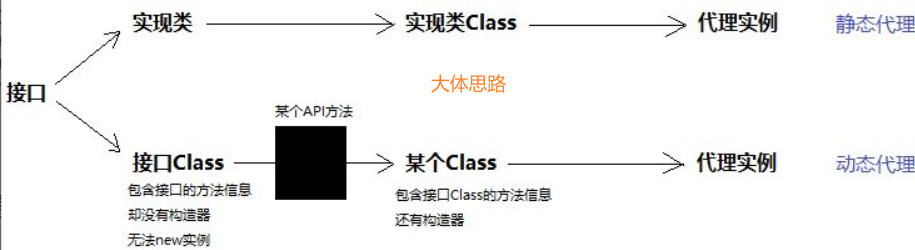
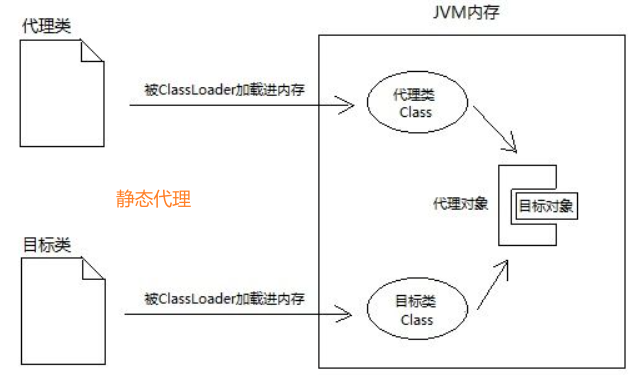
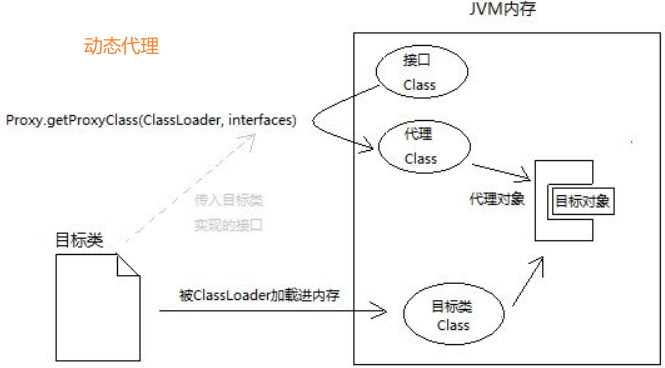
所以,按我理解,Proxy.getProxyClass()这个方法的本质就是:以Class造Class。
public class ProxyTest {
public static void main(String[] args) throws Throwable {
CalculatorImpl target = new CalculatorImpl();
//传入目标对象
//目的:1.根据它实现的接口生成代理对象 2.代理对象调用目标对象方法
Calculator calculatorProxy = (Calculator) getProxy(target);
calculatorProxy.add(1, 2);
calculatorProxy.subtract(2, 1);
}
private static Object getProxy(final Object target) throws Exception {
//参数1:类加载器; 参数2:目标对象、代理对象需要实现相同接口
Class proxyClazz = Proxy.getProxyClass(target.getClass().getClassLoader(), target.getClass().getInterfaces());
//得到有参构造器
Constructor constructor = proxyClazz.getConstructor(InvocationHandler.class);
//反射,创建实例
Object proxy = constructor.newInstance(new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println(method.getName() + "方法开始执行...");
Object result = method.invoke(target, args);
System.out.println(result);
System.out.println(method.getName() + "方法执行结束...");
return result;
}
});
return proxy;
}
}
😃不过实际编程中,一般不用getProxyClass(),而是使用Proxy类的另一个静态方法:Proxy.newProxyInstance(),直接返回代理实例,连中间得到代理Class对象的过程都帮你隐藏。
public class ProxyTest {
public static void main(String[] args) throws Throwable {
CalculatorImpl target = new CalculatorImpl();
Calculator calculatorProxy = (Calculator) getProxy(target);
calculatorProxy.add(1, 2);
calculatorProxy.subtract(2, 1);
}
private static Object getProxy(final Object target) throws Exception {
Object proxy = Proxy.newProxyInstance(
/*类加载器*/
target.getClass().getClassLoader(),
/*让代理对象和目标对象实现相同接口*/
target.getClass().getInterfaces(),
/*代理对象的方法最终都会被JVM导向它的invoke方法*/
new InvocationHandler(){
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println(method.getName() + "方法开始执行...");
Object result = method.invoke(target, args);
System.out.println(result);
System.out.println(method.getName() + "方法执行结束...");
return result;
}
}
);
return proxy;
}
}
- 另一个例子
//功能接口
public interface UserService {
void save(String user);
void update(String user);
}
//目标类
public class UserServiceImpl implements UserService {
@Override
public void save(String user) {
System.out.println("###业务功能:添加数据###");
}
@Override
public void update(String user) {
System.out.println("###业务功能:修改数据###");
}
}
//创建JDK动态代理的 InvocationHandler
public class ServiceInvocationHandler implements InvocationHandler {
private Object target; //目标对象
public ServiceInvocationHandler(Object target){
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
doLog(); //统一注入增强
Object result = method.invoke(target,args); //执行目标方法
doTransaction();//统一注入增强
return result; //返回结果
}
//增强功能点
public void doLog(){
System.out.println("---记录日志---");
}
//增强功能点
public void doTransaction(){
System.out.println("---提交事务---");
}
}
//使用JDK的Proxy创建动态代理对象并测试
public static void main(String[] args) {
//创建目标对象
UserService target = new UserServiceImpl();
//创建JDK动态增强接口,传入目标对象
InvocationHandler handler = new ServiceInvocationHandler(target);
//使用JDK的Proxy类创建代理对象
UserService proxy = (UserService) Proxy.newProxyInstance(
target.getClass().getClassLoader(),
target.getClass().getInterfaces(),
handler);
//使用代理对象,实现原功增强
proxy.save("张三");
}
JDK动态代理具体实现原理:
1、通过实现InvocationHandlet接口创建自己的调用处理器
2、通过为Proxy类指定ClassLoader对象和一组interface来创建动态代理
3、通过反射机制获取动态代理类的构造函数,其唯一参数类型就是调用处理器接口类型
4、通过构造函数创建动态代理类实例,构造时调用处理器对象作为参数参入
JDK动态代理是面向接口的代理模式,如果被代理目标没有接口那么Spring也无能为力,
Spring通过java的反射机制生产被代理接口的新的匿名实现类,重写了其中AOP的增强方法。
它是可以通过预编译方式和运行期动态代理实现在不修改源代码的情况下给程序动态统一添加功能的一种技术
10.4.5 cglib代理
静态代理和 JDK 代理模式都要求目标对象实现一个接口,但有时候目标对象只是一个单独的对象,并没有实现任何接口,就无法使用jdk动态代理了,jdk动态代理要求目标类必须是接口实现类。这时,我们需要第三方的一个名为cglib的依赖来实现动态代理。cglib可以通过为目标类创建子类的方式实现代理,子类可以重写父类中所有非final的方法。
cglib的思想是:通过继承父类所有公开的方法,然后重写这些方法,在重写时增强这些方法。
-
cglib(Code Generation Library)是一个基于ASM的字节码生成库,它允许我们在运行时对字节码进行修改和动态生成。cglib 通过继承方式实现代理。它广泛的被许多AOP的框架使用,比如我们的 Spring AOP。
-
cglib 包的底层是通过使用字节码处理框架 ASM 来转换字节码并生成新的类。
-
cglib 代理也被叫做子类代理,它是在内存中构建一个子类对象从而实现目标对象功能扩展。
(1)添加cglib依赖
<!-- cglib -->
<dependency>
<groupId>cglib</groupId>
<artifactId>cglib</artifactId>
<version>3.3.0</version>
</dependency>
(2)目标类没有实现任何接口
//目标类,不实现任何接口
public class UserService {
public void save(String user) {
System.out.println("###service:添加数据###");
}
public void update(String user) {
System.out.println("###service:修改数据###");
}
}
(3)创建增强拦截器
public class ServiceInterceptor implements MethodInterceptor {
@Override
public Object intercept(Object proxy, Method method, Object[] args, MethodProxy methodProxy) throws Throwable {
doLog(); //注入日志功能
Object result = methodProxy.invokeSuper(proxy, args); //执行原有的业务功能
doTransaction();//注入事务功能
return result;
}
//增强功能点
public void doLog(){
System.out.println("---记录日志---");
}
//增强功能点
public void doTransaction(){
System.out.println("---提交事务---");
}
}
(4)测试效果
public static void main(String[] args) {
//创建拦截器
ServiceInterceptor interceptor = new ServiceInterceptor();
//创建代理增强器(代理对象工厂)
Enhancer enhancer = new Enhancer();
//设置增强拦截器
enhancer.setCallback(interceptor);
//设置需要代理的目标类( 设置父类对象)
enhancer.setSuperclass(UserService.class);
//创建代理对象(子类)
UserService userService = (UserService) enhancer.create();
//执行业务方法
userService.save("张三");
}
- 另一个例子
(1)目标类
/**
* 目标对象,没有任何接口
* @author fred
*
*/
public class UserDaoImpl{
public void save() {
System.out.println("用户数据保存!");
}
}
(2)代理工厂类
public class ProxyFactory implements MethodInterceptor{
//目标对象
private Object target;
public ProxyFactory(Object target) {
super();
this.target = target;
}
//给目标对象创建一个代理对象
public Object getProxyInstance(){
//1.增强器
Enhancer en = new Enhancer();
//2.设置目标对象的类加载器
en.setClassLoader(target.getClass().getClassLoader());
//3.设置这个动态代理类的父类
en.setSuperclass(target.getClass());
//4.设置要传入的拦截器
en.setCallback(this);
//5.创建子类(代理对象)
return en.create();
}
@Override
public Object intercept(Object arg0, Method method,
Object[] args, MethodProxy arg3) throws Throwable {
System.out.println("开启事务...");
//执行目标对象的方法
Object obj = method.invoke(target, args);
System.out.println("提交事务...");
return obj;
