
js逆向的题目,第11题,jsl,加速乐,__jsl_clearance cookie破解
###
第十一题,jsl,加速乐
有一个国家网站就是用的这个,https://www.cnvd.org.cn/flaw/list.htm
观察一下返回:
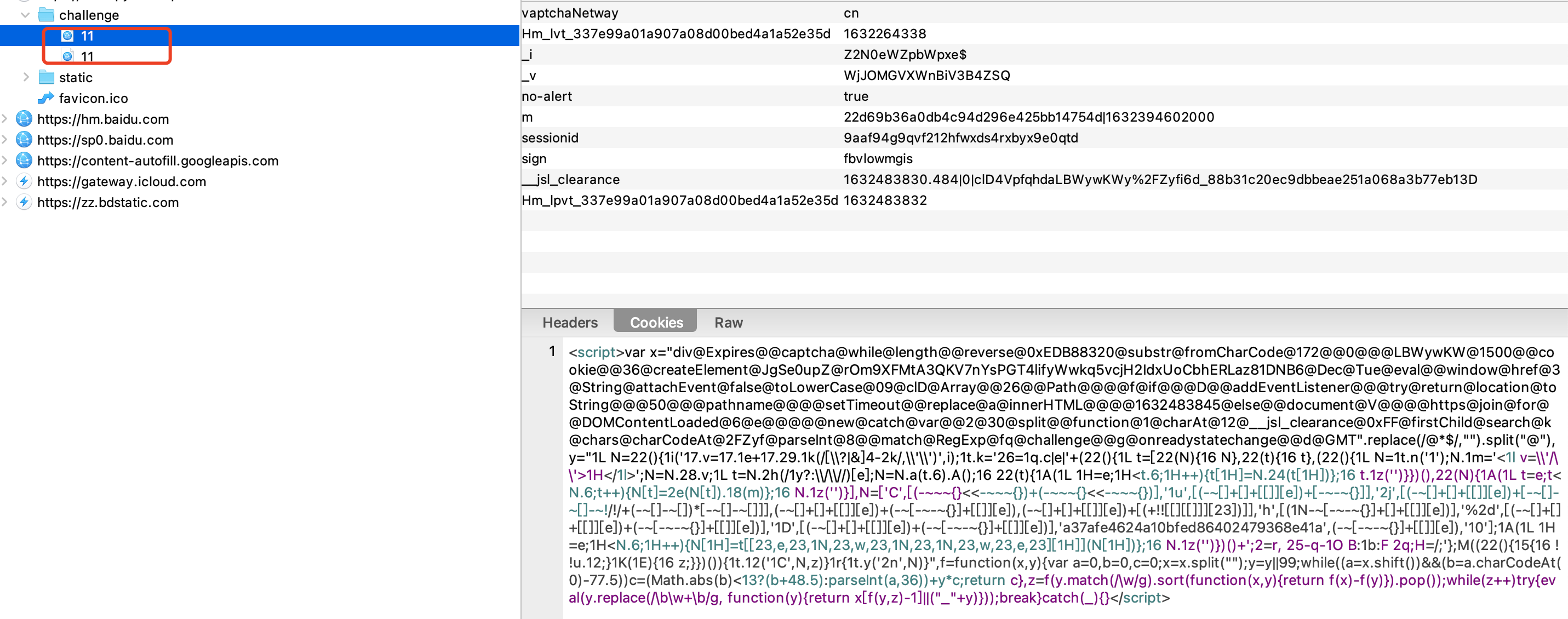
每一次会有两次请求,
这两次请求的,__jsl_clearance是不一样的,
第一次的请求是一段js代码
第二次的请求,才是正常的html代码,
重点就是第一次的这个请求,获取到这个script,然后通过python解析出来__jsl_clearance,然后带入第二次的请求的cookie,就可以了,
首先是返回了一串看不懂的代码,
格式化一下:可以使用在线工具格式化,https://www.bejson.com/jshtml_format/
x = "div@Expires@@captcha@while@length@@reverse@0xEDB88320@substr@fromCharCode@169@@0@@@LBWywKW@1500@@cookie@@36@createElement@JgSe0upZ@rOm9XFMtA3QKV7nYsPGT4lifyWwkq5vcjH2IdxUoCbhERLaz81DNB6@Dec@Tue@eval@@window@href@3@String@attachEvent@false@toLowerCase@09@clD@Array@@26@@Path@@@@f@if@@@D@@addEventListener@@@try@return@location@toString@@@50@@@pathname@@@@setTimeout@@replace@a@innerHTML@@@@1632475506@else@@document@V@@@@https@join@for@@DOMContentLoaded@6@e@@@@@new@catch@var@@2@30@split@@function@1@charAt@12@__jsl_clearance@0xFF@firstChild@search@k@chars@charCodeAt@2FZyf@parseInt@8@@match@RegExp@fq@challenge@@g@onreadystatechange@@d@GMT".replace(/@*$/, "").split("@"), y = "1L N=22(){1i('17.v=17.1e+17.29.1k(/[\\?|&]4-2k/,\\'\\')',i);1t.k='26=1q.c|e|'+(22(){1L t=[22(N){16 N},22(t){16 t},(22(){1L N=1t.n('1');N.1m='<1l v=\\'/\\'>1H</1l>';N=N.28.v;1L t=N.2h(/1y?:\\/\\//)[e];N=N.a(t.6).A();16 22(t){1A(1L 1H=e;1H<t.6;1H++){t[1H]=N.24(t[1H])};16 t.1z('')}})(),22(N){1A(1L t=e;t<N.6;t++){N[t]=2e(N[t]).18(m)};16 N.1z('')}],N=['C',[(-~~~{}<<-~~~{})+(-~~~{}<<-~~~{})],'1u',[(-~[]+[]+[[]][e])+[-~-~{}]],'2j',[(-~[]+[]+[[]][e])+[-~[]-~[]-~!/!