二十、mysql数据库
二十、mysql数据库
一、mysql数据库的基础知识
一、什么是数据
描述事物的符号记录称为数据,描述事物的符号既可以是数字,也可以是文字,图片,图像,声音,语言等,数据由多种表现形式,它们都可以经过数字化后存入计算机
二、什么是数据库
数据库就是存放数据的仓库,而且数据是按一定的格式存放的,数据库是长期存放在计算机内,有组织,可共享的数据
最原始的数据存放就是文件操作
文件操作的一些缺陷:
1.IO操作多,效率不高
2.多用户会竞争数据
3.需要网络来访问
4.用户登入要验证
三、常见数据库
关系型:数据之间存在某种关联关系,具有表结构
Oracle:目前最好的关系型数据库,体现在用户管理,分布式,商业用途收费
mysql:免费开源,功能支持没有Oracle强,但是可以满足中小企业使用,先后被sun和Oracle收购,mysql创始人担心mysql会闭源,于是另起炉灶,创建了Mariadb,Mariadb的使用和mysql方法一模一样
sqlserver:属于微软生态链,需要和Windows配合使用
DB2:IBM开发的大型关系型数据库,收费的,通常与硬件捆绑销售
非关系型:数据以key=value的形式来存储,数据存在内存中,速度快,没有表结构
MongoDB
Redis
memercach
四、数据库的相关概念
age=18,一个变量无法描述清楚数据
1.单个数据,称之为一个字段
age=18,name=maple,gender=male 一堆变量在一起,可以描述清楚数据
2.这一堆数据,称之为一条记录,对应着文件中的一行
文件需要分门别类,每个文件存储不同的数据
3.一个文件称之为表
文件越来越多,就得分文件夹
4.一个文件夹称之为库
数据库中包含所有内容:
字段,记录,表,库,DBMS,数据库服务器
数据库本质上就是一套C/S架构的socket软件
五、安装数据库与配置使用环境
1.代码 界面:傻瓜式安装,记住密码
2.绿色解压版:
1.5.7版本以后需要先初始化:mysqld --initialize-insecure
2.启动需要先进入安装目录,比较麻烦,需要添加到环境变量,打开环境变量,将mysql安装目录下的bin添加到path环境变量
3.将mysql加入到Windows的系统服务中
六、绿色版修改默认密码
注意:每次修改密码成功后,需要重启服务器
修改默认密码需要先登入成功
执行update语句直接修改user表中的密码
5.7版本
update mysql.user set authentication_string = password("需要修改的密码") where user = "root";
5.6版本
update mysql.user set password = password("需要修改的密码") where user = "root";
修改密码方式2 :不需要登入,需要知道旧密码
mysqladmin -uroot -p旧密码 password 新密码
破解密码,当忘记密码时,无法登入,也就不能直接执行update语句
破解思路:
1.启动服务器时,控制它不要加载授权表
2.无密码登入服务器
3.执行update mysql.user set authentication_string = password("需要修改的密码") where user = "root"
4.重启服务器
用到的系统指令:
1.mysqld直接运行服务器程序
2.mysql --skip-grant-tables跳过授权表,用于重设密码
3.tasklist | findstr mysqld taskkill /f /pid 结束服务器程序
4.mysql 运行客户端程序 -u用户名 -p密码 -h主机地址 -P端口号
5.mysqld --install 将mysqld注册当windows服务中 在服务中叫MySQL
Windows就是绑定了一个exe程序
sc delete mysql 删除windows服务
exit 退出客户端
5.7界面版,破解密码方法:
1.在my.ini文件的[mysqld]下添加一行skip-grant-tables
2.重启服务器
3.直接进入mysql修改密码
七、简单的sql语句
*****针对库的相关操作
增:
create database 库名称
删:
drop database 库名称
改:
alter database 库名称 要改的属性名称
alter database 库名称 DEFAULT CHARACTER SET utf8;
alter database 库名称 CHARSET utf8;
注意:在mysql中 utf8 不能写成utf-8
查:show databases;查看所有数据库
show create database 库名称; 查看建库的语句
命名规范:
大致和python命名规范相同,不区分大小写
1.不能使用纯数字
2.可以是数字,字母,下划线的组合
3.可以下划线开头
4.不能是关键字,如create
*****针对表相关的操作:
增:
建表时要明确数据库
use 数据库名
create table 表名称(字段名 类型(长度),。。。)
create table dog(nikename char(10)),gender char(10),age int);
创建时同时制定数据库
create table 库名称.表名称(字段名 类型(长度),。。。)
删:
drop table 表名;
改:
alter table 表名 drop|change|modify|add
drop 字段名称:alter table dog drop color;
change 旧的字段名 新的字段名 新的类型:alter table dog change gender sex char(2);
modify 字段名 新的类型:alter table dog modify color char(5);
add 字段名称 类型:alter table dog add color char(10);
重命名表:
rename table 旧表名称 to 新表名称:rename table dog to dogtable;
修改表的属性:
alter table 表名 属性名 值:alter table dogtable DEFAULT CHARSET gbk;
查:
show tables;查看所有表
desc 表名称;查看表结构
show create table 表名;查建表语句
*****针对记录的相关操作:
增:
insert into 表名 values(值1,值2.。。。)
删:
delete from 表名 where 字段名称=值
没有条件的话删除全部数据
改:
update 表名 set 字段名 =新的值 where 标识字段名(通常是name) = 值
没有条件的话修改全部值
查:
select *from 表名;*表示通配符,查看所有字段
select 字段名称1,字段名称2.。。。from 表名;
八、修改默认编码
配置文件放在安装路径根目录中,就是和bin同级的,名称必须叫my.ini
客户端的配置:
[client]
这里添加客户端的配置
[mysql]
这里也是添加客户端的配置
#如初始默认有账户密码
user=root
password=root
#默认的客户端编码
default-character-set=utf8
[mysqld]
#这里是服务端的配置
#默认的服务端编码
character-set-server = utf8
注意5.7界面版的,需要在bin同级目录和data同级目录都添加上my.ini文件
九、5.6版本和5.7版本的区别
1、5.7的绿色版需要初始化
2、5.6游客模式:没有密码也可以登入,但是无法操作数据,只能看到部分数据库
3、5.7绿色版中data数据存放目录是由初始化决定的,5.6ban就在安装目录中
4、密码存储字段名,在5.6中时password,而5.7中时authentication_string
二、更多详细SQL语句
1、详细的建表语句
create table 表名称(字段名 数据类型[(长度) 约束条件])
[]代表可选的
给数据分类的原因:
1.描述数据更加准确
2.节省内存空间
2、数据类型
1.整数类型:
默认有符号的
设置为无符号的
1.create table 表名称(字段名 tinyint unsigned);
2.建表后用alter修改:alter table 表名称 modify 字段名 属性值;
注意:对于整数类型而言长度不是数据所占的字节数,是现实数据时的宽度(字符数),默认情况下,存储数值的十进制位数小于所设置的显示宽度时,不会填充,没有任何效果。当数据的十进制位长度大于显示宽度时,可以正常显示
整数类型的具体分类:
tinyint:1个字节,最小整数型
smallint:2个字节,小整数型
mediumint:3个字节,中整数型
int:4个字节,整数型(常用)
bigint:8个字节,大整数型
总结区别:除了存储范围的不同,其他都一样,都是整型,默认有符号,显示宽度原理也相同
2.浮点类型:
浮点类型分类:
1.float:4字节
2.double:8字节
3.decimal :不固定字节
语法:
create table 表名称(字段名 float(m,d)
括号中的m和d,可以限制数据存储范围,与整型不同
m表示总长度,d表示小数部分的长度,长度的表示不是数据存储范围,而是字符长度,例如:10.12 总长为4 小数部分为2
各个类型的最大长度:
float:(255,30)
double:(255,30)
decimal:(65,30)
区别:
float与double的进度不同,都是不准确的小数
decimal是精准小数,不会丢失精度
具体使用哪种类型的根据使用场景判读,float能满足大部分使用场景,decimal适合银行系统,科学研究等
3.字符串类型:
常用的两种:
char:定长字符串
varchar:可变长度字符串
注意字符串中长度制定的是数据的字符长度,与字节没关系
create table 表名称(字段名 char,字段名 varchar(10));
在创建时varchar必须指定长度,char有默认值,默认值为1
不同点:
a char(3) b char(3)
A 3个空格,B3个空格
char类型在取数据时,就是根据长度来获取的,不关心真实数据长度,无论数据有多长,占用的空间是固定的,造成了一定的存储空间浪费
a varchar(30) b varchar(30)
(1)A (2)AB
varchar类型在取数据时,先获取数据长度,在根据长度获取真实数据,需要计算数据的真实长度,所以需要先在存储数据前加一个字节用来计算长度,再存储真实数据,不会浪费存储空间,但是由于需要计算数据的长度,所以存取速度比定长类型的慢
相同点:
括号中的数字,都是表示存储最大字符长度
4.枚举:enum,可以指定一堆字符串的值,在插入数据时,数据必须是这堆字符串中的某一个,多选一
5.集合:set,可以指定一堆字符串的值,在插入数据时,数据必须在这堆字符串中的某一个或多个,多选多
