BUIR论文阅读笔记
这个领域不熟悉,是看的第一篇论文,记录细一点
Abstract
单类协作过滤(OCCF)的目标是识别出与之呈正相关但尚未交互的用户-项目对,其中只有一小部分积极的用户-项目交互被观察到,对于积极和消极交互的区分建模,以往的工作在一定程度上依赖于负抽样,即将未观察到的用户项目对视为负对,因为实际的负对是未知的。然而,负抽样方案有关键的局限性,因为它可能选择“正但未观察到”的对作为负的。本文提出了一种新的OCCF框架,即BUIR,它不需要负采样。为了使正相关用户和项目的表示相互相似,同时避免崩溃的解决方案。BUIR采用了两个不同的编码器网络,相互学习,第一个编码器被训练预测第二个编码器的输出作为其目标,而第二个编码器通过缓慢逼近第一个编码器提供一致的目标。此外对编码器输入应用了随机数据增强。BUIR基于用户和项目的邻域信息,在每次编码是随机生成每个积极交互的增强视图
Introduction
介绍一下OCCF的目标是通过只使用少量观察到的交互来识别大量未观察到的交互中最有可能的积极的用户-项目交互
解决OCCF问题最主要的方法是区分性建模,它明确地旨在区分积极的用户-项目交互和消极的对应交互。
但是OCCF存在一个问题,就是假设所有未观察到的交互作用都是负的,会造成尚未交互的项目会被认为不如有交互的项目。所以目前的方法要么使用所有未观察到的用户-项目交互作为负抽样,要么采用负抽样,以随机的方式随机抽样未观察到的用户-项目交互。最后为了更好的效果和更快的速度还提出了从非均匀分布中采样的策略
但是负采样在以下方面有严重的局限性,首先,随着用户-项目交互变得更加稀疏,关于负面交互的基本假设变得不那么有效。因为随着观察到的积极交互作用较少,“积极但未观察到的”交互作用的数量就会增加,因此,取样正确的消极交互作用变得更加困难。这种监管的不确定性最终会降低top-𝐾推荐的性能。其次,收敛速度和最终的性能取决于负抽样分布的具体选择。
所以为了解决上面的局限性,提出了一种新的OCCF框架,不需要负采样来训练模型。其主要思想是,给定一个积极的用户-项目交互。主要思想是,给定一个积极的用户-项目交互(𝑢,𝑣),使𝑢和𝑣的表示彼此相似。但是也存在一个问题,如果没有负面的监督,可能会很快收敛到编码器网络为所有的用户和项目输出相同的表示的情况。
我们认为上面的崩溃解是由在单个编码器的端到端学习框架内同时优化𝑢和𝑣引起的。于是采用类似于学生-教师的网络。具体来说,BUIR通过使用两种不同的编码器网络,即在线编码器和目标编码器,直接引导用户和项目的表示。高级的思想是只训练在线编码器进行𝑢和𝑣之间的预测任务,其中其预测的目标由目标编码器提供。也就是说,对在线编码器进行了优化,使它的用户(和项目)向量更接近由目标编码器计算的项目(和用户)向量。同时,采用基于动量的移动平均对目标编码器进行更新,以缓慢地接近在线编码器,这鼓励了为在线编码器的目标提供增强的表示。通过这样做,在线编码器可以捕获𝑢和𝑣之间的正相关关系到表示中,同时防止模型崩溃到平凡解,而无需显式地使用任何负交互作用进行优化。