}
}
(3)测试类
public class MainTest {
public static void main(String[] args) {
//目标对象
UserDaoImpl userDao = new UserDaoImpl();
//代理对象
UserDaoImpl proxy =
(UserDaoImpl) new ProxyFactory(userDao).getProxyInstance();
//执行代理对象方法
proxy.save();
}
}
10.4.6 两种动态代理的区别
动态代理有两种实现方式:
- JDK动态代理:需要被代理的目标类 必须实现相应接口。利用反射机制生成一个实现代理接口的匿名类,在调用具体方法前调用InvokeHandler来处理。
- CGlib动态代理:通过继承被代理的目标类实现代理,所以不需要目标类实现接口。利用ASM(开源的Java字节码编辑库,操作字节码)开源包,将代理对象类的class文件加载进来,通过修改其字节码生成子类来处理。
(1)二者区别:JDK代理只能对实现接口的类生成代理;CGlib是针对类实现代理,对指定的类生成一个子类,并覆盖其中的方法,这种通过继承类的实现方式,不能代理final修饰的类。
细节补充(了解就好):如果AOP是通过JDK动态代理实现的,那么接口的实现类在应用了切面后,真正放在IOC容器中的是代理类的对象,目标类并没有被放到IOC容器中,所以根据目标类的类型从IOC容器中是找不到的,例如:ac.getBean(UserServiceImpl.class);
(2)性能对比:
-
jdk创建对象的速度远大于cglib,这是由于cglib创建对象时需要操作字节码。
-
cglib执行速度略大于jdk,所以比较适合单例模式。
-
另外由于cglib的大部分类是直接对Java字节码进行操作,这样生成的类会在JVM的永久代中。如果动态代理操作过多,容易造成永久代满,触发OutOfMemory。
(3)核心思想:
- jdk是通过持有对象来实现增强的;
- cglib是通过继承来实现增强的
值得注意的是
spring默认使用jdk动态代理,如果类没有接口,在使用cglib实现动态代理。
10.4.7 从动态代理到AOP
AOP(面向切面编程)主要的的实现技术主要有 Spring AOP 和 AspectJ
- AspectJ是语言级别的AOP实现,扩展了Java语言,定义了AOP语法,能够在编译期提供横切代码的织入,所以它有专门的编译器用来生成遵守Java字节码规范的Class文件;
- Spring AOP本质上底层还是动态代理,所以Spring AOP是不需要有专门的编辑器的;
AspectJ 的底层技术就是静态代理,用一种 AspectJ 支持的特定语言编写切面,通过一个命令来编译,生成一个新的代理类,该代理类增强了业务类,这是在编译时增强,相对于下面说的运行时增强,编译时增强的性能更好。(AspectJ 的静态代理,不像我们前边介绍的需要为每一个目标类手动编写一个代理类,AspectJ 框架可以在编译时就生成目标类的“代理类”,在这里加了个双引号,是因为实际上它并没有生成一个新的类,而是把代理逻辑直接编译到目标类里面了)
Spring AOP 采用的是动态代理,在运行期间对业务方法进行增强,所以不会生成新类,对于动态代理技术,Spring AOP 提供了对 JDK 动态代理的支持以及 CGLib 的支持。
所以,AspectJ在编译时就增强了目标对象,Spring AOP的动态代理则是在每次运行时动态的增强,生成AOP代理对象。区别在于生成AOP代理对象的时机不同,相对来说AspectJ的静态代理方式具有更好的性能,但是AspectJ需要特定的编译器进行处理,而Spring AOP则无需特定的编译器处理。默认情况下,Spring对实现了接口的类使用 JDK Proxy方式,否则的话使用CGLib。不过可以通过配置指定 Spring AOP 都通过 CGLib 来生成代理类。
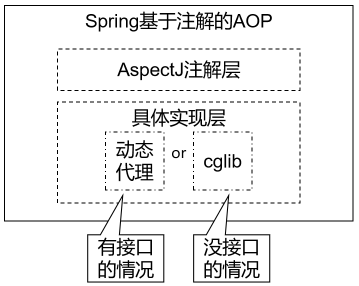
10.5 AOP的相关术语
注意:AOP相关的术语不是唯一的,其实官方文档对这些术语的介绍也不是很清晰,它本身是不存在的,都是一些概念相关的东西,简单了解这些术语是什么意思就好。
AOP相关术语的整体截图:
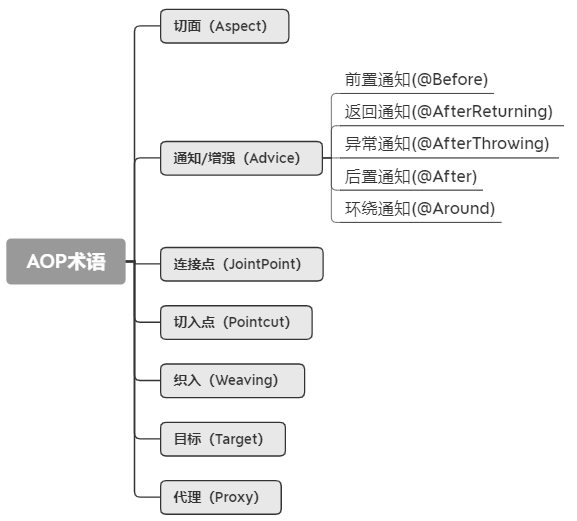
| 术语 | 描述 |
|---|---|
| 切面(Aspect) | 切面由切入点(Pointcut)和通知(Advice)组成,它既包括了横切逻辑的定义、也包括了连接点的定义,所以通常来说它是一个类,就是被@Aspect注解注上的类。 |
| 通知/增强(Advice) | AOP在特定的切入点上执行的增强处理,也就是具体的横切逻辑。简单来说就定义了是干什么的,具体是在哪干。Spring AOP提供了5种Advice类型给我们:前置、后置、返回、异常、环绕,下面会详细介绍 |
| 连接点(JointPoint) | 目标类中每个成员方法都可以称之为连接点,一个连接点总是代表一个方法执行。可以这么理解:把方法排成一排,每一个横切位置看成x轴方向,把方法从上到下执行的顺序看成y轴,x轴和y轴的交叉点就是连接点。 |
| 切入点(Pointcut) | 定位连接点的方式。上面也说了,每个方法都可以称之为连接点,我们具体定位到某一个方法就称为切入点,在程序中主要体现为书写切入点表达式。切点分为execution方式和annotation方式。前者可以用路径表达式指定哪些类织入切面,后者可以指定被哪些注解修饰的代码织入切面。 |
| 织入(Weaving) | 就是通过动态代理,将通知添加到目标类的具体连接点上的过程。 |
| 目标(Target) | 表示被代理的目标对象。 |
| 代理(Proxy) | 表示向目标对象应用通知之后创建的代理对象。 |
通知/增强(Advice)中提供的五中类型(非常重要):
| 通知类型 | 描述 |
|---|---|
| 前置通知(@Before) | 在我们执行目标方法之前运行。 |
| 返回通知(@AfterReturning) | 在我们的目标方法正常返回值后运行。 |
| 异常通知(@AfterThrowing) | 在我们的目标方法出现异常后运行。 |
| 后置通知(@After) | 在我们目标方法运行结束之后 ,不管有没有异常。 |
| 环绕通知(@Around) | 包括上面四种通知对应的所有位置。 |
为了方便理解上面的通知类型,下面结合try-catch-finally模型举例:

11、基于AspectJ注解实现AOP
11.1 Spring对AOP的支持
Spring提供了3种类型的AOP支持:
-
基于AspectJ注解驱动的切面(推荐):使用注解的方式,这是最简洁和最方便的!
- AspectJ注解底层是静态代理,所以目标类必须实现接口(静态代理和 JDK 代理模式都要求目标对象实现一个接口,但除此之外,静态代理还要求代理类也实现接口)
-
基于XML的AOP:使用XML配置,aop命名空间
-
基于代理的经典SpringAOP:需要实现接口,手动创建代理
11.2 AspectJ相关的注解
AspectJ相关注解:
- @Aspect:标记这个类是一个切面类。
AspectJ增强相关注解:
| 注解 | 描述 |
|---|---|
| @Before | 表示将当前方法标记为前置通知 |
| @AfterReturning | 表示将当前方法标记为返回通知 |
| @AfterThrowing | 表示将当前方法标记为异常通知 |
| @After | 表示将当前方法标记为后置通知 |
| @Around | 表示将当前方法标记为环绕通知 |
| @Pointcut | 表示定义重用切入点表达式,一次定义,处处使用,一处修改,处处生效 |
| @DeclareParents | 表示将当前方法标记为引介通知(不要求掌握) |
PointCut Designators (切点指示器),是切点表达式的重要组成部分
11.3 注解AOP的简单例子
①、编写代理对象接口
/**
* 代理对象接口
*/
public interface IUserService {
void addUser(String userName,Integer age);
}
②、编写代理对象接口的实现类
/**
* 目标类,代理对象实现类,会被动态代理
*/
@Service
public class UserServiceImpl implements IUserService{
@Override
public void addUser(String userName, Integer age) {
System.out.println(userName+":"+age);
}
}
③、编写切面类
注意:AspectJ切入点表达式语法:
execution(<访问修饰符>? <返回类型> <全限定名>? <方法名称>(<参数类型>) <异常>?),通过execution函数,可以定义切入的方法。代码块中带
?符号的匹配式都是可选的,对于execution必不可少的只有三个:
- 返回类型
- 方法名
- 参数
/**
* 创建日志切面类
*/
@Aspect // @Aspect注解标记这个类是一个切面类
@Component // @Component注解标记这个被扫描包扫描到时需要加入IOC容器
public class LogAspect { //定义一个日志切面类
// @Before注解将当前方法标记为前置通知
// value属性:配置当前通知的切入点表达式,通俗来说就是这个通知往谁身上套
@Before(value = "execution(public void com.thr.aop.target.UserServiceImpl.addUser(String,Integer))")
// 在通知方法中,声明JoinPoint类型的形参,就可以在Spring调用当前方法时把这个类型的对象传入
public void doBefore(JoinPoint joinPoint) {
// 1.通过JoinPoint对象获取目标方法的签名
// 所谓方法的签名就是指方法声明时指定的相关信息,包括方法名、方法所在类等等
Signature signature = joinPoint.getSignature();
// 2.通过方法签名对象可以获取方法名
String methodName = signature.getName();
// 3.通过JoinPoint对象获取目标方法被调用时传入的参数
Object[] args = joinPoint.getArgs();
// 4.为了方便展示参数数据,把参数从数组类型转换为List集合
List<Object> argList = Arrays.asList(args);
System.out.println("[前置通知]"+ methodName +"方法开始执行,参数列表是:" + argList);
}
}
④、编写配置文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:aop="http://www.springframework.org/schema/aop"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/aop https://www.springframework.org/schema/aop/spring-aop.xsd">
<!-- 配置自动扫描的包 -->
<context:component-scan base-package="com.thr.aop"/>
<!-- 开启基于AspectJ注解的AOP功能 -->
<aop:aspectj-autoproxy/>
</beans>
⑤、编写测试类
public class AOPTest {
//创建ApplicationContext对象
private ApplicationContext ac = new ClassPathXmlApplicationContext("applicationContext.xml");
@Test
public void testAOP(){
// 1.从IOC容器中获取接口类型的对象
IUserService userService = ac.getBean(IUserService.class);
// 2.调用方法查看是否应用了切面中的通知
userService.addUser("张三",20);
}
}
⑥、运行结果
11.4 切入点表达式语法(重要)
在上面的例子中,切入点表达式是写死的,如果有很多地方要切入的话,就要在切面类中编写大量重复性的代码,扩展性和实用性不高,所以下面来学习一下更加强大的切入点表达式。
注意:AspectJ切入点表达式语法:
execution(<访问修饰符>? <返回类型> <全限定名>? <方法名称>(<参数类型>) <异常>?),通过execution函数,可以定义切入的方法。代码块中带?符号的匹配式都是可选的,对于execution必不可少的只有三个:
- 返回类型
- 方法名
- 参数
完整的传统切入点表达式:execution(public void com.thr.aop.target.UserServiceImpl.addUser(String,Integer))
上面最大可以简写为:execution(* ...*(..)) 表示匹配任意修饰符,返回值,包,类,方法,参数。
本小节部分引用自:切入点表达式的写法详解_咸鸭蛋白的博客-CSDN博客_切入点表达式详解
切入点表达式的写法
execution(<访问修饰符>? <返回类型> <全限定名>? <方法名称>(<参数类型>) <异常>?)
