jmeter全面总结-8-1-jmeter实战
再次系统的整理一下深入一下性能测试
整个压测思路的总结
为什么要压测?压测的目的是什么?
是新项目上线压测?如果是新项目上线,你怎么进行全面测试?
实际也是环境搭建,然后核心流程梳理,就是测试核心流程就可以了,
是老项目的重新性能摸底?
还是单接口的接口性能测试?
-
压测前的准备
-
1,压测环境,环境不对,一切白费,
比如系统的架构,使用的服务器配置,使用的软件的版本,
比如Nginx,比如mysql,比如redis,等等 -
2,压测场景数据准备和场景梳理其中,场景梳理是非常重要,而梳理流程要对系统的架构,系统接口的请求流要非常熟悉,这是一个难点,需要和开发详细沟通,
-
3,数据准备,
-
-
压测脚本编写
而脚本编写,和压测执行,反而是比较简单的事情, -
压测执行
-
1,压测方案,压测策略的梳理,
你压测的目标是什么?你如何进行压测? -
2,压测结果的收集
包括服务端数据收集
jmeter压测数据收集 -
3,压测结果分析
对性能数据的监控分析,分析是非常复杂的,性能的瓶颈的原因多种多样,
比如代码问题,SQL问题,或者其他问题导致的性能瓶颈,需要更加的细分
-
-
压测报告
如果能达到性能要求这个就比较好说了,
如果达不到性能要求,你至少你表明,之前是多少,出现了什么性能瓶颈,经过了优化,之后又达到了多少
压测是一个很专业的事情,涉及到的知识面非常的广,而压测不是测试部门的单独的事情,涉及到开发,测试,运维,都要全员参与,
压测是一个严谨的事情,
一,压测环境搭建
1,要和现网的环境保持一致,这是测试现网的容量
2,还需要测试单机的并发情况
3,然后看增加机器的情况,看看性能的变化,
4,这个过程,可能需要开发协助
二,压测场景梳理
压测场景,至少又要分成两部分
1是单接口的压测
2是多接口的场景压测,要梳理流程,
具体如何进行业务梳理
下面用一个订餐的网站作为案例,来说明如何梳理业务
-
梳理日常业务场景
-
尽量真实的模拟用户行为,让压测结果更贴近真实结果
-
正常与异常用例场景都需要被覆盖到
正常: 登录成功场景
异常: 登录失败场景 -
压力测试涉及的业务内容
首页
登录
浏览饭店列表
选择饭店
添加购物车
提交订单
查看订单
三,编写脚本前的准备
1,要知道压测的接口地址
2,要添加压测环境的业务数据
比如用户数据
商品数据
等等
新建用户(添加数据
梳理测试商户数据
梳理测试商品数据
数据是一个很重要的内容,数据量要足够,数据要有多样性,否则不具有真实性
- 压测业务流程控制
预计接口访问次数
不同接口的分流比例
数据传递位置(参数?响应payload? Header? Cookie? )
