


08第十天JDBC开发
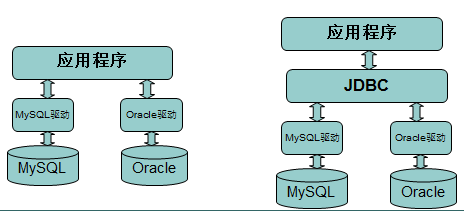
一、JDBC:Java
DataBase Connectivity
(一)、JDBC基础
1、数据库驱动:
数据库厂商为了方便开发人员从程序中操作数据库而提供的一套jar包,通过导入这个jar包就可以调用其中的方法操作数据库,这样的jar包就叫做数据库驱动。
2、JDBC:两个包,包括java.sql和javax.sql。开发JDBC应用需要以上2个包的支持外,还需要导入相应JDBC的数据库实现(即数据库驱动)。
sun定义的一套标准,本质上是一大堆的操作数据库的接口,所有数据库厂商为java设计的数据库驱动都实现过这套接口,这样一来同一了不同数据库驱动的方法,开发人员只需要学习JDBC就会使用任意数据库驱动了。
(二)、JDBC实现
1、新建Java项目-->新建lib文件夹-->导入mysql-connector-java-5.1.40-bin.jar-->邮右键build path -->add to build path--》新建类。
六个步骤实现JDBC:

package com.lmd.jdbc;//接口,面向接口编程,更换数据库不变,通用性import java.sql.Connection;import java.sql.DriverManager;import java.sql.ResultSet;import java.sql.SQLException;import java.sql.Statement;//mysql做的实现import com.mysql.jdbc.Driver;public class JDBCDemo1 {public static void main(String[] args) throws SQLException{//1.注册数据库驱动DriverManager.registerDriver(new Driver());//Class.forName("com.mysql.jdbc.Driver");//2.获取数据库连接String url = "jdbc:mysql://localhost:3306/day10";Connection con = DriverManager.getConnection(url, "root", "666666");//Connection con = DriverManager.getConnection(url +//"?user=root&password=666666");//Connection con = DriverManager.getConnection("jdbc:mysql://///day10?user=root&password=666666");//3.获取传输器对象Statement st = con.createStatement();//4.利用传输器传输sql语句到数据库中执行,获取结果集对象ResultSet rs = st.executeQuery("select * from user");//5.遍历结果集获取查询结果while(rs.next()){String name = rs.getString("name");System.out.println(name);}//6.关闭资源rs.close();st.close();con.close();}}
2、DriverManager
(1)、Jdbc程序中的DriverManager用于加载驱动,并创建与数据库的链接,这个API的常用方法:
DriverManager.registerDriver(new Driver());
DriverManager.getConnection(url, user, password);
注意:在实际开发中并不推荐采用registerDriver方法注册驱动。原因有二:
1)、查看Driver的源代码可以看到,如果采用此种方式,会导致驱动程序注册两次,也就是在内存中会有两个Driver对象。
2)、程序依赖mysql的api,脱离mysql的jar包,程序将无法编译,将来程序切换底层数据库将会非常麻烦。 创建mysql的Driver对象,导致程序和具体的mysql驱动绑死在一起,在切换数据库时需改动JAVA代码。
package com.mysql.jdbc;import java.sql.SQLException;public class Driver extends NonRegisteringDriver implements java.sql.Driver {// Register ourselves with the DriverManagerstatic {try {java.sql.DriverManager.registerDriver(new Driver());} catch (SQLException E) {throw new RuntimeException("Can't register driver!");}}public Driver() throws SQLException {// Required for Class.forName().newInstance()}}
(2)、推荐方式:Class.forName(“com.mysql.jdbc.Driver”);
采用此种方式不会导致驱动对象在内存中重复出现,并且采用此种方式,程序仅仅只需要一个字符串,不需要依赖具体的驱动,使程序的灵活性更高。
同样,在开发中也不建议采用具体的驱动类型指向getConnection方法返回的connection对象。
3、数据库URL
URL用于标识数据库的位置,程序员通过URL地址告诉JDBC程序连接哪个数据库,URL的写法为:
常用数据库URL地址的写法:Oracle写法:jdbc:oracle:thin:@localhost:1521:sidSqlServer—jdbc:microsoft:sqlserver://localhost:1433; DatabaseName=sidMySql—jdbc:mysql://localhost:3306/sidMysql的url地址的简写形式: jdbc:mysql:///sid常用属性:useUnicode=true&characterEncoding=UTF-8
4、程序详解—Connection
Jdbc程序中的Connection,它用于代表数据库的链接,Connection是数据库编程中最重要的一个对象,客户端与数据库所有交互都是通过connection对象完成的,这个对象的常用方法:
ResultSet createStatement():创建向数据库发送sql的statement对象。PrepareStatement prepareStatement(sql) :创建向数据库发送预编译sql的PrepareSatement对象。CallableStatement prepareCall(sql):创建执行存储过程的callableStatement对象。void setAutoCommit(boolean autoCommit):设置事务是否自动提交。void commit() :在链接上提交事务。void rollback() :在此链接上回滚事务。
5、程序详解—Statement
Jdbc程序中的Connection,它用于代表数据库的链接,Connection是数据库编程中最重要的一个对象,客户端与数据库所有交互都是通过connection对象完成的,这个对象的常用方法:
int executeUpdate(String sql):用于向数据库发送insert、update或delete语句boolean execute(String sql):用于向数据库发送任意sql语句void addBatch(String sql) :把多条sql语句放到一个批处理中。int[] executeBatch():向数据库发送一批sql语句执行。
6、程序详解—ResultSet
(1)、 Jdbc程序中的ResultSet用于代表Sql语句的执行结果。Resultset封装执行结果时,采用的类似于表格的方式。ResultSet 对象维护了一个指向表格数据行的游标,初始的时候,游标在第一行之前,调用ResultSet.next() 方法,可以使游标指向具体的数据行,进行调用方法获取该行的数据。
(2)、ResultSet既然用于封装执行结果的,所以该对象提供的都是用于获取数据的get方法:
获取任意类型的数据getObject(int index)getObject(string columnName)获取指定类型的数据,例如:getString(int index)getString(String columnName)
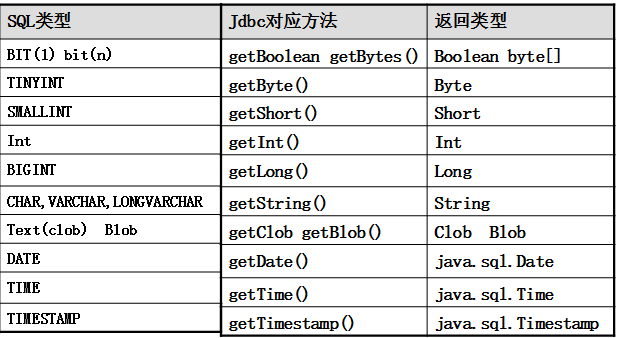
ResultSet还提供了对结果集进行滚动的方法:boolean next():移动到下一行boolean previous():移动到前一行boolean absolute(int row):移动到指定行void beforeFirst():移动resultSet的最前面。void afterLast() :移动到resultSet的最后面。
例如:
表中:zs lisi wangwurs.next(); rs.next(); 打印:lisirs.previous();//zsrs.absolute(3);//wangwu 第三行String name = rs.getString("name");System.out.println(name);
7、程序详解—释放资源
(1)、Jdbc程序运行完后,切记要释放程序在运行过程中,创建的那些与数据库进行交互的对象,
这些对象通常是ResultSet、Statement和Connection对象。
(2)、特别是Connection对象,它是非常稀有的资源,用完后必须马上释放,如果Connection不能及时、正确的关闭,
极易导致系统宕机。Connection的使用原则是尽量晚创建,尽量早的释放。
(3)、为确保资源释放代码能运行,资源释放代码也一定要放在finally语句中。
若 if (rs != null) rs.close(); 加到 try...catch...中,后面要加一个 rs=null; 变成垃圾对象被回收。完整的如下:
public class JDBCDemo1 {public static void main(String[] args){Connection conn = null;Statement stat = null;ResultSet rs = null;try {Class.forName("com.mysql.jdbc.Driver");String url = "jdbc:mysql://localhost:3306/day10";conn = DriverManager.getConnection(url, "root", "666666");stat = conn.createStatement();rs = stat.executeQuery("select * from user");while(rs.next()){String name = rs.getString("name");System.out.println(name);}} catch (Exception e) {e.printStackTrace();} finally {if (rs != null) {try {rs.close();} catch (SQLException e) {e.printStackTrace();}finally {rs = null;}}if (stat != null) {try {stat.close();} catch (SQLException e) {e.printStackTrace();}finally {stat = null;}}if (conn != null) {try {conn.close();} catch (SQLException e) {e.printStackTrace();}finally {conn = null;}}}}}
(三)、JDBC增删改查
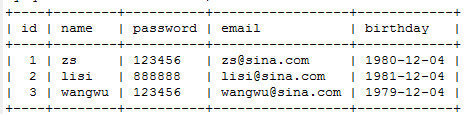
create database day10 character set utf8 collate utf8_general_ci;use day10;create table user(id int primary key auto_increment,name varchar(40),password varchar(40),email varchar(60),birthday date)character set utf8 collate utf8_general_ci;insert into user(name,password,email,birthday) values('zs','123456','zs@sina.com','1980-12-04');insert into user(name,password,email,birthday) values('lisi','123456','lisi@sina.com','1981-12-04');insert into user(name,password,email,birthday) values('wangwu','123456','wangwu@sina.com','1979-12-04');
