
安卓逆向8-Frida-脱壳,使用引力播这个app
###
使用frida脱壳
安卓逆向,写代码的难度是比较小的,
难度大,是因为要分析原理,比如frida脱壳,这个其实代码很简单,十几行代码就好了,但是要懂得原理才可以,
###
之前使用的工具脱壳的
就是Xposed的一个工具组件,
现在我们使用frida 来开发脱壳,
毕竟作为开发,还是需要了解这个的,
###
脱壳要懂得原理,这个难度比较大,
真正写代码是非常简单的,几十行代码就搞定了,
###
使用frida脱壳的原理,
还是壳加载源app到内存之后,从内存中取出这个源app的代码,然后使用frida把这个保存到本地,就实现了脱壳了
###
frida脱壳使用到的api
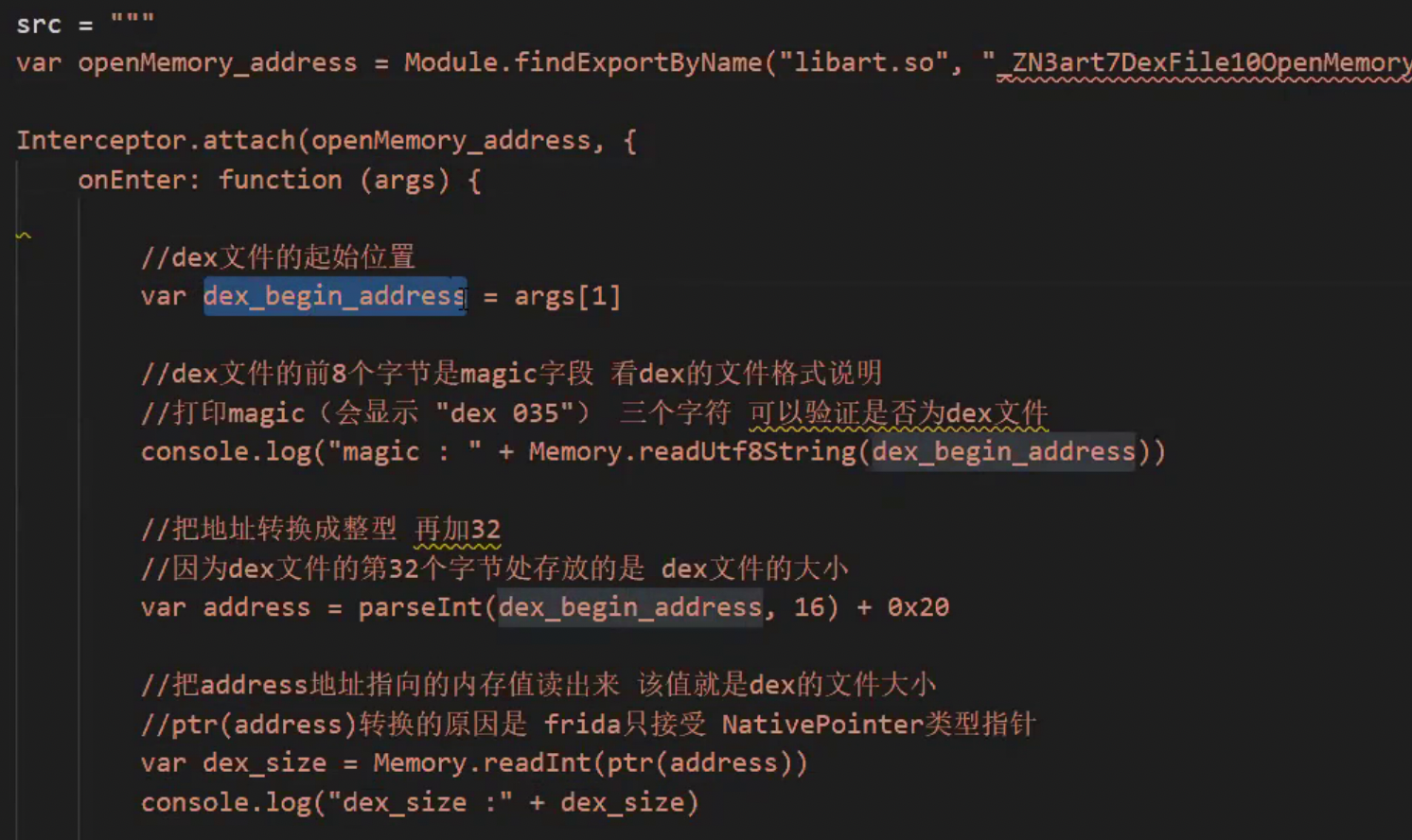
function_address = Module.findExportByName(libname, function); Interceptor.attach(address, func); Interceptor.attach(address, onEnter: function (args) { }, onLeave: function (retval) { } ) File 模块 写文件流程 new File(filepath, mode) write(data) flush() close() file = new File("yuanrenxue.dex", "wb") //data 是字符串或者 arrayBuffer // readByteArray() 返回的arrayBuffer file.write(data) file.flush() file.close() //把内存里的值转成字符串 Memory.readUtf8String() //把内存里的值转换成整型 Memory.readInt() //以begin为起始位置,从内存中读length长度的数据出来 返回ArrayBuffer类型 Memory.readByteArray(begin, length) //把地址转换成NativePointer类型 frida里操作内存地址需要NativePointer类型 ptr() JS api #把其它进制转换成10进制 parseInt(num, radix)