访问修饰符:可以省略
返回值类型:
- 返回值类型:可以指定类型。比如 String,Integer等
- *,表示任意字符。比如 Str* ,或者 *
全限定名:
- 可以写 . (一个点):表示当前包下的类或者子包。比如 com.huang.aop
- 可以写 .. (两个点):表示当前包里所有的类或者子包下的类。比如 com..aop
- * :表示任意字符。比如: com.hua* , com.* (开头为hua的所有包都可以表示)
方法名称:
- 可以指定类名。比如: UserServiceImpl
- * 表示任意字符。比如: *ServiceImpl , *
参数类型:
- 可以指定类型。比如: String,Integer 表示第一个参数是String,第二个参数是Integer类型
- * 表示任意字符。比如:String, * 表示第一个参数是String,第二个参数是任意类型
- Str*, Integer 表示第一个参数类型Str开头,第二个参数是Integer类型
- 可以使用..表示任意个数、任意类型的参数
包目录:

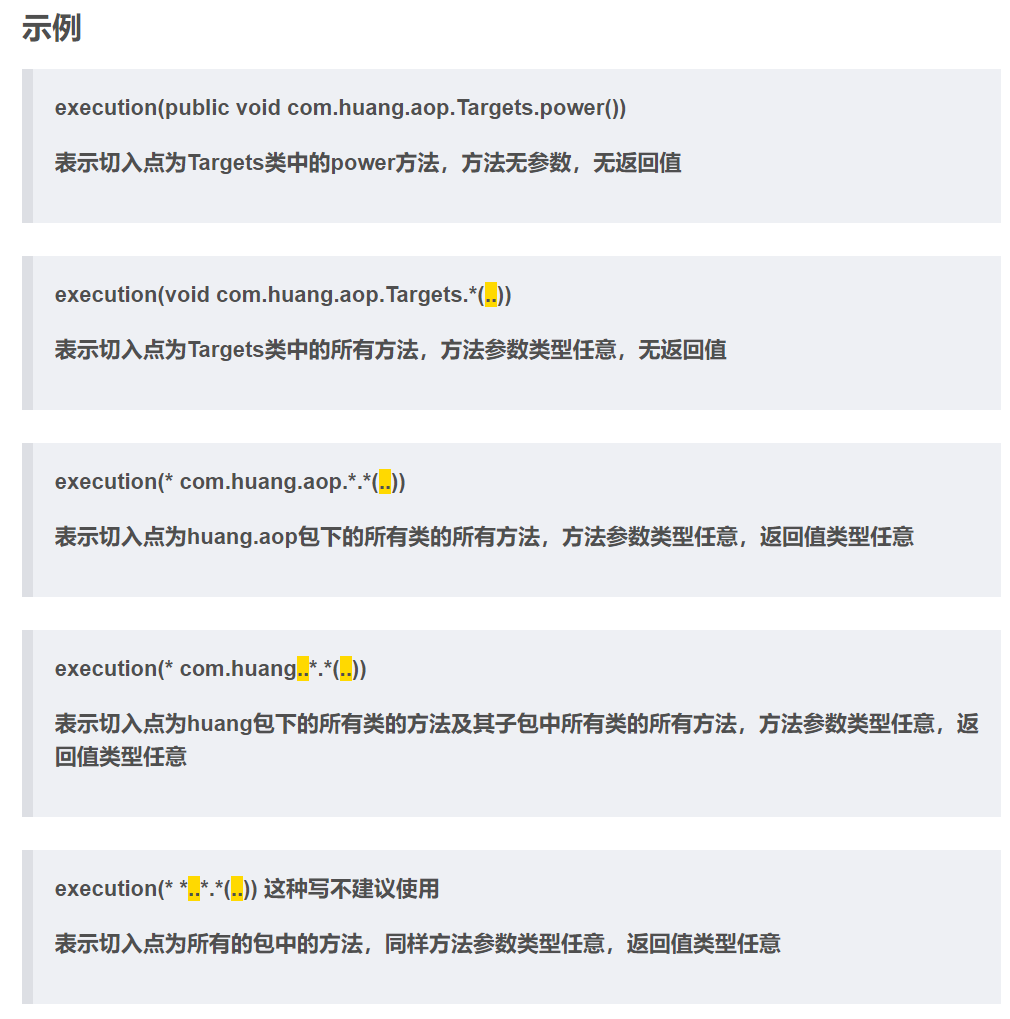
对于execution()表达式整体可以使用三个逻辑运算符号(了解,几乎不用)
-
execution() || execution()表示满足两个execution()中的任何一个即可
-
execution() && execution()表示两个execution()表达式必须都满足
-
!execution()表示不满足表达式的其他方法
AOP切入点表达式补充:
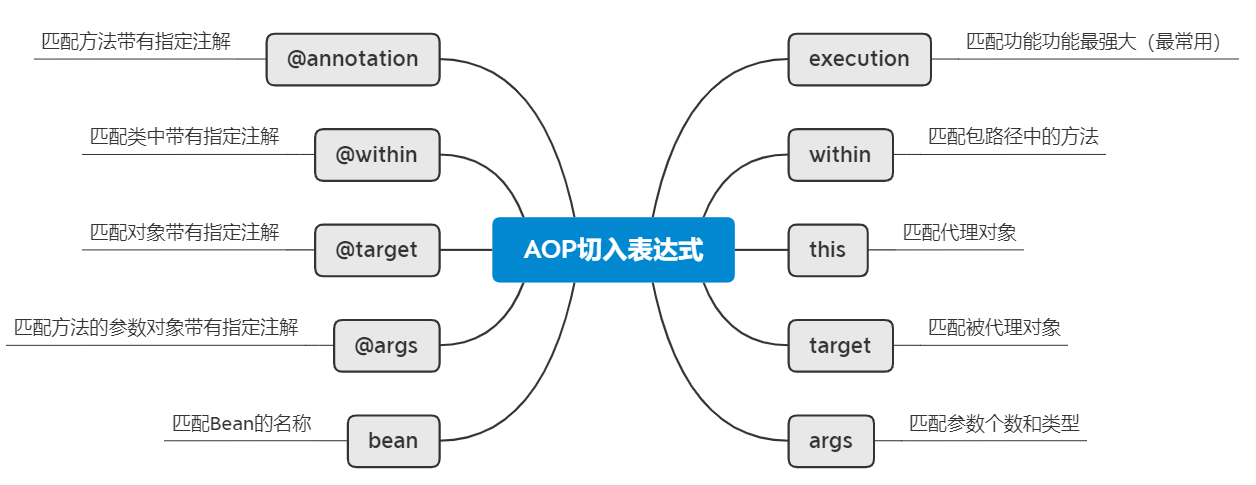
上面相关函数的详细使用可以参考:spring aop中pointcut表达式完整版
11.5 重用切入点表达式
这里需要用到@Pointcut注解。在一处声明切入点表达式之后,在其它有需要的地方引用这个切入点表达式就好。易于维护,一处修改,处处生效。声明方式如下:
// 切入点表达式重用
@Pointcut("execution(* *..*.add*(..))")
public void doPointCut() {}
在同一个类内部引用时:
@Before(value = "doPointCut()")
public void doBefore(JoinPoint joinPoint) {
在不同类中引用:
@Before(value = "com.thr.aop.aspect.LogAspect.doPointCut")
public void doBefore(JoinPoint joinPoint) {
11.6 注解AOP的完整例子
基于前面简单的例子,除了切面类LogAspect代码需要改变之外,其它的类中代码都不变。
- JoinPoint参数: 有时我们希望在通知方法中可以获取到当前织入的业务方法的相关信息,根据不同的上下文实现不同的功能,这时可以在通知方法中加入JointPoint类型参数,该参数可以获取到当前业务方法的上下文信息。
/**
* 创建日志切面类
*/
@Aspect // @Aspect注解标记这个类是一个切面类
@Component // @Component注解标记这个被扫描包扫描到时需要加入IOC容器
public class LogAspect { //定义一个日志切面类
// 使用@Pointcut注解重用切入点表达式
// 当前类引用时:doPointCut()
// 其他类引用时:com.thr.aop.aspect.LogAspect.doPointCut()
@Pointcut(value = "execution(* *..*.add*(..))")
public void doPointCut() {
}
// @Before注解将当前方法标记为前置通知
// value属性:配置当前通知的切入点表达式,通俗来说就是这个通知往谁身上套
@Before(value = "doPointCut()")
public void doBefore(JoinPoint joinPoint) { // 在通知方法中,声明JoinPoint类型的形参,就可以在Spring调用当前方法时把这个类型的对象传入
// 1.通过JoinPoint对象获取目标方法的签名
// 所谓方法的签名就是指方法声明时指定的相关信息,包括方法名、方法所在类等等
Signature signature = joinPoint.getSignature();
// 2.通过方法签名对象可以获取方法名
String methodName = signature.getName();
// 3.通过JoinPoint对象获取目标方法被调用时传入的参数
Object[] args = joinPoint.getArgs();
// 4.为了方便展示参数数据,把参数从数组类型转换为List集合
List<Object> argList = Arrays.asList(args);
System.out.println("[前置通知]" + methodName + "方法开始执行,参数列表是:" + argList);
}
// @AfterReturning注解将当前方法标记为返回通知
// 使用returning指定一个形参名,Spring会在调用当前方法时,把目标方法的返回值从这个位置传入
@AfterReturning(value = "doPointCut()", returning = "returnValue")
public void doAfterReturning(JoinPoint joinPoint, Object returnValue) {
String methodName = joinPoint.getSignature().getName();
System.out.println("[返回通知]" + methodName + "方法成功结束,返回值是:" + returnValue);
}
// @AfterThrowing注解将当前方法标记为异常通知
// 使用throwing属性指定一个形参名称,Spring调用当前方法时,会把目标方法抛出的异常对象从这里传入
@AfterThrowing(value = "doPointCut()", throwing = "throwable")
public void doAfterThrowing(JoinPoint joinPoint, Throwable throwable) {
String methodName = joinPoint.getSignature().getName();
System.out.println("[异常通知]" + methodName + "方法异常结束,异常信息是:" + throwable.getMessage());
}
// @After注解将当前方法标记为后置通知
@After(value = "doPointCut()")
public void doAfter(JoinPoint joinPoint) {
String methodName = joinPoint.getSignature().getName();
System.out.println("[后置通知]" + methodName + "方法最终结束");
}
}
折叠
运行结果:
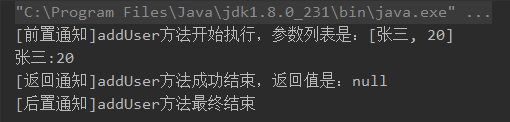
小细节,通知执行的顺序
-
Spring版本5.3.x以前:
- 前置通知
- 目标操作
- 后置通知
- 返回通知或异常通知
-
Spring版本5.3.x以后:
- 前置通知
- 目标操作
- 返回通知或异常通知
- 后置通知
11.7 环绕通知的举例
环绕通知就是前面四个通知的结合,但Spring官方建议选用“能实现所需行为的功能最小的通知类型”: 提供最简单的编程模式,减少了出错的可能性。,本例在环绕通知中触发异常通知。
①、修改代理对象接口的实现类
/**
* 目标类,会被动态代理
*/
@Service
public class UserServiceImpl implements IUserService {
@Override
public void addUser(String userName, Integer age) {
//出现异常
int i = 1;
int j = 0;
int x = i / j;
System.out.println(userName + ":" + age);
}
}
②、编写环绕通知切面类
- 环绕通知是包裹着业务方法的,因此环绕通知方法需要声明一个类型为“ProceedingJoinPoint”的参数,该参数表示实际业务方法的调用连接点,通过它可以控制业务方法的调用、传递参数及接收返回值。
/**
* 创建日志环绕通知切面类
*/
@Aspect // @Aspect注解标记这个类是一个切面类
@Component // @Component注解标记这个被扫描包扫描到时需要加入IOC容器
public class Log1Aspect { //定义一个日志切面类
// 使用@Pointcut注解重用切入点表达式
// 当前类引用时:doPointCut()
// 其他类引用时:com.thr.aop.aspect.LogAspect.doPointCut()
@Pointcut(value = "execution(* *..*.add*(..))")