mysql> select * from user;+----+--------+----------+-----------------+------------+| id | name | password | email | birthday |+----+--------+----------+-----------------+------------+| 1 | zs | 123456 | zs@sina.com | 1980-12-04 || 2 | lisi | 123456 | lisi@sina.com | 1981-12-04 || 3 | wangwu | 123456 | wangwu@sina.com | 1979-12-04 |+----+--------+----------+-----------------+------------+
package com.lmd.util;import java.io.FileNotFoundException/FileReader;import java.sql.Connection/DriverManager/ResultSet;import java.sql.SQLException/Statement;import java.util.Properties;public class JDBCUtils {private static Properties prop = null;private JDBCUtils(){ }//只解析一次,放在静态代码块里static{prop = new Properties();try {prop.load(new FileReader(JDBCUtils.class.getClassLoader().getResource("config.properties").getPath()));} catch (FileNotFoundException e) {e.printStackTrace();} catch (Exception e) {e.printStackTrace();throw new RuntimeException(e);}}/*** 获取连接* @return* @throws ClassNotFoundException* @throws SQLException*/public static Connection getConn() throws ClassNotFoundException, SQLException{//1、注册数据库驱动Class.forName(prop.getProperty("driver"));//2、获取连接return DriverManager.getConnection(prop.getProperty("url"),prop.getProperty("username"), prop.getProperty("password"));}/*** 关闭连接* @param rs* @param stat* @param conn*/public static void close(ResultSet rs, Statement stat, Connection conn) {if (rs != null) {try {rs.close();} catch (SQLException e) {e.printStackTrace();}finally {rs = null;}}if (stat != null) {try {stat.close();} catch (SQLException e) {e.printStackTrace();}finally {stat = null;}}if (conn != null) {try {conn.close();} catch (SQLException e) {e.printStackTrace();}finally {conn = null;}}}}
配置文件:config.properties 在src下driver=com.mysql.jdbc.Driverurl=jdbc:mysql://localhost:3306/day10username=rootpassword=66666
1、使用executeUpdate(String sql)方法完成数据添加操作,示例操作:
@Testpublic void add(){Connection conn = null;Statement stat = null;try {//1、注册数据库驱动;2、获取数据库连接conn = JDBCUtils.getConn();//3、获取传输器对象stat = conn.createStatement();//4、利用传输器传输sql语句到数据库中执行,获取结果集对象int count = stat.executeUpdate("insert into user values(null,'lily','666666','lily8@163.com','1990-12-22')");//5、处理结果if (count>0) {System.out.println("执行成功!影响到的行数为"+count);} else {System.out.println("执行失败!");}} catch (Exception e) {e.printStackTrace();} finally {//6、关闭连接JDBCUtils.close(null, stat, conn);}}
结果如下:

2、使用executeUpdate(String sql)方法完成数据修改操作,示例操作:
public void update(){Connection conn = null;Statement stat = null;try {conn = JDBCUtils.getConn();stat = conn.createStatement();stat.executeUpdate("update user set password='888888' where id=2");} catch (Exception e) {e.printStackTrace();} finally {//6、关闭连接JDBCUtils.close(null, stat, conn);}}
结果如下:

3、使用executeQuery(String sql)方法完成数据查询操作,示例操作:
@Testpublic void find(){Connection conn = null;Statement stat = null;ResultSet rs = null;try {conn = JDBCUtils.getConn();stat = conn.createStatement();rs = stat.executeQuery("select * from user where name='lily'");while (rs.next()) {String name = rs.getString("name");String password = rs.getString("password");System.out.println(name+":"+password);}} catch (Exception e) {e.printStackTrace();} finally {//6、关闭连接JDBCUtils.close(null, stat, conn);}}
结果如下:

4、使用 executeUpdate(String sql)方法完成数据删除操作,示例操作:
@Testpublic void delete(){Connection conn = null;Statement stat = null;try {conn = JDBCUtils.getConn();stat = conn.createStatement();stat.executeUpdate("delete from user where name='lily'");} catch (Exception e) {e.printStackTrace();} finally {//6、关闭连接JDBCUtils.close(null, stat, conn);}}
结果如下:
(四)、案例:改写前面讲解的用户注册和登陆案例,实现如下需求:
1、把xml换成数据库,重写XmlUserDao。2、定义DAO接口,并定义Dao工厂,实现service层和dao层的解耦。3、自定义dao异常。4、防范sql注入攻击
一、为什么:要分层使软件具有结构性,便于开发、维护和管理。将不同功能模块独立,在需要替换某一模块时不需要改动其他模块,方便代码的复用、替换二、层与层耦合的概念,利用工厂类解耦在分层结构中,我们希望将各个功能约束在各自的模块(层)当中的,而当属于某一层的对象、方法“入侵”到了其他层,如将web层的ServletContext对象传入service层,或service层调用XMLDao独有的方法,就会导致层与层之间的关系过于“紧密”,当需要修改某一层时不可避免的要修改其他关联的层,这和我们软件分层最初的设想-----层与层分离,一个层尽量不依赖其他层存在,当修改一层时无需修改另一层的设想是违背的。这种“入侵”造成的“紧密”关系就早做层与层之间发生的“耦合”,而去掉这种耦合性的过程就叫做层与层之间“解耦”利用工厂类可以实现解耦的功能三、如何判断一项功能到底属于哪一层某一项功能属于哪一层,往往是不能明确确定出来的,这时可以参考如下标准进行判断:1、此项功能在业务逻辑上更贴近与哪一层,放在哪一层更能较少耦合2、此项功能是否必须使用某一层特有的对象3、如果放在哪一层都可以,那么放在哪一层更方便技术上的实现,及方便代码的编写和维护四、异常的处理1、如果一个异常抛给上一层会增加程序的耦合性,请当场解决:如将xml解析错误抛给service层,那么当换成mysqldao时,还需要修改service去掉xml解析异常的处理。2、如果上一层明确需要此异常进行代码的流转,请抛出:如当查找一个用户信息而用户找不到时,可以抛出一个用户找不到异常,明确要求上一层处理。3、如果这一层和上一层都能解决尽量在这一层解决掉。4、如果这一层不能解决,而上一层能解决抛给上一层。5、如果所有层都不能解决,则应抛出给虚拟机使线程停止,但是如果直接抛出这个异常,则还需要调用者一级一级继续- 往上抛出最后才能抛给虚拟机,所以还不如在出现异常的位置直接try...catch住后转换为RuntimeException抛出。
:如读取配置文件出错,任何层都不能解决,转为RuntimeException抛出,停止线程。
1、改写案例
(1)、把xml换成数据库,重写XmlUserDao。
create table users(id int primary key auto_increment,username varchar(20),password varchar(50),nickname varchar(40),email varchar(50));insert into users values(null,'admin','admin','admin','admin8@qq.com');

(2)、重写XmlUserDao,改为MysqlUserDao.java。
1)、将XmlUserDao中的方法定义到一个接口中,注意:
使用接口定义使用的三个方法;接口一定要有注释,并且是文档注释。
方法注释一方都放在接口中,而非实现类中。
在接口中使用接口注释后,当鼠标移到实现类中方法上就会有提示。
package com.lmd.dao;- import com.lmd.domain.User;
- public interface UserDao {
/*** 根据用户名查找用户* @param username 用户名* @return 根据用户名找到的用户信息bean,若没找到返回null*/public User findUserByUserName(String username);/*** 添加用户* @param user 要添加的用户信息bean*/public void addUser(User user);/*** 根据用户名和密码查找对应的用户* @param username 用户名* @param password 密码* @return 找到的用户,若没找到返回null*/public User findUserByUNandPSW(String username, String password);}
2)、仍需要前面设置的config.properties和JDBCUtils.java,开发MysqlUserDao.java:
修改User.java,增加id;修改UserService.java一句话。
//private XmlUserDao dao = new XmlUserDao();private MysqlUserDao dao = new MysqlUserDao();
这个切换数据库会改变代码,不太好,后面会讲怎么办? 这是一种耦合,后面会利用工厂类实现解耦。