###
复习app加固和脱壳的原理


你只有知道了这个加固壳是怎么运行的你才知道在哪一步脱壳,
###
了解dex文件格式
###
本质还是需要需要懂这个dex文件的格式,里面做了什么,是怎么保存的,
里面有一个重要的属性,就是dex的数据具体有多大字节,这就是文件的长度,所以我们操作内存的依据就是这个,

我们读取内存里面的dex数据的时候,就是从32个字节往后,一直加dex的文件大小,这就是dex文件我们要读取的起始位置,
###
内存的概念,
因为我们是从内存把dex文件拿出来,所以还是需要知道这个内存怎么回事
比如一个4G的内存,可能是分成了1万份,每一份都是有一个id的,
关于内存的概念,还是理解不深刻,我需要单独学习一下计算机基础的知识,
###
怎么确定hook的点,
我们要知道dex加载的时候经过了很多的流程,我们怎么知道在哪一个流程去取内存呢?
第一个方法,就是你对安卓原理很通,熟悉代码逻辑,但是这个很难,真正做安卓app开发的,也未必搞得清楚,因为他们只是调用相关的api,做应用层的开发,对底层可能也不太清楚
第二个方法,我们通过查资料,了解dex加载的流程,我们就是这种人,
可能dex加载要经过10个方法,我们每一个做hook,看哪一个方法之后可以把内存dump出来,
经过测试是这个openmemory的方法之后,会把dex加载到内存,所以我们hook这个函数,

这个方法在libart.so库这个里面
我们可以使用ida工具,打开这个库,查看这个方法的导出方法名,然后就知道了我们要hook这个方法,
怎么查看这个方法的导出方法名?
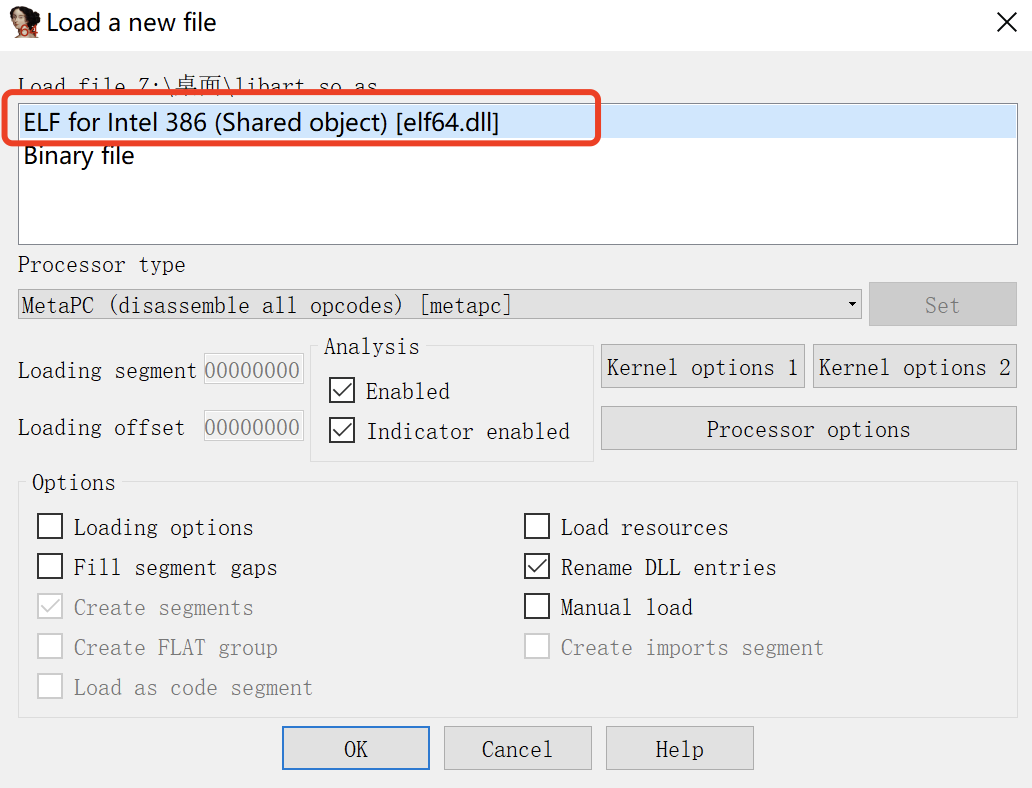
打开ida,主要使用ida,不要用ida64,
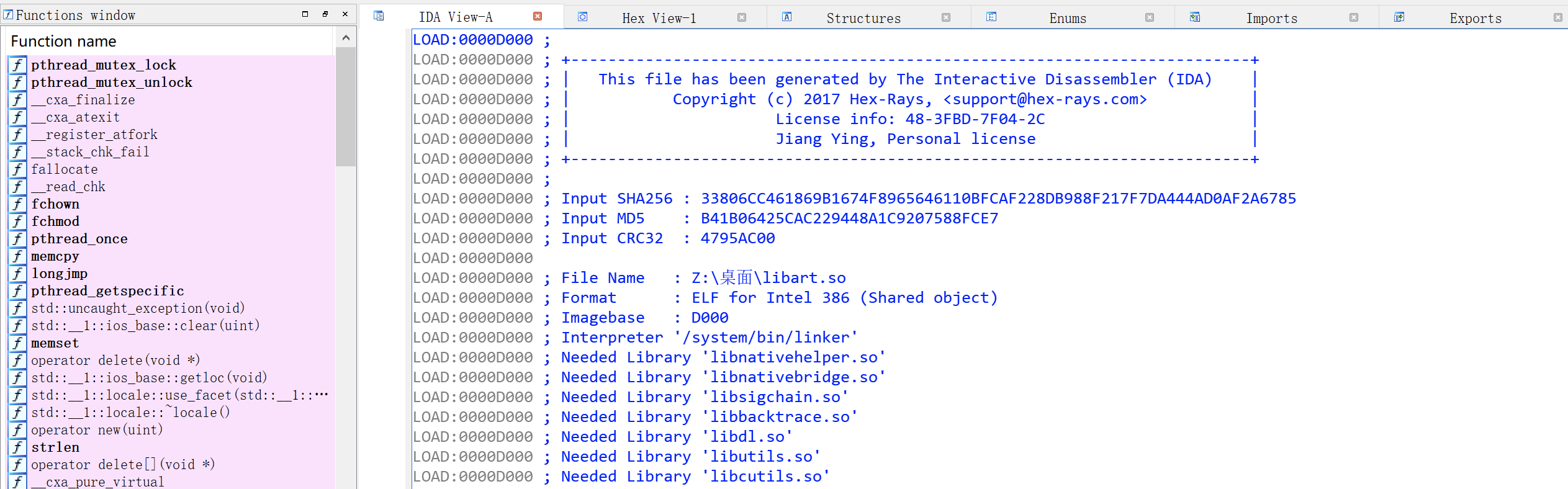
左边就是so文件里面的函数,右边就是具体的函数信息,
