pandas模块学习
pandas学习
在df中查找所有时间戳列并将其转换为datatime
# use to_datetime rather than astype, you have more control over conversion
df.loc[:, dtcols] = pd.to_datetime(df.loc[:, dtcols], errors='coerce')
Series的index和values属性
Python pandas,Series取值,Series切片,Series的index和values属性,布尔索引
这个要注意
pandas行列显示不完全的解决办法
添加如下代码,即可解决。
#显示所有列
pd.set_option('display.max_columns', None)
#显示所有行
pd.set_option('display.max_rows', None)
#设置value的显示长度为100,默认为50
pd.set_option('max_colwidth',100)
根据自己的需要更改相应的设置即可。
pandas中根据列的值选取多行数据
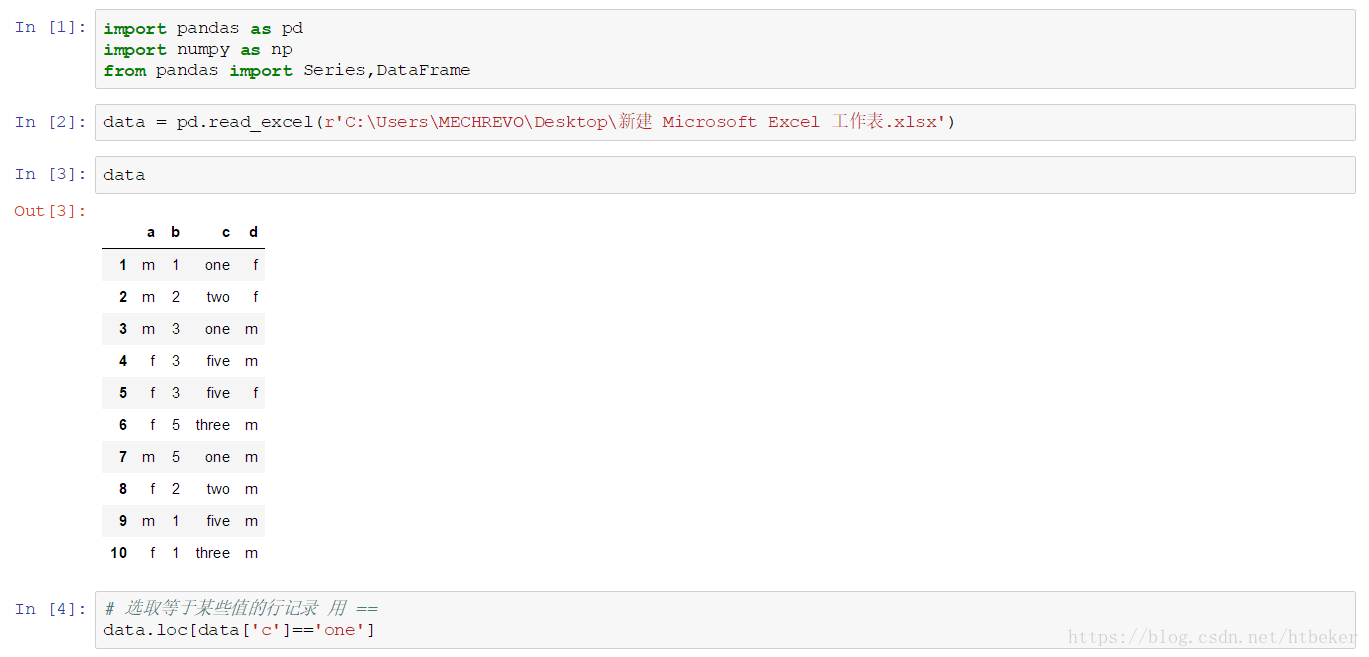
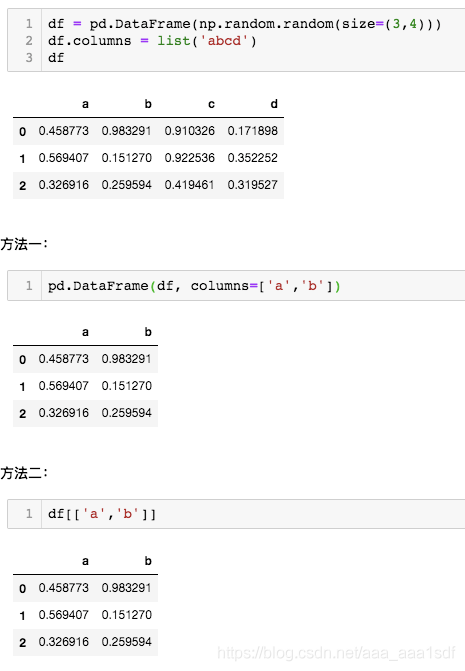
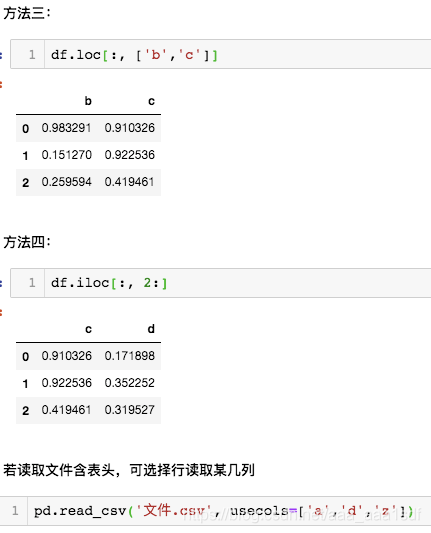
pandas 读取或者选择某几列
pandas排序
import pandas as pd
fpath = "./datas/beijing_tianqi_2018.csv"
df = pd.read_csv(fpath)
# 替换掉温度的后缀℃
df["bWendu"] = df["bWendu"].str.replace("℃", "").astype('int64')
df["yWendu"] = df["yWendu"].str.replace("℃", "").astype('int64')
#DataFrame的排序
df.sort_values(by="aqi")
df.sort_values(by="aqi", ascending=False)
#多列排序
# 按空气质量等级、最高温度排序,默认升序
df.sort_values(by=["aqiLevel", "bWendu"])
# 两个字段都是降序
df.sort_values(by=["aqiLevel", "bWendu"], ascending=False)
# 分别指定升序和降序
df.sort_values(by=["aqiLevel", "bWendu"], ascending=[True, False])
pandas列筛选
https://www.bbsmax.com/A/pRdBGRVazn/
pandas筛选包括df[df[列名]xx]
以>,<,,>=,<=来进行选择(“等于”一定是用‘==’,如果用‘=’就不是判断大小了):
如果要选择某列等于多个数值或者字符串时,要用到.isin(), 我们把df修改了一下(isin()括号里面应该是个list):
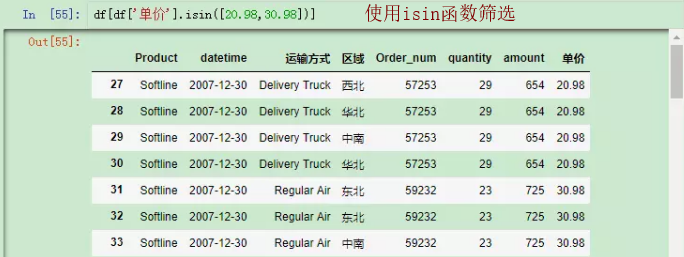
,我们有时候并不只是考虑某一列,还需要考虑另外若干列的情况。例如,我们需要过滤掉appPlatform=2而且appID=278和appID=382的样本呢?非常简单。
df[(-df['appID'].isin([278,382]))&(-df['appPlatform'].isin([2]))]
平时使用最多的筛选应该是字符串的模糊筛选,在SQL语句里用的是like,在pandas里我们可以用.str.contains()来实现。
【pandas】df.str.contains包含多个值写法
直接上代码
df['A'].str.contains('str1|str2')
pandas 查看有多少行,多少列
维度查看:df.shape
(144, 3)
pandas 查看某一列的类型