/+(-~[]-~[])*[-~[]-~[]]],(-~[]+[]+[[]][e])+(-~[-~-~{}]+[[]][e]),(-~[]+[]+[[]][e])+[(+!![[][[]]][23])]],'h',[(1N-~[-~-~{}]+[]+[[]][e])],'%2d',[(-~[]+[]+[[]][e])+(-~[-~-~{}]+[[]][e])],'1D',[(-~[]+[]+[[]][e])+(-~[-~-~{}]+[[]][e])],'600815c295779fd3d4cb72f393ed1405',(-~[-~-~{}]+[[]][e]),'10'];1A(1L 1H=e;1H<N.6;1H++){N[1H]=t[[23,e,23,1N,23,w,23,1N,23,1N,23,w,23,e,23][1H]](N[1H])};16 N.1z('')})()+';2=r, 25-q-1O B:1b:F 2q;H=/;'};M((22(){15{16 !!u.12;}1K(1E){16 z;}})()){1t.12('1C',N,z)}1r{1t.y('2n',N)}", f = function(x, y) { var a = 0, b = 0, c = 0; x = x.split(""); y = y || 99; while ((a = x.shift()) && (b = a.charCodeAt(0) - 77.5)) c = (Math.abs(b) < 13 ? (b + 48.5) : parseInt(a, 36)) + y * c; return c }, z = f(y.match(/\w/g).sort(function(x, y) { return f(x) - f(y) }).pop()); while (z++) try { eval(y.replace(/\b\w+\b/g, function(y) { return x[f(y, z) - 1] || ("_" + y) })); break } catch(_) {}
倒数第7行的,eval是做解密处理之后的代码,我们将eval替换为return之后,使用execjs模块做处理之后,可以得到能看的懂的代码。
import execjs _JS = execjs.compile(open('gt.js').read()) jsl_clearance = _JS.call('getJSL') print(jsl_clearance)
得到的代码: 
格式化:
var _N = function() { setTimeout('location.href=location.pathname+location.search.replace(/[\?|&]captcha-challenge/,\'\')', 1500); document.cookie = '__jsl_clearance=1632476092.668|0|' + (function() { var _t = [function(_N) { return _N }, function(_t) { return _t }, (function() { var _N = document.createElement('div'); _N.innerHTML = '<a href=\'/\'>_1H</a>'; _N = _N.firstChild.href; var _t = _N.match(/https?:\/\//)[0]; _N = _N.substr(_t.length).toLowerCase(); return function(_t) { for (var _1H = 0; _1H < _t.length; _1H++) { _t[_1H] = _N.charAt(_t[_1H]) }; return _t.join('') } })(), function(_N) { for (var _t = 0; _t < _N.length; _t++) { _N[_t] = parseInt(_N[_t]).toString(36) }; return _N.join('') }], _N = ['clD', [( - ~~~ {} << -~~~ {}) + ( - ~~~ {} << -~~~ {})], 'V', [( - ~ [] + [] + [[]][0]) + [ - ~ - ~ {}]], 'fq', [( - ~ [] + [] + [[]][0]) + [ - ~ [] - ~ [] - ~ ! /!