四,编写jmeter压测脚本
录制
手动,熟练了之后,手动创建就行了
如果多个接口有关联关系,就需要数据提取的问题,比如提取json,如果是html页面就需要xpath提取,
还有就是结果断言校验,需要提取数据,
脚本包括几个部分
1,请求
2,查看结果树
3,聚合报告
4,断言

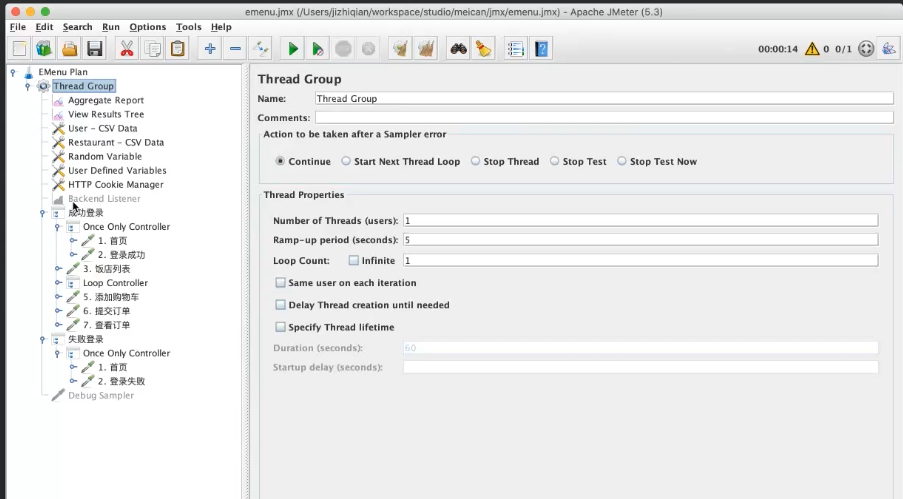
成功和失败的场景,都有覆盖,if判断一个随机数来控制,
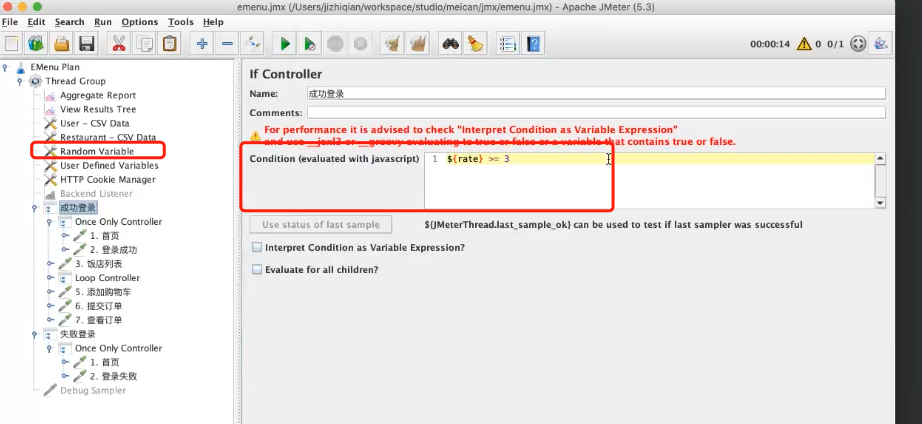
多次选择,使用循环来控制,产生一个随机数,1-4,可能是循环请求选择饭店的接口,1次,或者4次等,
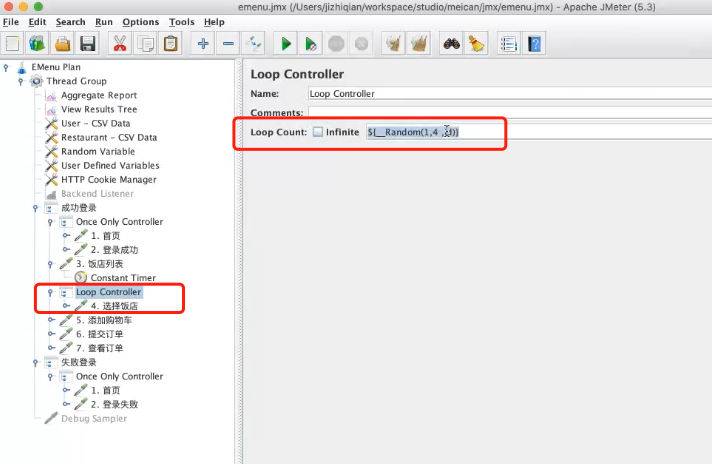
上面的if和for循环可以通过添加逻辑控制器来实现
csv 文件

随机数

cookie信息,header信息
五,压测执行策略
压测执行,也不是乱来的
需要执行一个压测执行策略,
我们压测的目标要定好
就是寻找系统的最大并发数是多少
找到系统的瓶颈点
最终是要验证能够支撑多大并发数,峰值数
找到一个最合理的系统可支撑最大并发数
性能基线数据
新的系统,是根据需求,比如你想要达到多少并发,
已经上线的系统,是根据现网跑出来的数据,作为基线数据,所以现有的系统,你需要去监控自己的流量,
如果你连自己的现网性能监控,现网流量监控都没有,实际你去做什么性能测试没有意义,先把现网性能监控搞起来吧,
这都是基础能力建设,
压测策略
短时低并发
短时高并发,
长时低并发
长时高并发,
关键是并发和运行时间的设置,这两个是策略的关键,
一般会使用逐渐加压的方式,然后观察tps,如果并发增加tps不变了,就是一个瓶颈了,
制定压测策略
第一步:不同的并发数 10,15,20,25,30
并发数设定: 10,20,30,40,50,9 0
并发数设定原则 : 从小-> 大,先粗粒度,再细化
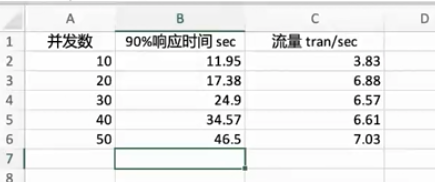
第二步:记录结果,
测试5个并发,然后统计数据,每一次的并发执行需要持续5分钟,保证记录结果是稳定住了,
- 1,被测接口的环境配置,几核cpu,几G内存
- 2,被测接口是哪一个,也就是url地址
- 3,并发数
- 4,95响应时间,这是一个重要指标,也就是95延时的记录
- 5,tps的记录,吞吐量
- 6,这个时候被测服务的cpu占用是多少
- 7,这个时候被测服务的内存占用是多少
这几个都要记录,
所以你压测的时候要关注压测结果,还要关注压测服务的状态,不然你安装性能监控平台做什么?
