Self-Supervised Learning for Recommender Systems A Survey论文阅读笔记
Abstract
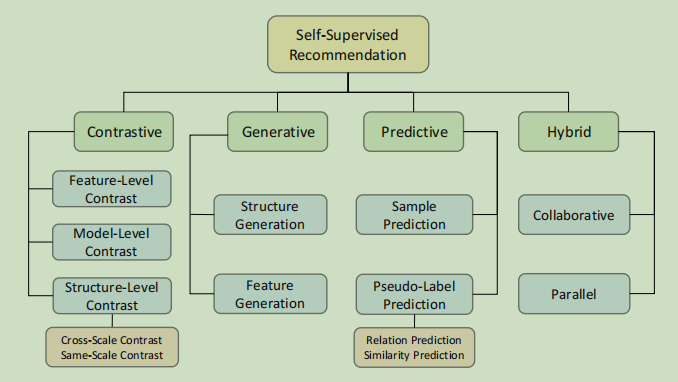
这篇文章提出了自监督学习推荐的独家定义,定期将现有的SSR方法分为四类:对比,生成、预测和混合。对于每个类别,阐述了它的概念和表述,所涉及的方法,以及它的优缺点。
Definition and Taxonomy
Definition and Formulation
介绍SSR的定义,三个关键特征总结如下:
- 半自动地利用原始数据本身来获得更多的监督信号
- 结合一个自监督任务使用增强数据训练或预训练推荐模型
- 自监督任务的设计是为了提高推荐效果,而不是作为一个最终目标
详细说明一下第二点,第二点描述了SSR的设置,这是与传统推荐模型的一个关键区别。这里增强数据是指通过对原始数据应用各种转换而生成的新的训练示例(例如扰动图的边缘下降)并且自监督任务是指生成和利用增强数据的过程(例如从邻近节点的破坏特征生成结构)。自监督任务和增强数据的合并是SSR的先决条件
考虑带推荐系统中不同的数据类型和优化目标,需要一个模型无关的框架来制定SSR,虽然编码器和投影头的具体结构和数量可能因模型而有所不同,但大多数现有的方法都可以描述为编码器+投影头体系(Encoder+Projection-Head)结构。为了适应不同的数据模式,一系列的神经网络可以作为编码器,而投影头(也称为生成模型的解码器)通常是一个轻量级的结构,如线性变换,浅MLP或非参数映射。编码器的目的是学习用户和项目的分布式表示H,而投影头为推荐任务或特定的自监督任务改进H,基于这个体系结构,SSR可以表述如下:
\(f_{\theta^*},g_{\phi^*},\mathbf{H}^*=\arg\min_{f_\theta,g\phi}\mathcal{L}\left(g_\phi(f_\theta(\mathcal{D},\tilde{\mathcal{D}}))\right)\)
之后公式的每个符号的具体细节见原始论文
Taxonomy
将现有的SSR模型分为四类,分别是对比,预测,生成和混合
Contrastive Method
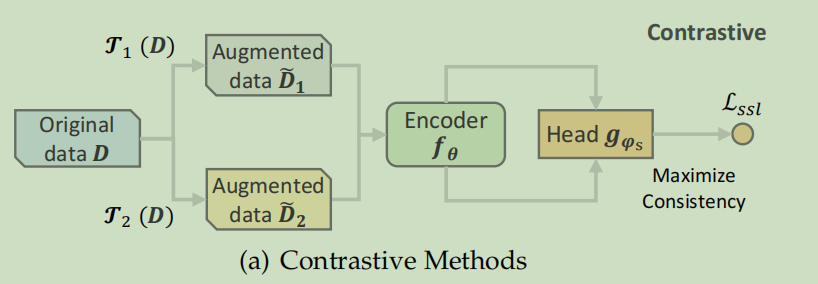
对比方法的基本思想是将每个实例视为一个类,然后将同一实例的变体拉入嵌入空间,并将不同实例的变体分开,其中变体是通过对原始数据施加不同的转换而创建的。通常同一实例的两个变体被认为是正对,不同实例的变体被认为是彼此的负样本。一个变体应该以内非必要的变体,而不是显著地修改原始实例。该方法通过最大化正对的一致性,同时最小化负对之间的一致性,可以获得推荐的判别表示。我们将对比任务表述为:
\(f_\theta^*=\arg\min_{f_\theta,g_{\phi_s}}\mathcal{L}_{ssl}\big(g_{\phi_s}(f_\theta(\tilde{\mathcal{D}}_1),f_\theta(\tilde{\mathcal{D}}_2))\big)\)
Generative Method
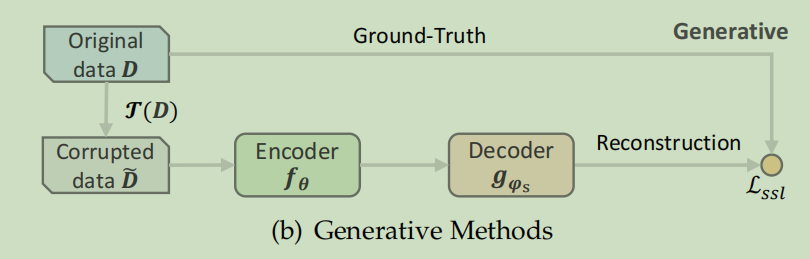
生成方法从掩码语言模型中获得灵感,如BERT。这些模型采用了一个自我监督的任务,其中原始的用户/项目配置文件从其损坏的版本中重建。该模型被训练成从其他数据中预测一部分可用数据,其中结构和特征重建是最常见的任务。自监督的任务通常被表述为:
\(f_\theta^*=\arg\min_{f_\theta,g_{\phi_s}}\mathcal{L}_{ssl}\Big(g_{\phi_s}\left(f_\theta(\tilde{\mathcal{D}})\right),\mathcal{D}\Big)\)
Predictive Method
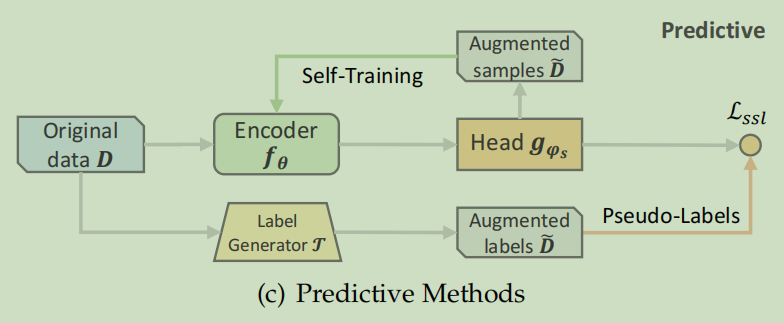
SSR中的预测方法与生成方法相似,因为都涉及到预测,但其潜在目标不同。生成方法侧重于预测原始数据的缺失部分,这可以看作是自我预测的一种形式,相比之下,预测方法从原始数据中生成新的样本或标签来指导借口任务。我们将现有的预测SSR方法分为两类:基于样本和基于伪标签。基于样本的方法旨在基于当前的编码器参数来预测信息样本。然后将这些预测的样本反馈到编码器中,以生成具有更高可信度的新样本。基于伪标签的方法通过生成器生成标签,该生成器可以是另一个编码器或基于规则的选择器。这些生成的标签被用作ground-truth来指导指导编码器。基于为标签的方法可以表述如下:
\(f_\theta^*=\arg\min_{f_\theta,g_{\phi_s}}\mathcal{L}_{ssl}\Big(g_{\phi_s}\big(f_\theta(\mathcal{D})\big),\tilde{\mathcal{D}}\Big)\)
Hybrid Method
上述每一种方法都有其独特的优势,可以利用不同的自监督信号。获得全面自监督的一个可行策略是将各种自监督的任务相结合,并将其整合到一个单一的推荐模型中。混合方法通常需要多个编码器和投影头,不同的自监督任务可以进行并行操作或协作操作,以增强自监督信号。各种接口任务的组合通常被表述为上述类别中不同的自监督损失的加权和。
Typical Training Schemes
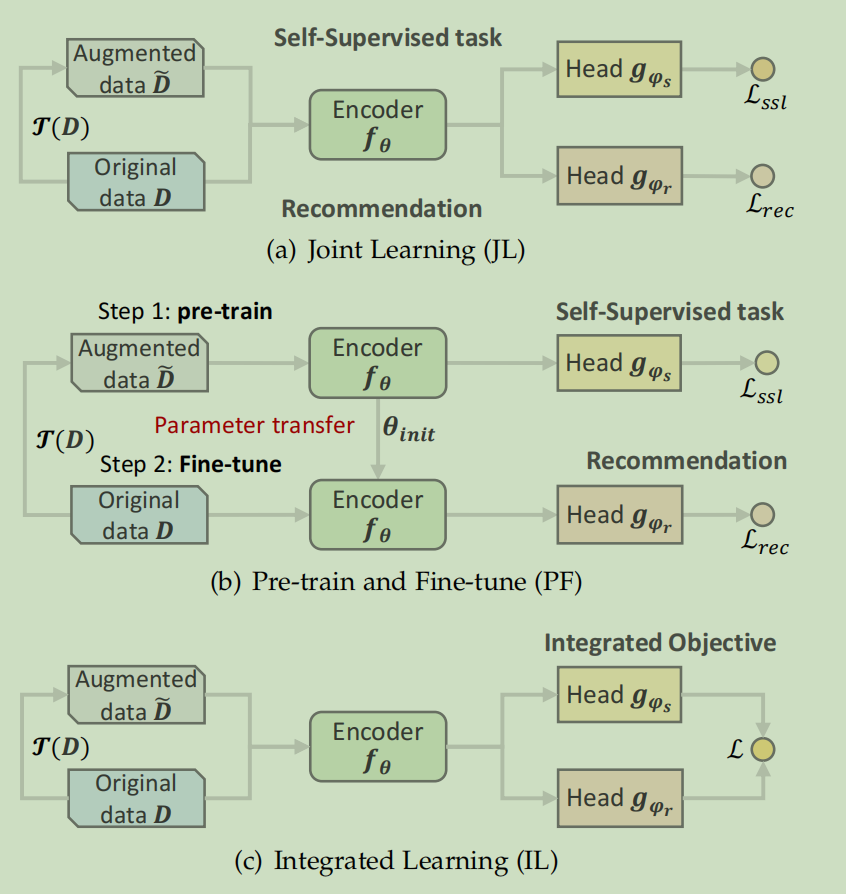
这里介绍三种典型的SSR训练方案,联合学习,预训练和微调,集成学习
Joint Learning
借口任务和推荐任务与共享变啊目前进行联合优化,借口任务的输出通常不具有优先级,而是被认为是有助于规范推荐任务的辅助任务
\(\boldsymbol{\Theta}^*=\underset{f_\theta,g_\phi}{\operatorname*{\arg\min}}\mathcal{L}_{rec}(g_{\phi_r}(f_\theta(\mathcal{D})))+\alpha\mathcal{L}_{ssl}(g_{\phi_s}(f_\theta(\tilde{\mathcal{D}})))\)
Pre-training and Fine-tuning(PF)
PF方案包括两个阶段,预训练和微调。在预训练阶段,编码器通过对增强数据的自监督任务进行预训练,以实现良好的参数初始化。然后对原始数据和投影头进行微调。先前对图的研究引入了另一种训练方案,即无监督表示学习。该方案首先对编码器进行预训练,然后冻结它,只学习下游任务的少量附加参数。
\(\begin{aligned}f_{\theta_{init}}&=\arg\min_{f_{\theta},g_{\phi_{s}}}\mathcal{L}_{ssl}(g_{\phi_{s}}(f_{\theta}(\tilde{\mathcal{D}}),\mathcal{D}))\\\Theta^*&=\arg\min_{f_{\theta_{init}},g_{\phi_{r}}}\mathcal{L}_{rec}(g_{\phi_{r}}(f_{\theta}(\mathcal{D})))\end{aligned}\)