package com.lmd.dao;import java.sql.Connection;import java.sql.ResultSet;import java.sql.Statement;import com.lmd.domain.User;import com.lmd.util.JDBCUtils;public class MysqlUserDao implements UserDao{@Overridepublic User findUserByUserName(String username) {String sql = "select * from users where username='"+username+"'";Connection conn = null;Statement stat = null;ResultSet rs = null;try {conn = JDBCUtils.getConn();stat = conn.createStatement();rs = stat.executeQuery(sql);if (rs.next()) {User user = new User();user.setId(rs.getInt("id"));user.setUsername(rs.getString("username"));user.setPassword(rs.getString("password"));user.setNickname(rs.getString("nickname"));user.setEmail(rs.getString("email"));return user;} else {return null;}} catch (Exception e) {e.printStackTrace();throw new RuntimeException(e);} finally {JDBCUtils.close(rs, stat, conn);}}@Overridepublic void addUser(User user) {String sql = "insert into users values (null,'"+user.getUsername()+"','"+user.getPassword()+"','"+user.getNickname()+"','"+user.getEmail()+"')";Connection conn = null;Statement stat = null;try {conn = JDBCUtils.getConn();stat = conn.createStatement();stat.executeUpdate(sql);} catch (Exception e) {e.printStackTrace();throw new RuntimeException(e);} finally {JDBCUtils.close(null, stat, conn);}}@Overridepublic User findUserByUNandPSW(String username, String password) {String sql = "select * from users where username='"+username+"' and password='"+password+"'";Connection conn = null;Statement stat = null;ResultSet rs = null;try {conn = JDBCUtils.getConn();stat = conn.createStatement();rs = stat.executeQuery(sql);if (rs.next()) {User user = new User();user.setId(rs.getInt("id"));user.setUsername(rs.getString("username"));user.setPassword(rs.getString("password"));user.setNickname(rs.getString("nickname"));user.setEmail(rs.getString("email"));return user;} else {return null;}} catch (Exception e) {e.printStackTrace();throw new RuntimeException(e);} finally {JDBCUtils.close(rs, stat, conn);}}}

2、定义DAO接口,并定义Dao工厂,实现service层和dao层的解耦。
package com.lmd.factory;import java.io.FileReader;import java.util.Properties;import com.lmd.dao.UserDao;/*** 单例模式:保证在整个应用程序的生命周期中,* 任何一个时刻,单例类的实例只存在一个(也可以不存在)* @author angel11288**/public class DaoFactory {private static DaoFactory factory = new DaoFactory();//配置文件只读一次private static Properties prop = null;static{try {prop = new Properties();prop.load(new FileReader(DaoFactory.class.getClassLoader().getResource("config.properties").getPath()));} catch (Exception e) {e.printStackTrace();throw new RuntimeException(e);}}private DaoFactory() {}public static DaoFactory getFactory() {return factory;}public UserDao getDao() {try {String cla = prop.getProperty("UserDao");//com.lmd.dao.MysqlUserDaoreturn (UserDao)Class.forName(cla).newInstance();} catch (Exception e) {e.printStackTrace();throw new RuntimeException(e);}}}
修改UserService:
//private XmlUserDao dao = new XmlUserDao();//private MysqlUserDao dao = new MysqlUserDao();private UserDao dao = DaoFactory.getFactory().getDao();