所以要密切关注性能监控压测运行状态
第三步:测试期望结果
这个过程需要反复验证,
通过上面的表格记录,
在20个并发上面之后,流量(就是指的吞吐量)的变化已经不大了,响应时间变长了
所以最优的流量是在10-20之间,
所以合理的最大并发就在10-20
所以下一轮的并发会更加的精确,比如10 12 15 18 20
然后再来一轮,
可以先把并发数往大增加,压出问题之后,再逐步减少找到系统可以支持的最合理最大并发数
最终是要验证能够支撑多大并发数,峰值数
找到一个最合理的系统可支撑最大并发数
这个过程的关注点:
-
1,关注并发数和95延时的关系,这个如果延时太高,结果是没有意义的,
-
2,关注并发数和错误率的关系,定义可接受范围, <= 0.1% or <= 0.5% or must = 0%,
不能大于0.5%,如果是1%,2%,就不行了,因为100个里面有1,2两个错误,这是不能接受的,
错误率过大那结果也是没有意义的,
如果高并发出错率偏高,可以尝试降低并发数,以获取更合理的结果 -
3,关注并发数和吞吐量tps的关系,如果持续加压,但是tps不增加,那结果就要分析了,
这个时候一般95延时会变高,也就是很多响应出现了较长时间的等待,
同时观察被测机器的cpu和内存,如果已经达到了较高的水平,那就说明这是一个临界值了,
如果cpu和内存还有很大的空间,就要继续分析了,
通过上述的过程,分析合理最大并发数,使用合理最大并发数,进行长时压测验证结论
压测过程的注意点:
-
1,关于执行机,
实际工作过程中,发压机 与 被压测应用需要运行在不同机器上
发压机就是jmeter所在的机器,
被测应用就是我们的要压测的网站,不要搞错了不是分布式压测里面的控制机和执行机的概念,
因为jmeter本身也是会占用资源的, -
2,关于网络
如果要减少网络的干扰,那就压测执行机和被压测系统在同一个网络,减少网络的干扰
发压机就是jmeter所在的机器,
被测应用就是我们的要压测的网站,这是减少网络对压测结果的干扰,
如果你想要真实的网络,那就是使用普通网络,都行
但是一般就是在同一网络压测,减少网络干扰,毕竟我们压测的系统,还是要尽量减少网络的问题
总之,性能的干扰因素越少,结果就越稳定
压测过程资源利用率,tps和响应时间的关系

横轴是并发数,number of concurrent users