public void doPointCut() {
}
// 使用表示当前方法是环绕通知
@Around(value = "doPointCut()")
public Object doAround(ProceedingJoinPoint joinPoint) {
// 获取目标方法名
String methodName = joinPoint.getSignature().getName();
// 声明一个变量,用来接收目标方法的返回值
Object targetMethodReturnValue = null;
// 获取外界调用目标方法时传入的实参
Object[] args = joinPoint.getArgs();
try {
// 调用目标方法之前的位置相当于前置通知
System.out.println("[环绕通知]" + methodName + "方法开始执行,参数列表:" + Arrays.asList(args));
// 通过ProceedingJoinPoint对象的proceed(Object[] var1)调用目标方法
targetMethodReturnValue = joinPoint.proceed();
// 调用目标方法成功返回之后的位置相当于返回通知
System.out.println("[环绕通知]" + methodName + "方法成功返回,返回值是:" + targetMethodReturnValue);
} catch (Throwable throwable) {
throwable.printStackTrace();
// 调用目标方法抛出异常之后的位置相当于异常通知
System.out.println("[环绕通知]" + methodName + "方法抛出异常,异常信息:" + throwable.getMessage());
} finally {
// 调用目标方法最终结束之后的位置相当于后置通知
System.out.println("[环绕通知]" + methodName + "方法最终结束");
}
// 将目标方法的返回值返回
// 这里如果环绕通知没有把目标方法的返回值返回,外界将无法获取这个返回值数据
return targetMethodReturnValue;
}
}
③、运行结果
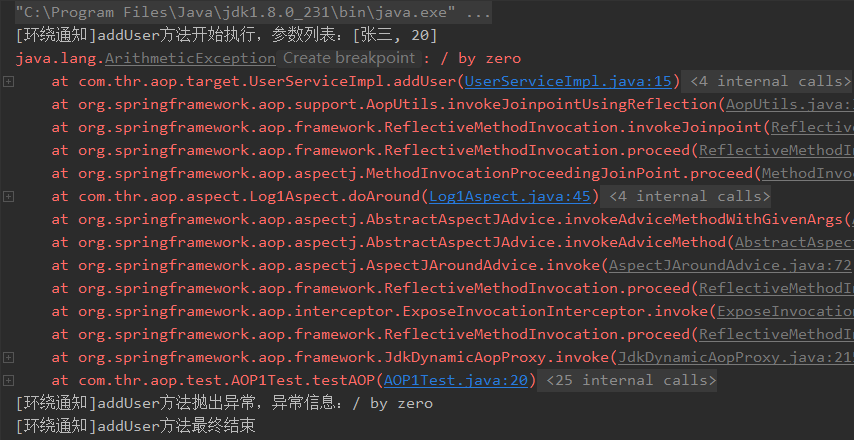
11.8 切面的优先级
[1]概念:相同目标方法上同时存在多个切面时,切面的优先级控制切面的内外嵌套顺序。
- 优先级高的切面:外面
- 优先级低的切面:里面
使用@Order注解可以控制切面的优先级:
- @Order(较小的数):优先级高
- @Order(较大的数):优先级低
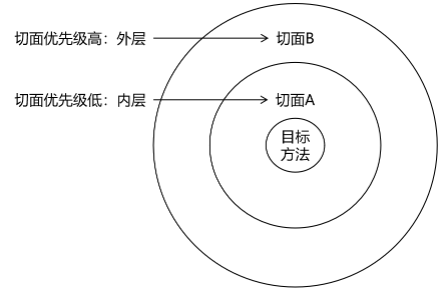
[2]实际意义:实际开发时,如果有多个切面嵌套的情况,要慎重考虑。例如:如果事务切面优先级高,那么在缓存中命中数据的情况下,事务切面的操作都浪费了。
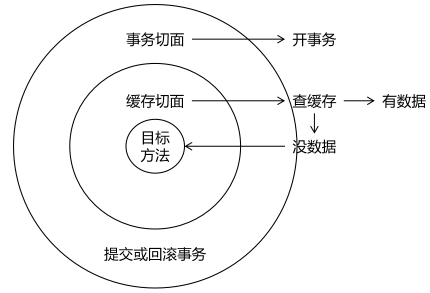
此时应该将缓存切面的优先级提高,在事务操作之前先检查缓存中是否存在目标数据。
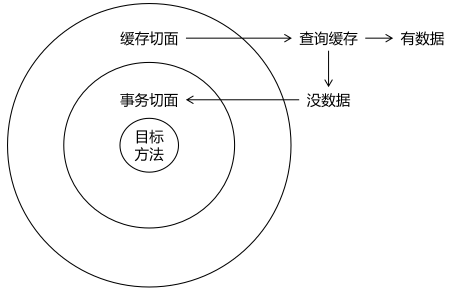
参考资料:
- 好文,写得比较全面:https://zhuanlan.zhihu.com/p/25522841
- 写得不错,可以参考学习一下:https://blog.csdn.net/mu_wind/article/details/10275
12、基于XML的方式实现AOP
12.1 XML配置相关元素
我们知道注解很方便,并且是很强大的东西,并且在平时的开发中基本都会使用注解开发,但基于 XML 的方式我们仍然需要了解,其实就跟注解差不多的功能,只是换了一种形式,下面先来了解一下 AOP 中可以配置的元素:
| AOP 配置元素 | 用途 |
|---|---|
aop:advisor |
定义 AOP 的通知其(一种很古老的方式,很少使用) |
aop:aspect |
定义一个切面 |
aop:before |
定义前置通知 |
aop:after |
定义后置通知 |
aop:around |
定义环绕通知 |
aop:after-returning |
定义返回通知 |
aop:after-throwing |
定义异常通知 |
aop:config |
顶层的 AOP 配置元素。大多数的aop:*元素必须包含在aop:config中 |
aop:declare-parents |
给通知引入新的额外接口,增强功能 |
aop:pointcut |
定义切点 |
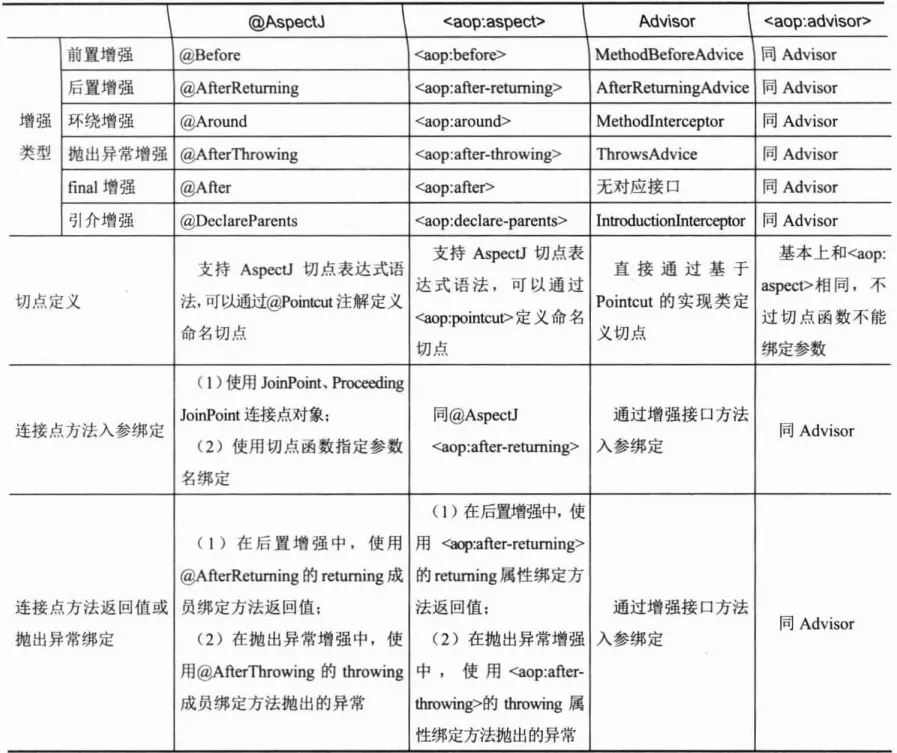
12.2 基于XML配置AOP
[1]、配置applicationContext.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:aop="http://www.springframework.org/schema/aop"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/aop https://www.springframework.org/schema/aop/spring-aop.xsd">
<!-- 将被代理的目标类加入IOC容器 -->
<bean class="com.thr.aop.target.UserServiceImpl" id="userService"/>
<!-- 将切面类加入IOC容器 -->
<bean class="com.thr.aop.aspect.LogXmlAspect" id="logXmlAspect"/>
<!-- 配置AOP -->
<aop:config>
<!-- 声明切入点表达式 -->
<aop:pointcut id="logPointCut" expression="execution(* *..*.*(..))"/>
<!-- 配置切面,使用ref属性引用切面类对应的bean。如有需要可以使用order属性指定当前切面的优先级数值 -->
<aop:aspect ref="logXmlAspect">
<!-- 配置具体通知方法,通过pointcut-ref属性引用上面已声明的切入点表达式 -->
<aop:before method="doBefore" pointcut-ref="logPointCut"/>
<!-- 在返回通知中使用returning属性指定接收方法返回值的变量名 -->
<aop:after-returning method="doAfterReturning" pointcut-ref="logPointCut" returning="returnValue"/>
<!-- 在异常通知中使用throwing属性指定接收异常对象的变量名 -->
<aop:after-throwing method="doAfterThrowing" pointcut-ref="logPointCut" throwing="throwable"/>
<!-- 配置后置通知 -->
<aop:after method="doAfter" pointcut-ref="logPointCut"/>
</aop:aspect>
</aop:config>
</beans>
[2]、创建目标接口
/**
* 目标类接口
*/
public interface IUserService {
void addUser(String userName,Integer age);
}
[3]、创建目标接口实现类
/**
* 目标类,会被动态代理
*/
@Service
public class UserServiceImpl implements IUserService {
@Override
public void addUser(String userName, Integer age) {
System.out.println(userName + ":" + age);
}
}
[4]、创建切面类
/**
* 创建日志切面类
*/
public class LogXmlAspect {
public void doBefore(JoinPoint joinPoint) { // 在通知方法中,声明JoinPoint类型的形参,就可以在Spring调用当前方法时把这个类型的对象传入
// 1.通过JoinPoint对象获取目标方法的签名
// 所谓方法的签名就是指方法声明时指定的相关信息,包括方法名、方法所在类等等
Signature signature = joinPoint.getSignature();
// 2.通过方法签名对象可以获取方法名
String methodName = signature.getName();
// 3.通过JoinPoint对象获取目标方法被调用时传入的参数
Object[] args = joinPoint.getArgs();
// 4.为了方便展示参数数据,把参数从数组类型转换为List集合
List<Object> argList = Arrays.asList(args);
System.out.println("[前置通知]" + methodName + "方法开始执行,参数列表是:" + argList);
}
public void doAfterReturning(JoinPoint joinPoint, Object returnValue) {
String methodName = joinPoint.getSignature().getName();
System.out.println("[返回通知]" + methodName + "方法成功结束,返回值是:" + returnValue);
}
public void doAfterThrowing(JoinPoint joinPoint, Throwable throwable) {
String methodName = joinPoint.getSignature().getName();
System.out.println("[异常通知]" + methodName + "方法异常结束,异常信息是:" + throwable.getMessage());
}
public void doAfter(JoinPoint joinPoint) {
String methodName = joinPoint.getSignature().getName();
System.out.println("[后置通知]" + methodName + "方法最终结束");
}
}
[5]、创建测试类
public class XmlAOPTest {
//创建ApplicationContext对象
private ApplicationContext ac = new ClassPathXmlApplicationContext("applicationContext.xml");
@Test
public void testAOP(){
// 1.从IOC容器中获取接口类型的对象
IUserService userService = ac.getBean(IUserService.class);
// 2.调用方法查看是否应用了切面中的通知
userService.addUser("张三",20);
}
}
[6]、运行结果
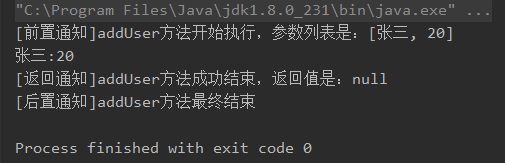
13、Spring中对事务的支持
13.1 事务的回顾
13.1.1 什么是事务?
