采集免费ip,制作自己的代理ip池
采集免费ip,制作自己的代理ip池
第一步,选择一个免费代理ip的网站,把他们网站的所有ip都爬取下来,
http://www.xiladaili.com/gaoni/6/
http://www.xsdaili.cn/dayProxy/ip/2459.html
http://www.dailiip.cc/freedailiip/2020/0929/966.html
http://31f.cn/https://www.chenjiayu.cn/archives6462.html
https://www.89ip.cn/index.html
https://www.kuaidaili.com/free/inha/
https://www.feizhuip.com/news-getInfo-id-1122.html
http://ip.yqie.com/ipproxy.htm
http://www.ip3366.net/free/?stype=3
http://www.pachongdaili.com/free/freelist1.html
免费的代理IP不同网站质量也不尽相同,如果大家对于代理IP质量要求比较高,或者需要大量稳定代理IP的话,还是建议大家进行购买啦~
提取的时候,使用正则表达式,
这种免费代理,绝大部分,都是不可用的,
第二步,用request库去请求验证这个ip,然后把可用的ip,都提取出来,
要想判断所使用的代理IP是否有用,只需要通过代理IP访问IP地址查询网站抓取地址以及归属地信息并与不使用代理IP时的地址信息以及归属地信息进行比较即可。
在浏览器访问icanhazip.com,浏览器会直接返回你的出口IP(也叫公网IP)。或者百度“IP”也可以返回你的出口IP。
浏览器访问IP138.com 或者http://ip.chinaz.com/,就可以得到外网地址。icanhazip.com
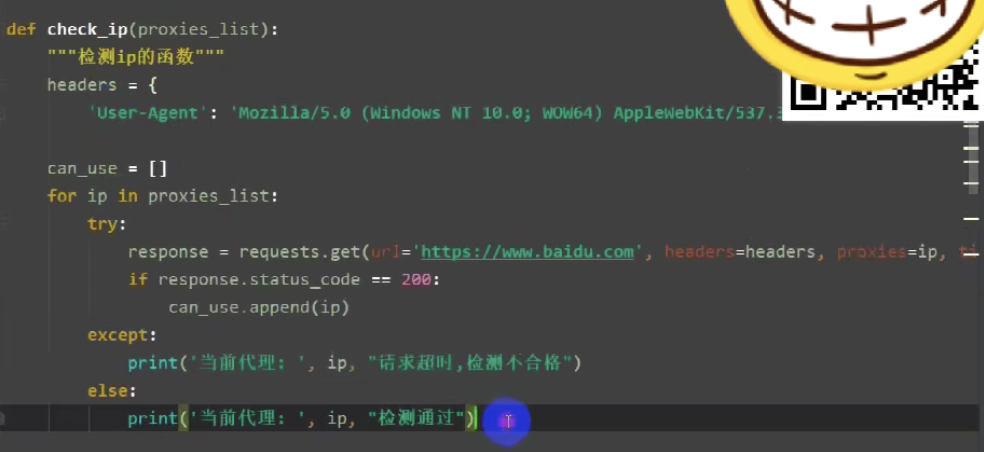
第三步,把可用的ip,都保存到数据库,
如此就能拿到新鲜免费的代理ip了,为了使得ip能多次使用,我将其存入mysql数据库中。
写入代码如下
def insert(self,l): print("插入{}条".format(len(l))) self.cur.executemany("insert into xc values(%s,%s,%s,%s,%s)",l) self.con.commit()
读取代码如下
def select(self): a=self.cur.execute("select ip,port,xieyi from xc") info=self.cur.fetchall() return info
整个过程使用python+re+request+mysql来完成,
####
import re import requests import pymysql import time class xiciSpider(object): def __init__(self): self.req=requests.Session() self.headers={ 'Accept-Encoding':'gzip, deflate, br', 'Accept-Language':'zh-CN,zh;q=0.8', 'Referer':'http://www.xicidaili.com/nn/', 'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 ' '(KHTML, like Gecko) Ubuntu Chromium/60.0.3112.113 Chrome/60.0.3112.113 Safari/537.36', } self.proxyHeaders={ 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 ' '(KHTML, like Gecko) Ubuntu Chromium/60.0.3112.113 Chrome/60.0.3112.113 Safari/537.36', } self.con=pymysql.Connect( host='127.0.0.1', user='root', password="*****", database='xici', port=3306, charset='utf8', ) self.cur=self.con.cursor() def getPage(self,url): page=self.req.get(url,headers=self.headers).text # print(page) return page def Page(self,text): time.sleep(2) pattern=re.compile(u'<tr class=".*?">.*?' +u'<td class="country"><img.*?/></td>.*?' +u'<td>(\d+\.\d+\.\d+\.\d+)</td>.*?' +u'<td>(\d+)</td>.*?' +u'<td>.*?' +u'<a href=".*?">(.*?)</a>.*?' +u'</td>.*?' +u'<td class="country">(.*?)</td>.*?' +u'<td>([A-Z]+)</td>.*?' +'</tr>' ,re.S) l=re.findall(pattern,text) return l # print(result[0]) def getUrl(self,pageNum): url='http://www.xicidaili.com/nn/'+str(pageNum) return url def insert(self,l): print("插入{}条".format(len(l))) self.cur.executemany("insert into xc values(%s,%s,%s,%s,%s)",l) self.con.commit() def select(self): a=self.cur.execute("select ip,port,xieyi from xc") info=self.cur.fetchall() return info def getAccessIP(self,size=1): info=self.select() p=[] for i in info: if len(p)==size: return p try: self.req.get("http://www.baidu.com",proxies={"{}".format(i[2]):"{}://{}:{}".format(i[2],i[0],i[1])},timeout=5) p.append(i) except Exception: print("{} is valid".format(i)) print(p) def getNewipToMysql(self): for i in range(2300): page=self.getPage(self.getUrl(i)) p.insert(self.Page(page)) if __name__=='__main__': p=xiciSpider() # p.Page(p.getPage('http://www.xicidaili.com/nn/')) # for i in range(2300): # page=p.getPage(p.getUrl(i)) # p.insert(p.Page(page)) p.getAccessIP()
#####
from xc import xiciSpider p=xiciSpider() #第一次先运行这个方法,现将ip存入mysql p.getNewipToMysql() #获取可用代理ip,默认获取1个,可指定size大小 ip=p.getAccessIP() print(ip)
####
######

 浙公网安备 33010602011771号
浙公网安备 33010602011771号