set和enum的共同点:数据都是字符串类型
三、严格模式
1.什么是严格模式:
对插入的数据严格要求,不在范围内的直接报错,例如往tinyint类型中插入大于255的数字
2.什么是非严格模式:
不对插入的数据严格要求,不在范围内也可以保存,保存的是当前类型最大支持的值
5.6默认是非严格模式
5.7默认是严格模式
查看SQL模式:
select @@sql_mode;
show varchar like 'sql_mode';
修改sql模式:
set @@sql_mode=‘值’;
正常情况不需要修改
四、日期和时间
常用的关键字:
year:年份
time:时间
date:日期
datetime:日期时间
timestamp:日期时间
timestamp的特点:可以给null自动输入当前时间,当这条记录被修改了会自动更新当前时间
*****注意:时间格式都必须加引号
datetime 和 timestam的区别 8字节 4字节 1001-9999 1970-2038 默认null 默认为当前时间 并且 update语句会自动更新为当前时间 以上所有类型都可以使用now() 函数来输入当前时间 在插入数据时 都可以使用字符串的方式来插入 insert into t8 value(now());
五、约束
约束就是一种对数据的限制
例如:数据类型 unsigned无符号,字符串长度,浮点的长度
约束的作用:
为了保证数据的正确性,完整性
例如:要存储密码char(20)只能限制类型和长度,无法保证数据的正确性
额外的约束语法:
创建时指定约束:
create table 表名称(字段名 类型(长度) 约束名称1 约束名称n,......);
后期修改的方式添加约束:
alter table 表名称 modify 字段名 类型(长度) 约束名称1 约束名称n,....);
常用的约束:
NOT NULL:非空约束,限制该字段的值不能为空
UNIQUE:唯一性约束,限制该字段的值是唯一的不能出现重复
DEFAULT:默认值约束,如果插入数据时没有指定该字段的值,则使用默认设置的值
PRIMARY KEY:主键约束,限制该字段不能为空,并且是唯一的,可以唯一标识一条数据
FOREIGN KEY:外键约束,用来指向另一个表的主键
注意点:
1.每一个表应该有一个主键,需要唯一标识,否则可能出现完全相同的两个数据,无法区分
2.UNIQUE 只能约束不能重复,但是可以为空,这样也不能唯一标识
3.UNIQUE NOT NULL 不能为空且唯一,可以唯一标识一条数据,约束的前后顺序没有关系
UNIQUE NOT NULL 与主键约束的区别:
1.UNIQUE NOT NULL 不能被其他表引用(不能作为其他表的外键)
2.UNIQUE NOT NULL 约束一个表中可以有多个,但是主键只能有一个
撤销约束名:
撤销UNIQUE约束:alter table 表名称 drop index 字段名;
撤销PRIMARY KEY约束:alter table 表名称 drop PRIMARY KEY;
撤销FOREIGN KEY约束:alter table 表名称 drop FOREIGN KEY 字段名;
撤销NOT NULL 约束:alter table 表名称 modify 字段名 数据类型 null;
六、初识索引
1.索引用于加速查询
2.InnoDB中,索引是树形结构
为了提高查询效率,InnoDB为的是找一个不为空且唯一的字段作为主键
如果表中不存在这样的字段,会自动帮你建一个隐藏主键字段,但是无法提升查询效率
只要是使用InnoDB就应该为每个表指定一个非空且唯一的字段
InnoDB组织数据时,首先使用主键,如果没有主键,找一个非空且唯一的,如果也没有,那么就建一个隐藏字段
多字段联合主键:不常用
例如:学生表 stu_id course_id 作为联合主键
1 1 已有数据
1 2 可以插入
2 1 可以插入
1 1 不能插入
只有当两个字段都重复才算重复
当一个表中,由于业务需求没有一个非空且唯一的字段时,我们可以建一个新的字段专门作为主键,从而来管理主键的值
由于管理主键的值比较麻烦,需要记得上一次插入的主键值,mysql可以帮你自动管理主键,auto_increment自动增加主键值,所以auto_increment一般就用整型字段表示,并且该字段必须具备索引,通常都和主键一起连用
手动修改自动增长的计数:
alter table 表名称 auto_increment 新的值;
注意:如果新的值小于当前的最大值,是无效的
通常建一个表就要建一个主键,主键的类型通常是整型
insert 语句的其他用法:
insert into 表名(字段名1,字段名n,。。。)values(值1,值n,。。。)
可以选择行得插入某些字段,要求值的顺序必须与表名后面声明的字段名一致
七、引擎
引擎:一个产品或服务的核心部分称之为引擎
mysql的核心功能就是存取数据
mysql存储引擎就是负责存取数据的那一段代码
查看引擎:show engines;
mysql的主要引擎:
1.InnoDB:默认引擎,存储在硬盘中
2.MRG_MYISAM:
3.MEMORY:
4.BLACKHOLE:数据存进去就立即消失
5.MyISAM:
6.CSV :
7.ARCHIVE :
8.PERFORMANCE_SCHEMA :
9.FEDERATED :
启动引擎语句:create table 表名称(字段名 类型)engine=引擎名称;
八、多表关联
1、多对一:
把所有数据都存放在一张表中的弊端:
1.表的组织结构复杂不清晰
2.浪费空间
3.扩展性极差
所以需要表与表之间的关系来解决问题
例如:
create table dept(id int primary key auto_increment,name char(20),job char(20));
create table emp(id int primary key auto_increment,name char(20),gendr char,age int,salary float,d_id int);
以上代码可以建立关联关系,但是这个关系是逻辑上的,实际不存在,需要为他建立物理上的关联,我们可以通过外键来约束
create table 表名(字段名 类型(长度),foreign key(外键的字段名称) references 对方表名(对方主键名));
使用外键时,必须分清主从关系
外键的第一种约束:
先建主表
再建从表
create table dept(id int primary key auto_increment,name char(20),job char(20));
create table emp(id int primary key auto_increment,name char(20),d_id int,foreign key(d_id) references dept(id));
外键的第二个约束:
先插入主表
再插入从表
外键的第三个约束:
删除记录时
先删除从表记录
再删除主表记录
外键的第四个约束:
从表更新外键时,必须保证外键是存在的
外键的第五个约束:
更新主表的id时
必须先删除从表关联的数据
或者把关联数据关联到其他的主表id
外键的第六个约束:
删除主表时,要先删除从表
2、级联
有了这几个约束后,主表和从表中的数据必然是完整的,相应也会受到外键约束,当主表要删除和更新操作时就会被限制,很多情况下,我们就是要删除一个部门的表,然而需要至少2条sql语句来搞定,这时我们就可以使用级联
create table emp( id int primary key auto_increment, name char(20), d_id int, foreign key(d_id) references dept(id) on delete cascade on update cascade );
on delete cascade:当主表删除记录时,从表相关联的记录同步删除
on update cascade:当主表id更新时,从表相关联的记录同步更新
注意点:单向操作,只能是操作主表影响从表,不能是操作从表想来影响主表。
3、多对多
两张表之间是一个双向的多对一关系,称之为多对多
实现多对多需要建立第三张表,该表中有一个字段关联表1,另一字段关联表2
例如:老师和学生
一个老师可以教多个学生,一个学生可以被多个老师教,老师表和学生表是多对多的关系,需要一个中间表专门存储关联关系
create table teacher(id int primary key auto_increment,name char(15)); create table student(id int primary key auto_increment,name char(15)); #中间表 create table tsr( id int primary key auto_increment, t_id int,s_id int, foreign key(t_id) references teacher(id), foreign key(s_id) references student(id) );
#现在老师和学生 都是主表 关系表是从表 #先插入老师和学生数据 insert into teacher values (1,"高跟"), (2,"矮跟"); insert into student values (1,"炜哥"), (2,"仨疯"); # 插入对应关系 insert into tsr values (null,1,1), (null,1,2), (null,2,2);
4、一对一
一对一就是左表的一条记录唯一对应右表的一条记录,反之也一样
例如:客户和学生
一个客户只能产生一个学生,一个学生只能对应一个客户,这样的关系是一对一的,使用外键来关联,但是需要给外键加上唯一约束,客户和学生有主从关系,需要先建立客户再建学生
create table customer(c_id int primary key auto_increment, name char(20),phonenum char(11),addr char(20)); create table student1(s_id int primary key auto_increment, name char(20), class char(11), number char(20), housenum char(20),c_id int UNIQUE, foreign key(c_id) references customer(c_id) );
一对一的另一种使用场景:
当一个表中字段太多,而常用字段不多时,可以采取垂直分表的方式来提高效率
例如:原有的person表中有,姓名,性别,年龄,身份证,地址,名族,身高,体重,血型,学历,政治,联系方式
我们可以把原表拆分为2个,一个常用,一个不常用
person_use info:姓名,性别,年龄,联系方式
person_details info:身份证,地址,名族,身高,体重,血型,学历,政治
也有另一种提升效率的方式,水平分表