事务就是由一组SQL组成的单元,该单元要么整体执行成功,要么整体执行失败。
13.1.2 事务的ACID属性
- 原子性(Atomicity):指事务中包含所操作的SQL是一个不可分割的工作单位,要么都执行成功,要么都执行失败,其中只要有一条SQL出现错误都会回滚到原来的状态。
- 一致性(Consistency):事务的执行不能破坏数据库数据的完整性和一致性,一个事务在执行之前和执行之后,数据库都必须处于一致性状态。比如A和B两者的钱加起来一共是1000,那么不管A和B之间如何转账、转几次账,事务结束后两个用户的钱相加起来应该还得是1000,并且在当前事务中,A减了多少钱,B加了多钱这个中间状态是不可见的,这就是事务的一致性。
- 隔离性(Isolation):一个事务所做的修改在最终提交以前,对其他事务是不可见的。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。比如A正在从一张银行卡中取钱,在A取钱结束前,B不能向这张卡转账。
- 持久性(Durability):指的是一个事务一旦被提交,数据就被永远的存储到磁盘上了,即使系统发生故障,数据仍然不会丢失。
13.1.3 事务执行过程中的并发问题(脏读、幻读、不可重复读)
- 脏读:事务A读取了事务B更新并且未提交的数据,然后B回滚操作,那么A读取到的数据是脏数据
- 初始状态:数据库中age字段数据的值是20
- T1把age修改为了30
- T2读取了age现在的值:30
- T1回滚了自己的操作,age恢复为了原来的20
- 此时T2读取到的30就是一个不存在的“脏”的数据
- 不可重复读:事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果不一致。(一个事务对同一行数据重复读取两次,但是却得到了不同的结果)
- T1第一次读取age是20
- T2修改age为30并提交事务,此时age确定修改为了30
- T1第二次读取age得到的是30
- 幻读:事务A从一个表中读取了一个字段,然后B在该表中插入/删除了一些新的行。 之后, 如果 A 再次读取同一个表, 就会多/少几行,就好像发生了幻觉一样,这就叫幻读。
- 老师A将60分以下的成绩改为60分但未提交
- 老师B将70分-60分的成绩改为50分
- 老师A再查询60分以下学生成绩还有一批数据
补充:不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表
13.1.4 事务的隔离级别
SQL标准定义了4种隔离级别(从低到高),分别对应可能出现的数据不一致的情况:
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读-未提交(read-uncommitted) | 是 | 是 | 是 |
| 读-已提交(read-committed) | 否 | 是 | 是 |
| 可重复读(repeatable-read) | 否 | 否 | 是 |
| 串行化(serializable) | 否 | 否 | 否 |
4种隔离级别的描述:
- 读未提交(read-uncommitted):允许A事务读取其他事务未提交和已提交的数据
- 读已提交(read-committed):只允许A事务读取其他事务已提交的数据
- 可重复读(repeatable-read):确保事务可以多次从一个字段中读取相同的值。在这个事务持续期间,禁止其他事务对这个字段进行更新;注意:mysql中使用了MVCC多版本控制技术,在这个级别也可以避免幻读。(mysql的默认隔离级别)
- 串行化(serializable):锁定整个表,让对整个表的操作全部排队串行执行。能解决所有并发问题,安全性最好,但是性能极差,基本不用。
13.2 Spring中的事务介绍
Spring框架中对事务的支持有两种:
- 编程式事务管理
- 声明式事务管理(推荐)
13.2.1 Spring事务的相关接口
Spring事务管理的相关接口有三个,如下:
- PlatformTransactionManager:事务管理器,为不同的数据访问技术的事务提供不同的接口实现
- TransactionDefinition: 事务定义信息(传播行为、事务隔离级别、只读、超时、回滚规则)
- TransactionStatus: 事务的运行状态
Spring的事务机制是用统一的机制来处理不同数据访问技术的事务处理,Spring并不直接管理事务,而是提供了多种事务管理器。Spring的事务机制提供了一个org.springframework.transaction.PlatformTransactionManager接口,将事务管理的职责委托给JDBC或者Hibernate等持久化机制所提供的相关平台框架的事务来实现。通过这个接口,Spring为各个平台如JDBC、Hibernate等都提供了对应的事务管理器,其具体的实现就是各个平台自己的事情了,对应的相关实现如下表所示。
| 数据库访问技术 | 实现 |
|---|---|
| JDBC | DataSourceTransactionManager |
| JPA | JpaTransactionManager |
| Hibernate | HibernateJpaTransactionManager |
| JDO | JdoTransactionManager |
| 分布式事务 | JtaTransactionManager |
13.2.2 编程式事务管理
编程式事务管理:事务的相关操作完全由开发人员通过编码实现。所以编程式事务管理是侵入性事务管理,使用TransactionTemplate或者直接使用PlatformTransactionManager,对于编程式事务管理,Spring推荐使用TransactionTemplate。但是我们基本不推荐使用编程式事务。下图展示的是编程式事务的实现,完全有程序员来实现。

编程式事务管理举例:
(1)配置事务管理器
对于JDBC和MyBatis技术,选择的事务管理器是:DataSourceTransactionManager 类。通过以下代码,我们可以为Spring配置事务管理器。
<!--事务管理器-->
<bean id="transactionManager"
class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource" />
</bean>
(2)配置事务模板
如果要在业务层中通过编码来实现事务管理,则需要配置事务管理模板,模板简化了连接的开闭和事务的管理,只要我们写核心业务代码就可以了。
<!-- 事务模板对象 -->
<bean id="transactionTemplate"
class="org.springframework.transaction.support.TransactionTemplate">
<property name="transactionManager" ref="transactionManager" />
</bean>
(3)业务层中实现事务管理
@Service
public class CategoryServiceImpl implements CategoryService {
@Autowired
private CategoryMapper categoryMapper;
@Autowired
private TransactionTemplate transactionTemplate;
@Override
public void deleteAll(int... ids) {
//使用TransactionTemplate实现编程式事务管理
transactionTemplate.execute(new TransactionCallbackWithoutResult() {
protected void doInTransactionWithoutResult(TransactionStatus status) {
for(int id : ids){
categoryMapper.delete(id);
}
}
});
}
}
13.2.3 声明式事务管理
声明式事务管理:事务的控制交给Spring框架来管理,开发人员只需要在Spring框架的配置文件中声明你需要的功能即可。
Spring中声明式事务管理的底层是基于AOP来完成的,其本质是对方法前后进行拦截,然后在目标方法开始之前创建或者加入一个事务,执行完目标方法之后根据执行的情况提交或者回滚。声明式事务它将具体业务与事务处理部分解耦,代码侵入性很低,所以在实际开发中声明式事务用的比较多。
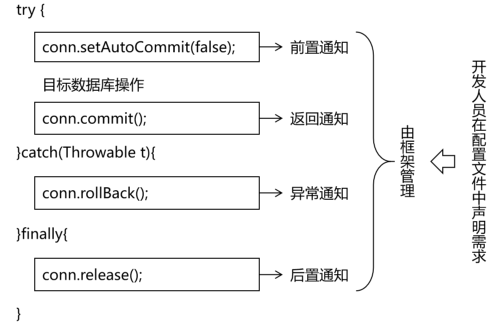
13.2.3.1 基于注解的声明式事务
在Spring中使用声明式事务一般会使用注解来实现,即@Transactional注解,该注解可以使用在类、接口和方法上:
- 作用在类:表示所有该类的 public 方法都配置相同的事务属性信息。
- 作用在方法:当类配置了@Transactional,方法也配置了@Transactional,方法的事务会覆盖类的事务配置信息。
- 作用于接口:不推荐这种使用方法,因为一旦标注在Interface上并且配置了Spring AOP 使用CGLib动态代理,将会导致@Transactional注解失效。
@Transactional
public class Trans {
@Transactional
public void saveSomething() {
//...相关操作
}
}
需要特别注意的是,此@Transactional注解来自org.springframework.transaction.annotation包,而不是javax.transaction。
@Transactional注解中常用参数:
value:当在配置文件中有多个 TransactionManager,可以用该属性指定选择哪个事务管理器。propagation:事务的传播行为,默认值为 REQUIRED。isolation:事务的隔离级别,默认值为 DEFAULT,即采用数据库的默认隔离级别。timeout:事务的超时时间(单位是秒),默认值为 -1。如果超过该时间限制但事务还未提交,则自动回滚事务。readOnly:用于指定事务是否为只读事务,默认值为 false。为了忽略那些不需要事务的方法,比如select读取数据,可以设置readOnly = true。rollbackFor:指定能够触发事务回滚的异常类型,可以指定多个异常类型。noRollbackFor:指定不用回滚事务的异常类型,可以指定多个异常类型。
下面是@Transactional注解的简单使用(定义的是异常类是class对象):
@Transactional(
propagation = Propagation.REQUIRED, // 传播行为
isolation = Isolation.DEFAULT, // 隔离级别
timeout = 1000, // 事务的超时时间(单位是秒)
readOnly = true, // 事务是否为只读
rollbackFor = Exception.class, // 能够触发事务回滚的异常类型
noRollbackFor = Exception.class // 不用回滚事务的异常类型
)
public void doSomething() {
//...相关操作
}
注意:在Spring中使用事务还需要在xml配置文件中配置如下内容:
<!-- 1.配置事务管理器的bean -->
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager" >
<!-- 给事务管理器装配数据源 -->
<property name="dataSource" ref="dataSource"/>
</bean>
<!-- 2.开启基于注解的声明式事务 -->
<!-- 在transaction-manager属性中指定前面配置的事务管理器的bean的id -->
<!-- transaction-manager属性的默认值是transactionManager,如果正好前面bean的id就是这个默认值,那么transaction-manager属性可以省略不配 -->
<tx:annotation-driven transaction-manager="transactionManager"/>
<!-- 3.配置自动扫描的包 -->
<context:component-scan base-package="com.thr.service"/>
13.2.3.2 基于XML的声明式事务
基于XML的方式配置声明式事务也比较的简单,其配置的方式如下所示:
<!-- 配置基于XML的声明式事务 -->
<aop:config>
<!-- 配置事务切面的切入点表达式 -->
<aop:pointcut id="txPointCut" expression="execution(* *..*Service.*(..))"/>
<!-- 将切入点表达式和事务通知关联起来 -->
<aop:advisor advice-ref="txAdvice" pointcut-ref="txPointCut"/>
</aop:config>
<!-- 配置事务通知:包括对事务管理器的关联,还有事务属性 -->
<!-- 如果事务管理器的bean的id正好是transactionManager,则transaction-manager属性可以省略 -->
<tx:advice id="txAdvice" transaction-manager="transactionManager">
<!-- 给具体的事务方法配置事务属性 -->
<tx:attributes>
<!-- 指定具体的事务方法 -->
<tx:method name="get*" read-only="true"/>
<tx:method name="query*" read-only="true"/>
<tx:method name="count*" read-only="true"/>
<!-- 增删改方法 -->
<tx:method name="update*" rollback-for="java.lang.Exception" propagation="REQUIRES_NEW"/>
<tx:method name="insert*" rollback-for="java.lang.Exception" propagation="REQUIRES_NEW"/>
<tx:method name="delete*" rollback-for="java.lang.Exception" propagation="REQUIRES_NEW"/>
</tx:attributes>
</tx:advice>
注意事项:
- 虽然切入点表达式已经定位到了所有需要事务的方法,但是在tx:attributes中还是必须配置事务属性。这两个条件缺一不可。缺少任何一个条件,方法都加不上事务。
- 另外,tx:advice导入时需要注意名称空间的值,不要导错了,因为导错了很难发现。
参考链接:
13.2.3.3 Transactional失效场景
(1)@Transactional应用在非public方法上
该注解只能应用于public方法。只要public方法回滚了,那么public方法内部的调用的方法也就都回滚了,只要一个回滚的入口就好了。
(2)@Transactional注解属性propagation设置错误
这种失效是由于配置错导致的,若是错误的配置一下三种,事务将不会发生回滚。
TransactionDefinition.PROPAGATION_SUPPORTS:如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
TransactionDefinition.PROPAGATION_NOT_SUPPORTED:以非事务方式运行,如果当前存在事务,则把当前事务挂起。
TransactionDefinition.PROPAGATION_NEVER:以非事务方式运行,如果当前存在事务,则抛出异常
(3)@Transactional注解属性rollbackFor错误
rollbackFor属性配置当发生何种异常的时候会回滚。
Spring默认抛出了RuntimeException异常、继承自RuntimeException的异常又或者是Error时才回滚事务;其他异常不会回滚。
所以当我们希望发生我们指定的异常时回滚,那么就需要配置这个属性了,当然也可以配置为Exception异常大类。
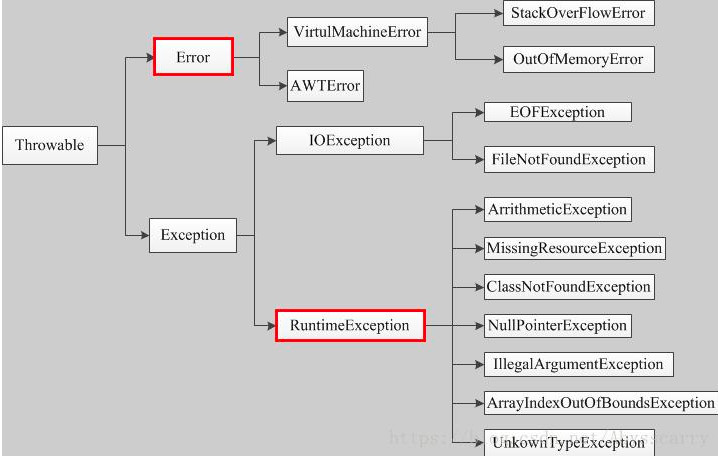
(4)@Transactional在同一个方法中调用,导致@Transactional失效
开发中避免不了类中方法的调用,比如有一个A类,内有B、C两个public方法。B声明事务,C未声明事务。当B调用C,那么B失败则事务回滚;但是当C调用B的时候,C失败,那么事务不会回滚
(5)异常被catch,导致回滚失败
当方法使用@Transactional的时候,但是方法内部 try-catch了异常则没有抛出,无法回滚。
A、B两个方法,A声明事务;A方法调用B方法并且try-catch了B方法,当B方法执行报错的时候,A不能回滚。
13.3 理解事务参数
配置Spring声明式事务管理时,<tx:method>配置元素除用于声明业务方法名外,还提供了若干属性用于控制事务细节:propagation、isolaction、read-only、timeout等等。
13.3.1 propagation(事务传播行为)
事务的传播机制一般用在事务的嵌套中,当事务方法被另一个事务方法调用时,则应该指定事务如何传播。比如事务方法A直接或间接调用了方法B,那么这两个方法是各自作为独立的方法提交,还是内层的事务合并到外层的事务一起提交,这就是需要事务传播机制的配置来确定怎么样执行。
注:事务的传播行为和隔离级别都定义在TransactionDefinition接口中:

事务的传播行为如下表所示(主要学习前两个即可,其它的简单了解):
| 事务传播行为 | 描述 |
|---|---|
| PROPAGATION_REQUIRED | 支持外层事务。这是Spring默认的传播机制,能满足绝大部分业务需求,如果外层有事务,则当前事务加入到外层事务,一块提交,一块回滚。如果外层没有事务,则创建一个新的事务。 |
| PROPAGATION_REQUIRES_NEW | 不支持外层事务。该事务传播机制是每次都会新开启一个事务,同时把外层事务挂起,当前事务执行完毕,恢复上层事务的执行。如果外层没有事务,执行当前新开启的事务即可。 |
| PROPAGATION_SUPPORTS | 支持外层事务。如果外层有事务,则加入外层事务,如果外层没有事务,则直接使用非事务方式执行。完全依赖外层的事务 |
| PROPAGATION_NOT_SUPPORTED | 不支持外层事务。该传播机制不支持事务,如果外层存在事务则挂起,执行完当前代码,则恢复外层事务,无论是否异常都不会回滚当前的代码 |
| PROPAGATION_NEVER | 不支持外层事务。该传播机制不支持外层事务,即如果外层有事务就抛出异常 |
| PROPAGATION_MANDATORY | 支持外层事务。与NEVER相反,如果外层没有事务,则抛出异常 |
| PROPAGATION_NESTED | Spring 所特有的。该传播机制的特点是可以保存状态保存点,当前事务回滚到某一个点,从而避免所有的嵌套事务都回滚,即各自回滚各自的,如果子事务没有把异常吃掉,基本还是会引起全部回滚,等价于TransactionDefinition.PROPAGATION_REQUIRED。 |
简单测试REQUIRED和REQUIRES_NEW两种传播行为:
①、在EmployeeServiceImpl中增加了两个方法:updateOne()和updateTwo():

②、创建一个PropagationServiceImpl类

③、junit测试代码:
④、测试结论:
测试REQUIRED:两个方法的操作都没有生效,updateTwo()方法回滚,导致updateOne()也一起被回滚,因为他们都在propagationService.update()方法开启的同一个事务内。
测试REQUIRES_NEW:把updateOne()和updateTwo()这两个方法上都使用下面的设置:
@Transactional(readOnly = false, propagation = Propagation.REQUIRES_NEW)
结果:
- updateOne()没有受影响,成功实现了更新
- updateTwo()自己回滚
原因:上面两个方法各自运行在自己的事务中。
13.3.2 isolaction(隔离级别)