此外,我们引入了一种随机数据增强技术来缓解我们的框架中的数据稀疏性问题。利用增强视图的输入交互,生成基于每个用户和项目的邻居信息。当正用户-项目对被传递到编码器时,应用随机增强,从而产生用户-项目对的不同视图。也就是说,通过使我们的编码器使用用户(和项目)邻居的随机子集作为输入特性,它产生了类似的效果,可以在没有任何人工干预的情况下增加数据本身的正对的数量。最后,让BUIR学习每个积极的用户-项目对的各种视图。
Method
首先用一个编码器来描述整个学习过程,编码器将用户ID和项目ID作为输入,以及如何使用这些表示来推断交互分数,最后我们引入了一种带有扩展编码器的随机数据增强来进一步利用邻域信息
模型的整体结构如下:
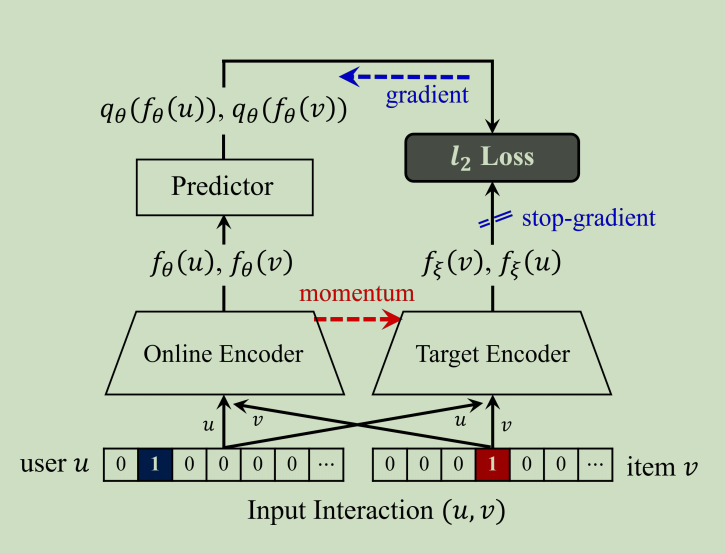
Bootstrapping the Representations
设f为编码器网络,以产生用户和项目的表示,编码器最简单的架构是一个单一嵌入层,将每个用户id和项目id映射到一个d维的嵌入向量。每个编码器由一个用户编码器和一个项目编码器组成,它们用一个one-hot向量表示用户id和项目id作为它们的输入。
BUIR利用了具有相同结构的两种不同编码器网络,在线编码器\(f_{\theta}\)和目标编码器\(f_{\xi}\)。BUIR的核心思想是以目标编码器的输入作为目标,对在线编码器进行训练,同时逐步改进目标编码器。BUIR与现有的端到端学习框架的主要区别在于,在线编码器和目标编码器以不同的方式进行更新。在线编码器经过训练,使其输出与目标之间的误差最小化,而目标网络则根据动量更新进行缓慢更新,以保持其输出一致。
对于每个观察到的交互作用,BUIR损失是基于相互预测的均方误差。使用预测器\(q_{\theta}\)。它包含两个错误项,一个用于更新在线用户向量\(f_\theta(u)\)以及准确预测目标向量\(f_\xi(v)\),另一个用于更新在线项目向量\(f_\theta(v)\)以及预测目标用户向量\(f_\xi(u)\)。最后的损失如下:
\(\begin{aligned} \mathcal{L}_{\theta,\xi}(u,v)& =l_2\left[q_\theta\left(f_\theta(u)\right),f_\xi(v)\right]+l_2\left[q_\theta\left(f_\theta(v)\right),f_\xi(u)\right] \\ &\begin{aligned}&\approx-\frac{q_\theta\left(f_\theta(u)\right)^{\top}f_\xi(v)}{\|q_\theta\left(f_\theta(u)\right)\|_2\|f_\xi(v)\|_2}-\frac{q_\theta\left(f_\theta(v)\right)^{\top}f_\xi(u)}{\|q_\theta\left(f_\theta(v)\right)\|_2\|f_\xi(u)\|_2}\end{aligned} \end{aligned}\)
然后对在线编码器和目标编码器的参数进行优化
\(\begin{aligned}\theta&\leftarrow\theta-\eta\cdot\nabla_\theta\mathcal{L}_{\theta,\xi}\\\xi&\leftarrow\tau\cdot\xi+(1-\tau)\cdot\theta\end{aligned}\)
