Hibernate一级缓冲

Hibernate的一级缓冲
什么是缓冲
缓冲概念:
数据存在数据库中,数据库本身就是一个文件系统,使用流的方式操作文件,但是文件中有很多的内容,用流的操作得效率就低。
解决办法:
- 把数据存在内存中,不需要使用流的方式,可以直接读取内存中的数据;
- 把数据放到内存中,提升读取效率;
Hibernate缓冲
1、Hibernate帮我们提供了很多优化的方式,hibernate的缓冲就是优化的一种方式;
2、Hibernate缓冲特点:
a) 第一类:Hibernate一级缓冲;
- Hibernate的一级缓冲默认就是打开的。
- Hibernate的一级缓冲有使用的范围,是session的范围(从创建session到关闭session)。
- Hibernate的一级缓冲中,存储的数据必须是持久状态。
b) 第二类:Hibernate二级缓冲;
- 目前已经不使用了,使用了替代技术redis
- 二级缓冲默认不是打开的,需要配置才能用
- 二级缓冲的使用范围不是session,而是整个sessionfactory的范围。
验证一级缓冲的存在
a) 验证方式
- 首先根据id=1查询,返回对象(第一次查询需要查询数据库)。
- 其次再根据id=1查询,返回对象(第二次不需要查询数据库)。
|
//根据id=4查询 //执行了第一次查询后是否查询数据库(是否有查询语句的输出) User user1 = session.get(User.class, 4); System.out.println(user1); //再一次根据id=4查询 //执行第二次查询是否有第二次的查询语句输出 User user2 = session.get(User.class, 4); System.out.println(user2); |
|
Hibernate: select user0_.ID as ID1_0_0_, user0_.USERNAME as USERNAME2_0_0_, user0_.PASSWORD as PASSWORD3_0_0_, user0_.ADDRESS as ADDRESS4_0_0_ from USER user0_ where user0_.ID=? User [id=4, username=hello, password=111111, address=shanxi] User [id=4, username=hello, password=111111, address=shanxi] |
|
第一次执行get方法后,发送了sql语句查询数据库; 第二次执行get方法后,没有发送sql语句,查询了以及缓冲; |
一级缓冲的执行过程
1、首先是去一级缓冲中找数据,而第一次发现没有要的数据,这个时候才会去数据库查询数据(这个时候是持久态对象)。其次把user1的持久态对象放到一级缓冲中。
2、执行了第二次查询,首先查询的是一级缓冲内容,发现以后需要的数据,直接返回。
说明:第一次查询结束的时候,放到缓冲中的数据是零散的,如id=1,username=xxx,再一次查询的时候找到对应的id后重新组装成了新的对象。

Hibernate一级缓冲特性
说明:持久态会自动更新数据库。
|
//1根据id查询 User user = session.get(User.class, 4); user.setUsername("qqqqq");//这里不需要调用更新 transaction.commit(); |
|
Hibernate: select user0_.ID as ID1_0_0_, user0_.USERNAME as USERNAME2_0_0_, user0_.PASSWORD as PASSWORD3_0_0_, user0_.ADDRESS as ADDRESS4_0_0_ from USER user0_ where user0_.ID=? Hibernate: update USER set USERNAME=?, PASSWORD=?, ADDRESS=? where ID=? |
下面进行讲解执行过程(了解)
Hibernate一级缓冲执行特性
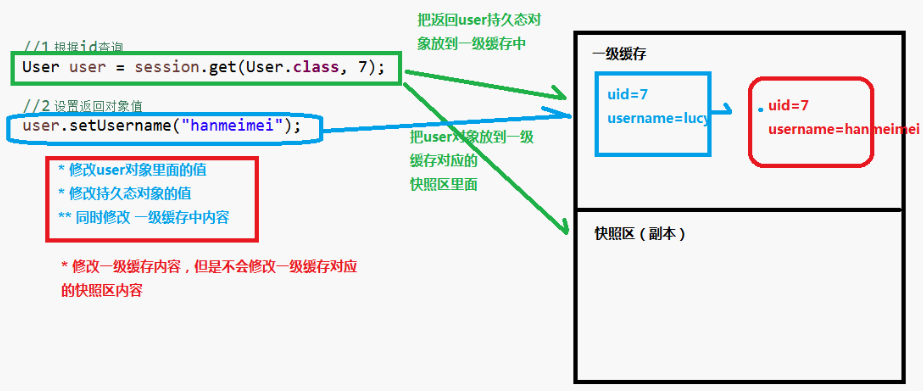
接着上图继续解释(重点):
1、最后提交事务;
2、提交事务的时候,做的事情是:
比较
比较一级缓冲的内容和对应的快照区内容是否相同,如果不相同,把一级缓冲内容更新到数据库里面,如果相同就不做更新。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号