简单使用yolov5识别滑块缺口
一、数据集准备
文件夹创建

images=>存放图片

labels=>存放标注坐标

gap.yaml =>yolov5训练配置文件
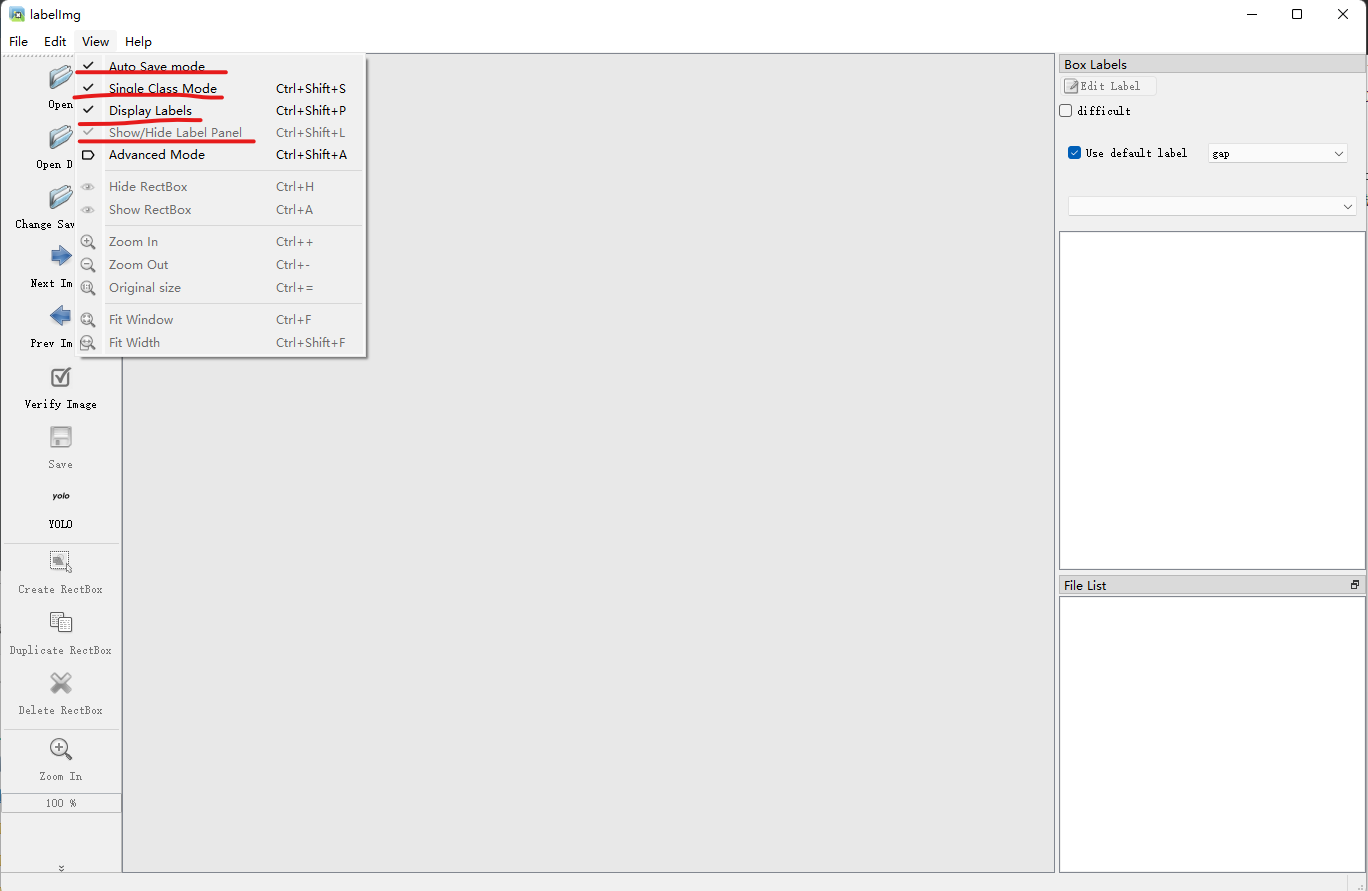
使用https://github.com/tzutalin/labelImg进行人工标注,将标注结果保存在lables文件夹
labelImg添加标注类型