/ + ( - ~ [] - ~ []) * [ - ~ [] - ~ []]], ( - ~ [] + [] + [[]][0]) + ( - ~ [ - ~ - ~ {}] + [[]][0]), ( - ~ [] + [] + [[]][0]) + [( + !![[][[]]][1])]], 'LBWywKW', [(2 - ~ [ - ~ - ~ {}] + [] + [[]][0])], '%2FZyf', [( - ~ [] + [] + [[]][0]) + ( - ~ [ - ~ - ~ {}] + [[]][0])], '6', [( - ~ [] + [] + [[]][0]) + ( - ~ [ - ~ - ~ {}] + [[]][0])], '_da9e2b8f7a806bd14acd902a40c22c43', ( - ~ [ - ~ - ~ {}] + [[]][0]), 'D']; for (var _1H = 0; _1H < _N.length; _1H++) { _N[_1H] = _t[[1, 0, 1, 2, 1, 3, 1, 2, 1, 2, 1, 3, 1, 0, 1][_1H]](_N[_1H]) }; return _N.join('') })() + ';Expires=Tue, 12-Dec-30 09:50:26 GMT;Path=/;' }; if ((function() { try { return !! window.addEventListener; } catch(e) { return false; } })()) { document.addEventListener('DOMContentLoaded', _N, false) } else { document.attachEvent('onreadystatechange', _N) }
这里面就有我们想要的__jsl_clearance
其实也可以hook cookie获取到
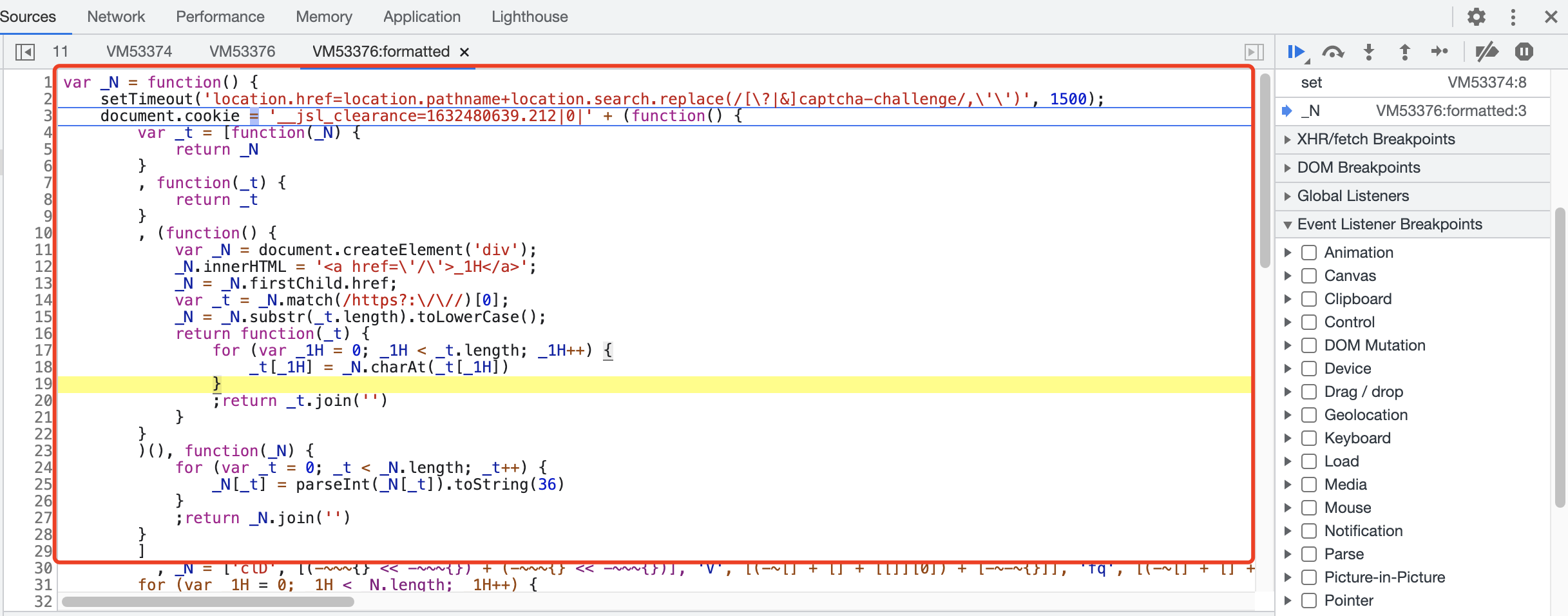
然后把这一块代码拿出来,
注意这里面有一段是dom操作所以直接替换一下,

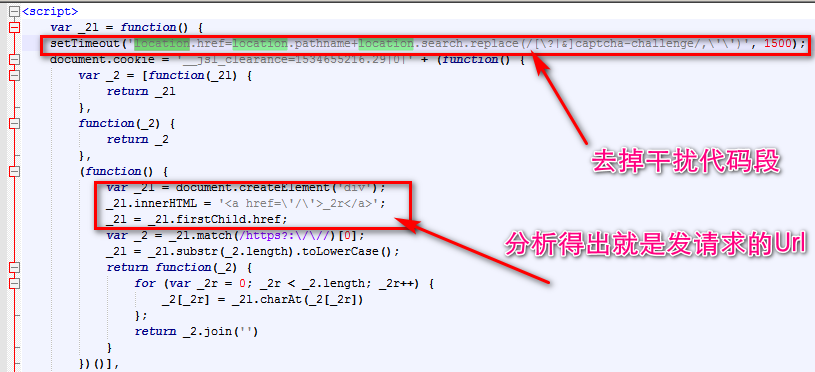
按图上所说的修改代码如下,为便于查看结果,把document.cookie =修改为console.log()后面的括号一定要找到
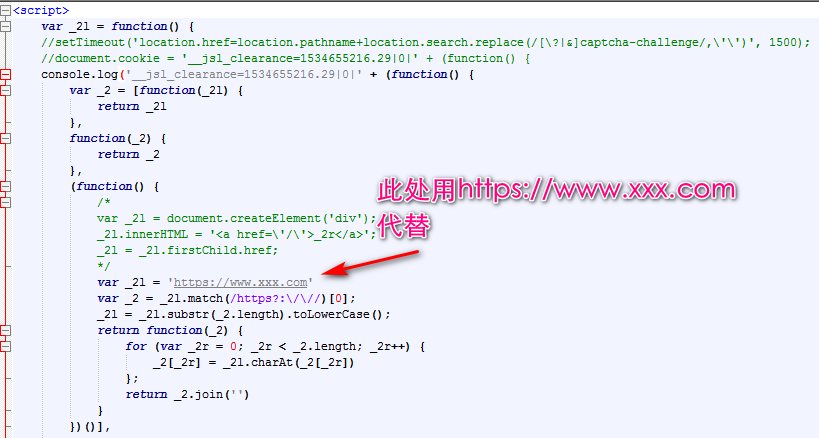
js代码:
function _N() { // setTimeout('location.href=location.pathname+location.search.replace(/[\?|&]captcha-challenge/,\'\')', 1500); // console.log( cookie = '__jsl_clearance=1632476092.668|0|' + (function() { var _t = [function(_N) { return _N }, function(_t) { return _t }, (function() { var _N = 'https://www.python-spider.com/'; var _t = _N.match(/https?:\/\//)[0]; _N = _N.substr(_t.length).toLowerCase(); return function(_t) { for (var _1H = 0; _1H < _t.length; _1H++) { _t[_1H] = _N.charAt(_t[_1H]) }; return _t.join('') } })(), function(_N) { for (var _t = 0; _t < _N.length; _t++) { _N[_t] = parseInt(_N[_t]).toString(36) }; return _N.join('') }], _N = ['clD', [( - ~~~ {} << -~~~ {}) + ( - ~~~ {} << -~~~ {})], 'V', [( - ~ [] + [] + [[]][0]) + [ - ~ - ~ {}]], 'fq', [( - ~ [] + [] + [[]][0]) + [ - ~ [] - ~ [] - ~ ! /!/ + ( - ~ [] - ~ []) * [ - ~ [] - ~ []]], ( - ~ [] + [] + [[]][0]) + ( - ~ [ - ~ - ~ {}] + [[]][0]), ( - ~ [] + [] + [[]][0]) + [( + !![[][[]]][1])]], 'LBWywKW', [(2 - ~ [ - ~ - ~ {}] + [] + [[]][0])], '%2FZyf', [( - ~ [] + [] + [[]][0]) + ( - ~ [ - ~ - ~ {}] + [[]][0])], '6', [( - ~ [] + [] + [[]][0]) + ( - ~ [ - ~ - ~ {}] + [[]][0])], '_da9e2b8f7a806bd14acd902a40c22c43', ( - ~ [ - ~ - ~ {}] + [[]][0]), 'D']; for (var _1H = 0; _1H < _N.length; _1H++) { _N[_1H] = _t[[1, 0, 1, 2, 1, 3, 1, 2, 1, 2, 1, 3, 1, 0, 1][_1H]](_N[_1H]) }; return _N.join('') })() + ';Expires=Tue, 12-Dec-30 09:50:26 GMT;Path=/;' // ) return cookie }; // console.log(_N) // console.log(_N());
python代用代码
import execjs _JS = execjs.compile(open('11.js').read()) jsl_clearance = _JS.call('_N') print(jsl_clearance)
然后结果:
__jsl_clearance=1632476092.668|0|clD4VpfqhdaLBWywKWy%2FZyfi6d_da9e2b8f7a806bd14acd902a40c22c433D;Expires=Tue, 12-Dec-30 09:50:26 GMT;Path=/;
重点就是获取到这个script,然后通过python解析出来,然后带入下一次的请求,就可以了,
python代码:
import requests import re import execjs import urllib3 urllib3.disable_warnings() url = "https://www.python-spider.com/challenge/11" headers = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 ' '(KHTML, like Gecko) Ubuntu Chromium/60.0.3112.113 Chrome/60.0.3112.113 Safari/537.36', } cookies = 