scrapy-redis分布式爬虫,使用post方法
https://github.com/rmax/scrapy-redis
把源码中的 src 复制到 自己项目中
from scrapy_redis.spiders import RedisSpider
class HmmSpider(RedisSpider):
name = 'spider_redis'
allowed_domains = ['xxx1.com']
redis_key = "redisqueue_online"
custom_settings = {
'SCHEDULER' : "scrapy_redis.scheduler.Scheduler", # 启用Redis调度存储请求队列
'SCHEDULER_PERSIST' : True, # 不清除Redis队列、这样可以暂停/恢复 爬取
'DUPEFILTER_CLASS' : "scrapy_redis.dupefilter.RFPDupeFilter", # 确保所有的爬虫通过Redis去重
'SCHEDULER_QUEUE_CLASS' : 'scrapy_redis.queue.SpiderPriorityQueue',
'REDIS_HOST': '111.131.124.111',
'REDIS_PORT': '6379',
'REDIS_ENCODING': 'utf-8',
'REDIS_PARAMS': {'password': '1234'}
}
重写 ,发送post 请求
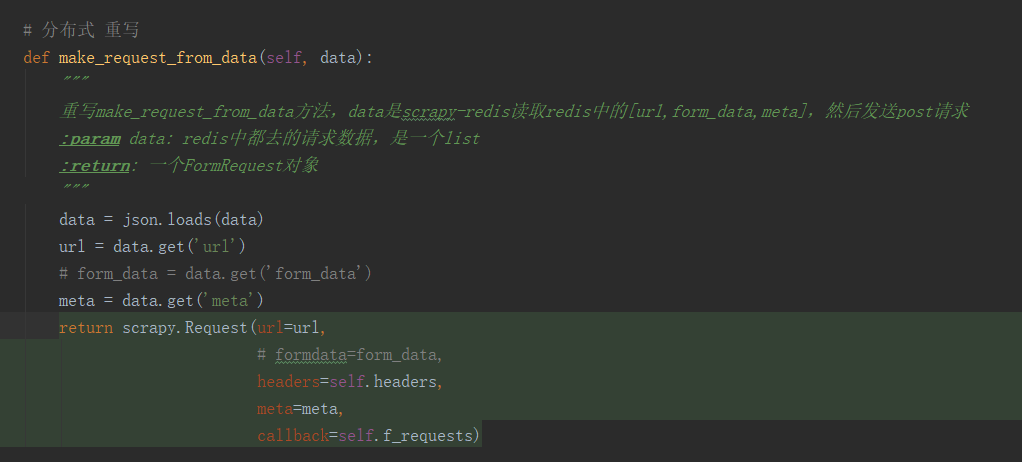
因为 要爬取的 post 请求 都是相同url ,参数不同, 修改源码中的 dupefilter.py
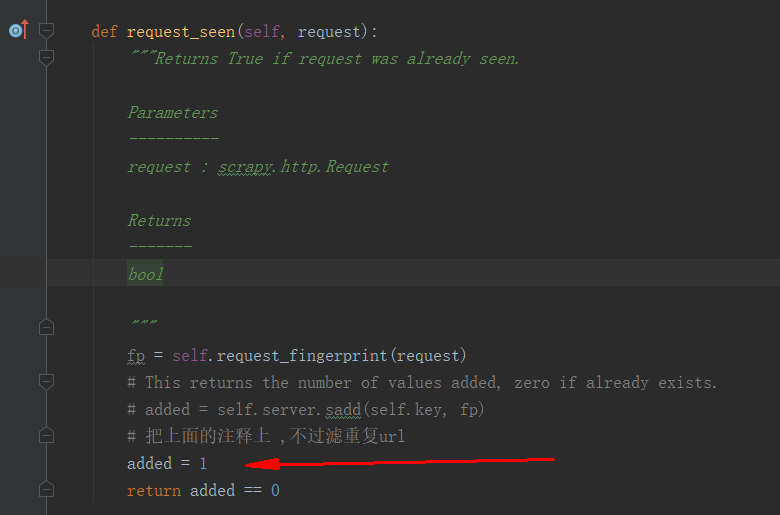
https://www.cnblogs.com/chenhuabin/p/10867285.html
https://www.jianshu.com/p/5baa1d5eb6d9
https://blog.csdn.net/lm_is_dc/article/details/81057811

 浙公网安备 33010602011771号
浙公网安备 33010602011771号