
RAC3——RAC原理开始
1、RAC并发
RAC的本质是一个数据库,只不过现在这个数据库运行在了多台计算机上,在原先的单实例中,一个进程是否可以修改一条数据,取决于是否有其他进程(同一台计算机上)并发修改。在RAC环境下,这种判断已经不够了,还必须坚持其他计算机上的进程是否有并发修改。
于是RAC要解决的第一个问题就是:如何在多台计算机环境下感知并发的存在?
对于检查本机上的并发,用传统的单实例中的锁机制就可以解决,单对于其他计算机上的并发检测,必须引入一个新的机制,这个机制就是分布式锁管理器(distributed lock management DLM),我们可以把DLM想象成一个“仲裁”,他记录着哪个节点正在用哪种方式操作哪个数据,比负责协调解决节点间的竞争。
下面我们用一个例子来说明DLM的机制原理:
一个2节点的RAC,节点1想要修改数据A,节点1想DLM请求,DLM发现数据A还没有被任何节点使用,DLM就授权给节点1,并向DLM登记节点1对数据1的使用,这时,节点2也想修改数据A,节点2向DLM请求,DLM发现数据A正被节点1使用,DLM就会请求节点1,“先给节点2用吧”,节点1收到请求后释放其对数据1的占用,节点2能够操作数据A。DLM记录这个过程。
需要强调的是DLM负责的是节点间的协调,而节点内的协调不是DLM的责任,我们继续考虑上面的例子:
这时,节点2的进程1在修改数据A,节点2的进程2也想修改数据A,节点2仍然请求DLM,但是DLM发现节点2已经有权限,无序授权。进程2对DLM的请求被通过,但是进程2是否能够修改数据A,还需要进一步通过传统的锁模式检查。
解决了第一个问题后,第二个问题就出现了,我们上文提到的数据A到底是啥呢?或者说DLM到底在那个层次上对资源的冲突进行协调?那个A是一行记录?还是一个数据块?还是一个数据文件?哈哈——答案是:数据块!!!
也就是说,进程想要修改A时,向DLM提出申请的是“数据块A的操作权限”。
oracle集群发展历史分为两个阶段,最初的是oracle并行服务器(oracle parallel server OPS),之后到9i时改成RAC,两个阶段的DLM名称也不同 ,ops的叫做pcm,RAC的叫做Cache Fusion。现在看来我们只需知道一点:现在DLM的名称叫Cache Fusion。
在DLM中,根据资源数量,活动密集程度,把资源分成两类:cache fusion 和 non-cache fusion。
cache fusion resource:是指数据块这种资源,包括 普通数据块,索引数据块,段头块(segement header), undo 数据块。