当一个表中数据记录太多时,查询效率会降低,可以采取水平分表方式,字段完全相同,就是表名不同
总结:在日常开发中,如果性能要求贼高,不应该使用外键
1.效率会降低
2.耦合关系多起来,以后的管理会麻烦
3.很有可能产生错误数据
5、清空表
delete from 表名称;
该条命令确实可以将表里的所有记录都删除,但是不会将id重置为0,所以该条命令根本不是用来清空表的,而是用来删除表中某些符合条件的记录
例如:delete from T1 where id>10;
如果要清空表,就使用truncate T1;将整张表重置,它的执行过程是先记录表结构,再删除整个表再重新建出新表,自增的id会归零
6、补充:表的修改,复制,蠕虫复制
1.修改表:
add:添加字段 after,first
after:添加字段到指定字段后面
first:添加字段到最前面
modify:修改字段类型
change:修改字段名称或类型
drop:删除字段
rename:改表名
2.复制表:
create table 新的表名 select *from 原表名;
只复制数据,结构,不能复制约束
当条件不成立时,只是复制表结构
create table 新的表名 select *from 原表名 where 1=2;
3.蠕虫复制:
本质就是自我复制
insert into 表名称 select *from 自己的表名称;
如果有主键,避开主键字段
insert into 表名称(其他字段)select 其他字段 from 表名称;
九、表查询
1、不带关键字的查询
select {1.*|2.字段名|3.四则运算|4.聚合函数} from 表名 [where 条件]
1.表示查询所有字段
2.可以手动查询需要的字段
3.字段的值可以进行加减乘除运算
4.聚合函数,用于统计数据
select 的完整语法:
例如:
create table stu(id int primary key auto_increment,name char(10),math float,english float); insert into stu values(null,"赵云",90,30); insert into stu values(null,"小乔",90,60); insert into stu values(null,"小乔",90,60); insert into stu values(null,"大乔",10,70); insert into stu values(null,"李清照",100,100); insert into stu values(null,"铁拐李",20,55); insert into stu values(null,"小李子",20,55);
2、关键字的作用
distinct:去除重复数据,所有数据全部都重复才算重复
where:在逐行读取数据时的一个判断条件
group by:对数据分组
having:对分组后的数据进行过滤
order by:对结果排序
limit:指定获取数据条数
distinct:去除重复数据,所有数据全部都重复才算重复 select distinct name,math,english from stu ;
where:在逐行读取数据时的一个判断条件 select *from stu where math=90;
group by:对数据分组,group by后面跟的字段名需要与from前面的字段名一一对应,原因是group by会把分组以外的字段名数据都隐藏起来 select math from stu group by math;
注意:
1.只有出现在group by 后面的字段 才可以被显示 其他都被影藏了
2.聚合函数不能写在where的后面,where最先执行,它的作用硬盘读取数据并过滤,以为数据还没有读取完,此时不能进行统计
聚合函数:
sum
count
avg
max
min
having:对分组后的数据进行过滤 select math from stu group by math having math>90;
order by:对结果排序 select *from stu order by math;
order by 排序用的
asc 表示升序 是默认的
desc 表示降序
by 后面可以有多个排序依据
limit:指定获取数据条数 select *from stu limit 0,2;
limit a,b
limit 1,5
从1开始 到5结束 错误
从1开始 不包含1 取5条
分页查询
每页显示3条 共有10条数据
if 10 % 3 == 0:
10 / 3
else:
10/3 +1
总页数4
第一页
select *from emp limit(0,3)
第二页
select *from emp limit(3,3)
第二页
select *from emp limit(6,3)
起始位置的算法
页数 - 1 * 条数
1 - 1 = 0 * 3 = 0
2 - 1 = 1 * 3 = 3
完整的select 语句 语法:
select [distinct] * from 表名
[where
group by
having
order by
limit
]
注意在书写时,必须按照这个顺序来写,但是书写顺序不代表执行顺序
数据库的执行顺序伪代码:
def from(): 打开文件 def where(): 对读取的数据进行过滤 def group_by(): 对数据分组 def having(): 对分组后的数据进行过滤 def distinct(): 去除重复数据 def order(): 排序 def limit(): 指定获取条数 select 语句的执行顺序 def select(sql): data = from() data = where(data) data = group by(data) data = having(data) data = distinct(data) data = orderby(data) data = limit(data) return data;
指定显示格式:
concat()函数用于拼接字符串
select ( case when english + math > 120 then concat(name," nice") when english + math <= 130 then concat(name," shit") end ) ,english,math from stu;
where约束:
1. 比较运算符:> < >= <= <> != 2. between 80 and 100 值在10到20之间 3. in(80,90,100) 值是10或20或30 4. like 'egon%' pattern可以是%或_, %表示任意多字符 _表示一个字符 5. 逻辑运算符:在多个条件直接可以使用逻辑运算符 and or not
聚合函数:
#计算函数 SELECT COUNT(*) FROM 表名; #计算后加条件过滤 SELECT COUNT(*) FROM 表名 WHERE 字段名=1; #求最大值 SELECT MAX(salary) FROM 表名; #求最小值 SELECT MIN(salary) FROM 表名; #求平均值 SELECT AVG(salary) FROM 表名; #求总合 SELECT SUM(salary) FROM 表名; #求总合加条件过滤 SELECT SUM(salary) FROM 表名 WHERE 字段名=3;
了解:
在mysql 5.6中 分组后会默认显示 每组的第一条记录 这是没有意义的,
在5.7中不显示 因为5.7中sql_mode中自带ONLY_FULL_GROUP_BY group by 后面可以有多个分组与依据 会按照顺序执行
3、正则表达式匹配
由于like只能使用%和_不太灵活
可以将like换为regexp 来使用正则表达式
regexp正则表达式匹配 select *from stu where math regexp '9';
模式 描述 ^ 匹配输入字符串的开始位置。 $ 匹配输入字符串的结束位置。 . 匹配任何字符(包括回车和新行) [...] 字符集合。匹配所包含的任意一个字符。例如, '[abc]' 可以匹配 "plain" 中的 'a'。 [^...] 负值字符集合。匹配未包含的任意字符。例如, '[^abc]' 可以匹配 "plain" 中的'p'。 p1|p2|p3 匹配 p1 或 p2 或 p3。例如,'z|food' 能匹配 "z" 或 "food"。'(z|f)ood' 则匹配 "zood" 或 "food"。 # ^ 匹配 name 名称 以 "e" 开头的数据 select * from person where name REGEXP '^e'; # $ 匹配 name 名称 以 "n" 结尾的数据 select * from person where name REGEXP 'n$'; # . 匹配 name 名称 第二位后包含"x"的人员 "."表示任意字符 select * from person where name REGEXP '.x'; # [abci] 匹配 name 名称中含有指定集合内容的人员 select * from person where name REGEXP '[abci]'; # [^alex] 匹配 不符合集合中条件的内容 , ^表示取反 select * from person where name REGEXP '[^alex]'; #注意1:^只有在[]内才是取反的意思,在别的地方都是表示开始处匹配 #注意2 : 简单理解 name REGEXP '[^alex]' 等价于 name != 'alex' # 'a|x' 匹配 条件中的任意值 select * from person where name REGEXP 'a|x'; #查询以w开头以i结尾的数据 select * from person where name regexp '^w.*i$'; #注意:^w 表示w开头, .*表示中间可以有任意多个字符, i$表示以 i结尾
4、多表查询
例如:
#数据准备 create table emp (id int,name char(10),sex char,dept_id int); insert emp values(1,"大黄","m",1); insert emp values(2,"老王","m",2); insert emp values(3,"老李","w",30); create table dept (id int,name char(10)); insert dept values(1,"市场"); insert dept values(2,"财务"); insert dept values(3,"行政");
1、笛卡尔积查询
select *from 表1,表n
查询结果是:
将左表中的每条记录与右表中的每条记录都关联一遍,因为它不知道什么样的对应关系是正确的,只能帮你全都对一遍
如果a表有m条记录,b表有n条记录