搜索openMemory,然后再IDA view-A,使用F5,把这个汇编语言,转换成为c语言,下面一长串就是方法名,
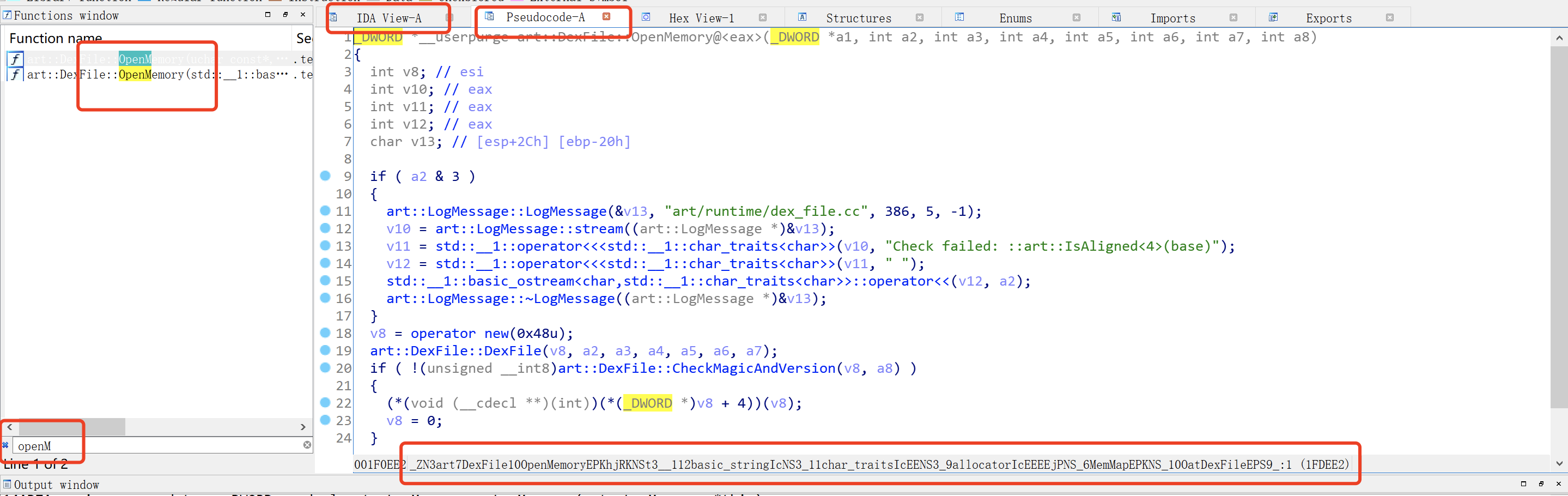
底部这一长串就是这个导出方法名,我们使用ida的目的,就是为了找到这个导出方法名,
###
怎么找到这个libart.so
libart.so位置是在 /system/lib/libart.so
adb pull /system/lib/libart.so ~/Desktop
这个libart.so和某一个app没有关系,我们找到这个so库,是为了知道里面的openmemory方法名,
这个openmemory方法就是把dex文件读取进入内存的,所以我们要hook这个方法,
###
案例,还是使用的引力播这个app,
我使用的是mumu模拟器+引力播+frida,进行脱壳,
首先第一步,把这个libart.so拿出来,
adb pull /system/lib/libart.so ~/Desktop
第二步:使用ida工具,获取到这个openmemory的方法名,
_ZN3art7DexFile100penMemoryEPKhjRKNSt3__112basic_stringIcNS3_11char_traitsIcEENS3_9allocatorIcEEEEjPNS_6MemMapEPKNS_100atDexFileEPS9_
使用ida可以,还可以
主要是要拿到安卓/system/lib/下的一个叫做libart.so,放到电脑
然后在电脑端使用命令nm libart.so |grep OpenMemory
来导出OpenMemory里面的名称

第三步,开始写代码
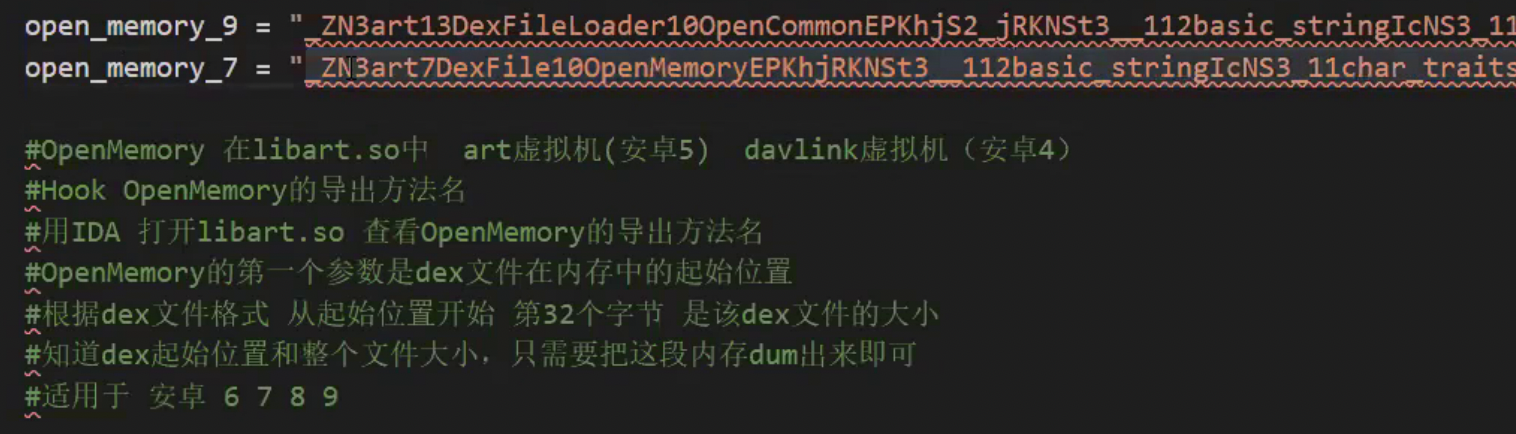
一个9,一个7是什么,是因为在安卓9和安卓7,是不同的名字,
###
####

代码:
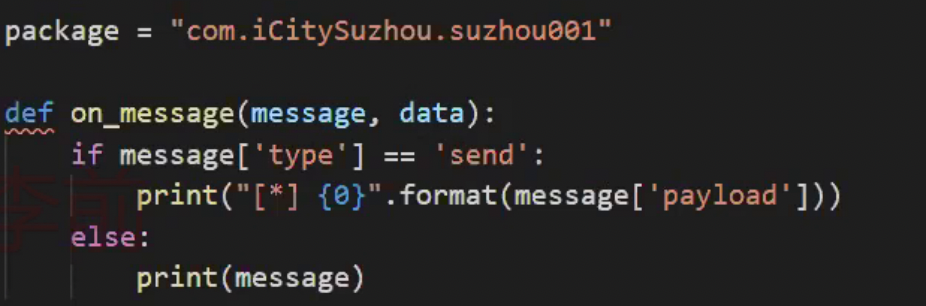
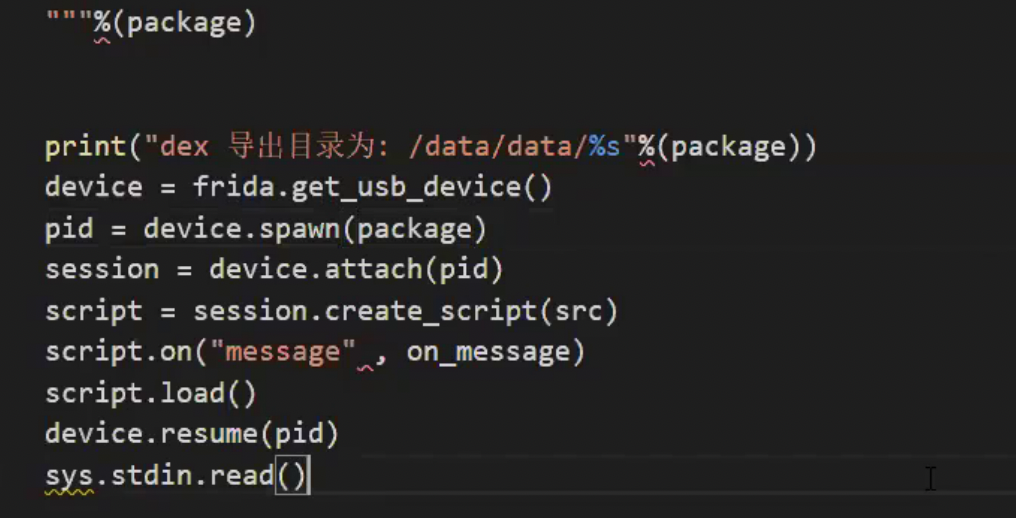