'vaptchaNetway=cn; Hm_lvt_337e99a01a907a08d00bed4a1a52e35d=1632264338; _i=Z2N0eWZpbWpxe$; _v=WjJOMGVXWnBiV3B4ZSQ; no-alert=true; m=22d69b36a0db4c94d296e425bb14754d|1632394602000; sessionid=9aaf94g9qvf212hfwxds4rxbyx9e0qtd; sign=fbvlowmgis; Hm_lpvt_337e99a01a907a08d00bed4a1a52e35d=1632475023; __jsl_clearance=1632475231.182|0|clD4VpfqhdaLBWywKWy%2FZyfi6d_e312254a795fc84cc2f930f5259980093D' cookies = {i.split("=")[0].strip(): i.split("=")[1].strip() for i in cookies.split(";")} resp = requests.get(url, headers=headers, cookies=cookies, verify=False) # print(resp.text) html = resp.text #匹配js代码,只取以<script>开关 以</script>结束 ret = re.findall('\\s*?<script>(.*?)</script>',html) #获得到js代码 js = ret[0] # print(js) #由于Js代码加密了,需要解密,即第一次console.log打印的代码,返回给Python做处理, 把eval 换成return, js = js.replace(r"eval(", r"return (") jsstr = "function getResult(){" + js + "};" ctx = execjs.compile(jsstr) #这一步就是得到解密之后的js了 调用解密,得到返回的代码 js = ctx.call('getResult') # print(js) # 由于Python调用Js库的特性问题,只能return返回值且最外层只能用一个函数供外面调用且不支持像window,document这类元素,JS代码中若包含都统统要去掉,通过分析如下代码没有无用 # 首先获取正则获到_21的函数体部分代码如下: code = [] start = False; deep = 0; for c in js: if not start: if c == '{': start = True deep += 1 else: continue else: if c == '{': deep += 1 code.append(c) elif c == '}': deep -= 1 if deep == 0: break else: code.append(c) else: code.append(c) #获取函数主体 func_body = ''.join(code) # print(func_body) # 接下来正则去掉__jsl_clearance=和之前的部分,代码如下: #去掉前面设置Cookie的部分 pattern = re.compile(r'(.*?__jsl_clearance=)') #设置为返回值,去掉前的值 func_body = re.sub(pattern, '', func_body) # print(func_body) # 经过多次测试__jsl_clearance=有可能是一个变量替换的所以用时间戳来判断,并处理 # 如果不是时间戳开头,就再次处理下,从头到时间戳,也可以直接到时间戳的位置 if str(func_body[0:10]).isnumeric(): func_body = 'return \'' + func_body; else: ret = re.findall(r'(.