非数据块资源全部都归类为non-cache fusion resource :包括数据文件,控制文件,数据字典视图,library cache,row cache等等。
对于典型的non-cache-fusion资源,我们对library cache做一个说明,library cache中主要存的是sql语句,执行计划,plsql的包,存储过程,还有这些对象所引用的对象,当这些sql语句进行编译的时候,会对这些对象应用的对象加上一个library cache lock ,而在这些sql对象执行的时候,会对这些引用的对象加上library cache pin来保证sql语句执行的过程中应用对象的结构不会发生变化。
需要特别说明的是,当编译完成后,引用对象上的library cache lock会由shared或者exclusive模式转变成null模式,null模式的library cache look相当于一个触发器,每当引用的对象的结构遭到改变,或者定义被修改,如添加一列。。那么引用他的sql语句编译的对象就成了无效的了,需要对那个sql语句重新编译。例如:select * from a。编译后这个语句的执行计划对象会在a上加一个null模式的library cache lock。当我们改变a的机构(如增加一个新字段),此触发器就会导致select * from a 这个语句的执行计划失效。重新执行此sql的时候,需要重新编译。
在RAC环境下这个问题进一步的延伸,在每个节点上,都有可能有表a的引用对象。在任何一个节点上对a的结构进行了修改,那其他所有节点上a的对象都应被置为无效。因此:除了传统的library cache lock之外,每个节点的LCK0进程会对本实例library cache 中对象加一个shared mode的IV(Invalidation) instance lock。如果某用户想要修改对象的定义。必须先获得一个Exclusive 模式的IV锁,这会通知本地的LCK0进程释放shared mode锁。本地LCK0释放这个shared mode锁之前,会通知其他节点的LCK0,其他节点的LCK0进程收到这个消息,会将本地library cache 中的相关的对象置为无效。
这是一种广播机制,这种通信过程是通过实例的LMD(此进程详细介绍在下一节)进程完成的。
Row Cache中存放的是数据字典,其目的是编译过程减少对磁盘的访问。其内容也需要在所有实例中同步。其同步机制和library cache 是一样的,也是由LCK0进程完成。