笛卡尔积结果为m*n记录
需要自己筛选出正确的关联关系
select *from emp,dept where emp.dept_id = dept.id;
2、内连接查询,就是笛卡尔积查询
select *from emp [inner] join dept; select *from emp inner join dept where emp.dept_id = dept.id;
3、左外连接查询
select *from emp left join dept on emp.dept_id = dept.id; 左表数据全部显示 右表只显示匹配上的
4、右外连接查询
select *from emp right join dept on emp.dept_id = dept.id; 右表数据全部显示 左表只显示匹配上的
内和外的理解:内指的是匹配上的数据,外指的是没有匹配上的数据
5、全外连接
select *from emp full join dept on emp.dept_id = dept.id; 注意:此full语句mysql不支持
union 合并查询结果 select *from emp left join dept on emp.dept_id = dept.id union select *from emp right join dept on emp.dept_id = dept.id; union 去除重复数据 ,只能合并字段数量相同的表 union all 不会去除重复数据
on 关键字:
在单表中where的作用是筛选过滤条件,在多表中where是连接多表,满足条件就连接,不满足就不连接,为了区分是单表还是多表,新增加了一个名字就是on,只要是连接多表条件的就使用on
三表查询:
例如:
create table stu(id int primary key auto_increment,name char(10)); create table tea(id int primary key auto_increment,name char(10)); create table tsr(id int primary key auto_increment,t_id int,s_id int, foreign key(s_id) references stu(id), foreign key(s_id) references stu(id)); insert into stu values(null,"张三"),(null,"李四"); insert into tea values(null,"egon"),(null,"wer"); insert into tsr values(null,1,1),(null,1,2),(null,2,2); select *from stu join tea join tsr on stu.id = tsr.s_id and tea.id = tsr.t_id where tea.name = "egon";
多表查询的套路:
1.把所有表都连起来
2.加上连接条件
3.如果有别的过滤条件加上where
5、子查询
当一个查询的结果是另一个查询的条件时,这个查询称之为子查询(内层查询)
什么时候使用子查询:
当一个查询无法得到想要的结果时,需要多次查询
解决问题的思路:
就是把一个复杂的问题,拆分为多个简单的问题
然后把一个复杂的查询,拆分成多个简单的查询
in 关键字查询
查询平均年龄⼤于25的部⻔名称 ⼦查询⽅式: 平均年龄⼤于25的部⻔id有哪些? 先要求出每个部⻔的平年龄! 筛选出平均年龄⼤于25的部⻔id 拿着部⻔id 去查询部⻔表查询 select name from dept where id in (select dept_id from emp group by dept_id having avg(age) > 25);
exists 关键字⼦查询 exists 后跟⼦查询 ⼦查询有结果是为True 没有结果时为False 为true时外层执行 为false外层不执⾏行 select *from emp where exists (select *from emp where salary > 1000);
6、在mysql中的操作
mysql> select *from dept,emp; +------+--------+------+--------+------+---------+ | id | name | id | name | sex | dept_id | +------+--------+------+--------+------+---------+ | 1 | 市场 | 1 | 大黄 | m | 1 | | 2 | 财务 | 1 | 大黄 | m | 1 | | 3 | 行政 | 1 | 大黄 | m | 1 | | 1 | 市场 | 2 | 老王 | m | 2 | | 2 | 财务 | 2 | 老王 | m | 2 | | 3 | 行政 | 2 | 老王 | m | 2 | | 1 | 市场 | 3 | 老李 | w | 30 | | 2 | 财务 | 3 | 老李 | w | 30 | | 3 | 行政 | 3 | 老李 | w | 30 | +------+--------+------+--------+------+---------+ 9 rows in set (0.01 sec) mysql> select *from dept; +------+--------+ | id | name | +------+--------+ | 1 | 市场 | | 2 | 财务 | | 3 | 行政 | +------+--------+ 3 rows in set (0.00 sec) mysql> select *from emp; +------+--------+------+---------+ | id | name | sex | dept_id | +------+--------+------+---------+ | 1 | 大黄 | m | 1 | | 2 | 老王 | m | 2 | | 3 | 老李 | w | 30 | +------+--------+------+---------+ 3 rows in set (0.00 sec) mysql> select *from dept,emp where dept.id=emp.id; +------+--------+------+--------+------+---------+ | id | name | id | name | sex | dept_id | +------+--------+------+--------+------+---------+ | 1 | 市场 | 1 | 大黄 | m | 1 | | 2 | 财务 | 2 | 老王 | m | 2 | | 3 | 行政 | 3 | 老李 | w | 30 | +------+--------+------+--------+------+---------+ 3 rows in set (0.00 sec) mysql> select *from dept join emp on dept.id=emp.id; +------+--------+------+--------+------+---------+ | id | name | id | name | sex | dept_id | +------+--------+------+--------+------+---------+ | 1 | 市场 | 1 | 大黄 | m | 1 | | 2 | 财务 | 2 | 老王 | m | 2 | | 3 | 行政 | 3 | 老李 | w | 30 | +------+--------+------+--------+------+---------+ 3 rows in set (0.00 sec) mysql> select *from dept join emp on dept.id=emp.dept_id; +------+--------+------+--------+------+---------+ | id | name | id | name | sex | dept_id | +------+--------+------+--------+------+---------+ | 1 | 市场 | 1 | 大黄 | m | 1 | | 2 | 财务 | 2 | 老王 | m | 2 | +------+--------+------+--------+------+---------+ 2 rows in set (0.00 sec) mysql> select *from dept left join emp on dept.id=emp.dept_id; +------+--------+------+--------+------+---------+ | id | name | id | name | sex | dept_id | +------+--------+------+--------+------+---------+ | 1 | 市场 | 1 | 大黄 | m | 1 | | 2 | 财务 | 2 | 老王 | m | 2 | | 3 | 行政 | NULL | NULL | NULL | NULL | +------+--------+------+--------+------+---------+ 3 rows in set (0.00 sec) mysql> select *from dept right join emp on dept.id=emp.dept_id; +------+--------+------+--------+------+---------+ | id | name | id | name | sex | dept_id | +------+--------+------+--------+------+---------+ | 1 | 市场 | 1 | 大黄 | m | 1 | | 2 | 财务 | 2 | 老王 | m | 2 | | NULL | NULL | 3 | 老李 | w | 30 | +------+--------+------+--------+------+---------+ 3 rows in set (0.00 sec) mysql> select *from dept right join emp on dept.id=emp.dept_id -> union -> select *from dept left join emp on dept.id=emp.dept_id; +------+--------+------+--------+------+---------+ | id | name | id | name | sex | dept_id | +------+--------+------+--------+------+---------+ | 1 | 市场 | 1 | 大黄 | m | 1 | | 2 | 财务 | 2 | 老王 | m | 2 | | NULL | NULL | 3 | 老李 | w | 30 | | 3 | 行政 | NULL | NULL | NULL | NULL | +------+--------+------+--------+------+---------+ 4 rows in set (0.02 sec)