Integrated Learning
在该方案中,借口任务和推荐任务协调一致,形成一个统一的目标
损失函数通常量化了两个输出之间的不同信息或互信息
\(\boldsymbol{\Theta}^*=\arg\min_{f_\theta,g_\phi}\mathcal{L}\left(g_{\phi_r}(f_\theta(\mathcal{D})),g_{\phi_s}(f_\theta(\tilde{\mathcal{D}}))\right)\)
Data Augmentation
SSR中常用的数据增强技术分为三类
- 基于序列
- 基于图
- 基于特征
Sequence-based Augmentation
基于序列的数据增强主要分为以下几种:
- 项目掩码
- 项目裁剪
- 项目重排
- 项目替换
- 项目插入

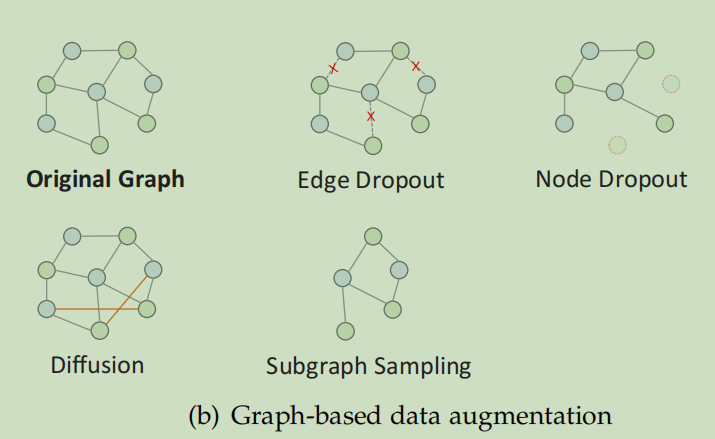
Graph-based Augmentation
基于图的增强主要分为以下几种
- Edge/Node Dropout
- Graph Diffusion:与基于dropout的方法相反。基于扩散的增强方法是将边添加到图中来创建视图,可以利用计算用户和项目表示的相似性来发现可能的边,并保留具有top-k相似性的边,当随机添加边时,该方法可用于生成负样本
- Subgraph Sampling 对一部分节点和边进行采用,以形成子图,或者说子图对局部结构进行采样
Feature-based Augmentation
基于特征的增强主要分为以下几种
- Feature Dropout
- Feature Shuffling
- Feature Clustering 将CL与聚类结合
- Feature Mixing 将原始用户/项目功能和其他用户/项目或以前版本的功能混合,以合成信息丰富的消极/积极的例子
- Feature Perturbation 特征扰动
Contrastive Methods
基于对比学习的自监督学习可以分为三种:结构级对比(structure-level),特征级对比(feature-level)和模型级对比(model-level)
Structure-Level Contrast
可以将结构级对比分为两类:同尺度对比和跨尺度对比。相同尺度的对比包括来自两个相同尺度对象的视图,可以进一步分为两个层次:局部-局部和全局-全局。交叉尺度对比包括来自两个不同尺度的对象的视图,分为局部-全局和局部-上下文。在图结构中,局部指节点,全局指图
Local-Local Contrast
最大化用户/项目节点表示之间的互信息
\(f_\theta^*=\arg\min_{f_\theta,g_{\phi s}}\mathcal{L}_{\mathcal{MI}}(g_{\phi_s}(\tilde{\mathbf{h}}_i,\tilde{\mathbf{h}}_j))\)
h是经过增强视图中学习到的结点表示
这个层次的对比学习有以下的论文
首先是基于dropout进行增强的论文
- SGL:基于dropout的增强,三种策略,node dropout,edge dropout和random walk