数据表基本信息(维度、列名称、数据格式、所占空间等):df.info()
每一列数据的格式:df.dtypes
某一列格式:df['B'].dtype
这里需要强调的是object类型实际上可以包括多种不同的类型,比如一列数据里,既有整型、浮点型,也有字符串类型,这些在pandas中都会被标识为‘object’,所以在处理数据时,可能需要额外的一些方法提前将这些字段做清洗,str.replace(),float(),int(),astype(),apply()等等。
pandas 数据清洗:空值None和缺失值NaN的处理
1.含义
空值一般表示数据未知、不适用或将在以后添加数据。缺失值是指数据集中某个或某些属性的值是不完整的。
一般空值使用None表示,缺失值使用NaN表示。
2.判断方法
Pandas中提供了一些用于检查或处理空值和缺失值的函数或方法
使用isnull()和notnull()函数可以判断数据集中是否存在空值和缺失值
对于缺失数据可以使用dropna()和fillna()方法对缺失值进行删除和填充
3.处理方式
3.1 删除所在行/列
删除含有空值或缺失值的行或列可以使用dropna()方法或drop()方法
关于dropna()方法或drop()方法的使用可以参考:pandas drop()和dropna()函数使用详解
3.2 填充缺失值和空值
填充缺失值和空值的方式有很多种,比如人工填写、热卡填充等,Pandas中的fillna()方法可以实现填充空值或缺失值。
关于fillna()方法的使用可以参考:pandas filna()函数的使用详解
pandas isnull()和notnull()的用法
isnull()函数的语法格式如下:
import pandas as pd
obj = None
print(pd.isnull(obj))
obj2 = 'd'
print(pd.isnull(obj2))
结果:
True
False
上述函数中只有一个参数obj,表示检查空值的对象。
isnull()函数会返回一个布尔类型的值,如果返回的结果为True,则说明有空值或缺失值,否则为False。(NaN或None映射到True值,其它内容映射到False)
notnull()与isnull()函数的功能是一样的,都可以判断数据中是否存在空值或缺失值,不同之处在于,前者发现数据中有空值或缺失值时返回False,后者返回的是True。
series_obj = Series([1, None, NaN])
# 检查是否不为空值或缺失值
pd.notnull(series_obj)
结果:
0 True
1 False
2 False
使用pandas将float64转换为str
df = pd.read_excel(r"filename.xlsx")
列A是一个float64类型,
df["columnA] = df["columnA].astype(str)
使用pandas字符串操作
import pandas as pd
fpath='./datas/beijing_tianqi/beijing_tianqi_2018.csv'
df=pd.read_csv(fpath)
df.head()
df.dtypes
获取Series的str属性,使用各种字符串处理函数
获取最高温度的Series的温度列
#获取最高温度的Series的温度列
df['bWendu'].str
字符串替换函数
#字符串替换函数
df['bWendu'].str.replace('℃','')
#判断是不是数字
df['bWendu'].str.isnumeric()
df['aqi'].str.len()
#从ymd这一列挑选出2018-03这类型的数据,返回的是一个Boolean类型
condition=df['ymd'].str.startswith('2018-03')
condition
# 需要多次str处理的链式操作
#原因:每次调用函数,都会返回一个新的series