事务的隔离级别定义了一个事务可能受其他并发事务影响的程度。隔离级别可以不同程度的解决脏读、不可重复读、幻读。
- ISOLATION_DEFAULT:使用后端数据库默认的隔离级别, Mysql 默认采用的 REPEATABLE_READ隔离级别,Oracle 默认采用的 READ_COMMITTED隔离级别。
- ISOLATION_READ_UNCOMMITTED:读-未提交,允许读取尚未提交事务的数据,可能会导致脏读、不可重复读、幻读。
- ISOLATION_READ_COMMITTED:读-已提交,读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
- ISOLATION_REPEATABLE_READ:可重复读,可以阻止脏读和不可重复读,但幻读仍有可能发生。
- ISOLATION_SERIALIZABLE:串行化,这种级别是最高级别,完全服从ACID的隔离级别,确保阻止脏读、不可重复读以及幻读。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰。但是严重影响程序的性能。几乎不会用到该级别。
13.3.3 read-only(只读)
一个事务如果是做查询操作,可以设置为只读,此时数据库可以针对查询操作来做优化,有利于提高性能。
@Transactional(readOnly = true)
public void doSomething() {
//...相关操作
}
如果是针对增删改方法设置只读属性,则会抛出下面异常:
表面的异常信息:TransientDataAccessResourceException: PreparedStatementCallback
根本原因:SQLException: Connection is read-only. Queries leading to data modification are not allowed(连接是只读的。查询导向数据的修改是不允许的。)
实际开发时建议把查询操作设置为只读。
13.3.4 timeout(超时)
一个数据库操作有可能因为网络或死锁等问题卡住很长时间,从而导致数据库连接等资源一直处于被占用的状态。所以我们可以设置一个超时属性,让一个事务执行太长时间后,主动回滚。事务结束后把资源释放出来。
@Transactional(timeout = 60) //单位为秒
public void doSomething() {
//...相关操作
}
13.3.5 rollbackfor(事务回滚的异常)
-
rollbackfor(哪些类型异常会执行回滚)
rollbackFor属性配置当发生何种异常的时候会回滚。该配置默认值是RuntimeException,即运行时异常及其子类异常都会引发事务回滚,但其余的检查异常不会引起回滚。如果所有异常都需要回滚事务,可以配置为Exception异常大类。
-
noRollbackFor(哪些类型异常不会导致执行回滚)
抛出指定的异常类型,不回滚事务,也可以指定多个异常类型。
在@Transactional注解中如果不配置rollbackFor属性,那么事物只会在遇到RuntimeException的时候才会回滚,加上rollbackFor=Exception.class,可以让事物在遇到非运行时异常时也回滚。
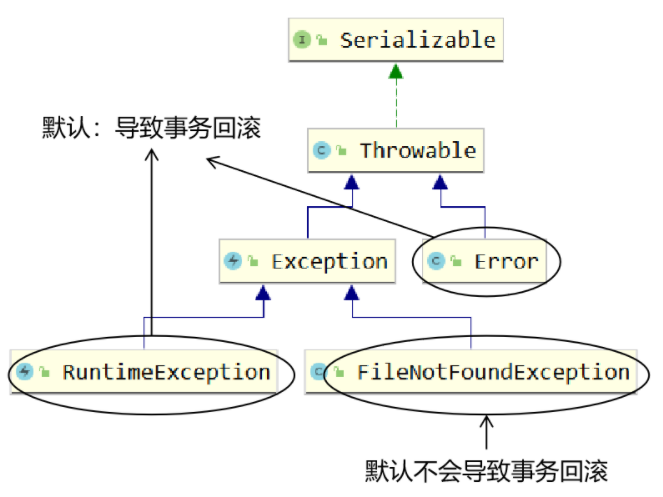
设置方式如下所示(实际开发时通常也建议设置为根据Exception异常回滚):
@Transactional(
propagation = Propagation.REQUIRED, // 传播行为
isolation = Isolation.DEFAULT, // 隔离级别
timeout = 3000, // 事务的超时时间
readOnly = true, // 事务是否为只读
rollbackFor = Exception.class, // 能够触发事务回滚的异常类型
)
public void doSomething() {
//...相关操作
}
14、使用注解驱动单元测试
为了方便单元测试Spring同样提供了单元测试组件“spring-test”,该组件可以让我们在单元测试中使用依赖注入
(1)导入spring-test组件依赖
<!-- Spring 测试 -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>4.3.9.RELEASE</version>
</dependency>
(2)在单元测试中使用依赖注入
spring-test组件提供的@ContextConfiguration注解用于指定Spring配置信息的位置;而@RunWith注解用于指定Spring测试的运行加载器,与JUnit4配对的是SpringJUnit4ClassRunner类。
配置这两个注解后,我们就能使用@Autowired直接注入被测试的对象了。
@ContextConfiguration("classpath:spring-beans.xml")
@RunWith(SpringJUnit4ClassRunner.class)
public class CategoryMapperTest {
@Autowired
private CategoryMapper target;
@Test
public void testSelectById() {
assertEquals("喜剧", target.selectById(1).getName());
}
@Test
public void testInsert() {
Category c = new Category(0,"Test");
target.insert(c);
System.out.println(c.getId());
}
}
(3)带回滚式的单元测试
对DAO执行单元测试的一个大麻烦是:一旦执行过增删改方法后,数据库就会“脏”掉了,里面的数据就不是原来的样子了,者对于我们判断查询方法是否正确造成了影响。如果DAO单元测试之后,数据能够像事务一样被回滚,那就太好了。
Spring为我们提供了这样的方法,只要在测试代码上加上@Transactional和@Rollback注解,我们就能使用带回滚功能的DAO测试。每个测试方法在直接结束之后,会把事务回滚掉,而不是提交。数据库就不会被弄“脏”了。
@ContextConfiguration("classpath:spring-beans.xml")
@RunWith(SpringJUnit4ClassRunner.class)
@Transactional
@Rollback
public class CategoryMapperTest {
@Autowired
private CategoryMapper target;
@Test
public void testSelectById() {
assertEquals("喜剧", target.fetchById(1).getName());
}
@Test
public void testInsert() {
Category c = new Category(0,"Test");
target.insert(c);
System.out.println(c.getId());
}
}
15、Spring 整合 MyBatis
在前面的MyBatis的使用中,代码中依然存在部分冗余的代码,比如说SqlSession对象的打开和关闭,比如事务的提交等等。既然Spring可以通过DI和AOP管理Java Bean并简化代码,那Spring当然可以为MyBatis简化DAO的开发开发。
这里我们打算使用Spring整合MyBatis,让MyBatis变得前所未有的简洁好用。
有两种方式整合:
- 使用SqlSessionTemplate整合
- 使用Mapper接口代理整合
15.1 使用SqlSessionTemplate整合
前文提到,MyBatis有两种使用方式:一是“Statment API(命名查询)”方式,二是“Mapper API(接口代理)”方式,这里先介绍第一种,这种方式下,DAO是需要编码实现的。
(1)导入所需依赖(jar包)
要实现Spring整合MyBatis,需要添加以下依赖:
1)需要使用”spring-orm”组件,提供模板模式和事务支持;
2)需要使用“mybatis-spring”组件,该组件由MyBatis官方提供;
3)需要数据源“commons-dbcp”组件,该组件负责提供连接池,提供JDBC连接并提高数据库的连接性能。
具体Maven依赖如下(注意新添加的红色部分)。
<!-- mysql jdbc -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.8</version>
</dependency>
<!-- dbcp 数据源(连接池),必须 -->
<dependency>
<groupId>commons-dbcp</groupId>
<artifactId>commons-dbcp</artifactId>
<version>1.4</version>
</dependency>
<!-- MyBatis 核心 -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.1</version>
</dependency>
<!-- MyBatis与Spring整合包 ,必须,整合Spring的关键 -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
<version>1.3.3</version>
</dependency>
<!-- Junit测试,可选,仅用于单元测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<!-- Spring DI容器 -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>4.3.9.RELEASE</version>
</dependency>
<!-- Spring ORM 数据访问组件 -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-orm</artifactId>
<version>4.3.9.RELEASE</version>
</dependency>
(2)配置SqlSessionFactory对象
在Spring的beans配置文件中配置DBCP数据源 和 MyBatis的Session工厂对象
需要注意的是:
1) “dataSource”对象关键要配置JDBC所需要的4个连接常量
2) “sqlSessionFactory”对象需要配置:“dataSource”属性来获取连接;
3)“mapperLocations”属性来指定Mapper XML文件的位置,它会做统一扫描;
4)“typeAliasesPackage”属性指定数据实体的默认包名,以使得mapper中可以直接用实体类的简称。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation=" http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<!-- 配置DBCP数据源(连接池) -->
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource"
destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver" />
<property name="url" value="jdbc:mysql://localhost:3306/MyCinema" />
<property name="username" value="root" />
<property name="password" value="1234" />
</bean>
<!-- 配置MyBatis的SessionFactory -->
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="mapperLocations" value="classpath:mappers/*.xml" />
<property name="typeAliasesPackage" value="com.bjpowernode.model" />
</bean>
</beans>
使用Spring配置SqlSessionFactory后,理论上MyBatis的原生配置文件mybatis-config.xml就可以不要了。但如果有些复杂的MyBatis配置需要保留mybatis-config.xml的话,我们也可以使用如下写法。
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource" />
<!--若有复杂的MyBatis配置信息,依然可以保留 mybatis-config.xml,否则该配置文件可以去掉-->
<property name="configLocation" value="classpath:mybatis-config.xml" />
<property name="mapperLocations" value="classpath:mappers/*.xml" />
<property name="typeAliasesPackage" value="com.bjpowernode.model" />
</bean>
(3)配置SqlSessionTemplate对象
SqlSessionTemplate对象负责简化原生MyBatis的SqlSession操作,有了它,我们不需要关心SqlSession的open和close,甚至是事务的commit,我们只需要执行所需操作即可。
<!-- 配置SqlSessionTemplate对象 -->
<bean id="sqlSessionTemplate" class="org.mybatis.spring.SqlSessionTemplate">
<constructor-arg name="sqlSessionFactory" ref="sqlSessionFactory"/>
</bean>
(4)为DAO的依赖注入SqlSessionTemplate并使用它
DAO对象的实现如下:
public class CategoryMapperImpl implements CategoryMapper {
private SqlSessionTemplate sqlSessionTemplate;
//用于依赖注入
public void setSqlSessionTemplate(SqlSessionTemplate value){
this.sqlSessionTemplate = value;
}
public Category selectById(int id) {
return sqlSessionTemplate.selectOne("com.bjpowernode.mapper.CategoryMapper.selectById", id);
}
public void insert(Category c) {
sqlSessionTemplate.insert("com.bjpowernode.mapper.CategoryMapper.insert", c);
}
}
为DAO配置sqlSessionTemplate
<!-- 吧sqlSessionTemplate对象依赖注入到DAO对象 -->
<bean id="categoryMapper" class="com.bjpowernode.mapper.impl.CategoryMapperImpl">
<property name="sqlSessionTemplate" ref="sqlSessionTemplate" />
</bean>
15.2 使用Mapper接口代理整合
上述方式虽然已经对mybatis进行了简化,但“Statement API(命名查询)”的方式属于弱类型编程,容易出错,而且必须编写Mapper接口的实现对象有点多此一举,为此,应该还有更简单的方式。Spring可以通过AOP技术,为Mapper接口直接生成动态代理对象,我们根本不需要为DAO层提供实现,直接把Spring代理的Mapper注入给业务就好了。
15.2.1 使用 MapperFactoryBean 配置单个Mapper对象
MapperFactoryBean工厂可以生成 Mapper接口对象,只需指定SqlSessionFactory 和接口位置即可。下面代码为Spring配置了CategoryMapper接口对象。
<!-- 使用MapperFactoryBean创建单个Mapper对象 -->
<bean id="categoryMapper" class="org.mybatis.spring.mapper.MapperFactoryBean">
<property name="mapperInterface" value="com.bjpowernode.mapper.CategoryMapper" />
<property name="sqlSessionFactory" ref="sqlSessionFactory" />
</bean>
15.2.2 使用 MapperScannerConfigurer 批量生成所有 Mapper 对象
MapperFactoryBean每次只能配置一个Mapper接口,MyBatis-Spring整合包还提供了更为方便的MapperScannerConfigurer可以为我们批量配置Mapper接口对象。
我们只要:通过MapperScannerConfigurer的basePackage属性指定了Mapper接口所在包位置,通过 sqlSessionFactoryBeanName指定 sqlSessionFactory 的 bean 的 id 就可以批量生成所有Mapper对象。
<!-- 扫描DAO接口所在包名,Spring会自动代理生成其下的接口实现类 -->
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="com.bjpowernode.mapper" />
<property name="sqlSessionFactoryBeanName" value="sqlSessionFactory" />
</bean>
配置完成后,我们的Mapper单元测试又可以通过了。
15.2.3 在业务对象中使用Mapper对象
经过上述配置,Mapper接口对象已经保存在Spring 容器中,我们只需要依赖注入,就可以在业务对象中使用Mapper对象。
public class CategoryServiceImpl implements CategoryService {
private CategoryMapper categoryMapper;
public void setCategoryMapper(CategoryMapper categoryMapper) {
this.categoryMapper = categoryMapper;
}
@Override
public Category queryById(Integer id) {
return categoryMapper.selectById(id);
}
@Override
public int save(Category category) {
return categoryMapper.insert(category);
}
}
依赖注入配置:
<!-- 业务对象 -->
<bean id="categoryService" class="com.bjpowernode.service.impl.CategoryServiceImpl">
<property name="categoryMapper" ref="categoryMapper" />
</bean>
如果使用Spring注解配置的话,上述业务对象也可以实现为:
spring-beans.xml
<!--把业务类托管到Spring中-->
<context:component-scan base-package="com.bjpowernode.service" />
CategoryServiceImpl.java
@Service //向Spring托管业务对象
public class CategoryServiceImpl implements CategoryService{
@Autowired //使用注解实现依赖注入
private CategoryMapper categoryMapper;
//......