- DCL:利用随机edge-dropout来扰动一个节点的l跳自我网络,得到两个子图,使两个子图上学习到的节点表示之间的一致性最大化
- HHGR:提出了一种基于组推荐的双尺度node dropout的方法,包括粗粒度和细粒度的退出方案,该方案是从所有组中删除部分用户节点,并分别只从特定组中删除随机选择的成员节点,也是让节点表示之间的互信息最大化
然后是基于子图采样进行增强的论文
- CCDR:使用两种类型的对比任务,intra-CL和inter-CL,intra-CL的任务类似于DCL中的对比任务,使用图注意网络作为编码器在目标域中进行。Inter-CL任务的目的是最大化在源域和目标域中学习到的相同对象的表示之间的互信息
- PCRec:将跨域推荐与CL连接起来,使用随机游走抽样r-hop自我网络来增加数据,在源域中预训练一个GIN编码器,然后利用交互数据对矩阵分解模型进行微调,以便在目标域中进行推荐。
Global-Global Contrast
全局对比一般用于顺序推荐模型中,其中一个序列被认为是用户的全局视图
\(f_{\theta}^{*}=\underset{f_{\theta},g_{\phi_{s}}}{\operatorname{arg}\operatorname*{min}}\mathcal{L}_{\mathcal{MI}}(g_{\phi_{s}}(\mathrm{Agg}(f_{\theta}(\tilde{S}_{i})),\mathrm{Agg}(f_{\theta}(\tilde{S}_{j})))\)
S是经过增强的序列
DHCN通过建模会话内和会话间的结构信息,创建了给定会话的两个基于超图的视图。它将同一会话的表示视为正对,而不同会话的损坏表示视为负对。
Local-Global Contrast
局部-全局对比的目的是将高级全局信息编码为局部结构表示,并统一全局和局部语义。它经常用于图形学习场景,可以表述为:
\(f_{\theta}^{*}=\arg\min_{f_{\theta},g_{\phi_{s}}}\mathcal{L}_{\mathcal{MI}}(g_{\phi_{s}}(\tilde{\mathbf{h}},\mathcal{R}(f_{\theta}(\tilde{\mathcal{G}},\tilde{\mathbf{A}})))\)
R是生成全局级图表示的Readout函数
下面是相关的论文
- EGLN:提出通过将合并的用户-项目对表示与全局表示进行对比来实现局部-全局一致性,全局表示是所有用户-项目对表示的平均值。还采用了图扩散的方式进行数据增强,通过计算用户与项目之间的相似性,得到一个增广图邻接矩阵,保留了前k个相似性。矩阵和用户/项目表示相互迭代学习,并通过图形编码器进行更新
- BiGI:生成用户-项目对表示时,只采用其h-hop子图进行聚合
- HGCL:构造了用户和项目节点类型特定的同构图。对于每个齐次图,它使用DGI管道来最大限度地提高图的局部和整个图的全局表示之间的互信息。它还提出了一种跨类型的对比方法来独立不同类型的同构图之间的局部信息和全局信息
Local-Context Contrast
局部上下文对比在图和基于序列的场景中都可以观察到,其中上下文是通过采样自我网络或聚类来构建的,这种对比可以表述为:
\(f_\theta^*=\arg\min_{f_\theta,g_{\phi_s}}\mathcal{L}_{\mathcal{M}\mathcal{I}}(g_{\phi_s}(\mathbf{h}_i,\mathcal{R}(f_\theta(\mathcal{C}_j)))\)
\(\mathcal{C}_j\)表示节点j的上下文
下面是相关论文
- NCL:设计了一个典型的对比目标来捕获用户/项目与其原型之间的相关性,这个原型代表了一组语义邻居。利用K-means对所有用户或项目嵌入进行聚类得到原型,并使用EM算法对原型进行递归调整
- MHCN:通过定义三种类型的三角形社会关系,并使用多通道超图编码器对其进行建模,对于每个通道中的每个用户,MHCN分层地最大化了用户表示、用户自我超图表示和全局超图表示之间的互信息。
- HCCF:提出参数化超图依赖矩阵,而不是手动定义超图结构,然后对比了来自用户-项目图和参数化超图的表示
- SMIN:使用一个具有不同上下文聚合顺序的用户-项目矩阵链来对比节点与其上下文之间的关系
Feature-Level Contrast
数据集中的特征/属性信息有限,对特征级对比的探索较少。数据通常以多字段的格式组织起来,并且可以使用大量的分类特性,如用户画像和项目类别。通常,这种类型的对比可以定义为:
\(f_\theta^*=\arg\min_{f_\theta,g_{\phi_s}}\mathcal{L}_{\mathcal{MI}}(g_{\phi_s}(f_\theta(\tilde{\mathbf{x}}_i),f_\theta(\tilde{\mathbf{x}}_j)))\)
其中x是通过修改输入特征或通过模型学习而获得的特征级增强
以下是相关论文
- SL4Rec,采用了双塔结构,并对项目特征应用相关的特征屏蔽和推出,以实现更有意义的特征增强。它将高度相关的特征进行掩码,通过互信息来进行测量,但是保留的特征可能无法弥补被掩盖的特征背后的语义
- SLMRec:考虑了推荐数据的多种模式,并利用特征的dropout和mask来创建具有不同粒度的数据增强。然后进行一个模型无关的对比任务和一个模型特定的对比任务
Model-Level Contrast
前两类方法都是从数据的角度提取自监督信号,但它们并没有以端到端的方式实现。而模型级的方法是保持输入不变,并动态地修改模型体系结构,以动态地增加视图对。这些模型级增强之间的对比被表述为:
\(f_\theta^*=\arg\min_{f_\theta,g_{\phi_s}}\mathcal{L}_{\mathcal{MI}}(g_{\phi_s}(f_{\theta^{\prime}}(\mathcal{D}),f_{\theta^{\prime\prime}}(\mathcal{D})))\)
神经元mask是一种常用的干扰模型的技术,以下是相关的论文:
- SimGCL&XSimGCL:向隐藏表示中添加随机统一噪声以进行增强,从而阐述更统一的节点表示,并且减轻流行偏差问题。调整噪声大小可以提供对表示一致性的更细粒度的调节,并且XSimGCL提出了跨层对比
Contrastive Loss
一般来说,对比损失的优化目标是最大化两个表示之间的互信息,定义为:
\(\mathcal{MI}\left(\mathbf{h}_{i},\mathbf{h}_{j}\right)=\mathbb{E}_{P\left(\mathbf{h}_{i},\mathbf{h}_{j}\right)}\log\frac{P\left(\mathbf{h}_{i},\mathbf{h}_{j}\right)}{P\left(\mathbf{h}_{i}\right)P\left(\mathbf{h}_{j}\right)}\)