配置文件config.properties:
driver=com.mysql.jdbc.Driverurl=jdbc:mysql://localhost:3306/day10username=rootpassword=666666UserDao=com.lmd.dao.MysqlUserDao#UserDao=com.lmd.dao.XmlUserDao
3、自定义dao异常。
4、SQL注入攻击:定义DAO接口,并定义Dao工厂,实现service层和dao层的解耦。
(1)、由于dao中执行的SQL语句是拼接出来的,其中有一部分内容是由用户从客户端传入,所以当用户传入的数据中包含sql关键字时,就有可能通过这些关键字改变sql语句的语义,从而执行一些特殊的操作,这样的攻击方式就叫做sql注入攻击。 (登陆之后,注销,再次回来,只有用户名也可以登录)
admin 'or' 1=1,密码空,也可以登录成功。
(2)、PreperedStatement是Statement的孩子,它的实例对象可以通过调用Connection.preparedStatement()
方法获得,相对于Statement对象而言:
1)、PreperedStatement可以避免SQL注入的问题。
2)、Statement会使数据库频繁编译SQL,可能造成数据库缓冲区溢出。
PreparedStatement 可对SQL进行预编译,从而提高数据库的执行效率。
3)、并且PreperedStatement对于sql中的参数,允许使用占位符的形式进行替换,简化sql语句的编写。
PreparedStatement利用预编译的机制将sql语句的主干和参数分别传输给数据库服务器,从而使数据库分辨
的出哪些是sql语句的主干哪些是参数,这样一来即使参数中带了sql的关键字,数据库服务器也仅仅将他当
作参数值使用,关键字不会起作用,从而从原理上防止了sql注入的问题
package com.lmd.jdbc;import java.sql.Connection;import java.sql.ResultSet;import java.sql.PreparedStatement;import com.lmd.util.JDBCUtils;public class JDBCDemo3 {public static void main(String[] args) {Connection conn = null;PreparedStatement ps = null;ResultSet rs = null;try {conn = JDBCUtils.getConn();//主干语句ps = conn.prepareStatement("select * from user where name=? and password=?");ps.setString(1, "lisi");ps.setString(2, "888888");rs = ps.executeQuery();while (rs.next()) {System.out.println(rs.getString("email"));}} catch (Exception e) {e.printStackTrace();} finally {JDBCUtils.close(rs, ps, conn);}}}
(3)、PreparedStatement主要有如下的三个优点:
~1.可以防止sql注入。
~2.由于使用了预编译机制,执行的效率要高于Statement。
~3.sql语句使用?形式替代参数,然后再用方法设置?的值,比起拼接字符串,代码更加优雅。
二、JDBC应用
(一)、使用JDBC处理大数据
1、基础:
(1)、在实际开发中,程序需要把大文本 Text 或二进制数据 Blob保存到数据库。Text是mysql叫法,Oracle中叫Clob。
(2)、基本概念:大数据也称之为LOB(Large Objects),LOB又分为:clob和blob
1)、clob用于存储大文本。Text
2)、blob用于存储二进制数据,例如图像、声音、二进制文等。
(3)、对MySQL而言只有blob,而没有clob,mysql存储大文本采用的是Text,Text和blob分别又分为:
1)、Text:TINYTEXT(255)、TEXT(64k)、MEDIUMTEXT(16M)和LONGTEXT(4G)
2)、Blob:TINYBLOB、BLOB、MEDIUMBLOB和LONGBLOB
2、使用JDBC处理大文本:
(1)、对于MySQL中的Text类型,可调用如下方法设置:
PreparedStatement.setCharacterStream(index, reader, length);//注意length长度须设置,并且设置为int型//当包过大时修改配置:[mysqld] max_allowed_packet=64M
(2)、对MySQL中的Text类型,可调用如下方法获取:
reader = resultSet. getCharacterStream(i);等价于reader = resultSet.getClob(i).getCharacterStream()
package com.lmd.job;/** create table textdemo(* id int primary key auto_increment,* name varchar(20),* content MEDIUMTEXT* );*/import java.io.File/FileReader;import java.sql.Connection/PreparedStatement/ResultSet;- import org.junit.Test;
- import com.lmd.util.JDBCUtils;
public class TextDemo1 {@Testpublic void addText() {Connection conn = null;PreparedStatement ps = null;ResultSet rs = null;try{conn = JDBCUtils.getConn();ps = conn.prepareStatement("insert into textdemo values (null, ?,?)");ps.setString(1, "三生三世十里桃花.txt");File file = new File("三生三世十里桃花.txt");ps.setCharacterStream(2, new FileReader(file), file.length());ps.executeUpdate();} catch(Exception e){e.printStackTrace();} finally {JDBCUtils.close(rs, ps, conn);}}}