2、 GRD(Global Resource Directory )
可以把 GRD 看作一个内部数据库,这里记录的是每一个数据块在集群间分布图,它位于每一个实例的SGA 中,但是每个实例 SGA 中都是部分 GRD , 所有实例的GR 汇总在一起就是个完整的 GRD 。
RAC 会根据每个资源的名称从集群中选择一 个节点作为它的 Master Node , 而其他节点叫作 Shadow Node。 Master Node 的 GRD 中记录了该资源在所有节 点上的使用信息 ,而 Shadow Node 的 GRD 中只需要记录资源在该节点上的使用情况,这些信息实际就是PCM Lock信息 。 PCM Lock 有 3个属性: Mode ,Role和 PI(Past Image)。下图显示了GRD内容结构: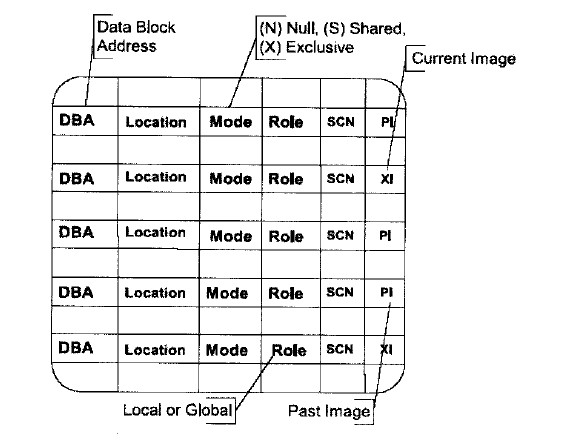
3、PCM Lock
由上文我们知道了GRD中记录的是pcm lock信息,这种锁有3个属性:mode,role,PI。
下面我们挨个看看这三个属性是怎么个意思:
1)mode:这个属性用于描述锁的模式,其中有3种取值,如下所示:

2)role:每个数据块可以被多个节点修改,role这个属性是用来描述“脏数据块”在集群间的分布状况的,其中有local 和 global 两个取值,下面结合mode来解释各个role的含义:
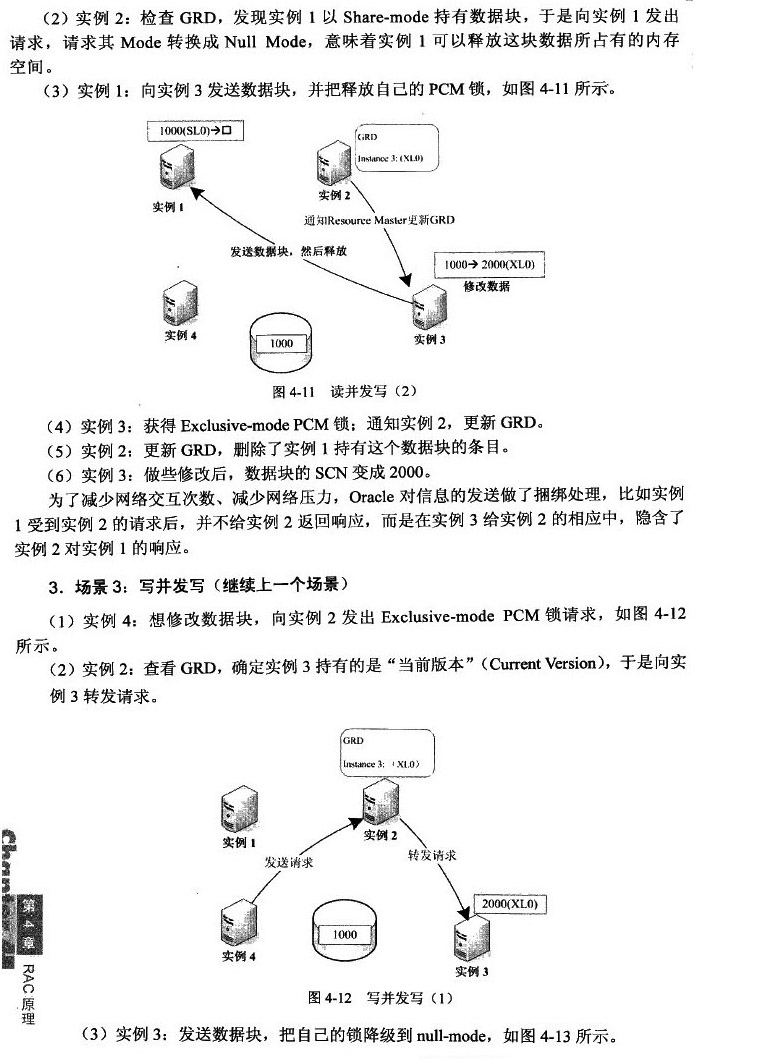
对于local role,可能的mode 只会是S 和 X;如果mode是S ,代表这个内存数据块时和磁盘上的内容完全一致的;如果mode是X,则代表这个数据块在内存中做过修改,但是修改没有被写回磁盘,也就是“脏数据块”;对于拥有local role的实例而言,如果要把这个数据块写到磁盘,不需要联系GRD,由本实例完成即可。
如果拥有local role的X mode 的实例要给其他实例发送这个数据块,如果发送的是和磁盘一直的版本,也就是说接收方收到的也是磁盘一致的版本,那么本实例就仍然保持local role; 如果发送的是和磁盘不一致的版本,那么角色就要转变成global,同时接收方的角色也是global,代表同时有多个实例拥有“脏数据块”版本。
如果是global role,可能的mode 是S,X,Null,global role 首先意味着有多个实例拥有和磁盘一致版本,这时如果想要把这个数据写到擦盘,必须联系GRD,由拥有数据块的current版本来完成写动作。