但是直接优化互信息是比较困难的,一个可行的方式是最大化其下界,有两个最常用的下界
- Jensen-Shannon Estimator
- InfoNCE
Jensen-Shannon Estimator
Jensen-Shannon散度可以有效地优化并保证稳定的性能
\(\begin{aligned} \mathcal{MI}_\mathrm{JSD}\left(\mathbf{h}_i,\mathbf{h}_j\right)& =-\mathbb{E}_{\mathcal{P}}\left[\log\left(f_{\mathrm{D}}\left(\mathbf{h}_{i},\mathbf{h}_{j}\right)\right)\right] \\ &-\left.\mathbb{E}_{\mathcal{P}\times\tilde{\mathcal{P}}}\left[\log\left(1-f_{\mathrm{D}}\left(\mathbf{h}_i,\tilde{\mathbf{h}}_j\right)\right)\right]\right. \end{aligned}\)
P表示hi,hj的联合分布
InfoNCE
修改后的最终版本:
\(\mathcal{MI}_{NCE}^{+}=-\mathbb{E}\bigg[\log\frac{\sum_{j\in\mathcal{N}_i^{+}}e^{-\mathbf{z}_i^{\top}\mathbf{z}_j/\tau}}{\sum_{n\in\mathcal{N}_i^{-}\cup\mathcal{N}_i^{+}}e^{-\mathbf{z}_i^{\top}\mathbf{z}_n/\tau}}\bigg]\)
Pros and Cons
对比方法经常受到高质量数据增强的未知标准的影响
现有的对比方法大多基于任意的数据扩充,并通过试错法进行选择,既没有严格理解它们是如何以及为什么起作用的,也没有规则或指导方针清楚说明什么是推荐的好处。此外,一些被认为是有用的常见的增强,最近甚至被证明对推荐性能有负面影响。因此,如果不知道什么增强是有用的,对比任务可能会失败。
Generative Methods
生成SSR方法的目的是通过重构原始版本的输入来编码数据中的内在相关性。我们根据其重建的目标将这些方法分为两类:结构生成和特征生成
Structure Generation
这个分支主要用于序列模型,这个分支是利用结构信息来监督模型,通过将基于掩码/dropout的增强运算符用于原始结构,得到损坏版本,然后对其进行恢复,结构的恢复可以表述为:
\(f_\theta^*=\underset{f_\theta,g_{\phi}s}{\operatorname*{\arg\min}}\mathcal{L}_{ssl}\left(g_{\phi_s}\left(f_\theta(\tilde{\mathcal{S}})\right),S\right)\)
- PMGT:利用采样的子图进行图重建任务,提出了一种对每个项目节点的子图进行采样的采样方法,并根据邻居的重要性将采样的子图重排为有序序列,然后将子图输入到Transformer中
Feature Generation
特征生成可以被理解为一个回归问题,可以表述为:
\(f_{\theta}^{*}=\arg\min_{f_{\theta},g_{\phi_{s}}}\left\|g_{\phi_{s}}\left(f_{\theta}(\tilde{\mathcal{D}})\right)-\mathbf{X}\right\|^{2}\)
X是特征的通用符号,可以是用户画像的属性、项目文本特性或学习的用户/项目表示
- PT-GNN 提出模拟元学习设置来对GNN模型进行预训练。它选择具有足够交互作用的用户/项目作为目标用户/项目,并对采样的K个邻居进行图卷积,以预测目标从整个图中学习到的ground-truth嵌入。优化这种重构损失直接提高了嵌入能力,使模型能够容易切快速地适应冷启动用户/项目
Pros and Cons
现有的方式主要依赖掩码模型管道,依赖Transformer来取得显著的效果。通常也会面临密集计算的挑战。
Predictive Methods
预测性SSR方法从完整的原始数据中获得的自生成的监督信号。根据预测性自监督任务的预测结果,可以将预测方法分为两个分支:样本预测和伪标签预测
Sample Prediction
自训练是半监督学习的一种风格,它与样本预测分支的SSL有关。在原始数据上对SSR模型进行预训练,并使用预训练的参数作为增强数据来预测推荐任务的潜在信息样本,然后使用这些示例来增强推荐任务或递归地生成更好的示例。基于SSL的样本预测与纯自训练的区别在于,在半监督学习中,有有限数量的未标记样本可用,而在SSL中,样本是动态生成的。
Pseudo-Label Prediction
在这个分支中,有两种形式的伪标签:预定义的离散值和预先计算/学习到的连续值。前者描述了两个对象之间的关系,相应的预测任务预测该关系是否存在。后者描述了给定对象的属性值、概率分布或特征向量。相应的预测任务旨在最小化输出与预先计算的连续值之间的差异。这些预测任务可以表述为关系预测和相似度预测
Relation Prediction
关系预测任务可以表示为一个分类问题,其中预定义的关系作为伪标签,是免费自生成的,可以表述为
\(f_{\theta^{*}}=\underset{f_{\theta},g_{\phi_{s}}}{\operatorname{arg}\operatorname*{min}_{ce}}\left(g_{\phi_{s}}\left(f_{\theta}(o_{i},o_{j})\right),\mathcal{T}(o_{i},o_{j})\right)\)
- CHEST:提出对异构用户-项目图进行预定义的基于元路径的随机游走,以连接用户-项目对。它以元路径类型预测为借口任务,对基于Transformer的模型进行预训练,预测用户-项目对之间是否存在特定元路径的路径实例
Similarity Prediction
相似度预测任务可以表述为一个回归问题,其中预先计算/学习到的连续值作为模型输出需要近似的目标,可以表述为:
\(f_{\theta^*}=\arg\min_{f_\theta,g_{\phi_s}}\left\|g_{\phi_s}\left(f_{\theta}(\mathcal{D})\right)-\mathcal{T}(\mathcal{D})\right\|^2\)
T是产生目标的标签生成器,它可以是学习目标的编码器,也可以是预先计算目标的一系列动作
以下是相关论文