十、mysql用户管理
1、数据库的安全非常重要,不可能随便分配root账户,应该按照不同开发岗位的需求分配不同的账户和权限,在mysql中,将用户相关的数据存放在mysql库中:
账户和权限的存放文件顺序:
user——》db——》tables_priv——》columns_priv
如果用户拥有对所有库的访问权:存放在user文件中
如果用户拥有对部分库的访问权:存放在db文件中
如果用户拥有对部分表的访问权:存放在tables_priv文件中
如果用户拥有对表中的某些字段的访问权:存放在columns_priv文件中
2、创建新账户
语法:
create user "账户名"@"主机名" identified by 密码 create user "tom"@"localhost" identified by "123";
授予所有数据库所有表的所有权限给maple这个用户,并允许maple在任意一台电脑上登入:
如果用户在不存在会自动创建
grant all on *.* to "maple"@"%" identified by "123" with grant option; with grant option:这个用户可以将拥有的权限授予别人
授予db1数据库所有表的所有权限给jack这个用户 并允许maple在任意一台电脑登录: grant all on db1.* to "maple"@"%" identified by "123"; 授予db1数据库的emp表的所有权限给maple这个用户 并允许maple在任意一台电脑登录: grant all on db1.emp to "maple"@"%" identified by "123"; 授予db1数据库的emp表的name字段的查询权限给maple这个用户 并允许maple在任意一台电脑登录: grant select(name) on db1.emp to "maple"@"%" identified by "123";
3、收回权限
语法:
REVOKE all privileges [column] on db1.table from user@"host"; 如何授权就如何收回 因为不同权限信息存到不同的表中 REVOKE all privileges on db1.emp from maple@"%"; 立即刷新权限信息 flush privileges;
4、删除用户
语法:
drop user 用户名@主机 drop user maple@% 当你在云服务器部署了 mysql环境时,你的程序无法直接连接到服务器 ,需要授予在任意一台电脑登录的权限 grant all on *.* to "maple"@"%" identified by "123" with grant option;
十一、pymysql
后期开发中都是用框架代替在cmd中写mysql语句,所有我们以后要学习pymysql模块
使用pymysql使我们能方便的在程序中连接数据库,然后进行增删改查的擦作
1 import pymysql 2 3 conn=pymysql.connect(host='127.0.0.1', 4 port=3306, 5 user='root', 6 password='123', 7 database='db2', 8 charset='utf8') 9 # cursor 游标对象 负责执行sql语句 获取返回的数据 10 # pymysql.cursors.DictCursor指定使用字典类型的游标 默认是元祖类型 11 cursor=conn.cursor(pymysql.cursors.DictCursor) 12 13 sql='select *from emp2;' 14 15 # 返回值是本次查询的记录条数 16 res=cursor.execute(sql) 17 print(res) 18 # 提取一条结果,游标移动到第二条记录前 19 res=cursor.fetchone() 20 print(res) 21 # 提取所有结果,游标移动到最后 22 res=cursor.fetchall() 23 for line in res: 24 print(line) 25 26 # 提取指定条数结果,游标移动到指定条数后 27 res=cursor.fetchmany(3) 28 print(res) 29 30 # 游标从当前位置往前移动1条记录 31 cursor.scroll(-1,mode='relative') 32 33 # 游标从开始位置往后移动1条记录 34 cursor.scroll(1,mode="absolute") 35 36 # 增删改pymysql不会自动提交 ,对数据的修改不会持久化 需要手动commit 37 conn.commit()
#防止sql注入攻击 import pymysql conn = pymysql.connect( host="127.0.0.1", port=3306, user="root", password="123", database="db2", charset="utf8" ) # cursor 游标对象 负责执行sql语句 获取返回的数据 # pymysql.cursors.DictCursor指定使用字典类型的游标 默认是元祖类型 cursor = conn.cursor(pymysql.cursors.DictCursor) name = input("输入用户名:") pwd = input("输入密码:") sql = "select *from user where name = %s and password = %s" res = cursor.execute(sql,(name,pwd)) if res: print("登录成功") else: print("登录失败") # 什么是sql注入攻击 一些了解sql语法的攻击者 可以通过一些特殊符号 来修改 sql执行逻辑 达到绕过验证的效果 # 避免的方式 1.在输入时加上正则判断 不允许输入与sql相关的关键字 这种方式 无法避免 代理服务器发起的攻击 # 2.在服务器端 执行sql前先来一波判断 # pymysql中已经帮你做了处理 只要将参数的拼接交给pymysql来完成就能够避免攻击
十二、视图
1、什么是视图
视图是由一张表或多张表的查询结果构成的一张虚拟表
2、为什么使用视图
当我们在使用多表查询时,我们的sql语句可能会非常的复杂,如果每次都编写以便sql语句的话,无疑是一件麻烦的事情,这时候就可以使用视图来避免多次编写sql的问题
简单的说可以帮我们节省sql的编写
视图的另一个作用是:可以用不同的视图来展示开放不同数据的访问
例如:
同一张工资表,老板可以查看全部,部门主管可以查看该部门所有人,员工只能看自己的一条记录
3、使用方法
创建视图
CREATE [OR REPLACE] VIEW view_name [(column_list)]
AS select_statement
加上or replace时如果已经存在相同视图则替换原有视图
column_list指定哪些字段要出现在视图中
注意:由于是一张虚拟表,视图中的数据实际上来源于其他表,所以在视图中的数据不会出现在硬盘上
使用视图
视图是一张虚拟表,所有使用方式与普通表没有区别
查看视图
1.desc view_name;//查看数据结构
2.show create view view_name;//查看创建语句
修改视图
alter view_name select_statement
删除视图
drop view view_name
案列1:简化多表sql语句
#准备数据 create database db02 charset utf8; use db02 create table student( s_id int(3), name varchar(20), math float, chinese float ); insert into student values(1,'tom',80,70),(2,'jack',80,80),(3,'rose',60,75); create table stu_info( s_id int(3), class varchar(50), addr varchar(100) ); insert into stu_info values(1,'二班','安徽'),(2,'二班','湖南'),(3,'三班','黑龙江'); #创建视图包含 编号 学生的姓名 和班级 create view stu_v (编号,姓名,班级) as select student.s_id,student.name ,stu_info.class from student,stu_info where student.s_id=stu_info.s_id; # 查看视图中的数据 select *from stu_v;
案例2:隔离数据
# 创建工资表 create table salarys( id int primary key, name char(10), salary double, dept char(10) ); insert into salarys values (1,"刘强东",900000,"市场"), (2,"马云",800090,"市场"), (3,"李彦宏",989090,"财务"), (4,"马化腾",87879999,"财务"); # 创建市场部视图 create view dept_sc as select *from salarys where dept = "市场"; # 查看市场部视图 select *from dept_sc;
注意:对视图数据的insert update delete会同步到原表中,但由于视图可能是部分字段,很多时候会失败
总结:mysql可以分担程序中的部分逻辑,但这样一来后续的维护会变得更麻烦,如果需要改表结构,那意味着视图也需要相应的修改,没有直接在程序中修改sql来的方便
十三、触发器
1、什么是触发器
触发器是一段与表有关的mysql程序,当这个表在某个时间点发生了某种事件时,将会自动执行相应的触发器程序
2、何时使用触发器
当我们想要在一个表记录被更新时,做一些操作时就可以使用触发器
但是我们完全可以在python中来完成这个事情,因为python的扩展性更强,语法更简单
3、创建触发器
语法:
CREATE TRIGGER t_name t_time t_event ON table_name FOR EACH ROW
begin
stmts.....