import frida import sys package = 'com.iCitySuzhou.suzhou001' def on_message(message, data): if message['type'] == 'send': print("[*]{0}".format(message['payload'])) else: print(message) # a安卓七 open_memory_7 = '_ZN3art7DexFile10OpenMemoryEPKhjRKNSt3__112basic_stringIcNS3_11char_traitsIcEENS3_9allocatorIcEEEEjPNS_6MemMapEPKNS_10OatDexFileEPS9_' open_memory_6 = '_ZN3art7DexFile100penMemoryEPKhjRKNSt3__112basic_stringIcNS3_11char_traitsIcEENS3_9allocatorIcEEEEjPNS_6MemMapEPKNS_100atDexFileEPS9_' # 所以安卓6和安卓7的这个名字是一样的, # 安卓九 open_memory_9 = '_ZN3art7DexFile10OpenMemoryERKNSt3__112basic_stringIcNS1_11char_traitsIcEENS1_9allocatorIcEEEEjPNS_6MemMapEPS7_' # OpenMemory在libart.so中,在/data/lib/下 art是虚拟机 # Hook OpenMemory 导出方法名 # 用 nm libart.so |grep OpenMemory 查看导出导OpenMemory方法名 # OpenMemroy的第一个参数是dex文件,在内存的起始位置 # 根据dex文件格式,从起始位置开始 第32个字节 是该dex文件的大小 # 知道dex起始位置和整个文件的大小,只是要把这段内存dump出来即可 # 实用与安卓 6 7 8 9 