3)past Image: 下面通过一个例子说明什么是past image,假设一个2节点的rac集群,某个数据块在磁盘上的scn=100:
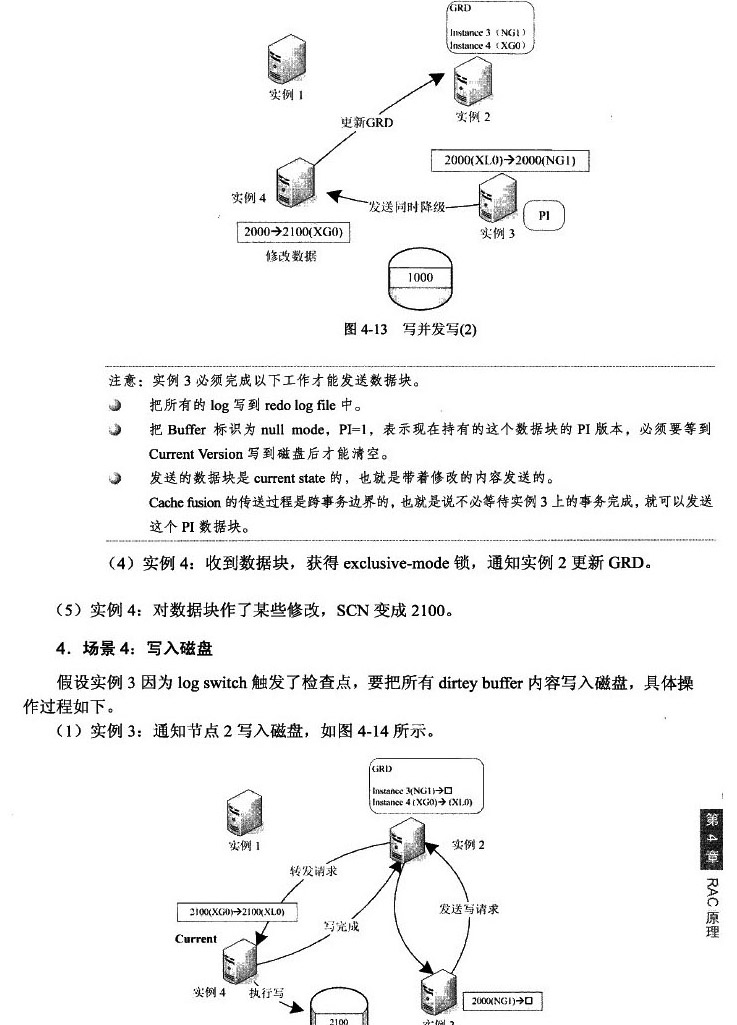
好了下面我们开始。。。实例1要修改这个数据块,从磁盘读入SGA进行修改,修改后内存的scn=110。实例2也要修改该这个数据块,实例1就会通过cache fusion 把这个数据块传送给实例2,发送的是scn=110的版本,即current copy的数据块;这时实例1还会保留这个scn=110的数据块在sga中,但是不能在进行任何修改操作,这时实例1拥有的这个拷贝就是一个past image,其中scn=110;在实例1发送这个数据块之前,会把log buffer 的内容写到redo log中。接下来实例2修改这个数据块,修改后的scn=120;注意,此时磁盘上的版本仍然是scn=100;假设实例1现在因为日志切换,触发了检查点动作,因为实例1上的数据块是个脏数据块(但不是最脏的,哈哈,还有实例2上那个scn=120的版本最脏),所以要把这个数据块也同步到磁盘。实例1会找到GRD,发现实例2拥有这个数据块的current版本,GRD会通知实例2把这个数据块写入磁盘。实例2完成写入之后,会通知其他实例(所有拥有PI版本的实例)释放他们拥有的PI内存了。这时,实例1会在log buffer中记录一条BWR(block write record)记录,然后释放PI内存。
假设实例2没有完成写时就异常宕机了,这时会触发实例1上进行crash recovery(不同与单实例instance recovery)虽然修改动作都被记录在各个节点的联机日志中,但是因为实例1拥有最近的PI,所以只需要实例1的PI及实例2的联机日志就可以完成恢复。
所以,past image代表着这个实例的SGA中是否拥有和磁盘内容不一致的版本,以及版本顺序,并不是代表这个节点是否曾经修改过这个数据块,past image主要能够加速crash recovery的恢复过程。
下面通过读写实例介绍RAC的工作过程:


4、AST
到现在为止,想必各位已经知道了所谓的cache fusion资源(也就是数据块)是如何被传输工作的了,但是前面的讲述故意遗漏了一个细节还没有交代,就是这些请求在DLM中是如何管理的,主要是避免分散读者的注意力,现在把这部分内容补上。