end
支持的时间点t_time:时间发生前和发生前后before|after
支持的事件t_even:update insert delete
在触发器中可以访问到将被修改的那一行数据,根据事件不同,能访问也不同,update可用old访问旧数据,new访问新数据,insert 可用new访问新数据delete,可用old访问旧数据
可以将new和old看做一个对象其中封装了这列数据的所有字段
案例:
有cmd表和错误日志表,需要:在cmd执行失败时自动将信息存储到错误日志表中
#准备数据 CREATE TABLE cmd ( id INT PRIMARY KEY auto_increment, USER CHAR (32), priv CHAR (10), cmd CHAR (64), sub_time datetime, #提交时间 success enum ('yes', 'no') #0代表执行失败 ); #错误日志表 CREATE TABLE errlog ( id INT PRIMARY KEY auto_increment, err_cmd CHAR (64), err_time datetime ); # 创建触发器 delimiter // create trigger trigger1 after insert on cmd for each row begin if new.success = "no" then insert into errlog values(null,new.cmd,new.sub_time); end if; end// delimiter ; #往表cmd中插入记录,触发触发器,根据IF的条件决定是否插入错误日志 INSERT INTO cmd ( USER, priv, cmd, sub_time, success ) VALUES ('egon','0755','ls -l /etc',NOW(),'yes'), ('egon','0755','cat /etc/passwd',NOW(),'no'), ('egon','0755','useradd xxx',NOW(),'no'), ('egon','0755','ps aux',NOW(),'yes'); # 查看错误日志表中的记录是否有自动插入 select *from errlog;
delimiter用于修改默认的行结束符,由于在触发器中有多条sql语句,他们需要使用分号来结束,但是触发器是一个整体,所有我们需要先更换默认的结束符,在触发器编写完后再将结束符设置回分号
注意:外键不能触发事件,主表删除了某个主键,从表也会相应删除,但是并不会执行触发器,触发器中不能使用事务,相同时间点的相同事件的触发器不能同时存在
4、删除触发器
语法: drop trigger trigger_name; 案例: drop trigger trigger1;
同样的这种需求我们完全可以在python中来完成,mysql最想完成的事情是将所有能处理的逻辑全部放到mysql中,那样一来应用程序开发者的活儿就变少了,相应的数据库管理员的工资就高了,可惜大多中小公司都没有专门的DBA
十四、事务
1、什么是事务
事务是逻辑上的一组操作,要么都成功,要么都失败
2、为什么需要事务
很多时候一个数据操作,不是一个sql语句就能完成的,可能有很多个sql语句,如果部分sql执行成功而部分sql执行失败将导致数据错乱
例如转账操作:
1.从原有账户减去转账金额
2.给目标账户加上转账 金额
若中间突然断电了或系统崩溃了,钱就不翼而飞了
3、使用事务
start transaction;开始事务,在这条语句之后的sql将处在同一事务,并不会立即修改数据库
commit;提交事务,让这个事务中的sql立即执行数据的操作
rollback;回滚事务,取消这个事务,这个事务不会对数据库中的数据产生任何影响
案例:转账过程中发生异常
#准备数据 create table account( id int primary key auto_increment, name varchar(20), money double ); insert into account values(1,'赵大儿子',1000); insert into account values(2,'刘大牛',1000); insert into account values(3,'猪头三',1000); insert into account values(4,'王进',1000); insert into account values(5,'黄卉',1000); # 赵大儿子刘大牛佳转账1000块 # 未使用事务 update account set money = money - 1000 where id = 1; update account set moneys = money - 1000 where id = 1; # money打错了导致执行失败 # 在python中使用事务处理 sql = 'update account set money = money - 1000 where id = 1;' sql2 = 'update account set moneys = money + 1000 where id = 2;' # money打错了导致执行失败 try: cursor.execute(sql) cursor.execute(sql2) conn.commit() except: conn.rollback()
注意:事务的回滚的前提是能捕捉到异常,否则无法决定何时回滚,python中很简单就能实现了,另外mysql中需要使用存储过程才能捕获异常
4、事务的四个特性
1.原子性:
事务是一组不可分割的单位,要么同时成功,要么同时失败
2.一致性:
事务前后的数据完整性因该保持一致,(数据库的完整性:如果数据库在某一时间点下,所有的数据都符合所有的约束,则称数据量为完整性的状态)
3.隔离性:
事务的隔离性是指多个用户并发访问数据时,一个用户的事务不能被其他用户的事务所干扰,多个并发事务之间数据要相互隔离
4.持久性:
持久性是指一个事务一旦被提交,它对数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响
5、事务的用户隔离级别
数据库使用者可以控制数据库工作在哪个级别下,就可与防止不同的隔离性问题
1.read uncommitted 不做任何隔离,可能脏读,幻读
2.read committed 可以防止脏读,不能防止不可重复读,和幻读
3.repeatable read 可以防止脏读和不可重复读,不能防止幻读
4.serializable 数据库运行在串行化,所有问题都没有了,就是性能低
6、修改隔离级别
#查询当前级别 select @@tx_isolation; #修改级别 set [session|global] transaction isolation level。。。。; #实例 set global transaction isolation level repeatable read;
十五、存储过程
1、什么是存储过程
存储过程是一组任意的sql语句的集合,存储在mysql中,调用存储过程时将会执行其包含的所有sql语句,与python中函数类似
2、为什么使用存储过程
回顾触发器与视图都是为了简化应用程序中sql语句的书写,但是还是需要编写,而存储过程中可以包含任何的sql语句,包括视图,事务,流程控制等,这样一来,应用程序可以从sql语句中完全解放,mysql可以代替应用程序完成数据相关的逻辑处理,但是有缺点,请看下面的对比
3、三种开发方式对比
1.应用程序仅负责业务逻辑编写,所有与数据相关的逻辑都交给mysql来完成,通过存储过程
优点:
应用程序与数据处理完全解耦合,一堆复杂的sql被封装成了一个简单的存储过程,考虑到网络环境因素,效率高,应用程序开发者不需要编写sql语句,开发效率高
缺点:
python语法与mysql语法区别巨大,学习成本高,并且各种数据库的语法大不相同,所以移植性非常差,应用程序开发者与BDA的库部门沟通成本也高,造成整体效率低
2.应用程序不仅编写业务逻辑,还需要编写所有的sql语句
优点:
扩展性高,对于应用程序开发者而言,扩展性和维护性相较于第一种都有所提高
缺点:
sql语句过于复杂,导致开发效率低,且需要考虑sql优化问题
3.应用程序仅负责业务逻辑,sql语句的编写交给ORM框架,(以后常用方案)
优点:
应用程序开发者不需要编写sql语句,开发效率高
缺点:
执行效率低,由于需要将对象的操作转化为sql语句,且需要通过网络发送大量sql语句
4、创建存储过程
create procedure pro_name(p_Type p_name data_type) begin sql语句......流程控制 end
p_type:参数类型
in:表示输入参数
out:表示输出参数
inout:表示既能输入,又能输出
p_name:参数名称
data_type:参数类型,可以是mysql支持的所有数据类型
案例:使用存储过程完成对student表的查询
delimiter // create procedure p1(in m int,in n int,out res int) begin select *from student where chinese > m and chinese < n; #select *from student where chineseXXX > m and chinese < n; #修改错误的列名以测试执行失败 set res = 100; end// delimiter ; set @res = 0; #调用存储过程 call p1(70,80,@res); #查看执行结果 select @res;
#*****需要注意的是,存储过程的out类参数必须是一个变量,不能是值;
5、在python中调用存储过程
1 import pymysql 2 #建立连接 3 conn = pymysql.connect( 4 host="127.0.0.1", 5 user="root", 6 password="admin", 7 database="db02" 8 ) 9 # 获取游标 10 cursor = conn.cursor(pymysql.cursors.DictCursor) 11 12 # 调用用存储过程 13 cursor.callproc("p1",(70,80,0)) #p1为存储过程名 会自动为为每个值设置变量,名称为 @_p1_0,@_p1_1,@_p1_2 14 # 提取执行结果是否有结果取决于存储过程中的sql语句 15 print(cursor.fetchall()) 16 # 获取执行状态 17 cursor.execute("select @_p1_2") 18 print(cursor.fetchone())
此处pymysql会自动将参数都设置一个变量,所以可以直接传入一个值,当然值如果作为输出参数的话,传入什么都无所谓
6、删除存储过程
drop procedure 过程名称;
修改存储过程意义不大,不如删除重写
查看存储过程
#当前库所有存储过程名称 select `name` from mysql.proc where db = 'db02' and `type` = 'PROCEDURE'; #查看创建语句 show create procedure p1;
7、存储过程中的事务应用
存储过程中的支持任何的sql语句包括事务
案例:模拟转账中发送异常,进行回滚
delimiter // create PROCEDURE p5( OUT p_return_code tinyint ) BEGIN DECLARE exit handler for sqlexception BEGIN # ERROR set p_return_code = 1; rollback; END; # exit 也可以换成continue 表示发送异常时继续执行 DECLARE exit handler for sqlwarning BEGIN # WARNING set p_return_code = 2; rollback; END; START TRANSACTION; update account set money = money - 1000 where id = 1; update account set moneys = money - 1000 where id = 1; # moneys字段导致异常 COMMIT; # SUCCESS set p_return_code = 0; #0代表执行成功 END // delimiter ; #在mysql中调用存储过程 set @res=123; call p5(@res); select @res;
总结:抛开沟通成本,学习成本,存储过程无疑是效率最高的处理方式,面试会问,一些公司也有一些现存的存储过程,重点掌握!