纵轴有三个,系统资源利用utilization,tps每秒响应throughout,响应时间response time,
第一阶段light load, 并发增加,响应时间会变慢,系统的tps也增加,系统的性能会逐渐打满,
第一和第二阶段临界值就是最优性能点,optimum number of concurrent user
第二阶段heavy load ,系统的性能增加不怎么变化了,系统性能处于比较满的状态
第二和第三阶段临界点,就是最大性能点,maximum number of concurrent user
第三阶段buckle zone,随着并发增加,系统性能减低,甚至不影响了,是一个不能接收的阶段,
当然时间上测试过程的曲线不会这么工整,因为在中间的heavy 阶段可能就出现error了,而tps还能往上增加,但是已经没有多大的意义了,
这个图很重要,所有的系统的性能都离不开这三个阶段,
这个图具有很好的指导意义,
六,性能监控平台
这个性能监控平台,主要是为了压测数据收集
有两部分
1,jmeter的数据收集
性能监控平台好处
- JMeter原生测试测试报告带来的“痛苦"
- 不具备实时性
- 报告中的数据是测试时间段内的平均值
- 长相问题
- 性能监控平台的优势
- 实时展示]Meter压测数据
- 数据范围可选
- 界面更友好
性能监控平台使用的是influxdb,和grafana
JMeter: 压测工具,产生压测数据
InfluxDB: 开源时序数据库, 特别适合用于处理和分析资源监控数据,用于存储压测数据
Grafana: 度量分析与可视化图标展示工具,可以支持不用种类的数据源,用于将存储于InfluxDB中的数据以图表的形式展示出来
前面的文章已经讲过了,都是docker方式
这两个可以结合使用,如果有差异,要以jmeter的聚合报告为准,因为监控平台可能会有传输的问题,
2,服务器的性能数据
使用的是prometheus,和grafana,
前面的文章已经讲过了,都是docker方式
七,压测数据分析
根据数据分析性能瓶颈
另外压测的数据结果是会变动的,就好像人的血糖,你不同的时间去测量,也会变化的,因为网络原因等,还是有关系的,
针对变动的问题,可以多次测量取平均值的方式也是可以的,当然时间周期就会比较久一点
