js逆向的题目,练习题12题,css静态字体反爬,
#####
js逆向-css静态字体反爬
练习题,第12题,
静态css反爬,利用字体
反爬原理:
1、主要利用font-family属性,例如设置为my-font
2、在HTML里面不常见(不可读)的unicode
3、在CSS字体(my-font)中将其映射到常见(可读)到字体,例如数字
4、爬虫在抓取数据的时候只能抓到unicode,而不是真实的数据
应对措施
1、下载woff字体文件,转化为tff文件
2、用百度字体编辑器打开tff文件,并确定其unicode与其实际的映射关系
3、将下载的HTML内容按照映射关系替换
4、解析HTML并获取正确的数据
难点:
有些网站会动态生成woff,这种反爬措施比较难以自动化绕开
重点,将woff文件转换为xml文件
找到这个字体文件,
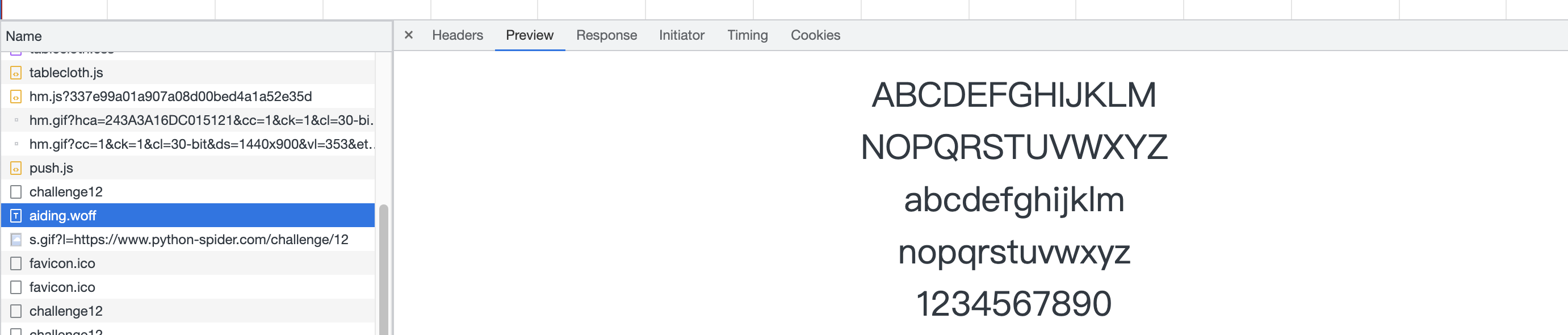
##
使用python将woff文件转换为xml文件
中间需要安装一个工具,
pip install fontTools
import os import requests from fontTools.ttLib import TTFont base_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) url = "https://www.python-spider.com/static/font/challenge12/aiding.woff" resp = requests.get(url=url) with open("aiding.woff", "wb") as f: f.write(resp.content) f.close() font = TTFont("aiding.woff") font.saveXML("aiding.xml") # 转换为xml文件
###
实际上,这个题,不需要知道这个css字体也是没有问题的,
因为数字都是固定的,所以可以直接做替换就可以了,
这个题难度不大
import requests import time import json import urllib3 urllib3.disable_warnings() url = "https://www.python-spider.com/api/challenge12" headers = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 ' '(KHTML, like Gecko) Ubuntu Chromium/60.0.3112.113 Chrome/60.0.3112.113 Safari/537.36', } all_page_sum = [] for page in range(1,101): time.sleep(1) data = { "page":page } resp = requests.post(url, headers=headers, data=data, verify=False) # print(resp.text) text_json = json.loads(resp.text) # print(text_json["data"]) list1 = [] for i in text_json["data"]: # print(i["value"]) list1.append(i["value"]) list2 = [] for i in list1: str1 = i \ .replace('', "0").replace('', "1").replace('', "2") \ .replace('', "3").replace('', "4").replace('', "5") \ .replace('', "6").replace('', "7").replace('', "8") \ .replace('', "9").replace(" ", "") list2.append(int(str1)) # print(list2) all_page_sum.append(sum(list2)) print("第 {} 页的合计".format(page),sum(list2)) print("all page sum ",sum(all_page_sum))
#####
####
技术改变命运

 浙公网安备 33010602011771号
浙公网安备 33010602011771号