Lucene
一、Lucene相关
突出的优点
1.首先导入相关的jar包
2.编写工具类
主要分为3步:
第一步建立FSDirectory,指定文档存放的路径。
第二步获取IndexWriter,通过这个来进行文档的相关操作。
第三步进行增删改查。
package com.feng; import java.io.File; import java.io.IOException; import java.util.ArrayList; import java.util.List; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.document.Document; import org.apache.lucene.index.CorruptIndexException; import org.apache.lucene.index.IndexReader; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.index.IndexWriterConfig; import org.apache.lucene.index.IndexWriterConfig.OpenMode; import org.apache.lucene.index.Term; import org.apache.lucene.queryParser.QueryParser; import org.apache.lucene.search.IndexSearcher; import org.apache.lucene.search.Query; import org.apache.lucene.search.ScoreDoc; import org.apache.lucene.search.TopDocs; import org.apache.lucene.store.FSDirectory; import org.apache.lucene.store.LockObtainFailedException; import org.apache.lucene.util.Version; import org.wltea.analyzer.lucene.IKAnalyzer; public class LuceneUtil { public static Version version = Version.LUCENE_35; public static File indexPath = new File("F:/workspace/document"); public static Analyzer analyzer = new IKAnalyzer(); private static FSDirectory fsDirectory; private static void initFSDirectory(){ try { fsDirectory = FSDirectory.open(indexPath); } catch (IOException e) { e.printStackTrace(); } } public static FSDirectory getFSDirectory(){ if(fsDirectory == null) initFSDirectory(); if(!LuceneUtil.indexPath.isDirectory()) LuceneUtil.indexPath.mkdirs(); return fsDirectory; } public static void addDoc(Document doc){ try { IndexWriterConfig iwc = new IndexWriterConfig(LuceneUtil.version, LuceneUtil.analyzer); iwc.setOpenMode(OpenMode.CREATE_OR_APPEND); IndexWriter indexWriter = new IndexWriter(LuceneUtil.getFSDirectory(), iwc); indexWriter.addDocument(doc); indexWriter.close(); } catch (CorruptIndexException e) { e.printStackTrace(); } catch (LockObtainFailedException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } } public static void updateDoc(String id, Document doc) { try { IndexWriterConfig iwc = new IndexWriterConfig(LuceneUtil.version, LuceneUtil.analyzer); iwc.setOpenMode(OpenMode.CREATE_OR_APPEND); IndexWriter indexWriter = new IndexWriter(LuceneUtil.getFSDirectory(), iwc); indexWriter.updateDocument(new Term("id", id), doc); indexWriter.close(); }catch (Exception e) { e.printStackTrace(); } } public static void deleteDoc(String id){ try { IndexWriterConfig iwc = new IndexWriterConfig(LuceneUtil.version, LuceneUtil.analyzer); iwc.setOpenMode(OpenMode.CREATE_OR_APPEND); IndexWriter indexWriter = new IndexWriter(LuceneUtil.getFSDirectory(), iwc); indexWriter.deleteDocuments(new Term("id", id)); indexWriter.close(); }catch (Exception e) { e.printStackTrace(); } } public static List<Document> query(String id, String name, String sex){ try { QueryParser parser = new QueryParser(LuceneUtil.version, "problem", new IKAnalyzer()); parser.setAllowLeadingWildcard(true); String s = ""; if(id != null){ s += "+(id:*"+id+"*)"; } if(name != null) s += "+(name:*"+name+"*)"; if(sex != null) s += "+(sex:*"+sex+"*)"; Query query1 = parser.parse(s); IndexReader r = IndexReader.open(LuceneUtil.getFSDirectory()); IndexSearcher indexSearcher = new IndexSearcher(r); TopDocs docs = indexSearcher.search(query1, 100); int totalHits = docs.totalHits; System.out.println("查询文档总数 :"+totalHits); List<Document> result = new ArrayList<Document>(); for (ScoreDoc doc : docs.scoreDocs) { Document document = indexSearcher.doc(doc.doc); result.add(document); } indexSearcher.close(); r.close(); return result; } catch (Exception e) { e.printStackTrace(); } return new ArrayList<Document>(); } }
这里要注意的是上面IndexWriterConfig.setOpenMode(OpenMode);的方法是指定IndexWriter的操作模式,分别有三种
OpenMode.CREATE: 创建或覆盖
OpenMode.APPEND: 追加
OpenMode.CREATE_OR_APPEND: 如果不存在则创建,否则追加
3.测试
Lucene的增删改查都是以DOCUMENT的形式交互的
3.1添加
@org.junit.Test public void add(){ Document doc = new Document(); /** * field的构造属性 * 1.field的名称,查询时就是通过这个名称来查找 * 2.field的值 * 3.是否存储该field * 4.是否分词,是否建立索引 * NOT_ANALYZED_NO_NORMS:不分词,不建立索引 * NOT_ANALYZED:不分词,建立索引 */ doc.add(new Field("id", "1", Field.Store.YES, Field.Index.NOT_ANALYZED_NO_NORMS)); doc.add(new Field("name", "fengzp", Field.Store.YES, Field.Index.NOT_ANALYZED)); doc.add(new Field("sex", "man", Field.Store.YES, Field.Index.NOT_ANALYZED)); LuceneUtil.addDoc(doc); }
添加后本地就会生成相应的文件:
3.2查询
@org.junit.Test public void query(){ List<Document> list = LuceneUtil.query("1", null, null); for(Document document : list){ System.out.println("id : "+document.get("id")); System.out.println("name : "+document.get("name")); System.out.println("sex : "+document.get("sex")); } }
返回结果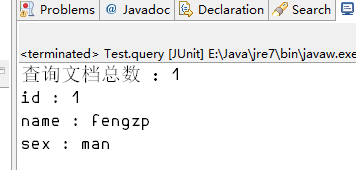
3.3更新
@org.junit.Test public void update(){ Document doc = new Document(); doc.add(new Field("id", "1", Field.Store.YES, Field.Index.NOT_ANALYZED_NO_NORMS)); doc.add(new Field("name", "fengzp123", Field.Store.YES, Field.Index.NOT_ANALYZED)); doc.add(new Field("sex", "man123", Field.Store.YES, Field.Index.NOT_ANALYZED)); LuceneUtil.updateDoc("1", doc); }
查询结果: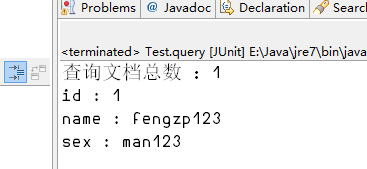
3.4删除
@org.junit.Test public void delete(){ LuceneUtil.deleteDoc("1"); }
查询结果:
这样看下来,是不是跟数据库的操作好相似呢。
三、lucene的查询详解
lucene 的搜索相当强大,它提供了很多辅助查询类,每个类都继承自Query类,各自完成一种特殊的查询,你可以像搭积木一样将它们任意组合使用,完成一些复杂操作;另外lucene还提供了Sort类对结果进行排序,提供了Filter类对查询条件进行限制。你或许会不自觉地拿它跟SQL语句进行比较: “lucene能执行and、or、order by、where、like ‘%xx%’操作吗?”回答是:“当然没问题!”