但是不能变动的离谱,
八,自动化压测
为啥要自动化压测呢?
手动逐步加压
需要人肉改并发数,然后等待完成
烦!!!! !
所以,制定好策略,让程序自动加压,自动等待,完成后坐收报告计算机努力的干活,我去做更重要的事情希望测试生涯由此变得美好一些
实现思路:
JMeter 脚本 (jmx 文件) - 压测逻辑
Shell- 控制逻辑
不能绕开麻烦,并发数的更改 - 想想Linux的三剑客之一哦
jMeter 静默运行 -脱离UI限制,使得自动化运行更稳定
实际并发数的修改,可以在写jmeter脚本的时候,并发数不写具体的数值,而是写一个事前定义好的变量,
然后使用python进行并发数替换,然后在执行jmeter进行运行,
所以不用使用shell,而是使用python进行逻辑控制,
JMeter 静默压测
静默->脱离UI运行]Meter压测
好处:命令运行更容易"搞事情
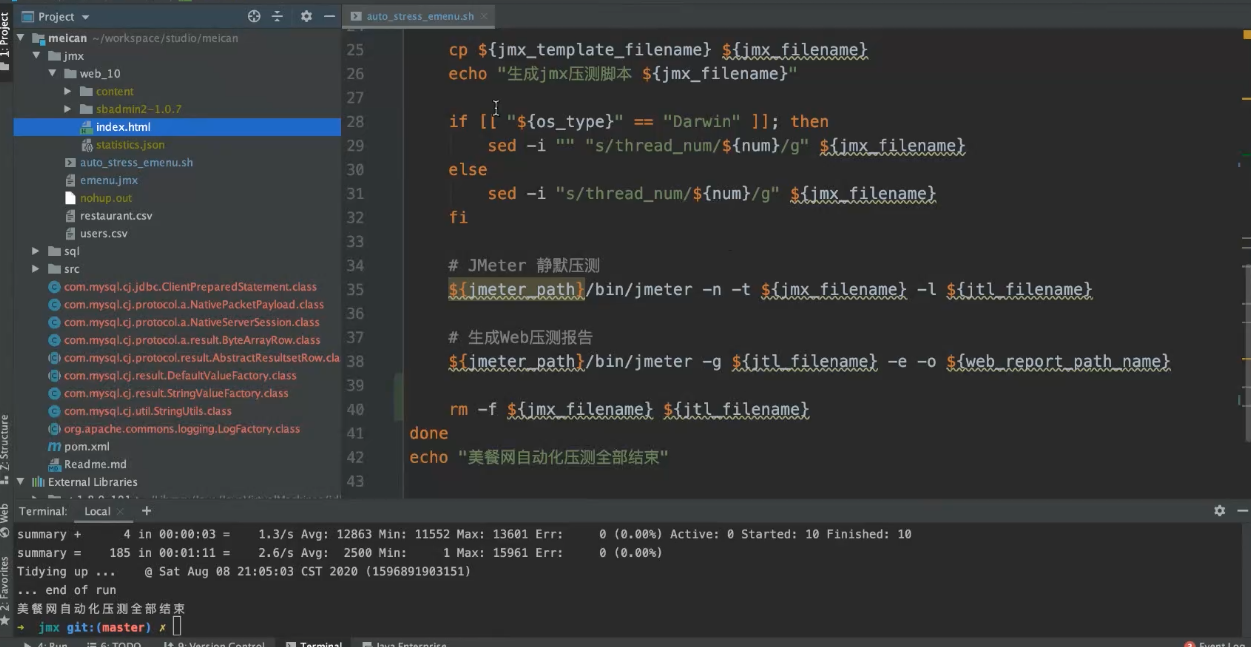
命令格式: jmeter -n -t simx file -l $itl file
imx]Meter压测程序脚本文件,压测控制过程记录在imx文件中
itl 文件是]Meter压测请求响应数据的原始文件
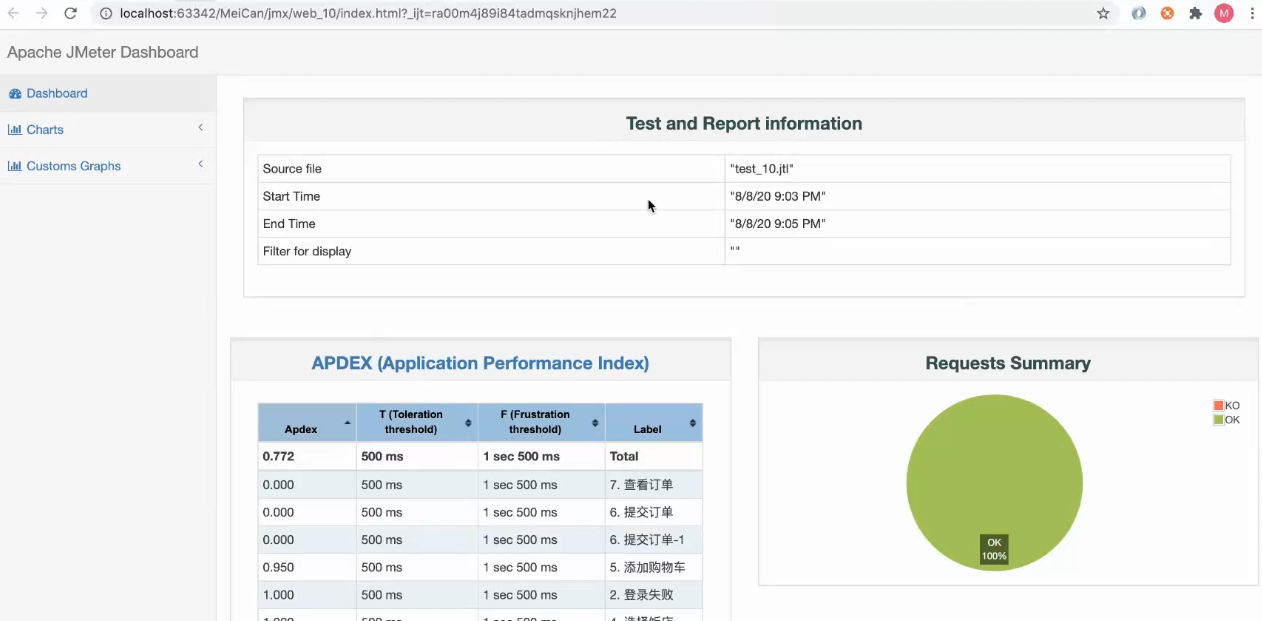
自动生成Web版压测报告
实施静默压测之后,通过命令直接生成对应的html压测报告
过程:it原始数据-> html 压测报告
好处:快捷、省事、节约时间命令格式:
jmeter -g $itl file -o $web report folder
可以与静默压测命令整合:
jmeter -n -t Sjmx file -l $jtl file -o $web report folder

怎么改变脚本文件的并发数,就是使用三剑客来改文件的并发数,

九,测试报告生成
jmeter有一个自己的报告
补充
1,异步接口测试,
异步接口一般都会很快,因为只是一个触发,服务器后面还在后面算结果
比如银行结算的接口,
这个性能可以看后台单位时间能处理的数据,比如两小时处理了两千万的数据,这就是他的性能情况,
那么需要多少台机器,才能全部跑完,是可以算出来的,

 浙公网安备 33010602011771号
浙公网安备 33010602011771号