df['ymd'].str.replace('-','').slice(0,6)
#'Series' object has no attribute 'slice'---意思就是series不能够直接去调用slice函数,必须经过str调用后才可以使用
df['ymd'].str.replace('-','').str.slice(0,6)--这样就就可以了,
pandas 列元素大小写转换
df.xx.str.lower()
将列元素全部转换为小写
df.xx.str.upper()
将列元素全部转换为大写
即如果字符串中的所有字符均为十进制字符,则isdecimal()方法将返回True。 如果不是,则返回False。
data_test['number_1'].str.isdecimal()
pandas循环遍历
使用 iteritems() 方法循环遍历列
iteritems() 方法返回一个迭代器,可以遍历数据帧中的每一列。以下是一个示例:
、使用 iterrows() 方法循环遍历行
iterrows() 方法返回一个迭代器,可以遍历数据帧中的每一行。以下是一个示例:
import pandas as pd
# 创建数据帧
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
# 使用 iterrows() 方法遍历行
for index, row in df.iterrows():
print(index, row['A'], row['B'])
在上面的示例中,我们首先创建了一个简单的数据帧。然后,我们使用 iterrows() 方法遍历每一行,并输出行的索引和值。
import pandas as pd
# 创建数据帧
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
# 使用 iteritems() 方法遍历列
for column, values in df.iteritems():
print(column, values.tolist())
3、使用 apply() 方法循环遍历行或列
apply() 方法接受一个函数作为参数,并将其应用于数据帧的每一行或每一列。以下是一个示例:
import pandas as pd
# 创建数据帧
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
# 使用 apply() 方法遍历每一行,并计算每行的和
sums = df.apply(lambda x: x.sum(), axis=1)
print(sums)
# 使用 apply() 方法遍历每一列,并计算每列的平均值
means = df.apply(lambda x: x.mean(), axis=0)
print(means)
在上面的示例中,我们首先创建了一个简单的数据帧。然后,我们使用 apply() 方法遍历每一行,并计算每行的和,或者遍历每一列,并计算每列的平均值。注意,apply() 方法的 axis 参数用于指定应该应用函数的轴,axis=1 表示应用于每一行,axis=0 表示应用于每一列。
除了上述方法之外,pandas 还提供了许多其他方法,例如 applymap()、map() 和 transform() 等,可以根据需要使用。你可以查看 pandas 官方文档以获取更多关于循环遍历的方法和用法。
Python Pandas 根据一列或几列的值,对另一列赋值
- 根据某一列值得范围,对另一列进行赋值。
需求1:将人口超过 1000 的城市评级为 ‘一级’,人口不足 1000 的评级为 ’二级‘。
table.loc[(table.人口 >= 1000) ,'评级'] = '一级'
table.loc[(table.人口 < 1000) ,'评级'] = '二级'
还可以直接等于b列,
table.loc[(table.人口 < 1000) ,'评级'] = table.家庭

 浙公网安备 33010602011771号
浙公网安备 33010602011771号