- BUIR:是一种具有代表性的预测SSR方法,依赖两个非对称图编码器在没有负采样的情况下相互监督。这两个编码器被彼此训练来预测彼此的项目表示输出,通过引导表示实现自监督。特别地,在线网络以端到端的方式进行更新,而目标编码器通过基于动量的移动平均线进行更新,以缓慢地接近在线编码器
- SelfCF:继承了BUIR的优点,并通过只使用一个共享编码器进一步对其进行简化。为了获得更多的监督信号来学习区别表示,它干扰共享编码器的输出
相似性预测还能被用于解决推荐系统中的选择偏差
- RDC:在RDC中,定义了支点用户和非支点用户,其中非支点用户通过评价他们非常喜欢或不喜欢的项目来获得有偏见的推荐。RDC通过使得非支点用户的评分分布特征和支点用户相似,使用动态计算的评分分布特征作为自监督信号的评分分布特征来纠正偏差,类似的任务也用于用户偏好解纠缠
- DUAL:基于元路径的随机游走连接用户-项目对,并记录元路径实例的数量作为交互的概率度量。分配一个路径回归任务来预测预先计算的概率,并将路径语义集成到节点表示中,以增强推荐
Pros and Cons
与主要依赖静态增强算子的对比生成方法和生成方法相比,预测方法以更灵活的方式获取样本和伪标签。基于演化的模型参数对样本进行预测,细化自监督信号,并将其与优化目标对齐,有可能提高推荐性能。然而在使用预增强标签时需要谨慎。大多数当前的方法使用启发式方法获得伪标签,而没有评估他们推荐系统的相关性。因此专家知识应该被合并到伪标签集合中,这增加了开发预测SSR的费用。
Hybrid Methods
混合方法组合了多种类型的借口任务来利用不同的自监督信号。我们根据自监督任务的相互作用,将混合方法分为两组,包括协同SSR和并行SSR
Collaborative Self-Supervision
为了得到全面的自监督信号,多个自监督任务协同工作,通过在该分支下生成更多的信息样本来增强对比任务
- SEPT:第一个通过基于样本的社会推荐预测任务来整合SSL和三训练的SSR模型。它用不同的社会语义在三个视图上构建了三个图编码器。这些编码器可以预测其他两个编码器的语义相似的样本,然后再对比任务中作为积极的自监督信号。改进后的编码器递归地预测信息更丰富的样本
Parallel Self-Supervision
在这个分支中,不同的自监督任务之间没有相关性,它们是并行工作的
- CHEST:使用课程学习和自监督学习来对异构信息网络上的基于Transformer的推荐模型进行预训练。CHEST基于元路径的随机游走,形成特定于交互的子图,并与生成任务中的其余部分一起预测子图中的mask节点/边,从而利用局部上下文信息。对比任务通过将原始子图和增强子图拉近来学习子图级语义,利用全局相关性
- MPT:扩展了PT-GNN,以提高冷启动推荐的表示能力。它增加了对比任务来捕获不同子图之间的相互关联,并增加了数据,以便使用节点删除/替换/掩蔽来训练基于GNN和基于转换器的编码器。对比任务和生成任务与它们自己的参数并行进行,然后进行合并和微调
Pros and Cons
混合方法组合了多个自监督的任务,以实现增强和全面的自监督。特别是协作方法,其中生成/预测任务通过动态生成样本来服务于对比任务,在训练效果方面比静态的具有显著优势。然而混合方法面临着协调多个自监督任务的问题。他们经常难以平衡不同的自监督任务,需要手动搜索超参数或昂贵的领域知识。此外,不同的自监督任务也可能相互干扰,这可能需要更复杂的架构,因此,与只有一个自监督学习的任务相比,混合SSR具有更高的训练成本。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号