修改java虚拟机启动内存大小:
查看安装目录下的myeclipse.ini:
#utf8 (do not remove)-startupplugins/org.eclipse.equinox.launcher_1.3.100.v20150511-1540.jar--launcher.libraryplugins/org.eclipse.equinox.launcher.win32.win32.x86_64_1.1.300.v20150602-1417-vmD:\Program Files\MyEclipse2016\binary\com.sun.java.jdk8.win32.x86_64_1.8.0.u66\bin\javaw.exe-configurationD:\Program Files\MyEclipse2016\configuration-installD:\Program Files\MyEclipse2016-vmargs-Xmx1024m-XX:ReservedCodeCacheSize=64m-Dosgi.nls.warnings=ignore
异常处理
1.Exception in thread "main" java.lang.AbstractMethodError: com.mysql.jdbc.PreparedStatement.setCharacterStream(ILjava/io/Reader;J)Vps.setCharacterStream(2, new FileReader(file), file.length());- 第三个参数是long型的是从1.6才开始支持的,驱动里还没有开始支持。
解决方案:ps.setCharacterStream(2, new FileReader(file), (int)file.length());2.Exception in thread "main" java.lang.OutOfMemoryError: Java heap space文件大小过大,导致PreparedStatement中数据多大占用内存,内存溢出-Xms256M-Xmx256M3.com.mysql.jdbc.PacketTooBigException: Packet for query is too large (10886466 > 1048576).You can change this value on the server by setting the max_allowed_packet' variable.数据库连接传输用的包不够大,传输大文本时报此错误在my.ini中配置max_allowed_packet指定包的大小
1、修改java虚拟机启动内存大小:
CMD修改:java -Xms 64M -Xmx 128M
MyEclipse中Run-->Run config...-->Arugument-->VMargument:-Xms64m 换行 -Xmx 128m
2、com.mysql.jdbc.PacketTooBigException: Packet for query is too large (6882307 > 4194304).
You can change this value on the server by setting the max_allowed_packet' variable.
修改C:\ProgramData\MySQL\MySQL Server 5.6下的my.ini:在[msqld]中写

public void findText() {Connection conn = null;PreparedStatement ps = null;ResultSet rs = null;try{conn = JDBCUtils.getConn();ps = conn.prepareStatement("select * from textdemo where id=?");ps.setInt(1,2);rs = ps.executeQuery();while (rs.next()) {String name = rs.getString("name");System.out.println(name);//三生三世十里桃花.txtReader reader = rs.getCharacterStream("content");Writer writer = new FileWriter(name);char[] chs = new char[1024];int len = 0;while ((len = reader.read(chs))!=-1) {writer.write(chs, 0, len);}reader.close();writer.close();}} catch(Exception e){e.printStackTrace();} finally {JDBCUtils.close(rs, ps, conn);}}
3、使用JDBC处理二进制数据:
(1)、对于MySQL中的BLOB类型,可调用如下方法设置:
PreparedStatement. setBinaryStream(i, inputStream, length);
(2)、对MySQL中的BLOB类型,可调用如下方法获取:
InputStream in = resultSet.getBinaryStream(i);InputStream in = resultSet.getBlob(i).getBinaryStream();
@Testpublic void addBlob() {try{conn = JDBCUtils.getConn();ps = conn.prepareStatement("insert into blobdemo values (null,?,?)");ps.setString(1, "欢迎您.mp3");File file = new File("1.mp3");ps.setBinaryStream(2, new FileInputStream(file), file.length());ps.executeUpdate();}}@Testpublic void findBlob() {try{conn = JDBCUtils.getConn();ps = conn.prepareStatement("select * from blobdemo where id=?");ps.setInt(1,1);rs = ps.executeQuery();while (rs.next()) {String name = rs.getString("name");System.out.println(name);//欢迎您.mp3InputStream input = rs.getBinaryStream("content");OutputStream output = new FileOutputStream(name);byte[] bys = new byte[1024];int len = 0;while ((len = input.read(bys))!=-1) {output.write(bys, 0, len);}input.close();output.close();}}