*?)([0-9]{10})\.',func_body) if len(ret) > 0 and len(ret[0])> 1 and (ret[0][1]).isnumeric(): pattern = re.compile(r'(.*?)[0-9]{10}\.') func_body = re.sub(pattern,'return \'' + ret[0][1]+'.', func_body) else: #没有找到时间戳 print(func_body) # 接下来处理document.createElement的位置按图上的位置到href值是url pattern = re.compile(r"document\..*?\.href") url_my = 'https://www.python-spider.com/' func_body = re.sub(pattern,"\""+ url_my+ "\"", func_body) # print(func_body) # 接下来处理windows元素的干扰问题,windows这个干扰随机变化的只能用则处理,还有可能是多个种 #去掉window干扰 #func_body = func_body.replace("window['__p'+'hantom'+'as']","\"\"") #func_body = func_body.replace("while(window._phantom||window.__phantomas){};", ""); # pattern = re.compile("(window\[[^\]]+\])") # func_body = re.sub(pattern,"undefined", func_body) # 经统计有多种类型的windows元素干扰 # (window.headless + [[]][0]) # ret = re.findall(r'window[^\+\]]*', func_body) # if len(ret) > 0: # func_body = func_body.replace(ret[0], "\"\"") # 关于干扰问题还有多个变量的干扰比如retrun,function被他替换成了 # 一个别的变量名,这种比较变态了,只有少数的情况,基本上面的处理 # 可以达到90%以上的能返回了 # 最后直接合成完成的JS函数给Python调用,代码如下: jsstr = "function getResult(){" + func_body + "};"; ctx = execjs.compile(jsstr) # 调用获取cookie cookie_value = ctx.call('getResult') # print(cookie_value) cookie_value = cookie_value.split(";") # print(cookie_value[0]) cookies["__jsl_clearance"] = cookie_value[0] # print(cookies) resp = requests.get(url, headers=headers, cookies=cookies, verify=False) # print(resp.text) print(resp.text) ret = re.findall('[0-9]{4}',resp.text) # print(ret[0:9]) ret = [int(i) for i in ret] print(ret) print(len(ret)) if len(ret) == 12: print(ret[0:10]) print(sum(ret[0:10]))
####

 浙公网安备 33010602011771号
浙公网安备 33010602011771号