src = """ var openMemory_address=Module.findExportByName('libart.so','_ZN3art7DexFile10OpenMemoryEPKhjRKNSt3__112basic_stringIcNS3_11char_traitsIcEENS3_9allocatorIcEEEEjPNS_6MemMapEPKNS_10OatDexFileEPS9_'); Interceptor.attach(openMemory_address,{ onEnter: function(args){ //dex文件的起始位置 var dex_begin_address=args[1] //dex文件的前八个字节是magic字段 //打印magic(会显示dex 035) 三个字符 可以验证是否未dex文件 console.log('magic:'+Memory.readUtf8String(dex_begin_address)) // 把地址转换成整型 再加32 //因为dex文件的第三十二个字节处存放的dex文件的大小 var address=parseInt(dex_begin_address,16)+0x20 //把address地址指向的内存值读出来,该值就是dex的文件大小 //ptr(address)转换的原因是frida只接受NativePointer类型指针 var dex_size=Memory.readInt(ptr(address)) console.log('dex_size:'+dex_size) //frida写文件,把内存中的数据写到本地 var timestamp=new Date().getTime(); var file=new File('/data/data/%s/'+timestamp+'.dex','wb') //Memory.readByteArray(begin,length) //把内存的数据读出来,从begin开始,取length长度 file.write(Memory.readByteArray(dex_begin_address,dex_size)) file.flush() file.close() send('dex begin address:'+parseInt(dex_begin_address,16)) send('dex file size:'+dex_size) }, onLeave: function(retval){ if (retval.toInt32()>0){} } }); """ % (package) print('dex 导出目录为:/data/data/%s' % (package)) deveice = frida.get_usb_device() pid = deveice.spawn([package]) process = deveice.attach(pid) # 创建运行脚本 script = process.create_script(src) # 输入打印,写死 script.on('message', on_message) print('[*] Running CTF') # 写死 script.load() # 重启程序 deveice.resume(pid) # 写死 sys.stdin.read()
第四步,把app运行起来,然后运行我们的脱壳程序,
ok,成功获得我们想要的dex文件,就是成功脱壳了,

然后会有多个,我们使用jadx依次打开,其中查看是哪一个包含我们的代码
###
上面是代码
操作步骤:
1,要先把app运行起来,因为这个时候,就说明这个加固app的dex文件加载到了内存里面
2,然后运行我们的脱壳程序, 正常运行就是脱壳成功了
3,在app对应的目录,看看,应该是生成了导出的dex文件,
###
难点,是找到hook的点,
###
你能开发出来这个脱壳程序,在爬虫领域就是比较牛逼的了,
但是这个没有这么容易,大部分的app不是这么简单的,还做了混淆等其他的限制,没有办法单独使用frida就能脱壳出来,还需要其他的知识,
####

 浙公网安备 33010602011771号
浙公网安备 33010602011771号