}
16、优化Spring配置
16.1 引用 *.properties 配置文件实现Spring的配置
实际中,某些程序员喜欢把一些公共的配置信息配置在Java属性文件中(xxx.properties)以便可以在多个地方反复使用,而不仅仅供Spring使用,这时,我们也可以在Spring中引用对应的*. properties文件配置信息。如下所示,我们把与jdbc链接相关的信息放置在jdbc.Properties配置文件中。
(1)设置properties文件(jdbc.properties)
jdbc.driver=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:3306/mycinema
jdbc.username=root
jdbc.password=1234
(2)在Spring配置文件中引入。
<!-- 配置引入*.properties文件 -->
<bean class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer">
<property name="location" value="classpath:jdbc.properties"/>
</bean>
<!-- 配置引入jdbc.properties文件中的配置 -->
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</bean>
<!-- Dao实现类 -->
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="com.bjpowernode.mapper"/>
<property name="sqlSessionFactoryBeanName" value="sqlSessionFactory"/>
</bean>
16.2 在Java Web环境下使用Spring
在Web环境中,应用程序是由Web服务器启动的,Spring要作为对象容器(对象工厂)为各层提供依赖注入功能,就必须在Web服务器启动时创建Spring实例,并在整个应用程序生命周期中保持唯一。这时,我们就不能在测试方法(或main方法)中随便创建ApplicationContext()对象了,因为Web应用程序并不是由测试方法启动的。
针对这个问题,Spring提供了Web服务器的监听程序,使用监听器监听Web应用程序的启动事件,并在事件处理函数中创建Spring实例并使用单例模式缓存起来(存放到Web应用程序上下文中,即ServletContext类型的application对象)。这样在Web程序的任意地方,就可以获取到唯一的Spring实例并实现依赖注入了。
下面介绍在Web环境中使用Spring的注意事项:
(1)在项目种添加Spring Web依赖
<!-- Spring Web(启动监听器) -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-web</artifactId>
<version>4.3.9.RELEASE</version>
</dependency>
<!-- JSTL -->
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>jstl</artifactId>
<version>1.2</version>
<scope>runtime</scope>
</dependency>
<!-- Servlet API -->
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>3.0.1</version>
<scope>provided</scope>
</dependency>
(2)配置web.xml,设置Spring Web监听器,在Web应用启动时创建并缓存Spring容器
<?xml version="1.0" encoding="UTF-8"?>
<web-app version="3.0" xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee
http://java.sun.com/xml/ns/javaee/web-app_3_0.xsd">
<!-- 启动Spring容器的监听器 -->
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
</listener>
<!-- 指定监听器需要加载的Spring配置文件位置 -->
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:applicationContext.xml</param-value>
</context-param>
</web-app>
(3)在Servlet/JSP等请求处理器中获取Spring容器和它所管理的Bean
在请求上下文中,可以通过以下方法获取Spring容器:
ApplicationContext ctx = WebApplicationContextUtils.getRequiredWebApplicationContext(ServletContext object)
下面是Servlet中使用Spring容器的示例:
@WebServlet("/admin/category-list")
public class CategoryListServlet extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
//获取Spring容器
ApplicationContext ctx = WebApplicationContextUtils.getRequiredWebApplicationContext(this.getServletContext());
//获取Spring管理的bean对象
CategoryBiz categoryBiz = (CategoryBiz)ctx.getBean("categoryBiz");
//执行请求处理
request.setAttribute("categories", categoryBiz.getAll());
request.getRequestDispatcher("/admin/category-list.jsp").forward(request, response);
}
}
16.3 Spring配置文件拆分策略及方法
本小节内容摘自:
- 分离你的spring配置文件,让结构更清晰 - LinkinStar - 博客园 (cnblogs.com)
- 拆分Spring配置文件(Web)_闪电蛙的博客-CSDN博客_spring配置文件拆分
- spring配置文件拆分策略及方法 - 请叫我小老弟 - 博客园 (cnblogs.com)
以前,spring的配置文件从一开始的一点,到后面的逐渐变多,慢慢的,在一个spring的配置文件中就包含了好几块不同的bean的配置。有springMVC的,有mybatis的,等等。所有的都配置在一起看起来很不舒服,但是苦于之前配置方式不对就一直没有修改,这次进行分离。
16.3.1 拆分策略
- 如果一个开发人员负责一个模块,我们采用公用配置(包括数据源、事务等)+每个系统模块一个单独配置文件(包括Dao、Service、Web控制器)的形式
- 如果是按照分层进行的分工,我们采用公用配置(包括数据源、事务等)+DAO Bean配置+业务逻辑Bean配置+Web控制器配置的形式
16.3.2 分离配置文件
我分离出了如下的配置
- application.xml:主配置文件
- spring-dao.xml:主要是jdbc连接,mybatis的sqlSessionFactory等配置,总之和数据库打交道
- spring-quartz.xml:很简单,就只是定时器的配置。
- spring-redis.xml:是redis的配置
- spring-service.xml:是事务、扫描、注解等配置
- spring-web.xml:则是springMVC的相关配置
- spring-interceptor.xml:拦截器
可以根据自己的需要继续往上面添加
至此,所有的分离基本完成,你就可以根据自己的需要进行配置修改了。
16.3.3 配置文件载入方法
如果有多个配置文件需要载入,可以分别传入多个配置文件名,或以String[]方式传入多个配置文件名。或者还可以采用通配符(*)来加载多个具有一定命名规则的配置文件。如下
ApplicationContext ctx = new ClassPathXmlApplicationContext("application.xml",
"spring-dao.xml",
"spring-quartz.xml",
"spring-redis.xml",
"spring-service.xml",
"spring-web.xml",
"spring-interceptor.xml");
String[] configs = {("application.xml","spring-dao.xml", "spring-quartz.xml",
"spring-redis.xml","spring-service.xml","spring-web.xml",
"spring-interceptor.xml"};
ApplicationContext ctx = new ClassPathXmlApplicationContext(configs);
ApplicationContext ctx = new ClassPathXmlApplicationContext("application.xml","spring-*.xml");
建议通过通配符(*)的方式配置多个Spring配置文件,建议在给Spring配置文件命名时遵循一定的规律
16.3.5 配置web.xml
有三种方法:
[1]IOC容器的位置
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>
classpath:application.xml
classpath:spring-dao.xml
classpath:spring-quartz.xml
classpath:spring-redis.xml
classpath:spring-web.xml
classpath:spring-interceptor.xml
</param-value>
</context-param>
或者是
<context-param>
<!-- 监听器的父类ContextLoader中有一个属性contextConfigLocation,该属性保存着容器配置文件的位置 -->
<param-name>contextConfigLocation</param-name>
<param-value>
classpath:application.xml
<!-- 以下的*是一个通配符 -->
classpath:spring-*.xml.xml
</param-value>
</context-param>
[2]在主配置文件中加载其他文件
<!--application.xml-->
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.5.xsd">
<!--使用import导入-->
<import resource="classpath:spring-dao.xml"/>
<import resource="classpath:spring-quartz.xml"/>
<import resource="classpath:spring-redis.xml"/>
<import resource="classpath:spring-web.xml"/>
<import resource="classpath:spring-interceptor.xml"/>
</beans>
[3]推荐
原来我们spring的配置是:
<context-param>
<!-- 监听器的父类ContextLoader中有一个属性contextConfigLocation,该属性保存着容器配置文件的位置 -->
<param-name>contextConfigLocation</param-name>
<param-value>
classpath:application.xml
<!-- 以下的*是一个通配符 -->
classpath:spring-*.xml.xml
</param-value>
</context-param>
<listener>
<listener-class>org.springframework.web.context.ContextLoaderListener</listener-class>
</listener>
苦于上下文和listener所以我们这次把这些都删了。
利用所有都采用servlet的配置方式去配置。如下
<servlet>
<servlet-name>springMVC_dispatcher</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
<init-param>
<param-name>contextConfigLocation</param-name>
<param-value>
classpath:application.xml
classpath:spring-*.xml
</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>springMVC_dispatcher</servlet-name>
<url-pattern>/</url-pattern>
</servlet-mapping>
这个配置文件将会读取项目根目录下spring文件夹下以spring-开头的spring配置文件。没错。可以和context-param和listener拜拜了。
16.3.3 分离的好处
分离之后,明显赶紧结构化清晰很多。相关的配置很清楚在那一块。之后需要新加入配置也很简单。需要指出的是,每个配置文件上面的协议最好写清楚,不要一股脑全部复制粘贴,用到什么写什么。尽可能的简化配置文件,让配置文件看的明白。
16.3.4 各个配置文件参考
下面是各个配置文件参考,只是作为参考,需要根据实际需求改动。如果配置有不合理的地方也请原谅并指出。谢谢。
spring-web:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:mvc="http://www.springframework.org/schema/mvc"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.3.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/mvc
http://www.springframework.org/schema/mvc/spring-mvc.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop.xsd">
<!-- 注解 -->
<mvc:annotation-driven/>
<!-- 扫描包 -->
<context:component-scan base-package="com.ssm.controller">
<context:include-filter type="annotation" expression="org.springframework.stereotype.Controller"/>
</context:component-scan>
<!-- 允许访问路径 -->
<mvc:resources location="/resources/" mapping="/resources/**/"/>
<!-- 视图解析器配置 -->
<bean class="org.springframework.web.servlet.view.ContentNegotiatingViewResolver">
<property name="viewResolvers">
<list>
<bean class="org.springframework.web.servlet.view.BeanNameViewResolver"/>
<bean class="org.springframework.web.servlet.view.InternalResourceViewResolver">
<property name="prefix" value="/WEB-INF/pages/"/>
<property name="suffix" value=".jsp"/>
</bean>
</list>
</property>
<property name="defaultViews">
<list>
<bean class="org.springframework.web.servlet.view.json.MappingJackson2JsonView"/>
</list>
</property>
</bean>
<!-- 文件上传配置 -->
<bean id="multipartResolver" class="org.springframework.web.multipart.commons.CommonsMultipartResolver">
<property name="maxUploadSize" value="524288000"/>
<property name="defaultEncoding" value="UTF-8"/>
<property name="resolveLazily" value="true"/>
</bean>
<!--全局异常捕捉 -->
<bean class="com.ssm.exception.GlobalExceptionResolver" />
</beans>
spring-service:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.3.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<!--扫描包(包含子包)下所有使用注解的类型-->
<context:component-scan base-package="com.ssm">
<context:exclude-filter type="annotation" expression="org.springframework.stereotype.Controller"/>