十六、函数
函数与python中的定义一致
1、内置函数
日期相关:

字符相关
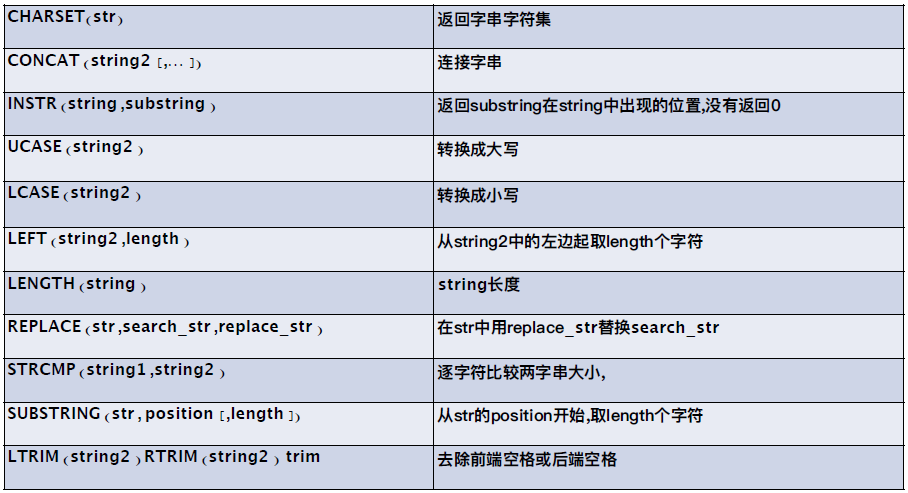
数字相关
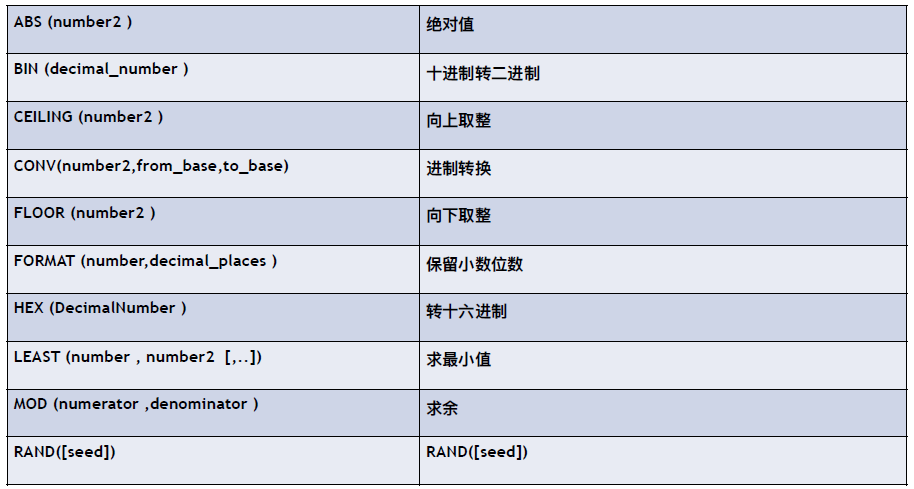
其他函数
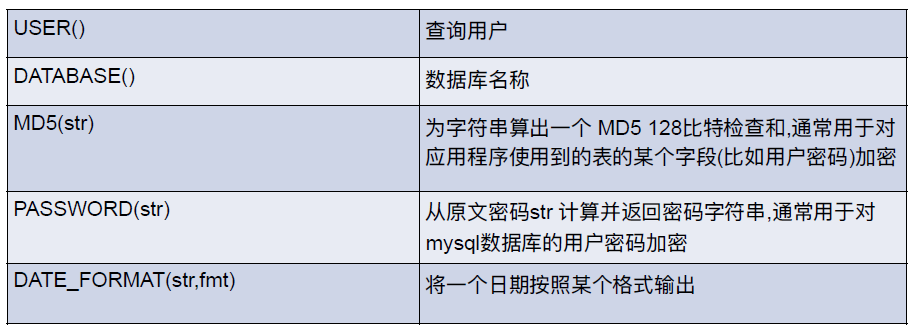
当然还包括之前学习的聚合函数
2、自定义函数
语法:
CREATE FUNCTION f_name(paramters) returns dataType; return value;
说明:paramters只能是in输入参数,参数名,类型,必须有返回值,不能加begin和end returns后面是返回值的类型,这里不加分号,return后面是要返回的值
案例:将两数相加
create function addfuntion(a int,b int) returns int return a + b; #执行函数 select addfuntion(1,1);
#注意:
函数只能返回一个值,函数一般不涉及数据的增删改查,就是一个通用的功能,调用自定义函数,与调用系统一致,不需要call,使用select可获得返回值,函数中不能使用sql语句,就像在Java中不能识别sql语句一样
十七、数据备份与恢复
1、使用mysqldump程序进行备份
#db_name [table_name,,,]这里填写想要备份的库名称或表名称 #fileName.sql这里填写想要备份到的路径和sql文件名 mysqldump -u -p db_name [table_name,,,] > fileName.sql
可以选择要备份哪些表,如果不制定就全部备份
#示例: #单库备份 mysqldump -uroot -p123 db1 > db1.sql mysqldump -uroot -p123 db1 table1 table2 > db1-table1-table2.sql #多库备份 mysqldump -uroot -p123 --databases db1 db2 mysql db3 > db1_db2_mysql_db3.sql #备份所有库 mysqldump -uroot -p123 --all-databases > all.sql
2、使用mysql进行恢复
1.退出数据库后
#filename.sql想要恢复的路径和sql文件名 mysql -u -p < filename.sql;
#这里要注意,sql文件里必须要有创建库名和使用库名的sql语句:
create database db;
use db
必须加上这两句sql语句
2.不用退出数据库的操作:
第一步:创建空数据库
第二步:选择数据库
第三步:然后使用source filename;来进行恢复
use db1; source /root/db1.sql
3、数据库迁移
务必保证在相同版本之间迁移 # mysqldump -h 源IP -uroot -p123 --databases db1 | mysql -h 目标IP -uroot -p456
十八、流程控制
1、if语句的使用
if条件then语句;end if;第二种 if elseif if 条件 then 语句1;elseif 条件 then 语句2;else 语句3;end if;
案例:编写过程,实现输入一个整数type范围1-2输出type=1 or type=2 or type=other;
create procedure showType(in type int,out result char(20)) begin if type = 1 then set result = "type = 1"; elseif type = 2 then set result = "type = 2"; else set result = "type = other"; end if; end
2、if语句的使用
大体意思与Swtich一样的 你给我一个值 我对它进行选择 然后执行匹配上的语句
语法:
create procedure caseTest(in type int) begin CASE type when 1 then select "type = 1"; when 2 then select "type = 2"; else select "type = other"; end case; end
3、定义变量
declare 变量名 类型 default 值; 例如: declare i int default 0;
4、while循环
循环输出10次hello mysql create procedure showHello() begin declare i int default 0; while i < 10 do select "hello mysql"; set i = i + 1; end while; end
5、loop循环
#没有条件 需要自己定义结束语句 #语法: #输出十次hello mysql; create procedure showloop() begin declare i int default 0; aloop: LOOP select "hello loop"; set i = i + 1; if i > 9 then leave aloop; end if; end LOOP aloop; end
6、repeat循环
#类似do while #输出10次hello repeat create procedure showRepeat() begin declare i int default 0; repeat select "hello repeat"; set i = i + 1; until i > 9 end repeat; end #输出0-100之间的奇数 create procedure showjishu() begin declare i int default 0; aloop: loop set i = i + 1; if i >= 101 then leave aloop; end if; if i % 2 = 0 then iterate aloop; end if; select i; end loop aloop; end
十九、详细介绍索引
1、什么是索引
在关系型数据库中,索引是一种单独的,物理的对数据库表中一列或多列的值,进行排序的一种数据存储结构,又称之为key
索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需要的内容
2、为什么需要索引
索引是提升查询效率最有效的方法,在数据库中插入数据会引发索引的重建,简单的说索引就是帮我们加快查询速度
3、索引的数据结构
索引是独立于真实数据的一个存储结构,这个结构的目的是要尽可能降低io操作次数,减少查找的次数,以最少的io找到需要的数据,其实就是B+树结构,还需要二分查找法的支持
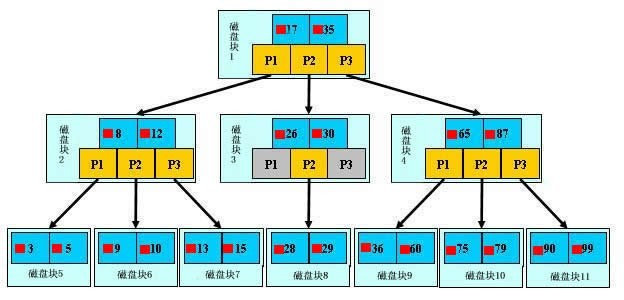
4、最左匹配原则
由于B+树的数据是复合的数据结构,当有多个字段 被添加索引时,比如联合索引,在用查询语句时,必须使用最左索引匹配原则,这样才能起到快速查找的目的
5、聚集索引
主键设置就是聚集索引,而除了主键之外的索引都是非聚集索引,也称为辅助索引
聚集索引的特点:
1.叶子节点保存的就是完整的一行记录,如果设置了主键,主键就作为聚集索引
2.如果没有主键,则找第一个not null 且unique的列作为聚集索引
3.如果也没有这样的列,innodb会在表内自动产生一个聚集索引,它是自增的
6、辅助索引
除了聚集索引之外的索引都称之为辅助索引
辅助索引的特点:
其叶子节点保存的是索引数据与所在行的主键值,innodb用这个主键值来从聚集索引中搜查找数据
7、覆盖索引
覆盖索引指的是需要的数据仅在辅助索引中就能找到
#假设stu表的name字段是一个辅助索引 select name from stu where name = "jack";
#这样的话则不需要在查找聚集索引数据已经找到
8、回表
如果要查找的数据在辅助索引中不存在,则需要回到聚集索引中查找,这种现象就称回表
# name字段是一个辅助索引 而sex字段不是索引 select sex from stu where name = "jack"; #需要从辅助索引中获取主键的值,在拿着主键值到聚集索引中找到sex的值
9、查询速度对比
聚集索引>覆盖索引>非覆盖索引
案例:
准备一张表数据量在百万级别
