scrapy怎么同时运行多个爬虫?
######
可以通过以下几种方式:
1.开启多个命令行,分别执行scrapy cralw xxxx
2.编写一个脚本,写入以下代码,执行工程下的所有爬虫:
from scrapy.utils.project import get_project_settings from scrapy.crawler import CrawlerProcess def main(): setting = get_project_settings() process = CrawlerProcess(setting) didntWorkSpider = ['sample'] for spider_name in process.spiders.list(): if spider_name in didntWorkSpider : continue print("Running spider %s" % (spider_name)) process.crawl(spider_name) process.start()
3.使用scrapyd,部署爬虫,通过scrapyd的API调用爬虫
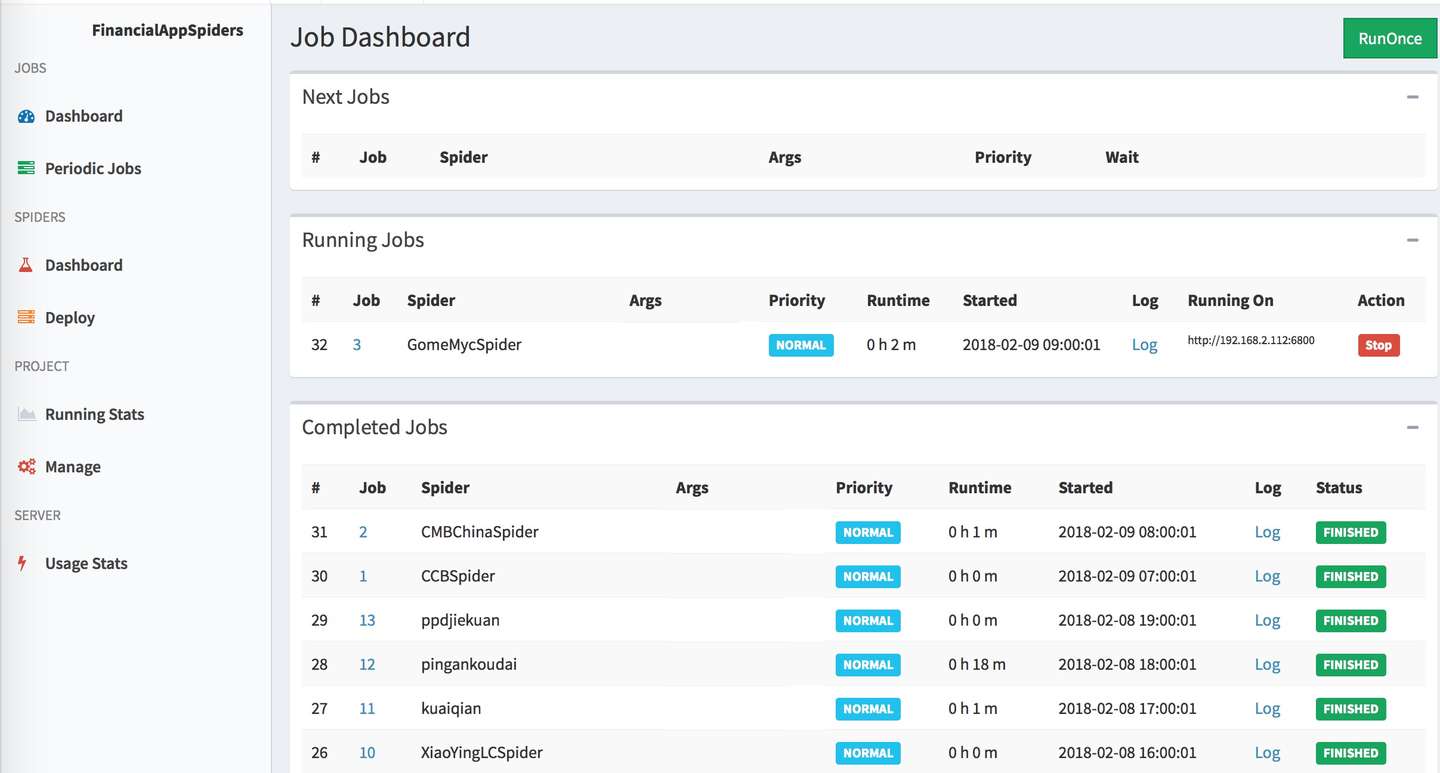
4.推荐使用spiderkeeper或者gerapy,这两个提供的WebUI都很好用,个人更喜欢spiderkeeper一些,因为可以定时运行爬虫。
如图:
####
####
技术改变命运

 浙公网安备 33010602011771号
浙公网安备 33010602011771号