</context:component-scan>
<!--配置事务管理器(mybatis采用的是JDBC的事务管理器)-->
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"></property>
</bean>
<!--配置基于注解的声明式事务,默认使用注解来管理事务行为-->
<tx:annotation-driven transaction-manager="transactionManager"/>
</beans>
spring-redis:(还需优化,只是简单测试,之后会有)
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.3.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<bean id="redisDao" class="com.ssm.dao.cache.RedisDao">
<constructor-arg index="0" value="localhost" />
<constructor-arg index="1" value="6379" />
</bean>
</beans>
spring-quartz:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:task="http://www.springframework.org/schema/task"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.3.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/task
http://www.springframework.org/schema/task/spring-task.xsd ">
<task:annotation-driven />
<context:annotation-config />
<context:component-scan base-package="com.ssm.quartz"/>
</beans>
spring-dao:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.3.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<context:property-placeholder location="classpath:resources/jdbc.properties"/>
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="${jdbc.driverClassName}" />
<property name="url" value="${jdbc.url}" />
<property name="username" value="${jdbc.username}" />
<property name="password" value="${jdbc.password}" />
<property name="minIdle" value="${jdbc.minIdle}"></property>
<property name="maxIdle" value="${jdbc.maxIdle}"></property>
<property name="maxWait" value="${jdbc.maxWait}"></property>
<property name="maxActive" value="${jdbc.maxActive}"></property>
<property name="initialSize" value="${jdbc.initialSize}"></property>
<property name="testWhileIdle"><value>true</value></property>
<property name="testOnBorrow"><value>true</value></property>
<property name="testOnReturn"><value>false</value></property>
</bean>
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<!--注入数据库连接池-->
<property name="dataSource" ref="dataSource" />
<!--扫描entity包,使用别名,多个用;隔开-->
<property name="typeAliasesPackage" value="com/ssm/entity" />
<!--扫描sql配置文件:mapper需要的xml文件-->
<property name="mapperLocations" value="classpath*:com/ssm/dao/sqlxml/*.xml"></property>
</bean>
<bean id="sqlSessionTemplate" class="org.mybatis.spring.SqlSessionTemplate">
<constructor-arg name="sqlSessionFactory" ref="sqlSessionFactory" />
</bean>
<!--配置扫描Dao接口包,动态实现DAO接口,注入到spring容器-->
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<!--注入SqlSessionFactory-->
<property name="sqlSessionFactoryBeanName" value="sqlSessionFactory"/>
<!-- 给出需要扫描的Dao接口-->
<property name="basePackage" value="com.ssm.dao"/>
</bean>
</beans>
spring-interceptor:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:mvc="http://www.springframework.org/schema/mvc"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.3.xsd
http://www.springframework.org/schema/mvc
http://www.springframework.org/schema/mvc/spring-mvc.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<!-- 拦截器 -->
<mvc:interceptors>
<mvc:interceptor>
<mvc:mapping path="/xxx/**/*.htm"/>
<bean class="com.ssm.interceptor.Interceptor"></bean>
</mvc:interceptor>
</mvc:interceptors>
</beans>
附:设计模式简介
1 、设计模式概述
1.1 什么是设计模式
设计模式:软件设计中的“三十六计”;是人们在长期的软件开发中的经验总结;是对某些特定问题的经过实践检验的特定解决方法;被广泛运用在Java框架技术中。
1.2 GoF的23种面向对象设计模式
(1)GoF
“四人组(Gang of Four,简称GoF,分别是IBM的四位著名软件科学家Erich Gamma、Richard Helm、Ralph Johnson和John Vlissides归纳发表了23种在软件开发中使用频率较高的设计模式,旨在用模式来统一沟通面向对象方法在分析、设计和实现间的鸿沟。

(2)23种设计模式
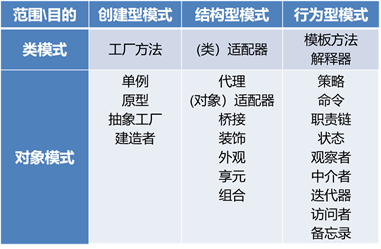
2、工厂模式(简单工厂)
2.1 工厂模式概念
(1)工厂模式基本概念
使用者仅依赖于抽象产品(接口),而把具体产品(实现类)的创建过程交给工厂方法来实现,在需要切换不同具体产品时,仅调整工厂就可以实现。
简单工厂模式,又叫做静态工厂方法模式,不属于GoF的23种设计模式之一,可以理解为工厂模式的一个特殊简单实现。
(2)作用
在Java开发中我们通常遵守面向接口编程原则。所谓面向接口,就是说模块与模块之间要通过接口来调用,不应该依赖于具体的实现类。面向接口编程有利模块的于分工和测试,也为未来提供了升级替换的可能。
但在实际中,接口只能用于声明,对象的创建还需要“new”关键字,new的后面跟的必须是具体类,因此仅仅用接口并不能实现面向对象编程,我们还需要让对象的创建语句也不出现具体类。
CategoryDao categoryDao = new CategoryDaoMySqlImpl(); //基于MySQL实现的DAO
//CategoryDao categoryDao = new CategoryDaoOracleImpl(); //基于Oracle实现的DAO
categoryDao.save("科幻"); //调用DAO
工厂模式”就是用于解决这一问题,使得调用者与实现者彻底的分离。
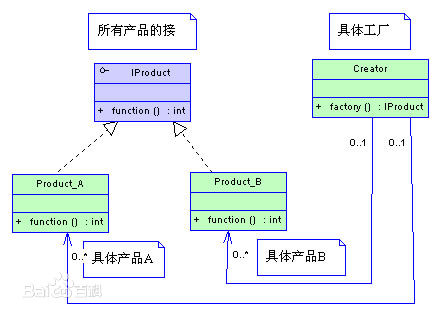
2.2 简单工厂的实现
(1)编写工厂类
public class DaoFactory {
public static CategoryDao createCategoryDao(String type) {
if("mysql".equals(type)) {
return new CategoryDaoMySqlImpl();
}else if("oracle".equals(type)){
return new CategoryDaoOracleImpl();
}else {
throw new RuntimeException("没有“"+type+"”类型的DAO对象");
}
}
}
(2)调用工厂类
CategoryDao categoryDao = DaoFactory.createCategoryDao("mysql"); //从工厂中获取实现类对象
categoryDao.save("科幻"); //调用
具体类的创建被封装在了Factory对象中,使用环境中不再出现具体类。
2.3 反射工厂
由于反射技术可以根据“完全限定类名”动态加载并创建一个未知的类对象,因此可以用来实现一个创建任意(未知)类对象的工厂。
实际中,反射加载所需要的“完全限定类名”应该通过“配置文件”(一般是properties文件或者XML文件)来描述,每个对象应配置相应的“对象名”和“类名”,“对象名”被硬编码到程序中,而“类名”则通过配置读取或修改。这样一来,就可以实现模块中只使用一组抽象产品(接口),而具体产品(实现类)可以通过配置来切换,以实现真正的面向接口编程。
下面使用objects.xml配置文件来记录一组具体产品的类名:
<?xml version="1.0" encoding="utf-8"?>
<objects>
<object name="categoryDao" class="com.bjpowernode.dao.impl.CategoryDaoMySqlImpl" />
<!-- 可以继续配置其他DAO对象或需要通过反射加载的对象 -->
</objects>
在实际使用中,通过BeanFactory类来创建具体产品:
CategoryDao categoryDao = (CategoryDao)RefectionFactory.getInstance("categoryDao");
categoryDao.insert("科幻");
而反射工厂的实现大致如下:
public class RefectionFactory {
//把配置文件加载为一个Map<对象名,对象类名>
private static Map<String,String> objectMap = new HashMap<>();
//配置文件名
private static String configFile = "objects.xml";
//加载配置文件
static{
try {
//使用Java的DOM模型解析XML文件
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder db = dbf.newDocumentBuilder();
Document document = db.parse(RefectionFactory.class.getClassLoader().getResourceAsStream(configFile));
NodeList nodeList = document.getElementsByTagName("object"); //获取文档所有<object>元素
for(int i=0; i<nodeList.getLength(); i++){
Element element = (Element)nodeList.item(i);
String name = element.getAttribute("name");
String className = element.getAttribute("class");
objectMap.put(name, className); //把name属性值作为key,class属性值作为value保存到Map
}
}catch (Exception e){
throw new RuntimeException(configFile+"加载失败", e);
}
}
//反射工厂方法
public static Object getInstance(String objectName){
try{
String className = objectMap.get(objectName); //根据对象名获取对象类型
Class clz = Class.forName(className); //反射加载类
return clz.newInstance(); //反射创建对象
}catch (Exception e){
throw new RuntimeException("反射工厂创建对象失败",e);
}
}
}
3、单例模式(Singleton)
3.1 什么是单例模式
单例模式是23种面向对象设计模式种的一种,是面试中最常考查的模式。
单例模式:确保某个类只有一个实例,而且自行实例化并向整个系统提供这个实例。单例模式关键点又如下三个:
(1)只能有一个实例;
(2)它必须自行创建这个实例;
(3)它须自行向整个系统提供这个实例。
单例模式根据创建实例的时机分为懒汉模式和饿汉模式。
3.2 单例模式——懒汉模式
所谓懒汉模式是指在类加载的时候不需要创建实例,采用延迟加载的方式。在运行时调用时才创建实例。使用“时间换空间”.
public class Singleton {
//用一个null值的变量来存放实例,在类加载的时候没有创建实例
private static Singleton instance = null;
//私有的构造方法
private Singleton() {
}
//调用这个方法的时候首先看看是不是第一次调用
public static Singleton getInstance() {
if(instance == null)
instance = new Singleton();
return instance;
}
}
这种方式保证了延迟加载的特性,从线程安全的角度上来说,懒汉式是不安全的,在多线程下无法正常工作。,假设,现在有线程A和线程B同时去调用getInstance方法,就可能出现线程并发的情况。解决方法就是线程同步,使用synchronized关键字解决。
public static synchronized Singleton getInstance() {
if(instance == null)
instance = new Singleton();
return instance;
}
使用sychronized同步整个方法虽然可以防止并发,但也会导致执行性能低下,为了照顾性能问题,单例模式的懒汉模式最终会写写成双重检查(double check)的方式。
public class Singleton {
private static Singleton instance = null;
//私有的构造方法
private Singleton() {
}
//使用双重检查和线程同步
public static Singleton getInstance() {
if(instance==null){ //第一次检查
synchronized (Singleton.class){ //线程同步
if(instance == null) //第二次检查
instance = new Singleton(); //创建对象
}
}
return instance;
}
}
3.3 饿汉模式
所谓饿汉模式是指在类加载的时候就完成了初始化操作,所以类加载的速度较慢。但是获取速度很快,使用“空间换时间”。由于饿汉模式在初始化已经自行实例化,因此不存在线程安全问题。
public class Singleton {
//用static修饰是为了在类加载的时候就创建实例
private static Singleton instance = new Singleton();
//私有的构造方法
private Singleton() {
}
//static修饰可以通过类直接调用这个方法
public static Singleton getInstance() {
return instance;
}
}
3.4 Spring的Bean与单例模式
我们所编写的Java Bean虽然没有直接使用单例模式,但Spring管理的Bean的方式默认都是单例的。不需要每次都创建实例,主要是基于性能的考虑。所以,一般不要在Spring管理的Bean中定义成员变量,否则会导致严重的线程安全以问题。必要时可以使用@Scope(“prototype”) 将 Bean 变成多例的来解决,但是这种方式效率低,也违背了Spring设计的初衷。通常情况下,功能Java Bean(如DAO、业务和控制器等对象)中都没有成员变量,只有方法,没有属性,所以不存在线程安全的问题,完全可以单例使用。