3.1 各种各样的Query
下面我们看看lucene到底允许我们进行哪些查询操作:
3.1.1 TermQuery
首先介绍最基本的查询,如果你想执行一个这样的查询:“在content域中包含‘lucene’的document”,那么你可以用TermQuery:
Term t = new Term("content", " lucene";
Query query = new TermQuery(t);
3.1.2 BooleanQuery
如果你想这么查询:“在content域中包含java或perl的document”,那么你可以建立两个TermQuery并把它们用BooleanQuery连接起来:
TermQuery termQuery1 = new TermQuery(new Term("content", "java");
TermQuery termQuery 2 = new TermQuery(new Term("content", "perl");
BooleanQuery booleanQuery = new BooleanQuery();
booleanQuery.add(termQuery 1, BooleanClause.Occur.SHOULD);
booleanQuery.add(termQuery 2, BooleanClause.Occur.SHOULD);
3.1.3 WildcardQuery
如果你想对某单词进行通配符查询,你可以用WildcardQuery,通配符包括’?’匹配一个任意字符和’*’匹配零个或多个任意字符,例如你搜索’use*’,你可能找到’useful’或者’useless’:
Query query = new WildcardQuery(new Term("content", "use*");
3.1.4 PhraseQuery
你可能对中日关系比较感兴趣,想查找‘中’和‘日’挨得比较近(5个字的距离内)的文章,超过这个距离的不予考虑,你可以:
PhraseQuery query = new PhraseQuery();
query.setSlop(5);
query.add(new Term("content ", “中”));
query.add(new Term(“content”, “日”));
那么它可能搜到“中日合作……”、“中方和日方……”,但是搜不到“中国某高层领导说日本欠扁”。
3.1.5 PrefixQuery
如果你想搜以‘中’开头的词语,你可以用PrefixQuery:
PrefixQuery query = new PrefixQuery(new Term("content ", "中");
3.1.6 FuzzyQuery
FuzzyQuery用来搜索相似的term,使用Levenshtein算法。假设你想搜索跟‘wuzza’相似的词语,你可以:
Query query = new FuzzyQuery(new Term("content", "wuzza");
你可能得到‘fuzzy’和‘wuzzy’。
3.1.7 RangeQuery
另一个常用的Query是RangeQuery,你也许想搜索时间域从20060101到20060130之间的document,你可以用RangeQuery:
RangeQuery query = new RangeQuery(new Term(“time”, “20060101”), new Term(“time”, “20060130”), true);
最后的true表示用闭合区间。
3.2 QueryParser
看了这么多Query,你可能会问:“不会让我自己组合各种Query吧,太麻烦了!”当然不会,lucene提供了一种类似于SQL语句的查询语句,我们姑且叫它lucene语句,通过它,你可以把各种查询一句话搞定,lucene会自动把它们查分成小块交给相应Query执行。下面我们对应每种 Query演示一下:
TermQuery可以用“field:key”方式,例如“content:lucene”。
BooleanQuery中‘与’用‘+’,‘或’用‘ ’,例如“content:java contenterl”。
WildcardQuery仍然用‘?’和‘*’,例如“content:use*”。
PhraseQuery用‘~’,例如“content:"中日"~5”。
PrefixQuery用‘*’,例如“中*”。
FuzzyQuery用‘~’,例如“content: wuzza ~”。
RangeQuery用‘[]’或‘{}’,前者表示闭区间,后者表示开区间,例如“time:[20060101 TO 20060130]”,注意TO区分大小写。
你可以任意组合query string,完成复杂操作,例如“标题或正文包括lucene,并且时间在20060101到20060130之间的文章”可以表示为:“+ (title:lucene content:lucene) +time:[20060101 TO 20060130]”。代码如下:
Directory dir = FSDirectory.getDirectory(PATH, false);
IndexSearcher is = new IndexSearcher(dir);
QueryParser parser = new QueryParser("content", new StandardAnalyzer());
Query query = parser.parse("+(title:lucene content:lucene) +time:[20060101 TO 20060130]";
Hits hits = is.search(query);
for (int i = 0; i < hits.length(); i++)
{
Document doc = hits.doc(i);
System.out.println(doc.get("title");
}
is.close();
首先我们创建一个在指定文件目录上的IndexSearcher。
然后创建一个使用StandardAnalyzer作为分析器的QueryParser,它默认搜索的域是content。
接着我们用QueryParser来parse查询字串,生成一个Query。
然后利用这个Query去查找结果,结果以Hits的形式返回。
这个Hits对象包含一个列表,我们挨个把它的内容显示出来
3.3 排序:Sort
有时你想要一个排好序的结果集,就像SQL语句的“order by”,lucene能做到:通过Sort。
Sort sort = new Sort(“time”); //相当于SQL的“order by time”
Sort sort = new Sort(“time”, true); // 相当于SQL的“order by time desc”

 浙公网安备 33010602011771号
浙公网安备 33010602011771号