
GNN学习 Knowledge Graph Embedding(更新中)
GNN学习 Knowledge Graph Embedding
前面提到的方法都是只有一种边的类型,接下来要扩展到有向,多种边的类型的图上,即异质图(heterogeneous graph)
异质图有这样的几种类型:
- Relational GCNs
- Knowledge Graphs
- Embeddings for KG Completion
一个异质图可以被定义为
\(G=(V,E,R,T)\)
V是带有节点类型的节点\(v_i\in V\)
E是带有关系类型的边\((v_i,r,v_j)\in E\)
T是节点类型\(T(v_i)\)
R是关系类型\(r\in R\)
1.Relational GCNs
RGCN就是把GCN扩展到异质图上
从只有一种边的有向图开始,仅沿着边的方向进行信息的传递
如果一个图有多种关系的类型,那么在信息传递时,我们可以对不同的边的类型使用不同的权重
于是,我们就可以得出RGCN的一般表达
\(h_v^{l+1}=\sigma(\sum_{r\in R}\sum_{u\in N_v^r}\frac1{c_{v,r}}W_r^lh_u^l+W_0^lh_v^l)\)
其中,通过每种关系的节点的度数进行归一化 \(c_{v,r}=|N_v^r|\)
图神经网络可以写成Message+Aggregation的形式
Message:
- 对于给定关系的所有邻居\(m_{u,r}^l=\frac1{c_{v,r}}W_r^lh_u^l\)
- 自环传递\(m_v^l=W_0^lh_v^l\)
Aggregation
对邻居和自己传递过来的信息进行求和操作
\(h_v^{l+1}=\sigma(Sum(\{m_{u,r}^l,u\in\{N(v)\cup\{v\}\}\}))\)
RGCN的scalability
每种关系都需要L个权重矩阵\(W_r^1,W_r^2...W_r^L\)
每个权重矩阵的尺寸为\(d^{l+1}\times d^l\),其中\(d^l\)时第l层的嵌入维度
参数量随关系类的数量迅速增长,容易产生过拟合的问题
有两种方式来正则化权重矩阵
- block diagonal matrices
- Basis/Dictionary learning
1.block diagonal matrices
使权重矩阵变稀疏,减少非0元素的数量
具体做法是让权重矩阵成为对角块的形式
缺点在于只有相邻神经元可以通过权重矩阵交互,需要多加几层神经网络
2.Basis Learning
在不同关系之间共享权重参数
做法:将特定关系的权重矩阵表示为基础变换的线性组合形式
\(W_r=\sum_{b=1}^Ba_{rb}\cdot V_b\)
\(V_b\)在关系间共享,是基础矩阵
\(a_{rb}\)是\(V_b\)的重要性权重
对于每个关系,我们就只需要学习\(\{a_{rb}\}_{b=1}^B\)这B个标量了,其中B是常数
3.应用实例
1.链接预测
在异质图中,将每种关系对应的边都分成training message edges, training supervision edges, validation edges, test edges四类
这样分是因为有些关系的边很少,混一起分可能有些关系类型的边可能分不到四类
假定\((E,r_3,A)\)是training supervision edge,其余的边是Training message edges
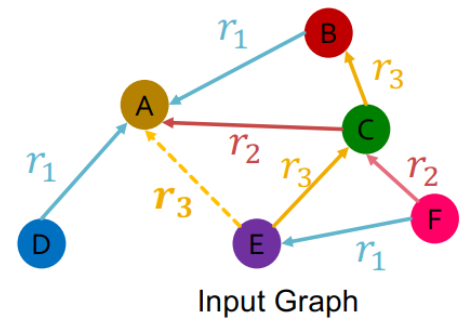
使用RGCN给\((E,r_3,A)\)打分
- 首先得到最后一层节点E和节点A的输出向量
- 使用关系专用的打分函数\(f_r:\mathbb{R}^d\times \mathbb{R^d} \rightarrow \mathbb{R}\)
-
- 比如\(f_{r_1}(h_E,h_A)=h_E^TW_{r_1}h_A,W_{r1}\in \mathbb{R}^{d\times d}\)
1.训练阶段:用training messages edges预测training supervision edges
- 1.使用RGCN给\((E,r_3,A)\)打分
- 2.通过扰乱 supervison edge得到negative edge。比如破坏\((E,r_3,A)\)的尾节点得到\((E,r_3,B)\)和\((E,r_3,D)\),negative edge不能属于training messages edges或training supervision edges
- 用GNN模型给negative edge打分
- 优化交叉熵损失函数,使在training supervision edge上的得分最大,negative edge上的得分最低
2.测试阶段
用training messages edges和training supervision edges来预测validation edges,\((E,r_3,D)\)的得分应该比所有的negatives edges的得分更高
negative edges就是尾节点不在training messages edges和training supervision edges中的以E为头节点,\(r_3\)为关系的边
具体步骤:
1.计算\((E,r_3,D)\)的得分
2.计算所有negative edge的得分
3.获得\((E,r_3,D)\)的排名RK
4.计算指标
- Hits@k:RK<=k的次数越高越好
- Reciprocal rank:\(\frac1{RK}\)越高越好