create table usr(id int,name char(10),gender char(3),email char(30)); #准备数据 delimiter // create procedure addData(in num int) begin declare i int default 0; while i < num do insert into usr values(i,"jack","m",concat("xxxx",i,"@qq.com")); set i = i + 1; end while; end// delimiter ; #执行查询语句 观察查询时间 select count(*) from usr where id = 1; #1 row in set (3.85 sec) #时间在秒级别 比较慢 1. #添加主键 alter table usr add primary key(id); #再次查询 select count(*) from usr where id = 1; #1 row in set (0.00 sec) #基本在毫秒级就能完成 提升非常大 2. #当条件为范围查询时 select count(*) from usr where id > 1; #速度依然很慢 对于这种查询没有办法可以优化因为需要的数据就是那么多 #缩小查询范围 速度立马就快了 select count(*) from usr where id > 1 and id < 10; #当查询语句中匹配字段没有索引时 效率测试 select count(*) from usr where name = "jack"; #1 row in set (2.85 sec) # 速度慢 3. # 为name字段添加索引 create index name_index on usr(name); # 再次查询 select count(*) from usr where name = "jack"; #1 row in set (3.89 sec) # 速度反而降低了 为什么? #由于name字段的区分度非常低 完全无法区分 ,因为值都相同 这样一来B+树会没有任何的子节点,像一根竹竿每一都匹配相当于,有几条记录就有几次io ,所有要注意 区分度低的字段不应该建立索引,不能加速查询反而降低写入效率, #同理 性别字段也不应该建立索引,email字段更加适合建立索引 # 修改查询语句为 select count(*) from usr where name = "aaaaaaaaa"; #1 row in set (0.00 sec) 速度非常快因为在 树根位置就已经判断出树中没有这个数据 全部跳过了 # 模糊匹配时 select count(*) from usr where name like "xxx"; #快 select count(*) from usr where name like "xxx%"; #快 select count(*) from usr where name like "%xxx"; #慢 #由于索引是比较大小 会从左边开始匹配 很明显所有字符都能匹配% 所以全都匹配了一遍 4.索引字段不能参加运算 select count(*) from usr where id * 12 = 120; #速度非常慢原因在于 mysql需要取出所有列的id 进行运算之后才能判断是否成立 #解决方案 select count(*) from usr where id = 120/12; #速度提升了 因为在读取数据时 条件就一定固定了 相当于 select count(*) from usr where id = 10; #速度自然快了 5.有多个匹配条件时 索引的执行顺序 and 和 or #先看and #先删除所有的索引 alter table usr drop primary key; drop index name_index on usr; #测试 select count(*) from usr where name = "jack" and gender = "m" and id = 1 and email = "xxxx2@qq.com"; #1 row in set (1.34 sec) 时间在秒级 #为name字段添加索引 create index name_index on usr(name); #测试 select count(*) from usr where name = "jack" and gender = "m" and id = 1 and email = "xxxx2@qq.com"; #1 row in set (17.82 sec) 反而时间更长了 #为gender字段添加索引 create index gender_index on usr(gender); #测试 select count(*) from usr where name = "jack" and gender = "m" and id = 1 and email = "xxxx2@qq.com"; #1 row in set (16.83 sec) gender字段任然不具备区分度 #为id加上索引 alter table usr add primary key(id); #测试 select count(*) from usr where name = "jack" and gender = "m" and id = 1 and email = "xxxx1@qq.com"; #1 row in set (0.00 sec) id子弹区分度高 速度提升 #虽然三个字段都有索引 mysql并不是从左往右傻傻的去查 而是找出一个区分度高的字段优先匹配 #改为范围匹配 select count(*) from usr where name = "jack" and gender = "m" and id > 1 and email = "xxxx1@qq.com"; #速度变慢了 #删除id索引 为email建立索引 alter table usr drop primary key; create index email_index on usr(email); #测试 select count(*) from usr where name = "jack" and gender = "m" and id = 1 and email = "xxxx2@qq.com"; #1 row in set (0.00 sec) 速度非常快 #对于or条件 都是从左往右匹配 select count(*) from usr where name = "jackxxxx" or email = "xxxx0@qq.com"; #注意 必须or两边都有索引才会使用索引 6.多字段联合索引 为什么需要联合索引 案例: select count(*) from usr where name = "jack" and gender = "m" and id > 3 and email = "xxxx2@qq.com"; 假设所有字段都是区分度非常高的字段,那么除看id为谁添加索引都能够提升速度,但是如果sql语句中没有出现所以字段,那就无法加速查询,最简单的办法是为每个字段都加上索引,但是索引也是一种数据,会占用内存空间,并且降低写入效率 此处就可以使用联合索引, 联合索引最重要的是顺序 按照最左匹配原则 应该将区分度高的放在左边 区分度低的放到右边 #删除其他索引 drop index name_index on usr; drop index email_index on usr; #联合索引 create index mul_index on usr(email,name,gender,id); # 查询测试 select count(*) from usr where name = "xx" and id = 1 and email = "xx"; 只要语句中出现了最左侧的索引(email) 无论在前在后都能提升效率 drop index mul_index on usr;
面试题
1.以下有2表,一句sql,请描述该sql执行的过程,并写出执行之后的结果
+----+---------------------+--------+--------+ | id | time | name | token | +----+---------------------+--------+--------+ | 1 | 2019-06-18 23:04:00 | 小明 | token1 | | 2 | 2019-06-18 23:10:00 | 小白 | token2 | | 3 | 2019-06-18 23:11:00 | 小华 | token3 | | 4 | 2019-06-18 23:11:00 | 小红 | token4 | | 5 | 2019-06-18 23:11:00 | 小黄 | token5 | | 6 | 2019-06-18 23:11:00 | 小黑 | token6 | +----+---------------------+--------+--------+
+----+---------------------+-------+--------+ | id | time | class | token | +----+---------------------+-------+--------+ | 1 | 2019-06-17 23:07:00 | A1 | token1 | | 2 | 2019-06-18 23:12:00 | A1 | token2 | | 3 | 2019-06-18 23:12:00 | A1 | token3 | | 4 | 2019-06-17 23:12:00 | A2 | token4 | | 5 | 2019-06-18 23:12:00 | A2 | token5 | | 6 | 2019-06-17 23:12:00 | A3 | token6 | +----+---------------------+-------+--------+
SELECT
z.class,
SUM(IF(z.type = 1, 1, 0)) AS important,
SUM(IF(z.type = 0, 1, 0)) AS unimportant
FROM
(SELECT
b.class,
CASE DATE(a.time) = DATE(b.time)
WHEN TRUE THEN 1
ELSE 0
END type
FROM
a, b
WHERE
a.token = b.token) AS z
GROUP BY z.class;
#执行结果 +-------+-----------+-------------+ | class | important | unimportant | +-------+-----------+-------------+ | A1 | 2 | 1 | | A2 | 1 | 1 | | A3 | 0 | 1 | +-------+-----------+-------------+

 浙公网安备 33010602011771号
浙公网安备 33010602011771号