Mycat原理、应用场景
Mycat原理
Mycat的原理并不复杂,复杂的是代码,如果代码也不复杂,那么早就成为一个传说了。
Mycat的原理中最重要的一个动词是“拦截”,它拦截了用户发送过来的SQL语句,首先对SQL语句做了一些特定的分析:如分
片分析、路由分析、读写分离分析、缓存分析等,然后将此SQL发往后端的真实数据库,并将返回的结果做适当的处理,最终再
返回给用户。
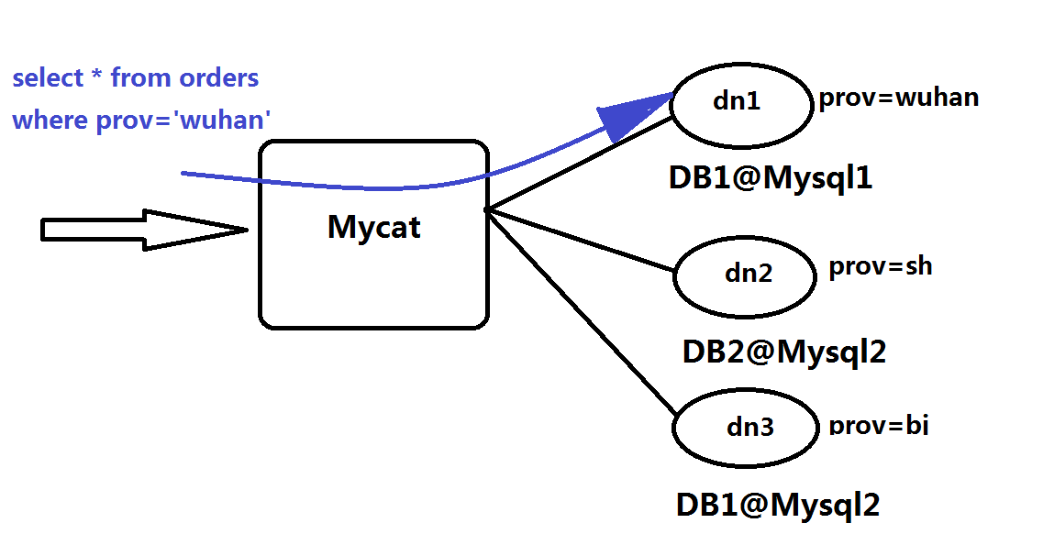
上述图片里,Orders表被分为三个分片datanode(简称dn),这三个分片是分布在两台MySQL Server上(DataHost),即
datanode=database@datahost方式,因此你可以用一台到N台服务器来分片,分片规则为(sharding rule)典型的字符串枚举
分片规则,一个规则的定义是分片字段(sharding column)+分片函数(rule function),这里的分片字段为prov而分片函数为字
符串枚举方式。
当Mycat收到一个SQL时,会先解析这个SQL,查找涉及到的表,然后看此表的定义,如果有分片规则,则获取到SQL里分片字
段的值,并匹配分片函数,得到该SQL对应的分片列表,然后将SQL发往这些分片去执行,最后收集和处理所有分片返回的结果
数据,并输出到客户端。以select * from Orders where prov=?语句为例,查到prov=wuhan,按照分片函数,wuhan返回
dn1,于是SQL就发给了MySQL1,去取DB1上的查询结果,并返回给用户。
如果上述SQL改为select * from Orders where prov in (‘wuhan’,‘beijing’),那么,SQL就会发给MySQL1与MySQL2去
执行,然后结果集合并后输出给用户。但通常业务中我们的SQL会有Order By 以及Limit翻页语法,此时就涉及到结果集在
Mycat端的二次处理,这部分的代码也比较复杂,而最复杂的则属两个表的Jion问题,为此,Mycat提出了创新性的ER分片、全
局表、HBT(Human Brain Tech)人工智能的Catlet、以及结合Storm/Spark引擎等十八般武艺的解决办法,从而成为目前业界
最强大的方案,这就是开源的力量!
应用场景
Mycat发展到现在,适用的场景已经很丰富,而且不断有新用户给出新的创新性的方案,以下是几个典型的应用场景:
单纯的读写分离,此时配置最为简单,支持读写分离,主从切换
分表分库,对于超过1000万的表进行分片,最大支持1000亿的单表分片
多租户应用,每个应用一个库,但应用程序只连接Mycat,从而不改造程序本身,实现多租户化
报表系统,借助于Mycat的分表能力,处理大规模报表的统计
替代Hbase,分析大数据
作为海量数据实时查询的一种简单有效方案,比如100亿条频繁查询的记录需要在3秒内查询出来结果,除了基于主键的查
询,还可能存在范围查询或其他属性查询,此时Mycat可能是最简单有效的选择
Mycat长期路线图
强化分布式数据库中间件的方面的功能,使之具备丰富的插件、强大的数据库智能优化功能、全面的系统监控能力、以及方
便的数据运维工具,实现在线数据扩容、迁移等高级功能
进一步挺进大数据计算领域,深度结合Spark Stream和Storm等分布式实时流引擎,能够完成快速的巨表关联、排序、分组
聚合等 OLAP方向的能力,并集成一些热门常用的实时分析算法,让工程师以及DBA们更容易用Mycat实现一些高级数据分
析处理功能。
不断强化Mycat开源社区的技术水平,吸引更多的IT技术专家,使得Mycat社区成为中国的Apache,并将Mycat推到Apache
基金会,成为国内顶尖开源项目,最终能够让一部分志愿者成为专职的Mycat开发者,荣耀跟实力一起提升。
依托Mycat社区,聚集100个CXO级别的精英,众筹建设亲亲山庄,Mycat社区+亲亲山庄=中国最大IT O2O社区
收录于:Mycat权威指南,感谢作者


 浙公网安备 33010602011771号
浙公网安备 33010602011771号