但是:图片和音乐等一般不会存在数据库中,只需要知道就行。大文件一般放在服务器的硬盘上,访问的是服务器存在的
文件的硬盘路径,通过读路径得到大文件。
3、使用JDBC进行批处理:
(1)、业务场景:当需要向数据库发送一批SQL语句执行时,应避免向数据库一条条的发送执行,而应采用JDBC的
批处理机制,以提升执行效率。
(2)、实现批处理有两种方式,第一种方式:
1)、void Statement.addBatch(sql) 。
2)、执行批处理SQL语句。
3)、int[] executeBatch()方法:执行批处理命令。返回包含批中每个命令的一个元素的更新计数所组成的数组。
4)、void clearBatch()方法:清除批处理命令 。
采用Statement.addBatch(sql)方式实现批处理:
优点:可以向数据库发送多条不同的SQL语句。
缺点:SQL语句没有预编译。当向数据库发送多条语句相同,但仅参数不同的SQL语句时,需重复写上很多条SQL语句。
package com.lmd.batch;import java.sql.Connection;import java.sql.ResultSet;import java.sql.Statement;import com.lmd.util.JDBCUtils;public class StatementBatch {public static void main(String[] args) {Connection conn = null;Statement stat = null;try {conn = JDBCUtils.getConn();stat = conn.createStatement();stat.addBatch("create database day10batch");stat.addBatch("use day10batch");stat.addBatch("create table batchdemo("+"id int primary key auto_increment,"+ "name varchar(20))");stat.addBatch("insert into batchdemo values(null,'aaa')");stat.addBatch("insert into batchdemo values(null,'bbb')");stat.addBatch("insert into batchdemo values(null,'ccc')");stat.addBatch("insert into batchdemo values(null,'ddd')");stat.executeBatch();//返回int类型的数组} catch (Exception e) {e.printStackTrace();} finally {JDBCUtils.close(null, stat, conn);}}}
结果如下:
mysql> use day10batch;Database changedmysql> select * from batchdemo;+----+------+| id | name |+----+------+| 1 | aaa || 2 | bbb || 3 | ccc || 4 | ddd |+----+------+4 rows in setmysql>
(3)、实现批处理有两种方式,第一种方式: PreparedStatement.addBatch()
采用PreparedStatement.addBatch()实现批处理,将一组参数添加到此 PreparedStatement 对象的批处理命令中。
优点:发送的是预编译后的SQL语句,执行效率高。
缺点:只能应用在SQL语句相同,但参数不同的批处理中。因此此种形式的批处理经常用于在同一个表中批量插入数据,或批量更新表的数据。
package com.lmd.batch;- import java.sql.Connection;
import java.sql.PreparedStatement;- import com.lmd.util.JDBCUtils;
- /*
create table psbatch(id int primary key auto_increment,name varchar(20));*/public class PreparedStatementBatch {public static void main(String[] args) {Connection conn = null;PreparedStatement ps = null;try {conn = JDBCUtils.getConn();ps = conn.prepareStatement("insert into psbatch values(null,?)");for (int i = 0; i < 100001; i++) {ps.setString(1, "name"+i);ps.addBatch();if (i%1000==0) {ps.executeBatch();ps.clearBatch();}}ps.executeBatch();//为了剩下的那一条记录} catch (Exception e) {e.printStackTrace();} finally {JDBCUtils.close(null, ps, conn);}}}
结果如下:
mysql> select count(*) from psbatch;+----------+| count(*) |+----------+| 419 |+----------+1 row in setmysql> select count(*) from psbatch;+----------+| count(*) |+----------+| 689 |+----------+1 row in setmysql>