DLM使用两个队列跟踪所有的lock 请求,并用两个ASTs(asynchronous traps)来完成请求的发送和响应,实际就是异步中断(interrupt)或者陷阱(trap)。下图显示的是资源和队列的关系,granted queue中记录的是所有已经获得的lock的进程,而convert queue记录时是所有等待lock的进程。
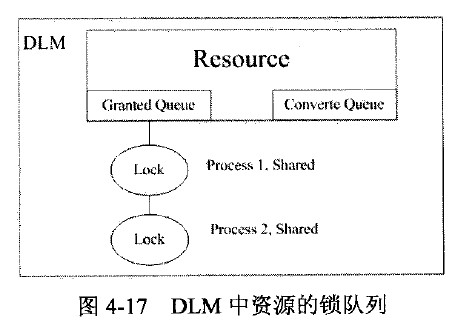
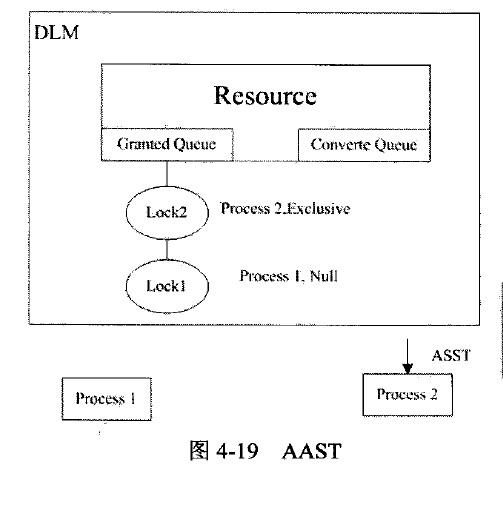
进程1和进程2拥有数据块S模式的锁,因此在granted queue 中有记录,假设现在进程2要获得X模式的锁,进程2必须先向DLM提出请求;请求提交给DLM后,DLM就要把进程2放在convert queue中。向拥有不兼容模式锁的进程1发送一个blocking ASTs,这是一个异步请求,所以DLM不必等待响应。当进程1接受到这个BAST之后,就会把这个lock降级为null模式,DLM把进程2的锁模式转换为x模式,如下图所示:
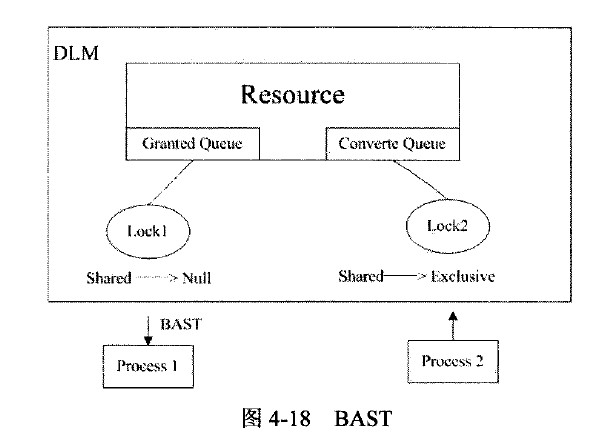
然后,DLM发送一个acquisition ASTn(AAST)给进程2,并把进程2放到Granted queue中,如下图所示,进程2就可以继续处理了:
5、RAC并发控制总结
在cache fusion中,每一个数据块都会被映射成一个cache fusion 资源,或者说是一个PCM资源,pcm资源实际是一个数据结构,资源的名称就是数据块的地址(dba)。每个数据请求动作是分步完成的。首先把数据块地址x转换成pcm资源名称,然后把这个pcm资源请求提交给DLM,DLM进行global lock的申请,释放活动,只有获得了pcm lock,才能继续下一步;也就是说第一步“实例要获得数据块的使用权”
除了获得数据块的使用权,还要考虑数据块状态。在单实例中,进程想要修改数据块,必须在数据块的当前版本(current copy)上进行修改,在RAC环境下也一样,如果实例要修改该数据块,必须获得这个数据块的当前版本拷贝,这就涉及一系列的问题:如何获得数据块的拷贝在集群节点间的分布图,如何知道哪个节点拥有的是当前的拷贝,如何完成传递过程,这一些问题的解决机制就是内存融合技术(cache fusion) 。一旦实例获得了访问权限,并且也得到了正确的版本。然后进程就能访问资源了,进程间仍然使用传统的lock,latch,这一点和单实例没有区别。
- 转:http://blog.csdn.net/cymm_liu/article/details/7899432


 浙公网安备 33010602011771号
浙公网安备 33010602011771号