注意红色位置

二、下载yolov5训练
下载地址https://github.com/ultralytics/yolov5
配置好环境,直接在命令行输入:
python train.py --img 640 --batch-size 4 --epochs 10 --data d:\MyDataset\Captcha_gap\gap.yaml --weights yolov5s.pt --nosave --cache
主要修改--batch-size,--epochs,--data
--batch-size,--epochs根据你电脑的配置修改,数值越大训练效果和时间越长,但有可能会爆内存错误,此时就得调小
--data是你准备的训练配置文件
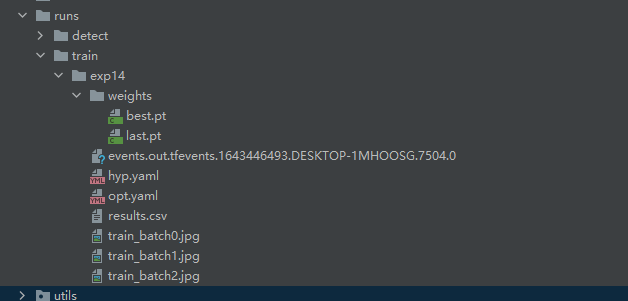
训练结束后会在run/train下生成一个文件夹exp开头的,训练成功会生成一个weights文件夹,里面有2个文件,一个是best.pt(最优模型)一个是last.pt(最后模型)
三、进行接口推理
三种方式:
1.命令行:
python detect.py --weights runs/train/exp14/weights/best.pt --img 640 --conf 0.25 --source D:\MyDataset\Captcha_gap\images\0ca47576-3b27-4b67-97bc-bf0205fad9fd.png
2.torch.hub:
import torch
# Model
model = torch.hub.load('ultralytics/yolov5',"custom",path=r'D:\PycharmProjects\pytorch_pro\yolov5\runs\train\exp14\weights\best.pt') # or yolov5m, yolov5l, yolov5x, custom
# Images
img = r'D:\MyDataset\Captcha_gap\images\5e6e475c-754d-4723-9412-4c048988a4d0.png' # or file, Path, PIL, OpenCV, numpy, list
# Inference
results = model(img)
# Results
results.show() # or .show(), .save(), .crop(), .pandas(), etc.
3.inference
import torch
import numpy as np
from models.experimental import attempt_load
from utils.general import non_max_suppression, scale_coords
from utils.torch_utils import select_device
import cv2
from random import randint
from utils.datasets import letterbox
class Detector(object):
def __init__(self):
self.img_size = 640
self.threshold = 0.4
self.max_frame = 160
self.init_model()
def init_model(self):
self.weights = r'D:\PycharmProjects\pytorch_pro\yolov5\runs\train\exp14\weights\best.pt'
self.device = '-1' if torch.cuda.is_available() else 'cpu'
self.device = select_device(self.device)
model = attempt_load(self.weights, map_location=self.device)
model.to(self.device).eval()
model.half()
# torch.save(model, 'test.pt')
self.m = model
self.names = model.module.names if hasattr(
model, 'module') else model.names
self.colors = [
(randint(0, 255), randint(0, 255), randint(0, 255)) for _ in self.names
]
def preprocess(self, img):
img0 = img.copy()
img = letterbox(img, new_shape=self.img_size)[0]
img = img[:, :, ::-1].transpose(2, 0, 1)
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(self.device)
img = img.half() # 半精度
img /= 255.0 # 图像归一化
if img.ndimension() == 3:
img = img.unsqueeze(0)
return img0, img
def plot_bboxes(self, image, bboxes, line_thickness=None):
tl = line_thickness or round(
0.002 * (image.shape[0] + image.shape[1]) / 2) + 1 # line/font thickness
for (x1, y1, x2, y2, cls_id, conf) in bboxes:
color = self.colors[self.names.index(cls_id)]
c1, c2 = (x1, y1), (x2, y2)
cv2.rectangle(image, c1, c2, color,
thickness=tl, lineType=cv2.LINE_AA)
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(
cls_id, 0, fontScale=tl / 3, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(image, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(image, '{} ID-{:.2f}'.format(cls_id, conf), (c1[0], c1[1] - 2), 0, tl / 3,
[225, 255, 255], thickness=tf, lineType=cv2.LINE_AA)
return image
def detect(self, im):
im0, img = self.preprocess(im)
pred = self.m(img, augment=False)[0]
pred = pred.float()
pred = non_max_suppression(pred, self.threshold, 0.3)
pred_boxes = []
image_info = {}
count = 0
for det in pred:
if det is not None and len(det):
det[:, :4] = scale_coords(
img.shape[2:], det[:, :4], im0.shape).round()
for *x, conf, cls_id in det:
lbl = self.names[int(cls_id)]
x1, y1 = int(x[0]), int(x[1])
x2, y2 = int(x[2]), int(x[3])
pred_boxes.append(
(x1, y1, x2, y2, lbl, conf))
count += 1
key = '{}-{:02}'.format(lbl, count)
# image_info[key] = ['{}×{}'.format(
# x2-x1, y2-y1), np.round(float(conf), 3)]
image_info[key]={"conf":np.round(float(conf), 3),"x1":x1,"y1":y1,"x2":x2,"y2":y2}
im = self.plot_bboxes(im, pred_boxes)
return im, image_info
if __name__ == '__main__':
model = Detector()
img=cv2.imread(r'D:\MyDataset\Captcha_gap\images\5e6e475c-754d-4723-9412-4c048988a4d0.png')
img_y, image_info = model.detect(img)
print(img_y, image_info)
四、结果展示
{'gap-01': {'conf': 0.932, 'x1': 182, 'y1': 87, 'x2': 228, 'y2': 134}}



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架