在线编码器通过通过从反向传播的梯度得到有效的优化,而目标编码器被更新为在线编码器的平均值
我们提出的方法中更新目标编码器的方向与更新在线编码器的方向完全不同(真的吗,看看后面有没有分析),有效的阻止了两个编码器收敛到崩溃解
Top-K Preferred Item Prediction
当我们将每个正交互作用的u和v之间的预测误差最小化时,它们的正相关概念性被编码到它们的表示之间的l2距离中,也就是说损失函数之间的值越小,用户-项目对越有可能发生交互,意味着损失和交互的得分成反比。为了考虑u和v之间的对称关系,我们基于交叉预测任务定义了一个交互得分
\(s(u,v)=q_\theta\left(f_\theta(u)\right)^{\top}f_\theta(v)+f_\theta(u)^{\top}q_\theta\left(f_\theta(v)\right)\)
对于交互分数的计算,我们只使用从在线编码器中获得的表示,只有通过在线编码器才能有效的推断出交互分数
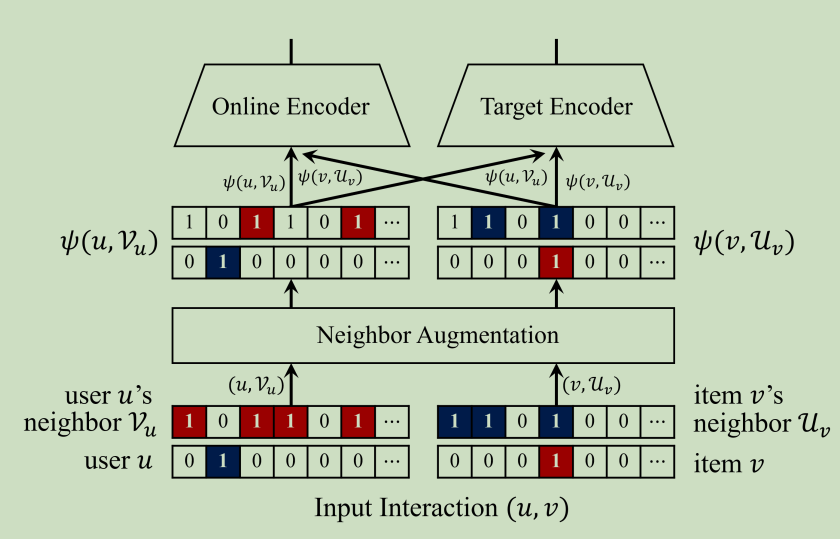
Neighbor-based Data Augmentation
OCCF的另一个可用的来源时用户和项目的社区信息,于是使用了一个基于邻居的编码器,它另外将一组给定的用户作为输入,也就是说该编码器能够学习这种特征集输入,以多热向量表示,捕获用户/项目的共现和它们的关系
在我们的框架中,将多热输入添加到单热输入中,在这种情况下,与用户u或项目v相关的在线编码器参数共享用于计算\(f_\theta(u,\mathcal{V}_u)\)和\(f_\theta(v,\mathcal{U}_v)\),因此它们通过两种类型的监督更新,即优化不仅作为目标,而且作为邻居,这带来了正则化的影响
但是为了获取和开发更丰富的监督,我们扩展了我们的框架,以考虑更多的项目-用户交互,这些交互基于其邻居信息以自监督的方式进行增强,于是我们采用了一种增强技术,在训练的过程中随机应用于每个输入交互,这种随机数据增强允许编码器学习轻微扰动的交互,称为交互的增强视图,通过这样做,BUIR可以有效地学习表示,即使在交互数量很小的情况下。增强函数如下:
\(\begin{aligned}\psi(u,\mathcal{V}_u)&=(u,\mathcal{V}_u'),\mathrm{~where~}\mathcal{V}_u'\sim\{\mathcal{S}|\mathcal{S}\subseteq\mathcal{V}_u\},\\\psi(v,\mathcal{U}_v)&=(v,\mathcal{U}_v'),\mathrm{~where~}\mathcal{U}_v'\sim\{\mathcal{S}|\mathcal{S}\subseteq\mathcal{U}_v\}.\end{aligned}\)
随机扰动的模型如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号